
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NSMCE2-SNTB1 (FusionGDB2 ID:60531) |
Fusion Gene Summary for NSMCE2-SNTB1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NSMCE2-SNTB1 | Fusion gene ID: 60531 | Hgene | Tgene | Gene symbol | NSMCE2 | SNTB1 | Gene ID | 286053 | 6641 |
| Gene name | NSE2 (MMS21) homolog, SMC5-SMC6 complex SUMO ligase | syntrophin beta 1 | |
| Synonyms | C8orf36|MMS21|NSE2|ZMIZ7 | 59-DAP|A1B|BSYN2|DAPA1B|SNT2|SNT2B1|TIP-43 | |
| Cytomap | 8q24.13 | 8q24.12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | E3 SUMO-protein ligase NSE2E3 SUMO-protein transferase NSE2NSMCE2/PVT1 fusionPVT1/NSMCE2 fusionmethyl methanesulfonate sensitivity gene 21non-SMC element 2, MMS21 homolognon-structural maintenance of chromosomes element 2 homologzinc finger, MIZ-ty | beta-1-syntrophin59 kDa dystrophin-associated protein A1 basic component 1dystrophin-associated protein A1, 59kD, basic component 1syntrophin, beta 1 (dystrophin-associated protein A1, 59kDa, basic component 1)syntrophin-2tax interaction protein 43 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000287437, ENST00000517315, ENST00000522563, ENST00000521460, | ENST00000519177, ENST00000395601, ENST00000517992, | |
| Fusion gene scores | * DoF score | 23 X 24 X 7=3864 | 6 X 6 X 6=216 |
| # samples | 29 | 8 | |
| ** MAII score | log2(29/3864*10)=-3.73597028882084 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/216*10)=-1.43295940727611 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NSMCE2 [Title/Abstract] AND SNTB1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NSMCE2(126163519)-SNTB1(121587465), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across NSMCE2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SNTB1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A8-A08B-01A | NSMCE2 | chr8 | 126163519 | - | SNTB1 | chr8 | 121587465 | - |
| ChimerDB4 | BRCA | TCGA-A8-A08B-01A | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
Top |
Fusion Gene ORF analysis for NSMCE2-SNTB1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000287437 | ENST00000519177 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| 5CDS-5UTR | ENST00000517315 | ENST00000519177 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| 5CDS-5UTR | ENST00000522563 | ENST00000519177 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| In-frame | ENST00000287437 | ENST00000395601 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| In-frame | ENST00000287437 | ENST00000517992 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| In-frame | ENST00000517315 | ENST00000395601 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| In-frame | ENST00000517315 | ENST00000517992 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| In-frame | ENST00000522563 | ENST00000395601 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| In-frame | ENST00000522563 | ENST00000517992 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| intron-3CDS | ENST00000521460 | ENST00000395601 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| intron-3CDS | ENST00000521460 | ENST00000517992 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| intron-5UTR | ENST00000521460 | ENST00000519177 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000287437 | NSMCE2 | chr8 | 126163519 | + | ENST00000395601 | SNTB1 | chr8 | 121587465 | - | 4233 | 480 | 120 | 1100 | 326 |
| ENST00000287437 | NSMCE2 | chr8 | 126163519 | + | ENST00000517992 | SNTB1 | chr8 | 121587465 | - | 1457 | 480 | 120 | 1100 | 326 |
| ENST00000522563 | NSMCE2 | chr8 | 126163519 | + | ENST00000395601 | SNTB1 | chr8 | 121587465 | - | 4120 | 367 | 103 | 987 | 294 |
| ENST00000522563 | NSMCE2 | chr8 | 126163519 | + | ENST00000517992 | SNTB1 | chr8 | 121587465 | - | 1344 | 367 | 103 | 987 | 294 |
| ENST00000517315 | NSMCE2 | chr8 | 126163519 | + | ENST00000395601 | SNTB1 | chr8 | 121587465 | - | 4036 | 283 | 199 | 903 | 234 |
| ENST00000517315 | NSMCE2 | chr8 | 126163519 | + | ENST00000517992 | SNTB1 | chr8 | 121587465 | - | 1260 | 283 | 199 | 903 | 234 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000287437 | ENST00000395601 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - | 0.000939562 | 0.99906045 |
| ENST00000287437 | ENST00000517992 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - | 0.005361615 | 0.9946384 |
| ENST00000522563 | ENST00000395601 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - | 0.00094726 | 0.9990527 |
| ENST00000522563 | ENST00000517992 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - | 0.005728733 | 0.9942713 |
| ENST00000517315 | ENST00000395601 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - | 0.001322418 | 0.99867755 |
| ENST00000517315 | ENST00000517992 | NSMCE2 | chr8 | 126163519 | + | SNTB1 | chr8 | 121587465 | - | 0.006305798 | 0.9936941 |
Top |
Fusion Genomic Features for NSMCE2-SNTB1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
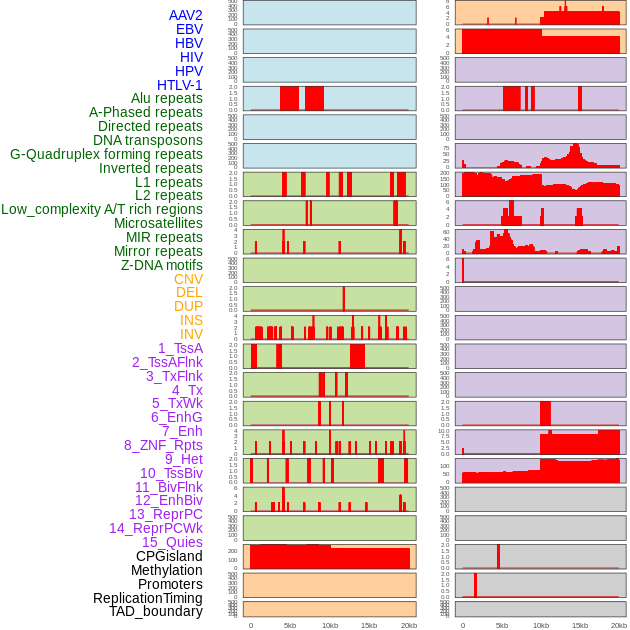 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NSMCE2-SNTB1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:126163519/chr8:121587465) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000395601 | 3 | 8 | 482_538 | 332 | 539.0 | Domain | Note=SU | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000517992 | 2 | 7 | 482_538 | 332 | 539.0 | Domain | Note=SU | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000395601 | 3 | 8 | 518_538 | 332 | 539.0 | Region | Calmodulin-binding | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000517992 | 2 | 7 | 518_538 | 332 | 539.0 | Region | Calmodulin-binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NSMCE2 | chr8:126163519 | chr8:121587465 | ENST00000287437 | + | 4 | 8 | 154_236 | 88 | 248.0 | Zinc finger | SP-RING-type |
| Hgene | NSMCE2 | chr8:126163519 | chr8:121587465 | ENST00000522563 | + | 3 | 7 | 154_236 | 88 | 248.0 | Zinc finger | SP-RING-type |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000395601 | 3 | 8 | 2_10 | 332 | 539.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000517992 | 2 | 7 | 2_10 | 332 | 539.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000395601 | 3 | 8 | 112_195 | 332 | 539.0 | Domain | PDZ | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000395601 | 3 | 8 | 19_298 | 332 | 539.0 | Domain | PH 1 | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000395601 | 3 | 8 | 322_433 | 332 | 539.0 | Domain | PH 2 | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000517992 | 2 | 7 | 112_195 | 332 | 539.0 | Domain | PDZ | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000517992 | 2 | 7 | 19_298 | 332 | 539.0 | Domain | PH 1 | |
| Tgene | SNTB1 | chr8:126163519 | chr8:121587465 | ENST00000517992 | 2 | 7 | 322_433 | 332 | 539.0 | Domain | PH 2 |
Top |
Fusion Gene Sequence for NSMCE2-SNTB1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >60531_60531_1_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000287437_SNTB1_chr8_121587465_ENST00000395601_length(transcript)=4233nt_BP=480nt GCCCGCTCTCACTTTTCAGCGGCAGGCGAAGGGGGCTGAGGAAAGGAGGTGGGTCTAGGCAGGGGAAATTGGGGTGCCACCAGACGGAGA CAGCTTGGACTACCAGAATCAAGCACTCTTTTGGAAGAGGGTAATCTCTCTCCAAAAACTGAGGACACTTACCTTCCCCATATATTGAGT CCAGCTGTGTTTGGTGGCCCAGGTACTAATTTCAAGATGCCAGGACGTTCCAGTTCAAATTCAGGTTCAACTGGTTTCATCTCCTTCAGT GGTGTAGAGTCTGCTCTCTCCTCCTTGAAAAACTTCCAAGCCTGTATCAACTCTGGTATGGACACAGCTTCTAGTGTTGCTTTGGATCTT GTGGAAAGTCAGACTGAAGTGAGTAGTGAATATAGTATGGACAAGGCAATGGTTGAATTTGCTACATTGGATCGGCAACTAAACCATTAT GTAAAGGCTGTTCAATCTACAATAAATCATGTGCCAGGGGAGAGCAAGAAACAGTGGAAACCAGCCCTGGTTGTGCTGACTGAGAAAGAC CTTTTAATCTATGACAGCATGCCACGGAGGAAGGAAGCCTGGTTCAGCCCAGTTCACACATACCCTCTTCTTGCCACCAGGCTGGTCCAT TCAGGTCCAGGAAAGGGATCACCCCAGGCTGGTGTGGATCTGTCCTTTGCAACGCGAACTGGTACCAGGCAAGGGATTGAAACACATCTC TTCAGAGCAGAGACCAGCAGGGACCTCTCCCACTGGACAAGGAGCATAGTACAGGGTTGCCACAATTCTGCTGAACTCATTGCTGAAATC AGCACTGCTTGCACCTACAAAAACCAGGAGTGCCGTTTGACCATACATTATGAGAATGGATTTTCTATTACCACTGAACCACAGGAGGGT GCCTTTCCCAAGACCATCATACAGTCTCCTTATGAAAAGCTCAAAATGTCTTCAGATGATGGAATCAGGATGCTGTATTTAGATTTTGGA GGCAAAGATGGAGAGATTCAACTGGACCTTCATTCCTGCCCCAAGCCAATTGTTTTCATCATTCATTCCTTCCTGTCAGCTAAGATTACA AGACTGGGCTTGGTGGCCTGAAGACAGGGGTGACTTGCCTTTGAGAAAAGAAGGGCTGCAATGCCACCAGAGAACGTGATGTCAGACACC ATCTGTAGTGAGCAGCGCACCAGATGTAGCGTGCTACAGTCAGCTTTAGCTCTCAAGAGTCGTATGTAACTGTCCCAGACTCCTCTGTCA GTTTCAGCAACTACAAGGGATACCCTGCGAAAGTACCATGAGAAATATCAGAGTAAAACTTTCTAGAACAGTACAAGGTTAAAGAGGTGA GGTGACGGGAAATACACAGCATAGCTTTGAAATAATGACAACCAAGGACATGACCATTAGAACAGCATGTGCAGATCTTAATCATCCCAG TTCCTAGGCAACTTGTTCACCAGGTACGCAAGGGCCGAATAGTTGAGAAATGGACATTCTTACCTACTCCTCCTAGCCCCCTATCCCCAG TAACAGTGATCCCTTTTCTTATTGTGATTTATTTCCTAATTCTTGCTGAGTTGACTTTCCCTTGTAGGAAAAGAAAAATATTTCAAATAG AAACCCACCTTTTATTTAAGTATGAAGCAGCTGTTACTTTTTAAAAAATGAATTATCTTTCAATGGTGTAGAATGATTCCAAAGTGTCTC CATTAGCATATACTGAGCAGGAATTAAATAAAGCATCAGATACTGATCTGAGCTGTAAGCTGGTAGAATCTGAGCCAAAGTAGACTGCTT AAATTGATAAGCTTTGCTAAAGAGTTGTATGCACAAAGGATGATTAATTCTGGGACTATACTCACACCAAGGTCTGCTGTCTTATAGCCA AGAATTACAGCTTTATTTATAGAGAGTGAATTATGGGTATTTTTTCAGAAAATATTGTCATCTGATATACACATAAAACAACTCACATTG TTGGAGTTAACTAATTATCCCCATTTCATGGTTTTCAGTGGCAACTTACTGACCCTTGTTTTTGCCTGTGCTTGTATGCATGCATTTTCA AGCAAGTAATAAAGCAGCCTCATTTAATTCTGGATAATGCTGGGTTTTACATATAGACTGAATGCTATAATCAAATCTATTGACAGTATC TGCAGTTCTTTCAGAATTCCAGGGAAATAATATAACGACCTGATATCTTTCTACAGGAATATTTTCAGACATTATATAGCACATTACTGA TTTAATGCTTTTACTTTTATCTTTCAAAACAAATTCACTAAAAATAACACCTATTGATTTTGAAGTCACTTTTCTCAAACCTTGAAAATG AGCTCTAGGATCTCTATAAACATTTCTAACACTTTTCCTGTAGTTTACATAGACAGACATCTGTTGTTAGACCTGTGTGTTTTTAAAGAA TCATATGTTAACAAATACCCATGCAAAGAGCTTCAAAAAGTGAAACCGTGTTAAAGGAACACAATTTTTCTCACTCAGACATATTTGTTT ATTGAATTGCAAAGTTTTATTTTAAATCAGCATTTCCCCAAAGAATATATCATATGACGCTAGTTCCAAGGGGCTTGACTGAGTGGTGTT TTGCTGGGGGGAGACAGGGGTTTGTTAATACACTTTACTAAATACTGAGCTGAAAAATGTTAAATAGATTTCACGATTGCCTCCTTGAAG ATTTTAAAGTTCATTGTGGTTCTTCAAGGCGAAATCCGGTGAACCATTCCTCACACTTACCTACAGGACTCTTTTCTAATGGAGCATCTT GTGAAGCTAGTGGGTTTTTTTGTTGTTGTTATTTGTTTTTTTTTTTTAATGCTTTAGAAAACACAGCTTTAGGATATTGACTTTTTGTTT ATTTCTATTTTCAAATGCTGAAAAGTCAAGTCCCAGTTTGAATACCATAGAAAAGCTTTGATGCATTTGTAAATTATATTGCACTCTTTC ACTATATATTTTCAAAATCACTGGAATGTTGTTATACAAGAGAATTATAATTGTGTATTGTAAATAACATATTAAAATACATATATTAAT GCCAATAGTTAAATTCAACAATATGTAATCTAAGGTGCTCGGTTCTACATGAAGTATGAGTTAACTGCTCATAATTAAGTTGCCAAGATT CTATTATATATTTATAGACAAATTAAAATGATCATAATTACAAATATGATTTCTTTATCACTTAAGCTTTGGGCTGATTAATATCTGTGT GGGGGTCAATGGAAACTACATTCTCTACATTTATAAACATTTAATTTAATTATTTATATTTTAGGAAAATATATTTGAATAAAATTAATG CATTTTCTAGAGTAAATTAAAATGTTATTAGCAAGAAATAGAAAATTTGACTAAGATAATTGTGTATATGAATCATTTTTCCCCCAAGTT AAAATGTATCATAATAGAGAGGCTCTAATGAATCAATTTCCAATACTCATTTCTTTCTTATTTTGAATTCAAGTTACAATGACTTTACAC TGTAGATTTTAATCTTGTCTGATGTGTGCTGGTGTGTATGACACAAACTCATAAGTCTGGATCATGCTTGGGTACAGTCAATGAATCAAC CGAGTCACTTTGAGGAATTTGTTTTTGTCCAATTTGCTCTGTGCTCAATCCCATGAATTATTAAATTTACAATGTTTGTCCCCAAATGAA AACCAATATAAATGAATGATGTTTTAATCTGTACTTTATGGGAAGTTGCCTATTTGTCAGTAGATGTGGTTAAGTGAGTCCTCTGGTGCA GTGACATCCTTTTAAGCCATCTCATAGGGATTTAAAGAAGGCCAATAGGAATATAGATATTGGTTTTTCTTTCTCTGACTTGAACTAAGT AGGAGAAACCAAACCATAAACCTATTACAAACTACCCAGGCAGAGGCATTTACTTAATTCATCAACTAGTGCAATTAAAACCCTGAAAAC ACATGATCCTTGTTGACTCTGCTTGGTTGAAGCAGGAAAGAATGGTCTTGATGGTCAGAAAGTTTTAAAATTAATGGGCAGGGCCTTTCT GGACCCTGTTTTCCAAACACGTTAGATATTCCGTCTTGAGGGGATTGGAGTAGGCTACAGTGAGGGGGTAATTTTTGGATGTATCTGGAC TTTTAAAAAATGTGCCTATATTTATAGCACCATGAATATTATGTAAAATTTATATATGAATTAAATAAATATTCACCTCTGATTTCCAGT >60531_60531_1_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000287437_SNTB1_chr8_121587465_ENST00000395601_length(amino acids)=326AA_BP=120 MEEGNLSPKTEDTYLPHILSPAVFGGPGTNFKMPGRSSSNSGSTGFISFSGVESALSSLKNFQACINSGMDTASSVALDLVESQTEVSSE YSMDKAMVEFATLDRQLNHYVKAVQSTINHVPGESKKQWKPALVVLTEKDLLIYDSMPRRKEAWFSPVHTYPLLATRLVHSGPGKGSPQA GVDLSFATRTGTRQGIETHLFRAETSRDLSHWTRSIVQGCHNSAELIAEISTACTYKNQECRLTIHYENGFSITTEPQEGAFPKTIIQSP -------------------------------------------------------------- >60531_60531_2_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000287437_SNTB1_chr8_121587465_ENST00000517992_length(transcript)=1457nt_BP=480nt GCCCGCTCTCACTTTTCAGCGGCAGGCGAAGGGGGCTGAGGAAAGGAGGTGGGTCTAGGCAGGGGAAATTGGGGTGCCACCAGACGGAGA CAGCTTGGACTACCAGAATCAAGCACTCTTTTGGAAGAGGGTAATCTCTCTCCAAAAACTGAGGACACTTACCTTCCCCATATATTGAGT CCAGCTGTGTTTGGTGGCCCAGGTACTAATTTCAAGATGCCAGGACGTTCCAGTTCAAATTCAGGTTCAACTGGTTTCATCTCCTTCAGT GGTGTAGAGTCTGCTCTCTCCTCCTTGAAAAACTTCCAAGCCTGTATCAACTCTGGTATGGACACAGCTTCTAGTGTTGCTTTGGATCTT GTGGAAAGTCAGACTGAAGTGAGTAGTGAATATAGTATGGACAAGGCAATGGTTGAATTTGCTACATTGGATCGGCAACTAAACCATTAT GTAAAGGCTGTTCAATCTACAATAAATCATGTGCCAGGGGAGAGCAAGAAACAGTGGAAACCAGCCCTGGTTGTGCTGACTGAGAAAGAC CTTTTAATCTATGACAGCATGCCACGGAGGAAGGAAGCCTGGTTCAGCCCAGTTCACACATACCCTCTTCTTGCCACCAGGCTGGTCCAT TCAGGTCCAGGAAAGGGATCACCCCAGGCTGGTGTGGATCTGTCCTTTGCAACGCGAACTGGTACCAGGCAAGGGATTGAAACACATCTC TTCAGAGCAGAGACCAGCAGGGACCTCTCCCACTGGACAAGGAGCATAGTACAGGGTTGCCACAATTCTGCTGAACTCATTGCTGAAATC AGCACTGCTTGCACCTACAAAAACCAGGAGTGCCGTTTGACCATACATTATGAGAATGGATTTTCTATTACCACTGAACCACAGGAGGGT GCCTTTCCCAAGACCATCATACAGTCTCCTTATGAAAAGCTCAAAATGTCTTCAGATGATGGAATCAGGATGCTGTATTTAGATTTTGGA GGCAAAGATGGAGAGATTCAACTGGACCTTCATTCCTGCCCCAAGCCAATTGTTTTCATCATTCATTCCTTCCTGTCAGCTAAGATTACA AGACTGGGCTTGGTGGCCTGAAGACAGGGGTGACTTGCCTTTGAGAAAAGAAGGGCTGCAATGCCACCAGAGAACGTGATGTCAGACACC ATCTGTAGTGAGCAGCGCACCAGATGTAGCGTGCTACAGTCAGCTTTAGCTCTCAAGAGTCGTATGTAACTGTCCCAGACTCCTCTGTCA GTTTCAGCAACTACAAGGGATACCCTGCGAAAGTACCATGAGAAATATCAGAGTAAAACTTTCTAGAACAGTACAAGGTTAAAGAGGTGA GGTGACGGGAAATACACAGCATAGCTTTGAAATAATGACAACCAAGGACATGACCATTAGAACAGCATGTGCAGATCTTAATCATCCCAG >60531_60531_2_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000287437_SNTB1_chr8_121587465_ENST00000517992_length(amino acids)=326AA_BP=120 MEEGNLSPKTEDTYLPHILSPAVFGGPGTNFKMPGRSSSNSGSTGFISFSGVESALSSLKNFQACINSGMDTASSVALDLVESQTEVSSE YSMDKAMVEFATLDRQLNHYVKAVQSTINHVPGESKKQWKPALVVLTEKDLLIYDSMPRRKEAWFSPVHTYPLLATRLVHSGPGKGSPQA GVDLSFATRTGTRQGIETHLFRAETSRDLSHWTRSIVQGCHNSAELIAEISTACTYKNQECRLTIHYENGFSITTEPQEGAFPKTIIQSP -------------------------------------------------------------- >60531_60531_3_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000517315_SNTB1_chr8_121587465_ENST00000395601_length(transcript)=4036nt_BP=283nt TAATATGTGGTCTTTTGTGACTGGCTGTTTTCTTAGCATAAGGTTTTCAAGGTTCATCCATGTTGCATGTATCAGTGAGAGAGGTGGATG CTTTGGAGCTTTTGGCTCAGAAATGATAATGTACATAACACAGGCAGCCATGAGTTAAAATGCAAGTTCTGCTATCTGCTAGCTCTCTGA AGTGAGTAGTGAATATAGTATGGACAAGGCAATGGTTGAATTTGCTACATTGGATCGGCAACTAAACCATTATGTAAAGGCTGTTCAATC TACAATAAATCATGTGCCAGGGGAGAGCAAGAAACAGTGGAAACCAGCCCTGGTTGTGCTGACTGAGAAAGACCTTTTAATCTATGACAG CATGCCACGGAGGAAGGAAGCCTGGTTCAGCCCAGTTCACACATACCCTCTTCTTGCCACCAGGCTGGTCCATTCAGGTCCAGGAAAGGG ATCACCCCAGGCTGGTGTGGATCTGTCCTTTGCAACGCGAACTGGTACCAGGCAAGGGATTGAAACACATCTCTTCAGAGCAGAGACCAG CAGGGACCTCTCCCACTGGACAAGGAGCATAGTACAGGGTTGCCACAATTCTGCTGAACTCATTGCTGAAATCAGCACTGCTTGCACCTA CAAAAACCAGGAGTGCCGTTTGACCATACATTATGAGAATGGATTTTCTATTACCACTGAACCACAGGAGGGTGCCTTTCCCAAGACCAT CATACAGTCTCCTTATGAAAAGCTCAAAATGTCTTCAGATGATGGAATCAGGATGCTGTATTTAGATTTTGGAGGCAAAGATGGAGAGAT TCAACTGGACCTTCATTCCTGCCCCAAGCCAATTGTTTTCATCATTCATTCCTTCCTGTCAGCTAAGATTACAAGACTGGGCTTGGTGGC CTGAAGACAGGGGTGACTTGCCTTTGAGAAAAGAAGGGCTGCAATGCCACCAGAGAACGTGATGTCAGACACCATCTGTAGTGAGCAGCG CACCAGATGTAGCGTGCTACAGTCAGCTTTAGCTCTCAAGAGTCGTATGTAACTGTCCCAGACTCCTCTGTCAGTTTCAGCAACTACAAG GGATACCCTGCGAAAGTACCATGAGAAATATCAGAGTAAAACTTTCTAGAACAGTACAAGGTTAAAGAGGTGAGGTGACGGGAAATACAC AGCATAGCTTTGAAATAATGACAACCAAGGACATGACCATTAGAACAGCATGTGCAGATCTTAATCATCCCAGTTCCTAGGCAACTTGTT CACCAGGTACGCAAGGGCCGAATAGTTGAGAAATGGACATTCTTACCTACTCCTCCTAGCCCCCTATCCCCAGTAACAGTGATCCCTTTT CTTATTGTGATTTATTTCCTAATTCTTGCTGAGTTGACTTTCCCTTGTAGGAAAAGAAAAATATTTCAAATAGAAACCCACCTTTTATTT AAGTATGAAGCAGCTGTTACTTTTTAAAAAATGAATTATCTTTCAATGGTGTAGAATGATTCCAAAGTGTCTCCATTAGCATATACTGAG CAGGAATTAAATAAAGCATCAGATACTGATCTGAGCTGTAAGCTGGTAGAATCTGAGCCAAAGTAGACTGCTTAAATTGATAAGCTTTGC TAAAGAGTTGTATGCACAAAGGATGATTAATTCTGGGACTATACTCACACCAAGGTCTGCTGTCTTATAGCCAAGAATTACAGCTTTATT TATAGAGAGTGAATTATGGGTATTTTTTCAGAAAATATTGTCATCTGATATACACATAAAACAACTCACATTGTTGGAGTTAACTAATTA TCCCCATTTCATGGTTTTCAGTGGCAACTTACTGACCCTTGTTTTTGCCTGTGCTTGTATGCATGCATTTTCAAGCAAGTAATAAAGCAG CCTCATTTAATTCTGGATAATGCTGGGTTTTACATATAGACTGAATGCTATAATCAAATCTATTGACAGTATCTGCAGTTCTTTCAGAAT TCCAGGGAAATAATATAACGACCTGATATCTTTCTACAGGAATATTTTCAGACATTATATAGCACATTACTGATTTAATGCTTTTACTTT TATCTTTCAAAACAAATTCACTAAAAATAACACCTATTGATTTTGAAGTCACTTTTCTCAAACCTTGAAAATGAGCTCTAGGATCTCTAT AAACATTTCTAACACTTTTCCTGTAGTTTACATAGACAGACATCTGTTGTTAGACCTGTGTGTTTTTAAAGAATCATATGTTAACAAATA CCCATGCAAAGAGCTTCAAAAAGTGAAACCGTGTTAAAGGAACACAATTTTTCTCACTCAGACATATTTGTTTATTGAATTGCAAAGTTT TATTTTAAATCAGCATTTCCCCAAAGAATATATCATATGACGCTAGTTCCAAGGGGCTTGACTGAGTGGTGTTTTGCTGGGGGGAGACAG GGGTTTGTTAATACACTTTACTAAATACTGAGCTGAAAAATGTTAAATAGATTTCACGATTGCCTCCTTGAAGATTTTAAAGTTCATTGT GGTTCTTCAAGGCGAAATCCGGTGAACCATTCCTCACACTTACCTACAGGACTCTTTTCTAATGGAGCATCTTGTGAAGCTAGTGGGTTT TTTTGTTGTTGTTATTTGTTTTTTTTTTTTAATGCTTTAGAAAACACAGCTTTAGGATATTGACTTTTTGTTTATTTCTATTTTCAAATG CTGAAAAGTCAAGTCCCAGTTTGAATACCATAGAAAAGCTTTGATGCATTTGTAAATTATATTGCACTCTTTCACTATATATTTTCAAAA TCACTGGAATGTTGTTATACAAGAGAATTATAATTGTGTATTGTAAATAACATATTAAAATACATATATTAATGCCAATAGTTAAATTCA ACAATATGTAATCTAAGGTGCTCGGTTCTACATGAAGTATGAGTTAACTGCTCATAATTAAGTTGCCAAGATTCTATTATATATTTATAG ACAAATTAAAATGATCATAATTACAAATATGATTTCTTTATCACTTAAGCTTTGGGCTGATTAATATCTGTGTGGGGGTCAATGGAAACT ACATTCTCTACATTTATAAACATTTAATTTAATTATTTATATTTTAGGAAAATATATTTGAATAAAATTAATGCATTTTCTAGAGTAAAT TAAAATGTTATTAGCAAGAAATAGAAAATTTGACTAAGATAATTGTGTATATGAATCATTTTTCCCCCAAGTTAAAATGTATCATAATAG AGAGGCTCTAATGAATCAATTTCCAATACTCATTTCTTTCTTATTTTGAATTCAAGTTACAATGACTTTACACTGTAGATTTTAATCTTG TCTGATGTGTGCTGGTGTGTATGACACAAACTCATAAGTCTGGATCATGCTTGGGTACAGTCAATGAATCAACCGAGTCACTTTGAGGAA TTTGTTTTTGTCCAATTTGCTCTGTGCTCAATCCCATGAATTATTAAATTTACAATGTTTGTCCCCAAATGAAAACCAATATAAATGAAT GATGTTTTAATCTGTACTTTATGGGAAGTTGCCTATTTGTCAGTAGATGTGGTTAAGTGAGTCCTCTGGTGCAGTGACATCCTTTTAAGC CATCTCATAGGGATTTAAAGAAGGCCAATAGGAATATAGATATTGGTTTTTCTTTCTCTGACTTGAACTAAGTAGGAGAAACCAAACCAT AAACCTATTACAAACTACCCAGGCAGAGGCATTTACTTAATTCATCAACTAGTGCAATTAAAACCCTGAAAACACATGATCCTTGTTGAC TCTGCTTGGTTGAAGCAGGAAAGAATGGTCTTGATGGTCAGAAAGTTTTAAAATTAATGGGCAGGGCCTTTCTGGACCCTGTTTTCCAAA CACGTTAGATATTCCGTCTTGAGGGGATTGGAGTAGGCTACAGTGAGGGGGTAATTTTTGGATGTATCTGGACTTTTAAAAAATGTGCCT >60531_60531_3_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000517315_SNTB1_chr8_121587465_ENST00000395601_length(amino acids)=234AA_BP=28 MDKAMVEFATLDRQLNHYVKAVQSTINHVPGESKKQWKPALVVLTEKDLLIYDSMPRRKEAWFSPVHTYPLLATRLVHSGPGKGSPQAGV DLSFATRTGTRQGIETHLFRAETSRDLSHWTRSIVQGCHNSAELIAEISTACTYKNQECRLTIHYENGFSITTEPQEGAFPKTIIQSPYE -------------------------------------------------------------- >60531_60531_4_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000517315_SNTB1_chr8_121587465_ENST00000517992_length(transcript)=1260nt_BP=283nt TAATATGTGGTCTTTTGTGACTGGCTGTTTTCTTAGCATAAGGTTTTCAAGGTTCATCCATGTTGCATGTATCAGTGAGAGAGGTGGATG CTTTGGAGCTTTTGGCTCAGAAATGATAATGTACATAACACAGGCAGCCATGAGTTAAAATGCAAGTTCTGCTATCTGCTAGCTCTCTGA AGTGAGTAGTGAATATAGTATGGACAAGGCAATGGTTGAATTTGCTACATTGGATCGGCAACTAAACCATTATGTAAAGGCTGTTCAATC TACAATAAATCATGTGCCAGGGGAGAGCAAGAAACAGTGGAAACCAGCCCTGGTTGTGCTGACTGAGAAAGACCTTTTAATCTATGACAG CATGCCACGGAGGAAGGAAGCCTGGTTCAGCCCAGTTCACACATACCCTCTTCTTGCCACCAGGCTGGTCCATTCAGGTCCAGGAAAGGG ATCACCCCAGGCTGGTGTGGATCTGTCCTTTGCAACGCGAACTGGTACCAGGCAAGGGATTGAAACACATCTCTTCAGAGCAGAGACCAG CAGGGACCTCTCCCACTGGACAAGGAGCATAGTACAGGGTTGCCACAATTCTGCTGAACTCATTGCTGAAATCAGCACTGCTTGCACCTA CAAAAACCAGGAGTGCCGTTTGACCATACATTATGAGAATGGATTTTCTATTACCACTGAACCACAGGAGGGTGCCTTTCCCAAGACCAT CATACAGTCTCCTTATGAAAAGCTCAAAATGTCTTCAGATGATGGAATCAGGATGCTGTATTTAGATTTTGGAGGCAAAGATGGAGAGAT TCAACTGGACCTTCATTCCTGCCCCAAGCCAATTGTTTTCATCATTCATTCCTTCCTGTCAGCTAAGATTACAAGACTGGGCTTGGTGGC CTGAAGACAGGGGTGACTTGCCTTTGAGAAAAGAAGGGCTGCAATGCCACCAGAGAACGTGATGTCAGACACCATCTGTAGTGAGCAGCG CACCAGATGTAGCGTGCTACAGTCAGCTTTAGCTCTCAAGAGTCGTATGTAACTGTCCCAGACTCCTCTGTCAGTTTCAGCAACTACAAG GGATACCCTGCGAAAGTACCATGAGAAATATCAGAGTAAAACTTTCTAGAACAGTACAAGGTTAAAGAGGTGAGGTGACGGGAAATACAC AGCATAGCTTTGAAATAATGACAACCAAGGACATGACCATTAGAACAGCATGTGCAGATCTTAATCATCCCAGTTCCTAGGCAACTTGTT >60531_60531_4_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000517315_SNTB1_chr8_121587465_ENST00000517992_length(amino acids)=234AA_BP=28 MDKAMVEFATLDRQLNHYVKAVQSTINHVPGESKKQWKPALVVLTEKDLLIYDSMPRRKEAWFSPVHTYPLLATRLVHSGPGKGSPQAGV DLSFATRTGTRQGIETHLFRAETSRDLSHWTRSIVQGCHNSAELIAEISTACTYKNQECRLTIHYENGFSITTEPQEGAFPKTIIQSPYE -------------------------------------------------------------- >60531_60531_5_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000522563_SNTB1_chr8_121587465_ENST00000395601_length(transcript)=4120nt_BP=367nt AGCGGCAGGCGAAGGGGGCTGAGGAAAGGAGGTGGGTCTAGGCAGGGGAAATTGGGGTGCCACCAGACGGAGACAGCTTGGACTACCAGG TACTAATTTCAAGATGCCAGGACGTTCCAGTTCAAATTCAGGTTCAACTGGTTTCATCTCCTTCAGTGGTGTAGAGTCTGCTCTCTCCTC CTTGAAAAACTTCCAAGCCTGTATCAACTCTGGTATGGACACAGCTTCTAGTGTTGCTTTGGATCTTGTGGAAAGTCAGACTGAAGTGAG TAGTGAATATAGTATGGACAAGGCAATGGTTGAATTTGCTACATTGGATCGGCAACTAAACCATTATGTAAAGGCTGTTCAATCTACAAT AAATCATGTGCCAGGGGAGAGCAAGAAACAGTGGAAACCAGCCCTGGTTGTGCTGACTGAGAAAGACCTTTTAATCTATGACAGCATGCC ACGGAGGAAGGAAGCCTGGTTCAGCCCAGTTCACACATACCCTCTTCTTGCCACCAGGCTGGTCCATTCAGGTCCAGGAAAGGGATCACC CCAGGCTGGTGTGGATCTGTCCTTTGCAACGCGAACTGGTACCAGGCAAGGGATTGAAACACATCTCTTCAGAGCAGAGACCAGCAGGGA CCTCTCCCACTGGACAAGGAGCATAGTACAGGGTTGCCACAATTCTGCTGAACTCATTGCTGAAATCAGCACTGCTTGCACCTACAAAAA CCAGGAGTGCCGTTTGACCATACATTATGAGAATGGATTTTCTATTACCACTGAACCACAGGAGGGTGCCTTTCCCAAGACCATCATACA GTCTCCTTATGAAAAGCTCAAAATGTCTTCAGATGATGGAATCAGGATGCTGTATTTAGATTTTGGAGGCAAAGATGGAGAGATTCAACT GGACCTTCATTCCTGCCCCAAGCCAATTGTTTTCATCATTCATTCCTTCCTGTCAGCTAAGATTACAAGACTGGGCTTGGTGGCCTGAAG ACAGGGGTGACTTGCCTTTGAGAAAAGAAGGGCTGCAATGCCACCAGAGAACGTGATGTCAGACACCATCTGTAGTGAGCAGCGCACCAG ATGTAGCGTGCTACAGTCAGCTTTAGCTCTCAAGAGTCGTATGTAACTGTCCCAGACTCCTCTGTCAGTTTCAGCAACTACAAGGGATAC CCTGCGAAAGTACCATGAGAAATATCAGAGTAAAACTTTCTAGAACAGTACAAGGTTAAAGAGGTGAGGTGACGGGAAATACACAGCATA GCTTTGAAATAATGACAACCAAGGACATGACCATTAGAACAGCATGTGCAGATCTTAATCATCCCAGTTCCTAGGCAACTTGTTCACCAG GTACGCAAGGGCCGAATAGTTGAGAAATGGACATTCTTACCTACTCCTCCTAGCCCCCTATCCCCAGTAACAGTGATCCCTTTTCTTATT GTGATTTATTTCCTAATTCTTGCTGAGTTGACTTTCCCTTGTAGGAAAAGAAAAATATTTCAAATAGAAACCCACCTTTTATTTAAGTAT GAAGCAGCTGTTACTTTTTAAAAAATGAATTATCTTTCAATGGTGTAGAATGATTCCAAAGTGTCTCCATTAGCATATACTGAGCAGGAA TTAAATAAAGCATCAGATACTGATCTGAGCTGTAAGCTGGTAGAATCTGAGCCAAAGTAGACTGCTTAAATTGATAAGCTTTGCTAAAGA GTTGTATGCACAAAGGATGATTAATTCTGGGACTATACTCACACCAAGGTCTGCTGTCTTATAGCCAAGAATTACAGCTTTATTTATAGA GAGTGAATTATGGGTATTTTTTCAGAAAATATTGTCATCTGATATACACATAAAACAACTCACATTGTTGGAGTTAACTAATTATCCCCA TTTCATGGTTTTCAGTGGCAACTTACTGACCCTTGTTTTTGCCTGTGCTTGTATGCATGCATTTTCAAGCAAGTAATAAAGCAGCCTCAT TTAATTCTGGATAATGCTGGGTTTTACATATAGACTGAATGCTATAATCAAATCTATTGACAGTATCTGCAGTTCTTTCAGAATTCCAGG GAAATAATATAACGACCTGATATCTTTCTACAGGAATATTTTCAGACATTATATAGCACATTACTGATTTAATGCTTTTACTTTTATCTT TCAAAACAAATTCACTAAAAATAACACCTATTGATTTTGAAGTCACTTTTCTCAAACCTTGAAAATGAGCTCTAGGATCTCTATAAACAT TTCTAACACTTTTCCTGTAGTTTACATAGACAGACATCTGTTGTTAGACCTGTGTGTTTTTAAAGAATCATATGTTAACAAATACCCATG CAAAGAGCTTCAAAAAGTGAAACCGTGTTAAAGGAACACAATTTTTCTCACTCAGACATATTTGTTTATTGAATTGCAAAGTTTTATTTT AAATCAGCATTTCCCCAAAGAATATATCATATGACGCTAGTTCCAAGGGGCTTGACTGAGTGGTGTTTTGCTGGGGGGAGACAGGGGTTT GTTAATACACTTTACTAAATACTGAGCTGAAAAATGTTAAATAGATTTCACGATTGCCTCCTTGAAGATTTTAAAGTTCATTGTGGTTCT TCAAGGCGAAATCCGGTGAACCATTCCTCACACTTACCTACAGGACTCTTTTCTAATGGAGCATCTTGTGAAGCTAGTGGGTTTTTTTGT TGTTGTTATTTGTTTTTTTTTTTTAATGCTTTAGAAAACACAGCTTTAGGATATTGACTTTTTGTTTATTTCTATTTTCAAATGCTGAAA AGTCAAGTCCCAGTTTGAATACCATAGAAAAGCTTTGATGCATTTGTAAATTATATTGCACTCTTTCACTATATATTTTCAAAATCACTG GAATGTTGTTATACAAGAGAATTATAATTGTGTATTGTAAATAACATATTAAAATACATATATTAATGCCAATAGTTAAATTCAACAATA TGTAATCTAAGGTGCTCGGTTCTACATGAAGTATGAGTTAACTGCTCATAATTAAGTTGCCAAGATTCTATTATATATTTATAGACAAAT TAAAATGATCATAATTACAAATATGATTTCTTTATCACTTAAGCTTTGGGCTGATTAATATCTGTGTGGGGGTCAATGGAAACTACATTC TCTACATTTATAAACATTTAATTTAATTATTTATATTTTAGGAAAATATATTTGAATAAAATTAATGCATTTTCTAGAGTAAATTAAAAT GTTATTAGCAAGAAATAGAAAATTTGACTAAGATAATTGTGTATATGAATCATTTTTCCCCCAAGTTAAAATGTATCATAATAGAGAGGC TCTAATGAATCAATTTCCAATACTCATTTCTTTCTTATTTTGAATTCAAGTTACAATGACTTTACACTGTAGATTTTAATCTTGTCTGAT GTGTGCTGGTGTGTATGACACAAACTCATAAGTCTGGATCATGCTTGGGTACAGTCAATGAATCAACCGAGTCACTTTGAGGAATTTGTT TTTGTCCAATTTGCTCTGTGCTCAATCCCATGAATTATTAAATTTACAATGTTTGTCCCCAAATGAAAACCAATATAAATGAATGATGTT TTAATCTGTACTTTATGGGAAGTTGCCTATTTGTCAGTAGATGTGGTTAAGTGAGTCCTCTGGTGCAGTGACATCCTTTTAAGCCATCTC ATAGGGATTTAAAGAAGGCCAATAGGAATATAGATATTGGTTTTTCTTTCTCTGACTTGAACTAAGTAGGAGAAACCAAACCATAAACCT ATTACAAACTACCCAGGCAGAGGCATTTACTTAATTCATCAACTAGTGCAATTAAAACCCTGAAAACACATGATCCTTGTTGACTCTGCT TGGTTGAAGCAGGAAAGAATGGTCTTGATGGTCAGAAAGTTTTAAAATTAATGGGCAGGGCCTTTCTGGACCCTGTTTTCCAAACACGTT AGATATTCCGTCTTGAGGGGATTGGAGTAGGCTACAGTGAGGGGGTAATTTTTGGATGTATCTGGACTTTTAAAAAATGTGCCTATATTT >60531_60531_5_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000522563_SNTB1_chr8_121587465_ENST00000395601_length(amino acids)=294AA_BP=88 MPGRSSSNSGSTGFISFSGVESALSSLKNFQACINSGMDTASSVALDLVESQTEVSSEYSMDKAMVEFATLDRQLNHYVKAVQSTINHVP GESKKQWKPALVVLTEKDLLIYDSMPRRKEAWFSPVHTYPLLATRLVHSGPGKGSPQAGVDLSFATRTGTRQGIETHLFRAETSRDLSHW TRSIVQGCHNSAELIAEISTACTYKNQECRLTIHYENGFSITTEPQEGAFPKTIIQSPYEKLKMSSDDGIRMLYLDFGGKDGEIQLDLHS -------------------------------------------------------------- >60531_60531_6_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000522563_SNTB1_chr8_121587465_ENST00000517992_length(transcript)=1344nt_BP=367nt AGCGGCAGGCGAAGGGGGCTGAGGAAAGGAGGTGGGTCTAGGCAGGGGAAATTGGGGTGCCACCAGACGGAGACAGCTTGGACTACCAGG TACTAATTTCAAGATGCCAGGACGTTCCAGTTCAAATTCAGGTTCAACTGGTTTCATCTCCTTCAGTGGTGTAGAGTCTGCTCTCTCCTC CTTGAAAAACTTCCAAGCCTGTATCAACTCTGGTATGGACACAGCTTCTAGTGTTGCTTTGGATCTTGTGGAAAGTCAGACTGAAGTGAG TAGTGAATATAGTATGGACAAGGCAATGGTTGAATTTGCTACATTGGATCGGCAACTAAACCATTATGTAAAGGCTGTTCAATCTACAAT AAATCATGTGCCAGGGGAGAGCAAGAAACAGTGGAAACCAGCCCTGGTTGTGCTGACTGAGAAAGACCTTTTAATCTATGACAGCATGCC ACGGAGGAAGGAAGCCTGGTTCAGCCCAGTTCACACATACCCTCTTCTTGCCACCAGGCTGGTCCATTCAGGTCCAGGAAAGGGATCACC CCAGGCTGGTGTGGATCTGTCCTTTGCAACGCGAACTGGTACCAGGCAAGGGATTGAAACACATCTCTTCAGAGCAGAGACCAGCAGGGA CCTCTCCCACTGGACAAGGAGCATAGTACAGGGTTGCCACAATTCTGCTGAACTCATTGCTGAAATCAGCACTGCTTGCACCTACAAAAA CCAGGAGTGCCGTTTGACCATACATTATGAGAATGGATTTTCTATTACCACTGAACCACAGGAGGGTGCCTTTCCCAAGACCATCATACA GTCTCCTTATGAAAAGCTCAAAATGTCTTCAGATGATGGAATCAGGATGCTGTATTTAGATTTTGGAGGCAAAGATGGAGAGATTCAACT GGACCTTCATTCCTGCCCCAAGCCAATTGTTTTCATCATTCATTCCTTCCTGTCAGCTAAGATTACAAGACTGGGCTTGGTGGCCTGAAG ACAGGGGTGACTTGCCTTTGAGAAAAGAAGGGCTGCAATGCCACCAGAGAACGTGATGTCAGACACCATCTGTAGTGAGCAGCGCACCAG ATGTAGCGTGCTACAGTCAGCTTTAGCTCTCAAGAGTCGTATGTAACTGTCCCAGACTCCTCTGTCAGTTTCAGCAACTACAAGGGATAC CCTGCGAAAGTACCATGAGAAATATCAGAGTAAAACTTTCTAGAACAGTACAAGGTTAAAGAGGTGAGGTGACGGGAAATACACAGCATA >60531_60531_6_NSMCE2-SNTB1_NSMCE2_chr8_126163519_ENST00000522563_SNTB1_chr8_121587465_ENST00000517992_length(amino acids)=294AA_BP=88 MPGRSSSNSGSTGFISFSGVESALSSLKNFQACINSGMDTASSVALDLVESQTEVSSEYSMDKAMVEFATLDRQLNHYVKAVQSTINHVP GESKKQWKPALVVLTEKDLLIYDSMPRRKEAWFSPVHTYPLLATRLVHSGPGKGSPQAGVDLSFATRTGTRQGIETHLFRAETSRDLSHW TRSIVQGCHNSAELIAEISTACTYKNQECRLTIHYENGFSITTEPQEGAFPKTIIQSPYEKLKMSSDDGIRMLYLDFGGKDGEIQLDLHS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NSMCE2-SNTB1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NSMCE2-SNTB1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NSMCE2-SNTB1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies