
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NFIC-SPATA33 (FusionGDB2 ID:58925) |
Fusion Gene Summary for NFIC-SPATA33 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NFIC-SPATA33 | Fusion gene ID: 58925 | Hgene | Tgene | Gene symbol | NFIC | SPATA33 | Gene ID | 4782 | 124045 |
| Gene name | nuclear factor I C | spermatogenesis associated 33 | |
| Synonyms | CTF|CTF5|NF-I|NFI | C16orf55 | |
| Cytomap | 19p13.3 | 16q24.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nuclear factor 1 C-typeCCAAT-box-binding transcription factorNF-I/CNF1-CTGGCA-binding proteinnuclear factor I/C (CCAAT-binding transcription factor) | spermatogenesis-associated protein 33 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P08651 | Q96N06 | |
| Ensembl transtripts involved in fusion gene | ENST00000346156, ENST00000395111, ENST00000586919, ENST00000589123, ENST00000341919, ENST00000443272, ENST00000588839, ENST00000590282, | ENST00000566857, ENST00000568929, ENST00000579310, ENST00000301031, | |
| Fusion gene scores | * DoF score | 30 X 20 X 13=7800 | 3 X 1 X 3=9 |
| # samples | 36 | 3 | |
| ** MAII score | log2(36/7800*10)=-4.4374053123073 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/9*10)=1.73696559416621 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: NFIC [Title/Abstract] AND SPATA33 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NFIC(3359683)-SPATA33(89735694), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | NFIC-SPATA33 seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NFIC | GO:0000122 | negative regulation of transcription by RNA polymerase II | 19706729 |
| Hgene | NFIC | GO:0045944 | positive regulation of transcription by RNA polymerase II | 1524678|19706729 |
| Fusion gene breakpoints across NFIC (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SPATA33 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ACC | TCGA-OR-A5K2-01A | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
Top |
Fusion Gene ORF analysis for NFIC-SPATA33 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000346156 | ENST00000566857 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| 5CDS-intron | ENST00000346156 | ENST00000568929 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| 5CDS-intron | ENST00000395111 | ENST00000566857 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| 5CDS-intron | ENST00000395111 | ENST00000568929 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| 5CDS-intron | ENST00000586919 | ENST00000566857 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| 5CDS-intron | ENST00000586919 | ENST00000568929 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| 5CDS-intron | ENST00000589123 | ENST00000566857 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| 5CDS-intron | ENST00000589123 | ENST00000568929 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| Frame-shift | ENST00000346156 | ENST00000579310 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| Frame-shift | ENST00000395111 | ENST00000579310 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| Frame-shift | ENST00000586919 | ENST00000579310 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| Frame-shift | ENST00000589123 | ENST00000579310 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| In-frame | ENST00000346156 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| In-frame | ENST00000395111 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| In-frame | ENST00000586919 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| In-frame | ENST00000589123 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-3CDS | ENST00000341919 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-3CDS | ENST00000341919 | ENST00000579310 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-3CDS | ENST00000443272 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-3CDS | ENST00000443272 | ENST00000579310 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-3CDS | ENST00000588839 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-3CDS | ENST00000588839 | ENST00000579310 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-3CDS | ENST00000590282 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-3CDS | ENST00000590282 | ENST00000579310 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-intron | ENST00000341919 | ENST00000566857 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-intron | ENST00000341919 | ENST00000568929 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-intron | ENST00000443272 | ENST00000566857 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-intron | ENST00000443272 | ENST00000568929 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-intron | ENST00000588839 | ENST00000566857 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-intron | ENST00000588839 | ENST00000568929 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-intron | ENST00000590282 | ENST00000566857 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| intron-intron | ENST00000590282 | ENST00000568929 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000589123 | NFIC | chr19 | 3359683 | + | ENST00000301031 | SPATA33 | chr16 | 89735694 | + | 2105 | 123 | 1212 | 310 | 300 |
| ENST00000346156 | NFIC | chr19 | 3359683 | + | ENST00000301031 | SPATA33 | chr16 | 89735694 | + | 2050 | 68 | 1157 | 255 | 300 |
| ENST00000395111 | NFIC | chr19 | 3359683 | + | ENST00000301031 | SPATA33 | chr16 | 89735694 | + | 2021 | 39 | 1128 | 226 | 300 |
| ENST00000586919 | NFIC | chr19 | 3359683 | + | ENST00000301031 | SPATA33 | chr16 | 89735694 | + | 1985 | 3 | 1092 | 190 | 300 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000589123 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + | 0.8437852 | 0.1562148 |
| ENST00000346156 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + | 0.93350047 | 0.066499546 |
| ENST00000395111 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + | 0.9768088 | 0.023191275 |
| ENST00000586919 | ENST00000301031 | NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735694 | + | 0.9808921 | 0.019107908 |
Top |
Fusion Genomic Features for NFIC-SPATA33 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735693 | + | 0.000394873 | 0.9996051 |
| NFIC | chr19 | 3359683 | + | SPATA33 | chr16 | 89735693 | + | 0.000394873 | 0.9996051 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
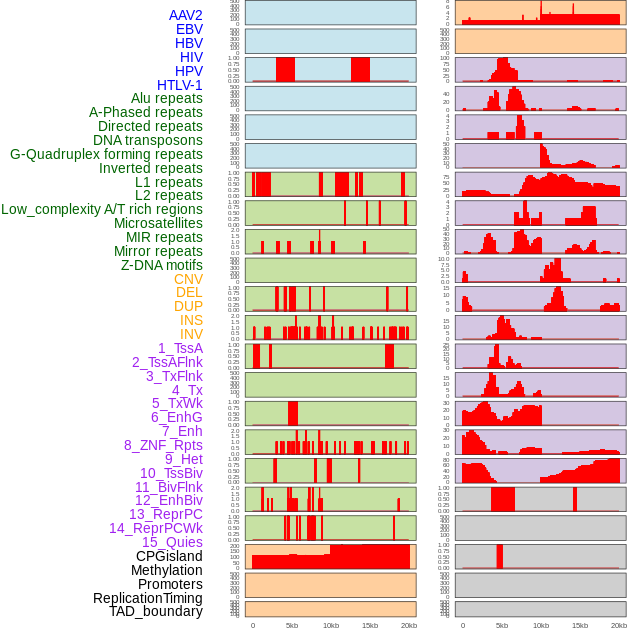 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
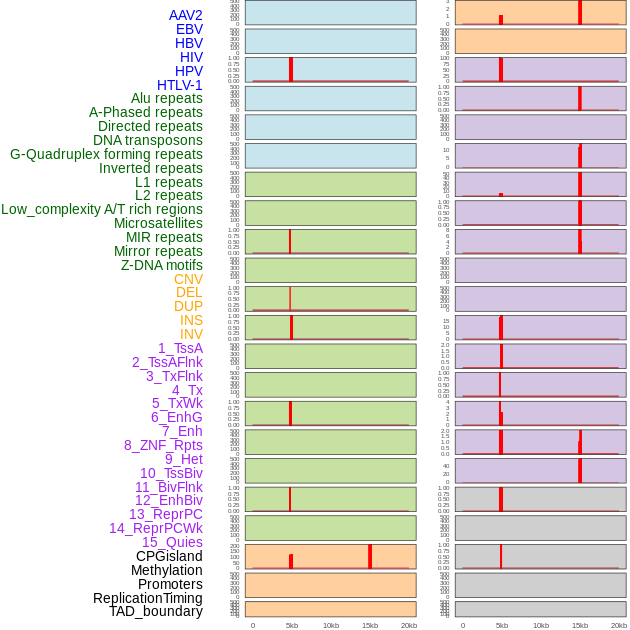 |
Top |
Fusion Protein Features for NFIC-SPATA33 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:3359683/chr16:89735694) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NFIC | SPATA33 |
| FUNCTION: Recognizes and binds the palindromic sequence 5'-TTGGCNNNNNGCCAA-3' present in viral and cellular promoters and in the origin of replication of adenovirus type 2. These proteins are individually capable of activating transcription and replication. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000341919 | + | 1 | 9 | 1_195 | 0 | 429.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000346156 | + | 1 | 9 | 1_195 | 1 | 669.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000395111 | + | 1 | 10 | 1_195 | 1 | 548.3333333333334 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000443272 | + | 1 | 11 | 1_195 | 0 | 509.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000586919 | + | 1 | 8 | 1_195 | 1 | 407.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000589123 | + | 1 | 11 | 1_195 | 1 | 500.0 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000590282 | + | 1 | 10 | 1_195 | 0 | 461.6666666666667 | DNA binding | CTF/NF-I |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000341919 | + | 1 | 9 | 404_412 | 0 | 429.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000346156 | + | 1 | 9 | 404_412 | 1 | 669.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000395111 | + | 1 | 10 | 404_412 | 1 | 548.3333333333334 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000443272 | + | 1 | 11 | 404_412 | 0 | 509.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000586919 | + | 1 | 8 | 404_412 | 1 | 407.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000589123 | + | 1 | 11 | 404_412 | 1 | 500.0 | Motif | 9aaTAD |
| Hgene | NFIC | chr19:3359683 | chr16:89735694 | ENST00000590282 | + | 1 | 10 | 404_412 | 0 | 461.6666666666667 | Motif | 9aaTAD |
Top |
Fusion Gene Sequence for NFIC-SPATA33 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >58925_58925_1_NFIC-SPATA33_NFIC_chr19_3359683_ENST00000346156_SPATA33_chr16_89735694_ENST00000301031_length(transcript)=2050nt_BP=68nt CCCCCCCTCGCCGGGGACCGAGCGCGCTCGCTCCGGCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGAGAAACCTGATGTAAAGCAAAA GTCCAGCAGGAAGAAAGTGGTCGTTCCACAGATCATCATCACGCGAGCGTCGAATGAGACGCTAGTCAGTTGCAGTTCCAGCGGGAGTGA CCAGCAGAGAACCATTCGGGAGCCGGAGGACTGGGGCCCCTACCGGCGGCACAGGAACCCCAGTACAGCAGACGCCTATAATTCACATCT CAAAGAATAAACAAGCACCTTTGCATGGCACTCGCTACTCCCTGCGATAGGCGTCTCGGGAACAGCCGCCTCACCCTGTGAGAAGCCGAG GCCCCTTCTCCAGTGCTCTCGGGGAGGTTGCACCAGGCCCACCCCACCCTGTGAGAAACTGCAGCCCCCTTCTCCAGTGCTTTCGGGGAG GGTGCACCAGGCCCGCCCCACCTTGTGAGAAGCCGTGGCCCCCTTCTCCAGTGCTCTCAGGGAGGGTGCACCAGGCCTGCCCCCGCCGTG AGAAACTGCAGTCCCCTTCTCCAGTGCTCTCGGGGAGGGTGCACCAGGCCCACCCCACCCTGTGAGAACCTGCAGCCCCCTTCTCCAATG CTCTCGGGGAGGGTACACCAGGGTTGCCCCACCCTGTGAGAAGCCACCGCCCCCTTCTCCAGTGCTCTCGGGGAGGGTGCACCAGGGCTG CCCCACGCTGTAAGAAGCCGCCGCCCCCTTCTCCAGTGCTCTCCAGCCCGCCCCACCCTGTGAGAAGCCATGGCCCCTTCTCCAGTGCTT TTGGGGAGGGTGCACCAGGGCCACCCCACCCTGTGAGAAGCCGTGGCCCCCTTCTCCAGTGCTTTCGGGGAGGGTACACCAGGCCCGCCC CACCCTGTGAGAAGCCGTGGCCCCCTTCTCCCGTGCTCTCAGGGAGGGTGCACCAGGCCTGCCCCCGCCTTGAGAAACTGCAGCCCCCTT CTCCAGTGCTCTGGGGGAGGGTGCACCAGGCCTGCCCACCCTGTGAGAAACTGCACCCCCTTCTCCAGTGCTCTCGGGGAGGGTGCACCA GGCCCGCCCCACCCTGTGAGAAGCCGCAGCCCGTTCTCCATTGCCATTTGGTCCTGCCTTCCCCAGAGCTGCTAGCAGCTCGGTCGAGGC AAGAGTGACTGGCTCAGAGAGCGAGCTTTGTGGTATTGATAAATGAATAAATTAGTATGTTCATGTTGGAAGTGGCTGGCTCTGCAGAGT GATGGACAGCAGGTGGCATCTTACATTGTGATTTGTGGTGCACAGTTAAAACACTTCCCTTCGTTTCAGAAGGAGACAATGTGAATACTT GGAAATTATAGTGAATAAGATGCCTCCCAAACTTGAGGAAAAGGTCAGATTCTAAGAGCTAAACGTTAAGATGTAATGTTCCAGAACAAA GAGGCCCAGAGTCACTGAACGGGGCCCCAGGGCTCCTAGCTTGAGTGTAATCTGAGTCAGCTTATGAAAAGGCCCCAAAGAAGAAAGTGG AATGTGTGCTGGGCACATGGGACAGCCATGGCACTGAGACTTTGGAAGTGGCCTTGCCAGCGCTGTCCTGTCTTTCTGGCCCACAGATGA GGGCTCCTGATTGTGGAAGGCCACGGAAGGGACCTGAACACGATGGCACGAGACAAGTTATCTCCTGTGACTGCTCCTCTCCAGCAACCC TCAGCTCAGGCTAGACTTTCCCCCTGTGTTGAGAATGCCCTGCCCTGTGTGGAAGCCTGATGCATTTAGTGACAGTGTGTTAGCTTTGTT AGTTTCTAGTCTGGCCAGCAGGCTTTCCATGTGATCTGCCATTGGCTTGCTTCAGTGGCCAGTGGAGCCAGGGGTGTCCACCAGAGTCTT GGACACAGACTTCTGAGGTGGCAGCGGGAGGGAGCCTGCTCCCTGCCACACACGTACAATTTCTAATCCATACAGGCCTATGTAGTATAT >58925_58925_1_NFIC-SPATA33_NFIC_chr19_3359683_ENST00000346156_SPATA33_chr16_89735694_ENST00000301031_length(amino acids)=300AA_BP=16 MLAALGKAGPNGNGERAAASHRVGRAWCTLPESTGEGGAVSHRVGRPGAPSPRALEKGAAVSQGGGRPGAPSLRAREKGATASHRVGRAW CTLPESTGEGGHGFSQGGVALVHPPQKHWRRGHGFSQGGAGWRALEKGAAASYSVGQPWCTLPESTGEGGGGFSQGGATLVYPPREHWRR GLQVLTGWGGPGAPSPRALEKGTAVSHGGGRPGAPSLRALEKGATASHKVGRAWCTLPESTGEGGCSFSQGGVGLVQPPREHWRRGLGFS -------------------------------------------------------------- >58925_58925_2_NFIC-SPATA33_NFIC_chr19_3359683_ENST00000395111_SPATA33_chr16_89735694_ENST00000301031_length(transcript)=2021nt_BP=39nt GCTCCGGCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGAGAAACCTGATGTAAAGCAAAAGTCCAGCAGGAAGAAAGTGGTCGTTCCAC AGATCATCATCACGCGAGCGTCGAATGAGACGCTAGTCAGTTGCAGTTCCAGCGGGAGTGACCAGCAGAGAACCATTCGGGAGCCGGAGG ACTGGGGCCCCTACCGGCGGCACAGGAACCCCAGTACAGCAGACGCCTATAATTCACATCTCAAAGAATAAACAAGCACCTTTGCATGGC ACTCGCTACTCCCTGCGATAGGCGTCTCGGGAACAGCCGCCTCACCCTGTGAGAAGCCGAGGCCCCTTCTCCAGTGCTCTCGGGGAGGTT GCACCAGGCCCACCCCACCCTGTGAGAAACTGCAGCCCCCTTCTCCAGTGCTTTCGGGGAGGGTGCACCAGGCCCGCCCCACCTTGTGAG AAGCCGTGGCCCCCTTCTCCAGTGCTCTCAGGGAGGGTGCACCAGGCCTGCCCCCGCCGTGAGAAACTGCAGTCCCCTTCTCCAGTGCTC TCGGGGAGGGTGCACCAGGCCCACCCCACCCTGTGAGAACCTGCAGCCCCCTTCTCCAATGCTCTCGGGGAGGGTACACCAGGGTTGCCC CACCCTGTGAGAAGCCACCGCCCCCTTCTCCAGTGCTCTCGGGGAGGGTGCACCAGGGCTGCCCCACGCTGTAAGAAGCCGCCGCCCCCT TCTCCAGTGCTCTCCAGCCCGCCCCACCCTGTGAGAAGCCATGGCCCCTTCTCCAGTGCTTTTGGGGAGGGTGCACCAGGGCCACCCCAC CCTGTGAGAAGCCGTGGCCCCCTTCTCCAGTGCTTTCGGGGAGGGTACACCAGGCCCGCCCCACCCTGTGAGAAGCCGTGGCCCCCTTCT CCCGTGCTCTCAGGGAGGGTGCACCAGGCCTGCCCCCGCCTTGAGAAACTGCAGCCCCCTTCTCCAGTGCTCTGGGGGAGGGTGCACCAG GCCTGCCCACCCTGTGAGAAACTGCACCCCCTTCTCCAGTGCTCTCGGGGAGGGTGCACCAGGCCCGCCCCACCCTGTGAGAAGCCGCAG CCCGTTCTCCATTGCCATTTGGTCCTGCCTTCCCCAGAGCTGCTAGCAGCTCGGTCGAGGCAAGAGTGACTGGCTCAGAGAGCGAGCTTT GTGGTATTGATAAATGAATAAATTAGTATGTTCATGTTGGAAGTGGCTGGCTCTGCAGAGTGATGGACAGCAGGTGGCATCTTACATTGT GATTTGTGGTGCACAGTTAAAACACTTCCCTTCGTTTCAGAAGGAGACAATGTGAATACTTGGAAATTATAGTGAATAAGATGCCTCCCA AACTTGAGGAAAAGGTCAGATTCTAAGAGCTAAACGTTAAGATGTAATGTTCCAGAACAAAGAGGCCCAGAGTCACTGAACGGGGCCCCA GGGCTCCTAGCTTGAGTGTAATCTGAGTCAGCTTATGAAAAGGCCCCAAAGAAGAAAGTGGAATGTGTGCTGGGCACATGGGACAGCCAT GGCACTGAGACTTTGGAAGTGGCCTTGCCAGCGCTGTCCTGTCTTTCTGGCCCACAGATGAGGGCTCCTGATTGTGGAAGGCCACGGAAG GGACCTGAACACGATGGCACGAGACAAGTTATCTCCTGTGACTGCTCCTCTCCAGCAACCCTCAGCTCAGGCTAGACTTTCCCCCTGTGT TGAGAATGCCCTGCCCTGTGTGGAAGCCTGATGCATTTAGTGACAGTGTGTTAGCTTTGTTAGTTTCTAGTCTGGCCAGCAGGCTTTCCA TGTGATCTGCCATTGGCTTGCTTCAGTGGCCAGTGGAGCCAGGGGTGTCCACCAGAGTCTTGGACACAGACTTCTGAGGTGGCAGCGGGA GGGAGCCTGCTCCCTGCCACACACGTACAATTTCTAATCCATACAGGCCTATGTAGTATATACACACATACGCAGAGCCTTAGGAATTGT >58925_58925_2_NFIC-SPATA33_NFIC_chr19_3359683_ENST00000395111_SPATA33_chr16_89735694_ENST00000301031_length(amino acids)=300AA_BP=16 MLAALGKAGPNGNGERAAASHRVGRAWCTLPESTGEGGAVSHRVGRPGAPSPRALEKGAAVSQGGGRPGAPSLRAREKGATASHRVGRAW CTLPESTGEGGHGFSQGGVALVHPPQKHWRRGHGFSQGGAGWRALEKGAAASYSVGQPWCTLPESTGEGGGGFSQGGATLVYPPREHWRR GLQVLTGWGGPGAPSPRALEKGTAVSHGGGRPGAPSLRALEKGATASHKVGRAWCTLPESTGEGGCSFSQGGVGLVQPPREHWRRGLGFS -------------------------------------------------------------- >58925_58925_3_NFIC-SPATA33_NFIC_chr19_3359683_ENST00000586919_SPATA33_chr16_89735694_ENST00000301031_length(transcript)=1985nt_BP=3nt ATGAGAAACCTGATGTAAAGCAAAAGTCCAGCAGGAAGAAAGTGGTCGTTCCACAGATCATCATCACGCGAGCGTCGAATGAGACGCTAG TCAGTTGCAGTTCCAGCGGGAGTGACCAGCAGAGAACCATTCGGGAGCCGGAGGACTGGGGCCCCTACCGGCGGCACAGGAACCCCAGTA CAGCAGACGCCTATAATTCACATCTCAAAGAATAAACAAGCACCTTTGCATGGCACTCGCTACTCCCTGCGATAGGCGTCTCGGGAACAG CCGCCTCACCCTGTGAGAAGCCGAGGCCCCTTCTCCAGTGCTCTCGGGGAGGTTGCACCAGGCCCACCCCACCCTGTGAGAAACTGCAGC CCCCTTCTCCAGTGCTTTCGGGGAGGGTGCACCAGGCCCGCCCCACCTTGTGAGAAGCCGTGGCCCCCTTCTCCAGTGCTCTCAGGGAGG GTGCACCAGGCCTGCCCCCGCCGTGAGAAACTGCAGTCCCCTTCTCCAGTGCTCTCGGGGAGGGTGCACCAGGCCCACCCCACCCTGTGA GAACCTGCAGCCCCCTTCTCCAATGCTCTCGGGGAGGGTACACCAGGGTTGCCCCACCCTGTGAGAAGCCACCGCCCCCTTCTCCAGTGC TCTCGGGGAGGGTGCACCAGGGCTGCCCCACGCTGTAAGAAGCCGCCGCCCCCTTCTCCAGTGCTCTCCAGCCCGCCCCACCCTGTGAGA AGCCATGGCCCCTTCTCCAGTGCTTTTGGGGAGGGTGCACCAGGGCCACCCCACCCTGTGAGAAGCCGTGGCCCCCTTCTCCAGTGCTTT CGGGGAGGGTACACCAGGCCCGCCCCACCCTGTGAGAAGCCGTGGCCCCCTTCTCCCGTGCTCTCAGGGAGGGTGCACCAGGCCTGCCCC CGCCTTGAGAAACTGCAGCCCCCTTCTCCAGTGCTCTGGGGGAGGGTGCACCAGGCCTGCCCACCCTGTGAGAAACTGCACCCCCTTCTC CAGTGCTCTCGGGGAGGGTGCACCAGGCCCGCCCCACCCTGTGAGAAGCCGCAGCCCGTTCTCCATTGCCATTTGGTCCTGCCTTCCCCA GAGCTGCTAGCAGCTCGGTCGAGGCAAGAGTGACTGGCTCAGAGAGCGAGCTTTGTGGTATTGATAAATGAATAAATTAGTATGTTCATG TTGGAAGTGGCTGGCTCTGCAGAGTGATGGACAGCAGGTGGCATCTTACATTGTGATTTGTGGTGCACAGTTAAAACACTTCCCTTCGTT TCAGAAGGAGACAATGTGAATACTTGGAAATTATAGTGAATAAGATGCCTCCCAAACTTGAGGAAAAGGTCAGATTCTAAGAGCTAAACG TTAAGATGTAATGTTCCAGAACAAAGAGGCCCAGAGTCACTGAACGGGGCCCCAGGGCTCCTAGCTTGAGTGTAATCTGAGTCAGCTTAT GAAAAGGCCCCAAAGAAGAAAGTGGAATGTGTGCTGGGCACATGGGACAGCCATGGCACTGAGACTTTGGAAGTGGCCTTGCCAGCGCTG TCCTGTCTTTCTGGCCCACAGATGAGGGCTCCTGATTGTGGAAGGCCACGGAAGGGACCTGAACACGATGGCACGAGACAAGTTATCTCC TGTGACTGCTCCTCTCCAGCAACCCTCAGCTCAGGCTAGACTTTCCCCCTGTGTTGAGAATGCCCTGCCCTGTGTGGAAGCCTGATGCAT TTAGTGACAGTGTGTTAGCTTTGTTAGTTTCTAGTCTGGCCAGCAGGCTTTCCATGTGATCTGCCATTGGCTTGCTTCAGTGGCCAGTGG AGCCAGGGGTGTCCACCAGAGTCTTGGACACAGACTTCTGAGGTGGCAGCGGGAGGGAGCCTGCTCCCTGCCACACACGTACAATTTCTA ATCCATACAGGCCTATGTAGTATATACACACATACGCAGAGCCTTAGGAATTGTGAAAGGCCAATCAAAACTTGGGGCCCTAATTTCACT >58925_58925_3_NFIC-SPATA33_NFIC_chr19_3359683_ENST00000586919_SPATA33_chr16_89735694_ENST00000301031_length(amino acids)=300AA_BP=16 MLAALGKAGPNGNGERAAASHRVGRAWCTLPESTGEGGAVSHRVGRPGAPSPRALEKGAAVSQGGGRPGAPSLRAREKGATASHRVGRAW CTLPESTGEGGHGFSQGGVALVHPPQKHWRRGHGFSQGGAGWRALEKGAAASYSVGQPWCTLPESTGEGGGGFSQGGATLVYPPREHWRR GLQVLTGWGGPGAPSPRALEKGTAVSHGGGRPGAPSLRALEKGATASHKVGRAWCTLPESTGEGGCSFSQGGVGLVQPPREHWRRGLGFS -------------------------------------------------------------- >58925_58925_4_NFIC-SPATA33_NFIC_chr19_3359683_ENST00000589123_SPATA33_chr16_89735694_ENST00000301031_length(transcript)=2105nt_BP=123nt GCTCGCTCCCTCCCCCGCGCGCCCTCCCTCGCCGCCTCCTCCCGCCGCCTGCGGCCCCCCCCTCGCCGGGGACCGAGCGCGCTCGCTCCG GCGCCGGCCTCGCCTCCTCGCAGCAGCGCCATGAGAAACCTGATGTAAAGCAAAAGTCCAGCAGGAAGAAAGTGGTCGTTCCACAGATCA TCATCACGCGAGCGTCGAATGAGACGCTAGTCAGTTGCAGTTCCAGCGGGAGTGACCAGCAGAGAACCATTCGGGAGCCGGAGGACTGGG GCCCCTACCGGCGGCACAGGAACCCCAGTACAGCAGACGCCTATAATTCACATCTCAAAGAATAAACAAGCACCTTTGCATGGCACTCGC TACTCCCTGCGATAGGCGTCTCGGGAACAGCCGCCTCACCCTGTGAGAAGCCGAGGCCCCTTCTCCAGTGCTCTCGGGGAGGTTGCACCA GGCCCACCCCACCCTGTGAGAAACTGCAGCCCCCTTCTCCAGTGCTTTCGGGGAGGGTGCACCAGGCCCGCCCCACCTTGTGAGAAGCCG TGGCCCCCTTCTCCAGTGCTCTCAGGGAGGGTGCACCAGGCCTGCCCCCGCCGTGAGAAACTGCAGTCCCCTTCTCCAGTGCTCTCGGGG AGGGTGCACCAGGCCCACCCCACCCTGTGAGAACCTGCAGCCCCCTTCTCCAATGCTCTCGGGGAGGGTACACCAGGGTTGCCCCACCCT GTGAGAAGCCACCGCCCCCTTCTCCAGTGCTCTCGGGGAGGGTGCACCAGGGCTGCCCCACGCTGTAAGAAGCCGCCGCCCCCTTCTCCA GTGCTCTCCAGCCCGCCCCACCCTGTGAGAAGCCATGGCCCCTTCTCCAGTGCTTTTGGGGAGGGTGCACCAGGGCCACCCCACCCTGTG AGAAGCCGTGGCCCCCTTCTCCAGTGCTTTCGGGGAGGGTACACCAGGCCCGCCCCACCCTGTGAGAAGCCGTGGCCCCCTTCTCCCGTG CTCTCAGGGAGGGTGCACCAGGCCTGCCCCCGCCTTGAGAAACTGCAGCCCCCTTCTCCAGTGCTCTGGGGGAGGGTGCACCAGGCCTGC CCACCCTGTGAGAAACTGCACCCCCTTCTCCAGTGCTCTCGGGGAGGGTGCACCAGGCCCGCCCCACCCTGTGAGAAGCCGCAGCCCGTT CTCCATTGCCATTTGGTCCTGCCTTCCCCAGAGCTGCTAGCAGCTCGGTCGAGGCAAGAGTGACTGGCTCAGAGAGCGAGCTTTGTGGTA TTGATAAATGAATAAATTAGTATGTTCATGTTGGAAGTGGCTGGCTCTGCAGAGTGATGGACAGCAGGTGGCATCTTACATTGTGATTTG TGGTGCACAGTTAAAACACTTCCCTTCGTTTCAGAAGGAGACAATGTGAATACTTGGAAATTATAGTGAATAAGATGCCTCCCAAACTTG AGGAAAAGGTCAGATTCTAAGAGCTAAACGTTAAGATGTAATGTTCCAGAACAAAGAGGCCCAGAGTCACTGAACGGGGCCCCAGGGCTC CTAGCTTGAGTGTAATCTGAGTCAGCTTATGAAAAGGCCCCAAAGAAGAAAGTGGAATGTGTGCTGGGCACATGGGACAGCCATGGCACT GAGACTTTGGAAGTGGCCTTGCCAGCGCTGTCCTGTCTTTCTGGCCCACAGATGAGGGCTCCTGATTGTGGAAGGCCACGGAAGGGACCT GAACACGATGGCACGAGACAAGTTATCTCCTGTGACTGCTCCTCTCCAGCAACCCTCAGCTCAGGCTAGACTTTCCCCCTGTGTTGAGAA TGCCCTGCCCTGTGTGGAAGCCTGATGCATTTAGTGACAGTGTGTTAGCTTTGTTAGTTTCTAGTCTGGCCAGCAGGCTTTCCATGTGAT CTGCCATTGGCTTGCTTCAGTGGCCAGTGGAGCCAGGGGTGTCCACCAGAGTCTTGGACACAGACTTCTGAGGTGGCAGCGGGAGGGAGC CTGCTCCCTGCCACACACGTACAATTTCTAATCCATACAGGCCTATGTAGTATATACACACATACGCAGAGCCTTAGGAATTGTGAAAGG >58925_58925_4_NFIC-SPATA33_NFIC_chr19_3359683_ENST00000589123_SPATA33_chr16_89735694_ENST00000301031_length(amino acids)=300AA_BP=16 MLAALGKAGPNGNGERAAASHRVGRAWCTLPESTGEGGAVSHRVGRPGAPSPRALEKGAAVSQGGGRPGAPSLRAREKGATASHRVGRAW CTLPESTGEGGHGFSQGGVALVHPPQKHWRRGHGFSQGGAGWRALEKGAAASYSVGQPWCTLPESTGEGGGGFSQGGATLVYPPREHWRR GLQVLTGWGGPGAPSPRALEKGTAVSHGGGRPGAPSLRALEKGATASHKVGRAWCTLPESTGEGGCSFSQGGVGLVQPPREHWRRGLGFS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NFIC-SPATA33 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NFIC-SPATA33 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NFIC-SPATA33 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies