
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NUP88-NLRP1 (FusionGDB2 ID:61096) |
Fusion Gene Summary for NUP88-NLRP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NUP88-NLRP1 | Fusion gene ID: 61096 | Hgene | Tgene | Gene symbol | NUP88 | NLRP1 | Gene ID | 4927 | 22861 |
| Gene name | nucleoporin 88 | NLR family pyrin domain containing 1 | |
| Synonyms | FADS4 | AIADK|CARD7|CIDED|CLR17.1|DEFCAP|DEFCAP-L/S|JRRP|MSPC|NAC|NALP1|PP1044|SLEV1|VAMAS1 | |
| Cytomap | 17p13.2 | 17p13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nuclear pore complex protein Nup88karyoporinnuclear pore complex protein 88nucleoporin 88kDanucleoporin Nup88 | NACHT, LRR and PYD domains-containing protein 1NACHT, LRR and PYD containing protein 1NACHT, leucine rich repeat and PYD (pyrin domain) containing 1NACHT, leucine rich repeat and PYD containing 1caspase recruitment domain protein 7caspase recruitment | |
| Modification date | 20200322 | 20200322 | |
| UniProtAcc | . | P59046 | |
| Ensembl transtripts involved in fusion gene | ENST00000573584, ENST00000573169, | ENST00000571307, ENST00000354411, ENST00000577119, ENST00000262467, ENST00000269280, ENST00000345221, ENST00000572272, | |
| Fusion gene scores | * DoF score | 5 X 5 X 3=75 | 11 X 7 X 7=539 |
| # samples | 5 | 11 | |
| ** MAII score | log2(5/75*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/539*10)=-2.29278174922785 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NUP88 [Title/Abstract] AND NLRP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NUP88(5319833)-NLRP1(5440260), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | NLRP1 | GO:0006919 | activation of cysteine-type endopeptidase activity involved in apoptotic process | 15212762 |
| Tgene | NLRP1 | GO:0051402 | neuron apoptotic process | 15212762 |
| Fusion gene breakpoints across NUP88 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
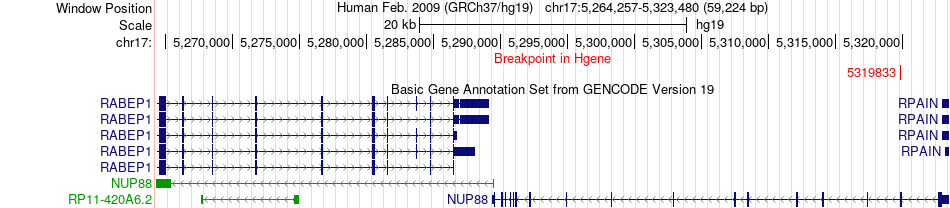 |
| Fusion gene breakpoints across NLRP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-KQ-A41N-01A | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
Top |
Fusion Gene ORF analysis for NUP88-NLRP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000573584 | ENST00000571307 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| 5CDS-intron | ENST00000573584 | ENST00000354411 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| 5CDS-intron | ENST00000573584 | ENST00000577119 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| In-frame | ENST00000573584 | ENST00000262467 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| In-frame | ENST00000573584 | ENST00000269280 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| In-frame | ENST00000573584 | ENST00000345221 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| In-frame | ENST00000573584 | ENST00000572272 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| intron-3CDS | ENST00000573169 | ENST00000262467 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| intron-3CDS | ENST00000573169 | ENST00000269280 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| intron-3CDS | ENST00000573169 | ENST00000345221 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| intron-3CDS | ENST00000573169 | ENST00000572272 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| intron-5UTR | ENST00000573169 | ENST00000571307 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| intron-intron | ENST00000573169 | ENST00000354411 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| intron-intron | ENST00000573169 | ENST00000577119 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000573584 | NUP88 | chr17 | 5319833 | - | ENST00000262467 | NLRP1 | chr17 | 5440260 | - | 2664 | 977 | 453 | 2234 | 593 |
| ENST00000573584 | NUP88 | chr17 | 5319833 | - | ENST00000345221 | NLRP1 | chr17 | 5440260 | - | 3032 | 977 | 453 | 2396 | 647 |
| ENST00000573584 | NUP88 | chr17 | 5319833 | - | ENST00000269280 | NLRP1 | chr17 | 5440260 | - | 3024 | 977 | 453 | 2396 | 647 |
| ENST00000573584 | NUP88 | chr17 | 5319833 | - | ENST00000572272 | NLRP1 | chr17 | 5440260 | - | 2529 | 977 | 453 | 2528 | 691 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000573584 | ENST00000262467 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - | 0.004706148 | 0.9952938 |
| ENST00000573584 | ENST00000345221 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - | 0.00568863 | 0.99431133 |
| ENST00000573584 | ENST00000269280 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - | 0.005739518 | 0.99426055 |
| ENST00000573584 | ENST00000572272 | NUP88 | chr17 | 5319833 | - | NLRP1 | chr17 | 5440260 | - | 0.006407454 | 0.99359256 |
Top |
Fusion Genomic Features for NUP88-NLRP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
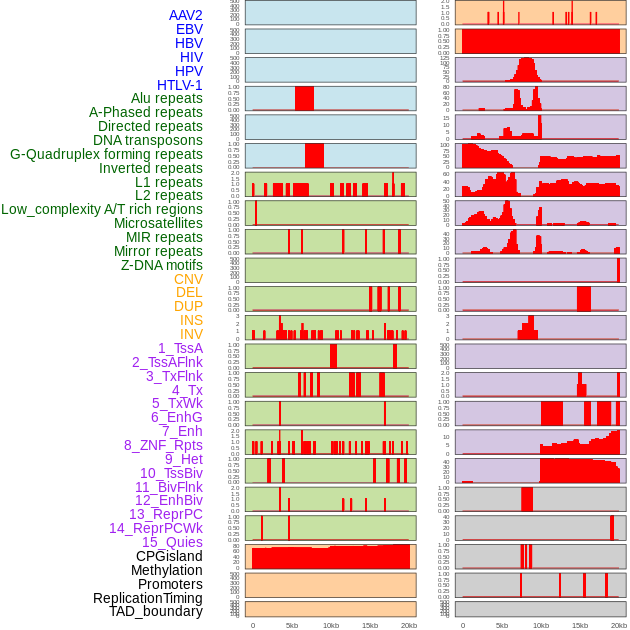 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NUP88-NLRP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:5319833/chr17:5440260) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | NLRP1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Plays an essential role as an potent mitigator of inflammation (PubMed:30559449). Primarily expressed in dendritic cells and macrophages, inhibits both canonical and non-canonical NF-kappa-B and ERK activation pathways (PubMed:15489334, PubMed:17947705). Functions as a negative regulator of NOD2 by targeting it to degradation via the proteasome pathway (PubMed:30559449). In turn, promotes bacterial tolerance (PubMed:30559449). Inhibits also the DDX58-mediated immune signaling against RNA viruses by reducing the E3 ubiquitin ligase TRIM25-mediated 'Lys-63'-linked DDX58 activation but enhancing the E3 ubiquitin ligase RNF125-mediated 'Lys-48'-linked DDX58 degradation (PubMed:30902577). Acts also as a negative regulator of inflammatory response to mitigate obesity and obesity-associated diseases in adipose tissue (By similarity). {ECO:0000250|UniProtKB:E9Q5R7, ECO:0000269|PubMed:15489334, ECO:0000269|PubMed:17947705, ECO:0000269|PubMed:30559449, ECO:0000269|PubMed:30902577}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 1079_1364 | 956 | 1430.0 | Domain | FIIND | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 1374_1463 | 956 | 1430.0 | Domain | CARD | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 1079_1364 | 956 | 1430.0 | Domain | FIIND | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 1374_1463 | 956 | 1430.0 | Domain | CARD | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 1079_1364 | 0 | 1444.0 | Domain | FIIND | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 1374_1463 | 0 | 1444.0 | Domain | CARD | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 1_92 | 0 | 1444.0 | Domain | Pyrin | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 328_637 | 0 | 1444.0 | Domain | NACHT | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 1079_1364 | 956 | 1474.0 | Domain | FIIND | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 1374_1463 | 956 | 1474.0 | Domain | CARD | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 1079_1364 | 0 | 1400.0 | Domain | FIIND | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 1374_1463 | 0 | 1400.0 | Domain | CARD | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 1_92 | 0 | 1400.0 | Domain | Pyrin | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 328_637 | 0 | 1400.0 | Domain | NACHT | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 334_341 | 0 | 1444.0 | Nucleotide binding | ATP | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 334_341 | 0 | 1400.0 | Nucleotide binding | ATP | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 809_830 | 0 | 1444.0 | Repeat | Note=LRR 1 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 838_858 | 0 | 1444.0 | Repeat | Note=LRR 2 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 866_887 | 0 | 1444.0 | Repeat | Note=LRR 3 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 895_915 | 0 | 1444.0 | Repeat | Note=LRR 4 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 923_944 | 0 | 1444.0 | Repeat | Note=LRR 5 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000354411 | 0 | 16 | 950_973 | 0 | 1444.0 | Repeat | Note=LRR 6 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 809_830 | 0 | 1400.0 | Repeat | Note=LRR 1 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 838_858 | 0 | 1400.0 | Repeat | Note=LRR 2 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 866_887 | 0 | 1400.0 | Repeat | Note=LRR 3 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 895_915 | 0 | 1400.0 | Repeat | Note=LRR 4 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 923_944 | 0 | 1400.0 | Repeat | Note=LRR 5 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000577119 | 0 | 15 | 950_973 | 0 | 1400.0 | Repeat | Note=LRR 6 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NUP88 | chr17:5319833 | chr17:5440260 | ENST00000573584 | - | 2 | 17 | 585_651 | 155 | 742.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 1_92 | 956 | 1430.0 | Domain | Pyrin | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 328_637 | 956 | 1430.0 | Domain | NACHT | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 1_92 | 956 | 1430.0 | Domain | Pyrin | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 328_637 | 956 | 1430.0 | Domain | NACHT | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 1_92 | 956 | 1474.0 | Domain | Pyrin | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 328_637 | 956 | 1474.0 | Domain | NACHT | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 334_341 | 956 | 1430.0 | Nucleotide binding | ATP | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 334_341 | 956 | 1430.0 | Nucleotide binding | ATP | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 334_341 | 956 | 1474.0 | Nucleotide binding | ATP | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 809_830 | 956 | 1430.0 | Repeat | Note=LRR 1 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 838_858 | 956 | 1430.0 | Repeat | Note=LRR 2 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 866_887 | 956 | 1430.0 | Repeat | Note=LRR 3 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 895_915 | 956 | 1430.0 | Repeat | Note=LRR 4 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 923_944 | 956 | 1430.0 | Repeat | Note=LRR 5 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000269280 | 7 | 17 | 950_973 | 956 | 1430.0 | Repeat | Note=LRR 6 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 809_830 | 956 | 1430.0 | Repeat | Note=LRR 1 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 838_858 | 956 | 1430.0 | Repeat | Note=LRR 2 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 866_887 | 956 | 1430.0 | Repeat | Note=LRR 3 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 895_915 | 956 | 1430.0 | Repeat | Note=LRR 4 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 923_944 | 956 | 1430.0 | Repeat | Note=LRR 5 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000345221 | 6 | 16 | 950_973 | 956 | 1430.0 | Repeat | Note=LRR 6 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 809_830 | 956 | 1474.0 | Repeat | Note=LRR 1 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 838_858 | 956 | 1474.0 | Repeat | Note=LRR 2 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 866_887 | 956 | 1474.0 | Repeat | Note=LRR 3 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 895_915 | 956 | 1474.0 | Repeat | Note=LRR 4 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 923_944 | 956 | 1474.0 | Repeat | Note=LRR 5 | |
| Tgene | NLRP1 | chr17:5319833 | chr17:5440260 | ENST00000572272 | 6 | 17 | 950_973 | 956 | 1474.0 | Repeat | Note=LRR 6 |
Top |
Fusion Gene Sequence for NUP88-NLRP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >61096_61096_1_NUP88-NLRP1_NUP88_chr17_5319833_ENST00000573584_NLRP1_chr17_5440260_ENST00000262467_length(transcript)=2664nt_BP=977nt ACAGACCCCTGGGAGGTGTACTTTCCGGGTGCAGACCGCGAATGGATCGCAGCGTATTCTGGGAAGTGTTGTTTTATCGACCGGCCCCAC GTGGAGACAGATTTAGGCATCCAAGCGAAATGCGTGAGGCCAGCCCGACCTGCACTGAGGGAGGTAAGTCTTGAGGGAAAGTTCTGGATG CCTGGGTTTACCCAGATGGAGGTGTCCAATAGGCAATTAGATACACAAGTCTCAGGCTCTCCCCAGGTGCTAGATTTCCAGCAGCACCAC CATTATGTTGACTTCTCGTCCCGCCCCCTTGGGCTTCAGAAATAATGGTGATTGGCTTTCCCTTGGTGACGCCCCTGCTTGGTGGGCTGG CCTCGCCTTCGCCCCCCGACCTGGCACGAGCCTCTCGAGCTTCCGGGCCGTCTGCTCGGTGATTGGCCGAAACAGTGAGTGGACGGCCGC GGATTGGCTGTGCTCAGCGGCGGGCTGAGCAACTGGAGTGAGGGGAGCAGTTGGGCCAAGATGGCGGCCGCCGAGGGACCGGTGGGCGAC GGCGAGCTGTGGCAGACCTGGCTTCCTAACCACGTCGTGTTCTTGCGGCTCCGGGAGGGACTGAAAAACCAGAGTCCAACCGAAGCTGAG AAACCAGCTTCTTCGTCGTTGCCTTCGTCGCCGCCGCCGCAGTTGCTGACGAGAAACGTGGTCTTTGGCCTCGGCGGAGAGCTTTTCCTG TGGGACGGAGAAGACAGCTCCTTCTTAGTCGTTCGCCTTCGGGGCCCCAGCGGCGGCGGCGAAGAGCCCGCCCTGTCCCAGTACCAGAGA TTGCTTTGCATAAATCCACCCCTGTTTGAAATCTATCAAGTCTTGTTAAGCCCAACACAACATCATGTAGCACTTATAGGAATAAAAGGA CTTATGGTATTAGAATTACCTAAAAGATGGGGGAAGAATTCTGAATTTGAAGGTGGAAAATCAACAGTGAATTGTAGGCTGGACCAGACA ACTCTGAGTGATGAGATGAGGCAGGAACTGAGGGCCCTGGAGCAGGAGAAACCTCAGCTGCTCATCTTCAGCAGACGGAAACCAAGTGTG ATGACCCCTACTGAGGGCCTGGATACGGGAGAGATGAGTAATAGCACATCCTCACTCAAGCGGCAGAGACTCGGATCAGAGAGGGCGGCT TCCCATGTTGCTCAGGCTAATCTCAAACTCCTGGACGTGAGCAAGATCTTCCCAATTGCTGAGATTGCAGGCAAGAGCCACGAGGAAAGC TCCCCAGAGGTAGTACCGGTGGAACTCTTGTGCGTGCCTTCTCCTGCCTCTCAAGGGGACCTGCATACGAAGCCTTTGGGGACTGACGAT GACTTCTGGGGCCCCACGGGGCCTGTGGCTACTGAGGTAGTTGACAAAGAAAAGAACTTGTACCGAGTTCACTTCCCTGTAGCTGGCTCC TACCGCTGGCCCAACACGGGTCTCTGCTTTGTGATGAGAGAAGCGGTGACCGTTGAGATTGAATTCTGTGTGTGGGACCAGTTCCTGGGT GAGATCAACCCACAGCACAGCTGGATGGTGGCAGGGCCTCTGCTGGACATCAAGGCTGAGCCTGGAGCTGTGGAAGCTGTGCACCTCCCT CACTTTGTGGCTCTCCAAGGGGGCCATGTGGACACATCCCTGTTCCAAATGGCCCACTTTAAAGAGGAGGGGATGCTCCTGGAGAAGCCA GCCAGGGTGGAGCTGCATCACATAGTTCTGGAAAACCCCAGCTTCTCCCCCTTGGGAGTCCTCCTGAAAATGATCCATAATGCCCTGCGC TTCATTCCCGTCACCTCTGTGGTGTTGCTTTACCACCGCGTCCATCCTGAGGAAGTCACCTTCCACCTCTACCTGATCCCAAGTGACTGC TCCATTCGGAAGGCCATAGATGATCTAGAAATGAAATTCCAGTTTGTGCGAATCCACAAGCCACCCCCGCTGACCCCACTTTATATGGGC TGTCGTTACACTGTGTCTGGGTCTGGTTCAGGGATGCTGGAAATACTCCCCAAGGAACTGGAGCTCTGCTATCGAAGCCCTGGAGAAGAC CAGCTGTTCTCGGAGTTCTACGTTGGCCACTTGGGATCAGGGATCAGGCTGCAAGTGAAAGACAAGAAAGATGAGACTCTGGTGTGGGAG GCCTTGGTGAAACCAGGAAGGAACACCAGCCAGCCGTGGAACCTCAGGTGCAACAGAGACGCCAGGAGATACTAGTGCCCAGCAGCCTGC GGCAGTACCAATGAAGCCAGAGAGGGCTTGGTGGATGACAAGGAGGCCTGAGTAGACCGCAGGTGGGTCTGAGAAATGGGCTTAGGTGAG GCAGGTCTTTGAAGGATTTGTTCTTAATCATATGCGAGATGCTCAAAAGGCTGGATGCCTGCTTTTGTGGGTGAAGAGCAAGAAGAGAAA ACAGGTTGTACACATACAGATGCAGATGGAGAGACAGAGAAAAAAAAGGAAGAAGGCAGAGAAATGCACCAATTCTTGAGCTGTATTATC TCTGGACCTTGGGATTGTGGGAGGCTTTATTTTACTACTGATTTTGCCTACACTGTTTTCTCAATTTCTAGTTTTCTACAAAGATGATGT >61096_61096_1_NUP88-NLRP1_NUP88_chr17_5319833_ENST00000573584_NLRP1_chr17_5440260_ENST00000262467_length(amino acids)=593AA_BP=174 MAVLSGGLSNWSEGSSWAKMAAAEGPVGDGELWQTWLPNHVVFLRLREGLKNQSPTEAEKPASSSLPSSPPPQLLTRNVVFGLGGELFLW DGEDSSFLVVRLRGPSGGGEEPALSQYQRLLCINPPLFEIYQVLLSPTQHHVALIGIKGLMVLELPKRWGKNSEFEGGKSTVNCRLDQTT LSDEMRQELRALEQEKPQLLIFSRRKPSVMTPTEGLDTGEMSNSTSSLKRQRLGSERAASHVAQANLKLLDVSKIFPIAEIAGKSHEESS PEVVPVELLCVPSPASQGDLHTKPLGTDDDFWGPTGPVATEVVDKEKNLYRVHFPVAGSYRWPNTGLCFVMREAVTVEIEFCVWDQFLGE INPQHSWMVAGPLLDIKAEPGAVEAVHLPHFVALQGGHVDTSLFQMAHFKEEGMLLEKPARVELHHIVLENPSFSPLGVLLKMIHNALRF IPVTSVVLLYHRVHPEEVTFHLYLIPSDCSIRKAIDDLEMKFQFVRIHKPPPLTPLYMGCRYTVSGSGSGMLEILPKELELCYRSPGEDQ -------------------------------------------------------------- >61096_61096_2_NUP88-NLRP1_NUP88_chr17_5319833_ENST00000573584_NLRP1_chr17_5440260_ENST00000269280_length(transcript)=3024nt_BP=977nt ACAGACCCCTGGGAGGTGTACTTTCCGGGTGCAGACCGCGAATGGATCGCAGCGTATTCTGGGAAGTGTTGTTTTATCGACCGGCCCCAC GTGGAGACAGATTTAGGCATCCAAGCGAAATGCGTGAGGCCAGCCCGACCTGCACTGAGGGAGGTAAGTCTTGAGGGAAAGTTCTGGATG CCTGGGTTTACCCAGATGGAGGTGTCCAATAGGCAATTAGATACACAAGTCTCAGGCTCTCCCCAGGTGCTAGATTTCCAGCAGCACCAC CATTATGTTGACTTCTCGTCCCGCCCCCTTGGGCTTCAGAAATAATGGTGATTGGCTTTCCCTTGGTGACGCCCCTGCTTGGTGGGCTGG CCTCGCCTTCGCCCCCCGACCTGGCACGAGCCTCTCGAGCTTCCGGGCCGTCTGCTCGGTGATTGGCCGAAACAGTGAGTGGACGGCCGC GGATTGGCTGTGCTCAGCGGCGGGCTGAGCAACTGGAGTGAGGGGAGCAGTTGGGCCAAGATGGCGGCCGCCGAGGGACCGGTGGGCGAC GGCGAGCTGTGGCAGACCTGGCTTCCTAACCACGTCGTGTTCTTGCGGCTCCGGGAGGGACTGAAAAACCAGAGTCCAACCGAAGCTGAG AAACCAGCTTCTTCGTCGTTGCCTTCGTCGCCGCCGCCGCAGTTGCTGACGAGAAACGTGGTCTTTGGCCTCGGCGGAGAGCTTTTCCTG TGGGACGGAGAAGACAGCTCCTTCTTAGTCGTTCGCCTTCGGGGCCCCAGCGGCGGCGGCGAAGAGCCCGCCCTGTCCCAGTACCAGAGA TTGCTTTGCATAAATCCACCCCTGTTTGAAATCTATCAAGTCTTGTTAAGCCCAACACAACATCATGTAGCACTTATAGGAATAAAAGGA CTTATGGTATTAGAATTACCTAAAAGATGGGGGAAGAATTCTGAATTTGAAGGTGGAAAATCAACAGTGAATTGTAGGCTGGACCAGACA ACTCTGAGTGATGAGATGAGGCAGGAACTGAGGGCCCTGGAGCAGGAGAAACCTCAGCTGCTCATCTTCAGCAGACGGAAACCAAGTGTG ATGACCCCTACTGAGGGCCTGGATACGGGAGAGATGAGTAATAGCACATCCTCACTCAAGCGGCAGAGACTCGGATCAGAGAGGGCGGCT TCCCATGTTGCTCAGGCTAATCTCAAACTCCTGGACGTGAGCAAGATCTTCCCAATTGCTGAGATTGCAGAGGAAAGCTCCCCAGAGGTA GTACCGGTGGAACTCTTGTGCGTGCCTTCTCCTGCCTCTCAAGGGGACCTGCATACGAAGCCTTTGGGGACTGACGATGACTTCTGGGGC CCCACGGGGCCTGTGGCTACTGAGGTAGTTGACAAAGAAAAGAACTTGTACCGAGTTCACTTCCCTGTAGCTGGCTCCTACCGCTGGCCC AACACGGGTCTCTGCTTTGTGATGAGAGAAGCGGTGACCGTTGAGATTGAATTCTGTGTGTGGGACCAGTTCCTGGGTGAGATCAACCCA CAGCACAGCTGGATGGTGGCAGGGCCTCTGCTGGACATCAAGGCTGAGCCTGGAGCTGTGGAAGCTGTGCACCTCCCTCACTTTGTGGCT CTCCAAGGGGGCCATGTGGACACATCCCTGTTCCAAATGGCCCACTTTAAAGAGGAGGGGATGCTCCTGGAGAAGCCAGCCAGGGTGGAG CTGCATCACATAGTTCTGGAAAACCCCAGCTTCTCCCCCTTGGGAGTCCTCCTGAAAATGATCCATAATGCCCTGCGCTTCATTCCCGTC ACCTCTGTGGTGTTGCTTTACCACCGCGTCCATCCTGAGGAAGTCACCTTCCACCTCTACCTGATCCCAAGTGACTGCTCCATTCGGAAG GAACTGGAGCTCTGCTATCGAAGCCCTGGAGAAGACCAGCTGTTCTCGGAGTTCTACGTTGGCCACTTGGGATCAGGGATCAGGCTGCAA GTGAAAGACAAGAAAGATGAGACTCTGGTGTGGGAGGCCTTGGTGAAACCAGGAGATCTCATGCCTGCAACTACTCTGATCCCTCCAGCC CGCATAGCCGTACCTTCACCTCTGGATGCCCCGCAGTTGCTGCACTTTGTGGACCAGTATCGAGAGCAGCTGATAGCCCGAGTGACATCG GTGGAGGTTGTCTTGGACAAACTGCATGGACAGGTGCTGAGCCAGGAGCAGTACGAGAGGGTGCTGGCTGAGAACACGAGGCCCAGCCAG ATGCGGAAGCTGTTCAGCTTGAGCCAGTCCTGGGACCGGAAGTGCAAAGATGGACTCTACCAAGCCCTGAAGGAGACCCATCCTCACCTC ATTATGGAACTCTGGGAGAAGGGCAGCAAAAAGGGACTCCTGCCACTCAGCAGCTGAAGTATCAACACCAGCCCTTGACCCTTGAGTCCT GGCTTTGGCTGACCCTTCTTTGGGTCTCAGTTTCTTTCTCTGCAAACAAGTTGCCATCTGGTTTGCCTTCCAGCACTAAAGTAATGGAAC TTTGATGATGCCTTTGCTGGGCATTATGTGTCCATGCCAGGGATGCCACAGGGGGCCCCAGTCCAGGTGGCCTAACAGCATCTCAGGGAA TGTCCATCTGGAGCTGGCAAGACCCCTGCAGACCTCATAGAGCCTCATCTGGTGGCCACAGCAGCCAAGCCTAGAGCCCTCCGGATCCCA TCCAGGCGCAAAGAGGAATAGGAGGGACATGGAACCATTTGCCTCTGGCTGTGTCACAGGGTGAGCCCCAAAATTGGGGTTCAGCGTGGG AGGCCACGTGGATTCTTGGCTTTGTACAGGAAGATCTACAAGAGCAAGCCAACAGAGTAAAGTGGAAGGAAGTTTATTCAGAAAATAAAG GAGTATCACAGCTCTTTTAGAATTTGTCTAGCAGGCTTTCCAGTTTTTACCAGAAAACCCCTATAAATTAAAAATTTTTTACTTAAATTT >61096_61096_2_NUP88-NLRP1_NUP88_chr17_5319833_ENST00000573584_NLRP1_chr17_5440260_ENST00000269280_length(amino acids)=647AA_BP=174 MAVLSGGLSNWSEGSSWAKMAAAEGPVGDGELWQTWLPNHVVFLRLREGLKNQSPTEAEKPASSSLPSSPPPQLLTRNVVFGLGGELFLW DGEDSSFLVVRLRGPSGGGEEPALSQYQRLLCINPPLFEIYQVLLSPTQHHVALIGIKGLMVLELPKRWGKNSEFEGGKSTVNCRLDQTT LSDEMRQELRALEQEKPQLLIFSRRKPSVMTPTEGLDTGEMSNSTSSLKRQRLGSERAASHVAQANLKLLDVSKIFPIAEIAEESSPEVV PVELLCVPSPASQGDLHTKPLGTDDDFWGPTGPVATEVVDKEKNLYRVHFPVAGSYRWPNTGLCFVMREAVTVEIEFCVWDQFLGEINPQ HSWMVAGPLLDIKAEPGAVEAVHLPHFVALQGGHVDTSLFQMAHFKEEGMLLEKPARVELHHIVLENPSFSPLGVLLKMIHNALRFIPVT SVVLLYHRVHPEEVTFHLYLIPSDCSIRKELELCYRSPGEDQLFSEFYVGHLGSGIRLQVKDKKDETLVWEALVKPGDLMPATTLIPPAR IAVPSPLDAPQLLHFVDQYREQLIARVTSVEVVLDKLHGQVLSQEQYERVLAENTRPSQMRKLFSLSQSWDRKCKDGLYQALKETHPHLI -------------------------------------------------------------- >61096_61096_3_NUP88-NLRP1_NUP88_chr17_5319833_ENST00000573584_NLRP1_chr17_5440260_ENST00000345221_length(transcript)=3032nt_BP=977nt ACAGACCCCTGGGAGGTGTACTTTCCGGGTGCAGACCGCGAATGGATCGCAGCGTATTCTGGGAAGTGTTGTTTTATCGACCGGCCCCAC GTGGAGACAGATTTAGGCATCCAAGCGAAATGCGTGAGGCCAGCCCGACCTGCACTGAGGGAGGTAAGTCTTGAGGGAAAGTTCTGGATG CCTGGGTTTACCCAGATGGAGGTGTCCAATAGGCAATTAGATACACAAGTCTCAGGCTCTCCCCAGGTGCTAGATTTCCAGCAGCACCAC CATTATGTTGACTTCTCGTCCCGCCCCCTTGGGCTTCAGAAATAATGGTGATTGGCTTTCCCTTGGTGACGCCCCTGCTTGGTGGGCTGG CCTCGCCTTCGCCCCCCGACCTGGCACGAGCCTCTCGAGCTTCCGGGCCGTCTGCTCGGTGATTGGCCGAAACAGTGAGTGGACGGCCGC GGATTGGCTGTGCTCAGCGGCGGGCTGAGCAACTGGAGTGAGGGGAGCAGTTGGGCCAAGATGGCGGCCGCCGAGGGACCGGTGGGCGAC GGCGAGCTGTGGCAGACCTGGCTTCCTAACCACGTCGTGTTCTTGCGGCTCCGGGAGGGACTGAAAAACCAGAGTCCAACCGAAGCTGAG AAACCAGCTTCTTCGTCGTTGCCTTCGTCGCCGCCGCCGCAGTTGCTGACGAGAAACGTGGTCTTTGGCCTCGGCGGAGAGCTTTTCCTG TGGGACGGAGAAGACAGCTCCTTCTTAGTCGTTCGCCTTCGGGGCCCCAGCGGCGGCGGCGAAGAGCCCGCCCTGTCCCAGTACCAGAGA TTGCTTTGCATAAATCCACCCCTGTTTGAAATCTATCAAGTCTTGTTAAGCCCAACACAACATCATGTAGCACTTATAGGAATAAAAGGA CTTATGGTATTAGAATTACCTAAAAGATGGGGGAAGAATTCTGAATTTGAAGGTGGAAAATCAACAGTGAATTGTAGGCTGGACCAGACA ACTCTGAGTGATGAGATGAGGCAGGAACTGAGGGCCCTGGAGCAGGAGAAACCTCAGCTGCTCATCTTCAGCAGACGGAAACCAAGTGTG ATGACCCCTACTGAGGGCCTGGATACGGGAGAGATGAGTAATAGCACATCCTCACTCAAGCGGCAGAGACTCGGATCAGAGAGGGCGGCT TCCCATGTTGCTCAGGCTAATCTCAAACTCCTGGACGTGAGCAAGATCTTCCCAATTGCTGAGATTGCAGAGGAAAGCTCCCCAGAGGTA GTACCGGTGGAACTCTTGTGCGTGCCTTCTCCTGCCTCTCAAGGGGACCTGCATACGAAGCCTTTGGGGACTGACGATGACTTCTGGGGC CCCACGGGGCCTGTGGCTACTGAGGTAGTTGACAAAGAAAAGAACTTGTACCGAGTTCACTTCCCTGTAGCTGGCTCCTACCGCTGGCCC AACACGGGTCTCTGCTTTGTGATGAGAGAAGCGGTGACCGTTGAGATTGAATTCTGTGTGTGGGACCAGTTCCTGGGTGAGATCAACCCA CAGCACAGCTGGATGGTGGCAGGGCCTCTGCTGGACATCAAGGCTGAGCCTGGAGCTGTGGAAGCTGTGCACCTCCCTCACTTTGTGGCT CTCCAAGGGGGCCATGTGGACACATCCCTGTTCCAAATGGCCCACTTTAAAGAGGAGGGGATGCTCCTGGAGAAGCCAGCCAGGGTGGAG CTGCATCACATAGTTCTGGAAAACCCCAGCTTCTCCCCCTTGGGAGTCCTCCTGAAAATGATCCATAATGCCCTGCGCTTCATTCCCGTC ACCTCTGTGGTGTTGCTTTACCACCGCGTCCATCCTGAGGAAGTCACCTTCCACCTCTACCTGATCCCAAGTGACTGCTCCATTCGGAAG GAACTGGAGCTCTGCTATCGAAGCCCTGGAGAAGACCAGCTGTTCTCGGAGTTCTACGTTGGCCACTTGGGATCAGGGATCAGGCTGCAA GTGAAAGACAAGAAAGATGAGACTCTGGTGTGGGAGGCCTTGGTGAAACCAGGAGATCTCATGCCTGCAACTACTCTGATCCCTCCAGCC CGCATAGCCGTACCTTCACCTCTGGATGCCCCGCAGTTGCTGCACTTTGTGGACCAGTATCGAGAGCAGCTGATAGCCCGAGTGACATCG GTGGAGGTTGTCTTGGACAAACTGCATGGACAGGTGCTGAGCCAGGAGCAGTACGAGAGGGTGCTGGCTGAGAACACGAGGCCCAGCCAG ATGCGGAAGCTGTTCAGCTTGAGCCAGTCCTGGGACCGGAAGTGCAAAGATGGACTCTACCAAGCCCTGAAGGAGACCCATCCTCACCTC ATTATGGAACTCTGGGAGAAGGGCAGCAAAAAGGGACTCCTGCCACTCAGCAGCTGAAGTATCAACACCAGCCCTTGACCCTTGAGTCCT GGCTTTGGCTGACCCTTCTTTGGGTCTCAGTTTCTTTCTCTGCAAACAAGTTGCCATCTGGTTTGCCTTCCAGCACTAAAGTAATGGAAC TTTGATGATGCCTTTGCTGGGCATTATGTGTCCATGCCAGGGATGCCACAGGGGGCCCCAGTCCAGGTGGCCTAACAGCATCTCAGGGAA TGTCCATCTGGAGCTGGCAAGACCCCTGCAGACCTCATAGAGCCTCATCTGGTGGCCACAGCAGCCAAGCCTAGAGCCCTCCGGATCCCA TCCAGGCGCAAAGAGGAATAGGAGGGACATGGAACCATTTGCCTCTGGCTGTGTCACAGGGTGAGCCCCAAAATTGGGGTTCAGCGTGGG AGGCCACGTGGATTCTTGGCTTTGTACAGGAAGATCTACAAGAGCAAGCCAACAGAGTAAAGTGGAAGGAAGTTTATTCAGAAAATAAAG GAGTATCACAGCTCTTTTAGAATTTGTCTAGCAGGCTTTCCAGTTTTTACCAGAAAACCCCTATAAATTAAAAATTTTTTACTTAAATTT >61096_61096_3_NUP88-NLRP1_NUP88_chr17_5319833_ENST00000573584_NLRP1_chr17_5440260_ENST00000345221_length(amino acids)=647AA_BP=174 MAVLSGGLSNWSEGSSWAKMAAAEGPVGDGELWQTWLPNHVVFLRLREGLKNQSPTEAEKPASSSLPSSPPPQLLTRNVVFGLGGELFLW DGEDSSFLVVRLRGPSGGGEEPALSQYQRLLCINPPLFEIYQVLLSPTQHHVALIGIKGLMVLELPKRWGKNSEFEGGKSTVNCRLDQTT LSDEMRQELRALEQEKPQLLIFSRRKPSVMTPTEGLDTGEMSNSTSSLKRQRLGSERAASHVAQANLKLLDVSKIFPIAEIAEESSPEVV PVELLCVPSPASQGDLHTKPLGTDDDFWGPTGPVATEVVDKEKNLYRVHFPVAGSYRWPNTGLCFVMREAVTVEIEFCVWDQFLGEINPQ HSWMVAGPLLDIKAEPGAVEAVHLPHFVALQGGHVDTSLFQMAHFKEEGMLLEKPARVELHHIVLENPSFSPLGVLLKMIHNALRFIPVT SVVLLYHRVHPEEVTFHLYLIPSDCSIRKELELCYRSPGEDQLFSEFYVGHLGSGIRLQVKDKKDETLVWEALVKPGDLMPATTLIPPAR IAVPSPLDAPQLLHFVDQYREQLIARVTSVEVVLDKLHGQVLSQEQYERVLAENTRPSQMRKLFSLSQSWDRKCKDGLYQALKETHPHLI -------------------------------------------------------------- >61096_61096_4_NUP88-NLRP1_NUP88_chr17_5319833_ENST00000573584_NLRP1_chr17_5440260_ENST00000572272_length(transcript)=2529nt_BP=977nt ACAGACCCCTGGGAGGTGTACTTTCCGGGTGCAGACCGCGAATGGATCGCAGCGTATTCTGGGAAGTGTTGTTTTATCGACCGGCCCCAC GTGGAGACAGATTTAGGCATCCAAGCGAAATGCGTGAGGCCAGCCCGACCTGCACTGAGGGAGGTAAGTCTTGAGGGAAAGTTCTGGATG CCTGGGTTTACCCAGATGGAGGTGTCCAATAGGCAATTAGATACACAAGTCTCAGGCTCTCCCCAGGTGCTAGATTTCCAGCAGCACCAC CATTATGTTGACTTCTCGTCCCGCCCCCTTGGGCTTCAGAAATAATGGTGATTGGCTTTCCCTTGGTGACGCCCCTGCTTGGTGGGCTGG CCTCGCCTTCGCCCCCCGACCTGGCACGAGCCTCTCGAGCTTCCGGGCCGTCTGCTCGGTGATTGGCCGAAACAGTGAGTGGACGGCCGC GGATTGGCTGTGCTCAGCGGCGGGCTGAGCAACTGGAGTGAGGGGAGCAGTTGGGCCAAGATGGCGGCCGCCGAGGGACCGGTGGGCGAC GGCGAGCTGTGGCAGACCTGGCTTCCTAACCACGTCGTGTTCTTGCGGCTCCGGGAGGGACTGAAAAACCAGAGTCCAACCGAAGCTGAG AAACCAGCTTCTTCGTCGTTGCCTTCGTCGCCGCCGCCGCAGTTGCTGACGAGAAACGTGGTCTTTGGCCTCGGCGGAGAGCTTTTCCTG TGGGACGGAGAAGACAGCTCCTTCTTAGTCGTTCGCCTTCGGGGCCCCAGCGGCGGCGGCGAAGAGCCCGCCCTGTCCCAGTACCAGAGA TTGCTTTGCATAAATCCACCCCTGTTTGAAATCTATCAAGTCTTGTTAAGCCCAACACAACATCATGTAGCACTTATAGGAATAAAAGGA CTTATGGTATTAGAATTACCTAAAAGATGGGGGAAGAATTCTGAATTTGAAGGTGGAAAATCAACAGTGAATTGTAGGCTGGACCAGACA ACTCTGAGTGATGAGATGAGGCAGGAACTGAGGGCCCTGGAGCAGGAGAAACCTCAGCTGCTCATCTTCAGCAGACGGAAACCAAGTGTG ATGACCCCTACTGAGGGCCTGGATACGGGAGAGATGAGTAATAGCACATCCTCACTCAAGCGGCAGAGACTCGGATCAGAGAGGGCGGCT TCCCATGTTGCTCAGGCTAATCTCAAACTCCTGGACGTGAGCAAGATCTTCCCAATTGCTGAGATTGCAGAGGAAAGCTCCCCAGAGGTA GTACCGGTGGAACTCTTGTGCGTGCCTTCTCCTGCCTCTCAAGGGGACCTGCATACGAAGCCTTTGGGGACTGACGATGACTTCTGGGGC CCCACGGGGCCTGTGGCTACTGAGGTAGTTGACAAAGAAAAGAACTTGTACCGAGTTCACTTCCCTGTAGCTGGCTCCTACCGCTGGCCC AACACGGGTCTCTGCTTTGTGATGAGAGAAGCGGTGACCGTTGAGATTGAATTCTGTGTGTGGGACCAGTTCCTGGGTGAGATCAACCCA CAGCACAGCTGGATGGTGGCAGGGCCTCTGCTGGACATCAAGGCTGAGCCTGGAGCTGTGGAAGCTGTGCACCTCCCTCACTTTGTGGCT CTCCAAGGGGGCCATGTGGACACATCCCTGTTCCAAATGGCCCACTTTAAAGAGGAGGGGATGCTCCTGGAGAAGCCAGCCAGGGTGGAG CTGCATCACATAGTTCTGGAAAACCCCAGCTTCTCCCCCTTGGGAGTCCTCCTGAAAATGATCCATAATGCCCTGCGCTTCATTCCCGTC ACCTCTGTGGTGTTGCTTTACCACCGCGTCCATCCTGAGGAAGTCACCTTCCACCTCTACCTGATCCCAAGTGACTGCTCCATTCGGAAG GCCATAGATGATCTAGAAATGAAATTCCAGTTTGTGCGAATCCACAAGCCACCCCCGCTGACCCCACTTTATATGGGCTGTCGTTACACT GTGTCTGGGTCTGGTTCAGGGATGCTGGAAATACTCCCCAAGGAACTGGAGCTCTGCTATCGAAGCCCTGGAGAAGACCAGCTGTTCTCG GAGTTCTACGTTGGCCACTTGGGATCAGGGATCAGGCTGCAAGTGAAAGACAAGAAAGATGAGACTCTGGTGTGGGAGGCCTTGGTGAAA CCAGGAGATCTCATGCCTGCAACTACTCTGATCCCTCCAGCCCGCATAGCCGTACCTTCACCTCTGGATGCCCCGCAGTTGCTGCACTTT GTGGACCAGTATCGAGAGCAGCTGATAGCCCGAGTGACATCGGTGGAGGTTGTCTTGGACAAACTGCATGGACAGGTGCTGAGCCAGGAG CAGTACGAGAGGGTGCTGGCTGAGAACACGAGGCCCAGCCAGATGCGGAAGCTGTTCAGCTTGAGCCAGTCCTGGGACCGGAAGTGCAAA GATGGACTCTACCAAGCCCTGAAGGAGACCCATCCTCACCTCATTATGGAACTCTGGGAGAAGGGCAGCAAAAAGGGACTCCTGCCACTC >61096_61096_4_NUP88-NLRP1_NUP88_chr17_5319833_ENST00000573584_NLRP1_chr17_5440260_ENST00000572272_length(amino acids)=691AA_BP=174 MAVLSGGLSNWSEGSSWAKMAAAEGPVGDGELWQTWLPNHVVFLRLREGLKNQSPTEAEKPASSSLPSSPPPQLLTRNVVFGLGGELFLW DGEDSSFLVVRLRGPSGGGEEPALSQYQRLLCINPPLFEIYQVLLSPTQHHVALIGIKGLMVLELPKRWGKNSEFEGGKSTVNCRLDQTT LSDEMRQELRALEQEKPQLLIFSRRKPSVMTPTEGLDTGEMSNSTSSLKRQRLGSERAASHVAQANLKLLDVSKIFPIAEIAEESSPEVV PVELLCVPSPASQGDLHTKPLGTDDDFWGPTGPVATEVVDKEKNLYRVHFPVAGSYRWPNTGLCFVMREAVTVEIEFCVWDQFLGEINPQ HSWMVAGPLLDIKAEPGAVEAVHLPHFVALQGGHVDTSLFQMAHFKEEGMLLEKPARVELHHIVLENPSFSPLGVLLKMIHNALRFIPVT SVVLLYHRVHPEEVTFHLYLIPSDCSIRKAIDDLEMKFQFVRIHKPPPLTPLYMGCRYTVSGSGSGMLEILPKELELCYRSPGEDQLFSE FYVGHLGSGIRLQVKDKKDETLVWEALVKPGDLMPATTLIPPARIAVPSPLDAPQLLHFVDQYREQLIARVTSVEVVLDKLHGQVLSQEQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NUP88-NLRP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NUP88-NLRP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NUP88-NLRP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies