
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NPM1-VIM (FusionGDB2 ID:59993) |
Fusion Gene Summary for NPM1-VIM |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NPM1-VIM | Fusion gene ID: 59993 | Hgene | Tgene | Gene symbol | NPM1 | VIM | Gene ID | 4869 | 7431 |
| Gene name | nucleophosmin 1 | vimentin | |
| Synonyms | B23|NPM | - | |
| Cytomap | 5q35.1 | 10p13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nucleophosminnucleolar protein NO38nucleophosmin (nucleolar phosphoprotein B23, numatrin)nucleophosmin/nucleoplasmin family, member 1testicular tissue protein Li 128 | vimentinepididymis secretory sperm binding protein | |
| Modification date | 20200329 | 20200327 | |
| UniProtAcc | P06748 | VMAC | |
| Ensembl transtripts involved in fusion gene | ENST00000296930, ENST00000351986, ENST00000393820, ENST00000517671, | ENST00000485947, ENST00000224237, ENST00000544301, | |
| Fusion gene scores | * DoF score | 21 X 25 X 6=3150 | 42 X 25 X 11=11550 |
| # samples | 32 | 41 | |
| ** MAII score | log2(32/3150*10)=-3.29920801838728 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(41/11550*10)=-4.81612513168534 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NPM1 [Title/Abstract] AND VIM [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NPM1(170815010)-VIM(17278293), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NPM1 | GO:0006281 | DNA repair | 19188445 |
| Hgene | NPM1 | GO:0006334 | nucleosome assembly | 11602260 |
| Hgene | NPM1 | GO:0006913 | nucleocytoplasmic transport | 16041368 |
| Hgene | NPM1 | GO:0008104 | protein localization | 18420587 |
| Hgene | NPM1 | GO:0008284 | positive regulation of cell proliferation | 22528486 |
| Hgene | NPM1 | GO:0032071 | regulation of endodeoxyribonuclease activity | 19188445 |
| Hgene | NPM1 | GO:0034644 | cellular response to UV | 19160485 |
| Hgene | NPM1 | GO:0043066 | negative regulation of apoptotic process | 12882984 |
| Hgene | NPM1 | GO:0044387 | negative regulation of protein kinase activity by regulation of protein phosphorylation | 12882984 |
| Hgene | NPM1 | GO:0045727 | positive regulation of translation | 12882984 |
| Hgene | NPM1 | GO:0045893 | positive regulation of transcription, DNA-templated | 22528486 |
| Hgene | NPM1 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 19160485 |
| Hgene | NPM1 | GO:0060699 | regulation of endoribonuclease activity | 19188445 |
| Hgene | NPM1 | GO:0060735 | regulation of eIF2 alpha phosphorylation by dsRNA | 12882984 |
| Hgene | NPM1 | GO:1902751 | positive regulation of cell cycle G2/M phase transition | 22528486 |
| Fusion gene breakpoints across NPM1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across VIM (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LGG | TCGA-FG-6692-01A | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
Top |
Fusion Gene ORF analysis for NPM1-VIM |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000296930 | ENST00000485947 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| 5CDS-intron | ENST00000351986 | ENST00000485947 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| 5CDS-intron | ENST00000393820 | ENST00000485947 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| 5CDS-intron | ENST00000517671 | ENST00000485947 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| In-frame | ENST00000296930 | ENST00000224237 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| In-frame | ENST00000296930 | ENST00000544301 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| In-frame | ENST00000351986 | ENST00000224237 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| In-frame | ENST00000351986 | ENST00000544301 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| In-frame | ENST00000393820 | ENST00000224237 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| In-frame | ENST00000393820 | ENST00000544301 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| In-frame | ENST00000517671 | ENST00000224237 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| In-frame | ENST00000517671 | ENST00000544301 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000517671 | NPM1 | chr5 | 170815010 | + | ENST00000544301 | VIM | chr10 | 17278293 | + | 635 | 193 | 42 | 320 | 92 |
| ENST00000517671 | NPM1 | chr5 | 170815010 | + | ENST00000224237 | VIM | chr10 | 17278293 | + | 643 | 193 | 42 | 320 | 92 |
| ENST00000296930 | NPM1 | chr5 | 170815010 | + | ENST00000544301 | VIM | chr10 | 17278293 | + | 801 | 359 | 70 | 486 | 138 |
| ENST00000296930 | NPM1 | chr5 | 170815010 | + | ENST00000224237 | VIM | chr10 | 17278293 | + | 809 | 359 | 70 | 486 | 138 |
| ENST00000351986 | NPM1 | chr5 | 170815010 | + | ENST00000544301 | VIM | chr10 | 17278293 | + | 620 | 178 | 42 | 305 | 87 |
| ENST00000351986 | NPM1 | chr5 | 170815010 | + | ENST00000224237 | VIM | chr10 | 17278293 | + | 628 | 178 | 42 | 305 | 87 |
| ENST00000393820 | NPM1 | chr5 | 170815010 | + | ENST00000544301 | VIM | chr10 | 17278293 | + | 598 | 156 | 20 | 283 | 87 |
| ENST00000393820 | NPM1 | chr5 | 170815010 | + | ENST00000224237 | VIM | chr10 | 17278293 | + | 606 | 156 | 20 | 283 | 87 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000517671 | ENST00000544301 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + | 0.21970975 | 0.78029025 |
| ENST00000517671 | ENST00000224237 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + | 0.22249295 | 0.77750707 |
| ENST00000296930 | ENST00000544301 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + | 0.52027524 | 0.4797248 |
| ENST00000296930 | ENST00000224237 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + | 0.49824056 | 0.50175947 |
| ENST00000351986 | ENST00000544301 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + | 0.20146249 | 0.79853755 |
| ENST00000351986 | ENST00000224237 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + | 0.20475306 | 0.7952469 |
| ENST00000393820 | ENST00000544301 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + | 0.14488982 | 0.8551102 |
| ENST00000393820 | ENST00000224237 | NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278293 | + | 0.1608595 | 0.8391405 |
Top |
Fusion Genomic Features for NPM1-VIM |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278292 | + | 0.000158896 | 0.9998411 |
| NPM1 | chr5 | 170815010 | + | VIM | chr10 | 17278292 | + | 0.000158896 | 0.9998411 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
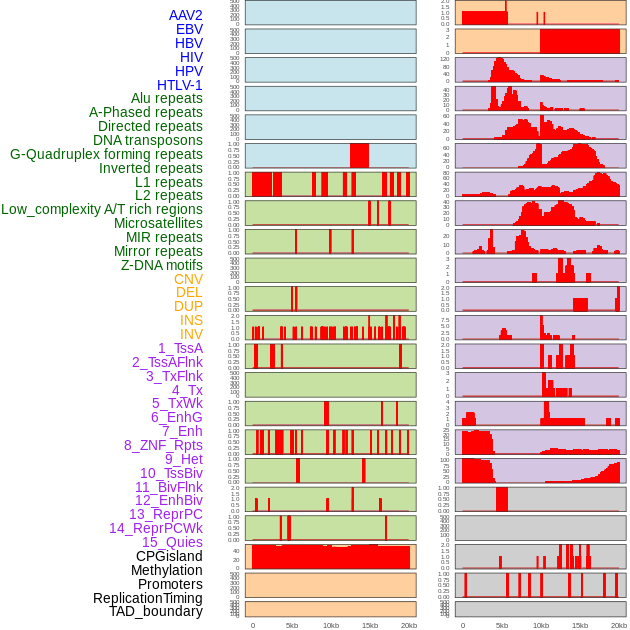 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
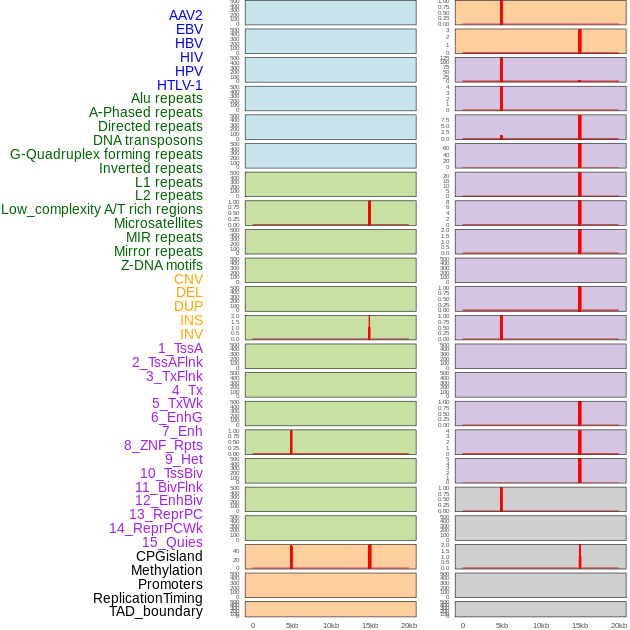 |
Top |
Fusion Protein Features for NPM1-VIM |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:170815010/chr10:17278293) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NPM1 | VIM |
| FUNCTION: Involved in diverse cellular processes such as ribosome biogenesis, centrosome duplication, protein chaperoning, histone assembly, cell proliferation, and regulation of tumor suppressors p53/TP53 and ARF. Binds ribosome presumably to drive ribosome nuclear export. Associated with nucleolar ribonucleoprotein structures and bind single-stranded nucleic acids. Acts as a chaperonin for the core histones H3, H2B and H4. Stimulates APEX1 endonuclease activity on apurinic/apyrimidinic (AP) double-stranded DNA but inhibits APEX1 endonuclease activity on AP single-stranded RNA. May exert a control of APEX1 endonuclease activity within nucleoli devoted to repair AP on rDNA and the removal of oxidized rRNA molecules. In concert with BRCA2, regulates centrosome duplication. Regulates centriole duplication: phosphorylation by PLK2 is able to trigger centriole replication. Negatively regulates the activation of EIF2AK2/PKR and suppresses apoptosis through inhibition of EIF2AK2/PKR autophosphorylation. Antagonizes the inhibitory effect of ATF5 on cell proliferation and relieves ATF5-induced G2/M blockade (PubMed:22528486). In complex with MYC enhances the transcription of MYC target genes (PubMed:25956029). {ECO:0000269|PubMed:12882984, ECO:0000269|PubMed:16107701, ECO:0000269|PubMed:17015463, ECO:0000269|PubMed:18809582, ECO:0000269|PubMed:19188445, ECO:0000269|PubMed:20352051, ECO:0000269|PubMed:21084279, ECO:0000269|PubMed:22002061, ECO:0000269|PubMed:22528486, ECO:0000269|PubMed:25956029}. | 169 |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000296930 | + | 1 | 11 | 1_9 | 19 | 295.0 | Compositional bias | Note=Met-rich |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000351986 | + | 1 | 10 | 1_9 | 19 | 266.0 | Compositional bias | Note=Met-rich |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000393820 | + | 1 | 10 | 1_9 | 19 | 260.0 | Compositional bias | Note=Met-rich |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000517671 | + | 2 | 12 | 1_9 | 19 | 295.0 | Compositional bias | Note=Met-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000296930 | + | 1 | 11 | 120_132 | 19 | 295.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000296930 | + | 1 | 11 | 161_188 | 19 | 295.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000351986 | + | 1 | 10 | 120_132 | 19 | 266.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000351986 | + | 1 | 10 | 161_188 | 19 | 266.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000393820 | + | 1 | 10 | 120_132 | 19 | 260.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000393820 | + | 1 | 10 | 161_188 | 19 | 260.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000517671 | + | 2 | 12 | 120_132 | 19 | 295.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000517671 | + | 2 | 12 | 161_188 | 19 | 295.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000296930 | + | 1 | 11 | 152_157 | 19 | 295.0 | Motif | Nuclear localization signal |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000296930 | + | 1 | 11 | 191_197 | 19 | 295.0 | Motif | Nuclear localization signal |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000351986 | + | 1 | 10 | 152_157 | 19 | 266.0 | Motif | Nuclear localization signal |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000351986 | + | 1 | 10 | 191_197 | 19 | 266.0 | Motif | Nuclear localization signal |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000393820 | + | 1 | 10 | 152_157 | 19 | 260.0 | Motif | Nuclear localization signal |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000393820 | + | 1 | 10 | 191_197 | 19 | 260.0 | Motif | Nuclear localization signal |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000517671 | + | 2 | 12 | 152_157 | 19 | 295.0 | Motif | Nuclear localization signal |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000517671 | + | 2 | 12 | 191_197 | 19 | 295.0 | Motif | Nuclear localization signal |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000296930 | + | 1 | 11 | 243_294 | 19 | 295.0 | Region | Note=Required for nucleolar localization |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000351986 | + | 1 | 10 | 243_294 | 19 | 266.0 | Region | Note=Required for nucleolar localization |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000393820 | + | 1 | 10 | 243_294 | 19 | 260.0 | Region | Note=Required for nucleolar localization |
| Hgene | NPM1 | chr5:170815010 | chr10:17278293 | ENST00000517671 | + | 2 | 12 | 243_294 | 19 | 295.0 | Region | Note=Required for nucleolar localization |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 154_245 | 424 | 467.0 | Coiled coil | Ontology_term=ECO:0000269 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 303_407 | 424 | 467.0 | Coiled coil | Ontology_term=ECO:0000269 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 96_131 | 424 | 467.0 | Coiled coil | Ontology_term=ECO:0000269 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 154_245 | 424 | 467.0 | Coiled coil | Ontology_term=ECO:0000269 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 303_407 | 424 | 467.0 | Coiled coil | Ontology_term=ECO:0000269 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 96_131 | 424 | 467.0 | Coiled coil | Ontology_term=ECO:0000269 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 103_411 | 424 | 467.0 | Domain | IF rod | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 103_411 | 424 | 467.0 | Domain | IF rod | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 326_329 | 424 | 467.0 | Motif | [IL]-x-C-x-x-[DE] motif | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 326_329 | 424 | 467.0 | Motif | [IL]-x-C-x-x-[DE] motif | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 132_153 | 424 | 467.0 | Region | Note=Linker 1 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 246_268 | 424 | 467.0 | Region | Note=Linker 12 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 269_407 | 424 | 467.0 | Region | Note=Coil 2 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 2_95 | 424 | 467.0 | Region | Note=Head | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000224237 | 6 | 9 | 408_466 | 424 | 467.0 | Region | Note=Tail | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 132_153 | 424 | 467.0 | Region | Note=Linker 1 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 246_268 | 424 | 467.0 | Region | Note=Linker 12 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 269_407 | 424 | 467.0 | Region | Note=Coil 2 | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 2_95 | 424 | 467.0 | Region | Note=Head | |
| Tgene | VIM | chr5:170815010 | chr10:17278293 | ENST00000544301 | 7 | 10 | 408_466 | 424 | 467.0 | Region | Note=Tail |
Top |
Fusion Gene Sequence for NPM1-VIM |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >59993_59993_1_NPM1-VIM_NPM1_chr5_170815010_ENST00000296930_VIM_chr10_17278293_ENST00000224237_length(transcript)=809nt_BP=359nt AGTGCGCGTGCTCGGTGGGAGCCCGCGGAGTACCTGGAAGGAGGTGGGGGCGAGGTAGAAAGGAGTGGGGTTGAAAAGCGCTTGCGCAGG ACGGCTACGGTACGGGGGTGGGAGGGCTTCGGAGCACGCGCGCGGAGGCGGGACTTGGGAAGCGCTCGCGAGATCTTCAGGGTCTATATA TAAGCGCGGGGAGCCTGCGTCCTTTCCCTGGTGTGATTCCGTCCTGCGCGGTTGTTCTCTGGAGCAGCGTTCTTTTATCTCCGTCCGCCT TCTCTCCTACCTAAGTGCGTGCCGCCACCCGATGGAAGATTCGATGGACATGGACATGAGCCCCCTGAGGCCCCAGAACTATCTTTTCGA AACTAATCTGGATTCACTCCCTCTGGTTGATACCCACTCAAAAAGGACACTTCTGATTAAGACGGTTGAAACTAGAGATGGACAGGTTAT CAACGAAACTTCTCAGCATCACGATGACCTTGAATAAAAATTGCACACACTCAGTGCAGCAATATATTACCAGCAAGAATAAAAAAGAAA TCCATATCTTAAAGAAACAGCTTTCAAGTGCCTTTCTGCAGTTTTTCAGGAGCGCAAGATAGATTTGGAATAGGAATAAGCTCTAGTTCT TAACAACCGACACTCCTACAAGATTTAGAAAAAAGTTTACAACATAATCTAGTTTACAGAAAAATCTTGTGCTAGAATACTTTTTAAAAG >59993_59993_1_NPM1-VIM_NPM1_chr5_170815010_ENST00000296930_VIM_chr10_17278293_ENST00000224237_length(amino acids)=138AA_BP=96 MKSACAGRLRYGGGRASEHARGGGTWEALARSSGSIYKRGEPASFPWCDSVLRGCSLEQRSFISVRLLSYLSACRHPMEDSMDMDMSPLR -------------------------------------------------------------- >59993_59993_2_NPM1-VIM_NPM1_chr5_170815010_ENST00000296930_VIM_chr10_17278293_ENST00000544301_length(transcript)=801nt_BP=359nt AGTGCGCGTGCTCGGTGGGAGCCCGCGGAGTACCTGGAAGGAGGTGGGGGCGAGGTAGAAAGGAGTGGGGTTGAAAAGCGCTTGCGCAGG ACGGCTACGGTACGGGGGTGGGAGGGCTTCGGAGCACGCGCGCGGAGGCGGGACTTGGGAAGCGCTCGCGAGATCTTCAGGGTCTATATA TAAGCGCGGGGAGCCTGCGTCCTTTCCCTGGTGTGATTCCGTCCTGCGCGGTTGTTCTCTGGAGCAGCGTTCTTTTATCTCCGTCCGCCT TCTCTCCTACCTAAGTGCGTGCCGCCACCCGATGGAAGATTCGATGGACATGGACATGAGCCCCCTGAGGCCCCAGAACTATCTTTTCGA AACTAATCTGGATTCACTCCCTCTGGTTGATACCCACTCAAAAAGGACACTTCTGATTAAGACGGTTGAAACTAGAGATGGACAGGTTAT CAACGAAACTTCTCAGCATCACGATGACCTTGAATAAAAATTGCACACACTCAGTGCAGCAATATATTACCAGCAAGAATAAAAAAGAAA TCCATATCTTAAAGAAACAGCTTTCAAGTGCCTTTCTGCAGTTTTTCAGGAGCGCAAGATAGATTTGGAATAGGAATAAGCTCTAGTTCT TAACAACCGACACTCCTACAAGATTTAGAAAAAAGTTTACAACATAATCTAGTTTACAGAAAAATCTTGTGCTAGAATACTTTTTAAAAG >59993_59993_2_NPM1-VIM_NPM1_chr5_170815010_ENST00000296930_VIM_chr10_17278293_ENST00000544301_length(amino acids)=138AA_BP=96 MKSACAGRLRYGGGRASEHARGGGTWEALARSSGSIYKRGEPASFPWCDSVLRGCSLEQRSFISVRLLSYLSACRHPMEDSMDMDMSPLR -------------------------------------------------------------- >59993_59993_3_NPM1-VIM_NPM1_chr5_170815010_ENST00000351986_VIM_chr10_17278293_ENST00000224237_length(transcript)=628nt_BP=178nt AAGCGCGGGGAGCCTGCGTCCTTTCCCTGGTGTGATTCCGTCCTGCGCGGTTGTTCTCTGGAGCAGCGTTCTTTTATCTCCGTCCGCCTT CTCTCCTACCTAAGTGCGTGCCGCCACCCGATGGAAGATTCGATGGACATGGACATGAGCCCCCTGAGGCCCCAGAACTATCTTTTCGAA ACTAATCTGGATTCACTCCCTCTGGTTGATACCCACTCAAAAAGGACACTTCTGATTAAGACGGTTGAAACTAGAGATGGACAGGTTATC AACGAAACTTCTCAGCATCACGATGACCTTGAATAAAAATTGCACACACTCAGTGCAGCAATATATTACCAGCAAGAATAAAAAAGAAAT CCATATCTTAAAGAAACAGCTTTCAAGTGCCTTTCTGCAGTTTTTCAGGAGCGCAAGATAGATTTGGAATAGGAATAAGCTCTAGTTCTT AACAACCGACACTCCTACAAGATTTAGAAAAAAGTTTACAACATAATCTAGTTTACAGAAAAATCTTGTGCTAGAATACTTTTTAAAAGG >59993_59993_3_NPM1-VIM_NPM1_chr5_170815010_ENST00000351986_VIM_chr10_17278293_ENST00000224237_length(amino acids)=87AA_BP=45 -------------------------------------------------------------- >59993_59993_4_NPM1-VIM_NPM1_chr5_170815010_ENST00000351986_VIM_chr10_17278293_ENST00000544301_length(transcript)=620nt_BP=178nt AAGCGCGGGGAGCCTGCGTCCTTTCCCTGGTGTGATTCCGTCCTGCGCGGTTGTTCTCTGGAGCAGCGTTCTTTTATCTCCGTCCGCCTT CTCTCCTACCTAAGTGCGTGCCGCCACCCGATGGAAGATTCGATGGACATGGACATGAGCCCCCTGAGGCCCCAGAACTATCTTTTCGAA ACTAATCTGGATTCACTCCCTCTGGTTGATACCCACTCAAAAAGGACACTTCTGATTAAGACGGTTGAAACTAGAGATGGACAGGTTATC AACGAAACTTCTCAGCATCACGATGACCTTGAATAAAAATTGCACACACTCAGTGCAGCAATATATTACCAGCAAGAATAAAAAAGAAAT CCATATCTTAAAGAAACAGCTTTCAAGTGCCTTTCTGCAGTTTTTCAGGAGCGCAAGATAGATTTGGAATAGGAATAAGCTCTAGTTCTT AACAACCGACACTCCTACAAGATTTAGAAAAAAGTTTACAACATAATCTAGTTTACAGAAAAATCTTGTGCTAGAATACTTTTTAAAAGG >59993_59993_4_NPM1-VIM_NPM1_chr5_170815010_ENST00000351986_VIM_chr10_17278293_ENST00000544301_length(amino acids)=87AA_BP=45 -------------------------------------------------------------- >59993_59993_5_NPM1-VIM_NPM1_chr5_170815010_ENST00000393820_VIM_chr10_17278293_ENST00000224237_length(transcript)=606nt_BP=156nt TTCCCTGGTGTGATTCCGTCCTGCGCGGTTGTTCTCTGGAGCAGCGTTCTTTTATCTCCGTCCGCCTTCTCTCCTACCTAAGTGCGTGCC GCCACCCGATGGAAGATTCGATGGACATGGACATGAGCCCCCTGAGGCCCCAGAACTATCTTTTCGAAACTAATCTGGATTCACTCCCTC TGGTTGATACCCACTCAAAAAGGACACTTCTGATTAAGACGGTTGAAACTAGAGATGGACAGGTTATCAACGAAACTTCTCAGCATCACG ATGACCTTGAATAAAAATTGCACACACTCAGTGCAGCAATATATTACCAGCAAGAATAAAAAAGAAATCCATATCTTAAAGAAACAGCTT TCAAGTGCCTTTCTGCAGTTTTTCAGGAGCGCAAGATAGATTTGGAATAGGAATAAGCTCTAGTTCTTAACAACCGACACTCCTACAAGA TTTAGAAAAAAGTTTACAACATAATCTAGTTTACAGAAAAATCTTGTGCTAGAATACTTTTTAAAAGGTATTTTGAATACCATTAAAACT >59993_59993_5_NPM1-VIM_NPM1_chr5_170815010_ENST00000393820_VIM_chr10_17278293_ENST00000224237_length(amino acids)=87AA_BP=45 -------------------------------------------------------------- >59993_59993_6_NPM1-VIM_NPM1_chr5_170815010_ENST00000393820_VIM_chr10_17278293_ENST00000544301_length(transcript)=598nt_BP=156nt TTCCCTGGTGTGATTCCGTCCTGCGCGGTTGTTCTCTGGAGCAGCGTTCTTTTATCTCCGTCCGCCTTCTCTCCTACCTAAGTGCGTGCC GCCACCCGATGGAAGATTCGATGGACATGGACATGAGCCCCCTGAGGCCCCAGAACTATCTTTTCGAAACTAATCTGGATTCACTCCCTC TGGTTGATACCCACTCAAAAAGGACACTTCTGATTAAGACGGTTGAAACTAGAGATGGACAGGTTATCAACGAAACTTCTCAGCATCACG ATGACCTTGAATAAAAATTGCACACACTCAGTGCAGCAATATATTACCAGCAAGAATAAAAAAGAAATCCATATCTTAAAGAAACAGCTT TCAAGTGCCTTTCTGCAGTTTTTCAGGAGCGCAAGATAGATTTGGAATAGGAATAAGCTCTAGTTCTTAACAACCGACACTCCTACAAGA TTTAGAAAAAAGTTTACAACATAATCTAGTTTACAGAAAAATCTTGTGCTAGAATACTTTTTAAAAGGTATTTTGAATACCATTAAAACT >59993_59993_6_NPM1-VIM_NPM1_chr5_170815010_ENST00000393820_VIM_chr10_17278293_ENST00000544301_length(amino acids)=87AA_BP=45 -------------------------------------------------------------- >59993_59993_7_NPM1-VIM_NPM1_chr5_170815010_ENST00000517671_VIM_chr10_17278293_ENST00000224237_length(transcript)=643nt_BP=193nt GGGCGATGTCCTTGCTAATTTGGAGACTGATTCAGTCCCCTTTTGGCCCCCAAGTTACGTAAAGATAAGGACTTTGGAGATGTTTTCTCA GGAAGGACAGAGCTGAAAAACAAAGTTCCTGCGTGCCGCCACCCGATGGAAGATTCGATGGACATGGACATGAGCCCCCTGAGGCCCCAG AACTATCTTTTCGAAACTAATCTGGATTCACTCCCTCTGGTTGATACCCACTCAAAAAGGACACTTCTGATTAAGACGGTTGAAACTAGA GATGGACAGGTTATCAACGAAACTTCTCAGCATCACGATGACCTTGAATAAAAATTGCACACACTCAGTGCAGCAATATATTACCAGCAA GAATAAAAAAGAAATCCATATCTTAAAGAAACAGCTTTCAAGTGCCTTTCTGCAGTTTTTCAGGAGCGCAAGATAGATTTGGAATAGGAA TAAGCTCTAGTTCTTAACAACCGACACTCCTACAAGATTTAGAAAAAAGTTTACAACATAATCTAGTTTACAGAAAAATCTTGTGCTAGA ATACTTTTTAAAAGGTATTTTGAATACCATTAAAACTGCTTTTTTTTTTCCAGCAAGTATCCAACCAACTTGGTTCTGCTTCAATAAATC >59993_59993_7_NPM1-VIM_NPM1_chr5_170815010_ENST00000517671_VIM_chr10_17278293_ENST00000224237_length(amino acids)=92AA_BP=50 MAPKLRKDKDFGDVFSGRTELKNKVPACRHPMEDSMDMDMSPLRPQNYLFETNLDSLPLVDTHSKRTLLIKTVETRDGQVINETSQHHDD -------------------------------------------------------------- >59993_59993_8_NPM1-VIM_NPM1_chr5_170815010_ENST00000517671_VIM_chr10_17278293_ENST00000544301_length(transcript)=635nt_BP=193nt GGGCGATGTCCTTGCTAATTTGGAGACTGATTCAGTCCCCTTTTGGCCCCCAAGTTACGTAAAGATAAGGACTTTGGAGATGTTTTCTCA GGAAGGACAGAGCTGAAAAACAAAGTTCCTGCGTGCCGCCACCCGATGGAAGATTCGATGGACATGGACATGAGCCCCCTGAGGCCCCAG AACTATCTTTTCGAAACTAATCTGGATTCACTCCCTCTGGTTGATACCCACTCAAAAAGGACACTTCTGATTAAGACGGTTGAAACTAGA GATGGACAGGTTATCAACGAAACTTCTCAGCATCACGATGACCTTGAATAAAAATTGCACACACTCAGTGCAGCAATATATTACCAGCAA GAATAAAAAAGAAATCCATATCTTAAAGAAACAGCTTTCAAGTGCCTTTCTGCAGTTTTTCAGGAGCGCAAGATAGATTTGGAATAGGAA TAAGCTCTAGTTCTTAACAACCGACACTCCTACAAGATTTAGAAAAAAGTTTACAACATAATCTAGTTTACAGAAAAATCTTGTGCTAGA ATACTTTTTAAAAGGTATTTTGAATACCATTAAAACTGCTTTTTTTTTTCCAGCAAGTATCCAACCAACTTGGTTCTGCTTCAATAAATC >59993_59993_8_NPM1-VIM_NPM1_chr5_170815010_ENST00000517671_VIM_chr10_17278293_ENST00000544301_length(amino acids)=92AA_BP=50 MAPKLRKDKDFGDVFSGRTELKNKVPACRHPMEDSMDMDMSPLRPQNYLFETNLDSLPLVDTHSKRTLLIKTVETRDGQVINETSQHHDD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NPM1-VIM |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NPM1-VIM |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NPM1-VIM |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies