
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NSFL1C-HOOK2 (FusionGDB2 ID:60480) |
Fusion Gene Summary for NSFL1C-HOOK2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NSFL1C-HOOK2 | Fusion gene ID: 60480 | Hgene | Tgene | Gene symbol | NSFL1C | HOOK2 | Gene ID | 55968 | 29911 |
| Gene name | NSFL1 cofactor | hook microtubule tethering protein 2 | |
| Synonyms | P47|UBX1|UBXD10|UBXN2C|dJ776F14.1 | HK2 | |
| Cytomap | 20p13 | 19p13.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | NSFL1 cofactor p47NSFL1 (p97) cofactor (p47)SHP1 homologUBX domain-containing protein 2Cp97 cofactor p47 | protein Hook homolog 2h-hook2hHK2hook homolog 2 | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | . | Q96ED9 | |
| Ensembl transtripts involved in fusion gene | ENST00000216879, ENST00000350991, ENST00000353088, ENST00000476071, ENST00000381658, ENST00000461211, | ENST00000589965, ENST00000264827, ENST00000397668, | |
| Fusion gene scores | * DoF score | 4 X 5 X 3=60 | 9 X 10 X 6=540 |
| # samples | 5 | 12 | |
| ** MAII score | log2(5/60*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/540*10)=-2.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NSFL1C [Title/Abstract] AND HOOK2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NSFL1C(1447365)-HOOK2(12885711), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across NSFL1C (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across HOOK2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SARC | TCGA-FX-A48G-01A | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
Top |
Fusion Gene ORF analysis for NSFL1C-HOOK2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000216879 | ENST00000589965 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| 5CDS-5UTR | ENST00000350991 | ENST00000589965 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| 5CDS-5UTR | ENST00000353088 | ENST00000589965 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| 5CDS-5UTR | ENST00000476071 | ENST00000589965 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| 5UTR-3CDS | ENST00000381658 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| 5UTR-3CDS | ENST00000381658 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| 5UTR-5UTR | ENST00000381658 | ENST00000589965 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| In-frame | ENST00000216879 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| In-frame | ENST00000216879 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| In-frame | ENST00000350991 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| In-frame | ENST00000350991 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| In-frame | ENST00000353088 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| In-frame | ENST00000353088 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| In-frame | ENST00000476071 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| In-frame | ENST00000476071 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| intron-3CDS | ENST00000461211 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| intron-3CDS | ENST00000461211 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| intron-5UTR | ENST00000461211 | ENST00000589965 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000353088 | NSFL1C | chr20 | 1447365 | - | ENST00000397668 | HOOK2 | chr19 | 12885711 | - | 2503 | 109 | 4 | 2223 | 739 |
| ENST00000353088 | NSFL1C | chr20 | 1447365 | - | ENST00000264827 | HOOK2 | chr19 | 12885711 | - | 2496 | 109 | 4 | 2217 | 737 |
| ENST00000476071 | NSFL1C | chr20 | 1447365 | - | ENST00000397668 | HOOK2 | chr19 | 12885711 | - | 2593 | 199 | 94 | 2313 | 739 |
| ENST00000476071 | NSFL1C | chr20 | 1447365 | - | ENST00000264827 | HOOK2 | chr19 | 12885711 | - | 2586 | 199 | 94 | 2307 | 737 |
| ENST00000216879 | NSFL1C | chr20 | 1447365 | - | ENST00000397668 | HOOK2 | chr19 | 12885711 | - | 3367 | 973 | 868 | 3087 | 739 |
| ENST00000216879 | NSFL1C | chr20 | 1447365 | - | ENST00000264827 | HOOK2 | chr19 | 12885711 | - | 3360 | 973 | 868 | 3081 | 737 |
| ENST00000350991 | NSFL1C | chr20 | 1447365 | - | ENST00000397668 | HOOK2 | chr19 | 12885711 | - | 2519 | 125 | 20 | 2239 | 739 |
| ENST00000350991 | NSFL1C | chr20 | 1447365 | - | ENST00000264827 | HOOK2 | chr19 | 12885711 | - | 2512 | 125 | 20 | 2233 | 737 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000353088 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - | 0.015746463 | 0.9842535 |
| ENST00000353088 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - | 0.016153492 | 0.98384655 |
| ENST00000476071 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - | 0.016253756 | 0.9837463 |
| ENST00000476071 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - | 0.016704688 | 0.98329526 |
| ENST00000216879 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - | 0.022149015 | 0.977851 |
| ENST00000216879 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - | 0.02273522 | 0.97726476 |
| ENST00000350991 | ENST00000397668 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - | 0.015819965 | 0.98418 |
| ENST00000350991 | ENST00000264827 | NSFL1C | chr20 | 1447365 | - | HOOK2 | chr19 | 12885711 | - | 0.016206818 | 0.9837932 |
Top |
Fusion Genomic Features for NSFL1C-HOOK2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
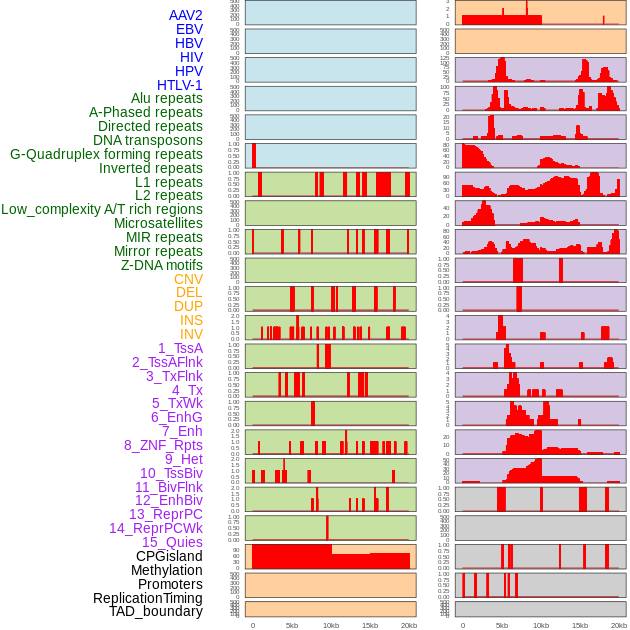 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NSFL1C-HOOK2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:1447365/chr19:12885711) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | HOOK2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Component of the FTS/Hook/FHIP complex (FHF complex). The FHF complex may function to promote vesicle trafficking and/or fusion via the homotypic vesicular protein sorting complex (the HOPS complex). Contributes to the establishment and maintenance of centrosome function. May function in the positioning or formation of aggresomes, which are pericentriolar accumulations of misfolded proteins, proteasomes and chaperones. {ECO:0000269|PubMed:17140400, ECO:0000269|PubMed:17540036, ECO:0000269|PubMed:18799622}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000264827 | 0 | 22 | 180_427 | 15 | 718.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000264827 | 0 | 22 | 455_607 | 15 | 718.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000397668 | 0 | 23 | 180_427 | 15 | 720.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000397668 | 0 | 23 | 455_607 | 15 | 720.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000264827 | 0 | 22 | 533_719 | 15 | 718.0 | Region | Note=Required for localization to the centrosome and induction of aggresome formation | |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000397668 | 0 | 23 | 533_719 | 15 | 720.0 | Region | Note=Required for localization to the centrosome and induction of aggresome formation |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000216879 | - | 1 | 9 | 84_90 | 35 | 371.0 | Compositional bias | Note=Poly-Glu |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000353088 | - | 1 | 8 | 84_90 | 35 | 340.0 | Compositional bias | Note=Poly-Glu |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000381658 | - | 1 | 8 | 84_90 | 0 | 260.0 | Compositional bias | Note=Poly-Glu |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000476071 | - | 1 | 10 | 84_90 | 35 | 373.0 | Compositional bias | Note=Poly-Glu |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000216879 | - | 1 | 9 | 179_244 | 35 | 371.0 | Domain | SEP |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000216879 | - | 1 | 9 | 291_368 | 35 | 371.0 | Domain | UBX |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000353088 | - | 1 | 8 | 179_244 | 35 | 340.0 | Domain | SEP |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000353088 | - | 1 | 8 | 291_368 | 35 | 340.0 | Domain | UBX |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000381658 | - | 1 | 8 | 179_244 | 0 | 260.0 | Domain | SEP |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000381658 | - | 1 | 8 | 291_368 | 0 | 260.0 | Domain | UBX |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000476071 | - | 1 | 10 | 179_244 | 35 | 373.0 | Domain | SEP |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000476071 | - | 1 | 10 | 291_368 | 35 | 373.0 | Domain | UBX |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000216879 | - | 1 | 9 | 109_115 | 35 | 371.0 | Motif | Note=Nuclear localization signal |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000216879 | - | 1 | 9 | 172_175 | 35 | 371.0 | Motif | Note=Nuclear localization signal |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000353088 | - | 1 | 8 | 109_115 | 35 | 340.0 | Motif | Note=Nuclear localization signal |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000353088 | - | 1 | 8 | 172_175 | 35 | 340.0 | Motif | Note=Nuclear localization signal |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000381658 | - | 1 | 8 | 109_115 | 0 | 260.0 | Motif | Note=Nuclear localization signal |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000381658 | - | 1 | 8 | 172_175 | 0 | 260.0 | Motif | Note=Nuclear localization signal |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000476071 | - | 1 | 10 | 109_115 | 35 | 373.0 | Motif | Note=Nuclear localization signal |
| Hgene | NSFL1C | chr20:1447365 | chr19:12885711 | ENST00000476071 | - | 1 | 10 | 172_175 | 35 | 373.0 | Motif | Note=Nuclear localization signal |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000264827 | 0 | 22 | 6_122 | 15 | 718.0 | Domain | Calponin-homology (CH) | |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000397668 | 0 | 23 | 6_122 | 15 | 720.0 | Domain | Calponin-homology (CH) | |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000264827 | 0 | 22 | 1_161 | 15 | 718.0 | Region | Note=Required for localization to the centrosome and induction of aggresome formation | |
| Tgene | HOOK2 | chr20:1447365 | chr19:12885711 | ENST00000397668 | 0 | 23 | 1_161 | 15 | 720.0 | Region | Note=Required for localization to the centrosome and induction of aggresome formation |
Top |
Fusion Gene Sequence for NSFL1C-HOOK2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >60480_60480_1_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000216879_HOOK2_chr19_12885711_ENST00000264827_length(transcript)=3360nt_BP=973nt AAGTTCCTCTTTGGAGAGGCAAGAGGGCAAAGAAGCTGAGGACCCAGAAGACAGGATTGTGCCTAAGAAAGTGGCCTTGGAGCAGAGGCC CAAAGAAAGCGGGGAGAGCGCCTTGCCCATCGGTAAGGGAAAGGTGCTCCAGGCACAGAAGCAGCTAATGCAACGGCCCTGAGGCAAATG CAAGATAACTGGCAAGTTCCAGGAACAGCAAGGAGGGCAAGGCGCCTGGAGCAGAGGAAGCTAGCGGATCCCTTGATGAGAGGGAGGAAC TGGCCCATCTCTCATGGGTCCTGCAGGCAGGCCATGAGACTGTCTTTTATGCGGGGCGAGATAACGAGGCATGGACGTGTTGTGAGCGGA GGCCTAGCCTGTTCAAGGTCTGAATTTTTACCCCTAGAATGTAAGAAGCATGGGAGCAGGGACTTTGTTTTGCTCCCTGCCATATCCACA GCCCTAGAAAAACGTCGGGCCATTGATAGCTCTCAGTAAATGCTTGACAAGTAAGTGAATGAACGAATGCACAATTAATGAAATGAGGGC TGCGTCAATGAATAACTGGGAATCTGACTCCTGCAGGGAGCCTTCAGCCCACAGGTGTATGTAAGACCCGCCCCGCCTCTCATCCTTCGG GCTCCCACCCCCGCCGTTAGGCTGCGGTTCGCGCCGCGGTCGCCAGAGGGCGCGGAGCGGCGGGGCTTCCCGCACGGAGGGCTTTGCGTG AGGCACCGCGTGGGGCGGGGCTGCGGGCGGGCTCCCAGCTGCTGGGCCCTCATCGGCTGGGCCTCGTCGACCGGCAAGCGGAACGCGGCA GCGGGGCTGGGCCTGTGCGGCGGCCGCCGGAGCGCTTTGGAAGGCGCACGGGGCGAAGATGGCGGCGGAGCGACAGGAGGCGCTGAGGGA GTTCGTGGCGGTGACGGGCGCCGAGGAGGACCGGGCCCGCTTCTTTCTCGAGTCGGCCGGCTGGGACTTGCAGTTACAGACGTTCCACGT TCCGTCTCCCTGTGCCAGCCCTCAGGACCTGAGCAGCGGCCTTGCCGTAGCCTATGTGCTGAACCAGATAGACCCCTCCTGGTTCAACGA GGCATGGCTCCAGGGCATCTCGGAAGATCCAGGTCCCAACTGGAAGCTGAAGGTCAGCAATCTGAAGATGGTCTTACGGAGCCTAGTAGA GTACTCCCAGGATGTCCTGGCGCATCCTGTGTCAGAAGAGCATCTCCCAGATGTGAGCCTCATTGGAGAGTTCTCAGACCCGGCAGAGCT CGGCAAGCTGCTTCAGCTGGTGCTGGGCTGTGCCATCAGTTGCGAGAAAAAGCAGGACCACATCCAGAGAATCATGACGCTGGAAGAATC GGTTCAGCATGTGGTGATGGAAGCCATCCAAGAGCTCATGACCAAAGACACTCCTGACTCCCTGTCACCAGAGACGTATGGCAACTTTGA CAGCCAGTCCCGCAGGTACTATTTCCTAAGTGAGGAGGCTGAGGAGGGGGACGAATTACAGCAGCGCTGTCTGGATCTGGAGCGGCAGCT GATGCTCCTGTCAGAGGAGAAGCAGAGCCTGGCGCAAGAGAATGCAGGGCTGCGGGAGCGGATGGGCCGGCCTGAAGGCGAGGGTACCCC AGGTCTCACTGCCAAGAAGCTGCTGCTGCTGCAATCCCAGCTGGAGCAGTTGCAGGAGGAGAACTTCAGGCTGGAGAGTGGCAGGGAGGA TGAGCGCCTGCGCTGTGCCGAGCTGGAGAGGGAGGTTGCGGAGCTGCAGCACCGGAACCAGGCGCTGACTAGCCTGGCCCAGGAGGCACA GGCCCTGAAGGATGAGATGGATGAACTACGGCAGTCTTCGGAGCGTGCTGGGCAGCTGGAGGCCACGCTGACCAGTTGCCGGCGCCGCTT GGGCGAGCTGAGGGAGCTGCGGCGGCAGGTGCGGCAGCTGGAGGAACGCAACGCCGGCCACGCCGAGCGCACGCGACAACTGGAGGATGA GCTACGCCGAGCGGGCTCCCTGCGCGCCCAGCTGGAGGCGCAGCGGCGGCAGGTGCAGGAACTGCAGGGCCAGCGGCAGGAGGAGGCCAT GAAGGCCGAGAAATGGCTATTTGAATGCCGCAACCTGGAGGAAAAGTATGAGTCGGTGACAAAGGAGAAGGAGCGGCTGTTGGCGGAGCG GGACTCCTTGCGGGAGGCCAATGAGGAGCTGCGCTGCGCCCAGCTGCAGCCGCGGGGGTTGACCCAGGCCGATCCCTCACTGGATCCCAC CTCCACACCCGTGGATAACTTAGCCGCAGAGATCCTGCCTGCGGAGCTCAGGGAGACGCTCCTGCGGCTTCAGCTGGAGAACAAGCGGCT GTGCAGGCAGGAGGCGGCCGACCGGGAGCGGCAGGAGGAGCTGCAGCGCCACCTGGAGGATGCCAACCGCGCGCGCCACGGGTTGGAGAC GCAGCACCGGCTGAACCAGCAGCAGCTATCCGAGCTGCGGGCCCAGGTGGAGGACCTGCAGAAAGCCCTGCAGGAGCAGGGGGGCAAGAC TGAAGATTCCATTTTGCTGAAAAGGAAGCTGGAGGAACATTTGCAGAAGCTTCATGAGGCAGATCTGGAGTTGCAGAGGAAGCGGGAGTA CATTGAGGAGCTGGAGCCACCCACTGACAGCAGCACAGCCCGGCGGATCGAGGAGCTGCAGCATAACTTGCAGAAGAAGGACGCGGACTT GCGGGCCATGGAGGAGCGATACCGCCGCTACGTGGACAAGGCCCGCATGGTCATGCAGACCATGGAACCCAAGCAGCGGCCAGCTGCGGG GGCACCTCCAGAACTCCATTCCCTGAGGACACAGCTCCGAGAACGGGATGTCCGCATCCGACACCTGGAGATGGACTTTGAGAAAAGCCG AAGTCAGCGGGAGCAGGAAGAAAAGCTGCTCATCAGTGCCTGGTATAATATGGGCATGGCCTTGCAGCAGCGAGCTGGGGAGGAGCGGGC GCCTGCCCATGCCCAGTCATTCCTGGCACAGCAGCGGCTGGCAACCAATTCTCGCCGTGGACCCTTGGGACGCCTGGCATCTCTGAACCT TCGCCCCACTGACAAGCACTGACAGACCTCACAATCAAGCCAGCCTGGGCTCCACCCACCCTGGCTTCCTCCAGCTCACATGGCGCCCAG CACTGGGCTTCAGCCAGGTGCTCGAGAGCTTTGAGGCCATGATCTCTGCTCTTCCCTCTCCCAGATTGGTGGGGAGGGAGGGCGGGAGGT AGATATAGGCCTGTTCTTTTTAGCAATGTGATTCTTGTTGTTGATTCTCTCTCTGGAGTTCATGTGCTGCCTCAGGAGACTCTGATTTTA >60480_60480_1_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000216879_HOOK2_chr19_12885711_ENST00000264827_length(amino acids)=737AA_BP=34 MAAERQEALREFVAVTGAEEDRARFFLESAGWDLQLQTFHVPSPCASPQDLSSGLAVAYVLNQIDPSWFNEAWLQGISEDPGPNWKLKVS NLKMVLRSLVEYSQDVLAHPVSEEHLPDVSLIGEFSDPAELGKLLQLVLGCAISCEKKQDHIQRIMTLEESVQHVVMEAIQELMTKDTPD SLSPETYGNFDSQSRRYYFLSEEAEEGDELQQRCLDLERQLMLLSEEKQSLAQENAGLRERMGRPEGEGTPGLTAKKLLLLQSQLEQLQE ENFRLESGREDERLRCAELEREVAELQHRNQALTSLAQEAQALKDEMDELRQSSERAGQLEATLTSCRRRLGELRELRRQVRQLEERNAG HAERTRQLEDELRRAGSLRAQLEAQRRQVQELQGQRQEEAMKAEKWLFECRNLEEKYESVTKEKERLLAERDSLREANEELRCAQLQPRG LTQADPSLDPTSTPVDNLAAEILPAELRETLLRLQLENKRLCRQEAADRERQEELQRHLEDANRARHGLETQHRLNQQQLSELRAQVEDL QKALQEQGGKTEDSILLKRKLEEHLQKLHEADLELQRKREYIEELEPPTDSSTARRIEELQHNLQKKDADLRAMEERYRRYVDKARMVMQ TMEPKQRPAAGAPPELHSLRTQLRERDVRIRHLEMDFEKSRSQREQEEKLLISAWYNMGMALQQRAGEERAPAHAQSFLAQQRLATNSRR -------------------------------------------------------------- >60480_60480_2_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000216879_HOOK2_chr19_12885711_ENST00000397668_length(transcript)=3367nt_BP=973nt AAGTTCCTCTTTGGAGAGGCAAGAGGGCAAAGAAGCTGAGGACCCAGAAGACAGGATTGTGCCTAAGAAAGTGGCCTTGGAGCAGAGGCC CAAAGAAAGCGGGGAGAGCGCCTTGCCCATCGGTAAGGGAAAGGTGCTCCAGGCACAGAAGCAGCTAATGCAACGGCCCTGAGGCAAATG CAAGATAACTGGCAAGTTCCAGGAACAGCAAGGAGGGCAAGGCGCCTGGAGCAGAGGAAGCTAGCGGATCCCTTGATGAGAGGGAGGAAC TGGCCCATCTCTCATGGGTCCTGCAGGCAGGCCATGAGACTGTCTTTTATGCGGGGCGAGATAACGAGGCATGGACGTGTTGTGAGCGGA GGCCTAGCCTGTTCAAGGTCTGAATTTTTACCCCTAGAATGTAAGAAGCATGGGAGCAGGGACTTTGTTTTGCTCCCTGCCATATCCACA GCCCTAGAAAAACGTCGGGCCATTGATAGCTCTCAGTAAATGCTTGACAAGTAAGTGAATGAACGAATGCACAATTAATGAAATGAGGGC TGCGTCAATGAATAACTGGGAATCTGACTCCTGCAGGGAGCCTTCAGCCCACAGGTGTATGTAAGACCCGCCCCGCCTCTCATCCTTCGG GCTCCCACCCCCGCCGTTAGGCTGCGGTTCGCGCCGCGGTCGCCAGAGGGCGCGGAGCGGCGGGGCTTCCCGCACGGAGGGCTTTGCGTG AGGCACCGCGTGGGGCGGGGCTGCGGGCGGGCTCCCAGCTGCTGGGCCCTCATCGGCTGGGCCTCGTCGACCGGCAAGCGGAACGCGGCA GCGGGGCTGGGCCTGTGCGGCGGCCGCCGGAGCGCTTTGGAAGGCGCACGGGGCGAAGATGGCGGCGGAGCGACAGGAGGCGCTGAGGGA GTTCGTGGCGGTGACGGGCGCCGAGGAGGACCGGGCCCGCTTCTTTCTCGAGTCGGCCGGCTGGGACTTGCAGTTACAGACGTTCCACGT TCCGTCTCCCTGTGCCAGCCCTCAGGACCTGAGCAGCGGCCTTGCCGTAGCCTATGTGCTGAACCAGATAGACCCCTCCTGGTTCAACGA GGCATGGCTCCAGGGCATCTCGGAAGATCCAGGTCCCAACTGGAAGCTGAAGGTCAGCAATCTGAAGATGGTCTTACGGAGCCTAGTAGA GTACTCCCAGGATGTCCTGGCGCATCCTGTGTCAGAAGAGCATCTCCCAGATGTGAGCCTCATTGGAGAGTTCTCAGACCCGGCAGAGCT CGGCAAGCTGCTTCAGCTGGTGCTGGGCTGTGCCATCAGTTGCGAGAAAAAGCAGGACCACATCCAGAGAATCATGACGCTGGAAGAATC GGTTCAGCATGTGGTGATGGAAGCCATCCAAGAGCTCATGACCAAAGACACTCCTGACTCCCTGTCACCAGAGACGTATGGCAACTTTGA CAGCCAGTCCCGCAGGTACTATTTCCTAAGTGAGGAGGCTGAGGAGGGGGACGAATTACAGCAGCGCTGTCTGGATCTGGAGCGGCAGCT GATGCTCCTGTCAGAGGAGAAGCAGAGCCTGGCGCAAGAGAATGCAGGGCTGCGGGAGCGGATGGGCCGGCCTGAAGGCGAGGGTACCCC AGGTCTCACTGCCAAGAAGCTGCTGCTGCTGCAATCCCAGCTGGAGCAGTTGCAGGAGGAGAACTTCAGGCTGGAGAGTGGCAGGGAGGA TGAGCGCCTGCGCTGTGCCGAGCTGGAGAGGGAGGTTGCGGAGCTGCAGCACCGGAACCAGGCGCTGACTAGCCTGGCCCAGGAGGCACA GGCCCTGAAGGATGAGATGGATGAACTACGGCAGTCTTCGGAGCGTGCTGGGCAGCTGGAGGCCACGCTGACCAGTTGCCGGCGCCGCTT GGGCGAGCTGAGGGAGCTGCGGCGGCAGGTGCGGCAGCTGGAGGAACGCAACGCCGGCCACGCCGAGCGCACGCGACAACTGGAGGATGA GCTACGCCGAGCGGGCTCCCTGCGCGCCCAGCTGGAGGCGCAGCGGCGGCAGGTGCAGGAACTGCAGGGCCAGCGGCAGGAGGAGGCCAT GAAGGCCGAGAAATGGCTATTTGAATGCCGCAACCTGGAGGAAAAGTATGAGTCGGTGACAAAGGAGAAGGAGCGGCTGTTGGCGGAGCG GGACTCCTTGCGGGAGGCCAATGAGGAGCTGCGCTGCGCCCAGCTGCAGCCGCGGGGGTTGACCCAGGCCGATCCCTCACTGGATCCCAC CTCCACACCCGTGGATAACTTAGCCGCAGAGATCCTGCCTGCGGAGCTCAGGGAGACGCTCCTGCGGCTTCAGCTGGAGAACAAGCGGCT GTGCAGGCAGGAGGCGGCCGACCGGGAGCGGCAGGAGGAGCTGCAGCGCCACCTGGAGGATGCCAACCGCGCGCGCCACGGGTTGGAGAC GCAGCACCGGCTGAACCAGCAGCAGCTATCCGAGCTGCGGGCCCAGGTGGAGGACCTGCAGAAAGCCCTGCAGGAGCAGGGGGGCAAGAC TGAAGATGCCATTTCCATTTTGCTGAAAAGGAAGCTGGAGGAACATTTGCAGAAGCTTCATGAGGCAGATCTGGAGTTGCAGAGGAAGCG GGAGTACATTGAGGAGCTGGAGCCACCCACTGACAGCAGCACAGCCCGGCGGATCGAGGAGCTGCAGCATAACTTGCAGAAGAAGGACGC GGACTTGCGGGCCATGGAGGAGCGATACCGCCGCTACGTGGACAAGGCCCGCATGGTCATGCAGACCATGGAACCCAAGCAGCGGCCAGC TGCGGGGGCACCTCCAGAACTCCATTCCCTGAGGACACAGCTCCGAGAACGGGATGTCCGCATCCGACACCTGGAGATGGACTTTGAGAA AAGCCGAAGTCAGCGGGAGCAGGAAGAAAAGCTGCTCATCAGTGCCTGGTATAATATGGGCATGGCCTTGCAGCAGCGAGCTGGGGAGGA GCGGGCGCCTGCCCATGCCCAGTCATTCCTGGCACAGCAGCGGCTGGCAACCAATTCTCGCCGTGGACCCTTGGGACGCCTGGCATCTCT GAACCTTCGCCCCACTGACAAGCACTGACAGACCTCACAATCAAGCCAGCCTGGGCTCCACCCACCCTGGCTTCCTCCAGCTCACATGGC GCCCAGCACTGGGCTTCAGCCAGGTGCTCGAGAGCTTTGAGGCCATGATCTCTGCTCTTCCCTCTCCCAGATTGGTGGGGAGGGAGGGCG GGAGGTAGATATAGGCCTGTTCTTTTTAGCAATGTGATTCTTGTTGTTGATTCTCTCTCTGGAGTTCATGTGCTGCCTCAGGAGACTCTG >60480_60480_2_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000216879_HOOK2_chr19_12885711_ENST00000397668_length(amino acids)=739AA_BP=34 MAAERQEALREFVAVTGAEEDRARFFLESAGWDLQLQTFHVPSPCASPQDLSSGLAVAYVLNQIDPSWFNEAWLQGISEDPGPNWKLKVS NLKMVLRSLVEYSQDVLAHPVSEEHLPDVSLIGEFSDPAELGKLLQLVLGCAISCEKKQDHIQRIMTLEESVQHVVMEAIQELMTKDTPD SLSPETYGNFDSQSRRYYFLSEEAEEGDELQQRCLDLERQLMLLSEEKQSLAQENAGLRERMGRPEGEGTPGLTAKKLLLLQSQLEQLQE ENFRLESGREDERLRCAELEREVAELQHRNQALTSLAQEAQALKDEMDELRQSSERAGQLEATLTSCRRRLGELRELRRQVRQLEERNAG HAERTRQLEDELRRAGSLRAQLEAQRRQVQELQGQRQEEAMKAEKWLFECRNLEEKYESVTKEKERLLAERDSLREANEELRCAQLQPRG LTQADPSLDPTSTPVDNLAAEILPAELRETLLRLQLENKRLCRQEAADRERQEELQRHLEDANRARHGLETQHRLNQQQLSELRAQVEDL QKALQEQGGKTEDAISILLKRKLEEHLQKLHEADLELQRKREYIEELEPPTDSSTARRIEELQHNLQKKDADLRAMEERYRRYVDKARMV MQTMEPKQRPAAGAPPELHSLRTQLRERDVRIRHLEMDFEKSRSQREQEEKLLISAWYNMGMALQQRAGEERAPAHAQSFLAQQRLATNS -------------------------------------------------------------- >60480_60480_3_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000350991_HOOK2_chr19_12885711_ENST00000264827_length(transcript)=2512nt_BP=125nt GGAAGGCGCACGGGGCGAAGATGGCGGCGGAGCGACAGGAGGCGCTGAGGGAGTTCGTGGCGGTGACGGGCGCCGAGGAGGACCGGGCCC GCTTCTTTCTCGAGTCGGCCGGCTGGGACTTGCAGTTACAGACGTTCCACGTTCCGTCTCCCTGTGCCAGCCCTCAGGACCTGAGCAGCG GCCTTGCCGTAGCCTATGTGCTGAACCAGATAGACCCCTCCTGGTTCAACGAGGCATGGCTCCAGGGCATCTCGGAAGATCCAGGTCCCA ACTGGAAGCTGAAGGTCAGCAATCTGAAGATGGTCTTACGGAGCCTAGTAGAGTACTCCCAGGATGTCCTGGCGCATCCTGTGTCAGAAG AGCATCTCCCAGATGTGAGCCTCATTGGAGAGTTCTCAGACCCGGCAGAGCTCGGCAAGCTGCTTCAGCTGGTGCTGGGCTGTGCCATCA GTTGCGAGAAAAAGCAGGACCACATCCAGAGAATCATGACGCTGGAAGAATCGGTTCAGCATGTGGTGATGGAAGCCATCCAAGAGCTCA TGACCAAAGACACTCCTGACTCCCTGTCACCAGAGACGTATGGCAACTTTGACAGCCAGTCCCGCAGGTACTATTTCCTAAGTGAGGAGG CTGAGGAGGGGGACGAATTACAGCAGCGCTGTCTGGATCTGGAGCGGCAGCTGATGCTCCTGTCAGAGGAGAAGCAGAGCCTGGCGCAAG AGAATGCAGGGCTGCGGGAGCGGATGGGCCGGCCTGAAGGCGAGGGTACCCCAGGTCTCACTGCCAAGAAGCTGCTGCTGCTGCAATCCC AGCTGGAGCAGTTGCAGGAGGAGAACTTCAGGCTGGAGAGTGGCAGGGAGGATGAGCGCCTGCGCTGTGCCGAGCTGGAGAGGGAGGTTG CGGAGCTGCAGCACCGGAACCAGGCGCTGACTAGCCTGGCCCAGGAGGCACAGGCCCTGAAGGATGAGATGGATGAACTACGGCAGTCTT CGGAGCGTGCTGGGCAGCTGGAGGCCACGCTGACCAGTTGCCGGCGCCGCTTGGGCGAGCTGAGGGAGCTGCGGCGGCAGGTGCGGCAGC TGGAGGAACGCAACGCCGGCCACGCCGAGCGCACGCGACAACTGGAGGATGAGCTACGCCGAGCGGGCTCCCTGCGCGCCCAGCTGGAGG CGCAGCGGCGGCAGGTGCAGGAACTGCAGGGCCAGCGGCAGGAGGAGGCCATGAAGGCCGAGAAATGGCTATTTGAATGCCGCAACCTGG AGGAAAAGTATGAGTCGGTGACAAAGGAGAAGGAGCGGCTGTTGGCGGAGCGGGACTCCTTGCGGGAGGCCAATGAGGAGCTGCGCTGCG CCCAGCTGCAGCCGCGGGGGTTGACCCAGGCCGATCCCTCACTGGATCCCACCTCCACACCCGTGGATAACTTAGCCGCAGAGATCCTGC CTGCGGAGCTCAGGGAGACGCTCCTGCGGCTTCAGCTGGAGAACAAGCGGCTGTGCAGGCAGGAGGCGGCCGACCGGGAGCGGCAGGAGG AGCTGCAGCGCCACCTGGAGGATGCCAACCGCGCGCGCCACGGGTTGGAGACGCAGCACCGGCTGAACCAGCAGCAGCTATCCGAGCTGC GGGCCCAGGTGGAGGACCTGCAGAAAGCCCTGCAGGAGCAGGGGGGCAAGACTGAAGATTCCATTTTGCTGAAAAGGAAGCTGGAGGAAC ATTTGCAGAAGCTTCATGAGGCAGATCTGGAGTTGCAGAGGAAGCGGGAGTACATTGAGGAGCTGGAGCCACCCACTGACAGCAGCACAG CCCGGCGGATCGAGGAGCTGCAGCATAACTTGCAGAAGAAGGACGCGGACTTGCGGGCCATGGAGGAGCGATACCGCCGCTACGTGGACA AGGCCCGCATGGTCATGCAGACCATGGAACCCAAGCAGCGGCCAGCTGCGGGGGCACCTCCAGAACTCCATTCCCTGAGGACACAGCTCC GAGAACGGGATGTCCGCATCCGACACCTGGAGATGGACTTTGAGAAAAGCCGAAGTCAGCGGGAGCAGGAAGAAAAGCTGCTCATCAGTG CCTGGTATAATATGGGCATGGCCTTGCAGCAGCGAGCTGGGGAGGAGCGGGCGCCTGCCCATGCCCAGTCATTCCTGGCACAGCAGCGGC TGGCAACCAATTCTCGCCGTGGACCCTTGGGACGCCTGGCATCTCTGAACCTTCGCCCCACTGACAAGCACTGACAGACCTCACAATCAA GCCAGCCTGGGCTCCACCCACCCTGGCTTCCTCCAGCTCACATGGCGCCCAGCACTGGGCTTCAGCCAGGTGCTCGAGAGCTTTGAGGCC ATGATCTCTGCTCTTCCCTCTCCCAGATTGGTGGGGAGGGAGGGCGGGAGGTAGATATAGGCCTGTTCTTTTTAGCAATGTGATTCTTGT >60480_60480_3_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000350991_HOOK2_chr19_12885711_ENST00000264827_length(amino acids)=737AA_BP=34 MAAERQEALREFVAVTGAEEDRARFFLESAGWDLQLQTFHVPSPCASPQDLSSGLAVAYVLNQIDPSWFNEAWLQGISEDPGPNWKLKVS NLKMVLRSLVEYSQDVLAHPVSEEHLPDVSLIGEFSDPAELGKLLQLVLGCAISCEKKQDHIQRIMTLEESVQHVVMEAIQELMTKDTPD SLSPETYGNFDSQSRRYYFLSEEAEEGDELQQRCLDLERQLMLLSEEKQSLAQENAGLRERMGRPEGEGTPGLTAKKLLLLQSQLEQLQE ENFRLESGREDERLRCAELEREVAELQHRNQALTSLAQEAQALKDEMDELRQSSERAGQLEATLTSCRRRLGELRELRRQVRQLEERNAG HAERTRQLEDELRRAGSLRAQLEAQRRQVQELQGQRQEEAMKAEKWLFECRNLEEKYESVTKEKERLLAERDSLREANEELRCAQLQPRG LTQADPSLDPTSTPVDNLAAEILPAELRETLLRLQLENKRLCRQEAADRERQEELQRHLEDANRARHGLETQHRLNQQQLSELRAQVEDL QKALQEQGGKTEDSILLKRKLEEHLQKLHEADLELQRKREYIEELEPPTDSSTARRIEELQHNLQKKDADLRAMEERYRRYVDKARMVMQ TMEPKQRPAAGAPPELHSLRTQLRERDVRIRHLEMDFEKSRSQREQEEKLLISAWYNMGMALQQRAGEERAPAHAQSFLAQQRLATNSRR -------------------------------------------------------------- >60480_60480_4_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000350991_HOOK2_chr19_12885711_ENST00000397668_length(transcript)=2519nt_BP=125nt GGAAGGCGCACGGGGCGAAGATGGCGGCGGAGCGACAGGAGGCGCTGAGGGAGTTCGTGGCGGTGACGGGCGCCGAGGAGGACCGGGCCC GCTTCTTTCTCGAGTCGGCCGGCTGGGACTTGCAGTTACAGACGTTCCACGTTCCGTCTCCCTGTGCCAGCCCTCAGGACCTGAGCAGCG GCCTTGCCGTAGCCTATGTGCTGAACCAGATAGACCCCTCCTGGTTCAACGAGGCATGGCTCCAGGGCATCTCGGAAGATCCAGGTCCCA ACTGGAAGCTGAAGGTCAGCAATCTGAAGATGGTCTTACGGAGCCTAGTAGAGTACTCCCAGGATGTCCTGGCGCATCCTGTGTCAGAAG AGCATCTCCCAGATGTGAGCCTCATTGGAGAGTTCTCAGACCCGGCAGAGCTCGGCAAGCTGCTTCAGCTGGTGCTGGGCTGTGCCATCA GTTGCGAGAAAAAGCAGGACCACATCCAGAGAATCATGACGCTGGAAGAATCGGTTCAGCATGTGGTGATGGAAGCCATCCAAGAGCTCA TGACCAAAGACACTCCTGACTCCCTGTCACCAGAGACGTATGGCAACTTTGACAGCCAGTCCCGCAGGTACTATTTCCTAAGTGAGGAGG CTGAGGAGGGGGACGAATTACAGCAGCGCTGTCTGGATCTGGAGCGGCAGCTGATGCTCCTGTCAGAGGAGAAGCAGAGCCTGGCGCAAG AGAATGCAGGGCTGCGGGAGCGGATGGGCCGGCCTGAAGGCGAGGGTACCCCAGGTCTCACTGCCAAGAAGCTGCTGCTGCTGCAATCCC AGCTGGAGCAGTTGCAGGAGGAGAACTTCAGGCTGGAGAGTGGCAGGGAGGATGAGCGCCTGCGCTGTGCCGAGCTGGAGAGGGAGGTTG CGGAGCTGCAGCACCGGAACCAGGCGCTGACTAGCCTGGCCCAGGAGGCACAGGCCCTGAAGGATGAGATGGATGAACTACGGCAGTCTT CGGAGCGTGCTGGGCAGCTGGAGGCCACGCTGACCAGTTGCCGGCGCCGCTTGGGCGAGCTGAGGGAGCTGCGGCGGCAGGTGCGGCAGC TGGAGGAACGCAACGCCGGCCACGCCGAGCGCACGCGACAACTGGAGGATGAGCTACGCCGAGCGGGCTCCCTGCGCGCCCAGCTGGAGG CGCAGCGGCGGCAGGTGCAGGAACTGCAGGGCCAGCGGCAGGAGGAGGCCATGAAGGCCGAGAAATGGCTATTTGAATGCCGCAACCTGG AGGAAAAGTATGAGTCGGTGACAAAGGAGAAGGAGCGGCTGTTGGCGGAGCGGGACTCCTTGCGGGAGGCCAATGAGGAGCTGCGCTGCG CCCAGCTGCAGCCGCGGGGGTTGACCCAGGCCGATCCCTCACTGGATCCCACCTCCACACCCGTGGATAACTTAGCCGCAGAGATCCTGC CTGCGGAGCTCAGGGAGACGCTCCTGCGGCTTCAGCTGGAGAACAAGCGGCTGTGCAGGCAGGAGGCGGCCGACCGGGAGCGGCAGGAGG AGCTGCAGCGCCACCTGGAGGATGCCAACCGCGCGCGCCACGGGTTGGAGACGCAGCACCGGCTGAACCAGCAGCAGCTATCCGAGCTGC GGGCCCAGGTGGAGGACCTGCAGAAAGCCCTGCAGGAGCAGGGGGGCAAGACTGAAGATGCCATTTCCATTTTGCTGAAAAGGAAGCTGG AGGAACATTTGCAGAAGCTTCATGAGGCAGATCTGGAGTTGCAGAGGAAGCGGGAGTACATTGAGGAGCTGGAGCCACCCACTGACAGCA GCACAGCCCGGCGGATCGAGGAGCTGCAGCATAACTTGCAGAAGAAGGACGCGGACTTGCGGGCCATGGAGGAGCGATACCGCCGCTACG TGGACAAGGCCCGCATGGTCATGCAGACCATGGAACCCAAGCAGCGGCCAGCTGCGGGGGCACCTCCAGAACTCCATTCCCTGAGGACAC AGCTCCGAGAACGGGATGTCCGCATCCGACACCTGGAGATGGACTTTGAGAAAAGCCGAAGTCAGCGGGAGCAGGAAGAAAAGCTGCTCA TCAGTGCCTGGTATAATATGGGCATGGCCTTGCAGCAGCGAGCTGGGGAGGAGCGGGCGCCTGCCCATGCCCAGTCATTCCTGGCACAGC AGCGGCTGGCAACCAATTCTCGCCGTGGACCCTTGGGACGCCTGGCATCTCTGAACCTTCGCCCCACTGACAAGCACTGACAGACCTCAC AATCAAGCCAGCCTGGGCTCCACCCACCCTGGCTTCCTCCAGCTCACATGGCGCCCAGCACTGGGCTTCAGCCAGGTGCTCGAGAGCTTT GAGGCCATGATCTCTGCTCTTCCCTCTCCCAGATTGGTGGGGAGGGAGGGCGGGAGGTAGATATAGGCCTGTTCTTTTTAGCAATGTGAT >60480_60480_4_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000350991_HOOK2_chr19_12885711_ENST00000397668_length(amino acids)=739AA_BP=34 MAAERQEALREFVAVTGAEEDRARFFLESAGWDLQLQTFHVPSPCASPQDLSSGLAVAYVLNQIDPSWFNEAWLQGISEDPGPNWKLKVS NLKMVLRSLVEYSQDVLAHPVSEEHLPDVSLIGEFSDPAELGKLLQLVLGCAISCEKKQDHIQRIMTLEESVQHVVMEAIQELMTKDTPD SLSPETYGNFDSQSRRYYFLSEEAEEGDELQQRCLDLERQLMLLSEEKQSLAQENAGLRERMGRPEGEGTPGLTAKKLLLLQSQLEQLQE ENFRLESGREDERLRCAELEREVAELQHRNQALTSLAQEAQALKDEMDELRQSSERAGQLEATLTSCRRRLGELRELRRQVRQLEERNAG HAERTRQLEDELRRAGSLRAQLEAQRRQVQELQGQRQEEAMKAEKWLFECRNLEEKYESVTKEKERLLAERDSLREANEELRCAQLQPRG LTQADPSLDPTSTPVDNLAAEILPAELRETLLRLQLENKRLCRQEAADRERQEELQRHLEDANRARHGLETQHRLNQQQLSELRAQVEDL QKALQEQGGKTEDAISILLKRKLEEHLQKLHEADLELQRKREYIEELEPPTDSSTARRIEELQHNLQKKDADLRAMEERYRRYVDKARMV MQTMEPKQRPAAGAPPELHSLRTQLRERDVRIRHLEMDFEKSRSQREQEEKLLISAWYNMGMALQQRAGEERAPAHAQSFLAQQRLATNS -------------------------------------------------------------- >60480_60480_5_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000353088_HOOK2_chr19_12885711_ENST00000264827_length(transcript)=2496nt_BP=109nt GAAGATGGCGGCGGAGCGACAGGAGGCGCTGAGGGAGTTCGTGGCGGTGACGGGCGCCGAGGAGGACCGGGCCCGCTTCTTTCTCGAGTC GGCCGGCTGGGACTTGCAGTTACAGACGTTCCACGTTCCGTCTCCCTGTGCCAGCCCTCAGGACCTGAGCAGCGGCCTTGCCGTAGCCTA TGTGCTGAACCAGATAGACCCCTCCTGGTTCAACGAGGCATGGCTCCAGGGCATCTCGGAAGATCCAGGTCCCAACTGGAAGCTGAAGGT CAGCAATCTGAAGATGGTCTTACGGAGCCTAGTAGAGTACTCCCAGGATGTCCTGGCGCATCCTGTGTCAGAAGAGCATCTCCCAGATGT GAGCCTCATTGGAGAGTTCTCAGACCCGGCAGAGCTCGGCAAGCTGCTTCAGCTGGTGCTGGGCTGTGCCATCAGTTGCGAGAAAAAGCA GGACCACATCCAGAGAATCATGACGCTGGAAGAATCGGTTCAGCATGTGGTGATGGAAGCCATCCAAGAGCTCATGACCAAAGACACTCC TGACTCCCTGTCACCAGAGACGTATGGCAACTTTGACAGCCAGTCCCGCAGGTACTATTTCCTAAGTGAGGAGGCTGAGGAGGGGGACGA ATTACAGCAGCGCTGTCTGGATCTGGAGCGGCAGCTGATGCTCCTGTCAGAGGAGAAGCAGAGCCTGGCGCAAGAGAATGCAGGGCTGCG GGAGCGGATGGGCCGGCCTGAAGGCGAGGGTACCCCAGGTCTCACTGCCAAGAAGCTGCTGCTGCTGCAATCCCAGCTGGAGCAGTTGCA GGAGGAGAACTTCAGGCTGGAGAGTGGCAGGGAGGATGAGCGCCTGCGCTGTGCCGAGCTGGAGAGGGAGGTTGCGGAGCTGCAGCACCG GAACCAGGCGCTGACTAGCCTGGCCCAGGAGGCACAGGCCCTGAAGGATGAGATGGATGAACTACGGCAGTCTTCGGAGCGTGCTGGGCA GCTGGAGGCCACGCTGACCAGTTGCCGGCGCCGCTTGGGCGAGCTGAGGGAGCTGCGGCGGCAGGTGCGGCAGCTGGAGGAACGCAACGC CGGCCACGCCGAGCGCACGCGACAACTGGAGGATGAGCTACGCCGAGCGGGCTCCCTGCGCGCCCAGCTGGAGGCGCAGCGGCGGCAGGT GCAGGAACTGCAGGGCCAGCGGCAGGAGGAGGCCATGAAGGCCGAGAAATGGCTATTTGAATGCCGCAACCTGGAGGAAAAGTATGAGTC GGTGACAAAGGAGAAGGAGCGGCTGTTGGCGGAGCGGGACTCCTTGCGGGAGGCCAATGAGGAGCTGCGCTGCGCCCAGCTGCAGCCGCG GGGGTTGACCCAGGCCGATCCCTCACTGGATCCCACCTCCACACCCGTGGATAACTTAGCCGCAGAGATCCTGCCTGCGGAGCTCAGGGA GACGCTCCTGCGGCTTCAGCTGGAGAACAAGCGGCTGTGCAGGCAGGAGGCGGCCGACCGGGAGCGGCAGGAGGAGCTGCAGCGCCACCT GGAGGATGCCAACCGCGCGCGCCACGGGTTGGAGACGCAGCACCGGCTGAACCAGCAGCAGCTATCCGAGCTGCGGGCCCAGGTGGAGGA CCTGCAGAAAGCCCTGCAGGAGCAGGGGGGCAAGACTGAAGATTCCATTTTGCTGAAAAGGAAGCTGGAGGAACATTTGCAGAAGCTTCA TGAGGCAGATCTGGAGTTGCAGAGGAAGCGGGAGTACATTGAGGAGCTGGAGCCACCCACTGACAGCAGCACAGCCCGGCGGATCGAGGA GCTGCAGCATAACTTGCAGAAGAAGGACGCGGACTTGCGGGCCATGGAGGAGCGATACCGCCGCTACGTGGACAAGGCCCGCATGGTCAT GCAGACCATGGAACCCAAGCAGCGGCCAGCTGCGGGGGCACCTCCAGAACTCCATTCCCTGAGGACACAGCTCCGAGAACGGGATGTCCG CATCCGACACCTGGAGATGGACTTTGAGAAAAGCCGAAGTCAGCGGGAGCAGGAAGAAAAGCTGCTCATCAGTGCCTGGTATAATATGGG CATGGCCTTGCAGCAGCGAGCTGGGGAGGAGCGGGCGCCTGCCCATGCCCAGTCATTCCTGGCACAGCAGCGGCTGGCAACCAATTCTCG CCGTGGACCCTTGGGACGCCTGGCATCTCTGAACCTTCGCCCCACTGACAAGCACTGACAGACCTCACAATCAAGCCAGCCTGGGCTCCA CCCACCCTGGCTTCCTCCAGCTCACATGGCGCCCAGCACTGGGCTTCAGCCAGGTGCTCGAGAGCTTTGAGGCCATGATCTCTGCTCTTC CCTCTCCCAGATTGGTGGGGAGGGAGGGCGGGAGGTAGATATAGGCCTGTTCTTTTTAGCAATGTGATTCTTGTTGTTGATTCTCTCTCT >60480_60480_5_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000353088_HOOK2_chr19_12885711_ENST00000264827_length(amino acids)=737AA_BP=34 MAAERQEALREFVAVTGAEEDRARFFLESAGWDLQLQTFHVPSPCASPQDLSSGLAVAYVLNQIDPSWFNEAWLQGISEDPGPNWKLKVS NLKMVLRSLVEYSQDVLAHPVSEEHLPDVSLIGEFSDPAELGKLLQLVLGCAISCEKKQDHIQRIMTLEESVQHVVMEAIQELMTKDTPD SLSPETYGNFDSQSRRYYFLSEEAEEGDELQQRCLDLERQLMLLSEEKQSLAQENAGLRERMGRPEGEGTPGLTAKKLLLLQSQLEQLQE ENFRLESGREDERLRCAELEREVAELQHRNQALTSLAQEAQALKDEMDELRQSSERAGQLEATLTSCRRRLGELRELRRQVRQLEERNAG HAERTRQLEDELRRAGSLRAQLEAQRRQVQELQGQRQEEAMKAEKWLFECRNLEEKYESVTKEKERLLAERDSLREANEELRCAQLQPRG LTQADPSLDPTSTPVDNLAAEILPAELRETLLRLQLENKRLCRQEAADRERQEELQRHLEDANRARHGLETQHRLNQQQLSELRAQVEDL QKALQEQGGKTEDSILLKRKLEEHLQKLHEADLELQRKREYIEELEPPTDSSTARRIEELQHNLQKKDADLRAMEERYRRYVDKARMVMQ TMEPKQRPAAGAPPELHSLRTQLRERDVRIRHLEMDFEKSRSQREQEEKLLISAWYNMGMALQQRAGEERAPAHAQSFLAQQRLATNSRR -------------------------------------------------------------- >60480_60480_6_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000353088_HOOK2_chr19_12885711_ENST00000397668_length(transcript)=2503nt_BP=109nt GAAGATGGCGGCGGAGCGACAGGAGGCGCTGAGGGAGTTCGTGGCGGTGACGGGCGCCGAGGAGGACCGGGCCCGCTTCTTTCTCGAGTC GGCCGGCTGGGACTTGCAGTTACAGACGTTCCACGTTCCGTCTCCCTGTGCCAGCCCTCAGGACCTGAGCAGCGGCCTTGCCGTAGCCTA TGTGCTGAACCAGATAGACCCCTCCTGGTTCAACGAGGCATGGCTCCAGGGCATCTCGGAAGATCCAGGTCCCAACTGGAAGCTGAAGGT CAGCAATCTGAAGATGGTCTTACGGAGCCTAGTAGAGTACTCCCAGGATGTCCTGGCGCATCCTGTGTCAGAAGAGCATCTCCCAGATGT GAGCCTCATTGGAGAGTTCTCAGACCCGGCAGAGCTCGGCAAGCTGCTTCAGCTGGTGCTGGGCTGTGCCATCAGTTGCGAGAAAAAGCA GGACCACATCCAGAGAATCATGACGCTGGAAGAATCGGTTCAGCATGTGGTGATGGAAGCCATCCAAGAGCTCATGACCAAAGACACTCC TGACTCCCTGTCACCAGAGACGTATGGCAACTTTGACAGCCAGTCCCGCAGGTACTATTTCCTAAGTGAGGAGGCTGAGGAGGGGGACGA ATTACAGCAGCGCTGTCTGGATCTGGAGCGGCAGCTGATGCTCCTGTCAGAGGAGAAGCAGAGCCTGGCGCAAGAGAATGCAGGGCTGCG GGAGCGGATGGGCCGGCCTGAAGGCGAGGGTACCCCAGGTCTCACTGCCAAGAAGCTGCTGCTGCTGCAATCCCAGCTGGAGCAGTTGCA GGAGGAGAACTTCAGGCTGGAGAGTGGCAGGGAGGATGAGCGCCTGCGCTGTGCCGAGCTGGAGAGGGAGGTTGCGGAGCTGCAGCACCG GAACCAGGCGCTGACTAGCCTGGCCCAGGAGGCACAGGCCCTGAAGGATGAGATGGATGAACTACGGCAGTCTTCGGAGCGTGCTGGGCA GCTGGAGGCCACGCTGACCAGTTGCCGGCGCCGCTTGGGCGAGCTGAGGGAGCTGCGGCGGCAGGTGCGGCAGCTGGAGGAACGCAACGC CGGCCACGCCGAGCGCACGCGACAACTGGAGGATGAGCTACGCCGAGCGGGCTCCCTGCGCGCCCAGCTGGAGGCGCAGCGGCGGCAGGT GCAGGAACTGCAGGGCCAGCGGCAGGAGGAGGCCATGAAGGCCGAGAAATGGCTATTTGAATGCCGCAACCTGGAGGAAAAGTATGAGTC GGTGACAAAGGAGAAGGAGCGGCTGTTGGCGGAGCGGGACTCCTTGCGGGAGGCCAATGAGGAGCTGCGCTGCGCCCAGCTGCAGCCGCG GGGGTTGACCCAGGCCGATCCCTCACTGGATCCCACCTCCACACCCGTGGATAACTTAGCCGCAGAGATCCTGCCTGCGGAGCTCAGGGA GACGCTCCTGCGGCTTCAGCTGGAGAACAAGCGGCTGTGCAGGCAGGAGGCGGCCGACCGGGAGCGGCAGGAGGAGCTGCAGCGCCACCT GGAGGATGCCAACCGCGCGCGCCACGGGTTGGAGACGCAGCACCGGCTGAACCAGCAGCAGCTATCCGAGCTGCGGGCCCAGGTGGAGGA CCTGCAGAAAGCCCTGCAGGAGCAGGGGGGCAAGACTGAAGATGCCATTTCCATTTTGCTGAAAAGGAAGCTGGAGGAACATTTGCAGAA GCTTCATGAGGCAGATCTGGAGTTGCAGAGGAAGCGGGAGTACATTGAGGAGCTGGAGCCACCCACTGACAGCAGCACAGCCCGGCGGAT CGAGGAGCTGCAGCATAACTTGCAGAAGAAGGACGCGGACTTGCGGGCCATGGAGGAGCGATACCGCCGCTACGTGGACAAGGCCCGCAT GGTCATGCAGACCATGGAACCCAAGCAGCGGCCAGCTGCGGGGGCACCTCCAGAACTCCATTCCCTGAGGACACAGCTCCGAGAACGGGA TGTCCGCATCCGACACCTGGAGATGGACTTTGAGAAAAGCCGAAGTCAGCGGGAGCAGGAAGAAAAGCTGCTCATCAGTGCCTGGTATAA TATGGGCATGGCCTTGCAGCAGCGAGCTGGGGAGGAGCGGGCGCCTGCCCATGCCCAGTCATTCCTGGCACAGCAGCGGCTGGCAACCAA TTCTCGCCGTGGACCCTTGGGACGCCTGGCATCTCTGAACCTTCGCCCCACTGACAAGCACTGACAGACCTCACAATCAAGCCAGCCTGG GCTCCACCCACCCTGGCTTCCTCCAGCTCACATGGCGCCCAGCACTGGGCTTCAGCCAGGTGCTCGAGAGCTTTGAGGCCATGATCTCTG CTCTTCCCTCTCCCAGATTGGTGGGGAGGGAGGGCGGGAGGTAGATATAGGCCTGTTCTTTTTAGCAATGTGATTCTTGTTGTTGATTCT >60480_60480_6_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000353088_HOOK2_chr19_12885711_ENST00000397668_length(amino acids)=739AA_BP=34 MAAERQEALREFVAVTGAEEDRARFFLESAGWDLQLQTFHVPSPCASPQDLSSGLAVAYVLNQIDPSWFNEAWLQGISEDPGPNWKLKVS NLKMVLRSLVEYSQDVLAHPVSEEHLPDVSLIGEFSDPAELGKLLQLVLGCAISCEKKQDHIQRIMTLEESVQHVVMEAIQELMTKDTPD SLSPETYGNFDSQSRRYYFLSEEAEEGDELQQRCLDLERQLMLLSEEKQSLAQENAGLRERMGRPEGEGTPGLTAKKLLLLQSQLEQLQE ENFRLESGREDERLRCAELEREVAELQHRNQALTSLAQEAQALKDEMDELRQSSERAGQLEATLTSCRRRLGELRELRRQVRQLEERNAG HAERTRQLEDELRRAGSLRAQLEAQRRQVQELQGQRQEEAMKAEKWLFECRNLEEKYESVTKEKERLLAERDSLREANEELRCAQLQPRG LTQADPSLDPTSTPVDNLAAEILPAELRETLLRLQLENKRLCRQEAADRERQEELQRHLEDANRARHGLETQHRLNQQQLSELRAQVEDL QKALQEQGGKTEDAISILLKRKLEEHLQKLHEADLELQRKREYIEELEPPTDSSTARRIEELQHNLQKKDADLRAMEERYRRYVDKARMV MQTMEPKQRPAAGAPPELHSLRTQLRERDVRIRHLEMDFEKSRSQREQEEKLLISAWYNMGMALQQRAGEERAPAHAQSFLAQQRLATNS -------------------------------------------------------------- >60480_60480_7_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000476071_HOOK2_chr19_12885711_ENST00000264827_length(transcript)=2586nt_BP=199nt GGCTGGGCCTCGTCGACCGGCAAGCGGAACGCGGCAGCGGGGCTGGGCCTGTGCGGCGGCCGCCGGAGCGCTTTGGAAGGCGCACGGGGC GAAGATGGCGGCGGAGCGACAGGAGGCGCTGAGGGAGTTCGTGGCGGTGACGGGCGCCGAGGAGGACCGGGCCCGCTTCTTTCTCGAGTC GGCCGGCTGGGACTTGCAGTTACAGACGTTCCACGTTCCGTCTCCCTGTGCCAGCCCTCAGGACCTGAGCAGCGGCCTTGCCGTAGCCTA TGTGCTGAACCAGATAGACCCCTCCTGGTTCAACGAGGCATGGCTCCAGGGCATCTCGGAAGATCCAGGTCCCAACTGGAAGCTGAAGGT CAGCAATCTGAAGATGGTCTTACGGAGCCTAGTAGAGTACTCCCAGGATGTCCTGGCGCATCCTGTGTCAGAAGAGCATCTCCCAGATGT GAGCCTCATTGGAGAGTTCTCAGACCCGGCAGAGCTCGGCAAGCTGCTTCAGCTGGTGCTGGGCTGTGCCATCAGTTGCGAGAAAAAGCA GGACCACATCCAGAGAATCATGACGCTGGAAGAATCGGTTCAGCATGTGGTGATGGAAGCCATCCAAGAGCTCATGACCAAAGACACTCC TGACTCCCTGTCACCAGAGACGTATGGCAACTTTGACAGCCAGTCCCGCAGGTACTATTTCCTAAGTGAGGAGGCTGAGGAGGGGGACGA ATTACAGCAGCGCTGTCTGGATCTGGAGCGGCAGCTGATGCTCCTGTCAGAGGAGAAGCAGAGCCTGGCGCAAGAGAATGCAGGGCTGCG GGAGCGGATGGGCCGGCCTGAAGGCGAGGGTACCCCAGGTCTCACTGCCAAGAAGCTGCTGCTGCTGCAATCCCAGCTGGAGCAGTTGCA GGAGGAGAACTTCAGGCTGGAGAGTGGCAGGGAGGATGAGCGCCTGCGCTGTGCCGAGCTGGAGAGGGAGGTTGCGGAGCTGCAGCACCG GAACCAGGCGCTGACTAGCCTGGCCCAGGAGGCACAGGCCCTGAAGGATGAGATGGATGAACTACGGCAGTCTTCGGAGCGTGCTGGGCA GCTGGAGGCCACGCTGACCAGTTGCCGGCGCCGCTTGGGCGAGCTGAGGGAGCTGCGGCGGCAGGTGCGGCAGCTGGAGGAACGCAACGC CGGCCACGCCGAGCGCACGCGACAACTGGAGGATGAGCTACGCCGAGCGGGCTCCCTGCGCGCCCAGCTGGAGGCGCAGCGGCGGCAGGT GCAGGAACTGCAGGGCCAGCGGCAGGAGGAGGCCATGAAGGCCGAGAAATGGCTATTTGAATGCCGCAACCTGGAGGAAAAGTATGAGTC GGTGACAAAGGAGAAGGAGCGGCTGTTGGCGGAGCGGGACTCCTTGCGGGAGGCCAATGAGGAGCTGCGCTGCGCCCAGCTGCAGCCGCG GGGGTTGACCCAGGCCGATCCCTCACTGGATCCCACCTCCACACCCGTGGATAACTTAGCCGCAGAGATCCTGCCTGCGGAGCTCAGGGA GACGCTCCTGCGGCTTCAGCTGGAGAACAAGCGGCTGTGCAGGCAGGAGGCGGCCGACCGGGAGCGGCAGGAGGAGCTGCAGCGCCACCT GGAGGATGCCAACCGCGCGCGCCACGGGTTGGAGACGCAGCACCGGCTGAACCAGCAGCAGCTATCCGAGCTGCGGGCCCAGGTGGAGGA CCTGCAGAAAGCCCTGCAGGAGCAGGGGGGCAAGACTGAAGATTCCATTTTGCTGAAAAGGAAGCTGGAGGAACATTTGCAGAAGCTTCA TGAGGCAGATCTGGAGTTGCAGAGGAAGCGGGAGTACATTGAGGAGCTGGAGCCACCCACTGACAGCAGCACAGCCCGGCGGATCGAGGA GCTGCAGCATAACTTGCAGAAGAAGGACGCGGACTTGCGGGCCATGGAGGAGCGATACCGCCGCTACGTGGACAAGGCCCGCATGGTCAT GCAGACCATGGAACCCAAGCAGCGGCCAGCTGCGGGGGCACCTCCAGAACTCCATTCCCTGAGGACACAGCTCCGAGAACGGGATGTCCG CATCCGACACCTGGAGATGGACTTTGAGAAAAGCCGAAGTCAGCGGGAGCAGGAAGAAAAGCTGCTCATCAGTGCCTGGTATAATATGGG CATGGCCTTGCAGCAGCGAGCTGGGGAGGAGCGGGCGCCTGCCCATGCCCAGTCATTCCTGGCACAGCAGCGGCTGGCAACCAATTCTCG CCGTGGACCCTTGGGACGCCTGGCATCTCTGAACCTTCGCCCCACTGACAAGCACTGACAGACCTCACAATCAAGCCAGCCTGGGCTCCA CCCACCCTGGCTTCCTCCAGCTCACATGGCGCCCAGCACTGGGCTTCAGCCAGGTGCTCGAGAGCTTTGAGGCCATGATCTCTGCTCTTC CCTCTCCCAGATTGGTGGGGAGGGAGGGCGGGAGGTAGATATAGGCCTGTTCTTTTTAGCAATGTGATTCTTGTTGTTGATTCTCTCTCT >60480_60480_7_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000476071_HOOK2_chr19_12885711_ENST00000264827_length(amino acids)=737AA_BP=34 MAAERQEALREFVAVTGAEEDRARFFLESAGWDLQLQTFHVPSPCASPQDLSSGLAVAYVLNQIDPSWFNEAWLQGISEDPGPNWKLKVS NLKMVLRSLVEYSQDVLAHPVSEEHLPDVSLIGEFSDPAELGKLLQLVLGCAISCEKKQDHIQRIMTLEESVQHVVMEAIQELMTKDTPD SLSPETYGNFDSQSRRYYFLSEEAEEGDELQQRCLDLERQLMLLSEEKQSLAQENAGLRERMGRPEGEGTPGLTAKKLLLLQSQLEQLQE ENFRLESGREDERLRCAELEREVAELQHRNQALTSLAQEAQALKDEMDELRQSSERAGQLEATLTSCRRRLGELRELRRQVRQLEERNAG HAERTRQLEDELRRAGSLRAQLEAQRRQVQELQGQRQEEAMKAEKWLFECRNLEEKYESVTKEKERLLAERDSLREANEELRCAQLQPRG LTQADPSLDPTSTPVDNLAAEILPAELRETLLRLQLENKRLCRQEAADRERQEELQRHLEDANRARHGLETQHRLNQQQLSELRAQVEDL QKALQEQGGKTEDSILLKRKLEEHLQKLHEADLELQRKREYIEELEPPTDSSTARRIEELQHNLQKKDADLRAMEERYRRYVDKARMVMQ TMEPKQRPAAGAPPELHSLRTQLRERDVRIRHLEMDFEKSRSQREQEEKLLISAWYNMGMALQQRAGEERAPAHAQSFLAQQRLATNSRR -------------------------------------------------------------- >60480_60480_8_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000476071_HOOK2_chr19_12885711_ENST00000397668_length(transcript)=2593nt_BP=199nt GGCTGGGCCTCGTCGACCGGCAAGCGGAACGCGGCAGCGGGGCTGGGCCTGTGCGGCGGCCGCCGGAGCGCTTTGGAAGGCGCACGGGGC GAAGATGGCGGCGGAGCGACAGGAGGCGCTGAGGGAGTTCGTGGCGGTGACGGGCGCCGAGGAGGACCGGGCCCGCTTCTTTCTCGAGTC GGCCGGCTGGGACTTGCAGTTACAGACGTTCCACGTTCCGTCTCCCTGTGCCAGCCCTCAGGACCTGAGCAGCGGCCTTGCCGTAGCCTA TGTGCTGAACCAGATAGACCCCTCCTGGTTCAACGAGGCATGGCTCCAGGGCATCTCGGAAGATCCAGGTCCCAACTGGAAGCTGAAGGT CAGCAATCTGAAGATGGTCTTACGGAGCCTAGTAGAGTACTCCCAGGATGTCCTGGCGCATCCTGTGTCAGAAGAGCATCTCCCAGATGT GAGCCTCATTGGAGAGTTCTCAGACCCGGCAGAGCTCGGCAAGCTGCTTCAGCTGGTGCTGGGCTGTGCCATCAGTTGCGAGAAAAAGCA GGACCACATCCAGAGAATCATGACGCTGGAAGAATCGGTTCAGCATGTGGTGATGGAAGCCATCCAAGAGCTCATGACCAAAGACACTCC TGACTCCCTGTCACCAGAGACGTATGGCAACTTTGACAGCCAGTCCCGCAGGTACTATTTCCTAAGTGAGGAGGCTGAGGAGGGGGACGA ATTACAGCAGCGCTGTCTGGATCTGGAGCGGCAGCTGATGCTCCTGTCAGAGGAGAAGCAGAGCCTGGCGCAAGAGAATGCAGGGCTGCG GGAGCGGATGGGCCGGCCTGAAGGCGAGGGTACCCCAGGTCTCACTGCCAAGAAGCTGCTGCTGCTGCAATCCCAGCTGGAGCAGTTGCA GGAGGAGAACTTCAGGCTGGAGAGTGGCAGGGAGGATGAGCGCCTGCGCTGTGCCGAGCTGGAGAGGGAGGTTGCGGAGCTGCAGCACCG GAACCAGGCGCTGACTAGCCTGGCCCAGGAGGCACAGGCCCTGAAGGATGAGATGGATGAACTACGGCAGTCTTCGGAGCGTGCTGGGCA GCTGGAGGCCACGCTGACCAGTTGCCGGCGCCGCTTGGGCGAGCTGAGGGAGCTGCGGCGGCAGGTGCGGCAGCTGGAGGAACGCAACGC CGGCCACGCCGAGCGCACGCGACAACTGGAGGATGAGCTACGCCGAGCGGGCTCCCTGCGCGCCCAGCTGGAGGCGCAGCGGCGGCAGGT GCAGGAACTGCAGGGCCAGCGGCAGGAGGAGGCCATGAAGGCCGAGAAATGGCTATTTGAATGCCGCAACCTGGAGGAAAAGTATGAGTC GGTGACAAAGGAGAAGGAGCGGCTGTTGGCGGAGCGGGACTCCTTGCGGGAGGCCAATGAGGAGCTGCGCTGCGCCCAGCTGCAGCCGCG GGGGTTGACCCAGGCCGATCCCTCACTGGATCCCACCTCCACACCCGTGGATAACTTAGCCGCAGAGATCCTGCCTGCGGAGCTCAGGGA GACGCTCCTGCGGCTTCAGCTGGAGAACAAGCGGCTGTGCAGGCAGGAGGCGGCCGACCGGGAGCGGCAGGAGGAGCTGCAGCGCCACCT GGAGGATGCCAACCGCGCGCGCCACGGGTTGGAGACGCAGCACCGGCTGAACCAGCAGCAGCTATCCGAGCTGCGGGCCCAGGTGGAGGA CCTGCAGAAAGCCCTGCAGGAGCAGGGGGGCAAGACTGAAGATGCCATTTCCATTTTGCTGAAAAGGAAGCTGGAGGAACATTTGCAGAA GCTTCATGAGGCAGATCTGGAGTTGCAGAGGAAGCGGGAGTACATTGAGGAGCTGGAGCCACCCACTGACAGCAGCACAGCCCGGCGGAT CGAGGAGCTGCAGCATAACTTGCAGAAGAAGGACGCGGACTTGCGGGCCATGGAGGAGCGATACCGCCGCTACGTGGACAAGGCCCGCAT GGTCATGCAGACCATGGAACCCAAGCAGCGGCCAGCTGCGGGGGCACCTCCAGAACTCCATTCCCTGAGGACACAGCTCCGAGAACGGGA TGTCCGCATCCGACACCTGGAGATGGACTTTGAGAAAAGCCGAAGTCAGCGGGAGCAGGAAGAAAAGCTGCTCATCAGTGCCTGGTATAA TATGGGCATGGCCTTGCAGCAGCGAGCTGGGGAGGAGCGGGCGCCTGCCCATGCCCAGTCATTCCTGGCACAGCAGCGGCTGGCAACCAA TTCTCGCCGTGGACCCTTGGGACGCCTGGCATCTCTGAACCTTCGCCCCACTGACAAGCACTGACAGACCTCACAATCAAGCCAGCCTGG GCTCCACCCACCCTGGCTTCCTCCAGCTCACATGGCGCCCAGCACTGGGCTTCAGCCAGGTGCTCGAGAGCTTTGAGGCCATGATCTCTG CTCTTCCCTCTCCCAGATTGGTGGGGAGGGAGGGCGGGAGGTAGATATAGGCCTGTTCTTTTTAGCAATGTGATTCTTGTTGTTGATTCT >60480_60480_8_NSFL1C-HOOK2_NSFL1C_chr20_1447365_ENST00000476071_HOOK2_chr19_12885711_ENST00000397668_length(amino acids)=739AA_BP=34 MAAERQEALREFVAVTGAEEDRARFFLESAGWDLQLQTFHVPSPCASPQDLSSGLAVAYVLNQIDPSWFNEAWLQGISEDPGPNWKLKVS NLKMVLRSLVEYSQDVLAHPVSEEHLPDVSLIGEFSDPAELGKLLQLVLGCAISCEKKQDHIQRIMTLEESVQHVVMEAIQELMTKDTPD SLSPETYGNFDSQSRRYYFLSEEAEEGDELQQRCLDLERQLMLLSEEKQSLAQENAGLRERMGRPEGEGTPGLTAKKLLLLQSQLEQLQE ENFRLESGREDERLRCAELEREVAELQHRNQALTSLAQEAQALKDEMDELRQSSERAGQLEATLTSCRRRLGELRELRRQVRQLEERNAG HAERTRQLEDELRRAGSLRAQLEAQRRQVQELQGQRQEEAMKAEKWLFECRNLEEKYESVTKEKERLLAERDSLREANEELRCAQLQPRG LTQADPSLDPTSTPVDNLAAEILPAELRETLLRLQLENKRLCRQEAADRERQEELQRHLEDANRARHGLETQHRLNQQQLSELRAQVEDL QKALQEQGGKTEDAISILLKRKLEEHLQKLHEADLELQRKREYIEELEPPTDSSTARRIEELQHNLQKKDADLRAMEERYRRYVDKARMV MQTMEPKQRPAAGAPPELHSLRTQLRERDVRIRHLEMDFEKSRSQREQEEKLLISAWYNMGMALQQRAGEERAPAHAQSFLAQQRLATNS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NSFL1C-HOOK2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NSFL1C-HOOK2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NSFL1C-HOOK2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies