
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NSMCE4A-ATE1 (FusionGDB2 ID:60541) |
Fusion Gene Summary for NSMCE4A-ATE1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NSMCE4A-ATE1 | Fusion gene ID: 60541 | Hgene | Tgene | Gene symbol | NSMCE4A | ATE1 | Gene ID | 54780 | 11101 |
| Gene name | NSE4 homolog A, SMC5-SMC6 complex component | arginyltransferase 1 | |
| Synonyms | C10orf86|NS4EA|NSE4A | - | |
| Cytomap | 10q26.13 | 10q26.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | non-structural maintenance of chromosomes element 4 homolog ANSE4 homolog, SMC5-SMC6 complex component Anon-SMC element 4 homolog A | arginyl-tRNA--protein transferase 1R-transferase 1arginine-tRNA--protein transferase 1arginyl-tRNA-protein transferase | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | O95260 | |
| Ensembl transtripts involved in fusion gene | ENST00000369017, ENST00000369023, ENST00000538652, ENST00000489266, | ENST00000481784, ENST00000224652, ENST00000369040, ENST00000369043, ENST00000535655, ENST00000540606, ENST00000543447, | |
| Fusion gene scores | * DoF score | 1 X 3 X 1=3 | 11 X 10 X 8=880 |
| # samples | 1 | 18 | |
| ** MAII score | log2(1/3*10)=1.73696559416621 | log2(18/880*10)=-2.28950661719499 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NSMCE4A [Title/Abstract] AND ATE1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ATE1(123658356)-NSMCE4A(123721032), # samples:2 NSMCE4A(123724801)-ATE1(123503373), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ATE1-NSMCE4A seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. NSMCE4A-ATE1 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across NSMCE4A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ATE1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
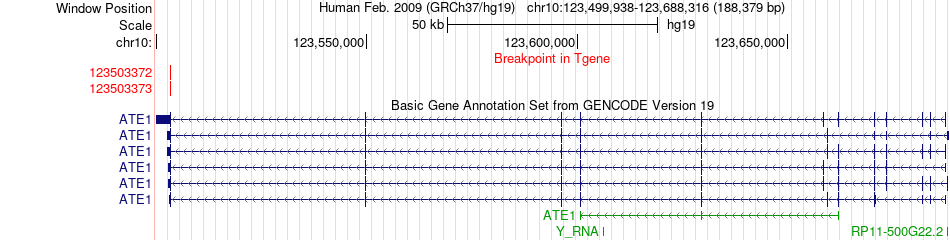 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-D8-A142-01A | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| ChimerDB4 | BRCA | TCGA-D8-A142-01A | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| ChimerDB4 | BRCA | TCGA-D8-A142-01A | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
Top |
Fusion Gene ORF analysis for NSMCE4A-ATE1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000369017 | ENST00000481784 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5CDS-intron | ENST00000369017 | ENST00000481784 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5CDS-intron | ENST00000369017 | ENST00000481784 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5CDS-intron | ENST00000369023 | ENST00000481784 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5CDS-intron | ENST00000369023 | ENST00000481784 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5CDS-intron | ENST00000369023 | ENST00000481784 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5CDS-intron | ENST00000538652 | ENST00000481784 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5CDS-intron | ENST00000538652 | ENST00000481784 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5CDS-intron | ENST00000538652 | ENST00000481784 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000224652 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000224652 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000224652 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000369040 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000369040 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000369040 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000369043 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000369043 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000369043 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000535655 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000535655 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000535655 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000540606 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000540606 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000540606 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000543447 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000543447 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5UTR-3CDS | ENST00000489266 | ENST00000543447 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-intron | ENST00000489266 | ENST00000481784 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| 5UTR-intron | ENST00000489266 | ENST00000481784 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| 5UTR-intron | ENST00000489266 | ENST00000481784 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369017 | ENST00000224652 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369017 | ENST00000369040 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369017 | ENST00000369040 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000369017 | ENST00000369043 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369017 | ENST00000369043 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000369017 | ENST00000535655 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369017 | ENST00000535655 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000369017 | ENST00000540606 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369017 | ENST00000543447 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369017 | ENST00000543447 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000369023 | ENST00000224652 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369023 | ENST00000224652 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000369023 | ENST00000369040 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369023 | ENST00000369043 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369023 | ENST00000535655 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369023 | ENST00000540606 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000369023 | ENST00000540606 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000369023 | ENST00000543447 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000224652 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000224652 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000538652 | ENST00000369040 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000369040 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000538652 | ENST00000369040 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000369043 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000369043 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000538652 | ENST00000369043 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000535655 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000535655 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000538652 | ENST00000535655 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000540606 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000540606 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000538652 | ENST00000543447 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| Frame-shift | ENST00000538652 | ENST00000543447 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| Frame-shift | ENST00000538652 | ENST00000543447 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369017 | ENST00000224652 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369017 | ENST00000224652 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| In-frame | ENST00000369017 | ENST00000369040 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369017 | ENST00000369043 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369017 | ENST00000535655 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369017 | ENST00000540606 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369017 | ENST00000540606 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| In-frame | ENST00000369017 | ENST00000543447 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369023 | ENST00000224652 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369023 | ENST00000369040 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369023 | ENST00000369040 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| In-frame | ENST00000369023 | ENST00000369043 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369023 | ENST00000369043 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| In-frame | ENST00000369023 | ENST00000535655 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369023 | ENST00000535655 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| In-frame | ENST00000369023 | ENST00000540606 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369023 | ENST00000543447 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000369023 | ENST00000543447 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - |
| In-frame | ENST00000538652 | ENST00000224652 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| In-frame | ENST00000538652 | ENST00000540606 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000369023 | NSMCE4A | chr10 | 123724801 | - | ENST00000369043 | ATE1 | chr10 | 123503373 | - | 4240 | 805 | 52 | 1065 | 337 |
| ENST00000369023 | NSMCE4A | chr10 | 123724801 | - | ENST00000535655 | ATE1 | chr10 | 123503373 | - | 1723 | 805 | 52 | 1065 | 337 |
| ENST00000369023 | NSMCE4A | chr10 | 123724801 | - | ENST00000369040 | ATE1 | chr10 | 123503373 | - | 1480 | 805 | 52 | 1065 | 337 |
| ENST00000369023 | NSMCE4A | chr10 | 123724801 | - | ENST00000543447 | ATE1 | chr10 | 123503373 | - | 1195 | 805 | 52 | 1065 | 337 |
| ENST00000369017 | NSMCE4A | chr10 | 123724801 | - | ENST00000224652 | ATE1 | chr10 | 123503373 | - | 1530 | 782 | 29 | 1042 | 337 |
| ENST00000369017 | NSMCE4A | chr10 | 123724801 | - | ENST00000540606 | ATE1 | chr10 | 123503373 | - | 1339 | 782 | 29 | 1042 | 337 |
| ENST00000369023 | NSMCE4A | chr10 | 123724800 | - | ENST00000369043 | ATE1 | chr10 | 123503372 | - | 4240 | 805 | 52 | 1065 | 337 |
| ENST00000369023 | NSMCE4A | chr10 | 123724800 | - | ENST00000535655 | ATE1 | chr10 | 123503372 | - | 1723 | 805 | 52 | 1065 | 337 |
| ENST00000369023 | NSMCE4A | chr10 | 123724800 | - | ENST00000369040 | ATE1 | chr10 | 123503372 | - | 1480 | 805 | 52 | 1065 | 337 |
| ENST00000369023 | NSMCE4A | chr10 | 123724800 | - | ENST00000543447 | ATE1 | chr10 | 123503372 | - | 1195 | 805 | 52 | 1065 | 337 |
| ENST00000369017 | NSMCE4A | chr10 | 123724800 | - | ENST00000224652 | ATE1 | chr10 | 123503372 | - | 1530 | 782 | 29 | 1042 | 337 |
| ENST00000369017 | NSMCE4A | chr10 | 123724800 | - | ENST00000540606 | ATE1 | chr10 | 123503372 | - | 1339 | 782 | 29 | 1042 | 337 |
| ENST00000369023 | NSMCE4A | chr10 | 123727169 | - | ENST00000224652 | ATE1 | chr10 | 123503372 | - | 1453 | 705 | 52 | 711 | 219 |
| ENST00000369023 | NSMCE4A | chr10 | 123727169 | - | ENST00000540606 | ATE1 | chr10 | 123503372 | - | 1262 | 705 | 52 | 711 | 219 |
| ENST00000538652 | NSMCE4A | chr10 | 123727169 | - | ENST00000224652 | ATE1 | chr10 | 123503372 | - | 1562 | 814 | 42 | 392 | 116 |
| ENST00000538652 | NSMCE4A | chr10 | 123727169 | - | ENST00000540606 | ATE1 | chr10 | 123503372 | - | 1371 | 814 | 494 | 0 | 165 |
| ENST00000369017 | NSMCE4A | chr10 | 123727169 | - | ENST00000369043 | ATE1 | chr10 | 123503372 | - | 4117 | 682 | 29 | 688 | 219 |
| ENST00000369017 | NSMCE4A | chr10 | 123727169 | - | ENST00000535655 | ATE1 | chr10 | 123503372 | - | 1600 | 682 | 29 | 688 | 219 |
| ENST00000369017 | NSMCE4A | chr10 | 123727169 | - | ENST00000369040 | ATE1 | chr10 | 123503372 | - | 1357 | 682 | 29 | 688 | 219 |
| ENST00000369017 | NSMCE4A | chr10 | 123727169 | - | ENST00000543447 | ATE1 | chr10 | 123503372 | - | 1072 | 682 | 29 | 688 | 219 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000369023 | ENST00000369043 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - | 0.002860106 | 0.99713993 |
| ENST00000369023 | ENST00000535655 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - | 0.006254063 | 0.9937459 |
| ENST00000369023 | ENST00000369040 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - | 0.014039356 | 0.9859606 |
| ENST00000369023 | ENST00000543447 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - | 0.025620827 | 0.97437924 |
| ENST00000369017 | ENST00000224652 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - | 0.009831289 | 0.9901687 |
| ENST00000369017 | ENST00000540606 | NSMCE4A | chr10 | 123724801 | - | ATE1 | chr10 | 123503373 | - | 0.016194893 | 0.9838051 |
| ENST00000369023 | ENST00000369043 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - | 0.002860106 | 0.99713993 |
| ENST00000369023 | ENST00000535655 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - | 0.006254063 | 0.9937459 |
| ENST00000369023 | ENST00000369040 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - | 0.014039356 | 0.9859606 |
| ENST00000369023 | ENST00000543447 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - | 0.025620827 | 0.97437924 |
| ENST00000369017 | ENST00000224652 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - | 0.009831289 | 0.9901687 |
| ENST00000369017 | ENST00000540606 | NSMCE4A | chr10 | 123724800 | - | ATE1 | chr10 | 123503372 | - | 0.016194893 | 0.9838051 |
| ENST00000369023 | ENST00000224652 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - | 0.004661819 | 0.9953382 |
| ENST00000369023 | ENST00000540606 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - | 0.006004785 | 0.99399525 |
| ENST00000538652 | ENST00000224652 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - | 0.7260647 | 0.27393532 |
| ENST00000538652 | ENST00000540606 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - | 0.7576679 | 0.24233213 |
| ENST00000369017 | ENST00000369043 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - | 0.002082592 | 0.99791735 |
| ENST00000369017 | ENST00000535655 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - | 0.003374582 | 0.9966254 |
| ENST00000369017 | ENST00000369040 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - | 0.005251722 | 0.9947483 |
| ENST00000369017 | ENST00000543447 | NSMCE4A | chr10 | 123727169 | - | ATE1 | chr10 | 123503372 | - | 0.006817649 | 0.99318236 |
Top |
Fusion Genomic Features for NSMCE4A-ATE1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
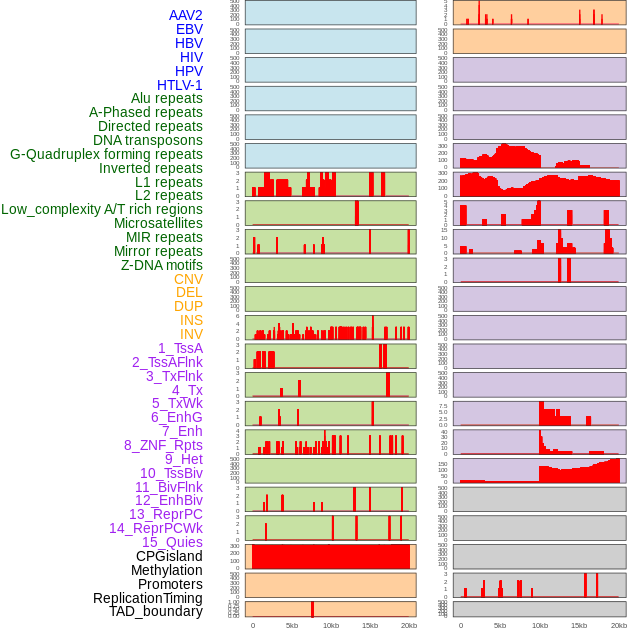 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NSMCE4A-ATE1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:123658356/chr10:123721032) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | ATE1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Involved in the post-translational conjugation of arginine to the N-terminal aspartate or glutamate of a protein. This arginylation is required for degradation of the protein via the ubiquitin pathway. Does not arginylate cysteine residues (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for NSMCE4A-ATE1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >60541_60541_1_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369017_ATE1_chr10_123503372_ENST00000224652_length(transcript)=1530nt_BP=782nt GTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCGGGGCCGGGGCCGCGACCCGCATC GGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGCGCGGGAGCGCAGAGAGGCCCCAG AGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTTGGAGGCGGAGGCCGACCAAGGCC TGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAA CAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTT CAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATA TGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAA CAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATACGGAGAGTGCCCTGTGCCAAAGC CACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGATGAGGATCGCAGTACGGAACCTGA CCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGGAGGCTGCTGTTCT GCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCCGGGAAGTTCCTGT GTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACATTTTTTATTTTGA CTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAACTGCATTATGACCT AGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATTTTGTAAAATGAAG AAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAGACTGTTTCCTCAGGCCCATTTTA AACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAATATGTCTTCTCAAGAACAAAACT GTGCTGTTACAACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTTGAAAAAATAAAACATTAAAATGG >60541_60541_1_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369017_ATE1_chr10_123503372_ENST00000224652_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_2_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369017_ATE1_chr10_123503372_ENST00000540606_length(transcript)=1339nt_BP=782nt GTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCGGGGCCGGGGCCGCGACCCGCATC GGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGCGCGGGAGCGCAGAGAGGCCCCAG AGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTTGGAGGCGGAGGCCGACCAAGGCC TGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAA CAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTT CAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATA TGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAA CAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATACGGAGAGTGCCCTGTGCCAAAGC CACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGATGAGGATCGCAGTACGGAACCTGA CCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGGAGGCTGCTGTTCT GCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCCGGGAAGTTCCTGT GTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACATTTTTTATTTTGA CTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAACTGCATTATGACCT AGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATTTTGTAAAATGAAG >60541_60541_2_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369017_ATE1_chr10_123503372_ENST00000540606_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_3_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369023_ATE1_chr10_123503372_ENST00000369040_length(transcript)=1480nt_BP=805nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATA CGGAGAGTGCCCTGTGCCAAAGCCACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGAT GAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGAC CCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTT CACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCAC AAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAG ATTTTAAAACTGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCC TGTTTGTATTTTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAG ACTGTTTCCTCAGGCCCATTTTAAACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAA >60541_60541_3_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369023_ATE1_chr10_123503372_ENST00000369040_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_4_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369023_ATE1_chr10_123503372_ENST00000369043_length(transcript)=4240nt_BP=805nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATA CGGAGAGTGCCCTGTGCCAAAGCCACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGAT GAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGAC CCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTT CACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCAC AAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAG ATTTTAAAACTGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCC TGTTTGTATTTTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAG ACTGTTTCCTCAGGCCCATTTTAAACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAA TATGTCTTCTCAAGAACAAAACTGTGCTGTTACAACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTT GAAAAAATAAAACATTAAAATGGAGCTTGTGTTAGCATCAGGTATCCATTTGTTCAGGACAGTCCTGTTCATGTCTGTTGTCTTGGCATA GTTTTTTCCCCTAGAATATAGTACTCCCTTTTACTCTAAAAAATATCCCAGTTTGGACAATAAAATACATAATTACTCTAGTTATATTAT TTGCTTTACTTCTAAAAATGTAAGAAATTGAATTTTTTTAAAGAAAAATGTTGGTTCCTGCCTTGATCTAAGTCTCATCCAAAGGAAATA AATAGTCACTAGTTTTTTATCTTACAACTCAGGACATTTGTCTTTGGTTATTAATGGAAATTAGTATGTGATTACTTTCATAGTTATGCC ACAAATCACATTGAAGAAGGAATCATTCCGACCTCTGTTCCAGGACAAGAGCTAGAACAATCCATTTCTTGTCCTTTGATTTGAGAGTCA CAGTCAGGGTGGCTTCTGCCACCCTTAGTAACTCAGAGCAGAGGCCAGCCCCCTCCTTCCCTCACTTTCTTTTGCTGAGTCCTTTGCCCA CCTGTCAAGGTGGCAGGCACTGTGCTGGGTACAGGAGGACAGTCAGACATGTCCCTTCTTAGCTATAGTCGAGCTGTCTGGGAAACAGGA TGAAAAACAGGAGGGTTATTTTCTTGTGCCCTCTTTGTCAGCTGATCCCCTCTTCTGCTACCAGCTATTTGGCCAGCAAGCCGTTTTTAG TCCCCACTTTGCCCATTTTTCTGTTTTGGTTCATCGTTTCTTAAAAGCCATGTTATAAAACATGGTAGTTTGAATCCTGTTGCTAATTTT AAACTTTCCTCTAAAATGTACTGAATTTTGACAAAAATTTGAAAATATCCTCAGCTAACTAGAATAAAAAGGATCATAAAACAATGATTT TAAAACTGAAATCTCTAGAAACTCAACATCCAAGTCAGCCGCATTTCTTCATTCAGAGTGTGTGTGTCACACCTGCCAAGGTGCTGCGTA CTCTGCTAACCGAGCTAGAGTAGTGAGCAAAGCCATTTTCTCTGATCACAAGATTTTACATTTTTCTGGGATTTTGACCTGCAAAGTAGT CTCGTAAGAGCATTTGAGAGACTTACTTGGAACTGCCTTCAGAATCTATAGAGCCTTTTTTCTCTTTTTCCTCTAAAATGAAAAGAGCTT CATTTTATGATTATAACAAAAGTGACACTGTAAGCAGTTAGAACATTAAGAAGTATAAATAAAAAGTAAAAATCATCTACAACCCTACCA TACTCAGAAGGAGAAAAGAACTGTCATGTATGTATACACACATACCTATGTAATTTTAATATAAATAGAATTATGTTCTACATGCTGTTT TATTTCCTCAACAGTAAATTATGGACATGTCTGAAATGTGAAATAAATTTCAAAATAAGGCTTCAGAAAGTGTAGTAAGTAATCTCTGCA TTATTAAAAATAAGCAGGGTAGGGCTGGTACTTGGCTCGCTTAGCATTTGAATGTCCAACTTGGTGTTATCACTGTATCTTCCCTCCATT TGTCTTTGTGATTAGCATGTAAAATGGTATTCATAAAGATCACAACCCTTGAATATCAGATGAAGAGAAAACTTGACTCCAACATCTTAC CACAACTCTGGTTTCTTCCTGCAGAATTCATTTTCAGAGGAAAATGATGAATCATCCCTGTCTGTGAACCACTGTGCTTTCCTTGAGGGT GGCATTGTAGGTTGACACCAGCAAAGACTCAGAGTGACTTGAGCATTGGAGATCCTTCTACTTGGCTGCTGTATTCATGCATTATGTTGG TTTGAGAATAGCTAGTGTATTGATCCAAGTAGTCAAAGTGTCTTAAAAGGACACCTATTTGTCCTTTTGAGCCCCAGCTGAGTGAATACT GATAGTGGACTAGAAAAGCATAGTCAAGAAAAGTGACCCACCTTGTTACTTGACCAGCAGTCTAGCTGAGAGATCTGATTTTATGTTCGT AACTTTCTGTAAAGAAAGACACAAGGACTTTTCAAAGACAGTTTATATCTTTCCAAGGCAGGAAGCTTTGCATTTGCAATCTTAGTGTTG TGTCCCTTTCTGATTTTCAAATACATCACACCTGCCTTCCTGTTTTGGGAGCAAAGATGTAATTTCAATTCCCCTTGCTACCGTCCTTAT TTAAATTATTTCCATTCTAAGAGATTTTTGTTATTTTTTTAAATGTAATCTGAGCACTTTTTTGTATTCTAAAAGATAGATGATATCAGA TAAATATGTTGTACATTTGATTAAAATTATTTAGATAAATATTACTATGTTGACTTTTAAATAGCTTTATCCTATTTTTCATTCATTTTG CAAATATTTGTTGTGTGTAGTTTCTTAACGTGTCAGAATCTATTATGTAAAAGAACCTTTCCAGATTTCTGAACAGTATATGCTTTGATT TTATAGGCTTTATATTATTTCAGTATGAATAAAGATAAGGAATATGAAACAGTTAACTAAAATGTATCTGTCGTTGCTAACTTGAAAAAT GAAGTAGAAACAGTTGGAAAATGTTTGAATTAGAAGTTATTCAAGTGCACACTCTTTTCTAAAAGAAAGCCAATGACTATAAGGCAAAAG AAGTTTGACTGCATGTGGTATTTTTTGCTCTTGTATATGCTTTTTGAACAAGCTATTTGATAAAGCCTGAATGGAAAAAATAAAGCTGTT >60541_60541_4_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369023_ATE1_chr10_123503372_ENST00000369043_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_5_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369023_ATE1_chr10_123503372_ENST00000535655_length(transcript)=1723nt_BP=805nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATA CGGAGAGTGCCCTGTGCCAAAGCCACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGAT GAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGAC CCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTT CACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCAC AAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAG ATTTTAAAACTGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCC TGTTTGTATTTTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAG ACTGTTTCCTCAGGCCCATTTTAAACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAA TATGTCTTCTCAAGAACAAAACTGTGCTGTTACAACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTT GAAAAAATAAAACATTAAAATGGAGCTTGTGTTAGCATCAGGTATCCATTTGTTCAGGACAGTCCTGTTCATGTCTGTTGTCTTGGCATA GTTTTTTCCCCTAGAATATAGTACTCCCTTTTACTCTAAAAAATATCCCAGTTTGGACAATAAAATACATAATTACTCTAGTTATATTAT >60541_60541_5_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369023_ATE1_chr10_123503372_ENST00000535655_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_6_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369023_ATE1_chr10_123503372_ENST00000543447_length(transcript)=1195nt_BP=805nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATA CGGAGAGTGCCCTGTGCCAAAGCCACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGAT GAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGAC CCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTT CACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCAC AAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAG >60541_60541_6_NSMCE4A-ATE1_NSMCE4A_chr10_123724800_ENST00000369023_ATE1_chr10_123503372_ENST00000543447_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_7_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369017_ATE1_chr10_123503373_ENST00000224652_length(transcript)=1530nt_BP=782nt GTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCGGGGCCGGGGCCGCGACCCGCATC GGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGCGCGGGAGCGCAGAGAGGCCCCAG AGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTTGGAGGCGGAGGCCGACCAAGGCC TGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAA CAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTT CAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATA TGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAA CAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATACGGAGAGTGCCCTGTGCCAAAGC CACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGATGAGGATCGCAGTACGGAACCTGA CCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGGAGGCTGCTGTTCT GCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCCGGGAAGTTCCTGT GTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACATTTTTTATTTTGA CTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAACTGCATTATGACCT AGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATTTTGTAAAATGAAG AAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAGACTGTTTCCTCAGGCCCATTTTA AACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAATATGTCTTCTCAAGAACAAAACT GTGCTGTTACAACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTTGAAAAAATAAAACATTAAAATGG >60541_60541_7_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369017_ATE1_chr10_123503373_ENST00000224652_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_8_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369017_ATE1_chr10_123503373_ENST00000540606_length(transcript)=1339nt_BP=782nt GTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCGGGGCCGGGGCCGCGACCCGCATC GGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGCGCGGGAGCGCAGAGAGGCCCCAG AGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTTGGAGGCGGAGGCCGACCAAGGCC TGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAA CAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTT CAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATA TGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAA CAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATACGGAGAGTGCCCTGTGCCAAAGC CACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGATGAGGATCGCAGTACGGAACCTGA CCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGGAGGCTGCTGTTCT GCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCCGGGAAGTTCCTGT GTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACATTTTTTATTTTGA CTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAACTGCATTATGACCT AGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATTTTGTAAAATGAAG >60541_60541_8_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369017_ATE1_chr10_123503373_ENST00000540606_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_9_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369023_ATE1_chr10_123503373_ENST00000369040_length(transcript)=1480nt_BP=805nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATA CGGAGAGTGCCCTGTGCCAAAGCCACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGAT GAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGAC CCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTT CACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCAC AAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAG ATTTTAAAACTGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCC TGTTTGTATTTTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAG ACTGTTTCCTCAGGCCCATTTTAAACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAA >60541_60541_9_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369023_ATE1_chr10_123503373_ENST00000369040_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_10_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369023_ATE1_chr10_123503373_ENST00000369043_length(transcript)=4240nt_BP=805nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATA CGGAGAGTGCCCTGTGCCAAAGCCACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGAT GAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGAC CCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTT CACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCAC AAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAG ATTTTAAAACTGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCC TGTTTGTATTTTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAG ACTGTTTCCTCAGGCCCATTTTAAACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAA TATGTCTTCTCAAGAACAAAACTGTGCTGTTACAACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTT GAAAAAATAAAACATTAAAATGGAGCTTGTGTTAGCATCAGGTATCCATTTGTTCAGGACAGTCCTGTTCATGTCTGTTGTCTTGGCATA GTTTTTTCCCCTAGAATATAGTACTCCCTTTTACTCTAAAAAATATCCCAGTTTGGACAATAAAATACATAATTACTCTAGTTATATTAT TTGCTTTACTTCTAAAAATGTAAGAAATTGAATTTTTTTAAAGAAAAATGTTGGTTCCTGCCTTGATCTAAGTCTCATCCAAAGGAAATA AATAGTCACTAGTTTTTTATCTTACAACTCAGGACATTTGTCTTTGGTTATTAATGGAAATTAGTATGTGATTACTTTCATAGTTATGCC ACAAATCACATTGAAGAAGGAATCATTCCGACCTCTGTTCCAGGACAAGAGCTAGAACAATCCATTTCTTGTCCTTTGATTTGAGAGTCA CAGTCAGGGTGGCTTCTGCCACCCTTAGTAACTCAGAGCAGAGGCCAGCCCCCTCCTTCCCTCACTTTCTTTTGCTGAGTCCTTTGCCCA CCTGTCAAGGTGGCAGGCACTGTGCTGGGTACAGGAGGACAGTCAGACATGTCCCTTCTTAGCTATAGTCGAGCTGTCTGGGAAACAGGA TGAAAAACAGGAGGGTTATTTTCTTGTGCCCTCTTTGTCAGCTGATCCCCTCTTCTGCTACCAGCTATTTGGCCAGCAAGCCGTTTTTAG TCCCCACTTTGCCCATTTTTCTGTTTTGGTTCATCGTTTCTTAAAAGCCATGTTATAAAACATGGTAGTTTGAATCCTGTTGCTAATTTT AAACTTTCCTCTAAAATGTACTGAATTTTGACAAAAATTTGAAAATATCCTCAGCTAACTAGAATAAAAAGGATCATAAAACAATGATTT TAAAACTGAAATCTCTAGAAACTCAACATCCAAGTCAGCCGCATTTCTTCATTCAGAGTGTGTGTGTCACACCTGCCAAGGTGCTGCGTA CTCTGCTAACCGAGCTAGAGTAGTGAGCAAAGCCATTTTCTCTGATCACAAGATTTTACATTTTTCTGGGATTTTGACCTGCAAAGTAGT CTCGTAAGAGCATTTGAGAGACTTACTTGGAACTGCCTTCAGAATCTATAGAGCCTTTTTTCTCTTTTTCCTCTAAAATGAAAAGAGCTT CATTTTATGATTATAACAAAAGTGACACTGTAAGCAGTTAGAACATTAAGAAGTATAAATAAAAAGTAAAAATCATCTACAACCCTACCA TACTCAGAAGGAGAAAAGAACTGTCATGTATGTATACACACATACCTATGTAATTTTAATATAAATAGAATTATGTTCTACATGCTGTTT TATTTCCTCAACAGTAAATTATGGACATGTCTGAAATGTGAAATAAATTTCAAAATAAGGCTTCAGAAAGTGTAGTAAGTAATCTCTGCA TTATTAAAAATAAGCAGGGTAGGGCTGGTACTTGGCTCGCTTAGCATTTGAATGTCCAACTTGGTGTTATCACTGTATCTTCCCTCCATT TGTCTTTGTGATTAGCATGTAAAATGGTATTCATAAAGATCACAACCCTTGAATATCAGATGAAGAGAAAACTTGACTCCAACATCTTAC CACAACTCTGGTTTCTTCCTGCAGAATTCATTTTCAGAGGAAAATGATGAATCATCCCTGTCTGTGAACCACTGTGCTTTCCTTGAGGGT GGCATTGTAGGTTGACACCAGCAAAGACTCAGAGTGACTTGAGCATTGGAGATCCTTCTACTTGGCTGCTGTATTCATGCATTATGTTGG TTTGAGAATAGCTAGTGTATTGATCCAAGTAGTCAAAGTGTCTTAAAAGGACACCTATTTGTCCTTTTGAGCCCCAGCTGAGTGAATACT GATAGTGGACTAGAAAAGCATAGTCAAGAAAAGTGACCCACCTTGTTACTTGACCAGCAGTCTAGCTGAGAGATCTGATTTTATGTTCGT AACTTTCTGTAAAGAAAGACACAAGGACTTTTCAAAGACAGTTTATATCTTTCCAAGGCAGGAAGCTTTGCATTTGCAATCTTAGTGTTG TGTCCCTTTCTGATTTTCAAATACATCACACCTGCCTTCCTGTTTTGGGAGCAAAGATGTAATTTCAATTCCCCTTGCTACCGTCCTTAT TTAAATTATTTCCATTCTAAGAGATTTTTGTTATTTTTTTAAATGTAATCTGAGCACTTTTTTGTATTCTAAAAGATAGATGATATCAGA TAAATATGTTGTACATTTGATTAAAATTATTTAGATAAATATTACTATGTTGACTTTTAAATAGCTTTATCCTATTTTTCATTCATTTTG CAAATATTTGTTGTGTGTAGTTTCTTAACGTGTCAGAATCTATTATGTAAAAGAACCTTTCCAGATTTCTGAACAGTATATGCTTTGATT TTATAGGCTTTATATTATTTCAGTATGAATAAAGATAAGGAATATGAAACAGTTAACTAAAATGTATCTGTCGTTGCTAACTTGAAAAAT GAAGTAGAAACAGTTGGAAAATGTTTGAATTAGAAGTTATTCAAGTGCACACTCTTTTCTAAAAGAAAGCCAATGACTATAAGGCAAAAG AAGTTTGACTGCATGTGGTATTTTTTGCTCTTGTATATGCTTTTTGAACAAGCTATTTGATAAAGCCTGAATGGAAAAAATAAAGCTGTT >60541_60541_10_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369023_ATE1_chr10_123503373_ENST00000369043_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_11_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369023_ATE1_chr10_123503373_ENST00000535655_length(transcript)=1723nt_BP=805nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATA CGGAGAGTGCCCTGTGCCAAAGCCACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGAT GAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGAC CCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTT CACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCAC AAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAG ATTTTAAAACTGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCC TGTTTGTATTTTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAG ACTGTTTCCTCAGGCCCATTTTAAACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAA TATGTCTTCTCAAGAACAAAACTGTGCTGTTACAACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTT GAAAAAATAAAACATTAAAATGGAGCTTGTGTTAGCATCAGGTATCCATTTGTTCAGGACAGTCCTGTTCATGTCTGTTGTCTTGGCATA GTTTTTTCCCCTAGAATATAGTACTCCCTTTTACTCTAAAAAATATCCCAGTTTGGACAATAAAATACATAATTACTCTAGTTATATTAT >60541_60541_11_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369023_ATE1_chr10_123503373_ENST00000535655_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_12_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369023_ATE1_chr10_123503373_ENST00000543447_length(transcript)=1195nt_BP=805nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTGTTGGGTTCAATATA CGGAGAGTGCCCTGTGCCAAAGCCACGAGTTGATCGTCCAAGAAAAGTTCCTGTGATACAAGAGGAGAGGGCAATGCCTGCCCAGTGGAT GAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGAC CCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTT CACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCAC AAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAG >60541_60541_12_NSMCE4A-ATE1_NSMCE4A_chr10_123724801_ENST00000369023_ATE1_chr10_123503373_ENST00000543447_length(amino acids)=337AA_BP=0 MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE LIRDEDSPDFEFIVYDSWKITGRTAENTFNKTHTFHFLLGSIYGECPVPKPRVDRPRKVPVIQEERAMPAQWMRIAVRNLTDCRCFTREP -------------------------------------------------------------- >60541_60541_13_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369017_ATE1_chr10_123503372_ENST00000369040_length(transcript)=1357nt_BP=682nt GTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCGGGGCCGGGGCCGCGACCCGCATC GGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGCGCGGGAGCGCAGAGAGGCCCCAG AGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTTGGAGGCGGAGGCCGACCAAGGCC TGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAA CAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTT CAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATA TGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAA CAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTTGGATGAGGATCGCAGTACGGAACCTGACCGATTGCAG GTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCC AGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGA TGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACATTTTTTATTTTGACTATCTATGG CTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAACTGCATTATGACCTAGCCCCCATA ATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATTTTGTAAAATGAAGAAGTGAATCT AAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAGACTGTTTCCTCAGGCCCATTTTAAACTGAACTT ATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAATATGTCTTCTCAAGAACAAAACTGTGCTGTTAC >60541_60541_13_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369017_ATE1_chr10_123503372_ENST00000369040_length(amino acids)=219AA_BP= MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE -------------------------------------------------------------- >60541_60541_14_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369017_ATE1_chr10_123503372_ENST00000369043_length(transcript)=4117nt_BP=682nt GTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCGGGGCCGGGGCCGCGACCCGCATC GGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGCGCGGGAGCGCAGAGAGGCCCCAG AGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTTGGAGGCGGAGGCCGACCAAGGCC TGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAA CAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTT CAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATA TGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAA CAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTTGGATGAGGATCGCAGTACGGAACCTGACCGATTGCAG GTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCC AGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGA TGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACATTTTTTATTTTGACTATCTATGG CTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAACTGCATTATGACCTAGCCCCCATA ATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATTTTGTAAAATGAAGAAGTGAATCT AAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAGACTGTTTCCTCAGGCCCATTTTAAACTGAACTT ATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAATATGTCTTCTCAAGAACAAAACTGTGCTGTTAC AACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTTGAAAAAATAAAACATTAAAATGGAGCTTGTGTT AGCATCAGGTATCCATTTGTTCAGGACAGTCCTGTTCATGTCTGTTGTCTTGGCATAGTTTTTTCCCCTAGAATATAGTACTCCCTTTTA CTCTAAAAAATATCCCAGTTTGGACAATAAAATACATAATTACTCTAGTTATATTATTTGCTTTACTTCTAAAAATGTAAGAAATTGAAT TTTTTTAAAGAAAAATGTTGGTTCCTGCCTTGATCTAAGTCTCATCCAAAGGAAATAAATAGTCACTAGTTTTTTATCTTACAACTCAGG ACATTTGTCTTTGGTTATTAATGGAAATTAGTATGTGATTACTTTCATAGTTATGCCACAAATCACATTGAAGAAGGAATCATTCCGACC TCTGTTCCAGGACAAGAGCTAGAACAATCCATTTCTTGTCCTTTGATTTGAGAGTCACAGTCAGGGTGGCTTCTGCCACCCTTAGTAACT CAGAGCAGAGGCCAGCCCCCTCCTTCCCTCACTTTCTTTTGCTGAGTCCTTTGCCCACCTGTCAAGGTGGCAGGCACTGTGCTGGGTACA GGAGGACAGTCAGACATGTCCCTTCTTAGCTATAGTCGAGCTGTCTGGGAAACAGGATGAAAAACAGGAGGGTTATTTTCTTGTGCCCTC TTTGTCAGCTGATCCCCTCTTCTGCTACCAGCTATTTGGCCAGCAAGCCGTTTTTAGTCCCCACTTTGCCCATTTTTCTGTTTTGGTTCA TCGTTTCTTAAAAGCCATGTTATAAAACATGGTAGTTTGAATCCTGTTGCTAATTTTAAACTTTCCTCTAAAATGTACTGAATTTTGACA AAAATTTGAAAATATCCTCAGCTAACTAGAATAAAAAGGATCATAAAACAATGATTTTAAAACTGAAATCTCTAGAAACTCAACATCCAA GTCAGCCGCATTTCTTCATTCAGAGTGTGTGTGTCACACCTGCCAAGGTGCTGCGTACTCTGCTAACCGAGCTAGAGTAGTGAGCAAAGC CATTTTCTCTGATCACAAGATTTTACATTTTTCTGGGATTTTGACCTGCAAAGTAGTCTCGTAAGAGCATTTGAGAGACTTACTTGGAAC TGCCTTCAGAATCTATAGAGCCTTTTTTCTCTTTTTCCTCTAAAATGAAAAGAGCTTCATTTTATGATTATAACAAAAGTGACACTGTAA GCAGTTAGAACATTAAGAAGTATAAATAAAAAGTAAAAATCATCTACAACCCTACCATACTCAGAAGGAGAAAAGAACTGTCATGTATGT ATACACACATACCTATGTAATTTTAATATAAATAGAATTATGTTCTACATGCTGTTTTATTTCCTCAACAGTAAATTATGGACATGTCTG AAATGTGAAATAAATTTCAAAATAAGGCTTCAGAAAGTGTAGTAAGTAATCTCTGCATTATTAAAAATAAGCAGGGTAGGGCTGGTACTT GGCTCGCTTAGCATTTGAATGTCCAACTTGGTGTTATCACTGTATCTTCCCTCCATTTGTCTTTGTGATTAGCATGTAAAATGGTATTCA TAAAGATCACAACCCTTGAATATCAGATGAAGAGAAAACTTGACTCCAACATCTTACCACAACTCTGGTTTCTTCCTGCAGAATTCATTT TCAGAGGAAAATGATGAATCATCCCTGTCTGTGAACCACTGTGCTTTCCTTGAGGGTGGCATTGTAGGTTGACACCAGCAAAGACTCAGA GTGACTTGAGCATTGGAGATCCTTCTACTTGGCTGCTGTATTCATGCATTATGTTGGTTTGAGAATAGCTAGTGTATTGATCCAAGTAGT CAAAGTGTCTTAAAAGGACACCTATTTGTCCTTTTGAGCCCCAGCTGAGTGAATACTGATAGTGGACTAGAAAAGCATAGTCAAGAAAAG TGACCCACCTTGTTACTTGACCAGCAGTCTAGCTGAGAGATCTGATTTTATGTTCGTAACTTTCTGTAAAGAAAGACACAAGGACTTTTC AAAGACAGTTTATATCTTTCCAAGGCAGGAAGCTTTGCATTTGCAATCTTAGTGTTGTGTCCCTTTCTGATTTTCAAATACATCACACCT GCCTTCCTGTTTTGGGAGCAAAGATGTAATTTCAATTCCCCTTGCTACCGTCCTTATTTAAATTATTTCCATTCTAAGAGATTTTTGTTA TTTTTTTAAATGTAATCTGAGCACTTTTTTGTATTCTAAAAGATAGATGATATCAGATAAATATGTTGTACATTTGATTAAAATTATTTA GATAAATATTACTATGTTGACTTTTAAATAGCTTTATCCTATTTTTCATTCATTTTGCAAATATTTGTTGTGTGTAGTTTCTTAACGTGT CAGAATCTATTATGTAAAAGAACCTTTCCAGATTTCTGAACAGTATATGCTTTGATTTTATAGGCTTTATATTATTTCAGTATGAATAAA GATAAGGAATATGAAACAGTTAACTAAAATGTATCTGTCGTTGCTAACTTGAAAAATGAAGTAGAAACAGTTGGAAAATGTTTGAATTAG AAGTTATTCAAGTGCACACTCTTTTCTAAAAGAAAGCCAATGACTATAAGGCAAAAGAAGTTTGACTGCATGTGGTATTTTTTGCTCTTG >60541_60541_14_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369017_ATE1_chr10_123503372_ENST00000369043_length(amino acids)=219AA_BP= MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE -------------------------------------------------------------- >60541_60541_15_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369017_ATE1_chr10_123503372_ENST00000535655_length(transcript)=1600nt_BP=682nt GTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCGGGGCCGGGGCCGCGACCCGCATC GGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGCGCGGGAGCGCAGAGAGGCCCCAG AGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTTGGAGGCGGAGGCCGACCAAGGCC TGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAA CAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTT CAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATA TGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAA CAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTTGGATGAGGATCGCAGTACGGAACCTGACCGATTGCAG GTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCC AGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGA TGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACATTTTTTATTTTGACTATCTATGG CTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAACTGCATTATGACCTAGCCCCCATA ATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATTTTGTAAAATGAAGAAGTGAATCT AAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAGACTGTTTCCTCAGGCCCATTTTAAACTGAACTT ATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAATATGTCTTCTCAAGAACAAAACTGTGCTGTTAC AACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTTGAAAAAATAAAACATTAAAATGGAGCTTGTGTT AGCATCAGGTATCCATTTGTTCAGGACAGTCCTGTTCATGTCTGTTGTCTTGGCATAGTTTTTTCCCCTAGAATATAGTACTCCCTTTTA >60541_60541_15_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369017_ATE1_chr10_123503372_ENST00000535655_length(amino acids)=219AA_BP= MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE -------------------------------------------------------------- >60541_60541_16_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369017_ATE1_chr10_123503372_ENST00000543447_length(transcript)=1072nt_BP=682nt GTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCGGGGCCGGGGCCGCGACCCGCATC GGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGCGCGGGAGCGCAGAGAGGCCCCAG AGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTTGGAGGCGGAGGCCGACCAAGGCC TGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAA CAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTT CAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATA TGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAA CAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTTGGATGAGGATCGCAGTACGGAACCTGACCGATTGCAG GTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCC AGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGA TGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACATTTTTTATTTTGACTATCTATGG >60541_60541_16_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369017_ATE1_chr10_123503372_ENST00000543447_length(amino acids)=219AA_BP= MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE -------------------------------------------------------------- >60541_60541_17_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369023_ATE1_chr10_123503372_ENST00000224652_length(transcript)=1453nt_BP=705nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTTGGATGAGGATCGCA GTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGG AGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCC GGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACA TTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAAC TGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATT TTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAGACTGTTTCCT CAGGCCCATTTTAAACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCACTTAGAAAATATGTCTTCT CAAGAACAAAACTGTGCTGTTACAACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAATAGAGAACTTGAAAAAATAA >60541_60541_17_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369023_ATE1_chr10_123503372_ENST00000224652_length(amino acids)=219AA_BP= MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE -------------------------------------------------------------- >60541_60541_18_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369023_ATE1_chr10_123503372_ENST00000540606_length(transcript)=1262nt_BP=705nt AGTTTCTGGCGCGAACTTCCGCCGTTCCGAAGTTGCACGGTGAATTGGCGCTATGTCTGGGGACAGCAGCGGCCGCGGGCCAGAGGGCCG GGGCCGGGGCCGCGACCCGCATCGGGATCGCACCCGCTCCCGCTCCCGCTCGCGGTCCCCTTTGTCGCCCAGGTCCCGCCGCGGCTCTGC GCGGGAGCGCAGAGAGGCCCCAGAGCGCCCGAGCCTGGAGGACACAGAGCCGTCGGATTCCGGGGACGAGATGATGGACCCGGCCAGCTT GGAGGCGGAGGCCGACCAAGGCCTGTGCCGCCAGATCCGCCATCAGTACCGGGCGCTCATCAACTCCGTCCAACAAAACCGTGAGGACAT ACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAGCAAGAGAAGCAGTCCTGGA TGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCTCCTTTGACATGTTAAGATA TGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATAGTCCTGATTTTGAATTCAT AGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACTTTCTTGGATGAGGATCGCA GTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAGCAGAAAGACCCAAGTGAGG AGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAACTGACCTGTTCACCTCTGCC GGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTCACCACCCACAAATTAGACA TTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTTAATATAAAGATTTTAAAAC TGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTCAAATTCTCCTGTTTGTATT TTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAATTAAAACAGACTGTTTCCT >60541_60541_18_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000369023_ATE1_chr10_123503372_ENST00000540606_length(amino acids)=219AA_BP= MSGDSSGRGPEGRGRGRDPHRDRTRSRSRSRSPLSPRSRRGSARERREAPERPSLEDTEPSDSGDEMMDPASLEAEADQGLCRQIRHQYR ALINSVQQNREDILNAGDKLTEVLEEANTLFNEVSRAREAVLDAHFLVLASDLGKEKAKQLRSDLSSFDMLRYVETLLTHMGVNPLEAEE -------------------------------------------------------------- >60541_60541_19_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000538652_ATE1_chr10_123503372_ENST00000224652_length(transcript)=1562nt_BP=814nt AGTAGAGACGCGCCGGGTGCCAGCCCCTCGCCGCACCTTAAATTGTTGACAAAGTGCTCCCACTTTGTGGCTGGAGCCGTACGACCTTGG CGCGGGTCCCCGAGTGGCGGGCTGGAAAAGCTGGAGGCCAGAGCCGTTCGCGGACTCGCCCGAGCCCAGCCAGCCAGTGGGGAGAGGCAG GACGCGGACTCCGCGTGCTTTGATTGCGCCCGGCAGTCCTCGGCGTGGGCTCCCGGCCTCGCAGCGGCAGCTGCAGCTGCAGCGGCACGC GAGAGCTGTCAAATGCACGTTCTCGGACCCCACCCGGACCCGCGGAATTCGAATCTCTGGGTGGGTCCGCGCAACTGTGGAGTGGCCCTC CAGGTGATGGTGTGTATTGCTTGCAAAGTTTGAGAACCACTCAGTTATGGAGCACTCAGAGGCTGCAGCCGGAGTCCAGCCCTTTGGGTT AAGAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAG CAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCT CCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATA GTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACT TTCTTGGATGAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAG CAGAAAGACCCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAAC TGACCTGTTCACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTC ACCACCCACAAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTT AATATAAAGATTTTAAAACTGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTC AAATTCTCCTGTTTGTATTTTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAA TTAAAACAGACTGTTTCCTCAGGCCCATTTTAAACTGAACTTATGCTAGGAAACCTTAAGTATGGGGAAGGTAGAAAGTTCATTTCATCA CTTAGAAAATATGTCTTCTCAAGAACAAAACTGTGCTGTTACAACTCAGTGTTCAATGTGAAATTGCTGCCAAATGTTATGTAGTTTAAT >60541_60541_19_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000538652_ATE1_chr10_123503372_ENST00000224652_length(amino acids)=116AA_BP= MLTKCSHFVAGAVRPWRGSPSGGLEKLEARAVRGLARAQPASGERQDADSACFDCARQSSAWAPGLAAAAAAAAARESCQMHVLGPHPDP -------------------------------------------------------------- >60541_60541_20_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000538652_ATE1_chr10_123503372_ENST00000540606_length(transcript)=1371nt_BP=814nt AGTAGAGACGCGCCGGGTGCCAGCCCCTCGCCGCACCTTAAATTGTTGACAAAGTGCTCCCACTTTGTGGCTGGAGCCGTACGACCTTGG CGCGGGTCCCCGAGTGGCGGGCTGGAAAAGCTGGAGGCCAGAGCCGTTCGCGGACTCGCCCGAGCCCAGCCAGCCAGTGGGGAGAGGCAG GACGCGGACTCCGCGTGCTTTGATTGCGCCCGGCAGTCCTCGGCGTGGGCTCCCGGCCTCGCAGCGGCAGCTGCAGCTGCAGCGGCACGC GAGAGCTGTCAAATGCACGTTCTCGGACCCCACCCGGACCCGCGGAATTCGAATCTCTGGGTGGGTCCGCGCAACTGTGGAGTGGCCCTC CAGGTGATGGTGTGTATTGCTTGCAAAGTTTGAGAACCACTCAGTTATGGAGCACTCAGAGGCTGCAGCCGGAGTCCAGCCCTTTGGGTT AAGAAAACCGTGAGGACATACTGAATGCCGGTGACAAATTAACAGAGGTCCTTGAAGAGGCTAACACTCTGTTTAATGAAGTGTCCCGAG CAAGAGAAGCAGTCCTGGATGCCCACTTTCTTGTTTTGGCTTCAGATTTGGGCAAAGAGAAAGCAAAGCAGCTGCGCTCAGACCTGAGCT CCTTTGACATGTTAAGATATGTTGAAACTCTACTCACACATATGGGTGTAAATCCGCTAGAAGCTGAAGAACTCATCCGTGATGAAGATA GTCCTGATTTTGAATTCATAGTCTATGACTCCTGGAAGATAACAGGCAGAACAGCAGAAAACACCTTTAATAAAACCCATACATTCCACT TTCTTGGATGAGGATCGCAGTACGGAACCTGACCGATTGCAGGTGTTTCACAAGAGAGCCATCATGCCTTACGGTGTTTATAAGAAACAG CAGAAAGACCCAAGTGAGGAGGCTGCTGTTCTGCAGTACGCCAGCCTGGTGGGGCAGAAGTGCTCCGAGCGGATGCTGCTGTTCAGAAAC TGACCTGTTCACCTCTGCCGGGAAGTTCCTGTGTTGTGCTGATGATTTGTGCCAGGATACATATTCAGTACCTGTGGGGAAATAACTGTC ACCACCCACAAATTAGACATTTTTTATTTTGACTATCTATGGCTTTTAAAAAATATTTTGTGGCAATGTATCTGTGAGAATCTCATAGTT AATATAAAGATTTTAAAACTGCATTATGACCTAGCCCCCATAATTGGGATTTATCATTTTGGAGGATTCTTTCTAGAGCAAGATACGCTC AAATTCTCCTGTTTGTATTTTGTAAAATGAAGAAGTGAATCTAAGTAACTTAATCACAGTTGTGCATTTTTTTTGGTTCTGTTAGAGAAA >60541_60541_20_NSMCE4A-ATE1_NSMCE4A_chr10_123727169_ENST00000538652_ATE1_chr10_123503372_ENST00000540606_length(amino acids)=165AA_BP= MLICHRHSVCPHGFLNPKGWTPAAASECSITEWFSNFASNTHHHLEGHSTVARTHPEIRIPRVRVGSENVHLTALACRCSCSCRCEAGSP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NSMCE4A-ATE1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NSMCE4A-ATE1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NSMCE4A-ATE1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies