
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NFE2L1-ENG (FusionGDB2 ID:58820) |
Fusion Gene Summary for NFE2L1-ENG |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NFE2L1-ENG | Fusion gene ID: 58820 | Hgene | Tgene | Gene symbol | NFE2L1 | ENG | Gene ID | 4779 | 2022 |
| Gene name | nuclear factor, erythroid 2 like 1 | endoglin | |
| Synonyms | LCR-F1|NRF1|TCF11 | END|HHT1|ORW1 | |
| Cytomap | 17q21.32 | 9q34.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | endoplasmic reticulum membrane sensor NFE2L1NF-E2-related factor 1NFE2-related factor 1TCF-11locus control region-factor 1nuclear factor erythroid 2-related factor 1nuclear factor, erythroid derived 2, like 1protein NRF1, p120 formtranscription fa | endoglinCD105 antigen | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | Q14494 | Q8NFI3 | |
| Ensembl transtripts involved in fusion gene | ENST00000357480, ENST00000361665, ENST00000362042, ENST00000536222, ENST00000582155, ENST00000583378, ENST00000585291, ENST00000579481, | ENST00000480266, ENST00000344849, ENST00000373203, | |
| Fusion gene scores | * DoF score | 18 X 12 X 13=2808 | 6 X 7 X 4=168 |
| # samples | 20 | 6 | |
| ** MAII score | log2(20/2808*10)=-3.81147103052984 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/168*10)=-1.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NFE2L1 [Title/Abstract] AND ENG [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NFE2L1(46134864)-ENG(130582316), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | ENG | GO:0001934 | positive regulation of protein phosphorylation | 12015308 |
| Tgene | ENG | GO:0010862 | positive regulation of pathway-restricted SMAD protein phosphorylation | 12015308 |
| Tgene | ENG | GO:0017015 | regulation of transforming growth factor beta receptor signaling pathway | 15702480 |
| Tgene | ENG | GO:0030336 | negative regulation of cell migration | 19736306 |
| Tgene | ENG | GO:0030513 | positive regulation of BMP signaling pathway | 17068149 |
| Tgene | ENG | GO:0031953 | negative regulation of protein autophosphorylation | 12015308 |
| Fusion gene breakpoints across NFE2L1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
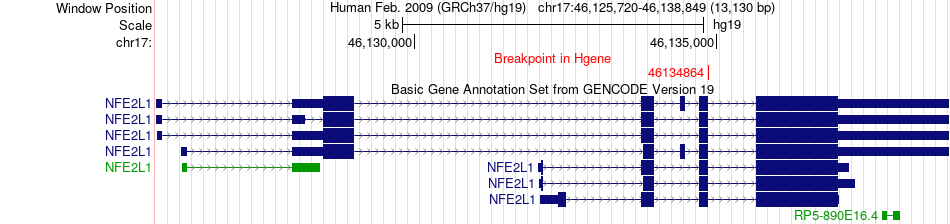 |
| Fusion gene breakpoints across ENG (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-AC-A2FF-01A | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
Top |
Fusion Gene ORF analysis for NFE2L1-ENG |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000357480 | ENST00000480266 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| 5CDS-5UTR | ENST00000361665 | ENST00000480266 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| 5CDS-5UTR | ENST00000362042 | ENST00000480266 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| 5CDS-5UTR | ENST00000536222 | ENST00000480266 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| 5CDS-5UTR | ENST00000582155 | ENST00000480266 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| 5CDS-5UTR | ENST00000583378 | ENST00000480266 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| 5CDS-5UTR | ENST00000585291 | ENST00000480266 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000357480 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000357480 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000361665 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000361665 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000362042 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000362042 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000536222 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000536222 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000582155 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000582155 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000583378 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000583378 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000585291 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| In-frame | ENST00000585291 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| intron-3CDS | ENST00000579481 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| intron-3CDS | ENST00000579481 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| intron-5UTR | ENST00000579481 | ENST00000480266 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000362042 | NFE2L1 | chr17 | 46134864 | + | ENST00000373203 | ENG | chr9 | 130582316 | - | 3101 | 1588 | 616 | 2430 | 604 |
| ENST00000362042 | NFE2L1 | chr17 | 46134864 | + | ENST00000344849 | ENG | chr9 | 130582316 | - | 3232 | 1588 | 616 | 2331 | 571 |
| ENST00000585291 | NFE2L1 | chr17 | 46134864 | + | ENST00000373203 | ENG | chr9 | 130582316 | - | 2710 | 1197 | 291 | 2039 | 582 |
| ENST00000585291 | NFE2L1 | chr17 | 46134864 | + | ENST00000344849 | ENG | chr9 | 130582316 | - | 2841 | 1197 | 291 | 1940 | 549 |
| ENST00000357480 | NFE2L1 | chr17 | 46134864 | + | ENST00000373203 | ENG | chr9 | 130582316 | - | 3000 | 1487 | 605 | 2329 | 574 |
| ENST00000357480 | NFE2L1 | chr17 | 46134864 | + | ENST00000344849 | ENG | chr9 | 130582316 | - | 3131 | 1487 | 605 | 2230 | 541 |
| ENST00000361665 | NFE2L1 | chr17 | 46134864 | + | ENST00000373203 | ENG | chr9 | 130582316 | - | 3056 | 1543 | 604 | 2385 | 593 |
| ENST00000361665 | NFE2L1 | chr17 | 46134864 | + | ENST00000344849 | ENG | chr9 | 130582316 | - | 3187 | 1543 | 604 | 2286 | 560 |
| ENST00000582155 | NFE2L1 | chr17 | 46134864 | + | ENST00000373203 | ENG | chr9 | 130582316 | - | 1972 | 459 | 51 | 1301 | 416 |
| ENST00000582155 | NFE2L1 | chr17 | 46134864 | + | ENST00000344849 | ENG | chr9 | 130582316 | - | 2103 | 459 | 51 | 1202 | 383 |
| ENST00000583378 | NFE2L1 | chr17 | 46134864 | + | ENST00000373203 | ENG | chr9 | 130582316 | - | 1922 | 409 | 34 | 1251 | 405 |
| ENST00000583378 | NFE2L1 | chr17 | 46134864 | + | ENST00000344849 | ENG | chr9 | 130582316 | - | 2053 | 409 | 34 | 1152 | 372 |
| ENST00000536222 | NFE2L1 | chr17 | 46134864 | + | ENST00000373203 | ENG | chr9 | 130582316 | - | 2326 | 813 | 261 | 1655 | 464 |
| ENST00000536222 | NFE2L1 | chr17 | 46134864 | + | ENST00000344849 | ENG | chr9 | 130582316 | - | 2457 | 813 | 261 | 1556 | 431 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000362042 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.005312759 | 0.9946872 |
| ENST00000362042 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.004929914 | 0.9950701 |
| ENST00000585291 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.010068733 | 0.9899312 |
| ENST00000585291 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.008413845 | 0.9915862 |
| ENST00000357480 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.005256672 | 0.99474335 |
| ENST00000357480 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.004856703 | 0.9951433 |
| ENST00000361665 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.004899406 | 0.99510056 |
| ENST00000361665 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.004281692 | 0.9957183 |
| ENST00000582155 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.042853 | 0.95714706 |
| ENST00000582155 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.030930776 | 0.9690692 |
| ENST00000583378 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.068965346 | 0.9310346 |
| ENST00000583378 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.048389055 | 0.9516109 |
| ENST00000536222 | ENST00000373203 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.10707814 | 0.89292186 |
| ENST00000536222 | ENST00000344849 | NFE2L1 | chr17 | 46134864 | + | ENG | chr9 | 130582316 | - | 0.08552697 | 0.914473 |
Top |
Fusion Genomic Features for NFE2L1-ENG |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
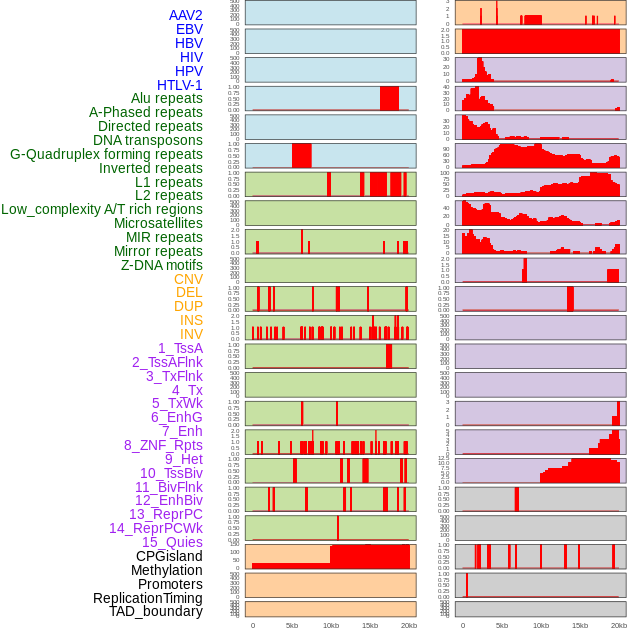 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NFE2L1-ENG |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:46134864/chr9:130582316) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NFE2L1 | ENG |
| FUNCTION: [Endoplasmic reticulum membrane sensor NFE2L1]: Endoplasmic reticulum membrane sensor that translocates into the nucleus in response to various stresses to act as a transcription factor (PubMed:20932482, PubMed:24448410). Constitutes a precursor of the transcription factor NRF1 (By similarity). Able to detect various cellular stresses, such as cholesterol excess, oxidative stress or proteasome inhibition (PubMed:20932482). In response to stress, it is released from the endoplasmic reticulum membrane following cleavage by the protease DDI2 and translocates into the nucleus to form the transcription factor NRF1 (By similarity). Acts as a key sensor of cholesterol excess: in excess cholesterol conditions, the endoplasmic reticulum membrane form of the protein directly binds cholesterol via its CRAC motif, preventing cleavage and release of the transcription factor NRF1, thereby allowing expression of genes promoting cholesterol removal, such as CD36 (By similarity). Involved in proteasome homeostasis: in response to proteasome inhibition, it is released from the endoplasmic reticulum membrane, translocates to the nucleus and activates expression of genes encoding proteasome subunits (PubMed:20932482). {ECO:0000250|UniProtKB:Q61985, ECO:0000269|PubMed:20932482, ECO:0000269|PubMed:24448410}.; FUNCTION: [Transcription factor NRF1]: CNC-type bZIP family transcription factor that translocates to the nucleus and regulates expression of target genes in response to various stresses (PubMed:8932385, PubMed:9421508). Heterodimerizes with small-Maf proteins (MAFF, MAFG or MAFK) and binds DNA motifs including the antioxidant response elements (AREs), which regulate expression of genes involved in oxidative stress response (PubMed:8932385, PubMed:9421508). Activates or represses expression of target genes, depending on the context (PubMed:8932385, PubMed:9421508). Plays a key role in cholesterol homeostasis by acting as a sensor of cholesterol excess: in low cholesterol conditions, translocates into the nucleus and represses expression of genes involved in defense against cholesterol excess, such as CD36 (By similarity). In excess cholesterol conditions, the endoplasmic reticulum membrane form of the protein directly binds cholesterol via its CRAC motif, preventing cleavage and release of the transcription factor NRF1, thereby allowing expression of genes promoting cholesterol removal (By similarity). Critical for redox balance in response to oxidative stress: acts by binding the AREs motifs on promoters and mediating activation of oxidative stress response genes, such as GCLC, GCLM, GSS, MT1 and MT2 (By similarity). Plays an essential role during fetal liver hematopoiesis: probably has a protective function against oxidative stress and is involved in lipid homeostasis in the liver (By similarity). Involved in proteasome homeostasis: in response to proteasome inhibition, mediates the 'bounce-back' of proteasome subunits by translocating into the nucleus and activating expression of genes encoding proteasome subunits (PubMed:20932482). Also involved in regulating glucose flux (By similarity). Together with CEBPB; represses expression of DSPP during odontoblast differentiation (PubMed:15308669). In response to ascorbic acid induction, activates expression of SP7/Osterix in osteoblasts. {ECO:0000250|UniProtKB:Q61985, ECO:0000269|PubMed:15308669, ECO:0000269|PubMed:20932482, ECO:0000269|PubMed:8932385, ECO:0000269|PubMed:9421508}. | FUNCTION: Endoglycosidase that releases N-glycans from glycoproteins by cleaving the beta-1,4-glycosidic bond in the N,N'-diacetylchitobiose core. Involved in the processing of free oligosaccharides in the cytosol. {ECO:0000269|PubMed:12114544}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 125_288 | 294 | 743.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 125_288 | 324 | 773.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 125_288 | 294 | 743.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 191_199 | 294 | 743.0 | Region | Cholesterol recognition/amino acid consensus (CRAC) region |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 191_199 | 324 | 773.0 | Region | Cholesterol recognition/amino acid consensus (CRAC) region |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 191_199 | 294 | 743.0 | Region | Cholesterol recognition/amino acid consensus (CRAC) region |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 7_24 | 294 | 743.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 7_24 | 324 | 773.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 7_24 | 294 | 743.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 399_401 | 378 | 626.0 | Motif | Cell attachment site | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 399_401 | 378 | 659.0 | Motif | Cell attachment site | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 612_658 | 378 | 626.0 | Topological domain | Cytoplasmic | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 612_658 | 378 | 659.0 | Topological domain | Cytoplasmic | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 587_611 | 378 | 626.0 | Transmembrane | Helical | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 587_611 | 378 | 659.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 496_517 | 294 | 743.0 | Compositional bias | Note=Poly-Ser |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 496_517 | 324 | 773.0 | Compositional bias | Note=Poly-Ser |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 496_517 | 294 | 743.0 | Compositional bias | Note=Poly-Ser |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 654_717 | 294 | 743.0 | Domain | bZIP |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 654_717 | 324 | 773.0 | Domain | bZIP |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 654_717 | 294 | 743.0 | Domain | bZIP |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 476_480 | 294 | 743.0 | Motif | Destruction motif |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 476_480 | 324 | 773.0 | Motif | Destruction motif |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 476_480 | 294 | 743.0 | Motif | Destruction motif |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 379_383 | 294 | 743.0 | Region | CPD |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 656_675 | 294 | 743.0 | Region | Basic motif |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000357480 | + | 4 | 5 | 682_696 | 294 | 743.0 | Region | Leucine-zipper |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 379_383 | 324 | 773.0 | Region | CPD |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 656_675 | 324 | 773.0 | Region | Basic motif |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000362042 | + | 5 | 6 | 682_696 | 324 | 773.0 | Region | Leucine-zipper |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 379_383 | 294 | 743.0 | Region | CPD |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 656_675 | 294 | 743.0 | Region | Basic motif |
| Hgene | NFE2L1 | chr17:46134864 | chr9:130582316 | ENST00000585291 | + | 5 | 6 | 682_696 | 294 | 743.0 | Region | Leucine-zipper |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 336_576 | 378 | 626.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 336_576 | 378 | 659.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 363_533 | 378 | 626.0 | Domain | ZP | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 363_533 | 378 | 659.0 | Domain | ZP | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 200_330 | 378 | 626.0 | Region | OR1%2C C-terminal part | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 26_46 | 378 | 626.0 | Region | OR1%2C N-terminal part | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 47_199 | 378 | 626.0 | Region | OR2 | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 200_330 | 378 | 659.0 | Region | OR1%2C C-terminal part | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 26_46 | 378 | 659.0 | Region | OR1%2C N-terminal part | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 47_199 | 378 | 659.0 | Region | OR2 | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000344849 | 7 | 14 | 26_586 | 378 | 626.0 | Topological domain | Extracellular | |
| Tgene | ENG | chr17:46134864 | chr9:130582316 | ENST00000373203 | 7 | 15 | 26_586 | 378 | 659.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for NFE2L1-ENG |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58820_58820_1_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000357480_ENG_chr9_130582316_ENST00000344849_length(transcript)=3131nt_BP=1487nt CCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGACGCCGAGCTAA GCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCAAAGAAAA TAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAACTAATGT GAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAACAGTTGTACTTT CAGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTCCTCTGGGGCCG TCAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGCGGCAGAGCAGT GGCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAAGAAATACTTAA CGGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCAC TCCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACC CCAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTG AGGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTG GCCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTG TAGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGC GTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCG AGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCA TAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTG ATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCA GCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCA ATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGG GCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCG TCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCA AGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCA AAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGA ACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCG GGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCGCACACGCGTGAGTACCCCAGGCCCCCACAGTGAGCATGCCGGGCCCCTCCAT CCACCCGGGGGAGCCCAGTGAAGCCTCTGAGGGATTGAGGGGCCCTGGCCAGGACCCTGACCTCCGCCCCTGCCCCCGCTCCCGCTCCCA GGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACC CAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGA GCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTC AGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATG GCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCT GGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCA GAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTG GGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGG >58820_58820_1_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000357480_ENG_chr9_130582316_ENST00000344849_length(amino acids)=541AA_BP=293 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLIDILWR QDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPALQNNLLSPL LTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEAVVNILSSSSPQRKKVHCLN MDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGNCVSLLSPSPEGDPRFSFLL HFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTREYPRPP -------------------------------------------------------------- >58820_58820_2_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000357480_ENG_chr9_130582316_ENST00000373203_length(transcript)=3000nt_BP=1487nt CCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGACGCCGAGCTAA GCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCAAAGAAAA TAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAACTAATGT GAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAACAGTTGTACTTT CAGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTCCTCTGGGGCCG TCAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGCGGCAGAGCAGT GGCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAAGAAATACTTAA CGGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCAC TCCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACC CCAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTG AGGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTG GCCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTG TAGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGC GTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCG AGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCA TAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTG ATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCA GCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCA ATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGG GCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCG TCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCA AGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCA AAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGA ACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCG GGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCGCACACGCGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCCGG CCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCCCC CCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACCCA GAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGGGT CCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCCAA GTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCCAG GCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGCCT AACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGCTC CTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGGGGGAGTAGCCAAGCTGCTTGTCCTGGGCCTGCCCCTGTGTATTCAC >58820_58820_2_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000357480_ENG_chr9_130582316_ENST00000373203_length(amino acids)=574AA_BP=293 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLIDILWR QDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPALQNNLLSPL LTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEAVVNILSSSSPQRKKVHCLN MDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGNCVSLLSPSPEGDPRFSFLL HFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKRE -------------------------------------------------------------- >58820_58820_3_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000361665_ENG_chr9_130582316_ENST00000344849_length(transcript)=3187nt_BP=1543nt AGGGAAGTAGCACTTGTTCGCTGGCCGCCCCTGGAGGCTAGAAGCTCCGGCGCCGAGAGTGGGCATGGCGACTTGGTCTCAGCCGGACTC GGGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCAAAGAAAAT AAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAACTAATGTG AGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAACAGTTGTACTTTC AGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTCCTCTGGGGCCGT CAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGCGGCAGAGCAGTG GCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAAGAAATACTTAAC GGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCACT CCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACCC CAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTGA GGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTGG CCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTGT AGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGA GCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGT GGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGGTGCCTAGTGGGGAGGACCAGACGGCCCTGTCCCTGGAAGAGTGCCTTAGGCTGCT GGAAGCCACCTGCCCCTTTGGGGAGAATGCTGAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCC TGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCAT CATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGT CTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATC ACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTC CAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCA CCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCC CGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCG TCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGAACATCATCAGCCCTGACCTGTCTGGTTGCACAAG CAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTA CTCGCACACGCGTGAGTACCCCAGGCCCCCACAGTGAGCATGCCGGGCCCCTCCATCCACCCGGGGGAGCCCAGTGAAGCCTCTGAGGGA TTGAGGGGCCCTGGCCAGGACCCTGACCTCCGCCCCTGCCCCCGCTCCCGCTCCCAGGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGG TGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCAT AGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCT CCACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGA ACACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTT GTAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGC CAGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACAC CTGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTG GGAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGGGGGAGTAGCCAAGCTGCTTGTCCTGGGCCTGCCC >58820_58820_3_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000361665_ENG_chr9_130582316_ENST00000344849_length(amino acids)=560AA_BP=312 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLGAGREV FDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQVPSGEDQTALSLEECLRLLEATCPFGENAEFPADISSITE AVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEA VVNILSSSSPQRKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGN CVSLLSPSPEGDPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGAL -------------------------------------------------------------- >58820_58820_4_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000361665_ENG_chr9_130582316_ENST00000373203_length(transcript)=3056nt_BP=1543nt AGGGAAGTAGCACTTGTTCGCTGGCCGCCCCTGGAGGCTAGAAGCTCCGGCGCCGAGAGTGGGCATGGCGACTTGGTCTCAGCCGGACTC GGGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCAAAGAAAAT AAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAACTAATGTG AGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAACAGTTGTACTTTC AGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTCCTCTGGGGCCGT CAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGCGGCAGAGCAGTG GCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAAGAAATACTTAAC GGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCACT CCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACCC CAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTGA GGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTGG CCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTGT AGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGA GCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGT GGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGGTGCCTAGTGGGGAGGACCAGACGGCCCTGTCCCTGGAAGAGTGCCTTAGGCTGCT GGAAGCCACCTGCCCCTTTGGGGAGAATGCTGAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCC TGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCAT CATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGT CTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATC ACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTC CAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCA CCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCC CGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCG TCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGAACATCATCAGCCCTGACCTGTCTGGTTGCACAAG CAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTA CTCGCACACGCGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCAT CGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCG CCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCG CCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGT CTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGT GAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGG GCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGA GCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAG >58820_58820_4_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000361665_ENG_chr9_130582316_ENST00000373203_length(amino acids)=593AA_BP=312 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLGAGREV FDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQVPSGEDQTALSLEECLRLLEATCPFGENAEFPADISSITE AVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEA VVNILSSSSPQRKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGN CVSLLSPSPEGDPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGAL -------------------------------------------------------------- >58820_58820_5_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000362042_ENG_chr9_130582316_ENST00000344849_length(transcript)=3232nt_BP=1588nt AAGCGGAGGCTCCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGA CGCCGAGCTAAGCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCA GCCAAAGAAAATAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGG ACAACTAATGTGAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAAC AGTTGTACTTTCAGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTC CTCTGGGGCCGTCAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGC GGCAGAGCAGTGGCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAA GAAATACTTAACGGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACA GCTTCCCCCACTCCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTA TGGTATCCACCCCAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGT GCCAACCACTGAGGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGA GAGTTCCAGTGGCCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGA TTTGGGGGCTGTAGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCT GGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACAC CTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGGTGCCTAGTGG GGAGGACCAGACGGCCCTGTCCCTGGAAGAGTGCCTTAGGCTGCTGGAAGCCACCTGCCCCTTTGGGGAGAATGCTGAGTTTCCAGCAGA CATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGA GTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTT CTGGGACCCCAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAG TATGATCAGCAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTC TTTCCAGCTGGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGT GTCCCCATCCGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGG CCGGGCGGCCAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGT ACCCATACCCAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTT CATGCGCTTGAACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGC CTTCCTCATCGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCGCACACGCGTGAGTACCCCAGGCCCCCACAGTGAGCATGCCG GGCCCCTCCATCCACCCGGGGGAGCCCAGTGAAGCCTCTGAGGGATTGAGGGGCCCTGGCCAGGACCCTGACCTCCGCCCCTGCCCCCGC TCCCGCTCCCAGGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCA TCGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCC GCCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCC GCCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGG TCTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGG TGAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAG GGCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGG AGCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCA >58820_58820_5_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000362042_ENG_chr9_130582316_ENST00000344849_length(amino acids)=571AA_BP=323 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLIDILWR QDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQVPSGEDQTALSLEECLRLLEATCPFGENA EFPADISSITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGM QVSASMISNEAVVNILSSSSPQRKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTV ELIQGRAAKGNCVSLLSPSPEGDPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLG -------------------------------------------------------------- >58820_58820_6_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000362042_ENG_chr9_130582316_ENST00000373203_length(transcript)=3101nt_BP=1588nt AAGCGGAGGCTCCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGA CGCCGAGCTAAGCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCA GCCAAAGAAAATAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGG ACAACTAATGTGAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAAGTAAGTCACGTGGGCCCTTGAGGACCTGGACTGGGTTAGGAAC AGTTGTACTTTCAGAGGTGAGGTGTCGAGAAGGGAAAGTGAATGTGGTCTGGAGTGTGTCCTTGGCCTTGGCTCCACAGGGTGTGCTTTC CTCTGGGGCCGTCAGGGAGCTCATCCCTTGTGTTCTGCCAGGGTGGGGTACGGGGTTTGACACTGAGGAGGGTAACCTGCTGGCTGGAGC GGCAGAGCAGTGGCCTTGATTTGTCTTTTGGAAGATTTTAAAAACCAAAAAGCATAAACATTCTGGTCCTTCAGCAATGCTTTCTCTGAA GAAATACTTAACGGAAGGACTTCTCCAGTTCACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACA GCTTCCCCCACTCCGGGAGATCATCCTGGGGCCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTA TGGTATCCACCCCAAGAGCATAGACCTGGACAATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGT GCCAACCACTGAGGTAAATGCCTGGCTGGTTCACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGA GAGTTCCAGTGGCCTCCAAGATGTGACAGGCCCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGA TTTGGGGGCTGTAGCCCCCCCAGTCAGTGGAGACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCT GGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACAC CTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGGTGCCTAGTGG GGAGGACCAGACGGCCCTGTCCCTGGAAGAGTGCCTTAGGCTGCTGGAAGCCACCTGCCCCTTTGGGGAGAATGCTGAGTTTCCAGCAGA CATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGA GTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTT CTGGGACCCCAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAG TATGATCAGCAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTC TTTCCAGCTGGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGT GTCCCCATCCGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGG CCGGGCGGCCAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGT ACCCATACCCAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTT CATGCGCTTGAACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGC CTTCCTCATCGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCGCACACGCGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGT GGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATA GCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTC CACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAA CACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTG TAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCC AGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACC TGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGG GAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGGGGGAGTAGCCAAGCTGCTTGTCCTGGGCCTGCCCC >58820_58820_6_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000362042_ENG_chr9_130582316_ENST00000373203_length(amino acids)=604AA_BP=323 MLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARRLLSQVRAL DRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDIDLIDILWR QDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQVPSGEDQTALSLEECLRLLEATCPFGENA EFPADISSITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGM QVSASMISNEAVVNILSSSSPQRKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTV ELIQGRAAKGNCVSLLSPSPEGDPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLG -------------------------------------------------------------- >58820_58820_7_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000536222_ENG_chr9_130582316_ENST00000344849_length(transcript)=2457nt_BP=813nt AGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGTGAGCTCAGGGTGGGGGCAGCTGGGCGCCTGAGTGGA ACTGGGGTTGTGAGGTGGGAGGGGGCTGCTCAAGGATGGAGGAAGGGGGCTGGCTGGGCCGCCCAGGCAGCAGCACGGGCGGGGCACCCT CCTCAGGCCCCTCGGAGCTAGCAAGGGGCCACCCTTCCAGCCTGGTGTGCTCCCTGAAAGCCAAGAGCTCCTTGCAGCCCCCTGTCCGGC TTCCCGGCACCGGCTGCCCTGGGGCTCATCTCGCAGACCATGACCCGCCTGGACCGCAGCTCTCACAGTGGTGGGGGCCATGCCAAAGGC AGCCGGCCCCTTAACTCTTTGCTGGCTGGTCACCGGGTGGCCCAGCCCGCCTCTGCTCCTGGGTCCAGGGCTTCTGTTCAGGACATAGAT CTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTG GAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAG ACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAA AACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATG CAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTGCGCAGT GCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCACAGCGG AAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAACACCATC GAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTGGACTTG GGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAGGGTGAC CCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCCAAGACC GGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGAACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAAGGCCTC GTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCGCACACG CGTGAGTACCCCAGGCCCCCACAGTGAGCATGCCGGGCCCCTCCATCCACCCGGGGGAGCCCAGTGAAGCCTCTGAGGGATTGAGGGGCC CTGGCCAGGACCCTGACCTCCGCCCCTGCCCCCGCTCCCGCTCCCAGGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCC GGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCC CCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACC CAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGG GTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCC AAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCC AGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGC CTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGC TCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGGGGGAGTAGCCAAGCTGCTTGTCCTGGGCCTGCCCCTGTGTATTC >58820_58820_7_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000536222_ENG_chr9_130582316_ENST00000344849_length(amino acids)=431AA_BP=183 MSGFPAPAALGLISQTMTRLDRSSHSGGGHAKGSRPLNSLLAGHRVAQPASAPGSRASVQDIDLIDILWRQDIDLGAGREVFDYSHRQKE QDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSI MEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEAVVNILSSSSPQRKKVHCLNMDSLSFQLGLYLSPHFLQAS NTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGNCVSLLSPSPEGDPRFSFLLHFYTVPIPKTGTLSCTVALR -------------------------------------------------------------- >58820_58820_8_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000536222_ENG_chr9_130582316_ENST00000373203_length(transcript)=2326nt_BP=813nt AGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGTGAGCTCAGGGTGGGGGCAGCTGGGCGCCTGAGTGGA ACTGGGGTTGTGAGGTGGGAGGGGGCTGCTCAAGGATGGAGGAAGGGGGCTGGCTGGGCCGCCCAGGCAGCAGCACGGGCGGGGCACCCT CCTCAGGCCCCTCGGAGCTAGCAAGGGGCCACCCTTCCAGCCTGGTGTGCTCCCTGAAAGCCAAGAGCTCCTTGCAGCCCCCTGTCCGGC TTCCCGGCACCGGCTGCCCTGGGGCTCATCTCGCAGACCATGACCCGCCTGGACCGCAGCTCTCACAGTGGTGGGGGCCATGCCAAAGGC AGCCGGCCCCTTAACTCTTTGCTGGCTGGTCACCGGGTGGCCCAGCCCGCCTCTGCTCCTGGGTCCAGGGCTTCTGTTCAGGACATAGAT CTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTG GAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAG ACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAA AACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATG CAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTGCGCAGT GCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCACAGCGG AAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAACACCATC GAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTGGACTTG GGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAGGGTGAC CCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCCAAGACC GGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGAACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAAGGCCTC GTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCGCACACG CGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACC CAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGA GCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTC AGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATG GCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCT GGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCA GAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTG GGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGG >58820_58820_8_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000536222_ENG_chr9_130582316_ENST00000373203_length(amino acids)=464AA_BP=183 MSGFPAPAALGLISQTMTRLDRSSHSGGGHAKGSRPLNSLLAGHRVAQPASAPGSRASVQDIDLIDILWRQDIDLGAGREVFDYSHRQKE QDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSI MEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEAVVNILSSSSPQRKKVHCLNMDSLSFQLGLYLSPHFLQAS NTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGNCVSLLSPSPEGDPRFSFLLHFYTVPIPKTGTLSCTVALR PKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSHTRSPSKREPVVAVAAPASSESSSTNHSI -------------------------------------------------------------- >58820_58820_9_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000582155_ENG_chr9_130582316_ENST00000344849_length(transcript)=2103nt_BP=459nt AGGATAGGCCCAGGAGGGAGCTTGCTTTCCTCTGCAGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGAC ATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAG GATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGAT GGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCT CTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATG GAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTG CGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCA CAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAAC ACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTG GACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAG GGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCC AAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGAACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAA GGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCG CACACGCGTGAGTACCCCAGGCCCCCACAGTGAGCATGCCGGGCCCCTCCATCCACCCGGGGGAGCCCAGTGAAGCCTCTGAGGGATTGA GGGGCCCTGGCCAGGACCCTGACCTCCGCCCCTGCCCCCGCTCCCGCTCCCAGGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGC TGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCC CCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCAC TCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACAC CTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAA AAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGC CCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGA ACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAG CCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGGGGGAGTAGCCAAGCTGCTTGTCCTGGGCCTGCCCCTGT >58820_58820_9_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000582155_ENG_chr9_130582316_ENST00000344849_length(amino acids)=383AA_BP=135 MGWESHLTAASADIDLIDILWRQDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISS ITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMIS NEAVVNILSSSSPQRKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAA KGNCVSLLSPSPEGDPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLI -------------------------------------------------------------- >58820_58820_10_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000582155_ENG_chr9_130582316_ENST00000373203_length(transcript)=1972nt_BP=459nt AGGATAGGCCCAGGAGGGAGCTTGCTTTCCTCTGCAGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGAC ATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAG GATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGAT GGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCT CTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATG GAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTG CGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCA CAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAAC ACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTG GACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAG GGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCC AAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGAACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAA GGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCG CACACGCGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGG AGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAG CTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTC CCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGG GATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAAC TGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCC AGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCC AGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAG >58820_58820_10_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000582155_ENG_chr9_130582316_ENST00000373203_length(amino acids)=416AA_BP=135 MGWESHLTAASADIDLIDILWRQDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISS ITEAVPSESEPPALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMIS NEAVVNILSSSSPQRKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAA KGNCVSLLSPSPEGDPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLI -------------------------------------------------------------- >58820_58820_11_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000583378_ENG_chr9_130582316_ENST00000344849_length(transcript)=2053nt_BP=409nt GAGCTTGCTTTCCTCTGCAGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGATATTGATCTGGGGGCTGG GCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGG CGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAG CATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATT TGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCC CAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAG CAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCT GGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATC CGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGC CAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACC CAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTT GAACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCAT CGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCGCACACGCGTGAGTACCCCAGGCCCCCACAGTGAGCATGCCGGGCCCCTCC ATCCACCCGGGGGAGCCCAGTGAAGCCTCTGAGGGATTGAGGGGCCCTGGCCAGGACCCTGACCTCCGCCCCTGCCCCCGCTCCCGCTCC CAGGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCA CCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGG GAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTC TCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATA TGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAG CTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCC CAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCC TGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGA >58820_58820_11_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000583378_ENG_chr9_130582316_ENST00000344849_length(amino acids)=372AA_BP=124 MGWESHLTAASADIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEP PALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEAVVNILSSS SPQRKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGNCVSLLSPS PEGDPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYI -------------------------------------------------------------- >58820_58820_12_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000583378_ENG_chr9_130582316_ENST00000373203_length(transcript)=1922nt_BP=409nt GAGCTTGCTTTCCTCTGCAGCTTGAGCACGGAGCATGGGGTGGGAGTCCCATCTCACTGCAGCCTCTGCGGATATTGATCTGGGGGCTGG GCGTGAGGTTTTTGACTATAGTCACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGG CGAGGGCGCGGAAGCTCTGGCACGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAG CATAACAGAAGCAGTGCCTAGTGAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATT TGATTTGGAACAGCAGTGGCAAGATCTCATGTCCATCATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCC CAGCTGTGAGGCAGAGGACAGGGGTGACAAGTTTGTCTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAG CAATGAGGCGGTGGTCAATATCCTGTCGAGCTCATCACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCT GGGCCTCTACCTCAGCCCACACTTCCTCCAGGCCTCCAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATC CGTCTCCGAGTTCCTGCTCCAGTTAGACAGCTGCCACCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGC CAAGGGCAACTGTGTGAGCCTGCTGTCCCCAAGCCCCGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACC CAAAACCGGCACCCTCAGCTGCACGGTAGCCCTGCGTCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTT GAACATCATCAGCCCTGACCTGTCTGGTTGCACAAGCAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCAT CGGGGCCCTGCTCACTGCTGCACTCTGGTACATCTACTCGCACACGCGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCC GGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCC CCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACC CAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGG GTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCC AAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCC AGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGC CTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGC TCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGGGGGAGTAGCCAAGCTGCTTGTCCTGGGCCTGCCCCTGTGTATTC >58820_58820_12_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000583378_ENG_chr9_130582316_ENST00000373203_length(amino acids)=405AA_BP=124 MGWESHLTAASADIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEP PALQNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEAVVNILSSS SPQRKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGNCVSLLSPS PEGDPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYI -------------------------------------------------------------- >58820_58820_13_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000585291_ENG_chr9_130582316_ENST00000344849_length(transcript)=2841nt_BP=1197nt GGAGGCTCCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGACGCC GAGCTAAGCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCA AAGAAAATAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAA CTAATGTGAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAACAATGCTTTCTCTGAAGAAATACTTAACGGAAGGACTTCTCCAGTTC ACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCACTCCGGGAGATCATCCTGGGG CCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACCCCAAGAGCATAGACCTGGAC AATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTGAGGTAAATGCCTGGCTGGTT CACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTGGCCTCCAAGATGTGACAGGC CCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTGTAGCCCCCCCAGTCAGTGGA GACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGT CACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCA CGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGT GAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAA GATCTCATGTCCATCATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCAGCTGTGAGGCAGAGGACAGG GGTGACAAGTTTGTCTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCAATGAGGCGGTGGTCAATATC CTGTCGAGCTCATCACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGGGCCTCTACCTCAGCCCACAC TTCCTCCAGGCCTCCAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCGTCTCCGAGTTCCTGCTCCAG TTAGACAGCTGCCACCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCAAGGGCAACTGTGTGAGCCTG CTGTCCCCAAGCCCCGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCAAAACCGGCACCCTCAGCTGC ACGGTAGCCCTGCGTCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGAACATCATCAGCCCTGACCTG TCTGGTTGCACAAGCAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCGGGGCCCTGCTCACTGCTGCA CTCTGGTACATCTACTCGCACACGCGTGAGTACCCCAGGCCCCCACAGTGAGCATGCCGGGCCCCTCCATCCACCCGGGGGAGCCCAGTG AAGCCTCTGAGGGATTGAGGGGCCCTGGCCAGGACCCTGACCTCCGCCCCTGCCCCCGCTCCCGCTCCCAGGTTCCCCCAGCAAGCGGGA GCCCGTGGTGGCGGTGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGCACCAACCACAGCATCGGGAGCACCCAGAGCACCCCCTGCTCCAC CAGCAGCATGGCATAGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAGAGACTGAGCAGCCGCCAGCTGGGAGCACTGGTGTGAACTCACCC TGGGAGCCAGTCCTCCACTCGACCCAGAATGGAGCCTGCTCTCCGCGCCTACCCTTCCCGCCTCCCTCTCAGAGGCCTGCTGCCAGTGCA GCCACTGGCTTGGAACACCTTGGGGTCCCTCCACCCCACAGAACCTTCAACCCAGTGGGTCTGGGATATGGCTGCCCAGGAGACAGACCA CTTGCCACGCTGTTGTAAAAACCCAAGTCCCTGTCATTTGAACCTGGATCCAGCACTGGTGAACTGAGCTGGGCAGGAAGGGAGAACTTG AAACAGATTCAGGCCAGCCCAGCCAGGCCAACAGCACCTCCCCGCTGGGAAGAGAAGAGGGCCCAGCCCAGAGCCACCTGGATCTATCCC TGCGGCCTCCACACCTGAACTTGCCTAACTAACTGGCAGGGGAGACAGGAGCCTAGCGGAGCCCAGCCTGGGAGCCCAGAGGGTGGCAAG AACAGTGGGCGTTGGGAGCCTAGCTCCTGCCACATGGAGCCCCCTCTGCCGGTCGGGCAGCCAGCAGAGGGGGAGTAGCCAAGCTGCTTG >58820_58820_13_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000585291_ENG_chr9_130582316_ENST00000344849_length(amino acids)=549AA_BP=301 MYVDCGETMLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARR LLSQVRALDRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDI DLIDILWRQDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPAL QNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEAVVNILSSSSPQ RKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGNCVSLLSPSPEG DPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSH -------------------------------------------------------------- >58820_58820_14_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000585291_ENG_chr9_130582316_ENST00000373203_length(transcript)=2710nt_BP=1197nt GGAGGCTCCGAGCTCTAGGCCGGCCGGCGGTGGCGGCGGCGAGGCCGGGACTCGGGCTTAGGGCCTGCTGTGGAGGCAGCGGCGGACGCC GAGCTAAGCAGTTTCTCTGGAAACCCCCCTGGTAAGTGTGGAGGAGGCGGGACACTCTGACCCAAGACGAAAGGCCTGTAGCTCCAGCCA AAGAAAATAAACCTTAGGAGGGAGAAGGAAAAAAAAAATCCATCAGCTGTTCCTGAGAACAGCCTGCATTGGAATCTACAGAGAGGACAA CTAATGTGAGTGAGGAAGTGACTGTATGTGGACTGTGGAGAAACAATGCTTTCTCTGAAGAAATACTTAACGGAAGGACTTCTCCAGTTC ACCATTCTGCTGAGTTTGATTGGGGTACGGGTGGACGTGGATACTTACCTGACCTCACAGCTTCCCCCACTCCGGGAGATCATCCTGGGG CCCAGTTCTGCCTATACTCAGACCCAGTTCCACAACCTGAGGAATACCTTGGATGGCTATGGTATCCACCCCAAGAGCATAGACCTGGAC AATTACTTCACTGCCCGGCGGCTCCTCAGTCAGGTGAGGGCCCTGGACAGGTTCCAGGTGCCAACCACTGAGGTAAATGCCTGGCTGGTT CACCGAGACCCAGAGGGGTCTGTCTCTGGCAGTCAGCCCAACTCAGGCCTCGCCCTCGAGAGTTCCAGTGGCCTCCAAGATGTGACAGGC CCAGACAACGGGGTGCGAGAAAGCGAAACGGAGCAGGGATTCGGTGAAGATTTGGAGGATTTGGGGGCTGTAGCCCCCCCAGTCAGTGGA GACTTAACCAAAGAGGACATAGATCTGATTGACATCCTTTGGCGACAGGATATTGATCTGGGGGCTGGGCGTGAGGTTTTTGACTATAGT CACCGCCAGAAGGAGCAGGATGTGGAGAAGGAGCTGCGAGATGGAGGCGAGCAGGACACCTGGGCAGGCGAGGGCGCGGAAGCTCTGGCA CGGAACCTGCTAGTGGATGGAGAGACTGGGGAGAGCTTCCCTGCACAGTTTCCAGCAGACATTTCCAGCATAACAGAAGCAGTGCCTAGT GAGAGTGAGCCCCCTGCTCTTCAAAACAACCTCTTGTCTCCTCTTCTGACCGGGACAGAGTCACCATTTGATTTGGAACAGCAGTGGCAA GATCTCATGTCCATCATGGAAATGCAGCATTTGAAGTGCACCATCACGGGCCTGACCTTCTGGGACCCCAGCTGTGAGGCAGAGGACAGG GGTGACAAGTTTGTCTTGCGCAGTGCTTACTCCAGCTGTGGCATGCAGGTGTCAGCAAGTATGATCAGCAATGAGGCGGTGGTCAATATC CTGTCGAGCTCATCACCACAGCGGAAAAAGGTGCACTGCCTCAACATGGACAGCCTCTCTTTCCAGCTGGGCCTCTACCTCAGCCCACAC TTCCTCCAGGCCTCCAACACCATCGAGCCGGGGCAGCAGAGCTTTGTGCAGGTCAGAGTGTCCCCATCCGTCTCCGAGTTCCTGCTCCAG TTAGACAGCTGCCACCTGGACTTGGGGCCTGAGGGAGGCACCGTGGAACTCATCCAGGGCCGGGCGGCCAAGGGCAACTGTGTGAGCCTG CTGTCCCCAAGCCCCGAGGGTGACCCGCGCTTCAGCTTCCTCCTCCACTTCTACACAGTACCCATACCCAAAACCGGCACCCTCAGCTGC ACGGTAGCCCTGCGTCCCAAGACCGGGTCTCAAGACCAGGAAGTCCATAGGACTGTCTTCATGCGCTTGAACATCATCAGCCCTGACCTG TCTGGTTGCACAAGCAAAGGCCTCGTCCTGCCCGCCGTGCTGGGCATCACCTTTGGTGCCTTCCTCATCGGGGCCCTGCTCACTGCTGCA CTCTGGTACATCTACTCGCACACGCGTTCCCCCAGCAAGCGGGAGCCCGTGGTGGCGGTGGCTGCCCCGGCCTCCTCGGAGAGCAGCAGC ACCAACCACAGCATCGGGAGCACCCAGAGCACCCCCTGCTCCACCAGCAGCATGGCATAGCCCCGGCCCCCCGCGCTCGCCCAGCAGGAG AGACTGAGCAGCCGCCAGCTGGGAGCACTGGTGTGAACTCACCCTGGGAGCCAGTCCTCCACTCGACCCAGAATGGAGCCTGCTCTCCGC GCCTACCCTTCCCGCCTCCCTCTCAGAGGCCTGCTGCCAGTGCAGCCACTGGCTTGGAACACCTTGGGGTCCCTCCACCCCACAGAACCT TCAACCCAGTGGGTCTGGGATATGGCTGCCCAGGAGACAGACCACTTGCCACGCTGTTGTAAAAACCCAAGTCCCTGTCATTTGAACCTG GATCCAGCACTGGTGAACTGAGCTGGGCAGGAAGGGAGAACTTGAAACAGATTCAGGCCAGCCCAGCCAGGCCAACAGCACCTCCCCGCT GGGAAGAGAAGAGGGCCCAGCCCAGAGCCACCTGGATCTATCCCTGCGGCCTCCACACCTGAACTTGCCTAACTAACTGGCAGGGGAGAC AGGAGCCTAGCGGAGCCCAGCCTGGGAGCCCAGAGGGTGGCAAGAACAGTGGGCGTTGGGAGCCTAGCTCCTGCCACATGGAGCCCCCTC TGCCGGTCGGGCAGCCAGCAGAGGGGGAGTAGCCAAGCTGCTTGTCCTGGGCCTGCCCCTGTGTATTCACCACCAATAAATCAGACCATG >58820_58820_14_NFE2L1-ENG_NFE2L1_chr17_46134864_ENST00000585291_ENG_chr9_130582316_ENST00000373203_length(amino acids)=582AA_BP=301 MYVDCGETMLSLKKYLTEGLLQFTILLSLIGVRVDVDTYLTSQLPPLREIILGPSSAYTQTQFHNLRNTLDGYGIHPKSIDLDNYFTARR LLSQVRALDRFQVPTTEVNAWLVHRDPEGSVSGSQPNSGLALESSSGLQDVTGPDNGVRESETEQGFGEDLEDLGAVAPPVSGDLTKEDI DLIDILWRQDIDLGAGREVFDYSHRQKEQDVEKELRDGGEQDTWAGEGAEALARNLLVDGETGESFPAQFPADISSITEAVPSESEPPAL QNNLLSPLLTGTESPFDLEQQWQDLMSIMEMQHLKCTITGLTFWDPSCEAEDRGDKFVLRSAYSSCGMQVSASMISNEAVVNILSSSSPQ RKKVHCLNMDSLSFQLGLYLSPHFLQASNTIEPGQQSFVQVRVSPSVSEFLLQLDSCHLDLGPEGGTVELIQGRAAKGNCVSLLSPSPEG DPRFSFLLHFYTVPIPKTGTLSCTVALRPKTGSQDQEVHRTVFMRLNIISPDLSGCTSKGLVLPAVLGITFGAFLIGALLTAALWYIYSH -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NFE2L1-ENG |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NFE2L1-ENG |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NFE2L1-ENG |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies