
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NIT1-C12orf5 (FusionGDB2 ID:59230) |
Fusion Gene Summary for NIT1-C12orf5 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NIT1-C12orf5 | Fusion gene ID: 59230 | Hgene | Tgene | Gene symbol | NIT1 | C12orf5 | Gene ID | 4817 | 57103 |
| Gene name | nitrilase 1 | TP53 induced glycolysis regulatory phosphatase | |
| Synonyms | - | C12orf5|FR2BP | |
| Cytomap | 1q23.3 | 12p13.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | deaminated glutathione amidasedGSH amidase | fructose-2,6-bisphosphatase TIGARTP53-induced glycolysis and apoptosis regulatorfructose-2,6-bisphosphate 2-phosphataseprobable fructose-2,6-bisphosphatase TIGARtransactivated by NS3TP2 protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q99622 | |
| Ensembl transtripts involved in fusion gene | ENST00000496861, ENST00000368007, ENST00000368008, ENST00000368009, ENST00000392190, | ENST00000179259, ENST00000537251, | |
| Fusion gene scores | * DoF score | 3 X 1 X 2=6 | 1 X 1 X 1=1 |
| # samples | 3 | 1 | |
| ** MAII score | log2(3/6*10)=2.32192809488736 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: NIT1 [Title/Abstract] AND C12orf5 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NIT1(161090022)-C12orf5(4458985), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | C12orf5 | GO:0006003 | fructose 2,6-bisphosphate metabolic process | 19015259 |
| Tgene | C12orf5 | GO:0006974 | cellular response to DNA damage stimulus | 25928429 |
| Tgene | C12orf5 | GO:0030388 | fructose 1,6-bisphosphate metabolic process | 19015259 |
| Tgene | C12orf5 | GO:0043069 | negative regulation of programmed cell death | 23185017 |
| Tgene | C12orf5 | GO:0071279 | cellular response to cobalt ion | 25928429 |
| Tgene | C12orf5 | GO:0071456 | cellular response to hypoxia | 23185017 |
| Tgene | C12orf5 | GO:1903301 | positive regulation of hexokinase activity | 23185017 |
| Fusion gene breakpoints across NIT1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
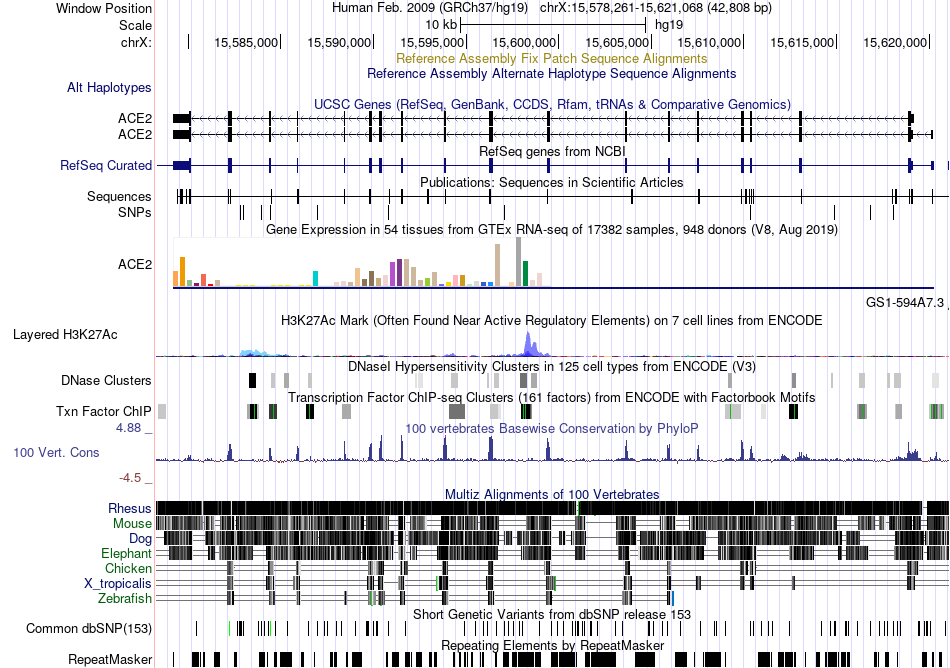 |
| Fusion gene breakpoints across C12orf5 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
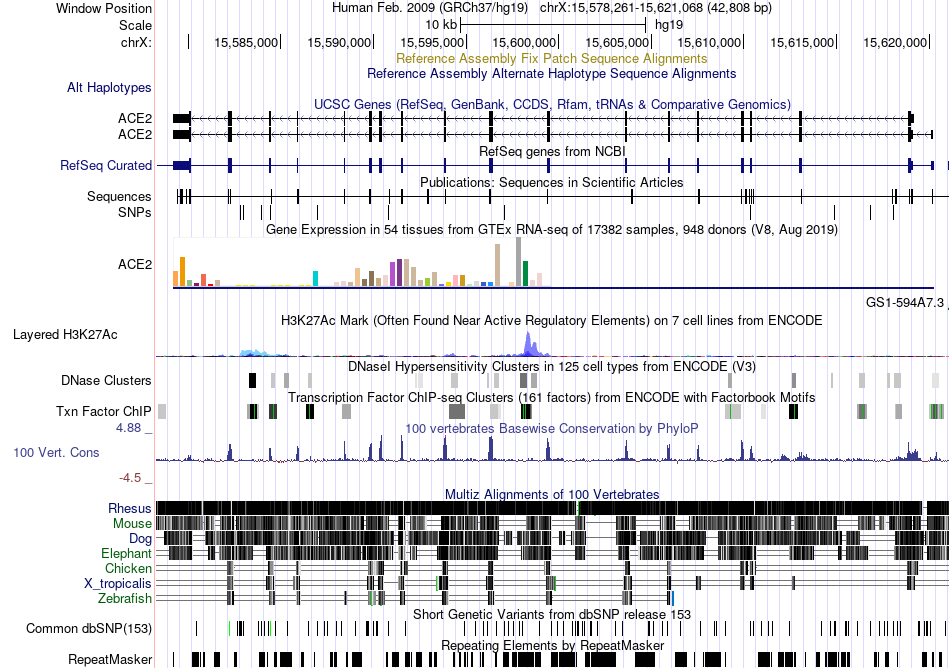 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SARC | TCGA-DX-A240-01A | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
Top |
Fusion Gene ORF analysis for NIT1-C12orf5 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000496861 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| 3UTR-3UTR | ENST00000496861 | ENST00000537251 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| 5CDS-3UTR | ENST00000368007 | ENST00000537251 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| 5CDS-3UTR | ENST00000368008 | ENST00000537251 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| 5CDS-3UTR | ENST00000368009 | ENST00000537251 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| 5CDS-3UTR | ENST00000392190 | ENST00000537251 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| In-frame | ENST00000368007 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| In-frame | ENST00000368008 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| In-frame | ENST00000368009 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| In-frame | ENST00000392190 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000368009 | NIT1 | chr1 | 161090022 | - | ENST00000179259 | C12orf5 | chr12 | 4458985 | + | 1895 | 793 | 76 | 1413 | 445 |
| ENST00000368007 | NIT1 | chr1 | 161090022 | - | ENST00000179259 | C12orf5 | chr12 | 4458985 | + | 2156 | 1054 | 382 | 1674 | 430 |
| ENST00000392190 | NIT1 | chr1 | 161090022 | - | ENST00000179259 | C12orf5 | chr12 | 4458985 | + | 1925 | 823 | 103 | 1443 | 446 |
| ENST00000368008 | NIT1 | chr1 | 161090022 | - | ENST00000179259 | C12orf5 | chr12 | 4458985 | + | 1878 | 776 | 59 | 1396 | 445 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000368009 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + | 0.004434868 | 0.9955651 |
| ENST00000368007 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + | 0.000783181 | 0.9992168 |
| ENST00000392190 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + | 0.00201191 | 0.9979881 |
| ENST00000368008 | ENST00000179259 | NIT1 | chr1 | 161090022 | - | C12orf5 | chr12 | 4458985 | + | 0.004353901 | 0.99564606 |
Top |
Fusion Genomic Features for NIT1-C12orf5 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
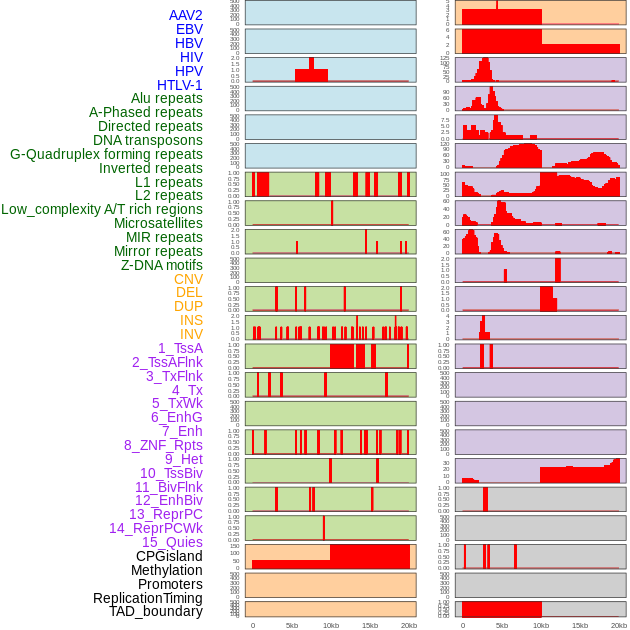 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NIT1-C12orf5 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:161090022/chr12:4458985) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | C12orf5 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: In brain, may be required for corpus callosum development. {ECO:0000269|PubMed:23453666}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NIT1 | chr1:161090022 | chr12:4458985 | ENST00000368007 | - | 5 | 6 | 46_298 | 224 | 313.0 | Domain | CN hydrolase |
| Hgene | NIT1 | chr1:161090022 | chr12:4458985 | ENST00000368009 | - | 6 | 7 | 46_298 | 239 | 328.0 | Domain | CN hydrolase |
| Hgene | NIT1 | chr1:161090022 | chr12:4458985 | ENST00000392190 | - | 6 | 7 | 46_298 | 203 | 292.0 | Domain | CN hydrolase |
Top |
Fusion Gene Sequence for NIT1-C12orf5 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >59230_59230_1_NIT1-C12orf5_NIT1_chr1_161090022_ENST00000368007_C12orf5_chr12_4458985_ENST00000179259_length(transcript)=2156nt_BP=1054nt GCTTCTGGCTCCAGACCGCCCTCCGGATCGGACCCTGCGAATGGTTTTGGCTATATCTTCATGTAGGACCTACTCCCTATCCCGTCGGCC GCGGTGAATCCCACCTGCGGTGCTTTAACTTGTGTAACAGAGATGCTGCCTCTGGGAGAGGCGGGGAGGGACGGGCCAACTGGAGCGGGC GGCGGGAGGGTGGAGGGCGGGGCGCGGCTTGGGGCCTGGGTTCCTTTGCCCCTTGCCCACCAGGGAGGGGTGGGAGACGAGAGAGGGTGA ACTTTCCCCTGCGAGATTCTGGTGAAAGGGGAAATATGCTTCGAGTCAGTAAAGCTGCGCAAGTGCACAGTCAAGGAGAGAGTCTTGGGA AAACCAAGGATAGTTCCCGGAGATGACTTTTGGACTGCGGAAACGTTTGTCAGAGGAAAGAGGCTTCAGTTTAATGCCCAGAGCCATGGC TATCTCCTCTTCCTCCTGCGAACTGCCCCTGGTGGCTGTGTGCCAGGTAACATCGACGCCAGACAAGCAACAGAACTTTAAAACATGTGC TGAGCTGGTTCGAGAGGCTGCCAGACTGGGTGCCTGCCTGGCTTTCCTGCCTGAGGCATTTGACTTCATTGCACGGGACCCTGCAGAGAC GCTACACCTGTCTGAACCACTGGGTGGGAAACTTTTGGAAGAATACACCCAGCTTGCCAGGGAATGTGGACTCTGGCTGTCCTTGGGTGG TTTCCATGAGCGTGGCCAAGACTGGGAGCAGACTCAGAAAATCTACAATTGTCACGTGCTGCTGAACAGCAAAGGGGCAGTAGTGGCCAC TTACAGGAAGACACATCTGTGTGACGTAGAGATTCCAGGGCAGGGGCCTATGTGTGAAAGCAACTCTACCATGCCTGGGCCCAGTCTTGA GTCACCTGTCAGCACACCAGCAGGCAAGATTGGTCTAGCTGTCTGCTATGACATGCGGTTCCCTGAACTCTCTCTGGCATTGGCTCAAGC TGGAGCAGAGATACTTACCTATCCTTCAGCTTTTGGATCCATTACAGGCCCAGCCCACTGGGAGACCATGCATGGAATTTTGGAGAGAAG CAAATTTTGCAAAGATATGACGGTAAAGTATGACTCAAGACTTCGGGAAAGGAAATACGGGGTTGTAGAAGGCAAAGCGCTAAGTGAGCT GAGGGCCATGGCCAAAGCAGCCAGGGAAGAGTGCCCTGTGTTTACACCGCCCGGAGGAGAGACGCTGGACCAGGTGAAAATGCGTGGAAT AGACTTTTTTGAATTTCTTTGTCAACTAATCCTGAAAGAAGCGGATCAAAAAGAACAGTTTTCCCAAGGATCTCCAAGCAACTGTCTGGA AACTTCTTTGGCAGAGATATTTCCTTTAGGAAAAAATCACAGCTCTAAAGTTAATTCAGACAGCGGTATTCCAGGATTAGCAGCCAGTGT CTTAGTTGTGAGTCACGGTGCTTACATGAGAAGTCTGTTTGATTATTTTCTGACTGACCTTAAGTGTTCCTTACCAGCCACTCTGAGCAG ATCTGAACTTATGTCAGTCACTCCCAATACAGGGATGAGTCTCTTTATCATAAACTTTGAGGAAGGAAGAGAAGTTAAACCAACGGTTCA GTGTATTTGTATGAACCTACAGGATCATCTAAATGGACTGACTGAAACTCGCTAAGGTTAAATCTGCATCAAAATCTAACCATTTTGAGC CTCTGAAGGGAGTGCCATTGGCTTTATTTACTTCTCTCCTCTGCTAGTTCTGATTTGGAAACAGTTAAAAGCCAATTTTTAGCTCCAGTG GAACCATAGCCACATAAAACTTTAATGGACAACCATATAGAATTAACTTATTTTGTCCAAGTACAGTTGGCATTTTCCAGAATAATTTTA CCACCCTGCTAGATGTCATCTCTGGATTGCACATGGATGATGAAGGAACTCAGCATTGAAAGTTGGGGGATTAGTAACCTTGTTACAACG GTTTCTTTTTCATTTTAGCCTATTTTAATGGCTATTGGTAAGATACTGTATGTTTTTAGTATCTCATCCAGTGCTTAGAAGAAAGAATGG >59230_59230_1_NIT1-C12orf5_NIT1_chr1_161090022_ENST00000368007_C12orf5_chr12_4458985_ENST00000179259_length(amino acids)=430AA_BP=224 MTFGLRKRLSEERGFSLMPRAMAISSSSCELPLVAVCQVTSTPDKQQNFKTCAELVREAARLGACLAFLPEAFDFIARDPAETLHLSEPL GGKLLEEYTQLARECGLWLSLGGFHERGQDWEQTQKIYNCHVLLNSKGAVVATYRKTHLCDVEIPGQGPMCESNSTMPGPSLESPVSTPA GKIGLAVCYDMRFPELSLALAQAGAEILTYPSAFGSITGPAHWETMHGILERSKFCKDMTVKYDSRLRERKYGVVEGKALSELRAMAKAA REECPVFTPPGGETLDQVKMRGIDFFEFLCQLILKEADQKEQFSQGSPSNCLETSLAEIFPLGKNHSSKVNSDSGIPGLAASVLVVSHGA -------------------------------------------------------------- >59230_59230_2_NIT1-C12orf5_NIT1_chr1_161090022_ENST00000368008_C12orf5_chr12_4458985_ENST00000179259_length(transcript)=1878nt_BP=776nt CTTCTGGCTCCAGACCGCCCTCCGGATCGGACCCTGCGAATGGTTTTGGCTATATCTTCATGCTGGGCTTCATCACCAGGCCTCCTCACA GATTCCTGTCCCTTCTGTGTCCTGGACTCCGGATACCTCAACTCTCAGTACTTTGTGCTCAGCCCAGGCCCAGAGCCATGGCTATCTCCT CTTCCTCCTGCGAACTGCCCCTGGTGGCTGTGTGCCAGGTAACATCGACGCCAGACAAGCAACAGAACTTTAAAACATGTGCTGAGCTGG TTCGAGAGGCTGCCAGACTGGGTGCCTGCCTGGCTTTCCTGCCTGAGGCATTTGACTTCATTGCACGGGACCCTGCAGAGACGCTACACC TGTCTGAACCACTGGGTGGGAAACTTTTGGAAGAATACACCCAGCTTGCCAGGGAATGTGGACTCTGGCTGTCCTTGGGTGGTTTCCATG AGCGTGGCCAAGACTGGGAGCAGACTCAGAAAATCTACAATTGTCACGTGCTGCTGAACAGCAAAGGGGCAGTAGTGGCCACTTACAGGA AGACACATCTGTGTGACGTAGAGATTCCAGGGCAGGGGCCTATGTGTGAAAGCAACTCTACCATGCCTGGGCCCAGTCTTGAGTCACCTG TCAGCACACCAGCAGGCAAGATTGGTCTAGCTGTCTGCTATGACATGCGGTTCCCTGAACTCTCTCTGGCATTGGCTCAAGCTGGAGCAG AGATACTTACCTATCCTTCAGCTTTTGGATCCATTACAGGCCCAGCCCACTGGGAGACCATGCATGGAATTTTGGAGAGAAGCAAATTTT GCAAAGATATGACGGTAAAGTATGACTCAAGACTTCGGGAAAGGAAATACGGGGTTGTAGAAGGCAAAGCGCTAAGTGAGCTGAGGGCCA TGGCCAAAGCAGCCAGGGAAGAGTGCCCTGTGTTTACACCGCCCGGAGGAGAGACGCTGGACCAGGTGAAAATGCGTGGAATAGACTTTT TTGAATTTCTTTGTCAACTAATCCTGAAAGAAGCGGATCAAAAAGAACAGTTTTCCCAAGGATCTCCAAGCAACTGTCTGGAAACTTCTT TGGCAGAGATATTTCCTTTAGGAAAAAATCACAGCTCTAAAGTTAATTCAGACAGCGGTATTCCAGGATTAGCAGCCAGTGTCTTAGTTG TGAGTCACGGTGCTTACATGAGAAGTCTGTTTGATTATTTTCTGACTGACCTTAAGTGTTCCTTACCAGCCACTCTGAGCAGATCTGAAC TTATGTCAGTCACTCCCAATACAGGGATGAGTCTCTTTATCATAAACTTTGAGGAAGGAAGAGAAGTTAAACCAACGGTTCAGTGTATTT GTATGAACCTACAGGATCATCTAAATGGACTGACTGAAACTCGCTAAGGTTAAATCTGCATCAAAATCTAACCATTTTGAGCCTCTGAAG GGAGTGCCATTGGCTTTATTTACTTCTCTCCTCTGCTAGTTCTGATTTGGAAACAGTTAAAAGCCAATTTTTAGCTCCAGTGGAACCATA GCCACATAAAACTTTAATGGACAACCATATAGAATTAACTTATTTTGTCCAAGTACAGTTGGCATTTTCCAGAATAATTTTACCACCCTG CTAGATGTCATCTCTGGATTGCACATGGATGATGAAGGAACTCAGCATTGAAAGTTGGGGGATTAGTAACCTTGTTACAACGGTTTCTTT TTCATTTTAGCCTATTTTAATGGCTATTGGTAAGATACTGTATGTTTTTAGTATCTCATCCAGTGCTTAGAAGAAAGAATGGTTTATAAT >59230_59230_2_NIT1-C12orf5_NIT1_chr1_161090022_ENST00000368008_C12orf5_chr12_4458985_ENST00000179259_length(amino acids)=445AA_BP=239 MLGFITRPPHRFLSLLCPGLRIPQLSVLCAQPRPRAMAISSSSCELPLVAVCQVTSTPDKQQNFKTCAELVREAARLGACLAFLPEAFDF IARDPAETLHLSEPLGGKLLEEYTQLARECGLWLSLGGFHERGQDWEQTQKIYNCHVLLNSKGAVVATYRKTHLCDVEIPGQGPMCESNS TMPGPSLESPVSTPAGKIGLAVCYDMRFPELSLALAQAGAEILTYPSAFGSITGPAHWETMHGILERSKFCKDMTVKYDSRLRERKYGVV EGKALSELRAMAKAAREECPVFTPPGGETLDQVKMRGIDFFEFLCQLILKEADQKEQFSQGSPSNCLETSLAEIFPLGKNHSSKVNSDSG -------------------------------------------------------------- >59230_59230_3_NIT1-C12orf5_NIT1_chr1_161090022_ENST00000368009_C12orf5_chr12_4458985_ENST00000179259_length(transcript)=1895nt_BP=793nt GCCCACTCGCTGCGGCGCTTCTGGCTCCAGACCGCCCTCCGGATCGGACCCTGCGAATGGTTTTGGCTATATCTTCATGCTGGGCTTCAT CACCAGGCCTCCTCACAGATTCCTGTCCCTTCTGTGTCCTGGACTCCGGATACCTCAACTCTCAGTACTTTGTGCTCAGCCCAGGCCCAG AGCCATGGCTATCTCCTCTTCCTCCTGCGAACTGCCCCTGGTGGCTGTGTGCCAGGTAACATCGACGCCAGACAAGCAACAGAACTTTAA AACATGTGCTGAGCTGGTTCGAGAGGCTGCCAGACTGGGTGCCTGCCTGGCTTTCCTGCCTGAGGCATTTGACTTCATTGCACGGGACCC TGCAGAGACGCTACACCTGTCTGAACCACTGGGTGGGAAACTTTTGGAAGAATACACCCAGCTTGCCAGGGAATGTGGACTCTGGCTGTC CTTGGGTGGTTTCCATGAGCGTGGCCAAGACTGGGAGCAGACTCAGAAAATCTACAATTGTCACGTGCTGCTGAACAGCAAAGGGGCAGT AGTGGCCACTTACAGGAAGACACATCTGTGTGACGTAGAGATTCCAGGGCAGGGGCCTATGTGTGAAAGCAACTCTACCATGCCTGGGCC CAGTCTTGAGTCACCTGTCAGCACACCAGCAGGCAAGATTGGTCTAGCTGTCTGCTATGACATGCGGTTCCCTGAACTCTCTCTGGCATT GGCTCAAGCTGGAGCAGAGATACTTACCTATCCTTCAGCTTTTGGATCCATTACAGGCCCAGCCCACTGGGAGACCATGCATGGAATTTT GGAGAGAAGCAAATTTTGCAAAGATATGACGGTAAAGTATGACTCAAGACTTCGGGAAAGGAAATACGGGGTTGTAGAAGGCAAAGCGCT AAGTGAGCTGAGGGCCATGGCCAAAGCAGCCAGGGAAGAGTGCCCTGTGTTTACACCGCCCGGAGGAGAGACGCTGGACCAGGTGAAAAT GCGTGGAATAGACTTTTTTGAATTTCTTTGTCAACTAATCCTGAAAGAAGCGGATCAAAAAGAACAGTTTTCCCAAGGATCTCCAAGCAA CTGTCTGGAAACTTCTTTGGCAGAGATATTTCCTTTAGGAAAAAATCACAGCTCTAAAGTTAATTCAGACAGCGGTATTCCAGGATTAGC AGCCAGTGTCTTAGTTGTGAGTCACGGTGCTTACATGAGAAGTCTGTTTGATTATTTTCTGACTGACCTTAAGTGTTCCTTACCAGCCAC TCTGAGCAGATCTGAACTTATGTCAGTCACTCCCAATACAGGGATGAGTCTCTTTATCATAAACTTTGAGGAAGGAAGAGAAGTTAAACC AACGGTTCAGTGTATTTGTATGAACCTACAGGATCATCTAAATGGACTGACTGAAACTCGCTAAGGTTAAATCTGCATCAAAATCTAACC ATTTTGAGCCTCTGAAGGGAGTGCCATTGGCTTTATTTACTTCTCTCCTCTGCTAGTTCTGATTTGGAAACAGTTAAAAGCCAATTTTTA GCTCCAGTGGAACCATAGCCACATAAAACTTTAATGGACAACCATATAGAATTAACTTATTTTGTCCAAGTACAGTTGGCATTTTCCAGA ATAATTTTACCACCCTGCTAGATGTCATCTCTGGATTGCACATGGATGATGAAGGAACTCAGCATTGAAAGTTGGGGGATTAGTAACCTT GTTACAACGGTTTCTTTTTCATTTTAGCCTATTTTAATGGCTATTGGTAAGATACTGTATGTTTTTAGTATCTCATCCAGTGCTTAGAAG AAAGAATGGTTTATAATTCCCAGTACATGTTTATATTGACTGTGTTATATTTTTAAATCCTTTAAATAAAAAATCCTTATAAGTTTATGT >59230_59230_3_NIT1-C12orf5_NIT1_chr1_161090022_ENST00000368009_C12orf5_chr12_4458985_ENST00000179259_length(amino acids)=445AA_BP=239 MLGFITRPPHRFLSLLCPGLRIPQLSVLCAQPRPRAMAISSSSCELPLVAVCQVTSTPDKQQNFKTCAELVREAARLGACLAFLPEAFDF IARDPAETLHLSEPLGGKLLEEYTQLARECGLWLSLGGFHERGQDWEQTQKIYNCHVLLNSKGAVVATYRKTHLCDVEIPGQGPMCESNS TMPGPSLESPVSTPAGKIGLAVCYDMRFPELSLALAQAGAEILTYPSAFGSITGPAHWETMHGILERSKFCKDMTVKYDSRLRERKYGVV EGKALSELRAMAKAAREECPVFTPPGGETLDQVKMRGIDFFEFLCQLILKEADQKEQFSQGSPSNCLETSLAEIFPLGKNHSSKVNSDSG -------------------------------------------------------------- >59230_59230_4_NIT1-C12orf5_NIT1_chr1_161090022_ENST00000392190_C12orf5_chr12_4458985_ENST00000179259_length(transcript)=1925nt_BP=823nt CTTCTGGCTCCAGACCGCCCTCCGGATCGGACCCTGCGAATGGTTTTGGCTATATCTTCATGTAGGACCTACTCCCTATCCCGTCGGCCG CGGTGAATCCCACCTGCGGCTGGGCTTCATCACCAGGCCTCCTCACAGATTCCTGTCCCTTCTGTGTCCTGGACTCCGGATACCTCAACT CTCAGTACTTTGTGCTCAGCCCAGGCCCAGAGCCATGGCTATCTCCTCTTCCTCCTGCGAACTGCCCCTGGTGGCTGTGTGCCAGGTAAC ATCGACGCCAGACAAGCAACAGAACTTTAAAACATGTGCTGAGCTGGTTCGAGAGGCTGCCAGACTGGGTGCCTGCCTGGCTTTCCTGCC TGAGGCATTTGACTTCATTGCACGGGACCCTGCAGAGACGCTACACCTGTCTGAACCACTGGGTGGGAAACTTTTGGAAGAATACACCCA GCTTGCCAGGGAATGTGGACTCTGGCTGTCCTTGGGTGGTTTCCATGAGCGTGGCCAAGACTGGGAGCAGACTCAGAAAATCTACAATTG TCACGTGCTGCTGAACAGCAAAGGGGCAGTAGTGGCCACTTACAGGAAGACACATCTGTGTGACGTAGAGATTCCAGGGCAGGGGCCTAT GTGTGAAAGCAACTCTACCATGCCTGGGCCCAGTCTTGAGTCACCTGTCAGCACACCAGCAGGCAAGATTGGTCTAGCTGTCTGCTATGA CATGCGGTTCCCTGAACTCTCTCTGGCATTGGCTCAAGCTGGAGCAGAGATACTTACCTATCCTTCAGCTTTTGGATCCATTACAGGCCC AGCCCACTGGGAGACCATGCATGGAATTTTGGAGAGAAGCAAATTTTGCAAAGATATGACGGTAAAGTATGACTCAAGACTTCGGGAAAG GAAATACGGGGTTGTAGAAGGCAAAGCGCTAAGTGAGCTGAGGGCCATGGCCAAAGCAGCCAGGGAAGAGTGCCCTGTGTTTACACCGCC CGGAGGAGAGACGCTGGACCAGGTGAAAATGCGTGGAATAGACTTTTTTGAATTTCTTTGTCAACTAATCCTGAAAGAAGCGGATCAAAA AGAACAGTTTTCCCAAGGATCTCCAAGCAACTGTCTGGAAACTTCTTTGGCAGAGATATTTCCTTTAGGAAAAAATCACAGCTCTAAAGT TAATTCAGACAGCGGTATTCCAGGATTAGCAGCCAGTGTCTTAGTTGTGAGTCACGGTGCTTACATGAGAAGTCTGTTTGATTATTTTCT GACTGACCTTAAGTGTTCCTTACCAGCCACTCTGAGCAGATCTGAACTTATGTCAGTCACTCCCAATACAGGGATGAGTCTCTTTATCAT AAACTTTGAGGAAGGAAGAGAAGTTAAACCAACGGTTCAGTGTATTTGTATGAACCTACAGGATCATCTAAATGGACTGACTGAAACTCG CTAAGGTTAAATCTGCATCAAAATCTAACCATTTTGAGCCTCTGAAGGGAGTGCCATTGGCTTTATTTACTTCTCTCCTCTGCTAGTTCT GATTTGGAAACAGTTAAAAGCCAATTTTTAGCTCCAGTGGAACCATAGCCACATAAAACTTTAATGGACAACCATATAGAATTAACTTAT TTTGTCCAAGTACAGTTGGCATTTTCCAGAATAATTTTACCACCCTGCTAGATGTCATCTCTGGATTGCACATGGATGATGAAGGAACTC AGCATTGAAAGTTGGGGGATTAGTAACCTTGTTACAACGGTTTCTTTTTCATTTTAGCCTATTTTAATGGCTATTGGTAAGATACTGTAT GTTTTTAGTATCTCATCCAGTGCTTAGAAGAAAGAATGGTTTATAATTCCCAGTACATGTTTATATTGACTGTGTTATATTTTTAAATCC >59230_59230_4_NIT1-C12orf5_NIT1_chr1_161090022_ENST00000392190_C12orf5_chr12_4458985_ENST00000179259_length(amino acids)=446AA_BP=240 MRLGFITRPPHRFLSLLCPGLRIPQLSVLCAQPRPRAMAISSSSCELPLVAVCQVTSTPDKQQNFKTCAELVREAARLGACLAFLPEAFD FIARDPAETLHLSEPLGGKLLEEYTQLARECGLWLSLGGFHERGQDWEQTQKIYNCHVLLNSKGAVVATYRKTHLCDVEIPGQGPMCESN STMPGPSLESPVSTPAGKIGLAVCYDMRFPELSLALAQAGAEILTYPSAFGSITGPAHWETMHGILERSKFCKDMTVKYDSRLRERKYGV VEGKALSELRAMAKAAREECPVFTPPGGETLDQVKMRGIDFFEFLCQLILKEADQKEQFSQGSPSNCLETSLAEIFPLGKNHSSKVNSDS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NIT1-C12orf5 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NIT1-C12orf5 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NIT1-C12orf5 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies