
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NF2-PIAS1 (FusionGDB2 ID:58731) |
Fusion Gene Summary for NF2-PIAS1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NF2-PIAS1 | Fusion gene ID: 58731 | Hgene | Tgene | Gene symbol | NF2 | PIAS1 | Gene ID | 4771 | 8554 |
| Gene name | neurofibromin 2 | protein inhibitor of activated STAT 1 | |
| Synonyms | ACN|BANF|SCH | DDXBP1|GBP|GU/RH-II|ZMIZ3 | |
| Cytomap | 22q12.2 | 15q23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | merlinmoesin-ezrin-radixin likemoesin-ezrin-radixin-like proteinmoesin-ezrin-radizin-like proteinneurofibromin 2 (bilateral acoustic neuroma)schwannomerlinschwannomin | E3 SUMO-protein ligase PIAS1AR interacting proteinDEAD/H (Asp-Glu-Ala-Asp/His) box binding protein 1DEAD/H box-binding protein 1E3 SUMO-protein transferase PIAS1RNA helicase II-binding proteingu-binding proteinprotein inhibitor of activated STAT pr | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | P35240 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000334961, ENST00000338641, ENST00000347330, ENST00000353887, ENST00000361166, ENST00000361452, ENST00000361676, ENST00000397789, ENST00000403435, ENST00000403999, ENST00000413209, | ENST00000567417, ENST00000249636, ENST00000545237, | |
| Fusion gene scores | * DoF score | 15 X 11 X 7=1155 | 12 X 13 X 7=1092 |
| # samples | 18 | 15 | |
| ** MAII score | log2(18/1155*10)=-2.68182403997375 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(15/1092*10)=-2.86393845042397 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NF2 [Title/Abstract] AND PIAS1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NF2(30000101)-PIAS1(68378644), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NF2 | GO:0008285 | negative regulation of cell proliferation | 12444102|20178741 |
| Hgene | NF2 | GO:0022408 | negative regulation of cell-cell adhesion | 17210637 |
| Hgene | NF2 | GO:0042532 | negative regulation of tyrosine phosphorylation of STAT protein | 12444102 |
| Hgene | NF2 | GO:0046426 | negative regulation of JAK-STAT cascade | 12444102 |
| Tgene | PIAS1 | GO:0016925 | protein sumoylation | 18579533 |
| Tgene | PIAS1 | GO:0033235 | positive regulation of protein sumoylation | 17696781|21965678 |
| Fusion gene breakpoints across NF2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
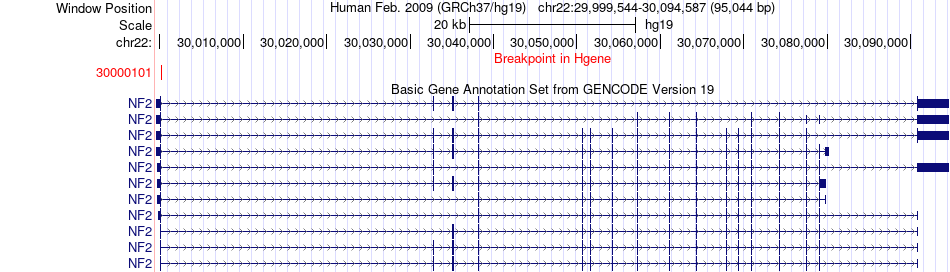 |
| Fusion gene breakpoints across PIAS1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | MESO | TCGA-LK-A4O7-01A | NF2 | chr22 | 30000101 | - | PIAS1 | chr15 | 68378644 | + |
| ChimerDB4 | MESO | TCGA-LK-A4O7-01A | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
Top |
Fusion Gene ORF analysis for NF2-PIAS1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000334961 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000338641 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000347330 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000353887 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000361166 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000361452 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000361676 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000397789 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000403435 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000403999 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| 5CDS-intron | ENST00000413209 | ENST00000567417 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000334961 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000334961 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000338641 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000338641 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000347330 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000347330 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000353887 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000353887 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000361166 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000361166 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000361452 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000361452 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000361676 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000361676 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000397789 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000397789 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000403435 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000403435 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000403999 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000403999 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000413209 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| In-frame | ENST00000413209 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000347330 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2718 | 557 | 362 | 2488 | 708 |
| ENST00000347330 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2718 | 557 | 362 | 2488 | 708 |
| ENST00000413209 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2718 | 557 | 362 | 2488 | 708 |
| ENST00000413209 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2718 | 557 | 362 | 2488 | 708 |
| ENST00000338641 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2716 | 555 | 360 | 2486 | 708 |
| ENST00000338641 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2716 | 555 | 360 | 2486 | 708 |
| ENST00000403435 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2686 | 525 | 330 | 2456 | 708 |
| ENST00000403435 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2686 | 525 | 330 | 2456 | 708 |
| ENST00000361452 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2657 | 496 | 301 | 2427 | 708 |
| ENST00000361452 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2657 | 496 | 301 | 2427 | 708 |
| ENST00000403999 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2641 | 480 | 285 | 2411 | 708 |
| ENST00000403999 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2641 | 480 | 285 | 2411 | 708 |
| ENST00000334961 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2547 | 386 | 191 | 2317 | 708 |
| ENST00000334961 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2547 | 386 | 191 | 2317 | 708 |
| ENST00000353887 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2527 | 366 | 171 | 2297 | 708 |
| ENST00000353887 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2527 | 366 | 171 | 2297 | 708 |
| ENST00000361166 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2275 | 114 | 0 | 2045 | 681 |
| ENST00000361166 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2275 | 114 | 0 | 2045 | 681 |
| ENST00000397789 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2275 | 114 | 0 | 2045 | 681 |
| ENST00000397789 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2275 | 114 | 0 | 2045 | 681 |
| ENST00000361676 | NF2 | chr22 | 30000101 | + | ENST00000249636 | PIAS1 | chr15 | 68378644 | + | 2275 | 114 | 0 | 2045 | 681 |
| ENST00000361676 | NF2 | chr22 | 30000101 | + | ENST00000545237 | PIAS1 | chr15 | 68378644 | + | 2275 | 114 | 0 | 2045 | 681 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000347330 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002650409 | 0.9973496 |
| ENST00000347330 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002650409 | 0.9973496 |
| ENST00000413209 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002650409 | 0.9973496 |
| ENST00000413209 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002650409 | 0.9973496 |
| ENST00000338641 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002642148 | 0.9973578 |
| ENST00000338641 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002642148 | 0.9973578 |
| ENST00000403435 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002664969 | 0.997335 |
| ENST00000403435 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002664969 | 0.997335 |
| ENST00000361452 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002784196 | 0.99721575 |
| ENST00000361452 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002784196 | 0.99721575 |
| ENST00000403999 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002672466 | 0.99732757 |
| ENST00000403999 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002672466 | 0.99732757 |
| ENST00000334961 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002662889 | 0.99733704 |
| ENST00000334961 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002662889 | 0.99733704 |
| ENST00000353887 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002665267 | 0.9973347 |
| ENST00000353887 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.002665267 | 0.9973347 |
| ENST00000361166 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.001779271 | 0.99822074 |
| ENST00000361166 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.001779271 | 0.99822074 |
| ENST00000397789 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.001779271 | 0.99822074 |
| ENST00000397789 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.001779271 | 0.99822074 |
| ENST00000361676 | ENST00000249636 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.001779271 | 0.99822074 |
| ENST00000361676 | ENST00000545237 | NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378644 | + | 0.001779271 | 0.99822074 |
Top |
Fusion Genomic Features for NF2-PIAS1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378643 | + | 6.03E-10 | 1 |
| NF2 | chr22 | 30000101 | + | PIAS1 | chr15 | 68378643 | + | 6.03E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for NF2-PIAS1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:30000101/chr15:68378644) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NF2 | . |
| FUNCTION: Probable regulator of the Hippo/SWH (Sav/Wts/Hpo) signaling pathway, a signaling pathway that plays a pivotal role in tumor suppression by restricting proliferation and promoting apoptosis. Along with WWC1 can synergistically induce the phosphorylation of LATS1 and LATS2 and can probably function in the regulation of the Hippo/SWH (Sav/Wts/Hpo) signaling pathway. May act as a membrane stabilizing protein. May inhibit PI3 kinase by binding to AGAP2 and impairing its stimulating activity. Suppresses cell proliferation and tumorigenesis by inhibiting the CUL4A-RBX1-DDB1-VprBP/DCAF1 E3 ubiquitin-protein ligase complex. {ECO:0000269|PubMed:20159598, ECO:0000269|PubMed:20178741, ECO:0000269|PubMed:21167305}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 577_634 | 8 | 652.0 | Compositional bias | Note=Ser-rich | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 11_45 | 8 | 652.0 | Domain | SAP | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 124_288 | 8 | 652.0 | Domain | PINIT | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 19_23 | 8 | 652.0 | Motif | Note=LXXLL motif | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 368_380 | 8 | 652.0 | Motif | Nuclear localization signal | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 56_64 | 8 | 652.0 | Motif | Nuclear localization signal | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 462_473 | 8 | 652.0 | Region | SUMO1-binding | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 520_615 | 8 | 652.0 | Region | Note=4 X 4 AA repeats of N-T-S-L | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 520_523 | 8 | 652.0 | Repeat | Note=1 | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 557_560 | 8 | 652.0 | Repeat | Note=2 | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 598_601 | 8 | 652.0 | Repeat | Note=3%3B approximate | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 612_615 | 8 | 652.0 | Repeat | Note=4%3B approximate | |
| Tgene | PIAS1 | chr22:30000101 | chr15:68378644 | ENST00000249636 | 0 | 14 | 320_397 | 8 | 652.0 | Zinc finger | SP-RING-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000334961 | + | 1 | 15 | 327_465 | 38 | 451.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000338641 | + | 1 | 16 | 327_465 | 38 | 596.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000347330 | + | 1 | 10 | 327_465 | 38 | 1312.6666666666667 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000353887 | + | 1 | 15 | 327_465 | 38 | 406.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000361166 | + | 1 | 17 | 327_465 | 38 | 571.3333333333334 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000361452 | + | 1 | 16 | 327_465 | 38 | 1665.6666666666667 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000361676 | + | 1 | 16 | 327_465 | 38 | 531.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000397789 | + | 1 | 17 | 327_465 | 38 | 573.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000403435 | + | 1 | 17 | 327_465 | 38 | 541.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000403999 | + | 1 | 16 | 327_465 | 38 | 591.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000413209 | + | 1 | 5 | 327_465 | 38 | 166.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000334961 | + | 1 | 15 | 22_311 | 38 | 451.0 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000338641 | + | 1 | 16 | 22_311 | 38 | 596.0 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000347330 | + | 1 | 10 | 22_311 | 38 | 1312.6666666666667 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000353887 | + | 1 | 15 | 22_311 | 38 | 406.0 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000361166 | + | 1 | 17 | 22_311 | 38 | 571.3333333333334 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000361452 | + | 1 | 16 | 22_311 | 38 | 1665.6666666666667 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000361676 | + | 1 | 16 | 22_311 | 38 | 531.0 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000397789 | + | 1 | 17 | 22_311 | 38 | 573.0 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000403435 | + | 1 | 17 | 22_311 | 38 | 541.0 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000403999 | + | 1 | 16 | 22_311 | 38 | 591.0 | Domain | FERM |
| Hgene | NF2 | chr22:30000101 | chr15:68378644 | ENST00000413209 | + | 1 | 5 | 22_311 | 38 | 166.0 | Domain | FERM |
Top |
Fusion Gene Sequence for NF2-PIAS1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58731_58731_1_NF2-PIAS1_NF2_chr22_30000101_ENST00000334961_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2547nt_BP=386nt TCCCGGAGTGCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTC CGCTCAGGCAGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGT GGCCCTGAGGCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCG CCATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGG ACGCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACA AGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAAC TCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGT CTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAAC TGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAAC TGATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGC AAATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTC CACAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATG GCGTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTT GGACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAA AGGGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAA GGGTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAA CTCTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATG GCTTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAA AGGAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGT CCTCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGA CCTGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAA GCCTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACT TACAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAG ATGATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTT CTCTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCA CAAACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCA TCCCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTG TTTTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAG >58731_58731_1_NF2-PIAS1_NF2_chr22_30000101_ENST00000334961_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_2_NF2-PIAS1_NF2_chr22_30000101_ENST00000334961_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2547nt_BP=386nt TCCCGGAGTGCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTC CGCTCAGGCAGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGT GGCCCTGAGGCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCG CCATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGG ACGCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACA AGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAAC TCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGT CTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAAC TGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAAC TGATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGC AAATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTC CACAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATG GCGTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTT GGACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAA AGGGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAA GGGTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAA CTCTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATG GCTTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAA AGGAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGT CCTCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGA CCTGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAA GCCTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACT TACAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAG ATGATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTT CTCTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCA CAAACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCA TCCCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTG TTTTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAG >58731_58731_2_NF2-PIAS1_NF2_chr22_30000101_ENST00000334961_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_3_NF2-PIAS1_NF2_chr22_30000101_ENST00000338641_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2716nt_BP=555nt CGCTTCCCGCGGGCGCGCGGAGTGAGGACGGTGACAGCCACGCGCGCGCGTACGCGCCCGATGCAGCGCGGCCCCGTGACCCTAGTCGGC CGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCCCGAATCCCGGAGTGC CGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGCAG GGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAGGC CTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCGGG GCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGATG GAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGACGC AAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGCGG CGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTACC ATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCCCA CATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAACCC ACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTAGT TCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAGAT CACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAACCA AAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAGAA ATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAAGG AATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTCTA CTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACATT CAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTATG GAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTACAG GAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATAAA AACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTTCC CTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTGCT GTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGATTA GATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAGAC CTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAACC ACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGAGC AGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCCCA GATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTCCT TTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGACTGCCTGTGT >58731_58731_3_NF2-PIAS1_NF2_chr22_30000101_ENST00000338641_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_4_NF2-PIAS1_NF2_chr22_30000101_ENST00000338641_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2716nt_BP=555nt CGCTTCCCGCGGGCGCGCGGAGTGAGGACGGTGACAGCCACGCGCGCGCGTACGCGCCCGATGCAGCGCGGCCCCGTGACCCTAGTCGGC CGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCCCGAATCCCGGAGTGC CGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGCAG GGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAGGC CTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCGGG GCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGATG GAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGACGC AAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGCGG CGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTACC ATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCCCA CATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAACCC ACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTAGT TCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAGAT CACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAACCA AAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAGAA ATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAAGG AATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTCTA CTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACATT CAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTATG GAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTACAG GAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATAAA AACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTTCC CTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTGCT GTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGATTA GATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAGAC CTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAACC ACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGAGC AGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCCCA GATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTCCT TTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGACTGCCTGTGT >58731_58731_4_NF2-PIAS1_NF2_chr22_30000101_ENST00000338641_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_5_NF2-PIAS1_NF2_chr22_30000101_ENST00000347330_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2718nt_BP=557nt TGCGCTTCCCGCGGGCGCGCGGAGTGAGGACGGTGACAGCCACGCGCGCGCGTACGCGCCCGATGCAGCGCGGCCCCGTGACCCTAGTCG GCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCCCGAATCCCGGAGT GCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGC AGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAG GCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCG GGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGA TGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGAC GCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGC GGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTA CCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCC CACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAAC CCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTA GTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAG ATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAAC CAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAG AAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAA GGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTC TACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACA TTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTA TGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTAC AGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATA AAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTT CCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTG CTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGAT TAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAG ACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAA CCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGA GCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCC CAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTC CTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGACTGCCTGT >58731_58731_5_NF2-PIAS1_NF2_chr22_30000101_ENST00000347330_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_6_NF2-PIAS1_NF2_chr22_30000101_ENST00000347330_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2718nt_BP=557nt TGCGCTTCCCGCGGGCGCGCGGAGTGAGGACGGTGACAGCCACGCGCGCGCGTACGCGCCCGATGCAGCGCGGCCCCGTGACCCTAGTCG GCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCCCGAATCCCGGAGT GCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGC AGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAG GCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCG GGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGA TGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGAC GCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGC GGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTA CCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCC CACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAAC CCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTA GTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAG ATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAAC CAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAG AAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAA GGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTC TACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACA TTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTA TGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTAC AGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATA AAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTT CCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTG CTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGAT TAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAG ACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAA CCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGA GCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCC CAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTC CTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGACTGCCTGT >58731_58731_6_NF2-PIAS1_NF2_chr22_30000101_ENST00000347330_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_7_NF2-PIAS1_NF2_chr22_30000101_ENST00000353887_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2527nt_BP=366nt CCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGCAGGGTCCTCGC GGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAGGCCTGTGCAGC AACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCGGGGCCATCGCT TCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGATGGAGTTCAAT TGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGACGCAAACACGAA CTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGCGGCGGTTCCCA CAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTACCATTCCACAA CTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCCCACATCTTACA TCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAACCCACCAGTCTA GCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTAGTTCCATGGAT ATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAGATCACTTCCCA CCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAACCAAAGCGACCC AGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAGAAATTGGAAGA AACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAAGGAATCCGGAT CATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTCTACTATGTCCA CTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACATTCAGATGAAT GAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTATGGAAATCCTA AAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTACAGGAAGTTTCT GCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATAAAAACAAGAAA GTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTTCCCTATCTCCC ACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTGCTGTAGACACA AGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGATTAGATTTCTTT CCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAGACCTCCTACAC TCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAACCACCAATGGA AGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGAGCAGCACGGAC ACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCCCAGATCGAATG AACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTCCTTTTTTTAGG GAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGACTGCCTGTGTGATAAAACA >58731_58731_7_NF2-PIAS1_NF2_chr22_30000101_ENST00000353887_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_8_NF2-PIAS1_NF2_chr22_30000101_ENST00000353887_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2527nt_BP=366nt CCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGCAGGGTCCTCGC GGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAGGCCTGTGCAGC AACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCGGGGCCATCGCT TCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGATGGAGTTCAAT TGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGACGCAAACACGAA CTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGCGGCGGTTCCCA CAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTACCATTCCACAA CTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCCCACATCTTACA TCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAACCCACCAGTCTA GCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTAGTTCCATGGAT ATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAGATCACTTCCCA CCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAACCAAAGCGACCC AGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAGAAATTGGAAGA AACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAAGGAATCCGGAT CATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTCTACTATGTCCA CTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACATTCAGATGAAT GAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTATGGAAATCCTA AAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTACAGGAAGTTTCT GCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATAAAAACAAGAAA GTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTTCCCTATCTCCC ACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTGCTGTAGACACA AGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGATTAGATTTCTTT CCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAGACCTCCTACAC TCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAACCACCAATGGA AGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGAGCAGCACGGAC ACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCCCAGATCGAATG AACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTCCTTTTTTTAGG GAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGACTGCCTGTGTGATAAAACA >58731_58731_8_NF2-PIAS1_NF2_chr22_30000101_ENST00000353887_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_9_NF2-PIAS1_NF2_chr22_30000101_ENST00000361166_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2275nt_BP=114nt ATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGAC GCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAG CACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTC TATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCT CCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTG GAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTG ATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAA ATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCA CAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGC GTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGG ACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAG GGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGG GTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACT CTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGC TTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAG GAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCC TCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACC TGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGC CTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTA CAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGAT GATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCT CTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACA AACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATC CCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTT TTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGAC >58731_58731_9_NF2-PIAS1_NF2_chr22_30000101_ENST00000361166_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=681AA_BP=38 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGRKHELLTKALHLLKAGCSPAVQMKIKEL YRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELPHLTSALHPVHPDIKLQKLPFYDLLDEL IKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQEDHFPPNLCVKVNTKPCSLPGYLPPTKNG VEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIRNPDHSRALIKEKLTADPDSEIATTSLR VSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFMEILKYCTDCDEIQFKEDGTWAPMRSKK EVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPSLSPTSPLNNKGILSLPHQASPVSRTPS LPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQDLLHSSRFFPYTSSQMFLDQLSAGGSTS -------------------------------------------------------------- >58731_58731_10_NF2-PIAS1_NF2_chr22_30000101_ENST00000361166_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2275nt_BP=114nt ATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGAC GCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAG CACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTC TATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCT CCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTG GAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTG ATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAA ATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCA CAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGC GTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGG ACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAG GGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGG GTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACT CTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGC TTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAG GAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCC TCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACC TGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGC CTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTA CAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGAT GATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCT CTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACA AACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATC CCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTT TTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGAC >58731_58731_10_NF2-PIAS1_NF2_chr22_30000101_ENST00000361166_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=681AA_BP=38 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGRKHELLTKALHLLKAGCSPAVQMKIKEL YRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELPHLTSALHPVHPDIKLQKLPFYDLLDEL IKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQEDHFPPNLCVKVNTKPCSLPGYLPPTKNG VEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIRNPDHSRALIKEKLTADPDSEIATTSLR VSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFMEILKYCTDCDEIQFKEDGTWAPMRSKK EVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPSLSPTSPLNNKGILSLPHQASPVSRTPS LPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQDLLHSSRFFPYTSSQMFLDQLSAGGSTS -------------------------------------------------------------- >58731_58731_11_NF2-PIAS1_NF2_chr22_30000101_ENST00000361452_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2657nt_BP=496nt GATGCAGCGCGGCCCCGTGACCCTAGTCGGCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTC CCCGGCATCTCCGGCCCGAATCCCGGAGTGCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCC CGTCCCCCAACTCCCCTTTCCGCTCAGGCAGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCC GGGCAGCCGGCCACCATGGTGGCCCTGAGGCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGG TCCCGGGCCTGAGCCCCGCGCCATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCAC CGTGAGGATCGTCACCATGGACGCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTT GGGCTACGCCGGGAGAAACAAGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGT GCAAATGAAAATTAAGGAACTCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAG TCCTATGCCAGCAACTTTGTCTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCT TCTGGGACCTAAACATGAACTGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATT TTATGATTTACTGGATGAACTGATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTT GACACCACAACAAGTGCAGCAAATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTG TTTATCAGAAACCAGTTGTCCACAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTA CCTTCCACCTACAAAAAATGGCGTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACC AAACACGATTGTTGTTTCTTGGACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCT TCTTCAGAGGTTACGAGCAAAGGGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGA AATAGCTACAACCAGCCTAAGGGTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCA TCTACAATGTTTTGACGCAACTCTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATA TGAACACCTTATTATTGATGGCTTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTG GGCACCGATGAGATCAAAAAAGGAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCA GGTAGCGTCTCACCACCAGTCCTCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGA AGAGCCATCTGCCAAGAGGACCTGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATC TCCAGTATCCCGCACCCCAAGCCTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACAT GACACCCATGCCTTACGACTTACAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGC TGCAGCAGCAGCAGTTTCAGATGATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTT AAGTGCAGGAGGCAGTACTTCTCTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGA AAGCCATAGCCACACCGTCACAAACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATT CCCAGGCCCTGCTGCTCCCATCCCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTT TAGAAAAGTATACAAGCGTGTTTTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTA >58731_58731_11_NF2-PIAS1_NF2_chr22_30000101_ENST00000361452_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_12_NF2-PIAS1_NF2_chr22_30000101_ENST00000361452_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2657nt_BP=496nt GATGCAGCGCGGCCCCGTGACCCTAGTCGGCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTC CCCGGCATCTCCGGCCCGAATCCCGGAGTGCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCC CGTCCCCCAACTCCCCTTTCCGCTCAGGCAGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCC GGGCAGCCGGCCACCATGGTGGCCCTGAGGCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGG TCCCGGGCCTGAGCCCCGCGCCATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCAC CGTGAGGATCGTCACCATGGACGCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTT GGGCTACGCCGGGAGAAACAAGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGT GCAAATGAAAATTAAGGAACTCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAG TCCTATGCCAGCAACTTTGTCTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCT TCTGGGACCTAAACATGAACTGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATT TTATGATTTACTGGATGAACTGATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTT GACACCACAACAAGTGCAGCAAATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTG TTTATCAGAAACCAGTTGTCCACAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTA CCTTCCACCTACAAAAAATGGCGTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACC AAACACGATTGTTGTTTCTTGGACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCT TCTTCAGAGGTTACGAGCAAAGGGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGA AATAGCTACAACCAGCCTAAGGGTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCA TCTACAATGTTTTGACGCAACTCTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATA TGAACACCTTATTATTGATGGCTTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTG GGCACCGATGAGATCAAAAAAGGAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCA GGTAGCGTCTCACCACCAGTCCTCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGA AGAGCCATCTGCCAAGAGGACCTGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATC TCCAGTATCCCGCACCCCAAGCCTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACAT GACACCCATGCCTTACGACTTACAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGC TGCAGCAGCAGCAGTTTCAGATGATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTT AAGTGCAGGAGGCAGTACTTCTCTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGA AAGCCATAGCCACACCGTCACAAACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATT CCCAGGCCCTGCTGCTCCCATCCCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTT TAGAAAAGTATACAAGCGTGTTTTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTA >58731_58731_12_NF2-PIAS1_NF2_chr22_30000101_ENST00000361452_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_13_NF2-PIAS1_NF2_chr22_30000101_ENST00000361676_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2275nt_BP=114nt ATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGAC GCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAG CACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTC TATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCT CCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTG GAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTG ATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAA ATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCA CAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGC GTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGG ACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAG GGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGG GTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACT CTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGC TTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAG GAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCC TCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACC TGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGC CTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTA CAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGAT GATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCT CTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACA AACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATC CCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTT TTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGAC >58731_58731_13_NF2-PIAS1_NF2_chr22_30000101_ENST00000361676_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=681AA_BP=38 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGRKHELLTKALHLLKAGCSPAVQMKIKEL YRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELPHLTSALHPVHPDIKLQKLPFYDLLDEL IKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQEDHFPPNLCVKVNTKPCSLPGYLPPTKNG VEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIRNPDHSRALIKEKLTADPDSEIATTSLR VSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFMEILKYCTDCDEIQFKEDGTWAPMRSKK EVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPSLSPTSPLNNKGILSLPHQASPVSRTPS LPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQDLLHSSRFFPYTSSQMFLDQLSAGGSTS -------------------------------------------------------------- >58731_58731_14_NF2-PIAS1_NF2_chr22_30000101_ENST00000361676_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2275nt_BP=114nt ATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGAC GCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAG CACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTC TATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCT CCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTG GAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTG ATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAA ATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCA CAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGC GTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGG ACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAG GGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGG GTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACT CTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGC TTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAG GAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCC TCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACC TGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGC CTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTA CAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGAT GATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCT CTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACA AACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATC CCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTT TTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGAC >58731_58731_14_NF2-PIAS1_NF2_chr22_30000101_ENST00000361676_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=681AA_BP=38 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGRKHELLTKALHLLKAGCSPAVQMKIKEL YRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELPHLTSALHPVHPDIKLQKLPFYDLLDEL IKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQEDHFPPNLCVKVNTKPCSLPGYLPPTKNG VEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIRNPDHSRALIKEKLTADPDSEIATTSLR VSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFMEILKYCTDCDEIQFKEDGTWAPMRSKK EVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPSLSPTSPLNNKGILSLPHQASPVSRTPS LPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQDLLHSSRFFPYTSSQMFLDQLSAGGSTS -------------------------------------------------------------- >58731_58731_15_NF2-PIAS1_NF2_chr22_30000101_ENST00000397789_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2275nt_BP=114nt ATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGAC GCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAG CACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTC TATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCT CCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTG GAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTG ATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAA ATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCA CAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGC GTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGG ACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAG GGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGG GTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACT CTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGC TTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAG GAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCC TCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACC TGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGC CTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTA CAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGAT GATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCT CTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACA AACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATC CCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTT TTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGAC >58731_58731_15_NF2-PIAS1_NF2_chr22_30000101_ENST00000397789_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=681AA_BP=38 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGRKHELLTKALHLLKAGCSPAVQMKIKEL YRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELPHLTSALHPVHPDIKLQKLPFYDLLDEL IKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQEDHFPPNLCVKVNTKPCSLPGYLPPTKNG VEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIRNPDHSRALIKEKLTADPDSEIATTSLR VSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFMEILKYCTDCDEIQFKEDGTWAPMRSKK EVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPSLSPTSPLNNKGILSLPHQASPVSRTPS LPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQDLLHSSRFFPYTSSQMFLDQLSAGGSTS -------------------------------------------------------------- >58731_58731_16_NF2-PIAS1_NF2_chr22_30000101_ENST00000397789_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2275nt_BP=114nt ATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGAC GCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAG CACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTC TATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCT CCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTG GAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTG ATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAA ATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCA CAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGC GTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGG ACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAG GGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGG GTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACT CTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGC TTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAG GAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCC TCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACC TGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGC CTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTA CAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGAT GATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCT CTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACA AACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATC CCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTT TTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGAC >58731_58731_16_NF2-PIAS1_NF2_chr22_30000101_ENST00000397789_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=681AA_BP=38 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGRKHELLTKALHLLKAGCSPAVQMKIKEL YRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELPHLTSALHPVHPDIKLQKLPFYDLLDEL IKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQEDHFPPNLCVKVNTKPCSLPGYLPPTKNG VEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIRNPDHSRALIKEKLTADPDSEIATTSLR VSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFMEILKYCTDCDEIQFKEDGTWAPMRSKK EVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPSLSPTSPLNNKGILSLPHQASPVSRTPS LPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQDLLHSSRFFPYTSSQMFLDQLSAGGSTS -------------------------------------------------------------- >58731_58731_17_NF2-PIAS1_NF2_chr22_30000101_ENST00000403435_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2686nt_BP=525nt GTGACAGCCACGCGCGCGCGTACGCGCCCGATGCAGCGCGGCCCCGTGACCCTAGTCGGCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCT GCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCCCGAATCCCGGAGTGCCGGGTCGCGCCTGCACCGAAGGTCCCGGCT CCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGCAGGGTCCTCGCGGCCCATGCTGGCCGCTGGGG ACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAGGCCTGTGCAGCAACTCCAGGGGGGCTAAAGGG CTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCT CTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGC CTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCAT TTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCA GACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCT GCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCAT CCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGC TTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGAC TTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTG AATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACC TCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATAT CTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAA GAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACA ATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTT TGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGAT GAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGAT GGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACC ATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAA GGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTC ATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAAT CAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTAT ACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGC AGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATC ATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAA CTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTA >58731_58731_17_NF2-PIAS1_NF2_chr22_30000101_ENST00000403435_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_18_NF2-PIAS1_NF2_chr22_30000101_ENST00000403435_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2686nt_BP=525nt GTGACAGCCACGCGCGCGCGTACGCGCCCGATGCAGCGCGGCCCCGTGACCCTAGTCGGCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCT GCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCCCGAATCCCGGAGTGCCGGGTCGCGCCTGCACCGAAGGTCCCGGCT CCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGCAGGGTCCTCGCGGCCCATGCTGGCCGCTGGGG ACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAGGCCTGTGCAGCAACTCCAGGGGGGCTAAAGGG CTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCT CTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGC CTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCAT TTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCA GACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCT GCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCAT CCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGC TTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGAC TTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTG AATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACC TCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATAT CTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAA GAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACA ATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTT TGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGAT GAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGAT GGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACC ATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAA GGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTC ATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAAT CAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTAT ACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGC AGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATC ATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAA CTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTA >58731_58731_18_NF2-PIAS1_NF2_chr22_30000101_ENST00000403435_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_19_NF2-PIAS1_NF2_chr22_30000101_ENST00000403999_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2641nt_BP=480nt GTGACCCTAGTCGGCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCC CGAATCCCGGAGTGCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCC TTTCCGCTCAGGCAGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCA TGGTGGCCCTGAGGCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCC CGCGCCATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACC ATGGACGCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGA AACAAGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAG GAACTCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACT TTGTCTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACAT GAACTGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGAT GAACTGATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTG CAGCAAATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGT TGTCCACAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAA AATGGCGTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTT TCTTGGACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGA GCAAAGGGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGC CTAAGGGTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGAC GCAACTCTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATT GATGGCTTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCA AAAAAGGAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCAC CAGTCCTCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAG AGGACCTGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACC CCAAGCCTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTAC GACTTACAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTT TCAGATGATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGT ACTTCTCTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACC GTCACAAACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCT CCCATCCCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAG CGTGTTTTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATC >58731_58731_19_NF2-PIAS1_NF2_chr22_30000101_ENST00000403999_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_20_NF2-PIAS1_NF2_chr22_30000101_ENST00000403999_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2641nt_BP=480nt GTGACCCTAGTCGGCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCC CGAATCCCGGAGTGCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCC TTTCCGCTCAGGCAGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCA TGGTGGCCCTGAGGCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCC CGCGCCATGGCCGGGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACC ATGGACGCCGAGATGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGA AACAAGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAG GAACTCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACT TTGTCTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACAT GAACTGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGAT GAACTGATAAAACCCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTG CAGCAAATCAGTAGTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGT TGTCCACAAGAAGATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAA AATGGCGTGGAACCAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTT TCTTGGACTGCAGAAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGA GCAAAGGGAATAAGGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGC CTAAGGGTTTCTCTACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGAC GCAACTCTTTACATTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATT GATGGCTTGTTTATGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCA AAAAAGGAAGTACAGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCAC CAGTCCTCAAATAAAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAG AGGACCTGTCCTTCCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACC CCAAGCCTTCCTGCTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTAC GACTTACAAGGATTAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTT TCAGATGATCAAGACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGT ACTTCTCTGCCAACCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACC GTCACAAACAGGAGCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCT CCCATCCCCACCCCAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAG CGTGTTTTTTTTCCTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATC >58731_58731_20_NF2-PIAS1_NF2_chr22_30000101_ENST00000403999_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_21_NF2-PIAS1_NF2_chr22_30000101_ENST00000413209_PIAS1_chr15_68378644_ENST00000249636_length(transcript)=2718nt_BP=557nt TGCGCTTCCCGCGGGCGCGCGGAGTGAGGACGGTGACAGCCACGCGCGCGCGTACGCGCCCGATGCAGCGCGGCCCCGTGACCCTAGTCG GCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCCCGAATCCCGGAGT GCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGC AGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAG GCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCG GGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGA TGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGAC GCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGC GGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTA CCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCC CACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAAC CCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTA GTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAG ATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAAC CAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAG AAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAA GGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTC TACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACA TTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTA TGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTAC AGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATA AAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTT CCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTG CTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGAT TAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAG ACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAA CCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGA GCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCC CAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTC CTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGACTGCCTGT >58731_58731_21_NF2-PIAS1_NF2_chr22_30000101_ENST00000413209_PIAS1_chr15_68378644_ENST00000249636_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- >58731_58731_22_NF2-PIAS1_NF2_chr22_30000101_ENST00000413209_PIAS1_chr15_68378644_ENST00000545237_length(transcript)=2718nt_BP=557nt TGCGCTTCCCGCGGGCGCGCGGAGTGAGGACGGTGACAGCCACGCGCGCGCGTACGCGCCCGATGCAGCGCGGCCCCGTGACCCTAGTCG GCCGCTGAGAGGCGCGCGGAGTCTGGGCCGCTGCCGTCTAGGGGTCCCGTCCCGAGGCGTCCCCGGCATCTCCGGCCCGAATCCCGGAGT GCCGGGTCGCGCCTGCACCGAAGGTCCCGGCTCCTGTGCCCTCCCTGCAGCCGTCAGGGCCCGTCCCCCAACTCCCCTTTCCGCTCAGGC AGGGTCCTCGCGGCCCATGCTGGCCGCTGGGGACCCGCGCAGCCCAGACCGTTCCCGGGCCGGGCAGCCGGCCACCATGGTGGCCCTGAG GCCTGTGCAGCAACTCCAGGGGGGCTAAAGGGCTCAGAGTGCAGGCCGTGGGGCGCGAGGGTCCCGGGCCTGAGCCCCGCGCCATGGCCG GGGCCATCGCTTCCCGCATGAGCTTCAGCTCTCTCAAGAGGAAGCAACCCAAGACGTTCACCGTGAGGATCGTCACCATGGACGCCGAGA TGGAGTTCAATTGCGAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGAC GCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGC GGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTA CCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCC CACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAAC CCACCAGTCTAGCATCAGACAACAGTCAGCGCTTTCGAGAAACCTGTTTTGCATTTGCCTTGACACCACAACAAGTGCAGCAAATCAGTA GTTCCATGGATATTTCTGGGACCAAATGTGACTTCACAGTACAGGTCCAGTTAAGGTTTTGTTTATCAGAAACCAGTTGTCCACAAGAAG ATCACTTCCCACCCAATCTTTGTGTGAAAGTGAATACAAAACCTTGCAGCCTTCCAGGTTACCTTCCACCTACAAAAAATGGCGTGGAAC CAAAGCGACCCAGCCGACCAATTAATATCACCTCACTTGTCCGACTGTCCACAACAGTACCAAACACGATTGTTGTTTCTTGGACTGCAG AAATTGGAAGAAACTATTCCATGGCAGTATATCTTGTAAAACAGTTGTCCTCAACAGTTCTTCTTCAGAGGTTACGAGCAAAGGGAATAA GGAATCCGGATCATTCTAGAGCTTTAATTAAAGAGAAGTTGACTGCGGATCCAGACAGTGAAATAGCTACAACCAGCCTAAGGGTTTCTC TACTATGTCCACTTGGTAAAATGCGGCTGACAATTCCGTGTCGGGCCCTTACATGTTCTCATCTACAATGTTTTGACGCAACTCTTTACA TTCAGATGAATGAGAAAAAACCAACCTGGGTTTGTCCTGTCTGTGATAAGAAGGCTCCATATGAACACCTTATTATTGATGGCTTGTTTA TGGAAATCCTAAAGTACTGTACAGACTGTGATGAAATACAATTTAAGGAGGATGGCACTTGGGCACCGATGAGATCAAAAAAGGAAGTAC AGGAAGTTTCTGCCTCTTACAATGGAGTCGATGGATGCTTGAGCTCCACATTGGAGCATCAGGTAGCGTCTCACCACCAGTCCTCAAATA AAAACAAGAAAGTAGAAGTGATTGACCTAACCATAGACAGTTCATCTGATGAAGAGGAAGAAGAGCCATCTGCCAAGAGGACCTGTCCTT CCCTATCTCCCACATCACCACTAAATAATAAAGGCATTTTAAGTCTTCCACATCAAGCATCTCCAGTATCCCGCACCCCAAGCCTTCCTG CTGTAGACACAAGCTACATTAATACCTCCCTCATCCAAGACTATAGGCATCCTTTCCACATGACACCCATGCCTTACGACTTACAAGGAT TAGATTTCTTTCCTTTCTTATCAGGAGACAATCAGCATTACAACACCTCCTTGCTTGCCGCTGCAGCAGCAGCAGTTTCAGATGATCAAG ACCTCCTACACTCGTCTCGGTTTTTCCCGTATACCTCCTCACAGATGTTTCTTGATCAGTTAAGTGCAGGAGGCAGTACTTCTCTGCCAA CCACCAATGGAAGCAGTAGTGGCAGTAACAGCAGCCTGGTTTCTTCCAACAGCCTAAGGGAAAGCCATAGCCACACCGTCACAAACAGGA GCAGCACGGACACGGCATCCATCTTTGGCATCATACCAGACATTATTTCATTGGACTGATTCCCAGGCCCTGCTGCTCCCATCCCCACCC CAGATCGAATGAACTTGGCAGAAAGAAGAGAACTTTGTGCTCTGTTTTACCTTACTCTGTTTAGAAAAGTATACAAGCGTGTTTTTTTTC CTTTTTTTAGGGAAAAAATTAAAAGAAATGTACAGAGAACAAAACTATATTTTCAGTTTTACTTTTGTATATAAATCTAAGACTGCCTGT >58731_58731_22_NF2-PIAS1_NF2_chr22_30000101_ENST00000413209_PIAS1_chr15_68378644_ENST00000545237_length(amino acids)=708AA_BP=65 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEQMVMSLRVSELQVLLGYAGRNKHGR KHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELP HLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLASDNSQRFRETCFAFALTPQQVQQISSSMDISGTKCDFTVQVQLRFCLSETSCPQED HFPPNLCVKVNTKPCSLPGYLPPTKNGVEPKRPSRPINITSLVRLSTTVPNTIVVSWTAEIGRNYSMAVYLVKQLSSTVLLQRLRAKGIR NPDHSRALIKEKLTADPDSEIATTSLRVSLLCPLGKMRLTIPCRALTCSHLQCFDATLYIQMNEKKPTWVCPVCDKKAPYEHLIIDGLFM EILKYCTDCDEIQFKEDGTWAPMRSKKEVQEVSASYNGVDGCLSSTLEHQVASHHQSSNKNKKVEVIDLTIDSSSDEEEEEPSAKRTCPS LSPTSPLNNKGILSLPHQASPVSRTPSLPAVDTSYINTSLIQDYRHPFHMTPMPYDLQGLDFFPFLSGDNQHYNTSLLAAAAAAVSDDQD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NF2-PIAS1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NF2-PIAS1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NF2-PIAS1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies