
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NME2-ACBD4 (FusionGDB2 ID:59416) |
Fusion Gene Summary for NME2-ACBD4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NME2-ACBD4 | Fusion gene ID: 59416 | Hgene | Tgene | Gene symbol | NME2 | ACBD4 | Gene ID | 4831 | 79777 |
| Gene name | NME/NM23 nucleoside diphosphate kinase 2 | acyl-CoA binding domain containing 4 | |
| Synonyms | NDKB|NDPK-B|NDPKB|NM23-H2|NM23B|PUF | HMFT0700 | |
| Cytomap | 17q21.33 | 17q21.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nucleoside diphosphate kinase BHEL-S-155anNDP kinase Bc-myc purine-binding transcription factor PUFc-myc transcription factorepididymis secretory sperm binding protein Li 155anhistidine protein kinase NDKBnon-metastatic cells 2, protein (NM23) expr | acyl-CoA-binding domain-containing protein 4acyl-Coenzyme A binding domain containing 4 | |
| Modification date | 20200327 | 20200320 | |
| UniProtAcc | P22392 | Q8NC06 | |
| Ensembl transtripts involved in fusion gene | ENST00000376392, ENST00000393193, ENST00000555572, | ENST00000321854, ENST00000376955, ENST00000591136, ENST00000592162, ENST00000398322, ENST00000431281, ENST00000586346, ENST00000591859, | |
| Fusion gene scores | * DoF score | 6 X 6 X 4=144 | 2 X 2 X 2=8 |
| # samples | 6 | 2 | |
| ** MAII score | log2(6/144*10)=-1.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(2/8*10)=1.32192809488736 | |
| Context | PubMed: NME2 [Title/Abstract] AND ACBD4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NME2(49244317)-ACBD4(43216388), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | NME2-ACBD4 seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. NME2-ACBD4 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. NME2-ACBD4 seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. NME2-ACBD4 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NME2 | GO:0006165 | nucleoside diphosphate phosphorylation | 25679041 |
| Hgene | NME2 | GO:0007229 | integrin-mediated signaling pathway | 11919189 |
| Hgene | NME2 | GO:0009142 | nucleoside triphosphate biosynthetic process | 1851158|25679041 |
| Hgene | NME2 | GO:0045893 | positive regulation of transcription, DNA-templated | 8392752 |
| Hgene | NME2 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 15703214 |
| Fusion gene breakpoints across NME2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
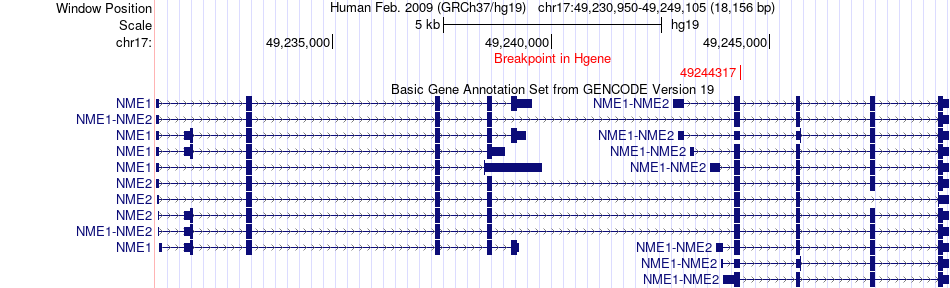 |
| Fusion gene breakpoints across ACBD4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-44-3396-01A | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
Top |
Fusion Gene ORF analysis for NME2-ACBD4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000376392 | ENST00000321854 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000376392 | ENST00000376955 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000376392 | ENST00000591136 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000376392 | ENST00000592162 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000393193 | ENST00000321854 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000393193 | ENST00000376955 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000393193 | ENST00000591136 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000393193 | ENST00000592162 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000555572 | ENST00000321854 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000555572 | ENST00000376955 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000555572 | ENST00000591136 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| 5CDS-intron | ENST00000555572 | ENST00000592162 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| Frame-shift | ENST00000376392 | ENST00000398322 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| Frame-shift | ENST00000393193 | ENST00000398322 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| Frame-shift | ENST00000555572 | ENST00000398322 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000376392 | ENST00000431281 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000376392 | ENST00000586346 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000376392 | ENST00000591859 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000393193 | ENST00000431281 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000393193 | ENST00000586346 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000393193 | ENST00000591859 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000555572 | ENST00000431281 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000555572 | ENST00000586346 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| In-frame | ENST00000555572 | ENST00000591859 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000393193 | NME2 | chr17 | 49244317 | + | ENST00000431281 | ACBD4 | chr17 | 43216388 | + | 1418 | 548 | 38 | 886 | 282 |
| ENST00000393193 | NME2 | chr17 | 49244317 | + | ENST00000591859 | ACBD4 | chr17 | 43216388 | + | 1422 | 548 | 38 | 886 | 282 |
| ENST00000393193 | NME2 | chr17 | 49244317 | + | ENST00000586346 | ACBD4 | chr17 | 43216388 | + | 1096 | 548 | 38 | 886 | 282 |
| ENST00000376392 | NME2 | chr17 | 49244317 | + | ENST00000431281 | ACBD4 | chr17 | 43216388 | + | 1404 | 534 | 24 | 872 | 282 |
| ENST00000376392 | NME2 | chr17 | 49244317 | + | ENST00000591859 | ACBD4 | chr17 | 43216388 | + | 1408 | 534 | 24 | 872 | 282 |
| ENST00000376392 | NME2 | chr17 | 49244317 | + | ENST00000586346 | ACBD4 | chr17 | 43216388 | + | 1082 | 534 | 24 | 872 | 282 |
| ENST00000555572 | NME2 | chr17 | 49244317 | + | ENST00000431281 | ACBD4 | chr17 | 43216388 | + | 1592 | 722 | 176 | 1060 | 294 |
| ENST00000555572 | NME2 | chr17 | 49244317 | + | ENST00000591859 | ACBD4 | chr17 | 43216388 | + | 1596 | 722 | 176 | 1060 | 294 |
| ENST00000555572 | NME2 | chr17 | 49244317 | + | ENST00000586346 | ACBD4 | chr17 | 43216388 | + | 1270 | 722 | 176 | 1060 | 294 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000393193 | ENST00000431281 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.3164515 | 0.68354845 |
| ENST00000393193 | ENST00000591859 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.30981413 | 0.6901859 |
| ENST00000393193 | ENST00000586346 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.21146967 | 0.78853035 |
| ENST00000376392 | ENST00000431281 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.32327512 | 0.6767249 |
| ENST00000376392 | ENST00000591859 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.3194842 | 0.6805158 |
| ENST00000376392 | ENST00000586346 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.21825674 | 0.7817433 |
| ENST00000555572 | ENST00000431281 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.3749853 | 0.6250147 |
| ENST00000555572 | ENST00000591859 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.3714487 | 0.6285513 |
| ENST00000555572 | ENST00000586346 | NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216388 | + | 0.33206862 | 0.66793144 |
Top |
Fusion Genomic Features for NME2-ACBD4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216387 | + | 8.03E-09 | 1 |
| NME2 | chr17 | 49244317 | + | ACBD4 | chr17 | 43216387 | + | 8.03E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for NME2-ACBD4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:49244317/chr17:43216388) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NME2 | ACBD4 |
| FUNCTION: Major role in the synthesis of nucleoside triphosphates other than ATP. The ATP gamma phosphate is transferred to the NDP beta phosphate via a ping-pong mechanism, using a phosphorylated active-site intermediate (By similarity). Negatively regulates Rho activity by interacting with AKAP13/LBC (PubMed:15249197). Acts as a transcriptional activator of the MYC gene; binds DNA non-specifically (PubMed:8392752, PubMed:19435876). Binds to both single-stranded guanine- and cytosine-rich strands within the nuclease hypersensitive element (NHE) III(1) region of the MYC gene promoter. Does not bind to duplex NHE III(1) (PubMed:19435876). Has G-quadruplex (G4) DNA-binding activity, which is independent of its nucleotide-binding and kinase activity. Binds both folded and unfolded G4 with similar low nanomolar affinities. Stabilizes folded G4s regardless of whether they are prefolded or not (PubMed:25679041). Exhibits histidine protein kinase activity (PubMed:20946858). {ECO:0000250|UniProtKB:P36010, ECO:0000269|PubMed:15249197, ECO:0000269|PubMed:19435876, ECO:0000269|PubMed:20946858, ECO:0000269|PubMed:25679041, ECO:0000269|PubMed:8392752}. | FUNCTION: Binds medium- and long-chain acyl-CoA esters and may function as an intracellular carrier of acyl-CoA esters. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000321854 | 7 | 10 | 12_101 | 216 | 306.0 | Domain | ACB | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000376955 | 7 | 10 | 12_101 | 213 | 269.0 | Domain | ACB | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000398322 | 6 | 9 | 12_101 | 216 | 306.0 | Domain | ACB | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000431281 | 9 | 12 | 12_101 | 229 | 342.0 | Domain | ACB | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000586346 | 7 | 10 | 12_101 | 229 | 342.0 | Domain | ACB | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000591859 | 9 | 12 | 12_101 | 229 | 342.0 | Domain | ACB | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000321854 | 7 | 10 | 23_32 | 216 | 306.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000321854 | 7 | 10 | 43_47 | 216 | 306.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000376955 | 7 | 10 | 23_32 | 213 | 269.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000376955 | 7 | 10 | 43_47 | 213 | 269.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000398322 | 6 | 9 | 23_32 | 216 | 306.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000398322 | 6 | 9 | 43_47 | 216 | 306.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000431281 | 9 | 12 | 23_32 | 229 | 342.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000431281 | 9 | 12 | 43_47 | 229 | 342.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000586346 | 7 | 10 | 23_32 | 229 | 342.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000586346 | 7 | 10 | 43_47 | 229 | 342.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000591859 | 9 | 12 | 23_32 | 229 | 342.0 | Region | Note=Acyl-CoA binding | |
| Tgene | ACBD4 | chr17:49244317 | chr17:43216388 | ENST00000591859 | 9 | 12 | 43_47 | 229 | 342.0 | Region | Note=Acyl-CoA binding |
Top |
Fusion Gene Sequence for NME2-ACBD4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >59416_59416_1_NME2-ACBD4_NME2_chr17_49244317_ENST00000376392_ACBD4_chr17_43216388_ENST00000431281_length(transcript)=1404nt_BP=534nt CGGGCGCGTTTCGGGTGCTGGCGGCTGCAGCCGGAGTTCAAACCTAAGCAGCTGGAAGGAACCATGGCCAACTGTGAGCGTACCTTCATT GCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCCTTGTTGGTCTGAAA TTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGGTGAAATACATGCAC TCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCAACCCTGCAGACTCC AAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCGCCATCAAGCCGGAC GGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGTTCCTCCGGAGGGGT TGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCATGCAGGAGGTGCAGG CGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATGGCCCCTTGGGCTCC CGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAAGAGGTGACTGTCAG TGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTCAAAATTCCCCGTCC TGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCTTCACAGGGACGCTT CCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGCCGTGACTCGGGGGC GGGGCGATCGGGTCTCAGCCCCTGCCTTCCCCAGTCTCTGGGTCACCCGAATTTTCCCACCCCTGCTTCTCCCCGAGGAGGTTGAGCTCT TGAGCAAGTTGGGACTTGGGCCGGGGCCTGGAAGAATGATTGGCTGGGAGGCCGCGGGAGGGAGGCCAGGAGGCCCGGACCAGTTGGGAG GAGTGAGCAGGCCCCGGGGGAGGGGGATGAGCGCAGTTTGCTCGCTTTCCTCCCCTGCCGGCCCCCTCCGCCCCCACACACACTCGGGAC >59416_59416_1_NME2-ACBD4_NME2_chr17_49244317_ENST00000376392_ACBD4_chr17_43216388_ENST00000431281_length(amino acids)=282AA_BP=170 MQPEFKPKQLEGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLVKYMHSGPVVAMV WEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKFLRRGCGAARRGP RSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKRGDCQWRGLCSQL -------------------------------------------------------------- >59416_59416_2_NME2-ACBD4_NME2_chr17_49244317_ENST00000376392_ACBD4_chr17_43216388_ENST00000586346_length(transcript)=1082nt_BP=534nt CGGGCGCGTTTCGGGTGCTGGCGGCTGCAGCCGGAGTTCAAACCTAAGCAGCTGGAAGGAACCATGGCCAACTGTGAGCGTACCTTCATT GCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCCTTGTTGGTCTGAAA TTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGGTGAAATACATGCAC TCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCAACCCTGCAGACTCC AAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCGCCATCAAGCCGGAC GGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGTTCCTCCGGAGGGGT TGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCATGCAGGAGGTGCAGG CGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATGGCCCCTTGGGCTCC CGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAAGAGGTGACTGTCAG TGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTCAAAATTCCCCGTCC TGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCTTCACAGGGACGCTT CCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGCCGTGACTCGGGGGC >59416_59416_2_NME2-ACBD4_NME2_chr17_49244317_ENST00000376392_ACBD4_chr17_43216388_ENST00000586346_length(amino acids)=282AA_BP=170 MQPEFKPKQLEGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLVKYMHSGPVVAMV WEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKFLRRGCGAARRGP RSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKRGDCQWRGLCSQL -------------------------------------------------------------- >59416_59416_3_NME2-ACBD4_NME2_chr17_49244317_ENST00000376392_ACBD4_chr17_43216388_ENST00000591859_length(transcript)=1408nt_BP=534nt CGGGCGCGTTTCGGGTGCTGGCGGCTGCAGCCGGAGTTCAAACCTAAGCAGCTGGAAGGAACCATGGCCAACTGTGAGCGTACCTTCATT GCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCCTTGTTGGTCTGAAA TTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGGTGAAATACATGCAC TCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCAACCCTGCAGACTCC AAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCGCCATCAAGCCGGAC GGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGTTCCTCCGGAGGGGT TGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCATGCAGGAGGTGCAGG CGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATGGCCCCTTGGGCTCC CGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAAGAGGTGACTGTCAG TGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTCAAAATTCCCCGTCC TGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCTTCACAGGGACGCTT CCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGCCGTGACTCGGGGGC GGGGCGATCGGGTCTCAGCCCCTGCCTTCCCCAGTCTCTGGGTCACCCGAATTTTCCCACCCCTGCTTCTCCCCGAGGAGGTTGAGCTCT TGAGCAAGTTGGGACTTGGGCCGGGGCCTGGAAGAATGATTGGCTGGGAGGCCGCGGGAGGGAGGCCAGGAGGCCCGGACCAGTTGGGAG GAGTGAGCAGGCCCCGGGGGAGGGGGATGAGCGCAGTTTGCTCGCTTTCCTCCCCTGCCGGCCCCCTCCGCCCCCACACACACTCGGGAC >59416_59416_3_NME2-ACBD4_NME2_chr17_49244317_ENST00000376392_ACBD4_chr17_43216388_ENST00000591859_length(amino acids)=282AA_BP=170 MQPEFKPKQLEGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLVKYMHSGPVVAMV WEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKFLRRGCGAARRGP RSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKRGDCQWRGLCSQL -------------------------------------------------------------- >59416_59416_4_NME2-ACBD4_NME2_chr17_49244317_ENST00000393193_ACBD4_chr17_43216388_ENST00000431281_length(transcript)=1418nt_BP=548nt AACCACGTGGGTCCCGGGCGCGTTTCGGGTGCTGGCGGCTGCAGCCGGAGTTCAAACCTAAGCAGCTGGAAGGAACCATGGCCAACTGTG AGCGTACCTTCATTGCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCC TTGTTGGTCTGAAATTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGG TGAAATACATGCACTCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCA ACCCTGCAGACTCCAAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCG CCATCAAGCCGGACGGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGT TCCTCCGGAGGGGTTGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCAT GCAGGAGGTGCAGGCGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATG GCCCCTTGGGCTCCCGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAA GAGGTGACTGTCAGTGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTC AAAATTCCCCGTCCTGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCT TCACAGGGACGCTTCCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGC CGTGACTCGGGGGCGGGGCGATCGGGTCTCAGCCCCTGCCTTCCCCAGTCTCTGGGTCACCCGAATTTTCCCACCCCTGCTTCTCCCCGA GGAGGTTGAGCTCTTGAGCAAGTTGGGACTTGGGCCGGGGCCTGGAAGAATGATTGGCTGGGAGGCCGCGGGAGGGAGGCCAGGAGGCCC GGACCAGTTGGGAGGAGTGAGCAGGCCCCGGGGGAGGGGGATGAGCGCAGTTTGCTCGCTTTCCTCCCCTGCCGGCCCCCTCCGCCCCCA >59416_59416_4_NME2-ACBD4_NME2_chr17_49244317_ENST00000393193_ACBD4_chr17_43216388_ENST00000431281_length(amino acids)=282AA_BP=170 MQPEFKPKQLEGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLVKYMHSGPVVAMV WEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKFLRRGCGAARRGP RSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKRGDCQWRGLCSQL -------------------------------------------------------------- >59416_59416_5_NME2-ACBD4_NME2_chr17_49244317_ENST00000393193_ACBD4_chr17_43216388_ENST00000586346_length(transcript)=1096nt_BP=548nt AACCACGTGGGTCCCGGGCGCGTTTCGGGTGCTGGCGGCTGCAGCCGGAGTTCAAACCTAAGCAGCTGGAAGGAACCATGGCCAACTGTG AGCGTACCTTCATTGCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCC TTGTTGGTCTGAAATTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGG TGAAATACATGCACTCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCA ACCCTGCAGACTCCAAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCG CCATCAAGCCGGACGGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGT TCCTCCGGAGGGGTTGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCAT GCAGGAGGTGCAGGCGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATG GCCCCTTGGGCTCCCGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAA GAGGTGACTGTCAGTGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTC AAAATTCCCCGTCCTGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCT TCACAGGGACGCTTCCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGC >59416_59416_5_NME2-ACBD4_NME2_chr17_49244317_ENST00000393193_ACBD4_chr17_43216388_ENST00000586346_length(amino acids)=282AA_BP=170 MQPEFKPKQLEGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLVKYMHSGPVVAMV WEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKFLRRGCGAARRGP RSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKRGDCQWRGLCSQL -------------------------------------------------------------- >59416_59416_6_NME2-ACBD4_NME2_chr17_49244317_ENST00000393193_ACBD4_chr17_43216388_ENST00000591859_length(transcript)=1422nt_BP=548nt AACCACGTGGGTCCCGGGCGCGTTTCGGGTGCTGGCGGCTGCAGCCGGAGTTCAAACCTAAGCAGCTGGAAGGAACCATGGCCAACTGTG AGCGTACCTTCATTGCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCC TTGTTGGTCTGAAATTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGG TGAAATACATGCACTCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCA ACCCTGCAGACTCCAAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCG CCATCAAGCCGGACGGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGT TCCTCCGGAGGGGTTGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCAT GCAGGAGGTGCAGGCGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATG GCCCCTTGGGCTCCCGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAA GAGGTGACTGTCAGTGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTC AAAATTCCCCGTCCTGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCT TCACAGGGACGCTTCCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGC CGTGACTCGGGGGCGGGGCGATCGGGTCTCAGCCCCTGCCTTCCCCAGTCTCTGGGTCACCCGAATTTTCCCACCCCTGCTTCTCCCCGA GGAGGTTGAGCTCTTGAGCAAGTTGGGACTTGGGCCGGGGCCTGGAAGAATGATTGGCTGGGAGGCCGCGGGAGGGAGGCCAGGAGGCCC GGACCAGTTGGGAGGAGTGAGCAGGCCCCGGGGGAGGGGGATGAGCGCAGTTTGCTCGCTTTCCTCCCCTGCCGGCCCCCTCCGCCCCCA >59416_59416_6_NME2-ACBD4_NME2_chr17_49244317_ENST00000393193_ACBD4_chr17_43216388_ENST00000591859_length(amino acids)=282AA_BP=170 MQPEFKPKQLEGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLVKYMHSGPVVAMV WEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKFLRRGCGAARRGP RSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKRGDCQWRGLCSQL -------------------------------------------------------------- >59416_59416_7_NME2-ACBD4_NME2_chr17_49244317_ENST00000555572_ACBD4_chr17_43216388_ENST00000431281_length(transcript)=1592nt_BP=722nt GGAGTTCAAACCTAAGCAGCTGGAAGGGCCCTGTGGCTAGGTACCATAGAGTCTCTACACAGGACTAAGTCAGCCTGGTGTGCAGGGGAG GCAGACACACAAACAGAAAATTGGACTACAGTGCTAAGATGCTGTAAGAAGAGGTTAACTAAAGGACAGGAAGATGGGGCCAAGAGATGG TGCTACTGTCTACTTTAGGGATCGTCTTTCAAGGCGAGGGGCCTCCTATCTCAAGCTGTGATACAGGAACCATGGCCAACTGTGAGCGTA CCTTCATTGCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCCTTGTTG GTCTGAAATTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGGTGAAAT ACATGCACTCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCAACCCTG CAGACTCCAAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCGCCATCA AGCCGGACGGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGTTCCTCC GGAGGGGTTGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCATGCAGGA GGTGCAGGCGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATGGCCCCT TGGGCTCCCGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAAGAGGTG ACTGTCAGTGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTCAAAATT CCCCGTCCTGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCTTCACAG GGACGCTTCCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGCCGTGAC TCGGGGGCGGGGCGATCGGGTCTCAGCCCCTGCCTTCCCCAGTCTCTGGGTCACCCGAATTTTCCCACCCCTGCTTCTCCCCGAGGAGGT TGAGCTCTTGAGCAAGTTGGGACTTGGGCCGGGGCCTGGAAGAATGATTGGCTGGGAGGCCGCGGGAGGGAGGCCAGGAGGCCCGGACCA GTTGGGAGGAGTGAGCAGGCCCCGGGGGAGGGGGATGAGCGCAGTTTGCTCGCTTTCCTCCCCTGCCGGCCCCCTCCGCCCCCACACACA >59416_59416_7_NME2-ACBD4_NME2_chr17_49244317_ENST00000555572_ACBD4_chr17_43216388_ENST00000431281_length(amino acids)=294AA_BP=182 MVLLSTLGIVFQGEGPPISSCDTGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLV KYMHSGPVVAMVWEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKF LRRGCGAARRGPRSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKR -------------------------------------------------------------- >59416_59416_8_NME2-ACBD4_NME2_chr17_49244317_ENST00000555572_ACBD4_chr17_43216388_ENST00000586346_length(transcript)=1270nt_BP=722nt GGAGTTCAAACCTAAGCAGCTGGAAGGGCCCTGTGGCTAGGTACCATAGAGTCTCTACACAGGACTAAGTCAGCCTGGTGTGCAGGGGAG GCAGACACACAAACAGAAAATTGGACTACAGTGCTAAGATGCTGTAAGAAGAGGTTAACTAAAGGACAGGAAGATGGGGCCAAGAGATGG TGCTACTGTCTACTTTAGGGATCGTCTTTCAAGGCGAGGGGCCTCCTATCTCAAGCTGTGATACAGGAACCATGGCCAACTGTGAGCGTA CCTTCATTGCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCCTTGTTG GTCTGAAATTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGGTGAAAT ACATGCACTCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCAACCCTG CAGACTCCAAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCGCCATCA AGCCGGACGGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGTTCCTCC GGAGGGGTTGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCATGCAGGA GGTGCAGGCGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATGGCCCCT TGGGCTCCCGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAAGAGGTG ACTGTCAGTGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTCAAAATT CCCCGTCCTGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCTTCACAG GGACGCTTCCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGCCGTGAC >59416_59416_8_NME2-ACBD4_NME2_chr17_49244317_ENST00000555572_ACBD4_chr17_43216388_ENST00000586346_length(amino acids)=294AA_BP=182 MVLLSTLGIVFQGEGPPISSCDTGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLV KYMHSGPVVAMVWEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKF LRRGCGAARRGPRSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKR -------------------------------------------------------------- >59416_59416_9_NME2-ACBD4_NME2_chr17_49244317_ENST00000555572_ACBD4_chr17_43216388_ENST00000591859_length(transcript)=1596nt_BP=722nt GGAGTTCAAACCTAAGCAGCTGGAAGGGCCCTGTGGCTAGGTACCATAGAGTCTCTACACAGGACTAAGTCAGCCTGGTGTGCAGGGGAG GCAGACACACAAACAGAAAATTGGACTACAGTGCTAAGATGCTGTAAGAAGAGGTTAACTAAAGGACAGGAAGATGGGGCCAAGAGATGG TGCTACTGTCTACTTTAGGGATCGTCTTTCAAGGCGAGGGGCCTCCTATCTCAAGCTGTGATACAGGAACCATGGCCAACTGTGAGCGTA CCTTCATTGCGATCAAACCAGATGGGGTCCAGCGGGGTCTTGTGGGAGAGATTATCAAGCGTTTTGAGCAGAAAGGATTCCGCCTTGTTG GTCTGAAATTCATGCAAGCTTCCGAAGATCTTCTCAAGGAACACTACGTTGACCTGAAGGACCGTCCATTCTTTGCCGGCCTGGTGAAAT ACATGCACTCAGGGCCGGTAGTTGCCATGGTCTGGGAGGGGCTGAATGTGGTGAAGACGGGCCGAGTCATGCTCGGGGAGACCAACCCTG CAGACTCCAAGCCTGGGACCATCCGTGGAGACTTCTGCATACAAGTTGGCAGGACCATGGCCAACCTGGAGCGCACCTTCATCGCCATCA AGCCGGACGGCGTGCAGCGCGGCCTGGTGGGCGAGATCATCAAGCGCTTCGAGCAGAAGGGATTCCGCCTCGTGGCCATGAAGTTCCTCC GGAGGGGTTGCGGGGCAGCCCGCCGGGGCCCCAGGAGTTGGACGTGTGGCTGCTGGGGACAGTTCGAGCACTACAGGAGAGCATGCAGGA GGTGCAGGCGAGGGTGCAGAGCCTGGAGAGCATGCCCCGGCCCCCTGAGCAGAGGCCGCAGCCCAGGCCCAGTGCTCGGCCATGGCCCCT TGGGCTCCCGGGGCCCGCGCTGCTCTTCTTCCTCCTGTGGCCCTTCGTCGTCCAGTGGCTCTTCCGAATGTTTCGGACCCAAAAGAGGTG ACTGTCAGTGGAGGGGTCTCTGCAGCCAACTGAGACTATCTTGCTGTGCCCTGAGCCTTCCTAGGGTTTAGAAGAACAGCATTCAAAATT CCCCGTCCTGTCAGTGTTTGCCTTCGCACCTCCTCCCCTAAAGCAGCGCGGGGGGCAAATAAGACCCCACCCCTCCCTGCAGCTTCACAG GGACGCTTCCTTCCCTCCCCGCAACCACCCCAGGCTCCCCTGGGAGGCTGCAGTTGTGGTACACGTCCCCGGTGCTGGGTTGGCCGTGAC TCGGGGGCGGGGCGATCGGGTCTCAGCCCCTGCCTTCCCCAGTCTCTGGGTCACCCGAATTTTCCCACCCCTGCTTCTCCCCGAGGAGGT TGAGCTCTTGAGCAAGTTGGGACTTGGGCCGGGGCCTGGAAGAATGATTGGCTGGGAGGCCGCGGGAGGGAGGCCAGGAGGCCCGGACCA GTTGGGAGGAGTGAGCAGGCCCCGGGGGAGGGGGATGAGCGCAGTTTGCTCGCTTTCCTCCCCTGCCGGCCCCCTCCGCCCCCACACACA >59416_59416_9_NME2-ACBD4_NME2_chr17_49244317_ENST00000555572_ACBD4_chr17_43216388_ENST00000591859_length(amino acids)=294AA_BP=182 MVLLSTLGIVFQGEGPPISSCDTGTMANCERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVGLKFMQASEDLLKEHYVDLKDRPFFAGLV KYMHSGPVVAMVWEGLNVVKTGRVMLGETNPADSKPGTIRGDFCIQVGRTMANLERTFIAIKPDGVQRGLVGEIIKRFEQKGFRLVAMKF LRRGCGAARRGPRSWTCGCWGQFEHYRRACRRCRRGCRAWRACPGPLSRGRSPGPVLGHGPLGSRGPRCSSSSCGPSSSSGSSECFGPKR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NME2-ACBD4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Hgene | NME2 | chr17:49244317 | chr17:43216388 | ENST00000393193 | + | 5 | 8 | 1_66 | 157.0 | 268.0 | AKAP13 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NME2-ACBD4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NME2-ACBD4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies