
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARFRP1-ADRM1 (FusionGDB2 ID:5902) |
Fusion Gene Summary for ARFRP1-ADRM1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARFRP1-ADRM1 | Fusion gene ID: 5902 | Hgene | Tgene | Gene symbol | ARFRP1 | ADRM1 | Gene ID | 10139 | 11047 |
| Gene name | ADP ribosylation factor related protein 1 | adhesion regulating molecule 1 | |
| Synonyms | ARL18|ARP|Arp1 | ARM-1|ARM1|GP110 | |
| Cytomap | 20q13.33 | 20q13.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | ADP-ribosylation factor-related protein 1ARF-related protein 1SCG10 like-proteinepididymis secretory sperm binding proteinhelicase-like protein NHL | proteasomal ubiquitin receptor ADRM1110 kDa cell membrane glycoproteinM(r) 110,000 surface antigenproteasome regulatory particle non-ATPase 13proteasome ubiquitin receptorrpn13 homolog | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q13795 | Q16186 | |
| Ensembl transtripts involved in fusion gene | ENST00000324228, ENST00000359715, ENST00000440854, ENST00000607873, ENST00000609142, ENST00000485858, | ENST00000462554, ENST00000253003, | |
| Fusion gene scores | * DoF score | 4 X 4 X 2=32 | 8 X 6 X 5=240 |
| # samples | 4 | 8 | |
| ** MAII score | log2(4/32*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(8/240*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARFRP1 [Title/Abstract] AND ADRM1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARFRP1(62337708)-ADRM1(60881252), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ARFRP1-ADRM1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | ADRM1 | GO:0043248 | proteasome assembly | 16990800 |
| Fusion gene breakpoints across ARFRP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ADRM1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | COAD | TCGA-A6-5656 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
Top |
Fusion Gene ORF analysis for ARFRP1-ADRM1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000324228 | ENST00000462554 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| 5CDS-3UTR | ENST00000359715 | ENST00000462554 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| 5CDS-3UTR | ENST00000440854 | ENST00000462554 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| 5CDS-3UTR | ENST00000607873 | ENST00000462554 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| 5CDS-3UTR | ENST00000609142 | ENST00000462554 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| Frame-shift | ENST00000609142 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| In-frame | ENST00000324228 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| In-frame | ENST00000359715 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| In-frame | ENST00000440854 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| In-frame | ENST00000607873 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| intron-3CDS | ENST00000485858 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| intron-3UTR | ENST00000485858 | ENST00000462554 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000440854 | ARFRP1 | chr20 | 62337708 | - | ENST00000253003 | ADRM1 | chr20 | 60881252 | + | 1397 | 402 | 138 | 1295 | 385 |
| ENST00000359715 | ARFRP1 | chr20 | 62337708 | - | ENST00000253003 | ADRM1 | chr20 | 60881252 | + | 1826 | 831 | 531 | 1724 | 397 |
| ENST00000324228 | ARFRP1 | chr20 | 62337708 | - | ENST00000253003 | ADRM1 | chr20 | 60881252 | + | 1289 | 294 | 30 | 1187 | 385 |
| ENST00000607873 | ARFRP1 | chr20 | 62337708 | - | ENST00000253003 | ADRM1 | chr20 | 60881252 | + | 1325 | 330 | 165 | 1223 | 352 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000440854 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + | 0.011052458 | 0.9889475 |
| ENST00000359715 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + | 0.017947283 | 0.98205274 |
| ENST00000324228 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + | 0.010876489 | 0.9891235 |
| ENST00000607873 | ENST00000253003 | ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + | 0.008094439 | 0.99190557 |
Top |
Fusion Genomic Features for ARFRP1-ADRM1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + | 1.89E-06 | 0.9999981 |
| ARFRP1 | chr20 | 62337708 | - | ADRM1 | chr20 | 60881252 | + | 1.89E-06 | 0.9999981 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
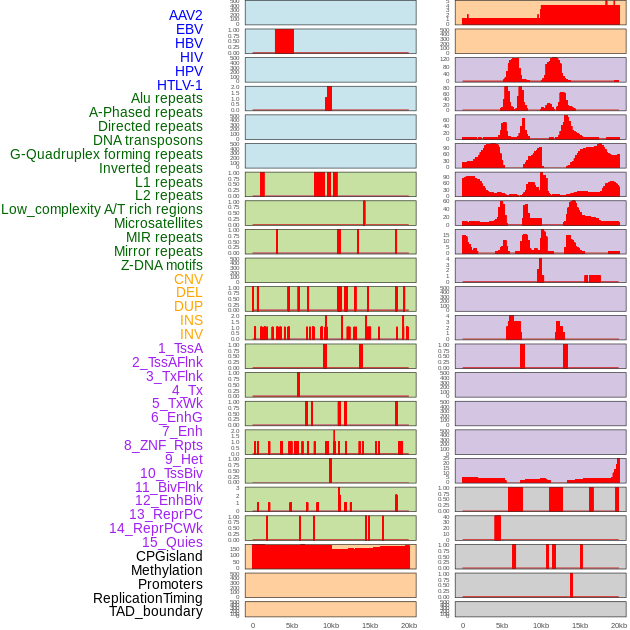 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
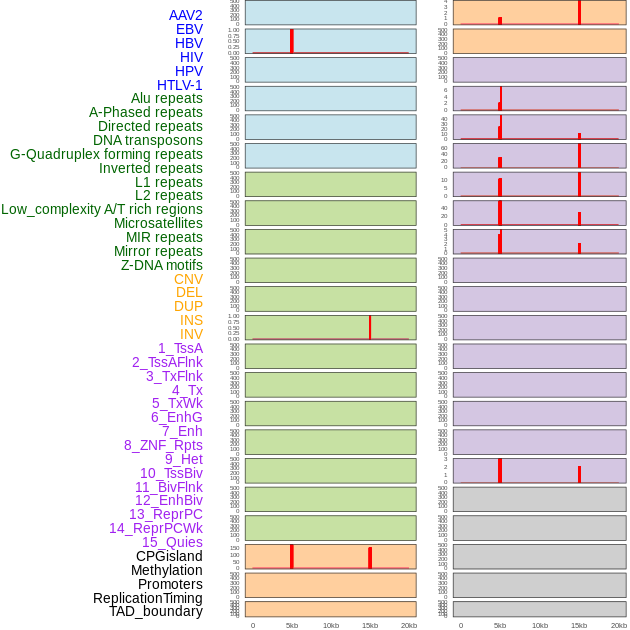 |
Top |
Fusion Protein Features for ARFRP1-ADRM1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:62337708/chr20:60881252) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARFRP1 | ADRM1 |
| FUNCTION: Trans-Golgi-associated GTPase that regulates protein sorting. Controls the targeting of ARL1 and its effector to the trans-Golgi. Required for the lipidation of chylomicrons in the intestine and required for VLDL lipidation in the liver. {ECO:0000250|UniProtKB:Q8BXL7}. | FUNCTION: Component of the 26S proteasome, a multiprotein complex involved in the ATP-dependent degradation of ubiquitinated proteins. This complex plays a key role in the maintenance of protein homeostasis by removing misfolded or damaged proteins, which could impair cellular functions, and by removing proteins whose functions are no longer required. Therefore, the proteasome participates in numerous cellular processes, including cell cycle progression, apoptosis, or DNA damage repair. Within the complex, functions as a proteasomal ubiquitin receptor. Engages and activates 19S-associated deubiquitinases UCHL5 and PSMD14 during protein degradation. UCHL5 reversibly associate with the 19S regulatory particle whereas PSMD14 is an intrinsic subunit of the proteasome lid subcomplex. {ECO:0000269|PubMed:16815440, ECO:0000269|PubMed:16906146, ECO:0000269|PubMed:16990800, ECO:0000269|PubMed:17139257, ECO:0000269|PubMed:18497817, ECO:0000269|PubMed:24752541, ECO:0000269|PubMed:25702870, ECO:0000269|PubMed:25702872}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000324228 | - | 4 | 8 | 24_31 | 88 | 202.0 | Nucleotide binding | GTP |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000324228 | - | 4 | 8 | 75_79 | 88 | 202.0 | Nucleotide binding | GTP |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000359715 | - | 3 | 7 | 24_31 | 88 | 202.0 | Nucleotide binding | GTP |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000359715 | - | 3 | 7 | 75_79 | 88 | 202.0 | Nucleotide binding | GTP |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000440854 | - | 4 | 7 | 24_31 | 88 | 174.0 | Nucleotide binding | GTP |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000440854 | - | 4 | 7 | 75_79 | 88 | 174.0 | Nucleotide binding | GTP |
| Tgene | ADRM1 | chr20:62337708 | chr20:60881252 | ENST00000253003 | 2 | 10 | 135_202 | 110 | 408.0 | Compositional bias | Note=Gly-rich | |
| Tgene | ADRM1 | chr20:62337708 | chr20:60881252 | ENST00000253003 | 2 | 10 | 193_257 | 110 | 408.0 | Compositional bias | Note=Ser-rich | |
| Tgene | ADRM1 | chr20:62337708 | chr20:60881252 | ENST00000253003 | 2 | 10 | 203_213 | 110 | 408.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | ADRM1 | chr20:62337708 | chr20:60881252 | ENST00000253003 | 2 | 10 | 277_391 | 110 | 408.0 | Domain | DEUBAD |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000324228 | - | 4 | 8 | 134_137 | 88 | 202.0 | Nucleotide binding | GTP |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000359715 | - | 3 | 7 | 134_137 | 88 | 202.0 | Nucleotide binding | GTP |
| Hgene | ARFRP1 | chr20:62337708 | chr20:60881252 | ENST00000440854 | - | 4 | 7 | 134_137 | 88 | 174.0 | Nucleotide binding | GTP |
| Tgene | ADRM1 | chr20:62337708 | chr20:60881252 | ENST00000253003 | 2 | 10 | 18_131 | 110 | 408.0 | Domain | Pru |
Top |
Fusion Gene Sequence for ARFRP1-ADRM1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5902_5902_1_ARFRP1-ADRM1_ARFRP1_chr20_62337708_ENST00000324228_ADRM1_chr20_60881252_ENST00000253003_length(transcript)=1289nt_BP=294nt GAGGCCCGAGGGGCGGCCCAGGACTCGAGGATGTACACGCTGCTGTCGGGCTTGTACAAGTACATGTTTCAGAAGGACGAGTACTGCATC CTGATCCTGGGCCTGGACAATGCTGGGAAGACGACCTTCCTGGAGCAGTCGAAAACCCGATTTAACAAGAACTACAAGGGGATGAGTCTA TCCAAAATCACCACCACCGTGGGCCTAAACATCGGCACTGTGGATGTGGGAAAGGCTCGGCTCATGTTCTGGGACTTAGGAGGGCAGGAA GAGCTGCAGTCTTTGTGGGACAAGGAACCCAAGACAGACCAGGATGAGGAGCATTGCCGGAAAGTCAACGAGTATCTGAACAACCCCCCG ATGCCTGGGGCGCTGGGGGCCAGCGGAAGCAGCGGCCACGAACTCTCTGCGCTAGGCGGTGAGGGTGGCCTGCAGAGCCTGCTGGGAAAC ATGAGCCACAGCCAGCTCATGCAGCTCATCGGACCAGCCGGCCTTGGAGGACTGGGTGGGCTGGGGGCCCTGACTGGACCTGGCCTGGCC AGCTTACTGGGGAGCAGTGGGCCTCCAGGGAGCAGCTCCTCCTCCAGCTCCCGGAGCCAGTCGGCAGCGGTCACCCCGTCATCCACCACC TCTTCCACCCGTGCCACCCCAGCCCCTTCTGCTCCAGCAGCTGCCTCAGCAACTAGCCCGAGCCCCGCGCCCAGTTCCGGGAATGGAGCC AGCACAGCAGCCAGCCCGACCCAGCCCATCCAGCTGAGCGACCTCCAGAGCATCCTGGCCACGATGAACGTACCAGCCGGGCCAGCAGGC GGCCAGCAAGTGGACCTGGCCAGTGTGCTGACGCCGGAGATAATGGCTCCCATCCTCGCCAACGCGGATGTCCAGGAGCGCCTGCTTCCC TACTTGCCATCTGGGGAGTCGCTGCCGCAGACCGCGGATGAGATCCAGAATACCCTGACCTCGCCCCAGTTCCAGCAGGCCCTGGGCATG TTCAGCGCAGCCTTGGCCTCGGGGCAGCTGGGCCCCCTCATGTGCCAGTTCGGTCTGCCTGCAGAGGCTGTGGAGGCCGCCAACAAGGGC GATGTGGAAGCGTTTGCCAAAGCCATGCAGAACAACGCCAAGCCCGAGCAGAAAGAGGGCGACACGAAGGACAAGAAGGACGAAGAGGAG GACATGAGCCTGGACTGAGCCACGCGCCGTCCTCCGAGGAACTGGGCGCTTGCAGTGCGTTGCACACCCTCACCTCCCACCCACTGATTA >5902_5902_1_ARFRP1-ADRM1_ARFRP1_chr20_62337708_ENST00000324228_ADRM1_chr20_60881252_ENST00000253003_length(amino acids)=385AA_BP=0 MYTLLSGLYKYMFQKDEYCILILGLDNAGKTTFLEQSKTRFNKNYKGMSLSKITTTVGLNIGTVDVGKARLMFWDLGGQEELQSLWDKEP KTDQDEEHCRKVNEYLNNPPMPGALGASGSSGHELSALGGEGGLQSLLGNMSHSQLMQLIGPAGLGGLGGLGALTGPGLASLLGSSGPPG SSSSSSSRSQSAAVTPSSTTSSTRATPAPSAPAAASATSPSPAPSSGNGASTAASPTQPIQLSDLQSILATMNVPAGPAGGQQVDLASVL TPEIMAPILANADVQERLLPYLPSGESLPQTADEIQNTLTSPQFQQALGMFSAALASGQLGPLMCQFGLPAEAVEAANKGDVEAFAKAMQ -------------------------------------------------------------- >5902_5902_2_ARFRP1-ADRM1_ARFRP1_chr20_62337708_ENST00000359715_ADRM1_chr20_60881252_ENST00000253003_length(transcript)=1826nt_BP=831nt GCACTCCAGGAGCAGCCGCGCCGCTGCTCACCCGCCCTGTAGTCCGCTCCCCCCAGGGCCGTCCCCGTTTTAAGAAATGGGGTGATGGGG CGTCCCTACCCGGCGCCTGCAGGGGCTCCTGGGGAGCGCGCCGGTGGCTCGCTGCTCCCGGGTGGGGCGCGGGGCTGGCGCTCGAGGGTG CCGTGGCCCAGGCGGGGCTGCAGCGAGTGTGTTCCCCGTTCCGCGCGCGTGAAGCGTGGGAGCGAAGCCTCGGGGGAGGGCGGGAGCGCG GCTGAGCTCACTGTGAACACCCGGCTGGGTAGTCCCGCGAGCAGGGGAGGGGCCGGAACCGATGTGTATGCGGAGAGGTCGCAGTCATTG CTGTGAGCAGGACACAGTGGCGGCTGACCTGGGAGAAGTTACAGAGGGACGGGGTGGGAGAGGGACGAGGAGTCGGGAATGGCCCCCAGG CTCTCGTCCTGAGCGGTCGGCTGGACGTGGGGCGCCACTGACCACCGTGGAGAAGCCCGGGGGAGGGGAGGTGCTTTCTGGCTGCACACT GACCTATGTTGGGGTGCCCAGGGCAGGATGTACACGCTGCTGTCGGGCTTGTACAAGTACATGTTTCAGAAGGACGAGTACTGCATCCTG ATCCTGGGCCTGGACAATGCTGGGAAGACGACCTTCCTGGAGCAGTCGAAAACCCGATTTAACAAGAACTACAAGGGGATGAGTCTATCC AAAATCACCACCACCGTGGGCCTAAACATCGGCACTGTGGATGTGGGAAAGGCTCGGCTCATGTTCTGGGACTTAGGAGGGCAGGAAGAG CTGCAGTCTTTGTGGGACAAGGAACCCAAGACAGACCAGGATGAGGAGCATTGCCGGAAAGTCAACGAGTATCTGAACAACCCCCCGATG CCTGGGGCGCTGGGGGCCAGCGGAAGCAGCGGCCACGAACTCTCTGCGCTAGGCGGTGAGGGTGGCCTGCAGAGCCTGCTGGGAAACATG AGCCACAGCCAGCTCATGCAGCTCATCGGACCAGCCGGCCTTGGAGGACTGGGTGGGCTGGGGGCCCTGACTGGACCTGGCCTGGCCAGC TTACTGGGGAGCAGTGGGCCTCCAGGGAGCAGCTCCTCCTCCAGCTCCCGGAGCCAGTCGGCAGCGGTCACCCCGTCATCCACCACCTCT TCCACCCGTGCCACCCCAGCCCCTTCTGCTCCAGCAGCTGCCTCAGCAACTAGCCCGAGCCCCGCGCCCAGTTCCGGGAATGGAGCCAGC ACAGCAGCCAGCCCGACCCAGCCCATCCAGCTGAGCGACCTCCAGAGCATCCTGGCCACGATGAACGTACCAGCCGGGCCAGCAGGCGGC CAGCAAGTGGACCTGGCCAGTGTGCTGACGCCGGAGATAATGGCTCCCATCCTCGCCAACGCGGATGTCCAGGAGCGCCTGCTTCCCTAC TTGCCATCTGGGGAGTCGCTGCCGCAGACCGCGGATGAGATCCAGAATACCCTGACCTCGCCCCAGTTCCAGCAGGCCCTGGGCATGTTC AGCGCAGCCTTGGCCTCGGGGCAGCTGGGCCCCCTCATGTGCCAGTTCGGTCTGCCTGCAGAGGCTGTGGAGGCCGCCAACAAGGGCGAT GTGGAAGCGTTTGCCAAAGCCATGCAGAACAACGCCAAGCCCGAGCAGAAAGAGGGCGACACGAAGGACAAGAAGGACGAAGAGGAGGAC ATGAGCCTGGACTGAGCCACGCGCCGTCCTCCGAGGAACTGGGCGCTTGCAGTGCGTTGCACACCCTCACCTCCCACCCACTGATTATTA >5902_5902_2_ARFRP1-ADRM1_ARFRP1_chr20_62337708_ENST00000359715_ADRM1_chr20_60881252_ENST00000253003_length(amino acids)=397AA_BP=1 MHTDLCWGAQGRMYTLLSGLYKYMFQKDEYCILILGLDNAGKTTFLEQSKTRFNKNYKGMSLSKITTTVGLNIGTVDVGKARLMFWDLGG QEELQSLWDKEPKTDQDEEHCRKVNEYLNNPPMPGALGASGSSGHELSALGGEGGLQSLLGNMSHSQLMQLIGPAGLGGLGGLGALTGPG LASLLGSSGPPGSSSSSSSRSQSAAVTPSSTTSSTRATPAPSAPAAASATSPSPAPSSGNGASTAASPTQPIQLSDLQSILATMNVPAGP AGGQQVDLASVLTPEIMAPILANADVQERLLPYLPSGESLPQTADEIQNTLTSPQFQQALGMFSAALASGQLGPLMCQFGLPAEAVEAAN -------------------------------------------------------------- >5902_5902_3_ARFRP1-ADRM1_ARFRP1_chr20_62337708_ENST00000440854_ADRM1_chr20_60881252_ENST00000253003_length(transcript)=1397nt_BP=402nt GGAGGCCGCTGGGACGCGGTTCAGCTCATTCCCTGAGGCCGGCCCGCGTCCCGTCAGGCGCCGCGCGGGGTTAGCGCGGGGTCAGCGGAG GTCAGCGGGGGTCAGCAGCAGCGGCTCCGAGGGCGCGGCGGACGCAGGATGTACACGCTGCTGTCGGGCTTGTACAAGTACATGTTTCAG AAGGACGAGTACTGCATCCTGATCCTGGGCCTGGACAATGCTGGGAAGACGACCTTCCTGGAGCAGTCGAAAACCCGATTTAACAAGAAC TACAAGGGGATGAGTCTATCCAAAATCACCACCACCGTGGGCCTAAACATCGGCACTGTGGATGTGGGAAAGGCTCGGCTCATGTTCTGG GACTTAGGAGGGCAGGAAGAGCTGCAGTCTTTGTGGGACAAGGAACCCAAGACAGACCAGGATGAGGAGCATTGCCGGAAAGTCAACGAG TATCTGAACAACCCCCCGATGCCTGGGGCGCTGGGGGCCAGCGGAAGCAGCGGCCACGAACTCTCTGCGCTAGGCGGTGAGGGTGGCCTG CAGAGCCTGCTGGGAAACATGAGCCACAGCCAGCTCATGCAGCTCATCGGACCAGCCGGCCTTGGAGGACTGGGTGGGCTGGGGGCCCTG ACTGGACCTGGCCTGGCCAGCTTACTGGGGAGCAGTGGGCCTCCAGGGAGCAGCTCCTCCTCCAGCTCCCGGAGCCAGTCGGCAGCGGTC ACCCCGTCATCCACCACCTCTTCCACCCGTGCCACCCCAGCCCCTTCTGCTCCAGCAGCTGCCTCAGCAACTAGCCCGAGCCCCGCGCCC AGTTCCGGGAATGGAGCCAGCACAGCAGCCAGCCCGACCCAGCCCATCCAGCTGAGCGACCTCCAGAGCATCCTGGCCACGATGAACGTA CCAGCCGGGCCAGCAGGCGGCCAGCAAGTGGACCTGGCCAGTGTGCTGACGCCGGAGATAATGGCTCCCATCCTCGCCAACGCGGATGTC CAGGAGCGCCTGCTTCCCTACTTGCCATCTGGGGAGTCGCTGCCGCAGACCGCGGATGAGATCCAGAATACCCTGACCTCGCCCCAGTTC CAGCAGGCCCTGGGCATGTTCAGCGCAGCCTTGGCCTCGGGGCAGCTGGGCCCCCTCATGTGCCAGTTCGGTCTGCCTGCAGAGGCTGTG GAGGCCGCCAACAAGGGCGATGTGGAAGCGTTTGCCAAAGCCATGCAGAACAACGCCAAGCCCGAGCAGAAAGAGGGCGACACGAAGGAC AAGAAGGACGAAGAGGAGGACATGAGCCTGGACTGAGCCACGCGCCGTCCTCCGAGGAACTGGGCGCTTGCAGTGCGTTGCACACCCTCA >5902_5902_3_ARFRP1-ADRM1_ARFRP1_chr20_62337708_ENST00000440854_ADRM1_chr20_60881252_ENST00000253003_length(amino acids)=385AA_BP=0 MYTLLSGLYKYMFQKDEYCILILGLDNAGKTTFLEQSKTRFNKNYKGMSLSKITTTVGLNIGTVDVGKARLMFWDLGGQEELQSLWDKEP KTDQDEEHCRKVNEYLNNPPMPGALGASGSSGHELSALGGEGGLQSLLGNMSHSQLMQLIGPAGLGGLGGLGALTGPGLASLLGSSGPPG SSSSSSSRSQSAAVTPSSTTSSTRATPAPSAPAAASATSPSPAPSSGNGASTAASPTQPIQLSDLQSILATMNVPAGPAGGQQVDLASVL TPEIMAPILANADVQERLLPYLPSGESLPQTADEIQNTLTSPQFQQALGMFSAALASGQLGPLMCQFGLPAEAVEAANKGDVEAFAKAMQ -------------------------------------------------------------- >5902_5902_4_ARFRP1-ADRM1_ARFRP1_chr20_62337708_ENST00000607873_ADRM1_chr20_60881252_ENST00000253003_length(transcript)=1325nt_BP=330nt GGGCAGCCGGGAAGCGGAGCGCGGAGGCCGCTGGGACGCGGTTCAGCTCATTCCCTGAGGCCGGCCCGCGTCCCGTCAGGCGCCGCGCGG GGTTAGCGCGGGGTCAGCGGAGGTCAGCGGGGGTCAGCAGCAGCGGCTCCGAGGGCGCGGCGGACGCAGACCTTCCTGGAGCAGTCGAAA ACCCGATTTAACAAGAACTACAAGGGGATGAGTCTATCCAAAATCACCACCACCGTGGGCCTAAACATCGGCACTGTGGATGTGGGAAAG GCTCGGCTCATGTTCTGGGACTTAGGAGGGCAGGAAGAGCTGCAGTCTTTGTGGGACAAGGAACCCAAGACAGACCAGGATGAGGAGCAT TGCCGGAAAGTCAACGAGTATCTGAACAACCCCCCGATGCCTGGGGCGCTGGGGGCCAGCGGAAGCAGCGGCCACGAACTCTCTGCGCTA GGCGGTGAGGGTGGCCTGCAGAGCCTGCTGGGAAACATGAGCCACAGCCAGCTCATGCAGCTCATCGGACCAGCCGGCCTTGGAGGACTG GGTGGGCTGGGGGCCCTGACTGGACCTGGCCTGGCCAGCTTACTGGGGAGCAGTGGGCCTCCAGGGAGCAGCTCCTCCTCCAGCTCCCGG AGCCAGTCGGCAGCGGTCACCCCGTCATCCACCACCTCTTCCACCCGTGCCACCCCAGCCCCTTCTGCTCCAGCAGCTGCCTCAGCAACT AGCCCGAGCCCCGCGCCCAGTTCCGGGAATGGAGCCAGCACAGCAGCCAGCCCGACCCAGCCCATCCAGCTGAGCGACCTCCAGAGCATC CTGGCCACGATGAACGTACCAGCCGGGCCAGCAGGCGGCCAGCAAGTGGACCTGGCCAGTGTGCTGACGCCGGAGATAATGGCTCCCATC CTCGCCAACGCGGATGTCCAGGAGCGCCTGCTTCCCTACTTGCCATCTGGGGAGTCGCTGCCGCAGACCGCGGATGAGATCCAGAATACC CTGACCTCGCCCCAGTTCCAGCAGGCCCTGGGCATGTTCAGCGCAGCCTTGGCCTCGGGGCAGCTGGGCCCCCTCATGTGCCAGTTCGGT CTGCCTGCAGAGGCTGTGGAGGCCGCCAACAAGGGCGATGTGGAAGCGTTTGCCAAAGCCATGCAGAACAACGCCAAGCCCGAGCAGAAA GAGGGCGACACGAAGGACAAGAAGGACGAAGAGGAGGACATGAGCCTGGACTGAGCCACGCGCCGTCCTCCGAGGAACTGGGCGCTTGCA >5902_5902_4_ARFRP1-ADRM1_ARFRP1_chr20_62337708_ENST00000607873_ADRM1_chr20_60881252_ENST00000253003_length(amino acids)=352AA_BP=1 MEQSKTRFNKNYKGMSLSKITTTVGLNIGTVDVGKARLMFWDLGGQEELQSLWDKEPKTDQDEEHCRKVNEYLNNPPMPGALGASGSSGH ELSALGGEGGLQSLLGNMSHSQLMQLIGPAGLGGLGGLGALTGPGLASLLGSSGPPGSSSSSSSRSQSAAVTPSSTTSSTRATPAPSAPA AASATSPSPAPSSGNGASTAASPTQPIQLSDLQSILATMNVPAGPAGGQQVDLASVLTPEIMAPILANADVQERLLPYLPSGESLPQTAD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARFRP1-ADRM1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | ADRM1 | chr20:62337708 | chr20:60881252 | ENST00000253003 | 2 | 10 | 253_407 | 110.0 | 408.0 | UCHL5 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARFRP1-ADRM1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARFRP1-ADRM1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies