
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARID1A-DGKA (FusionGDB2 ID:6372) |
Fusion Gene Summary for ARID1A-DGKA |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARID1A-DGKA | Fusion gene ID: 6372 | Hgene | Tgene | Gene symbol | ARID1A | DGKA | Gene ID | 8289 | 1606 |
| Gene name | AT-rich interaction domain 1A | diacylglycerol kinase alpha | |
| Synonyms | B120|BAF250|BAF250a|BM029|C1orf4|CSS2|ELD|MRD14|OSA1|P270|SMARCF1|hELD|hOSA1 | DAGK|DAGK1|DGK-alpha | |
| Cytomap | 1p36.11 | 12q13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AT-rich interactive domain-containing protein 1AARID domain-containing protein 1AAT rich interactive domain 1A (SWI-like)BRG1-associated factor 250aOSA1 nuclear proteinSWI-like proteinSWI/SNF complex protein p270SWI/SNF-related, matrix-associated, | diacylglycerol kinase alpha80 kDa diacylglycerol kinaseDAG kinase alphadiacylglycerol kinase, alpha 80kDadiglyceride kinase alpha | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | O14497 | P23743 | |
| Ensembl transtripts involved in fusion gene | ENST00000324856, ENST00000374152, ENST00000457599, ENST00000540690, | ENST00000549079, ENST00000331886, ENST00000394147, ENST00000551156, | |
| Fusion gene scores | * DoF score | 29 X 19 X 15=8265 | 11 X 10 X 7=770 |
| # samples | 45 | 12 | |
| ** MAII score | log2(45/8265*10)=-4.19901791296264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/770*10)=-2.68182403997375 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARID1A [Title/Abstract] AND DGKA [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARID1A(27106722)-DGKA(56346689), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ARID1A-DGKA seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. ARID1A-DGKA seems lost the major protein functional domain in Hgene partner, which is a epigenetic factor due to the frame-shifted ORF. ARID1A-DGKA seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. ARID1A-DGKA seems lost the major protein functional domain in Hgene partner, which is a tumor suppressor due to the frame-shifted ORF. ARID1A-DGKA seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. ARID1A-DGKA seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ARID1A | GO:0006337 | nucleosome disassembly | 8895581 |
| Hgene | ARID1A | GO:0006338 | chromatin remodeling | 11726552 |
| Hgene | ARID1A | GO:0030520 | intracellular estrogen receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0030521 | androgen receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0042921 | glucocorticoid receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0045893 | positive regulation of transcription, DNA-templated | 12200431 |
| Tgene | DGKA | GO:0006654 | phosphatidic acid biosynthetic process | 22627129 |
| Tgene | DGKA | GO:0046339 | diacylglycerol metabolic process | 22627129 |
| Tgene | DGKA | GO:0046486 | glycerolipid metabolic process | 22627129 |
| Tgene | DGKA | GO:0046834 | lipid phosphorylation | 18004883|22627129 |
| Fusion gene breakpoints across ARID1A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across DGKA (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SKCM | TCGA-EE-A17Z-06A | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
Top |
Fusion Gene ORF analysis for ARID1A-DGKA |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000324856 | ENST00000549079 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| 5CDS-3UTR | ENST00000374152 | ENST00000549079 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| 5CDS-3UTR | ENST00000457599 | ENST00000549079 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| 5CDS-3UTR | ENST00000540690 | ENST00000549079 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000324856 | ENST00000331886 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000324856 | ENST00000394147 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000324856 | ENST00000551156 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000457599 | ENST00000331886 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000457599 | ENST00000394147 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000457599 | ENST00000551156 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000540690 | ENST00000331886 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000540690 | ENST00000394147 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| Frame-shift | ENST00000540690 | ENST00000551156 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| In-frame | ENST00000374152 | ENST00000331886 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| In-frame | ENST00000374152 | ENST00000394147 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| In-frame | ENST00000374152 | ENST00000551156 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000374152 | ARID1A | chr1 | 27106722 | + | ENST00000331886 | DGKA | chr12 | 56346689 | + | 5323 | 4783 | 283 | 4782 | 1499 |
| ENST00000374152 | ARID1A | chr1 | 27106722 | + | ENST00000394147 | DGKA | chr12 | 56346689 | + | 5329 | 4783 | 283 | 4782 | 1499 |
| ENST00000374152 | ARID1A | chr1 | 27106722 | + | ENST00000551156 | DGKA | chr12 | 56346689 | + | 5335 | 4783 | 283 | 4782 | 1499 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000374152 | ENST00000331886 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + | 0.006443693 | 0.9935563 |
| ENST00000374152 | ENST00000394147 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + | 0.006369842 | 0.9936301 |
| ENST00000374152 | ENST00000551156 | ARID1A | chr1 | 27106722 | + | DGKA | chr12 | 56346689 | + | 0.006486926 | 0.99351305 |
Top |
Fusion Genomic Features for ARID1A-DGKA |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
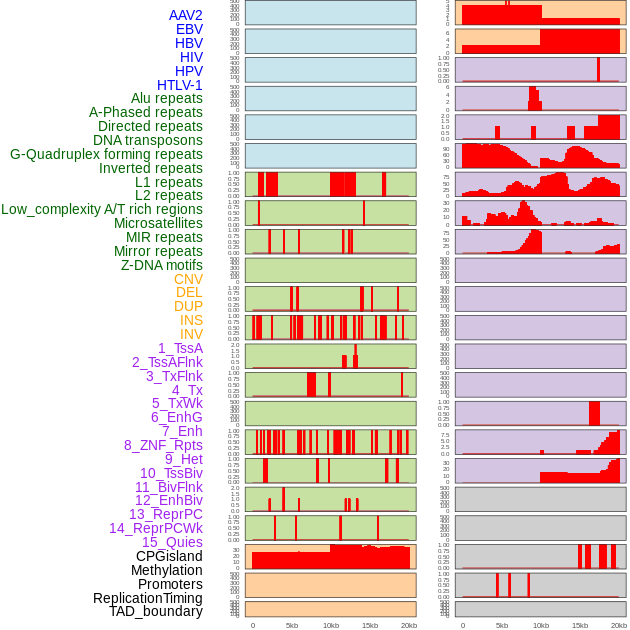 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ARID1A-DGKA |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:27106722/chr12:56346689) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARID1A | DGKA |
| FUNCTION: Involved in transcriptional activation and repression of select genes by chromatin remodeling (alteration of DNA-nucleosome topology). Component of SWI/SNF chromatin remodeling complexes that carry out key enzymatic activities, changing chromatin structure by altering DNA-histone contacts within a nucleosome in an ATP-dependent manner. Binds DNA non-specifically. Belongs to the neural progenitors-specific chromatin remodeling complex (npBAF complex) and the neuron-specific chromatin remodeling complex (nBAF complex). During neural development a switch from a stem/progenitor to a postmitotic chromatin remodeling mechanism occurs as neurons exit the cell cycle and become committed to their adult state. The transition from proliferating neural stem/progenitor cells to postmitotic neurons requires a switch in subunit composition of the npBAF and nBAF complexes. As neural progenitors exit mitosis and differentiate into neurons, npBAF complexes which contain ACTL6A/BAF53A and PHF10/BAF45A, are exchanged for homologous alternative ACTL6B/BAF53B and DPF1/BAF45B or DPF3/BAF45C subunits in neuron-specific complexes (nBAF). The npBAF complex is essential for the self-renewal/proliferative capacity of the multipotent neural stem cells. The nBAF complex along with CREST plays a role regulating the activity of genes essential for dendrite growth (By similarity). {ECO:0000250|UniProtKB:A2BH40, ECO:0000303|PubMed:12672490, ECO:0000303|PubMed:22952240, ECO:0000303|PubMed:26601204}. | FUNCTION: Diacylglycerol kinase that converts diacylglycerol/DAG into phosphatidic acid/phosphatidate/PA and regulates the respective levels of these two bioactive lipids (PubMed:2175712, PubMed:15544348). Thereby, acts as a central switch between the signaling pathways activated by these second messengers with different cellular targets and opposite effects in numerous biological processes (PubMed:2175712, PubMed:15544348). Also plays an important role in the biosynthesis of complex lipids (Probable). Can also phosphorylate 1-alkyl-2-acylglycerol in vitro as efficiently as diacylglycerol provided it contains an arachidonoyl group (PubMed:15544348). Also involved in the production of alkyl-lysophosphatidic acid, another bioactive lipid, through the phosphorylation of 1-alkyl-2-acetyl glycerol (PubMed:22627129). {ECO:0000269|PubMed:15544348, ECO:0000269|PubMed:2175712, ECO:0000269|PubMed:22627129, ECO:0000305}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000331886 | 0 | 24 | 123_134 | 0 | 736.0 | Calcium binding | 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000331886 | 0 | 24 | 168_179 | 0 | 736.0 | Calcium binding | 2 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000394147 | 0 | 24 | 123_134 | 0 | 736.0 | Calcium binding | 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000394147 | 0 | 24 | 168_179 | 0 | 736.0 | Calcium binding | 2 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000551156 | 0 | 24 | 123_134 | 0 | 736.0 | Calcium binding | 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000551156 | 0 | 24 | 168_179 | 0 | 736.0 | Calcium binding | 2 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000331886 | 0 | 24 | 110_145 | 0 | 736.0 | Domain | EF-hand 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000331886 | 0 | 24 | 155_190 | 0 | 736.0 | Domain | EF-hand 2 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000331886 | 0 | 24 | 372_506 | 0 | 736.0 | Domain | DAGKc | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000394147 | 0 | 24 | 110_145 | 0 | 736.0 | Domain | EF-hand 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000394147 | 0 | 24 | 155_190 | 0 | 736.0 | Domain | EF-hand 2 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000394147 | 0 | 24 | 372_506 | 0 | 736.0 | Domain | DAGKc | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000551156 | 0 | 24 | 110_145 | 0 | 736.0 | Domain | EF-hand 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000551156 | 0 | 24 | 155_190 | 0 | 736.0 | Domain | EF-hand 2 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000551156 | 0 | 24 | 372_506 | 0 | 736.0 | Domain | DAGKc | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000331886 | 0 | 24 | 205_253 | 0 | 736.0 | Zinc finger | Phorbol-ester/DAG-type 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000331886 | 0 | 24 | 269_319 | 0 | 736.0 | Zinc finger | Phorbol-ester/DAG-type 2 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000394147 | 0 | 24 | 205_253 | 0 | 736.0 | Zinc finger | Phorbol-ester/DAG-type 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000394147 | 0 | 24 | 269_319 | 0 | 736.0 | Zinc finger | Phorbol-ester/DAG-type 2 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000551156 | 0 | 24 | 205_253 | 0 | 736.0 | Zinc finger | Phorbol-ester/DAG-type 1 | |
| Tgene | DGKA | chr1:27106722 | chr12:56346689 | ENST00000551156 | 0 | 24 | 269_319 | 0 | 736.0 | Zinc finger | Phorbol-ester/DAG-type 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 1327_1404 | 0 | 2286.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 479_482 | 0 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 561_567 | 0 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 998_1001 | 0 | 2286.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 1327_1404 | 0 | 1903.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 479_482 | 0 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 561_567 | 0 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 998_1001 | 0 | 1903.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 1327_1404 | 0 | 2069.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 479_482 | 0 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 561_567 | 0 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 998_1001 | 0 | 2069.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 1017_1108 | 0 | 2286.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 1017_1108 | 0 | 1903.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 1017_1108 | 0 | 2069.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 1368_1387 | 0 | 2286.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 1709_1713 | 0 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 1967_1971 | 0 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 2085_2089 | 0 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000324856 | + | 1 | 20 | 295_299 | 0 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 1368_1387 | 0 | 1903.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 1709_1713 | 0 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 1967_1971 | 0 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 2085_2089 | 0 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000374152 | + | 1 | 19 | 295_299 | 0 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 1368_1387 | 0 | 2069.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 1709_1713 | 0 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 1967_1971 | 0 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 2085_2089 | 0 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27106722 | chr12:56346689 | ENST00000457599 | + | 1 | 20 | 295_299 | 0 | 2069.0 | Motif | Note=LXXLL |
Top |
Fusion Gene Sequence for ARID1A-DGKA |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6372_6372_1_ARID1A-DGKA_ARID1A_chr1_27106722_ENST00000374152_DGKA_chr12_56346689_ENST00000331886_length(transcript)=5323nt_BP=4783nt TGGATCTCAAGCAGTACCACAGTTACAAAGTAGTTTTTAGCTTACAAGGTGTTTTCACAAATAGGTGGTATTTTCATTTTTCAAATGACA AAATTAGGGTTCTGAGGCGGGTCAGTTGACTTAAAGGTTACTAGGTTGGTCTCATTGCTCTTTCAAAGTAACTGTATTTCTTTATAGCAT ACAGACTAAAAAAACCTGTGTACTTGGGTTATATATTCAGTGGCCAGAGGCCATCAAAGCTCAGGTTAATGAAATGCTCTTTATTTTGTA GCCATCCAGTCCAATGGATCAGATGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTC AGGACCGCAGCAAGGACATGGGTACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCA GAGTGCCATGGGCGGCCTCTCTTATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCC ATATTACAACCAGCAAAGTCCTCACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTC GTATCAGCAGCAGCCACAGTCTCAACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCA GTCCCCGGCTCCATACCCCTCCCAGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCC TTACCAGCAGCAGCAACCTCAGCAGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCA AACTGCCTATTCCCAGCAGCGCTTCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGAC CTCCAGTAAGGGAGGGCAAGAAGATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTGATCTATCTGGTTCAATAGATGACCT CCCCATGGGGACAGAAGGAGCTCTGAGTCCTGGAGTGAGCACATCAGGGATTTCCAGCAGCCAAGGAGAGCAGAGTAATCCAGCTCAGTC TCCTTTCTCTCCTCATACCTCCCCTCACCTGCCTGGCATCCGAGGCCCTTCCCCGTCCCCTGTTGGCTCTCCCGCCAGTGTTGCTCAGTC TCGCTCAGGACCACTCTCGCCTGCTGCAGTGCCAGGCAACCAGATGCCACCTCGGCCACCCAGTGGCCAGTCGGACAGCATCATGCATCC TTCCATGAACCAATCAAGCATTGCCCAAGATCGAGGTTATATGCAGAGGAACCCCCAGATGCCCCAGTACAGTTCCCCCCAGCCCGGCTC AGCCTTATCTCCGCGTCAGCCTTCCGGAGGACAGATACACACAGGCATGGGCTCCTACCAGCAGAACTCCATGGGGAGCTATGGTCCCCA GGGGGGTCAGTATGGCCCACAAGGTGGCTACCCCAGGCAGCCAAACTATAATGCCTTGCCCAATGCCAACTACCCCAGTGCAGGCATGGC TGGAGGCATAAACCCCATGGGTGCCGGAGGTCAAATGCATGGACAGCCTGGCATCCCACCTTATGGCACACTCCCTCCAGGGAGGATGAG TCACGCCTCCATGGGCAACCGGCCTTATGGCCCTAACATGGCCAATATGCCACCTCAGGTTGGGTCAGGGATGTGTCCCCCACCAGGGGG CATGAACCGGAAAACCCAAGAAACTGCTGTCGCCATGCATGTTGCTGCCAACTCTATCCAAAACAGGCCGCCAGGCTACCCCAATATGAA TCAAGGGGGCATGATGGGAACTGGACCTCCTTATGGACAAGGGATTAATAGTATGGCTGGCATGATCAACCCTCAGGGACCCCCATATTC CATGGGTGGAACCATGGCCAACAATTCTGCAGGGATGGCAGCCAGCCCAGAGATGATGGGCCTTGGGGATGTAAAGTTAACTCCAGCCAC CAAAATGAACAACAAGGCAGATGGGACACCCAAGACAGAATCCAAATCCAAGAAATCCAGTTCTTCTACTACAACCAATGAGAAGATCAC CAAGTTGTATGAGCTGGGTGGTGAGCCTGAGAGGAAGATGTGGGTGGACCGTTATCTGGCCTTCACTGAGGAGAAGGCCATGGGCATGAC AAATCTGCCTGCTGTGGGTAGGAAACCTCTGGACCTCTATCGCCTCTATGTGTCTGTGAAGGAGATTGGTGGATTGACTCAGGTCAACAA GAACAAAAAATGGCGGGAACTTGCAACCAACCTCAATGTGGGCACATCAAGCAGTGCTGCCAGCTCCTTGAAAAAGCAGTATATCCAGTG TCTCTATGCCTTTGAATGCAAGATTGAACGGGGAGAAGACCCTCCCCCAGACATCTTTGCAGCTGCTGATTCCAAGAAGTCCCAGCCCAA GATCCAGCCTCCCTCTCCTGCGGGATCAGGATCTATGCAGGGGCCCCAGACTCCCCAGTCAACCAGCAGTTCCATGGCAGAAGGAGGAGA CTTAAAGCCACCAACTCCAGCATCCACACCACACAGTCAGATCCCCCCATTGCCAGGCATGAGCAGGAGCAATTCAGTTGGGATCCAGGA TGCCTTTAATGATGGAAGTGACTCCACATTCCAGAAGCGGAATTCCATGACTCCAAACCCTGGGTATCAGCCCAGTATGAATACCTCTGA CATGATGGGGCGCATGTCCTATGAGCCAAATAAGGATCCTTATGGCAGCATGAGGAAAGCTCCAGGGAGTGATCCCTTCATGTCCTCAGG GCAGGGCCCCAACGGCGGGATGGGTGACCCCTACAGTCGTGCTGCCGGCCCTGGGCTAGGAAATGTGGCGATGGGACCACGACAGCACTA TCCCTATGGAGGTCCTTATGACAGAGTGAGGACGGAGCCTGGAATAGGGCCTGAGGGAAACATGAGCACTGGGGCCCCACAGCCGAATCT CATGCCTTCCAACCCAGACTCGGGGATGTATTCTCCTAGCCGCTACCCCCCGCAGCAGCAGCAGCAGCAGCAGCAACGACATGATTCCTA TGGCAATCAGTTCTCCACCCAAGGCACCCCTTCTGGCAGCCCCTTCCCCAGCCAGCAGACTACAATGTATCAACAGCAACAGCAGAATTA CAAGCGGCCAATGGATGGCACATATGGCCCTCCTGCCAAGCGGCACGAAGGGGAGATGTACAGCGTGCCATACAGCACTGGGCAGGGGCA GCCTCAGCAGCAGCAGTTGCCCCCAGCCCAGCCCCAGCCTGCCAGCCAGCAACAAGCTGCCCAGCCTTCCCCTCAGCAAGATGTATACAA CCAGTATGGCAATGCCTATCCTGCCACTGCCACAGCTGCTACTGAGCGCCGACCAGCAGGCGGCCCCCAGAACCAATTTCCATTCCAGTT TGGCCGAGACCGTGTCTCTGCACCCCCTGGCACCAATGCCCAGCAAAACATGCCACCACAAATGATGGGCGGCCCCATACAGGCATCAGC TGAGGTTGCTCAGCAAGGCACCATGTGGCAGGGGCGTAATGACATGACCTATAATTATGCCAACAGGCAGAGCACGGGCTCTGCCCCCCA GGGCCCCGCCTATCATGGCGTGAACCGAACAGATGAAATGCTGCACACAGATCAGAGGGCCAACCACGAAGGCTCGTGGCCTTCCCATGG CACACGCCAGCCCCCATATGGTCCCTCTGCCCCTGTGCCCCCCATGACAAGGCCCCCTCCATCTAACTACCAGCCCCCACCAAGCATGCA GAATCACATTCCTCAGGTATCCAGCCCTGCTCCCCTGCCCCGGCCAATGGAGAACCGCACCTCTCCTAGCAAGTCTCCATTCCTGCACTC TGGGATGAAAATGCAGAAGGCAGGTCCCCCAGTACCTGCCTCGCACATAGCACCTGCCCCTGTGCAGCCCCCCATGATTCGGCGGGATAT CACCTTCCCACCTGGCTCTGTTGAAGCCACACAGCCTGTGTTGAAGCAGAGGAGGCGGCTCACAATGAAAGACATTGGAACCCCGGAGGC ATGGCGGGTAATGATGTCCCTCAAGTCTGGTCTCCTGGCAGAGAGCACATGGGCATTAGATACCATCAACATCCTGCTGTATGATGACAA CAGCATCATGACCTTCAACCTCAGTCAGCTTTCCCCGCAGAGACTGGTCTTGGAAACCCTCAGCAAACTCAGCATCCAGGACAACAATGT GGACCTGATTCTGGCCACACCCCCCTTCAGCCGCCTGGAGAAGTTGTATAGCACTATGGTGCGCTTCCTCAGTGACCGAAAGAACCCGGT GTGCCGGGAGATGGCTGTGGTACTGCTGGCCAACCTGGCTCAGGGGGACAGCCTGGCAGCTCGTGCCATTGCAGTGCAGAAGGGCAGTAT CGGCAACCTCCTGGGCTTCCTAGAGGACAGCCTTGCCGCCACACAGTTCCAGCAGAGCCAGGCCAGCCTCCTCCACATGCAGAACCCACC CTTTGAGCCAACTAGTGTGGACATGATGCGGCGGGCTGCCCGCGCGCTGCTTGCCTTGGCCAAGGTGGACGAGAACCACTCAGAGTTTAC TCTGTACGAATCACGGCTGTTGGACATCTCGGTATCACCGTTGATGAACTCATTGGTTTCACAAGTCATTTGTGATGTACTGTTTTTGAT TGGCCAGTCATGACTGATATCCTGAAAACCTGTGTACCAGACCTAAGTGACAAGAGACTGGAAGTGGTTGGGCTGGAGGGTGCAATTGAG ATGGGCCAAATCTATACCAAGCTCAAGAATGCTGGACGTCGGCTGGCCAAGTGCTCTGAGATCACCTTCCACACCACAAAAACCCTTCCC ATGCAAATTGACGGAGAACCCTGGATGCAGACGCCCTGTACAATCAAGATCACCCACAAGAACCAGATGCCCATGCTCATGGGCCCACCC CCCCGCTCCACCAATTTCTTTGGCTTCTTGAGCTAAGGGGGACACCCTTGGCCTCCAAGCCAGCCTTGAACCCACCTCCCTGTCCCTGGA CTCTACTCCCGAGGCTCTGTACATTGCTGCCACATACTCCTGCCAGCTTGGGGGAGTGTTCCTTCACCCTCACAGTATTTATTATCCTGC ACCACCTCACTGTTCCCCATGCGCACACACATACACACACCCCAAAACACATACATTGAAAGTGCCTCATCTGAATAAAATGACTTGTGT >6372_6372_1_ARID1A-DGKA_ARID1A_chr1_27106722_ENST00000374152_DGKA_chr12_56346689_ENST00000331886_length(amino acids)=1499AA_BP= MDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQIPPYGQQGPSGYGQQGQTPYYNQ QSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQSTTQQHPQSQPPYSQPQAQSPYQQQ QPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNLSLQSRPSSLPDLSGSIDDLPMGT EGALSPGVSTSGISSSQGEQSNPAQSPFSPHTSPHLPGIRGPSPSPVGSPASVAQSRSGPLSPAAVPGNQMPPRPPSGQSDSIMHPSMNQ SSIAQDRGYMQRNPQMPQYSSPQPGSALSPRQPSGGQIHTGMGSYQQNSMGSYGPQGGQYGPQGGYPRQPNYNALPNANYPSAGMAGGIN PMGAGGQMHGQPGIPPYGTLPPGRMSHASMGNRPYGPNMANMPPQVGSGMCPPPGGMNRKTQETAVAMHVAANSIQNRPPGYPNMNQGGM MGTGPPYGQGINSMAGMINPQGPPYSMGGTMANNSAGMAASPEMMGLGDVKLTPATKMNNKADGTPKTESKSKKSSSSTTTNEKITKLYE LGGEPERKMWVDRYLAFTEEKAMGMTNLPAVGRKPLDLYRLYVSVKEIGGLTQVNKNKKWRELATNLNVGTSSSAASSLKKQYIQCLYAF ECKIERGEDPPPDIFAAADSKKSQPKIQPPSPAGSGSMQGPQTPQSTSSSMAEGGDLKPPTPASTPHSQIPPLPGMSRSNSVGIQDAFND GSDSTFQKRNSMTPNPGYQPSMNTSDMMGRMSYEPNKDPYGSMRKAPGSDPFMSSGQGPNGGMGDPYSRAAGPGLGNVAMGPRQHYPYGG PYDRVRTEPGIGPEGNMSTGAPQPNLMPSNPDSGMYSPSRYPPQQQQQQQQRHDSYGNQFSTQGTPSGSPFPSQQTTMYQQQQQNYKRPM DGTYGPPAKRHEGEMYSVPYSTGQGQPQQQQLPPAQPQPASQQQAAQPSPQQDVYNQYGNAYPATATAATERRPAGGPQNQFPFQFGRDR VSAPPGTNAQQNMPPQMMGGPIQASAEVAQQGTMWQGRNDMTYNYANRQSTGSAPQGPAYHGVNRTDEMLHTDQRANHEGSWPSHGTRQP PYGPSAPVPPMTRPPPSNYQPPPSMQNHIPQVSSPAPLPRPMENRTSPSKSPFLHSGMKMQKAGPPVPASHIAPAPVQPPMIRRDITFPP GSVEATQPVLKQRRRLTMKDIGTPEAWRVMMSLKSGLLAESTWALDTINILLYDDNSIMTFNLSQLSPQRLVLETLSKLSIQDNNVDLIL ATPPFSRLEKLYSTMVRFLSDRKNPVCREMAVVLLANLAQGDSLAARAIAVQKGSIGNLLGFLEDSLAATQFQQSQASLLHMQNPPFEPT -------------------------------------------------------------- >6372_6372_2_ARID1A-DGKA_ARID1A_chr1_27106722_ENST00000374152_DGKA_chr12_56346689_ENST00000394147_length(transcript)=5329nt_BP=4783nt TGGATCTCAAGCAGTACCACAGTTACAAAGTAGTTTTTAGCTTACAAGGTGTTTTCACAAATAGGTGGTATTTTCATTTTTCAAATGACA AAATTAGGGTTCTGAGGCGGGTCAGTTGACTTAAAGGTTACTAGGTTGGTCTCATTGCTCTTTCAAAGTAACTGTATTTCTTTATAGCAT ACAGACTAAAAAAACCTGTGTACTTGGGTTATATATTCAGTGGCCAGAGGCCATCAAAGCTCAGGTTAATGAAATGCTCTTTATTTTGTA GCCATCCAGTCCAATGGATCAGATGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTC AGGACCGCAGCAAGGACATGGGTACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCA GAGTGCCATGGGCGGCCTCTCTTATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCC ATATTACAACCAGCAAAGTCCTCACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTC GTATCAGCAGCAGCCACAGTCTCAACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCA GTCCCCGGCTCCATACCCCTCCCAGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCC TTACCAGCAGCAGCAACCTCAGCAGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCA AACTGCCTATTCCCAGCAGCGCTTCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGAC CTCCAGTAAGGGAGGGCAAGAAGATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTGATCTATCTGGTTCAATAGATGACCT CCCCATGGGGACAGAAGGAGCTCTGAGTCCTGGAGTGAGCACATCAGGGATTTCCAGCAGCCAAGGAGAGCAGAGTAATCCAGCTCAGTC TCCTTTCTCTCCTCATACCTCCCCTCACCTGCCTGGCATCCGAGGCCCTTCCCCGTCCCCTGTTGGCTCTCCCGCCAGTGTTGCTCAGTC TCGCTCAGGACCACTCTCGCCTGCTGCAGTGCCAGGCAACCAGATGCCACCTCGGCCACCCAGTGGCCAGTCGGACAGCATCATGCATCC TTCCATGAACCAATCAAGCATTGCCCAAGATCGAGGTTATATGCAGAGGAACCCCCAGATGCCCCAGTACAGTTCCCCCCAGCCCGGCTC AGCCTTATCTCCGCGTCAGCCTTCCGGAGGACAGATACACACAGGCATGGGCTCCTACCAGCAGAACTCCATGGGGAGCTATGGTCCCCA GGGGGGTCAGTATGGCCCACAAGGTGGCTACCCCAGGCAGCCAAACTATAATGCCTTGCCCAATGCCAACTACCCCAGTGCAGGCATGGC TGGAGGCATAAACCCCATGGGTGCCGGAGGTCAAATGCATGGACAGCCTGGCATCCCACCTTATGGCACACTCCCTCCAGGGAGGATGAG TCACGCCTCCATGGGCAACCGGCCTTATGGCCCTAACATGGCCAATATGCCACCTCAGGTTGGGTCAGGGATGTGTCCCCCACCAGGGGG CATGAACCGGAAAACCCAAGAAACTGCTGTCGCCATGCATGTTGCTGCCAACTCTATCCAAAACAGGCCGCCAGGCTACCCCAATATGAA TCAAGGGGGCATGATGGGAACTGGACCTCCTTATGGACAAGGGATTAATAGTATGGCTGGCATGATCAACCCTCAGGGACCCCCATATTC CATGGGTGGAACCATGGCCAACAATTCTGCAGGGATGGCAGCCAGCCCAGAGATGATGGGCCTTGGGGATGTAAAGTTAACTCCAGCCAC CAAAATGAACAACAAGGCAGATGGGACACCCAAGACAGAATCCAAATCCAAGAAATCCAGTTCTTCTACTACAACCAATGAGAAGATCAC CAAGTTGTATGAGCTGGGTGGTGAGCCTGAGAGGAAGATGTGGGTGGACCGTTATCTGGCCTTCACTGAGGAGAAGGCCATGGGCATGAC AAATCTGCCTGCTGTGGGTAGGAAACCTCTGGACCTCTATCGCCTCTATGTGTCTGTGAAGGAGATTGGTGGATTGACTCAGGTCAACAA GAACAAAAAATGGCGGGAACTTGCAACCAACCTCAATGTGGGCACATCAAGCAGTGCTGCCAGCTCCTTGAAAAAGCAGTATATCCAGTG TCTCTATGCCTTTGAATGCAAGATTGAACGGGGAGAAGACCCTCCCCCAGACATCTTTGCAGCTGCTGATTCCAAGAAGTCCCAGCCCAA GATCCAGCCTCCCTCTCCTGCGGGATCAGGATCTATGCAGGGGCCCCAGACTCCCCAGTCAACCAGCAGTTCCATGGCAGAAGGAGGAGA CTTAAAGCCACCAACTCCAGCATCCACACCACACAGTCAGATCCCCCCATTGCCAGGCATGAGCAGGAGCAATTCAGTTGGGATCCAGGA TGCCTTTAATGATGGAAGTGACTCCACATTCCAGAAGCGGAATTCCATGACTCCAAACCCTGGGTATCAGCCCAGTATGAATACCTCTGA CATGATGGGGCGCATGTCCTATGAGCCAAATAAGGATCCTTATGGCAGCATGAGGAAAGCTCCAGGGAGTGATCCCTTCATGTCCTCAGG GCAGGGCCCCAACGGCGGGATGGGTGACCCCTACAGTCGTGCTGCCGGCCCTGGGCTAGGAAATGTGGCGATGGGACCACGACAGCACTA TCCCTATGGAGGTCCTTATGACAGAGTGAGGACGGAGCCTGGAATAGGGCCTGAGGGAAACATGAGCACTGGGGCCCCACAGCCGAATCT CATGCCTTCCAACCCAGACTCGGGGATGTATTCTCCTAGCCGCTACCCCCCGCAGCAGCAGCAGCAGCAGCAGCAACGACATGATTCCTA TGGCAATCAGTTCTCCACCCAAGGCACCCCTTCTGGCAGCCCCTTCCCCAGCCAGCAGACTACAATGTATCAACAGCAACAGCAGAATTA CAAGCGGCCAATGGATGGCACATATGGCCCTCCTGCCAAGCGGCACGAAGGGGAGATGTACAGCGTGCCATACAGCACTGGGCAGGGGCA GCCTCAGCAGCAGCAGTTGCCCCCAGCCCAGCCCCAGCCTGCCAGCCAGCAACAAGCTGCCCAGCCTTCCCCTCAGCAAGATGTATACAA CCAGTATGGCAATGCCTATCCTGCCACTGCCACAGCTGCTACTGAGCGCCGACCAGCAGGCGGCCCCCAGAACCAATTTCCATTCCAGTT TGGCCGAGACCGTGTCTCTGCACCCCCTGGCACCAATGCCCAGCAAAACATGCCACCACAAATGATGGGCGGCCCCATACAGGCATCAGC TGAGGTTGCTCAGCAAGGCACCATGTGGCAGGGGCGTAATGACATGACCTATAATTATGCCAACAGGCAGAGCACGGGCTCTGCCCCCCA GGGCCCCGCCTATCATGGCGTGAACCGAACAGATGAAATGCTGCACACAGATCAGAGGGCCAACCACGAAGGCTCGTGGCCTTCCCATGG CACACGCCAGCCCCCATATGGTCCCTCTGCCCCTGTGCCCCCCATGACAAGGCCCCCTCCATCTAACTACCAGCCCCCACCAAGCATGCA GAATCACATTCCTCAGGTATCCAGCCCTGCTCCCCTGCCCCGGCCAATGGAGAACCGCACCTCTCCTAGCAAGTCTCCATTCCTGCACTC TGGGATGAAAATGCAGAAGGCAGGTCCCCCAGTACCTGCCTCGCACATAGCACCTGCCCCTGTGCAGCCCCCCATGATTCGGCGGGATAT CACCTTCCCACCTGGCTCTGTTGAAGCCACACAGCCTGTGTTGAAGCAGAGGAGGCGGCTCACAATGAAAGACATTGGAACCCCGGAGGC ATGGCGGGTAATGATGTCCCTCAAGTCTGGTCTCCTGGCAGAGAGCACATGGGCATTAGATACCATCAACATCCTGCTGTATGATGACAA CAGCATCATGACCTTCAACCTCAGTCAGCTTTCCCCGCAGAGACTGGTCTTGGAAACCCTCAGCAAACTCAGCATCCAGGACAACAATGT GGACCTGATTCTGGCCACACCCCCCTTCAGCCGCCTGGAGAAGTTGTATAGCACTATGGTGCGCTTCCTCAGTGACCGAAAGAACCCGGT GTGCCGGGAGATGGCTGTGGTACTGCTGGCCAACCTGGCTCAGGGGGACAGCCTGGCAGCTCGTGCCATTGCAGTGCAGAAGGGCAGTAT CGGCAACCTCCTGGGCTTCCTAGAGGACAGCCTTGCCGCCACACAGTTCCAGCAGAGCCAGGCCAGCCTCCTCCACATGCAGAACCCACC CTTTGAGCCAACTAGTGTGGACATGATGCGGCGGGCTGCCCGCGCGCTGCTTGCCTTGGCCAAGGTGGACGAGAACCACTCAGAGTTTAC TCTGTACGAATCACGGCTGTTGGACATCTCGGTATCACCGTTGATGAACTCATTGGTTTCACAAGTCATTTGTGATGTACTGTTTTTGAT TGGCCAGTCATGACTGATATCCTGAAAACCTGTGTACCAGACCTAAGTGACAAGAGACTGGAAGTGGTTGGGCTGGAGGGTGCAATTGAG ATGGGCCAAATCTATACCAAGCTCAAGAATGCTGGACGTCGGCTGGCCAAGTGCTCTGAGATCACCTTCCACACCACAAAAACCCTTCCC ATGCAAATTGACGGAGAACCCTGGATGCAGACGCCCTGTACAATCAAGATCACCCACAAGAACCAGATGCCCATGCTCATGGGCCCACCC CCCCGCTCCACCAATTTCTTTGGCTTCTTGAGCTAAGGGGGACACCCTTGGCCTCCAAGCCAGCCTTGAACCCACCTCCCTGTCCCTGGA CTCTACTCCCGAGGCTCTGTACATTGCTGCCACATACTCCTGCCAGCTTGGGGGAGTGTTCCTTCACCCTCACAGTATTTATTATCCTGC ACCACCTCACTGTTCCCCATGCGCACACACATACACACACCCCAAAACACATACATTGAAAGTGCCTCATCTGAATAAAATGACTTGTGT >6372_6372_2_ARID1A-DGKA_ARID1A_chr1_27106722_ENST00000374152_DGKA_chr12_56346689_ENST00000394147_length(amino acids)=1499AA_BP= MDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQIPPYGQQGPSGYGQQGQTPYYNQ QSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQSTTQQHPQSQPPYSQPQAQSPYQQQ QPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNLSLQSRPSSLPDLSGSIDDLPMGT EGALSPGVSTSGISSSQGEQSNPAQSPFSPHTSPHLPGIRGPSPSPVGSPASVAQSRSGPLSPAAVPGNQMPPRPPSGQSDSIMHPSMNQ SSIAQDRGYMQRNPQMPQYSSPQPGSALSPRQPSGGQIHTGMGSYQQNSMGSYGPQGGQYGPQGGYPRQPNYNALPNANYPSAGMAGGIN PMGAGGQMHGQPGIPPYGTLPPGRMSHASMGNRPYGPNMANMPPQVGSGMCPPPGGMNRKTQETAVAMHVAANSIQNRPPGYPNMNQGGM MGTGPPYGQGINSMAGMINPQGPPYSMGGTMANNSAGMAASPEMMGLGDVKLTPATKMNNKADGTPKTESKSKKSSSSTTTNEKITKLYE LGGEPERKMWVDRYLAFTEEKAMGMTNLPAVGRKPLDLYRLYVSVKEIGGLTQVNKNKKWRELATNLNVGTSSSAASSLKKQYIQCLYAF ECKIERGEDPPPDIFAAADSKKSQPKIQPPSPAGSGSMQGPQTPQSTSSSMAEGGDLKPPTPASTPHSQIPPLPGMSRSNSVGIQDAFND GSDSTFQKRNSMTPNPGYQPSMNTSDMMGRMSYEPNKDPYGSMRKAPGSDPFMSSGQGPNGGMGDPYSRAAGPGLGNVAMGPRQHYPYGG PYDRVRTEPGIGPEGNMSTGAPQPNLMPSNPDSGMYSPSRYPPQQQQQQQQRHDSYGNQFSTQGTPSGSPFPSQQTTMYQQQQQNYKRPM DGTYGPPAKRHEGEMYSVPYSTGQGQPQQQQLPPAQPQPASQQQAAQPSPQQDVYNQYGNAYPATATAATERRPAGGPQNQFPFQFGRDR VSAPPGTNAQQNMPPQMMGGPIQASAEVAQQGTMWQGRNDMTYNYANRQSTGSAPQGPAYHGVNRTDEMLHTDQRANHEGSWPSHGTRQP PYGPSAPVPPMTRPPPSNYQPPPSMQNHIPQVSSPAPLPRPMENRTSPSKSPFLHSGMKMQKAGPPVPASHIAPAPVQPPMIRRDITFPP GSVEATQPVLKQRRRLTMKDIGTPEAWRVMMSLKSGLLAESTWALDTINILLYDDNSIMTFNLSQLSPQRLVLETLSKLSIQDNNVDLIL ATPPFSRLEKLYSTMVRFLSDRKNPVCREMAVVLLANLAQGDSLAARAIAVQKGSIGNLLGFLEDSLAATQFQQSQASLLHMQNPPFEPT -------------------------------------------------------------- >6372_6372_3_ARID1A-DGKA_ARID1A_chr1_27106722_ENST00000374152_DGKA_chr12_56346689_ENST00000551156_length(transcript)=5335nt_BP=4783nt TGGATCTCAAGCAGTACCACAGTTACAAAGTAGTTTTTAGCTTACAAGGTGTTTTCACAAATAGGTGGTATTTTCATTTTTCAAATGACA AAATTAGGGTTCTGAGGCGGGTCAGTTGACTTAAAGGTTACTAGGTTGGTCTCATTGCTCTTTCAAAGTAACTGTATTTCTTTATAGCAT ACAGACTAAAAAAACCTGTGTACTTGGGTTATATATTCAGTGGCCAGAGGCCATCAAAGCTCAGGTTAATGAAATGCTCTTTATTTTGTA GCCATCCAGTCCAATGGATCAGATGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTC AGGACCGCAGCAAGGACATGGGTACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCA GAGTGCCATGGGCGGCCTCTCTTATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCC ATATTACAACCAGCAAAGTCCTCACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTC GTATCAGCAGCAGCCACAGTCTCAACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCA GTCCCCGGCTCCATACCCCTCCCAGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCC TTACCAGCAGCAGCAACCTCAGCAGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCA AACTGCCTATTCCCAGCAGCGCTTCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGAC CTCCAGTAAGGGAGGGCAAGAAGATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTGATCTATCTGGTTCAATAGATGACCT CCCCATGGGGACAGAAGGAGCTCTGAGTCCTGGAGTGAGCACATCAGGGATTTCCAGCAGCCAAGGAGAGCAGAGTAATCCAGCTCAGTC TCCTTTCTCTCCTCATACCTCCCCTCACCTGCCTGGCATCCGAGGCCCTTCCCCGTCCCCTGTTGGCTCTCCCGCCAGTGTTGCTCAGTC TCGCTCAGGACCACTCTCGCCTGCTGCAGTGCCAGGCAACCAGATGCCACCTCGGCCACCCAGTGGCCAGTCGGACAGCATCATGCATCC TTCCATGAACCAATCAAGCATTGCCCAAGATCGAGGTTATATGCAGAGGAACCCCCAGATGCCCCAGTACAGTTCCCCCCAGCCCGGCTC AGCCTTATCTCCGCGTCAGCCTTCCGGAGGACAGATACACACAGGCATGGGCTCCTACCAGCAGAACTCCATGGGGAGCTATGGTCCCCA GGGGGGTCAGTATGGCCCACAAGGTGGCTACCCCAGGCAGCCAAACTATAATGCCTTGCCCAATGCCAACTACCCCAGTGCAGGCATGGC TGGAGGCATAAACCCCATGGGTGCCGGAGGTCAAATGCATGGACAGCCTGGCATCCCACCTTATGGCACACTCCCTCCAGGGAGGATGAG TCACGCCTCCATGGGCAACCGGCCTTATGGCCCTAACATGGCCAATATGCCACCTCAGGTTGGGTCAGGGATGTGTCCCCCACCAGGGGG CATGAACCGGAAAACCCAAGAAACTGCTGTCGCCATGCATGTTGCTGCCAACTCTATCCAAAACAGGCCGCCAGGCTACCCCAATATGAA TCAAGGGGGCATGATGGGAACTGGACCTCCTTATGGACAAGGGATTAATAGTATGGCTGGCATGATCAACCCTCAGGGACCCCCATATTC CATGGGTGGAACCATGGCCAACAATTCTGCAGGGATGGCAGCCAGCCCAGAGATGATGGGCCTTGGGGATGTAAAGTTAACTCCAGCCAC CAAAATGAACAACAAGGCAGATGGGACACCCAAGACAGAATCCAAATCCAAGAAATCCAGTTCTTCTACTACAACCAATGAGAAGATCAC CAAGTTGTATGAGCTGGGTGGTGAGCCTGAGAGGAAGATGTGGGTGGACCGTTATCTGGCCTTCACTGAGGAGAAGGCCATGGGCATGAC AAATCTGCCTGCTGTGGGTAGGAAACCTCTGGACCTCTATCGCCTCTATGTGTCTGTGAAGGAGATTGGTGGATTGACTCAGGTCAACAA GAACAAAAAATGGCGGGAACTTGCAACCAACCTCAATGTGGGCACATCAAGCAGTGCTGCCAGCTCCTTGAAAAAGCAGTATATCCAGTG TCTCTATGCCTTTGAATGCAAGATTGAACGGGGAGAAGACCCTCCCCCAGACATCTTTGCAGCTGCTGATTCCAAGAAGTCCCAGCCCAA GATCCAGCCTCCCTCTCCTGCGGGATCAGGATCTATGCAGGGGCCCCAGACTCCCCAGTCAACCAGCAGTTCCATGGCAGAAGGAGGAGA CTTAAAGCCACCAACTCCAGCATCCACACCACACAGTCAGATCCCCCCATTGCCAGGCATGAGCAGGAGCAATTCAGTTGGGATCCAGGA TGCCTTTAATGATGGAAGTGACTCCACATTCCAGAAGCGGAATTCCATGACTCCAAACCCTGGGTATCAGCCCAGTATGAATACCTCTGA CATGATGGGGCGCATGTCCTATGAGCCAAATAAGGATCCTTATGGCAGCATGAGGAAAGCTCCAGGGAGTGATCCCTTCATGTCCTCAGG GCAGGGCCCCAACGGCGGGATGGGTGACCCCTACAGTCGTGCTGCCGGCCCTGGGCTAGGAAATGTGGCGATGGGACCACGACAGCACTA TCCCTATGGAGGTCCTTATGACAGAGTGAGGACGGAGCCTGGAATAGGGCCTGAGGGAAACATGAGCACTGGGGCCCCACAGCCGAATCT CATGCCTTCCAACCCAGACTCGGGGATGTATTCTCCTAGCCGCTACCCCCCGCAGCAGCAGCAGCAGCAGCAGCAACGACATGATTCCTA TGGCAATCAGTTCTCCACCCAAGGCACCCCTTCTGGCAGCCCCTTCCCCAGCCAGCAGACTACAATGTATCAACAGCAACAGCAGAATTA CAAGCGGCCAATGGATGGCACATATGGCCCTCCTGCCAAGCGGCACGAAGGGGAGATGTACAGCGTGCCATACAGCACTGGGCAGGGGCA GCCTCAGCAGCAGCAGTTGCCCCCAGCCCAGCCCCAGCCTGCCAGCCAGCAACAAGCTGCCCAGCCTTCCCCTCAGCAAGATGTATACAA CCAGTATGGCAATGCCTATCCTGCCACTGCCACAGCTGCTACTGAGCGCCGACCAGCAGGCGGCCCCCAGAACCAATTTCCATTCCAGTT TGGCCGAGACCGTGTCTCTGCACCCCCTGGCACCAATGCCCAGCAAAACATGCCACCACAAATGATGGGCGGCCCCATACAGGCATCAGC TGAGGTTGCTCAGCAAGGCACCATGTGGCAGGGGCGTAATGACATGACCTATAATTATGCCAACAGGCAGAGCACGGGCTCTGCCCCCCA GGGCCCCGCCTATCATGGCGTGAACCGAACAGATGAAATGCTGCACACAGATCAGAGGGCCAACCACGAAGGCTCGTGGCCTTCCCATGG CACACGCCAGCCCCCATATGGTCCCTCTGCCCCTGTGCCCCCCATGACAAGGCCCCCTCCATCTAACTACCAGCCCCCACCAAGCATGCA GAATCACATTCCTCAGGTATCCAGCCCTGCTCCCCTGCCCCGGCCAATGGAGAACCGCACCTCTCCTAGCAAGTCTCCATTCCTGCACTC TGGGATGAAAATGCAGAAGGCAGGTCCCCCAGTACCTGCCTCGCACATAGCACCTGCCCCTGTGCAGCCCCCCATGATTCGGCGGGATAT CACCTTCCCACCTGGCTCTGTTGAAGCCACACAGCCTGTGTTGAAGCAGAGGAGGCGGCTCACAATGAAAGACATTGGAACCCCGGAGGC ATGGCGGGTAATGATGTCCCTCAAGTCTGGTCTCCTGGCAGAGAGCACATGGGCATTAGATACCATCAACATCCTGCTGTATGATGACAA CAGCATCATGACCTTCAACCTCAGTCAGCTTTCCCCGCAGAGACTGGTCTTGGAAACCCTCAGCAAACTCAGCATCCAGGACAACAATGT GGACCTGATTCTGGCCACACCCCCCTTCAGCCGCCTGGAGAAGTTGTATAGCACTATGGTGCGCTTCCTCAGTGACCGAAAGAACCCGGT GTGCCGGGAGATGGCTGTGGTACTGCTGGCCAACCTGGCTCAGGGGGACAGCCTGGCAGCTCGTGCCATTGCAGTGCAGAAGGGCAGTAT CGGCAACCTCCTGGGCTTCCTAGAGGACAGCCTTGCCGCCACACAGTTCCAGCAGAGCCAGGCCAGCCTCCTCCACATGCAGAACCCACC CTTTGAGCCAACTAGTGTGGACATGATGCGGCGGGCTGCCCGCGCGCTGCTTGCCTTGGCCAAGGTGGACGAGAACCACTCAGAGTTTAC TCTGTACGAATCACGGCTGTTGGACATCTCGGTATCACCGTTGATGAACTCATTGGTTTCACAAGTCATTTGTGATGTACTGTTTTTGAT TGGCCAGTCATGACTGATATCCTGAAAACCTGTGTACCAGACCTAAGTGACAAGAGACTGGAAGTGGTTGGGCTGGAGGGTGCAATTGAG ATGGGCCAAATCTATACCAAGCTCAAGAATGCTGGACGTCGGCTGGCCAAGTGCTCTGAGATCACCTTCCACACCACAAAAACCCTTCCC ATGCAAATTGACGGAGAACCCTGGATGCAGACGCCCTGTACAATCAAGATCACCCACAAGAACCAGATGCCCATGCTCATGGGCCCACCC CCCCGCTCCACCAATTTCTTTGGCTTCTTGAGCTAAGGGGGACACCCTTGGCCTCCAAGCCAGCCTTGAACCCACCTCCCTGTCCCTGGA CTCTACTCCCGAGGCTCTGTACATTGCTGCCACATACTCCTGCCAGCTTGGGGGAGTGTTCCTTCACCCTCACAGTATTTATTATCCTGC ACCACCTCACTGTTCCCCATGCGCACACACATACACACACCCCAAAACACATACATTGAAAGTGCCTCATCTGAATAAAATGACTTGTGT >6372_6372_3_ARID1A-DGKA_ARID1A_chr1_27106722_ENST00000374152_DGKA_chr12_56346689_ENST00000551156_length(amino acids)=1499AA_BP= MDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQIPPYGQQGPSGYGQQGQTPYYNQ QSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQSTTQQHPQSQPPYSQPQAQSPYQQQ QPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNLSLQSRPSSLPDLSGSIDDLPMGT EGALSPGVSTSGISSSQGEQSNPAQSPFSPHTSPHLPGIRGPSPSPVGSPASVAQSRSGPLSPAAVPGNQMPPRPPSGQSDSIMHPSMNQ SSIAQDRGYMQRNPQMPQYSSPQPGSALSPRQPSGGQIHTGMGSYQQNSMGSYGPQGGQYGPQGGYPRQPNYNALPNANYPSAGMAGGIN PMGAGGQMHGQPGIPPYGTLPPGRMSHASMGNRPYGPNMANMPPQVGSGMCPPPGGMNRKTQETAVAMHVAANSIQNRPPGYPNMNQGGM MGTGPPYGQGINSMAGMINPQGPPYSMGGTMANNSAGMAASPEMMGLGDVKLTPATKMNNKADGTPKTESKSKKSSSSTTTNEKITKLYE LGGEPERKMWVDRYLAFTEEKAMGMTNLPAVGRKPLDLYRLYVSVKEIGGLTQVNKNKKWRELATNLNVGTSSSAASSLKKQYIQCLYAF ECKIERGEDPPPDIFAAADSKKSQPKIQPPSPAGSGSMQGPQTPQSTSSSMAEGGDLKPPTPASTPHSQIPPLPGMSRSNSVGIQDAFND GSDSTFQKRNSMTPNPGYQPSMNTSDMMGRMSYEPNKDPYGSMRKAPGSDPFMSSGQGPNGGMGDPYSRAAGPGLGNVAMGPRQHYPYGG PYDRVRTEPGIGPEGNMSTGAPQPNLMPSNPDSGMYSPSRYPPQQQQQQQQRHDSYGNQFSTQGTPSGSPFPSQQTTMYQQQQQNYKRPM DGTYGPPAKRHEGEMYSVPYSTGQGQPQQQQLPPAQPQPASQQQAAQPSPQQDVYNQYGNAYPATATAATERRPAGGPQNQFPFQFGRDR VSAPPGTNAQQNMPPQMMGGPIQASAEVAQQGTMWQGRNDMTYNYANRQSTGSAPQGPAYHGVNRTDEMLHTDQRANHEGSWPSHGTRQP PYGPSAPVPPMTRPPPSNYQPPPSMQNHIPQVSSPAPLPRPMENRTSPSKSPFLHSGMKMQKAGPPVPASHIAPAPVQPPMIRRDITFPP GSVEATQPVLKQRRRLTMKDIGTPEAWRVMMSLKSGLLAESTWALDTINILLYDDNSIMTFNLSQLSPQRLVLETLSKLSIQDNNVDLIL ATPPFSRLEKLYSTMVRFLSDRKNPVCREMAVVLLANLAQGDSLAARAIAVQKGSIGNLLGFLEDSLAATQFQQSQASLLHMQNPPFEPT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARID1A-DGKA |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARID1A-DGKA |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARID1A-DGKA |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies