
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NFX1-ACO1 (FusionGDB2 ID:59003) |
Fusion Gene Summary for NFX1-ACO1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NFX1-ACO1 | Fusion gene ID: 59003 | Hgene | Tgene | Gene symbol | NFX1 | ACO1 | Gene ID | 4799 | 48 |
| Gene name | nuclear transcription factor, X-box binding 1 | aconitase 1 | |
| Synonyms | NFX2|TEG-42|Tex42 | ACONS|HEL60|IREB1|IREBP|IREBP1|IRP1 | |
| Cytomap | 9p13.3 | 9p21.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | transcriptional repressor NF-X1nuclear transcription factor, X box-binding protein 1 | cytoplasmic aconitate hydrataseaconitase 1, solubleaconitate hydratase, cytoplasmiccitrate hydro-lyasecytoplasmic aconitasecytosplasmic aconitaseepididymis luminal protein 60epididymis secretory sperm binding proteinferritin repressor proteiniron | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q12986 | P21399 | |
| Ensembl transtripts involved in fusion gene | ENST00000379521, ENST00000379540, ENST00000318524, ENST00000463421, | ENST00000309951, ENST00000379923, ENST00000541043, | |
| Fusion gene scores | * DoF score | 16 X 12 X 11=2112 | 9 X 12 X 5=540 |
| # samples | 22 | 12 | |
| ** MAII score | log2(22/2112*10)=-3.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/540*10)=-2.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NFX1 [Title/Abstract] AND ACO1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NFX1(33351788)-ACO1(32440463), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NFX1 | GO:0000122 | negative regulation of transcription by RNA polymerase II | 7964459 |
| Hgene | NFX1 | GO:0051865 | protein autoubiquitination | 10500182 |
| Tgene | ACO1 | GO:0006101 | citrate metabolic process | 8041788|16527810 |
| Tgene | ACO1 | GO:0010040 | response to iron(II) ion | 8041788 |
| Fusion gene breakpoints across NFX1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ACO1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-18-4721-01A | NFX1 | chr9 | 33351788 | - | ACO1 | chr9 | 32440463 | + |
| ChimerDB4 | LUSC | TCGA-18-4721-01A | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| ChimerDB4 | LUSC | TCGA-18-4721 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
Top |
Fusion Gene ORF analysis for NFX1-ACO1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000379521 | ENST00000309951 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| In-frame | ENST00000379521 | ENST00000379923 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| In-frame | ENST00000379521 | ENST00000541043 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| In-frame | ENST00000379540 | ENST00000309951 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| In-frame | ENST00000379540 | ENST00000379923 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| In-frame | ENST00000379540 | ENST00000541043 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| intron-3CDS | ENST00000318524 | ENST00000309951 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| intron-3CDS | ENST00000318524 | ENST00000379923 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| intron-3CDS | ENST00000318524 | ENST00000541043 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| intron-3CDS | ENST00000463421 | ENST00000309951 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| intron-3CDS | ENST00000463421 | ENST00000379923 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| intron-3CDS | ENST00000463421 | ENST00000541043 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000379540 | NFX1 | chr9 | 33351788 | + | ENST00000541043 | ACO1 | chr9 | 32440463 | + | 3861 | 2717 | 50 | 3139 | 1029 |
| ENST00000379540 | NFX1 | chr9 | 33351788 | + | ENST00000379923 | ACO1 | chr9 | 32440463 | + | 3865 | 2717 | 50 | 3139 | 1029 |
| ENST00000379540 | NFX1 | chr9 | 33351788 | + | ENST00000309951 | ACO1 | chr9 | 32440463 | + | 7798 | 2717 | 50 | 3139 | 1029 |
| ENST00000379521 | NFX1 | chr9 | 33351788 | + | ENST00000541043 | ACO1 | chr9 | 32440463 | + | 3860 | 2716 | 49 | 3138 | 1029 |
| ENST00000379521 | NFX1 | chr9 | 33351788 | + | ENST00000379923 | ACO1 | chr9 | 32440463 | + | 3864 | 2716 | 49 | 3138 | 1029 |
| ENST00000379521 | NFX1 | chr9 | 33351788 | + | ENST00000309951 | ACO1 | chr9 | 32440463 | + | 7797 | 2716 | 49 | 3138 | 1029 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000379540 | ENST00000541043 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + | 0.000316836 | 0.99968314 |
| ENST00000379540 | ENST00000379923 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + | 0.000315189 | 0.9996848 |
| ENST00000379540 | ENST00000309951 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + | 0.00015813 | 0.9998418 |
| ENST00000379521 | ENST00000541043 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + | 0.000316545 | 0.9996835 |
| ENST00000379521 | ENST00000379923 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + | 0.000314899 | 0.99968517 |
| ENST00000379521 | ENST00000309951 | NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440463 | + | 0.000158123 | 0.9998418 |
Top |
Fusion Genomic Features for NFX1-ACO1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440462 | + | 6.94E-05 | 0.9999306 |
| NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440462 | + | 6.94E-05 | 0.9999306 |
| NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440462 | + | 6.94E-05 | 0.9999306 |
| NFX1 | chr9 | 33351788 | + | ACO1 | chr9 | 32440462 | + | 6.94E-05 | 0.9999306 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
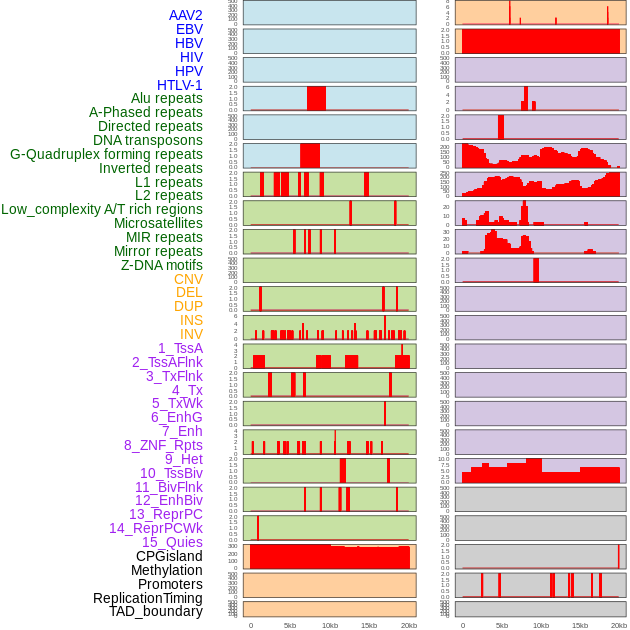 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
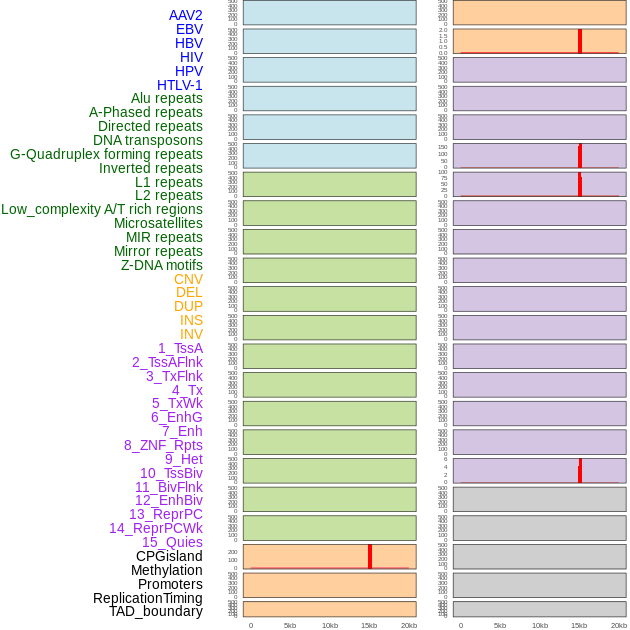 |
Top |
Fusion Protein Features for NFX1-ACO1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:33351788/chr9:32440463) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NFX1 | ACO1 |
| FUNCTION: Binds to the X-box motif of MHC class II genes and represses their expression. May play an important role in regulating the duration of an inflammatory response by limiting the period in which MHC class II molecules are induced by interferon-gamma. Isoform 3 binds to the X-box motif of TERT promoter and represses its expression. Together with PABPC1 or PABPC4, isoform 1 acts as a coactivator for TERT expression. Mediates E2-dependent ubiquitination. {ECO:0000269|PubMed:10500182, ECO:0000269|PubMed:15371341, ECO:0000269|PubMed:17267499}. | FUNCTION: Iron sensor. Binds a 4Fe-4S cluster and functions as aconitase when cellular iron levels are high. Functions as mRNA binding protein that regulates uptake, sequestration and utilization of iron when cellular iron levels are low. Binds to iron-responsive elements (IRES) in target mRNA species when iron levels are low. Binding of a 4Fe-4S cluster precludes RNA binding. {ECO:0000269|PubMed:1946430, ECO:0000269|PubMed:23891004, ECO:0000269|PubMed:8041788}.; FUNCTION: Catalyzes the isomerization of citrate to isocitrate via cis-aconitate. {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 358_409 | 885 | 1025.0 | Zinc finger | RING-type%3B atypical |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 453_471 | 885 | 1025.0 | Zinc finger | Note=NF-X1-type 1 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 506_525 | 885 | 1025.0 | Zinc finger | Note=NF-X1-type 2 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 567_586 | 885 | 1025.0 | Zinc finger | Note=NF-X1-type 3 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 632_655 | 885 | 1025.0 | Zinc finger | Note=NF-X1-type 4 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 694_713 | 885 | 1025.0 | Zinc finger | Note=NF-X1-type 5 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 721_740 | 885 | 1025.0 | Zinc finger | Note=NF-X1-type 6 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 832_854 | 885 | 1025.0 | Zinc finger | Note=NF-X1-type 7 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 863_884 | 885 | 1025.0 | Zinc finger | Note=NF-X1-type 8 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 358_409 | 885 | 1121.0 | Zinc finger | RING-type%3B atypical |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 453_471 | 885 | 1121.0 | Zinc finger | Note=NF-X1-type 1 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 506_525 | 885 | 1121.0 | Zinc finger | Note=NF-X1-type 2 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 567_586 | 885 | 1121.0 | Zinc finger | Note=NF-X1-type 3 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 632_655 | 885 | 1121.0 | Zinc finger | Note=NF-X1-type 4 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 694_713 | 885 | 1121.0 | Zinc finger | Note=NF-X1-type 5 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 721_740 | 885 | 1121.0 | Zinc finger | Note=NF-X1-type 6 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 832_854 | 885 | 1121.0 | Zinc finger | Note=NF-X1-type 7 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 863_884 | 885 | 1121.0 | Zinc finger | Note=NF-X1-type 8 |
| Tgene | ACO1 | chr9:33351788 | chr9:32440463 | ENST00000309951 | 17 | 21 | 779_780 | 749 | 890.0 | Region | Substrate binding | |
| Tgene | ACO1 | chr9:33351788 | chr9:32440463 | ENST00000379923 | 18 | 22 | 779_780 | 749 | 890.0 | Region | Substrate binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 1084_1089 | 0 | 834.0 | Compositional bias | Note=Poly-Pro |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 1084_1089 | 885 | 1025.0 | Compositional bias | Note=Poly-Pro |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 1084_1089 | 885 | 1121.0 | Compositional bias | Note=Poly-Pro |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 994_1062 | 0 | 834.0 | Domain | R3H |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 994_1062 | 885 | 1025.0 | Domain | R3H |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 994_1062 | 885 | 1121.0 | Domain | R3H |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 358_409 | 0 | 834.0 | Zinc finger | RING-type%3B atypical |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 453_471 | 0 | 834.0 | Zinc finger | Note=NF-X1-type 1 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 506_525 | 0 | 834.0 | Zinc finger | Note=NF-X1-type 2 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 567_586 | 0 | 834.0 | Zinc finger | Note=NF-X1-type 3 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 632_655 | 0 | 834.0 | Zinc finger | Note=NF-X1-type 4 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 694_713 | 0 | 834.0 | Zinc finger | Note=NF-X1-type 5 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 721_740 | 0 | 834.0 | Zinc finger | Note=NF-X1-type 6 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 832_854 | 0 | 834.0 | Zinc finger | Note=NF-X1-type 7 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 863_884 | 0 | 834.0 | Zinc finger | Note=NF-X1-type 8 |
| Tgene | ACO1 | chr9:33351788 | chr9:32440463 | ENST00000309951 | 17 | 21 | 205_207 | 749 | 890.0 | Region | Substrate binding | |
| Tgene | ACO1 | chr9:33351788 | chr9:32440463 | ENST00000379923 | 18 | 22 | 205_207 | 749 | 890.0 | Region | Substrate binding |
Top |
Fusion Gene Sequence for NFX1-ACO1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >59003_59003_1_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379521_ACO1_chr9_32440463_ENST00000309951_length(transcript)=7797nt_BP=2716nt ACGTGACCTGGTGACAGTGCTGACTTGGCTGTACAGCTCGATCTAGGTTCTGCGGCACGGGATGGCGGAGGCGCCTCCTGTCTCAGGTAC TTTTAAATTCAATACAGATGCTGCTGAATTCATTCCTCAGGAGAAAAAAAATTCTGGTCTAAATTGTGGGACTCAAAGGAGACTAGACTC TAATAGGATTGGTAGAAGAAATTACAGTTCACCACCTCCCTGTCACCTTTCCAGGCAGGTCCCTTATGATGAAATCTCTGCTGTTCATCA GCATAGTTATCATCCGTCAGGAAGCAAACCTAAGAGTCAGCAGACGTCTTTCCAGTCCTCTCCTTGTAATAAATCGCCCAAGAGCCATGG CCTTCAGAATCAACCTTGGCAGAAATTGAGGAATGAGAAGCACCATATCAGAGTCAAGAAAGCACAGAGTCTTGCTGAGCAGACCTCAGA TACAGCTGGATTAGAGAGCTCGACCAGATCAGAGAGTGGGACAGACCTCAGAGAGCATAGTCCTTCTGAGAGTGAGAAGGAAGTTGTGGG TGCAGATCCCAGGGGAGCAAAACCCAAAAAAGCAACACAGTTTGTATACAGCTATGGTAGAGGACCAAAAGTCAAGGGGAAACTCAAATG TGAATGGAGTAACCGAACAACTCCAAAACCGGAGGATGCTGGACCCGAAAGTACCAAACCTGTGGGGGTTTTCCACCCTGACTCTTCAGA GGCATCCTCTAGAAAAGGAGTATTGGATGGGTATGGAGCCAGACGAAATGAGCAGAGAAGATACCCACAGAAAAGGCCTCCCTGGGAAGT GGAGGGGGCCAGGCCACGACCAGGCAGAAATCCACCAAAACAGGAGGGCCACCGACATACAAACGCAGGACACAGAAACAACATGGGCCC CATTCCAAAGGATGACCTCAATGAAAGACCAGCAAAATCTACCTGTGACAGTGAGAACTTGGCAGTCATCAACAAGTCTTCCAGGAGGGT TGACCAAGAGAAATGCACTGTACGGAGGCAGGATCCTCAAGTAGTATCTCCTTTCTCCCGAGGCAAACAGAACCATGTGCTAAAGAATGT GGAAACGCACACAGGTTCTCTAATTGAACAACTAACAACAGAAAAATACGAGTGCATGGTGTGCTGTGAATTGGTTCGTGTCACGGCCCC AGTGTGGAGTTGTCAGAGCTGTTACCATGTGTTTCATTTGAACTGCATAAAGAAATGGGCAAGGTCTCCAGCATCTCAAGCAGATGGCCA GAGTGGTTGGAGGTGCCCTGCCTGTCAGAATGTTTCTGCACATGTTCCTAATACCTACACTTGTTTCTGTGGCAAGGTAAAGAATCCTGA GTGGAGCAGAAATGAAATTCCACATAGCTGTGGTGAGGTTTGTAGAAAGAAACAGCCTGGCCAGGACTGCCCACATTCCTGTAACCTTCT CTGCCATCCAGGACCCTGCCCACCCTGCCCTGCCTTTATGACAAAAACATGTGAATGTGGACGAACCAGGCACACAGTTCGCTGTGGTCA GGCTGTCTCAGTCCACTGTTCTAACCCATGTGAGAATATTTTGAACTGTGGTCAGCACCAGTGTGCTGAGCTGTGCCATGGGGGTCAGTG CCAGCCTTGCCAGATCATTTTGAACCAGGTATGCTATTGCGGCAGCACCTCCCGAGATGTGTTATGTGGAACCGATGTAGGAAAGTCTGA TGGATTTGGGGATTTCAGCTGTTTAAAGATATGTGGCAAGGACTTGAAATGCGGTAACCATACATGTTCGCAAGTGTGCCACCCTCAGCC CTGCCAGCAATGCCCACGGCTCCCCCAGCTGGTGCGCTGTTGCCCCTGTGGCCAAACTCCTCTCAGCCAATTGCTAGAACTTGGAAGTAG TAGTCGGAAAACATGCATGGACCCTGTGCCTTCATGTGGAAAAGTGTGCGGCAAGCCTCTGCCTTGTGGTTCCTTAGATTTCATTCATAC CTGTGAAAAGCTCTGCCATGAAGGAGACTGTGGACCATGCTCTCGCACATCAGTTATTTCCTGCAGATGCTCTTTCAGAACAAAGGAGCT TCCATGTACCAGTCTCAAAAGTGAAGATGCTACATTTATGTGTGACAAGCGGTGTAACAAGAAACGGTTGTGTGGACGGCATAAATGTAA TGAGATATGCTGTGTGGATAAGGAGCACAAGTGTCCTTTGATTTGTGGGAGGAAACTCCGTTGTGGCCTTCATAGGTGTGAAGAACCTTG TCATCGTGGAAACTGCCAGACATGCTGGCAAGCCAGTTTTGATGAATTAACCTGCCATTGTGGTGCATCAGTGATTTACCCTCCAGTTCC CTGTGGTACTAGGCCCCCTGAATGTACCCAAACCTGCGCTAGAGTCCATGAGTGTGACCATCCAGTATATCATTCTTGTCATAGTGAGGA GAAGTGTCCCCCTTGCACTTTCCTAACTCAGAAGTGGTGCATGGGCAAGCATGAGTTTCGGAGCAACATCCCCTGTCACCTGGTTGATAT CTCTTGCGGATTACCCTGCAGTGCCACGCTACCATGTGGGATGCACAAATGTCAGAGACTCTGTCACAAAGGGGAGTGTCTTGTGGATGA GCCCTGCAAGCAGCCCTGCACCACCCCCAGAGCTGACTGTGGTCACCCGTGTATGGCACCCTGCCATACCAGCTCACCCTGCCCTGTGAC TGCTTGTAAAGCTAAGCTTGATGTGTTTGATGCTGCTGAGCGGTACCAGCAGGCAGGCCTTCCCCTGATCGTTCTGGCTGGCAAAGAGTA CGGTGCAGGCAGCTCCCGAGACTGGGCAGCTAAGGGCCCTTTCCTGCTGGGAATCAAAGCCGTCCTGGCCGAGAGCTACGAGCGCATTCA CCGCAGTAACCTGGTTGGGATGGGTGTGATCCCACTTGAATATCTCCCTGGTGAGAATGCAGATGCCCTGGGGCTCACAGGGCAAGAACG ATACACTATCATTATTCCAGAAAACCTCAAACCACAAATGAAAGTCCAGGTCAAGCTGGATACTGGCAAGACCTTCCAGGCTGTCATGAG GTTTGACACTGATGTGGAGCTCACTTATTTCCTCAACGGGGGCATCCTCAACTACATGATCCGCAAGATGGCCAAGTAGGAGACGTGCAC TTGGTGCTGCGCCCAGGGAGGAAGCCGCACCACCAGCCAGCGCAGGCCCTGGTGGAGAGGCCTCCCTGGCTGCCTCTGGGAGGGGTGCTG CCTTGTAGATGGAGCAAGTGAGCACTGAGGGTCTGGTGCCAATCCTGTAGGCACAAAACCAGAAGTTTCTACATTCTCTATTTTTGTTAA TCATCTTCTCTTTTTCCAGAATTTGGAAGCTAGAATGGTGGGAATGTCAGTAGTGCCAGAAAGAGAGAACCAAGCTTGTCTTTAAAGTTA CTGATCACAGGACGTTGCTTTTTCACTGTTTCCTATTAATCTTCAGCTGAACACAAGCAAACCTTCTCAGGAGGTGTCTCCTACCCTCTT ATTGTTCCTCTTACGCTCTGCTCAATGAAACCTTCCTCTTGAGGGTCATTTTCCTTTCTGTATTAATTATACCAGTGTTAAGTGACATAG ATAAGAACTTTGCACACTTCAAATCAGAGCAGTGATTCTCTCTTCTCTCCCCTTTTCCTTCAGAGTGAATCATCCAGACTCCTCATGGAT AGGTCGGGTGTTAAAGTTGTTTTGATTATGTACCTTTTGATAGATCCACATAAAAAGAAATGTGAAGTTTTCTTTTACTATCTTTTCATT TATCAAGCAGAGACCTTTGTTGGGAGGCGGTTTGGGAGAACACATTTCTAATTTGAATGAAATGAAATCTATTTTCAGTGAAAACTTGTT GACTTTGAGTTTTGCTGTGTTTGTGGCTAGAGTTTTGGGATATTTAGTACAGAGTGAATCTCACACCATATCATTGGGAAGCCTGAATAA CCTTCATATTCTCCCATTTTTACAACTCTATCAGAACTGTACGGGTATAACGGAAATGTTTAGGAACCATTATGCTCGCTCTTCCCTGTT TGGGAGCAGACAAGAAGGAAGAGTAGCCTGGTGGCAGTGGCAACGATATAAGTACATAAGGAAAAGCAGATAAACTTCAGGACACTAAAA ACCAATTATCTGCTCATTTTTACCCCTGTAGTCATTTCTGGGCATGCCTTAGTTTGCTTGGGTTGCTATAATGTAATGCCATAGACTGGC TGAAAGAACAGAAATGTATTTTCTCACAGTTATGGAGGCTGGAATTCTGAGATCAAAGTTGAAGCCACTTCATTTTCTGGTGAGGACACT CTTCCTGGTTTACAGATGGCCACCTTCTTGCTTGTTCTCACATGGCATTTCTTTGGTATGTGCCTGGTGGGGGAGAGAGAAAATAGGCTC TCATGTCTCTTCTTACAGCAACACTAATTGTATTGGATCAGGGTCCCACTCTTATGGAGACCCAGGAAAGCTGGTGGTATAACAACTTGG TTCAAGTCCAAATGCCTAAGAACCTGGGGAGGGGCATGGGGAATGCTGGTATAAGTCCCAGAGTCTGAATGCCCAGGAACAAGCAGGAGC TGTGATGTCCAAGGACAGGAGGGCAGGATCTTTGTAATGAATTTTTAATGTCAACCTTAGCACTCAGGGGATATGGCCTGGTCATCAGAA CATCTGGAATCTAATCCTCTTTCTACTTCTCACCAGATGAGGGATCAAGACAGGTTATTTAGCATCCCTGCACTTGCGGTCCTGGGGATC TTATTTATATTCATTTAAAAAATAAATTACAAACAAACAGCCAGGCGCAGTGGCTCATGCCTATAATTCCATCACTTTGGGAGGCCGAGG TGGGTAGATCACCTGAGGTCAGGAGTTCTAGACCAGCCTGGCCAACATGGTGAAACCCCGTCTCTACTAAAAATACAAAAAATTAGCCAG GTGTGGTATTGTGTGCCTGTAATCCCAGCTACACAGGAGGCTGAGGCAGGAGAATTGCTTAAACCCGGGATGCAGAGGCTGCAGTGAGCC GAGATCGTGCCATTGCACGCCCGCCTGGGCTACAAGAGCAAAGCTCCGTCTCAAAAAAAAAAAAAAATTACAAACAAACAGAACTCCATT GTACAAAAAAACCTGTGATCCTCAAGTTAAGATCAGTCCTAGAATAAAAACACTAAGAATGGCTGAGAAAACAGACCTCCACCCTCTCAG CTCTCCATTACTGAGCAGCTGGGGAGCTGTCTCGCTCCCCGCATTCAGTGGCTCCTGTGGTCTGTATTTTTGTATCCTCCCCAAAATTCA GGTGGTGAAACCTTAACCCCCCAGGTAATGGTAATAGAAGCTGGGGCCTTTGGAAGGTGATTAGATCATGAGGGTAGTGCCTTTTAAAAG AGACTCAAGATAAGATAGAGACCCCCTCATTTCTTCTGCCATGGGAGAACACAGCAAGAAGTCACCATCCGTGAACCAGAAAGTGGGTTC TCACCAGATACTGAATCTGCCAGTGCCTTGAACCTAGACTTTCCAGCCAGAACTGTGAGAAATTTCTATTGTTTATAAGCCACCCAGTTG ATATTTAGTTACAGCAGCCCAACCAAGACTGTGGTTATGAGGAAACAAACACATTATTGTGGCTAGACTAATGGAATTGGGTCCCTTACC TCCAAGTACACCCTCTGTCCTTTTCGGTAAAAATATCTTCGCCAGGCACGGTGTCTCATGCCTATGATCCCAACACTTTGGGAGGCCGAG GCTGGAGGGTTGCTTGAGCCCAGAAGTTTGAGACCAGCCTGGGCAACACTCTACAAAAAAAAAAATAAATAAATAAATAAATAAAATAAA TCAGCCAGGTGTGCACCTGTGGTCCCAGCTGTTCAGGAGGCTGAGGTGGGAGGATCACTTGAGCCTGGGAGGTCGTGGCTATGATTGCTC CACTGCACTCCAGCCTGGGCAATAGAGTGAGACCCTATCAATCAATCACCACCCCCCCCCCCCCCAAAAAAAAAAGTATCTTGGCCAGTG TCTCAACCTTGCCCACTAACAAGCCTAAATAAACCAACTTCTTTTACCTGGTTCTTTAAGGGCTGCTCGTCTTACTATCCAAATTAAAAA TCTGCTGTTCTCCCTCCCATATTCTTTGCGAATGAAGATTCCCCTGTTTGTTTGGATAGTTTTCCAAATTCATTACTGCATTCCTGGCAT CCGCAGCAAGCTAAGAGTTAGTTAATATTTTTAATATAGCAAATAAGGATGAGGGATGCCCTTCATGTGTATTTACACACCAGATTTTTA TGGTACATAGGGAGTAATCTAGGGAAAAGATATATTAGGCATGAATCTTAGCTGTGGTAGAAGCACAGCTCAAATTAGCTTAAGGAAAAA AAAAAAAAAGCTGGCTCATAGAACTTGAGGACAGTGGTGGCCATGACTATGGGCTTGATTGGATCTAGTGACTCAAGCTCCCTTCCATTT GCCCCTCCAACCACCCCCCCATCCCTCCACCAATCATACCTTCTGTTGGCCTCTGCAGTAGAGTGGCCTCTTCTGGGCCCTTCCACATGC CAGGGGATATGGCCACCAGCAGTTCTGGGGAAACCATTAGTAATTTGTGATCGTAGAGATTTGTCTCCCAGTATTCCCTAGGGCAAAAAT ATTGGGAGTTCCTAGTCACCTAAATGAAGAACCTTATTTTTAGCAGTTTCCCTTTCAGGGCTCTAACAGGACTGTGGAGTAATGTACGGG GTTATGTAGGAGCAATGCAGAGCCACTTTTGAAAAACAGTAGCCAAGGTTCTACTGGCTGCCTTCTTAGGACATTATTAAATATCATAAA CACAAGTGGAATTTAACACCCAGCCAGTTTGTGTTCAACCAGACAGCGTCATTATGAACAAAGATTATATAACGATAGCTGATATTAAGT AAGTTTTAAAAGTTGACATCCCAAGAGTGAAGCCTACTTATTCAGTACAGATTTGTTGAATGAAATTCGTAGTTTTATTTTACGGCATAA TGAAACAGAGTTCCAGACATGTACCTGCCAAATTTGGTTCTGGTTGTCTTATCGTATGCAGGCTGGATACCTGCTACTGTGCTTCTACAG GATGTTAACAGTGTCCCCTGAGTAAAACAGTTCCACGGTCAGTACATTTGGGAACCACTGAGTTAAATGGGTTTTATCACTGCAGAACAG ACACAAGAACAATGTGTGCTGTAAATCACTGTTTGCAGGGAAGGTGGCAGCAAATGGCACAGAAACCCACCTGACCACAGACTGCTTTCT TCTGGGCGTTCACGCACTGTGCTCCACAGGATACTCTTGAGAAACATTGAGCTATGGTTGGTCTGTTGTTTGAAATTCAAATAATAATGA ATCCATTTTAAGGACAGGAATTGGTTTACTGACCTTGATGTTGGGATGACTCTTCATTTCAGGGTGAAAATATCACAGCATCAGCACAGG CCAGGACCACAGAGATAACAAGGTGGTAGTTGTGTAACAGGTTGTGTCTGAACCACAGGAGCTTCAAAACATACACGGCTGGACACCCTG CCAGGATGCTCTAATGGGGCTGGGCATGTGTCCATGAAAAAGACTCCCCAGTTGTTTCTAAAATGTGGCCTTTGTTCTAGAAATGCAATG ACCAGCATTTGGGAGTCAGTCAAAAGATCCACTTCCTAAAAGCCTACCTGCTCATTTCTTTCATTCAATACATATTAACCAAGTGCCTAC >59003_59003_1_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379521_ACO1_chr9_32440463_ENST00000309951_length(amino acids)=1029AA_BP=889 MRHGMAEAPPVSGTFKFNTDAAEFIPQEKKNSGLNCGTQRRLDSNRIGRRNYSSPPPCHLSRQVPYDEISAVHQHSYHPSGSKPKSQQTS FQSSPCNKSPKSHGLQNQPWQKLRNEKHHIRVKKAQSLAEQTSDTAGLESSTRSESGTDLREHSPSESEKEVVGADPRGAKPKKATQFVY SYGRGPKVKGKLKCEWSNRTTPKPEDAGPESTKPVGVFHPDSSEASSRKGVLDGYGARRNEQRRYPQKRPPWEVEGARPRPGRNPPKQEG HRHTNAGHRNNMGPIPKDDLNERPAKSTCDSENLAVINKSSRRVDQEKCTVRRQDPQVVSPFSRGKQNHVLKNVETHTGSLIEQLTTEKY ECMVCCELVRVTAPVWSCQSCYHVFHLNCIKKWARSPASQADGQSGWRCPACQNVSAHVPNTYTCFCGKVKNPEWSRNEIPHSCGEVCRK KQPGQDCPHSCNLLCHPGPCPPCPAFMTKTCECGRTRHTVRCGQAVSVHCSNPCENILNCGQHQCAELCHGGQCQPCQIILNQVCYCGST SRDVLCGTDVGKSDGFGDFSCLKICGKDLKCGNHTCSQVCHPQPCQQCPRLPQLVRCCPCGQTPLSQLLELGSSSRKTCMDPVPSCGKVC GKPLPCGSLDFIHTCEKLCHEGDCGPCSRTSVISCRCSFRTKELPCTSLKSEDATFMCDKRCNKKRLCGRHKCNEICCVDKEHKCPLICG RKLRCGLHRCEEPCHRGNCQTCWQASFDELTCHCGASVIYPPVPCGTRPPECTQTCARVHECDHPVYHSCHSEEKCPPCTFLTQKWCMGK HEFRSNIPCHLVDISCGLPCSATLPCGMHKCQRLCHKGECLVDEPCKQPCTTPRADCGHPCMAPCHTSSPCPVTACKAKLDVFDAAERYQ QAGLPLIVLAGKEYGAGSSRDWAAKGPFLLGIKAVLAESYERIHRSNLVGMGVIPLEYLPGENADALGLTGQERYTIIIPENLKPQMKVQ -------------------------------------------------------------- >59003_59003_2_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379521_ACO1_chr9_32440463_ENST00000379923_length(transcript)=3864nt_BP=2716nt ACGTGACCTGGTGACAGTGCTGACTTGGCTGTACAGCTCGATCTAGGTTCTGCGGCACGGGATGGCGGAGGCGCCTCCTGTCTCAGGTAC TTTTAAATTCAATACAGATGCTGCTGAATTCATTCCTCAGGAGAAAAAAAATTCTGGTCTAAATTGTGGGACTCAAAGGAGACTAGACTC TAATAGGATTGGTAGAAGAAATTACAGTTCACCACCTCCCTGTCACCTTTCCAGGCAGGTCCCTTATGATGAAATCTCTGCTGTTCATCA GCATAGTTATCATCCGTCAGGAAGCAAACCTAAGAGTCAGCAGACGTCTTTCCAGTCCTCTCCTTGTAATAAATCGCCCAAGAGCCATGG CCTTCAGAATCAACCTTGGCAGAAATTGAGGAATGAGAAGCACCATATCAGAGTCAAGAAAGCACAGAGTCTTGCTGAGCAGACCTCAGA TACAGCTGGATTAGAGAGCTCGACCAGATCAGAGAGTGGGACAGACCTCAGAGAGCATAGTCCTTCTGAGAGTGAGAAGGAAGTTGTGGG TGCAGATCCCAGGGGAGCAAAACCCAAAAAAGCAACACAGTTTGTATACAGCTATGGTAGAGGACCAAAAGTCAAGGGGAAACTCAAATG TGAATGGAGTAACCGAACAACTCCAAAACCGGAGGATGCTGGACCCGAAAGTACCAAACCTGTGGGGGTTTTCCACCCTGACTCTTCAGA GGCATCCTCTAGAAAAGGAGTATTGGATGGGTATGGAGCCAGACGAAATGAGCAGAGAAGATACCCACAGAAAAGGCCTCCCTGGGAAGT GGAGGGGGCCAGGCCACGACCAGGCAGAAATCCACCAAAACAGGAGGGCCACCGACATACAAACGCAGGACACAGAAACAACATGGGCCC CATTCCAAAGGATGACCTCAATGAAAGACCAGCAAAATCTACCTGTGACAGTGAGAACTTGGCAGTCATCAACAAGTCTTCCAGGAGGGT TGACCAAGAGAAATGCACTGTACGGAGGCAGGATCCTCAAGTAGTATCTCCTTTCTCCCGAGGCAAACAGAACCATGTGCTAAAGAATGT GGAAACGCACACAGGTTCTCTAATTGAACAACTAACAACAGAAAAATACGAGTGCATGGTGTGCTGTGAATTGGTTCGTGTCACGGCCCC AGTGTGGAGTTGTCAGAGCTGTTACCATGTGTTTCATTTGAACTGCATAAAGAAATGGGCAAGGTCTCCAGCATCTCAAGCAGATGGCCA GAGTGGTTGGAGGTGCCCTGCCTGTCAGAATGTTTCTGCACATGTTCCTAATACCTACACTTGTTTCTGTGGCAAGGTAAAGAATCCTGA GTGGAGCAGAAATGAAATTCCACATAGCTGTGGTGAGGTTTGTAGAAAGAAACAGCCTGGCCAGGACTGCCCACATTCCTGTAACCTTCT CTGCCATCCAGGACCCTGCCCACCCTGCCCTGCCTTTATGACAAAAACATGTGAATGTGGACGAACCAGGCACACAGTTCGCTGTGGTCA GGCTGTCTCAGTCCACTGTTCTAACCCATGTGAGAATATTTTGAACTGTGGTCAGCACCAGTGTGCTGAGCTGTGCCATGGGGGTCAGTG CCAGCCTTGCCAGATCATTTTGAACCAGGTATGCTATTGCGGCAGCACCTCCCGAGATGTGTTATGTGGAACCGATGTAGGAAAGTCTGA TGGATTTGGGGATTTCAGCTGTTTAAAGATATGTGGCAAGGACTTGAAATGCGGTAACCATACATGTTCGCAAGTGTGCCACCCTCAGCC CTGCCAGCAATGCCCACGGCTCCCCCAGCTGGTGCGCTGTTGCCCCTGTGGCCAAACTCCTCTCAGCCAATTGCTAGAACTTGGAAGTAG TAGTCGGAAAACATGCATGGACCCTGTGCCTTCATGTGGAAAAGTGTGCGGCAAGCCTCTGCCTTGTGGTTCCTTAGATTTCATTCATAC CTGTGAAAAGCTCTGCCATGAAGGAGACTGTGGACCATGCTCTCGCACATCAGTTATTTCCTGCAGATGCTCTTTCAGAACAAAGGAGCT TCCATGTACCAGTCTCAAAAGTGAAGATGCTACATTTATGTGTGACAAGCGGTGTAACAAGAAACGGTTGTGTGGACGGCATAAATGTAA TGAGATATGCTGTGTGGATAAGGAGCACAAGTGTCCTTTGATTTGTGGGAGGAAACTCCGTTGTGGCCTTCATAGGTGTGAAGAACCTTG TCATCGTGGAAACTGCCAGACATGCTGGCAAGCCAGTTTTGATGAATTAACCTGCCATTGTGGTGCATCAGTGATTTACCCTCCAGTTCC CTGTGGTACTAGGCCCCCTGAATGTACCCAAACCTGCGCTAGAGTCCATGAGTGTGACCATCCAGTATATCATTCTTGTCATAGTGAGGA GAAGTGTCCCCCTTGCACTTTCCTAACTCAGAAGTGGTGCATGGGCAAGCATGAGTTTCGGAGCAACATCCCCTGTCACCTGGTTGATAT CTCTTGCGGATTACCCTGCAGTGCCACGCTACCATGTGGGATGCACAAATGTCAGAGACTCTGTCACAAAGGGGAGTGTCTTGTGGATGA GCCCTGCAAGCAGCCCTGCACCACCCCCAGAGCTGACTGTGGTCACCCGTGTATGGCACCCTGCCATACCAGCTCACCCTGCCCTGTGAC TGCTTGTAAAGCTAAGCTTGATGTGTTTGATGCTGCTGAGCGGTACCAGCAGGCAGGCCTTCCCCTGATCGTTCTGGCTGGCAAAGAGTA CGGTGCAGGCAGCTCCCGAGACTGGGCAGCTAAGGGCCCTTTCCTGCTGGGAATCAAAGCCGTCCTGGCCGAGAGCTACGAGCGCATTCA CCGCAGTAACCTGGTTGGGATGGGTGTGATCCCACTTGAATATCTCCCTGGTGAGAATGCAGATGCCCTGGGGCTCACAGGGCAAGAACG ATACACTATCATTATTCCAGAAAACCTCAAACCACAAATGAAAGTCCAGGTCAAGCTGGATACTGGCAAGACCTTCCAGGCTGTCATGAG GTTTGACACTGATGTGGAGCTCACTTATTTCCTCAACGGGGGCATCCTCAACTACATGATCCGCAAGATGGCCAAGTAGGAGACGTGCAC TTGGTGCTGCGCCCAGGGAGGAAGCCGCACCACCAGCCAGCGCAGGCCCTGGTGGAGAGGCCTCCCTGGCTGCCTCTGGGAGGGGTGCTG CCTTGTAGATGGAGCAAGTGAGCACTGAGGGTCTGGTGCCAATCCTGTAGGCACAAAACCAGAAGTTTCTACATTCTCTATTTTTGTTAA TCATCTTCTCTTTTTCCAGAATTTGGAAGCTAGAATGGTGGGAATGTCAGTAGTGCCAGAAAGAGAGAACCAAGCTTGTCTTTAAAGTTA CTGATCACAGGACGTTGCTTTTTCACTGTTTCCTATTAATCTTCAGCTGAACACAAGCAAACCTTCTCAGGAGGTGTCTCCTACCCTCTT ATTGTTCCTCTTACGCTCTGCTCAATGAAACCTTCCTCTTGAGGGTCATTTTCCTTTCTGTATTAATTATACCAGTGTTAAGTGACATAG ATAAGAACTTTGCACACTTCAAATCAGAGCAGTGATTCTCTCTTCTCTCCCCTTTTCCTTCAGAGTGAATCATCCAGACTCCTCATGGAT AGGTCGGGTGTTAAAGTTGTTTTGATTATGTACCTTTTGATAGATCCACATAAAAAGAAATGTGAAGTTTTCTTTTACTATCTTTTCATT >59003_59003_2_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379521_ACO1_chr9_32440463_ENST00000379923_length(amino acids)=1029AA_BP=889 MRHGMAEAPPVSGTFKFNTDAAEFIPQEKKNSGLNCGTQRRLDSNRIGRRNYSSPPPCHLSRQVPYDEISAVHQHSYHPSGSKPKSQQTS FQSSPCNKSPKSHGLQNQPWQKLRNEKHHIRVKKAQSLAEQTSDTAGLESSTRSESGTDLREHSPSESEKEVVGADPRGAKPKKATQFVY SYGRGPKVKGKLKCEWSNRTTPKPEDAGPESTKPVGVFHPDSSEASSRKGVLDGYGARRNEQRRYPQKRPPWEVEGARPRPGRNPPKQEG HRHTNAGHRNNMGPIPKDDLNERPAKSTCDSENLAVINKSSRRVDQEKCTVRRQDPQVVSPFSRGKQNHVLKNVETHTGSLIEQLTTEKY ECMVCCELVRVTAPVWSCQSCYHVFHLNCIKKWARSPASQADGQSGWRCPACQNVSAHVPNTYTCFCGKVKNPEWSRNEIPHSCGEVCRK KQPGQDCPHSCNLLCHPGPCPPCPAFMTKTCECGRTRHTVRCGQAVSVHCSNPCENILNCGQHQCAELCHGGQCQPCQIILNQVCYCGST SRDVLCGTDVGKSDGFGDFSCLKICGKDLKCGNHTCSQVCHPQPCQQCPRLPQLVRCCPCGQTPLSQLLELGSSSRKTCMDPVPSCGKVC GKPLPCGSLDFIHTCEKLCHEGDCGPCSRTSVISCRCSFRTKELPCTSLKSEDATFMCDKRCNKKRLCGRHKCNEICCVDKEHKCPLICG RKLRCGLHRCEEPCHRGNCQTCWQASFDELTCHCGASVIYPPVPCGTRPPECTQTCARVHECDHPVYHSCHSEEKCPPCTFLTQKWCMGK HEFRSNIPCHLVDISCGLPCSATLPCGMHKCQRLCHKGECLVDEPCKQPCTTPRADCGHPCMAPCHTSSPCPVTACKAKLDVFDAAERYQ QAGLPLIVLAGKEYGAGSSRDWAAKGPFLLGIKAVLAESYERIHRSNLVGMGVIPLEYLPGENADALGLTGQERYTIIIPENLKPQMKVQ -------------------------------------------------------------- >59003_59003_3_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379521_ACO1_chr9_32440463_ENST00000541043_length(transcript)=3860nt_BP=2716nt ACGTGACCTGGTGACAGTGCTGACTTGGCTGTACAGCTCGATCTAGGTTCTGCGGCACGGGATGGCGGAGGCGCCTCCTGTCTCAGGTAC TTTTAAATTCAATACAGATGCTGCTGAATTCATTCCTCAGGAGAAAAAAAATTCTGGTCTAAATTGTGGGACTCAAAGGAGACTAGACTC TAATAGGATTGGTAGAAGAAATTACAGTTCACCACCTCCCTGTCACCTTTCCAGGCAGGTCCCTTATGATGAAATCTCTGCTGTTCATCA GCATAGTTATCATCCGTCAGGAAGCAAACCTAAGAGTCAGCAGACGTCTTTCCAGTCCTCTCCTTGTAATAAATCGCCCAAGAGCCATGG CCTTCAGAATCAACCTTGGCAGAAATTGAGGAATGAGAAGCACCATATCAGAGTCAAGAAAGCACAGAGTCTTGCTGAGCAGACCTCAGA TACAGCTGGATTAGAGAGCTCGACCAGATCAGAGAGTGGGACAGACCTCAGAGAGCATAGTCCTTCTGAGAGTGAGAAGGAAGTTGTGGG TGCAGATCCCAGGGGAGCAAAACCCAAAAAAGCAACACAGTTTGTATACAGCTATGGTAGAGGACCAAAAGTCAAGGGGAAACTCAAATG TGAATGGAGTAACCGAACAACTCCAAAACCGGAGGATGCTGGACCCGAAAGTACCAAACCTGTGGGGGTTTTCCACCCTGACTCTTCAGA GGCATCCTCTAGAAAAGGAGTATTGGATGGGTATGGAGCCAGACGAAATGAGCAGAGAAGATACCCACAGAAAAGGCCTCCCTGGGAAGT GGAGGGGGCCAGGCCACGACCAGGCAGAAATCCACCAAAACAGGAGGGCCACCGACATACAAACGCAGGACACAGAAACAACATGGGCCC CATTCCAAAGGATGACCTCAATGAAAGACCAGCAAAATCTACCTGTGACAGTGAGAACTTGGCAGTCATCAACAAGTCTTCCAGGAGGGT TGACCAAGAGAAATGCACTGTACGGAGGCAGGATCCTCAAGTAGTATCTCCTTTCTCCCGAGGCAAACAGAACCATGTGCTAAAGAATGT GGAAACGCACACAGGTTCTCTAATTGAACAACTAACAACAGAAAAATACGAGTGCATGGTGTGCTGTGAATTGGTTCGTGTCACGGCCCC AGTGTGGAGTTGTCAGAGCTGTTACCATGTGTTTCATTTGAACTGCATAAAGAAATGGGCAAGGTCTCCAGCATCTCAAGCAGATGGCCA GAGTGGTTGGAGGTGCCCTGCCTGTCAGAATGTTTCTGCACATGTTCCTAATACCTACACTTGTTTCTGTGGCAAGGTAAAGAATCCTGA GTGGAGCAGAAATGAAATTCCACATAGCTGTGGTGAGGTTTGTAGAAAGAAACAGCCTGGCCAGGACTGCCCACATTCCTGTAACCTTCT CTGCCATCCAGGACCCTGCCCACCCTGCCCTGCCTTTATGACAAAAACATGTGAATGTGGACGAACCAGGCACACAGTTCGCTGTGGTCA GGCTGTCTCAGTCCACTGTTCTAACCCATGTGAGAATATTTTGAACTGTGGTCAGCACCAGTGTGCTGAGCTGTGCCATGGGGGTCAGTG CCAGCCTTGCCAGATCATTTTGAACCAGGTATGCTATTGCGGCAGCACCTCCCGAGATGTGTTATGTGGAACCGATGTAGGAAAGTCTGA TGGATTTGGGGATTTCAGCTGTTTAAAGATATGTGGCAAGGACTTGAAATGCGGTAACCATACATGTTCGCAAGTGTGCCACCCTCAGCC CTGCCAGCAATGCCCACGGCTCCCCCAGCTGGTGCGCTGTTGCCCCTGTGGCCAAACTCCTCTCAGCCAATTGCTAGAACTTGGAAGTAG TAGTCGGAAAACATGCATGGACCCTGTGCCTTCATGTGGAAAAGTGTGCGGCAAGCCTCTGCCTTGTGGTTCCTTAGATTTCATTCATAC CTGTGAAAAGCTCTGCCATGAAGGAGACTGTGGACCATGCTCTCGCACATCAGTTATTTCCTGCAGATGCTCTTTCAGAACAAAGGAGCT TCCATGTACCAGTCTCAAAAGTGAAGATGCTACATTTATGTGTGACAAGCGGTGTAACAAGAAACGGTTGTGTGGACGGCATAAATGTAA TGAGATATGCTGTGTGGATAAGGAGCACAAGTGTCCTTTGATTTGTGGGAGGAAACTCCGTTGTGGCCTTCATAGGTGTGAAGAACCTTG TCATCGTGGAAACTGCCAGACATGCTGGCAAGCCAGTTTTGATGAATTAACCTGCCATTGTGGTGCATCAGTGATTTACCCTCCAGTTCC CTGTGGTACTAGGCCCCCTGAATGTACCCAAACCTGCGCTAGAGTCCATGAGTGTGACCATCCAGTATATCATTCTTGTCATAGTGAGGA GAAGTGTCCCCCTTGCACTTTCCTAACTCAGAAGTGGTGCATGGGCAAGCATGAGTTTCGGAGCAACATCCCCTGTCACCTGGTTGATAT CTCTTGCGGATTACCCTGCAGTGCCACGCTACCATGTGGGATGCACAAATGTCAGAGACTCTGTCACAAAGGGGAGTGTCTTGTGGATGA GCCCTGCAAGCAGCCCTGCACCACCCCCAGAGCTGACTGTGGTCACCCGTGTATGGCACCCTGCCATACCAGCTCACCCTGCCCTGTGAC TGCTTGTAAAGCTAAGCTTGATGTGTTTGATGCTGCTGAGCGGTACCAGCAGGCAGGCCTTCCCCTGATCGTTCTGGCTGGCAAAGAGTA CGGTGCAGGCAGCTCCCGAGACTGGGCAGCTAAGGGCCCTTTCCTGCTGGGAATCAAAGCCGTCCTGGCCGAGAGCTACGAGCGCATTCA CCGCAGTAACCTGGTTGGGATGGGTGTGATCCCACTTGAATATCTCCCTGGTGAGAATGCAGATGCCCTGGGGCTCACAGGGCAAGAACG ATACACTATCATTATTCCAGAAAACCTCAAACCACAAATGAAAGTCCAGGTCAAGCTGGATACTGGCAAGACCTTCCAGGCTGTCATGAG GTTTGACACTGATGTGGAGCTCACTTATTTCCTCAACGGGGGCATCCTCAACTACATGATCCGCAAGATGGCCAAGTAGGAGACGTGCAC TTGGTGCTGCGCCCAGGGAGGAAGCCGCACCACCAGCCAGCGCAGGCCCTGGTGGAGAGGCCTCCCTGGCTGCCTCTGGGAGGGGTGCTG CCTTGTAGATGGAGCAAGTGAGCACTGAGGGTCTGGTGCCAATCCTGTAGGCACAAAACCAGAAGTTTCTACATTCTCTATTTTTGTTAA TCATCTTCTCTTTTTCCAGAATTTGGAAGCTAGAATGGTGGGAATGTCAGTAGTGCCAGAAAGAGAGAACCAAGCTTGTCTTTAAAGTTA CTGATCACAGGACGTTGCTTTTTCACTGTTTCCTATTAATCTTCAGCTGAACACAAGCAAACCTTCTCAGGAGGTGTCTCCTACCCTCTT ATTGTTCCTCTTACGCTCTGCTCAATGAAACCTTCCTCTTGAGGGTCATTTTCCTTTCTGTATTAATTATACCAGTGTTAAGTGACATAG ATAAGAACTTTGCACACTTCAAATCAGAGCAGTGATTCTCTCTTCTCTCCCCTTTTCCTTCAGAGTGAATCATCCAGACTCCTCATGGAT AGGTCGGGTGTTAAAGTTGTTTTGATTATGTACCTTTTGATAGATCCACATAAAAAGAAATGTGAAGTTTTCTTTTACTATCTTTTCATT >59003_59003_3_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379521_ACO1_chr9_32440463_ENST00000541043_length(amino acids)=1029AA_BP=889 MRHGMAEAPPVSGTFKFNTDAAEFIPQEKKNSGLNCGTQRRLDSNRIGRRNYSSPPPCHLSRQVPYDEISAVHQHSYHPSGSKPKSQQTS FQSSPCNKSPKSHGLQNQPWQKLRNEKHHIRVKKAQSLAEQTSDTAGLESSTRSESGTDLREHSPSESEKEVVGADPRGAKPKKATQFVY SYGRGPKVKGKLKCEWSNRTTPKPEDAGPESTKPVGVFHPDSSEASSRKGVLDGYGARRNEQRRYPQKRPPWEVEGARPRPGRNPPKQEG HRHTNAGHRNNMGPIPKDDLNERPAKSTCDSENLAVINKSSRRVDQEKCTVRRQDPQVVSPFSRGKQNHVLKNVETHTGSLIEQLTTEKY ECMVCCELVRVTAPVWSCQSCYHVFHLNCIKKWARSPASQADGQSGWRCPACQNVSAHVPNTYTCFCGKVKNPEWSRNEIPHSCGEVCRK KQPGQDCPHSCNLLCHPGPCPPCPAFMTKTCECGRTRHTVRCGQAVSVHCSNPCENILNCGQHQCAELCHGGQCQPCQIILNQVCYCGST SRDVLCGTDVGKSDGFGDFSCLKICGKDLKCGNHTCSQVCHPQPCQQCPRLPQLVRCCPCGQTPLSQLLELGSSSRKTCMDPVPSCGKVC GKPLPCGSLDFIHTCEKLCHEGDCGPCSRTSVISCRCSFRTKELPCTSLKSEDATFMCDKRCNKKRLCGRHKCNEICCVDKEHKCPLICG RKLRCGLHRCEEPCHRGNCQTCWQASFDELTCHCGASVIYPPVPCGTRPPECTQTCARVHECDHPVYHSCHSEEKCPPCTFLTQKWCMGK HEFRSNIPCHLVDISCGLPCSATLPCGMHKCQRLCHKGECLVDEPCKQPCTTPRADCGHPCMAPCHTSSPCPVTACKAKLDVFDAAERYQ QAGLPLIVLAGKEYGAGSSRDWAAKGPFLLGIKAVLAESYERIHRSNLVGMGVIPLEYLPGENADALGLTGQERYTIIIPENLKPQMKVQ -------------------------------------------------------------- >59003_59003_4_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379540_ACO1_chr9_32440463_ENST00000309951_length(transcript)=7798nt_BP=2717nt CACGTGACCTGGTGACAGTGCTGACTTGGCTGTACAGCTCGATCTAGGTTCTGCGGCACGGGATGGCGGAGGCGCCTCCTGTCTCAGGTA CTTTTAAATTCAATACAGATGCTGCTGAATTCATTCCTCAGGAGAAAAAAAATTCTGGTCTAAATTGTGGGACTCAAAGGAGACTAGACT CTAATAGGATTGGTAGAAGAAATTACAGTTCACCACCTCCCTGTCACCTTTCCAGGCAGGTCCCTTATGATGAAATCTCTGCTGTTCATC AGCATAGTTATCATCCGTCAGGAAGCAAACCTAAGAGTCAGCAGACGTCTTTCCAGTCCTCTCCTTGTAATAAATCGCCCAAGAGCCATG GCCTTCAGAATCAACCTTGGCAGAAATTGAGGAATGAGAAGCACCATATCAGAGTCAAGAAAGCACAGAGTCTTGCTGAGCAGACCTCAG ATACAGCTGGATTAGAGAGCTCGACCAGATCAGAGAGTGGGACAGACCTCAGAGAGCATAGTCCTTCTGAGAGTGAGAAGGAAGTTGTGG GTGCAGATCCCAGGGGAGCAAAACCCAAAAAAGCAACACAGTTTGTATACAGCTATGGTAGAGGACCAAAAGTCAAGGGGAAACTCAAAT GTGAATGGAGTAACCGAACAACTCCAAAACCGGAGGATGCTGGACCCGAAAGTACCAAACCTGTGGGGGTTTTCCACCCTGACTCTTCAG AGGCATCCTCTAGAAAAGGAGTATTGGATGGGTATGGAGCCAGACGAAATGAGCAGAGAAGATACCCACAGAAAAGGCCTCCCTGGGAAG TGGAGGGGGCCAGGCCACGACCAGGCAGAAATCCACCAAAACAGGAGGGCCACCGACATACAAACGCAGGACACAGAAACAACATGGGCC CCATTCCAAAGGATGACCTCAATGAAAGACCAGCAAAATCTACCTGTGACAGTGAGAACTTGGCAGTCATCAACAAGTCTTCCAGGAGGG TTGACCAAGAGAAATGCACTGTACGGAGGCAGGATCCTCAAGTAGTATCTCCTTTCTCCCGAGGCAAACAGAACCATGTGCTAAAGAATG TGGAAACGCACACAGGTTCTCTAATTGAACAACTAACAACAGAAAAATACGAGTGCATGGTGTGCTGTGAATTGGTTCGTGTCACGGCCC CAGTGTGGAGTTGTCAGAGCTGTTACCATGTGTTTCATTTGAACTGCATAAAGAAATGGGCAAGGTCTCCAGCATCTCAAGCAGATGGCC AGAGTGGTTGGAGGTGCCCTGCCTGTCAGAATGTTTCTGCACATGTTCCTAATACCTACACTTGTTTCTGTGGCAAGGTAAAGAATCCTG AGTGGAGCAGAAATGAAATTCCACATAGCTGTGGTGAGGTTTGTAGAAAGAAACAGCCTGGCCAGGACTGCCCACATTCCTGTAACCTTC TCTGCCATCCAGGACCCTGCCCACCCTGCCCTGCCTTTATGACAAAAACATGTGAATGTGGACGAACCAGGCACACAGTTCGCTGTGGTC AGGCTGTCTCAGTCCACTGTTCTAACCCATGTGAGAATATTTTGAACTGTGGTCAGCACCAGTGTGCTGAGCTGTGCCATGGGGGTCAGT GCCAGCCTTGCCAGATCATTTTGAACCAGGTATGCTATTGCGGCAGCACCTCCCGAGATGTGTTATGTGGAACCGATGTAGGAAAGTCTG ATGGATTTGGGGATTTCAGCTGTTTAAAGATATGTGGCAAGGACTTGAAATGCGGTAACCATACATGTTCGCAAGTGTGCCACCCTCAGC CCTGCCAGCAATGCCCACGGCTCCCCCAGCTGGTGCGCTGTTGCCCCTGTGGCCAAACTCCTCTCAGCCAATTGCTAGAACTTGGAAGTA GTAGTCGGAAAACATGCATGGACCCTGTGCCTTCATGTGGAAAAGTGTGCGGCAAGCCTCTGCCTTGTGGTTCCTTAGATTTCATTCATA CCTGTGAAAAGCTCTGCCATGAAGGAGACTGTGGACCATGCTCTCGCACATCAGTTATTTCCTGCAGATGCTCTTTCAGAACAAAGGAGC TTCCATGTACCAGTCTCAAAAGTGAAGATGCTACATTTATGTGTGACAAGCGGTGTAACAAGAAACGGTTGTGTGGACGGCATAAATGTA ATGAGATATGCTGTGTGGATAAGGAGCACAAGTGTCCTTTGATTTGTGGGAGGAAACTCCGTTGTGGCCTTCATAGGTGTGAAGAACCTT GTCATCGTGGAAACTGCCAGACATGCTGGCAAGCCAGTTTTGATGAATTAACCTGCCATTGTGGTGCATCAGTGATTTACCCTCCAGTTC CCTGTGGTACTAGGCCCCCTGAATGTACCCAAACCTGCGCTAGAGTCCATGAGTGTGACCATCCAGTATATCATTCTTGTCATAGTGAGG AGAAGTGTCCCCCTTGCACTTTCCTAACTCAGAAGTGGTGCATGGGCAAGCATGAGTTTCGGAGCAACATCCCCTGTCACCTGGTTGATA TCTCTTGCGGATTACCCTGCAGTGCCACGCTACCATGTGGGATGCACAAATGTCAGAGACTCTGTCACAAAGGGGAGTGTCTTGTGGATG AGCCCTGCAAGCAGCCCTGCACCACCCCCAGAGCTGACTGTGGTCACCCGTGTATGGCACCCTGCCATACCAGCTCACCCTGCCCTGTGA CTGCTTGTAAAGCTAAGCTTGATGTGTTTGATGCTGCTGAGCGGTACCAGCAGGCAGGCCTTCCCCTGATCGTTCTGGCTGGCAAAGAGT ACGGTGCAGGCAGCTCCCGAGACTGGGCAGCTAAGGGCCCTTTCCTGCTGGGAATCAAAGCCGTCCTGGCCGAGAGCTACGAGCGCATTC ACCGCAGTAACCTGGTTGGGATGGGTGTGATCCCACTTGAATATCTCCCTGGTGAGAATGCAGATGCCCTGGGGCTCACAGGGCAAGAAC GATACACTATCATTATTCCAGAAAACCTCAAACCACAAATGAAAGTCCAGGTCAAGCTGGATACTGGCAAGACCTTCCAGGCTGTCATGA GGTTTGACACTGATGTGGAGCTCACTTATTTCCTCAACGGGGGCATCCTCAACTACATGATCCGCAAGATGGCCAAGTAGGAGACGTGCA CTTGGTGCTGCGCCCAGGGAGGAAGCCGCACCACCAGCCAGCGCAGGCCCTGGTGGAGAGGCCTCCCTGGCTGCCTCTGGGAGGGGTGCT GCCTTGTAGATGGAGCAAGTGAGCACTGAGGGTCTGGTGCCAATCCTGTAGGCACAAAACCAGAAGTTTCTACATTCTCTATTTTTGTTA ATCATCTTCTCTTTTTCCAGAATTTGGAAGCTAGAATGGTGGGAATGTCAGTAGTGCCAGAAAGAGAGAACCAAGCTTGTCTTTAAAGTT ACTGATCACAGGACGTTGCTTTTTCACTGTTTCCTATTAATCTTCAGCTGAACACAAGCAAACCTTCTCAGGAGGTGTCTCCTACCCTCT TATTGTTCCTCTTACGCTCTGCTCAATGAAACCTTCCTCTTGAGGGTCATTTTCCTTTCTGTATTAATTATACCAGTGTTAAGTGACATA GATAAGAACTTTGCACACTTCAAATCAGAGCAGTGATTCTCTCTTCTCTCCCCTTTTCCTTCAGAGTGAATCATCCAGACTCCTCATGGA TAGGTCGGGTGTTAAAGTTGTTTTGATTATGTACCTTTTGATAGATCCACATAAAAAGAAATGTGAAGTTTTCTTTTACTATCTTTTCAT TTATCAAGCAGAGACCTTTGTTGGGAGGCGGTTTGGGAGAACACATTTCTAATTTGAATGAAATGAAATCTATTTTCAGTGAAAACTTGT TGACTTTGAGTTTTGCTGTGTTTGTGGCTAGAGTTTTGGGATATTTAGTACAGAGTGAATCTCACACCATATCATTGGGAAGCCTGAATA ACCTTCATATTCTCCCATTTTTACAACTCTATCAGAACTGTACGGGTATAACGGAAATGTTTAGGAACCATTATGCTCGCTCTTCCCTGT TTGGGAGCAGACAAGAAGGAAGAGTAGCCTGGTGGCAGTGGCAACGATATAAGTACATAAGGAAAAGCAGATAAACTTCAGGACACTAAA AACCAATTATCTGCTCATTTTTACCCCTGTAGTCATTTCTGGGCATGCCTTAGTTTGCTTGGGTTGCTATAATGTAATGCCATAGACTGG CTGAAAGAACAGAAATGTATTTTCTCACAGTTATGGAGGCTGGAATTCTGAGATCAAAGTTGAAGCCACTTCATTTTCTGGTGAGGACAC TCTTCCTGGTTTACAGATGGCCACCTTCTTGCTTGTTCTCACATGGCATTTCTTTGGTATGTGCCTGGTGGGGGAGAGAGAAAATAGGCT CTCATGTCTCTTCTTACAGCAACACTAATTGTATTGGATCAGGGTCCCACTCTTATGGAGACCCAGGAAAGCTGGTGGTATAACAACTTG GTTCAAGTCCAAATGCCTAAGAACCTGGGGAGGGGCATGGGGAATGCTGGTATAAGTCCCAGAGTCTGAATGCCCAGGAACAAGCAGGAG CTGTGATGTCCAAGGACAGGAGGGCAGGATCTTTGTAATGAATTTTTAATGTCAACCTTAGCACTCAGGGGATATGGCCTGGTCATCAGA ACATCTGGAATCTAATCCTCTTTCTACTTCTCACCAGATGAGGGATCAAGACAGGTTATTTAGCATCCCTGCACTTGCGGTCCTGGGGAT CTTATTTATATTCATTTAAAAAATAAATTACAAACAAACAGCCAGGCGCAGTGGCTCATGCCTATAATTCCATCACTTTGGGAGGCCGAG GTGGGTAGATCACCTGAGGTCAGGAGTTCTAGACCAGCCTGGCCAACATGGTGAAACCCCGTCTCTACTAAAAATACAAAAAATTAGCCA GGTGTGGTATTGTGTGCCTGTAATCCCAGCTACACAGGAGGCTGAGGCAGGAGAATTGCTTAAACCCGGGATGCAGAGGCTGCAGTGAGC CGAGATCGTGCCATTGCACGCCCGCCTGGGCTACAAGAGCAAAGCTCCGTCTCAAAAAAAAAAAAAAATTACAAACAAACAGAACTCCAT TGTACAAAAAAACCTGTGATCCTCAAGTTAAGATCAGTCCTAGAATAAAAACACTAAGAATGGCTGAGAAAACAGACCTCCACCCTCTCA GCTCTCCATTACTGAGCAGCTGGGGAGCTGTCTCGCTCCCCGCATTCAGTGGCTCCTGTGGTCTGTATTTTTGTATCCTCCCCAAAATTC AGGTGGTGAAACCTTAACCCCCCAGGTAATGGTAATAGAAGCTGGGGCCTTTGGAAGGTGATTAGATCATGAGGGTAGTGCCTTTTAAAA GAGACTCAAGATAAGATAGAGACCCCCTCATTTCTTCTGCCATGGGAGAACACAGCAAGAAGTCACCATCCGTGAACCAGAAAGTGGGTT CTCACCAGATACTGAATCTGCCAGTGCCTTGAACCTAGACTTTCCAGCCAGAACTGTGAGAAATTTCTATTGTTTATAAGCCACCCAGTT GATATTTAGTTACAGCAGCCCAACCAAGACTGTGGTTATGAGGAAACAAACACATTATTGTGGCTAGACTAATGGAATTGGGTCCCTTAC CTCCAAGTACACCCTCTGTCCTTTTCGGTAAAAATATCTTCGCCAGGCACGGTGTCTCATGCCTATGATCCCAACACTTTGGGAGGCCGA GGCTGGAGGGTTGCTTGAGCCCAGAAGTTTGAGACCAGCCTGGGCAACACTCTACAAAAAAAAAAATAAATAAATAAATAAATAAAATAA ATCAGCCAGGTGTGCACCTGTGGTCCCAGCTGTTCAGGAGGCTGAGGTGGGAGGATCACTTGAGCCTGGGAGGTCGTGGCTATGATTGCT CCACTGCACTCCAGCCTGGGCAATAGAGTGAGACCCTATCAATCAATCACCACCCCCCCCCCCCCCAAAAAAAAAAGTATCTTGGCCAGT GTCTCAACCTTGCCCACTAACAAGCCTAAATAAACCAACTTCTTTTACCTGGTTCTTTAAGGGCTGCTCGTCTTACTATCCAAATTAAAA ATCTGCTGTTCTCCCTCCCATATTCTTTGCGAATGAAGATTCCCCTGTTTGTTTGGATAGTTTTCCAAATTCATTACTGCATTCCTGGCA TCCGCAGCAAGCTAAGAGTTAGTTAATATTTTTAATATAGCAAATAAGGATGAGGGATGCCCTTCATGTGTATTTACACACCAGATTTTT ATGGTACATAGGGAGTAATCTAGGGAAAAGATATATTAGGCATGAATCTTAGCTGTGGTAGAAGCACAGCTCAAATTAGCTTAAGGAAAA AAAAAAAAAAGCTGGCTCATAGAACTTGAGGACAGTGGTGGCCATGACTATGGGCTTGATTGGATCTAGTGACTCAAGCTCCCTTCCATT TGCCCCTCCAACCACCCCCCCATCCCTCCACCAATCATACCTTCTGTTGGCCTCTGCAGTAGAGTGGCCTCTTCTGGGCCCTTCCACATG CCAGGGGATATGGCCACCAGCAGTTCTGGGGAAACCATTAGTAATTTGTGATCGTAGAGATTTGTCTCCCAGTATTCCCTAGGGCAAAAA TATTGGGAGTTCCTAGTCACCTAAATGAAGAACCTTATTTTTAGCAGTTTCCCTTTCAGGGCTCTAACAGGACTGTGGAGTAATGTACGG GGTTATGTAGGAGCAATGCAGAGCCACTTTTGAAAAACAGTAGCCAAGGTTCTACTGGCTGCCTTCTTAGGACATTATTAAATATCATAA ACACAAGTGGAATTTAACACCCAGCCAGTTTGTGTTCAACCAGACAGCGTCATTATGAACAAAGATTATATAACGATAGCTGATATTAAG TAAGTTTTAAAAGTTGACATCCCAAGAGTGAAGCCTACTTATTCAGTACAGATTTGTTGAATGAAATTCGTAGTTTTATTTTACGGCATA ATGAAACAGAGTTCCAGACATGTACCTGCCAAATTTGGTTCTGGTTGTCTTATCGTATGCAGGCTGGATACCTGCTACTGTGCTTCTACA GGATGTTAACAGTGTCCCCTGAGTAAAACAGTTCCACGGTCAGTACATTTGGGAACCACTGAGTTAAATGGGTTTTATCACTGCAGAACA GACACAAGAACAATGTGTGCTGTAAATCACTGTTTGCAGGGAAGGTGGCAGCAAATGGCACAGAAACCCACCTGACCACAGACTGCTTTC TTCTGGGCGTTCACGCACTGTGCTCCACAGGATACTCTTGAGAAACATTGAGCTATGGTTGGTCTGTTGTTTGAAATTCAAATAATAATG AATCCATTTTAAGGACAGGAATTGGTTTACTGACCTTGATGTTGGGATGACTCTTCATTTCAGGGTGAAAATATCACAGCATCAGCACAG GCCAGGACCACAGAGATAACAAGGTGGTAGTTGTGTAACAGGTTGTGTCTGAACCACAGGAGCTTCAAAACATACACGGCTGGACACCCT GCCAGGATGCTCTAATGGGGCTGGGCATGTGTCCATGAAAAAGACTCCCCAGTTGTTTCTAAAATGTGGCCTTTGTTCTAGAAATGCAAT GACCAGCATTTGGGAGTCAGTCAAAAGATCCACTTCCTAAAAGCCTACCTGCTCATTTCTTTCATTCAATACATATTAACCAAGTGCCTA >59003_59003_4_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379540_ACO1_chr9_32440463_ENST00000309951_length(amino acids)=1029AA_BP=889 MRHGMAEAPPVSGTFKFNTDAAEFIPQEKKNSGLNCGTQRRLDSNRIGRRNYSSPPPCHLSRQVPYDEISAVHQHSYHPSGSKPKSQQTS FQSSPCNKSPKSHGLQNQPWQKLRNEKHHIRVKKAQSLAEQTSDTAGLESSTRSESGTDLREHSPSESEKEVVGADPRGAKPKKATQFVY SYGRGPKVKGKLKCEWSNRTTPKPEDAGPESTKPVGVFHPDSSEASSRKGVLDGYGARRNEQRRYPQKRPPWEVEGARPRPGRNPPKQEG HRHTNAGHRNNMGPIPKDDLNERPAKSTCDSENLAVINKSSRRVDQEKCTVRRQDPQVVSPFSRGKQNHVLKNVETHTGSLIEQLTTEKY ECMVCCELVRVTAPVWSCQSCYHVFHLNCIKKWARSPASQADGQSGWRCPACQNVSAHVPNTYTCFCGKVKNPEWSRNEIPHSCGEVCRK KQPGQDCPHSCNLLCHPGPCPPCPAFMTKTCECGRTRHTVRCGQAVSVHCSNPCENILNCGQHQCAELCHGGQCQPCQIILNQVCYCGST SRDVLCGTDVGKSDGFGDFSCLKICGKDLKCGNHTCSQVCHPQPCQQCPRLPQLVRCCPCGQTPLSQLLELGSSSRKTCMDPVPSCGKVC GKPLPCGSLDFIHTCEKLCHEGDCGPCSRTSVISCRCSFRTKELPCTSLKSEDATFMCDKRCNKKRLCGRHKCNEICCVDKEHKCPLICG RKLRCGLHRCEEPCHRGNCQTCWQASFDELTCHCGASVIYPPVPCGTRPPECTQTCARVHECDHPVYHSCHSEEKCPPCTFLTQKWCMGK HEFRSNIPCHLVDISCGLPCSATLPCGMHKCQRLCHKGECLVDEPCKQPCTTPRADCGHPCMAPCHTSSPCPVTACKAKLDVFDAAERYQ QAGLPLIVLAGKEYGAGSSRDWAAKGPFLLGIKAVLAESYERIHRSNLVGMGVIPLEYLPGENADALGLTGQERYTIIIPENLKPQMKVQ -------------------------------------------------------------- >59003_59003_5_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379540_ACO1_chr9_32440463_ENST00000379923_length(transcript)=3865nt_BP=2717nt CACGTGACCTGGTGACAGTGCTGACTTGGCTGTACAGCTCGATCTAGGTTCTGCGGCACGGGATGGCGGAGGCGCCTCCTGTCTCAGGTA CTTTTAAATTCAATACAGATGCTGCTGAATTCATTCCTCAGGAGAAAAAAAATTCTGGTCTAAATTGTGGGACTCAAAGGAGACTAGACT CTAATAGGATTGGTAGAAGAAATTACAGTTCACCACCTCCCTGTCACCTTTCCAGGCAGGTCCCTTATGATGAAATCTCTGCTGTTCATC AGCATAGTTATCATCCGTCAGGAAGCAAACCTAAGAGTCAGCAGACGTCTTTCCAGTCCTCTCCTTGTAATAAATCGCCCAAGAGCCATG GCCTTCAGAATCAACCTTGGCAGAAATTGAGGAATGAGAAGCACCATATCAGAGTCAAGAAAGCACAGAGTCTTGCTGAGCAGACCTCAG ATACAGCTGGATTAGAGAGCTCGACCAGATCAGAGAGTGGGACAGACCTCAGAGAGCATAGTCCTTCTGAGAGTGAGAAGGAAGTTGTGG GTGCAGATCCCAGGGGAGCAAAACCCAAAAAAGCAACACAGTTTGTATACAGCTATGGTAGAGGACCAAAAGTCAAGGGGAAACTCAAAT GTGAATGGAGTAACCGAACAACTCCAAAACCGGAGGATGCTGGACCCGAAAGTACCAAACCTGTGGGGGTTTTCCACCCTGACTCTTCAG AGGCATCCTCTAGAAAAGGAGTATTGGATGGGTATGGAGCCAGACGAAATGAGCAGAGAAGATACCCACAGAAAAGGCCTCCCTGGGAAG TGGAGGGGGCCAGGCCACGACCAGGCAGAAATCCACCAAAACAGGAGGGCCACCGACATACAAACGCAGGACACAGAAACAACATGGGCC CCATTCCAAAGGATGACCTCAATGAAAGACCAGCAAAATCTACCTGTGACAGTGAGAACTTGGCAGTCATCAACAAGTCTTCCAGGAGGG TTGACCAAGAGAAATGCACTGTACGGAGGCAGGATCCTCAAGTAGTATCTCCTTTCTCCCGAGGCAAACAGAACCATGTGCTAAAGAATG TGGAAACGCACACAGGTTCTCTAATTGAACAACTAACAACAGAAAAATACGAGTGCATGGTGTGCTGTGAATTGGTTCGTGTCACGGCCC CAGTGTGGAGTTGTCAGAGCTGTTACCATGTGTTTCATTTGAACTGCATAAAGAAATGGGCAAGGTCTCCAGCATCTCAAGCAGATGGCC AGAGTGGTTGGAGGTGCCCTGCCTGTCAGAATGTTTCTGCACATGTTCCTAATACCTACACTTGTTTCTGTGGCAAGGTAAAGAATCCTG AGTGGAGCAGAAATGAAATTCCACATAGCTGTGGTGAGGTTTGTAGAAAGAAACAGCCTGGCCAGGACTGCCCACATTCCTGTAACCTTC TCTGCCATCCAGGACCCTGCCCACCCTGCCCTGCCTTTATGACAAAAACATGTGAATGTGGACGAACCAGGCACACAGTTCGCTGTGGTC AGGCTGTCTCAGTCCACTGTTCTAACCCATGTGAGAATATTTTGAACTGTGGTCAGCACCAGTGTGCTGAGCTGTGCCATGGGGGTCAGT GCCAGCCTTGCCAGATCATTTTGAACCAGGTATGCTATTGCGGCAGCACCTCCCGAGATGTGTTATGTGGAACCGATGTAGGAAAGTCTG ATGGATTTGGGGATTTCAGCTGTTTAAAGATATGTGGCAAGGACTTGAAATGCGGTAACCATACATGTTCGCAAGTGTGCCACCCTCAGC CCTGCCAGCAATGCCCACGGCTCCCCCAGCTGGTGCGCTGTTGCCCCTGTGGCCAAACTCCTCTCAGCCAATTGCTAGAACTTGGAAGTA GTAGTCGGAAAACATGCATGGACCCTGTGCCTTCATGTGGAAAAGTGTGCGGCAAGCCTCTGCCTTGTGGTTCCTTAGATTTCATTCATA CCTGTGAAAAGCTCTGCCATGAAGGAGACTGTGGACCATGCTCTCGCACATCAGTTATTTCCTGCAGATGCTCTTTCAGAACAAAGGAGC TTCCATGTACCAGTCTCAAAAGTGAAGATGCTACATTTATGTGTGACAAGCGGTGTAACAAGAAACGGTTGTGTGGACGGCATAAATGTA ATGAGATATGCTGTGTGGATAAGGAGCACAAGTGTCCTTTGATTTGTGGGAGGAAACTCCGTTGTGGCCTTCATAGGTGTGAAGAACCTT GTCATCGTGGAAACTGCCAGACATGCTGGCAAGCCAGTTTTGATGAATTAACCTGCCATTGTGGTGCATCAGTGATTTACCCTCCAGTTC CCTGTGGTACTAGGCCCCCTGAATGTACCCAAACCTGCGCTAGAGTCCATGAGTGTGACCATCCAGTATATCATTCTTGTCATAGTGAGG AGAAGTGTCCCCCTTGCACTTTCCTAACTCAGAAGTGGTGCATGGGCAAGCATGAGTTTCGGAGCAACATCCCCTGTCACCTGGTTGATA TCTCTTGCGGATTACCCTGCAGTGCCACGCTACCATGTGGGATGCACAAATGTCAGAGACTCTGTCACAAAGGGGAGTGTCTTGTGGATG AGCCCTGCAAGCAGCCCTGCACCACCCCCAGAGCTGACTGTGGTCACCCGTGTATGGCACCCTGCCATACCAGCTCACCCTGCCCTGTGA CTGCTTGTAAAGCTAAGCTTGATGTGTTTGATGCTGCTGAGCGGTACCAGCAGGCAGGCCTTCCCCTGATCGTTCTGGCTGGCAAAGAGT ACGGTGCAGGCAGCTCCCGAGACTGGGCAGCTAAGGGCCCTTTCCTGCTGGGAATCAAAGCCGTCCTGGCCGAGAGCTACGAGCGCATTC ACCGCAGTAACCTGGTTGGGATGGGTGTGATCCCACTTGAATATCTCCCTGGTGAGAATGCAGATGCCCTGGGGCTCACAGGGCAAGAAC GATACACTATCATTATTCCAGAAAACCTCAAACCACAAATGAAAGTCCAGGTCAAGCTGGATACTGGCAAGACCTTCCAGGCTGTCATGA GGTTTGACACTGATGTGGAGCTCACTTATTTCCTCAACGGGGGCATCCTCAACTACATGATCCGCAAGATGGCCAAGTAGGAGACGTGCA CTTGGTGCTGCGCCCAGGGAGGAAGCCGCACCACCAGCCAGCGCAGGCCCTGGTGGAGAGGCCTCCCTGGCTGCCTCTGGGAGGGGTGCT GCCTTGTAGATGGAGCAAGTGAGCACTGAGGGTCTGGTGCCAATCCTGTAGGCACAAAACCAGAAGTTTCTACATTCTCTATTTTTGTTA ATCATCTTCTCTTTTTCCAGAATTTGGAAGCTAGAATGGTGGGAATGTCAGTAGTGCCAGAAAGAGAGAACCAAGCTTGTCTTTAAAGTT ACTGATCACAGGACGTTGCTTTTTCACTGTTTCCTATTAATCTTCAGCTGAACACAAGCAAACCTTCTCAGGAGGTGTCTCCTACCCTCT TATTGTTCCTCTTACGCTCTGCTCAATGAAACCTTCCTCTTGAGGGTCATTTTCCTTTCTGTATTAATTATACCAGTGTTAAGTGACATA GATAAGAACTTTGCACACTTCAAATCAGAGCAGTGATTCTCTCTTCTCTCCCCTTTTCCTTCAGAGTGAATCATCCAGACTCCTCATGGA TAGGTCGGGTGTTAAAGTTGTTTTGATTATGTACCTTTTGATAGATCCACATAAAAAGAAATGTGAAGTTTTCTTTTACTATCTTTTCAT >59003_59003_5_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379540_ACO1_chr9_32440463_ENST00000379923_length(amino acids)=1029AA_BP=889 MRHGMAEAPPVSGTFKFNTDAAEFIPQEKKNSGLNCGTQRRLDSNRIGRRNYSSPPPCHLSRQVPYDEISAVHQHSYHPSGSKPKSQQTS FQSSPCNKSPKSHGLQNQPWQKLRNEKHHIRVKKAQSLAEQTSDTAGLESSTRSESGTDLREHSPSESEKEVVGADPRGAKPKKATQFVY SYGRGPKVKGKLKCEWSNRTTPKPEDAGPESTKPVGVFHPDSSEASSRKGVLDGYGARRNEQRRYPQKRPPWEVEGARPRPGRNPPKQEG HRHTNAGHRNNMGPIPKDDLNERPAKSTCDSENLAVINKSSRRVDQEKCTVRRQDPQVVSPFSRGKQNHVLKNVETHTGSLIEQLTTEKY ECMVCCELVRVTAPVWSCQSCYHVFHLNCIKKWARSPASQADGQSGWRCPACQNVSAHVPNTYTCFCGKVKNPEWSRNEIPHSCGEVCRK KQPGQDCPHSCNLLCHPGPCPPCPAFMTKTCECGRTRHTVRCGQAVSVHCSNPCENILNCGQHQCAELCHGGQCQPCQIILNQVCYCGST SRDVLCGTDVGKSDGFGDFSCLKICGKDLKCGNHTCSQVCHPQPCQQCPRLPQLVRCCPCGQTPLSQLLELGSSSRKTCMDPVPSCGKVC GKPLPCGSLDFIHTCEKLCHEGDCGPCSRTSVISCRCSFRTKELPCTSLKSEDATFMCDKRCNKKRLCGRHKCNEICCVDKEHKCPLICG RKLRCGLHRCEEPCHRGNCQTCWQASFDELTCHCGASVIYPPVPCGTRPPECTQTCARVHECDHPVYHSCHSEEKCPPCTFLTQKWCMGK HEFRSNIPCHLVDISCGLPCSATLPCGMHKCQRLCHKGECLVDEPCKQPCTTPRADCGHPCMAPCHTSSPCPVTACKAKLDVFDAAERYQ QAGLPLIVLAGKEYGAGSSRDWAAKGPFLLGIKAVLAESYERIHRSNLVGMGVIPLEYLPGENADALGLTGQERYTIIIPENLKPQMKVQ -------------------------------------------------------------- >59003_59003_6_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379540_ACO1_chr9_32440463_ENST00000541043_length(transcript)=3861nt_BP=2717nt CACGTGACCTGGTGACAGTGCTGACTTGGCTGTACAGCTCGATCTAGGTTCTGCGGCACGGGATGGCGGAGGCGCCTCCTGTCTCAGGTA CTTTTAAATTCAATACAGATGCTGCTGAATTCATTCCTCAGGAGAAAAAAAATTCTGGTCTAAATTGTGGGACTCAAAGGAGACTAGACT CTAATAGGATTGGTAGAAGAAATTACAGTTCACCACCTCCCTGTCACCTTTCCAGGCAGGTCCCTTATGATGAAATCTCTGCTGTTCATC AGCATAGTTATCATCCGTCAGGAAGCAAACCTAAGAGTCAGCAGACGTCTTTCCAGTCCTCTCCTTGTAATAAATCGCCCAAGAGCCATG GCCTTCAGAATCAACCTTGGCAGAAATTGAGGAATGAGAAGCACCATATCAGAGTCAAGAAAGCACAGAGTCTTGCTGAGCAGACCTCAG ATACAGCTGGATTAGAGAGCTCGACCAGATCAGAGAGTGGGACAGACCTCAGAGAGCATAGTCCTTCTGAGAGTGAGAAGGAAGTTGTGG GTGCAGATCCCAGGGGAGCAAAACCCAAAAAAGCAACACAGTTTGTATACAGCTATGGTAGAGGACCAAAAGTCAAGGGGAAACTCAAAT GTGAATGGAGTAACCGAACAACTCCAAAACCGGAGGATGCTGGACCCGAAAGTACCAAACCTGTGGGGGTTTTCCACCCTGACTCTTCAG AGGCATCCTCTAGAAAAGGAGTATTGGATGGGTATGGAGCCAGACGAAATGAGCAGAGAAGATACCCACAGAAAAGGCCTCCCTGGGAAG TGGAGGGGGCCAGGCCACGACCAGGCAGAAATCCACCAAAACAGGAGGGCCACCGACATACAAACGCAGGACACAGAAACAACATGGGCC CCATTCCAAAGGATGACCTCAATGAAAGACCAGCAAAATCTACCTGTGACAGTGAGAACTTGGCAGTCATCAACAAGTCTTCCAGGAGGG TTGACCAAGAGAAATGCACTGTACGGAGGCAGGATCCTCAAGTAGTATCTCCTTTCTCCCGAGGCAAACAGAACCATGTGCTAAAGAATG TGGAAACGCACACAGGTTCTCTAATTGAACAACTAACAACAGAAAAATACGAGTGCATGGTGTGCTGTGAATTGGTTCGTGTCACGGCCC CAGTGTGGAGTTGTCAGAGCTGTTACCATGTGTTTCATTTGAACTGCATAAAGAAATGGGCAAGGTCTCCAGCATCTCAAGCAGATGGCC AGAGTGGTTGGAGGTGCCCTGCCTGTCAGAATGTTTCTGCACATGTTCCTAATACCTACACTTGTTTCTGTGGCAAGGTAAAGAATCCTG AGTGGAGCAGAAATGAAATTCCACATAGCTGTGGTGAGGTTTGTAGAAAGAAACAGCCTGGCCAGGACTGCCCACATTCCTGTAACCTTC TCTGCCATCCAGGACCCTGCCCACCCTGCCCTGCCTTTATGACAAAAACATGTGAATGTGGACGAACCAGGCACACAGTTCGCTGTGGTC AGGCTGTCTCAGTCCACTGTTCTAACCCATGTGAGAATATTTTGAACTGTGGTCAGCACCAGTGTGCTGAGCTGTGCCATGGGGGTCAGT GCCAGCCTTGCCAGATCATTTTGAACCAGGTATGCTATTGCGGCAGCACCTCCCGAGATGTGTTATGTGGAACCGATGTAGGAAAGTCTG ATGGATTTGGGGATTTCAGCTGTTTAAAGATATGTGGCAAGGACTTGAAATGCGGTAACCATACATGTTCGCAAGTGTGCCACCCTCAGC CCTGCCAGCAATGCCCACGGCTCCCCCAGCTGGTGCGCTGTTGCCCCTGTGGCCAAACTCCTCTCAGCCAATTGCTAGAACTTGGAAGTA GTAGTCGGAAAACATGCATGGACCCTGTGCCTTCATGTGGAAAAGTGTGCGGCAAGCCTCTGCCTTGTGGTTCCTTAGATTTCATTCATA CCTGTGAAAAGCTCTGCCATGAAGGAGACTGTGGACCATGCTCTCGCACATCAGTTATTTCCTGCAGATGCTCTTTCAGAACAAAGGAGC TTCCATGTACCAGTCTCAAAAGTGAAGATGCTACATTTATGTGTGACAAGCGGTGTAACAAGAAACGGTTGTGTGGACGGCATAAATGTA ATGAGATATGCTGTGTGGATAAGGAGCACAAGTGTCCTTTGATTTGTGGGAGGAAACTCCGTTGTGGCCTTCATAGGTGTGAAGAACCTT GTCATCGTGGAAACTGCCAGACATGCTGGCAAGCCAGTTTTGATGAATTAACCTGCCATTGTGGTGCATCAGTGATTTACCCTCCAGTTC CCTGTGGTACTAGGCCCCCTGAATGTACCCAAACCTGCGCTAGAGTCCATGAGTGTGACCATCCAGTATATCATTCTTGTCATAGTGAGG AGAAGTGTCCCCCTTGCACTTTCCTAACTCAGAAGTGGTGCATGGGCAAGCATGAGTTTCGGAGCAACATCCCCTGTCACCTGGTTGATA TCTCTTGCGGATTACCCTGCAGTGCCACGCTACCATGTGGGATGCACAAATGTCAGAGACTCTGTCACAAAGGGGAGTGTCTTGTGGATG AGCCCTGCAAGCAGCCCTGCACCACCCCCAGAGCTGACTGTGGTCACCCGTGTATGGCACCCTGCCATACCAGCTCACCCTGCCCTGTGA CTGCTTGTAAAGCTAAGCTTGATGTGTTTGATGCTGCTGAGCGGTACCAGCAGGCAGGCCTTCCCCTGATCGTTCTGGCTGGCAAAGAGT ACGGTGCAGGCAGCTCCCGAGACTGGGCAGCTAAGGGCCCTTTCCTGCTGGGAATCAAAGCCGTCCTGGCCGAGAGCTACGAGCGCATTC ACCGCAGTAACCTGGTTGGGATGGGTGTGATCCCACTTGAATATCTCCCTGGTGAGAATGCAGATGCCCTGGGGCTCACAGGGCAAGAAC GATACACTATCATTATTCCAGAAAACCTCAAACCACAAATGAAAGTCCAGGTCAAGCTGGATACTGGCAAGACCTTCCAGGCTGTCATGA GGTTTGACACTGATGTGGAGCTCACTTATTTCCTCAACGGGGGCATCCTCAACTACATGATCCGCAAGATGGCCAAGTAGGAGACGTGCA CTTGGTGCTGCGCCCAGGGAGGAAGCCGCACCACCAGCCAGCGCAGGCCCTGGTGGAGAGGCCTCCCTGGCTGCCTCTGGGAGGGGTGCT GCCTTGTAGATGGAGCAAGTGAGCACTGAGGGTCTGGTGCCAATCCTGTAGGCACAAAACCAGAAGTTTCTACATTCTCTATTTTTGTTA ATCATCTTCTCTTTTTCCAGAATTTGGAAGCTAGAATGGTGGGAATGTCAGTAGTGCCAGAAAGAGAGAACCAAGCTTGTCTTTAAAGTT ACTGATCACAGGACGTTGCTTTTTCACTGTTTCCTATTAATCTTCAGCTGAACACAAGCAAACCTTCTCAGGAGGTGTCTCCTACCCTCT TATTGTTCCTCTTACGCTCTGCTCAATGAAACCTTCCTCTTGAGGGTCATTTTCCTTTCTGTATTAATTATACCAGTGTTAAGTGACATA GATAAGAACTTTGCACACTTCAAATCAGAGCAGTGATTCTCTCTTCTCTCCCCTTTTCCTTCAGAGTGAATCATCCAGACTCCTCATGGA TAGGTCGGGTGTTAAAGTTGTTTTGATTATGTACCTTTTGATAGATCCACATAAAAAGAAATGTGAAGTTTTCTTTTACTATCTTTTCAT >59003_59003_6_NFX1-ACO1_NFX1_chr9_33351788_ENST00000379540_ACO1_chr9_32440463_ENST00000541043_length(amino acids)=1029AA_BP=889 MRHGMAEAPPVSGTFKFNTDAAEFIPQEKKNSGLNCGTQRRLDSNRIGRRNYSSPPPCHLSRQVPYDEISAVHQHSYHPSGSKPKSQQTS FQSSPCNKSPKSHGLQNQPWQKLRNEKHHIRVKKAQSLAEQTSDTAGLESSTRSESGTDLREHSPSESEKEVVGADPRGAKPKKATQFVY SYGRGPKVKGKLKCEWSNRTTPKPEDAGPESTKPVGVFHPDSSEASSRKGVLDGYGARRNEQRRYPQKRPPWEVEGARPRPGRNPPKQEG HRHTNAGHRNNMGPIPKDDLNERPAKSTCDSENLAVINKSSRRVDQEKCTVRRQDPQVVSPFSRGKQNHVLKNVETHTGSLIEQLTTEKY ECMVCCELVRVTAPVWSCQSCYHVFHLNCIKKWARSPASQADGQSGWRCPACQNVSAHVPNTYTCFCGKVKNPEWSRNEIPHSCGEVCRK KQPGQDCPHSCNLLCHPGPCPPCPAFMTKTCECGRTRHTVRCGQAVSVHCSNPCENILNCGQHQCAELCHGGQCQPCQIILNQVCYCGST SRDVLCGTDVGKSDGFGDFSCLKICGKDLKCGNHTCSQVCHPQPCQQCPRLPQLVRCCPCGQTPLSQLLELGSSSRKTCMDPVPSCGKVC GKPLPCGSLDFIHTCEKLCHEGDCGPCSRTSVISCRCSFRTKELPCTSLKSEDATFMCDKRCNKKRLCGRHKCNEICCVDKEHKCPLICG RKLRCGLHRCEEPCHRGNCQTCWQASFDELTCHCGASVIYPPVPCGTRPPECTQTCARVHECDHPVYHSCHSEEKCPPCTFLTQKWCMGK HEFRSNIPCHLVDISCGLPCSATLPCGMHKCQRLCHKGECLVDEPCKQPCTTPRADCGHPCMAPCHTSSPCPVTACKAKLDVFDAAERYQ QAGLPLIVLAGKEYGAGSSRDWAAKGPFLLGIKAVLAESYERIHRSNLVGMGVIPLEYLPGENADALGLTGQERYTIIIPENLKPQMKVQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NFX1-ACO1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379521 | + | 16 | 21 | 9_26 | 885.0 | 1025.0 | PABPC1 and PABC4 |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000379540 | + | 16 | 24 | 9_26 | 885.0 | 1121.0 | PABPC1 and PABC4 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | NFX1 | chr9:33351788 | chr9:32440463 | ENST00000318524 | + | 1 | 16 | 9_26 | 0 | 834.0 | PABPC1 and PABC4 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NFX1-ACO1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NFX1-ACO1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies