
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NFE2L1-CARM1 (FusionGDB2 ID:58814) |
Fusion Gene Summary for NFE2L1-CARM1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NFE2L1-CARM1 | Fusion gene ID: 58814 | Hgene | Tgene | Gene symbol | NFE2L1 | CARM1 | Gene ID | 4779 | 10498 |
| Gene name | nuclear factor, erythroid 2 like 1 | coactivator associated arginine methyltransferase 1 | |
| Synonyms | LCR-F1|NRF1|TCF11 | PRMT4 | |
| Cytomap | 17q21.32 | 19p13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | endoplasmic reticulum membrane sensor NFE2L1NF-E2-related factor 1NFE2-related factor 1TCF-11locus control region-factor 1nuclear factor erythroid 2-related factor 1nuclear factor, erythroid derived 2, like 1protein NRF1, p120 formtranscription fa | histone-arginine methyltransferase CARM1protein arginine N-methyltransferase 4 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q14494 | Q86X55 | |
| Ensembl transtripts involved in fusion gene | ENST00000357480, ENST00000361665, ENST00000362042, ENST00000536222, ENST00000582155, ENST00000583378, ENST00000585291, ENST00000579481, | ENST00000327064, ENST00000344150, | |
| Fusion gene scores | * DoF score | 18 X 12 X 13=2808 | 4 X 7 X 10=280 |
| # samples | 20 | 12 | |
| ** MAII score | log2(20/2808*10)=-3.81147103052984 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/280*10)=-1.22239242133645 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NFE2L1 [Title/Abstract] AND CARM1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NFE2L1(46134864)-CARM1(11022860), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CARM1 | GO:0016571 | histone methylation | 19405910 |
| Fusion gene breakpoints across NFE2L1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
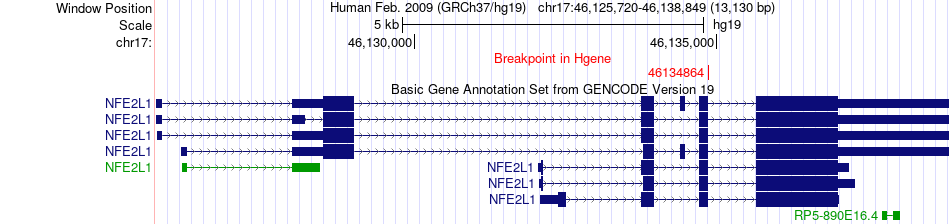 |
| Fusion gene breakpoints across CARM1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-HC-7232-01A | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| ChimerDB4 | PRAD | TCGA-HC-7232 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
Top |
Fusion Gene ORF analysis for NFE2L1-CARM1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000357480 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000357480 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000361665 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000361665 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000362042 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000362042 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000536222 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000536222 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000582155 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000582155 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000583378 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000583378 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000585291 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| In-frame | ENST00000585291 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| intron-3CDS | ENST00000579481 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| intron-3CDS | ENST00000579481 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000362042 | NFE2L1 | chr17 | 46134864 | + | ENST00000327064 | CARM1 | chr19 | 11022860 | + | 3872 | 1588 | 616 | 2856 | 746 |
| ENST00000362042 | NFE2L1 | chr17 | 46134864 | + | ENST00000344150 | CARM1 | chr19 | 11022860 | + | 3752 | 1588 | 616 | 2787 | 723 |
| ENST00000585291 | NFE2L1 | chr17 | 46134864 | + | ENST00000327064 | CARM1 | chr19 | 11022860 | + | 3481 | 1197 | 291 | 2465 | 724 |
| ENST00000585291 | NFE2L1 | chr17 | 46134864 | + | ENST00000344150 | CARM1 | chr19 | 11022860 | + | 3361 | 1197 | 291 | 2396 | 701 |
| ENST00000357480 | NFE2L1 | chr17 | 46134864 | + | ENST00000327064 | CARM1 | chr19 | 11022860 | + | 3771 | 1487 | 605 | 2755 | 716 |
| ENST00000357480 | NFE2L1 | chr17 | 46134864 | + | ENST00000344150 | CARM1 | chr19 | 11022860 | + | 3651 | 1487 | 605 | 2686 | 693 |
| ENST00000361665 | NFE2L1 | chr17 | 46134864 | + | ENST00000327064 | CARM1 | chr19 | 11022860 | + | 3827 | 1543 | 604 | 2811 | 735 |
| ENST00000361665 | NFE2L1 | chr17 | 46134864 | + | ENST00000344150 | CARM1 | chr19 | 11022860 | + | 3707 | 1543 | 604 | 2742 | 712 |
| ENST00000582155 | NFE2L1 | chr17 | 46134864 | + | ENST00000327064 | CARM1 | chr19 | 11022860 | + | 2743 | 459 | 51 | 1727 | 558 |
| ENST00000582155 | NFE2L1 | chr17 | 46134864 | + | ENST00000344150 | CARM1 | chr19 | 11022860 | + | 2623 | 459 | 51 | 1658 | 535 |
| ENST00000583378 | NFE2L1 | chr17 | 46134864 | + | ENST00000327064 | CARM1 | chr19 | 11022860 | + | 2693 | 409 | 34 | 1677 | 547 |
| ENST00000583378 | NFE2L1 | chr17 | 46134864 | + | ENST00000344150 | CARM1 | chr19 | 11022860 | + | 2573 | 409 | 34 | 1608 | 524 |
| ENST00000536222 | NFE2L1 | chr17 | 46134864 | + | ENST00000327064 | CARM1 | chr19 | 11022860 | + | 3097 | 813 | 261 | 2081 | 606 |
| ENST00000536222 | NFE2L1 | chr17 | 46134864 | + | ENST00000344150 | CARM1 | chr19 | 11022860 | + | 2977 | 813 | 261 | 2012 | 583 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000362042 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.001168036 | 0.9988319 |
| ENST00000362042 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.001419519 | 0.99858046 |
| ENST00000585291 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.001800093 | 0.9981998 |
| ENST00000585291 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.002192573 | 0.99780744 |
| ENST00000357480 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.001166988 | 0.998833 |
| ENST00000357480 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.001426954 | 0.99857306 |
| ENST00000361665 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.001401241 | 0.99859875 |
| ENST00000361665 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.001584002 | 0.99841595 |
| ENST00000582155 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.002905432 | 0.9970945 |
| ENST00000582155 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.002426823 | 0.9975732 |
| ENST00000583378 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.004324501 | 0.9956755 |
| ENST00000583378 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.003678824 | 0.9963212 |
| ENST00000536222 | ENST00000327064 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.007771059 | 0.9922289 |
| ENST00000536222 | ENST00000344150 | NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022860 | + | 0.00791772 | 0.99208224 |
Top |
Fusion Genomic Features for NFE2L1-CARM1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022859 | + | 0.00026886 | 0.9997311 |
| NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022859 | + | 0.00026886 | 0.9997311 |
| NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022859 | + | 0.00026886 | 0.9997311 |
| NFE2L1 | chr17 | 46134864 | + | CARM1 | chr19 | 11022859 | + | 0.00026886 | 0.9997311 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
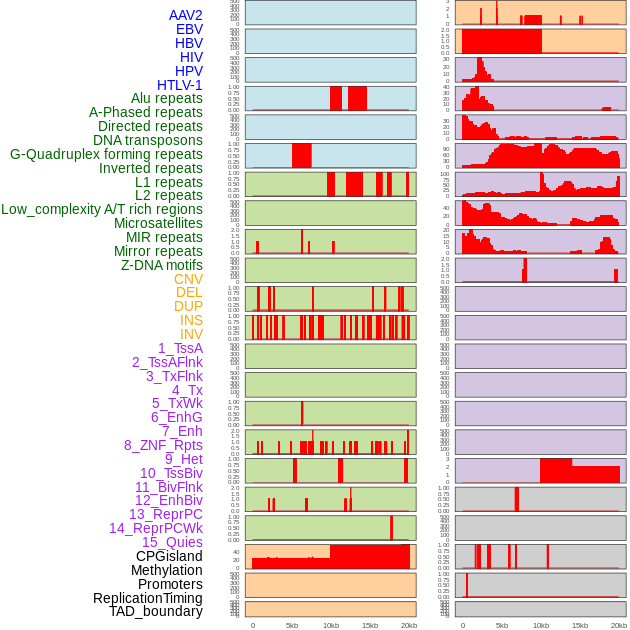 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
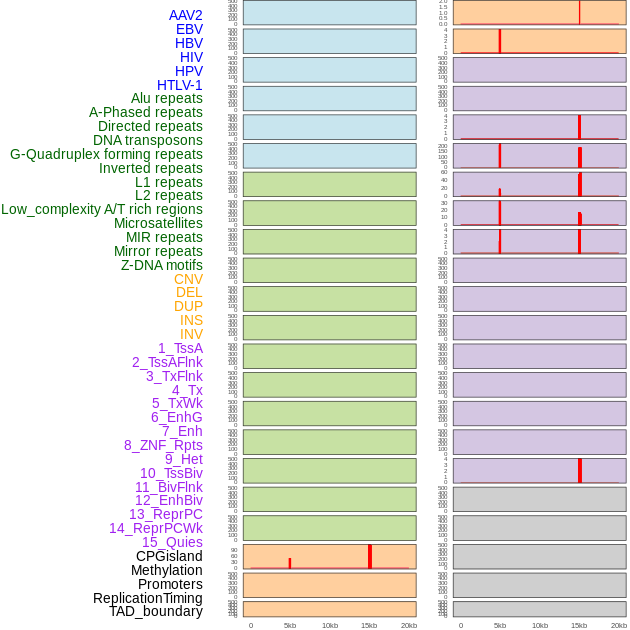 |
Top |
Fusion Protein Features for NFE2L1-CARM1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:46134864/chr19:11022860) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NFE2L1 | CARM1 |
| FUNCTION: [Endoplasmic reticulum membrane sensor NFE2L1]: Endoplasmic reticulum membrane sensor that translocates into the nucleus in response to various stresses to act as a transcription factor (PubMed:20932482, PubMed:24448410). Constitutes a precursor of the transcription factor NRF1 (By similarity). Able to detect various cellular stresses, such as cholesterol excess, oxidative stress or proteasome inhibition (PubMed:20932482). In response to stress, it is released from the endoplasmic reticulum membrane following cleavage by the protease DDI2 and translocates into the nucleus to form the transcription factor NRF1 (By similarity). Acts as a key sensor of cholesterol excess: in excess cholesterol conditions, the endoplasmic reticulum membrane form of the protein directly binds cholesterol via its CRAC motif, preventing cleavage and release of the transcription factor NRF1, thereby allowing expression of genes promoting cholesterol removal, such as CD36 (By similarity). Involved in proteasome homeostasis: in response to proteasome inhibition, it is released from the endoplasmic reticulum membrane, translocates to the nucleus and activates expression of genes encoding proteasome subunits (PubMed:20932482). {ECO:0000250|UniProtKB:Q61985, ECO:0000269|PubMed:20932482, ECO:0000269|PubMed:24448410}.; FUNCTION: [Transcription factor NRF1]: CNC-type bZIP family transcription factor that translocates to the nucleus and regulates expression of target genes in response to various stresses (PubMed:8932385, PubMed:9421508). Heterodimerizes with small-Maf proteins (MAFF, MAFG or MAFK) and binds DNA motifs including the antioxidant response elements (AREs), which regulate expression of genes involved in oxidative stress response (PubMed:8932385, PubMed:9421508). Activates or represses expression of target genes, depending on the context (PubMed:8932385, PubMed:9421508). Plays a key role in cholesterol homeostasis by acting as a sensor of cholesterol excess: in low cholesterol conditions, translocates into the nucleus and represses expression of genes involved in defense against cholesterol excess, such as CD36 (By similarity). In excess cholesterol conditions, the endoplasmic reticulum membrane form of the protein directly binds cholesterol via its CRAC motif, preventing cleavage and release of the transcription factor NRF1, thereby allowing expression of genes promoting cholesterol removal (By similarity). Critical for redox balance in response to oxidative stress: acts by binding the AREs motifs on promoters and mediating activation of oxidative stress response genes, such as GCLC, GCLM, GSS, MT1 and MT2 (By similarity). Plays an essential role during fetal liver hematopoiesis: probably has a protective function against oxidative stress and is involved in lipid homeostasis in the liver (By similarity). Involved in proteasome homeostasis: in response to proteasome inhibition, mediates the 'bounce-back' of proteasome subunits by translocating into the nucleus and activating expression of genes encoding proteasome subunits (PubMed:20932482). Also involved in regulating glucose flux (By similarity). Together with CEBPB; represses expression of DSPP during odontoblast differentiation (PubMed:15308669). In response to ascorbic acid induction, activates expression of SP7/Osterix in osteoblasts. {ECO:0000250|UniProtKB:Q61985, ECO:0000269|PubMed:15308669, ECO:0000269|PubMed:20932482, ECO:0000269|PubMed:8932385, ECO:0000269|PubMed:9421508}. | FUNCTION: Methylates (mono- and asymmetric dimethylation) the guanidino nitrogens of arginyl residues in several proteins involved in DNA packaging, transcription regulation, pre-mRNA splicing, and mRNA stability. Recruited to promoters upon gene activation together with histone acetyltransferases from EP300/P300 and p160 families, methylates histone H3 at 'Arg-17' (H3R17me), forming mainly asymmetric dimethylarginine (H3R17me2a), leading to activate transcription via chromatin remodeling. During nuclear hormone receptor activation and TCF7L2/TCF4 activation, acts synergically with EP300/P300 and either one of the p160 histone acetyltransferases NCOA1/SRC1, NCOA2/GRIP1 and NCOA3/ACTR or CTNNB1/beta-catenin to activate transcription. During myogenic transcriptional activation, acts together with NCOA3/ACTR as a coactivator for MEF2C. During monocyte inflammatory stimulation, acts together with EP300/P300 as a coactivator for NF-kappa-B. Acts as coactivator for PPARG, promotes adipocyte differentiation and the accumulation of brown fat tissue. Plays a role in the regulation of pre-mRNA alternative splicing by methylation of splicing factors. Also seems to be involved in p53/TP53 transcriptional activation. Methylates EP300/P300, both at 'Arg-2142', which may loosen its interaction with NCOA2/GRIP1, and at 'Arg-580' and 'Arg-604' in the KIX domain, which impairs its interaction with CREB and inhibits CREB-dependent transcriptional activation. Also methylates arginine residues in RNA-binding proteins PABPC1, ELAVL1 and ELAV4, which may affect their mRNA-stabilizing properties and the half-life of their target mRNAs. {ECO:0000269|PubMed:16497732, ECO:0000269|PubMed:19405910}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 125_288 | 294 | 743.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 125_288 | 324 | 773.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 125_288 | 294 | 743.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 191_199 | 294 | 743.0 | Region | Cholesterol recognition/amino acid consensus (CRAC) region |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 191_199 | 324 | 773.0 | Region | Cholesterol recognition/amino acid consensus (CRAC) region |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 191_199 | 294 | 743.0 | Region | Cholesterol recognition/amino acid consensus (CRAC) region |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 7_24 | 294 | 743.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 7_24 | 324 | 773.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 7_24 | 294 | 743.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Tgene | CARM1 | chr17:46134864 | chr19:11022860 | ENST00000327064 | 3 | 16 | 499_608 | 186 | 609.0 | Region | Transactivation domain | |
| Tgene | CARM1 | chr17:46134864 | chr19:11022860 | ENST00000344150 | 3 | 15 | 499_608 | 186 | 586.0 | Region | Transactivation domain |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 496_517 | 294 | 743.0 | Compositional bias | Note=Poly-Ser |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 496_517 | 324 | 773.0 | Compositional bias | Note=Poly-Ser |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 496_517 | 294 | 743.0 | Compositional bias | Note=Poly-Ser |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 654_717 | 294 | 743.0 | Domain | bZIP |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 654_717 | 324 | 773.0 | Domain | bZIP |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 654_717 | 294 | 743.0 | Domain | bZIP |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 476_480 | 294 | 743.0 | Motif | Destruction motif |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 476_480 | 324 | 773.0 | Motif | Destruction motif |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 476_480 | 294 | 743.0 | Motif | Destruction motif |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 379_383 | 294 | 743.0 | Region | CPD |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 656_675 | 294 | 743.0 | Region | Basic motif |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000357480 | + | 4 | 5 | 682_696 | 294 | 743.0 | Region | Leucine-zipper |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 379_383 | 324 | 773.0 | Region | CPD |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 656_675 | 324 | 773.0 | Region | Basic motif |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000362042 | + | 5 | 6 | 682_696 | 324 | 773.0 | Region | Leucine-zipper |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 379_383 | 294 | 743.0 | Region | CPD |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 656_675 | 294 | 743.0 | Region | Basic motif |
| Hgene | NFE2L1 | chr17:46134864 | chr19:11022860 | ENST00000585291 | + | 5 | 6 | 682_696 | 294 | 743.0 | Region | Leucine-zipper |
| Tgene | CARM1 | chr17:46134864 | chr19:11022860 | ENST00000327064 | 3 | 16 | 146_453 | 186 | 609.0 | Domain | SAM-dependent MTase PRMT-type | |
| Tgene | CARM1 | chr17:46134864 | chr19:11022860 | ENST00000344150 | 3 | 15 | 146_453 | 186 | 586.0 | Domain | SAM-dependent MTase PRMT-type |
Top |
Fusion Gene Sequence for NFE2L1-CARM1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58814_58814_1_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000357480_CARM1_chr19_11022860_ENST00000327064_length(transcript)=3771nt_BP=1487nt CCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGACGCCGAGCTAA GCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCAAAGAAAA TAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAACTAATGT GAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAACAGTTGTACTTT CAGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTCCTCTGGGGCCG TCAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGCGGCAGAGCAGT GGCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAAGAAATACTTAA CGGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCAC TCCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACC CCAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTG AGGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTG GCCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTG TAGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGC GTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCG AGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCA TAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTG ATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTT TTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACC TGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCT ACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTG ACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAG TGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCA AGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATT CAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGC CCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTA TTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAA ACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCA GCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGG GCCACAACAACCTGATTCCTTTAGCCAACACGGGGATTGTCAATCACACCCACTCCCGGATGGGCTCCATAATGAGCACGGGGATTGTCC AAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCCA TCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAAC CAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCTA TGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATATT TTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCAT GGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCC CCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCGC AGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGA GGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGCC CCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTT GGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAGC TAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGGG >58814_58814_1_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000357480_CARM1_chr19_11022860_ENST00000327064_length(amino acids)=716AA_BP=293 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLIDILWR QDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPALQNNLLSPL LTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTDRIVVIPGKVEEVSLPEQVD IIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDLSALRGAAVDEYFRQPVVDT FDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLTHWYQVRCLFQSPLFAKAGD TLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTYNLSSGMAVAGMPTAYDLSS -------------------------------------------------------------- >58814_58814_2_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000357480_CARM1_chr19_11022860_ENST00000344150_length(transcript)=3651nt_BP=1487nt CCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGACGCCGAGCTAA GCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCAAAGAAAA TAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAACTAATGT GAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAACAGTTGTACTTT CAGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTCCTCTGGGGCCG TCAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGCGGCAGAGCAGT GGCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAAGAAATACTTAA CGGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCAC TCCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACC CCAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTG AGGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTG GCCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTG TAGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGC GTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCG AGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCA TAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTG ATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTT TTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACC TGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCT ACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTG ACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAG TGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCA AGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATT CAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGC CCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTA TTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAA ACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCA GCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGG GCCACAACAACCTGATTCCTTTAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGT TCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGC GGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACC CGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTG AGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTC ATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTA GCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGA AAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGC GGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCG GGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTA GAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAA GGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATT >58814_58814_2_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000357480_CARM1_chr19_11022860_ENST00000344150_length(amino acids)=693AA_BP=293 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLIDILWR QDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPALQNNLLSPL LTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTDRIVVIPGKVEEVSLPEQVD IIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDLSALRGAAVDEYFRQPVVDT FDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLTHWYQVRCLFQSPLFAKAGD TLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTYNLSSGMAVAGMPTAYDLSS -------------------------------------------------------------- >58814_58814_3_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000361665_CARM1_chr19_11022860_ENST00000327064_length(transcript)=3827nt_BP=1543nt AGGGAAGTAGCACTTGTTCGCTGGCCGCCCCTGGAGGCTAGAAGCTCCGGCGCCGAGAGTGGGCATGGCGACTTGGTCTCAGCCGGACTC GGGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCAAAGAAAAT AAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAACTAATGTG AGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAACAGTTGTACTTTC AGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTCCTCTGGGGCCGT CAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGCGGCAGAGCAGTG GCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAAGAAATACTTAAC GGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCACT CCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACCC CAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTGA GGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTGG CCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTGT AGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGA GCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGT GGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGGTGCCTAGTGGGGAGGACCAGACGGCCCTGTCCCTGGAAGAGTGCCTTAGGCTGCT GGAAGCCACCTGCCCCTTTGGGGAGAATGCTGAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCC TGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCAT CATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGC GGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGT GGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTA CCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTGACGTCCACCTTGCACCCTTCACGGATGAACAGCT CTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGA TGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGC CAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGA CGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTT CCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTATTGCCAACAAAAGACAGAGCTACGACATCAGTAT TGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAAACCCCTTCTTTAGATACACGGGCACAACGCCCTC ACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGC AGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGGGCCACAACAACCTGATTCCTTTAGCCAACACGGG GATTGTCAATCACACCCACTCCCGGATGGGCTCCATAATGAGCACGGGGATTGTCCAAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGG CAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCCATGTCCATCCCGACCAA CACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGC GGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTTTTTTACACGATGTTGCC GCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTTGTGGGAGCCCTCGTCCC CCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAG CACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCCTCGGTCACAACGGACGT GACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAG CCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCA CCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCC TGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGG GGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTT GTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGGGAAGGGACCTTGCAGGGACCTCTCCCTCCAAAAAA >58814_58814_3_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000361665_CARM1_chr19_11022860_ENST00000327064_length(amino acids)=735AA_BP=312 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLGAGREV FDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQVPSGEDQTALSLEECLRLLEATCPFGENAEFPADISSITE AVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTD RIVVIPGKVEEVSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDL SALRGAAVDEYFRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLT HWYQVRCLFQSPLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTY NLSSGMAVAGMPTAYDLSSVIASGSSVGHNNLIPLANTGIVNHTHSRMGSIMSTGIVQGSSGAQGSGGGSTSAHYAVNSQFTMGGPAISM -------------------------------------------------------------- >58814_58814_4_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000361665_CARM1_chr19_11022860_ENST00000344150_length(transcript)=3707nt_BP=1543nt AGGGAAGTAGCACTTGTTCGCTGGCCGCCCCTGGAGGCTAGAAGCTCCGGCGCCGAGAGTGGGCATGGCGACTTGGTCTCAGCCGGACTC GGGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCAAAGAAAAT AAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAACTAATGTG AGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAACAGTTGTACTTTC AGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTCCTCTGGGGCCGT CAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGCGGCAGAGCAGTG GCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAAGAAATACTTAAC GGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCACT CCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACCC CAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTGA GGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTGG CCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTGT AGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGA GCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGT GGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGGTGCCTAGTGGGGAGGACCAGACGGCCCTGTCCCTGGAAGAGTGCCTTAGGCTGCT GGAAGCCACCTGCCCCTTTGGGGAGAATGCTGAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCC TGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCAT CATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGC GGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGT GGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTA CCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTGACGTCCACCTTGCACCCTTCACGGATGAACAGCT CTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGA TGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGC CAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGA CGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTT CCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTATTGCCAACAAAAGACAGAGCTACGACATCAGTAT TGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAAACCCCTTCTTTAGATACACGGGCACAACGCCCTC ACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGC AGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGGGCCACAACAACCTGATTCCTTTAGGGTCCTCCGG CGCCCAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTC GCCCATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAACCAAATGATGTCCC TGCCCGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGAC ACTTTTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATATTTTACACAAAATCA TGTTGTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGC CCTGCCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCA GGCCTCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGA AGCCAGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCC CCCTCCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCT GCTGTCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGA AGGCCACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCT GAGTAGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGGGAAGGGACCTTGCA >58814_58814_4_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000361665_CARM1_chr19_11022860_ENST00000344150_length(amino acids)=712AA_BP=312 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLGAGREV FDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQVPSGEDQTALSLEECLRLLEATCPFGENAEFPADISSITE AVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTD RIVVIPGKVEEVSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDL SALRGAAVDEYFRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLT HWYQVRCLFQSPLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTY -------------------------------------------------------------- >58814_58814_5_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000362042_CARM1_chr19_11022860_ENST00000327064_length(transcript)=3872nt_BP=1588nt AAGCGGAGGCTCCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGA CGCCGAGCTAAGCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCA GCCAAAGAAAATAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGG ACAACTAATGTGAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAAC AGTTGTACTTTCAGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTC CTCTGGGGCCGTCAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGC GGCAGAGCAGTGGCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAA GAAATACTTAACGGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACA GCTTCCCCCACTCCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTA TGGTATCCACCCCAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGT GCCAACCACTGAGGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGA GAGTTCCAGTGGCCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGA TTTGGGGGCTGTAGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCT GGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACAC CTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGGTGCCTAGTGG GGAGGACCAGACGGCCCTGTCCCTGGAAGAGTGCCTTAGGCTGCTGGAAGCCACCTGCCCCTTTGGGGAGAATGCTGAGTTTCCAGCAGA CATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGA GTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGAT CCTGTCGTTTTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAA GAGTAACAACCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGA GCCCATGGGCTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCC TACCATTGGTGACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATC TTTCCATGGAGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGAT CCTGATGGCCAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCA CATGCTGCATTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGC CCCGACAGAGCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGAC ATGTCTGCTTATTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCT GGATCTGAAAAACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTG GAACACGGGCAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGG CTCCAGCGTGGGCCACAACAACCTGATTCCTTTAGCCAACACGGGGATTGTCAATCACACCCACTCCCGGATGGGCTCCATAATGAGCAC GGGGATTGTCCAAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGG CGGCCCCGCCATCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAG CACCAGGAAACCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGC TCTCTTTGCTATGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTC GCTGCCATATTTTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGA ACAGGCGCCATGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAG GCGGGGCCTCCCCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAG TGTCAATCCGCAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGT GGCCCCGCCGAGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTC CGTCCTCGGCCCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGG CTGCAGGCCTTGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTT TTCCTTGTAGCTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTC CCCTGCCCGGGAAGGGACCTTGCAGGGACCTCTCCCTCCAAAAAAAGAAAAAAAGAAAAAGAAAGAAAAAATAAATGAGGAAACGTGTTG >58814_58814_5_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000362042_CARM1_chr19_11022860_ENST00000327064_length(amino acids)=746AA_BP=323 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLIDILWR QDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQVPSGEDQTALSLEECLRLLEATCPFGENA EFPADISSITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHA EVLVKSNNLTDRIVVIPGKVEEVSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANF WYQPSFHGVDLSALRGAAVDEYFRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTV WLSTAPTEPLTHWYQVRCLFQSPLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSP SENMWNTGSTYNLSSGMAVAGMPTAYDLSSVIASGSSVGHNNLIPLANTGIVNHTHSRMGSIMSTGIVQGSSGAQGSGGGSTSAHYAVNS -------------------------------------------------------------- >58814_58814_6_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000362042_CARM1_chr19_11022860_ENST00000344150_length(transcript)=3752nt_BP=1588nt AAGCGGAGGCTCCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGA CGCCGAGCTAAGCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCA GCCAAAGAAAATAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGG ACAACTAATGTGAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAAC AGTTGTACTTTCAGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTC CTCTGGGGCCGTCAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGC GGCAGAGCAGTGGCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAA GAAATACTTAACGGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACA GCTTCCCCCACTCCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTA TGGTATCCACCCCAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGT GCCAACCACTGAGGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGA GAGTTCCAGTGGCCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGA TTTGGGGGCTGTAGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCT GGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACAC CTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGGTGCCTAGTGG GGAGGACCAGACGGCCCTGTCCCTGGAAGAGTGCCTTAGGCTGCTGGAAGCCACCTGCCCCTTTGGGGAGAATGCTGAGTTTCCAGCAGA CATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGA GTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGAT CCTGTCGTTTTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAA GAGTAACAACCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGA GCCCATGGGCTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCC TACCATTGGTGACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATC TTTCCATGGAGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGAT CCTGATGGCCAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCA CATGCTGCATTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGC CCCGACAGAGCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGAC ATGTCTGCTTATTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCT GGATCTGAAAAACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTG GAACACGGGCAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGG CTCCAGCGTGGGCCACAACAACCTGATTCCTTTAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGT CAACAGCCAGTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGG GCCCGCCCCGCGGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAA GCTCGAACACCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACC TCCCGGCCCTGAGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGAC CTGGGCTTGTCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCA GTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTA TTTTTTTATGAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTC AGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCA CCCCACTGTCGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCA CTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGAT CTGTCACGGAAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACT >58814_58814_6_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000362042_CARM1_chr19_11022860_ENST00000344150_length(amino acids)=723AA_BP=323 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLIDILWR QDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQVPSGEDQTALSLEECLRLLEATCPFGENA EFPADISSITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHA EVLVKSNNLTDRIVVIPGKVEEVSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANF WYQPSFHGVDLSALRGAAVDEYFRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTV WLSTAPTEPLTHWYQVRCLFQSPLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSP SENMWNTGSTYNLSSGMAVAGMPTAYDLSSVIASGSSVGHNNLIPLGSSGAQGSGGGSTSAHYAVNSQFTMGGPAISMASPMSIPTNTMH -------------------------------------------------------------- >58814_58814_7_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000536222_CARM1_chr19_11022860_ENST00000327064_length(transcript)=3097nt_BP=813nt AGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGTGAGCTCAGGGTGGGGGCAGCTGGGCGCCTGAGTGGA ACTGGGGTTGTGAGGTGGGAGGGGGCTGCTCAAGGATGGAGGAAGGGGGCTGGCTGGGCCGCCCAGGCAGCAGCACGGGCGGGGCACCCT CCTCAGGCCCCTCGGAGCTAGCAAGGGGCCACCCTTCCAGCCTGGTGTGCTCCCTGAAAGCCAAGAGCTCCTTGCAGCCCCCTGTCCGGC TTCCCGGCACCGGCTGCCCTGGGGCTCATCTCGCAGACCATGACCCGCCTGGACCGCAGCTCTCACAGTGGTGGGGGCCATGCCAAAGGC AGCCGGCCCCTTAACTCTTTGCTGGCTGGTCACCGGGTGGCCCAGCCCGCCTCTGCTCCTGGGTCCAGGGCTTCTGTTCAGGACATAGAT CTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTG GAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAG ACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAA AACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATG CAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTGGAGGCC AGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAGGAGGTG TCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTCCACGCC AAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTGACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTACATGGAG CAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAGTATTTC CGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAAGAAGGA GATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTTGCTTTC ATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAGTCACCA CTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTATTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTGGCCCAG GTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAAACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCCCCACCC GGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGGATGCCG ACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGGGCCACAACAACCTGATTCCTTTAGCCAACACGGGGATTGTCAAT CACACCCACTCCCGGATGGGCTCCATAATGAGCACGGGGATTGTCCAAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGCACGAGT GCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACCATGCAC TACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCTTTCCCC CTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCGTCCCCA CCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCTCCTGCC CGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACCTGTCCC CCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACATGCTGC TTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAGCAGCCC CTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTCACACTT GAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCAGGTCCC CCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCAGACACA GACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAGACGCTC CAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGGGAAGGGACCTTGCAGGGACCTCTCCCTCCAAAAAAAGAAAAAAAG >58814_58814_7_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000536222_CARM1_chr19_11022860_ENST00000327064_length(amino acids)=606AA_BP=183 MSGFPAPAALGLISQTMTRLDRSSHSGGGHAKGSRPLNSLLAGHRVAQPASAPGSRASVQDIDLIDILWRQDIDLGAGREVFDYSHRQKE QDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSI MEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTDRIVVIPGKVEEVSLPEQVDIIISEPMGYMLFNERMLESY LHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDLSALRGAAVDEYFRQPVVDTFDIRILMAKSVKYTVNFLEA KEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLTHWYQVRCLFQSPLFAKAGDTLSGTCLLIANKRQSYDISI VAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTYNLSSGMAVAGMPTAYDLSSVIASGSSVGHNNLIPLANTG -------------------------------------------------------------- >58814_58814_8_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000536222_CARM1_chr19_11022860_ENST00000344150_length(transcript)=2977nt_BP=813nt AGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGTGAGCTCAGGGTGGGGGCAGCTGGGCGCCTGAGTGGA ACTGGGGTTGTGAGGTGGGAGGGGGCTGCTCAAGGATGGAGGAAGGGGGCTGGCTGGGCCGCCCAGGCAGCAGCACGGGCGGGGCACCCT CCTCAGGCCCCTCGGAGCTAGCAAGGGGCCACCCTTCCAGCCTGGTGTGCTCCCTGAAAGCCAAGAGCTCCTTGCAGCCCCCTGTCCGGC TTCCCGGCACCGGCTGCCCTGGGGCTCATCTCGCAGACCATGACCCGCCTGGACCGCAGCTCTCACAGTGGTGGGGGCCATGCCAAAGGC AGCCGGCCCCTTAACTCTTTGCTGGCTGGTCACCGGGTGGCCCAGCCCGCCTCTGCTCCTGGGTCCAGGGCTTCTGTTCAGGACATAGAT CTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTG GAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAG ACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAA AACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATG CAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTGGAGGCC AGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAGGAGGTG TCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTCCACGCC AAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTGACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTACATGGAG CAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAGTATTTC CGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAAGAAGGA GATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTTGCTTTC ATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAGTCACCA CTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTATTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTGGCCCAG GTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAAACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCCCCACCC GGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGGATGCCG ACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGGGCCACAACAACCTGATTCCTTTAGGGTCCTCCGGCGCCCAGGGC AGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCCATGTCC ATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCCCGCCGC CCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTTTTTTAC ACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTTGTGGGA GCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTGCCTGCC AGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCCTCGGTC ACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCCAGGCCG GCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCTCCCCAC CAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTGTCCTGT CCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGCCACTGC CGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGTAGCTCC CCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGGGAAGGGACCTTGCAGGGACCTCTC >58814_58814_8_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000536222_CARM1_chr19_11022860_ENST00000344150_length(amino acids)=583AA_BP=183 MSGFPAPAALGLISQTMTRLDRSSHSGGGHAKGSRPLNSLLAGHRVAQPASAPGSRASVQDIDLIDILWRQDIDLGAGREVFDYSHRQKE QDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSI MEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTDRIVVIPGKVEEVSLPEQVDIIISEPMGYMLFNERMLESY LHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDLSALRGAAVDEYFRQPVVDTFDIRILMAKSVKYTVNFLEA KEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLTHWYQVRCLFQSPLFAKAGDTLSGTCLLIANKRQSYDISI VAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTYNLSSGMAVAGMPTAYDLSSVIASGSSVGHNNLIPLGSSG -------------------------------------------------------------- >58814_58814_9_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000582155_CARM1_chr19_11022860_ENST00000327064_length(transcript)=2743nt_BP=459nt AGGATAGGCCCAGGAGGGAGCTTGCTTTCCTCTGCAGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGAC ATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAG GATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGAT GGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCT CTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATG GAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTG GAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAG GAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTC CACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTGACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTAC ATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAG TATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAA GAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTT GCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAG TCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTATTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTG GCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAAACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCC CCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGG ATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGGGCCACAACAACCTGATTCCTTTAGCCAACACGGGGATT GTCAATCACACCCACTCCCGGATGGGCTCCATAATGAGCACGGGGATTGTCCAAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGC ACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACC ATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCT TTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCG TCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCT CCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACC TGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACA TGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAG CAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTC ACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCA GGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCA GACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAG ACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGGGAAGGGACCTTGCAGGGACCTCTCCCTCCAAAAAAAGAA >58814_58814_9_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000582155_CARM1_chr19_11022860_ENST00000327064_length(amino acids)=558AA_BP=135 MGWESHLTAASADIDLIDILWRQDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISS ITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNN LTDRIVVIPGKVEEVSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHG VDLSALRGAAVDEYFRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTE PLTHWYQVRCLFQSPLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTG STYNLSSGMAVAGMPTAYDLSSVIASGSSVGHNNLIPLANTGIVNHTHSRMGSIMSTGIVQGSSGAQGSGGGSTSAHYAVNSQFTMGGPA -------------------------------------------------------------- >58814_58814_10_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000582155_CARM1_chr19_11022860_ENST00000344150_length(transcript)=2623nt_BP=459nt AGGATAGGCCCAGGAGGGAGCTTGCTTTCCTCTGCAGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGAC ATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAG GATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGAT GGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCT CTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATG GAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTG GAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAG GAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTC CACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTGACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTAC ATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAG TATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAA GAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTT GCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAG TCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTATTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTG GCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAAACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCC CCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGG ATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGGGCCACAACAACCTGATTCCTTTAGGGTCCTCCGGCGCC CAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCC ATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCC CGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTT TTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTT GTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTG CCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCC TCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCC AGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCT CCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTG TCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGC CACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGT AGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGGGAAGGGACCTTGCAGGGA >58814_58814_10_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000582155_CARM1_chr19_11022860_ENST00000344150_length(amino acids)=535AA_BP=135 MGWESHLTAASADIDLIDILWRQDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISS ITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNN LTDRIVVIPGKVEEVSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHG VDLSALRGAAVDEYFRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTE PLTHWYQVRCLFQSPLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTG -------------------------------------------------------------- >58814_58814_11_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000583378_CARM1_chr19_11022860_ENST00000327064_length(transcript)=2693nt_BP=409nt GAGCTTGCTTTCCTCTGCAGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGATATTGATCTGGGGGCTGG GCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGG CGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAG CATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATT TGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTT TTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAA CCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGG CTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGG TGACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGG AGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGC CAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCA TTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGA GCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCT TATTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAA AAACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGG CAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGT GGGCCACAACAACCTGATTCCTTTAGCCAACACGGGGATTGTCAATCACACCCACTCCCGGATGGGCTCCATAATGAGCACGGGGATTGT CCAAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGC CATCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAA ACCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGC TATGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATA TTTTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCC ATGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCT CCCCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCC GCAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCC GAGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGG CCCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCC TTGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTA GCTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCG >58814_58814_11_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000583378_CARM1_chr19_11022860_ENST00000327064_length(amino acids)=547AA_BP=124 MGWESHLTAASADIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEP PALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTDRIVVIPGK VEEVSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDLSALRGAAV DEYFRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLTHWYQVRCL FQSPLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTYNLSSGMAV AGMPTAYDLSSVIASGSSVGHNNLIPLANTGIVNHTHSRMGSIMSTGIVQGSSGAQGSGGGSTSAHYAVNSQFTMGGPAISMASPMSIPT -------------------------------------------------------------- >58814_58814_12_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000583378_CARM1_chr19_11022860_ENST00000344150_length(transcript)=2573nt_BP=409nt GAGCTTGCTTTCCTCTGCAGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGATATTGATCTGGGGGCTGG GCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGG CGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAG CATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATT TGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTT TTTTGCCGCCCAAGCTGGAGCACGGAAAATCTACGCGGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAA CCTGACGGACCGCATCGTGGTCATCCCGGGCAAGGTGGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGG CTACATGCTCTTCAACGAGCGCATGCTGGAGAGCTACCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGG TGACGTCCACCTTGCACCCTTCACGGATGAACAGCTCTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGG AGTGGACCTGTCGGCCCTCCGAGGTGCCGCGGTGGATGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGC CAAGTCTGTCAAGTACACGGTGAACTTCTTAGAAGCCAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCA TTCAGGGCTGGTCCACGGCCTGGCTTTCTGGTTTGACGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGA GCCCCTGACCCACTGGTACCAGGTGCGGTGCCTGTTCCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCT TATTGCCAACAAAAGACAGAGCTACGACATCAGTATTGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAA AAACCCCTTCTTTAGATACACGGGCACAACGCCCTCACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGG CAGCACCTACAACCTCAGCAGCGGGATGGCCGTGGCAGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGT GGGCCACAACAACCTGATTCCTTTAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCA GTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCC GCGGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACA CCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCC TGAGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTG TCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGG TAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTAT GAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCC GCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGT CGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGT TAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGG AAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCA >58814_58814_12_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000583378_CARM1_chr19_11022860_ENST00000344150_length(amino acids)=524AA_BP=124 MGWESHLTAASADIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEP PALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTDRIVVIPGK VEEVSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDLSALRGAAV DEYFRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLTHWYQVRCL FQSPLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTYNLSSGMAV -------------------------------------------------------------- >58814_58814_13_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000585291_CARM1_chr19_11022860_ENST00000327064_length(transcript)=3481nt_BP=1197nt GGAGGCTCCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGACGCC GAGCTAAGCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCA AAGAAAATAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAA CTAATGTGAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAACAATGCTTTCTCTGAAGAAATACTTAACGGAAGGACTTCTCCAGTTC ACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCACTCCGGGAGATCATCCTGGGG CCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACCCCAAGAGCATAGACCTGGAC AATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTGAGGTAAATGCCTGGCTGGTT CACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTGGCCTCCAAGATGTGACAGGC CCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTGTAGCCCCCCCAGTCAGTGGA GACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGT CACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCA CGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGT GAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAA GATCTCATGTCCATCATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTTTTGCCGCCCAAGCTGGAGCA CGGAAAATCTACGCGGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACCTGACGGACCGCATCGTGGTC ATCCCGGGCAAGGTGGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCTACATGCTCTTCAACGAGCGC ATGCTGGAGAGCTACCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTGACGTCCACCTTGCACCCTTC ACGGATGAACAGCTCTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAGTGGACCTGTCGGCCCTCCGA GGTGCCGCGGTGGATGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCAAGTCTGTCAAGTACACGGTG AACTTCTTAGAAGCCAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATTCAGGGCTGGTCCACGGCCTG GCTTTCTGGTTTGACGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGCCCCTGACCCACTGGTACCAG GTGCGGTGCCTGTTCCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTATTGCCAACAAAAGACAGAGC TACGACATCAGTATTGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAAACCCCTTCTTTAGATACACG GGCACAACGCCCTCACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCAGCACCTACAACCTCAGCAGC GGGATGGCCGTGGCAGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGGGCCACAACAACCTGATTCCT TTAGCCAACACGGGGATTGTCAATCACACCCACTCCCGGATGGGCTCCATAATGAGCACGGGGATTGTCCAAGGGTCCTCCGGCGCCCAG GGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCCATCTCCATGGCGTCGCCCATG TCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAACCAAATGATGTCCCTGCCCGC CGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCTATGGGAACTGGGACACTTTTT TACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATATTTTACACAAAATCATGTTGTG GGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCATGGGGCCTGCCAGCCCTGCCT GCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTCCCCTTCGACGACCAGGCCTCG GTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCGCAGACCCTCTGTGAAGCCAGG CCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCGAGGCTTCAGGGGCCCCCTCCC CACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGCCCCTGCCTCTTGCTGCTGTCC TGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCTTGGGCCCGGAGGGAAGGCCAC TGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAGCTAACGTTAGGCCTGAGTAGC TCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGGGAAGGGACCTTGCAGGGACCT >58814_58814_13_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000585291_CARM1_chr19_11022860_ENST00000327064_length(amino acids)=724AA_BP=301 MYVDCGETMLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARR LLSQVRALDRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDI DLIDILWRQDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPAL QNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTDRIVVIPGKVEE VSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDLSALRGAAVDEY FRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLTHWYQVRCLFQS PLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTYNLSSGMAVAGM PTAYDLSSVIASGSSVGHNNLIPLANTGIVNHTHSRMGSIMSTGIVQGSSGAQGSGGGSTSAHYAVNSQFTMGGPAISMASPMSIPTNTM -------------------------------------------------------------- >58814_58814_14_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000585291_CARM1_chr19_11022860_ENST00000344150_length(transcript)=3361nt_BP=1197nt GGAGGCTCCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGACGCC GAGCTAAGCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCA AAGAAAATAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAA CTAATGTGAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAACAATGCTTTCTCTGAAGAAATACTTAACGGAAGGACTTCTCCAGTTC ACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCACTCCGGGAGATCATCCTGGGG CCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACCCCAAGAGCATAGACCTGGAC AATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTGAGGTAAATGCCTGGCTGGTT CACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTGGCCTCCAAGATGTGACAGGC CCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTGTAGCCCCCCCAGTCAGTGGA GACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGT CACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCA CGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGT GAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAA GATCTCATGTCCATCATGGAAATGCAGATCGTTCTTGATGTTGGCTGTGGCTCTGGGATCCTGTCGTTTTTTGCCGCCCAAGCTGGAGCA CGGAAAATCTACGCGGTGGAGGCCAGCACCATGGCCCAGCACGCTGAGGTCTTGGTGAAGAGTAACAACCTGACGGACCGCATCGTGGTC ATCCCGGGCAAGGTGGAGGAGGTGTCACTCCCCGAGCAGGTGGACATCATCATCTCGGAGCCCATGGGCTACATGCTCTTCAACGAGCGC ATGCTGGAGAGCTACCTCCACGCCAAGAAGTACCTGAAGCCCAGCGGAAACATGTTTCCTACCATTGGTGACGTCCACCTTGCACCCTTC ACGGATGAACAGCTCTACATGGAGCAGTTCACCAAGGCCAACTTCTGGTACCAGCCATCTTTCCATGGAGTGGACCTGTCGGCCCTCCGA GGTGCCGCGGTGGATGAGTATTTCCGGCAGCCTGTGGTGGACACATTTGACATCCGGATCCTGATGGCCAAGTCTGTCAAGTACACGGTG AACTTCTTAGAAGCCAAAGAAGGAGATTTGCACAGGATAGAAATCCCATTCAAATTCCACATGCTGCATTCAGGGCTGGTCCACGGCCTG GCTTTCTGGTTTGACGTTGCTTTCATCGGCTCCATAATGACCGTGTGGCTGTCCACAGCCCCGACAGAGCCCCTGACCCACTGGTACCAG GTGCGGTGCCTGTTCCAGTCACCACTGTTCGCCAAGGCAGGGGACACGCTCTCAGGGACATGTCTGCTTATTGCCAACAAAAGACAGAGC TACGACATCAGTATTGTGGCCCAGGTGGACCAGACCGGCTCCAAGTCCAGTAACCTCCTGGATCTGAAAAACCCCTTCTTTAGATACACG GGCACAACGCCCTCACCCCCACCCGGCTCCCACTACACATCTCCCTCGGAAAACATGTGGAACACGGGCAGCACCTACAACCTCAGCAGC GGGATGGCCGTGGCAGGGATGCCGACCGCCTATGACTTGAGCAGTGTTATTGCCAGTGGCTCCAGCGTGGGCCACAACAACCTGATTCCT TTAGGGTCCTCCGGCGCCCAGGGCAGTGGTGGTGGCAGCACGAGTGCCCACTATGCAGTCAACAGCCAGTTCACCATGGGCGGCCCCGCC ATCTCCATGGCGTCGCCCATGTCCATCCCGACCAACACCATGCACTACGGGAGCTAGGGGCCCGCCCCGCGGACTGACAGCACCAGGAAA CCAAATGATGTCCCTGCCCGCCGCCCCCGCCGGGCGGCTTTCCCCCTTGTACTGGAGAAGCTCGAACACCCGGTCACAGCTCTCTTTGCT ATGGGAACTGGGACACTTTTTTACACGATGTTGCCGCCGTCCCCACCCTAACCCCCACCTCCCGGCCCTGAGCGTGTGTCGCTGCCATAT TTTACACAAAATCATGTTGTGGGAGCCCTCGTCCCCCCTCCTGCCCGCTCTACCCTGACCTGGGCTTGTCATCTGCTGGAACAGGCGCCA TGGGGCCTGCCAGCCCTGCCTGCCAGGTCCCTTAGCACCTGTCCCCCTGCCTGTCTCCAGTGGGAAGGTAGCCTGGCCAGGCGGGGCCTC CCCTTCGACGACCAGGCCTCGGTCACAACGGACGTGACATGCTGCTTTTTTTAATTTTATTTTTTTATGAAAAGAACCAGTGTCAATCCG CAGACCCTCTGTGAAGCCAGGCCGGCCGGGCCGAGCCAGCAGCCCCTCTCCCTAGACTCAGAGGCGCCGCGGGGAGGGGTGGCCCCGCCG AGGCTTCAGGGGCCCCCTCCCCACCAAAGGGTTCACCTCACACTTGAATGTACAACCCACCCCACTGTCGGGAAGGCCTCCGTCCTCGGC CCCTGCCTCTTGCTGCTGTCCTGTCCCCGAGCCCCTGCAGGTCCCCCCCCGCCCCCCCACTCAAGAGTTAGAGCAGGTGGCTGCAGGCCT TGGGCCCGGAGGGAAGGCCACTGCCGGCCACTTGGGGCAGACACAGACACCTCAAGGATCTGTCACGGAAGGCGTCCTTTTTCCTTGTAG CTAACGTTAGGCCTGAGTAGCTCCCCTCCATCCTTGTAGACGCTCCAGTCCCTACTACTGTGACGGCATTTCCATCCCTCCCCTGCCCGG >58814_58814_14_NFE2L1-CARM1_NFE2L1_chr17_46134864_ENST00000585291_CARM1_chr19_11022860_ENST00000344150_length(amino acids)=701AA_BP=301 MYVDCGETMLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARR LLSQVRALDRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDI DLIDILWRQDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPAL QNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQIVLDVGCGSGILSFFAAQAGARKIYAVEASTMAQHAEVLVKSNNLTDRIVVIPGKVEE VSLPEQVDIIISEPMGYMLFNERMLESYLHAKKYLKPSGNMFPTIGDVHLAPFTDEQLYMEQFTKANFWYQPSFHGVDLSALRGAAVDEY FRQPVVDTFDIRILMAKSVKYTVNFLEAKEGDLHRIEIPFKFHMLHSGLVHGLAFWFDVAFIGSIMTVWLSTAPTEPLTHWYQVRCLFQS PLFAKAGDTLSGTCLLIANKRQSYDISIVAQVDQTGSKSSNLLDLKNPFFRYTGTTPSPPPGSHYTSPSENMWNTGSTYNLSSGMAVAGM -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NFE2L1-CARM1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NFE2L1-CARM1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NFE2L1-CARM1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies