
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NFIC-CRB3 (FusionGDB2 ID:58905) |
Fusion Gene Summary for NFIC-CRB3 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NFIC-CRB3 | Fusion gene ID: 58905 | Hgene | Tgene | Gene symbol | NFIC | CRB3 | Gene ID | 4782 | 92359 |
| Gene name | nuclear factor I C | crumbs cell polarity complex component 3 | |
| Synonyms | CTF|CTF5|NF-I|NFI | - | |
| Cytomap | 19p13.3 | 19p13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nuclear factor 1 C-typeCCAAT-box-binding transcription factorNF-I/CNF1-CTGGCA-binding proteinnuclear factor I/C (CCAAT-binding transcription factor) | protein crumbs homolog 3crumbs 3, cell polarity complex componentcrumbs family member 3 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P08651 | Q9BUF7 | |
| Ensembl transtripts involved in fusion gene | ENST00000341919, ENST00000346156, ENST00000395111, ENST00000443272, ENST00000586919, ENST00000589123, ENST00000590282, ENST00000588839, | ENST00000308243, ENST00000356762, ENST00000598494, ENST00000600229, | |
| Fusion gene scores | * DoF score | 30 X 20 X 13=7800 | 4 X 5 X 2=40 |
| # samples | 36 | 5 | |
| ** MAII score | log2(36/7800*10)=-4.4374053123073 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/40*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: NFIC [Title/Abstract] AND CRB3 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NFIC(3452664)-CRB3(6466477), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | NFIC-CRB3 seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NFIC | GO:0000122 | negative regulation of transcription by RNA polymerase II | 19706729 |
| Hgene | NFIC | GO:0045944 | positive regulation of transcription by RNA polymerase II | 1524678|19706729 |
| Tgene | CRB3 | GO:0072659 | protein localization to plasma membrane | 17332497 |
| Fusion gene breakpoints across NFIC (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CRB3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-05-4427-01A | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
Top |
Fusion Gene ORF analysis for NFIC-CRB3 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000341919 | ENST00000308243 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| Frame-shift | ENST00000346156 | ENST00000308243 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| Frame-shift | ENST00000395111 | ENST00000308243 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| Frame-shift | ENST00000443272 | ENST00000308243 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| Frame-shift | ENST00000586919 | ENST00000308243 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| Frame-shift | ENST00000589123 | ENST00000308243 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| Frame-shift | ENST00000590282 | ENST00000308243 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000341919 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000341919 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000341919 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000346156 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000346156 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000346156 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000395111 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000395111 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000395111 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000443272 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000443272 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000443272 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000586919 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000586919 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000586919 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000589123 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000589123 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000589123 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000590282 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000590282 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| In-frame | ENST00000590282 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| intron-3CDS | ENST00000588839 | ENST00000308243 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| intron-3CDS | ENST00000588839 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| intron-3CDS | ENST00000588839 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| intron-3CDS | ENST00000588839 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000589123 | NFIC | chr19 | 3452664 | + | ENST00000598494 | CRB3 | chr19 | 6466477 | + | 2118 | 1362 | 48 | 1568 | 506 |
| ENST00000589123 | NFIC | chr19 | 3452664 | + | ENST00000600229 | CRB3 | chr19 | 6466477 | + | 2118 | 1362 | 48 | 1568 | 506 |
| ENST00000589123 | NFIC | chr19 | 3452664 | + | ENST00000356762 | CRB3 | chr19 | 6466477 | + | 1777 | 1362 | 48 | 1577 | 509 |
| ENST00000346156 | NFIC | chr19 | 3452664 | + | ENST00000598494 | CRB3 | chr19 | 6466477 | + | 1991 | 1235 | 65 | 1441 | 458 |
| ENST00000346156 | NFIC | chr19 | 3452664 | + | ENST00000600229 | CRB3 | chr19 | 6466477 | + | 1991 | 1235 | 65 | 1441 | 458 |
| ENST00000346156 | NFIC | chr19 | 3452664 | + | ENST00000356762 | CRB3 | chr19 | 6466477 | + | 1650 | 1235 | 65 | 1450 | 461 |
| ENST00000395111 | NFIC | chr19 | 3452664 | + | ENST00000598494 | CRB3 | chr19 | 6466477 | + | 2034 | 1278 | 36 | 1484 | 482 |
| ENST00000395111 | NFIC | chr19 | 3452664 | + | ENST00000600229 | CRB3 | chr19 | 6466477 | + | 2034 | 1278 | 36 | 1484 | 482 |
| ENST00000395111 | NFIC | chr19 | 3452664 | + | ENST00000356762 | CRB3 | chr19 | 6466477 | + | 1693 | 1278 | 36 | 1493 | 485 |
| ENST00000586919 | NFIC | chr19 | 3452664 | + | ENST00000598494 | CRB3 | chr19 | 6466477 | + | 1926 | 1170 | 0 | 1376 | 458 |
| ENST00000586919 | NFIC | chr19 | 3452664 | + | ENST00000600229 | CRB3 | chr19 | 6466477 | + | 1926 | 1170 | 0 | 1376 | 458 |
| ENST00000586919 | NFIC | chr19 | 3452664 | + | ENST00000356762 | CRB3 | chr19 | 6466477 | + | 1585 | 1170 | 0 | 1385 | 461 |
| ENST00000341919 | NFIC | chr19 | 3452664 | + | ENST00000598494 | CRB3 | chr19 | 6466477 | + | 2113 | 1357 | 88 | 1563 | 491 |
| ENST00000341919 | NFIC | chr19 | 3452664 | + | ENST00000600229 | CRB3 | chr19 | 6466477 | + | 2113 | 1357 | 88 | 1563 | 491 |
| ENST00000341919 | NFIC | chr19 | 3452664 | + | ENST00000356762 | CRB3 | chr19 | 6466477 | + | 1772 | 1357 | 88 | 1572 | 494 |
| ENST00000590282 | NFIC | chr19 | 3452664 | + | ENST00000598494 | CRB3 | chr19 | 6466477 | + | 2079 | 1323 | 54 | 1529 | 491 |
| ENST00000590282 | NFIC | chr19 | 3452664 | + | ENST00000600229 | CRB3 | chr19 | 6466477 | + | 2079 | 1323 | 54 | 1529 | 491 |
| ENST00000590282 | NFIC | chr19 | 3452664 | + | ENST00000356762 | CRB3 | chr19 | 6466477 | + | 1738 | 1323 | 54 | 1538 | 494 |
| ENST00000443272 | NFIC | chr19 | 3452664 | + | ENST00000598494 | CRB3 | chr19 | 6466477 | + | 2076 | 1320 | 51 | 1526 | 491 |
| ENST00000443272 | NFIC | chr19 | 3452664 | + | ENST00000600229 | CRB3 | chr19 | 6466477 | + | 2076 | 1320 | 51 | 1526 | 491 |
| ENST00000443272 | NFIC | chr19 | 3452664 | + | ENST00000356762 | CRB3 | chr19 | 6466477 | + | 1735 | 1320 | 51 | 1535 | 494 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000589123 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.03428471 | 0.96571535 |
| ENST00000589123 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.03428471 | 0.96571535 |
| ENST00000589123 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.035382174 | 0.96461785 |
| ENST00000346156 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.03743729 | 0.96256274 |
| ENST00000346156 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.03743729 | 0.96256274 |
| ENST00000346156 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.038565747 | 0.96143425 |
| ENST00000395111 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.0335961 | 0.9664039 |
| ENST00000395111 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.0335961 | 0.9664039 |
| ENST00000395111 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.03427879 | 0.96572125 |
| ENST00000586919 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.03526332 | 0.96473664 |
| ENST00000586919 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.03526332 | 0.96473664 |
| ENST00000586919 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.03473254 | 0.9652675 |
| ENST00000341919 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.033289373 | 0.96671057 |
| ENST00000341919 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.033289373 | 0.96671057 |
| ENST00000341919 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.030796846 | 0.9692031 |
| ENST00000590282 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.036440857 | 0.96355915 |
| ENST00000590282 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.036440857 | 0.96355915 |
| ENST00000590282 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.035106335 | 0.96489364 |
| ENST00000443272 | ENST00000598494 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.037051998 | 0.962948 |
| ENST00000443272 | ENST00000600229 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.037051998 | 0.962948 |
| ENST00000443272 | ENST00000356762 | NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466477 | + | 0.036033213 | 0.96396685 |
Top |
Fusion Genomic Features for NFIC-CRB3 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466476 | + | 5.49E-06 | 0.9999945 |
| NFIC | chr19 | 3452664 | + | CRB3 | chr19 | 6466476 | + | 5.49E-06 | 0.9999945 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
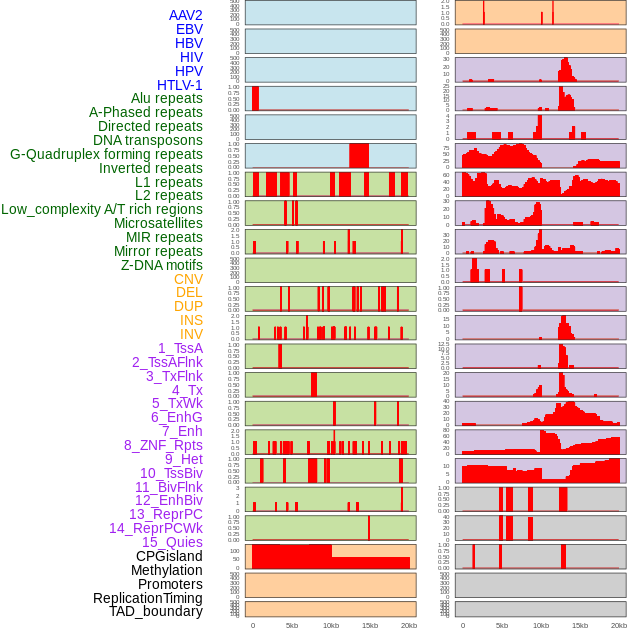 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
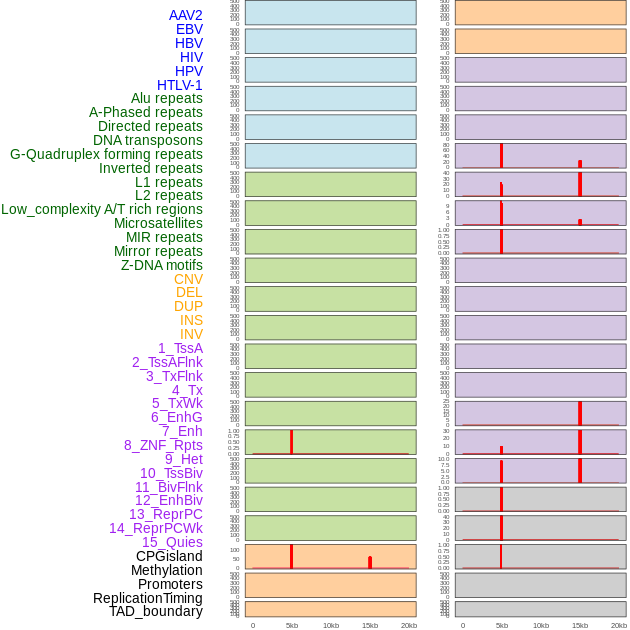 |
Top |
Fusion Protein Features for NFIC-CRB3 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:3452664/chr19:6466477) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NFIC | CRB3 |
| FUNCTION: Recognizes and binds the palindromic sequence 5'-TTGGCNNNNNGCCAA-3' present in viral and cellular promoters and in the origin of replication of adenovirus type 2. These proteins are individually capable of activating transcription and replication. | FUNCTION: Involved in the establishment of cell polarity in mammalian epithelial cells (PubMed:12771187, PubMed:14718572). Regulates the morphogenesis of tight junctions (PubMed:12771187, PubMed:14718572). Involved in promoting phosphorylation and cytoplasmic retention of transcriptional coactivators YAP1 and WWTR1/TAZ which leads to suppression of TGFB1-dependent transcription of target genes such as CCN2/CTGF, SERPINE1/PAI1, SNAI1/SNAIL1 and SMAD7 (By similarity). {ECO:0000250|UniProtKB:Q8QZT4, ECO:0000269|PubMed:12771187, ECO:0000269|PubMed:14718572}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000341919 | + | 8 | 9 | 1_195 | 423 | 429.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000346156 | + | 7 | 9 | 1_195 | 390 | 669.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000395111 | + | 8 | 10 | 1_195 | 414 | 548.3333333333334 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000443272 | + | 8 | 11 | 1_195 | 423 | 509.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000586919 | + | 7 | 8 | 1_195 | 390 | 407.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000589123 | + | 8 | 11 | 1_195 | 414 | 500.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000590282 | + | 8 | 10 | 1_195 | 423 | 461.6666666666667 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000341919 | + | 8 | 9 | 404_412 | 423 | 429.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000395111 | + | 8 | 10 | 404_412 | 414 | 548.3333333333334 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000443272 | + | 8 | 11 | 404_412 | 423 | 509.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000589123 | + | 8 | 11 | 404_412 | 414 | 500.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000590282 | + | 8 | 10 | 404_412 | 423 | 461.6666666666667 | Motif | 9aaTAD |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000308243 | 1 | 3 | 81_120 | 52 | 121.0 | Topological domain | Cytoplasmic | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000356762 | 2 | 5 | 81_120 | 52 | 124.0 | Topological domain | Cytoplasmic | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000598494 | 2 | 4 | 81_120 | 52 | 121.0 | Topological domain | Cytoplasmic | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000600229 | 2 | 4 | 81_120 | 52 | 121.0 | Topological domain | Cytoplasmic | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000308243 | 1 | 3 | 60_80 | 52 | 121.0 | Transmembrane | Helical | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000356762 | 2 | 5 | 60_80 | 52 | 124.0 | Transmembrane | Helical | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000598494 | 2 | 4 | 60_80 | 52 | 121.0 | Transmembrane | Helical | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000600229 | 2 | 4 | 60_80 | 52 | 121.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000346156 | + | 7 | 9 | 404_412 | 390 | 669.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3452664 | chr19:6466477 | ENST00000586919 | + | 7 | 8 | 404_412 | 390 | 407.0 | Motif | 9aaTAD |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000308243 | 1 | 3 | 27_59 | 52 | 121.0 | Topological domain | Extracellular | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000356762 | 2 | 5 | 27_59 | 52 | 124.0 | Topological domain | Extracellular | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000598494 | 2 | 4 | 27_59 | 52 | 121.0 | Topological domain | Extracellular | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000600229 | 2 | 4 | 27_59 | 52 | 121.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for NFIC-CRB3 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58905_58905_1_NFIC-CRB3_NFIC_chr19_3452664_ENST00000341919_CRB3_chr19_6466477_ENST00000356762_length(transcript)=1772nt_BP=1357nt GGGGGGGCGGGGGGGTGGTTTGGAAAAATGACTCAGTAAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGAT GTATTCGTCCCCGCTCTGCCTCACCCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTG GTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCT GCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGA CTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCT CCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCT GGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGC CTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCT GGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGAC TGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCT GCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACAC TTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGA CAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAG CGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCA CACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACC TGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGT GCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCC TCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGG GAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAA >58905_58905_1_NFIC-CRB3_NFIC_chr19_3452664_ENST00000341919_CRB3_chr19_6466477_ENST00000356762_length(amino acids)=494AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- >58905_58905_2_NFIC-CRB3_NFIC_chr19_3452664_ENST00000341919_CRB3_chr19_6466477_ENST00000598494_length(transcript)=2113nt_BP=1357nt GGGGGGGCGGGGGGGTGGTTTGGAAAAATGACTCAGTAAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGAT GTATTCGTCCCCGCTCTGCCTCACCCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTG GTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCT GCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGA CTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCT CCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCT GGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGC CTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCT GGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGAC TGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCT GCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACAC TTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGA CAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAG CGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCA CACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACC TGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGT GCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAA CCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTG TACACCGCAGCTGCCACCGAGACACCAGCCTCTGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGT GCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCT GTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACG GTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCT GGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCA >58905_58905_2_NFIC-CRB3_NFIC_chr19_3452664_ENST00000341919_CRB3_chr19_6466477_ENST00000598494_length(amino acids)=491AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- >58905_58905_3_NFIC-CRB3_NFIC_chr19_3452664_ENST00000341919_CRB3_chr19_6466477_ENST00000600229_length(transcript)=2113nt_BP=1357nt GGGGGGGCGGGGGGGTGGTTTGGAAAAATGACTCAGTAAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGAT GTATTCGTCCCCGCTCTGCCTCACCCAGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTG GTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCT GCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGA CTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCT CCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCT GGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGC CTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCT GGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGAC TGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCT GCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACAC TTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGA CAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAG CGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCA CACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACC TGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGT GCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAA CCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTG TACACCGCAGCTGCCACCGAGACACCAGCCTCTGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGT GCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCT GTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACG GTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCT GGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCA >58905_58905_3_NFIC-CRB3_NFIC_chr19_3452664_ENST00000341919_CRB3_chr19_6466477_ENST00000600229_length(amino acids)=491AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- >58905_58905_4_NFIC-CRB3_NFIC_chr19_3452664_ENST00000346156_CRB3_chr19_6466477_ENST00000356762_length(transcript)=1650nt_BP=1235nt CCCCCCCTCGCCGGGGACCGAGCGCGCTCGCTCCGGCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCG AGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGC GGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGG CCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCA ACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGT TCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACC ACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACGACCGACTTCCAGGAGAGCTTTGTCA CCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGC TGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGC ACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCA ACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGG ACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCG CTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACC CCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCA TCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGG GCACCTACCGGCCCAGTAGCGAGGAGCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCC TGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATC CACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTT >58905_58905_4_NFIC-CRB3_NFIC_chr19_3452664_ENST00000346156_CRB3_chr19_6466477_ENST00000356762_length(amino acids)=461AA_BP=390 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDT TDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSP SSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTA IRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQTEGTYRPSSEEQFSHAAEARAPQD -------------------------------------------------------------- >58905_58905_5_NFIC-CRB3_NFIC_chr19_3452664_ENST00000346156_CRB3_chr19_6466477_ENST00000598494_length(transcript)=1991nt_BP=1235nt CCCCCCCTCGCCGGGGACCGAGCGCGCTCGCTCCGGCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCG AGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGC GGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGG CCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCA ACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGT TCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACC ACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACGACCGACTTCCAGGAGAGCTTTGTCA CCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGC TGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGC ACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCA ACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGG ACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCG CTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACC CCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCA TCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGG GCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCT GAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTC TGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGC AGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCC TTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTC TCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCA GGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTTATATAAAATTAGTAGTGAG >58905_58905_5_NFIC-CRB3_NFIC_chr19_3452664_ENST00000346156_CRB3_chr19_6466477_ENST00000598494_length(amino acids)=458AA_BP=390 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDT TDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSP SSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTA IRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQTEGTYRPSSEEQVGARVPPTPNLK -------------------------------------------------------------- >58905_58905_6_NFIC-CRB3_NFIC_chr19_3452664_ENST00000346156_CRB3_chr19_6466477_ENST00000600229_length(transcript)=1991nt_BP=1235nt CCCCCCCTCGCCGGGGACCGAGCGCGCTCGCTCCGGCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCG AGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGC GGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGG CCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCA ACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGT TCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACC ACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACGACCGACTTCCAGGAGAGCTTTGTCA CCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGC TGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGC ACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCA ACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGG ACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCG CTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACC CCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCA TCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGG GCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCT GAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTC TGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGC AGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCC TTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTC TCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCA GGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTTATATAAAATTAGTAGTGAG >58905_58905_6_NFIC-CRB3_NFIC_chr19_3452664_ENST00000346156_CRB3_chr19_6466477_ENST00000600229_length(amino acids)=458AA_BP=390 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDT TDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSP SSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTA IRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQTEGTYRPSSEEQVGARVPPTPNLK -------------------------------------------------------------- >58905_58905_7_NFIC-CRB3_NFIC_chr19_3452664_ENST00000395111_CRB3_chr19_6466477_ENST00000356762_length(transcript)=1693nt_BP=1278nt GCTCCGGCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTC GCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTC AAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAG TGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGC ATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGAC GGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGAC CTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAG CCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACA CCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTC AGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGC GATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAG ACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATC GCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACC TACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCC AGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTG GCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGTTCTCCCATGCAGCCGAG GCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGT GTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCC >58905_58905_7_NFIC-CRB3_NFIC_chr19_3452664_ENST00000395111_CRB3_chr19_6466477_ENST00000356762_length(amino acids)=485AA_BP=414 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDA EQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGS KRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHP SSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQ -------------------------------------------------------------- >58905_58905_8_NFIC-CRB3_NFIC_chr19_3452664_ENST00000395111_CRB3_chr19_6466477_ENST00000598494_length(transcript)=2034nt_BP=1278nt GCTCCGGCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTC GCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTC AAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAG TGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGC ATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGAC GGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGAC CTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAG CCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACA CCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTC AGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGC GATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAG ACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATC GCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACC TACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCC AGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTG GCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCA CCGACCCCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGG TTGCTGGCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTCTGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTG GTGGGCTCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACC AACTTTTCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACT CCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCA GTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGAT >58905_58905_8_NFIC-CRB3_NFIC_chr19_3452664_ENST00000395111_CRB3_chr19_6466477_ENST00000598494_length(amino acids)=482AA_BP=414 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDA EQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGS KRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHP SSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQ -------------------------------------------------------------- >58905_58905_9_NFIC-CRB3_NFIC_chr19_3452664_ENST00000395111_CRB3_chr19_6466477_ENST00000600229_length(transcript)=2034nt_BP=1278nt GCTCCGGCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTC GCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTC AAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAG TGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGC ATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGAC GGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGAC CTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAG CCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACA CCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTC AGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGC GATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAG ACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATC GCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACC TACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCC AGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTG GCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCA CCGACCCCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGG TTGCTGGCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTCTGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTG GTGGGCTCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACC AACTTTTCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACT CCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCA GTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGAT >58905_58905_9_NFIC-CRB3_NFIC_chr19_3452664_ENST00000395111_CRB3_chr19_6466477_ENST00000600229_length(amino acids)=482AA_BP=414 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDA EQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGS KRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHP SSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQ -------------------------------------------------------------- >58905_58905_10_NFIC-CRB3_NFIC_chr19_3452664_ENST00000443272_CRB3_chr19_6466477_ENST00000356762_length(transcript)=1735nt_BP=1320nt AAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGATGTATTCGTCCCCGCTCTGCCTCACCCAGGATGAGTTC CACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAG AAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCG TCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGC TGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTC ATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGC GTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGC AGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCC GGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAG GGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAA TCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGG ACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCT CCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTG CATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAG GACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTG GTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACC TACCGGCCCAGTAGCGAGGAGCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCC ATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCC AGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTTATATA >58905_58905_10_NFIC-CRB3_NFIC_chr19_3452664_ENST00000443272_CRB3_chr19_6466477_ENST00000356762_length(amino acids)=494AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- >58905_58905_11_NFIC-CRB3_NFIC_chr19_3452664_ENST00000443272_CRB3_chr19_6466477_ENST00000598494_length(transcript)=2076nt_BP=1320nt AAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGATGTATTCGTCCCCGCTCTGCCTCACCCAGGATGAGTTC CACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAG AAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCG TCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGC TGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTC ATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGC GTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGC AGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCC GGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAG GGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAA TCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGG ACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCT CCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTG CATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAG GACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTG GTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACC TACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGAACG CTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTCTGATG GCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAGCTC AGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTTTCT TTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTG CATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAA GAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTTATATAAAATTAGTAGTGAGATGTA >58905_58905_11_NFIC-CRB3_NFIC_chr19_3452664_ENST00000443272_CRB3_chr19_6466477_ENST00000598494_length(amino acids)=491AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- >58905_58905_12_NFIC-CRB3_NFIC_chr19_3452664_ENST00000443272_CRB3_chr19_6466477_ENST00000600229_length(transcript)=2076nt_BP=1320nt AAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGATGTATTCGTCCCCGCTCTGCCTCACCCAGGATGAGTTC CACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAG AAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCG TCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGC TGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTC ATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGC GTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGC AGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCC GGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAG GGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAA TCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGG ACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCT CCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTG CATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAG GACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTG GTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACC TACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGAACG CTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTCTGATG GCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAGCTC AGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTTTCT TTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTG CATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAA GAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTTATATAAAATTAGTAGTGAGATGTA >58905_58905_12_NFIC-CRB3_NFIC_chr19_3452664_ENST00000443272_CRB3_chr19_6466477_ENST00000600229_length(amino acids)=491AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- >58905_58905_13_NFIC-CRB3_NFIC_chr19_3452664_ENST00000586919_CRB3_chr19_6466477_ENST00000356762_length(transcript)=1585nt_BP=1170nt ATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGC AAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAG CAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAG AAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGG CTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCAC CCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACG ACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACA GGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGC ACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCC AGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCA CCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATC GCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCC ATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCG CGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAG CTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGAC TCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGC AGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGA >58905_58905_13_NFIC-CRB3_NFIC_chr19_3452664_ENST00000586919_CRB3_chr19_6466477_ENST00000356762_length(amino acids)=461AA_BP=390 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDT TDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSP SSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTA IRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQTEGTYRPSSEEQFSHAAEARAPQD -------------------------------------------------------------- >58905_58905_14_NFIC-CRB3_NFIC_chr19_3452664_ENST00000586919_CRB3_chr19_6466477_ENST00000598494_length(transcript)=1926nt_BP=1170nt ATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGC AAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAG CAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAG AAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGG CTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCAC CCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACG ACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACA GGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGC ACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCC AGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCA CCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATC GCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCC ATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCG CGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAG CTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAACCTCAAG TTGCCGCCGGAAGAGCGGCTCATCTGAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTGTACACCG CAGCTGCCACCGAGACACCAGCCTCTGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGTGCAGCAT GTTGCCTCTGCTTGGCTGTGCCTGCAGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCTGTGTGTC CAGCAGGCCCCACAACCCCCTCTCCTTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGG GCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGT CAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTAT >58905_58905_14_NFIC-CRB3_NFIC_chr19_3452664_ENST00000586919_CRB3_chr19_6466477_ENST00000598494_length(amino acids)=458AA_BP=390 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDT TDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSP SSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTA IRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQTEGTYRPSSEEQVGARVPPTPNLK -------------------------------------------------------------- >58905_58905_15_NFIC-CRB3_NFIC_chr19_3452664_ENST00000586919_CRB3_chr19_6466477_ENST00000600229_length(transcript)=1926nt_BP=1170nt ATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGC AAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAG CAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAG AAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGG CTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCAC CCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGACACG ACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACA GGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGC ACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCC AGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCA CCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATC GCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCC ATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCG CGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAG CTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAACCTCAAG TTGCCGCCGGAAGAGCGGCTCATCTGAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTGTACACCG CAGCTGCCACCGAGACACCAGCCTCTGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGTGCAGCAT GTTGCCTCTGCTTGGCTGTGCCTGCAGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCTGTGTGTC CAGCAGGCCCCACAACCCCCTCTCCTTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGG GCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGT CAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTAT >58905_58905_15_NFIC-CRB3_NFIC_chr19_3452664_ENST00000586919_CRB3_chr19_6466477_ENST00000600229_length(amino acids)=458AA_BP=390 MDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECREDFVLSITGK KAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYLAYFVRERDT TDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSP SSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTA IRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALLVRKLREKRQTEGTYRPSSEEQVGARVPPTPNLK -------------------------------------------------------------- >58905_58905_16_NFIC-CRB3_NFIC_chr19_3452664_ENST00000589123_CRB3_chr19_6466477_ENST00000356762_length(transcript)=1777nt_BP=1362nt GCTCGCTCCCTCCCCCGCGCGCCCTCCCTCGCCGCCTCCTCCCGCCGCCTGCGGCCCCCCCCTCGCCGGGGACCGAGCGCGCTCGCTCCG GCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTAC ACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGAC GAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGC GAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGAC TGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAG CGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTAC CTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATC ACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTG GTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGA ACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTAC TACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAG ATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTG CACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTC CCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAG CAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTG TTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGTTCTCCCATGCAGCCGAGGCCCGG GCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACC TTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAG >58905_58905_16_NFIC-CRB3_NFIC_chr19_3452664_ENST00000589123_CRB3_chr19_6466477_ENST00000356762_length(amino acids)=509AA_BP=438 MRPPPRRGPSALAPAPASPPRSSAMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASR LLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQ PHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGH LAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPR LSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVF -------------------------------------------------------------- >58905_58905_17_NFIC-CRB3_NFIC_chr19_3452664_ENST00000589123_CRB3_chr19_6466477_ENST00000598494_length(transcript)=2118nt_BP=1362nt GCTCGCTCCCTCCCCCGCGCGCCCTCCCTCGCCGCCTCCTCCCGCCGCCTGCGGCCCCCCCCTCGCCGGGGACCGAGCGCGCTCGCTCCG GCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTAC ACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGAC GAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGC GAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGAC TGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAG CGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTAC CTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATC ACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTG GTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGA ACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTAC TACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAG ATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTG CACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTC CCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAG CAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTG TTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACC CCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTG GCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTCTGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGC TCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTT TCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGG AGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCC TCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCT >58905_58905_17_NFIC-CRB3_NFIC_chr19_3452664_ENST00000589123_CRB3_chr19_6466477_ENST00000598494_length(amino acids)=506AA_BP=438 MRPPPRRGPSALAPAPASPPRSSAMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASR LLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQ PHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGH LAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPR LSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVF -------------------------------------------------------------- >58905_58905_18_NFIC-CRB3_NFIC_chr19_3452664_ENST00000589123_CRB3_chr19_6466477_ENST00000600229_length(transcript)=2118nt_BP=1362nt GCTCGCTCCCTCCCCCGCGCGCCCTCCCTCGCCGCCTCCTCCCGCCGCCTGCGGCCCCCCCCTCGCCGGGGACCGAGCGCGCTCGCTCCG GCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGGATGAGTTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTAC ACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTCAAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGAC GAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGGGCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGC GAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCGGGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGAC TGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTGGTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAG CGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTGTGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTAC CTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGCGGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATC ACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACCTCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTG GTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTGCAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGA ACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCACAAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTAC TACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAACTGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAG ATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGACTCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTG CACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCTCTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTC CCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCCCAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAG CAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATCGTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTG TTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGCACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACC CCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGAACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTG GCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTCTGATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGC TCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAGCTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTT TCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTTTCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGG AGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCC TCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCT >58905_58905_18_NFIC-CRB3_NFIC_chr19_3452664_ENST00000589123_CRB3_chr19_6466477_ENST00000600229_length(amino acids)=506AA_BP=438 MRPPPRRGPSALAPAPASPPRSSAMDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASR LLAKLRKDIRPECREDFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQ PHHIGVAVKELDLYLAYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGH LAYDLNPASTGLRRTLPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPR LSSFTQHHRPVIAVHSGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVF -------------------------------------------------------------- >58905_58905_19_NFIC-CRB3_NFIC_chr19_3452664_ENST00000590282_CRB3_chr19_6466477_ENST00000356762_length(transcript)=1738nt_BP=1323nt AGTAAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGATGTATTCGTCCCCGCTCTGCCTCACCCAGGATGAG TTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTC AAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGG GCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCG GGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTG GTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTG TGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGC GGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACC TCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTG CAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCAC AAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAAC TGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGAC TCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCT CTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCC CAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATC GTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGC ACCTACCGGCCCAGTAGCGAGGAGCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTG CCCATCTAGGTCCCCTCTCCTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCA CCCAGTGCTTAATAGCAGGGAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTTAT >58905_58905_19_NFIC-CRB3_NFIC_chr19_3452664_ENST00000590282_CRB3_chr19_6466477_ENST00000356762_length(amino acids)=494AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- >58905_58905_20_NFIC-CRB3_NFIC_chr19_3452664_ENST00000590282_CRB3_chr19_6466477_ENST00000598494_length(transcript)=2079nt_BP=1323nt AGTAAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGATGTATTCGTCCCCGCTCTGCCTCACCCAGGATGAG TTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTC AAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGG GCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCG GGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTG GTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTG TGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGC GGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACC TCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTG CAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCAC AAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAAC TGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGAC TCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCT CTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCC CAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATC GTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGC ACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGA ACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTCTG ATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAG CTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTT TCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTC CTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGG GAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTTATATAAAATTAGTAGTGAGAT >58905_58905_20_NFIC-CRB3_NFIC_chr19_3452664_ENST00000590282_CRB3_chr19_6466477_ENST00000598494_length(amino acids)=491AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- >58905_58905_21_NFIC-CRB3_NFIC_chr19_3452664_ENST00000590282_CRB3_chr19_6466477_ENST00000600229_length(transcript)=2079nt_BP=1323nt AGTAAGTTCAGCGCGCCCGCTCCGGCCGGCCCTGCGCCTCCCGCCGCGCCCGGGATGTATTCGTCCCCGCTCTGCCTCACCCAGGATGAG TTCCACCCGTTCATCGAGGCCCTGCTGCCTCACGTCCGCGCCTTCGCCTACACCTGGTTCAACCTGCAGGCGCGGAAGCGCAAGTACTTC AAGAAGCACGAGAAGCGGATGTCGAAGGACGAGGAGCGTGCGGTCAAGGACGAGCTGCTGGGCGAGAAGCCCGAGGTCAAGCAGAAGTGG GCGTCGCGGCTGCTGGCCAAGCTGCGCAAGGACATCCGGCCCGAGTGCCGCGAGGACTTCGTGCTGAGCATCACCGGCAAGAAGGCGCCG GGCTGCGTGCTCTCCAACCCCGACCAGAAGGGCAAGATGCGGCGCATCGACTGTCTCCGGCAGGCGGACAAGGTGTGGCGGCTGGACCTG GTCATGGTCATCCTGTTCAAGGGCATCCCGCTGGAGAGCACCGACGGCGAGCGCCTGGTCAAGGCTGCGCAGTGCGGTCACCCGGTCCTG TGCGTGCAGCCGCACCACATTGGCGTGGCCGTCAAGGAGCTGGACCTCTACCTGGCCTACTTCGTGCGTGAGCGAGATGCAGAGCAAAGC GGCAGTCCCCGGACAGGGATGGGCTCTGACCAGGAGGACAGCAAGCCCATCACGCTGGACACGACCGACTTCCAGGAGAGCTTTGTCACC TCCGGCGTGTTCAGCGTCACTGAGCTCATCCAAGTGTCCCGGACACCCGTGGTGACTGGAACAGGACCCAACTTCTCCCTGGGGGAGCTG CAGGGGCACCTGGCATACGACCTGAACCCAGCCAGCACTGGCCTCAGAAGAACGCTGCCCAGCACCTCCTCCAGTGGGAGCAAGCGGCAC AAATCGGGCTCGATGGAGGAAGACGTGGACACGAGCCCTGGCGGCGATTACTACACTTCGCCCAGCTCGCCCACGAGTAGCAGCCGCAAC TGGACGGAGGACATGGAAGGAGGCATCTCGTCCCCGGTGAAGAAGACAGAGATGGACAAGTCACCATTCAACAGCCCGTCCCCCCAGGAC TCTCCCCGCCTCTCCAGCTTCACCCAGCACCACCGGCCCGTCATCGCCGTGCACAGCGGGATCGCCCGGAGCCCACACCCGTCCTCCGCT CTGCATTTCCCTACGACGTCCATCCTACCCCAGACGGCCTCCACCTACTTCCCCCACACGGCCATCCGCTACCCACCTCATCTCAACCCC CAGGACCCGCTCAAAGATCTTGTCTCGCTGGCCTGCGACCCAGCCAGCCAGCAACCTGGACCGCGTCCAGAAGCCATCACTGCTATCATC GTGGTCTTCTCCCTCTTGGCTGCCTTGCTCCTGGCTGTGGGGCTGGCACTGTTGGTGCGGAAGCTTCGGGAGAAGCGGCAGACGGAGGGC ACCTACCGGCCCAGTAGCGAGGAGCAGGTGGGTGCCCGCGTGCCACCGACCCCCAACCTCAAGTTGCCGCCGGAAGAGCGGCTCATCTGA ACGCTGGGGCCTGCTGCAGCCACCAACACTGCCCAGGACTGCGGGTTGCTGGCTTGTACACCGCAGCTGCCACCGAGACACCAGCCTCTG ATGGCTCAGGAGGACTTGTGGGGAGAGGCTGGGGGCACCCATGTGGTGGGCTCTGTGCAGCATGTTGCCTCTGCTTGGCTGTGCCTGCAG CTCAGGGTGCTGGGGCTCGGGACCCACCCCCCTGCTTGCGGAACCAACTTTTCTCTGTGTGTCCAGCAGGCCCCACAACCCCCTCTCCTT TCTTTCAGTTCTCCCATGCAGCCGAGGCCCGGGCCCCTCAGGACTCCAAGGAGACGGTGCAGGGCTGCCTGCCCATCTAGGTCCCCTCTC CTGCATCTGTCTCCCTTCATTGCTGTGTGACCTTGGGGAAAGGCAGTGCCCTCTCTGGGCAGTCAGATCCACCCAGTGCTTAATAGCAGG GAAGAAGGTACTTCAAAGACTCTGCCCCTGAGGTCAAGAGAGGATGGGGCTATTCACTTTTATATATTTATATAAAATTAGTAGTGAGAT >58905_58905_21_NFIC-CRB3_NFIC_chr19_3452664_ENST00000590282_CRB3_chr19_6466477_ENST00000600229_length(amino acids)=491AA_BP=423 MYSSPLCLTQDEFHPFIEALLPHVRAFAYTWFNLQARKRKYFKKHEKRMSKDEERAVKDELLGEKPEVKQKWASRLLAKLRKDIRPECRE DFVLSITGKKAPGCVLSNPDQKGKMRRIDCLRQADKVWRLDLVMVILFKGIPLESTDGERLVKAAQCGHPVLCVQPHHIGVAVKELDLYL AYFVRERDAEQSGSPRTGMGSDQEDSKPITLDTTDFQESFVTSGVFSVTELIQVSRTPVVTGTGPNFSLGELQGHLAYDLNPASTGLRRT LPSTSSSGSKRHKSGSMEEDVDTSPGGDYYTSPSSPTSSSRNWTEDMEGGISSPVKKTEMDKSPFNSPSPQDSPRLSSFTQHHRPVIAVH SGIARSPHPSSALHFPTTSILPQTASTYFPHTAIRYPPHLNPQDPLKDLVSLACDPASQQPGPRPEAITAIIVVFSLLAALLLAVGLALL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NFIC-CRB3 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000308243 | 1 | 3 | 84_120 | 52.0 | 121.0 | EPB41L5 | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000356762 | 2 | 5 | 84_120 | 52.0 | 124.0 | EPB41L5 | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000598494 | 2 | 4 | 84_120 | 52.0 | 121.0 | EPB41L5 | |
| Tgene | CRB3 | chr19:3452664 | chr19:6466477 | ENST00000600229 | 2 | 4 | 84_120 | 52.0 | 121.0 | EPB41L5 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NFIC-CRB3 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NFIC-CRB3 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies