
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NELFA-RGS12 (FusionGDB2 ID:58553) |
Fusion Gene Summary for NELFA-RGS12 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NELFA-RGS12 | Fusion gene ID: 58553 | Hgene | Tgene | Gene symbol | NELFA | RGS12 | Gene ID | 7469 | 6002 |
| Gene name | negative elongation factor complex member A | regulator of G protein signaling 12 | |
| Synonyms | NELF-A|P/OKcl.15|WHSC2 | - | |
| Cytomap | 4p16.3 | 4p16.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | negative elongation factor Awolf-Hirschhorn syndrome candidate 2 protein | regulator of G-protein signaling 12regulator of G-protein signalling 12 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9H3P2 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000382882, ENST00000411638, ENST00000542778, | ENST00000338806, ENST00000508158, ENST00000538395, ENST00000306648, ENST00000336727, ENST00000344733, ENST00000382788, ENST00000543385, | |
| Fusion gene scores | * DoF score | 3 X 2 X 3=18 | 6 X 8 X 5=240 |
| # samples | 3 | 8 | |
| ** MAII score | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(8/240*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NELFA [Title/Abstract] AND RGS12 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NELFA(2010477)-RGS12(3344664), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across NELFA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RGS12 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CG-5721-01A | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
Top |
Fusion Gene ORF analysis for NELFA-RGS12 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000382882 | ENST00000338806 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5CDS-intron | ENST00000382882 | ENST00000508158 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5CDS-intron | ENST00000382882 | ENST00000538395 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5CDS-intron | ENST00000411638 | ENST00000338806 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5CDS-intron | ENST00000411638 | ENST00000508158 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5CDS-intron | ENST00000411638 | ENST00000538395 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5UTR-3CDS | ENST00000542778 | ENST00000306648 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5UTR-3CDS | ENST00000542778 | ENST00000336727 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5UTR-3CDS | ENST00000542778 | ENST00000344733 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5UTR-3CDS | ENST00000542778 | ENST00000382788 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5UTR-3CDS | ENST00000542778 | ENST00000543385 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5UTR-intron | ENST00000542778 | ENST00000338806 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5UTR-intron | ENST00000542778 | ENST00000508158 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| 5UTR-intron | ENST00000542778 | ENST00000538395 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000382882 | ENST00000306648 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000382882 | ENST00000336727 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000382882 | ENST00000344733 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000382882 | ENST00000382788 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000382882 | ENST00000543385 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000411638 | ENST00000306648 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000411638 | ENST00000336727 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000411638 | ENST00000344733 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000411638 | ENST00000382788 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| In-frame | ENST00000411638 | ENST00000543385 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000382882 | NELFA | chr4 | 2010477 | - | ENST00000543385 | RGS12 | chr4 | 3344664 | + | 2128 | 1361 | 349 | 1104 | 251 |
| ENST00000382882 | NELFA | chr4 | 2010477 | - | ENST00000336727 | RGS12 | chr4 | 3344664 | + | 4816 | 1361 | 1118 | 3610 | 830 |
| ENST00000382882 | NELFA | chr4 | 2010477 | - | ENST00000344733 | RGS12 | chr4 | 3344664 | + | 4045 | 1361 | 1118 | 3823 | 901 |
| ENST00000382882 | NELFA | chr4 | 2010477 | - | ENST00000382788 | RGS12 | chr4 | 3344664 | + | 4889 | 1361 | 1118 | 3610 | 830 |
| ENST00000382882 | NELFA | chr4 | 2010477 | - | ENST00000306648 | RGS12 | chr4 | 3344664 | + | 3073 | 1361 | 1118 | 2953 | 611 |
| ENST00000411638 | NELFA | chr4 | 2010477 | - | ENST00000543385 | RGS12 | chr4 | 3344664 | + | 993 | 226 | 345 | 992 | 216 |
| ENST00000411638 | NELFA | chr4 | 2010477 | - | ENST00000336727 | RGS12 | chr4 | 3344664 | + | 3681 | 226 | 16 | 2475 | 819 |
| ENST00000411638 | NELFA | chr4 | 2010477 | - | ENST00000344733 | RGS12 | chr4 | 3344664 | + | 2910 | 226 | 16 | 2688 | 890 |
| ENST00000411638 | NELFA | chr4 | 2010477 | - | ENST00000382788 | RGS12 | chr4 | 3344664 | + | 3754 | 226 | 16 | 2475 | 819 |
| ENST00000411638 | NELFA | chr4 | 2010477 | - | ENST00000306648 | RGS12 | chr4 | 3344664 | + | 1938 | 226 | 16 | 1818 | 600 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000382882 | ENST00000543385 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.45060006 | 0.5494 |
| ENST00000382882 | ENST00000336727 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.006039969 | 0.99396 |
| ENST00000382882 | ENST00000344733 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.007134657 | 0.9928653 |
| ENST00000382882 | ENST00000382788 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.005475989 | 0.994524 |
| ENST00000382882 | ENST00000306648 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.020918554 | 0.9790814 |
| ENST00000411638 | ENST00000543385 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.10848878 | 0.8915112 |
| ENST00000411638 | ENST00000336727 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.004238312 | 0.9957617 |
| ENST00000411638 | ENST00000344733 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.005604958 | 0.994395 |
| ENST00000411638 | ENST00000382788 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.003680404 | 0.99631953 |
| ENST00000411638 | ENST00000306648 | NELFA | chr4 | 2010477 | - | RGS12 | chr4 | 3344664 | + | 0.017321445 | 0.98267853 |
Top |
Fusion Genomic Features for NELFA-RGS12 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NELFA | chr4 | 2010476 | - | RGS12 | chr4 | 3344663 | + | 6.38E-05 | 0.9999361 |
| NELFA | chr4 | 2010476 | - | RGS12 | chr4 | 3344663 | + | 6.38E-05 | 0.9999361 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
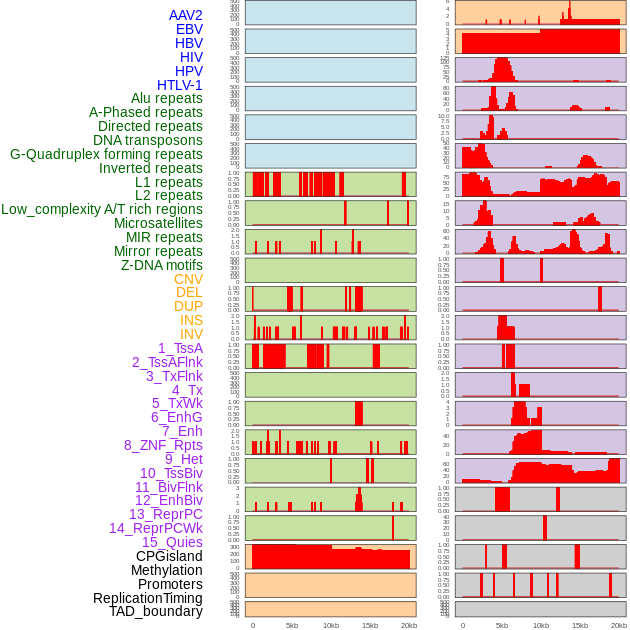 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
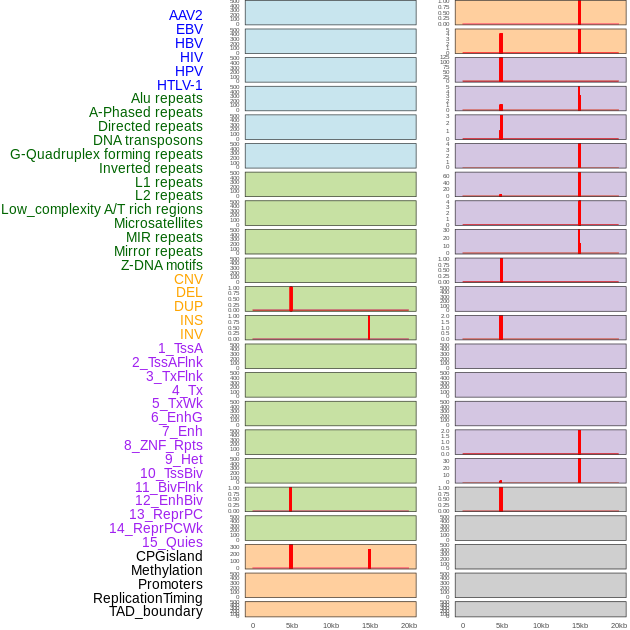 |
Top |
Fusion Protein Features for NELFA-RGS12 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr4:2010477/chr4:3344664) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NELFA | . |
| FUNCTION: Essential component of the NELF complex, a complex that negatively regulates the elongation of transcription by RNA polymerase II. The NELF complex, which acts via an association with the DSIF complex and causes transcriptional pausing, is counteracted by the P-TEFb kinase complex. {ECO:0000269|PubMed:10199401, ECO:0000269|PubMed:12563561, ECO:0000269|PubMed:12612062}.; FUNCTION: (Microbial infection) The NELF complex is involved in HIV-1 latency possibly involving recruitment of PCF11 to paused RNA polymerase II. {ECO:0000269|PubMed:23884411}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000306648 | 0 | 15 | 1034_1104 | 25 | 556.0 | Domain | RBD 2 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000306648 | 0 | 15 | 1187_1209 | 25 | 556.0 | Domain | GoLoco | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000306648 | 0 | 15 | 228_340 | 25 | 556.0 | Domain | PID | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000306648 | 0 | 15 | 22_98 | 25 | 556.0 | Domain | PDZ | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000306648 | 0 | 15 | 715_832 | 25 | 556.0 | Domain | RGS | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000306648 | 0 | 15 | 962_1032 | 25 | 556.0 | Domain | RBD 1 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000336727 | 1 | 17 | 1034_1104 | 627 | 1377.0 | Domain | RBD 2 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000336727 | 1 | 17 | 1187_1209 | 627 | 1377.0 | Domain | GoLoco | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000336727 | 1 | 17 | 715_832 | 627 | 1377.0 | Domain | RGS | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000336727 | 1 | 17 | 962_1032 | 627 | 1377.0 | Domain | RBD 1 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000338806 | 0 | 16 | 1034_1104 | 0 | 800.0 | Domain | RBD 2 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000338806 | 0 | 16 | 1187_1209 | 0 | 800.0 | Domain | GoLoco | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000338806 | 0 | 16 | 228_340 | 0 | 800.0 | Domain | PID | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000338806 | 0 | 16 | 22_98 | 0 | 800.0 | Domain | PDZ | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000338806 | 0 | 16 | 715_832 | 0 | 800.0 | Domain | RGS | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000338806 | 0 | 16 | 962_1032 | 0 | 800.0 | Domain | RBD 1 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000344733 | 1 | 18 | 1034_1104 | 627 | 1448.0 | Domain | RBD 2 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000344733 | 1 | 18 | 1187_1209 | 627 | 1448.0 | Domain | GoLoco | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000344733 | 1 | 18 | 715_832 | 627 | 1448.0 | Domain | RGS | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000344733 | 1 | 18 | 962_1032 | 627 | 1448.0 | Domain | RBD 1 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000382788 | 0 | 16 | 1034_1104 | 627 | 1377.0 | Domain | RBD 2 | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000382788 | 0 | 16 | 1187_1209 | 627 | 1377.0 | Domain | GoLoco | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000382788 | 0 | 16 | 715_832 | 627 | 1377.0 | Domain | RGS | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000382788 | 0 | 16 | 962_1032 | 627 | 1377.0 | Domain | RBD 1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NELFA | chr4:2010477 | chr4:3344664 | ENST00000382882 | - | 1 | 11 | 89_248 | 81 | 540.0 | Domain | HDAg |
| Hgene | NELFA | chr4:2010477 | chr4:3344664 | ENST00000411638 | - | 1 | 11 | 89_248 | 70 | 529.0 | Domain | HDAg |
| Hgene | NELFA | chr4:2010477 | chr4:3344664 | ENST00000382882 | - | 1 | 11 | 125_188 | 81 | 540.0 | Region | NELF-C/D-binding |
| Hgene | NELFA | chr4:2010477 | chr4:3344664 | ENST00000382882 | - | 1 | 11 | 189_248 | 81 | 540.0 | Region | RNAPII-binding |
| Hgene | NELFA | chr4:2010477 | chr4:3344664 | ENST00000411638 | - | 1 | 11 | 125_188 | 70 | 529.0 | Region | NELF-C/D-binding |
| Hgene | NELFA | chr4:2010477 | chr4:3344664 | ENST00000411638 | - | 1 | 11 | 189_248 | 70 | 529.0 | Region | RNAPII-binding |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000336727 | 1 | 17 | 228_340 | 627 | 1377.0 | Domain | PID | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000336727 | 1 | 17 | 22_98 | 627 | 1377.0 | Domain | PDZ | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000344733 | 1 | 18 | 228_340 | 627 | 1448.0 | Domain | PID | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000344733 | 1 | 18 | 22_98 | 627 | 1448.0 | Domain | PDZ | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000382788 | 0 | 16 | 228_340 | 627 | 1377.0 | Domain | PID | |
| Tgene | RGS12 | chr4:2010477 | chr4:3344664 | ENST00000382788 | 0 | 16 | 22_98 | 627 | 1377.0 | Domain | PDZ |
Top |
Fusion Gene Sequence for NELFA-RGS12 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58553_58553_1_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000306648_length(transcript)=3073nt_BP=1361nt GTGACTTCCGCAGGACTGCCAAGTTCAAGCCGCCAGGGCCAGGGCACTGCTAGCAGCTGGGCTGAGCCCTGTTCTCCCGGCGTTCCCACC GCCCAGTGGCAATAGCTGTGAACGGCGGCAGGAGCATGGCAGTGGAACAATAAGGAAAAGATCTTTTAAAAAAAAGATATAATACAGAAG CCAAGCAAGGCGGCCCCGACCTGTAACCCCAGCACTCTGGGAGGCAGAGGCGGGCGGGCGGATCGCTTGAGCCCAGGAGTTTGAGACCAG CCTGGCCAACATAGGAAGGCCTCGTCAAAAAGACAAAAGGGTAAAACGAATTTAATAAAATGAAGTTTAACTTTTACTCATGTTTGTATC TAATGACAAGCTTTTAAAACTGAAAAGTTCACTACTGGCTCCTGCCTGGCGGCTCCAGCCCGACTGGGGGCCGGGGCCTCCCTGCACTGT GGGGTCACGAGTGCCCCTGGACAGCTCCCGAGCGCCCTCCGACCCGCATGCTCAGCGCAGCCCCGTCGGCGGCGCGCCACGGGCAGAGCG GGCTCAGCGGGGGACGGAAGCTCAGCGCTGCGACCGGGATCCCGCAGGCTCGCTCCGCAGGGCCGCGGCTCCTCTCCGTGCAGGTGCTGG GCCCGCGGGGGCGGGGCGTCCACACGGTCCGCGCCGAGACCCAAGCGGGGAAAAAGCGAAGAGCGGACAGCGGGGCAGGTGCCACAGGGA GCCTCCGCCCCACCGCGCGAGCAGCAAGTCTGCGGCGCTTGACACCTGCACTGCGAATGCCAGGCCGCAGCCCGGGCTCCCAAGACGCGA ATACGCGCGCCTGCTCGTGACGTCATTTTTTGCGGTCTTCCCGAGAGCCAGCAGAGGGCGCCGCCATGATGTTTTACGGAAGCCGATAGT CCTTGCTCAGCGGCACCCCGTCCTTCCGGCTCTCGGCTTTGCCACAAAGCTTCCCGAAGACGCGGCCGCTACCCGGAGACGCGGTCGCCA CCCAGAAGCGCTCTCCCGGGAAGCCCCGCTCGTGGGACCGCGCCACCTGCGCCGCCTCTGCGGCCCGCAGCCCGACGGGCGCCGCCATGT TGGGGTCCTAGCGAGGGACGCGTAGGTGTCTTCATAAGATGCCGGGGCAGCGGCGCGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGA GCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGCGCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGG TCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAAGTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCA CGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCAACGCACGTCTGCTCGGAGATCATTTGGGAGATCCA AGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGTCTGCAACTGTGTCTGATGGCGAGTTGACGGGCGCCGACCTGAAGGACTGCG TCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCGGCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCG TGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTTTCTAAGGAAAGAATTCAGTGAAGAAAACATTTTAT TCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCTTTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTC TCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGACGACGTCCTCCGCGCACCTCACCCAGACATGTTCA AGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTTTCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGG CGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGCTTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTG TGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGAAGAGCTGGGGGATGAGGACAGCGAGAAGAAGCGGA AAGGCGCGTTTTTCTCGTGGTCGCGGACCAGGAGCACCGGGAGGTCCCAGAAAAAGAGGGAGCACGGGGACCACGCAGACGACGCCCTGC ATGCCAATGGAGGCCTGTGTCGCCGAGAGTCGCAGGGCTCTGTGTCCTCTGCGGGGAGCCTGGACCTGTCGGAGGCCTGCAGGACTTTGG CACCCGAGAAGGACAAGGCCACCAAGCACTGCTGCATTCATCTCCCGGATGGGACATCCTGCGTGGTGGCTGTCAAGGCGGGCTTCTCCA TCAAAGACATCCTGTCCGGACTCTGTGAGCGGCATGGCATCAACGGGGCGGCCGCGGACCTCTTCCTGGTGGGCGGGGACAAGCCTCTGG TGCTGCACCAAGACAGTAGCATCTTGGAGTCAAGGGACCTGCGCCTAGAAAAGCGCACCTTGTTTCGGCTGGATCTTGTTCCGATTAACC GGTCAGTGGGACTCAAGGCCAAGCCCACCAAGCCCGTCACGGAGGTGCTGCGGCCCGTGGTGGCCAGATACGGCCTGGACCTCAGTGGCC TGCTGGTGAGGCTGAGTGGAGAGAAGGAGCCCCTGGACCTTGGCGCCCCTATATCGAGTCTGGACGGACAGCGGGTTGTCTTGGAGGAGA AGGATCCTTCCAGAGGAAAGGCATCCGCAGATAAACAGAAAGGTGTGCCAGTGAAACAGAACACAGCTGTAAATTCCAGCTCCAGAAACC ACTCGGCTACGAGTTTTTTGAGCTTATTTCCAAAGCTCAGAGCAACAGAGCAGATGACCAACGTGGGCTGCTAAGGAAGGAAGACCTGGT GTTGCCAGAGTTCCTCCGTTTACCTCCTGGTTCCACAGAACTCACCCTCCCCACTCCAGCTGCTGTGGCCAAGGGCTTTAGCAAGAGAAG >58553_58553_1_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000306648_length(amino acids)=611AA_BP=81 MPGQRRALSPKMASMRESDTGLWLHNKLGATDELWAPPSIASLLTAAVIDNIRLCFHGLSSAVKLKLLLGTLHLPRRTVDEGSKFGRGTG LTQPSQRTSARRSFGRSKRFSITRSLDDLESATVSDGELTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGV RYFSDFLRKEFSEENILFWQACEYFNHVPAHDKKELSYRAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKF DSYTRFLKSPLYQECILAEVEGRALPDSQQVPSSPASKHSLGSDHSSVSTPKKLSGKSKSGRSLNEELGDEDSEKKRKGAFFSWSRTRST GRSQKKREHGDHADDALHANGGLCRRESQGSVSSAGSLDLSEACRTLAPEKDKATKHCCIHLPDGTSCVVAVKAGFSIKDILSGLCERHG INGAAADLFLVGGDKPLVLHQDSSILESRDLRLEKRTLFRLDLVPINRSVGLKAKPTKPVTEVLRPVVARYGLDLSGLLVRLSGEKEPLD -------------------------------------------------------------- >58553_58553_2_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000336727_length(transcript)=4816nt_BP=1361nt GTGACTTCCGCAGGACTGCCAAGTTCAAGCCGCCAGGGCCAGGGCACTGCTAGCAGCTGGGCTGAGCCCTGTTCTCCCGGCGTTCCCACC GCCCAGTGGCAATAGCTGTGAACGGCGGCAGGAGCATGGCAGTGGAACAATAAGGAAAAGATCTTTTAAAAAAAAGATATAATACAGAAG CCAAGCAAGGCGGCCCCGACCTGTAACCCCAGCACTCTGGGAGGCAGAGGCGGGCGGGCGGATCGCTTGAGCCCAGGAGTTTGAGACCAG CCTGGCCAACATAGGAAGGCCTCGTCAAAAAGACAAAAGGGTAAAACGAATTTAATAAAATGAAGTTTAACTTTTACTCATGTTTGTATC TAATGACAAGCTTTTAAAACTGAAAAGTTCACTACTGGCTCCTGCCTGGCGGCTCCAGCCCGACTGGGGGCCGGGGCCTCCCTGCACTGT GGGGTCACGAGTGCCCCTGGACAGCTCCCGAGCGCCCTCCGACCCGCATGCTCAGCGCAGCCCCGTCGGCGGCGCGCCACGGGCAGAGCG GGCTCAGCGGGGGACGGAAGCTCAGCGCTGCGACCGGGATCCCGCAGGCTCGCTCCGCAGGGCCGCGGCTCCTCTCCGTGCAGGTGCTGG GCCCGCGGGGGCGGGGCGTCCACACGGTCCGCGCCGAGACCCAAGCGGGGAAAAAGCGAAGAGCGGACAGCGGGGCAGGTGCCACAGGGA GCCTCCGCCCCACCGCGCGAGCAGCAAGTCTGCGGCGCTTGACACCTGCACTGCGAATGCCAGGCCGCAGCCCGGGCTCCCAAGACGCGA ATACGCGCGCCTGCTCGTGACGTCATTTTTTGCGGTCTTCCCGAGAGCCAGCAGAGGGCGCCGCCATGATGTTTTACGGAAGCCGATAGT CCTTGCTCAGCGGCACCCCGTCCTTCCGGCTCTCGGCTTTGCCACAAAGCTTCCCGAAGACGCGGCCGCTACCCGGAGACGCGGTCGCCA CCCAGAAGCGCTCTCCCGGGAAGCCCCGCTCGTGGGACCGCGCCACCTGCGCCGCCTCTGCGGCCCGCAGCCCGACGGGCGCCGCCATGT TGGGGTCCTAGCGAGGGACGCGTAGGTGTCTTCATAAGATGCCGGGGCAGCGGCGCGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGA GCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGCGCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGG TCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAAGTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCA CGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCAACGCACGTCTGCTCGGAGATCATTTGGGAGATCCA AGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGTCTGCAACTGTGTCTGATGGCGAGTTGACGGGCGCCGACCTGAAGGACTGCG TCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCGGCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCG TGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTTTCTAAGGAAAGAATTCAGTGAAGAAAACATTTTAT TCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCTTTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTC TCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGACGACGTCCTCCGCGCACCTCACCCAGACATGTTCA AGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTTTCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGG CGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGCTTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTG TGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGAAGAGCTGGGGGATGAGGACAGCGAGAAGAAGCGGA AAGGCGCGTTTTTCTCGTGGTCGCGGACCAGGAGCACCGGGAGGTCCCAGAAAAAGAGGGAGCACGGGGACCACGCAGACGACGCCCTGC ATGCCAATGGAGGCCTGTGTCGCCGAGAGTCGCAGGGCTCTGTGTCCTCTGCGGGGAGCCTGGACCTGTCGGAGGCCTGCAGGACTTTGG CACCCGAGAAGGACAAGGCCACCAAGCACTGCTGCATTCATCTCCCGGATGGGACATCCTGCGTGGTGGCTGTCAAGGCGGGCTTCTCCA TCAAAGACATCCTGTCCGGACTCTGTGAGCGGCATGGCATCAACGGGGCGGCCGCGGACCTCTTCCTGGTGGGCGGGGACAAGCCTCTGG TGCTGCACCAAGACAGTAGCATCTTGGAGTCAAGGGACCTGCGCCTAGAAAAGCGCACCTTGTTTCGGCTGGATCTTGTTCCGATTAACC GGTCAGTGGGACTCAAGGCCAAGCCCACCAAGCCCGTCACGGAGGTGCTGCGGCCCGTGGTGGCCAGATACGGCCTGGACCTCAGTGGCC TGCTGGTGAGGCTGAGTGGAGAGAAGGAGCCCCTGGACCTTGGCGCCCCTATATCGAGTCTGGACGGACAGCGGGTTGTCTTGGAGGAGA AGGATCCTTCCAGAGGAAAGGCATCCGCAGATAAACAGAAAGGTGTGCCAGTGAAACAGAACACAGCTGTAAATTCCAGCTCCAGAAACC ACTCGGCTACGGGAGAGGAAAGAACACTAGGCAAGTCTAATTCTATTAAAATAAAAGGAGAAAATGGAAAAAATGCTAGGGATCCCCGGC TTTCAAAGAGAGAAGAATCTATTGCAAAGATTGGGAAAAAAAAATATCAGAAAATTAATTTGGACGAAGCAGAGGAGTTTTTTGAGCTTA TTTCCAAAGCTCAGAGCAACAGAGCAGATGACCAACGTGGGCTGCTAAGGAAGGAAGACCTGGTGTTGCCAGAGTTCCTCCGTTTACCTC CTGGTTCCACAGAACTCACCCTCCCCACTCCAGCTGCTGTGGCCAAGGGCTTTAGCAAGAGAAGCGCCACAGGCAACGGCCGGGAGAGCG CCTCCCAGCCTGGCGAGCAGTGGGAGCCAGTCCAGGAGAGCAGCGACAGCCCGTCCACCAGCCCGGGCTCAGCCTCCAGCCCCCCTGGAC CTCCTGGGACGACCCCCCCCGGGCAGAAGTCTCCCAGCGGGCCCTTCTGCACTCCCCAGTCCCCCGTCTCCCTCGCGCAGGAGGGCACCG CCCAGATCTGGAAGAGGCAGTCTCAGGAAGTGGAGGCCGGGGGCATCCAGACGGTGGAGGATGAGCACGTGGCCGAGCTGACCCTGATGG GGGAGGGGGACATCAGCAGCCCCAACAGCACCTTGCTGCCGCCGCCCTCCACCCCCCAGGAAGTGCCAGGACCTTCCAGACCAGGTACCT CCAGGTTCTGATCCCTCCACCTTGGCCCCGTAAGCGTGGTCTGCTCAGCTTCCAGTCAGAAAGGACAGTGGGCCCCCGGCTGCCACTGTT TGCTGGTGGTCTCCGTGACCCCCTCCTCACCTGCTGGTTGGGGGCTTCCTTGGCCCTCTTGGAAAGGAGGGGCTCGTGTGGCCCCAGGCC AGTGTCTGTCAGGATGGTCCCCCCGAGGCGCTCTGGGCAGGCATCCTGGTGTCCTGAGAGGCTCTTGCAGGAATGATACGTGGCAGTGCC TGCAGCGAGGTCTGGGAACACCCTGGGTGAGGCCTGGGGGTTTCCGAAAATGGAGGCATTCCTTTCCAAATCTGGACAGCGATCGTTTTT AGTGTTTCTGTCTCAAGACTGGAAAACAATAGCATTTGTCTTGAGTGAGGAAGTGAAGCCCGCTGTGTTCATAGCAGGAGAGGGCTCCCA GACACAGGCCCGTCCTCGGAAGAGCCTTGAGAGTGCAGCTCGGACCCACCGGCGGCCCCCGTAGCAGGTGGTGTGGGTGCTCGGGAGTGG AGGTGACGTCAGCAGCGCTCTCTGACCGCGGGTGTCACGGGCATTTCTCAAAGGAAGCAGGGGATTCAGTGAGTGTGAAGGTGAACAGGA TGGCCTGGCAGCAGGGATGTTTCCGTGAGCCACAAATACCAGAAACTGAGGCGAGGCTCCCAGCAGCCGGTAGGGAAAGGTGTTTCCAGG GGTCCGAGGGCCGTGGCCTGCGTGGCCATCCCCTGGAGAGAGGAGCCGCTCAGGGTGCGCGTCATGGAGTGTGCTCAGGGGTGCGTGGAC ACCTCTGCTGTGGTTTGCTGCTGGGGGCGATGGGAGCGCCTCTCCGTCCTGTGCCCTGGTCCAGGATGCTGACAGCAGTGAGAGGCCTGC CGTGAGGTTTGGTCTTGTCAGACCTGTAGCCTGGACCTCGCCGGGGGACCAGGGAGTGCACGTCTGTAGATCTGTACATATCTGGGCCTT TGGAGGCCACGTGTGGCATGGGAGGGGCTACCTGGTCCCTTTCACAGCCAGGACACGCCTGGATGAGAAAGCCTGAGGTGCCTGGCATGC CCACCGGTGCCACTCTGCAGCCTCCACCCCTGGCCTGAGTCCCCCTCCATCCGTCTTGGTGGACACCTGTGTGGCTCTCACCTGCGTTTT >58553_58553_2_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000336727_length(amino acids)=830AA_BP=81 MPGQRRALSPKMASMRESDTGLWLHNKLGATDELWAPPSIASLLTAAVIDNIRLCFHGLSSAVKLKLLLGTLHLPRRTVDEGSKFGRGTG LTQPSQRTSARRSFGRSKRFSITRSLDDLESATVSDGELTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGV RYFSDFLRKEFSEENILFWQACEYFNHVPAHDKKELSYRAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKF DSYTRFLKSPLYQECILAEVEGRALPDSQQVPSSPASKHSLGSDHSSVSTPKKLSGKSKSGRSLNEELGDEDSEKKRKGAFFSWSRTRST GRSQKKREHGDHADDALHANGGLCRRESQGSVSSAGSLDLSEACRTLAPEKDKATKHCCIHLPDGTSCVVAVKAGFSIKDILSGLCERHG INGAAADLFLVGGDKPLVLHQDSSILESRDLRLEKRTLFRLDLVPINRSVGLKAKPTKPVTEVLRPVVARYGLDLSGLLVRLSGEKEPLD LGAPISSLDGQRVVLEEKDPSRGKASADKQKGVPVKQNTAVNSSSRNHSATGEERTLGKSNSIKIKGENGKNARDPRLSKREESIAKIGK KKYQKINLDEAEEFFELISKAQSNRADDQRGLLRKEDLVLPEFLRLPPGSTELTLPTPAAVAKGFSKRSATGNGRESASQPGEQWEPVQE SSDSPSTSPGSASSPPGPPGTTPPGQKSPSGPFCTPQSPVSLAQEGTAQIWKRQSQEVEAGGIQTVEDEHVAELTLMGEGDISSPNSTLL -------------------------------------------------------------- >58553_58553_3_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000344733_length(transcript)=4045nt_BP=1361nt GTGACTTCCGCAGGACTGCCAAGTTCAAGCCGCCAGGGCCAGGGCACTGCTAGCAGCTGGGCTGAGCCCTGTTCTCCCGGCGTTCCCACC GCCCAGTGGCAATAGCTGTGAACGGCGGCAGGAGCATGGCAGTGGAACAATAAGGAAAAGATCTTTTAAAAAAAAGATATAATACAGAAG CCAAGCAAGGCGGCCCCGACCTGTAACCCCAGCACTCTGGGAGGCAGAGGCGGGCGGGCGGATCGCTTGAGCCCAGGAGTTTGAGACCAG CCTGGCCAACATAGGAAGGCCTCGTCAAAAAGACAAAAGGGTAAAACGAATTTAATAAAATGAAGTTTAACTTTTACTCATGTTTGTATC TAATGACAAGCTTTTAAAACTGAAAAGTTCACTACTGGCTCCTGCCTGGCGGCTCCAGCCCGACTGGGGGCCGGGGCCTCCCTGCACTGT GGGGTCACGAGTGCCCCTGGACAGCTCCCGAGCGCCCTCCGACCCGCATGCTCAGCGCAGCCCCGTCGGCGGCGCGCCACGGGCAGAGCG GGCTCAGCGGGGGACGGAAGCTCAGCGCTGCGACCGGGATCCCGCAGGCTCGCTCCGCAGGGCCGCGGCTCCTCTCCGTGCAGGTGCTGG GCCCGCGGGGGCGGGGCGTCCACACGGTCCGCGCCGAGACCCAAGCGGGGAAAAAGCGAAGAGCGGACAGCGGGGCAGGTGCCACAGGGA GCCTCCGCCCCACCGCGCGAGCAGCAAGTCTGCGGCGCTTGACACCTGCACTGCGAATGCCAGGCCGCAGCCCGGGCTCCCAAGACGCGA ATACGCGCGCCTGCTCGTGACGTCATTTTTTGCGGTCTTCCCGAGAGCCAGCAGAGGGCGCCGCCATGATGTTTTACGGAAGCCGATAGT CCTTGCTCAGCGGCACCCCGTCCTTCCGGCTCTCGGCTTTGCCACAAAGCTTCCCGAAGACGCGGCCGCTACCCGGAGACGCGGTCGCCA CCCAGAAGCGCTCTCCCGGGAAGCCCCGCTCGTGGGACCGCGCCACCTGCGCCGCCTCTGCGGCCCGCAGCCCGACGGGCGCCGCCATGT TGGGGTCCTAGCGAGGGACGCGTAGGTGTCTTCATAAGATGCCGGGGCAGCGGCGCGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGA GCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGCGCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGG TCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAAGTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCA CGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCAACGCACGTCTGCTCGGAGATCATTTGGGAGATCCA AGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGTCTGCAACTGTGTCTGATGGCGAGTTGACGGGCGCCGACCTGAAGGACTGCG TCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCGGCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCG TGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTTTCTAAGGAAAGAATTCAGTGAAGAAAACATTTTAT TCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCTTTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTC TCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGACGACGTCCTCCGCGCACCTCACCCAGACATGTTCA AGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTTTCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGG CGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGCTTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTG TGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGAAGAGCTGGGGGATGAGGACAGCGAGAAGAAGCGGA AAGGCGCGTTTTTCTCGTGGTCGCGGACCAGGAGCACCGGGAGGTCCCAGAAAAAGAGGGAGCACGGGGACCACGCAGACGACGCCCTGC ATGCCAATGGAGGCCTGTGTCGCCGAGAGTCGCAGGGCTCTGTGTCCTCTGCGGGGAGCCTGGACCTGTCGGAGGCCTGCAGGACTTTGG CACCCGAGAAGGACAAGGCCACCAAGCACTGCTGCATTCATCTCCCGGATGGGACATCCTGCGTGGTGGCTGTCAAGGCGGGCTTCTCCA TCAAAGACATCCTGTCCGGACTCTGTGAGCGGCATGGCATCAACGGGGCGGCCGCGGACCTCTTCCTGGTGGGCGGGGACAAGCCTCTGG TGCTGCACCAAGACAGTAGCATCTTGGAGTCAAGGGACCTGCGCCTAGAAAAGCGCACCTTGTTTCGGCTGGATCTTGTTCCGATTAACC GGTCAGTGGGACTCAAGGCCAAGCCCACCAAGCCCGTCACGGAGGTGCTGCGGCCCGTGGTGGCCAGATACGGCCTGGACCTCAGTGGCC TGCTGGTGAGGCTGAGTGGAGAGAAGGAGCCCCTGGACCTTGGCGCCCCTATATCGAGTCTGGACGGACAGCGGGTTGTCTTGGAGGAGA AGGATCCTTCCAGAGGAAAGGCATCCGCAGATAAACAGAAAGGTGTGCCAGTGAAACAGAACACAGCTGTAAATTCCAGCTCCAGAAACC ACTCGGCTACGGGAGAGGAAAGAACACTAGGCAAGTCTAATTCTATTAAAATAAAAGGAGAAAATGGAAAAAATGCTAGGGATCCCCGGC TTTCAAAGAGAGAAGAATCTATTGCAAAGATTGGGAAAAAAAAATATCAGAAAATTAATTTGGACGAAGCAGAGGAGTTTTTTGAGCTTA TTTCCAAAGCTCAGAGCAACAGAGCAGATGACCAACGTGGGCTGCTAAGGAAGGAAGACCTGGTGTTGCCAGAGTTCCTCCGTTTACCTC CTGGTTCCACAGAACTCACCCTCCCCACTCCAGCTGCTGTGGCCAAGGGCTTTAGCAAGAGAAGCGCCACAGGCAACGGCCGGGAGAGCG CCTCCCAGCCTGGCGAGCAGTGGGAGCCAGTCCAGGAGAGCAGCGACAGCCCGTCCACCAGCCCGGGCTCAGCCTCCAGCCCCCCTGGAC CTCCTGGGACGACCCCCCCCGGGCAGAAGTCTCCCAGCGGGCCCTTCTGCACTCCCCAGTCCCCCGTCTCCCTCGCGCAGGAGGGCACCG CCCAGATCTGGAAGAGGCAGTCTCAGGAAGTGGAGGCCGGGGGCATCCAGACGGTGGAGGATGAGCACGTGGCCGAGCTGACCCTGATGG GGGAGGGGGACATCAGCAGCCCCAACAGCACCTTGCTGCCGCCGCCCTCCACCCCCCAGGAAGTGCCAGGACCTTCCAGACCAGGAAGTG GGACCCATGGCAGCCGAGACCTCCCAGTCAACAGAATCATCGATGTGGATCTTGTAACTGGCTCGGCGCCCGGGCGGGATGGTGGCATAG CGGGGGCACAGGCTGGCCCTGGGAGGTCGCAGGCCAGTGGTGGGCCTCCTACATCAGACCTCCCTGGCTTGGGCCCCGTCCCGGGTGAGC CTGCTAAGCCCAAGACCAGCGCTCACCACGCCACCTTCGTCTGAGCTGCCCTGGCCTGGCCAACTCTCCTGTGGACATGTCGGGGTGGGG CAGCCCAGGTGGATTCTGTGGGCCTCAGGGGGGCCACCCTGGCCACCACACCCTCAGGAGCCCAGCCAGGAGGGCAGGGGGTGACCTCGC >58553_58553_3_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000344733_length(amino acids)=901AA_BP=81 MPGQRRALSPKMASMRESDTGLWLHNKLGATDELWAPPSIASLLTAAVIDNIRLCFHGLSSAVKLKLLLGTLHLPRRTVDEGSKFGRGTG LTQPSQRTSARRSFGRSKRFSITRSLDDLESATVSDGELTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGV RYFSDFLRKEFSEENILFWQACEYFNHVPAHDKKELSYRAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKF DSYTRFLKSPLYQECILAEVEGRALPDSQQVPSSPASKHSLGSDHSSVSTPKKLSGKSKSGRSLNEELGDEDSEKKRKGAFFSWSRTRST GRSQKKREHGDHADDALHANGGLCRRESQGSVSSAGSLDLSEACRTLAPEKDKATKHCCIHLPDGTSCVVAVKAGFSIKDILSGLCERHG INGAAADLFLVGGDKPLVLHQDSSILESRDLRLEKRTLFRLDLVPINRSVGLKAKPTKPVTEVLRPVVARYGLDLSGLLVRLSGEKEPLD LGAPISSLDGQRVVLEEKDPSRGKASADKQKGVPVKQNTAVNSSSRNHSATGEERTLGKSNSIKIKGENGKNARDPRLSKREESIAKIGK KKYQKINLDEAEEFFELISKAQSNRADDQRGLLRKEDLVLPEFLRLPPGSTELTLPTPAAVAKGFSKRSATGNGRESASQPGEQWEPVQE SSDSPSTSPGSASSPPGPPGTTPPGQKSPSGPFCTPQSPVSLAQEGTAQIWKRQSQEVEAGGIQTVEDEHVAELTLMGEGDISSPNSTLL PPPSTPQEVPGPSRPGSGTHGSRDLPVNRIIDVDLVTGSAPGRDGGIAGAQAGPGRSQASGGPPTSDLPGLGPVPGEPAKPKTSAHHATF -------------------------------------------------------------- >58553_58553_4_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000382788_length(transcript)=4889nt_BP=1361nt GTGACTTCCGCAGGACTGCCAAGTTCAAGCCGCCAGGGCCAGGGCACTGCTAGCAGCTGGGCTGAGCCCTGTTCTCCCGGCGTTCCCACC GCCCAGTGGCAATAGCTGTGAACGGCGGCAGGAGCATGGCAGTGGAACAATAAGGAAAAGATCTTTTAAAAAAAAGATATAATACAGAAG CCAAGCAAGGCGGCCCCGACCTGTAACCCCAGCACTCTGGGAGGCAGAGGCGGGCGGGCGGATCGCTTGAGCCCAGGAGTTTGAGACCAG CCTGGCCAACATAGGAAGGCCTCGTCAAAAAGACAAAAGGGTAAAACGAATTTAATAAAATGAAGTTTAACTTTTACTCATGTTTGTATC TAATGACAAGCTTTTAAAACTGAAAAGTTCACTACTGGCTCCTGCCTGGCGGCTCCAGCCCGACTGGGGGCCGGGGCCTCCCTGCACTGT GGGGTCACGAGTGCCCCTGGACAGCTCCCGAGCGCCCTCCGACCCGCATGCTCAGCGCAGCCCCGTCGGCGGCGCGCCACGGGCAGAGCG GGCTCAGCGGGGGACGGAAGCTCAGCGCTGCGACCGGGATCCCGCAGGCTCGCTCCGCAGGGCCGCGGCTCCTCTCCGTGCAGGTGCTGG GCCCGCGGGGGCGGGGCGTCCACACGGTCCGCGCCGAGACCCAAGCGGGGAAAAAGCGAAGAGCGGACAGCGGGGCAGGTGCCACAGGGA GCCTCCGCCCCACCGCGCGAGCAGCAAGTCTGCGGCGCTTGACACCTGCACTGCGAATGCCAGGCCGCAGCCCGGGCTCCCAAGACGCGA ATACGCGCGCCTGCTCGTGACGTCATTTTTTGCGGTCTTCCCGAGAGCCAGCAGAGGGCGCCGCCATGATGTTTTACGGAAGCCGATAGT CCTTGCTCAGCGGCACCCCGTCCTTCCGGCTCTCGGCTTTGCCACAAAGCTTCCCGAAGACGCGGCCGCTACCCGGAGACGCGGTCGCCA CCCAGAAGCGCTCTCCCGGGAAGCCCCGCTCGTGGGACCGCGCCACCTGCGCCGCCTCTGCGGCCCGCAGCCCGACGGGCGCCGCCATGT TGGGGTCCTAGCGAGGGACGCGTAGGTGTCTTCATAAGATGCCGGGGCAGCGGCGCGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGA GCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGCGCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGG TCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAAGTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCA CGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCAACGCACGTCTGCTCGGAGATCATTTGGGAGATCCA AGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGTCTGCAACTGTGTCTGATGGCGAGTTGACGGGCGCCGACCTGAAGGACTGCG TCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCGGCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCG TGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTTTCTAAGGAAAGAATTCAGTGAAGAAAACATTTTAT TCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCTTTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTC TCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGACGACGTCCTCCGCGCACCTCACCCAGACATGTTCA AGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTTTCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGG CGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGCTTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTG TGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGAAGAGCTGGGGGATGAGGACAGCGAGAAGAAGCGGA AAGGCGCGTTTTTCTCGTGGTCGCGGACCAGGAGCACCGGGAGGTCCCAGAAAAAGAGGGAGCACGGGGACCACGCAGACGACGCCCTGC ATGCCAATGGAGGCCTGTGTCGCCGAGAGTCGCAGGGCTCTGTGTCCTCTGCGGGGAGCCTGGACCTGTCGGAGGCCTGCAGGACTTTGG CACCCGAGAAGGACAAGGCCACCAAGCACTGCTGCATTCATCTCCCGGATGGGACATCCTGCGTGGTGGCTGTCAAGGCGGGCTTCTCCA TCAAAGACATCCTGTCCGGACTCTGTGAGCGGCATGGCATCAACGGGGCGGCCGCGGACCTCTTCCTGGTGGGCGGGGACAAGCCTCTGG TGCTGCACCAAGACAGTAGCATCTTGGAGTCAAGGGACCTGCGCCTAGAAAAGCGCACCTTGTTTCGGCTGGATCTTGTTCCGATTAACC GGTCAGTGGGACTCAAGGCCAAGCCCACCAAGCCCGTCACGGAGGTGCTGCGGCCCGTGGTGGCCAGATACGGCCTGGACCTCAGTGGCC TGCTGGTGAGGCTGAGTGGAGAGAAGGAGCCCCTGGACCTTGGCGCCCCTATATCGAGTCTGGACGGACAGCGGGTTGTCTTGGAGGAGA AGGATCCTTCCAGAGGAAAGGCATCCGCAGATAAACAGAAAGGTGTGCCAGTGAAACAGAACACAGCTGTAAATTCCAGCTCCAGAAACC ACTCGGCTACGGGAGAGGAAAGAACACTAGGCAAGTCTAATTCTATTAAAATAAAAGGAGAAAATGGAAAAAATGCTAGGGATCCCCGGC TTTCAAAGAGAGAAGAATCTATTGCAAAGATTGGGAAAAAAAAATATCAGAAAATTAATTTGGACGAAGCAGAGGAGTTTTTTGAGCTTA TTTCCAAAGCTCAGAGCAACAGAGCAGATGACCAACGTGGGCTGCTAAGGAAGGAAGACCTGGTGTTGCCAGAGTTCCTCCGTTTACCTC CTGGTTCCACAGAACTCACCCTCCCCACTCCAGCTGCTGTGGCCAAGGGCTTTAGCAAGAGAAGCGCCACAGGCAACGGCCGGGAGAGCG CCTCCCAGCCTGGCGAGCAGTGGGAGCCAGTCCAGGAGAGCAGCGACAGCCCGTCCACCAGCCCGGGCTCAGCCTCCAGCCCCCCTGGAC CTCCTGGGACGACCCCCCCCGGGCAGAAGTCTCCCAGCGGGCCCTTCTGCACTCCCCAGTCCCCCGTCTCCCTCGCGCAGGAGGGCACCG CCCAGATCTGGAAGAGGCAGTCTCAGGAAGTGGAGGCCGGGGGCATCCAGACGGTGGAGGATGAGCACGTGGCCGAGCTGACCCTGATGG GGGAGGGGGACATCAGCAGCCCCAACAGCACCTTGCTGCCGCCGCCCTCCACCCCCCAGGAAGTGCCAGGACCTTCCAGACCAGGTACCT CCAGGTTCTGATCCCTCCACCTTGGCCCCGTAAGCGTGGTCTGCTCAGCTTCCAGTCAGAAAGGACAGTGGGCCCCCGGCTGCCACTGTT TGCTGGTGGTCTCCGTGACCCCCTCCTCACCTGCTGGTTGGGGGCTTCCTTGGCCCTCTTGGAAAGGAGGGGCTCGTGTGGCCCCAGGCC AGTGTCTGTCAGGATGGTCCCCCCGAGGCGCTCTGGGCAGGCATCCTGGTGTCCTGAGAGGCTCTTGCAGGAATGATACGTGGCAGTGCC TGCAGCGAGGTCTGGGAACACCCTGGGTGAGGCCTGGGGGTTTCCGAAAATGGAGGCATTCCTTTCCAAATCTGGACAGCGATCGTTTTT AGTGTTTCTGTCTCAAGACTGGAAAACAATAGCATTTGTCTTGAGTGAGGAAGTGAAGCCCGCTGTGTTCATAGCAGGAGAGGGCTCCCA GACACAGGCCCGTCCTCGGAAGAGCCTTGAGAGTGCAGCTCGGACCCACCGGCGGCCCCCGTAGCAGGTGGTGTGGGTGCTCGGGAGTGG AGGTGACGTCAGCAGCGCTCTCTGACCGCGGGTGTCACGGGCATTTCTCAAAGGAAGCAGGGGATTCAGTGAGTGTGAAGGTGAACAGGA TGGCCTGGCAGCAGGGATGTTTCCGTGAGCCACAAATACCAGAAACTGAGGCGAGGCTCCCAGCAGCCGGTAGGGAAAGGTGTTTCCAGG GGTCCGAGGGCCGTGGCCTGCGTGGCCATCCCCTGGAGAGAGGAGCCGCTCAGGGTGCGCGTCATGGAGTGTGCTCAGGGGTGCGTGGAC ACCTCTGCTGTGGTTTGCTGCTGGGGGCGATGGGAGCGCCTCTCCGTCCTGTGCCCTGGTCCAGGATGCTGACAGCAGTGAGAGGCCTGC CGTGAGGTTTGGTCTTGTCAGACCTGTAGCCTGGACCTCGCCGGGGGACCAGGGAGTGCACGTCTGTAGATCTGTACATATCTGGGCCTT TGGAGGCCACGTGTGGCATGGGAGGGGCTACCTGGTCCCTTTCACAGCCAGGACACGCCTGGATGAGAAAGCCTGAGGTGCCTGGCATGC CCACCGGTGCCACTCTGCAGCCTCCACCCCTGGCCTGAGTCCCCCTCCATCCGTCTTGGTGGACACCTGTGTGGCTCTCACCTGCGTTTT GAGTCTGTTCTTCCAGGAGTAATAAATTCTGGACATCATCACTGGACTGGCTTACAACTTTTCTTTCTCATTTGAAACTTTGTTTCCACT >58553_58553_4_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000382788_length(amino acids)=830AA_BP=81 MPGQRRALSPKMASMRESDTGLWLHNKLGATDELWAPPSIASLLTAAVIDNIRLCFHGLSSAVKLKLLLGTLHLPRRTVDEGSKFGRGTG LTQPSQRTSARRSFGRSKRFSITRSLDDLESATVSDGELTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGV RYFSDFLRKEFSEENILFWQACEYFNHVPAHDKKELSYRAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKF DSYTRFLKSPLYQECILAEVEGRALPDSQQVPSSPASKHSLGSDHSSVSTPKKLSGKSKSGRSLNEELGDEDSEKKRKGAFFSWSRTRST GRSQKKREHGDHADDALHANGGLCRRESQGSVSSAGSLDLSEACRTLAPEKDKATKHCCIHLPDGTSCVVAVKAGFSIKDILSGLCERHG INGAAADLFLVGGDKPLVLHQDSSILESRDLRLEKRTLFRLDLVPINRSVGLKAKPTKPVTEVLRPVVARYGLDLSGLLVRLSGEKEPLD LGAPISSLDGQRVVLEEKDPSRGKASADKQKGVPVKQNTAVNSSSRNHSATGEERTLGKSNSIKIKGENGKNARDPRLSKREESIAKIGK KKYQKINLDEAEEFFELISKAQSNRADDQRGLLRKEDLVLPEFLRLPPGSTELTLPTPAAVAKGFSKRSATGNGRESASQPGEQWEPVQE SSDSPSTSPGSASSPPGPPGTTPPGQKSPSGPFCTPQSPVSLAQEGTAQIWKRQSQEVEAGGIQTVEDEHVAELTLMGEGDISSPNSTLL -------------------------------------------------------------- >58553_58553_5_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000543385_length(transcript)=2128nt_BP=1361nt GTGACTTCCGCAGGACTGCCAAGTTCAAGCCGCCAGGGCCAGGGCACTGCTAGCAGCTGGGCTGAGCCCTGTTCTCCCGGCGTTCCCACC GCCCAGTGGCAATAGCTGTGAACGGCGGCAGGAGCATGGCAGTGGAACAATAAGGAAAAGATCTTTTAAAAAAAAGATATAATACAGAAG CCAAGCAAGGCGGCCCCGACCTGTAACCCCAGCACTCTGGGAGGCAGAGGCGGGCGGGCGGATCGCTTGAGCCCAGGAGTTTGAGACCAG CCTGGCCAACATAGGAAGGCCTCGTCAAAAAGACAAAAGGGTAAAACGAATTTAATAAAATGAAGTTTAACTTTTACTCATGTTTGTATC TAATGACAAGCTTTTAAAACTGAAAAGTTCACTACTGGCTCCTGCCTGGCGGCTCCAGCCCGACTGGGGGCCGGGGCCTCCCTGCACTGT GGGGTCACGAGTGCCCCTGGACAGCTCCCGAGCGCCCTCCGACCCGCATGCTCAGCGCAGCCCCGTCGGCGGCGCGCCACGGGCAGAGCG GGCTCAGCGGGGGACGGAAGCTCAGCGCTGCGACCGGGATCCCGCAGGCTCGCTCCGCAGGGCCGCGGCTCCTCTCCGTGCAGGTGCTGG GCCCGCGGGGGCGGGGCGTCCACACGGTCCGCGCCGAGACCCAAGCGGGGAAAAAGCGAAGAGCGGACAGCGGGGCAGGTGCCACAGGGA GCCTCCGCCCCACCGCGCGAGCAGCAAGTCTGCGGCGCTTGACACCTGCACTGCGAATGCCAGGCCGCAGCCCGGGCTCCCAAGACGCGA ATACGCGCGCCTGCTCGTGACGTCATTTTTTGCGGTCTTCCCGAGAGCCAGCAGAGGGCGCCGCCATGATGTTTTACGGAAGCCGATAGT CCTTGCTCAGCGGCACCCCGTCCTTCCGGCTCTCGGCTTTGCCACAAAGCTTCCCGAAGACGCGGCCGCTACCCGGAGACGCGGTCGCCA CCCAGAAGCGCTCTCCCGGGAAGCCCCGCTCGTGGGACCGCGCCACCTGCGCCGCCTCTGCGGCCCGCAGCCCGACGGGCGCCGCCATGT TGGGGTCCTAGCGAGGGACGCGTAGGTGTCTTCATAAGATGCCGGGGCAGCGGCGCGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGA GCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGCGCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGG TCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAAGTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCA CGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCAACGCACGTCTGCTCGGAGATCATTTGGGAGATCCA AGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGAGTTGACGGGCGCCGACCTGAAGGACTGCGTCAGCAACAACAGCCTGAGCAG CAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCGGCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCGTGTCCTTTGAGCGCCTGCTGCA GGACCCCGTCGGTGTCCGCTACTTCTCTGATTTTCTAAGGAAAGAATTCAGTGAAGAAAACATTTTATTCTGGCAGGCCTGTGAATATTT TAATCATGTTCCTGCACATGACAAAAAGGAGCTTTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTCTCTGCAGCAAAGCCACCACCCC GGTCAACATCGACAGCCAGGCCCAGCTAGCAGACGACGTCCTCCGCGCACCTCACCCAGACATGTTCAAGGAGCAGCAGCTGCAGATCTT CAATCTCATGAAGTTTGATAGCTACACTCGCTTTCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGGCGGAAGTGGAGGGCCGTGCACT CCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGCTTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTGTGTCCACGCCAAAAAAGTTAAG >58553_58553_5_NELFA-RGS12_NELFA_chr4_2010477_ENST00000382882_RGS12_chr4_3344664_ENST00000543385_length(amino acids)=251AA_BP= MFVSNDKLLKLKSSLLAPAWRLQPDWGPGPPCTVGSRVPLDSSRAPSDPHAQRSPVGGAPRAERAQRGTEAQRCDRDPAGSLRRAAAPLR AGAGPAGAGRPHGPRRDPSGEKAKSGQRGRCHREPPPHRASSKSAALDTCTANARPQPGLPRREYARLLVTSFFAVFPRASRGRRHDVLR -------------------------------------------------------------- >58553_58553_6_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000306648_length(transcript)=1938nt_BP=226nt CGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGAGCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGC GCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGGTCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAA GTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCACGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCA ACGCACGTCTGCTCGGAGATCATTTGGGAGATCCAAGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGTCTGCAACTGTGTCTGA TGGCGAGTTGACGGGCGCCGACCTGAAGGACTGCGTCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCG GCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCGTGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTT TCTAAGGAAAGAATTCAGTGAAGAAAACATTTTATTCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCT TTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTCTCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGA CGACGTCCTCCGCGCACCTCACCCAGACATGTTCAAGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTT TCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGGCGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGC TTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTGTGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGA AGAGCTGGGGGATGAGGACAGCGAGAAGAAGCGGAAAGGCGCGTTTTTCTCGTGGTCGCGGACCAGGAGCACCGGGAGGTCCCAGAAAAA GAGGGAGCACGGGGACCACGCAGACGACGCCCTGCATGCCAATGGAGGCCTGTGTCGCCGAGAGTCGCAGGGCTCTGTGTCCTCTGCGGG GAGCCTGGACCTGTCGGAGGCCTGCAGGACTTTGGCACCCGAGAAGGACAAGGCCACCAAGCACTGCTGCATTCATCTCCCGGATGGGAC ATCCTGCGTGGTGGCTGTCAAGGCGGGCTTCTCCATCAAAGACATCCTGTCCGGACTCTGTGAGCGGCATGGCATCAACGGGGCGGCCGC GGACCTCTTCCTGGTGGGCGGGGACAAGCCTCTGGTGCTGCACCAAGACAGTAGCATCTTGGAGTCAAGGGACCTGCGCCTAGAAAAGCG CACCTTGTTTCGGCTGGATCTTGTTCCGATTAACCGGTCAGTGGGACTCAAGGCCAAGCCCACCAAGCCCGTCACGGAGGTGCTGCGGCC CGTGGTGGCCAGATACGGCCTGGACCTCAGTGGCCTGCTGGTGAGGCTGAGTGGAGAGAAGGAGCCCCTGGACCTTGGCGCCCCTATATC GAGTCTGGACGGACAGCGGGTTGTCTTGGAGGAGAAGGATCCTTCCAGAGGAAAGGCATCCGCAGATAAACAGAAAGGTGTGCCAGTGAA ACAGAACACAGCTGTAAATTCCAGCTCCAGAAACCACTCGGCTACGAGTTTTTTGAGCTTATTTCCAAAGCTCAGAGCAACAGAGCAGAT GACCAACGTGGGCTGCTAAGGAAGGAAGACCTGGTGTTGCCAGAGTTCCTCCGTTTACCTCCTGGTTCCACAGAACTCACCCTCCCCACT >58553_58553_6_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000306648_length(amino acids)=600AA_BP=70 MASMRESDTGLWLHNKLGATDELWAPPSIASLLTAAVIDNIRLCFHGLSSAVKLKLLLGTLHLPRRTVDEGSKFGRGTGLTQPSQRTSAR RSFGRSKRFSITRSLDDLESATVSDGELTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGVRYFSDFLRKEF SEENILFWQACEYFNHVPAHDKKELSYRAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKFDSYTRFLKSPL YQECILAEVEGRALPDSQQVPSSPASKHSLGSDHSSVSTPKKLSGKSKSGRSLNEELGDEDSEKKRKGAFFSWSRTRSTGRSQKKREHGD HADDALHANGGLCRRESQGSVSSAGSLDLSEACRTLAPEKDKATKHCCIHLPDGTSCVVAVKAGFSIKDILSGLCERHGINGAAADLFLV GGDKPLVLHQDSSILESRDLRLEKRTLFRLDLVPINRSVGLKAKPTKPVTEVLRPVVARYGLDLSGLLVRLSGEKEPLDLGAPISSLDGQ -------------------------------------------------------------- >58553_58553_7_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000336727_length(transcript)=3681nt_BP=226nt CGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGAGCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGC GCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGGTCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAA GTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCACGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCA ACGCACGTCTGCTCGGAGATCATTTGGGAGATCCAAGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGTCTGCAACTGTGTCTGA TGGCGAGTTGACGGGCGCCGACCTGAAGGACTGCGTCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCG GCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCGTGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTT TCTAAGGAAAGAATTCAGTGAAGAAAACATTTTATTCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCT TTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTCTCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGA CGACGTCCTCCGCGCACCTCACCCAGACATGTTCAAGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTT TCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGGCGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGC TTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTGTGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGA AGAGCTGGGGGATGAGGACAGCGAGAAGAAGCGGAAAGGCGCGTTTTTCTCGTGGTCGCGGACCAGGAGCACCGGGAGGTCCCAGAAAAA GAGGGAGCACGGGGACCACGCAGACGACGCCCTGCATGCCAATGGAGGCCTGTGTCGCCGAGAGTCGCAGGGCTCTGTGTCCTCTGCGGG GAGCCTGGACCTGTCGGAGGCCTGCAGGACTTTGGCACCCGAGAAGGACAAGGCCACCAAGCACTGCTGCATTCATCTCCCGGATGGGAC ATCCTGCGTGGTGGCTGTCAAGGCGGGCTTCTCCATCAAAGACATCCTGTCCGGACTCTGTGAGCGGCATGGCATCAACGGGGCGGCCGC GGACCTCTTCCTGGTGGGCGGGGACAAGCCTCTGGTGCTGCACCAAGACAGTAGCATCTTGGAGTCAAGGGACCTGCGCCTAGAAAAGCG CACCTTGTTTCGGCTGGATCTTGTTCCGATTAACCGGTCAGTGGGACTCAAGGCCAAGCCCACCAAGCCCGTCACGGAGGTGCTGCGGCC CGTGGTGGCCAGATACGGCCTGGACCTCAGTGGCCTGCTGGTGAGGCTGAGTGGAGAGAAGGAGCCCCTGGACCTTGGCGCCCCTATATC GAGTCTGGACGGACAGCGGGTTGTCTTGGAGGAGAAGGATCCTTCCAGAGGAAAGGCATCCGCAGATAAACAGAAAGGTGTGCCAGTGAA ACAGAACACAGCTGTAAATTCCAGCTCCAGAAACCACTCGGCTACGGGAGAGGAAAGAACACTAGGCAAGTCTAATTCTATTAAAATAAA AGGAGAAAATGGAAAAAATGCTAGGGATCCCCGGCTTTCAAAGAGAGAAGAATCTATTGCAAAGATTGGGAAAAAAAAATATCAGAAAAT TAATTTGGACGAAGCAGAGGAGTTTTTTGAGCTTATTTCCAAAGCTCAGAGCAACAGAGCAGATGACCAACGTGGGCTGCTAAGGAAGGA AGACCTGGTGTTGCCAGAGTTCCTCCGTTTACCTCCTGGTTCCACAGAACTCACCCTCCCCACTCCAGCTGCTGTGGCCAAGGGCTTTAG CAAGAGAAGCGCCACAGGCAACGGCCGGGAGAGCGCCTCCCAGCCTGGCGAGCAGTGGGAGCCAGTCCAGGAGAGCAGCGACAGCCCGTC CACCAGCCCGGGCTCAGCCTCCAGCCCCCCTGGACCTCCTGGGACGACCCCCCCCGGGCAGAAGTCTCCCAGCGGGCCCTTCTGCACTCC CCAGTCCCCCGTCTCCCTCGCGCAGGAGGGCACCGCCCAGATCTGGAAGAGGCAGTCTCAGGAAGTGGAGGCCGGGGGCATCCAGACGGT GGAGGATGAGCACGTGGCCGAGCTGACCCTGATGGGGGAGGGGGACATCAGCAGCCCCAACAGCACCTTGCTGCCGCCGCCCTCCACCCC CCAGGAAGTGCCAGGACCTTCCAGACCAGGTACCTCCAGGTTCTGATCCCTCCACCTTGGCCCCGTAAGCGTGGTCTGCTCAGCTTCCAG TCAGAAAGGACAGTGGGCCCCCGGCTGCCACTGTTTGCTGGTGGTCTCCGTGACCCCCTCCTCACCTGCTGGTTGGGGGCTTCCTTGGCC CTCTTGGAAAGGAGGGGCTCGTGTGGCCCCAGGCCAGTGTCTGTCAGGATGGTCCCCCCGAGGCGCTCTGGGCAGGCATCCTGGTGTCCT GAGAGGCTCTTGCAGGAATGATACGTGGCAGTGCCTGCAGCGAGGTCTGGGAACACCCTGGGTGAGGCCTGGGGGTTTCCGAAAATGGAG GCATTCCTTTCCAAATCTGGACAGCGATCGTTTTTAGTGTTTCTGTCTCAAGACTGGAAAACAATAGCATTTGTCTTGAGTGAGGAAGTG AAGCCCGCTGTGTTCATAGCAGGAGAGGGCTCCCAGACACAGGCCCGTCCTCGGAAGAGCCTTGAGAGTGCAGCTCGGACCCACCGGCGG CCCCCGTAGCAGGTGGTGTGGGTGCTCGGGAGTGGAGGTGACGTCAGCAGCGCTCTCTGACCGCGGGTGTCACGGGCATTTCTCAAAGGA AGCAGGGGATTCAGTGAGTGTGAAGGTGAACAGGATGGCCTGGCAGCAGGGATGTTTCCGTGAGCCACAAATACCAGAAACTGAGGCGAG GCTCCCAGCAGCCGGTAGGGAAAGGTGTTTCCAGGGGTCCGAGGGCCGTGGCCTGCGTGGCCATCCCCTGGAGAGAGGAGCCGCTCAGGG TGCGCGTCATGGAGTGTGCTCAGGGGTGCGTGGACACCTCTGCTGTGGTTTGCTGCTGGGGGCGATGGGAGCGCCTCTCCGTCCTGTGCC CTGGTCCAGGATGCTGACAGCAGTGAGAGGCCTGCCGTGAGGTTTGGTCTTGTCAGACCTGTAGCCTGGACCTCGCCGGGGGACCAGGGA GTGCACGTCTGTAGATCTGTACATATCTGGGCCTTTGGAGGCCACGTGTGGCATGGGAGGGGCTACCTGGTCCCTTTCACAGCCAGGACA CGCCTGGATGAGAAAGCCTGAGGTGCCTGGCATGCCCACCGGTGCCACTCTGCAGCCTCCACCCCTGGCCTGAGTCCCCCTCCATCCGTC >58553_58553_7_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000336727_length(amino acids)=819AA_BP=70 MASMRESDTGLWLHNKLGATDELWAPPSIASLLTAAVIDNIRLCFHGLSSAVKLKLLLGTLHLPRRTVDEGSKFGRGTGLTQPSQRTSAR RSFGRSKRFSITRSLDDLESATVSDGELTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGVRYFSDFLRKEF SEENILFWQACEYFNHVPAHDKKELSYRAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKFDSYTRFLKSPL YQECILAEVEGRALPDSQQVPSSPASKHSLGSDHSSVSTPKKLSGKSKSGRSLNEELGDEDSEKKRKGAFFSWSRTRSTGRSQKKREHGD HADDALHANGGLCRRESQGSVSSAGSLDLSEACRTLAPEKDKATKHCCIHLPDGTSCVVAVKAGFSIKDILSGLCERHGINGAAADLFLV GGDKPLVLHQDSSILESRDLRLEKRTLFRLDLVPINRSVGLKAKPTKPVTEVLRPVVARYGLDLSGLLVRLSGEKEPLDLGAPISSLDGQ RVVLEEKDPSRGKASADKQKGVPVKQNTAVNSSSRNHSATGEERTLGKSNSIKIKGENGKNARDPRLSKREESIAKIGKKKYQKINLDEA EEFFELISKAQSNRADDQRGLLRKEDLVLPEFLRLPPGSTELTLPTPAAVAKGFSKRSATGNGRESASQPGEQWEPVQESSDSPSTSPGS ASSPPGPPGTTPPGQKSPSGPFCTPQSPVSLAQEGTAQIWKRQSQEVEAGGIQTVEDEHVAELTLMGEGDISSPNSTLLPPPSTPQEVPG -------------------------------------------------------------- >58553_58553_8_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000344733_length(transcript)=2910nt_BP=226nt CGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGAGCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGC GCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGGTCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAA GTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCACGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCA ACGCACGTCTGCTCGGAGATCATTTGGGAGATCCAAGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGTCTGCAACTGTGTCTGA TGGCGAGTTGACGGGCGCCGACCTGAAGGACTGCGTCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCG GCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCGTGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTT TCTAAGGAAAGAATTCAGTGAAGAAAACATTTTATTCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCT TTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTCTCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGA CGACGTCCTCCGCGCACCTCACCCAGACATGTTCAAGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTT TCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGGCGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGC TTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTGTGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGA AGAGCTGGGGGATGAGGACAGCGAGAAGAAGCGGAAAGGCGCGTTTTTCTCGTGGTCGCGGACCAGGAGCACCGGGAGGTCCCAGAAAAA GAGGGAGCACGGGGACCACGCAGACGACGCCCTGCATGCCAATGGAGGCCTGTGTCGCCGAGAGTCGCAGGGCTCTGTGTCCTCTGCGGG GAGCCTGGACCTGTCGGAGGCCTGCAGGACTTTGGCACCCGAGAAGGACAAGGCCACCAAGCACTGCTGCATTCATCTCCCGGATGGGAC ATCCTGCGTGGTGGCTGTCAAGGCGGGCTTCTCCATCAAAGACATCCTGTCCGGACTCTGTGAGCGGCATGGCATCAACGGGGCGGCCGC GGACCTCTTCCTGGTGGGCGGGGACAAGCCTCTGGTGCTGCACCAAGACAGTAGCATCTTGGAGTCAAGGGACCTGCGCCTAGAAAAGCG CACCTTGTTTCGGCTGGATCTTGTTCCGATTAACCGGTCAGTGGGACTCAAGGCCAAGCCCACCAAGCCCGTCACGGAGGTGCTGCGGCC CGTGGTGGCCAGATACGGCCTGGACCTCAGTGGCCTGCTGGTGAGGCTGAGTGGAGAGAAGGAGCCCCTGGACCTTGGCGCCCCTATATC GAGTCTGGACGGACAGCGGGTTGTCTTGGAGGAGAAGGATCCTTCCAGAGGAAAGGCATCCGCAGATAAACAGAAAGGTGTGCCAGTGAA ACAGAACACAGCTGTAAATTCCAGCTCCAGAAACCACTCGGCTACGGGAGAGGAAAGAACACTAGGCAAGTCTAATTCTATTAAAATAAA AGGAGAAAATGGAAAAAATGCTAGGGATCCCCGGCTTTCAAAGAGAGAAGAATCTATTGCAAAGATTGGGAAAAAAAAATATCAGAAAAT TAATTTGGACGAAGCAGAGGAGTTTTTTGAGCTTATTTCCAAAGCTCAGAGCAACAGAGCAGATGACCAACGTGGGCTGCTAAGGAAGGA AGACCTGGTGTTGCCAGAGTTCCTCCGTTTACCTCCTGGTTCCACAGAACTCACCCTCCCCACTCCAGCTGCTGTGGCCAAGGGCTTTAG CAAGAGAAGCGCCACAGGCAACGGCCGGGAGAGCGCCTCCCAGCCTGGCGAGCAGTGGGAGCCAGTCCAGGAGAGCAGCGACAGCCCGTC CACCAGCCCGGGCTCAGCCTCCAGCCCCCCTGGACCTCCTGGGACGACCCCCCCCGGGCAGAAGTCTCCCAGCGGGCCCTTCTGCACTCC CCAGTCCCCCGTCTCCCTCGCGCAGGAGGGCACCGCCCAGATCTGGAAGAGGCAGTCTCAGGAAGTGGAGGCCGGGGGCATCCAGACGGT GGAGGATGAGCACGTGGCCGAGCTGACCCTGATGGGGGAGGGGGACATCAGCAGCCCCAACAGCACCTTGCTGCCGCCGCCCTCCACCCC CCAGGAAGTGCCAGGACCTTCCAGACCAGGAAGTGGGACCCATGGCAGCCGAGACCTCCCAGTCAACAGAATCATCGATGTGGATCTTGT AACTGGCTCGGCGCCCGGGCGGGATGGTGGCATAGCGGGGGCACAGGCTGGCCCTGGGAGGTCGCAGGCCAGTGGTGGGCCTCCTACATC AGACCTCCCTGGCTTGGGCCCCGTCCCGGGTGAGCCTGCTAAGCCCAAGACCAGCGCTCACCACGCCACCTTCGTCTGAGCTGCCCTGGC CTGGCCAACTCTCCTGTGGACATGTCGGGGTGGGGCAGCCCAGGTGGATTCTGTGGGCCTCAGGGGGGCCACCCTGGCCACCACACCCTC AGGAGCCCAGCCAGGAGGGCAGGGGGTGACCTCGCTGGAGGCACTGGCCCCGGACATTCGCCATGCTGGCCATGGGGCTCCCTGGCCCTG >58553_58553_8_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000344733_length(amino acids)=890AA_BP=70 MASMRESDTGLWLHNKLGATDELWAPPSIASLLTAAVIDNIRLCFHGLSSAVKLKLLLGTLHLPRRTVDEGSKFGRGTGLTQPSQRTSAR RSFGRSKRFSITRSLDDLESATVSDGELTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGVRYFSDFLRKEF SEENILFWQACEYFNHVPAHDKKELSYRAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKFDSYTRFLKSPL YQECILAEVEGRALPDSQQVPSSPASKHSLGSDHSSVSTPKKLSGKSKSGRSLNEELGDEDSEKKRKGAFFSWSRTRSTGRSQKKREHGD HADDALHANGGLCRRESQGSVSSAGSLDLSEACRTLAPEKDKATKHCCIHLPDGTSCVVAVKAGFSIKDILSGLCERHGINGAAADLFLV GGDKPLVLHQDSSILESRDLRLEKRTLFRLDLVPINRSVGLKAKPTKPVTEVLRPVVARYGLDLSGLLVRLSGEKEPLDLGAPISSLDGQ RVVLEEKDPSRGKASADKQKGVPVKQNTAVNSSSRNHSATGEERTLGKSNSIKIKGENGKNARDPRLSKREESIAKIGKKKYQKINLDEA EEFFELISKAQSNRADDQRGLLRKEDLVLPEFLRLPPGSTELTLPTPAAVAKGFSKRSATGNGRESASQPGEQWEPVQESSDSPSTSPGS ASSPPGPPGTTPPGQKSPSGPFCTPQSPVSLAQEGTAQIWKRQSQEVEAGGIQTVEDEHVAELTLMGEGDISSPNSTLLPPPSTPQEVPG -------------------------------------------------------------- >58553_58553_9_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000382788_length(transcript)=3754nt_BP=226nt CGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGAGCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGC GCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGGTCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAA GTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCACGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCA ACGCACGTCTGCTCGGAGATCATTTGGGAGATCCAAGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGTCTGCAACTGTGTCTGA TGGCGAGTTGACGGGCGCCGACCTGAAGGACTGCGTCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCG GCGCCTGCGTGAGAGGAGGGTCGCCAGCTGGGCCGTGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTT TCTAAGGAAAGAATTCAGTGAAGAAAACATTTTATTCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCT TTCCTACAGGGCCCGGGAGATTTTCAGTAAGTTTCTCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGA CGACGTCCTCCGCGCACCTCACCCAGACATGTTCAAGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTT TCTGAAGTCCCCGCTGTACCAGGAATGCATCCTGGCGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGC TTCCAAGCACAGCCTCGGTTCAGACCACTCCAGTGTGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGA AGAGCTGGGGGATGAGGACAGCGAGAAGAAGCGGAAAGGCGCGTTTTTCTCGTGGTCGCGGACCAGGAGCACCGGGAGGTCCCAGAAAAA GAGGGAGCACGGGGACCACGCAGACGACGCCCTGCATGCCAATGGAGGCCTGTGTCGCCGAGAGTCGCAGGGCTCTGTGTCCTCTGCGGG GAGCCTGGACCTGTCGGAGGCCTGCAGGACTTTGGCACCCGAGAAGGACAAGGCCACCAAGCACTGCTGCATTCATCTCCCGGATGGGAC ATCCTGCGTGGTGGCTGTCAAGGCGGGCTTCTCCATCAAAGACATCCTGTCCGGACTCTGTGAGCGGCATGGCATCAACGGGGCGGCCGC GGACCTCTTCCTGGTGGGCGGGGACAAGCCTCTGGTGCTGCACCAAGACAGTAGCATCTTGGAGTCAAGGGACCTGCGCCTAGAAAAGCG CACCTTGTTTCGGCTGGATCTTGTTCCGATTAACCGGTCAGTGGGACTCAAGGCCAAGCCCACCAAGCCCGTCACGGAGGTGCTGCGGCC CGTGGTGGCCAGATACGGCCTGGACCTCAGTGGCCTGCTGGTGAGGCTGAGTGGAGAGAAGGAGCCCCTGGACCTTGGCGCCCCTATATC GAGTCTGGACGGACAGCGGGTTGTCTTGGAGGAGAAGGATCCTTCCAGAGGAAAGGCATCCGCAGATAAACAGAAAGGTGTGCCAGTGAA ACAGAACACAGCTGTAAATTCCAGCTCCAGAAACCACTCGGCTACGGGAGAGGAAAGAACACTAGGCAAGTCTAATTCTATTAAAATAAA AGGAGAAAATGGAAAAAATGCTAGGGATCCCCGGCTTTCAAAGAGAGAAGAATCTATTGCAAAGATTGGGAAAAAAAAATATCAGAAAAT TAATTTGGACGAAGCAGAGGAGTTTTTTGAGCTTATTTCCAAAGCTCAGAGCAACAGAGCAGATGACCAACGTGGGCTGCTAAGGAAGGA AGACCTGGTGTTGCCAGAGTTCCTCCGTTTACCTCCTGGTTCCACAGAACTCACCCTCCCCACTCCAGCTGCTGTGGCCAAGGGCTTTAG CAAGAGAAGCGCCACAGGCAACGGCCGGGAGAGCGCCTCCCAGCCTGGCGAGCAGTGGGAGCCAGTCCAGGAGAGCAGCGACAGCCCGTC CACCAGCCCGGGCTCAGCCTCCAGCCCCCCTGGACCTCCTGGGACGACCCCCCCCGGGCAGAAGTCTCCCAGCGGGCCCTTCTGCACTCC CCAGTCCCCCGTCTCCCTCGCGCAGGAGGGCACCGCCCAGATCTGGAAGAGGCAGTCTCAGGAAGTGGAGGCCGGGGGCATCCAGACGGT GGAGGATGAGCACGTGGCCGAGCTGACCCTGATGGGGGAGGGGGACATCAGCAGCCCCAACAGCACCTTGCTGCCGCCGCCCTCCACCCC CCAGGAAGTGCCAGGACCTTCCAGACCAGGTACCTCCAGGTTCTGATCCCTCCACCTTGGCCCCGTAAGCGTGGTCTGCTCAGCTTCCAG TCAGAAAGGACAGTGGGCCCCCGGCTGCCACTGTTTGCTGGTGGTCTCCGTGACCCCCTCCTCACCTGCTGGTTGGGGGCTTCCTTGGCC CTCTTGGAAAGGAGGGGCTCGTGTGGCCCCAGGCCAGTGTCTGTCAGGATGGTCCCCCCGAGGCGCTCTGGGCAGGCATCCTGGTGTCCT GAGAGGCTCTTGCAGGAATGATACGTGGCAGTGCCTGCAGCGAGGTCTGGGAACACCCTGGGTGAGGCCTGGGGGTTTCCGAAAATGGAG GCATTCCTTTCCAAATCTGGACAGCGATCGTTTTTAGTGTTTCTGTCTCAAGACTGGAAAACAATAGCATTTGTCTTGAGTGAGGAAGTG AAGCCCGCTGTGTTCATAGCAGGAGAGGGCTCCCAGACACAGGCCCGTCCTCGGAAGAGCCTTGAGAGTGCAGCTCGGACCCACCGGCGG CCCCCGTAGCAGGTGGTGTGGGTGCTCGGGAGTGGAGGTGACGTCAGCAGCGCTCTCTGACCGCGGGTGTCACGGGCATTTCTCAAAGGA AGCAGGGGATTCAGTGAGTGTGAAGGTGAACAGGATGGCCTGGCAGCAGGGATGTTTCCGTGAGCCACAAATACCAGAAACTGAGGCGAG GCTCCCAGCAGCCGGTAGGGAAAGGTGTTTCCAGGGGTCCGAGGGCCGTGGCCTGCGTGGCCATCCCCTGGAGAGAGGAGCCGCTCAGGG TGCGCGTCATGGAGTGTGCTCAGGGGTGCGTGGACACCTCTGCTGTGGTTTGCTGCTGGGGGCGATGGGAGCGCCTCTCCGTCCTGTGCC CTGGTCCAGGATGCTGACAGCAGTGAGAGGCCTGCCGTGAGGTTTGGTCTTGTCAGACCTGTAGCCTGGACCTCGCCGGGGGACCAGGGA GTGCACGTCTGTAGATCTGTACATATCTGGGCCTTTGGAGGCCACGTGTGGCATGGGAGGGGCTACCTGGTCCCTTTCACAGCCAGGACA CGCCTGGATGAGAAAGCCTGAGGTGCCTGGCATGCCCACCGGTGCCACTCTGCAGCCTCCACCCCTGGCCTGAGTCCCCCTCCATCCGTC TTGGTGGACACCTGTGTGGCTCTCACCTGCGTTTTGAGTCTGTTCTTCCAGGAGTAATAAATTCTGGACATCATCACTGGACTGGCTTAC >58553_58553_9_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000382788_length(amino acids)=819AA_BP=70 MASMRESDTGLWLHNKLGATDELWAPPSIASLLTAAVIDNIRLCFHGLSSAVKLKLLLGTLHLPRRTVDEGSKFGRGTGLTQPSQRTSAR RSFGRSKRFSITRSLDDLESATVSDGELTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGVRYFSDFLRKEF SEENILFWQACEYFNHVPAHDKKELSYRAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKFDSYTRFLKSPL YQECILAEVEGRALPDSQQVPSSPASKHSLGSDHSSVSTPKKLSGKSKSGRSLNEELGDEDSEKKRKGAFFSWSRTRSTGRSQKKREHGD HADDALHANGGLCRRESQGSVSSAGSLDLSEACRTLAPEKDKATKHCCIHLPDGTSCVVAVKAGFSIKDILSGLCERHGINGAAADLFLV GGDKPLVLHQDSSILESRDLRLEKRTLFRLDLVPINRSVGLKAKPTKPVTEVLRPVVARYGLDLSGLLVRLSGEKEPLDLGAPISSLDGQ RVVLEEKDPSRGKASADKQKGVPVKQNTAVNSSSRNHSATGEERTLGKSNSIKIKGENGKNARDPRLSKREESIAKIGKKKYQKINLDEA EEFFELISKAQSNRADDQRGLLRKEDLVLPEFLRLPPGSTELTLPTPAAVAKGFSKRSATGNGRESASQPGEQWEPVQESSDSPSTSPGS ASSPPGPPGTTPPGQKSPSGPFCTPQSPVSLAQEGTAQIWKRQSQEVEAGGIQTVEDEHVAELTLMGEGDISSPNSTLLPPPSTPQEVPG -------------------------------------------------------------- >58553_58553_10_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000543385_length(transcript)=993nt_BP=226nt CGCGCTTTCCCCCAAGATGGCGTCCATGCGGGAGAGCGACACGGGCCTGTGGCTGCACAACAAGCTGGGGGCCACGGACGAGCTGTGGGC GCCGCCCAGCATCGCGTCCCTGCTCACGGCCGCGGTCATCGACAACATCCGTCTCTGCTTCCATGGCCTCTCGTCGGCAGTGAAGCTCAA GTTGCTACTCGGGACGCTGCACCTCCCGCGCCGCACGGTGGACGAGGGCTCAAAATTTGGGCGGGGAACTGGACTCACTCAGCCTTCTCA ACGCACGTCTGCTCGGAGATCATTTGGGAGATCCAAGAGATTCAGTATCACTCGCTCCCTTGATGATCTTGAGAGTTGACGGGCGCCGAC CTGAAGGACTGCGTCAGCAACAACAGCCTGAGCAGCAATGCCAGCCTCCCCAGCGTGCAGAGCTGCCGGCGCCTGCGTGAGAGGAGGGTC GCCAGCTGGGCCGTGTCCTTTGAGCGCCTGCTGCAGGACCCCGTCGGTGTCCGCTACTTCTCTGATTTTCTAAGGAAAGAATTCAGTGAA GAAAACATTTTATTCTGGCAGGCCTGTGAATATTTTAATCATGTTCCTGCACATGACAAAAAGGAGCTTTCCTACAGGGCCCGGGAGATT TTCAGTAAGTTTCTCTGCAGCAAAGCCACCACCCCGGTCAACATCGACAGCCAGGCCCAGCTAGCAGACGACGTCCTCCGCGCACCTCAC CCAGACATGTTCAAGGAGCAGCAGCTGCAGATCTTCAATCTCATGAAGTTTGATAGCTACACTCGCTTTCTGAAGTCCCCGCTGTACCAG GAATGCATCCTGGCGGAAGTGGAGGGCCGTGCACTCCCGGACTCGCAGCAGGTCCCCAGCAGCCCGGCTTCCAAGCACAGCCTCGGTTCA GACCACTCCAGTGTGTCCACGCCAAAAAAGTTAAGTGGAAAATCAAAATCCGGCCGATCCCTGAATGAAGAGCTGGGGGATGAGGACAGC >58553_58553_10_NELFA-RGS12_NELFA_chr4_2010477_ENST00000411638_RGS12_chr4_3344664_ENST00000543385_length(amino acids)=216AA_BP= MTGADLKDCVSNNSLSSNASLPSVQSCRRLRERRVASWAVSFERLLQDPVGVRYFSDFLRKEFSEENILFWQACEYFNHVPAHDKKELSY RAREIFSKFLCSKATTPVNIDSQAQLADDVLRAPHPDMFKEQQLQIFNLMKFDSYTRFLKSPLYQECILAEVEGRALPDSQQVPSSPASK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NELFA-RGS12 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NELFA-RGS12 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NELFA-RGS12 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies