
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARID1A-BEND5 (FusionGDB2 ID:6371) |
Fusion Gene Summary for ARID1A-BEND5 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARID1A-BEND5 | Fusion gene ID: 6371 | Hgene | Tgene | Gene symbol | ARID1A | BEND5 | Gene ID | 8289 | 79656 |
| Gene name | AT-rich interaction domain 1A | BEN domain containing 5 | |
| Synonyms | B120|BAF250|BAF250a|BM029|C1orf4|CSS2|ELD|MRD14|OSA1|P270|SMARCF1|hELD|hOSA1 | C1orf165 | |
| Cytomap | 1p36.11 | 1p33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AT-rich interactive domain-containing protein 1AARID domain-containing protein 1AAT rich interactive domain 1A (SWI-like)BRG1-associated factor 250aOSA1 nuclear proteinSWI-like proteinSWI/SNF complex protein p270SWI/SNF-related, matrix-associated, | BEN domain-containing protein 5 | |
| Modification date | 20200329 | 20200327 | |
| UniProtAcc | O14497 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000324856, ENST00000457599, ENST00000374152, ENST00000540690, | ENST00000476096, ENST00000371833, | |
| Fusion gene scores | * DoF score | 29 X 19 X 15=8265 | 4 X 5 X 4=80 |
| # samples | 45 | 7 | |
| ** MAII score | log2(45/8265*10)=-4.19901791296264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/80*10)=-0.192645077942396 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARID1A [Title/Abstract] AND BEND5 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARID1A(27024031)-BEND5(49202124), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ARID1A | GO:0006337 | nucleosome disassembly | 8895581 |
| Hgene | ARID1A | GO:0006338 | chromatin remodeling | 11726552 |
| Hgene | ARID1A | GO:0030520 | intracellular estrogen receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0030521 | androgen receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0042921 | glucocorticoid receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0045893 | positive regulation of transcription, DNA-templated | 12200431 |
| Tgene | BEND5 | GO:0045892 | negative regulation of transcription, DNA-templated | 23468431 |
| Fusion gene breakpoints across ARID1A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across BEND5 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | GBM | TCGA-28-2514-01A | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| ChimerDB4 | GBM | TCGA-28-2514-01A | ARID1A | chr1 | 27024031 | - | BEND5 | chr1 | 49202124 | - |
| ChimerDB4 | GBM | TCGA-28-2514-01A | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| ChimerDB4 | GBM | TCGA-28-2514 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
Top |
Fusion Gene ORF analysis for ARID1A-BEND5 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000324856 | ENST00000476096 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| 5CDS-intron | ENST00000457599 | ENST00000476096 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| 5UTR-3CDS | ENST00000324856 | ENST00000371833 | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| 5UTR-intron | ENST00000324856 | ENST00000476096 | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| In-frame | ENST00000324856 | ENST00000371833 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| In-frame | ENST00000457599 | ENST00000371833 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| intron-3CDS | ENST00000374152 | ENST00000371833 | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| intron-3CDS | ENST00000374152 | ENST00000371833 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| intron-3CDS | ENST00000457599 | ENST00000371833 | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| intron-3CDS | ENST00000540690 | ENST00000371833 | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| intron-3CDS | ENST00000540690 | ENST00000371833 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| intron-intron | ENST00000374152 | ENST00000476096 | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| intron-intron | ENST00000374152 | ENST00000476096 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| intron-intron | ENST00000457599 | ENST00000476096 | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| intron-intron | ENST00000540690 | ENST00000476096 | ARID1A | chr1 | 27022592 | + | BEND5 | chr1 | 49202123 | - |
| intron-intron | ENST00000540690 | ENST00000476096 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000324856 | ARID1A | chr1 | 27024031 | + | ENST00000371833 | BEND5 | chr1 | 49202124 | - | 2243 | 1508 | 371 | 1879 | 502 |
| ENST00000457599 | ARID1A | chr1 | 27024031 | + | ENST00000371833 | BEND5 | chr1 | 49202124 | - | 1872 | 1137 | 0 | 1508 | 502 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000324856 | ENST00000371833 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - | 0.012414639 | 0.9875853 |
| ENST00000457599 | ENST00000371833 | ARID1A | chr1 | 27024031 | + | BEND5 | chr1 | 49202124 | - | 0.012198305 | 0.98780173 |
Top |
Fusion Genomic Features for ARID1A-BEND5 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
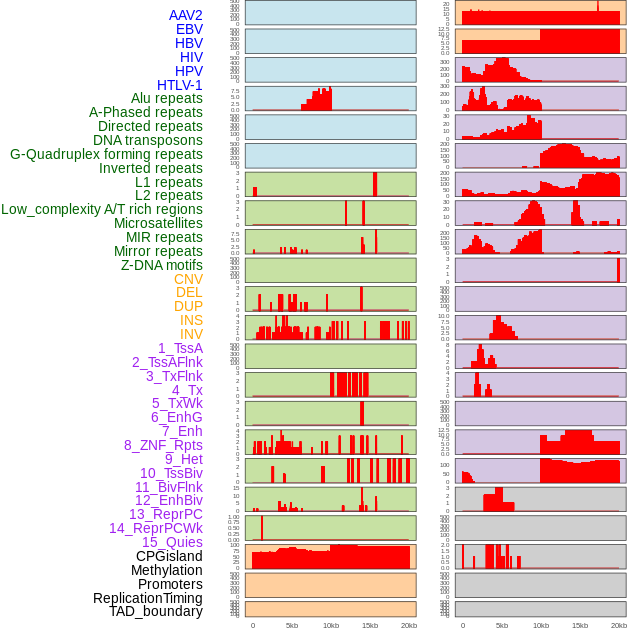 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ARID1A-BEND5 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:27024031/chr1:49202124) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARID1A | . |
| FUNCTION: Involved in transcriptional activation and repression of select genes by chromatin remodeling (alteration of DNA-nucleosome topology). Component of SWI/SNF chromatin remodeling complexes that carry out key enzymatic activities, changing chromatin structure by altering DNA-histone contacts within a nucleosome in an ATP-dependent manner. Binds DNA non-specifically. Belongs to the neural progenitors-specific chromatin remodeling complex (npBAF complex) and the neuron-specific chromatin remodeling complex (nBAF complex). During neural development a switch from a stem/progenitor to a postmitotic chromatin remodeling mechanism occurs as neurons exit the cell cycle and become committed to their adult state. The transition from proliferating neural stem/progenitor cells to postmitotic neurons requires a switch in subunit composition of the npBAF and nBAF complexes. As neural progenitors exit mitosis and differentiate into neurons, npBAF complexes which contain ACTL6A/BAF53A and PHF10/BAF45A, are exchanged for homologous alternative ACTL6B/BAF53B and DPF1/BAF45B or DPF3/BAF45C subunits in neuron-specific complexes (nBAF). The npBAF complex is essential for the self-renewal/proliferative capacity of the multipotent neural stem cells. The nBAF complex along with CREST plays a role regulating the activity of genes essential for dendrite growth (By similarity). {ECO:0000250|UniProtKB:A2BH40, ECO:0000303|PubMed:12672490, ECO:0000303|PubMed:22952240, ECO:0000303|PubMed:26601204}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 295_299 | 379 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 295_299 | 379 | 2069.0 | Motif | Note=LXXLL |
| Tgene | BEND5 | chr1:27024031 | chr1:49202124 | ENST00000371833 | 3 | 6 | 302_408 | 298 | 422.0 | Domain | BEN |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 1327_1404 | 379 | 2286.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 479_482 | 379 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 561_567 | 379 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 998_1001 | 379 | 2286.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 1327_1404 | 0 | 1903.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 479_482 | 0 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 561_567 | 0 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 998_1001 | 0 | 1903.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 1327_1404 | 379 | 2069.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 479_482 | 379 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 561_567 | 379 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 998_1001 | 379 | 2069.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 1017_1108 | 379 | 2286.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 1017_1108 | 0 | 1903.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 1017_1108 | 379 | 2069.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 1368_1387 | 379 | 2286.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 1709_1713 | 379 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 1967_1971 | 379 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000324856 | + | 1 | 20 | 2085_2089 | 379 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 1368_1387 | 0 | 1903.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 1709_1713 | 0 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 1967_1971 | 0 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 2085_2089 | 0 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000374152 | + | 1 | 19 | 295_299 | 0 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 1368_1387 | 379 | 2069.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 1709_1713 | 379 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 1967_1971 | 379 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27024031 | chr1:49202124 | ENST00000457599 | + | 1 | 20 | 2085_2089 | 379 | 2069.0 | Motif | Note=LXXLL |
| Tgene | BEND5 | chr1:27024031 | chr1:49202124 | ENST00000371833 | 3 | 6 | 180_243 | 298 | 422.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for ARID1A-BEND5 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6371_6371_1_ARID1A-BEND5_ARID1A_chr1_27024031_ENST00000324856_BEND5_chr1_49202124_ENST00000371833_length(transcript)=2243nt_BP=1508nt GAAAGCGGAGAGTCACAGCGGGGCCAGGCCCTGGGGAGCGGAGCCTCCACCGCCCCCCTCATTCCCAGGCAAGGGCTTGGGGGGAATGAG CCGGGAGAGCCGGGTCCCGAGCCTACAGAGCCGGGAGCAGCTGAGCCGCCGGCGCCTCGGCCGCCGCCGCCGCCTCCTCCTCCTCCGCCG CCGCCAGCCCGGAGCCTGAGCCGGCGGGGCGGGGGGGAGAGGAGCGAGCGCAGCGCAGCAGCGGAGCCCCGCGAGGCCCGCCCGGGCGGG TGGGGAGGGCAGCCCGGGGGACTGGGCCCCGGGGCGGGGTGGGAGGGGGGGAGAAGACGAAGACAGGGCCGGGTCTCTCCGCGGACGAGA CAGCGGGGATCATGGCCGCGCAGGTCGCCCCCGCCGCCGCCAGCAGCCTGGGCAACCCGCCGCCGCCGCCGCCCTCGGAGCTGAAGAAAG CCGAGCAGCAGCAGCGGGAGGAGGCGGGGGGCGAGGCGGCGGCGGCGGCAGCGGCCGAGCGCGGGGAAATGAAGGCAGCCGCCGGGCAGG AAAGCGAGGGCCCCGCCGTGGGGCCGCCGCAGCCGCTGGGAAAGGAGCTGCAGGACGGGGCCGAGAGCAATGGGGGTGGCGGCGGCGGCG GAGCCGGCAGCGGCGGCGGGCCCGGCGCGGAGCCGGACCTGAAGAACTCGAACGGGAACGCGGGCCCTAGGCCCGCCCTGAACAATAACC TCACGGAGCCGCCCGGCGGCGGCGGTGGCGGCAGCAGCGATGGGGTGGGGGCGCCTCCTCACTCAGCCGCGGCCGCCTTGCCGCCCCCAG CCTACGGCTTCGGGCAACCCTACGGCCGGAGCCCGTCTGCCGTCGCCGCCGCCGCGGCCGCCGTCTTCCACCAACAACATGGCGGACAAC AAAGCCCTGGCCTGGCAGCGCTGCAGAGCGGCGGCGGCGGGGGCCTGGAGCCCTACGCGGGGCCCCAGCAGAACTCTCACGACCACGGCT TCCCCAACCACCAGTACAACTCCTACTACCCCAACCGCAGCGCCTACCCCCCGCCCGCCCCGGCCTACGCGCTGAGCTCCCCGAGAGGTG GCACTCCGGGCTCCGGCGCGGCGGCGGCTGCCGGCTCCAAGCCGCCTCCCTCCTCCAGCGCCTCCGCCTCCTCGTCGTCTTCGTCCTTCG CTCAGCAGCGCTTCGGGGCCATGGGGGGAGGCGGCCCCTCCGCGGCCGGCGGGGGAACTCCCCAGCCCACCGCCACCCCCACCCTCAACC AACTGCTCACGTCGCCCAGCTCGGCCCGGGGCTACCAGGGCTACCCCGGGGGCGACTACAGTGGCGGGCCCCAGGACGGGGGCGCCGGCA AGGGCCCGGCGGACATGGCCTCGCAGTGTTGGGGGGCTGCGGCGGCGGCAGCTGCGGCGGCGGCCGCCTCGGGAGGGGCCCAACAAAGGA GCCACCACGCGCCCATGAGCCCCGGGAGCAGCGGCGGCGGGGGGCAGCCGCTCGCCCGGACCCCTCAGGTCCATCTGGGAAGCGGGATTT GGGTTGATGAGGAGAAATGGCACCAGCTACAAGTAACCCAAGGAGATTCCAAGTACACGAAGAACTTGGCAGTTATGATTTGGGGAACAG ATGTTCTGAAAAACAGAAGCGTCACAGGCGTCGCCACAAAAAAAAAGAAAGATGCAGTCCCTAAACCACCCCTCTCGCCTCACAAACTAA GCATCGTCAGAGAGTGTTTGTATGACAGAATAGCACAAGAAACTGTGGATGAAACTGAAATTGCACAGAGACTCTCCAAAGTCAACAAGT ACATCTGTGAAAAAATCATGGATATCAATAAATCCTGTAAAAATGAAGAACGAAGGGAAGCAAAATACAATTTGCAATAAACTTTGGATT TTTCATAAAGCTTTCGTGTTTTCCTTGTGTGGCATGTGATTTGCGAGCGATGGTGCCGTCCAAATCAGACCCCACCGTGCATGGTGGTGT GTGTGCAGGGATCCATCGGGTTCTGGGGTCAGCGGCTTGTTCTGAATGTGGACACTCCAAAGACGACAGATGGCTTTGCTGAGACTCAGG AGCAGCCTGGCACTGGTGTCCTTCTGGGAATGGGGAAAACACTCTTCTTGGAGGGGGATAAGGTTGCCTGAGTTGCCTGTCACTTGACTG >6371_6371_1_ARID1A-BEND5_ARID1A_chr1_27024031_ENST00000324856_BEND5_chr1_49202124_ENST00000371833_length(amino acids)=502AA_BP=378 MAAQVAPAAASSLGNPPPPPPSELKKAEQQQREEAGGEAAAAAAAERGEMKAAAGQESEGPAVGPPQPLGKELQDGAESNGGGGGGGAGS GGGPGAEPDLKNSNGNAGPRPALNNNLTEPPGGGGGGSSDGVGAPPHSAAAALPPPAYGFGQPYGRSPSAVAAAAAAVFHQQHGGQQSPG LAALQSGGGGGLEPYAGPQQNSHDHGFPNHQYNSYYPNRSAYPPPAPAYALSSPRGGTPGSGAAAAAGSKPPPSSSASASSSSSSFAQQR FGAMGGGGPSAAGGGTPQPTATPTLNQLLTSPSSARGYQGYPGGDYSGGPQDGGAGKGPADMASQCWGAAAAAAAAAAASGGAQQRSHHA PMSPGSSGGGGQPLARTPQVHLGSGIWVDEEKWHQLQVTQGDSKYTKNLAVMIWGTDVLKNRSVTGVATKKKKDAVPKPPLSPHKLSIVR -------------------------------------------------------------- >6371_6371_2_ARID1A-BEND5_ARID1A_chr1_27024031_ENST00000457599_BEND5_chr1_49202124_ENST00000371833_length(transcript)=1872nt_BP=1137nt ATGGCCGCGCAGGTCGCCCCCGCCGCCGCCAGCAGCCTGGGCAACCCGCCGCCGCCGCCGCCCTCGGAGCTGAAGAAAGCCGAGCAGCAG CAGCGGGAGGAGGCGGGGGGCGAGGCGGCGGCGGCGGCAGCGGCCGAGCGCGGGGAAATGAAGGCAGCCGCCGGGCAGGAAAGCGAGGGC CCCGCCGTGGGGCCGCCGCAGCCGCTGGGAAAGGAGCTGCAGGACGGGGCCGAGAGCAATGGGGGTGGCGGCGGCGGCGGAGCCGGCAGC GGCGGCGGGCCCGGCGCGGAGCCGGACCTGAAGAACTCGAACGGGAACGCGGGCCCTAGGCCCGCCCTGAACAATAACCTCACGGAGCCG CCCGGCGGCGGCGGTGGCGGCAGCAGCGATGGGGTGGGGGCGCCTCCTCACTCAGCCGCGGCCGCCTTGCCGCCCCCAGCCTACGGCTTC GGGCAACCCTACGGCCGGAGCCCGTCTGCCGTCGCCGCCGCCGCGGCCGCCGTCTTCCACCAACAACATGGCGGACAACAAAGCCCTGGC CTGGCAGCGCTGCAGAGCGGCGGCGGCGGGGGCCTGGAGCCCTACGCGGGGCCCCAGCAGAACTCTCACGACCACGGCTTCCCCAACCAC CAGTACAACTCCTACTACCCCAACCGCAGCGCCTACCCCCCGCCCGCCCCGGCCTACGCGCTGAGCTCCCCGAGAGGTGGCACTCCGGGC TCCGGCGCGGCGGCGGCTGCCGGCTCCAAGCCGCCTCCCTCCTCCAGCGCCTCCGCCTCCTCGTCGTCTTCGTCCTTCGCTCAGCAGCGC TTCGGGGCCATGGGGGGAGGCGGCCCCTCCGCGGCCGGCGGGGGAACTCCCCAGCCCACCGCCACCCCCACCCTCAACCAACTGCTCACG TCGCCCAGCTCGGCCCGGGGCTACCAGGGCTACCCCGGGGGCGACTACAGTGGCGGGCCCCAGGACGGGGGCGCCGGCAAGGGCCCGGCG GACATGGCCTCGCAGTGTTGGGGGGCTGCGGCGGCGGCAGCTGCGGCGGCGGCCGCCTCGGGAGGGGCCCAACAAAGGAGCCACCACGCG CCCATGAGCCCCGGGAGCAGCGGCGGCGGGGGGCAGCCGCTCGCCCGGACCCCTCAGGTCCATCTGGGAAGCGGGATTTGGGTTGATGAG GAGAAATGGCACCAGCTACAAGTAACCCAAGGAGATTCCAAGTACACGAAGAACTTGGCAGTTATGATTTGGGGAACAGATGTTCTGAAA AACAGAAGCGTCACAGGCGTCGCCACAAAAAAAAAGAAAGATGCAGTCCCTAAACCACCCCTCTCGCCTCACAAACTAAGCATCGTCAGA GAGTGTTTGTATGACAGAATAGCACAAGAAACTGTGGATGAAACTGAAATTGCACAGAGACTCTCCAAAGTCAACAAGTACATCTGTGAA AAAATCATGGATATCAATAAATCCTGTAAAAATGAAGAACGAAGGGAAGCAAAATACAATTTGCAATAAACTTTGGATTTTTCATAAAGC TTTCGTGTTTTCCTTGTGTGGCATGTGATTTGCGAGCGATGGTGCCGTCCAAATCAGACCCCACCGTGCATGGTGGTGTGTGTGCAGGGA TCCATCGGGTTCTGGGGTCAGCGGCTTGTTCTGAATGTGGACACTCCAAAGACGACAGATGGCTTTGCTGAGACTCAGGAGCAGCCTGGC ACTGGTGTCCTTCTGGGAATGGGGAAAACACTCTTCTTGGAGGGGGATAAGGTTGCCTGAGTTGCCTGTCACTTGACTGGGGTTTGAATG >6371_6371_2_ARID1A-BEND5_ARID1A_chr1_27024031_ENST00000457599_BEND5_chr1_49202124_ENST00000371833_length(amino acids)=502AA_BP=378 MAAQVAPAAASSLGNPPPPPPSELKKAEQQQREEAGGEAAAAAAAERGEMKAAAGQESEGPAVGPPQPLGKELQDGAESNGGGGGGGAGS GGGPGAEPDLKNSNGNAGPRPALNNNLTEPPGGGGGGSSDGVGAPPHSAAAALPPPAYGFGQPYGRSPSAVAAAAAAVFHQQHGGQQSPG LAALQSGGGGGLEPYAGPQQNSHDHGFPNHQYNSYYPNRSAYPPPAPAYALSSPRGGTPGSGAAAAAGSKPPPSSSASASSSSSSFAQQR FGAMGGGGPSAAGGGTPQPTATPTLNQLLTSPSSARGYQGYPGGDYSGGPQDGGAGKGPADMASQCWGAAAAAAAAAAASGGAQQRSHHA PMSPGSSGGGGQPLARTPQVHLGSGIWVDEEKWHQLQVTQGDSKYTKNLAVMIWGTDVLKNRSVTGVATKKKKDAVPKPPLSPHKLSIVR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARID1A-BEND5 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARID1A-BEND5 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARID1A-BEND5 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies