
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARFGEF2-HNF4A (FusionGDB2 ID:5869) |
Fusion Gene Summary for ARFGEF2-HNF4A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARFGEF2-HNF4A | Fusion gene ID: 5869 | Hgene | Tgene | Gene symbol | ARFGEF2 | HNF4A | Gene ID | 10564 | 6927 |
| Gene name | ADP ribosylation factor guanine nucleotide exchange factor 2 | HNF1 homeobox A | |
| Synonyms | BIG2|PVNH2|dJ1164I10.1 | HNF-1A|HNF1|HNF4A|IDDM20|LFB1|MODY3|TCF-1|TCF1 | |
| Cytomap | 20q13.13 | 12q24.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | brefeldin A-inhibited guanine nucleotide-exchange protein 2ADP-ribosylation factor guanine nucleotide-exchange factor 2 (brefeldin A-inhibited)brefeldin A-inhibited GEP 2 | hepatocyte nuclear factor 1-alphaHNF-1-alphaalbumin proximal factorhepatic nuclear factor 1interferon production regulator factorliver-specific transcription factor LF-B1transcription factor 1, hepatictruncated hepatocyte nuclear factor 1 alpha | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9Y6D5 | P41235 | |
| Ensembl transtripts involved in fusion gene | ENST00000371917, ENST00000493140, | ENST00000316099, ENST00000316673, ENST00000415691, ENST00000443598, ENST00000457232, ENST00000609795, | |
| Fusion gene scores | * DoF score | 15 X 13 X 9=1755 | 6 X 6 X 5=180 |
| # samples | 15 | 7 | |
| ** MAII score | log2(15/1755*10)=-3.54843662469604 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/180*10)=-1.36257007938471 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARFGEF2 [Title/Abstract] AND HNF4A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARFGEF2(47538547)-HNF4A(43034698), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ARFGEF2 | GO:0001881 | receptor recycling | 16477018 |
| Hgene | ARFGEF2 | GO:0035556 | intracellular signal transduction | 12571360 |
| Tgene | HNF4A | GO:0001779 | natural killer cell differentiation | 11301190 |
| Tgene | HNF4A | GO:0006357 | regulation of transcription by RNA polymerase II | 10330009 |
| Tgene | HNF4A | GO:0045893 | positive regulation of transcription, DNA-templated | 1989880|11980910|12453420 |
| Fusion gene breakpoints across ARFGEF2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across HNF4A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SARC | TCGA-DX-A1KX-01A | ARFGEF2 | chr20 | 47538547 | - | HNF4A | chr20 | 43034698 | + |
| ChimerDB4 | SARC | TCGA-DX-A1KX-01A | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
Top |
Fusion Gene ORF analysis for ARFGEF2-HNF4A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000371917 | ENST00000316099 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| In-frame | ENST00000371917 | ENST00000316673 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| In-frame | ENST00000371917 | ENST00000415691 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| In-frame | ENST00000371917 | ENST00000443598 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| In-frame | ENST00000371917 | ENST00000457232 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| In-frame | ENST00000371917 | ENST00000609795 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| intron-3CDS | ENST00000493140 | ENST00000316099 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| intron-3CDS | ENST00000493140 | ENST00000316673 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| intron-3CDS | ENST00000493140 | ENST00000415691 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| intron-3CDS | ENST00000493140 | ENST00000443598 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| intron-3CDS | ENST00000493140 | ENST00000457232 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| intron-3CDS | ENST00000493140 | ENST00000609795 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000371917 | ARFGEF2 | chr20 | 47538547 | + | ENST00000316673 | HNF4A | chr20 | 43034698 | + | 1437 | 121 | 0 | 1430 | 476 |
| ENST00000371917 | ARFGEF2 | chr20 | 47538547 | + | ENST00000609795 | HNF4A | chr20 | 43034698 | + | 1260 | 121 | 0 | 1259 | 419 |
| ENST00000371917 | ARFGEF2 | chr20 | 47538547 | + | ENST00000457232 | HNF4A | chr20 | 43034698 | + | 1407 | 121 | 0 | 1400 | 466 |
| ENST00000371917 | ARFGEF2 | chr20 | 47538547 | + | ENST00000443598 | HNF4A | chr20 | 43034698 | + | 1520 | 121 | 0 | 1259 | 419 |
| ENST00000371917 | ARFGEF2 | chr20 | 47538547 | + | ENST00000316099 | HNF4A | chr20 | 43034698 | + | 4611 | 121 | 0 | 1430 | 476 |
| ENST00000371917 | ARFGEF2 | chr20 | 47538547 | + | ENST00000415691 | HNF4A | chr20 | 43034698 | + | 2236 | 121 | 0 | 1400 | 466 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000371917 | ENST00000316673 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + | 0.008363198 | 0.9916368 |
| ENST00000371917 | ENST00000609795 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + | 0.013195487 | 0.9868045 |
| ENST00000371917 | ENST00000457232 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + | 0.004984147 | 0.9950159 |
| ENST00000371917 | ENST00000443598 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + | 0.010475894 | 0.98952407 |
| ENST00000371917 | ENST00000316099 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + | 0.009349771 | 0.9906502 |
| ENST00000371917 | ENST00000415691 | ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034698 | + | 0.01023785 | 0.9897621 |
Top |
Fusion Genomic Features for ARFGEF2-HNF4A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034697 | + | 3.15E-08 | 1 |
| ARFGEF2 | chr20 | 47538547 | + | HNF4A | chr20 | 43034697 | + | 3.15E-08 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
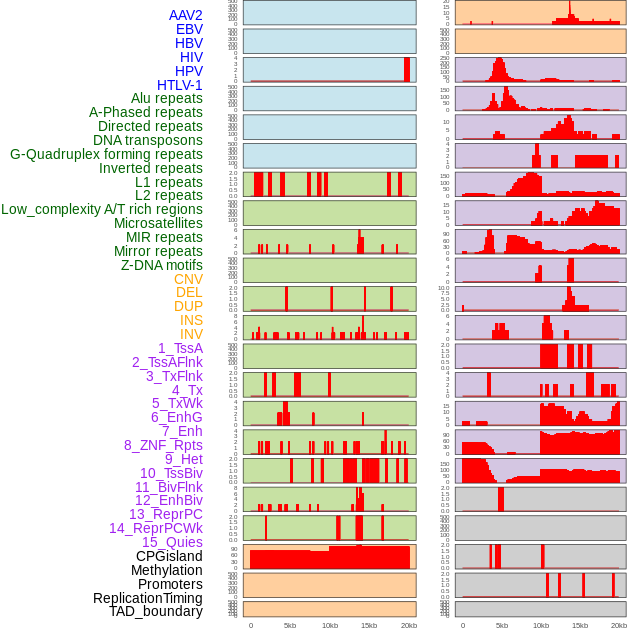 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
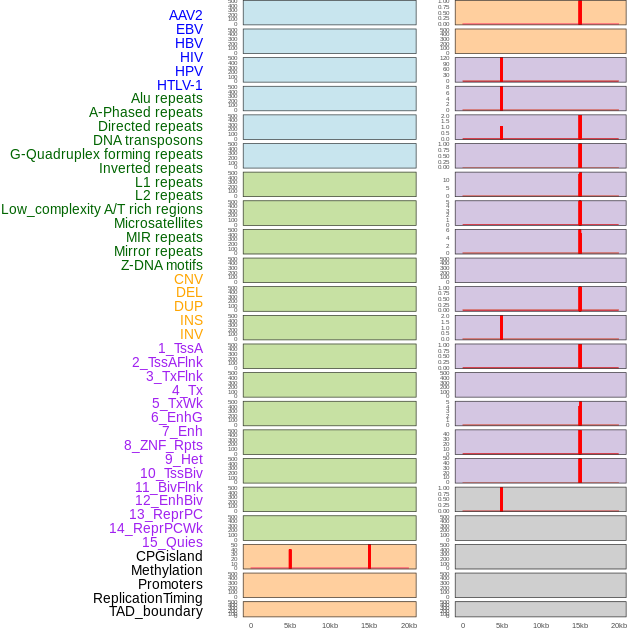 |
Top |
Fusion Protein Features for ARFGEF2-HNF4A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:47538547/chr20:43034698) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARFGEF2 | HNF4A |
| FUNCTION: Promotes guanine-nucleotide exchange on ARF1 and ARF3 and to a lower extent on ARF5 and ARF6. Promotes the activation of ARF1/ARF5/ARF6 through replacement of GDP with GTP. Involved in the regulation of Golgi vesicular transport. Required for the integrity of the endosomal compartment. Involved in trafficking from the trans-Golgi network (TGN) to endosomes and is required for membrane association of the AP-1 complex and GGA1. Seems to be involved in recycling of the transferrin receptor from recycling endosomes to the plasma membrane. Probably is involved in the exit of GABA(A) receptors from the endoplasmic reticulum. Involved in constitutive release of tumor necrosis factor receptor 1 via exosome-like vesicles; the function seems to involve PKA and specifically PRKAR2B. Proposed to act as A kinase-anchoring protein (AKAP) and may mediate crosstalk between Arf and PKA pathways. {ECO:0000269|PubMed:12051703, ECO:0000269|PubMed:12571360, ECO:0000269|PubMed:15385626, ECO:0000269|PubMed:16477018, ECO:0000269|PubMed:17276987, ECO:0000269|PubMed:18625701, ECO:0000269|PubMed:20360857}. | FUNCTION: Transcriptional regulator which controls the expression of hepatic genes during the transition of endodermal cells to hepatic progenitor cells, facilitating the recruitment of RNA pol II to the promoters of target genes (PubMed:30597922). Activates the transcription of CYP2C38 (By similarity). Represses the CLOCK-ARNTL/BMAL1 transcriptional activity and is essential for circadian rhythm maintenance and period regulation in the liver and colon cells (PubMed:30530698). {ECO:0000250|UniProtKB:P49698, ECO:0000269|PubMed:30530698, ECO:0000269|PubMed:30597922}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316099 | 0 | 10 | 57_132 | 38 | 475.0 | DNA binding | Nuclear receptor | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316673 | 0 | 10 | 57_132 | 16 | 453.0 | DNA binding | Nuclear receptor | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000415691 | 0 | 10 | 57_132 | 38 | 465.0 | DNA binding | Nuclear receptor | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000443598 | 0 | 8 | 57_132 | 38 | 418.0 | DNA binding | Nuclear receptor | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000457232 | 0 | 10 | 57_132 | 16 | 443.0 | DNA binding | Nuclear receptor | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316099 | 0 | 10 | 147_377 | 38 | 475.0 | Domain | NR LBD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316673 | 0 | 10 | 147_377 | 16 | 453.0 | Domain | NR LBD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000415691 | 0 | 10 | 147_377 | 38 | 465.0 | Domain | NR LBD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000443598 | 0 | 8 | 147_377 | 38 | 418.0 | Domain | NR LBD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000457232 | 0 | 10 | 147_377 | 16 | 443.0 | Domain | NR LBD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316099 | 0 | 10 | 368_376 | 38 | 475.0 | Motif | 9aaTAD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316673 | 0 | 10 | 368_376 | 16 | 453.0 | Motif | 9aaTAD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000415691 | 0 | 10 | 368_376 | 38 | 465.0 | Motif | 9aaTAD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000443598 | 0 | 8 | 368_376 | 38 | 418.0 | Motif | 9aaTAD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000457232 | 0 | 10 | 368_376 | 16 | 443.0 | Motif | 9aaTAD | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316099 | 0 | 10 | 60_80 | 38 | 475.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316099 | 0 | 10 | 96_120 | 38 | 475.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316673 | 0 | 10 | 60_80 | 16 | 453.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000316673 | 0 | 10 | 96_120 | 16 | 453.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000415691 | 0 | 10 | 60_80 | 38 | 465.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000415691 | 0 | 10 | 96_120 | 38 | 465.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000443598 | 0 | 8 | 60_80 | 38 | 418.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000443598 | 0 | 8 | 96_120 | 38 | 418.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000457232 | 0 | 10 | 60_80 | 16 | 443.0 | Zinc finger | NR C4-type | |
| Tgene | HNF4A | chr20:47538547 | chr20:43034698 | ENST00000457232 | 0 | 10 | 96_120 | 16 | 443.0 | Zinc finger | NR C4-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARFGEF2 | chr20:47538547 | chr20:43034698 | ENST00000371917 | + | 1 | 39 | 654_785 | 40 | 1786.0 | Domain | SEC7 |
Top |
Fusion Gene Sequence for ARFGEF2-HNF4A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5869_5869_1_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000316099_length(transcript)=4611nt_BP=121nt ATGCAGGAGAGCCAGACCAAGAGCATGTTCGTGTCCCGGGCCCTGGAGAAGATCCTAGCCGACAAGGAGGTGAAGCGGCCCCAGCACTCC CAGCTGCGCAGGGCCTGCCAGGTGGCGCTCGACACGTCCCCATCAGAAGGCACCAACCTCAACGCGCCCAACAGCCTGGGTGTCAGCGCC CTGTGTGCCATCTGCGGGGACCGGGCCACGGGCAAACACTACGGTGCCTCGAGCTGTGACGGCTGCAAGGGCTTCTTCCGGAGGAGCGTG CGGAAGAACCACATGTACTCCTGCAGATTTAGCCGGCAGTGCGTGGTGGACAAAGACAAGAGGAACCAGTGCCGCTACTGCAGGCTCAAG AAATGCTTCCGGGCTGGCATGAAGAAGGAAGCCGTCCAGAATGAGCGGGACCGGATCAGCACTCGAAGGTCAAGCTATGAGGACAGCAGC CTGCCCTCCATCAATGCGCTCCTGCAGGCGGAGGTCCTGTCCCGACAGATCACCTCCCCCGTCTCCGGGATCAACGGCGACATTCGGGCG AAGAAGATTGCCAGCATCGCAGATGTGTGTGAGTCCATGAAGGAGCAGCTGCTGGTTCTCGTTGAGTGGGCCAAGTACATCCCAGCTTTC TGCGAGCTCCCCCTGGACGACCAGGTGGCCCTGCTCAGAGCCCATGCTGGCGAGCACCTGCTGCTCGGAGCCACCAAGAGATCCATGGTG TTCAAGGACGTGCTGCTCCTAGGCAATGACTACATTGTCCCTCGGCACTGCCCGGAGCTGGCGGAGATGAGCCGGGTGTCCATACGCATC CTTGACGAGCTGGTGCTGCCCTTCCAGGAGCTGCAGATCGATGACAATGAGTATGCCTACCTCAAAGCCATCATCTTCTTTGACCCAGAT GCCAAGGGGCTGAGCGATCCAGGGAAGATCAAGCGGCTGCGTTCCCAGGTGCAGGTGAGCTTGGAGGACTACATCAACGACCGCCAGTAT GACTCGCGTGGCCGCTTTGGAGAGCTGCTGCTGCTGCTGCCCACCTTGCAGAGCATCACCTGGCAGATGATCGAGCAGATCCAGTTCATC AAGCTCTTCGGCATGGCCAAGATTGACAACCTGTTGCAGGAGATGCTGCTGGGAGGGTCCCCCAGCGATGCACCCCATGCCCACCACCCC CTGCACCCTCACCTGATGCAGGAACATATGGGAACCAACGTCATCGTTGCCAACACAATGCCCACTCACCTCAGCAACGGACAGATGTGT GAGTGGCCCCGACCCAGGGGACAGGCAGCCACCCCTGAGACCCCACAGCCCTCACCGCCAGGTGGCTCAGGGTCTGAGCCCTATAAGCTC CTGCCGGGAGCCGTCGCCACAATCGTCAAGCCCCTCTCTGCCATCCCCCAGCCGACCATCACCAAGCAGGAAGTTATCTAGCAAGCCGCT GGGGCTTGGGGGCTCCACTGGCTCCCCCCAGCCCCCTAAGAGAGCACCTGGTGATCACGTGGTCACGGCAAAGGAAGACGTGATGCCAGG ACCAGTCCCAGAGCAGGAATGGGAAGGATGAAGGGCCCGAGAACATGGCCTAAGGGCCACATCCCACTGCCACCCTTGACGCCCTGCTCT GGATAACAAGACTTTGACTTGGGGAGACCTCTACTGCCTTGGACAACTTTTCTCATGTTGAAGCCACTGCCTTCACCTTCACCTTCATCC ATGTCCAACCCCCGACTTCATCCCAAAGGACAGCCGCCTGGAGATGACTTGAGGCCTTACTTAAACCCAGCTCCCTTCTTCCCTAGCCTG GTGCTTCTCCTCTCCTAGCCCCTGTCATGGTGTCCAGACAGAGCCCTGTGAGGCTGGGTCCAATTGTGGCACTTGGGGCACCTTGCTCCT CCTTCTGCTGCTGCCCCCACCTCTGCTGCCTCCCTCTGCTGTCACCTTGCTCAGCCATCCCGTCTTCTCCAACACCACCTCTCCAGAGGC CAAGGAGGCCTTGGAAACGATTCCCCCAGTCATTCTGGGAACATGTTGTAAGCACTGACTGGGACCAGGCACCAGGCAGGGTCTAGAAGG CTGTGGTGAGGGAAGACGCCTTTCTCCTCCAACCCAACCTCATCCTCCTTCTTCAGGGACTTGGGTGGGTACTTGGGTGAGGATCCCTGA AGGCCTTCAACCCGAGAAAACAAACCCAGGTTGGCGACTGCAACAGGAACTTGGAGTGGAGAGGAAAAGCATCAGAAAGAGGCAGACCAT CCACCAGGCCTTTGAGAAAGGGTAGAATTCTGGCTGGTAGAGCAGGTGAGATGGGACATTCCAAAGAACAGCCTGAGCCAAGGCCTAGTG GTAGTAAGAATCTAGCAAGAATTGAGGAAGAATGGTGTGGGAGAGGGATGATGAAGAGAGAGAGGGCCTGCTGGAGAGCATAGGGTCTGG AACACCAGGCTGAGGTCCTGATCAGCTTCAAGGAGTATGCAGGGAGCTGGGCTTCCAGAAAATGAACACAGCAGTTCTGCAGAGGACGGG AGGCTGGAAGCTGGGAGGTCAGGTGGGGTGGATGATATAATGCGGGTGAGAGTAATGAGGCTTGGGGCTGGAGAGGACAAGATGGGTAAA CCCTCACATCAGAGTGACATCCAGGAGGAATAAGCTCCCAGGGCCTGTCTCAAGCTCTTCCTTACTCCCAGGCACTGTCTTAAGGCATCT GACATGCATCATCTCATTTAATCCTCCCTTCCTCCCTATTAACCTAGAGATTGTTTTTGTTTTTTATTCTCCTCCTCCCTCCCCGCCCTC ACCCGCCCCACTCCCTCCTAACCTAGAGATTGTTACAGAAGCTGAAATTGCGTTCTAAGAGGTGAAGTGATTTTTTTTCTGAAACTCACA CAACTAGGAAGTGGCTGAGTCAGGACTTGAACCCAGGTCTCCCTGGATCAGAACAGGAGCTCTTAACTACAGTGGCTGAATAGCTTCTCC AAAGGCTCCCTGTGTTCTCACCGTGATCAAGTTGAGGGGCTTCCGGCTCCCTTCTACAGCCTCAGAAACCAGACTCGTTCTTCTGGGAAC CCTGCCCACTCCCAGGACCAAGATTGGCCTGAGGCTGCACTAAAATTCACTTAGGGTCGAGCATCCTGTTTGCTGATAAATATTAAGGAG AATTCATGACTCTTGACAGCTTTTCTCTCTTCACTCCCCAAGTCAAGGGGAGGGGTGGCAGGGGTCTGTTTCCTGGAAGTCAGGCTCATC TGGCCTGTTGGCATGGGGGTGGGACAGTGTGCACAGTGTGGGGGCAGGGGAGGGCTAAGCAGGCCTGGGTTTGAGGGCTGCTCCGGAGAC CGTCACTCCAGGTGCATTCTGGAAGCATTAGACCCCAGGATGGAGCGACCAGCATGTCATCCATGTGGAATCTTGGTGGCTTTGAGGACA TTCTGGAAAATGCCACTGACCAGTGTGAACAAAAGGGATGTGTTATGGGGCTGGAGGTGTGATTAGGTAGGAGGGAAACTGTTGGACCGA CTCCTGCCCCCTGCTCAACACTGACCCCTCTGAGTGGTTGGAGGCAGTGCCCCAGTGCCCAGAAATCCCACCATTAGTGATTGTTTTTTA TGAGAAAGAGGCGTGGAGAAGTATTGGGGCAATGTGTCAGGGAGGAATCACCACATCCCTACGGCAGTCCCAGCCAAGCCCCCAATCCCA GCGGAGACTGTGCCCTGCTCAGAGCTCCCAAGCCTTCCCCCACCACCTCACTCAAGTGCCCCTGAAATCCCTGCCAGACGGCTCAGCCTG GTCTGCGGTAAGGCAGGGAGGCTGGAACCATTTCTGGGCATTGTGGTCATTCCCACTGTGTTCCTCCACCTCCTCCCTCCAGCGTTGCTC AGACCTCTGTCTTGGGAGAAAGGTTGAGATAAGAATGTCCCATGGAGTGCCGTGGGCAACAGTGGCCCTTCATGGGAACAATCTGTTGGA GCAGGGGGTCAGTTCTCTGCTGGGAATCTACCCCTTTCTGGAGGAGAAACCCATTCCACCTTAATAACTTTATTGTAATGTGAGAAACAC AAAACAAAGTTTACTTTTTTGACTCTAAGCTGACATGATATTAGAAAATCTCTCGCTCTCTTTTTTTTTTTTTTTTTTTTTTTTGGCTAC TTGAGTTGTGGTCCTAAAACATAAAATCTGATGGACAAACAGAGGGTTGCTGGGGGGACAAGCGTGGGCACAATTTCCCCACCAAGACAC CCTGATCTTCAGGCGGGTCTCAGGAGCTTCTAAAAATCCGCATGGCTCTCCTGAGAGTGGACAGAGGAGAGGAGAGGGTCAGAAATGAAC GCTCTTCTATTTCTTGTCATTACCAAGCCAATTACTTTTGCCAAATTTTTCTGTGATCTGCCCTGATTAAGATGAATTGTGAAATTTACA TCAAGCAATTATCAAAGCGGGCTGGGTCCCATCAGAACGACCCACATCTTTCTGTGGGTGTGAATGTCATTAGGTCTTGCGCTGACCCCT GAGCCCCCATCACTGCCGCCTGATGGGGCAAAGAAACAAAAAACATTTCTTACTCTTCTGTGTTTTAACAAAAGTTTATAAAACAAAATA >5869_5869_1_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000316099_length(amino acids)=476AA_BP=40 MQESQTKSMFVSRALEKILADKEVKRPQHSQLRRACQVALDTSPSEGTNLNAPNSLGVSALCAICGDRATGKHYGASSCDGCKGFFRRSV RKNHMYSCRFSRQCVVDKDKRNQCRYCRLKKCFRAGMKKEAVQNERDRISTRRSSYEDSSLPSINALLQAEVLSRQITSPVSGINGDIRA KKIASIADVCESMKEQLLVLVEWAKYIPAFCELPLDDQVALLRAHAGEHLLLGATKRSMVFKDVLLLGNDYIVPRHCPELAEMSRVSIRI LDELVLPFQELQIDDNEYAYLKAIIFFDPDAKGLSDPGKIKRLRSQVQVSLEDYINDRQYDSRGRFGELLLLLPTLQSITWQMIEQIQFI KLFGMAKIDNLLQEMLLGGSPSDAPHAHHPLHPHLMQEHMGTNVIVANTMPTHLSNGQMCEWPRPRGQAATPETPQPSPPGGSGSEPYKL -------------------------------------------------------------- >5869_5869_2_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000316673_length(transcript)=1437nt_BP=121nt ATGCAGGAGAGCCAGACCAAGAGCATGTTCGTGTCCCGGGCCCTGGAGAAGATCCTAGCCGACAAGGAGGTGAAGCGGCCCCAGCACTCC CAGCTGCGCAGGGCCTGCCAGGTGGCGCTCGACACGTCCCCATCAGAAGGCACCAACCTCAACGCGCCCAACAGCCTGGGTGTCAGCGCC CTGTGTGCCATCTGCGGGGACCGGGCCACGGGCAAACACTACGGTGCCTCGAGCTGTGACGGCTGCAAGGGCTTCTTCCGGAGGAGCGTG CGGAAGAACCACATGTACTCCTGCAGATTTAGCCGGCAGTGCGTGGTGGACAAAGACAAGAGGAACCAGTGCCGCTACTGCAGGCTCAAG AAATGCTTCCGGGCTGGCATGAAGAAGGAAGCCGTCCAGAATGAGCGGGACCGGATCAGCACTCGAAGGTCAAGCTATGAGGACAGCAGC CTGCCCTCCATCAATGCGCTCCTGCAGGCGGAGGTCCTGTCCCGACAGATCACCTCCCCCGTCTCCGGGATCAACGGCGACATTCGGGCG AAGAAGATTGCCAGCATCGCAGATGTGTGTGAGTCCATGAAGGAGCAGCTGCTGGTTCTCGTTGAGTGGGCCAAGTACATCCCAGCTTTC TGCGAGCTCCCCCTGGACGACCAGGTGGCCCTGCTCAGAGCCCATGCTGGCGAGCACCTGCTGCTCGGAGCCACCAAGAGATCCATGGTG TTCAAGGACGTGCTGCTCCTAGGCAATGACTACATTGTCCCTCGGCACTGCCCGGAGCTGGCGGAGATGAGCCGGGTGTCCATACGCATC CTTGACGAGCTGGTGCTGCCCTTCCAGGAGCTGCAGATCGATGACAATGAGTATGCCTACCTCAAAGCCATCATCTTCTTTGACCCAGAT GCCAAGGGGCTGAGCGATCCAGGGAAGATCAAGCGGCTGCGTTCCCAGGTGCAGGTGAGCTTGGAGGACTACATCAACGACCGCCAGTAT GACTCGCGTGGCCGCTTTGGAGAGCTGCTGCTGCTGCTGCCCACCTTGCAGAGCATCACCTGGCAGATGATCGAGCAGATCCAGTTCATC AAGCTCTTCGGCATGGCCAAGATTGACAACCTGTTGCAGGAGATGCTGCTGGGAGGGTCCCCCAGCGATGCACCCCATGCCCACCACCCC CTGCACCCTCACCTGATGCAGGAACATATGGGAACCAACGTCATCGTTGCCAACACAATGCCCACTCACCTCAGCAACGGACAGATGTGT GAGTGGCCCCGACCCAGGGGACAGGCAGCCACCCCTGAGACCCCACAGCCCTCACCGCCAGGTGGCTCAGGGTCTGAGCCCTATAAGCTC >5869_5869_2_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000316673_length(amino acids)=476AA_BP=40 MQESQTKSMFVSRALEKILADKEVKRPQHSQLRRACQVALDTSPSEGTNLNAPNSLGVSALCAICGDRATGKHYGASSCDGCKGFFRRSV RKNHMYSCRFSRQCVVDKDKRNQCRYCRLKKCFRAGMKKEAVQNERDRISTRRSSYEDSSLPSINALLQAEVLSRQITSPVSGINGDIRA KKIASIADVCESMKEQLLVLVEWAKYIPAFCELPLDDQVALLRAHAGEHLLLGATKRSMVFKDVLLLGNDYIVPRHCPELAEMSRVSIRI LDELVLPFQELQIDDNEYAYLKAIIFFDPDAKGLSDPGKIKRLRSQVQVSLEDYINDRQYDSRGRFGELLLLLPTLQSITWQMIEQIQFI KLFGMAKIDNLLQEMLLGGSPSDAPHAHHPLHPHLMQEHMGTNVIVANTMPTHLSNGQMCEWPRPRGQAATPETPQPSPPGGSGSEPYKL -------------------------------------------------------------- >5869_5869_3_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000415691_length(transcript)=2236nt_BP=121nt ATGCAGGAGAGCCAGACCAAGAGCATGTTCGTGTCCCGGGCCCTGGAGAAGATCCTAGCCGACAAGGAGGTGAAGCGGCCCCAGCACTCC CAGCTGCGCAGGGCCTGCCAGGTGGCGCTCGACACGTCCCCATCAGAAGGCACCAACCTCAACGCGCCCAACAGCCTGGGTGTCAGCGCC CTGTGTGCCATCTGCGGGGACCGGGCCACGGGCAAACACTACGGTGCCTCGAGCTGTGACGGCTGCAAGGGCTTCTTCCGGAGGAGCGTG CGGAAGAACCACATGTACTCCTGCAGATTTAGCCGGCAGTGCGTGGTGGACAAAGACAAGAGGAACCAGTGCCGCTACTGCAGGCTCAAG AAATGCTTCCGGGCTGGCATGAAGAAGGAAGCCGTCCAGAATGAGCGGGACCGGATCAGCACTCGAAGGTCAAGCTATGAGGACAGCAGC CTGCCCTCCATCAATGCGCTCCTGCAGGCGGAGGTCCTGTCCCGACAGATCACCTCCCCCGTCTCCGGGATCAACGGCGACATTCGGGCG AAGAAGATTGCCAGCATCGCAGATGTGTGTGAGTCCATGAAGGAGCAGCTGCTGGTTCTCGTTGAGTGGGCCAAGTACATCCCAGCTTTC TGCGAGCTCCCCCTGGACGACCAGGTGGCCCTGCTCAGAGCCCATGCTGGCGAGCACCTGCTGCTCGGAGCCACCAAGAGATCCATGGTG TTCAAGGACGTGCTGCTCCTAGGCAATGACTACATTGTCCCTCGGCACTGCCCGGAGCTGGCGGAGATGAGCCGGGTGTCCATACGCATC CTTGACGAGCTGGTGCTGCCCTTCCAGGAGCTGCAGATCGATGACAATGAGTATGCCTACCTCAAAGCCATCATCTTCTTTGACCCAGAT GCCAAGGGGCTGAGCGATCCAGGGAAGATCAAGCGGCTGCGTTCCCAGGTGCAGGTGAGCTTGGAGGACTACATCAACGACCGCCAGTAT GACTCGCGTGGCCGCTTTGGAGAGCTGCTGCTGCTGCTGCCCACCTTGCAGAGCATCACCTGGCAGATGATCGAGCAGATCCAGTTCATC AAGCTCTTCGGCATGGCCAAGATTGACAACCTGTTGCAGGAGATGCTGCTGGGAGGGTCCCCCAGCGATGCACCCCATGCCCACCACCCC CTGCACCCTCACCTGATGCAGGAACATATGGGAACCAACGTCATCGTTGCCAACACAATGCCCACTCACCTCAGCAACGGACAGATGTCC ACCCCTGAGACCCCACAGCCCTCACCGCCAGGTGGCTCAGGGTCTGAGCCCTATAAGCTCCTGCCGGGAGCCGTCGCCACAATCGTCAAG CCCCTCTCTGCCATCCCCCAGCCGACCATCACCAAGCAGGAAGTTATCTAGCAAGCCGCTGGGGCTTGGGGGCTCCACTGGCTCCCCCCA GCCCCCTAAGAGAGCACCTGGTGATCACGTGGTCACGGCAAAGGAAGACGTGATGCCAGGACCAGTCCCAGAGCAGGAATGGGAAGGATG AAGGGCCCGAGAACATGGCCTAAGGGCCACATCCCACTGCCACCCTTGACGCCCTGCTCTGGATAACAAGACTTTGACTTGGGGAGACCT CTACTGCCTTGGACAACTTTTCTCATGTTGAAGCCACTGCCTTCACCTTCACCTTCATCCATGTCCAACCCCCGACTTCATCCCAAAGGA CAGCCGCCTGGAGATGACTTGAGGCCTTACTTAAACCCAGCTCCCTTCTTCCCTAGCCTGGTGCTTCTCCTCTCCTAGCCCCTGTCATGG TGTCCAGACAGAGCCCTGTGAGGCTGGGTCCAATTGTGGCACTTGGGGCACCTTGCTCCTCCTTCTGCTGCTGCCCCCACCTCTGCTGCC TCCCTCTGCTGTCACCTTGCTCAGCCATCCCGTCTTCTCCAACACCACCTCTCCAGAGGCCAAGGAGGCCTTGGAAACGATTCCCCCAGT CATTCTGGGAACATGTTGTAAGCACTGACTGGGACCAGGCACCAGGCAGGGTCTAGAAGGCTGTGGTGAGGGAAGACGCCTTTCTCCTCC AACCCAACCTCATCCTCCTTCTTCAGGGACTTGGGTGGGTACTTGGGTGAGGATCCCTGAAGGCCTTCAACCCGAGAAAACAAACCCAGG >5869_5869_3_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000415691_length(amino acids)=466AA_BP=40 MQESQTKSMFVSRALEKILADKEVKRPQHSQLRRACQVALDTSPSEGTNLNAPNSLGVSALCAICGDRATGKHYGASSCDGCKGFFRRSV RKNHMYSCRFSRQCVVDKDKRNQCRYCRLKKCFRAGMKKEAVQNERDRISTRRSSYEDSSLPSINALLQAEVLSRQITSPVSGINGDIRA KKIASIADVCESMKEQLLVLVEWAKYIPAFCELPLDDQVALLRAHAGEHLLLGATKRSMVFKDVLLLGNDYIVPRHCPELAEMSRVSIRI LDELVLPFQELQIDDNEYAYLKAIIFFDPDAKGLSDPGKIKRLRSQVQVSLEDYINDRQYDSRGRFGELLLLLPTLQSITWQMIEQIQFI KLFGMAKIDNLLQEMLLGGSPSDAPHAHHPLHPHLMQEHMGTNVIVANTMPTHLSNGQMSTPETPQPSPPGGSGSEPYKLLPGAVATIVK -------------------------------------------------------------- >5869_5869_4_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000443598_length(transcript)=1520nt_BP=121nt ATGCAGGAGAGCCAGACCAAGAGCATGTTCGTGTCCCGGGCCCTGGAGAAGATCCTAGCCGACAAGGAGGTGAAGCGGCCCCAGCACTCC CAGCTGCGCAGGGCCTGCCAGGTGGCGCTCGACACGTCCCCATCAGAAGGCACCAACCTCAACGCGCCCAACAGCCTGGGTGTCAGCGCC CTGTGTGCCATCTGCGGGGACCGGGCCACGGGCAAACACTACGGTGCCTCGAGCTGTGACGGCTGCAAGGGCTTCTTCCGGAGGAGCGTG CGGAAGAACCACATGTACTCCTGCAGATTTAGCCGGCAGTGCGTGGTGGACAAAGACAAGAGGAACCAGTGCCGCTACTGCAGGCTCAAG AAATGCTTCCGGGCTGGCATGAAGAAGGAAGCCGTCCAGAATGAGCGGGACCGGATCAGCACTCGAAGGTCAAGCTATGAGGACAGCAGC CTGCCCTCCATCAATGCGCTCCTGCAGGCGGAGGTCCTGTCCCGACAGATCACCTCCCCCGTCTCCGGGATCAACGGCGACATTCGGGCG AAGAAGATTGCCAGCATCGCAGATGTGTGTGAGTCCATGAAGGAGCAGCTGCTGGTTCTCGTTGAGTGGGCCAAGTACATCCCAGCTTTC TGCGAGCTCCCCCTGGACGACCAGGTGGCCCTGCTCAGAGCCCATGCTGGCGAGCACCTGCTGCTCGGAGCCACCAAGAGATCCATGGTG TTCAAGGACGTGCTGCTCCTAGGCAATGACTACATTGTCCCTCGGCACTGCCCGGAGCTGGCGGAGATGAGCCGGGTGTCCATACGCATC CTTGACGAGCTGGTGCTGCCCTTCCAGGAGCTGCAGATCGATGACAATGAGTATGCCTACCTCAAAGCCATCATCTTCTTTGACCCAGAT GCCAAGGGGCTGAGCGATCCAGGGAAGATCAAGCGGCTGCGTTCCCAGGTGCAGGTGAGCTTGGAGGACTACATCAACGACCGCCAGTAT GACTCGCGTGGCCGCTTTGGAGAGCTGCTGCTGCTGCTGCCCACCTTGCAGAGCATCACCTGGCAGATGATCGAGCAGATCCAGTTCATC AAGCTCTTCGGCATGGCCAAGATTGACAACCTGTTGCAGGAGATGCTGCTGGGAGGTCCGTGCCAAGCCCAGGAGGGGCGGGGTTGGAGT GGGGACTCCCCAGGAGACAGGCCTCACACAGTGAGCTCACCCCTCAGCTCCTTGGCTTCCCCACTGTGCCGCTTTGGGCAAGTTGCTTAA CCTGTCTGTGCCTCAGTTTCCTCACCAGAAAAATGGGAACAAGGCAATGGTCTATTTGTTCAGGCACCGAGAACCTAGCACGTGCCAGTC ACTGTTCTAAGTGCTGGCAATTCAGCAAAGAACAAGATCTTTGCCCTCGGGGAGGCTGTGTGTGTGTGAGTATGTATGGATGCGTGGATA >5869_5869_4_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000443598_length(amino acids)=419AA_BP=40 MQESQTKSMFVSRALEKILADKEVKRPQHSQLRRACQVALDTSPSEGTNLNAPNSLGVSALCAICGDRATGKHYGASSCDGCKGFFRRSV RKNHMYSCRFSRQCVVDKDKRNQCRYCRLKKCFRAGMKKEAVQNERDRISTRRSSYEDSSLPSINALLQAEVLSRQITSPVSGINGDIRA KKIASIADVCESMKEQLLVLVEWAKYIPAFCELPLDDQVALLRAHAGEHLLLGATKRSMVFKDVLLLGNDYIVPRHCPELAEMSRVSIRI LDELVLPFQELQIDDNEYAYLKAIIFFDPDAKGLSDPGKIKRLRSQVQVSLEDYINDRQYDSRGRFGELLLLLPTLQSITWQMIEQIQFI -------------------------------------------------------------- >5869_5869_5_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000457232_length(transcript)=1407nt_BP=121nt ATGCAGGAGAGCCAGACCAAGAGCATGTTCGTGTCCCGGGCCCTGGAGAAGATCCTAGCCGACAAGGAGGTGAAGCGGCCCCAGCACTCC CAGCTGCGCAGGGCCTGCCAGGTGGCGCTCGACACGTCCCCATCAGAAGGCACCAACCTCAACGCGCCCAACAGCCTGGGTGTCAGCGCC CTGTGTGCCATCTGCGGGGACCGGGCCACGGGCAAACACTACGGTGCCTCGAGCTGTGACGGCTGCAAGGGCTTCTTCCGGAGGAGCGTG CGGAAGAACCACATGTACTCCTGCAGATTTAGCCGGCAGTGCGTGGTGGACAAAGACAAGAGGAACCAGTGCCGCTACTGCAGGCTCAAG AAATGCTTCCGGGCTGGCATGAAGAAGGAAGCCGTCCAGAATGAGCGGGACCGGATCAGCACTCGAAGGTCAAGCTATGAGGACAGCAGC CTGCCCTCCATCAATGCGCTCCTGCAGGCGGAGGTCCTGTCCCGACAGATCACCTCCCCCGTCTCCGGGATCAACGGCGACATTCGGGCG AAGAAGATTGCCAGCATCGCAGATGTGTGTGAGTCCATGAAGGAGCAGCTGCTGGTTCTCGTTGAGTGGGCCAAGTACATCCCAGCTTTC TGCGAGCTCCCCCTGGACGACCAGGTGGCCCTGCTCAGAGCCCATGCTGGCGAGCACCTGCTGCTCGGAGCCACCAAGAGATCCATGGTG TTCAAGGACGTGCTGCTCCTAGGCAATGACTACATTGTCCCTCGGCACTGCCCGGAGCTGGCGGAGATGAGCCGGGTGTCCATACGCATC CTTGACGAGCTGGTGCTGCCCTTCCAGGAGCTGCAGATCGATGACAATGAGTATGCCTACCTCAAAGCCATCATCTTCTTTGACCCAGAT GCCAAGGGGCTGAGCGATCCAGGGAAGATCAAGCGGCTGCGTTCCCAGGTGCAGGTGAGCTTGGAGGACTACATCAACGACCGCCAGTAT GACTCGCGTGGCCGCTTTGGAGAGCTGCTGCTGCTGCTGCCCACCTTGCAGAGCATCACCTGGCAGATGATCGAGCAGATCCAGTTCATC AAGCTCTTCGGCATGGCCAAGATTGACAACCTGTTGCAGGAGATGCTGCTGGGAGGGTCCCCCAGCGATGCACCCCATGCCCACCACCCC CTGCACCCTCACCTGATGCAGGAACATATGGGAACCAACGTCATCGTTGCCAACACAATGCCCACTCACCTCAGCAACGGACAGATGTCC ACCCCTGAGACCCCACAGCCCTCACCGCCAGGTGGCTCAGGGTCTGAGCCCTATAAGCTCCTGCCGGGAGCCGTCGCCACAATCGTCAAG >5869_5869_5_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000457232_length(amino acids)=466AA_BP=40 MQESQTKSMFVSRALEKILADKEVKRPQHSQLRRACQVALDTSPSEGTNLNAPNSLGVSALCAICGDRATGKHYGASSCDGCKGFFRRSV RKNHMYSCRFSRQCVVDKDKRNQCRYCRLKKCFRAGMKKEAVQNERDRISTRRSSYEDSSLPSINALLQAEVLSRQITSPVSGINGDIRA KKIASIADVCESMKEQLLVLVEWAKYIPAFCELPLDDQVALLRAHAGEHLLLGATKRSMVFKDVLLLGNDYIVPRHCPELAEMSRVSIRI LDELVLPFQELQIDDNEYAYLKAIIFFDPDAKGLSDPGKIKRLRSQVQVSLEDYINDRQYDSRGRFGELLLLLPTLQSITWQMIEQIQFI KLFGMAKIDNLLQEMLLGGSPSDAPHAHHPLHPHLMQEHMGTNVIVANTMPTHLSNGQMSTPETPQPSPPGGSGSEPYKLLPGAVATIVK -------------------------------------------------------------- >5869_5869_6_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000609795_length(transcript)=1260nt_BP=121nt ATGCAGGAGAGCCAGACCAAGAGCATGTTCGTGTCCCGGGCCCTGGAGAAGATCCTAGCCGACAAGGAGGTGAAGCGGCCCCAGCACTCC CAGCTGCGCAGGGCCTGCCAGGTGGCGCTCGACACGTCCCCATCAGAAGGCACCAACCTCAACGCGCCCAACAGCCTGGGTGTCAGCGCC CTGTGTGCCATCTGCGGGGACCGGGCCACGGGCAAACACTACGGTGCCTCGAGCTGTGACGGCTGCAAGGGCTTCTTCCGGAGGAGCGTG CGGAAGAACCACATGTACTCCTGCAGATTTAGCCGGCAGTGCGTGGTGGACAAAGACAAGAGGAACCAGTGCCGCTACTGCAGGCTCAAG AAATGCTTCCGGGCTGGCATGAAGAAGGAAGCCGTCCAGAATGAGCGGGACCGGATCAGCACTCGAAGGTCAAGCTATGAGGACAGCAGC CTGCCCTCCATCAATGCGCTCCTGCAGGCGGAGGTCCTGTCCCGACAGATCACCTCCCCCGTCTCCGGGATCAACGGCGACATTCGGGCG AAGAAGATTGCCAGCATCGCAGATGTGTGTGAGTCCATGAAGGAGCAGCTGCTGGTTCTCGTTGAGTGGGCCAAGTACATCCCAGCTTTC TGCGAGCTCCCCCTGGACGACCAGGTGGCCCTGCTCAGAGCCCATGCTGGCGAGCACCTGCTGCTCGGAGCCACCAAGAGATCCATGGTG TTCAAGGACGTGCTGCTCCTAGGCAATGACTACATTGTCCCTCGGCACTGCCCGGAGCTGGCGGAGATGAGCCGGGTGTCCATACGCATC CTTGACGAGCTGGTGCTGCCCTTCCAGGAGCTGCAGATCGATGACAATGAGTATGCCTACCTCAAAGCCATCATCTTCTTTGACCCAGAT GCCAAGGGGCTGAGCGATCCAGGGAAGATCAAGCGGCTGCGTTCCCAGGTGCAGGTGAGCTTGGAGGACTACATCAACGACCGCCAGTAT GACTCGCGTGGCCGCTTTGGAGAGCTGCTGCTGCTGCTGCCCACCTTGCAGAGCATCACCTGGCAGATGATCGAGCAGATCCAGTTCATC AAGCTCTTCGGCATGGCCAAGATTGACAACCTGTTGCAGGAGATGCTGCTGGGAGGTCCGTGCCAAGCCCAGGAGGGGCGGGGTTGGAGT GGGGACTCCCCAGGAGACAGGCCTCACACAGTGAGCTCACCCCTCAGCTCCTTGGCTTCCCCACTGTGCCGCTTTGGGCAAGTTGCTTAA >5869_5869_6_ARFGEF2-HNF4A_ARFGEF2_chr20_47538547_ENST00000371917_HNF4A_chr20_43034698_ENST00000609795_length(amino acids)=419AA_BP=40 MQESQTKSMFVSRALEKILADKEVKRPQHSQLRRACQVALDTSPSEGTNLNAPNSLGVSALCAICGDRATGKHYGASSCDGCKGFFRRSV RKNHMYSCRFSRQCVVDKDKRNQCRYCRLKKCFRAGMKKEAVQNERDRISTRRSSYEDSSLPSINALLQAEVLSRQITSPVSGINGDIRA KKIASIADVCESMKEQLLVLVEWAKYIPAFCELPLDDQVALLRAHAGEHLLLGATKRSMVFKDVLLLGNDYIVPRHCPELAEMSRVSIRI LDELVLPFQELQIDDNEYAYLKAIIFFDPDAKGLSDPGKIKRLRSQVQVSLEDYINDRQYDSRGRFGELLLLLPTLQSITWQMIEQIQFI -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARFGEF2-HNF4A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARFGEF2-HNF4A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARFGEF2-HNF4A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies