
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARHGAP20-ACP1 (FusionGDB2 ID:5984) |
Fusion Gene Summary for ARHGAP20-ACP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARHGAP20-ACP1 | Fusion gene ID: 5984 | Hgene | Tgene | Gene symbol | ARHGAP20 | ACP1 | Gene ID | 57569 | 4706 |
| Gene name | Rho GTPase activating protein 20 | NADH:ubiquinone oxidoreductase subunit AB1 | |
| Synonyms | RARHOGAP | ACP|ACP1|FASN2A|SDAP | |
| Cytomap | 11q22.3-q23.1 | 16p12.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | rho GTPase-activating protein 20RA and RhoGAP domain containing proteinrho GTPase activating protein 20 variant 2rho-type GTPase-activating protein 20 | acyl carrier protein, mitochondrialCI-SDAPNADH dehydrogenase (ubiquinone) 1, alpha/beta subcomplex, 1, 8kDaNADH-ubiquinone oxidoreductase 9.6 kDa subunitNADH:ubiquinone oxidoreductase SDAP subunitcomplex I SDAP subunitmitochondrial acyl carrier prot | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9P2F6 | P24666 | |
| Ensembl transtripts involved in fusion gene | ENST00000260283, ENST00000357139, ENST00000524756, ENST00000527598, ENST00000528829, ENST00000533353, ENST00000529591, | ENST00000484464, ENST00000272065, ENST00000272067, ENST00000405233, ENST00000407983, ENST00000439645, | |
| Fusion gene scores | * DoF score | 1 X 1 X 1=1 | 4 X 3 X 3=36 |
| # samples | 1 | 4 | |
| ** MAII score | log2(1/1*10)=3.32192809488736 | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: ARHGAP20 [Title/Abstract] AND ACP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARHGAP20(110477285)-ACP1(271866), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ARHGAP20-ACP1 seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. ARHGAP20-ACP1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across ARHGAP20 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ACP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | GBM | TCGA-19-0957-02A | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
Top |
Fusion Gene ORF analysis for ARHGAP20-ACP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000260283 | ENST00000484464 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| 5CDS-3UTR | ENST00000357139 | ENST00000484464 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| 5CDS-3UTR | ENST00000524756 | ENST00000484464 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| 5CDS-3UTR | ENST00000527598 | ENST00000484464 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| 5CDS-3UTR | ENST00000528829 | ENST00000484464 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| 5CDS-3UTR | ENST00000533353 | ENST00000484464 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000260283 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000260283 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000260283 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000260283 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000260283 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000527598 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000527598 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000527598 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000527598 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000527598 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000528829 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000528829 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000528829 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000528829 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| Frame-shift | ENST00000528829 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000357139 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000357139 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000357139 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000357139 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000357139 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000524756 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000524756 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000524756 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000524756 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000524756 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000533353 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000533353 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000533353 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000533353 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| In-frame | ENST00000533353 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| intron-3CDS | ENST00000529591 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| intron-3CDS | ENST00000529591 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| intron-3CDS | ENST00000529591 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| intron-3CDS | ENST00000529591 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| intron-3CDS | ENST00000529591 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| intron-3UTR | ENST00000529591 | ENST00000484464 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000357139 | ARHGAP20 | chr11 | 110477285 | - | ENST00000272067 | ACP1 | chr2 | 271866 | + | 2299 | 886 | 0 | 1319 | 439 |
| ENST00000357139 | ARHGAP20 | chr11 | 110477285 | - | ENST00000272065 | ACP1 | chr2 | 271866 | + | 2299 | 886 | 0 | 1319 | 439 |
| ENST00000357139 | ARHGAP20 | chr11 | 110477285 | - | ENST00000407983 | ACP1 | chr2 | 271866 | + | 1481 | 886 | 0 | 1181 | 393 |
| ENST00000357139 | ARHGAP20 | chr11 | 110477285 | - | ENST00000439645 | ACP1 | chr2 | 271866 | + | 1399 | 886 | 0 | 1100 | 366 |
| ENST00000357139 | ARHGAP20 | chr11 | 110477285 | - | ENST00000405233 | ACP1 | chr2 | 271866 | + | 1953 | 886 | 0 | 1055 | 351 |
| ENST00000524756 | ARHGAP20 | chr11 | 110477285 | - | ENST00000272067 | ACP1 | chr2 | 271866 | + | 2665 | 1252 | 204 | 1685 | 493 |
| ENST00000524756 | ARHGAP20 | chr11 | 110477285 | - | ENST00000272065 | ACP1 | chr2 | 271866 | + | 2665 | 1252 | 204 | 1685 | 493 |
| ENST00000524756 | ARHGAP20 | chr11 | 110477285 | - | ENST00000407983 | ACP1 | chr2 | 271866 | + | 1847 | 1252 | 204 | 1547 | 447 |
| ENST00000524756 | ARHGAP20 | chr11 | 110477285 | - | ENST00000439645 | ACP1 | chr2 | 271866 | + | 1765 | 1252 | 204 | 1466 | 420 |
| ENST00000524756 | ARHGAP20 | chr11 | 110477285 | - | ENST00000405233 | ACP1 | chr2 | 271866 | + | 2319 | 1252 | 204 | 1421 | 405 |
| ENST00000533353 | ARHGAP20 | chr11 | 110477285 | - | ENST00000272067 | ACP1 | chr2 | 271866 | + | 2551 | 1138 | 252 | 1571 | 439 |
| ENST00000533353 | ARHGAP20 | chr11 | 110477285 | - | ENST00000272065 | ACP1 | chr2 | 271866 | + | 2551 | 1138 | 252 | 1571 | 439 |
| ENST00000533353 | ARHGAP20 | chr11 | 110477285 | - | ENST00000407983 | ACP1 | chr2 | 271866 | + | 1733 | 1138 | 252 | 1433 | 393 |
| ENST00000533353 | ARHGAP20 | chr11 | 110477285 | - | ENST00000439645 | ACP1 | chr2 | 271866 | + | 1651 | 1138 | 252 | 1352 | 366 |
| ENST00000533353 | ARHGAP20 | chr11 | 110477285 | - | ENST00000405233 | ACP1 | chr2 | 271866 | + | 2205 | 1138 | 252 | 1307 | 351 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000357139 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.000558422 | 0.99944156 |
| ENST00000357139 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.000633487 | 0.9993666 |
| ENST00000357139 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.002473643 | 0.99752635 |
| ENST00000357139 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.001966446 | 0.9980336 |
| ENST00000357139 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.001609447 | 0.99839056 |
| ENST00000524756 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.001215363 | 0.9987846 |
| ENST00000524756 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.001340341 | 0.9986596 |
| ENST00000524756 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.008409887 | 0.9915901 |
| ENST00000524756 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.0063603 | 0.99363965 |
| ENST00000524756 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.003394045 | 0.996606 |
| ENST00000533353 | ENST00000272067 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.000751019 | 0.9992489 |
| ENST00000533353 | ENST00000272065 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.000863749 | 0.99913627 |
| ENST00000533353 | ENST00000407983 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.003528639 | 0.9964714 |
| ENST00000533353 | ENST00000439645 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.002747804 | 0.99725217 |
| ENST00000533353 | ENST00000405233 | ARHGAP20 | chr11 | 110477285 | - | ACP1 | chr2 | 271866 | + | 0.002011044 | 0.99798894 |
Top |
Fusion Genomic Features for ARHGAP20-ACP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARHGAP20 | chr11 | 110477284 | - | ACP1 | chr2 | 271865 | + | 0.002231961 | 0.99776804 |
| ARHGAP20 | chr11 | 110477284 | - | ACP1 | chr2 | 271865 | + | 0.002231961 | 0.99776804 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
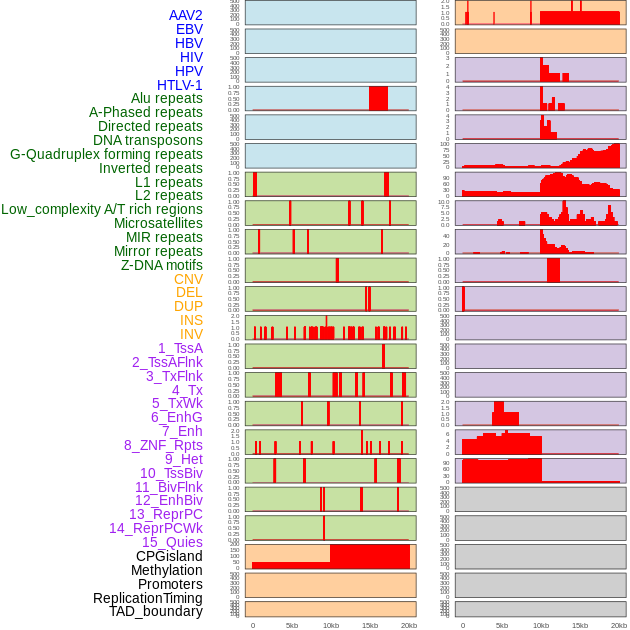 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
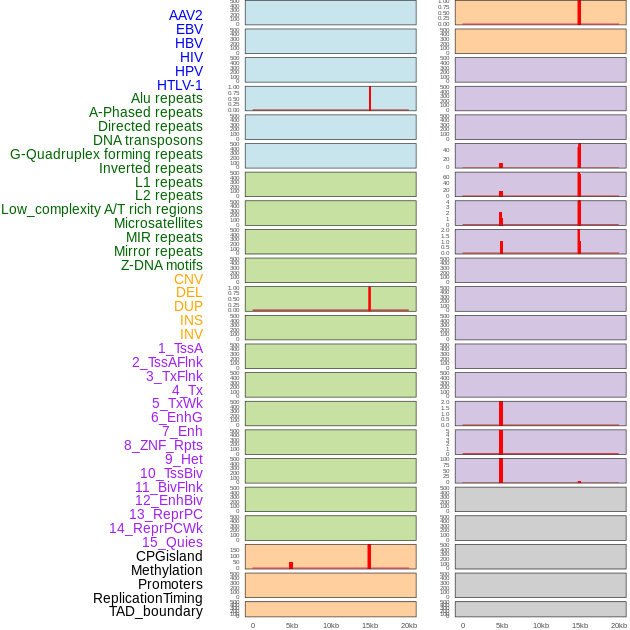 |
Top |
Fusion Protein Features for ARHGAP20-ACP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:110477285/chr2:271866) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARHGAP20 | ACP1 |
| FUNCTION: GTPase activator for the Rho-type GTPases by converting them to an inactive GDP-bound state. {ECO:0000250}. | FUNCTION: Acts on tyrosine phosphorylated proteins, low-MW aryl phosphates and natural and synthetic acyl phosphates. Isoform 3 does not possess phosphatase activity. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000260283 | - | 10 | 16 | 194_295 | 321 | 1192.0 | Domain | Ras-associating |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000260283 | - | 10 | 16 | 78_180 | 321 | 1192.0 | Domain | Note=PH |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000357139 | - | 9 | 15 | 194_295 | 295 | 1166.0 | Domain | Ras-associating |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000357139 | - | 9 | 15 | 78_180 | 295 | 1166.0 | Domain | Note=PH |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000524756 | - | 9 | 15 | 194_295 | 298 | 1169.0 | Domain | Ras-associating |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000524756 | - | 9 | 15 | 78_180 | 298 | 1169.0 | Domain | Note=PH |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000527598 | - | 9 | 15 | 78_180 | 285 | 1156.0 | Domain | Note=PH |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000528829 | - | 9 | 15 | 78_180 | 285 | 1156.0 | Domain | Note=PH |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000533353 | - | 10 | 16 | 194_295 | 295 | 1166.0 | Domain | Ras-associating |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000533353 | - | 10 | 16 | 78_180 | 295 | 1166.0 | Domain | Note=PH |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000260283 | - | 10 | 16 | 934_973 | 321 | 1192.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000357139 | - | 9 | 15 | 934_973 | 295 | 1166.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000524756 | - | 9 | 15 | 934_973 | 298 | 1169.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000527598 | - | 9 | 15 | 934_973 | 285 | 1156.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000528829 | - | 9 | 15 | 934_973 | 285 | 1156.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000529591 | - | 1 | 6 | 934_973 | 0 | 732.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000533353 | - | 10 | 16 | 934_973 | 295 | 1166.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000260283 | - | 10 | 16 | 365_551 | 321 | 1192.0 | Domain | Rho-GAP |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000357139 | - | 9 | 15 | 365_551 | 295 | 1166.0 | Domain | Rho-GAP |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000524756 | - | 9 | 15 | 365_551 | 298 | 1169.0 | Domain | Rho-GAP |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000527598 | - | 9 | 15 | 194_295 | 285 | 1156.0 | Domain | Ras-associating |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000527598 | - | 9 | 15 | 365_551 | 285 | 1156.0 | Domain | Rho-GAP |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000528829 | - | 9 | 15 | 194_295 | 285 | 1156.0 | Domain | Ras-associating |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000528829 | - | 9 | 15 | 365_551 | 285 | 1156.0 | Domain | Rho-GAP |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000529591 | - | 1 | 6 | 194_295 | 0 | 732.0 | Domain | Ras-associating |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000529591 | - | 1 | 6 | 365_551 | 0 | 732.0 | Domain | Rho-GAP |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000529591 | - | 1 | 6 | 78_180 | 0 | 732.0 | Domain | Note=PH |
| Hgene | ARHGAP20 | chr11:110477285 | chr2:271866 | ENST00000533353 | - | 10 | 16 | 365_551 | 295 | 1166.0 | Domain | Rho-GAP |
Top |
Fusion Gene Sequence for ARHGAP20-ACP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5984_5984_1_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000272065_length(transcript)=2299nt_BP=886nt ATGACATTTTGGATTATAATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTA CAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTG CTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAA ATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGC AACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGG CTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGG AATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACT GGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATT AAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATG GAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGA TCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACTTCCGGG TATGAGATAGGGAACCCCCCTGACTACCGAGGGCAGAGCTGCATGAAGAGGCACGGCATTCCCATGAGCCACGTTGCCCGGCAGATTACC AAAGAAGATTTTGCCACATTTGATTATATACTATGTATGGATGAAAGCAATCTGAGAGATTTGAATAGAAAAAGTAATCAAGTTAAAACC TGCAAAGCTAAAATTGAACTACTTGGGAGCTATGATCCACAAAAACAACTTATTATTGAAGATCCCTATTATGGGAATGACTCTGACTTT GAGACGGTGTACCAGCAGTGTGTCAGGTGCTGCAGAGCGTTCTTGGAGAAGGCCCACTGAGGCAGGTTCGTGCCCTGCTGCGGCCAGCCT GACTAGACCCCACCCTGAGGTCCTGCATTTCTCAGTCGGTGTGTAATCACGTTCCAGGGCCCAAAGCCCAGCTCTTTGTTCAGTTGACTT ACTGTTTCTTACCTTAAAAAGTAATTGTAGATGGAAATCAGTTGTGTTTGGCAGGAGAATCAATAAAAATCTTTGATTCAGACAGCTTAT GGGGTATTTTAAGCATTCTTAGACTAGTTGAACATCTCACTTTGCCCCAGTTACAAAAATAGTAGAACAAGCAACATAAAACAATGAAGG AAAACCTCACTTGAAGGCCCAGGTCAACATCTAAGCCTGTTGAGACTTAGATAATCGAGTCTACCTCTTCAGTAGGTTTGTGTGGATGGC CTGGAGGGCAGGTGCCCTCTGCTCCCCAGTGCTACCTCTCTCTTCCCTAGGGCCTTTTGTGGATTGACAGTAGTCCCCTCCGTAGGAGCT CACAGTCTAGATTAGAAGTGTTTTAATTTCTACACACCCATAGTGCACACTTGTATATTGAAAAGATAGGGAAGAGAGAAACATTTATGG AATCAGTCGTTGGCACCTTCAATACTTCATGATTTTTGTCGAGTTTACTTCATGAGGAGGTCAGCCCATTGGCTCCCATCTGAACCACTT TGCCTCTGAAACTTAATTACATCCAGAAAGAAGGACACTTGTATGCTAGTCTATGGTCAGTTGAGGAATATGACTGTTTTTATATGCACA TGTAACCCAAATGTCCAATATAAATTGGCTTATTTTTTAAAATAATTTTAAAAGTTGGGAAAAGTGTTATTATTTGGCATGCTTAAATAT TGAATAAGTATTCTTCATCAGCATTTAATAAATGTATAGGCAGATGTAAGGTAATTTCTGTGTATTTTGAGATAATGTCAAAATCATGAA >5984_5984_1_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000272065_length(amino acids)=439AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM EQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEAVFRKLVTDQNISENWRVDSAATSGYEIGNPPDYRGQSCMKRHGIPMSHVARQIT -------------------------------------------------------------- >5984_5984_2_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000272067_length(transcript)=2299nt_BP=886nt ATGACATTTTGGATTATAATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTA CAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTG CTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAA ATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGC AACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGG CTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGG AATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACT GGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATT AAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATG GAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGA TCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGGTCATTGACAGCGGTGCTGTTTCTGAC TGGAACGTGGGCCGGTCCCCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAGATTACC AAAGAAGATTTTGCCACATTTGATTATATACTATGTATGGATGAAAGCAATCTGAGAGATTTGAATAGAAAAAGTAATCAAGTTAAAACC TGCAAAGCTAAAATTGAACTACTTGGGAGCTATGATCCACAAAAACAACTTATTATTGAAGATCCCTATTATGGGAATGACTCTGACTTT GAGACGGTGTACCAGCAGTGTGTCAGGTGCTGCAGAGCGTTCTTGGAGAAGGCCCACTGAGGCAGGTTCGTGCCCTGCTGCGGCCAGCCT GACTAGACCCCACCCTGAGGTCCTGCATTTCTCAGTCGGTGTGTAATCACGTTCCAGGGCCCAAAGCCCAGCTCTTTGTTCAGTTGACTT ACTGTTTCTTACCTTAAAAAGTAATTGTAGATGGAAATCAGTTGTGTTTGGCAGGAGAATCAATAAAAATCTTTGATTCAGACAGCTTAT GGGGTATTTTAAGCATTCTTAGACTAGTTGAACATCTCACTTTGCCCCAGTTACAAAAATAGTAGAACAAGCAACATAAAACAATGAAGG AAAACCTCACTTGAAGGCCCAGGTCAACATCTAAGCCTGTTGAGACTTAGATAATCGAGTCTACCTCTTCAGTAGGTTTGTGTGGATGGC CTGGAGGGCAGGTGCCCTCTGCTCCCCAGTGCTACCTCTCTCTTCCCTAGGGCCTTTTGTGGATTGACAGTAGTCCCCTCCGTAGGAGCT CACAGTCTAGATTAGAAGTGTTTTAATTTCTACACACCCATAGTGCACACTTGTATATTGAAAAGATAGGGAAGAGAGAAACATTTATGG AATCAGTCGTTGGCACCTTCAATACTTCATGATTTTTGTCGAGTTTACTTCATGAGGAGGTCAGCCCATTGGCTCCCATCTGAACCACTT TGCCTCTGAAACTTAATTACATCCAGAAAGAAGGACACTTGTATGCTAGTCTATGGTCAGTTGAGGAATATGACTGTTTTTATATGCACA TGTAACCCAAATGTCCAATATAAATTGGCTTATTTTTTAAAATAATTTTAAAAGTTGGGAAAAGTGTTATTATTTGGCATGCTTAAATAT TGAATAAGTATTCTTCATCAGCATTTAATAAATGTATAGGCAGATGTAAGGTAATTTCTGTGTATTTTGAGATAATGTCAAAATCATGAA >5984_5984_2_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000272067_length(amino acids)=439AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM EQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEAVFRKLVTDQNISENWVIDSGAVSDWNVGRSPDPRAVSCLRNHGIHTAHKARQIT -------------------------------------------------------------- >5984_5984_3_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000405233_length(transcript)=1953nt_BP=886nt ATGACATTTTGGATTATAATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTA CAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTG CTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAA ATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGC AACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGG CTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGG AATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACT GGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATT AAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATG GAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGA TCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACTTCCGGT GGGTCATTGACAGCGGTGCTGTTTCTGACTGGAACGTGGGCCGGTCCCCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTC ACACAGCCCATAAAGCAAGACAGGTAGACAAGCTCTTGTTCAATTTCTAATATATAGAGTCCAGTAACTTGAGAAGTAGCGAAAGGATTA ACCAGACTTGTATATTAATGAATGTGTTTATTTAGGGTGAGCTTAACCAGCTATGGTGTGTCCATTTTGTTTCACTTCTGGTTGCACGGT GTTGAAAGACTTGCCTGACTTTGGAATTTACTTATTAAAATGCACATAAAAGCTAGGTAATTTATAATGAGAGAGCCTGACTGTGAGCTG GGGCTGAGCGGTGCTCTGTCTTCTGTTCCTTCCTGCATAATTTTTATTAAACATTTAGGCCATAGTAATCATCCTGCTGATATTGCAAGT TTGTTGCTAGAATGAGGTTATATAATATATACAAAAACATTTTTTCAACTGTAAAGTGCCTTAGTAATATAGGGTAATACCAGCAACATT ATGGATATATAATTATAGTCTATTGGGCCACACTTAAGTTTGGAGTCTAATAAAGTCACAATCAAATTCTGCAATTTCAATTGAAGATAA CCTTGTCTTTATATTATGAATTAGAAGCTAAAGTTGATTTTTCTAAGAGTTCTTTATTTAAATGAAGTACTCTGGGACTGACCTTTTCGG AAATGGAATCTTCATTGGTCAGGTGATTCAACATTTTTATACAATTTATCCATCCTCATCTCTTCAGGATTTGCATACCTTGCCAGTTTC TACTGGCCATTGTTGAAAATACATTTATTTGGAGAAGTCCAAAGCCAAGGGGCTCATGGGGCTGTGAAGTCCTTCTTGCTGCATCGTCCT >5984_5984_3_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000405233_length(amino acids)=351AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM -------------------------------------------------------------- >5984_5984_4_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000407983_length(transcript)=1481nt_BP=886nt ATGACATTTTGGATTATAATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTA CAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTG CTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAA ATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGC AACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGG CTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGG AATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACT GGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATT AAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATG GAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGA TCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACTTCCGGG TATGAGATAGGGAACCCCCCTGACTACCGAGGGCAGAGCTGCATGAAGAGGCACGGCATTCCCATGAGCCACGTTGCCCGGCAGGTACCG TCCTTGGACTTGAAGTTGTGTGTTTTGTGTTTCAGTGGGTCATTGACAGCGGTGCTGTTTCTGACTGGAACGTGGGCCGGTCCCCAGACC CAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAGGTAGACAAGCTCTTGTTCAATTTCTAATATA TAGAGTCCAGTAACTTGAGAAGTAGCGAAAGGATTAACCAGACTTGTATATTAATGAATGTGTTTATTTAGGGTGAGCTTAACCAGCTAT GGTGTGTCCATTTTGTTTCACTTCTGGTTGCACGGTGTTGAAAGACTTGCCTGACTTTGGAATTTACTTATTAAAATGCACATAAAAGCT >5984_5984_4_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000407983_length(amino acids)=393AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM EQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEAVFRKLVTDQNISENWRVDSAATSGYEIGNPPDYRGQSCMKRHGIPMSHVARQVP -------------------------------------------------------------- >5984_5984_5_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000439645_length(transcript)=1399nt_BP=886nt ATGACATTTTGGATTATAATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTA CAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTG CTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAA ATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGC AACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGG CTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGG AATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACT GGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATT AAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATG GAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGA TCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGGTCATTGACAGCGGTGCTGTTTCTGAC TGGAACGTGGGCCGGTCCCCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAGGTAGAC AAGCTCTTGTTCAATTTCTAATATATAGAGTCCAGTAACTTGAGAAGTAGCGAAAGGATTAACCAGACTTGTATATTAATGAATGTGTTT ATTTAGGGTGAGCTTAACCAGCTATGGTGTGTCCATTTTGTTTCACTTCTGGTTGCACGGTGTTGAAAGACTTGCCTGACTTTGGAATTT ACTTATTAAAATGCACATAAAAGCTAGGTAATTTATAATGAGAGAGCCTGACTGTGAGCTGGGGCTGAGCGGTGCTCTGTCTTCTGTTCC >5984_5984_5_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000357139_ACP1_chr2_271866_ENST00000439645_length(amino acids)=366AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM EQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEAVFRKLVTDQNISENWVIDSGAVSDWNVGRSPDPRAVSCLRNHGIHTAHKARQVD -------------------------------------------------------------- >5984_5984_6_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000272065_length(transcript)=2665nt_BP=1252nt ACAGCAGCGCGCTAGGCGGACGCCGCGGGAATTTGACGCTCGAGGCTCGCGGCCCCTAATGAGAGTCCCAGAACACTTCCCGCCCTTGAC GGCCAGCGGCAGCGCCGCCGCCTCCCGCAGAGCGCCCGCTTCTCCGTTTCTAGAGCCTTAGTCTCTCCTCGAGCGACCTCGCAGCCTCCC TCCCGTCTCCATCCGCCGCCGGTTCTGCAGCCCGGCTCCTCCCTCAGTCTAGGCGCGCGGGCTGTAGTGGGCGATCGCCTTTCCCCGACC CCTCGCCGTGCCCCTGGGCCTCCCGAAGTGGCCTGGGCGAGCACTGACTGCCCTTTGGCGGTGTCAGCCCCAAAGTCAGGGCCGGCGATG TCTGCCCGGGAGCGGCAGCCGGCGCTGAAGAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAA GCCCTACAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGG ACTCTGCTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTG GCCAAAATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGA GAAGGCAACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGAC AAATGGCTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGAC ATTGGGAATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGG ATAACTGGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATAT GGAATTAAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTC CTTATGGAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATT TGTCGATCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACT TCCGGGTATGAGATAGGGAACCCCCCTGACTACCGAGGGCAGAGCTGCATGAAGAGGCACGGCATTCCCATGAGCCACGTTGCCCGGCAG ATTACCAAAGAAGATTTTGCCACATTTGATTATATACTATGTATGGATGAAAGCAATCTGAGAGATTTGAATAGAAAAAGTAATCAAGTT AAAACCTGCAAAGCTAAAATTGAACTACTTGGGAGCTATGATCCACAAAAACAACTTATTATTGAAGATCCCTATTATGGGAATGACTCT GACTTTGAGACGGTGTACCAGCAGTGTGTCAGGTGCTGCAGAGCGTTCTTGGAGAAGGCCCACTGAGGCAGGTTCGTGCCCTGCTGCGGC CAGCCTGACTAGACCCCACCCTGAGGTCCTGCATTTCTCAGTCGGTGTGTAATCACGTTCCAGGGCCCAAAGCCCAGCTCTTTGTTCAGT TGACTTACTGTTTCTTACCTTAAAAAGTAATTGTAGATGGAAATCAGTTGTGTTTGGCAGGAGAATCAATAAAAATCTTTGATTCAGACA GCTTATGGGGTATTTTAAGCATTCTTAGACTAGTTGAACATCTCACTTTGCCCCAGTTACAAAAATAGTAGAACAAGCAACATAAAACAA TGAAGGAAAACCTCACTTGAAGGCCCAGGTCAACATCTAAGCCTGTTGAGACTTAGATAATCGAGTCTACCTCTTCAGTAGGTTTGTGTG GATGGCCTGGAGGGCAGGTGCCCTCTGCTCCCCAGTGCTACCTCTCTCTTCCCTAGGGCCTTTTGTGGATTGACAGTAGTCCCCTCCGTA GGAGCTCACAGTCTAGATTAGAAGTGTTTTAATTTCTACACACCCATAGTGCACACTTGTATATTGAAAAGATAGGGAAGAGAGAAACAT TTATGGAATCAGTCGTTGGCACCTTCAATACTTCATGATTTTTGTCGAGTTTACTTCATGAGGAGGTCAGCCCATTGGCTCCCATCTGAA CCACTTTGCCTCTGAAACTTAATTACATCCAGAAAGAAGGACACTTGTATGCTAGTCTATGGTCAGTTGAGGAATATGACTGTTTTTATA TGCACATGTAACCCAAATGTCCAATATAAATTGGCTTATTTTTTAAAATAATTTTAAAAGTTGGGAAAAGTGTTATTATTTGGCATGCTT AAATATTGAATAAGTATTCTTCATCAGCATTTAATAAATGTATAGGCAGATGTAAGGTAATTTCTGTGTATTTTGAGATAATGTCAAAAT >5984_5984_6_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000272065_length(amino acids)=493AA_BP=349 MQPGSSLSLGARAVVGDRLSPTPRRAPGPPEVAWASTDCPLAVSAPKSGPAMSARERQPALKKKMKTLAERRRSAPSLILDKALQKRPTT RDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAKIKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMK SFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIGNCAYSKTITVMNSDTANEVINMSLPMLGITGSERDY QLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLMEQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEA VFRKLVTDQNISENWRVDSAATSGYEIGNPPDYRGQSCMKRHGIPMSHVARQITKEDFATFDYILCMDESNLRDLNRKSNQVKTCKAKIE -------------------------------------------------------------- >5984_5984_7_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000272067_length(transcript)=2665nt_BP=1252nt ACAGCAGCGCGCTAGGCGGACGCCGCGGGAATTTGACGCTCGAGGCTCGCGGCCCCTAATGAGAGTCCCAGAACACTTCCCGCCCTTGAC GGCCAGCGGCAGCGCCGCCGCCTCCCGCAGAGCGCCCGCTTCTCCGTTTCTAGAGCCTTAGTCTCTCCTCGAGCGACCTCGCAGCCTCCC TCCCGTCTCCATCCGCCGCCGGTTCTGCAGCCCGGCTCCTCCCTCAGTCTAGGCGCGCGGGCTGTAGTGGGCGATCGCCTTTCCCCGACC CCTCGCCGTGCCCCTGGGCCTCCCGAAGTGGCCTGGGCGAGCACTGACTGCCCTTTGGCGGTGTCAGCCCCAAAGTCAGGGCCGGCGATG TCTGCCCGGGAGCGGCAGCCGGCGCTGAAGAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAA GCCCTACAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGG ACTCTGCTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTG GCCAAAATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGA GAAGGCAACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGAC AAATGGCTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGAC ATTGGGAATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGG ATAACTGGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATAT GGAATTAAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTC CTTATGGAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATT TGTCGATCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGGTCATTGACAGCGGTGCTGTT TCTGACTGGAACGTGGGCCGGTCCCCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAG ATTACCAAAGAAGATTTTGCCACATTTGATTATATACTATGTATGGATGAAAGCAATCTGAGAGATTTGAATAGAAAAAGTAATCAAGTT AAAACCTGCAAAGCTAAAATTGAACTACTTGGGAGCTATGATCCACAAAAACAACTTATTATTGAAGATCCCTATTATGGGAATGACTCT GACTTTGAGACGGTGTACCAGCAGTGTGTCAGGTGCTGCAGAGCGTTCTTGGAGAAGGCCCACTGAGGCAGGTTCGTGCCCTGCTGCGGC CAGCCTGACTAGACCCCACCCTGAGGTCCTGCATTTCTCAGTCGGTGTGTAATCACGTTCCAGGGCCCAAAGCCCAGCTCTTTGTTCAGT TGACTTACTGTTTCTTACCTTAAAAAGTAATTGTAGATGGAAATCAGTTGTGTTTGGCAGGAGAATCAATAAAAATCTTTGATTCAGACA GCTTATGGGGTATTTTAAGCATTCTTAGACTAGTTGAACATCTCACTTTGCCCCAGTTACAAAAATAGTAGAACAAGCAACATAAAACAA TGAAGGAAAACCTCACTTGAAGGCCCAGGTCAACATCTAAGCCTGTTGAGACTTAGATAATCGAGTCTACCTCTTCAGTAGGTTTGTGTG GATGGCCTGGAGGGCAGGTGCCCTCTGCTCCCCAGTGCTACCTCTCTCTTCCCTAGGGCCTTTTGTGGATTGACAGTAGTCCCCTCCGTA GGAGCTCACAGTCTAGATTAGAAGTGTTTTAATTTCTACACACCCATAGTGCACACTTGTATATTGAAAAGATAGGGAAGAGAGAAACAT TTATGGAATCAGTCGTTGGCACCTTCAATACTTCATGATTTTTGTCGAGTTTACTTCATGAGGAGGTCAGCCCATTGGCTCCCATCTGAA CCACTTTGCCTCTGAAACTTAATTACATCCAGAAAGAAGGACACTTGTATGCTAGTCTATGGTCAGTTGAGGAATATGACTGTTTTTATA TGCACATGTAACCCAAATGTCCAATATAAATTGGCTTATTTTTTAAAATAATTTTAAAAGTTGGGAAAAGTGTTATTATTTGGCATGCTT AAATATTGAATAAGTATTCTTCATCAGCATTTAATAAATGTATAGGCAGATGTAAGGTAATTTCTGTGTATTTTGAGATAATGTCAAAAT >5984_5984_7_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000272067_length(amino acids)=493AA_BP=349 MQPGSSLSLGARAVVGDRLSPTPRRAPGPPEVAWASTDCPLAVSAPKSGPAMSARERQPALKKKMKTLAERRRSAPSLILDKALQKRPTT RDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAKIKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMK SFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIGNCAYSKTITVMNSDTANEVINMSLPMLGITGSERDY QLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLMEQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEA VFRKLVTDQNISENWVIDSGAVSDWNVGRSPDPRAVSCLRNHGIHTAHKARQITKEDFATFDYILCMDESNLRDLNRKSNQVKTCKAKIE -------------------------------------------------------------- >5984_5984_8_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000405233_length(transcript)=2319nt_BP=1252nt ACAGCAGCGCGCTAGGCGGACGCCGCGGGAATTTGACGCTCGAGGCTCGCGGCCCCTAATGAGAGTCCCAGAACACTTCCCGCCCTTGAC GGCCAGCGGCAGCGCCGCCGCCTCCCGCAGAGCGCCCGCTTCTCCGTTTCTAGAGCCTTAGTCTCTCCTCGAGCGACCTCGCAGCCTCCC TCCCGTCTCCATCCGCCGCCGGTTCTGCAGCCCGGCTCCTCCCTCAGTCTAGGCGCGCGGGCTGTAGTGGGCGATCGCCTTTCCCCGACC CCTCGCCGTGCCCCTGGGCCTCCCGAAGTGGCCTGGGCGAGCACTGACTGCCCTTTGGCGGTGTCAGCCCCAAAGTCAGGGCCGGCGATG TCTGCCCGGGAGCGGCAGCCGGCGCTGAAGAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAA GCCCTACAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGG ACTCTGCTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTG GCCAAAATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGA GAAGGCAACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGAC AAATGGCTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGAC ATTGGGAATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGG ATAACTGGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATAT GGAATTAAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTC CTTATGGAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATT TGTCGATCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACT TCCGGTGGGTCATTGACAGCGGTGCTGTTTCTGACTGGAACGTGGGCCGGTCCCCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATG GCATTCACACAGCCCATAAAGCAAGACAGGTAGACAAGCTCTTGTTCAATTTCTAATATATAGAGTCCAGTAACTTGAGAAGTAGCGAAA GGATTAACCAGACTTGTATATTAATGAATGTGTTTATTTAGGGTGAGCTTAACCAGCTATGGTGTGTCCATTTTGTTTCACTTCTGGTTG CACGGTGTTGAAAGACTTGCCTGACTTTGGAATTTACTTATTAAAATGCACATAAAAGCTAGGTAATTTATAATGAGAGAGCCTGACTGT GAGCTGGGGCTGAGCGGTGCTCTGTCTTCTGTTCCTTCCTGCATAATTTTTATTAAACATTTAGGCCATAGTAATCATCCTGCTGATATT GCAAGTTTGTTGCTAGAATGAGGTTATATAATATATACAAAAACATTTTTTCAACTGTAAAGTGCCTTAGTAATATAGGGTAATACCAGC AACATTATGGATATATAATTATAGTCTATTGGGCCACACTTAAGTTTGGAGTCTAATAAAGTCACAATCAAATTCTGCAATTTCAATTGA AGATAACCTTGTCTTTATATTATGAATTAGAAGCTAAAGTTGATTTTTCTAAGAGTTCTTTATTTAAATGAAGTACTCTGGGACTGACCT TTTCGGAAATGGAATCTTCATTGGTCAGGTGATTCAACATTTTTATACAATTTATCCATCCTCATCTCTTCAGGATTTGCATACCTTGCC AGTTTCTACTGGCCATTGTTGAAAATACATTTATTTGGAGAAGTCCAAAGCCAAGGGGCTCATGGGGCTGTGAAGTCCTTCTTGCTGCAT >5984_5984_8_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000405233_length(amino acids)=405AA_BP=349 MQPGSSLSLGARAVVGDRLSPTPRRAPGPPEVAWASTDCPLAVSAPKSGPAMSARERQPALKKKMKTLAERRRSAPSLILDKALQKRPTT RDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAKIKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMK SFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIGNCAYSKTITVMNSDTANEVINMSLPMLGITGSERDY QLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLMEQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEA -------------------------------------------------------------- >5984_5984_9_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000407983_length(transcript)=1847nt_BP=1252nt ACAGCAGCGCGCTAGGCGGACGCCGCGGGAATTTGACGCTCGAGGCTCGCGGCCCCTAATGAGAGTCCCAGAACACTTCCCGCCCTTGAC GGCCAGCGGCAGCGCCGCCGCCTCCCGCAGAGCGCCCGCTTCTCCGTTTCTAGAGCCTTAGTCTCTCCTCGAGCGACCTCGCAGCCTCCC TCCCGTCTCCATCCGCCGCCGGTTCTGCAGCCCGGCTCCTCCCTCAGTCTAGGCGCGCGGGCTGTAGTGGGCGATCGCCTTTCCCCGACC CCTCGCCGTGCCCCTGGGCCTCCCGAAGTGGCCTGGGCGAGCACTGACTGCCCTTTGGCGGTGTCAGCCCCAAAGTCAGGGCCGGCGATG TCTGCCCGGGAGCGGCAGCCGGCGCTGAAGAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAA GCCCTACAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGG ACTCTGCTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTG GCCAAAATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGA GAAGGCAACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGAC AAATGGCTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGAC ATTGGGAATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGG ATAACTGGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATAT GGAATTAAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTC CTTATGGAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATT TGTCGATCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACT TCCGGGTATGAGATAGGGAACCCCCCTGACTACCGAGGGCAGAGCTGCATGAAGAGGCACGGCATTCCCATGAGCCACGTTGCCCGGCAG GTACCGTCCTTGGACTTGAAGTTGTGTGTTTTGTGTTTCAGTGGGTCATTGACAGCGGTGCTGTTTCTGACTGGAACGTGGGCCGGTCCC CAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAGGTAGACAAGCTCTTGTTCAATTTCT AATATATAGAGTCCAGTAACTTGAGAAGTAGCGAAAGGATTAACCAGACTTGTATATTAATGAATGTGTTTATTTAGGGTGAGCTTAACC AGCTATGGTGTGTCCATTTTGTTTCACTTCTGGTTGCACGGTGTTGAAAGACTTGCCTGACTTTGGAATTTACTTATTAAAATGCACATA >5984_5984_9_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000407983_length(amino acids)=447AA_BP=349 MQPGSSLSLGARAVVGDRLSPTPRRAPGPPEVAWASTDCPLAVSAPKSGPAMSARERQPALKKKMKTLAERRRSAPSLILDKALQKRPTT RDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAKIKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMK SFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIGNCAYSKTITVMNSDTANEVINMSLPMLGITGSERDY QLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLMEQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEA -------------------------------------------------------------- >5984_5984_10_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000439645_length(transcript)=1765nt_BP=1252nt ACAGCAGCGCGCTAGGCGGACGCCGCGGGAATTTGACGCTCGAGGCTCGCGGCCCCTAATGAGAGTCCCAGAACACTTCCCGCCCTTGAC GGCCAGCGGCAGCGCCGCCGCCTCCCGCAGAGCGCCCGCTTCTCCGTTTCTAGAGCCTTAGTCTCTCCTCGAGCGACCTCGCAGCCTCCC TCCCGTCTCCATCCGCCGCCGGTTCTGCAGCCCGGCTCCTCCCTCAGTCTAGGCGCGCGGGCTGTAGTGGGCGATCGCCTTTCCCCGACC CCTCGCCGTGCCCCTGGGCCTCCCGAAGTGGCCTGGGCGAGCACTGACTGCCCTTTGGCGGTGTCAGCCCCAAAGTCAGGGCCGGCGATG TCTGCCCGGGAGCGGCAGCCGGCGCTGAAGAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAA GCCCTACAAAAACGGCCTACTACCAGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGG ACTCTGCTGATTGATGGCCGGGCAGAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTG GCCAAAATCAAATATAACAATAACTTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGA GAAGGCAACACCAATGCCATGAAATCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGAC AAATGGCTCTCTCTCCTTCAGAGATACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGAC ATTGGGAATTGTGCCTACTCTAAAACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGG ATAACTGGCTCTGAGAGAGATTACCAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATAT GGAATTAAAATGAGCCATCTTCGAGACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTC CTTATGGAACAGCTCCCCCGAGAGATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATT TGTCGATCACCCATTGCAGAAGCAGTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGGTCATTGACAGCGGTGCTGTT TCTGACTGGAACGTGGGCCGGTCCCCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAG GTAGACAAGCTCTTGTTCAATTTCTAATATATAGAGTCCAGTAACTTGAGAAGTAGCGAAAGGATTAACCAGACTTGTATATTAATGAAT GTGTTTATTTAGGGTGAGCTTAACCAGCTATGGTGTGTCCATTTTGTTTCACTTCTGGTTGCACGGTGTTGAAAGACTTGCCTGACTTTG GAATTTACTTATTAAAATGCACATAAAAGCTAGGTAATTTATAATGAGAGAGCCTGACTGTGAGCTGGGGCTGAGCGGTGCTCTGTCTTC >5984_5984_10_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000524756_ACP1_chr2_271866_ENST00000439645_length(amino acids)=420AA_BP=349 MQPGSSLSLGARAVVGDRLSPTPRRAPGPPEVAWASTDCPLAVSAPKSGPAMSARERQPALKKKMKTLAERRRSAPSLILDKALQKRPTT RDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAKIKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMK SFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIGNCAYSKTITVMNSDTANEVINMSLPMLGITGSERDY QLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLMEQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEA -------------------------------------------------------------- >5984_5984_11_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000272065_length(transcript)=2551nt_BP=1138nt GTAGCCTTCTCAATAGCTTAGCCAAATTTCGGCGTCCTCGCTCTGTCTGCATTTTCCTTCATTGCTCTTTCACGTTTGGAATGCCCCCGT CTCTGCAGCCTGCAGACAGCGGAAACCGCGGGTGCAAATGTGCAGGGGCCGCTGACATGACCGGCTGCAGAAGCCCACTCAGGGTTACCC GAACAGGCTAGCGTTCGGGATTGCACAAGAGCCAAATTTGCCTGTGAAATAAAGATAGTAGTATCTACCCGGATGACATTTTGGATTATA ATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTACAAAAACGGCCTACTACC AGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTGCTGATTGATGGCCGGGCA GAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAAATCAAATATAACAATAAC TTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGCAACACCAATGCCATGAAA TCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGGCTCTCTCTCCTTCAGAGA TACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGGAATTGTGCCTACTCTAAA ACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACTGGCTCTGAGAGAGATTAC CAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATTAAAATGAGCCATCTTCGA GACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATGGAACAGCTCCCCCGAGAG ATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGATCACCCATTGCAGAAGCA GTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACTTCCGGGTATGAGATAGGGAACCCC CCTGACTACCGAGGGCAGAGCTGCATGAAGAGGCACGGCATTCCCATGAGCCACGTTGCCCGGCAGATTACCAAAGAAGATTTTGCCACA TTTGATTATATACTATGTATGGATGAAAGCAATCTGAGAGATTTGAATAGAAAAAGTAATCAAGTTAAAACCTGCAAAGCTAAAATTGAA CTACTTGGGAGCTATGATCCACAAAAACAACTTATTATTGAAGATCCCTATTATGGGAATGACTCTGACTTTGAGACGGTGTACCAGCAG TGTGTCAGGTGCTGCAGAGCGTTCTTGGAGAAGGCCCACTGAGGCAGGTTCGTGCCCTGCTGCGGCCAGCCTGACTAGACCCCACCCTGA GGTCCTGCATTTCTCAGTCGGTGTGTAATCACGTTCCAGGGCCCAAAGCCCAGCTCTTTGTTCAGTTGACTTACTGTTTCTTACCTTAAA AAGTAATTGTAGATGGAAATCAGTTGTGTTTGGCAGGAGAATCAATAAAAATCTTTGATTCAGACAGCTTATGGGGTATTTTAAGCATTC TTAGACTAGTTGAACATCTCACTTTGCCCCAGTTACAAAAATAGTAGAACAAGCAACATAAAACAATGAAGGAAAACCTCACTTGAAGGC CCAGGTCAACATCTAAGCCTGTTGAGACTTAGATAATCGAGTCTACCTCTTCAGTAGGTTTGTGTGGATGGCCTGGAGGGCAGGTGCCCT CTGCTCCCCAGTGCTACCTCTCTCTTCCCTAGGGCCTTTTGTGGATTGACAGTAGTCCCCTCCGTAGGAGCTCACAGTCTAGATTAGAAG TGTTTTAATTTCTACACACCCATAGTGCACACTTGTATATTGAAAAGATAGGGAAGAGAGAAACATTTATGGAATCAGTCGTTGGCACCT TCAATACTTCATGATTTTTGTCGAGTTTACTTCATGAGGAGGTCAGCCCATTGGCTCCCATCTGAACCACTTTGCCTCTGAAACTTAATT ACATCCAGAAAGAAGGACACTTGTATGCTAGTCTATGGTCAGTTGAGGAATATGACTGTTTTTATATGCACATGTAACCCAAATGTCCAA TATAAATTGGCTTATTTTTTAAAATAATTTTAAAAGTTGGGAAAAGTGTTATTATTTGGCATGCTTAAATATTGAATAAGTATTCTTCAT CAGCATTTAATAAATGTATAGGCAGATGTAAGGTAATTTCTGTGTATTTTGAGATAATGTCAAAATCATGAATATTTCAAAATAAACTGG >5984_5984_11_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000272065_length(amino acids)=439AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM EQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEAVFRKLVTDQNISENWRVDSAATSGYEIGNPPDYRGQSCMKRHGIPMSHVARQIT -------------------------------------------------------------- >5984_5984_12_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000272067_length(transcript)=2551nt_BP=1138nt GTAGCCTTCTCAATAGCTTAGCCAAATTTCGGCGTCCTCGCTCTGTCTGCATTTTCCTTCATTGCTCTTTCACGTTTGGAATGCCCCCGT CTCTGCAGCCTGCAGACAGCGGAAACCGCGGGTGCAAATGTGCAGGGGCCGCTGACATGACCGGCTGCAGAAGCCCACTCAGGGTTACCC GAACAGGCTAGCGTTCGGGATTGCACAAGAGCCAAATTTGCCTGTGAAATAAAGATAGTAGTATCTACCCGGATGACATTTTGGATTATA ATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTACAAAAACGGCCTACTACC AGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTGCTGATTGATGGCCGGGCA GAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAAATCAAATATAACAATAAC TTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGCAACACCAATGCCATGAAA TCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGGCTCTCTCTCCTTCAGAGA TACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGGAATTGTGCCTACTCTAAA ACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACTGGCTCTGAGAGAGATTAC CAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATTAAAATGAGCCATCTTCGA GACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATGGAACAGCTCCCCCGAGAG ATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGATCACCCATTGCAGAAGCA GTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGGTCATTGACAGCGGTGCTGTTTCTGACTGGAACGTGGGCCGGTCC CCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAGATTACCAAAGAAGATTTTGCCACA TTTGATTATATACTATGTATGGATGAAAGCAATCTGAGAGATTTGAATAGAAAAAGTAATCAAGTTAAAACCTGCAAAGCTAAAATTGAA CTACTTGGGAGCTATGATCCACAAAAACAACTTATTATTGAAGATCCCTATTATGGGAATGACTCTGACTTTGAGACGGTGTACCAGCAG TGTGTCAGGTGCTGCAGAGCGTTCTTGGAGAAGGCCCACTGAGGCAGGTTCGTGCCCTGCTGCGGCCAGCCTGACTAGACCCCACCCTGA GGTCCTGCATTTCTCAGTCGGTGTGTAATCACGTTCCAGGGCCCAAAGCCCAGCTCTTTGTTCAGTTGACTTACTGTTTCTTACCTTAAA AAGTAATTGTAGATGGAAATCAGTTGTGTTTGGCAGGAGAATCAATAAAAATCTTTGATTCAGACAGCTTATGGGGTATTTTAAGCATTC TTAGACTAGTTGAACATCTCACTTTGCCCCAGTTACAAAAATAGTAGAACAAGCAACATAAAACAATGAAGGAAAACCTCACTTGAAGGC CCAGGTCAACATCTAAGCCTGTTGAGACTTAGATAATCGAGTCTACCTCTTCAGTAGGTTTGTGTGGATGGCCTGGAGGGCAGGTGCCCT CTGCTCCCCAGTGCTACCTCTCTCTTCCCTAGGGCCTTTTGTGGATTGACAGTAGTCCCCTCCGTAGGAGCTCACAGTCTAGATTAGAAG TGTTTTAATTTCTACACACCCATAGTGCACACTTGTATATTGAAAAGATAGGGAAGAGAGAAACATTTATGGAATCAGTCGTTGGCACCT TCAATACTTCATGATTTTTGTCGAGTTTACTTCATGAGGAGGTCAGCCCATTGGCTCCCATCTGAACCACTTTGCCTCTGAAACTTAATT ACATCCAGAAAGAAGGACACTTGTATGCTAGTCTATGGTCAGTTGAGGAATATGACTGTTTTTATATGCACATGTAACCCAAATGTCCAA TATAAATTGGCTTATTTTTTAAAATAATTTTAAAAGTTGGGAAAAGTGTTATTATTTGGCATGCTTAAATATTGAATAAGTATTCTTCAT CAGCATTTAATAAATGTATAGGCAGATGTAAGGTAATTTCTGTGTATTTTGAGATAATGTCAAAATCATGAATATTTCAAAATAAACTGG >5984_5984_12_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000272067_length(amino acids)=439AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM EQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEAVFRKLVTDQNISENWVIDSGAVSDWNVGRSPDPRAVSCLRNHGIHTAHKARQIT -------------------------------------------------------------- >5984_5984_13_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000405233_length(transcript)=2205nt_BP=1138nt GTAGCCTTCTCAATAGCTTAGCCAAATTTCGGCGTCCTCGCTCTGTCTGCATTTTCCTTCATTGCTCTTTCACGTTTGGAATGCCCCCGT CTCTGCAGCCTGCAGACAGCGGAAACCGCGGGTGCAAATGTGCAGGGGCCGCTGACATGACCGGCTGCAGAAGCCCACTCAGGGTTACCC GAACAGGCTAGCGTTCGGGATTGCACAAGAGCCAAATTTGCCTGTGAAATAAAGATAGTAGTATCTACCCGGATGACATTTTGGATTATA ATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTACAAAAACGGCCTACTACC AGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTGCTGATTGATGGCCGGGCA GAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAAATCAAATATAACAATAAC TTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGCAACACCAATGCCATGAAA TCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGGCTCTCTCTCCTTCAGAGA TACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGGAATTGTGCCTACTCTAAA ACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACTGGCTCTGAGAGAGATTAC CAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATTAAAATGAGCCATCTTCGA GACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATGGAACAGCTCCCCCGAGAG ATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGATCACCCATTGCAGAAGCA GTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACTTCCGGTGGGTCATTGACAGCGGTG CTGTTTCTGACTGGAACGTGGGCCGGTCCCCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAA GACAGGTAGACAAGCTCTTGTTCAATTTCTAATATATAGAGTCCAGTAACTTGAGAAGTAGCGAAAGGATTAACCAGACTTGTATATTAA TGAATGTGTTTATTTAGGGTGAGCTTAACCAGCTATGGTGTGTCCATTTTGTTTCACTTCTGGTTGCACGGTGTTGAAAGACTTGCCTGA CTTTGGAATTTACTTATTAAAATGCACATAAAAGCTAGGTAATTTATAATGAGAGAGCCTGACTGTGAGCTGGGGCTGAGCGGTGCTCTG TCTTCTGTTCCTTCCTGCATAATTTTTATTAAACATTTAGGCCATAGTAATCATCCTGCTGATATTGCAAGTTTGTTGCTAGAATGAGGT TATATAATATATACAAAAACATTTTTTCAACTGTAAAGTGCCTTAGTAATATAGGGTAATACCAGCAACATTATGGATATATAATTATAG TCTATTGGGCCACACTTAAGTTTGGAGTCTAATAAAGTCACAATCAAATTCTGCAATTTCAATTGAAGATAACCTTGTCTTTATATTATG AATTAGAAGCTAAAGTTGATTTTTCTAAGAGTTCTTTATTTAAATGAAGTACTCTGGGACTGACCTTTTCGGAAATGGAATCTTCATTGG TCAGGTGATTCAACATTTTTATACAATTTATCCATCCTCATCTCTTCAGGATTTGCATACCTTGCCAGTTTCTACTGGCCATTGTTGAAA ATACATTTATTTGGAGAAGTCCAAAGCCAAGGGGCTCATGGGGCTGTGAAGTCCTTCTTGCTGCATCGTCCTGTGGTAGAAGGTGGAGGA >5984_5984_13_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000405233_length(amino acids)=351AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM -------------------------------------------------------------- >5984_5984_14_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000407983_length(transcript)=1733nt_BP=1138nt GTAGCCTTCTCAATAGCTTAGCCAAATTTCGGCGTCCTCGCTCTGTCTGCATTTTCCTTCATTGCTCTTTCACGTTTGGAATGCCCCCGT CTCTGCAGCCTGCAGACAGCGGAAACCGCGGGTGCAAATGTGCAGGGGCCGCTGACATGACCGGCTGCAGAAGCCCACTCAGGGTTACCC GAACAGGCTAGCGTTCGGGATTGCACAAGAGCCAAATTTGCCTGTGAAATAAAGATAGTAGTATCTACCCGGATGACATTTTGGATTATA ATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTACAAAAACGGCCTACTACC AGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTGCTGATTGATGGCCGGGCA GAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAAATCAAATATAACAATAAC TTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGCAACACCAATGCCATGAAA TCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGGCTCTCTCTCCTTCAGAGA TACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGGAATTGTGCCTACTCTAAA ACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACTGGCTCTGAGAGAGATTAC CAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATTAAAATGAGCCATCTTCGA GACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATGGAACAGCTCCCCCGAGAG ATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGATCACCCATTGCAGAAGCA GTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGAGGGTAGACAGCGCGGCAACTTCCGGGTATGAGATAGGGAACCCC CCTGACTACCGAGGGCAGAGCTGCATGAAGAGGCACGGCATTCCCATGAGCCACGTTGCCCGGCAGGTACCGTCCTTGGACTTGAAGTTG TGTGTTTTGTGTTTCAGTGGGTCATTGACAGCGGTGCTGTTTCTGACTGGAACGTGGGCCGGTCCCCAGACCCAAGAGCTGTGAGCTGCC TAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAGGTAGACAAGCTCTTGTTCAATTTCTAATATATAGAGTCCAGTAACTTGA GAAGTAGCGAAAGGATTAACCAGACTTGTATATTAATGAATGTGTTTATTTAGGGTGAGCTTAACCAGCTATGGTGTGTCCATTTTGTTT CACTTCTGGTTGCACGGTGTTGAAAGACTTGCCTGACTTTGGAATTTACTTATTAAAATGCACATAAAAGCTAGGTAATTTATAATGAGA >5984_5984_14_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000407983_length(amino acids)=393AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM EQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEAVFRKLVTDQNISENWRVDSAATSGYEIGNPPDYRGQSCMKRHGIPMSHVARQVP -------------------------------------------------------------- >5984_5984_15_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000439645_length(transcript)=1651nt_BP=1138nt GTAGCCTTCTCAATAGCTTAGCCAAATTTCGGCGTCCTCGCTCTGTCTGCATTTTCCTTCATTGCTCTTTCACGTTTGGAATGCCCCCGT CTCTGCAGCCTGCAGACAGCGGAAACCGCGGGTGCAAATGTGCAGGGGCCGCTGACATGACCGGCTGCAGAAGCCCACTCAGGGTTACCC GAACAGGCTAGCGTTCGGGATTGCACAAGAGCCAAATTTGCCTGTGAAATAAAGATAGTAGTATCTACCCGGATGACATTTTGGATTATA ATAAATAAGAAAATGAAAACACTAGCAGAAAGGAGGAGGAGCGCTCCATCTCTTATCCTGGATAAAGCCCTACAAAAACGGCCTACTACC AGGGACAGTCCTTCTGCTAGTGTTGACACATGCACATTTCTGTCATCATTAGTGTGCTCCAATAGGACTCTGCTGATTGATGGCCGGGCA GAACTCAAAAGAGGCCTCCAGAGGCAGGAGCGGCATCTTTTCCTATTCAATGATCTGTTTGTTGTGGCCAAAATCAAATATAACAATAAC TTTAAGATAAAAAATAAAATTAAATTAACTGATATGTGGACAGCAAGCTGTGTGGATGAAGTGGGAGAAGGCAACACCAATGCCATGAAA TCCTTTGTTTTGGGCTGGCCCACAGTGAACTTTGTGGCCACTTTCAGTTCTCCAGAACAAAAGGACAAATGGCTCTCTCTCCTTCAGAGA TACATCAATCTAGAGAAAGAAAAGGACTACCCGAAGAGCATTCCCCTCAAAATCTTCGCCAAGGACATTGGGAATTGTGCCTACTCTAAA ACTATAACAGTAATGAATTCAGATACAGCGAATGAAGTTATCAACATGTCATTACCAATGCTAGGGATAACTGGCTCTGAGAGAGATTAC CAGTTGTGGGTCAATTCTGGCAAAGAAGAGGCTCCATACCCACTCATTGGGCATGAATATCCATATGGAATTAAAATGAGCCATCTTCGA GACTCTGCACTCCTGACACCGGGATCAAAGGACTCTACCACCCCTTTCAACCTCCAGGAGCCCTTCCTTATGGAACAGCTCCCCCGAGAG ATGCAGTGCCAGTTCATCCTGAAGCCCAGCCGCCTGGCTGCAGCCCAGCAACTGAGTGGTAACATTTGTCGATCACCCATTGCAGAAGCA GTTTTCAGGAAACTTGTAACCGATCAAAACATCTCAGAGAATTGGGTCATTGACAGCGGTGCTGTTTCTGACTGGAACGTGGGCCGGTCC CCAGACCCAAGAGCTGTGAGCTGCCTAAGAAATCATGGCATTCACACAGCCCATAAAGCAAGACAGGTAGACAAGCTCTTGTTCAATTTC TAATATATAGAGTCCAGTAACTTGAGAAGTAGCGAAAGGATTAACCAGACTTGTATATTAATGAATGTGTTTATTTAGGGTGAGCTTAAC CAGCTATGGTGTGTCCATTTTGTTTCACTTCTGGTTGCACGGTGTTGAAAGACTTGCCTGACTTTGGAATTTACTTATTAAAATGCACAT AAAAGCTAGGTAATTTATAATGAGAGAGCCTGACTGTGAGCTGGGGCTGAGCGGTGCTCTGTCTTCTGTTCCTTCCTGCATAATTTTTAT >5984_5984_15_ARHGAP20-ACP1_ARHGAP20_chr11_110477285_ENST00000533353_ACP1_chr2_271866_ENST00000439645_length(amino acids)=366AA_BP=295 MTFWIIINKKMKTLAERRRSAPSLILDKALQKRPTTRDSPSASVDTCTFLSSLVCSNRTLLIDGRAELKRGLQRQERHLFLFNDLFVVAK IKYNNNFKIKNKIKLTDMWTASCVDEVGEGNTNAMKSFVLGWPTVNFVATFSSPEQKDKWLSLLQRYINLEKEKDYPKSIPLKIFAKDIG NCAYSKTITVMNSDTANEVINMSLPMLGITGSERDYQLWVNSGKEEAPYPLIGHEYPYGIKMSHLRDSALLTPGSKDSTTPFNLQEPFLM EQLPREMQCQFILKPSRLAAAQQLSGNICRSPIAEAVFRKLVTDQNISENWVIDSGAVSDWNVGRSPDPRAVSCLRNHGIHTAHKARQVD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARHGAP20-ACP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARHGAP20-ACP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARHGAP20-ACP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies