
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PAIP1-DAB2 (FusionGDB2 ID:62379) |
Fusion Gene Summary for PAIP1-DAB2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PAIP1-DAB2 | Fusion gene ID: 62379 | Hgene | Tgene | Gene symbol | PAIP1 | DAB2 | Gene ID | 10605 | 1601 |
| Gene name | poly(A) binding protein interacting protein 1 | DAB adaptor protein 2 | |
| Synonyms | - | DOC-2|DOC2 | |
| Cytomap | 5p12 | 5p13.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | polyadenylate-binding protein-interacting protein 1PABC1-interacting protein 1PABP-interacting protein 1PAIP-1 | disabled homolog 2DAB2, clathrin adaptor proteinDab, mitogen-responsive phosphoprotein, homolog 2adaptor molecule disabled-2differentially expressed in ovarian carcinoma 2differentially-expressed protein 2disabled homolog 2, mitogen-responsive phosp | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q5VWQ8 | |
| Ensembl transtripts involved in fusion gene | ENST00000306846, ENST00000338972, ENST00000436644, ENST00000514514, | ENST00000512525, ENST00000320816, ENST00000339788, ENST00000545653, ENST00000509337, | |
| Fusion gene scores | * DoF score | 5 X 4 X 4=80 | 8 X 9 X 2=144 |
| # samples | 6 | 10 | |
| ** MAII score | log2(6/80*10)=-0.415037499278844 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/144*10)=-0.526068811667588 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PAIP1 [Title/Abstract] AND DAB2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PAIP1(43555932)-DAB2(39375186), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | PAIP1-DAB2 seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. PAIP1-DAB2 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. PAIP1-DAB2 seems lost the major protein functional domain in Tgene partner, which is a tumor suppressor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | DAB2 | GO:0010718 | positive regulation of epithelial to mesenchymal transition | 15734730 |
| Tgene | DAB2 | GO:0010862 | positive regulation of pathway-restricted SMAD protein phosphorylation | 11387212 |
| Tgene | DAB2 | GO:0030511 | positive regulation of transforming growth factor beta receptor signaling pathway | 11387212 |
| Tgene | DAB2 | GO:0043066 | negative regulation of apoptotic process | 15734730 |
| Tgene | DAB2 | GO:0060391 | positive regulation of SMAD protein signal transduction | 11387212 |
| Fusion gene breakpoints across PAIP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across DAB2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-13-1506-01A | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| ChimerDB4 | OV | TCGA-13-1506 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
Top |
Fusion Gene ORF analysis for PAIP1-DAB2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000306846 | ENST00000512525 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| 5CDS-intron | ENST00000306846 | ENST00000512525 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| 5CDS-intron | ENST00000338972 | ENST00000512525 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| 5CDS-intron | ENST00000338972 | ENST00000512525 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| 5CDS-intron | ENST00000436644 | ENST00000512525 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| 5CDS-intron | ENST00000436644 | ENST00000512525 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| 5CDS-intron | ENST00000514514 | ENST00000512525 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| 5CDS-intron | ENST00000514514 | ENST00000512525 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000306846 | ENST00000320816 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000306846 | ENST00000320816 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000306846 | ENST00000339788 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000306846 | ENST00000339788 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000306846 | ENST00000545653 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000306846 | ENST00000545653 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000338972 | ENST00000509337 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000338972 | ENST00000509337 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000436644 | ENST00000320816 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000436644 | ENST00000320816 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000436644 | ENST00000339788 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000436644 | ENST00000339788 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000436644 | ENST00000545653 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000436644 | ENST00000545653 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000514514 | ENST00000320816 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000514514 | ENST00000320816 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000514514 | ENST00000339788 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000514514 | ENST00000339788 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000514514 | ENST00000545653 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| Frame-shift | ENST00000514514 | ENST00000545653 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000306846 | ENST00000509337 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000306846 | ENST00000509337 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000338972 | ENST00000320816 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000338972 | ENST00000320816 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000338972 | ENST00000339788 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000338972 | ENST00000339788 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000338972 | ENST00000545653 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000338972 | ENST00000545653 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000436644 | ENST00000509337 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000436644 | ENST00000509337 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000514514 | ENST00000509337 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - |
| In-frame | ENST00000514514 | ENST00000509337 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000306846 | PAIP1 | chr5 | 43555932 | - | ENST00000509337 | DAB2 | chr5 | 39375186 | - | 1144 | 668 | 233 | 733 | 166 |
| ENST00000436644 | PAIP1 | chr5 | 43555932 | - | ENST00000509337 | DAB2 | chr5 | 39375186 | - | 921 | 445 | 3 | 305 | 100 |
| ENST00000338972 | PAIP1 | chr5 | 43555932 | - | ENST00000339788 | DAB2 | chr5 | 39375186 | - | 2345 | 526 | 117 | 356 | 79 |
| ENST00000338972 | PAIP1 | chr5 | 43555932 | - | ENST00000320816 | DAB2 | chr5 | 39375186 | - | 2345 | 526 | 117 | 356 | 79 |
| ENST00000338972 | PAIP1 | chr5 | 43555932 | - | ENST00000545653 | DAB2 | chr5 | 39375186 | - | 2345 | 526 | 117 | 356 | 79 |
| ENST00000514514 | PAIP1 | chr5 | 43555932 | - | ENST00000509337 | DAB2 | chr5 | 39375186 | - | 905 | 429 | 231 | 494 | 87 |
| ENST00000306846 | PAIP1 | chr5 | 43555931 | - | ENST00000509337 | DAB2 | chr5 | 39375186 | - | 1144 | 668 | 233 | 733 | 166 |
| ENST00000436644 | PAIP1 | chr5 | 43555931 | - | ENST00000509337 | DAB2 | chr5 | 39375186 | - | 921 | 445 | 3 | 305 | 100 |
| ENST00000338972 | PAIP1 | chr5 | 43555931 | - | ENST00000339788 | DAB2 | chr5 | 39375186 | - | 2345 | 526 | 117 | 356 | 79 |
| ENST00000338972 | PAIP1 | chr5 | 43555931 | - | ENST00000320816 | DAB2 | chr5 | 39375186 | - | 2345 | 526 | 117 | 356 | 79 |
| ENST00000338972 | PAIP1 | chr5 | 43555931 | - | ENST00000545653 | DAB2 | chr5 | 39375186 | - | 2345 | 526 | 117 | 356 | 79 |
| ENST00000514514 | PAIP1 | chr5 | 43555931 | - | ENST00000509337 | DAB2 | chr5 | 39375186 | - | 905 | 429 | 231 | 494 | 87 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000306846 | ENST00000509337 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - | 0.0988649 | 0.9011351 |
| ENST00000436644 | ENST00000509337 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - | 0.07654176 | 0.9234583 |
| ENST00000338972 | ENST00000339788 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - | 0.8353914 | 0.1646086 |
| ENST00000338972 | ENST00000320816 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - | 0.8353914 | 0.1646086 |
| ENST00000338972 | ENST00000545653 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - | 0.8353914 | 0.1646086 |
| ENST00000514514 | ENST00000509337 | PAIP1 | chr5 | 43555932 | - | DAB2 | chr5 | 39375186 | - | 0.04021687 | 0.9597831 |
| ENST00000306846 | ENST00000509337 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - | 0.0988649 | 0.9011351 |
| ENST00000436644 | ENST00000509337 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - | 0.07654176 | 0.9234583 |
| ENST00000338972 | ENST00000339788 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - | 0.8353914 | 0.1646086 |
| ENST00000338972 | ENST00000320816 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - | 0.8353914 | 0.1646086 |
| ENST00000338972 | ENST00000545653 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - | 0.8353914 | 0.1646086 |
| ENST00000514514 | ENST00000509337 | PAIP1 | chr5 | 43555931 | - | DAB2 | chr5 | 39375186 | - | 0.04021687 | 0.9597831 |
Top |
Fusion Genomic Features for PAIP1-DAB2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
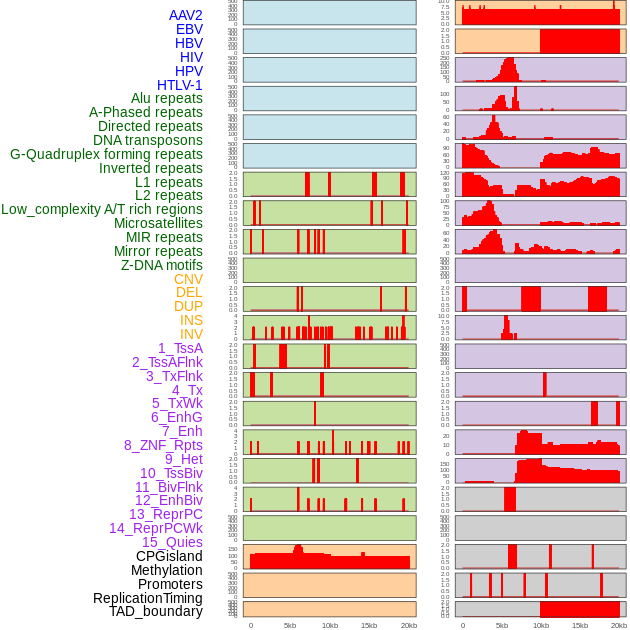 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PAIP1-DAB2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:43555932/chr5:39375186) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | DAB2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Functions as a scaffold protein implicated in the regulation of a large spectrum of both general and specialized signaling pathways. Involved in several processes such as innate immune response, inflammation and cell growth inhibition, apoptosis, cell survival, angiogenesis, cell migration and maturation. Plays also a role in cell cycle checkpoint control; reduces G1 phase cyclin levels resulting in G0/G1 cell cycle arrest. Mediates signal transduction by receptor-mediated inflammatory signals, such as the tumor necrosis factor (TNF), interferon (IFN) or lipopolysaccharide (LPS). Modulates the balance between phosphatidylinositol 3-kinase (PI3K)-AKT-mediated cell survival and apoptosis stimulated kinase (MAP3K5)-JNK signaling pathways; sequesters both AKT1 and MAP3K5 and counterbalances the activity of each kinase by modulating their phosphorylation status in response to proinflammatory stimuli. Acts as a regulator of the endoplasmic reticulum (ER) unfolded protein response (UPR) pathway; specifically involved in transduction of the ER stress-response to the JNK cascade through ERN1. Mediates TNF-alpha-induced apoptosis activation by facilitating dissociation of inhibitor 14-3-3 from MAP3K5; recruits the PP2A phosphatase complex which dephosphorylates MAP3K5 on 'Ser-966', leading to the dissociation of 13-3-3 proteins and activation of the MAP3K5-JNK signaling pathway in endothelial cells. Mediates also TNF/TRAF2-induced MAP3K5-JNK activation, while it inhibits CHUK-NF-kappa-B signaling. Acts a negative regulator in the IFN-gamma-mediated JAK-STAT signaling cascade by inhibiting smooth muscle cell (VSMCs) proliferation and intimal expansion, and thus, prevents graft arteriosclerosis (GA). Acts as a GTPase-activating protein (GAP) for the ADP ribosylation factor 6 (ARF6) and Ras. Promotes hydrolysis of the ARF6-bound GTP and thus, negatively regulates phosphatidylinositol 4,5-bisphosphate (PIP2)-dependent TLR4-TIRAP-MyD88 and NF-kappa-B signaling pathways in endothelial cells in response to lipopolysaccharides (LPS). Binds specifically to phosphatidylinositol 4-phosphate (PtdIns4P) and phosphatidylinositol 3-phosphate (PtdIns3P). In response to vascular endothelial growth factor (VEGFA), acts as a negative regulator of the VEGFR2-PI3K-mediated angiogenic signaling pathway by inhibiting endothelial cell migration and tube formation. In the developing brain, promotes both the transition from the multipolar to the bipolar stage and the radial migration of cortical neurons from the ventricular zone toward the superficial layer of the neocortex in a glial-dependent locomotion process. Probable downstream effector of the Reelin signaling pathway; promotes Purkinje cell (PC) dendrites development and formation of cerebellar synapses. Functions also as a tumor suppressor protein in prostate cancer progression; prevents cell proliferation and epithelial-to-mesenchymal transition (EMT) through activation of the glycogen synthase kinase-3 beta (GSK3B)-induced beta-catenin and inhibition of PI3K-AKT and Ras-MAPK survival downstream signaling cascades, respectively. {ECO:0000269|PubMed:12813029, ECO:0000269|PubMed:17389591, ECO:0000269|PubMed:18292600, ECO:0000269|PubMed:19033661, ECO:0000269|PubMed:19903888, ECO:0000269|PubMed:19948740, ECO:0000269|PubMed:20080667, ECO:0000269|PubMed:20154697, ECO:0000269|PubMed:21700930, ECO:0000269|PubMed:22696229}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 10_36 | 145 | 480.0 | Compositional bias | Note=Gly-rich |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 45_98 | 145 | 480.0 | Compositional bias | Note=Pro-rich |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 10_36 | 33 | 368.0 | Compositional bias | Note=Gly-rich |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 10_36 | 66 | 401.0 | Compositional bias | Note=Gly-rich |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 10_36 | 145 | 480.0 | Compositional bias | Note=Gly-rich |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 45_98 | 145 | 480.0 | Compositional bias | Note=Pro-rich |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 10_36 | 33 | 368.0 | Compositional bias | Note=Gly-rich |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 10_36 | 66 | 401.0 | Compositional bias | Note=Gly-rich |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 116_143 | 145 | 480.0 | Region | Note=PABPC1-interacting motif-2 (PAM2) |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 116_143 | 145 | 480.0 | Region | Note=PABPC1-interacting motif-2 (PAM2) |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 45_98 | 33 | 368.0 | Compositional bias | Note=Pro-rich |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 45_98 | 66 | 401.0 | Compositional bias | Note=Pro-rich |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 45_98 | 33 | 368.0 | Compositional bias | Note=Pro-rich |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 45_98 | 66 | 401.0 | Compositional bias | Note=Pro-rich |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 159_376 | 145 | 480.0 | Domain | Note=MIF4G |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 159_376 | 33 | 368.0 | Domain | Note=MIF4G |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 159_376 | 66 | 401.0 | Domain | Note=MIF4G |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 159_376 | 145 | 480.0 | Domain | Note=MIF4G |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 159_376 | 33 | 368.0 | Domain | Note=MIF4G |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 159_376 | 66 | 401.0 | Domain | Note=MIF4G |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 440_479 | 145 | 480.0 | Region | Note=PABPC1-interacting motif-1 (PAM1) |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 116_143 | 33 | 368.0 | Region | Note=PABPC1-interacting motif-2 (PAM2) |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 440_479 | 33 | 368.0 | Region | Note=PABPC1-interacting motif-1 (PAM1) |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 116_143 | 66 | 401.0 | Region | Note=PABPC1-interacting motif-2 (PAM2) |
| Hgene | PAIP1 | chr5:43555931 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 440_479 | 66 | 401.0 | Region | Note=PABPC1-interacting motif-1 (PAM1) |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000306846 | - | 2 | 11 | 440_479 | 145 | 480.0 | Region | Note=PABPC1-interacting motif-1 (PAM1) |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 116_143 | 33 | 368.0 | Region | Note=PABPC1-interacting motif-2 (PAM2) |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000338972 | - | 2 | 11 | 440_479 | 33 | 368.0 | Region | Note=PABPC1-interacting motif-1 (PAM1) |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 116_143 | 66 | 401.0 | Region | Note=PABPC1-interacting motif-2 (PAM2) |
| Hgene | PAIP1 | chr5:43555932 | chr5:39375186 | ENST00000436644 | - | 2 | 11 | 440_479 | 66 | 401.0 | Region | Note=PABPC1-interacting motif-1 (PAM1) |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000320816 | 12 | 15 | 45_196 | 749 | 1191.0 | Domain | PID | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000339788 | 11 | 14 | 45_196 | 531 | 1036.3333333333333 | Domain | PID | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000509337 | 10 | 13 | 45_196 | 728 | 805.0 | Domain | PID | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000545653 | 11 | 14 | 45_196 | 728 | 1149.0 | Domain | PID | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000320816 | 12 | 15 | 45_196 | 749 | 1191.0 | Domain | PID | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000339788 | 11 | 14 | 45_196 | 531 | 1036.3333333333333 | Domain | PID | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000509337 | 10 | 13 | 45_196 | 728 | 805.0 | Domain | PID | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000545653 | 11 | 14 | 45_196 | 728 | 1149.0 | Domain | PID | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000320816 | 12 | 15 | 293_295 | 749 | 1191.0 | Motif | Note=DPF 1 | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000320816 | 12 | 15 | 298_300 | 749 | 1191.0 | Motif | Note=DPF 2 | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000339788 | 11 | 14 | 293_295 | 531 | 1036.3333333333333 | Motif | Note=DPF 1 | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000339788 | 11 | 14 | 298_300 | 531 | 1036.3333333333333 | Motif | Note=DPF 2 | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000509337 | 10 | 13 | 293_295 | 728 | 805.0 | Motif | Note=DPF 1 | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000509337 | 10 | 13 | 298_300 | 728 | 805.0 | Motif | Note=DPF 2 | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000545653 | 11 | 14 | 293_295 | 728 | 1149.0 | Motif | Note=DPF 1 | |
| Tgene | DAB2 | chr5:43555931 | chr5:39375186 | ENST00000545653 | 11 | 14 | 298_300 | 728 | 1149.0 | Motif | Note=DPF 2 | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000320816 | 12 | 15 | 293_295 | 749 | 1191.0 | Motif | Note=DPF 1 | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000320816 | 12 | 15 | 298_300 | 749 | 1191.0 | Motif | Note=DPF 2 | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000339788 | 11 | 14 | 293_295 | 531 | 1036.3333333333333 | Motif | Note=DPF 1 | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000339788 | 11 | 14 | 298_300 | 531 | 1036.3333333333333 | Motif | Note=DPF 2 | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000509337 | 10 | 13 | 293_295 | 728 | 805.0 | Motif | Note=DPF 1 | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000509337 | 10 | 13 | 298_300 | 728 | 805.0 | Motif | Note=DPF 2 | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000545653 | 11 | 14 | 293_295 | 728 | 1149.0 | Motif | Note=DPF 1 | |
| Tgene | DAB2 | chr5:43555932 | chr5:39375186 | ENST00000545653 | 11 | 14 | 298_300 | 728 | 1149.0 | Motif | Note=DPF 2 |
Top |
Fusion Gene Sequence for PAIP1-DAB2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >62379_62379_1_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000306846_DAB2_chr5_39375186_ENST00000509337_length(transcript)=1144nt_BP=668nt CTGGAAAGCCGAGGGTAGCCGAGCGGGGCGGGCGCTCTGGAGCGGCGGGTGCTCGGGCTGCCGTCCGCTCCGCCAGAAGCACCGAGCAGC CGAGCCGGGGCCCGCCGCCCTCCTCCTCCATGAGGCCCGAGTGAGGCGCGGCGGCTATAGCCGACCCGCGGCGCCTTCCCCCCGCGTCCT ATCGCGAGCGCAGCGGCAGCGGCCCCTGGAGGAGGAGGCGGAGGAGGAGGAGCATGTCGGACGGTTTCGATCGGGCCCCAGGTGCTGGTC GGGGCCGGAGCCGGGGCCTGGGCCGCGGAGGGGGCGGGCCTGAGGGCGGCGGTTTCCCGAACGGAGCGGGGCCTGCTGAGCGGGCGCGGC ACCAGCCGCCGCAACCCAAAGCCCCGGGCTTCCTGCAGCCACCGCCGCTGCGCCAGCCCAGGACGACCCCGCCGCCAGGGGCCCAGTGCG AGGTCCCCGCCAGCCCCCAGCGGCCTTCCCGGCCCGGGGCGCTCCCAGAGCAAACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATA AAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGTAGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCC CTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCAACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAA ATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAAAAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCC AGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGCCTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTT TCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATTAAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTA CAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAACACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCAC >62379_62379_1_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000306846_DAB2_chr5_39375186_ENST00000509337_length(amino acids)=166AA_BP=145 MSDGFDRAPGAGRGRSRGLGRGGGGPEGGGFPNGAGPAERARHQPPQPKAPGFLQPPPLRQPRTTPPPGAQCEVPASPQRPSRPGALPEQ -------------------------------------------------------------- >62379_62379_2_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000338972_DAB2_chr5_39375186_ENST00000320816_length(transcript)=2345nt_BP=526nt ACATTTTCTTGAAATTTCTGGAGGGGAAGGTTAACGGGAAGAGAACGAAGCTTGTTAAACGTAGGTGTGACCTACTGTGGTAAACACCTA GGGTGAATTAAAGAGGGGACACATATTTTGATTCCGTTTCTACTCCCTTCCCCCGATGCTAACGGAGCAGGTGACAGTCTCCCAGGGACC ACTCCTCAGCAGTCCGCGGGTCTCGGCCGGAGCCGAGTCATTGAACACACCTGTGCGCCAGCGAACCCTGGCGCAGGGTCCACGCCCCCT CCCCCCGTGTTTTTATTTCCCGGGCGTCAACTGTCGGTCTCGCACGTCTCTCCTGAGAACTACCGAGTAGGTCGGGCCTGCCTGTGAGCA AACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGT AGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCA ACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAA AAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGC CTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATT AAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAA CACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATCCTTATTGTT CAGAGTTGTTTGGGGGTTCTGTTTCAGAGCATAAAACCTAAAGGTTATAGTAGAACAAGGCACCTTCTTAAAAGAAATCTTGCTTCAGAC CATCAGTTACAGAGAATTTCTAAAGTAAAATTGAAGCAACTACAACTTCTCCTTAGACACTTTGGAATCTAACCACTTAAGGACCTTTTT AAAGAGATAGCTTCTCTTCTTTCTGAAGATCAATTTCTCCCAAGGCCAAGATTGTCCTTTTCTCCCATTTCTTGCTAGCTATTGCAAATG AGGGAAGAACATTATTCATCTCTCCTCCCCTTTTTTTTCTGATTCTTTTTTCAGTCAGTTTTGCTCCTGGGTTCAAGTAGTATTACCACC CTTTCACAAGCAACAGACTCTCACAGGGCAAAAAAAAAAAAAAATCTAATGATTCACAGACAGATCTGGAGCCTCTCTTCATTCTCAGTA ATTGCTAGTCCCAAGAACTAGAATTGCAAATGGGCACAACCTATATCCTTCCTGTGGAAGAGGAGGCCACTCTCTTGAGCTGAAGTTCCA GAAGAGCAGTTAATGTTCAAGAGAAATTGAACTCAACTCAGCAACAAAGGACTCTATTTTGAAGAGCAACATATCACAAAGCTAAATGTG ATTGTGCCAAACACATTAGGTGCTTATTTGGGGTCATGCTAGGCCTTTATCAAGTAACTGGAAAACTTTTCTTGCAGCCACAATCTCAAT GTCGTTAGTAGGAAGATAAGAGGGGAGAAAAAGCTGTAGAACAAATGTTTGGGGTTACCATTGAAAATCTAATGTCTGCAATATTTTTCT CCTCACAACTTGGAAACGTTCCCAGTTCATTTTCAGTCCTGTTGTGAGCACAGTTCTGAAGGGTTTATTATTGTCAAAATAAGTTTTGTT TTGTTTTGTTTATGTTGGGTTTTTAATGTTGTCTCTTGACCCTTAATGCTCAGGTTCTTGTGGGAGTTAATCAGCCACATCCAATGTTAC CTTGAGGGGGAAGAAGAGGGTGATGCTCAGAAGCTAAACAAGACAGGGGCCACATGACCCTCTATTGATTAGCCCCAAGTAGAAAGTCCT GTGGTTTTATGTTTAATGGTAATAGTTGATCATATATGGCATAATTTTCTATCAGCTTCCTACTCAGTCACTATAAACACAGACTTGAAA TAGTACTTTAAATGTCCAAATACCTAAATGTGCTAAACTGGAGGTAACTATTTCTAGGTAGTTGAATTTTTGAAAGTCATGATCAGCCAC ACAACTGTTTTGTACATACTTATTTTCTCATGCACTTTTCTGTATGCAAATAAAGCTATAAATTTACTCATTTCAATAAACTGGAGTGGC >62379_62379_2_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000338972_DAB2_chr5_39375186_ENST00000320816_length(amino acids)=79AA_BP= -------------------------------------------------------------- >62379_62379_3_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000338972_DAB2_chr5_39375186_ENST00000339788_length(transcript)=2345nt_BP=526nt ACATTTTCTTGAAATTTCTGGAGGGGAAGGTTAACGGGAAGAGAACGAAGCTTGTTAAACGTAGGTGTGACCTACTGTGGTAAACACCTA GGGTGAATTAAAGAGGGGACACATATTTTGATTCCGTTTCTACTCCCTTCCCCCGATGCTAACGGAGCAGGTGACAGTCTCCCAGGGACC ACTCCTCAGCAGTCCGCGGGTCTCGGCCGGAGCCGAGTCATTGAACACACCTGTGCGCCAGCGAACCCTGGCGCAGGGTCCACGCCCCCT CCCCCCGTGTTTTTATTTCCCGGGCGTCAACTGTCGGTCTCGCACGTCTCTCCTGAGAACTACCGAGTAGGTCGGGCCTGCCTGTGAGCA AACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGT AGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCA ACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAA AAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGC CTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATT AAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAA CACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATCCTTATTGTT CAGAGTTGTTTGGGGGTTCTGTTTCAGAGCATAAAACCTAAAGGTTATAGTAGAACAAGGCACCTTCTTAAAAGAAATCTTGCTTCAGAC CATCAGTTACAGAGAATTTCTAAAGTAAAATTGAAGCAACTACAACTTCTCCTTAGACACTTTGGAATCTAACCACTTAAGGACCTTTTT AAAGAGATAGCTTCTCTTCTTTCTGAAGATCAATTTCTCCCAAGGCCAAGATTGTCCTTTTCTCCCATTTCTTGCTAGCTATTGCAAATG AGGGAAGAACATTATTCATCTCTCCTCCCCTTTTTTTTCTGATTCTTTTTTCAGTCAGTTTTGCTCCTGGGTTCAAGTAGTATTACCACC CTTTCACAAGCAACAGACTCTCACAGGGCAAAAAAAAAAAAAAATCTAATGATTCACAGACAGATCTGGAGCCTCTCTTCATTCTCAGTA ATTGCTAGTCCCAAGAACTAGAATTGCAAATGGGCACAACCTATATCCTTCCTGTGGAAGAGGAGGCCACTCTCTTGAGCTGAAGTTCCA GAAGAGCAGTTAATGTTCAAGAGAAATTGAACTCAACTCAGCAACAAAGGACTCTATTTTGAAGAGCAACATATCACAAAGCTAAATGTG ATTGTGCCAAACACATTAGGTGCTTATTTGGGGTCATGCTAGGCCTTTATCAAGTAACTGGAAAACTTTTCTTGCAGCCACAATCTCAAT GTCGTTAGTAGGAAGATAAGAGGGGAGAAAAAGCTGTAGAACAAATGTTTGGGGTTACCATTGAAAATCTAATGTCTGCAATATTTTTCT CCTCACAACTTGGAAACGTTCCCAGTTCATTTTCAGTCCTGTTGTGAGCACAGTTCTGAAGGGTTTATTATTGTCAAAATAAGTTTTGTT TTGTTTTGTTTATGTTGGGTTTTTAATGTTGTCTCTTGACCCTTAATGCTCAGGTTCTTGTGGGAGTTAATCAGCCACATCCAATGTTAC CTTGAGGGGGAAGAAGAGGGTGATGCTCAGAAGCTAAACAAGACAGGGGCCACATGACCCTCTATTGATTAGCCCCAAGTAGAAAGTCCT GTGGTTTTATGTTTAATGGTAATAGTTGATCATATATGGCATAATTTTCTATCAGCTTCCTACTCAGTCACTATAAACACAGACTTGAAA TAGTACTTTAAATGTCCAAATACCTAAATGTGCTAAACTGGAGGTAACTATTTCTAGGTAGTTGAATTTTTGAAAGTCATGATCAGCCAC ACAACTGTTTTGTACATACTTATTTTCTCATGCACTTTTCTGTATGCAAATAAAGCTATAAATTTACTCATTTCAATAAACTGGAGTGGC >62379_62379_3_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000338972_DAB2_chr5_39375186_ENST00000339788_length(amino acids)=79AA_BP= -------------------------------------------------------------- >62379_62379_4_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000338972_DAB2_chr5_39375186_ENST00000545653_length(transcript)=2345nt_BP=526nt ACATTTTCTTGAAATTTCTGGAGGGGAAGGTTAACGGGAAGAGAACGAAGCTTGTTAAACGTAGGTGTGACCTACTGTGGTAAACACCTA GGGTGAATTAAAGAGGGGACACATATTTTGATTCCGTTTCTACTCCCTTCCCCCGATGCTAACGGAGCAGGTGACAGTCTCCCAGGGACC ACTCCTCAGCAGTCCGCGGGTCTCGGCCGGAGCCGAGTCATTGAACACACCTGTGCGCCAGCGAACCCTGGCGCAGGGTCCACGCCCCCT CCCCCCGTGTTTTTATTTCCCGGGCGTCAACTGTCGGTCTCGCACGTCTCTCCTGAGAACTACCGAGTAGGTCGGGCCTGCCTGTGAGCA AACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGT AGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCA ACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAA AAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGC CTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATT AAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAA CACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATCCTTATTGTT CAGAGTTGTTTGGGGGTTCTGTTTCAGAGCATAAAACCTAAAGGTTATAGTAGAACAAGGCACCTTCTTAAAAGAAATCTTGCTTCAGAC CATCAGTTACAGAGAATTTCTAAAGTAAAATTGAAGCAACTACAACTTCTCCTTAGACACTTTGGAATCTAACCACTTAAGGACCTTTTT AAAGAGATAGCTTCTCTTCTTTCTGAAGATCAATTTCTCCCAAGGCCAAGATTGTCCTTTTCTCCCATTTCTTGCTAGCTATTGCAAATG AGGGAAGAACATTATTCATCTCTCCTCCCCTTTTTTTTCTGATTCTTTTTTCAGTCAGTTTTGCTCCTGGGTTCAAGTAGTATTACCACC CTTTCACAAGCAACAGACTCTCACAGGGCAAAAAAAAAAAAAAATCTAATGATTCACAGACAGATCTGGAGCCTCTCTTCATTCTCAGTA ATTGCTAGTCCCAAGAACTAGAATTGCAAATGGGCACAACCTATATCCTTCCTGTGGAAGAGGAGGCCACTCTCTTGAGCTGAAGTTCCA GAAGAGCAGTTAATGTTCAAGAGAAATTGAACTCAACTCAGCAACAAAGGACTCTATTTTGAAGAGCAACATATCACAAAGCTAAATGTG ATTGTGCCAAACACATTAGGTGCTTATTTGGGGTCATGCTAGGCCTTTATCAAGTAACTGGAAAACTTTTCTTGCAGCCACAATCTCAAT GTCGTTAGTAGGAAGATAAGAGGGGAGAAAAAGCTGTAGAACAAATGTTTGGGGTTACCATTGAAAATCTAATGTCTGCAATATTTTTCT CCTCACAACTTGGAAACGTTCCCAGTTCATTTTCAGTCCTGTTGTGAGCACAGTTCTGAAGGGTTTATTATTGTCAAAATAAGTTTTGTT TTGTTTTGTTTATGTTGGGTTTTTAATGTTGTCTCTTGACCCTTAATGCTCAGGTTCTTGTGGGAGTTAATCAGCCACATCCAATGTTAC CTTGAGGGGGAAGAAGAGGGTGATGCTCAGAAGCTAAACAAGACAGGGGCCACATGACCCTCTATTGATTAGCCCCAAGTAGAAAGTCCT GTGGTTTTATGTTTAATGGTAATAGTTGATCATATATGGCATAATTTTCTATCAGCTTCCTACTCAGTCACTATAAACACAGACTTGAAA TAGTACTTTAAATGTCCAAATACCTAAATGTGCTAAACTGGAGGTAACTATTTCTAGGTAGTTGAATTTTTGAAAGTCATGATCAGCCAC ACAACTGTTTTGTACATACTTATTTTCTCATGCACTTTTCTGTATGCAAATAAAGCTATAAATTTACTCATTTCAATAAACTGGAGTGGC >62379_62379_4_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000338972_DAB2_chr5_39375186_ENST00000545653_length(amino acids)=79AA_BP= -------------------------------------------------------------- >62379_62379_5_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000436644_DAB2_chr5_39375186_ENST00000509337_length(transcript)=921nt_BP=445nt GTTTTGGGGGAGAACTGGAAAGCCGAGGGTAGCCGAGCGGGGCGGGCGCTCTGGAGCGGCGGGTGCTCGGGCTGCCGTCCGCTCCGCCAG AAGCACCGAGCAGCCGAGCCGGGGCCCGCCGCCCTCCTCCTCCATGAGGCCCGAGTGAGGCGCGGCGGCTATAGCCGACCCGCGGCGCCT TCCCCCCGCGTCCTATCGCGAGCGCAGCGGCAGCGGCCCCTGGAGGAGGAGGCGGAGGAGGAGGAGCATGTCGGACGGTTTCGATCGGGC CCCAGAGCAAACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCA GGTGGTTGTAGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGC TTCTTCTCAACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAG AGGAATAAAAAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATT ATCTGTTGCCTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTT AAATAAATTAAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAAC CTTCTAGAACACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATC >62379_62379_5_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000436644_DAB2_chr5_39375186_ENST00000509337_length(amino acids)=100AA_BP= MGENWKAEGSRAGRALWSGGCSGCRPLRQKHRAAEPGPAALLLHEARVRRGGYSRPAAPSPRVLSRAQRQRPLEEEAEEEEHVGRFRSGP -------------------------------------------------------------- >62379_62379_6_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000514514_DAB2_chr5_39375186_ENST00000509337_length(transcript)=905nt_BP=429nt GGAAAGCCGAGGGTAGCCGAGCGGGGCGGGCGCTCTGGAGCGGCGGGTGCTCGGGCTGCCGTCCGCTCCGCCAGAAGCACCGAGCAGCCG AGCCGGGGCCCGCCGCCCTCCTCCTCCATGAGGCCCGAGTGAGGCGCGGCGGCTATAGCCGACCCGCGGCGCCTTCCCCCCGCGTCCTAT CGCGAGCGCAGCGGCAGCGGCCCCTGGAGGAGGAGGCGGAGGAGGAGGAGCATGTCGGACGGTTTCGATCGGGCCCCAGAGCAAACGAGG CCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGTAGCTCCT GTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCAACCTGTA TCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAAAAGGTTG GCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGCCTTATTT CTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATTAAGATCC TAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAACACCTGC CTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATCCTTATTGTTCAGAGTT >62379_62379_6_PAIP1-DAB2_PAIP1_chr5_43555931_ENST00000514514_DAB2_chr5_39375186_ENST00000509337_length(amino acids)=87AA_BP=66 -------------------------------------------------------------- >62379_62379_7_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000306846_DAB2_chr5_39375186_ENST00000509337_length(transcript)=1144nt_BP=668nt CTGGAAAGCCGAGGGTAGCCGAGCGGGGCGGGCGCTCTGGAGCGGCGGGTGCTCGGGCTGCCGTCCGCTCCGCCAGAAGCACCGAGCAGC CGAGCCGGGGCCCGCCGCCCTCCTCCTCCATGAGGCCCGAGTGAGGCGCGGCGGCTATAGCCGACCCGCGGCGCCTTCCCCCCGCGTCCT ATCGCGAGCGCAGCGGCAGCGGCCCCTGGAGGAGGAGGCGGAGGAGGAGGAGCATGTCGGACGGTTTCGATCGGGCCCCAGGTGCTGGTC GGGGCCGGAGCCGGGGCCTGGGCCGCGGAGGGGGCGGGCCTGAGGGCGGCGGTTTCCCGAACGGAGCGGGGCCTGCTGAGCGGGCGCGGC ACCAGCCGCCGCAACCCAAAGCCCCGGGCTTCCTGCAGCCACCGCCGCTGCGCCAGCCCAGGACGACCCCGCCGCCAGGGGCCCAGTGCG AGGTCCCCGCCAGCCCCCAGCGGCCTTCCCGGCCCGGGGCGCTCCCAGAGCAAACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATA AAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGTAGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCC CTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCAACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAA ATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAAAAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCC AGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGCCTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTT TCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATTAAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTA CAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAACACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCAC >62379_62379_7_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000306846_DAB2_chr5_39375186_ENST00000509337_length(amino acids)=166AA_BP=145 MSDGFDRAPGAGRGRSRGLGRGGGGPEGGGFPNGAGPAERARHQPPQPKAPGFLQPPPLRQPRTTPPPGAQCEVPASPQRPSRPGALPEQ -------------------------------------------------------------- >62379_62379_8_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000338972_DAB2_chr5_39375186_ENST00000320816_length(transcript)=2345nt_BP=526nt ACATTTTCTTGAAATTTCTGGAGGGGAAGGTTAACGGGAAGAGAACGAAGCTTGTTAAACGTAGGTGTGACCTACTGTGGTAAACACCTA GGGTGAATTAAAGAGGGGACACATATTTTGATTCCGTTTCTACTCCCTTCCCCCGATGCTAACGGAGCAGGTGACAGTCTCCCAGGGACC ACTCCTCAGCAGTCCGCGGGTCTCGGCCGGAGCCGAGTCATTGAACACACCTGTGCGCCAGCGAACCCTGGCGCAGGGTCCACGCCCCCT CCCCCCGTGTTTTTATTTCCCGGGCGTCAACTGTCGGTCTCGCACGTCTCTCCTGAGAACTACCGAGTAGGTCGGGCCTGCCTGTGAGCA AACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGT AGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCA ACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAA AAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGC CTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATT AAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAA CACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATCCTTATTGTT CAGAGTTGTTTGGGGGTTCTGTTTCAGAGCATAAAACCTAAAGGTTATAGTAGAACAAGGCACCTTCTTAAAAGAAATCTTGCTTCAGAC CATCAGTTACAGAGAATTTCTAAAGTAAAATTGAAGCAACTACAACTTCTCCTTAGACACTTTGGAATCTAACCACTTAAGGACCTTTTT AAAGAGATAGCTTCTCTTCTTTCTGAAGATCAATTTCTCCCAAGGCCAAGATTGTCCTTTTCTCCCATTTCTTGCTAGCTATTGCAAATG AGGGAAGAACATTATTCATCTCTCCTCCCCTTTTTTTTCTGATTCTTTTTTCAGTCAGTTTTGCTCCTGGGTTCAAGTAGTATTACCACC CTTTCACAAGCAACAGACTCTCACAGGGCAAAAAAAAAAAAAAATCTAATGATTCACAGACAGATCTGGAGCCTCTCTTCATTCTCAGTA ATTGCTAGTCCCAAGAACTAGAATTGCAAATGGGCACAACCTATATCCTTCCTGTGGAAGAGGAGGCCACTCTCTTGAGCTGAAGTTCCA GAAGAGCAGTTAATGTTCAAGAGAAATTGAACTCAACTCAGCAACAAAGGACTCTATTTTGAAGAGCAACATATCACAAAGCTAAATGTG ATTGTGCCAAACACATTAGGTGCTTATTTGGGGTCATGCTAGGCCTTTATCAAGTAACTGGAAAACTTTTCTTGCAGCCACAATCTCAAT GTCGTTAGTAGGAAGATAAGAGGGGAGAAAAAGCTGTAGAACAAATGTTTGGGGTTACCATTGAAAATCTAATGTCTGCAATATTTTTCT CCTCACAACTTGGAAACGTTCCCAGTTCATTTTCAGTCCTGTTGTGAGCACAGTTCTGAAGGGTTTATTATTGTCAAAATAAGTTTTGTT TTGTTTTGTTTATGTTGGGTTTTTAATGTTGTCTCTTGACCCTTAATGCTCAGGTTCTTGTGGGAGTTAATCAGCCACATCCAATGTTAC CTTGAGGGGGAAGAAGAGGGTGATGCTCAGAAGCTAAACAAGACAGGGGCCACATGACCCTCTATTGATTAGCCCCAAGTAGAAAGTCCT GTGGTTTTATGTTTAATGGTAATAGTTGATCATATATGGCATAATTTTCTATCAGCTTCCTACTCAGTCACTATAAACACAGACTTGAAA TAGTACTTTAAATGTCCAAATACCTAAATGTGCTAAACTGGAGGTAACTATTTCTAGGTAGTTGAATTTTTGAAAGTCATGATCAGCCAC ACAACTGTTTTGTACATACTTATTTTCTCATGCACTTTTCTGTATGCAAATAAAGCTATAAATTTACTCATTTCAATAAACTGGAGTGGC >62379_62379_8_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000338972_DAB2_chr5_39375186_ENST00000320816_length(amino acids)=79AA_BP= -------------------------------------------------------------- >62379_62379_9_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000338972_DAB2_chr5_39375186_ENST00000339788_length(transcript)=2345nt_BP=526nt ACATTTTCTTGAAATTTCTGGAGGGGAAGGTTAACGGGAAGAGAACGAAGCTTGTTAAACGTAGGTGTGACCTACTGTGGTAAACACCTA GGGTGAATTAAAGAGGGGACACATATTTTGATTCCGTTTCTACTCCCTTCCCCCGATGCTAACGGAGCAGGTGACAGTCTCCCAGGGACC ACTCCTCAGCAGTCCGCGGGTCTCGGCCGGAGCCGAGTCATTGAACACACCTGTGCGCCAGCGAACCCTGGCGCAGGGTCCACGCCCCCT CCCCCCGTGTTTTTATTTCCCGGGCGTCAACTGTCGGTCTCGCACGTCTCTCCTGAGAACTACCGAGTAGGTCGGGCCTGCCTGTGAGCA AACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGT AGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCA ACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAA AAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGC CTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATT AAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAA CACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATCCTTATTGTT CAGAGTTGTTTGGGGGTTCTGTTTCAGAGCATAAAACCTAAAGGTTATAGTAGAACAAGGCACCTTCTTAAAAGAAATCTTGCTTCAGAC CATCAGTTACAGAGAATTTCTAAAGTAAAATTGAAGCAACTACAACTTCTCCTTAGACACTTTGGAATCTAACCACTTAAGGACCTTTTT AAAGAGATAGCTTCTCTTCTTTCTGAAGATCAATTTCTCCCAAGGCCAAGATTGTCCTTTTCTCCCATTTCTTGCTAGCTATTGCAAATG AGGGAAGAACATTATTCATCTCTCCTCCCCTTTTTTTTCTGATTCTTTTTTCAGTCAGTTTTGCTCCTGGGTTCAAGTAGTATTACCACC CTTTCACAAGCAACAGACTCTCACAGGGCAAAAAAAAAAAAAAATCTAATGATTCACAGACAGATCTGGAGCCTCTCTTCATTCTCAGTA ATTGCTAGTCCCAAGAACTAGAATTGCAAATGGGCACAACCTATATCCTTCCTGTGGAAGAGGAGGCCACTCTCTTGAGCTGAAGTTCCA GAAGAGCAGTTAATGTTCAAGAGAAATTGAACTCAACTCAGCAACAAAGGACTCTATTTTGAAGAGCAACATATCACAAAGCTAAATGTG ATTGTGCCAAACACATTAGGTGCTTATTTGGGGTCATGCTAGGCCTTTATCAAGTAACTGGAAAACTTTTCTTGCAGCCACAATCTCAAT GTCGTTAGTAGGAAGATAAGAGGGGAGAAAAAGCTGTAGAACAAATGTTTGGGGTTACCATTGAAAATCTAATGTCTGCAATATTTTTCT CCTCACAACTTGGAAACGTTCCCAGTTCATTTTCAGTCCTGTTGTGAGCACAGTTCTGAAGGGTTTATTATTGTCAAAATAAGTTTTGTT TTGTTTTGTTTATGTTGGGTTTTTAATGTTGTCTCTTGACCCTTAATGCTCAGGTTCTTGTGGGAGTTAATCAGCCACATCCAATGTTAC CTTGAGGGGGAAGAAGAGGGTGATGCTCAGAAGCTAAACAAGACAGGGGCCACATGACCCTCTATTGATTAGCCCCAAGTAGAAAGTCCT GTGGTTTTATGTTTAATGGTAATAGTTGATCATATATGGCATAATTTTCTATCAGCTTCCTACTCAGTCACTATAAACACAGACTTGAAA TAGTACTTTAAATGTCCAAATACCTAAATGTGCTAAACTGGAGGTAACTATTTCTAGGTAGTTGAATTTTTGAAAGTCATGATCAGCCAC ACAACTGTTTTGTACATACTTATTTTCTCATGCACTTTTCTGTATGCAAATAAAGCTATAAATTTACTCATTTCAATAAACTGGAGTGGC >62379_62379_9_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000338972_DAB2_chr5_39375186_ENST00000339788_length(amino acids)=79AA_BP= -------------------------------------------------------------- >62379_62379_10_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000338972_DAB2_chr5_39375186_ENST00000545653_length(transcript)=2345nt_BP=526nt ACATTTTCTTGAAATTTCTGGAGGGGAAGGTTAACGGGAAGAGAACGAAGCTTGTTAAACGTAGGTGTGACCTACTGTGGTAAACACCTA GGGTGAATTAAAGAGGGGACACATATTTTGATTCCGTTTCTACTCCCTTCCCCCGATGCTAACGGAGCAGGTGACAGTCTCCCAGGGACC ACTCCTCAGCAGTCCGCGGGTCTCGGCCGGAGCCGAGTCATTGAACACACCTGTGCGCCAGCGAACCCTGGCGCAGGGTCCACGCCCCCT CCCCCCGTGTTTTTATTTCCCGGGCGTCAACTGTCGGTCTCGCACGTCTCTCCTGAGAACTACCGAGTAGGTCGGGCCTGCCTGTGAGCA AACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGT AGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCA ACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAA AAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGC CTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATT AAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAA CACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATCCTTATTGTT CAGAGTTGTTTGGGGGTTCTGTTTCAGAGCATAAAACCTAAAGGTTATAGTAGAACAAGGCACCTTCTTAAAAGAAATCTTGCTTCAGAC CATCAGTTACAGAGAATTTCTAAAGTAAAATTGAAGCAACTACAACTTCTCCTTAGACACTTTGGAATCTAACCACTTAAGGACCTTTTT AAAGAGATAGCTTCTCTTCTTTCTGAAGATCAATTTCTCCCAAGGCCAAGATTGTCCTTTTCTCCCATTTCTTGCTAGCTATTGCAAATG AGGGAAGAACATTATTCATCTCTCCTCCCCTTTTTTTTCTGATTCTTTTTTCAGTCAGTTTTGCTCCTGGGTTCAAGTAGTATTACCACC CTTTCACAAGCAACAGACTCTCACAGGGCAAAAAAAAAAAAAAATCTAATGATTCACAGACAGATCTGGAGCCTCTCTTCATTCTCAGTA ATTGCTAGTCCCAAGAACTAGAATTGCAAATGGGCACAACCTATATCCTTCCTGTGGAAGAGGAGGCCACTCTCTTGAGCTGAAGTTCCA GAAGAGCAGTTAATGTTCAAGAGAAATTGAACTCAACTCAGCAACAAAGGACTCTATTTTGAAGAGCAACATATCACAAAGCTAAATGTG ATTGTGCCAAACACATTAGGTGCTTATTTGGGGTCATGCTAGGCCTTTATCAAGTAACTGGAAAACTTTTCTTGCAGCCACAATCTCAAT GTCGTTAGTAGGAAGATAAGAGGGGAGAAAAAGCTGTAGAACAAATGTTTGGGGTTACCATTGAAAATCTAATGTCTGCAATATTTTTCT CCTCACAACTTGGAAACGTTCCCAGTTCATTTTCAGTCCTGTTGTGAGCACAGTTCTGAAGGGTTTATTATTGTCAAAATAAGTTTTGTT TTGTTTTGTTTATGTTGGGTTTTTAATGTTGTCTCTTGACCCTTAATGCTCAGGTTCTTGTGGGAGTTAATCAGCCACATCCAATGTTAC CTTGAGGGGGAAGAAGAGGGTGATGCTCAGAAGCTAAACAAGACAGGGGCCACATGACCCTCTATTGATTAGCCCCAAGTAGAAAGTCCT GTGGTTTTATGTTTAATGGTAATAGTTGATCATATATGGCATAATTTTCTATCAGCTTCCTACTCAGTCACTATAAACACAGACTTGAAA TAGTACTTTAAATGTCCAAATACCTAAATGTGCTAAACTGGAGGTAACTATTTCTAGGTAGTTGAATTTTTGAAAGTCATGATCAGCCAC ACAACTGTTTTGTACATACTTATTTTCTCATGCACTTTTCTGTATGCAAATAAAGCTATAAATTTACTCATTTCAATAAACTGGAGTGGC >62379_62379_10_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000338972_DAB2_chr5_39375186_ENST00000545653_length(amino acids)=79AA_BP= -------------------------------------------------------------- >62379_62379_11_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000436644_DAB2_chr5_39375186_ENST00000509337_length(transcript)=921nt_BP=445nt GTTTTGGGGGAGAACTGGAAAGCCGAGGGTAGCCGAGCGGGGCGGGCGCTCTGGAGCGGCGGGTGCTCGGGCTGCCGTCCGCTCCGCCAG AAGCACCGAGCAGCCGAGCCGGGGCCCGCCGCCCTCCTCCTCCATGAGGCCCGAGTGAGGCGCGGCGGCTATAGCCGACCCGCGGCGCCT TCCCCCCGCGTCCTATCGCGAGCGCAGCGGCAGCGGCCCCTGGAGGAGGAGGCGGAGGAGGAGGAGCATGTCGGACGGTTTCGATCGGGC CCCAGAGCAAACGAGGCCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCA GGTGGTTGTAGCTCCTGTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGC TTCTTCTCAACCTGTATCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAG AGGAATAAAAAGGTTGGCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATT ATCTGTTGCCTTATTTCTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTT AAATAAATTAAGATCCTAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAAC CTTCTAGAACACCTGCCTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATC >62379_62379_11_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000436644_DAB2_chr5_39375186_ENST00000509337_length(amino acids)=100AA_BP= MGENWKAEGSRAGRALWSGGCSGCRPLRQKHRAAEPGPAALLLHEARVRRGGYSRPAAPSPRVLSRAQRQRPLEEEAEEEEHVGRFRSGP -------------------------------------------------------------- >62379_62379_12_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000514514_DAB2_chr5_39375186_ENST00000509337_length(transcript)=905nt_BP=429nt GGAAAGCCGAGGGTAGCCGAGCGGGGCGGGCGCTCTGGAGCGGCGGGTGCTCGGGCTGCCGTCCGCTCCGCCAGAAGCACCGAGCAGCCG AGCCGGGGCCCGCCGCCCTCCTCCTCCATGAGGCCCGAGTGAGGCGCGGCGGCTATAGCCGACCCGCGGCGCCTTCCCCCCGCGTCCTAT CGCGAGCGCAGCGGCAGCGGCCCCTGGAGGAGGAGGCGGAGGAGGAGGAGCATGTCGGACGGTTTCGATCGGGCCCCAGAGCAAACGAGG CCCCTGAGAGCTCCACCTAGTTCACAGGATAAAATCCCACAGCAGAACTCGGAGTCAGCAATGGCTAAGCCCCAGGTGGTTGTAGCTCCT GTATTAATGTCTAAGCTGTCTGTGAATGCCCCTGAATTTTACCCTTCAGGTTATTCTTCCAGTTACACAGTGGCTTCTTCTCAACCTGTA TCTTCTGAGATGTATAGGGATCCATTTGGAAATCCTTTTGCCTAAATTCTGAACTTGGTCTGCAGACCATCCAGAGGAATAAAAAGGTTG GCCTTAGTAGTCAAAAACAAAGCTGATAGCCAGACACGTTCTGATTTCTGCCCTTGTTCCAGCTTTGACGTATTATCTGTTGCCTTATTT CTCATTGCCTCTTCTACTTGTAAAATGCTTTTCACTTTCTGTCTAGGTTAAAGCTAAACTGAATCTATGGCTTTAAATAAATTAAGATCC TAAACTCTCTAGCTTAAGTGTAAATGAAGTACAGTAGTTTCCCTACTGAACCCTGCCTCTTGTGTCCCTGGAACCTTCTAGAACACCTGC CTTCTACCCTCTGGTTGGGAGATGCAGCCACCACATCCCTTCATATCATACTGTTTTGAATAAATTTTCAAATCCTTATTGTTCAGAGTT >62379_62379_12_PAIP1-DAB2_PAIP1_chr5_43555932_ENST00000514514_DAB2_chr5_39375186_ENST00000509337_length(amino acids)=87AA_BP=66 -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PAIP1-DAB2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PAIP1-DAB2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PAIP1-DAB2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies