
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NDUFA10-SGPP2 (FusionGDB2 ID:58040) |
Fusion Gene Summary for NDUFA10-SGPP2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NDUFA10-SGPP2 | Fusion gene ID: 58040 | Hgene | Tgene | Gene symbol | NDUFA10 | SGPP2 | Gene ID | 4705 | 130367 |
| Gene name | NADH:ubiquinone oxidoreductase subunit A10 | sphingosine-1-phosphate phosphatase 2 | |
| Synonyms | CI-42KD|CI-42k|MC1DN22 | SPP2|SPPase2 | |
| Cytomap | 2q37.3 | 2q36.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | NADH dehydrogenase [ubiquinone] 1 alpha subcomplex subunit 10, mitochondrialNADH-ubiquinone oxidoreductase 42 kDa subunitcomplex I 42kDa subunit | sphingosine-1-phosphate phosphatase 2sphingosine 1-phosphate phosphohydrolase 2sphingosine-1-phosphatase 2sphingosine-1-phosphate phosphotase 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000252711, ENST00000307300, ENST00000404554, ENST00000407129, ENST00000471378, | ENST00000321276, | |
| Fusion gene scores | * DoF score | 8 X 7 X 4=224 | 6 X 4 X 6=144 |
| # samples | 9 | 8 | |
| ** MAII score | log2(9/224*10)=-1.31550182572793 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/144*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NDUFA10 [Title/Abstract] AND SGPP2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NDUFA10(240929491)-SGPP2(223386486), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | SGPP2 | GO:0006670 | sphingosine metabolic process | 12411432 |
| Fusion gene breakpoints across NDUFA10 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SGPP2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-39-5035-01A | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + |
| ChimerDB4 | LUSC | TCGA-39-5035 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + |
| ChimerDB4 | LUSC | TCGA-39-5035 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + |
Top |
Fusion Gene ORF analysis for NDUFA10-SGPP2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000252711 | ENST00000321276 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + |
| In-frame | ENST00000252711 | ENST00000321276 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + |
| In-frame | ENST00000307300 | ENST00000321276 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + |
| In-frame | ENST00000307300 | ENST00000321276 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + |
| In-frame | ENST00000404554 | ENST00000321276 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + |
| In-frame | ENST00000404554 | ENST00000321276 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + |
| intron-3CDS | ENST00000407129 | ENST00000321276 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + |
| intron-3CDS | ENST00000407129 | ENST00000321276 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + |
| intron-3CDS | ENST00000471378 | ENST00000321276 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + |
| intron-3CDS | ENST00000471378 | ENST00000321276 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000252711 | NDUFA10 | chr2 | 240929491 | - | ENST00000321276 | SGPP2 | chr2 | 223386486 | + | 3972 | 1100 | 101 | 1921 | 606 |
| ENST00000404554 | NDUFA10 | chr2 | 240929491 | - | ENST00000321276 | SGPP2 | chr2 | 223386486 | + | 3876 | 1004 | 5 | 1825 | 606 |
| ENST00000307300 | NDUFA10 | chr2 | 240929491 | - | ENST00000321276 | SGPP2 | chr2 | 223386486 | + | 3984 | 1112 | 23 | 1933 | 636 |
| ENST00000252711 | NDUFA10 | chr2 | 240929490 | - | ENST00000321276 | SGPP2 | chr2 | 223386485 | + | 3972 | 1100 | 101 | 1921 | 606 |
| ENST00000404554 | NDUFA10 | chr2 | 240929490 | - | ENST00000321276 | SGPP2 | chr2 | 223386485 | + | 3876 | 1004 | 5 | 1825 | 606 |
| ENST00000307300 | NDUFA10 | chr2 | 240929490 | - | ENST00000321276 | SGPP2 | chr2 | 223386485 | + | 3984 | 1112 | 23 | 1933 | 636 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000252711 | ENST00000321276 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + | 0.000542515 | 0.99945754 |
| ENST00000404554 | ENST00000321276 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + | 0.000514082 | 0.99948585 |
| ENST00000307300 | ENST00000321276 | NDUFA10 | chr2 | 240929491 | - | SGPP2 | chr2 | 223386486 | + | 0.00047094 | 0.9995291 |
| ENST00000252711 | ENST00000321276 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + | 0.000542515 | 0.99945754 |
| ENST00000404554 | ENST00000321276 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + | 0.000514082 | 0.99948585 |
| ENST00000307300 | ENST00000321276 | NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + | 0.00047094 | 0.9995291 |
Top |
Fusion Genomic Features for NDUFA10-SGPP2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + | 5.27E-06 | 0.99999475 |
| NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + | 5.27E-06 | 0.99999475 |
| NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + | 5.27E-06 | 0.99999475 |
| NDUFA10 | chr2 | 240929490 | - | SGPP2 | chr2 | 223386485 | + | 5.27E-06 | 0.99999475 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
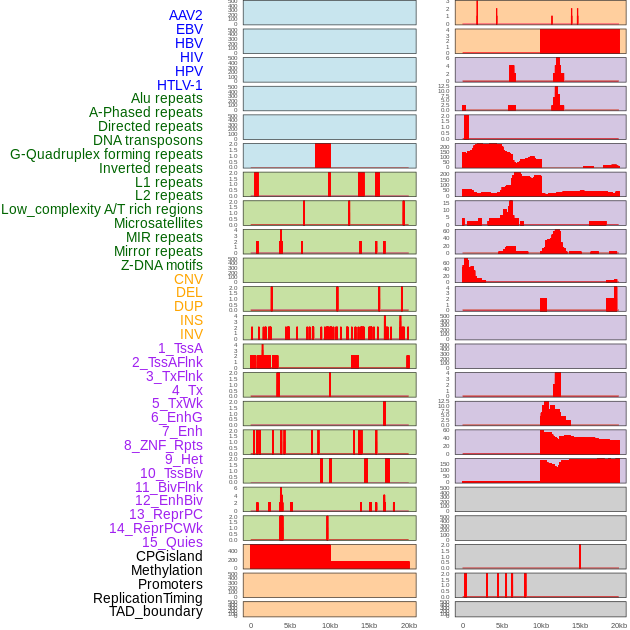 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
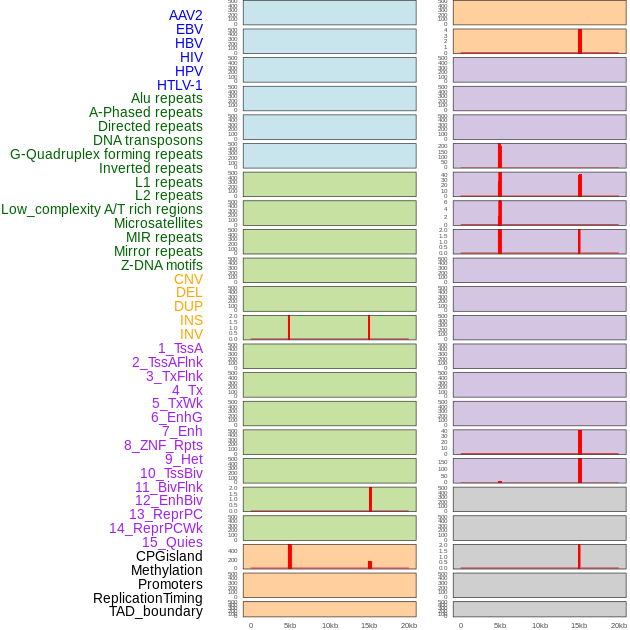 |
Top |
Fusion Protein Features for NDUFA10-SGPP2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:240929491/chr2:223386486) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 136_144 | 126 | 400.0 | Region | Phosphatase sequence motif I | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 163_166 | 126 | 400.0 | Region | Phosphatase sequence motif II | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 206_217 | 126 | 400.0 | Region | Phosphatase sequence motif III | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 136_144 | 126 | 400.0 | Region | Phosphatase sequence motif I | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 163_166 | 126 | 400.0 | Region | Phosphatase sequence motif II | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 206_217 | 126 | 400.0 | Region | Phosphatase sequence motif III | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 160_180 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 185_205 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 219_239 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 247_267 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 280_300 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 318_338 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 371_391 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 160_180 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 185_205 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 219_239 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 247_267 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 280_300 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 318_338 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 371_391 | 126 | 400.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 121_141 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929490 | chr2:223386485 | ENST00000321276 | 1 | 5 | 88_108 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 121_141 | 126 | 400.0 | Transmembrane | Helical | |
| Tgene | SGPP2 | chr2:240929491 | chr2:223386486 | ENST00000321276 | 1 | 5 | 88_108 | 126 | 400.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for NDUFA10-SGPP2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58040_58040_1_NDUFA10-SGPP2_NDUFA10_chr2_240929490_ENST00000252711_SGPP2_chr2_223386485_ENST00000321276_length(transcript)=3972nt_BP=1100nt GCACCCCGGCCGTGACGTCACGGCAGCGCGCCGGCCGCGAGAGAGGGCCCCGTCGCGACCGCGTCCCCTTGGGTCCTTGATCCTGAGCTG ACCGGGTAGCCATGGCCTTGCGGCTCCTGAAGCTGGCAGCGACGTCCGCGTCCGCCCGGGTCGTGGCGGCGGGCGCCCAGCGCGTGAGAG GAATTCATAGCAGTGTGCAGTGCAAACTGCGCTATGGAATGTGGCATTTCCTACTTGGGGATAAAGCAAGCAAAAGACTGACAGAACGCA GCAGAGTGATAACTGTAGATGGCAATATATGTACTGGAAAAGGCAAACTTGCAAAAGAAATAGCAGAGAAACTAGGCTTCAAGCACTTTC CTGAAGCGGGGATTCATTATCCAGACAGTACCACAGGAGATGGGAAGCCCCTCGCCACCGACTATAATGGCAACTGTAGTTTGGAGAAAT TTTACGATGATCCGAGAAGCAATGATGGCAACAGTTACCGCCTGCAGTCCTGGTTGTACAGCAGTCGCCTGCTGCAGTACTCAGATGCCT TGGAGCACTTGCTGACCACAGGACAAGGTGTTGTGTTGGAGCGCTCCATCTTCAGTGACTTTGTGTTCCTGGAGGCGATGTACAACCAGG GATTCATCCGAAAGCAGTGTGTGGACCACTACAACGAGGTGAAGAGCGTCACCATCTGCGATTACCTGCCCCCCCACCTGGTGATTTACA TCGATGTGCCCGTTCCAGAGGTCCAGAGGCGGATTCAGAAGAAAGGAGATCCACATGAAATGAAGATCACCTCTGCCTATCTACAGGACA TTGAGAATGCCTATAAGAAAACCTTTCTCCCTGAGATGAGTGAAAAATGTGAGGTTTTACAATATTCTGCAAGGGAAGCTCAAGATTCAA AAAAGGTGGTAGAGGACATTGAATACCTGAAGTTCGATAAAGGGCCGTGGCTCAAGCAGGACAATCGCACTTTATACCACCTGCGATTAC TGGTTCAGGATAAGTTTGAGGTGCTGAATTACACAAGCATTCCTATCTTTCTCCCGGAAGTCACCATTGGAGCTCATCAGACTGACCGTG TCTTACATCAGTTCAGAGAGTTGGTGATGTATATTGGCCAAGTGGCCAAGGATGTCTTGAAGTGGCCCCGTCCCTCCTCCCCTCCAGTTG TAAAACTGGAAAAGAGACTGATCGCTGAATATGGAATGCCATCCACCCACGCCATGGCGGCCACTGCCATTGCCTTCACCCTCCTTATCT CTACTATGGACAGATACCAGTATCCATTTGTGTTGGGACTGGTGATGGCCGTGGTGTTTTCCACCTTGGTGTGTCTCAGCAGGCTCTACA CTGGGATGCATACGGTCCTGGATGTGCTGGGTGGCGTCCTGATCACCGCACTCCTCATCGTCCTCACCTACCCTGCCTGGACCTTCATCG ACTGCCTGGACTCGGCCAGCCCCCTCTTCCCCGTGTGTGTCATAGTTGTGCCATTCTTCCTGTGTTACAATTACCCTGTTTCTGATTACT ACAGCCCAACCCGGGCGGACACCACCACCATTCTGGCTGCCGGGGCTGGAGTGACCATAGGATTCTGGATCAACCATTTCTTCCAGCTTG TATCCAAGCCCGCTGAATCTCTCCCTGTTATTCAGAACATCCCACCACTCACCACCTACATGTTAGTTTTGGGTCTGACCAAATTTGCAG TGGGAATTGTGTTGATCCTCTTGGTTCGTCAGCTTGTACAAAATCTCTCACTGCAAGTATTATACTCATGGTTCAAGGTGGTCACCAGGA ACAAGGAGGCCAGGCGGAGACTGGAGATTGAAGTGCCTTACAAGTTTGTTACCTACACATCTGTTGGCATCTGCGCTACAACCTTTGTGC CGATGCTTCACAGGTTTCTGGGATTACCCTGAGTCTCAAACAGTTGGAAACTAGCCCACTGGACATGAAAGCCAAGACATAGGAAAGTTA TTGGTAGGCAAATCTTGACAACTTATTTTTCTTTAACAACAACAAAAAGTCATACGGCTGTCTTGCTACTACCAGATAAATGATGCTGCT GTGTGAAAGGAAGAACTGTCTCATAGCGGTCATTGGTCGTCCGTGGTGGTTGGTTGTGCTACAGTTGAACCCAGGCTAAAGACCATAATC CGGATCTTTAAAGGCACACACCGCGCCCCCCCCCCCCCCGCCCGGCCCCTGCTCCTCTCGCTGTTGCACGGGCTTTGGATCTAGTCATGG GCTGGCAGGAATTGTGGCCTGGCTTAGGAATAGCTATGAGCCCCACTGGGTTCTGGAGAGCCAGTAGAGATGGGGTGATCTGGGAGGCTG GAGGTAGAGCCTTTCTTTTCCGTTACAACCTTGCCTAGCATGGAGTTATTTCTAAAATGGGAACTTTGGTCTAGGAGAAGGGGTGGCACC ATATGAAACGGCATTCCTTGGACAGGGTGACTTCCTTATCGTTTATTTGGTGATTTTTTGTTTTGTTTTGTTTGAGACAGGATCTTGCTC TGTTTCCCAGGCTGTATTACAGTGGCACAATCTCAGCTCACTGCAAACTCTGCCTCCCGGGCTCAAGCAATCCTCCTGCCTGAGCCAACT GAGTAGCTGGGACTGTAAGCATAGACCACCATGTGCCCAGCTAATTTTTGTAGAGACAGGGTTTCTCCATGTTGCCCAGGTACGTCTGAA ACTCCTGGGCTTAAGTGATCCACCCACCTCAGCCTCCCAAAGTGCTGGGATTATAGGCATGAGCCACTGTGCCCGGCCTCCTCCTTGTTA TGATCAAATTAGACTGTGCCTGGTTGGGTGGTAAGATCACTCTGAAAGAAAGCTCACTGTGAAGAGATGAAAGGTGGAGGCAGAGCTGTG AGGTCATGGGGAAAAGCCTGCTTTCCTTATAAGTCCTGCTGTTCATGTTGGAATAAGGATCTGCTCTTCCTTGTTTCCATGCATTTTGCA GGATTCCAGGTACCATTACCACACTCTTCTGACCCATGAAACCAACTGGCTGCTCACACATCACCAAACAGGTTGGGGGTTAGCCTTCAG CACAGGTGGATACATCTGGGATTCACTGAGATTCCTGCCCTCTCCTGCTTCCTAGTGGTTTGGGACAGGCCCTCTGCCCATCGTCAGCAG TTTTTTGCTTTCATACAAACCTGGAAGGCACTGGCATCTGCCTAGGAAAGTGGATCTGTGAAGAACAGATGAACTCAATCCTTTCTGGAG TCTGACAAAGAAGGGATAGGCTTCCTTGACATTGCCTGTCCTGACAAGGCCTCCCTGACATTACTCCTCCAATTTCACAGTTACCTTCTG TAAATCTATTTTCTCATCTACTGAATAGAATCAGGCGCCCTTTTTGTCTTCCCACCTCTTATCTCTTGGCAATTTTAAGGGGAATTAATG CAAGAACAACTTTAGTGTCTCTTGGGAAAACAAGCCAACCAAATACAAAACCCATTAAGCCTACTAGGGTGAGTCCTCTTAACATGGGAA GGCGATGATTATGCAAACACCGGAGTTCCCTCCTCTTCAGTTCCTAAGAATAAAGAACAGGTATCAAGAACTTTCTTTAAAGTTAGTGTA ACTATAGTTAACAAAGTATCCATTGAAGTTTAGTGCCTGTAGGACTGAGCCAGTGCTTTATCAACCCAACACATCATCACCATGTGCATA CTCTAGAAAAAAAAATAGCTTCCTTAAAAGTTACAGAGGCTCTTAACGTGTTAAAACCGAAAAATCACATTTTTCTTGATTTCAAATATG TTCTACGGCCTTACTGTTGGGATGATATTTAGTATGTAACTTAGCATTCCAATTTCTCAAGAATTTTTAGGCCGGGTGCGGTGGCTCATG CCTGTAATCCCAGCACTTTGGGAGGCCGAGGTGGGCGGACCACGAGGTCAGGAGATCGAGACCATCCTGGCTAACACGGTACCCCGTCTC >58040_58040_1_NDUFA10-SGPP2_NDUFA10_chr2_240929490_ENST00000252711_SGPP2_chr2_223386485_ENST00000321276_length(amino acids)=606AA_BP=333 MALRLLKLAATSASARVVAAGAQRVRGIHSSVQCKLRYGMWHFLLGDKASKRLTERSRVITVDGNICTGKGKLAKEIAEKLGFKHFPEAG IHYPDSTTGDGKPLATDYNGNCSLEKFYDDPRSNDGNSYRLQSWLYSSRLLQYSDALEHLLTTGQGVVLERSIFSDFVFLEAMYNQGFIR KQCVDHYNEVKSVTICDYLPPHLVIYIDVPVPEVQRRIQKKGDPHEMKITSAYLQDIENAYKKTFLPEMSEKCEVLQYSAREAQDSKKVV EDIEYLKFDKGPWLKQDNRTLYHLRLLVQDKFEVLNYTSIPIFLPEVTIGAHQTDRVLHQFRELVMYIGQVAKDVLKWPRPSSPPVVKLE KRLIAEYGMPSTHAMAATAIAFTLLISTMDRYQYPFVLGLVMAVVFSTLVCLSRLYTGMHTVLDVLGGVLITALLIVLTYPAWTFIDCLD SASPLFPVCVIVVPFFLCYNYPVSDYYSPTRADTTTILAAGAGVTIGFWINHFFQLVSKPAESLPVIQNIPPLTTYMLVLGLTKFAVGIV -------------------------------------------------------------- >58040_58040_2_NDUFA10-SGPP2_NDUFA10_chr2_240929490_ENST00000307300_SGPP2_chr2_223386485_ENST00000321276_length(transcript)=3984nt_BP=1112nt GATCCTGAGCTGACCGGGTAGCCATGGCCTTGCGGCTCCTGAAGCTGGCAGCGACGTCCGCGTCCGCCCGGGTCGTGGCGGCGGGCGCCC AGCGCGTGAGAGGAATTCATAGCAGTGTGCAGTGCAAACTGCGCTATGGAATGTGGCATTTCCTACTTGGGGATAAAGCAAGCAAAAGAC TGACAGAACGCAGCAGAGTGATAACTGTAGATGGCAATATATGTACTGGAAAAGGCAAACTTGCAAAAGAAATAGCAGAGAAACTAGGCT TCAAGCACTTTCCTGAAGCGGGGATTCATTATCCAGACAGTACCACAGGAGATGGGAAGCCCCTCGCCACCGACTATAATGGCAACTGTA GTTTGGAGAAATTTTACGATGATCCGAGAAGCAATGATGGCAACAGTTACCGCCTGCAGTCCTGGTTGTACAGCAGTCGCCTGCTGCAGT ACTCAGATGCCTTGGAGCACTTGCTGACCACAGGACAAGGTGTTGTGTTGGAGCGCTCCATCTTCAGTGACTTTGTGTTCCTGGAGGCGA TGTACAACCAGGGATTCATCCGAAAGCAGTGTGAGTCAGCATTGCAGACCCACTTCTGGACTGGGGTGGCTGGAGCCAGTGGAAAGCTGG AATCTGGGAGCTCAGAGGAAGTACTGTTGATTAATGAAAGAGGAGGCCGAAGCAAGCCAGGTGTGGACCACTACAACGAGGTGAAGAGCG TCACCATCTGCGATTACCTGCCCCCCCACCTGGTGATTTACATCGATGTGCCCGTTCCAGAGCCACATGAAATGAAGATCACCTCTGCCT ATCTACAGGACATTGAGAATGCCTATAAGAAAACCTTTCTCCCTGAGATGAGTGAAAAATGTGAGGTTTTACAATATTCTGCAAGGGAAG CTCAAGATTCAAAAAAGGTGGTAGAGGACATTGAATACCTGAAGTTCGATAAAGGGCCGTGGCTCAAGCAGGACAATCGCACTTTATACC ACCTGCGATTACTGGTTCAGGATAAGTTTGAGGTGCTGAATTACACAAGCATTCCTATCTTTCTCCCGGAAGTCACCATTGGAGCTCATC AGACTGACCGTGTCTTACATCAGTTCAGAGAGTTGGTGATGTATATTGGCCAAGTGGCCAAGGATGTCTTGAAGTGGCCCCGTCCCTCCT CCCCTCCAGTTGTAAAACTGGAAAAGAGACTGATCGCTGAATATGGAATGCCATCCACCCACGCCATGGCGGCCACTGCCATTGCCTTCA CCCTCCTTATCTCTACTATGGACAGATACCAGTATCCATTTGTGTTGGGACTGGTGATGGCCGTGGTGTTTTCCACCTTGGTGTGTCTCA GCAGGCTCTACACTGGGATGCATACGGTCCTGGATGTGCTGGGTGGCGTCCTGATCACCGCACTCCTCATCGTCCTCACCTACCCTGCCT GGACCTTCATCGACTGCCTGGACTCGGCCAGCCCCCTCTTCCCCGTGTGTGTCATAGTTGTGCCATTCTTCCTGTGTTACAATTACCCTG TTTCTGATTACTACAGCCCAACCCGGGCGGACACCACCACCATTCTGGCTGCCGGGGCTGGAGTGACCATAGGATTCTGGATCAACCATT TCTTCCAGCTTGTATCCAAGCCCGCTGAATCTCTCCCTGTTATTCAGAACATCCCACCACTCACCACCTACATGTTAGTTTTGGGTCTGA CCAAATTTGCAGTGGGAATTGTGTTGATCCTCTTGGTTCGTCAGCTTGTACAAAATCTCTCACTGCAAGTATTATACTCATGGTTCAAGG TGGTCACCAGGAACAAGGAGGCCAGGCGGAGACTGGAGATTGAAGTGCCTTACAAGTTTGTTACCTACACATCTGTTGGCATCTGCGCTA CAACCTTTGTGCCGATGCTTCACAGGTTTCTGGGATTACCCTGAGTCTCAAACAGTTGGAAACTAGCCCACTGGACATGAAAGCCAAGAC ATAGGAAAGTTATTGGTAGGCAAATCTTGACAACTTATTTTTCTTTAACAACAACAAAAAGTCATACGGCTGTCTTGCTACTACCAGATA AATGATGCTGCTGTGTGAAAGGAAGAACTGTCTCATAGCGGTCATTGGTCGTCCGTGGTGGTTGGTTGTGCTACAGTTGAACCCAGGCTA AAGACCATAATCCGGATCTTTAAAGGCACACACCGCGCCCCCCCCCCCCCCGCCCGGCCCCTGCTCCTCTCGCTGTTGCACGGGCTTTGG ATCTAGTCATGGGCTGGCAGGAATTGTGGCCTGGCTTAGGAATAGCTATGAGCCCCACTGGGTTCTGGAGAGCCAGTAGAGATGGGGTGA TCTGGGAGGCTGGAGGTAGAGCCTTTCTTTTCCGTTACAACCTTGCCTAGCATGGAGTTATTTCTAAAATGGGAACTTTGGTCTAGGAGA AGGGGTGGCACCATATGAAACGGCATTCCTTGGACAGGGTGACTTCCTTATCGTTTATTTGGTGATTTTTTGTTTTGTTTTGTTTGAGAC AGGATCTTGCTCTGTTTCCCAGGCTGTATTACAGTGGCACAATCTCAGCTCACTGCAAACTCTGCCTCCCGGGCTCAAGCAATCCTCCTG CCTGAGCCAACTGAGTAGCTGGGACTGTAAGCATAGACCACCATGTGCCCAGCTAATTTTTGTAGAGACAGGGTTTCTCCATGTTGCCCA GGTACGTCTGAAACTCCTGGGCTTAAGTGATCCACCCACCTCAGCCTCCCAAAGTGCTGGGATTATAGGCATGAGCCACTGTGCCCGGCC TCCTCCTTGTTATGATCAAATTAGACTGTGCCTGGTTGGGTGGTAAGATCACTCTGAAAGAAAGCTCACTGTGAAGAGATGAAAGGTGGA GGCAGAGCTGTGAGGTCATGGGGAAAAGCCTGCTTTCCTTATAAGTCCTGCTGTTCATGTTGGAATAAGGATCTGCTCTTCCTTGTTTCC ATGCATTTTGCAGGATTCCAGGTACCATTACCACACTCTTCTGACCCATGAAACCAACTGGCTGCTCACACATCACCAAACAGGTTGGGG GTTAGCCTTCAGCACAGGTGGATACATCTGGGATTCACTGAGATTCCTGCCCTCTCCTGCTTCCTAGTGGTTTGGGACAGGCCCTCTGCC CATCGTCAGCAGTTTTTTGCTTTCATACAAACCTGGAAGGCACTGGCATCTGCCTAGGAAAGTGGATCTGTGAAGAACAGATGAACTCAA TCCTTTCTGGAGTCTGACAAAGAAGGGATAGGCTTCCTTGACATTGCCTGTCCTGACAAGGCCTCCCTGACATTACTCCTCCAATTTCAC AGTTACCTTCTGTAAATCTATTTTCTCATCTACTGAATAGAATCAGGCGCCCTTTTTGTCTTCCCACCTCTTATCTCTTGGCAATTTTAA GGGGAATTAATGCAAGAACAACTTTAGTGTCTCTTGGGAAAACAAGCCAACCAAATACAAAACCCATTAAGCCTACTAGGGTGAGTCCTC TTAACATGGGAAGGCGATGATTATGCAAACACCGGAGTTCCCTCCTCTTCAGTTCCTAAGAATAAAGAACAGGTATCAAGAACTTTCTTT AAAGTTAGTGTAACTATAGTTAACAAAGTATCCATTGAAGTTTAGTGCCTGTAGGACTGAGCCAGTGCTTTATCAACCCAACACATCATC ACCATGTGCATACTCTAGAAAAAAAAATAGCTTCCTTAAAAGTTACAGAGGCTCTTAACGTGTTAAAACCGAAAAATCACATTTTTCTTG ATTTCAAATATGTTCTACGGCCTTACTGTTGGGATGATATTTAGTATGTAACTTAGCATTCCAATTTCTCAAGAATTTTTAGGCCGGGTG CGGTGGCTCATGCCTGTAATCCCAGCACTTTGGGAGGCCGAGGTGGGCGGACCACGAGGTCAGGAGATCGAGACCATCCTGGCTAACACG >58040_58040_2_NDUFA10-SGPP2_NDUFA10_chr2_240929490_ENST00000307300_SGPP2_chr2_223386485_ENST00000321276_length(amino acids)=636AA_BP=363 MALRLLKLAATSASARVVAAGAQRVRGIHSSVQCKLRYGMWHFLLGDKASKRLTERSRVITVDGNICTGKGKLAKEIAEKLGFKHFPEAG IHYPDSTTGDGKPLATDYNGNCSLEKFYDDPRSNDGNSYRLQSWLYSSRLLQYSDALEHLLTTGQGVVLERSIFSDFVFLEAMYNQGFIR KQCESALQTHFWTGVAGASGKLESGSSEEVLLINERGGRSKPGVDHYNEVKSVTICDYLPPHLVIYIDVPVPEPHEMKITSAYLQDIENA YKKTFLPEMSEKCEVLQYSAREAQDSKKVVEDIEYLKFDKGPWLKQDNRTLYHLRLLVQDKFEVLNYTSIPIFLPEVTIGAHQTDRVLHQ FRELVMYIGQVAKDVLKWPRPSSPPVVKLEKRLIAEYGMPSTHAMAATAIAFTLLISTMDRYQYPFVLGLVMAVVFSTLVCLSRLYTGMH TVLDVLGGVLITALLIVLTYPAWTFIDCLDSASPLFPVCVIVVPFFLCYNYPVSDYYSPTRADTTTILAAGAGVTIGFWINHFFQLVSKP AESLPVIQNIPPLTTYMLVLGLTKFAVGIVLILLVRQLVQNLSLQVLYSWFKVVTRNKEARRRLEIEVPYKFVTYTSVGICATTFVPMLH -------------------------------------------------------------- >58040_58040_3_NDUFA10-SGPP2_NDUFA10_chr2_240929490_ENST00000404554_SGPP2_chr2_223386485_ENST00000321276_length(transcript)=3876nt_BP=1004nt TAGCCATGGCCTTGCGGCTCCTGAAGCTGGCAGCGACGTCCGCGTCCGCCCGGGTCGTGGCGGCGGGCGCCCAGCGCGTGAGAGGAATTC ATAGCAGTGTGCAGTGCAAACTGCGCTATGGAATGTGGCATTTCCTACTTGGGGATAAAGCAAGCAAAAGACTGACAGAACGCAGCAGAG TGATAACTGTAGATGGCAATATATGTACTGGAAAAGGCAAACTTGCAAAAGAAATAGCAGAGAAACTAGGCTTCAAGCACTTTCCTGAAG CGGGGATTCATTATCCAGACAGTACCACAGGAGATGGGAAGCCCCTCGCCACCGACTATAATGGCAACTGTAGTTTGGAGAAATTTTACG ATGATCCGAGAAGCAATGATGGCAACAGTTACCGCCTGCAGTCCTGGTTGTACAGCAGTCGCCTGCTGCAGTACTCAGATGCCTTGGAGC ACTTGCTGACCACAGGACAAGGTGTTGTGTTGGAGCGCTCCATCTTCAGTGACTTTGTGTTCCTGGAGGCGATGTACAACCAGGGATTCA TCCGAAAGCAGTGTGTGGACCACTACAACGAGGTGAAGAGCGTCACCATCTGCGATTACCTGCCCCCCCACCTGGTGATTTACATCGATG TGCCCGTTCCAGAGGTCCAGAGGCGGATTCAGAAGAAAGGAGATCCACATGAAATGAAGATCACCTCTGCCTATCTACAGGACATTGAGA ATGCCTATAAGAAAACCTTTCTCCCTGAGATGAGTGAAAAATGTGAGGTTTTACAATATTCTGCAAGGGAAGCTCAAGATTCAAAAAAGG TGGTAGAGGACATTGAATACCTGAAGTTCGATAAAGGGCCGTGGCTCAAGCAGGACAATCGCACTTTATACCACCTGCGATTACTGGTTC AGGATAAGTTTGAGGTGCTGAATTACACAAGCATTCCTATCTTTCTCCCGGAAGTCACCATTGGAGCTCATCAGACTGACCGTGTCTTAC ATCAGTTCAGAGAGTTGGTGATGTATATTGGCCAAGTGGCCAAGGATGTCTTGAAGTGGCCCCGTCCCTCCTCCCCTCCAGTTGTAAAAC TGGAAAAGAGACTGATCGCTGAATATGGAATGCCATCCACCCACGCCATGGCGGCCACTGCCATTGCCTTCACCCTCCTTATCTCTACTA TGGACAGATACCAGTATCCATTTGTGTTGGGACTGGTGATGGCCGTGGTGTTTTCCACCTTGGTGTGTCTCAGCAGGCTCTACACTGGGA TGCATACGGTCCTGGATGTGCTGGGTGGCGTCCTGATCACCGCACTCCTCATCGTCCTCACCTACCCTGCCTGGACCTTCATCGACTGCC TGGACTCGGCCAGCCCCCTCTTCCCCGTGTGTGTCATAGTTGTGCCATTCTTCCTGTGTTACAATTACCCTGTTTCTGATTACTACAGCC CAACCCGGGCGGACACCACCACCATTCTGGCTGCCGGGGCTGGAGTGACCATAGGATTCTGGATCAACCATTTCTTCCAGCTTGTATCCA AGCCCGCTGAATCTCTCCCTGTTATTCAGAACATCCCACCACTCACCACCTACATGTTAGTTTTGGGTCTGACCAAATTTGCAGTGGGAA TTGTGTTGATCCTCTTGGTTCGTCAGCTTGTACAAAATCTCTCACTGCAAGTATTATACTCATGGTTCAAGGTGGTCACCAGGAACAAGG AGGCCAGGCGGAGACTGGAGATTGAAGTGCCTTACAAGTTTGTTACCTACACATCTGTTGGCATCTGCGCTACAACCTTTGTGCCGATGC TTCACAGGTTTCTGGGATTACCCTGAGTCTCAAACAGTTGGAAACTAGCCCACTGGACATGAAAGCCAAGACATAGGAAAGTTATTGGTA GGCAAATCTTGACAACTTATTTTTCTTTAACAACAACAAAAAGTCATACGGCTGTCTTGCTACTACCAGATAAATGATGCTGCTGTGTGA AAGGAAGAACTGTCTCATAGCGGTCATTGGTCGTCCGTGGTGGTTGGTTGTGCTACAGTTGAACCCAGGCTAAAGACCATAATCCGGATC TTTAAAGGCACACACCGCGCCCCCCCCCCCCCCGCCCGGCCCCTGCTCCTCTCGCTGTTGCACGGGCTTTGGATCTAGTCATGGGCTGGC AGGAATTGTGGCCTGGCTTAGGAATAGCTATGAGCCCCACTGGGTTCTGGAGAGCCAGTAGAGATGGGGTGATCTGGGAGGCTGGAGGTA GAGCCTTTCTTTTCCGTTACAACCTTGCCTAGCATGGAGTTATTTCTAAAATGGGAACTTTGGTCTAGGAGAAGGGGTGGCACCATATGA AACGGCATTCCTTGGACAGGGTGACTTCCTTATCGTTTATTTGGTGATTTTTTGTTTTGTTTTGTTTGAGACAGGATCTTGCTCTGTTTC CCAGGCTGTATTACAGTGGCACAATCTCAGCTCACTGCAAACTCTGCCTCCCGGGCTCAAGCAATCCTCCTGCCTGAGCCAACTGAGTAG CTGGGACTGTAAGCATAGACCACCATGTGCCCAGCTAATTTTTGTAGAGACAGGGTTTCTCCATGTTGCCCAGGTACGTCTGAAACTCCT GGGCTTAAGTGATCCACCCACCTCAGCCTCCCAAAGTGCTGGGATTATAGGCATGAGCCACTGTGCCCGGCCTCCTCCTTGTTATGATCA AATTAGACTGTGCCTGGTTGGGTGGTAAGATCACTCTGAAAGAAAGCTCACTGTGAAGAGATGAAAGGTGGAGGCAGAGCTGTGAGGTCA TGGGGAAAAGCCTGCTTTCCTTATAAGTCCTGCTGTTCATGTTGGAATAAGGATCTGCTCTTCCTTGTTTCCATGCATTTTGCAGGATTC CAGGTACCATTACCACACTCTTCTGACCCATGAAACCAACTGGCTGCTCACACATCACCAAACAGGTTGGGGGTTAGCCTTCAGCACAGG TGGATACATCTGGGATTCACTGAGATTCCTGCCCTCTCCTGCTTCCTAGTGGTTTGGGACAGGCCCTCTGCCCATCGTCAGCAGTTTTTT GCTTTCATACAAACCTGGAAGGCACTGGCATCTGCCTAGGAAAGTGGATCTGTGAAGAACAGATGAACTCAATCCTTTCTGGAGTCTGAC AAAGAAGGGATAGGCTTCCTTGACATTGCCTGTCCTGACAAGGCCTCCCTGACATTACTCCTCCAATTTCACAGTTACCTTCTGTAAATC TATTTTCTCATCTACTGAATAGAATCAGGCGCCCTTTTTGTCTTCCCACCTCTTATCTCTTGGCAATTTTAAGGGGAATTAATGCAAGAA CAACTTTAGTGTCTCTTGGGAAAACAAGCCAACCAAATACAAAACCCATTAAGCCTACTAGGGTGAGTCCTCTTAACATGGGAAGGCGAT GATTATGCAAACACCGGAGTTCCCTCCTCTTCAGTTCCTAAGAATAAAGAACAGGTATCAAGAACTTTCTTTAAAGTTAGTGTAACTATA GTTAACAAAGTATCCATTGAAGTTTAGTGCCTGTAGGACTGAGCCAGTGCTTTATCAACCCAACACATCATCACCATGTGCATACTCTAG AAAAAAAAATAGCTTCCTTAAAAGTTACAGAGGCTCTTAACGTGTTAAAACCGAAAAATCACATTTTTCTTGATTTCAAATATGTTCTAC GGCCTTACTGTTGGGATGATATTTAGTATGTAACTTAGCATTCCAATTTCTCAAGAATTTTTAGGCCGGGTGCGGTGGCTCATGCCTGTA ATCCCAGCACTTTGGGAGGCCGAGGTGGGCGGACCACGAGGTCAGGAGATCGAGACCATCCTGGCTAACACGGTACCCCGTCTCTACTGA >58040_58040_3_NDUFA10-SGPP2_NDUFA10_chr2_240929490_ENST00000404554_SGPP2_chr2_223386485_ENST00000321276_length(amino acids)=606AA_BP=333 MALRLLKLAATSASARVVAAGAQRVRGIHSSVQCKLRYGMWHFLLGDKASKRLTERSRVITVDGNICTGKGKLAKEIAEKLGFKHFPEAG IHYPDSTTGDGKPLATDYNGNCSLEKFYDDPRSNDGNSYRLQSWLYSSRLLQYSDALEHLLTTGQGVVLERSIFSDFVFLEAMYNQGFIR KQCVDHYNEVKSVTICDYLPPHLVIYIDVPVPEVQRRIQKKGDPHEMKITSAYLQDIENAYKKTFLPEMSEKCEVLQYSAREAQDSKKVV EDIEYLKFDKGPWLKQDNRTLYHLRLLVQDKFEVLNYTSIPIFLPEVTIGAHQTDRVLHQFRELVMYIGQVAKDVLKWPRPSSPPVVKLE KRLIAEYGMPSTHAMAATAIAFTLLISTMDRYQYPFVLGLVMAVVFSTLVCLSRLYTGMHTVLDVLGGVLITALLIVLTYPAWTFIDCLD SASPLFPVCVIVVPFFLCYNYPVSDYYSPTRADTTTILAAGAGVTIGFWINHFFQLVSKPAESLPVIQNIPPLTTYMLVLGLTKFAVGIV -------------------------------------------------------------- >58040_58040_4_NDUFA10-SGPP2_NDUFA10_chr2_240929491_ENST00000252711_SGPP2_chr2_223386486_ENST00000321276_length(transcript)=3972nt_BP=1100nt GCACCCCGGCCGTGACGTCACGGCAGCGCGCCGGCCGCGAGAGAGGGCCCCGTCGCGACCGCGTCCCCTTGGGTCCTTGATCCTGAGCTG ACCGGGTAGCCATGGCCTTGCGGCTCCTGAAGCTGGCAGCGACGTCCGCGTCCGCCCGGGTCGTGGCGGCGGGCGCCCAGCGCGTGAGAG GAATTCATAGCAGTGTGCAGTGCAAACTGCGCTATGGAATGTGGCATTTCCTACTTGGGGATAAAGCAAGCAAAAGACTGACAGAACGCA GCAGAGTGATAACTGTAGATGGCAATATATGTACTGGAAAAGGCAAACTTGCAAAAGAAATAGCAGAGAAACTAGGCTTCAAGCACTTTC CTGAAGCGGGGATTCATTATCCAGACAGTACCACAGGAGATGGGAAGCCCCTCGCCACCGACTATAATGGCAACTGTAGTTTGGAGAAAT TTTACGATGATCCGAGAAGCAATGATGGCAACAGTTACCGCCTGCAGTCCTGGTTGTACAGCAGTCGCCTGCTGCAGTACTCAGATGCCT TGGAGCACTTGCTGACCACAGGACAAGGTGTTGTGTTGGAGCGCTCCATCTTCAGTGACTTTGTGTTCCTGGAGGCGATGTACAACCAGG GATTCATCCGAAAGCAGTGTGTGGACCACTACAACGAGGTGAAGAGCGTCACCATCTGCGATTACCTGCCCCCCCACCTGGTGATTTACA TCGATGTGCCCGTTCCAGAGGTCCAGAGGCGGATTCAGAAGAAAGGAGATCCACATGAAATGAAGATCACCTCTGCCTATCTACAGGACA TTGAGAATGCCTATAAGAAAACCTTTCTCCCTGAGATGAGTGAAAAATGTGAGGTTTTACAATATTCTGCAAGGGAAGCTCAAGATTCAA AAAAGGTGGTAGAGGACATTGAATACCTGAAGTTCGATAAAGGGCCGTGGCTCAAGCAGGACAATCGCACTTTATACCACCTGCGATTAC TGGTTCAGGATAAGTTTGAGGTGCTGAATTACACAAGCATTCCTATCTTTCTCCCGGAAGTCACCATTGGAGCTCATCAGACTGACCGTG TCTTACATCAGTTCAGAGAGTTGGTGATGTATATTGGCCAAGTGGCCAAGGATGTCTTGAAGTGGCCCCGTCCCTCCTCCCCTCCAGTTG TAAAACTGGAAAAGAGACTGATCGCTGAATATGGAATGCCATCCACCCACGCCATGGCGGCCACTGCCATTGCCTTCACCCTCCTTATCT CTACTATGGACAGATACCAGTATCCATTTGTGTTGGGACTGGTGATGGCCGTGGTGTTTTCCACCTTGGTGTGTCTCAGCAGGCTCTACA CTGGGATGCATACGGTCCTGGATGTGCTGGGTGGCGTCCTGATCACCGCACTCCTCATCGTCCTCACCTACCCTGCCTGGACCTTCATCG ACTGCCTGGACTCGGCCAGCCCCCTCTTCCCCGTGTGTGTCATAGTTGTGCCATTCTTCCTGTGTTACAATTACCCTGTTTCTGATTACT ACAGCCCAACCCGGGCGGACACCACCACCATTCTGGCTGCCGGGGCTGGAGTGACCATAGGATTCTGGATCAACCATTTCTTCCAGCTTG TATCCAAGCCCGCTGAATCTCTCCCTGTTATTCAGAACATCCCACCACTCACCACCTACATGTTAGTTTTGGGTCTGACCAAATTTGCAG TGGGAATTGTGTTGATCCTCTTGGTTCGTCAGCTTGTACAAAATCTCTCACTGCAAGTATTATACTCATGGTTCAAGGTGGTCACCAGGA ACAAGGAGGCCAGGCGGAGACTGGAGATTGAAGTGCCTTACAAGTTTGTTACCTACACATCTGTTGGCATCTGCGCTACAACCTTTGTGC CGATGCTTCACAGGTTTCTGGGATTACCCTGAGTCTCAAACAGTTGGAAACTAGCCCACTGGACATGAAAGCCAAGACATAGGAAAGTTA TTGGTAGGCAAATCTTGACAACTTATTTTTCTTTAACAACAACAAAAAGTCATACGGCTGTCTTGCTACTACCAGATAAATGATGCTGCT GTGTGAAAGGAAGAACTGTCTCATAGCGGTCATTGGTCGTCCGTGGTGGTTGGTTGTGCTACAGTTGAACCCAGGCTAAAGACCATAATC CGGATCTTTAAAGGCACACACCGCGCCCCCCCCCCCCCCGCCCGGCCCCTGCTCCTCTCGCTGTTGCACGGGCTTTGGATCTAGTCATGG GCTGGCAGGAATTGTGGCCTGGCTTAGGAATAGCTATGAGCCCCACTGGGTTCTGGAGAGCCAGTAGAGATGGGGTGATCTGGGAGGCTG GAGGTAGAGCCTTTCTTTTCCGTTACAACCTTGCCTAGCATGGAGTTATTTCTAAAATGGGAACTTTGGTCTAGGAGAAGGGGTGGCACC ATATGAAACGGCATTCCTTGGACAGGGTGACTTCCTTATCGTTTATTTGGTGATTTTTTGTTTTGTTTTGTTTGAGACAGGATCTTGCTC TGTTTCCCAGGCTGTATTACAGTGGCACAATCTCAGCTCACTGCAAACTCTGCCTCCCGGGCTCAAGCAATCCTCCTGCCTGAGCCAACT GAGTAGCTGGGACTGTAAGCATAGACCACCATGTGCCCAGCTAATTTTTGTAGAGACAGGGTTTCTCCATGTTGCCCAGGTACGTCTGAA ACTCCTGGGCTTAAGTGATCCACCCACCTCAGCCTCCCAAAGTGCTGGGATTATAGGCATGAGCCACTGTGCCCGGCCTCCTCCTTGTTA TGATCAAATTAGACTGTGCCTGGTTGGGTGGTAAGATCACTCTGAAAGAAAGCTCACTGTGAAGAGATGAAAGGTGGAGGCAGAGCTGTG AGGTCATGGGGAAAAGCCTGCTTTCCTTATAAGTCCTGCTGTTCATGTTGGAATAAGGATCTGCTCTTCCTTGTTTCCATGCATTTTGCA GGATTCCAGGTACCATTACCACACTCTTCTGACCCATGAAACCAACTGGCTGCTCACACATCACCAAACAGGTTGGGGGTTAGCCTTCAG CACAGGTGGATACATCTGGGATTCACTGAGATTCCTGCCCTCTCCTGCTTCCTAGTGGTTTGGGACAGGCCCTCTGCCCATCGTCAGCAG TTTTTTGCTTTCATACAAACCTGGAAGGCACTGGCATCTGCCTAGGAAAGTGGATCTGTGAAGAACAGATGAACTCAATCCTTTCTGGAG TCTGACAAAGAAGGGATAGGCTTCCTTGACATTGCCTGTCCTGACAAGGCCTCCCTGACATTACTCCTCCAATTTCACAGTTACCTTCTG TAAATCTATTTTCTCATCTACTGAATAGAATCAGGCGCCCTTTTTGTCTTCCCACCTCTTATCTCTTGGCAATTTTAAGGGGAATTAATG CAAGAACAACTTTAGTGTCTCTTGGGAAAACAAGCCAACCAAATACAAAACCCATTAAGCCTACTAGGGTGAGTCCTCTTAACATGGGAA GGCGATGATTATGCAAACACCGGAGTTCCCTCCTCTTCAGTTCCTAAGAATAAAGAACAGGTATCAAGAACTTTCTTTAAAGTTAGTGTA ACTATAGTTAACAAAGTATCCATTGAAGTTTAGTGCCTGTAGGACTGAGCCAGTGCTTTATCAACCCAACACATCATCACCATGTGCATA CTCTAGAAAAAAAAATAGCTTCCTTAAAAGTTACAGAGGCTCTTAACGTGTTAAAACCGAAAAATCACATTTTTCTTGATTTCAAATATG TTCTACGGCCTTACTGTTGGGATGATATTTAGTATGTAACTTAGCATTCCAATTTCTCAAGAATTTTTAGGCCGGGTGCGGTGGCTCATG CCTGTAATCCCAGCACTTTGGGAGGCCGAGGTGGGCGGACCACGAGGTCAGGAGATCGAGACCATCCTGGCTAACACGGTACCCCGTCTC >58040_58040_4_NDUFA10-SGPP2_NDUFA10_chr2_240929491_ENST00000252711_SGPP2_chr2_223386486_ENST00000321276_length(amino acids)=606AA_BP=333 MALRLLKLAATSASARVVAAGAQRVRGIHSSVQCKLRYGMWHFLLGDKASKRLTERSRVITVDGNICTGKGKLAKEIAEKLGFKHFPEAG IHYPDSTTGDGKPLATDYNGNCSLEKFYDDPRSNDGNSYRLQSWLYSSRLLQYSDALEHLLTTGQGVVLERSIFSDFVFLEAMYNQGFIR KQCVDHYNEVKSVTICDYLPPHLVIYIDVPVPEVQRRIQKKGDPHEMKITSAYLQDIENAYKKTFLPEMSEKCEVLQYSAREAQDSKKVV EDIEYLKFDKGPWLKQDNRTLYHLRLLVQDKFEVLNYTSIPIFLPEVTIGAHQTDRVLHQFRELVMYIGQVAKDVLKWPRPSSPPVVKLE KRLIAEYGMPSTHAMAATAIAFTLLISTMDRYQYPFVLGLVMAVVFSTLVCLSRLYTGMHTVLDVLGGVLITALLIVLTYPAWTFIDCLD SASPLFPVCVIVVPFFLCYNYPVSDYYSPTRADTTTILAAGAGVTIGFWINHFFQLVSKPAESLPVIQNIPPLTTYMLVLGLTKFAVGIV -------------------------------------------------------------- >58040_58040_5_NDUFA10-SGPP2_NDUFA10_chr2_240929491_ENST00000307300_SGPP2_chr2_223386486_ENST00000321276_length(transcript)=3984nt_BP=1112nt GATCCTGAGCTGACCGGGTAGCCATGGCCTTGCGGCTCCTGAAGCTGGCAGCGACGTCCGCGTCCGCCCGGGTCGTGGCGGCGGGCGCCC AGCGCGTGAGAGGAATTCATAGCAGTGTGCAGTGCAAACTGCGCTATGGAATGTGGCATTTCCTACTTGGGGATAAAGCAAGCAAAAGAC TGACAGAACGCAGCAGAGTGATAACTGTAGATGGCAATATATGTACTGGAAAAGGCAAACTTGCAAAAGAAATAGCAGAGAAACTAGGCT TCAAGCACTTTCCTGAAGCGGGGATTCATTATCCAGACAGTACCACAGGAGATGGGAAGCCCCTCGCCACCGACTATAATGGCAACTGTA GTTTGGAGAAATTTTACGATGATCCGAGAAGCAATGATGGCAACAGTTACCGCCTGCAGTCCTGGTTGTACAGCAGTCGCCTGCTGCAGT ACTCAGATGCCTTGGAGCACTTGCTGACCACAGGACAAGGTGTTGTGTTGGAGCGCTCCATCTTCAGTGACTTTGTGTTCCTGGAGGCGA TGTACAACCAGGGATTCATCCGAAAGCAGTGTGAGTCAGCATTGCAGACCCACTTCTGGACTGGGGTGGCTGGAGCCAGTGGAAAGCTGG AATCTGGGAGCTCAGAGGAAGTACTGTTGATTAATGAAAGAGGAGGCCGAAGCAAGCCAGGTGTGGACCACTACAACGAGGTGAAGAGCG TCACCATCTGCGATTACCTGCCCCCCCACCTGGTGATTTACATCGATGTGCCCGTTCCAGAGCCACATGAAATGAAGATCACCTCTGCCT ATCTACAGGACATTGAGAATGCCTATAAGAAAACCTTTCTCCCTGAGATGAGTGAAAAATGTGAGGTTTTACAATATTCTGCAAGGGAAG CTCAAGATTCAAAAAAGGTGGTAGAGGACATTGAATACCTGAAGTTCGATAAAGGGCCGTGGCTCAAGCAGGACAATCGCACTTTATACC ACCTGCGATTACTGGTTCAGGATAAGTTTGAGGTGCTGAATTACACAAGCATTCCTATCTTTCTCCCGGAAGTCACCATTGGAGCTCATC AGACTGACCGTGTCTTACATCAGTTCAGAGAGTTGGTGATGTATATTGGCCAAGTGGCCAAGGATGTCTTGAAGTGGCCCCGTCCCTCCT CCCCTCCAGTTGTAAAACTGGAAAAGAGACTGATCGCTGAATATGGAATGCCATCCACCCACGCCATGGCGGCCACTGCCATTGCCTTCA CCCTCCTTATCTCTACTATGGACAGATACCAGTATCCATTTGTGTTGGGACTGGTGATGGCCGTGGTGTTTTCCACCTTGGTGTGTCTCA GCAGGCTCTACACTGGGATGCATACGGTCCTGGATGTGCTGGGTGGCGTCCTGATCACCGCACTCCTCATCGTCCTCACCTACCCTGCCT GGACCTTCATCGACTGCCTGGACTCGGCCAGCCCCCTCTTCCCCGTGTGTGTCATAGTTGTGCCATTCTTCCTGTGTTACAATTACCCTG TTTCTGATTACTACAGCCCAACCCGGGCGGACACCACCACCATTCTGGCTGCCGGGGCTGGAGTGACCATAGGATTCTGGATCAACCATT TCTTCCAGCTTGTATCCAAGCCCGCTGAATCTCTCCCTGTTATTCAGAACATCCCACCACTCACCACCTACATGTTAGTTTTGGGTCTGA CCAAATTTGCAGTGGGAATTGTGTTGATCCTCTTGGTTCGTCAGCTTGTACAAAATCTCTCACTGCAAGTATTATACTCATGGTTCAAGG TGGTCACCAGGAACAAGGAGGCCAGGCGGAGACTGGAGATTGAAGTGCCTTACAAGTTTGTTACCTACACATCTGTTGGCATCTGCGCTA CAACCTTTGTGCCGATGCTTCACAGGTTTCTGGGATTACCCTGAGTCTCAAACAGTTGGAAACTAGCCCACTGGACATGAAAGCCAAGAC ATAGGAAAGTTATTGGTAGGCAAATCTTGACAACTTATTTTTCTTTAACAACAACAAAAAGTCATACGGCTGTCTTGCTACTACCAGATA AATGATGCTGCTGTGTGAAAGGAAGAACTGTCTCATAGCGGTCATTGGTCGTCCGTGGTGGTTGGTTGTGCTACAGTTGAACCCAGGCTA AAGACCATAATCCGGATCTTTAAAGGCACACACCGCGCCCCCCCCCCCCCCGCCCGGCCCCTGCTCCTCTCGCTGTTGCACGGGCTTTGG ATCTAGTCATGGGCTGGCAGGAATTGTGGCCTGGCTTAGGAATAGCTATGAGCCCCACTGGGTTCTGGAGAGCCAGTAGAGATGGGGTGA TCTGGGAGGCTGGAGGTAGAGCCTTTCTTTTCCGTTACAACCTTGCCTAGCATGGAGTTATTTCTAAAATGGGAACTTTGGTCTAGGAGA AGGGGTGGCACCATATGAAACGGCATTCCTTGGACAGGGTGACTTCCTTATCGTTTATTTGGTGATTTTTTGTTTTGTTTTGTTTGAGAC AGGATCTTGCTCTGTTTCCCAGGCTGTATTACAGTGGCACAATCTCAGCTCACTGCAAACTCTGCCTCCCGGGCTCAAGCAATCCTCCTG CCTGAGCCAACTGAGTAGCTGGGACTGTAAGCATAGACCACCATGTGCCCAGCTAATTTTTGTAGAGACAGGGTTTCTCCATGTTGCCCA GGTACGTCTGAAACTCCTGGGCTTAAGTGATCCACCCACCTCAGCCTCCCAAAGTGCTGGGATTATAGGCATGAGCCACTGTGCCCGGCC TCCTCCTTGTTATGATCAAATTAGACTGTGCCTGGTTGGGTGGTAAGATCACTCTGAAAGAAAGCTCACTGTGAAGAGATGAAAGGTGGA GGCAGAGCTGTGAGGTCATGGGGAAAAGCCTGCTTTCCTTATAAGTCCTGCTGTTCATGTTGGAATAAGGATCTGCTCTTCCTTGTTTCC ATGCATTTTGCAGGATTCCAGGTACCATTACCACACTCTTCTGACCCATGAAACCAACTGGCTGCTCACACATCACCAAACAGGTTGGGG GTTAGCCTTCAGCACAGGTGGATACATCTGGGATTCACTGAGATTCCTGCCCTCTCCTGCTTCCTAGTGGTTTGGGACAGGCCCTCTGCC CATCGTCAGCAGTTTTTTGCTTTCATACAAACCTGGAAGGCACTGGCATCTGCCTAGGAAAGTGGATCTGTGAAGAACAGATGAACTCAA TCCTTTCTGGAGTCTGACAAAGAAGGGATAGGCTTCCTTGACATTGCCTGTCCTGACAAGGCCTCCCTGACATTACTCCTCCAATTTCAC AGTTACCTTCTGTAAATCTATTTTCTCATCTACTGAATAGAATCAGGCGCCCTTTTTGTCTTCCCACCTCTTATCTCTTGGCAATTTTAA GGGGAATTAATGCAAGAACAACTTTAGTGTCTCTTGGGAAAACAAGCCAACCAAATACAAAACCCATTAAGCCTACTAGGGTGAGTCCTC TTAACATGGGAAGGCGATGATTATGCAAACACCGGAGTTCCCTCCTCTTCAGTTCCTAAGAATAAAGAACAGGTATCAAGAACTTTCTTT AAAGTTAGTGTAACTATAGTTAACAAAGTATCCATTGAAGTTTAGTGCCTGTAGGACTGAGCCAGTGCTTTATCAACCCAACACATCATC ACCATGTGCATACTCTAGAAAAAAAAATAGCTTCCTTAAAAGTTACAGAGGCTCTTAACGTGTTAAAACCGAAAAATCACATTTTTCTTG ATTTCAAATATGTTCTACGGCCTTACTGTTGGGATGATATTTAGTATGTAACTTAGCATTCCAATTTCTCAAGAATTTTTAGGCCGGGTG CGGTGGCTCATGCCTGTAATCCCAGCACTTTGGGAGGCCGAGGTGGGCGGACCACGAGGTCAGGAGATCGAGACCATCCTGGCTAACACG >58040_58040_5_NDUFA10-SGPP2_NDUFA10_chr2_240929491_ENST00000307300_SGPP2_chr2_223386486_ENST00000321276_length(amino acids)=636AA_BP=363 MALRLLKLAATSASARVVAAGAQRVRGIHSSVQCKLRYGMWHFLLGDKASKRLTERSRVITVDGNICTGKGKLAKEIAEKLGFKHFPEAG IHYPDSTTGDGKPLATDYNGNCSLEKFYDDPRSNDGNSYRLQSWLYSSRLLQYSDALEHLLTTGQGVVLERSIFSDFVFLEAMYNQGFIR KQCESALQTHFWTGVAGASGKLESGSSEEVLLINERGGRSKPGVDHYNEVKSVTICDYLPPHLVIYIDVPVPEPHEMKITSAYLQDIENA YKKTFLPEMSEKCEVLQYSAREAQDSKKVVEDIEYLKFDKGPWLKQDNRTLYHLRLLVQDKFEVLNYTSIPIFLPEVTIGAHQTDRVLHQ FRELVMYIGQVAKDVLKWPRPSSPPVVKLEKRLIAEYGMPSTHAMAATAIAFTLLISTMDRYQYPFVLGLVMAVVFSTLVCLSRLYTGMH TVLDVLGGVLITALLIVLTYPAWTFIDCLDSASPLFPVCVIVVPFFLCYNYPVSDYYSPTRADTTTILAAGAGVTIGFWINHFFQLVSKP AESLPVIQNIPPLTTYMLVLGLTKFAVGIVLILLVRQLVQNLSLQVLYSWFKVVTRNKEARRRLEIEVPYKFVTYTSVGICATTFVPMLH -------------------------------------------------------------- >58040_58040_6_NDUFA10-SGPP2_NDUFA10_chr2_240929491_ENST00000404554_SGPP2_chr2_223386486_ENST00000321276_length(transcript)=3876nt_BP=1004nt TAGCCATGGCCTTGCGGCTCCTGAAGCTGGCAGCGACGTCCGCGTCCGCCCGGGTCGTGGCGGCGGGCGCCCAGCGCGTGAGAGGAATTC ATAGCAGTGTGCAGTGCAAACTGCGCTATGGAATGTGGCATTTCCTACTTGGGGATAAAGCAAGCAAAAGACTGACAGAACGCAGCAGAG TGATAACTGTAGATGGCAATATATGTACTGGAAAAGGCAAACTTGCAAAAGAAATAGCAGAGAAACTAGGCTTCAAGCACTTTCCTGAAG CGGGGATTCATTATCCAGACAGTACCACAGGAGATGGGAAGCCCCTCGCCACCGACTATAATGGCAACTGTAGTTTGGAGAAATTTTACG ATGATCCGAGAAGCAATGATGGCAACAGTTACCGCCTGCAGTCCTGGTTGTACAGCAGTCGCCTGCTGCAGTACTCAGATGCCTTGGAGC ACTTGCTGACCACAGGACAAGGTGTTGTGTTGGAGCGCTCCATCTTCAGTGACTTTGTGTTCCTGGAGGCGATGTACAACCAGGGATTCA TCCGAAAGCAGTGTGTGGACCACTACAACGAGGTGAAGAGCGTCACCATCTGCGATTACCTGCCCCCCCACCTGGTGATTTACATCGATG TGCCCGTTCCAGAGGTCCAGAGGCGGATTCAGAAGAAAGGAGATCCACATGAAATGAAGATCACCTCTGCCTATCTACAGGACATTGAGA ATGCCTATAAGAAAACCTTTCTCCCTGAGATGAGTGAAAAATGTGAGGTTTTACAATATTCTGCAAGGGAAGCTCAAGATTCAAAAAAGG TGGTAGAGGACATTGAATACCTGAAGTTCGATAAAGGGCCGTGGCTCAAGCAGGACAATCGCACTTTATACCACCTGCGATTACTGGTTC AGGATAAGTTTGAGGTGCTGAATTACACAAGCATTCCTATCTTTCTCCCGGAAGTCACCATTGGAGCTCATCAGACTGACCGTGTCTTAC ATCAGTTCAGAGAGTTGGTGATGTATATTGGCCAAGTGGCCAAGGATGTCTTGAAGTGGCCCCGTCCCTCCTCCCCTCCAGTTGTAAAAC TGGAAAAGAGACTGATCGCTGAATATGGAATGCCATCCACCCACGCCATGGCGGCCACTGCCATTGCCTTCACCCTCCTTATCTCTACTA TGGACAGATACCAGTATCCATTTGTGTTGGGACTGGTGATGGCCGTGGTGTTTTCCACCTTGGTGTGTCTCAGCAGGCTCTACACTGGGA TGCATACGGTCCTGGATGTGCTGGGTGGCGTCCTGATCACCGCACTCCTCATCGTCCTCACCTACCCTGCCTGGACCTTCATCGACTGCC TGGACTCGGCCAGCCCCCTCTTCCCCGTGTGTGTCATAGTTGTGCCATTCTTCCTGTGTTACAATTACCCTGTTTCTGATTACTACAGCC CAACCCGGGCGGACACCACCACCATTCTGGCTGCCGGGGCTGGAGTGACCATAGGATTCTGGATCAACCATTTCTTCCAGCTTGTATCCA AGCCCGCTGAATCTCTCCCTGTTATTCAGAACATCCCACCACTCACCACCTACATGTTAGTTTTGGGTCTGACCAAATTTGCAGTGGGAA TTGTGTTGATCCTCTTGGTTCGTCAGCTTGTACAAAATCTCTCACTGCAAGTATTATACTCATGGTTCAAGGTGGTCACCAGGAACAAGG AGGCCAGGCGGAGACTGGAGATTGAAGTGCCTTACAAGTTTGTTACCTACACATCTGTTGGCATCTGCGCTACAACCTTTGTGCCGATGC TTCACAGGTTTCTGGGATTACCCTGAGTCTCAAACAGTTGGAAACTAGCCCACTGGACATGAAAGCCAAGACATAGGAAAGTTATTGGTA GGCAAATCTTGACAACTTATTTTTCTTTAACAACAACAAAAAGTCATACGGCTGTCTTGCTACTACCAGATAAATGATGCTGCTGTGTGA AAGGAAGAACTGTCTCATAGCGGTCATTGGTCGTCCGTGGTGGTTGGTTGTGCTACAGTTGAACCCAGGCTAAAGACCATAATCCGGATC TTTAAAGGCACACACCGCGCCCCCCCCCCCCCCGCCCGGCCCCTGCTCCTCTCGCTGTTGCACGGGCTTTGGATCTAGTCATGGGCTGGC AGGAATTGTGGCCTGGCTTAGGAATAGCTATGAGCCCCACTGGGTTCTGGAGAGCCAGTAGAGATGGGGTGATCTGGGAGGCTGGAGGTA GAGCCTTTCTTTTCCGTTACAACCTTGCCTAGCATGGAGTTATTTCTAAAATGGGAACTTTGGTCTAGGAGAAGGGGTGGCACCATATGA AACGGCATTCCTTGGACAGGGTGACTTCCTTATCGTTTATTTGGTGATTTTTTGTTTTGTTTTGTTTGAGACAGGATCTTGCTCTGTTTC CCAGGCTGTATTACAGTGGCACAATCTCAGCTCACTGCAAACTCTGCCTCCCGGGCTCAAGCAATCCTCCTGCCTGAGCCAACTGAGTAG CTGGGACTGTAAGCATAGACCACCATGTGCCCAGCTAATTTTTGTAGAGACAGGGTTTCTCCATGTTGCCCAGGTACGTCTGAAACTCCT GGGCTTAAGTGATCCACCCACCTCAGCCTCCCAAAGTGCTGGGATTATAGGCATGAGCCACTGTGCCCGGCCTCCTCCTTGTTATGATCA AATTAGACTGTGCCTGGTTGGGTGGTAAGATCACTCTGAAAGAAAGCTCACTGTGAAGAGATGAAAGGTGGAGGCAGAGCTGTGAGGTCA TGGGGAAAAGCCTGCTTTCCTTATAAGTCCTGCTGTTCATGTTGGAATAAGGATCTGCTCTTCCTTGTTTCCATGCATTTTGCAGGATTC CAGGTACCATTACCACACTCTTCTGACCCATGAAACCAACTGGCTGCTCACACATCACCAAACAGGTTGGGGGTTAGCCTTCAGCACAGG TGGATACATCTGGGATTCACTGAGATTCCTGCCCTCTCCTGCTTCCTAGTGGTTTGGGACAGGCCCTCTGCCCATCGTCAGCAGTTTTTT GCTTTCATACAAACCTGGAAGGCACTGGCATCTGCCTAGGAAAGTGGATCTGTGAAGAACAGATGAACTCAATCCTTTCTGGAGTCTGAC AAAGAAGGGATAGGCTTCCTTGACATTGCCTGTCCTGACAAGGCCTCCCTGACATTACTCCTCCAATTTCACAGTTACCTTCTGTAAATC TATTTTCTCATCTACTGAATAGAATCAGGCGCCCTTTTTGTCTTCCCACCTCTTATCTCTTGGCAATTTTAAGGGGAATTAATGCAAGAA CAACTTTAGTGTCTCTTGGGAAAACAAGCCAACCAAATACAAAACCCATTAAGCCTACTAGGGTGAGTCCTCTTAACATGGGAAGGCGAT GATTATGCAAACACCGGAGTTCCCTCCTCTTCAGTTCCTAAGAATAAAGAACAGGTATCAAGAACTTTCTTTAAAGTTAGTGTAACTATA GTTAACAAAGTATCCATTGAAGTTTAGTGCCTGTAGGACTGAGCCAGTGCTTTATCAACCCAACACATCATCACCATGTGCATACTCTAG AAAAAAAAATAGCTTCCTTAAAAGTTACAGAGGCTCTTAACGTGTTAAAACCGAAAAATCACATTTTTCTTGATTTCAAATATGTTCTAC GGCCTTACTGTTGGGATGATATTTAGTATGTAACTTAGCATTCCAATTTCTCAAGAATTTTTAGGCCGGGTGCGGTGGCTCATGCCTGTA ATCCCAGCACTTTGGGAGGCCGAGGTGGGCGGACCACGAGGTCAGGAGATCGAGACCATCCTGGCTAACACGGTACCCCGTCTCTACTGA >58040_58040_6_NDUFA10-SGPP2_NDUFA10_chr2_240929491_ENST00000404554_SGPP2_chr2_223386486_ENST00000321276_length(amino acids)=606AA_BP=333 MALRLLKLAATSASARVVAAGAQRVRGIHSSVQCKLRYGMWHFLLGDKASKRLTERSRVITVDGNICTGKGKLAKEIAEKLGFKHFPEAG IHYPDSTTGDGKPLATDYNGNCSLEKFYDDPRSNDGNSYRLQSWLYSSRLLQYSDALEHLLTTGQGVVLERSIFSDFVFLEAMYNQGFIR KQCVDHYNEVKSVTICDYLPPHLVIYIDVPVPEVQRRIQKKGDPHEMKITSAYLQDIENAYKKTFLPEMSEKCEVLQYSAREAQDSKKVV EDIEYLKFDKGPWLKQDNRTLYHLRLLVQDKFEVLNYTSIPIFLPEVTIGAHQTDRVLHQFRELVMYIGQVAKDVLKWPRPSSPPVVKLE KRLIAEYGMPSTHAMAATAIAFTLLISTMDRYQYPFVLGLVMAVVFSTLVCLSRLYTGMHTVLDVLGGVLITALLIVLTYPAWTFIDCLD SASPLFPVCVIVVPFFLCYNYPVSDYYSPTRADTTTILAAGAGVTIGFWINHFFQLVSKPAESLPVIQNIPPLTTYMLVLGLTKFAVGIV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NDUFA10-SGPP2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NDUFA10-SGPP2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NDUFA10-SGPP2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies