
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARHGAP32-C20orf24 (FusionGDB2 ID:6068) |
Fusion Gene Summary for ARHGAP32-C20orf24 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARHGAP32-C20orf24 | Fusion gene ID: 6068 | Hgene | Tgene | Gene symbol | ARHGAP32 | C20orf24 | Gene ID | 9743 | 55969 |
| Gene name | Rho GTPase activating protein 32 | RAB5 interacting factor | |
| Synonyms | GC-GAP|GRIT|PX-RICS|RICS|p200RhoGAP|p250GAP | C20orf24|PNAS-11|RCAF1|RIP5 | |
| Cytomap | 11q24.3 | 20q11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | rho GTPase-activating protein 32GAB-associated CDC42GAB-associated Cdc42/Rac GTPase-activating proteinGTPase regulator interacting with TrkAGTPase-activating protein for Cdc42 and Rac1RhoGAP involved in the -catenin-N-cadherin and NMDA receptor signa | uncharacterized protein RAB5IFrab5-interacting proteinrespirasome complex assembly factor 1uncharacterized protein C20orf24 | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | A7KAX9 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000310343, ENST00000524655, ENST00000392657, ENST00000527272, | ENST00000342422, ENST00000344795, ENST00000373852, | |
| Fusion gene scores | * DoF score | 10 X 9 X 5=450 | 7 X 7 X 4=196 |
| # samples | 11 | 7 | |
| ** MAII score | log2(11/450*10)=-2.03242147769238 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/196*10)=-1.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARHGAP32 [Title/Abstract] AND C20orf24 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARHGAP32(128932175)-C20orf24(35236118), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across ARHGAP32 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
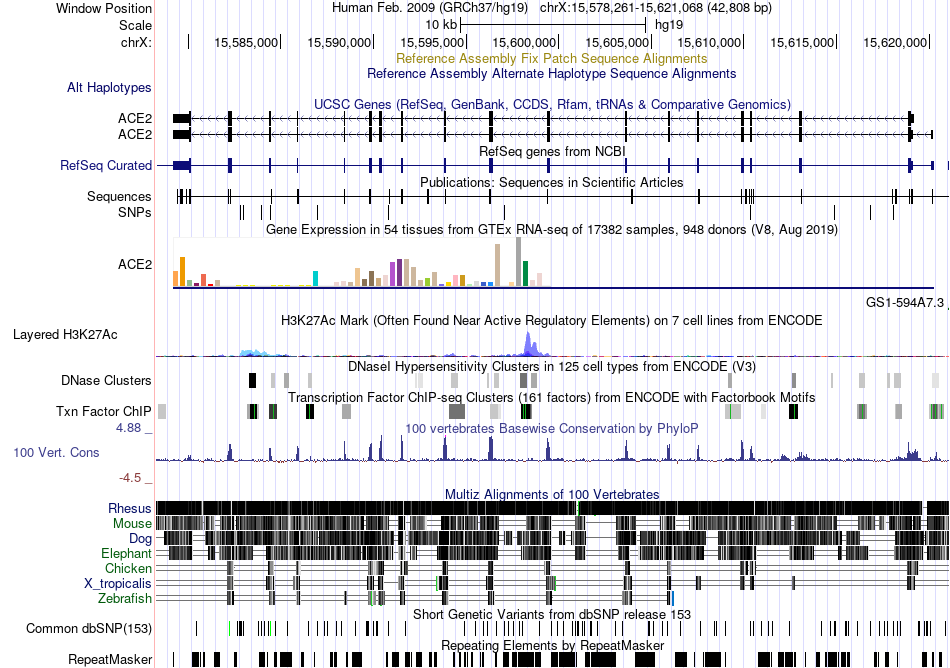 |
| Fusion gene breakpoints across C20orf24 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
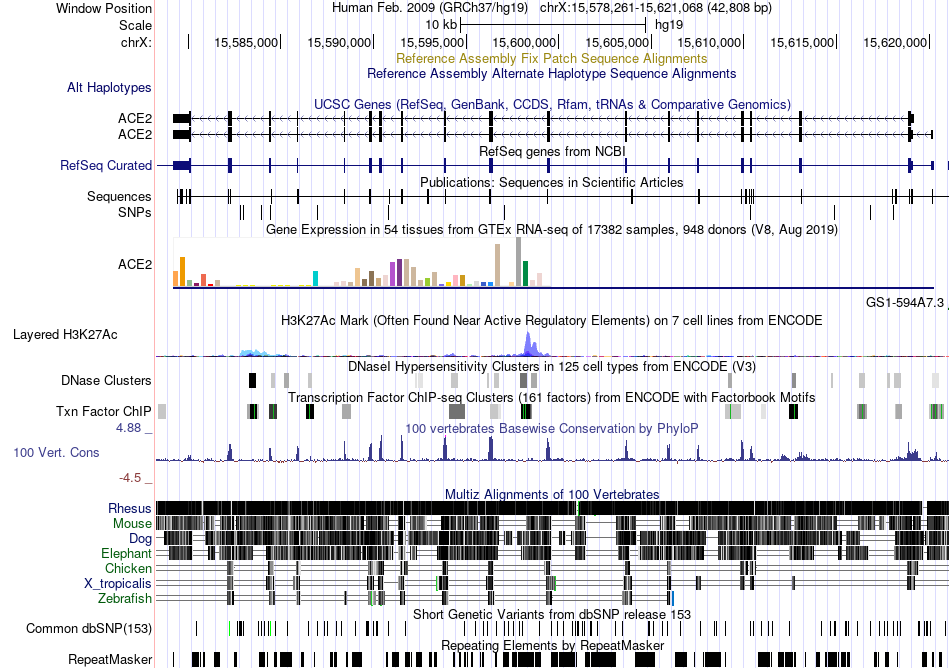 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-EW-A2FW-01A | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
Top |
Fusion Gene ORF analysis for ARHGAP32-C20orf24 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000310343 | ENST00000342422 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| In-frame | ENST00000310343 | ENST00000344795 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| In-frame | ENST00000310343 | ENST00000373852 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| In-frame | ENST00000524655 | ENST00000342422 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| In-frame | ENST00000524655 | ENST00000344795 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| In-frame | ENST00000524655 | ENST00000373852 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| intron-3CDS | ENST00000392657 | ENST00000342422 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| intron-3CDS | ENST00000392657 | ENST00000344795 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| intron-3CDS | ENST00000392657 | ENST00000373852 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| intron-3CDS | ENST00000527272 | ENST00000342422 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| intron-3CDS | ENST00000527272 | ENST00000344795 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| intron-3CDS | ENST00000527272 | ENST00000373852 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000310343 | ARHGAP32 | chr11 | 128932175 | - | ENST00000344795 | C20orf24 | chr20 | 35236118 | + | 1703 | 921 | 0 | 1196 | 398 |
| ENST00000310343 | ARHGAP32 | chr11 | 128932175 | - | ENST00000373852 | C20orf24 | chr20 | 35236118 | + | 1731 | 921 | 0 | 1220 | 406 |
| ENST00000310343 | ARHGAP32 | chr11 | 128932175 | - | ENST00000342422 | C20orf24 | chr20 | 35236118 | + | 1573 | 921 | 0 | 1238 | 412 |
| ENST00000524655 | ARHGAP32 | chr11 | 128932175 | - | ENST00000344795 | C20orf24 | chr20 | 35236118 | + | 1505 | 723 | 24 | 998 | 324 |
| ENST00000524655 | ARHGAP32 | chr11 | 128932175 | - | ENST00000373852 | C20orf24 | chr20 | 35236118 | + | 1533 | 723 | 24 | 1022 | 332 |
| ENST00000524655 | ARHGAP32 | chr11 | 128932175 | - | ENST00000342422 | C20orf24 | chr20 | 35236118 | + | 1375 | 723 | 24 | 1040 | 338 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000310343 | ENST00000344795 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + | 0.000170359 | 0.99982965 |
| ENST00000310343 | ENST00000373852 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + | 0.000154366 | 0.9998456 |
| ENST00000310343 | ENST00000342422 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + | 0.000191956 | 0.999808 |
| ENST00000524655 | ENST00000344795 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + | 0.000345953 | 0.99965405 |
| ENST00000524655 | ENST00000373852 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + | 0.000291541 | 0.9997085 |
| ENST00000524655 | ENST00000342422 | ARHGAP32 | chr11 | 128932175 | - | C20orf24 | chr20 | 35236118 | + | 0.00042846 | 0.9995715 |
Top |
Fusion Genomic Features for ARHGAP32-C20orf24 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARHGAP32 | chr11 | 128932174 | - | C20orf24 | chr20 | 35236117 | + | 1.21E-07 | 0.9999999 |
| ARHGAP32 | chr11 | 128932174 | - | C20orf24 | chr20 | 35236117 | + | 1.21E-07 | 0.9999999 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
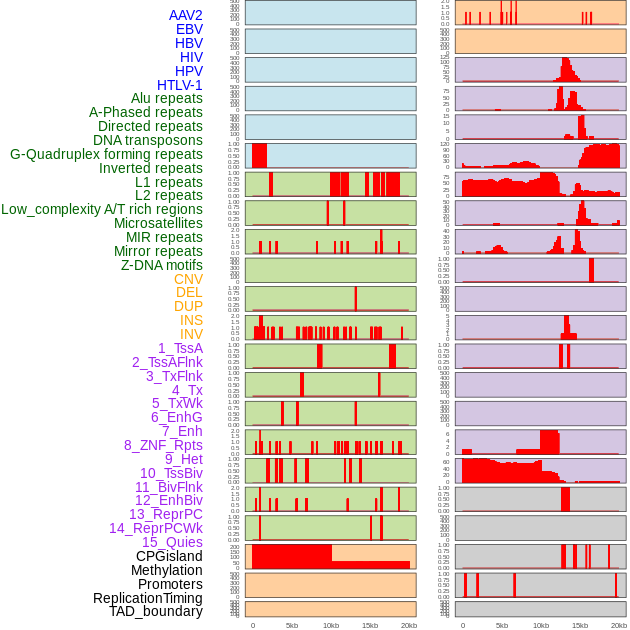 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
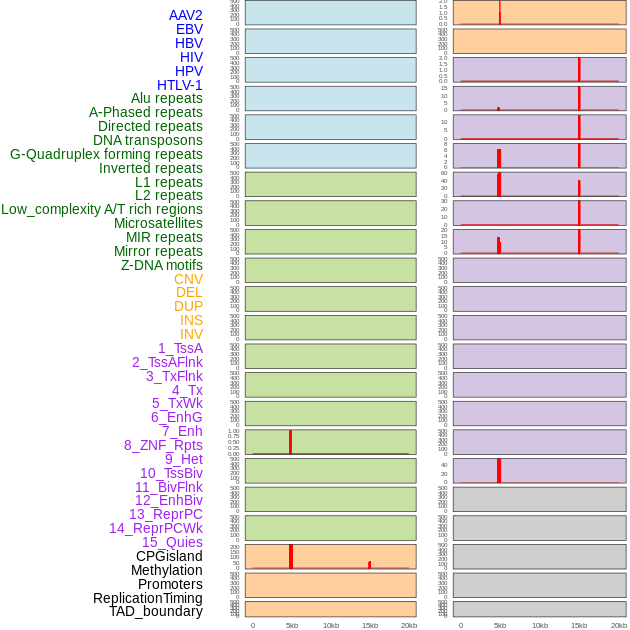 |
Top |
Fusion Protein Features for ARHGAP32-C20orf24 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:128932175/chr20:35236118) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARHGAP32 | . |
| FUNCTION: GTPase-activating protein (GAP) promoting GTP hydrolysis on RHOA, CDC42 and RAC1 small GTPases. May be involved in the differentiation of neuronal cells during the formation of neurite extensions. Involved in NMDA receptor activity-dependent actin reorganization in dendritic spines. May mediate cross-talks between Ras- and Rho-regulated signaling pathways in cell growth regulation. Isoform 2 has higher GAP activity (By similarity). {ECO:0000250, ECO:0000269|PubMed:12446789, ECO:0000269|PubMed:12454018, ECO:0000269|PubMed:12531901, ECO:0000269|PubMed:12788081, ECO:0000269|PubMed:12819203, ECO:0000269|PubMed:12857875, ECO:0000269|PubMed:17663722}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000310343 | - | 9 | 22 | 131_245 | 307 | 2088.0 | Domain | Note=PX%3B atypical |
| Tgene | C20orf24 | chr11:128932175 | chr20:35236118 | ENST00000342422 | 0 | 3 | 45_64 | 38 | 144.0 | Transmembrane | Helical | |
| Tgene | C20orf24 | chr11:128932175 | chr20:35236118 | ENST00000342422 | 0 | 3 | 68_90 | 38 | 144.0 | Transmembrane | Helical | |
| Tgene | C20orf24 | chr11:128932175 | chr20:35236118 | ENST00000344795 | 0 | 4 | 45_64 | 38 | 130.0 | Transmembrane | Helical | |
| Tgene | C20orf24 | chr11:128932175 | chr20:35236118 | ENST00000344795 | 0 | 4 | 68_90 | 38 | 130.0 | Transmembrane | Helical | |
| Tgene | C20orf24 | chr11:128932175 | chr20:35236118 | ENST00000373852 | 0 | 4 | 45_64 | 38 | 138.0 | Transmembrane | Helical | |
| Tgene | C20orf24 | chr11:128932175 | chr20:35236118 | ENST00000373852 | 0 | 4 | 68_90 | 38 | 138.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000310343 | - | 9 | 22 | 1031_1036 | 307 | 2088.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000310343 | - | 9 | 22 | 1305_1310 | 307 | 2088.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000392657 | - | 1 | 13 | 1031_1036 | 0 | 1739.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000392657 | - | 1 | 13 | 1305_1310 | 0 | 1739.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000527272 | - | 1 | 12 | 1031_1036 | 0 | 1739.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000527272 | - | 1 | 12 | 1305_1310 | 0 | 1739.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000310343 | - | 9 | 22 | 259_321 | 307 | 2088.0 | Domain | SH3 |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000310343 | - | 9 | 22 | 372_567 | 307 | 2088.0 | Domain | Rho-GAP |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000392657 | - | 1 | 13 | 131_245 | 0 | 1739.0 | Domain | Note=PX%3B atypical |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000392657 | - | 1 | 13 | 259_321 | 0 | 1739.0 | Domain | SH3 |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000392657 | - | 1 | 13 | 372_567 | 0 | 1739.0 | Domain | Rho-GAP |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000527272 | - | 1 | 12 | 131_245 | 0 | 1739.0 | Domain | Note=PX%3B atypical |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000527272 | - | 1 | 12 | 259_321 | 0 | 1739.0 | Domain | SH3 |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000527272 | - | 1 | 12 | 372_567 | 0 | 1739.0 | Domain | Rho-GAP |
Top |
Fusion Gene Sequence for ARHGAP32-C20orf24 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6068_6068_1_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000310343_C20orf24_chr20_35236118_ENST00000342422_length(transcript)=1573nt_BP=921nt ATGGAGACTGAAAGTGAGAGTAGCACTTTAGGGGATGACAGTGTCTTCTGGTTGGAGTCTGAAGTTATAATCCAGGTGACTGACTGTGAA GAGGAAGAAAGGGAAGAGAAGTTCAGGAAGATGAAGTCCTCAGTACATTCTGAAGAAGATGATTTTGTTCCAGAGCTACATAGAAATGTA CACCCTCGAGAGCGGCCTGATTGGGAAGAAACTCTTAGCGCAATGGCAAGAGGCGCAGATGTTCCAGAGATTCCTGGAGATCTTACTCTT AAGACGTGTGGCAGTACAGCCAGTATGAAGGTTAAGCATGTGAAAAAGTTACCCTTCACTAAAGGTCACTTTCCGAAGATGGCTGAATGT GCGCATTTCCATTATGAGAATGTTGAGTTCGGCAGCATACAGCTTTCACTTTCAGAAGAACAGAATGAAGTAATGAAAAATGGCTGTGAA TCTAAAGAGCTGGTCTACCTCGTGCAGATTGCTTGTCAGGGAAAAAGTTGGATTGTTAAAAGAAGTTATGAAGATTTTCGGGTACTTGAT AAACATCTTCATCTGTGTATTTATGACCGAAGATTTTCCCAGCTCTCAGAACTTCCCCGTTCTGACACCCTGAAGGACAGTCCAGAGTCG GTCACTCAGATGCTTATGGCTTACCTGTCACGCCTTTCAGCTATCGCTGGCAACAAGATCAACTGTGGGCCCGCCCTTACCTGGATGGAG ATTGATAATAAGGGAAATCACCTTTTGGTTCATGAGGAGTCATCCATCAACACTCCTGCTGTCGGTGCTGCCCATGTTATCAAGAGGTAC ACTGCTCGGGCCCCTGACGAACTGACCTTAGAGGTGGGAGACATTGTTTCTGTTATTGACATGCCCCCGAAAGTGTTAAGCACATGGTGG AGAGGCAAGCACGGATTCCAGGATGAATTTTTAGATGTGATCTACTGGTTCCGACAGATCATTGCTGTGGTCCTGGGTGTCATTTGGGGA GTTTTGCCATTACGAGGGTTCTTGGGAATAGCAGGGTCATTTGGATCATCTTTTACACTGCCATCCATTATGACTGATGGTGTACAGCTC CCAAGTGCTCCCTATCCAGTCCAAAGGACCCTCTTGATTACAGCACAGGAACTTGATCGTTGGGGAACCCCAGCCCCTTGGAACTTGGAA GACCCGTGTTTCCTGGACCGCGAATCAGTGTGTTGGGCATCAGTGTTTTCTGCAAGGGTTGTGACCTGAAACTTTTTAAAAACCACCCAC CTTTGGGGAAGCATTTCTGAATTTATCCATCACCAACCATTTCTTCTTGGATACCATCAAGTAACAGCTATTATTTGCCAAGTGGAGCTG TCATTTAATTTGATGCACCTCTGGATTCAGATGAAACATTAAATTGTCTTCCTCGATTCTCCATCGGGTGTAGAGTTTTTAAACTATCAA TGGCATTTCAAGTCTTCTGAAACAGCATGGCTGTATGTGCGTGGTCCATAGCACAGTACATGCAGCATCTAATAAGAGTTTCCATTGTAG >6068_6068_1_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000310343_C20orf24_chr20_35236118_ENST00000342422_length(amino acids)=412AA_BP=306 METESESSTLGDDSVFWLESEVIIQVTDCEEEEREEKFRKMKSSVHSEEDDFVPELHRNVHPRERPDWEETLSAMARGADVPEIPGDLTL KTCGSTASMKVKHVKKLPFTKGHFPKMAECAHFHYENVEFGSIQLSLSEEQNEVMKNGCESKELVYLVQIACQGKSWIVKRSYEDFRVLD KHLHLCIYDRRFSQLSELPRSDTLKDSPESVTQMLMAYLSRLSAIAGNKINCGPALTWMEIDNKGNHLLVHEESSINTPAVGAAHVIKRY TARAPDELTLEVGDIVSVIDMPPKVLSTWWRGKHGFQDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGSFGSSFTLPSIMTDGVQL -------------------------------------------------------------- >6068_6068_2_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000310343_C20orf24_chr20_35236118_ENST00000344795_length(transcript)=1703nt_BP=921nt ATGGAGACTGAAAGTGAGAGTAGCACTTTAGGGGATGACAGTGTCTTCTGGTTGGAGTCTGAAGTTATAATCCAGGTGACTGACTGTGAA GAGGAAGAAAGGGAAGAGAAGTTCAGGAAGATGAAGTCCTCAGTACATTCTGAAGAAGATGATTTTGTTCCAGAGCTACATAGAAATGTA CACCCTCGAGAGCGGCCTGATTGGGAAGAAACTCTTAGCGCAATGGCAAGAGGCGCAGATGTTCCAGAGATTCCTGGAGATCTTACTCTT AAGACGTGTGGCAGTACAGCCAGTATGAAGGTTAAGCATGTGAAAAAGTTACCCTTCACTAAAGGTCACTTTCCGAAGATGGCTGAATGT GCGCATTTCCATTATGAGAATGTTGAGTTCGGCAGCATACAGCTTTCACTTTCAGAAGAACAGAATGAAGTAATGAAAAATGGCTGTGAA TCTAAAGAGCTGGTCTACCTCGTGCAGATTGCTTGTCAGGGAAAAAGTTGGATTGTTAAAAGAAGTTATGAAGATTTTCGGGTACTTGAT AAACATCTTCATCTGTGTATTTATGACCGAAGATTTTCCCAGCTCTCAGAACTTCCCCGTTCTGACACCCTGAAGGACAGTCCAGAGTCG GTCACTCAGATGCTTATGGCTTACCTGTCACGCCTTTCAGCTATCGCTGGCAACAAGATCAACTGTGGGCCCGCCCTTACCTGGATGGAG ATTGATAATAAGGGAAATCACCTTTTGGTTCATGAGGAGTCATCCATCAACACTCCTGCTGTCGGTGCTGCCCATGTTATCAAGAGGTAC ACTGCTCGGGCCCCTGACGAACTGACCTTAGAGGTGGGAGACATTGTTTCTGTTATTGACATGCCCCCGAAAGTGTTAAGCACATGGTGG AGAGGCAAGCACGGATTCCAGGATGAATTTTTAGATGTGATCTACTGGTTCCGACAGATCATTGCTGTGGTCCTGGGTGTCATTTGGGGA GTTTTGCCATTACGAGGGTTCTTGGGAATAGCAGGATTCTGCCTGATCAATGCAGGAGTCCTGTACCTCTACTTCAGCAATTACCTACAG ATTGATGAGGAAGAATATGGTGGCACGTGGGAGCTCACGAAGGAAGGGTTTATGACCTCTTTTGCCTTGTTCATGGTCATTTGGATCATC TTTTACACTGCCATCCATTATGACTGATGGTGTACAGCTCCCAAGTGCTCCCTATCCAGTCCAAAGGACCCTCTTGATTACAGCACAGGA ACTTGATCGTTGGGGAACCCCAGCCCCTTGGAACTTGGAAGACCCGTGTTTCCTGGACCGCGAATCAGTGTGTTGGGCATCAGTGTTTTC TGCAAGGGTTGTGACCTGAAACTTTTTAAAAACCACCCACCTTTGGGGAAGCATTTCTGAATTTATCCATCACCAACCATTTCTTCTTGG ATACCATCAAGTAACAGCTATTATTTGCCAAGTGGAGCTGTCATTTAATTTGATGCACCTCTGGATTCAGATGAAACATTAAATTGTCTT CCTCGATTCTCCATCGGGTGTAGAGTTTTTAAACTATCAATGGCATTTCAAGTCTTCTGAAACAGCATGGCTGTATGTGCGTGGTCCATA >6068_6068_2_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000310343_C20orf24_chr20_35236118_ENST00000344795_length(amino acids)=398AA_BP=306 METESESSTLGDDSVFWLESEVIIQVTDCEEEEREEKFRKMKSSVHSEEDDFVPELHRNVHPRERPDWEETLSAMARGADVPEIPGDLTL KTCGSTASMKVKHVKKLPFTKGHFPKMAECAHFHYENVEFGSIQLSLSEEQNEVMKNGCESKELVYLVQIACQGKSWIVKRSYEDFRVLD KHLHLCIYDRRFSQLSELPRSDTLKDSPESVTQMLMAYLSRLSAIAGNKINCGPALTWMEIDNKGNHLLVHEESSINTPAVGAAHVIKRY TARAPDELTLEVGDIVSVIDMPPKVLSTWWRGKHGFQDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGFCLINAGVLYLYFSNYLQ -------------------------------------------------------------- >6068_6068_3_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000310343_C20orf24_chr20_35236118_ENST00000373852_length(transcript)=1731nt_BP=921nt ATGGAGACTGAAAGTGAGAGTAGCACTTTAGGGGATGACAGTGTCTTCTGGTTGGAGTCTGAAGTTATAATCCAGGTGACTGACTGTGAA GAGGAAGAAAGGGAAGAGAAGTTCAGGAAGATGAAGTCCTCAGTACATTCTGAAGAAGATGATTTTGTTCCAGAGCTACATAGAAATGTA CACCCTCGAGAGCGGCCTGATTGGGAAGAAACTCTTAGCGCAATGGCAAGAGGCGCAGATGTTCCAGAGATTCCTGGAGATCTTACTCTT AAGACGTGTGGCAGTACAGCCAGTATGAAGGTTAAGCATGTGAAAAAGTTACCCTTCACTAAAGGTCACTTTCCGAAGATGGCTGAATGT GCGCATTTCCATTATGAGAATGTTGAGTTCGGCAGCATACAGCTTTCACTTTCAGAAGAACAGAATGAAGTAATGAAAAATGGCTGTGAA TCTAAAGAGCTGGTCTACCTCGTGCAGATTGCTTGTCAGGGAAAAAGTTGGATTGTTAAAAGAAGTTATGAAGATTTTCGGGTACTTGAT AAACATCTTCATCTGTGTATTTATGACCGAAGATTTTCCCAGCTCTCAGAACTTCCCCGTTCTGACACCCTGAAGGACAGTCCAGAGTCG GTCACTCAGATGCTTATGGCTTACCTGTCACGCCTTTCAGCTATCGCTGGCAACAAGATCAACTGTGGGCCCGCCCTTACCTGGATGGAG ATTGATAATAAGGGAAATCACCTTTTGGTTCATGAGGAGTCATCCATCAACACTCCTGCTGTCGGTGCTGCCCATGTTATCAAGAGGTAC ACTGCTCGGGCCCCTGACGAACTGACCTTAGAGGTGGGAGACATTGTTTCTGTTATTGACATGCCCCCGAAAGTGTTAAGCACATGGTGG AGAGGCAAGCACGGATTCCAGGATGAATTTTTAGATGTGATCTACTGGTTCCGACAGATCATTGCTGTGGTCCTGGGTGTCATTTGGGGA GTTTTGCCATTACGAGGGTTCTTGGGAATAGCAGGATTCTGCCTGATCAATGCAGGAGTCCTGTACCTCTACTTCAGCAATTACCTACAG ATTGATGAGGAAGAATATGGTGGCACGTGGGAGCTCACGAAGGAAGGGTTTATGACCTCTTTTGCCTTGTTCATGGTATGTGTAGCTGAT AGTTTTACAACAGGTCATTTGGATCATCTTTTACACTGCCATCCATTATGACTGATGGTGTACAGCTCCCAAGTGCTCCCTATCCAGTCC AAAGGACCCTCTTGATTACAGCACAGGAACTTGATCGTTGGGGAACCCCAGCCCCTTGGAACTTGGAAGACCCGTGTTTCCTGGACCGCG AATCAGTGTGTTGGGCATCAGTGTTTTCTGCAAGGGTTGTGACCTGAAACTTTTTAAAAACCACCCACCTTTGGGGAAGCATTTCTGAAT TTATCCATCACCAACCATTTCTTCTTGGATACCATCAAGTAACAGCTATTATTTGCCAAGTGGAGCTGTCATTTAATTTGATGCACCTCT GGATTCAGATGAAACATTAAATTGTCTTCCTCGATTCTCCATCGGGTGTAGAGTTTTTAAACTATCAATGGCATTTCAAGTCTTCTGAAA CAGCATGGCTGTATGTGCGTGGTCCATAGCACAGTACATGCAGCATCTAATAAGAGTTTCCATTGTAGAATGTTTTCACATACTTGAATA >6068_6068_3_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000310343_C20orf24_chr20_35236118_ENST00000373852_length(amino acids)=406AA_BP=306 METESESSTLGDDSVFWLESEVIIQVTDCEEEEREEKFRKMKSSVHSEEDDFVPELHRNVHPRERPDWEETLSAMARGADVPEIPGDLTL KTCGSTASMKVKHVKKLPFTKGHFPKMAECAHFHYENVEFGSIQLSLSEEQNEVMKNGCESKELVYLVQIACQGKSWIVKRSYEDFRVLD KHLHLCIYDRRFSQLSELPRSDTLKDSPESVTQMLMAYLSRLSAIAGNKINCGPALTWMEIDNKGNHLLVHEESSINTPAVGAAHVIKRY TARAPDELTLEVGDIVSVIDMPPKVLSTWWRGKHGFQDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGFCLINAGVLYLYFSNYLQ -------------------------------------------------------------- >6068_6068_4_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000524655_C20orf24_chr20_35236118_ENST00000342422_length(transcript)=1375nt_BP=723nt GATTGGGAAGAAACTCTTAGCGCAATGGCAAGAGGCGCAGATGTTCCAGAGATTCCTGGAGATCTTACTCTTAAGACGTGTGGCAGTACA GCCAGTATGAAGGTTAAGCATGTGAAAAAGTTACCCTTCACTAAAGGTCACTTTCCGAAGATGGCTGAATGTGCGCATTTCCATTATGAG AATGTTGAGTTCGGCAGCATACAGCTTTCACTTTCAGAAGAACAGAATGAAGTAATGAAAAATGGCTGTGAATCTAAAGAGCTGGTCTAC CTCGTGCAGATTGCTTGTCAGGGAAAAAGTTGGATTGTTAAAAGAAGTTATGAAGATTTTCGGGTACTTGATAAACATCTTCATCTGTGT ATTTATGACCGAAGATTTTCCCAGCTCTCAGAACTTCCCCGTTCTGACACCCTGAAGGACAGTCCAGAGTCGGTCACTCAGATGCTTATG GCTTACCTGTCACGCCTTTCAGCTATCGCTGGCAACAAGATCAACTGTGGGCCCGCCCTTACCTGGATGGAGATTGATAATAAGGGAAAT CACCTTTTGGTTCATGAGGAGTCATCCATCAACACTCCTGCTGTCGGTGCTGCCCATGTTATCAAGAGGTACACTGCTCGGGCCCCTGAC GAACTGACCTTAGAGGTGGGAGACATTGTTTCTGTTATTGACATGCCCCCGAAAGTGTTAAGCACATGGTGGAGAGGCAAGCACGGATTC CAGGATGAATTTTTAGATGTGATCTACTGGTTCCGACAGATCATTGCTGTGGTCCTGGGTGTCATTTGGGGAGTTTTGCCATTACGAGGG TTCTTGGGAATAGCAGGGTCATTTGGATCATCTTTTACACTGCCATCCATTATGACTGATGGTGTACAGCTCCCAAGTGCTCCCTATCCA GTCCAAAGGACCCTCTTGATTACAGCACAGGAACTTGATCGTTGGGGAACCCCAGCCCCTTGGAACTTGGAAGACCCGTGTTTCCTGGAC CGCGAATCAGTGTGTTGGGCATCAGTGTTTTCTGCAAGGGTTGTGACCTGAAACTTTTTAAAAACCACCCACCTTTGGGGAAGCATTTCT GAATTTATCCATCACCAACCATTTCTTCTTGGATACCATCAAGTAACAGCTATTATTTGCCAAGTGGAGCTGTCATTTAATTTGATGCAC CTCTGGATTCAGATGAAACATTAAATTGTCTTCCTCGATTCTCCATCGGGTGTAGAGTTTTTAAACTATCAATGGCATTTCAAGTCTTCT GAAACAGCATGGCTGTATGTGCGTGGTCCATAGCACAGTACATGCAGCATCTAATAAGAGTTTCCATTGTAGAATGTTTTCACATACTTG >6068_6068_4_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000524655_C20orf24_chr20_35236118_ENST00000342422_length(amino acids)=338AA_BP=232 MARGADVPEIPGDLTLKTCGSTASMKVKHVKKLPFTKGHFPKMAECAHFHYENVEFGSIQLSLSEEQNEVMKNGCESKELVYLVQIACQG KSWIVKRSYEDFRVLDKHLHLCIYDRRFSQLSELPRSDTLKDSPESVTQMLMAYLSRLSAIAGNKINCGPALTWMEIDNKGNHLLVHEES SINTPAVGAAHVIKRYTARAPDELTLEVGDIVSVIDMPPKVLSTWWRGKHGFQDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGSF -------------------------------------------------------------- >6068_6068_5_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000524655_C20orf24_chr20_35236118_ENST00000344795_length(transcript)=1505nt_BP=723nt GATTGGGAAGAAACTCTTAGCGCAATGGCAAGAGGCGCAGATGTTCCAGAGATTCCTGGAGATCTTACTCTTAAGACGTGTGGCAGTACA GCCAGTATGAAGGTTAAGCATGTGAAAAAGTTACCCTTCACTAAAGGTCACTTTCCGAAGATGGCTGAATGTGCGCATTTCCATTATGAG AATGTTGAGTTCGGCAGCATACAGCTTTCACTTTCAGAAGAACAGAATGAAGTAATGAAAAATGGCTGTGAATCTAAAGAGCTGGTCTAC CTCGTGCAGATTGCTTGTCAGGGAAAAAGTTGGATTGTTAAAAGAAGTTATGAAGATTTTCGGGTACTTGATAAACATCTTCATCTGTGT ATTTATGACCGAAGATTTTCCCAGCTCTCAGAACTTCCCCGTTCTGACACCCTGAAGGACAGTCCAGAGTCGGTCACTCAGATGCTTATG GCTTACCTGTCACGCCTTTCAGCTATCGCTGGCAACAAGATCAACTGTGGGCCCGCCCTTACCTGGATGGAGATTGATAATAAGGGAAAT CACCTTTTGGTTCATGAGGAGTCATCCATCAACACTCCTGCTGTCGGTGCTGCCCATGTTATCAAGAGGTACACTGCTCGGGCCCCTGAC GAACTGACCTTAGAGGTGGGAGACATTGTTTCTGTTATTGACATGCCCCCGAAAGTGTTAAGCACATGGTGGAGAGGCAAGCACGGATTC CAGGATGAATTTTTAGATGTGATCTACTGGTTCCGACAGATCATTGCTGTGGTCCTGGGTGTCATTTGGGGAGTTTTGCCATTACGAGGG TTCTTGGGAATAGCAGGATTCTGCCTGATCAATGCAGGAGTCCTGTACCTCTACTTCAGCAATTACCTACAGATTGATGAGGAAGAATAT GGTGGCACGTGGGAGCTCACGAAGGAAGGGTTTATGACCTCTTTTGCCTTGTTCATGGTCATTTGGATCATCTTTTACACTGCCATCCAT TATGACTGATGGTGTACAGCTCCCAAGTGCTCCCTATCCAGTCCAAAGGACCCTCTTGATTACAGCACAGGAACTTGATCGTTGGGGAAC CCCAGCCCCTTGGAACTTGGAAGACCCGTGTTTCCTGGACCGCGAATCAGTGTGTTGGGCATCAGTGTTTTCTGCAAGGGTTGTGACCTG AAACTTTTTAAAAACCACCCACCTTTGGGGAAGCATTTCTGAATTTATCCATCACCAACCATTTCTTCTTGGATACCATCAAGTAACAGC TATTATTTGCCAAGTGGAGCTGTCATTTAATTTGATGCACCTCTGGATTCAGATGAAACATTAAATTGTCTTCCTCGATTCTCCATCGGG TGTAGAGTTTTTAAACTATCAATGGCATTTCAAGTCTTCTGAAACAGCATGGCTGTATGTGCGTGGTCCATAGCACAGTACATGCAGCAT >6068_6068_5_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000524655_C20orf24_chr20_35236118_ENST00000344795_length(amino acids)=324AA_BP=232 MARGADVPEIPGDLTLKTCGSTASMKVKHVKKLPFTKGHFPKMAECAHFHYENVEFGSIQLSLSEEQNEVMKNGCESKELVYLVQIACQG KSWIVKRSYEDFRVLDKHLHLCIYDRRFSQLSELPRSDTLKDSPESVTQMLMAYLSRLSAIAGNKINCGPALTWMEIDNKGNHLLVHEES SINTPAVGAAHVIKRYTARAPDELTLEVGDIVSVIDMPPKVLSTWWRGKHGFQDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGFC -------------------------------------------------------------- >6068_6068_6_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000524655_C20orf24_chr20_35236118_ENST00000373852_length(transcript)=1533nt_BP=723nt GATTGGGAAGAAACTCTTAGCGCAATGGCAAGAGGCGCAGATGTTCCAGAGATTCCTGGAGATCTTACTCTTAAGACGTGTGGCAGTACA GCCAGTATGAAGGTTAAGCATGTGAAAAAGTTACCCTTCACTAAAGGTCACTTTCCGAAGATGGCTGAATGTGCGCATTTCCATTATGAG AATGTTGAGTTCGGCAGCATACAGCTTTCACTTTCAGAAGAACAGAATGAAGTAATGAAAAATGGCTGTGAATCTAAAGAGCTGGTCTAC CTCGTGCAGATTGCTTGTCAGGGAAAAAGTTGGATTGTTAAAAGAAGTTATGAAGATTTTCGGGTACTTGATAAACATCTTCATCTGTGT ATTTATGACCGAAGATTTTCCCAGCTCTCAGAACTTCCCCGTTCTGACACCCTGAAGGACAGTCCAGAGTCGGTCACTCAGATGCTTATG GCTTACCTGTCACGCCTTTCAGCTATCGCTGGCAACAAGATCAACTGTGGGCCCGCCCTTACCTGGATGGAGATTGATAATAAGGGAAAT CACCTTTTGGTTCATGAGGAGTCATCCATCAACACTCCTGCTGTCGGTGCTGCCCATGTTATCAAGAGGTACACTGCTCGGGCCCCTGAC GAACTGACCTTAGAGGTGGGAGACATTGTTTCTGTTATTGACATGCCCCCGAAAGTGTTAAGCACATGGTGGAGAGGCAAGCACGGATTC CAGGATGAATTTTTAGATGTGATCTACTGGTTCCGACAGATCATTGCTGTGGTCCTGGGTGTCATTTGGGGAGTTTTGCCATTACGAGGG TTCTTGGGAATAGCAGGATTCTGCCTGATCAATGCAGGAGTCCTGTACCTCTACTTCAGCAATTACCTACAGATTGATGAGGAAGAATAT GGTGGCACGTGGGAGCTCACGAAGGAAGGGTTTATGACCTCTTTTGCCTTGTTCATGGTATGTGTAGCTGATAGTTTTACAACAGGTCAT TTGGATCATCTTTTACACTGCCATCCATTATGACTGATGGTGTACAGCTCCCAAGTGCTCCCTATCCAGTCCAAAGGACCCTCTTGATTA CAGCACAGGAACTTGATCGTTGGGGAACCCCAGCCCCTTGGAACTTGGAAGACCCGTGTTTCCTGGACCGCGAATCAGTGTGTTGGGCAT CAGTGTTTTCTGCAAGGGTTGTGACCTGAAACTTTTTAAAAACCACCCACCTTTGGGGAAGCATTTCTGAATTTATCCATCACCAACCAT TTCTTCTTGGATACCATCAAGTAACAGCTATTATTTGCCAAGTGGAGCTGTCATTTAATTTGATGCACCTCTGGATTCAGATGAAACATT AAATTGTCTTCCTCGATTCTCCATCGGGTGTAGAGTTTTTAAACTATCAATGGCATTTCAAGTCTTCTGAAACAGCATGGCTGTATGTGC GTGGTCCATAGCACAGTACATGCAGCATCTAATAAGAGTTTCCATTGTAGAATGTTTTCACATACTTGAATAAATCAAATCTTTAATTGA >6068_6068_6_ARHGAP32-C20orf24_ARHGAP32_chr11_128932175_ENST00000524655_C20orf24_chr20_35236118_ENST00000373852_length(amino acids)=332AA_BP=232 MARGADVPEIPGDLTLKTCGSTASMKVKHVKKLPFTKGHFPKMAECAHFHYENVEFGSIQLSLSEEQNEVMKNGCESKELVYLVQIACQG KSWIVKRSYEDFRVLDKHLHLCIYDRRFSQLSELPRSDTLKDSPESVTQMLMAYLSRLSAIAGNKINCGPALTWMEIDNKGNHLLVHEES SINTPAVGAAHVIKRYTARAPDELTLEVGDIVSVIDMPPKVLSTWWRGKHGFQDEFLDVIYWFRQIIAVVLGVIWGVLPLRGFLGIAGFC -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARHGAP32-C20orf24 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000310343 | - | 9 | 22 | 1685_2087 | 307.0 | 2088.0 | FYN |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000392657 | - | 1 | 13 | 1685_2087 | 0 | 1739.0 | FYN |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000527272 | - | 1 | 12 | 1685_2087 | 0 | 1739.0 | FYN |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000310343 | - | 9 | 22 | 1391_1711 | 307.0 | 2088.0 | GAB2 |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000392657 | - | 1 | 13 | 1391_1711 | 0 | 1739.0 | GAB2 |
| Hgene | ARHGAP32 | chr11:128932175 | chr20:35236118 | ENST00000527272 | - | 1 | 12 | 1391_1711 | 0 | 1739.0 | GAB2 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARHGAP32-C20orf24 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARHGAP32-C20orf24 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies