
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NFIA-RNLS (FusionGDB2 ID:58876) |
Fusion Gene Summary for NFIA-RNLS |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NFIA-RNLS | Fusion gene ID: 58876 | Hgene | Tgene | Gene symbol | NFIA | RNLS | Gene ID | 4774 | 55328 |
| Gene name | nuclear factor I A | renalase, FAD dependent amine oxidase | |
| Synonyms | BRMUTD|CTF|NF-I/A|NF1-A|NFI-A|NFI-L | C10orf59|RENALASE | |
| Cytomap | 1p31.3 | 10q23.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nuclear factor 1 A-typeCCAAT-box-binding transcription factorTGGCA-binding protein | renalaseMAO-Calpha-NAD(P)H oxidase/anomerasemonoamine oxidase-C | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | Q12857 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000371184, ENST00000371185, ENST00000371187, ENST00000371189, ENST00000371191, ENST00000403491, ENST00000407417, ENST00000485903, ENST00000357977, ENST00000479364, | ENST00000466945, ENST00000331772, ENST00000371947, ENST00000437752, | |
| Fusion gene scores | * DoF score | 21 X 22 X 8=3696 | 8 X 7 X 5=280 |
| # samples | 25 | 9 | |
| ** MAII score | log2(25/3696*10)=-3.88596475675397 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/280*10)=-1.63742992061529 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NFIA [Title/Abstract] AND RNLS [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NFIA(61554352)-RNLS(90122482), # samples:4 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NFIA | GO:0045944 | positive regulation of transcription by RNA polymerase II | 17010934 |
| Tgene | RNLS | GO:0010459 | negative regulation of heart rate | 15841207 |
| Tgene | RNLS | GO:0045776 | negative regulation of blood pressure | 15841207 |
| Fusion gene breakpoints across NFIA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RNLS (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | GBM | TCGA-19-0957-02A | NFIA | chr1 | 61554352 | - | RNLS | chr10 | 90122482 | - |
| ChimerDB4 | GBM | TCGA-19-0957-02A | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| ChimerDB4 | GBM | TCGA-19-0957 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
Top |
Fusion Gene ORF analysis for NFIA-RNLS |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000371184 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| 5CDS-5UTR | ENST00000371185 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| 5CDS-5UTR | ENST00000371187 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| 5CDS-5UTR | ENST00000371189 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| 5CDS-5UTR | ENST00000371191 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| 5CDS-5UTR | ENST00000403491 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| 5CDS-5UTR | ENST00000407417 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| 5CDS-5UTR | ENST00000485903 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371184 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371184 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371184 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371185 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371185 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371185 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371187 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371187 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371187 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371189 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371189 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371189 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371191 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371191 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000371191 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000403491 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000403491 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000403491 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000407417 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000407417 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000407417 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000485903 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000485903 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| In-frame | ENST00000485903 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| intron-3CDS | ENST00000357977 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| intron-3CDS | ENST00000357977 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| intron-3CDS | ENST00000357977 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| intron-3CDS | ENST00000479364 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| intron-3CDS | ENST00000479364 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| intron-3CDS | ENST00000479364 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| intron-5UTR | ENST00000357977 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| intron-5UTR | ENST00000479364 | ENST00000466945 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000371191 | NFIA | chr1 | 61554352 | + | ENST00000371947 | RNLS | chr10 | 90122482 | - | 2259 | 740 | 112 | 1161 | 349 |
| ENST00000371191 | NFIA | chr1 | 61554352 | + | ENST00000437752 | RNLS | chr10 | 90122482 | - | 1162 | 740 | 112 | 1161 | 350 |
| ENST00000371191 | NFIA | chr1 | 61554352 | + | ENST00000331772 | RNLS | chr10 | 90122482 | - | 1638 | 740 | 112 | 1242 | 376 |
| ENST00000407417 | NFIA | chr1 | 61554352 | + | ENST00000371947 | RNLS | chr10 | 90122482 | - | 2406 | 887 | 310 | 1308 | 332 |
| ENST00000407417 | NFIA | chr1 | 61554352 | + | ENST00000437752 | RNLS | chr10 | 90122482 | - | 1309 | 887 | 310 | 1308 | 333 |
| ENST00000407417 | NFIA | chr1 | 61554352 | + | ENST00000331772 | RNLS | chr10 | 90122482 | - | 1785 | 887 | 310 | 1389 | 359 |
| ENST00000371189 | NFIA | chr1 | 61554352 | + | ENST00000371947 | RNLS | chr10 | 90122482 | - | 2295 | 776 | 82 | 1197 | 371 |
| ENST00000371189 | NFIA | chr1 | 61554352 | + | ENST00000437752 | RNLS | chr10 | 90122482 | - | 1198 | 776 | 82 | 1197 | 372 |
| ENST00000371189 | NFIA | chr1 | 61554352 | + | ENST00000331772 | RNLS | chr10 | 90122482 | - | 1674 | 776 | 82 | 1278 | 398 |
| ENST00000403491 | NFIA | chr1 | 61554352 | + | ENST00000371947 | RNLS | chr10 | 90122482 | - | 2562 | 1043 | 343 | 1464 | 373 |
| ENST00000403491 | NFIA | chr1 | 61554352 | + | ENST00000437752 | RNLS | chr10 | 90122482 | - | 1465 | 1043 | 343 | 1464 | 374 |
| ENST00000403491 | NFIA | chr1 | 61554352 | + | ENST00000331772 | RNLS | chr10 | 90122482 | - | 1941 | 1043 | 343 | 1545 | 400 |
| ENST00000371187 | NFIA | chr1 | 61554352 | + | ENST00000371947 | RNLS | chr10 | 90122482 | - | 2249 | 730 | 30 | 1151 | 373 |
| ENST00000371187 | NFIA | chr1 | 61554352 | + | ENST00000437752 | RNLS | chr10 | 90122482 | - | 1152 | 730 | 30 | 1151 | 373 |
| ENST00000371187 | NFIA | chr1 | 61554352 | + | ENST00000331772 | RNLS | chr10 | 90122482 | - | 1628 | 730 | 30 | 1232 | 400 |
| ENST00000485903 | NFIA | chr1 | 61554352 | + | ENST00000371947 | RNLS | chr10 | 90122482 | - | 2147 | 628 | 69 | 1049 | 326 |
| ENST00000485903 | NFIA | chr1 | 61554352 | + | ENST00000437752 | RNLS | chr10 | 90122482 | - | 1050 | 628 | 69 | 1049 | 326 |
| ENST00000485903 | NFIA | chr1 | 61554352 | + | ENST00000331772 | RNLS | chr10 | 90122482 | - | 1526 | 628 | 69 | 1130 | 353 |
| ENST00000371185 | NFIA | chr1 | 61554352 | + | ENST00000371947 | RNLS | chr10 | 90122482 | - | 2122 | 603 | 44 | 1024 | 326 |
| ENST00000371185 | NFIA | chr1 | 61554352 | + | ENST00000437752 | RNLS | chr10 | 90122482 | - | 1025 | 603 | 44 | 1024 | 327 |
| ENST00000371185 | NFIA | chr1 | 61554352 | + | ENST00000331772 | RNLS | chr10 | 90122482 | - | 1501 | 603 | 44 | 1105 | 353 |
| ENST00000371184 | NFIA | chr1 | 61554352 | + | ENST00000371947 | RNLS | chr10 | 90122482 | - | 2116 | 597 | 38 | 1018 | 326 |
| ENST00000371184 | NFIA | chr1 | 61554352 | + | ENST00000437752 | RNLS | chr10 | 90122482 | - | 1019 | 597 | 38 | 1018 | 327 |
| ENST00000371184 | NFIA | chr1 | 61554352 | + | ENST00000331772 | RNLS | chr10 | 90122482 | - | 1495 | 597 | 38 | 1099 | 353 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000371191 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000233408 | 0.99976665 |
| ENST00000371191 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000578945 | 0.9994211 |
| ENST00000371191 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000224294 | 0.9997757 |
| ENST00000407417 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000136851 | 0.99986315 |
| ENST00000407417 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000517617 | 0.9994824 |
| ENST00000407417 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000164666 | 0.99983525 |
| ENST00000371189 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000423137 | 0.99957687 |
| ENST00000371189 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.00134571 | 0.99865425 |
| ENST00000371189 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000502282 | 0.99949765 |
| ENST00000403491 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000227172 | 0.99977285 |
| ENST00000403491 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.001393358 | 0.9986066 |
| ENST00000403491 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000396462 | 0.99960357 |
| ENST00000371187 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000159574 | 0.9998404 |
| ENST00000371187 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000510587 | 0.9994894 |
| ENST00000371187 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000230578 | 0.9997694 |
| ENST00000485903 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000168882 | 0.9998311 |
| ENST00000485903 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000506619 | 0.99949336 |
| ENST00000485903 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000200226 | 0.9997998 |
| ENST00000371185 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000155397 | 0.99984455 |
| ENST00000371185 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000497531 | 0.9995024 |
| ENST00000371185 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000200488 | 0.99979955 |
| ENST00000371184 | ENST00000371947 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000153271 | 0.9998467 |
| ENST00000371184 | ENST00000437752 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000480356 | 0.9995197 |
| ENST00000371184 | ENST00000331772 | NFIA | chr1 | 61554352 | + | RNLS | chr10 | 90122482 | - | 0.000193611 | 0.99980646 |
Top |
Fusion Genomic Features for NFIA-RNLS |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
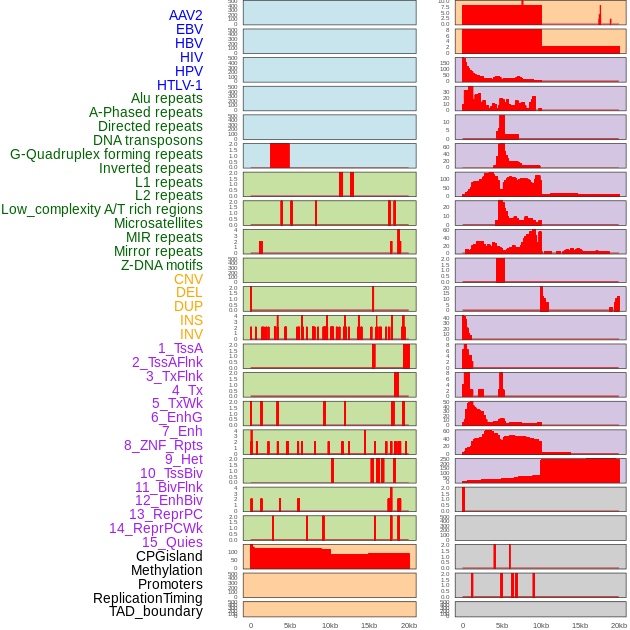 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NFIA-RNLS |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:61554352/chr10:90122482) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NFIA | . |
| FUNCTION: Recognizes and binds the palindromic sequence 5'-TTGGCNNNNNGCCAA-3' present in viral and cellular promoters and in the origin of replication of adenovirus type 2. These proteins are individually capable of activating transcription and replication. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFIA | chr1:61554352 | chr10:90122482 | ENST00000371189 | + | 3 | 12 | 1_194 | 231 | 555.0 | DNA binding | CTF/NF-I |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFIA | chr1:61554352 | chr10:90122482 | ENST00000371187 | + | 2 | 10 | 1_194 | 186 | 499.0 | DNA binding | CTF/NF-I |
| Hgene | NFIA | chr1:61554352 | chr10:90122482 | ENST00000403491 | + | 2 | 11 | 1_194 | 186 | 510.0 | DNA binding | CTF/NF-I |
| Hgene | NFIA | chr1:61554352 | chr10:90122482 | ENST00000407417 | + | 2 | 11 | 1_194 | 178 | 502.0 | DNA binding | CTF/NF-I |
| Hgene | NFIA | chr1:61554352 | chr10:90122482 | ENST00000371187 | + | 2 | 10 | 394_402 | 186 | 499.0 | Motif | 9aaTAD |
| Hgene | NFIA | chr1:61554352 | chr10:90122482 | ENST00000371189 | + | 3 | 12 | 394_402 | 231 | 555.0 | Motif | 9aaTAD |
| Hgene | NFIA | chr1:61554352 | chr10:90122482 | ENST00000403491 | + | 2 | 11 | 394_402 | 186 | 510.0 | Motif | 9aaTAD |
| Hgene | NFIA | chr1:61554352 | chr10:90122482 | ENST00000407417 | + | 2 | 11 | 394_402 | 178 | 502.0 | Motif | 9aaTAD |
| Tgene | RNLS | chr1:61554352 | chr10:90122482 | ENST00000331772 | 3 | 7 | 61_62 | 175 | 343.0 | Region | Note=FAD-binding | |
| Tgene | RNLS | chr1:61554352 | chr10:90122482 | ENST00000371947 | 3 | 7 | 61_62 | 175 | 316.0 | Region | Note=FAD-binding |
Top |
Fusion Gene Sequence for NFIA-RNLS |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58876_58876_1_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371184_RNLS_chr10_90122482_ENST00000331772_length(transcript)=1495nt_BP=597nt CACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAG CACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTA TGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAA AGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACC CAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTA AAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACA TAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGG CTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCA GTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCA CTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTT TGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTTACAAATGCTGCTGCCAACTGTCCTGGCCAAATGACTCTGC ATCACAAACCTTTCCTTGCATGTGGAGGGGATGGATTTACTCAGTCCAACTTTGATGGCTGCATCACTTCTGCCCTATGTGTTCTGGAAG CTTTAAAGAATTATATTTAGTGCCTATATCCTTATTCTCTACATGTGTATTGGGTTTTTATTTTCACAATTTTCTGTTATTGATTATTTT GTTTTCTATTTTGCTAAGAAAAATTACTGGAAAATTGTTCTTCACTTATTATCATTTTTCATGTGGAGTATAAAATCAATTTTGTAATTT TGATAGTTACAACCCATGCTAGAATGGAAATTCCTCACACCTTGCACCTTCCCTACTTTTCTGAATTGCTATGACTACTCCTTGTTGGAG GAAAAGTGGTACTTAAAAAATAACAAACGACTCTCTCAAAAAAATTACATTAAATCACAATAACAGTTTGTGTGCCAAAAACTTGATTAT >58876_58876_1_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371184_RNLS_chr10_90122482_ENST00000331772_length(amino acids)=353AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- >58876_58876_2_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371184_RNLS_chr10_90122482_ENST00000371947_length(transcript)=2116nt_BP=597nt CACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAG CACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTA TGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAA AGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACC CAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTA AAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACA TAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGG CTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCA GTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCA CTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTT TGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGAGCCCCT GGATGATGGCGATTGGATTTCCCATCTGACTTCCTGGAAATTGGAGCACACAGTCAGGTTTTATTTGATTTTTTTTTTTAAGGATACCAC TTCACAGCCTTTAGGATAGCTATTATTTAGAAGCAAAACAGAAGATAAATGTTGGCAAGGATGTGGAGATATTGGATTCCCTTGTGCAGT GCCGGTGGGAATGTAAAATGATGTAGCTACTATGGAAAATGATACGGCAATTTCTTTAGAAATGAAATATAGAATTGCTGTATGATCTGC AGTTCCACATCTGGATATCTATCCAAAAGAAGTGAAAGTAGGGACTTGAACGAACATTTGTACACCAATGTTCACAGCGGCTTTATTCAC AACAGCCAAAAGGTGGAAGCAACCCAGTGTCCATGGATAGATGAATAGATAAATAAAATGTGGTATAAACATACAATGGGCTATTGTTTA GCCTTAAAAGGGAAGGAAATTCTGACATGCTGCAATATGGATGAAGCTTAAAGTCATTATGCAAAGTGGAATAAGCCTATCACAAAAAAT AATATTACATAATTCTACTTATATGAGGAATCTAGAGCAGTCAGTTTCACAGAGACAGAAAATAGAATGGTGGTTGCCAAGGGCTGGGAG AAGAGGGCAATGGAGAGTGAGTGTTTAGTGGGTCAGAGTTTTAGTTTGGGAAGGTAAAAAGTTCTGGAGATGGATGATGGTTATGGGTGC TCAACAGTGTGAATGTACTTAATGCCACAGAACTGCACATTTAAATGTGGTTAAAATCATCACTTTTATGTTATGTATATTTACCACAAT AAATAAAGAAGTTGATATTTCTTATACTTACAAAGAGGAGAAGGGCATTTGCAAATCAACAAGAAGTGTGAGGCCCCTCTCTCTAGCAGA AAAATAGACTAAATCTATTTCTTTATCTTTTAACATCCTGTTTAAGGGAAATGCCAAAACAAATGGGAAAAAATACACACACACAAATAT ATATGAACATGTTTTGCCTCATGAGTAATCAAAATGTGTACATATGTATGTTTATGTATGTGTGTTTATATTTAAAATCGTGTTCTGCCT >58876_58876_2_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371184_RNLS_chr10_90122482_ENST00000371947_length(amino acids)=326AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- >58876_58876_3_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371184_RNLS_chr10_90122482_ENST00000437752_length(transcript)=1019nt_BP=597nt CACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAG CACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTA TGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAA AGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACC CAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTA AAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACA TAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGG CTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCA GTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCA CTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTT TGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGAGCCCCT >58876_58876_3_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371184_RNLS_chr10_90122482_ENST00000437752_length(amino acids)=327AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- >58876_58876_4_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371185_RNLS_chr10_90122482_ENST00000331772_length(transcript)=1501nt_BP=603nt ACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCA TCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAA AGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTC TGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTT CCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTT TGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCC ATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAAC TGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACA TCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTC ACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGC CGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTTACAAATGCTGCTGCCAACTGTCCTGGCCAAATGA CTCTGCATCACAAACCTTTCCTTGCATGTGGAGGGGATGGATTTACTCAGTCCAACTTTGATGGCTGCATCACTTCTGCCCTATGTGTTC TGGAAGCTTTAAAGAATTATATTTAGTGCCTATATCCTTATTCTCTACATGTGTATTGGGTTTTTATTTTCACAATTTTCTGTTATTGAT TATTTTGTTTTCTATTTTGCTAAGAAAAATTACTGGAAAATTGTTCTTCACTTATTATCATTTTTCATGTGGAGTATAAAATCAATTTTG TAATTTTGATAGTTACAACCCATGCTAGAATGGAAATTCCTCACACCTTGCACCTTCCCTACTTTTCTGAATTGCTATGACTACTCCTTG TTGGAGGAAAAGTGGTACTTAAAAAATAACAAACGACTCTCTCAAAAAAATTACATTAAATCACAATAACAGTTTGTGTGCCAAAAACTT >58876_58876_4_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371185_RNLS_chr10_90122482_ENST00000331772_length(amino acids)=353AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- >58876_58876_5_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371185_RNLS_chr10_90122482_ENST00000371947_length(transcript)=2122nt_BP=603nt ACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCA TCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAA AGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTC TGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTT CCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTT TGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCC ATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAAC TGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACA TCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTC ACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGC CGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGA GCCCCTGGATGATGGCGATTGGATTTCCCATCTGACTTCCTGGAAATTGGAGCACACAGTCAGGTTTTATTTGATTTTTTTTTTTAAGGA TACCACTTCACAGCCTTTAGGATAGCTATTATTTAGAAGCAAAACAGAAGATAAATGTTGGCAAGGATGTGGAGATATTGGATTCCCTTG TGCAGTGCCGGTGGGAATGTAAAATGATGTAGCTACTATGGAAAATGATACGGCAATTTCTTTAGAAATGAAATATAGAATTGCTGTATG ATCTGCAGTTCCACATCTGGATATCTATCCAAAAGAAGTGAAAGTAGGGACTTGAACGAACATTTGTACACCAATGTTCACAGCGGCTTT ATTCACAACAGCCAAAAGGTGGAAGCAACCCAGTGTCCATGGATAGATGAATAGATAAATAAAATGTGGTATAAACATACAATGGGCTAT TGTTTAGCCTTAAAAGGGAAGGAAATTCTGACATGCTGCAATATGGATGAAGCTTAAAGTCATTATGCAAAGTGGAATAAGCCTATCACA AAAAATAATATTACATAATTCTACTTATATGAGGAATCTAGAGCAGTCAGTTTCACAGAGACAGAAAATAGAATGGTGGTTGCCAAGGGC TGGGAGAAGAGGGCAATGGAGAGTGAGTGTTTAGTGGGTCAGAGTTTTAGTTTGGGAAGGTAAAAAGTTCTGGAGATGGATGATGGTTAT GGGTGCTCAACAGTGTGAATGTACTTAATGCCACAGAACTGCACATTTAAATGTGGTTAAAATCATCACTTTTATGTTATGTATATTTAC CACAATAAATAAAGAAGTTGATATTTCTTATACTTACAAAGAGGAGAAGGGCATTTGCAAATCAACAAGAAGTGTGAGGCCCCTCTCTCT AGCAGAAAAATAGACTAAATCTATTTCTTTATCTTTTAACATCCTGTTTAAGGGAAATGCCAAAACAAATGGGAAAAAATACACACACAC AAATATATATGAACATGTTTTGCCTCATGAGTAATCAAAATGTGTACATATGTATGTTTATGTATGTGTGTTTATATTTAAAATCGTGTT >58876_58876_5_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371185_RNLS_chr10_90122482_ENST00000371947_length(amino acids)=326AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- >58876_58876_6_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371185_RNLS_chr10_90122482_ENST00000437752_length(transcript)=1025nt_BP=603nt ACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCA TCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAA AGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTC TGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTT CCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTT TGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCC ATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAAC TGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACA TCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTC ACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGC CGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGA >58876_58876_6_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371185_RNLS_chr10_90122482_ENST00000437752_length(amino acids)=327AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- >58876_58876_7_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371187_RNLS_chr10_90122482_ENST00000331772_length(transcript)=1628nt_BP=730nt GACTTGGAAATGTGAACGCAAGAAGCAGGCTTGATTTTTTTTTCTCCCCCCTTCTCTCTCTCTCTCTCTCTCTCTCTTCCTCTCTCCCTC TTTCTCCTCTCTCACCCACACTCACGCACACCTCCAAACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCT CCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTG CAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAA AAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTT ACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCA GATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCC CCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTG CATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCT GGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAAT ATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTG CAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAG GTTACAAATGCTGCTGCCAACTGTCCTGGCCAAATGACTCTGCATCACAAACCTTTCCTTGCATGTGGAGGGGATGGATTTACTCAGTCC AACTTTGATGGCTGCATCACTTCTGCCCTATGTGTTCTGGAAGCTTTAAAGAATTATATTTAGTGCCTATATCCTTATTCTCTACATGTG TATTGGGTTTTTATTTTCACAATTTTCTGTTATTGATTATTTTGTTTTCTATTTTGCTAAGAAAAATTACTGGAAAATTGTTCTTCACTT ATTATCATTTTTCATGTGGAGTATAAAATCAATTTTGTAATTTTGATAGTTACAACCCATGCTAGAATGGAAATTCCTCACACCTTGCAC CTTCCCTACTTTTCTGAATTGCTATGACTACTCCTTGTTGGAGGAAAAGTGGTACTTAAAAAATAACAAACGACTCTCTCAAAAAAATTA CATTAAATCACAATAACAGTTTGTGTGCCAAAAACTTGATTATCCTTATGAAAATTTCAATTCTGAATAAAGAATAATCACATTATCAAA >58876_58876_7_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371187_RNLS_chr10_90122482_ENST00000331772_length(amino acids)=400AA_BP=233 MIFFSPPFSLSLSLSLPLSLFLLSHPHSRTPPNRTPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKK HEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVM VILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAG QYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVTNAAANCPG -------------------------------------------------------------- >58876_58876_8_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371187_RNLS_chr10_90122482_ENST00000371947_length(transcript)=2249nt_BP=730nt GACTTGGAAATGTGAACGCAAGAAGCAGGCTTGATTTTTTTTTCTCCCCCCTTCTCTCTCTCTCTCTCTCTCTCTCTTCCTCTCTCCCTC TTTCTCCTCTCTCACCCACACTCACGCACACCTCCAAACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCT CCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTG CAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAA AAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTT ACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCA GATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCC CCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTG CATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCT GGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAAT ATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTG CAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAG GTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGAGCCCCTGGATGATGGCGATTGGATTTCCCATCTGACTTCCTGGAAATTGGAGC ACACAGTCAGGTTTTATTTGATTTTTTTTTTTAAGGATACCACTTCACAGCCTTTAGGATAGCTATTATTTAGAAGCAAAACAGAAGATA AATGTTGGCAAGGATGTGGAGATATTGGATTCCCTTGTGCAGTGCCGGTGGGAATGTAAAATGATGTAGCTACTATGGAAAATGATACGG CAATTTCTTTAGAAATGAAATATAGAATTGCTGTATGATCTGCAGTTCCACATCTGGATATCTATCCAAAAGAAGTGAAAGTAGGGACTT GAACGAACATTTGTACACCAATGTTCACAGCGGCTTTATTCACAACAGCCAAAAGGTGGAAGCAACCCAGTGTCCATGGATAGATGAATA GATAAATAAAATGTGGTATAAACATACAATGGGCTATTGTTTAGCCTTAAAAGGGAAGGAAATTCTGACATGCTGCAATATGGATGAAGC TTAAAGTCATTATGCAAAGTGGAATAAGCCTATCACAAAAAATAATATTACATAATTCTACTTATATGAGGAATCTAGAGCAGTCAGTTT CACAGAGACAGAAAATAGAATGGTGGTTGCCAAGGGCTGGGAGAAGAGGGCAATGGAGAGTGAGTGTTTAGTGGGTCAGAGTTTTAGTTT GGGAAGGTAAAAAGTTCTGGAGATGGATGATGGTTATGGGTGCTCAACAGTGTGAATGTACTTAATGCCACAGAACTGCACATTTAAATG TGGTTAAAATCATCACTTTTATGTTATGTATATTTACCACAATAAATAAAGAAGTTGATATTTCTTATACTTACAAAGAGGAGAAGGGCA TTTGCAAATCAACAAGAAGTGTGAGGCCCCTCTCTCTAGCAGAAAAATAGACTAAATCTATTTCTTTATCTTTTAACATCCTGTTTAAGG GAAATGCCAAAACAAATGGGAAAAAATACACACACACAAATATATATGAACATGTTTTGCCTCATGAGTAATCAAAATGTGTACATATGT >58876_58876_8_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371187_RNLS_chr10_90122482_ENST00000371947_length(amino acids)=373AA_BP=233 MIFFSPPFSLSLSLSLPLSLFLLSHPHSRTPPNRTPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKK HEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVM VILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAG QYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVPSAGVILGC -------------------------------------------------------------- >58876_58876_9_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371187_RNLS_chr10_90122482_ENST00000437752_length(transcript)=1152nt_BP=730nt GACTTGGAAATGTGAACGCAAGAAGCAGGCTTGATTTTTTTTTCTCCCCCCTTCTCTCTCTCTCTCTCTCTCTCTCTTCCTCTCTCCCTC TTTCTCCTCTCTCACCCACACTCACGCACACCTCCAAACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCT CCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTG CAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAA AAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTT ACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCA GATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCC CCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTG CATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCT GGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAAT ATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTG CAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAG >58876_58876_9_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371187_RNLS_chr10_90122482_ENST00000437752_length(amino acids)=373AA_BP=233 MIFFSPPFSLSLSLSLPLSLFLLSHPHSRTPPNRTPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKK HEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVM VILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAG QYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVPSAGVILGC -------------------------------------------------------------- >58876_58876_10_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371189_RNLS_chr10_90122482_ENST00000331772_length(transcript)=1674nt_BP=776nt ACAATGCTTTGAGCCTTACCGCATTTCAGTGGGGGAAAAAAAGTTACCTAGGAGGTCTGATTTTTCAAAGAAATTTGCATACATGCAAAT GTGCCGCCCGGCCTCCTCCTCGGTTCTCTACGTGCCCACGCGGTGGCCCGGGGGGTGCGGGGCAACCTGGCAAAGTTGCCCAAGTCCTCC ACCGAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGC ACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTAT GTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAA GTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCC AGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAA AGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACAT AGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGC TGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAG TAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCAC TGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTT GCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTTACAAATGCTGCTGCCAACTGTCCTGGCCAAATGACTCTGCA TCACAAACCTTTCCTTGCATGTGGAGGGGATGGATTTACTCAGTCCAACTTTGATGGCTGCATCACTTCTGCCCTATGTGTTCTGGAAGC TTTAAAGAATTATATTTAGTGCCTATATCCTTATTCTCTACATGTGTATTGGGTTTTTATTTTCACAATTTTCTGTTATTGATTATTTTG TTTTCTATTTTGCTAAGAAAAATTACTGGAAAATTGTTCTTCACTTATTATCATTTTTCATGTGGAGTATAAAATCAATTTTGTAATTTT GATAGTTACAACCCATGCTAGAATGGAAATTCCTCACACCTTGCACCTTCCCTACTTTTCTGAATTGCTATGACTACTCCTTGTTGGAGG AAAAGTGGTACTTAAAAAATAACAAACGACTCTCTCAAAAAAATTACATTAAATCACAATAACAGTTTGTGTGCCAAAAACTTGATTATC >58876_58876_10_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371189_RNLS_chr10_90122482_ENST00000331772_length(amino acids)=398AA_BP=231 MQMCRPASSSVLYVPTRWPGGCGATWQSCPSPPPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHE KRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVI LFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQY ITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVTNAAANCPGQM -------------------------------------------------------------- >58876_58876_11_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371189_RNLS_chr10_90122482_ENST00000371947_length(transcript)=2295nt_BP=776nt ACAATGCTTTGAGCCTTACCGCATTTCAGTGGGGGAAAAAAAGTTACCTAGGAGGTCTGATTTTTCAAAGAAATTTGCATACATGCAAAT GTGCCGCCCGGCCTCCTCCTCGGTTCTCTACGTGCCCACGCGGTGGCCCGGGGGGTGCGGGGCAACCTGGCAAAGTTGCCCAAGTCCTCC ACCGAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGC ACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTAT GTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAA GTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCC AGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAA AGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACAT AGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGC TGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAG TAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCAC TGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTT GCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGAGCCCCTG GATGATGGCGATTGGATTTCCCATCTGACTTCCTGGAAATTGGAGCACACAGTCAGGTTTTATTTGATTTTTTTTTTTAAGGATACCACT TCACAGCCTTTAGGATAGCTATTATTTAGAAGCAAAACAGAAGATAAATGTTGGCAAGGATGTGGAGATATTGGATTCCCTTGTGCAGTG CCGGTGGGAATGTAAAATGATGTAGCTACTATGGAAAATGATACGGCAATTTCTTTAGAAATGAAATATAGAATTGCTGTATGATCTGCA GTTCCACATCTGGATATCTATCCAAAAGAAGTGAAAGTAGGGACTTGAACGAACATTTGTACACCAATGTTCACAGCGGCTTTATTCACA ACAGCCAAAAGGTGGAAGCAACCCAGTGTCCATGGATAGATGAATAGATAAATAAAATGTGGTATAAACATACAATGGGCTATTGTTTAG CCTTAAAAGGGAAGGAAATTCTGACATGCTGCAATATGGATGAAGCTTAAAGTCATTATGCAAAGTGGAATAAGCCTATCACAAAAAATA ATATTACATAATTCTACTTATATGAGGAATCTAGAGCAGTCAGTTTCACAGAGACAGAAAATAGAATGGTGGTTGCCAAGGGCTGGGAGA AGAGGGCAATGGAGAGTGAGTGTTTAGTGGGTCAGAGTTTTAGTTTGGGAAGGTAAAAAGTTCTGGAGATGGATGATGGTTATGGGTGCT CAACAGTGTGAATGTACTTAATGCCACAGAACTGCACATTTAAATGTGGTTAAAATCATCACTTTTATGTTATGTATATTTACCACAATA AATAAAGAAGTTGATATTTCTTATACTTACAAAGAGGAGAAGGGCATTTGCAAATCAACAAGAAGTGTGAGGCCCCTCTCTCTAGCAGAA AAATAGACTAAATCTATTTCTTTATCTTTTAACATCCTGTTTAAGGGAAATGCCAAAACAAATGGGAAAAAATACACACACACAAATATA TATGAACATGTTTTGCCTCATGAGTAATCAAAATGTGTACATATGTATGTTTATGTATGTGTGTTTATATTTAAAATCGTGTTCTGCCTT >58876_58876_11_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371189_RNLS_chr10_90122482_ENST00000371947_length(amino acids)=371AA_BP=231 MQMCRPASSSVLYVPTRWPGGCGATWQSCPSPPPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHE KRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVI LFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQY ITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVPSAGVILGCAK -------------------------------------------------------------- >58876_58876_12_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371189_RNLS_chr10_90122482_ENST00000437752_length(transcript)=1198nt_BP=776nt ACAATGCTTTGAGCCTTACCGCATTTCAGTGGGGGAAAAAAAGTTACCTAGGAGGTCTGATTTTTCAAAGAAATTTGCATACATGCAAAT GTGCCGCCCGGCCTCCTCCTCGGTTCTCTACGTGCCCACGCGGTGGCCCGGGGGGTGCGGGGCAACCTGGCAAAGTTGCCCAAGTCCTCC ACCGAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGC ACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTAT GTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAA GTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCC AGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAA AGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACAT AGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGC TGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAG TAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCAC TGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTT GCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGAGCCCCTG >58876_58876_12_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371189_RNLS_chr10_90122482_ENST00000437752_length(amino acids)=372AA_BP=231 MQMCRPASSSVLYVPTRWPGGCGATWQSCPSPPPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHE KRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVI LFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQY ITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVPSAGVILGCAK -------------------------------------------------------------- >58876_58876_13_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371191_RNLS_chr10_90122482_ENST00000331772_length(transcript)=1638nt_BP=740nt TTTTTTTTTTACCCATGATTCCATATGGTATGGACCGGACTACATGTTGCCCCACATGCCACTGCAAATGTTTTCTCAATTAGGTGTCTT ATCTCCCGTGAGTTAGCATCAGATGAAGCTTGCTGACAGCGTAATGGCAGGGAAAGCTTCCGACGGCTCCATCAAATGGCAGCTCTGCTA CGACATCTCGGCCAGAACTTGGTGGATGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATG GTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATT GCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGA TTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCT CCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCT TGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGC ATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTT TTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAA GAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCAT TGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAG ACATTCACAGGTTACAAATGCTGCTGCCAACTGTCCTGGCCAAATGACTCTGCATCACAAACCTTTCCTTGCATGTGGAGGGGATGGATT TACTCAGTCCAACTTTGATGGCTGCATCACTTCTGCCCTATGTGTTCTGGAAGCTTTAAAGAATTATATTTAGTGCCTATATCCTTATTC TCTACATGTGTATTGGGTTTTTATTTTCACAATTTTCTGTTATTGATTATTTTGTTTTCTATTTTGCTAAGAAAAATTACTGGAAAATTG TTCTTCACTTATTATCATTTTTCATGTGGAGTATAAAATCAATTTTGTAATTTTGATAGTTACAACCCATGCTAGAATGGAAATTCCTCA CACCTTGCACCTTCCCTACTTTTCTGAATTGCTATGACTACTCCTTGTTGGAGGAAAAGTGGTACTTAAAAAATAACAAACGACTCTCTC AAAAAAATTACATTAAATCACAATAACAGTTTGTGTGCCAAAAACTTGATTATCCTTATGAAAATTTCAATTCTGAATAAAGAATAATCA >58876_58876_13_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371191_RNLS_chr10_90122482_ENST00000331772_length(amino acids)=376AA_BP=209 MKLADSVMAGKASDGSIKWQLCYDISARTWWMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEV KQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCS NPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESS EIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVTNAAANCPGQMTLHHKPFLACGGDGFTQSNFDG -------------------------------------------------------------- >58876_58876_14_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371191_RNLS_chr10_90122482_ENST00000371947_length(transcript)=2259nt_BP=740nt TTTTTTTTTTACCCATGATTCCATATGGTATGGACCGGACTACATGTTGCCCCACATGCCACTGCAAATGTTTTCTCAATTAGGTGTCTT ATCTCCCGTGAGTTAGCATCAGATGAAGCTTGCTGACAGCGTAATGGCAGGGAAAGCTTCCGACGGCTCCATCAAATGGCAGCTCTGCTA CGACATCTCGGCCAGAACTTGGTGGATGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATG GTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATT GCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGA TTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCT CCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCT TGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGC ATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTT TTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAA GAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCAT TGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAG ACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGAGCCCCTGGATGATGGCGATTGGATTTCCCATCTGACTTCCTGG AAATTGGAGCACACAGTCAGGTTTTATTTGATTTTTTTTTTTAAGGATACCACTTCACAGCCTTTAGGATAGCTATTATTTAGAAGCAAA ACAGAAGATAAATGTTGGCAAGGATGTGGAGATATTGGATTCCCTTGTGCAGTGCCGGTGGGAATGTAAAATGATGTAGCTACTATGGAA AATGATACGGCAATTTCTTTAGAAATGAAATATAGAATTGCTGTATGATCTGCAGTTCCACATCTGGATATCTATCCAAAAGAAGTGAAA GTAGGGACTTGAACGAACATTTGTACACCAATGTTCACAGCGGCTTTATTCACAACAGCCAAAAGGTGGAAGCAACCCAGTGTCCATGGA TAGATGAATAGATAAATAAAATGTGGTATAAACATACAATGGGCTATTGTTTAGCCTTAAAAGGGAAGGAAATTCTGACATGCTGCAATA TGGATGAAGCTTAAAGTCATTATGCAAAGTGGAATAAGCCTATCACAAAAAATAATATTACATAATTCTACTTATATGAGGAATCTAGAG CAGTCAGTTTCACAGAGACAGAAAATAGAATGGTGGTTGCCAAGGGCTGGGAGAAGAGGGCAATGGAGAGTGAGTGTTTAGTGGGTCAGA GTTTTAGTTTGGGAAGGTAAAAAGTTCTGGAGATGGATGATGGTTATGGGTGCTCAACAGTGTGAATGTACTTAATGCCACAGAACTGCA CATTTAAATGTGGTTAAAATCATCACTTTTATGTTATGTATATTTACCACAATAAATAAAGAAGTTGATATTTCTTATACTTACAAAGAG GAGAAGGGCATTTGCAAATCAACAAGAAGTGTGAGGCCCCTCTCTCTAGCAGAAAAATAGACTAAATCTATTTCTTTATCTTTTAACATC CTGTTTAAGGGAAATGCCAAAACAAATGGGAAAAAATACACACACACAAATATATATGAACATGTTTTGCCTCATGAGTAATCAAAATGT GTACATATGTATGTTTATGTATGTGTGTTTATATTTAAAATCGTGTTCTGCCTTATGAGTAAACAAAAAGTATACAAATTAAAAACTATA >58876_58876_14_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371191_RNLS_chr10_90122482_ENST00000371947_length(amino acids)=349AA_BP=209 MKLADSVMAGKASDGSIKWQLCYDISARTWWMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEV KQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCS NPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESS -------------------------------------------------------------- >58876_58876_15_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371191_RNLS_chr10_90122482_ENST00000437752_length(transcript)=1162nt_BP=740nt TTTTTTTTTTACCCATGATTCCATATGGTATGGACCGGACTACATGTTGCCCCACATGCCACTGCAAATGTTTTCTCAATTAGGTGTCTT ATCTCCCGTGAGTTAGCATCAGATGAAGCTTGCTGACAGCGTAATGGCAGGGAAAGCTTCCGACGGCTCCATCAAATGGCAGCTCTGCTA CGACATCTCGGCCAGAACTTGGTGGATGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATG GTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATT GCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGA TTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCT CCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCT TGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGC ATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTT TTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAA GAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCAT TGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAG >58876_58876_15_NFIA-RNLS_NFIA_chr1_61554352_ENST00000371191_RNLS_chr10_90122482_ENST00000437752_length(amino acids)=350AA_BP=209 MKLADSVMAGKASDGSIKWQLCYDISARTWWMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEV KQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCS NPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESS -------------------------------------------------------------- >58876_58876_16_NFIA-RNLS_NFIA_chr1_61554352_ENST00000403491_RNLS_chr10_90122482_ENST00000331772_length(transcript)=1941nt_BP=1043nt GGCCGCGGAGGCTCGGGACCCGGCTGGCCGCGCGGCGCCGCAGCCGCCCCCTCCCCCACACCCCCTCCCCCCCGCGGCGGCGGCGCGAGC GGGCGGCGGCTGTGCGGTGCGGTGCAGAGCGGAGGCGGAGGCGGGCGCGCGGGCAGCTCGCGGGCACCCGGCCGGGCCGGCGCGGGAGCG GGAAAGGGTGCGCTATGCCTTTAACACCCGCGTACAGTAGGCATGTATAGTGGAGTGTAGGGAAACTCTAGGCGGGGTTAAAGTTCAGCT CATGGAGCGGCAATAGCGCTGGCTGGCTGGCTGCAGTTGAGCCGACTTGGAAATGTGAACGCAAGAAGCAGGCTTGATTTTTTTTTCTCC CCCCTTCTCTCTCTCTCTCTCTCTCTCTCTTCCTCTCTCCCTCTTTCTCCTCTCTCACCCACACTCACGCACACCTCCAAACCGCACACC CAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGCACT TCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTC AAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTT GCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGA CCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGG TATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGG GGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGT GAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAA TCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGT CCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCC TCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTTACAAATGCTGCTGCCAACTGTCCTGGCCAAATGACTCTGCATCA CAAACCTTTCCTTGCATGTGGAGGGGATGGATTTACTCAGTCCAACTTTGATGGCTGCATCACTTCTGCCCTATGTGTTCTGGAAGCTTT AAAGAATTATATTTAGTGCCTATATCCTTATTCTCTACATGTGTATTGGGTTTTTATTTTCACAATTTTCTGTTATTGATTATTTTGTTT TCTATTTTGCTAAGAAAAATTACTGGAAAATTGTTCTTCACTTATTATCATTTTTCATGTGGAGTATAAAATCAATTTTGTAATTTTGAT AGTTACAACCCATGCTAGAATGGAAATTCCTCACACCTTGCACCTTCCCTACTTTTCTGAATTGCTATGACTACTCCTTGTTGGAGGAAA AGTGGTACTTAAAAAATAACAAACGACTCTCTCAAAAAAATTACATTAAATCACAATAACAGTTTGTGTGCCAAAAACTTGATTATCCTT >58876_58876_16_NFIA-RNLS_NFIA_chr1_61554352_ENST00000403491_RNLS_chr10_90122482_ENST00000331772_length(amino acids)=400AA_BP=233 MIFFSPPFSLSLSLSLPLSLFLLSHPHSRTPPNRTPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKK HEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVM VILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAG QYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVTNAAANCPG -------------------------------------------------------------- >58876_58876_17_NFIA-RNLS_NFIA_chr1_61554352_ENST00000403491_RNLS_chr10_90122482_ENST00000371947_length(transcript)=2562nt_BP=1043nt GGCCGCGGAGGCTCGGGACCCGGCTGGCCGCGCGGCGCCGCAGCCGCCCCCTCCCCCACACCCCCTCCCCCCCGCGGCGGCGGCGCGAGC GGGCGGCGGCTGTGCGGTGCGGTGCAGAGCGGAGGCGGAGGCGGGCGCGCGGGCAGCTCGCGGGCACCCGGCCGGGCCGGCGCGGGAGCG GGAAAGGGTGCGCTATGCCTTTAACACCCGCGTACAGTAGGCATGTATAGTGGAGTGTAGGGAAACTCTAGGCGGGGTTAAAGTTCAGCT CATGGAGCGGCAATAGCGCTGGCTGGCTGGCTGCAGTTGAGCCGACTTGGAAATGTGAACGCAAGAAGCAGGCTTGATTTTTTTTTCTCC CCCCTTCTCTCTCTCTCTCTCTCTCTCTCTTCCTCTCTCCCTCTTTCTCCTCTCTCACCCACACTCACGCACACCTCCAAACCGCACACC CAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGCACT TCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTC AAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTT GCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGA CCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGG TATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGG GGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGT GAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAA TCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGT CCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCC TCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGAGCCCCTGGAT GATGGCGATTGGATTTCCCATCTGACTTCCTGGAAATTGGAGCACACAGTCAGGTTTTATTTGATTTTTTTTTTTAAGGATACCACTTCA CAGCCTTTAGGATAGCTATTATTTAGAAGCAAAACAGAAGATAAATGTTGGCAAGGATGTGGAGATATTGGATTCCCTTGTGCAGTGCCG GTGGGAATGTAAAATGATGTAGCTACTATGGAAAATGATACGGCAATTTCTTTAGAAATGAAATATAGAATTGCTGTATGATCTGCAGTT CCACATCTGGATATCTATCCAAAAGAAGTGAAAGTAGGGACTTGAACGAACATTTGTACACCAATGTTCACAGCGGCTTTATTCACAACA GCCAAAAGGTGGAAGCAACCCAGTGTCCATGGATAGATGAATAGATAAATAAAATGTGGTATAAACATACAATGGGCTATTGTTTAGCCT TAAAAGGGAAGGAAATTCTGACATGCTGCAATATGGATGAAGCTTAAAGTCATTATGCAAAGTGGAATAAGCCTATCACAAAAAATAATA TTACATAATTCTACTTATATGAGGAATCTAGAGCAGTCAGTTTCACAGAGACAGAAAATAGAATGGTGGTTGCCAAGGGCTGGGAGAAGA GGGCAATGGAGAGTGAGTGTTTAGTGGGTCAGAGTTTTAGTTTGGGAAGGTAAAAAGTTCTGGAGATGGATGATGGTTATGGGTGCTCAA CAGTGTGAATGTACTTAATGCCACAGAACTGCACATTTAAATGTGGTTAAAATCATCACTTTTATGTTATGTATATTTACCACAATAAAT AAAGAAGTTGATATTTCTTATACTTACAAAGAGGAGAAGGGCATTTGCAAATCAACAAGAAGTGTGAGGCCCCTCTCTCTAGCAGAAAAA TAGACTAAATCTATTTCTTTATCTTTTAACATCCTGTTTAAGGGAAATGCCAAAACAAATGGGAAAAAATACACACACACAAATATATAT GAACATGTTTTGCCTCATGAGTAATCAAAATGTGTACATATGTATGTTTATGTATGTGTGTTTATATTTAAAATCGTGTTCTGCCTTATG >58876_58876_17_NFIA-RNLS_NFIA_chr1_61554352_ENST00000403491_RNLS_chr10_90122482_ENST00000371947_length(amino acids)=373AA_BP=233 MIFFSPPFSLSLSLSLPLSLFLLSHPHSRTPPNRTPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKK HEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVM VILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAG QYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVPSAGVILGC -------------------------------------------------------------- >58876_58876_18_NFIA-RNLS_NFIA_chr1_61554352_ENST00000403491_RNLS_chr10_90122482_ENST00000437752_length(transcript)=1465nt_BP=1043nt GGCCGCGGAGGCTCGGGACCCGGCTGGCCGCGCGGCGCCGCAGCCGCCCCCTCCCCCACACCCCCTCCCCCCCGCGGCGGCGGCGCGAGC GGGCGGCGGCTGTGCGGTGCGGTGCAGAGCGGAGGCGGAGGCGGGCGCGCGGGCAGCTCGCGGGCACCCGGCCGGGCCGGCGCGGGAGCG GGAAAGGGTGCGCTATGCCTTTAACACCCGCGTACAGTAGGCATGTATAGTGGAGTGTAGGGAAACTCTAGGCGGGGTTAAAGTTCAGCT CATGGAGCGGCAATAGCGCTGGCTGGCTGGCTGCAGTTGAGCCGACTTGGAAATGTGAACGCAAGAAGCAGGCTTGATTTTTTTTTCTCC CCCCTTCTCTCTCTCTCTCTCTCTCTCTCTTCCTCTCTCCCTCTTTCTCCTCTCTCACCCACACTCACGCACACCTCCAAACCGCACACC CAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTCACCCAGGATGAATTTCATCCTTTCATCGAAGCACT TCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTTCAAAAAACATGAAAAGCGTATGTC AAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTT GCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGA CCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGG TATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCTCTGTGTCCAACCCCATCACATAGG GGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGT GAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTGGGCTGGGCAGTACATCACCAGTAA TCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCCTTCCCTCGTGATTCACACCACTGT CCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCC TCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCTAGGATGTGCGAAGAGCCCCTGGAT >58876_58876_18_NFIA-RNLS_NFIA_chr1_61554352_ENST00000403491_RNLS_chr10_90122482_ENST00000437752_length(amino acids)=374AA_BP=233 MIFFSPPFSLSLSLSLPLSLFLLSHPHSRTPPNRTPRRTRIPQRPAVMYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKK HEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVM VILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAG QYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSIEDVQELVFQQLENILPGLPQPIATKCQKWRHSQVPSAGVILGC -------------------------------------------------------------- >58876_58876_19_NFIA-RNLS_NFIA_chr1_61554352_ENST00000407417_RNLS_chr10_90122482_ENST00000331772_length(transcript)=1785nt_BP=887nt GTACAATCCAAAGCACGCAAGGCAAAACCAGAGCGAATCTGAGAACCAGCCAGCCCGGGTTGGATCGCTTTCAAAAGAGAGAGTGAGAGC GAGCGAGCGAGCGAGCGAGAGCGAGACAGTGAGAGAGGGAGAGAGCGCGCCTTGCAATTGCAAAAGCCTTCTGATTTGGAGTTAAAAAAA AAATTCTCCAAGAAGCCTGCAATTGGCCAACAGCTTTTTAAAAAATCTCTTCCGGGTTTTCAACGGTTCCAAGTTTATTTAGATATTTTT TAAATGCAAAAAAAAGGGGACAACAAATGAAGCAATTCGTCTGAGCATTTTAAAGTTTCTCACGTACTCTTTTTACATTGCAATGGATGA ATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTT CAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTG GGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCC ATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCT TGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCT CTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATG CCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTG GGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCC TTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCT GGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTTACAAATGCTGCTGCCAACTG TCCTGGCCAAATGACTCTGCATCACAAACCTTTCCTTGCATGTGGAGGGGATGGATTTACTCAGTCCAACTTTGATGGCTGCATCACTTC TGCCCTATGTGTTCTGGAAGCTTTAAAGAATTATATTTAGTGCCTATATCCTTATTCTCTACATGTGTATTGGGTTTTTATTTTCACAAT TTTCTGTTATTGATTATTTTGTTTTCTATTTTGCTAAGAAAAATTACTGGAAAATTGTTCTTCACTTATTATCATTTTTCATGTGGAGTA TAAAATCAATTTTGTAATTTTGATAGTTACAACCCATGCTAGAATGGAAATTCCTCACACCTTGCACCTTCCCTACTTTTCTGAATTGCT ATGACTACTCCTTGTTGGAGGAAAAGTGGTACTTAAAAAATAACAAACGACTCTCTCAAAAAAATTACATTAAATCACAATAACAGTTTG >58876_58876_19_NFIA-RNLS_NFIA_chr1_61554352_ENST00000407417_RNLS_chr10_90122482_ENST00000331772_length(amino acids)=359AA_BP=192 MSILKFLTYSFYIAMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIR PEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKE LDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVT -------------------------------------------------------------- >58876_58876_20_NFIA-RNLS_NFIA_chr1_61554352_ENST00000407417_RNLS_chr10_90122482_ENST00000371947_length(transcript)=2406nt_BP=887nt GTACAATCCAAAGCACGCAAGGCAAAACCAGAGCGAATCTGAGAACCAGCCAGCCCGGGTTGGATCGCTTTCAAAAGAGAGAGTGAGAGC GAGCGAGCGAGCGAGCGAGAGCGAGACAGTGAGAGAGGGAGAGAGCGCGCCTTGCAATTGCAAAAGCCTTCTGATTTGGAGTTAAAAAAA AAATTCTCCAAGAAGCCTGCAATTGGCCAACAGCTTTTTAAAAAATCTCTTCCGGGTTTTCAACGGTTCCAAGTTTATTTAGATATTTTT TAAATGCAAAAAAAAGGGGACAACAAATGAAGCAATTCGTCTGAGCATTTTAAAGTTTCTCACGTACTCTTTTTACATTGCAATGGATGA ATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTT CAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTG GGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCC ATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCT TGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCT CTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATG CCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTG GGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCC TTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCT GGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCT AGGATGTGCGAAGAGCCCCTGGATGATGGCGATTGGATTTCCCATCTGACTTCCTGGAAATTGGAGCACACAGTCAGGTTTTATTTGATT TTTTTTTTTAAGGATACCACTTCACAGCCTTTAGGATAGCTATTATTTAGAAGCAAAACAGAAGATAAATGTTGGCAAGGATGTGGAGAT ATTGGATTCCCTTGTGCAGTGCCGGTGGGAATGTAAAATGATGTAGCTACTATGGAAAATGATACGGCAATTTCTTTAGAAATGAAATAT AGAATTGCTGTATGATCTGCAGTTCCACATCTGGATATCTATCCAAAAGAAGTGAAAGTAGGGACTTGAACGAACATTTGTACACCAATG TTCACAGCGGCTTTATTCACAACAGCCAAAAGGTGGAAGCAACCCAGTGTCCATGGATAGATGAATAGATAAATAAAATGTGGTATAAAC ATACAATGGGCTATTGTTTAGCCTTAAAAGGGAAGGAAATTCTGACATGCTGCAATATGGATGAAGCTTAAAGTCATTATGCAAAGTGGA ATAAGCCTATCACAAAAAATAATATTACATAATTCTACTTATATGAGGAATCTAGAGCAGTCAGTTTCACAGAGACAGAAAATAGAATGG TGGTTGCCAAGGGCTGGGAGAAGAGGGCAATGGAGAGTGAGTGTTTAGTGGGTCAGAGTTTTAGTTTGGGAAGGTAAAAAGTTCTGGAGA TGGATGATGGTTATGGGTGCTCAACAGTGTGAATGTACTTAATGCCACAGAACTGCACATTTAAATGTGGTTAAAATCATCACTTTTATG TTATGTATATTTACCACAATAAATAAAGAAGTTGATATTTCTTATACTTACAAAGAGGAGAAGGGCATTTGCAAATCAACAAGAAGTGTG AGGCCCCTCTCTCTAGCAGAAAAATAGACTAAATCTATTTCTTTATCTTTTAACATCCTGTTTAAGGGAAATGCCAAAACAAATGGGAAA AAATACACACACACAAATATATATGAACATGTTTTGCCTCATGAGTAATCAAAATGTGTACATATGTATGTTTATGTATGTGTGTTTATA >58876_58876_20_NFIA-RNLS_NFIA_chr1_61554352_ENST00000407417_RNLS_chr10_90122482_ENST00000371947_length(amino acids)=332AA_BP=192 MSILKFLTYSFYIAMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIR PEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKE LDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVT -------------------------------------------------------------- >58876_58876_21_NFIA-RNLS_NFIA_chr1_61554352_ENST00000407417_RNLS_chr10_90122482_ENST00000437752_length(transcript)=1309nt_BP=887nt GTACAATCCAAAGCACGCAAGGCAAAACCAGAGCGAATCTGAGAACCAGCCAGCCCGGGTTGGATCGCTTTCAAAAGAGAGAGTGAGAGC GAGCGAGCGAGCGAGCGAGAGCGAGACAGTGAGAGAGGGAGAGAGCGCGCCTTGCAATTGCAAAAGCCTTCTGATTTGGAGTTAAAAAAA AAATTCTCCAAGAAGCCTGCAATTGGCCAACAGCTTTTTAAAAAATCTCTTCCGGGTTTTCAACGGTTCCAAGTTTATTTAGATATTTTT TAAATGCAAAAAAAAGGGGACAACAAATGAAGCAATTCGTCTGAGCATTTTAAAGTTTCTCACGTACTCTTTTTACATTGCAATGGATGA ATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAACGAAAATACTT CAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTCAAGCAGAAGTG GGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGGAAAAAACCTCC ATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGGAGGTTGGACCT TGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCTAATCCAGGGCT CTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTAATTAGTGAATG CCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATTGATGTCCCTTG GGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCAGAAATTGGGCC TTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTCTTCCAGCAGCT GGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCTGGTGTGATTCT >58876_58876_21_NFIA-RNLS_NFIA_chr1_61554352_ENST00000407417_RNLS_chr10_90122482_ENST00000437752_length(amino acids)=333AA_BP=192 MSILKFLTYSFYIAMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIR PEYREDFVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKE LDLYLAYFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVT -------------------------------------------------------------- >58876_58876_22_NFIA-RNLS_NFIA_chr1_61554352_ENST00000485903_RNLS_chr10_90122482_ENST00000331772_length(transcript)=1526nt_BP=628nt CACCCACACTCACGCACACCTCCAAACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTC ACCCAGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAA CGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTC AAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGG AAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGG AGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCT AATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTA ATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATT GATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCA GAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTC TTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTTACAAATGCT GCTGCCAACTGTCCTGGCCAAATGACTCTGCATCACAAACCTTTCCTTGCATGTGGAGGGGATGGATTTACTCAGTCCAACTTTGATGGC TGCATCACTTCTGCCCTATGTGTTCTGGAAGCTTTAAAGAATTATATTTAGTGCCTATATCCTTATTCTCTACATGTGTATTGGGTTTTT ATTTTCACAATTTTCTGTTATTGATTATTTTGTTTTCTATTTTGCTAAGAAAAATTACTGGAAAATTGTTCTTCACTTATTATCATTTTT CATGTGGAGTATAAAATCAATTTTGTAATTTTGATAGTTACAACCCATGCTAGAATGGAAATTCCTCACACCTTGCACCTTCCCTACTTT TCTGAATTGCTATGACTACTCCTTGTTGGAGGAAAAGTGGTACTTAAAAAATAACAAACGACTCTCTCAAAAAAATTACATTAAATCACA >58876_58876_22_NFIA-RNLS_NFIA_chr1_61554352_ENST00000485903_RNLS_chr10_90122482_ENST00000331772_length(amino acids)=353AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- >58876_58876_23_NFIA-RNLS_NFIA_chr1_61554352_ENST00000485903_RNLS_chr10_90122482_ENST00000371947_length(transcript)=2147nt_BP=628nt CACCCACACTCACGCACACCTCCAAACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTC ACCCAGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAA CGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTC AAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGG AAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGG AGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCT AATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTA ATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATT GATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCA GAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTC TTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCT GGTGTGATTCTAGGATGTGCGAAGAGCCCCTGGATGATGGCGATTGGATTTCCCATCTGACTTCCTGGAAATTGGAGCACACAGTCAGGT TTTATTTGATTTTTTTTTTTAAGGATACCACTTCACAGCCTTTAGGATAGCTATTATTTAGAAGCAAAACAGAAGATAAATGTTGGCAAG GATGTGGAGATATTGGATTCCCTTGTGCAGTGCCGGTGGGAATGTAAAATGATGTAGCTACTATGGAAAATGATACGGCAATTTCTTTAG AAATGAAATATAGAATTGCTGTATGATCTGCAGTTCCACATCTGGATATCTATCCAAAAGAAGTGAAAGTAGGGACTTGAACGAACATTT GTACACCAATGTTCACAGCGGCTTTATTCACAACAGCCAAAAGGTGGAAGCAACCCAGTGTCCATGGATAGATGAATAGATAAATAAAAT GTGGTATAAACATACAATGGGCTATTGTTTAGCCTTAAAAGGGAAGGAAATTCTGACATGCTGCAATATGGATGAAGCTTAAAGTCATTA TGCAAAGTGGAATAAGCCTATCACAAAAAATAATATTACATAATTCTACTTATATGAGGAATCTAGAGCAGTCAGTTTCACAGAGACAGA AAATAGAATGGTGGTTGCCAAGGGCTGGGAGAAGAGGGCAATGGAGAGTGAGTGTTTAGTGGGTCAGAGTTTTAGTTTGGGAAGGTAAAA AGTTCTGGAGATGGATGATGGTTATGGGTGCTCAACAGTGTGAATGTACTTAATGCCACAGAACTGCACATTTAAATGTGGTTAAAATCA TCACTTTTATGTTATGTATATTTACCACAATAAATAAAGAAGTTGATATTTCTTATACTTACAAAGAGGAGAAGGGCATTTGCAAATCAA CAAGAAGTGTGAGGCCCCTCTCTCTAGCAGAAAAATAGACTAAATCTATTTCTTTATCTTTTAACATCCTGTTTAAGGGAAATGCCAAAA CAAATGGGAAAAAATACACACACACAAATATATATGAACATGTTTTGCCTCATGAGTAATCAAAATGTGTACATATGTATGTTTATGTAT >58876_58876_23_NFIA-RNLS_NFIA_chr1_61554352_ENST00000485903_RNLS_chr10_90122482_ENST00000371947_length(amino acids)=326AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- >58876_58876_24_NFIA-RNLS_NFIA_chr1_61554352_ENST00000485903_RNLS_chr10_90122482_ENST00000437752_length(transcript)=1050nt_BP=628nt CACCCACACTCACGCACACCTCCAAACCGCACACCCAGACGCACACGCATACCCCAGCGCCCGGCAGTTATGTATTCTCCGCTCTGTCTC ACCCAGGATGAATTTCATCCTTTCATCGAAGCACTTCTGCCCCACGTCCGAGCCTTTGCCTACACATGGTTCAACCTGCAGGCCCGAAAA CGAAAATACTTCAAAAAACATGAAAAGCGTATGTCAAAAGAAGAAGAGAGAGCCGTGAAGGATGAATTGCTAAGTGAAAAACCAGAGGTC AAGCAGAAGTGGGCATCTCGACTTCTGGCAAAGTTGCGGAAAGATATCCGACCCGAATATCGAGAGGATTTTGTTCTTACAGTTACAGGG AAAAAACCTCCATGTTGTGTTCTTTCCAACCCAGACCAGAAAGGCAAGATGCGAAGAATTGACTGCCTCCGCCAGGCAGATAAAGTCTGG AGGTTGGACCTTGTTATGGTGATTTTGTTTAAAGGTATTCCGCTGGAAAGTACTGATGGCGAGCGCCTTGTAAAGTCCCCACAATGCTCT AATCCAGGGCTCTGTGTCCAACCCCATCACATAGGGGTTTCTGTTAAGGAACTCGATTTATATTTGGCATACTTTGTGCATGCAGCAGTA ATTAGTGAATGCCAAAGGCAGCAACTGGAGGCTGTGAGCTACTCCTCTCGATATGCTCTGGGCCTCTTTTATGAAGCTGGTACGAAGATT GATGTCCCTTGGGCTGGGCAGTACATCACCAGTAATCCCTGCATACGCTTCGTCTCCATTGATAATAAGAAGCGCAATATAGAGTCATCA GAAATTGGGCCTTCCCTCGTGATTCACACCACTGTCCCATTTGGAGTTACATACTTGGAACACAGCATTGAGGATGTGCAAGAGTTAGTC TTCCAGCAGCTGGAAAACATTTTGCCGGGTTTGCCTCAGCCAATTGCTACCAAATGCCAAAAATGGAGACATTCACAGGTACCAAGTGCT >58876_58876_24_NFIA-RNLS_NFIA_chr1_61554352_ENST00000485903_RNLS_chr10_90122482_ENST00000437752_length(amino acids)=326AA_BP=186 MYSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKEEERAVKDELLSEKPEVKQKWASRLLAKLRKDIRPEYRED FVLTVTGKKPPCCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKSPQCSNPGLCVQPHHIGVSVKELDLYLA YFVHAAVISECQRQQLEAVSYSSRYALGLFYEAGTKIDVPWAGQYITSNPCIRFVSIDNKKRNIESSEIGPSLVIHTTVPFGVTYLEHSI -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NFIA-RNLS |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NFIA-RNLS |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NFIA-RNLS |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies