
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NFATC2-CST7 (FusionGDB2 ID:58788) |
Fusion Gene Summary for NFATC2-CST7 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NFATC2-CST7 | Fusion gene ID: 58788 | Hgene | Tgene | Gene symbol | NFATC2 | CST7 | Gene ID | 4773 | 8530 |
| Gene name | nuclear factor of activated T cells 2 | cystatin F | |
| Synonyms | NFAT1|NFATP | CMAP | |
| Cytomap | 20q13.2 | 20p11.21 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nuclear factor of activated T-cells, cytoplasmic 2NF-ATc2NFAT pre-existing subunitNFAT transcription complex, preexisting componentT cell transcription factor NFAT1nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 2nuclear fact | cystatin-Fcystatin-7cystatin-like metastasis-associated proteinleukocystatin | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | Q13469 | O76096 | |
| Ensembl transtripts involved in fusion gene | ENST00000609507, ENST00000610033, ENST00000371564, ENST00000396009, ENST00000414705, ENST00000609943, | ENST00000376835, ENST00000480798, | |
| Fusion gene scores | * DoF score | 9 X 9 X 5=405 | 5 X 5 X 2=50 |
| # samples | 8 | 5 | |
| ** MAII score | log2(8/405*10)=-2.33985000288462 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/50*10)=0 | |
| Context | PubMed: NFATC2 [Title/Abstract] AND CST7 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NFATC2(50048604)-CST7(24937923), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | NFATC2-CST7 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. NFATC2-CST7 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. NFATC2-CST7 seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. NFATC2-CST7 seems lost the major protein functional domain in Hgene partner, which is a tumor suppressor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NFATC2 | GO:0016477 | cell migration | 21871017 |
| Hgene | NFATC2 | GO:0045893 | positive regulation of transcription, DNA-templated | 15790681 |
| Hgene | NFATC2 | GO:1905064 | negative regulation of vascular smooth muscle cell differentiation | 23853098 |
| Tgene | CST7 | GO:0010466 | negative regulation of peptidase activity | 15752368|18256700|22365146 |
| Fusion gene breakpoints across NFATC2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CST7 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-5813-01A | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
Top |
Fusion Gene ORF analysis for NFATC2-CST7 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000609507 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| Frame-shift | ENST00000609507 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| Frame-shift | ENST00000610033 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| Frame-shift | ENST00000610033 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| In-frame | ENST00000371564 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| In-frame | ENST00000371564 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| In-frame | ENST00000396009 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| In-frame | ENST00000396009 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| In-frame | ENST00000414705 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| In-frame | ENST00000414705 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| In-frame | ENST00000609943 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| In-frame | ENST00000609943 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000371564 | NFATC2 | chr20 | 50048604 | - | ENST00000376835 | CST7 | chr20 | 24937923 | + | 3524 | 2942 | 211 | 3309 | 1032 |
| ENST00000371564 | NFATC2 | chr20 | 50048604 | - | ENST00000480798 | CST7 | chr20 | 24937923 | + | 3526 | 2942 | 211 | 3309 | 1032 |
| ENST00000396009 | NFATC2 | chr20 | 50048604 | - | ENST00000376835 | CST7 | chr20 | 24937923 | + | 3524 | 2942 | 211 | 3309 | 1032 |
| ENST00000396009 | NFATC2 | chr20 | 50048604 | - | ENST00000480798 | CST7 | chr20 | 24937923 | + | 3526 | 2942 | 211 | 3309 | 1032 |
| ENST00000609943 | NFATC2 | chr20 | 50048604 | - | ENST00000376835 | CST7 | chr20 | 24937923 | + | 3446 | 2864 | 202 | 3231 | 1009 |
| ENST00000609943 | NFATC2 | chr20 | 50048604 | - | ENST00000480798 | CST7 | chr20 | 24937923 | + | 3448 | 2864 | 202 | 3231 | 1009 |
| ENST00000414705 | NFATC2 | chr20 | 50048604 | - | ENST00000376835 | CST7 | chr20 | 24937923 | + | 3244 | 2662 | 0 | 3029 | 1009 |
| ENST00000414705 | NFATC2 | chr20 | 50048604 | - | ENST00000480798 | CST7 | chr20 | 24937923 | + | 3246 | 2662 | 0 | 3029 | 1009 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000371564 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + | 0.005888656 | 0.99411136 |
| ENST00000371564 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + | 0.005746632 | 0.99425334 |
| ENST00000396009 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + | 0.005888656 | 0.99411136 |
| ENST00000396009 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + | 0.005746632 | 0.99425334 |
| ENST00000609943 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + | 0.005887936 | 0.9941121 |
| ENST00000609943 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + | 0.005752894 | 0.9942471 |
| ENST00000414705 | ENST00000376835 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + | 0.004813614 | 0.9951864 |
| ENST00000414705 | ENST00000480798 | NFATC2 | chr20 | 50048604 | - | CST7 | chr20 | 24937923 | + | 0.004700723 | 0.9952992 |
Top |
Fusion Genomic Features for NFATC2-CST7 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NFATC2 | chr20 | 50048603 | - | CST7 | chr20 | 24937922 | + | 0.5239763 | 0.47602367 |
| NFATC2 | chr20 | 50048603 | - | CST7 | chr20 | 24937922 | + | 0.5239763 | 0.47602367 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
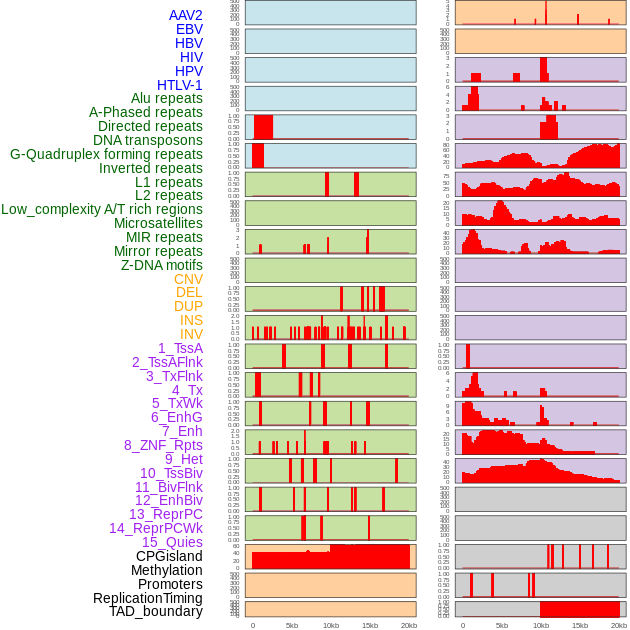 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
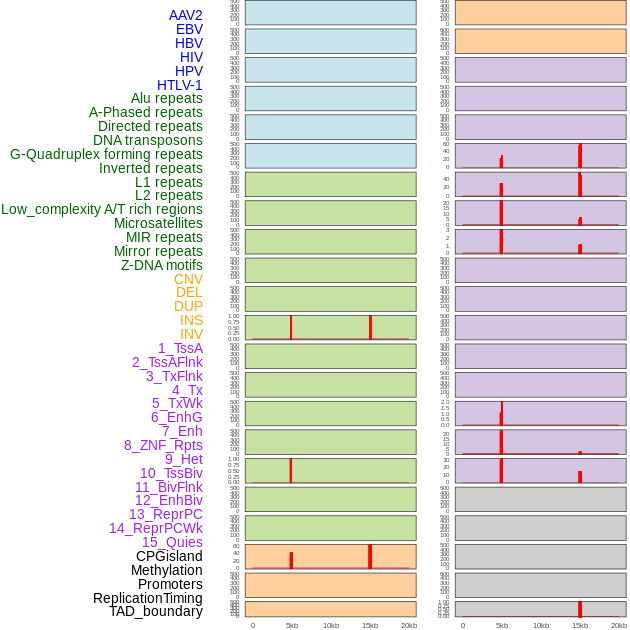 |
Top |
Fusion Protein Features for NFATC2-CST7 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:50048604/chr20:24937923) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NFATC2 | CST7 |
| FUNCTION: Plays a role in the inducible expression of cytokine genes in T-cells, especially in the induction of the IL-2, IL-3, IL-4, TNF-alpha or GM-CSF. Promotes invasive migration through the activation of GPC6 expression and WNT5A signaling pathway. {ECO:0000269|PubMed:15790681, ECO:0000269|PubMed:21871017}. | FUNCTION: Inhibits papain and cathepsin L but with affinities lower than other cystatins. May play a role in immune regulation through inhibition of a unique target in the hematopoietic system. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 421_428 | 907 | 1989.6666666666667 | DNA binding | . |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 421_428 | 907 | 926.0 | DNA binding | . |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 421_428 | 887 | 639.3333333333334 | DNA binding | . |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 392_574 | 907 | 1989.6666666666667 | Domain | RHD |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 392_574 | 907 | 926.0 | Domain | RHD |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 392_574 | 887 | 639.3333333333334 | Domain | RHD |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 251_253 | 907 | 1989.6666666666667 | Motif | Note=Nuclear localization signal |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 26_34 | 907 | 1989.6666666666667 | Motif | Note=9aaTAD |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 664_666 | 907 | 1989.6666666666667 | Motif | Note=Nuclear localization signal |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 251_253 | 907 | 926.0 | Motif | Note=Nuclear localization signal |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 26_34 | 907 | 926.0 | Motif | Note=9aaTAD |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 664_666 | 907 | 926.0 | Motif | Note=Nuclear localization signal |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 251_253 | 887 | 639.3333333333334 | Motif | Note=Nuclear localization signal |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 26_34 | 887 | 639.3333333333334 | Motif | Note=9aaTAD |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 664_666 | 887 | 639.3333333333334 | Motif | Note=Nuclear localization signal |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 904_913 | 887 | 639.3333333333334 | Motif | Note=Nuclear export signal |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 111_116 | 907 | 1989.6666666666667 | Region | Calcineurin-binding |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 119_199 | 907 | 1989.6666666666667 | Region | Note=Trans-activation domain A (TAD-A) |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 161_175 | 907 | 1989.6666666666667 | Region | Required for cytoplasmic retention of the phosphorylated form |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 184_286 | 907 | 1989.6666666666667 | Region | Note=3 X approximate SP repeats |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 111_116 | 907 | 926.0 | Region | Calcineurin-binding |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 119_199 | 907 | 926.0 | Region | Note=Trans-activation domain A (TAD-A) |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 161_175 | 907 | 926.0 | Region | Required for cytoplasmic retention of the phosphorylated form |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 184_286 | 907 | 926.0 | Region | Note=3 X approximate SP repeats |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 111_116 | 887 | 639.3333333333334 | Region | Calcineurin-binding |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 119_199 | 887 | 639.3333333333334 | Region | Note=Trans-activation domain A (TAD-A) |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 161_175 | 887 | 639.3333333333334 | Region | Required for cytoplasmic retention of the phosphorylated form |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 184_286 | 887 | 639.3333333333334 | Region | Note=3 X approximate SP repeats |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 184_200 | 907 | 1989.6666666666667 | Repeat | Note=1 |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 213_229 | 907 | 1989.6666666666667 | Repeat | Note=2 |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 272_286 | 907 | 1989.6666666666667 | Repeat | Note=3%3B approximate |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 184_200 | 907 | 926.0 | Repeat | Note=1 |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 213_229 | 907 | 926.0 | Repeat | Note=2 |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 272_286 | 907 | 926.0 | Repeat | Note=3%3B approximate |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 184_200 | 887 | 639.3333333333334 | Repeat | Note=1 |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 213_229 | 887 | 639.3333333333334 | Repeat | Note=2 |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000414705 | - | 9 | 11 | 272_286 | 887 | 639.3333333333334 | Repeat | Note=3%3B approximate |
| Tgene | CST7 | chr20:50048604 | chr20:24937923 | ENST00000376835 | 0 | 4 | 81_85 | 45 | 168.0 | Motif | Note=Secondary area of contact | |
| Tgene | CST7 | chr20:50048604 | chr20:24937923 | ENST00000480798 | 0 | 4 | 81_85 | 23 | 146.0 | Motif | Note=Secondary area of contact |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000371564 | - | 9 | 11 | 904_913 | 907 | 1989.6666666666667 | Motif | Note=Nuclear export signal |
| Hgene | NFATC2 | chr20:50048604 | chr20:24937923 | ENST00000396009 | - | 9 | 10 | 904_913 | 907 | 926.0 | Motif | Note=Nuclear export signal |
Top |
Fusion Gene Sequence for NFATC2-CST7 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58788_58788_1_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000371564_CST7_chr20_24937923_ENST00000376835_length(transcript)=3524nt_BP=2942nt AGCAGGAAGCTCGCGCCGCCGTCGCCGCCGCCGCTCAGCTTCCCCGGGCGCGTCCAGGACCCGCTGCGCCAGGCGCGCCGTCCCCGGACC CGGCGTGCGTCCCTACGAGGAAAGGGACCCCGCCGCTCGAGCCGCCTCCGCCAGCCCCACTGCGAGGGGTCCCAGAGCCAGCCGCGCCCG CCCTCGCCCCCGGCCCCGCAGCCTTCCCGCCCTGCGCGCCATGAACGCCCCCGAGCGGCAGCCCCAACCCGACGGCGGGGACGCCCCAGG CCACGAGCCTGGGGGCAGCCCCCAAGACGAGCTTGACTTCTCCATCCTCTTCGACTATGAGTATTTGAATCCGAACGAAGAAGAGCCGAA TGCACATAAGGTCGCCAGCCCACCCTCCGGACCCGCATACCCCGATGATGTCCTGGACTATGGCCTCAAGCCATACAGCCCCCTTGCTAG TCTCTCTGGCGAGCCCCCCGGCCGATTCGGAGAGCCGGATAGGGTAGGGCCGCAGAAGTTTCTGAGCGCGGCCAAGCCAGCAGGGGCCTC GGGCCTGAGCCCTCGGATCGAGATCACTCCGTCCCACGAACTGATCCAGGCAGTGGGGCCCCTCCGCATGAGAGACGCGGGCCTCCTGGT GGAGCAGCCGCCCCTGGCCGGGGTGGCCGCCAGCCCGAGGTTCACCCTGCCCGTGCCCGGCTTCGAGGGCTACCGCGAGCCGCTTTGCTT GAGCCCCGCTAGCAGCGGCTCCTCTGCCAGCTTCATTTCTGACACCTTCTCCCCCTACACCTCGCCCTGCGTCTCGCCCAATAACGGCGG GCCCGACGACCTGTGTCCGCAGTTTCAAAACATCCCTGCTCATTATTCCCCCAGAACCTCGCCAATAATGTCACCTCGAACCAGCCTCGC CGAGGACAGCTGCCTGGGCCGCCACTCGCCCGTGCCCCGTCCGGCCTCCCGCTCCTCATCGCCTGGTGCCAAGCGGAGGCATTCGTGCGC CGAGGCCTTGGTTGCCCTGCCGCCCGGAGCCTCACCCCAGCGCTCCCGGAGCCCCTCGCCGCAGCCCTCATCTCACGTGGCACCCCAGGA CCACGGCTCCCCGGCTGGGTACCCCCCTGTGGCTGGCTCTGCCGTGATCATGGATGCCCTGAACAGCCTCGCCACGGACTCGCCTTGTGG GATCCCCCCCAAGATGTGGAAGACCAGCCCTGACCCCTCGCCGGTGTCTGCCGCCCCATCCAAGGCCGGCCTGCCTCGCCACATCTACCC GGCCGTGGAGTTCCTGGGGCCCTGCGAGCAGGGCGAGAGGAGAAACTCGGCTCCAGAATCCATCCTGCTGGTTCCGCCCACTTGGCCCAA GCCGCTGGTGCCTGCCATTCCCATCTGCAGCATCCCAGTGACTGCATCCCTCCCTCCACTTGAGTGGCCGCTGTCCAGTCAGTCAGGCTC TTACGAGCTGCGGATCGAGGTGCAGCCCAAGCCACATCACCGGGCCCACTATGAGACAGAAGGCAGCCGAGGGGCTGTCAAAGCTCCAAC TGGAGGCCACCCTGTGGTTCAGCTCCATGGCTACATGGAAAACAAGCCTCTGGGACTTCAGATCTTCATTGGGACAGCTGATGAGCGGAT CCTTAAGCCGCACGCCTTCTACCAGGTGCACCGAATCACGGGGAAAACTGTCACCACCACCAGCTATGAGAAGATAGTGGGCAACACCAA AGTCCTGGAGATACCCTTGGAGCCCAAAAACAACATGAGGGCAACCATCGACTGTGCGGGGATCTTGAAGCTTAGAAACGCCGACATTGA GCTGCGGAAAGGCGAGACGGACATTGGAAGAAAGAACACGCGGGTGAGACTGGTTTTCCGAGTTCACATCCCAGAGTCCAGTGGCAGAAT CGTCTCTTTACAGACTGCATCTAACCCCATCGAGTGCTCCCAGCGATCTGCTCACGAGCTGCCCATGGTTGAAAGACAAGACACAGACAG CTGCCTGGTCTATGGCGGCCAGCAAATGATCCTCACGGGGCAGAACTTTACATCCGAGTCCAAAGTTGTGTTTACTGAGAAGACCACAGA TGGACAGCAAATTTGGGAGATGGAAGCCACGGTGGATAAGGACAAGAGCCAGCCCAACATGCTTTTTGTTGAGATCCCTGAATATCGGAA CAAGCATATCCGCACACCTGTAAAAGTGAACTTCTACGTCATCAATGGGAAGAGAAAACGAAGTCAGCCTCAGCACTTTACCTACCACCC AGTCCCAGCCATCAAGACGGAGCCCACGGATGAATATGACCCCACTCTGATCTGCAGCCCCACCCATGGAGGCCTGGGGAGCCAGCCTTA CTACCCCCAGCACCCGATGGTGGCCGAGTCCCCCTCCTGCCTCGTGGCCACCATGGCTCCCTGCCAGCAGTTCCGCACGGGGCTCTCATC CCCTGACGCCCGCTACCAGCAACAGAACCCAGCGGCCGTACTCTACCAGCGGAGCAAGAGCCTGAGCCCCAGCCTGCTGGGCTATCAGCA GCCGGCCCTCATGGCCGCCCCGCTGTCCCTTGCGGACGCTCACCGCTCTGTGCTGGTGCACGCCGGCTCCCAGGGCCAGAGCTCAGCCCT GCTCCACCCCTCTCCGACCAACCAGCAGGCCTCGCCTGTGATCCACTACTCACCCACCAACCAGCAGCTGCGCTGCGGAAGCCACCAGGA GTTCCAGCACATCATGTACTGCGAGAATTTCGCACCAGGCACCACCAGACCTGGCCCGCCCCCGGTCAGTCAAGGTCAGAGGCTGAGCCC GGGTTCCTACCCCACAGTCATTCAGCAGCAGAATGCCACGAGCCAAAGAGCCGCCAAAAACGGACCCCCGGTCAGTGACCAAAAGGAAGT ATTACCTGCGGGGGTGACCATTAAACAGGAGCAGAACTTGGACCAGACCTACTTGGATGATGATACTTGTTCCCAGGACCTTAACTCACG TGTGAAGCCAGGATTTCCTAAAACAATAAAGACCAATGACCCAGGAGTCCTCCAAGCAGCCAGATACAGTGTTGAAAAGTTCAACAACTG CACGAACGACATGTTCTTGTTCAAGGAGTCCCGCATCACAAGGGCCCTAGTTCAGATAGTGAAAGGCCTGAAATATATGCTGGAGGTGGA AATTGGCAGAACTACCTGCAAGAAAAACCAGCACCTGCGTCTGGATGACTGTGACTTCCAAACCAACCACACCTTGAAGCAGACTCTGAG CTGCTACTCTGAAGTCTGGGTCGTGCCCTGGCTCCAGCACTTCGAGGTGCCTGTTCTCCGTTGTCACTGACCCCCGCCTCTTCAGCAAGA CCACAGCCATGACAAACACCAGGATGCATGCTCCTTGTCCCCTCCCACCCGCCTCATGACCCAGCCTCACAGACCCTCTCAGGCCTCTGA CGAGTGAGCGGGTGAAGTGCCACTGGGTCACCGCAGGGCAGCTGGAATGGCAGCATGGTAGCACCTCCTAACAGATTAAATAGATCACAT >58788_58788_1_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000371564_CST7_chr20_24937923_ENST00000376835_length(amino acids)=1032AA_BP=910 MRAMNAPERQPQPDGGDAPGHEPGGSPQDELDFSILFDYEYLNPNEEEPNAHKVASPPSGPAYPDDVLDYGLKPYSPLASLSGEPPGRFG EPDRVGPQKFLSAAKPAGASGLSPRIEITPSHELIQAVGPLRMRDAGLLVEQPPLAGVAASPRFTLPVPGFEGYREPLCLSPASSGSSAS FISDTFSPYTSPCVSPNNGGPDDLCPQFQNIPAHYSPRTSPIMSPRTSLAEDSCLGRHSPVPRPASRSSSPGAKRRHSCAEALVALPPGA SPQRSRSPSPQPSSHVAPQDHGSPAGYPPVAGSAVIMDALNSLATDSPCGIPPKMWKTSPDPSPVSAAPSKAGLPRHIYPAVEFLGPCEQ GERRNSAPESILLVPPTWPKPLVPAIPICSIPVTASLPPLEWPLSSQSGSYELRIEVQPKPHHRAHYETEGSRGAVKAPTGGHPVVQLHG YMENKPLGLQIFIGTADERILKPHAFYQVHRITGKTVTTTSYEKIVGNTKVLEIPLEPKNNMRATIDCAGILKLRNADIELRKGETDIGR KNTRVRLVFRVHIPESSGRIVSLQTASNPIECSQRSAHELPMVERQDTDSCLVYGGQQMILTGQNFTSESKVVFTEKTTDGQQIWEMEAT VDKDKSQPNMLFVEIPEYRNKHIRTPVKVNFYVINGKRKRSQPQHFTYHPVPAIKTEPTDEYDPTLICSPTHGGLGSQPYYPQHPMVAES PSCLVATMAPCQQFRTGLSSPDARYQQQNPAAVLYQRSKSLSPSLLGYQQPALMAAPLSLADAHRSVLVHAGSQGQSSALLHPSPTNQQA SPVIHYSPTNQQLRCGSHQEFQHIMYCENFAPGTTRPGPPPVSQGQRLSPGSYPTVIQQQNATSQRAAKNGPPVSDQKEVLPAGVTIKQE QNLDQTYLDDDTCSQDLNSRVKPGFPKTIKTNDPGVLQAARYSVEKFNNCTNDMFLFKESRITRALVQIVKGLKYMLEVEIGRTTCKKNQ -------------------------------------------------------------- >58788_58788_2_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000371564_CST7_chr20_24937923_ENST00000480798_length(transcript)=3526nt_BP=2942nt AGCAGGAAGCTCGCGCCGCCGTCGCCGCCGCCGCTCAGCTTCCCCGGGCGCGTCCAGGACCCGCTGCGCCAGGCGCGCCGTCCCCGGACC CGGCGTGCGTCCCTACGAGGAAAGGGACCCCGCCGCTCGAGCCGCCTCCGCCAGCCCCACTGCGAGGGGTCCCAGAGCCAGCCGCGCCCG CCCTCGCCCCCGGCCCCGCAGCCTTCCCGCCCTGCGCGCCATGAACGCCCCCGAGCGGCAGCCCCAACCCGACGGCGGGGACGCCCCAGG CCACGAGCCTGGGGGCAGCCCCCAAGACGAGCTTGACTTCTCCATCCTCTTCGACTATGAGTATTTGAATCCGAACGAAGAAGAGCCGAA TGCACATAAGGTCGCCAGCCCACCCTCCGGACCCGCATACCCCGATGATGTCCTGGACTATGGCCTCAAGCCATACAGCCCCCTTGCTAG TCTCTCTGGCGAGCCCCCCGGCCGATTCGGAGAGCCGGATAGGGTAGGGCCGCAGAAGTTTCTGAGCGCGGCCAAGCCAGCAGGGGCCTC GGGCCTGAGCCCTCGGATCGAGATCACTCCGTCCCACGAACTGATCCAGGCAGTGGGGCCCCTCCGCATGAGAGACGCGGGCCTCCTGGT GGAGCAGCCGCCCCTGGCCGGGGTGGCCGCCAGCCCGAGGTTCACCCTGCCCGTGCCCGGCTTCGAGGGCTACCGCGAGCCGCTTTGCTT GAGCCCCGCTAGCAGCGGCTCCTCTGCCAGCTTCATTTCTGACACCTTCTCCCCCTACACCTCGCCCTGCGTCTCGCCCAATAACGGCGG GCCCGACGACCTGTGTCCGCAGTTTCAAAACATCCCTGCTCATTATTCCCCCAGAACCTCGCCAATAATGTCACCTCGAACCAGCCTCGC CGAGGACAGCTGCCTGGGCCGCCACTCGCCCGTGCCCCGTCCGGCCTCCCGCTCCTCATCGCCTGGTGCCAAGCGGAGGCATTCGTGCGC CGAGGCCTTGGTTGCCCTGCCGCCCGGAGCCTCACCCCAGCGCTCCCGGAGCCCCTCGCCGCAGCCCTCATCTCACGTGGCACCCCAGGA CCACGGCTCCCCGGCTGGGTACCCCCCTGTGGCTGGCTCTGCCGTGATCATGGATGCCCTGAACAGCCTCGCCACGGACTCGCCTTGTGG GATCCCCCCCAAGATGTGGAAGACCAGCCCTGACCCCTCGCCGGTGTCTGCCGCCCCATCCAAGGCCGGCCTGCCTCGCCACATCTACCC GGCCGTGGAGTTCCTGGGGCCCTGCGAGCAGGGCGAGAGGAGAAACTCGGCTCCAGAATCCATCCTGCTGGTTCCGCCCACTTGGCCCAA GCCGCTGGTGCCTGCCATTCCCATCTGCAGCATCCCAGTGACTGCATCCCTCCCTCCACTTGAGTGGCCGCTGTCCAGTCAGTCAGGCTC TTACGAGCTGCGGATCGAGGTGCAGCCCAAGCCACATCACCGGGCCCACTATGAGACAGAAGGCAGCCGAGGGGCTGTCAAAGCTCCAAC TGGAGGCCACCCTGTGGTTCAGCTCCATGGCTACATGGAAAACAAGCCTCTGGGACTTCAGATCTTCATTGGGACAGCTGATGAGCGGAT CCTTAAGCCGCACGCCTTCTACCAGGTGCACCGAATCACGGGGAAAACTGTCACCACCACCAGCTATGAGAAGATAGTGGGCAACACCAA AGTCCTGGAGATACCCTTGGAGCCCAAAAACAACATGAGGGCAACCATCGACTGTGCGGGGATCTTGAAGCTTAGAAACGCCGACATTGA GCTGCGGAAAGGCGAGACGGACATTGGAAGAAAGAACACGCGGGTGAGACTGGTTTTCCGAGTTCACATCCCAGAGTCCAGTGGCAGAAT CGTCTCTTTACAGACTGCATCTAACCCCATCGAGTGCTCCCAGCGATCTGCTCACGAGCTGCCCATGGTTGAAAGACAAGACACAGACAG CTGCCTGGTCTATGGCGGCCAGCAAATGATCCTCACGGGGCAGAACTTTACATCCGAGTCCAAAGTTGTGTTTACTGAGAAGACCACAGA TGGACAGCAAATTTGGGAGATGGAAGCCACGGTGGATAAGGACAAGAGCCAGCCCAACATGCTTTTTGTTGAGATCCCTGAATATCGGAA CAAGCATATCCGCACACCTGTAAAAGTGAACTTCTACGTCATCAATGGGAAGAGAAAACGAAGTCAGCCTCAGCACTTTACCTACCACCC AGTCCCAGCCATCAAGACGGAGCCCACGGATGAATATGACCCCACTCTGATCTGCAGCCCCACCCATGGAGGCCTGGGGAGCCAGCCTTA CTACCCCCAGCACCCGATGGTGGCCGAGTCCCCCTCCTGCCTCGTGGCCACCATGGCTCCCTGCCAGCAGTTCCGCACGGGGCTCTCATC CCCTGACGCCCGCTACCAGCAACAGAACCCAGCGGCCGTACTCTACCAGCGGAGCAAGAGCCTGAGCCCCAGCCTGCTGGGCTATCAGCA GCCGGCCCTCATGGCCGCCCCGCTGTCCCTTGCGGACGCTCACCGCTCTGTGCTGGTGCACGCCGGCTCCCAGGGCCAGAGCTCAGCCCT GCTCCACCCCTCTCCGACCAACCAGCAGGCCTCGCCTGTGATCCACTACTCACCCACCAACCAGCAGCTGCGCTGCGGAAGCCACCAGGA GTTCCAGCACATCATGTACTGCGAGAATTTCGCACCAGGCACCACCAGACCTGGCCCGCCCCCGGTCAGTCAAGGTCAGAGGCTGAGCCC GGGTTCCTACCCCACAGTCATTCAGCAGCAGAATGCCACGAGCCAAAGAGCCGCCAAAAACGGACCCCCGGTCAGTGACCAAAAGGAAGT ATTACCTGCGGGGGTGACCATTAAACAGGAGCAGAACTTGGACCAGACCTACTTGGATGATGATACTTGTTCCCAGGACCTTAACTCACG TGTGAAGCCAGGATTTCCTAAAACAATAAAGACCAATGACCCAGGAGTCCTCCAAGCAGCCAGATACAGTGTTGAAAAGTTCAACAACTG CACGAACGACATGTTCTTGTTCAAGGAGTCCCGCATCACAAGGGCCCTAGTTCAGATAGTGAAAGGCCTGAAATATATGCTGGAGGTGGA AATTGGCAGAACTACCTGCAAGAAAAACCAGCACCTGCGTCTGGATGACTGTGACTTCCAAACCAACCACACCTTGAAGCAGACTCTGAG CTGCTACTCTGAAGTCTGGGTCGTGCCCTGGCTCCAGCACTTCGAGGTGCCTGTTCTCCGTTGTCACTGACCCCCGCCTCTTCAGCAAGA CCACAGCCATGACAAACACCAGGATGCATGCTCCTTGTCCCCTCCCACCCGCCTCATGACCCAGCCTCACAGACCCTCTCAGGCCTCTGA CGAGTGAGCGGGTGAAGTGCCACTGGGTCACCGCAGGGCAGCTGGAATGGCAGCATGGTAGCACCTCCTAACAGATTAAATAGATCACAT >58788_58788_2_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000371564_CST7_chr20_24937923_ENST00000480798_length(amino acids)=1032AA_BP=910 MRAMNAPERQPQPDGGDAPGHEPGGSPQDELDFSILFDYEYLNPNEEEPNAHKVASPPSGPAYPDDVLDYGLKPYSPLASLSGEPPGRFG EPDRVGPQKFLSAAKPAGASGLSPRIEITPSHELIQAVGPLRMRDAGLLVEQPPLAGVAASPRFTLPVPGFEGYREPLCLSPASSGSSAS FISDTFSPYTSPCVSPNNGGPDDLCPQFQNIPAHYSPRTSPIMSPRTSLAEDSCLGRHSPVPRPASRSSSPGAKRRHSCAEALVALPPGA SPQRSRSPSPQPSSHVAPQDHGSPAGYPPVAGSAVIMDALNSLATDSPCGIPPKMWKTSPDPSPVSAAPSKAGLPRHIYPAVEFLGPCEQ GERRNSAPESILLVPPTWPKPLVPAIPICSIPVTASLPPLEWPLSSQSGSYELRIEVQPKPHHRAHYETEGSRGAVKAPTGGHPVVQLHG YMENKPLGLQIFIGTADERILKPHAFYQVHRITGKTVTTTSYEKIVGNTKVLEIPLEPKNNMRATIDCAGILKLRNADIELRKGETDIGR KNTRVRLVFRVHIPESSGRIVSLQTASNPIECSQRSAHELPMVERQDTDSCLVYGGQQMILTGQNFTSESKVVFTEKTTDGQQIWEMEAT VDKDKSQPNMLFVEIPEYRNKHIRTPVKVNFYVINGKRKRSQPQHFTYHPVPAIKTEPTDEYDPTLICSPTHGGLGSQPYYPQHPMVAES PSCLVATMAPCQQFRTGLSSPDARYQQQNPAAVLYQRSKSLSPSLLGYQQPALMAAPLSLADAHRSVLVHAGSQGQSSALLHPSPTNQQA SPVIHYSPTNQQLRCGSHQEFQHIMYCENFAPGTTRPGPPPVSQGQRLSPGSYPTVIQQQNATSQRAAKNGPPVSDQKEVLPAGVTIKQE QNLDQTYLDDDTCSQDLNSRVKPGFPKTIKTNDPGVLQAARYSVEKFNNCTNDMFLFKESRITRALVQIVKGLKYMLEVEIGRTTCKKNQ -------------------------------------------------------------- >58788_58788_3_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000396009_CST7_chr20_24937923_ENST00000376835_length(transcript)=3524nt_BP=2942nt AGCAGGAAGCTCGCGCCGCCGTCGCCGCCGCCGCTCAGCTTCCCCGGGCGCGTCCAGGACCCGCTGCGCCAGGCGCGCCGTCCCCGGACC CGGCGTGCGTCCCTACGAGGAAAGGGACCCCGCCGCTCGAGCCGCCTCCGCCAGCCCCACTGCGAGGGGTCCCAGAGCCAGCCGCGCCCG CCCTCGCCCCCGGCCCCGCAGCCTTCCCGCCCTGCGCGCCATGAACGCCCCCGAGCGGCAGCCCCAACCCGACGGCGGGGACGCCCCAGG CCACGAGCCTGGGGGCAGCCCCCAAGACGAGCTTGACTTCTCCATCCTCTTCGACTATGAGTATTTGAATCCGAACGAAGAAGAGCCGAA TGCACATAAGGTCGCCAGCCCACCCTCCGGACCCGCATACCCCGATGATGTCCTGGACTATGGCCTCAAGCCATACAGCCCCCTTGCTAG TCTCTCTGGCGAGCCCCCCGGCCGATTCGGAGAGCCGGATAGGGTAGGGCCGCAGAAGTTTCTGAGCGCGGCCAAGCCAGCAGGGGCCTC GGGCCTGAGCCCTCGGATCGAGATCACTCCGTCCCACGAACTGATCCAGGCAGTGGGGCCCCTCCGCATGAGAGACGCGGGCCTCCTGGT GGAGCAGCCGCCCCTGGCCGGGGTGGCCGCCAGCCCGAGGTTCACCCTGCCCGTGCCCGGCTTCGAGGGCTACCGCGAGCCGCTTTGCTT GAGCCCCGCTAGCAGCGGCTCCTCTGCCAGCTTCATTTCTGACACCTTCTCCCCCTACACCTCGCCCTGCGTCTCGCCCAATAACGGCGG GCCCGACGACCTGTGTCCGCAGTTTCAAAACATCCCTGCTCATTATTCCCCCAGAACCTCGCCAATAATGTCACCTCGAACCAGCCTCGC CGAGGACAGCTGCCTGGGCCGCCACTCGCCCGTGCCCCGTCCGGCCTCCCGCTCCTCATCGCCTGGTGCCAAGCGGAGGCATTCGTGCGC CGAGGCCTTGGTTGCCCTGCCGCCCGGAGCCTCACCCCAGCGCTCCCGGAGCCCCTCGCCGCAGCCCTCATCTCACGTGGCACCCCAGGA CCACGGCTCCCCGGCTGGGTACCCCCCTGTGGCTGGCTCTGCCGTGATCATGGATGCCCTGAACAGCCTCGCCACGGACTCGCCTTGTGG GATCCCCCCCAAGATGTGGAAGACCAGCCCTGACCCCTCGCCGGTGTCTGCCGCCCCATCCAAGGCCGGCCTGCCTCGCCACATCTACCC GGCCGTGGAGTTCCTGGGGCCCTGCGAGCAGGGCGAGAGGAGAAACTCGGCTCCAGAATCCATCCTGCTGGTTCCGCCCACTTGGCCCAA GCCGCTGGTGCCTGCCATTCCCATCTGCAGCATCCCAGTGACTGCATCCCTCCCTCCACTTGAGTGGCCGCTGTCCAGTCAGTCAGGCTC TTACGAGCTGCGGATCGAGGTGCAGCCCAAGCCACATCACCGGGCCCACTATGAGACAGAAGGCAGCCGAGGGGCTGTCAAAGCTCCAAC TGGAGGCCACCCTGTGGTTCAGCTCCATGGCTACATGGAAAACAAGCCTCTGGGACTTCAGATCTTCATTGGGACAGCTGATGAGCGGAT CCTTAAGCCGCACGCCTTCTACCAGGTGCACCGAATCACGGGGAAAACTGTCACCACCACCAGCTATGAGAAGATAGTGGGCAACACCAA AGTCCTGGAGATACCCTTGGAGCCCAAAAACAACATGAGGGCAACCATCGACTGTGCGGGGATCTTGAAGCTTAGAAACGCCGACATTGA GCTGCGGAAAGGCGAGACGGACATTGGAAGAAAGAACACGCGGGTGAGACTGGTTTTCCGAGTTCACATCCCAGAGTCCAGTGGCAGAAT CGTCTCTTTACAGACTGCATCTAACCCCATCGAGTGCTCCCAGCGATCTGCTCACGAGCTGCCCATGGTTGAAAGACAAGACACAGACAG CTGCCTGGTCTATGGCGGCCAGCAAATGATCCTCACGGGGCAGAACTTTACATCCGAGTCCAAAGTTGTGTTTACTGAGAAGACCACAGA TGGACAGCAAATTTGGGAGATGGAAGCCACGGTGGATAAGGACAAGAGCCAGCCCAACATGCTTTTTGTTGAGATCCCTGAATATCGGAA CAAGCATATCCGCACACCTGTAAAAGTGAACTTCTACGTCATCAATGGGAAGAGAAAACGAAGTCAGCCTCAGCACTTTACCTACCACCC AGTCCCAGCCATCAAGACGGAGCCCACGGATGAATATGACCCCACTCTGATCTGCAGCCCCACCCATGGAGGCCTGGGGAGCCAGCCTTA CTACCCCCAGCACCCGATGGTGGCCGAGTCCCCCTCCTGCCTCGTGGCCACCATGGCTCCCTGCCAGCAGTTCCGCACGGGGCTCTCATC CCCTGACGCCCGCTACCAGCAACAGAACCCAGCGGCCGTACTCTACCAGCGGAGCAAGAGCCTGAGCCCCAGCCTGCTGGGCTATCAGCA GCCGGCCCTCATGGCCGCCCCGCTGTCCCTTGCGGACGCTCACCGCTCTGTGCTGGTGCACGCCGGCTCCCAGGGCCAGAGCTCAGCCCT GCTCCACCCCTCTCCGACCAACCAGCAGGCCTCGCCTGTGATCCACTACTCACCCACCAACCAGCAGCTGCGCTGCGGAAGCCACCAGGA GTTCCAGCACATCATGTACTGCGAGAATTTCGCACCAGGCACCACCAGACCTGGCCCGCCCCCGGTCAGTCAAGGTCAGAGGCTGAGCCC GGGTTCCTACCCCACAGTCATTCAGCAGCAGAATGCCACGAGCCAAAGAGCCGCCAAAAACGGACCCCCGGTCAGTGACCAAAAGGAAGT ATTACCTGCGGGGGTGACCATTAAACAGGAGCAGAACTTGGACCAGACCTACTTGGATGATGATACTTGTTCCCAGGACCTTAACTCACG TGTGAAGCCAGGATTTCCTAAAACAATAAAGACCAATGACCCAGGAGTCCTCCAAGCAGCCAGATACAGTGTTGAAAAGTTCAACAACTG CACGAACGACATGTTCTTGTTCAAGGAGTCCCGCATCACAAGGGCCCTAGTTCAGATAGTGAAAGGCCTGAAATATATGCTGGAGGTGGA AATTGGCAGAACTACCTGCAAGAAAAACCAGCACCTGCGTCTGGATGACTGTGACTTCCAAACCAACCACACCTTGAAGCAGACTCTGAG CTGCTACTCTGAAGTCTGGGTCGTGCCCTGGCTCCAGCACTTCGAGGTGCCTGTTCTCCGTTGTCACTGACCCCCGCCTCTTCAGCAAGA CCACAGCCATGACAAACACCAGGATGCATGCTCCTTGTCCCCTCCCACCCGCCTCATGACCCAGCCTCACAGACCCTCTCAGGCCTCTGA CGAGTGAGCGGGTGAAGTGCCACTGGGTCACCGCAGGGCAGCTGGAATGGCAGCATGGTAGCACCTCCTAACAGATTAAATAGATCACAT >58788_58788_3_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000396009_CST7_chr20_24937923_ENST00000376835_length(amino acids)=1032AA_BP=910 MRAMNAPERQPQPDGGDAPGHEPGGSPQDELDFSILFDYEYLNPNEEEPNAHKVASPPSGPAYPDDVLDYGLKPYSPLASLSGEPPGRFG EPDRVGPQKFLSAAKPAGASGLSPRIEITPSHELIQAVGPLRMRDAGLLVEQPPLAGVAASPRFTLPVPGFEGYREPLCLSPASSGSSAS FISDTFSPYTSPCVSPNNGGPDDLCPQFQNIPAHYSPRTSPIMSPRTSLAEDSCLGRHSPVPRPASRSSSPGAKRRHSCAEALVALPPGA SPQRSRSPSPQPSSHVAPQDHGSPAGYPPVAGSAVIMDALNSLATDSPCGIPPKMWKTSPDPSPVSAAPSKAGLPRHIYPAVEFLGPCEQ GERRNSAPESILLVPPTWPKPLVPAIPICSIPVTASLPPLEWPLSSQSGSYELRIEVQPKPHHRAHYETEGSRGAVKAPTGGHPVVQLHG YMENKPLGLQIFIGTADERILKPHAFYQVHRITGKTVTTTSYEKIVGNTKVLEIPLEPKNNMRATIDCAGILKLRNADIELRKGETDIGR KNTRVRLVFRVHIPESSGRIVSLQTASNPIECSQRSAHELPMVERQDTDSCLVYGGQQMILTGQNFTSESKVVFTEKTTDGQQIWEMEAT VDKDKSQPNMLFVEIPEYRNKHIRTPVKVNFYVINGKRKRSQPQHFTYHPVPAIKTEPTDEYDPTLICSPTHGGLGSQPYYPQHPMVAES PSCLVATMAPCQQFRTGLSSPDARYQQQNPAAVLYQRSKSLSPSLLGYQQPALMAAPLSLADAHRSVLVHAGSQGQSSALLHPSPTNQQA SPVIHYSPTNQQLRCGSHQEFQHIMYCENFAPGTTRPGPPPVSQGQRLSPGSYPTVIQQQNATSQRAAKNGPPVSDQKEVLPAGVTIKQE QNLDQTYLDDDTCSQDLNSRVKPGFPKTIKTNDPGVLQAARYSVEKFNNCTNDMFLFKESRITRALVQIVKGLKYMLEVEIGRTTCKKNQ -------------------------------------------------------------- >58788_58788_4_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000396009_CST7_chr20_24937923_ENST00000480798_length(transcript)=3526nt_BP=2942nt AGCAGGAAGCTCGCGCCGCCGTCGCCGCCGCCGCTCAGCTTCCCCGGGCGCGTCCAGGACCCGCTGCGCCAGGCGCGCCGTCCCCGGACC CGGCGTGCGTCCCTACGAGGAAAGGGACCCCGCCGCTCGAGCCGCCTCCGCCAGCCCCACTGCGAGGGGTCCCAGAGCCAGCCGCGCCCG CCCTCGCCCCCGGCCCCGCAGCCTTCCCGCCCTGCGCGCCATGAACGCCCCCGAGCGGCAGCCCCAACCCGACGGCGGGGACGCCCCAGG CCACGAGCCTGGGGGCAGCCCCCAAGACGAGCTTGACTTCTCCATCCTCTTCGACTATGAGTATTTGAATCCGAACGAAGAAGAGCCGAA TGCACATAAGGTCGCCAGCCCACCCTCCGGACCCGCATACCCCGATGATGTCCTGGACTATGGCCTCAAGCCATACAGCCCCCTTGCTAG TCTCTCTGGCGAGCCCCCCGGCCGATTCGGAGAGCCGGATAGGGTAGGGCCGCAGAAGTTTCTGAGCGCGGCCAAGCCAGCAGGGGCCTC GGGCCTGAGCCCTCGGATCGAGATCACTCCGTCCCACGAACTGATCCAGGCAGTGGGGCCCCTCCGCATGAGAGACGCGGGCCTCCTGGT GGAGCAGCCGCCCCTGGCCGGGGTGGCCGCCAGCCCGAGGTTCACCCTGCCCGTGCCCGGCTTCGAGGGCTACCGCGAGCCGCTTTGCTT GAGCCCCGCTAGCAGCGGCTCCTCTGCCAGCTTCATTTCTGACACCTTCTCCCCCTACACCTCGCCCTGCGTCTCGCCCAATAACGGCGG GCCCGACGACCTGTGTCCGCAGTTTCAAAACATCCCTGCTCATTATTCCCCCAGAACCTCGCCAATAATGTCACCTCGAACCAGCCTCGC CGAGGACAGCTGCCTGGGCCGCCACTCGCCCGTGCCCCGTCCGGCCTCCCGCTCCTCATCGCCTGGTGCCAAGCGGAGGCATTCGTGCGC CGAGGCCTTGGTTGCCCTGCCGCCCGGAGCCTCACCCCAGCGCTCCCGGAGCCCCTCGCCGCAGCCCTCATCTCACGTGGCACCCCAGGA CCACGGCTCCCCGGCTGGGTACCCCCCTGTGGCTGGCTCTGCCGTGATCATGGATGCCCTGAACAGCCTCGCCACGGACTCGCCTTGTGG GATCCCCCCCAAGATGTGGAAGACCAGCCCTGACCCCTCGCCGGTGTCTGCCGCCCCATCCAAGGCCGGCCTGCCTCGCCACATCTACCC GGCCGTGGAGTTCCTGGGGCCCTGCGAGCAGGGCGAGAGGAGAAACTCGGCTCCAGAATCCATCCTGCTGGTTCCGCCCACTTGGCCCAA GCCGCTGGTGCCTGCCATTCCCATCTGCAGCATCCCAGTGACTGCATCCCTCCCTCCACTTGAGTGGCCGCTGTCCAGTCAGTCAGGCTC TTACGAGCTGCGGATCGAGGTGCAGCCCAAGCCACATCACCGGGCCCACTATGAGACAGAAGGCAGCCGAGGGGCTGTCAAAGCTCCAAC TGGAGGCCACCCTGTGGTTCAGCTCCATGGCTACATGGAAAACAAGCCTCTGGGACTTCAGATCTTCATTGGGACAGCTGATGAGCGGAT CCTTAAGCCGCACGCCTTCTACCAGGTGCACCGAATCACGGGGAAAACTGTCACCACCACCAGCTATGAGAAGATAGTGGGCAACACCAA AGTCCTGGAGATACCCTTGGAGCCCAAAAACAACATGAGGGCAACCATCGACTGTGCGGGGATCTTGAAGCTTAGAAACGCCGACATTGA GCTGCGGAAAGGCGAGACGGACATTGGAAGAAAGAACACGCGGGTGAGACTGGTTTTCCGAGTTCACATCCCAGAGTCCAGTGGCAGAAT CGTCTCTTTACAGACTGCATCTAACCCCATCGAGTGCTCCCAGCGATCTGCTCACGAGCTGCCCATGGTTGAAAGACAAGACACAGACAG CTGCCTGGTCTATGGCGGCCAGCAAATGATCCTCACGGGGCAGAACTTTACATCCGAGTCCAAAGTTGTGTTTACTGAGAAGACCACAGA TGGACAGCAAATTTGGGAGATGGAAGCCACGGTGGATAAGGACAAGAGCCAGCCCAACATGCTTTTTGTTGAGATCCCTGAATATCGGAA CAAGCATATCCGCACACCTGTAAAAGTGAACTTCTACGTCATCAATGGGAAGAGAAAACGAAGTCAGCCTCAGCACTTTACCTACCACCC AGTCCCAGCCATCAAGACGGAGCCCACGGATGAATATGACCCCACTCTGATCTGCAGCCCCACCCATGGAGGCCTGGGGAGCCAGCCTTA CTACCCCCAGCACCCGATGGTGGCCGAGTCCCCCTCCTGCCTCGTGGCCACCATGGCTCCCTGCCAGCAGTTCCGCACGGGGCTCTCATC CCCTGACGCCCGCTACCAGCAACAGAACCCAGCGGCCGTACTCTACCAGCGGAGCAAGAGCCTGAGCCCCAGCCTGCTGGGCTATCAGCA GCCGGCCCTCATGGCCGCCCCGCTGTCCCTTGCGGACGCTCACCGCTCTGTGCTGGTGCACGCCGGCTCCCAGGGCCAGAGCTCAGCCCT GCTCCACCCCTCTCCGACCAACCAGCAGGCCTCGCCTGTGATCCACTACTCACCCACCAACCAGCAGCTGCGCTGCGGAAGCCACCAGGA GTTCCAGCACATCATGTACTGCGAGAATTTCGCACCAGGCACCACCAGACCTGGCCCGCCCCCGGTCAGTCAAGGTCAGAGGCTGAGCCC GGGTTCCTACCCCACAGTCATTCAGCAGCAGAATGCCACGAGCCAAAGAGCCGCCAAAAACGGACCCCCGGTCAGTGACCAAAAGGAAGT ATTACCTGCGGGGGTGACCATTAAACAGGAGCAGAACTTGGACCAGACCTACTTGGATGATGATACTTGTTCCCAGGACCTTAACTCACG TGTGAAGCCAGGATTTCCTAAAACAATAAAGACCAATGACCCAGGAGTCCTCCAAGCAGCCAGATACAGTGTTGAAAAGTTCAACAACTG CACGAACGACATGTTCTTGTTCAAGGAGTCCCGCATCACAAGGGCCCTAGTTCAGATAGTGAAAGGCCTGAAATATATGCTGGAGGTGGA AATTGGCAGAACTACCTGCAAGAAAAACCAGCACCTGCGTCTGGATGACTGTGACTTCCAAACCAACCACACCTTGAAGCAGACTCTGAG CTGCTACTCTGAAGTCTGGGTCGTGCCCTGGCTCCAGCACTTCGAGGTGCCTGTTCTCCGTTGTCACTGACCCCCGCCTCTTCAGCAAGA CCACAGCCATGACAAACACCAGGATGCATGCTCCTTGTCCCCTCCCACCCGCCTCATGACCCAGCCTCACAGACCCTCTCAGGCCTCTGA CGAGTGAGCGGGTGAAGTGCCACTGGGTCACCGCAGGGCAGCTGGAATGGCAGCATGGTAGCACCTCCTAACAGATTAAATAGATCACAT >58788_58788_4_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000396009_CST7_chr20_24937923_ENST00000480798_length(amino acids)=1032AA_BP=910 MRAMNAPERQPQPDGGDAPGHEPGGSPQDELDFSILFDYEYLNPNEEEPNAHKVASPPSGPAYPDDVLDYGLKPYSPLASLSGEPPGRFG EPDRVGPQKFLSAAKPAGASGLSPRIEITPSHELIQAVGPLRMRDAGLLVEQPPLAGVAASPRFTLPVPGFEGYREPLCLSPASSGSSAS FISDTFSPYTSPCVSPNNGGPDDLCPQFQNIPAHYSPRTSPIMSPRTSLAEDSCLGRHSPVPRPASRSSSPGAKRRHSCAEALVALPPGA SPQRSRSPSPQPSSHVAPQDHGSPAGYPPVAGSAVIMDALNSLATDSPCGIPPKMWKTSPDPSPVSAAPSKAGLPRHIYPAVEFLGPCEQ GERRNSAPESILLVPPTWPKPLVPAIPICSIPVTASLPPLEWPLSSQSGSYELRIEVQPKPHHRAHYETEGSRGAVKAPTGGHPVVQLHG YMENKPLGLQIFIGTADERILKPHAFYQVHRITGKTVTTTSYEKIVGNTKVLEIPLEPKNNMRATIDCAGILKLRNADIELRKGETDIGR KNTRVRLVFRVHIPESSGRIVSLQTASNPIECSQRSAHELPMVERQDTDSCLVYGGQQMILTGQNFTSESKVVFTEKTTDGQQIWEMEAT VDKDKSQPNMLFVEIPEYRNKHIRTPVKVNFYVINGKRKRSQPQHFTYHPVPAIKTEPTDEYDPTLICSPTHGGLGSQPYYPQHPMVAES PSCLVATMAPCQQFRTGLSSPDARYQQQNPAAVLYQRSKSLSPSLLGYQQPALMAAPLSLADAHRSVLVHAGSQGQSSALLHPSPTNQQA SPVIHYSPTNQQLRCGSHQEFQHIMYCENFAPGTTRPGPPPVSQGQRLSPGSYPTVIQQQNATSQRAAKNGPPVSDQKEVLPAGVTIKQE QNLDQTYLDDDTCSQDLNSRVKPGFPKTIKTNDPGVLQAARYSVEKFNNCTNDMFLFKESRITRALVQIVKGLKYMLEVEIGRTTCKKNQ -------------------------------------------------------------- >58788_58788_5_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000414705_CST7_chr20_24937923_ENST00000376835_length(transcript)=3244nt_BP=2662nt ATGCAGAGAGAGGCTGCGTTCAGACTGGGGCACTGCCATCCCCTCCGCATCATGGGGTCTGTGGACCAAGAAGAGCCGAATGCACATAAG GTCGCCAGCCCACCCTCCGGACCCGCATACCCCGATGATGTCCTGGACTATGGCCTCAAGCCATACAGCCCCCTTGCTAGTCTCTCTGGC GAGCCCCCCGGCCGATTCGGAGAGCCGGATAGGGTAGGGCCGCAGAAGTTTCTGAGCGCGGCCAAGCCAGCAGGGGCCTCGGGCCTGAGC CCTCGGATCGAGATCACTCCGTCCCACGAACTGATCCAGGCAGTGGGGCCCCTCCGCATGAGAGACGCGGGCCTCCTGGTGGAGCAGCCG CCCCTGGCCGGGGTGGCCGCCAGCCCGAGGTTCACCCTGCCCGTGCCCGGCTTCGAGGGCTACCGCGAGCCGCTTTGCTTGAGCCCCGCT AGCAGCGGCTCCTCTGCCAGCTTCATTTCTGACACCTTCTCCCCCTACACCTCGCCCTGCGTCTCGCCCAATAACGGCGGGCCCGACGAC CTGTGTCCGCAGTTTCAAAACATCCCTGCTCATTATTCCCCCAGAACCTCGCCAATAATGTCACCTCGAACCAGCCTCGCCGAGGACAGC TGCCTGGGCCGCCACTCGCCCGTGCCCCGTCCGGCCTCCCGCTCCTCATCGCCTGGTGCCAAGCGGAGGCATTCGTGCGCCGAGGCCTTG GTTGCCCTGCCGCCCGGAGCCTCACCCCAGCGCTCCCGGAGCCCCTCGCCGCAGCCCTCATCTCACGTGGCACCCCAGGACCACGGCTCC CCGGCTGGGTACCCCCCTGTGGCTGGCTCTGCCGTGATCATGGATGCCCTGAACAGCCTCGCCACGGACTCGCCTTGTGGGATCCCCCCC AAGATGTGGAAGACCAGCCCTGACCCCTCGCCGGTGTCTGCCGCCCCATCCAAGGCCGGCCTGCCTCGCCACATCTACCCGGCCGTGGAG TTCCTGGGGCCCTGCGAGCAGGGCGAGAGGAGAAACTCGGCTCCAGAATCCATCCTGCTGGTTCCGCCCACTTGGCCCAAGCCGCTGGTG CCTGCCATTCCCATCTGCAGCATCCCAGTGACTGCATCCCTCCCTCCACTTGAGTGGCCGCTGTCCAGTCAGTCAGGCTCTTACGAGCTG CGGATCGAGGTGCAGCCCAAGCCACATCACCGGGCCCACTATGAGACAGAAGGCAGCCGAGGGGCTGTCAAAGCTCCAACTGGAGGCCAC CCTGTGGTTCAGCTCCATGGCTACATGGAAAACAAGCCTCTGGGACTTCAGATCTTCATTGGGACAGCTGATGAGCGGATCCTTAAGCCG CACGCCTTCTACCAGGTGCACCGAATCACGGGGAAAACTGTCACCACCACCAGCTATGAGAAGATAGTGGGCAACACCAAAGTCCTGGAG ATACCCTTGGAGCCCAAAAACAACATGAGGGCAACCATCGACTGTGCGGGGATCTTGAAGCTTAGAAACGCCGACATTGAGCTGCGGAAA GGCGAGACGGACATTGGAAGAAAGAACACGCGGGTGAGACTGGTTTTCCGAGTTCACATCCCAGAGTCCAGTGGCAGAATCGTCTCTTTA CAGACTGCATCTAACCCCATCGAGTGCTCCCAGCGATCTGCTCACGAGCTGCCCATGGTTGAAAGACAAGACACAGACAGCTGCCTGGTC TATGGCGGCCAGCAAATGATCCTCACGGGGCAGAACTTTACATCCGAGTCCAAAGTTGTGTTTACTGAGAAGACCACAGATGGACAGCAA ATTTGGGAGATGGAAGCCACGGTGGATAAGGACAAGAGCCAGCCCAACATGCTTTTTGTTGAGATCCCTGAATATCGGAACAAGCATATC CGCACACCTGTAAAAGTGAACTTCTACGTCATCAATGGGAAGAGAAAACGAAGTCAGCCTCAGCACTTTACCTACCACCCAGTCCCAGCC ATCAAGACGGAGCCCACGGATGAATATGACCCCACTCTGATCTGCAGCCCCACCCATGGAGGCCTGGGGAGCCAGCCTTACTACCCCCAG CACCCGATGGTGGCCGAGTCCCCCTCCTGCCTCGTGGCCACCATGGCTCCCTGCCAGCAGTTCCGCACGGGGCTCTCATCCCCTGACGCC CGCTACCAGCAACAGAACCCAGCGGCCGTACTCTACCAGCGGAGCAAGAGCCTGAGCCCCAGCCTGCTGGGCTATCAGCAGCCGGCCCTC ATGGCCGCCCCGCTGTCCCTTGCGGACGCTCACCGCTCTGTGCTGGTGCACGCCGGCTCCCAGGGCCAGAGCTCAGCCCTGCTCCACCCC TCTCCGACCAACCAGCAGGCCTCGCCTGTGATCCACTACTCACCCACCAACCAGCAGCTGCGCTGCGGAAGCCACCAGGAGTTCCAGCAC ATCATGTACTGCGAGAATTTCGCACCAGGCACCACCAGACCTGGCCCGCCCCCGGTCAGTCAAGGTCAGAGGCTGAGCCCGGGTTCCTAC CCCACAGTCATTCAGCAGCAGAATGCCACGAGCCAAAGAGCCGCCAAAAACGGACCCCCGGTCAGTGACCAAAAGGAAGTATTACCTGCG GGGGTGACCATTAAACAGGAGCAGAACTTGGACCAGACCTACTTGGATGATGATACTTGTTCCCAGGACCTTAACTCACGTGTGAAGCCA GGATTTCCTAAAACAATAAAGACCAATGACCCAGGAGTCCTCCAAGCAGCCAGATACAGTGTTGAAAAGTTCAACAACTGCACGAACGAC ATGTTCTTGTTCAAGGAGTCCCGCATCACAAGGGCCCTAGTTCAGATAGTGAAAGGCCTGAAATATATGCTGGAGGTGGAAATTGGCAGA ACTACCTGCAAGAAAAACCAGCACCTGCGTCTGGATGACTGTGACTTCCAAACCAACCACACCTTGAAGCAGACTCTGAGCTGCTACTCT GAAGTCTGGGTCGTGCCCTGGCTCCAGCACTTCGAGGTGCCTGTTCTCCGTTGTCACTGACCCCCGCCTCTTCAGCAAGACCACAGCCAT GACAAACACCAGGATGCATGCTCCTTGTCCCCTCCCACCCGCCTCATGACCCAGCCTCACAGACCCTCTCAGGCCTCTGACGAGTGAGCG GGTGAAGTGCCACTGGGTCACCGCAGGGCAGCTGGAATGGCAGCATGGTAGCACCTCCTAACAGATTAAATAGATCACATTTGCTTCTAA >58788_58788_5_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000414705_CST7_chr20_24937923_ENST00000376835_length(amino acids)=1009AA_BP=887 MQREAAFRLGHCHPLRIMGSVDQEEPNAHKVASPPSGPAYPDDVLDYGLKPYSPLASLSGEPPGRFGEPDRVGPQKFLSAAKPAGASGLS PRIEITPSHELIQAVGPLRMRDAGLLVEQPPLAGVAASPRFTLPVPGFEGYREPLCLSPASSGSSASFISDTFSPYTSPCVSPNNGGPDD LCPQFQNIPAHYSPRTSPIMSPRTSLAEDSCLGRHSPVPRPASRSSSPGAKRRHSCAEALVALPPGASPQRSRSPSPQPSSHVAPQDHGS PAGYPPVAGSAVIMDALNSLATDSPCGIPPKMWKTSPDPSPVSAAPSKAGLPRHIYPAVEFLGPCEQGERRNSAPESILLVPPTWPKPLV PAIPICSIPVTASLPPLEWPLSSQSGSYELRIEVQPKPHHRAHYETEGSRGAVKAPTGGHPVVQLHGYMENKPLGLQIFIGTADERILKP HAFYQVHRITGKTVTTTSYEKIVGNTKVLEIPLEPKNNMRATIDCAGILKLRNADIELRKGETDIGRKNTRVRLVFRVHIPESSGRIVSL QTASNPIECSQRSAHELPMVERQDTDSCLVYGGQQMILTGQNFTSESKVVFTEKTTDGQQIWEMEATVDKDKSQPNMLFVEIPEYRNKHI RTPVKVNFYVINGKRKRSQPQHFTYHPVPAIKTEPTDEYDPTLICSPTHGGLGSQPYYPQHPMVAESPSCLVATMAPCQQFRTGLSSPDA RYQQQNPAAVLYQRSKSLSPSLLGYQQPALMAAPLSLADAHRSVLVHAGSQGQSSALLHPSPTNQQASPVIHYSPTNQQLRCGSHQEFQH IMYCENFAPGTTRPGPPPVSQGQRLSPGSYPTVIQQQNATSQRAAKNGPPVSDQKEVLPAGVTIKQEQNLDQTYLDDDTCSQDLNSRVKP GFPKTIKTNDPGVLQAARYSVEKFNNCTNDMFLFKESRITRALVQIVKGLKYMLEVEIGRTTCKKNQHLRLDDCDFQTNHTLKQTLSCYS -------------------------------------------------------------- >58788_58788_6_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000414705_CST7_chr20_24937923_ENST00000480798_length(transcript)=3246nt_BP=2662nt ATGCAGAGAGAGGCTGCGTTCAGACTGGGGCACTGCCATCCCCTCCGCATCATGGGGTCTGTGGACCAAGAAGAGCCGAATGCACATAAG GTCGCCAGCCCACCCTCCGGACCCGCATACCCCGATGATGTCCTGGACTATGGCCTCAAGCCATACAGCCCCCTTGCTAGTCTCTCTGGC GAGCCCCCCGGCCGATTCGGAGAGCCGGATAGGGTAGGGCCGCAGAAGTTTCTGAGCGCGGCCAAGCCAGCAGGGGCCTCGGGCCTGAGC CCTCGGATCGAGATCACTCCGTCCCACGAACTGATCCAGGCAGTGGGGCCCCTCCGCATGAGAGACGCGGGCCTCCTGGTGGAGCAGCCG CCCCTGGCCGGGGTGGCCGCCAGCCCGAGGTTCACCCTGCCCGTGCCCGGCTTCGAGGGCTACCGCGAGCCGCTTTGCTTGAGCCCCGCT AGCAGCGGCTCCTCTGCCAGCTTCATTTCTGACACCTTCTCCCCCTACACCTCGCCCTGCGTCTCGCCCAATAACGGCGGGCCCGACGAC CTGTGTCCGCAGTTTCAAAACATCCCTGCTCATTATTCCCCCAGAACCTCGCCAATAATGTCACCTCGAACCAGCCTCGCCGAGGACAGC TGCCTGGGCCGCCACTCGCCCGTGCCCCGTCCGGCCTCCCGCTCCTCATCGCCTGGTGCCAAGCGGAGGCATTCGTGCGCCGAGGCCTTG GTTGCCCTGCCGCCCGGAGCCTCACCCCAGCGCTCCCGGAGCCCCTCGCCGCAGCCCTCATCTCACGTGGCACCCCAGGACCACGGCTCC CCGGCTGGGTACCCCCCTGTGGCTGGCTCTGCCGTGATCATGGATGCCCTGAACAGCCTCGCCACGGACTCGCCTTGTGGGATCCCCCCC AAGATGTGGAAGACCAGCCCTGACCCCTCGCCGGTGTCTGCCGCCCCATCCAAGGCCGGCCTGCCTCGCCACATCTACCCGGCCGTGGAG TTCCTGGGGCCCTGCGAGCAGGGCGAGAGGAGAAACTCGGCTCCAGAATCCATCCTGCTGGTTCCGCCCACTTGGCCCAAGCCGCTGGTG CCTGCCATTCCCATCTGCAGCATCCCAGTGACTGCATCCCTCCCTCCACTTGAGTGGCCGCTGTCCAGTCAGTCAGGCTCTTACGAGCTG CGGATCGAGGTGCAGCCCAAGCCACATCACCGGGCCCACTATGAGACAGAAGGCAGCCGAGGGGCTGTCAAAGCTCCAACTGGAGGCCAC CCTGTGGTTCAGCTCCATGGCTACATGGAAAACAAGCCTCTGGGACTTCAGATCTTCATTGGGACAGCTGATGAGCGGATCCTTAAGCCG CACGCCTTCTACCAGGTGCACCGAATCACGGGGAAAACTGTCACCACCACCAGCTATGAGAAGATAGTGGGCAACACCAAAGTCCTGGAG ATACCCTTGGAGCCCAAAAACAACATGAGGGCAACCATCGACTGTGCGGGGATCTTGAAGCTTAGAAACGCCGACATTGAGCTGCGGAAA GGCGAGACGGACATTGGAAGAAAGAACACGCGGGTGAGACTGGTTTTCCGAGTTCACATCCCAGAGTCCAGTGGCAGAATCGTCTCTTTA CAGACTGCATCTAACCCCATCGAGTGCTCCCAGCGATCTGCTCACGAGCTGCCCATGGTTGAAAGACAAGACACAGACAGCTGCCTGGTC TATGGCGGCCAGCAAATGATCCTCACGGGGCAGAACTTTACATCCGAGTCCAAAGTTGTGTTTACTGAGAAGACCACAGATGGACAGCAA ATTTGGGAGATGGAAGCCACGGTGGATAAGGACAAGAGCCAGCCCAACATGCTTTTTGTTGAGATCCCTGAATATCGGAACAAGCATATC CGCACACCTGTAAAAGTGAACTTCTACGTCATCAATGGGAAGAGAAAACGAAGTCAGCCTCAGCACTTTACCTACCACCCAGTCCCAGCC ATCAAGACGGAGCCCACGGATGAATATGACCCCACTCTGATCTGCAGCCCCACCCATGGAGGCCTGGGGAGCCAGCCTTACTACCCCCAG CACCCGATGGTGGCCGAGTCCCCCTCCTGCCTCGTGGCCACCATGGCTCCCTGCCAGCAGTTCCGCACGGGGCTCTCATCCCCTGACGCC CGCTACCAGCAACAGAACCCAGCGGCCGTACTCTACCAGCGGAGCAAGAGCCTGAGCCCCAGCCTGCTGGGCTATCAGCAGCCGGCCCTC ATGGCCGCCCCGCTGTCCCTTGCGGACGCTCACCGCTCTGTGCTGGTGCACGCCGGCTCCCAGGGCCAGAGCTCAGCCCTGCTCCACCCC TCTCCGACCAACCAGCAGGCCTCGCCTGTGATCCACTACTCACCCACCAACCAGCAGCTGCGCTGCGGAAGCCACCAGGAGTTCCAGCAC ATCATGTACTGCGAGAATTTCGCACCAGGCACCACCAGACCTGGCCCGCCCCCGGTCAGTCAAGGTCAGAGGCTGAGCCCGGGTTCCTAC CCCACAGTCATTCAGCAGCAGAATGCCACGAGCCAAAGAGCCGCCAAAAACGGACCCCCGGTCAGTGACCAAAAGGAAGTATTACCTGCG GGGGTGACCATTAAACAGGAGCAGAACTTGGACCAGACCTACTTGGATGATGATACTTGTTCCCAGGACCTTAACTCACGTGTGAAGCCA GGATTTCCTAAAACAATAAAGACCAATGACCCAGGAGTCCTCCAAGCAGCCAGATACAGTGTTGAAAAGTTCAACAACTGCACGAACGAC ATGTTCTTGTTCAAGGAGTCCCGCATCACAAGGGCCCTAGTTCAGATAGTGAAAGGCCTGAAATATATGCTGGAGGTGGAAATTGGCAGA ACTACCTGCAAGAAAAACCAGCACCTGCGTCTGGATGACTGTGACTTCCAAACCAACCACACCTTGAAGCAGACTCTGAGCTGCTACTCT GAAGTCTGGGTCGTGCCCTGGCTCCAGCACTTCGAGGTGCCTGTTCTCCGTTGTCACTGACCCCCGCCTCTTCAGCAAGACCACAGCCAT GACAAACACCAGGATGCATGCTCCTTGTCCCCTCCCACCCGCCTCATGACCCAGCCTCACAGACCCTCTCAGGCCTCTGACGAGTGAGCG GGTGAAGTGCCACTGGGTCACCGCAGGGCAGCTGGAATGGCAGCATGGTAGCACCTCCTAACAGATTAAATAGATCACATTTGCTTCTAA >58788_58788_6_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000414705_CST7_chr20_24937923_ENST00000480798_length(amino acids)=1009AA_BP=887 MQREAAFRLGHCHPLRIMGSVDQEEPNAHKVASPPSGPAYPDDVLDYGLKPYSPLASLSGEPPGRFGEPDRVGPQKFLSAAKPAGASGLS PRIEITPSHELIQAVGPLRMRDAGLLVEQPPLAGVAASPRFTLPVPGFEGYREPLCLSPASSGSSASFISDTFSPYTSPCVSPNNGGPDD LCPQFQNIPAHYSPRTSPIMSPRTSLAEDSCLGRHSPVPRPASRSSSPGAKRRHSCAEALVALPPGASPQRSRSPSPQPSSHVAPQDHGS PAGYPPVAGSAVIMDALNSLATDSPCGIPPKMWKTSPDPSPVSAAPSKAGLPRHIYPAVEFLGPCEQGERRNSAPESILLVPPTWPKPLV PAIPICSIPVTASLPPLEWPLSSQSGSYELRIEVQPKPHHRAHYETEGSRGAVKAPTGGHPVVQLHGYMENKPLGLQIFIGTADERILKP HAFYQVHRITGKTVTTTSYEKIVGNTKVLEIPLEPKNNMRATIDCAGILKLRNADIELRKGETDIGRKNTRVRLVFRVHIPESSGRIVSL QTASNPIECSQRSAHELPMVERQDTDSCLVYGGQQMILTGQNFTSESKVVFTEKTTDGQQIWEMEATVDKDKSQPNMLFVEIPEYRNKHI RTPVKVNFYVINGKRKRSQPQHFTYHPVPAIKTEPTDEYDPTLICSPTHGGLGSQPYYPQHPMVAESPSCLVATMAPCQQFRTGLSSPDA RYQQQNPAAVLYQRSKSLSPSLLGYQQPALMAAPLSLADAHRSVLVHAGSQGQSSALLHPSPTNQQASPVIHYSPTNQQLRCGSHQEFQH IMYCENFAPGTTRPGPPPVSQGQRLSPGSYPTVIQQQNATSQRAAKNGPPVSDQKEVLPAGVTIKQEQNLDQTYLDDDTCSQDLNSRVKP GFPKTIKTNDPGVLQAARYSVEKFNNCTNDMFLFKESRITRALVQIVKGLKYMLEVEIGRTTCKKNQHLRLDDCDFQTNHTLKQTLSCYS -------------------------------------------------------------- >58788_58788_7_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000609943_CST7_chr20_24937923_ENST00000376835_length(transcript)=3446nt_BP=2864nt TCTGGAGTAAGCCGGATCGCGGAGCCGCGCCGACTCCGCCGAGCCGGGAGCCGGGAGGCGCGCAGCTCCCGGGTCGCTCCGAGGCTCCTC GGCCAGGGCAGCCCCGCGGGCACGCGGTAGAGAAGACGGCGTCCCCTCGGCTGCTGGTCGATACAAACAGATCCCCCTTTCCAAACACGC GCCAAGTCCCCGTGCCCTCCAGATGCAGAGAGAGGCTGCGTTCAGACTGGGGCACTGCCATCCCCTCCGCATCATGGGGTCTGTGGACCA AGAAGAGCCGAATGCACATAAGGTCGCCAGCCCACCCTCCGGACCCGCATACCCCGATGATGTCCTGGACTATGGCCTCAAGCCATACAG CCCCCTTGCTAGTCTCTCTGGCGAGCCCCCCGGCCGATTCGGAGAGCCGGATAGGGTAGGGCCGCAGAAGTTTCTGAGCGCGGCCAAGCC AGCAGGGGCCTCGGGCCTGAGCCCTCGGATCGAGATCACTCCGTCCCACGAACTGATCCAGGCAGTGGGGCCCCTCCGCATGAGAGACGC GGGCCTCCTGGTGGAGCAGCCGCCCCTGGCCGGGGTGGCCGCCAGCCCGAGGTTCACCCTGCCCGTGCCCGGCTTCGAGGGCTACCGCGA GCCGCTTTGCTTGAGCCCCGCTAGCAGCGGCTCCTCTGCCAGCTTCATTTCTGACACCTTCTCCCCCTACACCTCGCCCTGCGTCTCGCC CAATAACGGCGGGCCCGACGACCTGTGTCCGCAGTTTCAAAACATCCCTGCTCATTATTCCCCCAGAACCTCGCCAATAATGTCACCTCG AACCAGCCTCGCCGAGGACAGCTGCCTGGGCCGCCACTCGCCCGTGCCCCGTCCGGCCTCCCGCTCCTCATCGCCTGGTGCCAAGCGGAG GCATTCGTGCGCCGAGGCCTTGGTTGCCCTGCCGCCCGGAGCCTCACCCCAGCGCTCCCGGAGCCCCTCGCCGCAGCCCTCATCTCACGT GGCACCCCAGGACCACGGCTCCCCGGCTGGGTACCCCCCTGTGGCTGGCTCTGCCGTGATCATGGATGCCCTGAACAGCCTCGCCACGGA CTCGCCTTGTGGGATCCCCCCCAAGATGTGGAAGACCAGCCCTGACCCCTCGCCGGTGTCTGCCGCCCCATCCAAGGCCGGCCTGCCTCG CCACATCTACCCGGCCGTGGAGTTCCTGGGGCCCTGCGAGCAGGGCGAGAGGAGAAACTCGGCTCCAGAATCCATCCTGCTGGTTCCGCC CACTTGGCCCAAGCCGCTGGTGCCTGCCATTCCCATCTGCAGCATCCCAGTGACTGCATCCCTCCCTCCACTTGAGTGGCCGCTGTCCAG TCAGTCAGGCTCTTACGAGCTGCGGATCGAGGTGCAGCCCAAGCCACATCACCGGGCCCACTATGAGACAGAAGGCAGCCGAGGGGCTGT CAAAGCTCCAACTGGAGGCCACCCTGTGGTTCAGCTCCATGGCTACATGGAAAACAAGCCTCTGGGACTTCAGATCTTCATTGGGACAGC TGATGAGCGGATCCTTAAGCCGCACGCCTTCTACCAGGTGCACCGAATCACGGGGAAAACTGTCACCACCACCAGCTATGAGAAGATAGT GGGCAACACCAAAGTCCTGGAGATACCCTTGGAGCCCAAAAACAACATGAGGGCAACCATCGACTGTGCGGGGATCTTGAAGCTTAGAAA CGCCGACATTGAGCTGCGGAAAGGCGAGACGGACATTGGAAGAAAGAACACGCGGGTGAGACTGGTTTTCCGAGTTCACATCCCAGAGTC CAGTGGCAGAATCGTCTCTTTACAGACTGCATCTAACCCCATCGAGTGCTCCCAGCGATCTGCTCACGAGCTGCCCATGGTTGAAAGACA AGACACAGACAGCTGCCTGGTCTATGGCGGCCAGCAAATGATCCTCACGGGGCAGAACTTTACATCCGAGTCCAAAGTTGTGTTTACTGA GAAGACCACAGATGGACAGCAAATTTGGGAGATGGAAGCCACGGTGGATAAGGACAAGAGCCAGCCCAACATGCTTTTTGTTGAGATCCC TGAATATCGGAACAAGCATATCCGCACACCTGTAAAAGTGAACTTCTACGTCATCAATGGGAAGAGAAAACGAAGTCAGCCTCAGCACTT TACCTACCACCCAGTCCCAGCCATCAAGACGGAGCCCACGGATGAATATGACCCCACTCTGATCTGCAGCCCCACCCATGGAGGCCTGGG GAGCCAGCCTTACTACCCCCAGCACCCGATGGTGGCCGAGTCCCCCTCCTGCCTCGTGGCCACCATGGCTCCCTGCCAGCAGTTCCGCAC GGGGCTCTCATCCCCTGACGCCCGCTACCAGCAACAGAACCCAGCGGCCGTACTCTACCAGCGGAGCAAGAGCCTGAGCCCCAGCCTGCT GGGCTATCAGCAGCCGGCCCTCATGGCCGCCCCGCTGTCCCTTGCGGACGCTCACCGCTCTGTGCTGGTGCACGCCGGCTCCCAGGGCCA GAGCTCAGCCCTGCTCCACCCCTCTCCGACCAACCAGCAGGCCTCGCCTGTGATCCACTACTCACCCACCAACCAGCAGCTGCGCTGCGG AAGCCACCAGGAGTTCCAGCACATCATGTACTGCGAGAATTTCGCACCAGGCACCACCAGACCTGGCCCGCCCCCGGTCAGTCAAGGTCA GAGGCTGAGCCCGGGTTCCTACCCCACAGTCATTCAGCAGCAGAATGCCACGAGCCAAAGAGCCGCCAAAAACGGACCCCCGGTCAGTGA CCAAAAGGAAGTATTACCTGCGGGGGTGACCATTAAACAGGAGCAGAACTTGGACCAGACCTACTTGGATGATGATACTTGTTCCCAGGA CCTTAACTCACGTGTGAAGCCAGGATTTCCTAAAACAATAAAGACCAATGACCCAGGAGTCCTCCAAGCAGCCAGATACAGTGTTGAAAA GTTCAACAACTGCACGAACGACATGTTCTTGTTCAAGGAGTCCCGCATCACAAGGGCCCTAGTTCAGATAGTGAAAGGCCTGAAATATAT GCTGGAGGTGGAAATTGGCAGAACTACCTGCAAGAAAAACCAGCACCTGCGTCTGGATGACTGTGACTTCCAAACCAACCACACCTTGAA GCAGACTCTGAGCTGCTACTCTGAAGTCTGGGTCGTGCCCTGGCTCCAGCACTTCGAGGTGCCTGTTCTCCGTTGTCACTGACCCCCGCC TCTTCAGCAAGACCACAGCCATGACAAACACCAGGATGCATGCTCCTTGTCCCCTCCCACCCGCCTCATGACCCAGCCTCACAGACCCTC TCAGGCCTCTGACGAGTGAGCGGGTGAAGTGCCACTGGGTCACCGCAGGGCAGCTGGAATGGCAGCATGGTAGCACCTCCTAACAGATTA >58788_58788_7_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000609943_CST7_chr20_24937923_ENST00000376835_length(amino acids)=1009AA_BP=887 MQREAAFRLGHCHPLRIMGSVDQEEPNAHKVASPPSGPAYPDDVLDYGLKPYSPLASLSGEPPGRFGEPDRVGPQKFLSAAKPAGASGLS PRIEITPSHELIQAVGPLRMRDAGLLVEQPPLAGVAASPRFTLPVPGFEGYREPLCLSPASSGSSASFISDTFSPYTSPCVSPNNGGPDD LCPQFQNIPAHYSPRTSPIMSPRTSLAEDSCLGRHSPVPRPASRSSSPGAKRRHSCAEALVALPPGASPQRSRSPSPQPSSHVAPQDHGS PAGYPPVAGSAVIMDALNSLATDSPCGIPPKMWKTSPDPSPVSAAPSKAGLPRHIYPAVEFLGPCEQGERRNSAPESILLVPPTWPKPLV PAIPICSIPVTASLPPLEWPLSSQSGSYELRIEVQPKPHHRAHYETEGSRGAVKAPTGGHPVVQLHGYMENKPLGLQIFIGTADERILKP HAFYQVHRITGKTVTTTSYEKIVGNTKVLEIPLEPKNNMRATIDCAGILKLRNADIELRKGETDIGRKNTRVRLVFRVHIPESSGRIVSL QTASNPIECSQRSAHELPMVERQDTDSCLVYGGQQMILTGQNFTSESKVVFTEKTTDGQQIWEMEATVDKDKSQPNMLFVEIPEYRNKHI RTPVKVNFYVINGKRKRSQPQHFTYHPVPAIKTEPTDEYDPTLICSPTHGGLGSQPYYPQHPMVAESPSCLVATMAPCQQFRTGLSSPDA RYQQQNPAAVLYQRSKSLSPSLLGYQQPALMAAPLSLADAHRSVLVHAGSQGQSSALLHPSPTNQQASPVIHYSPTNQQLRCGSHQEFQH IMYCENFAPGTTRPGPPPVSQGQRLSPGSYPTVIQQQNATSQRAAKNGPPVSDQKEVLPAGVTIKQEQNLDQTYLDDDTCSQDLNSRVKP GFPKTIKTNDPGVLQAARYSVEKFNNCTNDMFLFKESRITRALVQIVKGLKYMLEVEIGRTTCKKNQHLRLDDCDFQTNHTLKQTLSCYS -------------------------------------------------------------- >58788_58788_8_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000609943_CST7_chr20_24937923_ENST00000480798_length(transcript)=3448nt_BP=2864nt TCTGGAGTAAGCCGGATCGCGGAGCCGCGCCGACTCCGCCGAGCCGGGAGCCGGGAGGCGCGCAGCTCCCGGGTCGCTCCGAGGCTCCTC GGCCAGGGCAGCCCCGCGGGCACGCGGTAGAGAAGACGGCGTCCCCTCGGCTGCTGGTCGATACAAACAGATCCCCCTTTCCAAACACGC GCCAAGTCCCCGTGCCCTCCAGATGCAGAGAGAGGCTGCGTTCAGACTGGGGCACTGCCATCCCCTCCGCATCATGGGGTCTGTGGACCA AGAAGAGCCGAATGCACATAAGGTCGCCAGCCCACCCTCCGGACCCGCATACCCCGATGATGTCCTGGACTATGGCCTCAAGCCATACAG CCCCCTTGCTAGTCTCTCTGGCGAGCCCCCCGGCCGATTCGGAGAGCCGGATAGGGTAGGGCCGCAGAAGTTTCTGAGCGCGGCCAAGCC AGCAGGGGCCTCGGGCCTGAGCCCTCGGATCGAGATCACTCCGTCCCACGAACTGATCCAGGCAGTGGGGCCCCTCCGCATGAGAGACGC GGGCCTCCTGGTGGAGCAGCCGCCCCTGGCCGGGGTGGCCGCCAGCCCGAGGTTCACCCTGCCCGTGCCCGGCTTCGAGGGCTACCGCGA GCCGCTTTGCTTGAGCCCCGCTAGCAGCGGCTCCTCTGCCAGCTTCATTTCTGACACCTTCTCCCCCTACACCTCGCCCTGCGTCTCGCC CAATAACGGCGGGCCCGACGACCTGTGTCCGCAGTTTCAAAACATCCCTGCTCATTATTCCCCCAGAACCTCGCCAATAATGTCACCTCG AACCAGCCTCGCCGAGGACAGCTGCCTGGGCCGCCACTCGCCCGTGCCCCGTCCGGCCTCCCGCTCCTCATCGCCTGGTGCCAAGCGGAG GCATTCGTGCGCCGAGGCCTTGGTTGCCCTGCCGCCCGGAGCCTCACCCCAGCGCTCCCGGAGCCCCTCGCCGCAGCCCTCATCTCACGT GGCACCCCAGGACCACGGCTCCCCGGCTGGGTACCCCCCTGTGGCTGGCTCTGCCGTGATCATGGATGCCCTGAACAGCCTCGCCACGGA CTCGCCTTGTGGGATCCCCCCCAAGATGTGGAAGACCAGCCCTGACCCCTCGCCGGTGTCTGCCGCCCCATCCAAGGCCGGCCTGCCTCG CCACATCTACCCGGCCGTGGAGTTCCTGGGGCCCTGCGAGCAGGGCGAGAGGAGAAACTCGGCTCCAGAATCCATCCTGCTGGTTCCGCC CACTTGGCCCAAGCCGCTGGTGCCTGCCATTCCCATCTGCAGCATCCCAGTGACTGCATCCCTCCCTCCACTTGAGTGGCCGCTGTCCAG TCAGTCAGGCTCTTACGAGCTGCGGATCGAGGTGCAGCCCAAGCCACATCACCGGGCCCACTATGAGACAGAAGGCAGCCGAGGGGCTGT CAAAGCTCCAACTGGAGGCCACCCTGTGGTTCAGCTCCATGGCTACATGGAAAACAAGCCTCTGGGACTTCAGATCTTCATTGGGACAGC TGATGAGCGGATCCTTAAGCCGCACGCCTTCTACCAGGTGCACCGAATCACGGGGAAAACTGTCACCACCACCAGCTATGAGAAGATAGT GGGCAACACCAAAGTCCTGGAGATACCCTTGGAGCCCAAAAACAACATGAGGGCAACCATCGACTGTGCGGGGATCTTGAAGCTTAGAAA CGCCGACATTGAGCTGCGGAAAGGCGAGACGGACATTGGAAGAAAGAACACGCGGGTGAGACTGGTTTTCCGAGTTCACATCCCAGAGTC CAGTGGCAGAATCGTCTCTTTACAGACTGCATCTAACCCCATCGAGTGCTCCCAGCGATCTGCTCACGAGCTGCCCATGGTTGAAAGACA AGACACAGACAGCTGCCTGGTCTATGGCGGCCAGCAAATGATCCTCACGGGGCAGAACTTTACATCCGAGTCCAAAGTTGTGTTTACTGA GAAGACCACAGATGGACAGCAAATTTGGGAGATGGAAGCCACGGTGGATAAGGACAAGAGCCAGCCCAACATGCTTTTTGTTGAGATCCC TGAATATCGGAACAAGCATATCCGCACACCTGTAAAAGTGAACTTCTACGTCATCAATGGGAAGAGAAAACGAAGTCAGCCTCAGCACTT TACCTACCACCCAGTCCCAGCCATCAAGACGGAGCCCACGGATGAATATGACCCCACTCTGATCTGCAGCCCCACCCATGGAGGCCTGGG GAGCCAGCCTTACTACCCCCAGCACCCGATGGTGGCCGAGTCCCCCTCCTGCCTCGTGGCCACCATGGCTCCCTGCCAGCAGTTCCGCAC GGGGCTCTCATCCCCTGACGCCCGCTACCAGCAACAGAACCCAGCGGCCGTACTCTACCAGCGGAGCAAGAGCCTGAGCCCCAGCCTGCT GGGCTATCAGCAGCCGGCCCTCATGGCCGCCCCGCTGTCCCTTGCGGACGCTCACCGCTCTGTGCTGGTGCACGCCGGCTCCCAGGGCCA GAGCTCAGCCCTGCTCCACCCCTCTCCGACCAACCAGCAGGCCTCGCCTGTGATCCACTACTCACCCACCAACCAGCAGCTGCGCTGCGG AAGCCACCAGGAGTTCCAGCACATCATGTACTGCGAGAATTTCGCACCAGGCACCACCAGACCTGGCCCGCCCCCGGTCAGTCAAGGTCA GAGGCTGAGCCCGGGTTCCTACCCCACAGTCATTCAGCAGCAGAATGCCACGAGCCAAAGAGCCGCCAAAAACGGACCCCCGGTCAGTGA CCAAAAGGAAGTATTACCTGCGGGGGTGACCATTAAACAGGAGCAGAACTTGGACCAGACCTACTTGGATGATGATACTTGTTCCCAGGA CCTTAACTCACGTGTGAAGCCAGGATTTCCTAAAACAATAAAGACCAATGACCCAGGAGTCCTCCAAGCAGCCAGATACAGTGTTGAAAA GTTCAACAACTGCACGAACGACATGTTCTTGTTCAAGGAGTCCCGCATCACAAGGGCCCTAGTTCAGATAGTGAAAGGCCTGAAATATAT GCTGGAGGTGGAAATTGGCAGAACTACCTGCAAGAAAAACCAGCACCTGCGTCTGGATGACTGTGACTTCCAAACCAACCACACCTTGAA GCAGACTCTGAGCTGCTACTCTGAAGTCTGGGTCGTGCCCTGGCTCCAGCACTTCGAGGTGCCTGTTCTCCGTTGTCACTGACCCCCGCC TCTTCAGCAAGACCACAGCCATGACAAACACCAGGATGCATGCTCCTTGTCCCCTCCCACCCGCCTCATGACCCAGCCTCACAGACCCTC TCAGGCCTCTGACGAGTGAGCGGGTGAAGTGCCACTGGGTCACCGCAGGGCAGCTGGAATGGCAGCATGGTAGCACCTCCTAACAGATTA >58788_58788_8_NFATC2-CST7_NFATC2_chr20_50048604_ENST00000609943_CST7_chr20_24937923_ENST00000480798_length(amino acids)=1009AA_BP=887 MQREAAFRLGHCHPLRIMGSVDQEEPNAHKVASPPSGPAYPDDVLDYGLKPYSPLASLSGEPPGRFGEPDRVGPQKFLSAAKPAGASGLS PRIEITPSHELIQAVGPLRMRDAGLLVEQPPLAGVAASPRFTLPVPGFEGYREPLCLSPASSGSSASFISDTFSPYTSPCVSPNNGGPDD LCPQFQNIPAHYSPRTSPIMSPRTSLAEDSCLGRHSPVPRPASRSSSPGAKRRHSCAEALVALPPGASPQRSRSPSPQPSSHVAPQDHGS PAGYPPVAGSAVIMDALNSLATDSPCGIPPKMWKTSPDPSPVSAAPSKAGLPRHIYPAVEFLGPCEQGERRNSAPESILLVPPTWPKPLV PAIPICSIPVTASLPPLEWPLSSQSGSYELRIEVQPKPHHRAHYETEGSRGAVKAPTGGHPVVQLHGYMENKPLGLQIFIGTADERILKP HAFYQVHRITGKTVTTTSYEKIVGNTKVLEIPLEPKNNMRATIDCAGILKLRNADIELRKGETDIGRKNTRVRLVFRVHIPESSGRIVSL QTASNPIECSQRSAHELPMVERQDTDSCLVYGGQQMILTGQNFTSESKVVFTEKTTDGQQIWEMEATVDKDKSQPNMLFVEIPEYRNKHI RTPVKVNFYVINGKRKRSQPQHFTYHPVPAIKTEPTDEYDPTLICSPTHGGLGSQPYYPQHPMVAESPSCLVATMAPCQQFRTGLSSPDA RYQQQNPAAVLYQRSKSLSPSLLGYQQPALMAAPLSLADAHRSVLVHAGSQGQSSALLHPSPTNQQASPVIHYSPTNQQLRCGSHQEFQH IMYCENFAPGTTRPGPPPVSQGQRLSPGSYPTVIQQQNATSQRAAKNGPPVSDQKEVLPAGVTIKQEQNLDQTYLDDDTCSQDLNSRVKP GFPKTIKTNDPGVLQAARYSVEKFNNCTNDMFLFKESRITRALVQIVKGLKYMLEVEIGRTTCKKNQHLRLDDCDFQTNHTLKQTLSCYS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NFATC2-CST7 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NFATC2-CST7 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NFATC2-CST7 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies