
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NRG1-STMN2 (FusionGDB2 ID:60283) |
Fusion Gene Summary for NRG1-STMN2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NRG1-STMN2 | Fusion gene ID: 60283 | Hgene | Tgene | Gene symbol | NRG1 | STMN2 | Gene ID | 3084 | 11075 |
| Gene name | neuregulin 1 | stathmin 2 | |
| Synonyms | ARIA|GGF|GGF2|HGL|HRG|HRG1|HRGA|MST131|MSTP131|NDF|NRG1-IT2|SMDF | SCG10|SCGN10 | |
| Cytomap | 8p12 | 8q21.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | pro-neuregulin-1, membrane-bound isoformacetylcholine receptor-inducing activityglial growth factor 2heregulin, alpha (45kD, ERBB2 p185-activator)neu differentiation factorpro-NRG1sensory and motor neuron derived factor | stathmin-2neuron-specific growth-associated proteinneuronal growth-associated protein (silencer element)stathmin-like 2superior cervical ganglia, neural specific 10superior cervical ganglion-10 protein | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | Q02297 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000287842, ENST00000287845, ENST00000338921, ENST00000341377, ENST00000356819, ENST00000405005, ENST00000519301, ENST00000520407, ENST00000521670, ENST00000523079, ENST00000520502, ENST00000523681, ENST00000539990, | ENST00000518491, ENST00000220876, ENST00000518111, | |
| Fusion gene scores | * DoF score | 12 X 10 X 7=840 | 4 X 2 X 3=24 |
| # samples | 12 | 4 | |
| ** MAII score | log2(12/840*10)=-2.8073549220576 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/24*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: NRG1 [Title/Abstract] AND STMN2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NRG1(32463201)-STMN2(80549037), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NRG1 | GO:0003222 | ventricular trabecula myocardium morphogenesis | 17336907 |
| Hgene | NRG1 | GO:0031334 | positive regulation of protein complex assembly | 10559227 |
| Hgene | NRG1 | GO:0038127 | ERBB signaling pathway | 11389077 |
| Hgene | NRG1 | GO:0038129 | ERBB3 signaling pathway | 27353365 |
| Hgene | NRG1 | GO:0045892 | negative regulation of transcription, DNA-templated | 15073182 |
| Hgene | NRG1 | GO:0051048 | negative regulation of secretion | 10559227 |
| Hgene | NRG1 | GO:0060379 | cardiac muscle cell myoblast differentiation | 17336907 |
| Hgene | NRG1 | GO:0060956 | endocardial cell differentiation | 17336907 |
| Tgene | STMN2 | GO:0007026 | negative regulation of microtubule depolymerization | 18452648 |
| Tgene | STMN2 | GO:0010976 | positive regulation of neuron projection development | 18452648|21215777 |
| Tgene | STMN2 | GO:0010977 | negative regulation of neuron projection development | 18452648 |
| Tgene | STMN2 | GO:0031115 | negative regulation of microtubule polymerization | 18452648|21215777 |
| Tgene | STMN2 | GO:0031117 | positive regulation of microtubule depolymerization | 18452648 |
| Tgene | STMN2 | GO:1990090 | cellular response to nerve growth factor stimulus | 21215777 |
| Fusion gene breakpoints across NRG1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
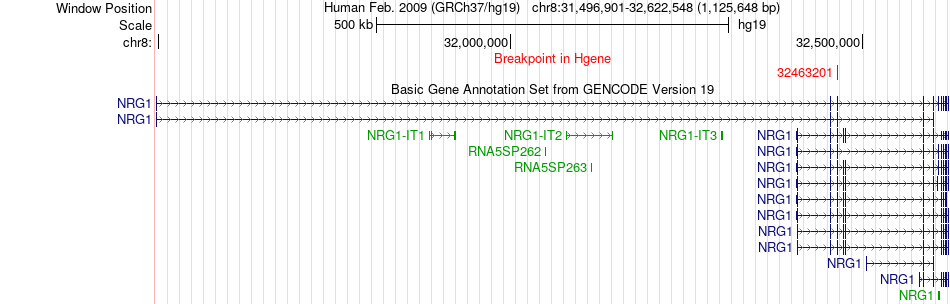 |
| Fusion gene breakpoints across STMN2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-FC-A4JI-01A | NRG1 | chr8 | 32463201 | - | STMN2 | chr8 | 80549037 | + |
| ChimerDB4 | PRAD | TCGA-FC-A4JI-01A | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| ChimerDB4 | PRAD | TCGA-FC-A4JI | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
Top |
Fusion Gene ORF analysis for NRG1-STMN2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000287842 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000287845 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000338921 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000341377 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000356819 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000405005 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000519301 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000520407 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000521670 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| 5CDS-5UTR | ENST00000523079 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000287842 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000287842 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000287845 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000287845 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000338921 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000338921 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000341377 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000341377 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000356819 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000356819 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000405005 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000405005 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000519301 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000519301 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000520407 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000520407 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000521670 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000521670 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000523079 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| In-frame | ENST00000523079 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-3CDS | ENST00000520502 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-3CDS | ENST00000520502 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-3CDS | ENST00000523681 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-3CDS | ENST00000523681 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-3CDS | ENST00000539990 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-3CDS | ENST00000539990 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-5UTR | ENST00000520502 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-5UTR | ENST00000523681 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| intron-5UTR | ENST00000539990 | ENST00000518491 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000519301 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2168 | 346 | 9 | 866 | 285 |
| ENST00000519301 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1082 | 346 | 9 | 890 | 293 |
| ENST00000520407 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 3097 | 1275 | 230 | 1795 | 521 |
| ENST00000520407 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 2011 | 1275 | 230 | 1819 | 529 |
| ENST00000523079 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2739 | 917 | 154 | 1437 | 427 |
| ENST00000523079 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1653 | 917 | 154 | 1461 | 435 |
| ENST00000338921 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2739 | 917 | 154 | 1437 | 427 |
| ENST00000338921 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1653 | 917 | 154 | 1461 | 435 |
| ENST00000356819 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2739 | 917 | 154 | 1437 | 427 |
| ENST00000356819 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1653 | 917 | 154 | 1461 | 435 |
| ENST00000287845 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2739 | 917 | 154 | 1437 | 427 |
| ENST00000287845 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1653 | 917 | 154 | 1461 | 435 |
| ENST00000341377 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2739 | 917 | 154 | 1437 | 427 |
| ENST00000341377 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1653 | 917 | 154 | 1461 | 435 |
| ENST00000287842 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2682 | 860 | 97 | 1380 | 427 |
| ENST00000287842 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1596 | 860 | 97 | 1404 | 435 |
| ENST00000521670 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2330 | 508 | 108 | 1028 | 306 |
| ENST00000521670 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1244 | 508 | 108 | 1052 | 314 |
| ENST00000405005 | NRG1 | chr8 | 32463201 | + | ENST00000220876 | STMN2 | chr8 | 80549037 | + | 2222 | 400 | 0 | 920 | 306 |
| ENST00000405005 | NRG1 | chr8 | 32463201 | + | ENST00000518111 | STMN2 | chr8 | 80549037 | + | 1136 | 400 | 0 | 944 | 314 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000519301 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.001310021 | 0.99868995 |
| ENST00000519301 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.003812257 | 0.99618775 |
| ENST00000520407 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.001762203 | 0.9982377 |
| ENST00000520407 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.008567645 | 0.9914323 |
| ENST00000523079 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.00152102 | 0.99847895 |
| ENST00000523079 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.005219879 | 0.9947802 |
| ENST00000338921 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.00152102 | 0.99847895 |
| ENST00000338921 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.005219879 | 0.9947802 |
| ENST00000356819 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.00152102 | 0.99847895 |
| ENST00000356819 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.005219879 | 0.9947802 |
| ENST00000287845 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.00152102 | 0.99847895 |
| ENST00000287845 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.005219879 | 0.9947802 |
| ENST00000341377 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.00152102 | 0.99847895 |
| ENST00000341377 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.005219879 | 0.9947802 |
| ENST00000287842 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.001388943 | 0.998611 |
| ENST00000287842 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.005309243 | 0.9946907 |
| ENST00000521670 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.00094464 | 0.9990553 |
| ENST00000521670 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.003309703 | 0.9966903 |
| ENST00000405005 | ENST00000220876 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.000838247 | 0.9991617 |
| ENST00000405005 | ENST00000518111 | NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549037 | + | 0.00308882 | 0.9969112 |
Top |
Fusion Genomic Features for NRG1-STMN2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549036 | + | 8.03E-05 | 0.9999198 |
| NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549036 | + | 8.03E-05 | 0.9999198 |
| NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549036 | + | 8.03E-05 | 0.9999198 |
| NRG1 | chr8 | 32463201 | + | STMN2 | chr8 | 80549036 | + | 8.03E-05 | 0.9999198 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
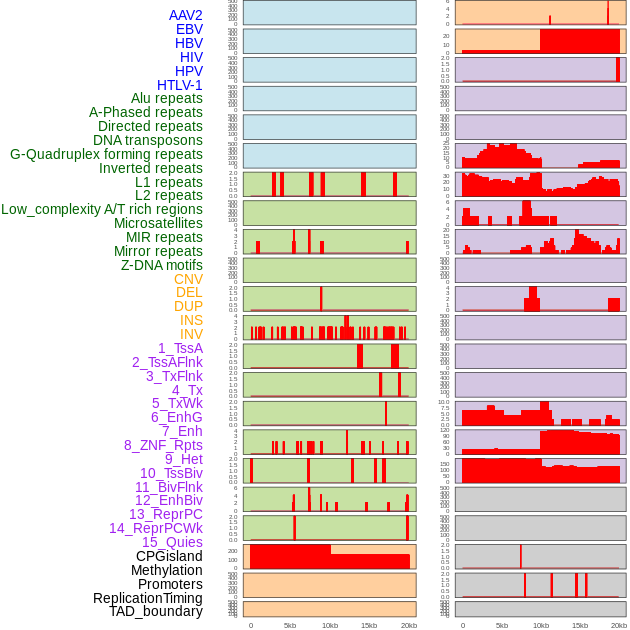 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
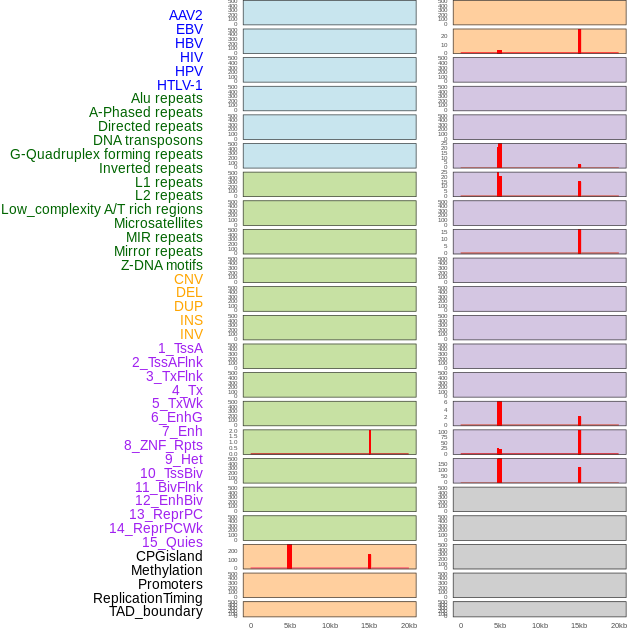 |
Top |
Fusion Protein Features for NRG1-STMN2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:32463201/chr8:80549037) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NRG1 | . |
| FUNCTION: Direct ligand for ERBB3 and ERBB4 tyrosine kinase receptors. Concomitantly recruits ERBB1 and ERBB2 coreceptors, resulting in ligand-stimulated tyrosine phosphorylation and activation of the ERBB receptors. The multiple isoforms perform diverse functions such as inducing growth and differentiation of epithelial, glial, neuronal, and skeletal muscle cells; inducing expression of acetylcholine receptor in synaptic vesicles during the formation of the neuromuscular junction; stimulating lobuloalveolar budding and milk production in the mammary gland and inducing differentiation of mammary tumor cells; stimulating Schwann cell proliferation; implication in the development of the myocardium such as trabeculation of the developing heart. Isoform 10 may play a role in motor and sensory neuron development. Binds to ERBB4 (PubMed:10867024, PubMed:7902537). Binds to ERBB3 (PubMed:20682778). Acts as a ligand for integrins and binds (via EGF domain) to integrins ITGAV:ITGB3 or ITGA6:ITGB4. Its binding to integrins and subsequent ternary complex formation with integrins and ERRB3 are essential for NRG1-ERBB signaling. Induces the phosphorylation and activation of MAPK3/ERK1, MAPK1/ERK2 and AKT1 (PubMed:20682778). Ligand-dependent ERBB4 endocytosis is essential for the NRG1-mediated activation of these kinases in neurons (By similarity). {ECO:0000250|UniProtKB:P43322, ECO:0000269|PubMed:10867024, ECO:0000269|PubMed:1348215, ECO:0000269|PubMed:20682778, ECO:0000269|PubMed:7902537}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520407 | + | 3 | 5 | 165_177 | 348 | 423.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000287842 | + | 3 | 12 | 37_128 | 133 | 638.0 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000341377 | + | 3 | 13 | 37_128 | 133 | 525.3333333333334 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000356819 | + | 3 | 13 | 37_128 | 133 | 646.0 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000405005 | + | 3 | 12 | 37_128 | 133 | 641.0 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520407 | + | 3 | 5 | 178_222 | 348 | 423.0 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520407 | + | 3 | 5 | 37_128 | 348 | 423.0 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000521670 | + | 3 | 13 | 37_128 | 133 | 477.3333333333333 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000523079 | + | 3 | 11 | 37_128 | 133 | 421.0 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520407 | + | 3 | 5 | 20_242 | 348 | 423.0 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520407 | + | 3 | 5 | 243_265 | 348 | 423.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Tgene | STMN2 | chr8:32463201 | chr8:80549037 | ENST00000220876 | 0 | 5 | 75_179 | 6 | 180.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | STMN2 | chr8:32463201 | chr8:80549037 | ENST00000518111 | 0 | 6 | 75_179 | 6 | 188.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | STMN2 | chr8:32463201 | chr8:80549037 | ENST00000220876 | 0 | 5 | 38_179 | 6 | 180.0 | Domain | SLD | |
| Tgene | STMN2 | chr8:32463201 | chr8:80549037 | ENST00000518111 | 0 | 6 | 38_179 | 6 | 188.0 | Domain | SLD | |
| Tgene | STMN2 | chr8:32463201 | chr8:80549037 | ENST00000220876 | 0 | 5 | 39_96 | 6 | 180.0 | Region | Regulatory/phosphorylation domain | |
| Tgene | STMN2 | chr8:32463201 | chr8:80549037 | ENST00000518111 | 0 | 6 | 39_96 | 6 | 188.0 | Region | Regulatory/phosphorylation domain |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000287842 | + | 3 | 12 | 165_177 | 133 | 638.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000341377 | + | 3 | 13 | 165_177 | 133 | 525.3333333333334 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000356819 | + | 3 | 13 | 165_177 | 133 | 646.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000405005 | + | 3 | 12 | 165_177 | 133 | 641.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000519301 | + | 3 | 11 | 165_177 | 112 | 591.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520502 | + | 1 | 3 | 165_177 | 0 | 297.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000521670 | + | 3 | 13 | 165_177 | 133 | 477.3333333333333 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000523079 | + | 3 | 11 | 165_177 | 133 | 421.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000287842 | + | 3 | 12 | 178_222 | 133 | 638.0 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000341377 | + | 3 | 13 | 178_222 | 133 | 525.3333333333334 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000356819 | + | 3 | 13 | 178_222 | 133 | 646.0 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000405005 | + | 3 | 12 | 178_222 | 133 | 641.0 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000519301 | + | 3 | 11 | 178_222 | 112 | 591.0 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000519301 | + | 3 | 11 | 37_128 | 112 | 591.0 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520502 | + | 1 | 3 | 178_222 | 0 | 297.0 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520502 | + | 1 | 3 | 37_128 | 0 | 297.0 | Domain | Note=Ig-like C2-type |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000521670 | + | 3 | 13 | 178_222 | 133 | 477.3333333333333 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000523079 | + | 3 | 11 | 178_222 | 133 | 421.0 | Domain | EGF-like |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000287842 | + | 3 | 12 | 20_242 | 133 | 638.0 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000287842 | + | 3 | 12 | 266_640 | 133 | 638.0 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000341377 | + | 3 | 13 | 20_242 | 133 | 525.3333333333334 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000341377 | + | 3 | 13 | 266_640 | 133 | 525.3333333333334 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000356819 | + | 3 | 13 | 20_242 | 133 | 646.0 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000356819 | + | 3 | 13 | 266_640 | 133 | 646.0 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000405005 | + | 3 | 12 | 20_242 | 133 | 641.0 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000405005 | + | 3 | 12 | 266_640 | 133 | 641.0 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000519301 | + | 3 | 11 | 20_242 | 112 | 591.0 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000519301 | + | 3 | 11 | 266_640 | 112 | 591.0 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520407 | + | 3 | 5 | 266_640 | 348 | 423.0 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520502 | + | 1 | 3 | 20_242 | 0 | 297.0 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520502 | + | 1 | 3 | 266_640 | 0 | 297.0 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000521670 | + | 3 | 13 | 20_242 | 133 | 477.3333333333333 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000521670 | + | 3 | 13 | 266_640 | 133 | 477.3333333333333 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000523079 | + | 3 | 11 | 20_242 | 133 | 421.0 | Topological domain | Extracellular |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000523079 | + | 3 | 11 | 266_640 | 133 | 421.0 | Topological domain | Cytoplasmic |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000287842 | + | 3 | 12 | 243_265 | 133 | 638.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000341377 | + | 3 | 13 | 243_265 | 133 | 525.3333333333334 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000356819 | + | 3 | 13 | 243_265 | 133 | 646.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000405005 | + | 3 | 12 | 243_265 | 133 | 641.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000519301 | + | 3 | 11 | 243_265 | 112 | 591.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000520502 | + | 1 | 3 | 243_265 | 0 | 297.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000521670 | + | 3 | 13 | 243_265 | 133 | 477.3333333333333 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Hgene | NRG1 | chr8:32463201 | chr8:80549037 | ENST00000523079 | + | 3 | 11 | 243_265 | 133 | 421.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| Tgene | STMN2 | chr8:32463201 | chr8:80549037 | ENST00000220876 | 0 | 5 | 1_26 | 6 | 180.0 | Region | Membrane attachment | |
| Tgene | STMN2 | chr8:32463201 | chr8:80549037 | ENST00000518111 | 0 | 6 | 1_26 | 6 | 188.0 | Region | Membrane attachment |
Top |
Fusion Gene Sequence for NRG1-STMN2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >60283_60283_1_NRG1-STMN2_NRG1_chr8_32463201_ENST00000287842_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2682nt_BP=860nt GTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGAGGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCG GCGGCGGCTGCCGGACGATGGGAGCGTGAGCAGGACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACG CGAGCCGCCAGCGGTGGGACCCATCGACGACTTCCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCG GACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGCAGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTC CCCCTCGAGGGACAAACTTTTCCCAAACCCGATCCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGT CTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAGAGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGC GGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCGATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTG TGAAACCAGTTCTGAATACTCCTCTCTCAGATTCAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAA GATACAAAAAAAGCCAGGGAAGTCAGAACTTCGCATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAA ATTAGGAAATGACAGTGCCTCTGCCAATATCACCATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACT GATCTGCTCTTGCTTTTACCCGGAACCTCGCAACATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTC TGGCCAGGCTTTTGAGCTGATCTTGAAGCCACCATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTC CCTGGAGGAGATCCAGAAGAAACTGGAGGCTGCAGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAG GGAACACGAGCGAGAAGTCCTTCAGAAGGCTTTGGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGA ACAAATTAAGGAAAACCGTGAGGCTAATCTAGCTGCTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTGCGCAGGAA CAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATG GATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAAAAATTAAA AAAAATCAATGCGGTCTCTTTGCAGAATGTTTTGCTTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACATTTTTGTTA AAAAATACAAGTATTGCATTATGCAAGTTATTTCATAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCACTCAAATGA ATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCATGTCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGGTGCTAGAA ACCCACCATTGCCTAATGACCTAGAAGGCTTTGTTGTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGACTCCACATG AACCTTCACATTTGTTCGCTCATAATCTACTTACTGCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCATTTACTTC TGCTTCTCCTGGATTATGTGCTACAAATGTGCTTTGGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGGGTAGAAGC AAAAAGTTGAACCTTTTAAAGTGCTGAACACAAATCCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGTGGGCTTAA TTCTCTAGTTTAAGTTCTTTTGATGGAATGAATTAATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGTTCATTTTA AGCTCTTACCTATAGTACAAGTACATGATGCTACTGAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAACACACATAC AAACAAAATCAAAAACACTGCGGACTTTCACTCAAGCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACACCAACAAC AAAACACTCCATCTGTGAAGCTGACGCAGTTAAGGGGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCACCATAAGTA CCTATCGCAGTTTTGAAGTCGTTTCTCCCCAACTCCCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCTATTTTCCT >60283_60283_1_NRG1-STMN2_NRG1_chr8_32463201_ENST00000287842_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=427AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_2_NRG1-STMN2_NRG1_chr8_32463201_ENST00000287842_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1596nt_BP=860nt GTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGAGGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCG GCGGCGGCTGCCGGACGATGGGAGCGTGAGCAGGACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACG CGAGCCGCCAGCGGTGGGACCCATCGACGACTTCCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCG GACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGCAGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTC CCCCTCGAGGGACAAACTTTTCCCAAACCCGATCCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGT CTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAGAGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGC GGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCGATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTG TGAAACCAGTTCTGAATACTCCTCTCTCAGATTCAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAA GATACAAAAAAAGCCAGGGAAGTCAGAACTTCGCATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAA ATTAGGAAATGACAGTGCCTCTGCCAATATCACCATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACT GATCTGCTCTTGCTTTTACCCGGAACCTCGCAACATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTC TGGCCAGGCTTTTGAGCTGATCTTGAAGCCACCATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTC CCTGGAGGAGATCCAGAAGAAACTGGAGGCTGCAGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAG GGAACACGAGCGAGAAGTCCTTCAGAAGGCTTTGGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGA ACAAATTAAGGAAAACCGTGAGGCTAATCTAGCTGCTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCTGAACTAAA AGAATCTATAGAGTCTCAATTTCTGGAGCTTCAGAGGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAAC TCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGC >60283_60283_2_NRG1-STMN2_NRG1_chr8_32463201_ENST00000287842_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=435AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_3_NRG1-STMN2_NRG1_chr8_32463201_ENST00000287845_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2739nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAG CAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGAC ATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAAAAATTAAAAAAAATCAATGCGGTCTCTTTGCAGAATGTTTT GCTTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACATTTTTGTTAAAAAATACAAGTATTGCATTATGCAAGTTATTT CATAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCACTCAAATGAATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCA TGTCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGGTGCTAGAAACCCACCATTGCCTAATGACCTAGAAGGCTTTG TTGTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGACTCCACATGAACCTTCACATTTGTTCGCTCATAATCTACTTA CTGCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCATTTACTTCTGCTTCTCCTGGATTATGTGCTACAAATGTGCT TTGGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGGGTAGAAGCAAAAAGTTGAACCTTTTAAAGTGCTGAACACAA ATCCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGTGGGCTTAATTCTCTAGTTTAAGTTCTTTTGATGGAATGAAT TAATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGTTCATTTTAAGCTCTTACCTATAGTACAAGTACATGATGCTA CTGAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAACACACATACAAACAAAATCAAAAACACTGCGGACTTTCACTC AAGCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACACCAACAACAAAACACTCCATCTGTGAAGCTGACGCAGTTAA GGGGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCACCATAAGTACCTATCGCAGTTTTGAAGTCGTTTCTCCCCAAC TCCCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCTATTTTCCTGTATGTCATTGTGAGCAAGCTGTGATTAATAAA >60283_60283_3_NRG1-STMN2_NRG1_chr8_32463201_ENST00000287845_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=427AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_4_NRG1-STMN2_NRG1_chr8_32463201_ENST00000287845_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1653nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCTGAACTAAAAGAATCTATAGAGTCTCAATTTCTGGAGCTTCA GAGGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAG GGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTA >60283_60283_4_NRG1-STMN2_NRG1_chr8_32463201_ENST00000287845_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=435AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_5_NRG1-STMN2_NRG1_chr8_32463201_ENST00000338921_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2739nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAG CAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGAC ATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAAAAATTAAAAAAAATCAATGCGGTCTCTTTGCAGAATGTTTT GCTTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACATTTTTGTTAAAAAATACAAGTATTGCATTATGCAAGTTATTT CATAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCACTCAAATGAATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCA TGTCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGGTGCTAGAAACCCACCATTGCCTAATGACCTAGAAGGCTTTG TTGTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGACTCCACATGAACCTTCACATTTGTTCGCTCATAATCTACTTA CTGCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCATTTACTTCTGCTTCTCCTGGATTATGTGCTACAAATGTGCT TTGGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGGGTAGAAGCAAAAAGTTGAACCTTTTAAAGTGCTGAACACAA ATCCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGTGGGCTTAATTCTCTAGTTTAAGTTCTTTTGATGGAATGAAT TAATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGTTCATTTTAAGCTCTTACCTATAGTACAAGTACATGATGCTA CTGAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAACACACATACAAACAAAATCAAAAACACTGCGGACTTTCACTC AAGCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACACCAACAACAAAACACTCCATCTGTGAAGCTGACGCAGTTAA GGGGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCACCATAAGTACCTATCGCAGTTTTGAAGTCGTTTCTCCCCAAC TCCCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCTATTTTCCTGTATGTCATTGTGAGCAAGCTGTGATTAATAAA >60283_60283_5_NRG1-STMN2_NRG1_chr8_32463201_ENST00000338921_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=427AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_6_NRG1-STMN2_NRG1_chr8_32463201_ENST00000338921_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1653nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCTGAACTAAAAGAATCTATAGAGTCTCAATTTCTGGAGCTTCA GAGGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAG GGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTA >60283_60283_6_NRG1-STMN2_NRG1_chr8_32463201_ENST00000338921_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=435AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_7_NRG1-STMN2_NRG1_chr8_32463201_ENST00000341377_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2739nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAG CAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGAC ATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAAAAATTAAAAAAAATCAATGCGGTCTCTTTGCAGAATGTTTT GCTTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACATTTTTGTTAAAAAATACAAGTATTGCATTATGCAAGTTATTT CATAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCACTCAAATGAATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCA TGTCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGGTGCTAGAAACCCACCATTGCCTAATGACCTAGAAGGCTTTG TTGTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGACTCCACATGAACCTTCACATTTGTTCGCTCATAATCTACTTA CTGCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCATTTACTTCTGCTTCTCCTGGATTATGTGCTACAAATGTGCT TTGGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGGGTAGAAGCAAAAAGTTGAACCTTTTAAAGTGCTGAACACAA ATCCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGTGGGCTTAATTCTCTAGTTTAAGTTCTTTTGATGGAATGAAT TAATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGTTCATTTTAAGCTCTTACCTATAGTACAAGTACATGATGCTA CTGAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAACACACATACAAACAAAATCAAAAACACTGCGGACTTTCACTC AAGCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACACCAACAACAAAACACTCCATCTGTGAAGCTGACGCAGTTAA GGGGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCACCATAAGTACCTATCGCAGTTTTGAAGTCGTTTCTCCCCAAC TCCCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCTATTTTCCTGTATGTCATTGTGAGCAAGCTGTGATTAATAAA >60283_60283_7_NRG1-STMN2_NRG1_chr8_32463201_ENST00000341377_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=427AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_8_NRG1-STMN2_NRG1_chr8_32463201_ENST00000341377_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1653nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCTGAACTAAAAGAATCTATAGAGTCTCAATTTCTGGAGCTTCA GAGGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAG GGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTA >60283_60283_8_NRG1-STMN2_NRG1_chr8_32463201_ENST00000341377_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=435AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_9_NRG1-STMN2_NRG1_chr8_32463201_ENST00000356819_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2739nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAG CAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGAC ATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAAAAATTAAAAAAAATCAATGCGGTCTCTTTGCAGAATGTTTT GCTTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACATTTTTGTTAAAAAATACAAGTATTGCATTATGCAAGTTATTT CATAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCACTCAAATGAATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCA TGTCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGGTGCTAGAAACCCACCATTGCCTAATGACCTAGAAGGCTTTG TTGTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGACTCCACATGAACCTTCACATTTGTTCGCTCATAATCTACTTA CTGCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCATTTACTTCTGCTTCTCCTGGATTATGTGCTACAAATGTGCT TTGGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGGGTAGAAGCAAAAAGTTGAACCTTTTAAAGTGCTGAACACAA ATCCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGTGGGCTTAATTCTCTAGTTTAAGTTCTTTTGATGGAATGAAT TAATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGTTCATTTTAAGCTCTTACCTATAGTACAAGTACATGATGCTA CTGAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAACACACATACAAACAAAATCAAAAACACTGCGGACTTTCACTC AAGCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACACCAACAACAAAACACTCCATCTGTGAAGCTGACGCAGTTAA GGGGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCACCATAAGTACCTATCGCAGTTTTGAAGTCGTTTCTCCCCAAC TCCCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCTATTTTCCTGTATGTCATTGTGAGCAAGCTGTGATTAATAAA >60283_60283_9_NRG1-STMN2_NRG1_chr8_32463201_ENST00000356819_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=427AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_10_NRG1-STMN2_NRG1_chr8_32463201_ENST00000356819_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1653nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCTGAACTAAAAGAATCTATAGAGTCTCAATTTCTGGAGCTTCA GAGGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAG GGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTA >60283_60283_10_NRG1-STMN2_NRG1_chr8_32463201_ENST00000356819_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=435AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_11_NRG1-STMN2_NRG1_chr8_32463201_ENST00000405005_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2222nt_BP=400nt ATGTCCGAGCGCAAAGAAGGCAGAGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGC CAGAGCCCAGCCTTGCCTCCCCGATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGT TCTGAATACTCCTCTCTCAGATTCAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAA AAGCCAGGGAAGTCAGAACTTCGCATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAAT GACAGTGCCTCTGCCAATATCACCATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCT TGCTTTTACCCGGAACCTCGCAACATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCT TTTGAGCTGATCTTGAAGCCACCATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAG ATCCAGAAGAAACTGGAGGCTGCAGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAG CGAGAAGTCCTTCAGAAGGCTTTGGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAG GAAAACCGTGAGGCTAATCTAGCTGCTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTC CAGGTTGAACTGTCTGGCTGAAGCAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGA TATCAGGATGGGGAATGTATGACATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAAAAATTAAAAAAAATCAAT GCGGTCTCTTTGCAGAATGTTTTGCTTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACATTTTTGTTAAAAAATACAA GTATTGCATTATGCAAGTTATTTCATAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCACTCAAATGAATTTGCTAGG TCTGTTCTTTTTGAAGCTCCCCATGTCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGGTGCTAGAAACCCACCATT GCCTAATGACCTAGAAGGCTTTGTTGTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGACTCCACATGAACCTTCACA TTTGTTCGCTCATAATCTACTTACTGCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCATTTACTTCTGCTTCTCCT GGATTATGTGCTACAAATGTGCTTTGGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGGGTAGAAGCAAAAAGTTGA ACCTTTTAAAGTGCTGAACACAAATCCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGTGGGCTTAATTCTCTAGTT TAAGTTCTTTTGATGGAATGAATTAATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGTTCATTTTAAGCTCTTACC TATAGTACAAGTACATGATGCTACTGAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAACACACATACAAACAAAATC AAAAACACTGCGGACTTTCACTCAAGCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACACCAACAACAAAACACTCC ATCTGTGAAGCTGACGCAGTTAAGGGGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCACCATAAGTACCTATCGCAG TTTTGAAGTCGTTTCTCCCCAACTCCCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCTATTTTCCTGTATGTCATT >60283_60283_11_NRG1-STMN2_NRG1_chr8_32463201_ENST00000405005_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=306AA_BP=133 MSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCETSSEYSSLRFKWFKNGNELNRKNKPQNIKIQK KPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLICSCFYPEPRNINIYTYDDMEVKQINKRASGQA FELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREHEREVLQKALEENNNFSKMAEEKLILKMEQIK -------------------------------------------------------------- >60283_60283_12_NRG1-STMN2_NRG1_chr8_32463201_ENST00000405005_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1136nt_BP=400nt ATGTCCGAGCGCAAAGAAGGCAGAGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGC CAGAGCCCAGCCTTGCCTCCCCGATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGT TCTGAATACTCCTCTCTCAGATTCAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAA AAGCCAGGGAAGTCAGAACTTCGCATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAAT GACAGTGCCTCTGCCAATATCACCATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCT TGCTTTTACCCGGAACCTCGCAACATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCT TTTGAGCTGATCTTGAAGCCACCATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAG ATCCAGAAGAAACTGGAGGCTGCAGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAG CGAGAAGTCCTTCAGAAGGCTTTGGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAG GAAAACCGTGAGGCTAATCTAGCTGCTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCTGAACTAAAAGAATCTATA GAGTCTCAATTTCTGGAGCTTCAGAGGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGA ACTGTCTGGCTGAAGCAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGA >60283_60283_12_NRG1-STMN2_NRG1_chr8_32463201_ENST00000405005_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=314AA_BP=133 MSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCETSSEYSSLRFKWFKNGNELNRKNKPQNIKIQK KPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLICSCFYPEPRNINIYTYDDMEVKQINKRASGQA FELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREHEREVLQKALEENNNFSKMAEEKLILKMEQIK -------------------------------------------------------------- >60283_60283_13_NRG1-STMN2_NRG1_chr8_32463201_ENST00000519301_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2168nt_BP=346nt GGCAGCAGCATGGGGAAAGGACGCGCGGGCCGAGTTGGCACCACAGCCTTGCCTCCCCGATTGAAAGAGATGAAAAGCCAGGAATCGGCT GCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATTCAAGTGGTTCAAGAATGGGAATGAATTGAAT CGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCGCATTAACAAAGCATCACTGGCTGATTCTGGA GAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCACCATCGTGGAATCAAACGCCTACAAGGAAAAA ATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAACATCAACATCTATACTTACGATGATATGGAA GTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACCATCTCCTATCTCAGAAGCCCCACGAACTTTA GCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGCAGAGGAAAGAAGAAAGTCTCAGGAGGCCCAG GTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTTGGAGGAGAACAACAACTTCAGCAAGATGGCG GAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGCTGCTATTATTGAACGTCTGCAGGAAAAGGAG AGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAGGGTCTGGCACGCCCCACCAATAG TAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTAAAAAGAACTCATTATAAAAAAAA AAAAACAAAAAAAATCAAAAATTAAAAAAAATCAATGCGGTCTCTTTGCAGAATGTTTTGCTTGATGTTTAAAAAATACCTTGGATCTTA TTTTGTAAATACTTACATTTTTGTTAAAAAATACAAGTATTGCATTATGCAAGTTATTTCATAATCTTACATGTCCTGTAACAGGCTTTT GATGTTGTGTCTTTCCACTCAAATGAATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCATGTCTAACTCCATTCCAAAAGAAAAATGAGG TCAGTAGACAGTCTATGGTGCTAGAAACCCACCATTGCCTAATGACCTAGAAGGCTTTGTTGTCTCTGAGCTTGACTAAGACCATACCTA GATCACAGGTATTATGACTCCACATGAACCTTCACATTTGTTCGCTCATAATCTACTTACTGCCTAAAAACTACAAAACCAGGCTAAGAA ATACCACCAGTCATAGCATTTACTTCTGCTTCTCCTGGATTATGTGCTACAAATGTGCTTTGGCTTTAGAAAGGGATGGATGAGAAGACA GACCTGAGACCAATCTGGGTAGAAGCAAAAAGTTGAACCTTTTAAAGTGCTGAACACAAATCCAAATTCGAATGGTTCAAGCAGCCGTGA AATCGCTCTTCATAAAGTGGGCTTAATTCTCTAGTTTAAGTTCTTTTGATGGAATGAATTAATTAATGTGTCAGGTGGCTTATTTGTGGA TGCCATGATTGATGATGTTCATTTTAAGCTCTTACCTATAGTACAAGTACATGATGCTACTGAATATTTTTCCACTTGGAAACTGTGAGC TGGTTGTTGCATTAAAACACACATACAAACAAAATCAAAAACACTGCGGACTTTCACTCAAGCTGGTCTTTCTTCCCCAGTGTAAGGCAA TCCTGCCTACTAACAACACCAACAACAAAACACTCCATCTGTGAAGCTGACGCAGTTAAGGGGGCTAGGCAGGGCATTTGTGCCAACTAA GAATCACCAGATACCCACCATAAGTACCTATCGCAGTTTTGAAGTCGTTTCTCCCCAACTCCCAACTCCTGAAGGTTGCTGCCTGCATAT TTACTCTTCATTAGTGCTATTTTCCTGTATGTCATTGTGAGCAAGCTGTGATTAATAAAGAATTGGAGTTCTGTGAACTAATAAAGGTTT >60283_60283_13_NRG1-STMN2_NRG1_chr8_32463201_ENST00000519301_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=285AA_BP=112 MGKGRAGRVGTTALPPRLKEMKSQESAAGSKLVLRCETSSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYM CKVISKLGNDSASANITIVESNAYKEKMKELSMLSLICSCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASP KKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREHEREVLQKALEENNNFSKMAEEKLILKMEQIKENREANLAAIIERLQEKERHA -------------------------------------------------------------- >60283_60283_14_NRG1-STMN2_NRG1_chr8_32463201_ENST00000519301_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1082nt_BP=346nt GGCAGCAGCATGGGGAAAGGACGCGCGGGCCGAGTTGGCACCACAGCCTTGCCTCCCCGATTGAAAGAGATGAAAAGCCAGGAATCGGCT GCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATTCAAGTGGTTCAAGAATGGGAATGAATTGAAT CGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCGCATTAACAAAGCATCACTGGCTGATTCTGGA GAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCACCATCGTGGAATCAAACGCCTACAAGGAAAAA ATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAACATCAACATCTATACTTACGATGATATGGAA GTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACCATCTCCTATCTCAGAAGCCCCACGAACTTTA GCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGCAGAGGAAAGAAGAAAGTCTCAGGAGGCCCAG GTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTTGGAGGAGAACAACAACTTCAGCAAGATGGCG GAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGCTGCTATTATTGAACGTCTGCAGGAAAAGCTG GTCAAGTTTATTTCTTCTGAACTAAAAGAATCTATAGAGTCTCAATTTCTGGAGCTTCAGAGGGAAGGAGAGAAGCAATGAGAGGCATGC TGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCC CCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAA >60283_60283_14_NRG1-STMN2_NRG1_chr8_32463201_ENST00000519301_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=293AA_BP=112 MGKGRAGRVGTTALPPRLKEMKSQESAAGSKLVLRCETSSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYM CKVISKLGNDSASANITIVESNAYKEKMKELSMLSLICSCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASP KKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREHEREVLQKALEENNNFSKMAEEKLILKMEQIKENREANLAAIIERLQEKLVKF -------------------------------------------------------------- >60283_60283_15_NRG1-STMN2_NRG1_chr8_32463201_ENST00000520407_STMN2_chr8_80549037_ENST00000220876_length(transcript)=3097nt_BP=1275nt TTTTTTTTGCCCTTATACCTCTTCGCCTTTCTGTGGTTCCATCCACTTCTTCCCCCTCCTCCTCCCATAAACAACTCTCCTACCCCTGCA CCCCCAATAAATAAATAAAAGGAGGAGGGCAAGGGGGGAGGAGGAGGAGTGGTGCTGCGAGGGGAAGGAAAAGGGAGGCAGCGCGAGAGA GCCGGGCAGAGTCCGAACCGACAGCCAGAAGCCCGCACGCACCTCGCACCATGAGATGGCGACGCGCCCCGCGCCGCTCCGGGCGTCCCG GCCCCCGGGCCCAGCGCCCCGGCTCCGCCGCCCGCTCGTCGCCGCCGCTGCCGCTGCTGCCACTACTGCTGCTGCTGGGGACCGCGGCCC TGGCGCCGGGGGCGGCGGCCGGCAACGAGGCGGCTCCCGCGGGGGCCTCGGTGTGCTACTCGTCCCCGCCCAGCGTGGGATCGGTGCAGG AGCTAGCTCAGCGCGCCGCGGTGGTGATCGAGGGAAAGGTGCACCCGCAGCGGCGGCAGCAGGGGGCACTCGACAGGAAGGCGGCGGCGG CGGCGGGCGAGGCAGGGGCGTGGGGCGGCGATCGCGAGCCGCCAGCCGCGGGCCCACGGGCGCTGGGGCCGCCCGCCGAGGAGCCGCTGC TCGCCGCCAACGGGACCGTGCCCTCTTGGCCCACCGCCCCGGTGCCCAGCGCCGGCGAGCCCGGGGAGGAGGCGCCCTATCTGGTGAAGG TGCACCAGGTGTGGGCGGTGAAAGCCGGGGGCTTGAAGAAGGACTCGCTGCTCACCGTGCGCCTGGGGACCTGGGGCCACCCCGCCTTCC CCTCCTGCGGGAGGCTCAAGGAGGACAGCAGGTACATCTTCTTCATGGAGCCCGACGCCAACAGCACCAGCCGCGCGCCGGCCGCCTTCC GAGCCTCTTTCCCCCCTCTGGAGACGGGCCGGAACCTCAAGAAGGAGGTCAGCCGGGTGCTGTGCAAGCGGTGCGCCTTGCCTCCCCGAT TGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATTCA AGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCGCA TTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCACCA TCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAACA TCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACCAT CTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGCAG AGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTTGG AGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGCTG CTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCA AGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACAT GGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAAAAATTAAAAAAAATCAATGCGGTCTCTTTGCAGAATGTTTTGC TTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACATTTTTGTTAAAAAATACAAGTATTGCATTATGCAAGTTATTTCA TAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCACTCAAATGAATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCATG TCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGGTGCTAGAAACCCACCATTGCCTAATGACCTAGAAGGCTTTGTT GTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGACTCCACATGAACCTTCACATTTGTTCGCTCATAATCTACTTACT GCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCATTTACTTCTGCTTCTCCTGGATTATGTGCTACAAATGTGCTTT GGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGGGTAGAAGCAAAAAGTTGAACCTTTTAAAGTGCTGAACACAAAT CCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGTGGGCTTAATTCTCTAGTTTAAGTTCTTTTGATGGAATGAATTA ATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGTTCATTTTAAGCTCTTACCTATAGTACAAGTACATGATGCTACT GAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAACACACATACAAACAAAATCAAAAACACTGCGGACTTTCACTCAA GCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACACCAACAACAAAACACTCCATCTGTGAAGCTGACGCAGTTAAGG GGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCACCATAAGTACCTATCGCAGTTTTGAAGTCGTTTCTCCCCAACTC CCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCTATTTTCCTGTATGTCATTGTGAGCAAGCTGTGATTAATAAAGA >60283_60283_15_NRG1-STMN2_NRG1_chr8_32463201_ENST00000520407_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=521AA_BP=348 MRWRRAPRRSGRPGPRAQRPGSAARSSPPLPLLPLLLLLGTAALAPGAAAGNEAAPAGASVCYSSPPSVGSVQELAQRAAVVIEGKVHPQ RRQQGALDRKAAAAAGEAGAWGGDREPPAAGPRALGPPAEEPLLAANGTVPSWPTAPVPSAGEPGEEAPYLVKVHQVWAVKAGGLKKDSL LTVRLGTWGHPAFPSCGRLKEDSRYIFFMEPDANSTSRAPAAFRASFPPLETGRNLKKEVSRVLCKRCALPPRLKEMKSQESAAGSKLVL RCETSSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSML SLICSCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAE -------------------------------------------------------------- >60283_60283_16_NRG1-STMN2_NRG1_chr8_32463201_ENST00000520407_STMN2_chr8_80549037_ENST00000518111_length(transcript)=2011nt_BP=1275nt TTTTTTTTGCCCTTATACCTCTTCGCCTTTCTGTGGTTCCATCCACTTCTTCCCCCTCCTCCTCCCATAAACAACTCTCCTACCCCTGCA CCCCCAATAAATAAATAAAAGGAGGAGGGCAAGGGGGGAGGAGGAGGAGTGGTGCTGCGAGGGGAAGGAAAAGGGAGGCAGCGCGAGAGA GCCGGGCAGAGTCCGAACCGACAGCCAGAAGCCCGCACGCACCTCGCACCATGAGATGGCGACGCGCCCCGCGCCGCTCCGGGCGTCCCG GCCCCCGGGCCCAGCGCCCCGGCTCCGCCGCCCGCTCGTCGCCGCCGCTGCCGCTGCTGCCACTACTGCTGCTGCTGGGGACCGCGGCCC TGGCGCCGGGGGCGGCGGCCGGCAACGAGGCGGCTCCCGCGGGGGCCTCGGTGTGCTACTCGTCCCCGCCCAGCGTGGGATCGGTGCAGG AGCTAGCTCAGCGCGCCGCGGTGGTGATCGAGGGAAAGGTGCACCCGCAGCGGCGGCAGCAGGGGGCACTCGACAGGAAGGCGGCGGCGG CGGCGGGCGAGGCAGGGGCGTGGGGCGGCGATCGCGAGCCGCCAGCCGCGGGCCCACGGGCGCTGGGGCCGCCCGCCGAGGAGCCGCTGC TCGCCGCCAACGGGACCGTGCCCTCTTGGCCCACCGCCCCGGTGCCCAGCGCCGGCGAGCCCGGGGAGGAGGCGCCCTATCTGGTGAAGG TGCACCAGGTGTGGGCGGTGAAAGCCGGGGGCTTGAAGAAGGACTCGCTGCTCACCGTGCGCCTGGGGACCTGGGGCCACCCCGCCTTCC CCTCCTGCGGGAGGCTCAAGGAGGACAGCAGGTACATCTTCTTCATGGAGCCCGACGCCAACAGCACCAGCCGCGCGCCGGCCGCCTTCC GAGCCTCTTTCCCCCCTCTGGAGACGGGCCGGAACCTCAAGAAGGAGGTCAGCCGGGTGCTGTGCAAGCGGTGCGCCTTGCCTCCCCGAT TGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATTCA AGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCGCA TTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCACCA TCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAACA TCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACCAT CTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGCAG AGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTTGG AGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGCTG CTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCTGAACTAAAAGAATCTATAGAGTCTCAATTTCTGGAGCTTCAGA GGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAGGG TCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTAAA >60283_60283_16_NRG1-STMN2_NRG1_chr8_32463201_ENST00000520407_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=529AA_BP=348 MRWRRAPRRSGRPGPRAQRPGSAARSSPPLPLLPLLLLLGTAALAPGAAAGNEAAPAGASVCYSSPPSVGSVQELAQRAAVVIEGKVHPQ RRQQGALDRKAAAAAGEAGAWGGDREPPAAGPRALGPPAEEPLLAANGTVPSWPTAPVPSAGEPGEEAPYLVKVHQVWAVKAGGLKKDSL LTVRLGTWGHPAFPSCGRLKEDSRYIFFMEPDANSTSRAPAAFRASFPPLETGRNLKKEVSRVLCKRCALPPRLKEMKSQESAAGSKLVL RCETSSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSML SLICSCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAE -------------------------------------------------------------- >60283_60283_17_NRG1-STMN2_NRG1_chr8_32463201_ENST00000521670_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2330nt_BP=508nt TCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGATCCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAG CGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAGAGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCG GAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCGATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTC CTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATTCAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAA AATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCGCATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTG ATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCACCATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATG CTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAACATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAA CGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACCATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAA GACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGCAGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCA GAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTTGGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTG AAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGCTGCTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTG CGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATA TTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAA AAATTAAAAAAAATCAATGCGGTCTCTTTGCAGAATGTTTTGCTTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACAT TTTTGTTAAAAAATACAAGTATTGCATTATGCAAGTTATTTCATAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCAC TCAAATGAATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCATGTCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGG TGCTAGAAACCCACCATTGCCTAATGACCTAGAAGGCTTTGTTGTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGAC TCCACATGAACCTTCACATTTGTTCGCTCATAATCTACTTACTGCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCA TTTACTTCTGCTTCTCCTGGATTATGTGCTACAAATGTGCTTTGGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGG GTAGAAGCAAAAAGTTGAACCTTTTAAAGTGCTGAACACAAATCCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGT GGGCTTAATTCTCTAGTTTAAGTTCTTTTGATGGAATGAATTAATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGT TCATTTTAAGCTCTTACCTATAGTACAAGTACATGATGCTACTGAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAAC ACACATACAAACAAAATCAAAAACACTGCGGACTTTCACTCAAGCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACA CCAACAACAAAACACTCCATCTGTGAAGCTGACGCAGTTAAGGGGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCAC CATAAGTACCTATCGCAGTTTTGAAGTCGTTTCTCCCCAACTCCCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCT >60283_60283_17_NRG1-STMN2_NRG1_chr8_32463201_ENST00000521670_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=306AA_BP=133 MSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCETSSEYSSLRFKWFKNGNELNRKNKPQNIKIQK KPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLICSCFYPEPRNINIYTYDDMEVKQINKRASGQA FELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREHEREVLQKALEENNNFSKMAEEKLILKMEQIK -------------------------------------------------------------- >60283_60283_18_NRG1-STMN2_NRG1_chr8_32463201_ENST00000521670_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1244nt_BP=508nt TCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGATCCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAG CGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAGAGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCG GAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCGATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTC CTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATTCAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAA AATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCGCATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTG ATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCACCATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATG CTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAACATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAA CGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACCATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAA GACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGCAGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCA GAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTTGGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTG AAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGCTGCTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCT GAACTAAAAGAATCTATAGAGTCTCAATTTCTGGAGCTTCAGAGGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAA CAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATG >60283_60283_18_NRG1-STMN2_NRG1_chr8_32463201_ENST00000521670_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=314AA_BP=133 MSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCETSSEYSSLRFKWFKNGNELNRKNKPQNIKIQK KPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLICSCFYPEPRNINIYTYDDMEVKQINKRASGQA FELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREHEREVLQKALEENNNFSKMAEEKLILKMEQIK -------------------------------------------------------------- >60283_60283_19_NRG1-STMN2_NRG1_chr8_32463201_ENST00000523079_STMN2_chr8_80549037_ENST00000220876_length(transcript)=2739nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAG CAAGGGAGGGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGAC ATGGTTTAAAAAGAACTCATTATAAAAAAAAAAAAACAAAAAAAATCAAAAATTAAAAAAAATCAATGCGGTCTCTTTGCAGAATGTTTT GCTTGATGTTTAAAAAATACCTTGGATCTTATTTTGTAAATACTTACATTTTTGTTAAAAAATACAAGTATTGCATTATGCAAGTTATTT CATAATCTTACATGTCCTGTAACAGGCTTTTGATGTTGTGTCTTTCCACTCAAATGAATTTGCTAGGTCTGTTCTTTTTGAAGCTCCCCA TGTCTAACTCCATTCCAAAAGAAAAATGAGGTCAGTAGACAGTCTATGGTGCTAGAAACCCACCATTGCCTAATGACCTAGAAGGCTTTG TTGTCTCTGAGCTTGACTAAGACCATACCTAGATCACAGGTATTATGACTCCACATGAACCTTCACATTTGTTCGCTCATAATCTACTTA CTGCCTAAAAACTACAAAACCAGGCTAAGAAATACCACCAGTCATAGCATTTACTTCTGCTTCTCCTGGATTATGTGCTACAAATGTGCT TTGGCTTTAGAAAGGGATGGATGAGAAGACAGACCTGAGACCAATCTGGGTAGAAGCAAAAAGTTGAACCTTTTAAAGTGCTGAACACAA ATCCAAATTCGAATGGTTCAAGCAGCCGTGAAATCGCTCTTCATAAAGTGGGCTTAATTCTCTAGTTTAAGTTCTTTTGATGGAATGAAT TAATTAATGTGTCAGGTGGCTTATTTGTGGATGCCATGATTGATGATGTTCATTTTAAGCTCTTACCTATAGTACAAGTACATGATGCTA CTGAATATTTTTCCACTTGGAAACTGTGAGCTGGTTGTTGCATTAAAACACACATACAAACAAAATCAAAAACACTGCGGACTTTCACTC AAGCTGGTCTTTCTTCCCCAGTGTAAGGCAATCCTGCCTACTAACAACACCAACAACAAAACACTCCATCTGTGAAGCTGACGCAGTTAA GGGGGCTAGGCAGGGCATTTGTGCCAACTAAGAATCACCAGATACCCACCATAAGTACCTATCGCAGTTTTGAAGTCGTTTCTCCCCAAC TCCCAACTCCTGAAGGTTGCTGCCTGCATATTTACTCTTCATTAGTGCTATTTTCCTGTATGTCATTGTGAGCAAGCTGTGATTAATAAA >60283_60283_19_NRG1-STMN2_NRG1_chr8_32463201_ENST00000523079_STMN2_chr8_80549037_ENST00000220876_length(amino acids)=427AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- >60283_60283_20_NRG1-STMN2_NRG1_chr8_32463201_ENST00000523079_STMN2_chr8_80549037_ENST00000518111_length(transcript)=1653nt_BP=917nt GAGGCCAGGGGAGGGTGCGAAGGAGGCGCCTGCCTCCAACCTGCGGGCGGGAGGTGGGTGGCTGCGGGGCAATTGAAAAAGAGCCGGCGA GGAGTTCCCCGAAACTTGTTGGAACTCCGGGCTCGCGCGGAGGCCAGGAGCTGAGCGGCGGCGGCTGCCGGACGATGGGAGCGTGAGCAG GACGGTGATAACCTCTCCCCGATCGGGTTGCGAGGGCGCCGGGCAGAGGCCAGGACGCGAGCCGCCAGCGGTGGGACCCATCGACGACTT CCCGGGGCGACAGGAGCAGCCCCGAGAGCCAGGGCGAGCGCCCGTTCCAGGTGGCCGGACCGCCCGCCGCGTCCGCGCCGCGCTCCCTGC AGGCAACGGGAGACGCCCCCGCGCAGCGCGAGCGCCTCAGCGCGGCCGCTCGCTCTCCCCCTCGAGGGACAAACTTTTCCCAAACCCGAT CCGAGCCCTTGGACCAAACTCGCCTGCGCCGAGAGCCGTCCGCGTAGAGCGCTCCGTCTCCGGCGAGATGTCCGAGCGCAAAGAAGGCAG AGGCAAAGGGAAGGGCAAGAAGAAGGAGCGAGGCTCCGGCAAGAAGCCGGAGTCCGCGGCGGGCAGCCAGAGCCCAGCCTTGCCTCCCCG ATTGAAAGAGATGAAAAGCCAGGAATCGGCTGCAGGTTCCAAACTAGTCCTTCGGTGTGAAACCAGTTCTGAATACTCCTCTCTCAGATT CAAGTGGTTCAAGAATGGGAATGAATTGAATCGAAAAAACAAACCACAAAATATCAAGATACAAAAAAAGCCAGGGAAGTCAGAACTTCG CATTAACAAAGCATCACTGGCTGATTCTGGAGAGTATATGTGCAAAGTGATCAGCAAATTAGGAAATGACAGTGCCTCTGCCAATATCAC CATCGTGGAATCAAACGCCTACAAGGAAAAAATGAAGGAGCTGTCCATGCTGTCACTGATCTGCTCTTGCTTTTACCCGGAACCTCGCAA CATCAACATCTATACTTACGATGATATGGAAGTGAAGCAAATCAACAAACGTGCCTCTGGCCAGGCTTTTGAGCTGATCTTGAAGCCACC ATCTCCTATCTCAGAAGCCCCACGAACTTTAGCTTCTCCAAAGAAGAAAGACCTGTCCCTGGAGGAGATCCAGAAGAAACTGGAGGCTGC AGAGGAAAGAAGAAAGTCTCAGGAGGCCCAGGTGCTGAAACAATTGGCAGAGAAGAGGGAACACGAGCGAGAAGTCCTTCAGAAGGCTTT GGAGGAGAACAACAACTTCAGCAAGATGGCGGAGGAAAAGCTGATCCTGAAAATGGAACAAATTAAGGAAAACCGTGAGGCTAATCTAGC TGCTATTATTGAACGTCTGCAGGAAAAGCTGGTCAAGTTTATTTCTTCTGAACTAAAAGAATCTATAGAGTCTCAATTTCTGGAGCTTCA GAGGGAAGGAGAGAAGCAATGAGAGGCATGCTGCGGAGGTGCGCAGGAACAAGGAACTCCAGGTTGAACTGTCTGGCTGAAGCAAGGGAG GGTCTGGCACGCCCCACCAATAGTAAATCCCCCTGCCTATATTATAATGGATCATGCGATATCAGGATGGGGAATGTATGACATGGTTTA >60283_60283_20_NRG1-STMN2_NRG1_chr8_32463201_ENST00000523079_STMN2_chr8_80549037_ENST00000518111_length(amino acids)=435AA_BP=254 MPDDGSVSRTVITSPRSGCEGAGQRPGREPPAVGPIDDFPGRQEQPREPGRAPVPGGRTARRVRAALPAGNGRRPRAARAPQRGRSLSPS RDKLFPNPIRALGPNSPAPRAVRVERSVSGEMSERKEGRGKGKGKKKERGSGKKPESAAGSQSPALPPRLKEMKSQESAAGSKLVLRCET SSEYSSLRFKWFKNGNELNRKNKPQNIKIQKKPGKSELRINKASLADSGEYMCKVISKLGNDSASANITIVESNAYKEKMKELSMLSLIC SCFYPEPRNINIYTYDDMEVKQINKRASGQAFELILKPPSPISEAPRTLASPKKKDLSLEEIQKKLEAAEERRKSQEAQVLKQLAEKREH -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NRG1-STMN2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NRG1-STMN2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NRG1-STMN2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies