
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARID1A-NUDC (FusionGDB2 ID:6382) |
Fusion Gene Summary for ARID1A-NUDC |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARID1A-NUDC | Fusion gene ID: 6382 | Hgene | Tgene | Gene symbol | ARID1A | NUDC | Gene ID | 8289 | 10726 |
| Gene name | AT-rich interaction domain 1A | nuclear distribution C, dynein complex regulator | |
| Synonyms | B120|BAF250|BAF250a|BM029|C1orf4|CSS2|ELD|MRD14|OSA1|P270|SMARCF1|hELD|hOSA1 | HNUDC|MNUDC|NPD011 | |
| Cytomap | 1p36.11 | 1p36.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AT-rich interactive domain-containing protein 1AARID domain-containing protein 1AAT rich interactive domain 1A (SWI-like)BRG1-associated factor 250aOSA1 nuclear proteinSWI-like proteinSWI/SNF complex protein p270SWI/SNF-related, matrix-associated, | nuclear migration protein nudCnuclear distribution C homolognuclear distribution gene C homolognuclear distribution protein C homolognudC nuclear distribution protein | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | O14497 | NUDCD3 | |
| Ensembl transtripts involved in fusion gene | ENST00000324856, ENST00000374152, ENST00000457599, ENST00000540690, | ENST00000321265, ENST00000484772, | |
| Fusion gene scores | * DoF score | 29 X 19 X 15=8265 | 11 X 11 X 8=968 |
| # samples | 45 | 15 | |
| ** MAII score | log2(45/8265*10)=-4.19901791296264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(15/968*10)=-2.69004454677871 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARID1A [Title/Abstract] AND NUDC [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARID1A(27059283)-NUDC(27267948), # samples:2 ARID1A(27059283)-NUDC(27250580), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ARID1A-NUDC seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. ARID1A-NUDC seems lost the major protein functional domain in Hgene partner, which is a epigenetic factor due to the frame-shifted ORF. ARID1A-NUDC seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. ARID1A-NUDC seems lost the major protein functional domain in Hgene partner, which is a tumor suppressor due to the frame-shifted ORF. ARID1A-NUDC seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ARID1A | GO:0006337 | nucleosome disassembly | 8895581 |
| Hgene | ARID1A | GO:0006338 | chromatin remodeling | 11726552 |
| Hgene | ARID1A | GO:0030520 | intracellular estrogen receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0030521 | androgen receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0042921 | glucocorticoid receptor signaling pathway | 12200431 |
| Hgene | ARID1A | GO:0045893 | positive regulation of transcription, DNA-templated | 12200431 |
| Fusion gene breakpoints across ARID1A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NUDC (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-AR-A1AI-01A | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| ChimerDB4 | BRCA | TCGA-AR-A1AI-01A | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| ChimerDB4 | BRCA | TCGA-AR-A1AI-01A | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| ChimerDB4 | OV | TCGA-24-1928-01A | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| ChimerDB4 | OV | TCGA-24-1928 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| ChimerDB4 | UCEC | TCGA-AP-A0LI-01A | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
Top |
Fusion Gene ORF analysis for ARID1A-NUDC |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000324856 | ENST00000321265 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| 5CDS-intron | ENST00000324856 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| 5CDS-intron | ENST00000324856 | ENST00000484772 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| 5CDS-intron | ENST00000324856 | ENST00000484772 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| 5CDS-intron | ENST00000324856 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| 5CDS-intron | ENST00000324856 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| 5CDS-intron | ENST00000374152 | ENST00000321265 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| 5CDS-intron | ENST00000374152 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| 5CDS-intron | ENST00000374152 | ENST00000484772 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| 5CDS-intron | ENST00000374152 | ENST00000484772 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| 5CDS-intron | ENST00000374152 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| 5CDS-intron | ENST00000374152 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| 5CDS-intron | ENST00000457599 | ENST00000321265 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| 5CDS-intron | ENST00000457599 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| 5CDS-intron | ENST00000457599 | ENST00000484772 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| 5CDS-intron | ENST00000457599 | ENST00000484772 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| 5CDS-intron | ENST00000457599 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| 5CDS-intron | ENST00000457599 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| Frame-shift | ENST00000324856 | ENST00000321265 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| Frame-shift | ENST00000374152 | ENST00000321265 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| Frame-shift | ENST00000457599 | ENST00000321265 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| In-frame | ENST00000324856 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| In-frame | ENST00000324856 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| In-frame | ENST00000324856 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| In-frame | ENST00000374152 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| In-frame | ENST00000374152 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| In-frame | ENST00000374152 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| In-frame | ENST00000457599 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| In-frame | ENST00000457599 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| In-frame | ENST00000457599 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| intron-3CDS | ENST00000540690 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| intron-3CDS | ENST00000540690 | ENST00000321265 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| intron-3CDS | ENST00000540690 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| intron-3CDS | ENST00000540690 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| intron-intron | ENST00000540690 | ENST00000321265 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| intron-intron | ENST00000540690 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + |
| intron-intron | ENST00000540690 | ENST00000484772 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27237619 | + |
| intron-intron | ENST00000540690 | ENST00000484772 | ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250580 | + |
| intron-intron | ENST00000540690 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + |
| intron-intron | ENST00000540690 | ENST00000484772 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000324856 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27267948 | + | 3809 | 2291 | 371 | 3127 | 918 |
| ENST00000457599 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27267948 | + | 3438 | 1920 | 0 | 2756 | 918 |
| ENST00000374152 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27267948 | + | 2572 | 1054 | 283 | 1890 | 535 |
| ENST00000324856 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27267947 | + | 3809 | 2291 | 371 | 3127 | 918 |
| ENST00000457599 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27267947 | + | 3438 | 1920 | 0 | 2756 | 918 |
| ENST00000374152 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27267947 | + | 2572 | 1054 | 283 | 1890 | 535 |
| ENST00000324856 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27250580 | + | 3887 | 2291 | 371 | 3205 | 944 |
| ENST00000457599 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27250580 | + | 3516 | 1920 | 0 | 2834 | 944 |
| ENST00000374152 | ARID1A | chr1 | 27059283 | + | ENST00000321265 | NUDC | chr1 | 27250580 | + | 2650 | 1054 | 283 | 1968 | 561 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000324856 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + | 0.011949034 | 0.98805094 |
| ENST00000457599 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + | 0.013097569 | 0.98690236 |
| ENST00000374152 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267948 | + | 0.009550712 | 0.99044925 |
| ENST00000324856 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + | 0.011949034 | 0.98805094 |
| ENST00000457599 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + | 0.013097569 | 0.98690236 |
| ENST00000374152 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + | 0.009550712 | 0.99044925 |
| ENST00000324856 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + | 0.010097281 | 0.98990273 |
| ENST00000457599 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + | 0.011124977 | 0.98887503 |
| ENST00000374152 | ENST00000321265 | ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250580 | + | 0.011006889 | 0.9889931 |
Top |
Fusion Genomic Features for ARID1A-NUDC |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250579 | + | 0.030522421 | 0.96947753 |
| ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250579 | + | 0.030522421 | 0.96947753 |
| ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250579 | + | 0.001483849 | 0.99851614 |
| ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + | 3.02E-09 | 1 |
| ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + | 3.02E-09 | 1 |
| ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250579 | + | 0.030522421 | 0.96947753 |
| ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27250579 | + | 0.030522421 | 0.96947753 |
| ARID1A | chr1 | 27088810 | + | NUDC | chr1 | 27250579 | + | 0.001483849 | 0.99851614 |
| ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + | 3.02E-09 | 1 |
| ARID1A | chr1 | 27059283 | + | NUDC | chr1 | 27267947 | + | 3.02E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
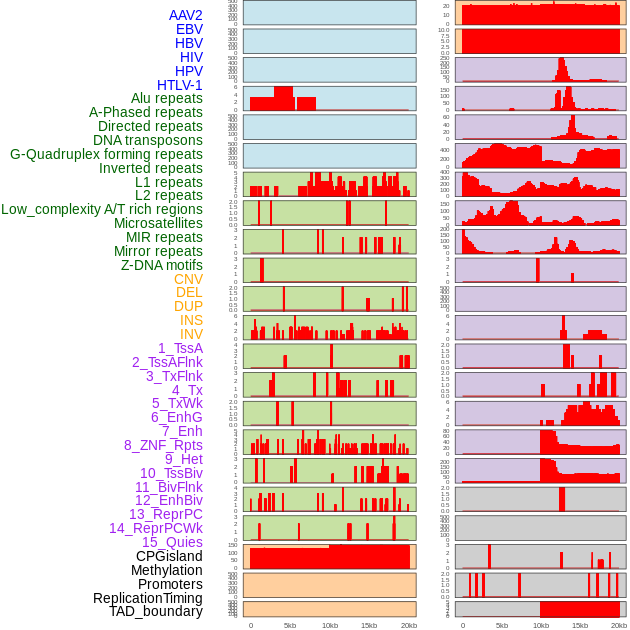 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
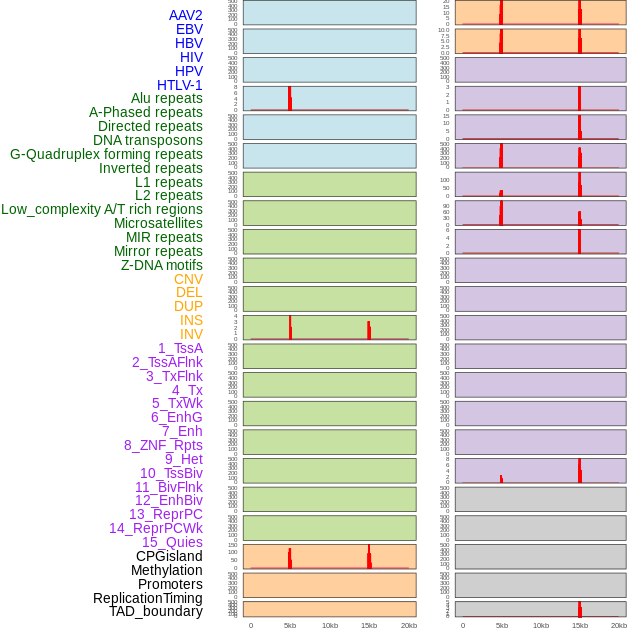 |
Top |
Fusion Protein Features for ARID1A-NUDC |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:27059283/chr1:27267948) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARID1A | NUDC |
| FUNCTION: Involved in transcriptional activation and repression of select genes by chromatin remodeling (alteration of DNA-nucleosome topology). Component of SWI/SNF chromatin remodeling complexes that carry out key enzymatic activities, changing chromatin structure by altering DNA-histone contacts within a nucleosome in an ATP-dependent manner. Binds DNA non-specifically. Belongs to the neural progenitors-specific chromatin remodeling complex (npBAF complex) and the neuron-specific chromatin remodeling complex (nBAF complex). During neural development a switch from a stem/progenitor to a postmitotic chromatin remodeling mechanism occurs as neurons exit the cell cycle and become committed to their adult state. The transition from proliferating neural stem/progenitor cells to postmitotic neurons requires a switch in subunit composition of the npBAF and nBAF complexes. As neural progenitors exit mitosis and differentiate into neurons, npBAF complexes which contain ACTL6A/BAF53A and PHF10/BAF45A, are exchanged for homologous alternative ACTL6B/BAF53B and DPF1/BAF45B or DPF3/BAF45C subunits in neuron-specific complexes (nBAF). The npBAF complex is essential for the self-renewal/proliferative capacity of the multipotent neural stem cells. The nBAF complex along with CREST plays a role regulating the activity of genes essential for dendrite growth (By similarity). {ECO:0000250|UniProtKB:A2BH40, ECO:0000303|PubMed:12672490, ECO:0000303|PubMed:22952240, ECO:0000303|PubMed:26601204}. | 361 |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 479_482 | 640 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 561_567 | 640 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 479_482 | 640 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 561_567 | 640 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 479_482 | 640 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 561_567 | 640 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 479_482 | 640 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 561_567 | 640 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 479_482 | 640 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 561_567 | 640 | 2286.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 479_482 | 640 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 561_567 | 640 | 2069.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 295_299 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 295_299 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 295_299 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 295_299 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 295_299 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 295_299 | 640 | 2069.0 | Motif | Note=LXXLL |
| Tgene | NUDC | chr1:27059283 | chr1:27250580 | ENST00000321265 | 0 | 9 | 60_134 | 27 | 332.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUDC | chr1:27059283 | chr1:27267947 | ENST00000321265 | 1 | 9 | 60_134 | 53 | 332.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUDC | chr1:27059283 | chr1:27267948 | ENST00000321265 | 1 | 9 | 60_134 | 53 | 332.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUDC | chr1:27059283 | chr1:27250580 | ENST00000321265 | 0 | 9 | 167_258 | 27 | 332.0 | Domain | CS | |
| Tgene | NUDC | chr1:27059283 | chr1:27267947 | ENST00000321265 | 1 | 9 | 167_258 | 53 | 332.0 | Domain | CS | |
| Tgene | NUDC | chr1:27059283 | chr1:27267948 | ENST00000321265 | 1 | 9 | 167_258 | 53 | 332.0 | Domain | CS | |
| Tgene | NUDC | chr1:27059283 | chr1:27250580 | ENST00000321265 | 0 | 9 | 68_74 | 27 | 332.0 | Motif | Nuclear localization signal | |
| Tgene | NUDC | chr1:27059283 | chr1:27267947 | ENST00000321265 | 1 | 9 | 68_74 | 53 | 332.0 | Motif | Nuclear localization signal | |
| Tgene | NUDC | chr1:27059283 | chr1:27267948 | ENST00000321265 | 1 | 9 | 68_74 | 53 | 332.0 | Motif | Nuclear localization signal |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 1327_1404 | 640 | 2286.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 998_1001 | 640 | 2286.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 1327_1404 | 257 | 1903.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 479_482 | 257 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 561_567 | 257 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 998_1001 | 257 | 1903.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 1327_1404 | 640 | 2069.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 998_1001 | 640 | 2069.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 1327_1404 | 640 | 2286.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 998_1001 | 640 | 2286.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 1327_1404 | 257 | 1903.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 479_482 | 257 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 561_567 | 257 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 998_1001 | 257 | 1903.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 1327_1404 | 640 | 2069.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 998_1001 | 640 | 2069.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 1327_1404 | 640 | 2286.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 998_1001 | 640 | 2286.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 1327_1404 | 257 | 1903.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 479_482 | 257 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 561_567 | 257 | 1903.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 998_1001 | 257 | 1903.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 1327_1404 | 640 | 2069.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 998_1001 | 640 | 2069.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 1017_1108 | 640 | 2286.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 1017_1108 | 257 | 1903.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 1017_1108 | 640 | 2069.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 1017_1108 | 640 | 2286.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 1017_1108 | 257 | 1903.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 1017_1108 | 640 | 2069.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 1017_1108 | 640 | 2286.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 1017_1108 | 257 | 1903.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 1017_1108 | 640 | 2069.0 | Domain | ARID |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 1368_1387 | 640 | 2286.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 1709_1713 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 1967_1971 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000324856 | + | 4 | 20 | 2085_2089 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 1368_1387 | 257 | 1903.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 1709_1713 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 1967_1971 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 2085_2089 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000374152 | + | 3 | 19 | 295_299 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 1368_1387 | 640 | 2069.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 1709_1713 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 1967_1971 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27250580 | ENST00000457599 | + | 4 | 20 | 2085_2089 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 1368_1387 | 640 | 2286.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 1709_1713 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 1967_1971 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000324856 | + | 4 | 20 | 2085_2089 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 1368_1387 | 257 | 1903.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 1709_1713 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 1967_1971 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 2085_2089 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000374152 | + | 3 | 19 | 295_299 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 1368_1387 | 640 | 2069.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 1709_1713 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 1967_1971 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267947 | ENST00000457599 | + | 4 | 20 | 2085_2089 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 1368_1387 | 640 | 2286.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 1709_1713 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 1967_1971 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000324856 | + | 4 | 20 | 2085_2089 | 640 | 2286.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 1368_1387 | 257 | 1903.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 1709_1713 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 1967_1971 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 2085_2089 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000374152 | + | 3 | 19 | 295_299 | 257 | 1903.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 1368_1387 | 640 | 2069.0 | Motif | Nuclear localization signal |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 1709_1713 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 1967_1971 | 640 | 2069.0 | Motif | Note=LXXLL |
| Hgene | ARID1A | chr1:27059283 | chr1:27267948 | ENST00000457599 | + | 4 | 20 | 2085_2089 | 640 | 2069.0 | Motif | Note=LXXLL |
Top |
Fusion Gene Sequence for ARID1A-NUDC |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6382_6382_1_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000324856_NUDC_chr1_27250580_ENST00000321265_length(transcript)=3887nt_BP=2291nt GAAAGCGGAGAGTCACAGCGGGGCCAGGCCCTGGGGAGCGGAGCCTCCACCGCCCCCCTCATTCCCAGGCAAGGGCTTGGGGGGAATGAG CCGGGAGAGCCGGGTCCCGAGCCTACAGAGCCGGGAGCAGCTGAGCCGCCGGCGCCTCGGCCGCCGCCGCCGCCTCCTCCTCCTCCGCCG CCGCCAGCCCGGAGCCTGAGCCGGCGGGGCGGGGGGGAGAGGAGCGAGCGCAGCGCAGCAGCGGAGCCCCGCGAGGCCCGCCCGGGCGGG TGGGGAGGGCAGCCCGGGGGACTGGGCCCCGGGGCGGGGTGGGAGGGGGGGAGAAGACGAAGACAGGGCCGGGTCTCTCCGCGGACGAGA CAGCGGGGATCATGGCCGCGCAGGTCGCCCCCGCCGCCGCCAGCAGCCTGGGCAACCCGCCGCCGCCGCCGCCCTCGGAGCTGAAGAAAG CCGAGCAGCAGCAGCGGGAGGAGGCGGGGGGCGAGGCGGCGGCGGCGGCAGCGGCCGAGCGCGGGGAAATGAAGGCAGCCGCCGGGCAGG AAAGCGAGGGCCCCGCCGTGGGGCCGCCGCAGCCGCTGGGAAAGGAGCTGCAGGACGGGGCCGAGAGCAATGGGGGTGGCGGCGGCGGCG GAGCCGGCAGCGGCGGCGGGCCCGGCGCGGAGCCGGACCTGAAGAACTCGAACGGGAACGCGGGCCCTAGGCCCGCCCTGAACAATAACC TCACGGAGCCGCCCGGCGGCGGCGGTGGCGGCAGCAGCGATGGGGTGGGGGCGCCTCCTCACTCAGCCGCGGCCGCCTTGCCGCCCCCAG CCTACGGCTTCGGGCAACCCTACGGCCGGAGCCCGTCTGCCGTCGCCGCCGCCGCGGCCGCCGTCTTCCACCAACAACATGGCGGACAAC AAAGCCCTGGCCTGGCAGCGCTGCAGAGCGGCGGCGGCGGGGGCCTGGAGCCCTACGCGGGGCCCCAGCAGAACTCTCACGACCACGGCT TCCCCAACCACCAGTACAACTCCTACTACCCCAACCGCAGCGCCTACCCCCCGCCCGCCCCGGCCTACGCGCTGAGCTCCCCGAGAGGTG GCACTCCGGGCTCCGGCGCGGCGGCGGCTGCCGGCTCCAAGCCGCCTCCCTCCTCCAGCGCCTCCGCCTCCTCGTCGTCTTCGTCCTTCG CTCAGCAGCGCTTCGGGGCCATGGGGGGAGGCGGCCCCTCCGCGGCCGGCGGGGGAACTCCCCAGCCCACCGCCACCCCCACCCTCAACC AACTGCTCACGTCGCCCAGCTCGGCCCGGGGCTACCAGGGCTACCCCGGGGGCGACTACAGTGGCGGGCCCCAGGACGGGGGCGCCGGCA AGGGCCCGGCGGACATGGCCTCGCAGTGTTGGGGGGCTGCGGCGGCGGCAGCTGCGGCGGCGGCCGCCTCGGGAGGGGCCCAACAAAGGA GCCACCACGCGCCCATGAGCCCCGGGAGCAGCGGCGGCGGGGGGCAGCCGCTCGCCCGGACCCCTCAGCCATCCAGTCCAATGGATCAGA TGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTCAGGACCGCAGCAAGGACATGGGT ACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCAGAGTGCCATGGGCGGCCTCTCTT ATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCCATATTACAACCAGCAAAGTCCTC ACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTCGTATCAGCAGCAGCCACAGTCTC AACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCAGTCCCCGGCTCCATACCCCTCCC AGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCCTTACCAGCAGCAGCAACCTCAGC AGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCAAACTGCCTATTCCCAGCAGCGCT TCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGACCTCCAGTAAGGGAGGGCAAGAAG ATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTGTGAACACCTTCTTCAGCTTCCTTCGACGCAAAACAGACTTTTTCA TTGGAGGAGAAGAAGGGATGGCAGAGAAGCTTATCACACAGACTTTCAGCCACCACAATCAGCTGGCACAGAAGACCCGGCGGGAGAAGA GAGCCCGGCAGGAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGCCAAGGAAGCCAAGTCAGAGACCTCAGGGCCCCAGA TCAAGGAGCTAACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAAAAAGGATGCAGAGAATCATGAGGCCCAGCTCAAGA ACGGCAGCCTTGACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGATGAGAAGGACAAAGGAAAACTGAAGCCCAACCTAG GCAACGGGGCAGACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGACCTGGCGGTCCCTTTCTGTGTGAACTTCCGGCTGA AAGGGAAGGACATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAAGGGGCAGCCAGCGATCATTGATGGGGAGCTCTACA ATGAAGTGAAGGTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGACTGTGCATCTGGAGAAGATCAATAAGATGGAGTGGT GGAGCCGCTTGGTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGAGAATTCCAAGCTGTCAGACCTGGACAGTGAGACTC GCAGCATGGTGGAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCCAACTTCAGACGAACAGAAGAAACAGGAGATTCTGA AGAAGTTCATGGATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTAGCCCCTGTTTTTTCCTCCCTGAACTCTTGGGGCTG AGCTGCAACCACCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAGGGCTTGGGGCAGGCATGGGACTGGCCCAGGCACAC AGGTCCCGGGGCATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTTGGCCTACTGTTACACATTAAAACGATTTGCCCAGC TCCTTCTGTGTCCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACGGCTGCTGCTGGGAACTGGGAGTTTGGCTTCTAGCC CAGATTCTGCCATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTTCTCATTACTTAAAGATTAAAACAAGGCTTGGCCGG GTGTGATGGTTCATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGATCACCTGATGTCAGGAGTTTGAGACCAGCTTGGCCA ACATGGAGAAACCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGTGCACACCTGTAATCCCAGCTACTCGGGAGGCTGAG GCAGGAGAATCGCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCACTACTTCACTCCAGCATGGGTGACAGAGACTCCATC >6382_6382_1_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000324856_NUDC_chr1_27250580_ENST00000321265_length(amino acids)=944AA_BP=0 MAAQVAPAAASSLGNPPPPPPSELKKAEQQQREEAGGEAAAAAAAERGEMKAAAGQESEGPAVGPPQPLGKELQDGAESNGGGGGGGAGS GGGPGAEPDLKNSNGNAGPRPALNNNLTEPPGGGGGGSSDGVGAPPHSAAAALPPPAYGFGQPYGRSPSAVAAAAAAVFHQQHGGQQSPG LAALQSGGGGGLEPYAGPQQNSHDHGFPNHQYNSYYPNRSAYPPPAPAYALSSPRGGTPGSGAAAAAGSKPPPSSSASASSSSSSFAQQR FGAMGGGGPSAAGGGTPQPTATPTLNQLLTSPSSARGYQGYPGGDYSGGPQDGGAGKGPADMASQCWGAAAAAAAAAAASGGAQQRSHHA PMSPGSSGGGGQPLARTPQPSSPMDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQ IPPYGQQGPSGYGQQGQTPYYNQQSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQST TQQHPQSQPPYSQPQAQSPYQQQQPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNL SLQSRPSSLPLVNTFFSFLRRKTDFFIGGEEGMAEKLITQTFSHHNQLAQKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKEL TDEEAERLQLEIDQKKDAENHEAQLKNGSLDSPGKQDTEEDEEEDEKDKGKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKD MVVDIQRRHLRVGLKGQPAIIDGELYNEVKVEESSWLIEDGKVVTVHLEKINKMEWWSRLVSSDPEINTKKINPENSKLSDLDSETRSMV -------------------------------------------------------------- >6382_6382_2_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000324856_NUDC_chr1_27267947_ENST00000321265_length(transcript)=3809nt_BP=2291nt GAAAGCGGAGAGTCACAGCGGGGCCAGGCCCTGGGGAGCGGAGCCTCCACCGCCCCCCTCATTCCCAGGCAAGGGCTTGGGGGGAATGAG CCGGGAGAGCCGGGTCCCGAGCCTACAGAGCCGGGAGCAGCTGAGCCGCCGGCGCCTCGGCCGCCGCCGCCGCCTCCTCCTCCTCCGCCG CCGCCAGCCCGGAGCCTGAGCCGGCGGGGCGGGGGGGAGAGGAGCGAGCGCAGCGCAGCAGCGGAGCCCCGCGAGGCCCGCCCGGGCGGG TGGGGAGGGCAGCCCGGGGGACTGGGCCCCGGGGCGGGGTGGGAGGGGGGGAGAAGACGAAGACAGGGCCGGGTCTCTCCGCGGACGAGA CAGCGGGGATCATGGCCGCGCAGGTCGCCCCCGCCGCCGCCAGCAGCCTGGGCAACCCGCCGCCGCCGCCGCCCTCGGAGCTGAAGAAAG CCGAGCAGCAGCAGCGGGAGGAGGCGGGGGGCGAGGCGGCGGCGGCGGCAGCGGCCGAGCGCGGGGAAATGAAGGCAGCCGCCGGGCAGG AAAGCGAGGGCCCCGCCGTGGGGCCGCCGCAGCCGCTGGGAAAGGAGCTGCAGGACGGGGCCGAGAGCAATGGGGGTGGCGGCGGCGGCG GAGCCGGCAGCGGCGGCGGGCCCGGCGCGGAGCCGGACCTGAAGAACTCGAACGGGAACGCGGGCCCTAGGCCCGCCCTGAACAATAACC TCACGGAGCCGCCCGGCGGCGGCGGTGGCGGCAGCAGCGATGGGGTGGGGGCGCCTCCTCACTCAGCCGCGGCCGCCTTGCCGCCCCCAG CCTACGGCTTCGGGCAACCCTACGGCCGGAGCCCGTCTGCCGTCGCCGCCGCCGCGGCCGCCGTCTTCCACCAACAACATGGCGGACAAC AAAGCCCTGGCCTGGCAGCGCTGCAGAGCGGCGGCGGCGGGGGCCTGGAGCCCTACGCGGGGCCCCAGCAGAACTCTCACGACCACGGCT TCCCCAACCACCAGTACAACTCCTACTACCCCAACCGCAGCGCCTACCCCCCGCCCGCCCCGGCCTACGCGCTGAGCTCCCCGAGAGGTG GCACTCCGGGCTCCGGCGCGGCGGCGGCTGCCGGCTCCAAGCCGCCTCCCTCCTCCAGCGCCTCCGCCTCCTCGTCGTCTTCGTCCTTCG CTCAGCAGCGCTTCGGGGCCATGGGGGGAGGCGGCCCCTCCGCGGCCGGCGGGGGAACTCCCCAGCCCACCGCCACCCCCACCCTCAACC AACTGCTCACGTCGCCCAGCTCGGCCCGGGGCTACCAGGGCTACCCCGGGGGCGACTACAGTGGCGGGCCCCAGGACGGGGGCGCCGGCA AGGGCCCGGCGGACATGGCCTCGCAGTGTTGGGGGGCTGCGGCGGCGGCAGCTGCGGCGGCGGCCGCCTCGGGAGGGGCCCAACAAAGGA GCCACCACGCGCCCATGAGCCCCGGGAGCAGCGGCGGCGGGGGGCAGCCGCTCGCCCGGACCCCTCAGCCATCCAGTCCAATGGATCAGA TGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTCAGGACCGCAGCAAGGACATGGGT ACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCAGAGTGCCATGGGCGGCCTCTCTT ATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCCATATTACAACCAGCAAAGTCCTC ACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTCGTATCAGCAGCAGCCACAGTCTC AACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCAGTCCCCGGCTCCATACCCCTCCC AGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCCTTACCAGCAGCAGCAACCTCAGC AGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCAAACTGCCTATTCCCAGCAGCGCT TCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGACCTCCAGTAAGGGAGGGCAAGAAG ATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTATCACACAGACTTTCAGCCACCACAATCAGCTGGCACAGAAGACCC GGCGGGAGAAGAGAGCCCGGCAGGAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGCCAAGGAAGCCAAGTCAGAGACCT CAGGGCCCCAGATCAAGGAGCTAACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAAAAAGGATGCAGAGAATCATGAGG CCCAGCTCAAGAACGGCAGCCTTGACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGATGAGAAGGACAAAGGAAAACTGA AGCCCAACCTAGGCAACGGGGCAGACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGACCTGGCGGTCCCTTTCTGTGTGA ACTTCCGGCTGAAAGGGAAGGACATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAAGGGGCAGCCAGCGATCATTGATG GGGAGCTCTACAATGAAGTGAAGGTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGACTGTGCATCTGGAGAAGATCAATA AGATGGAGTGGTGGAGCCGCTTGGTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGAGAATTCCAAGCTGTCAGACCTGG ACAGTGAGACTCGCAGCATGGTGGAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCCAACTTCAGACGAACAGAAGAAAC AGGAGATTCTGAAGAAGTTCATGGATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTAGCCCCTGTTTTTTCCTCCCTGAA CTCTTGGGGCTGAGCTGCAACCACCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAGGGCTTGGGGCAGGCATGGGACTG GCCCAGGCACACAGGTCCCGGGGCATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTTGGCCTACTGTTACACATTAAAAC GATTTGCCCAGCTCCTTCTGTGTCCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACGGCTGCTGCTGGGAACTGGGAGTT TGGCTTCTAGCCCAGATTCTGCCATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTTCTCATTACTTAAAGATTAAAACA AGGCTTGGCCGGGTGTGATGGTTCATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGATCACCTGATGTCAGGAGTTTGAGA CCAGCTTGGCCAACATGGAGAAACCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGTGCACACCTGTAATCCCAGCTACT CGGGAGGCTGAGGCAGGAGAATCGCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCACTACTTCACTCCAGCATGGGTGAC >6382_6382_2_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000324856_NUDC_chr1_27267947_ENST00000321265_length(amino acids)=918AA_BP=0 MAAQVAPAAASSLGNPPPPPPSELKKAEQQQREEAGGEAAAAAAAERGEMKAAAGQESEGPAVGPPQPLGKELQDGAESNGGGGGGGAGS GGGPGAEPDLKNSNGNAGPRPALNNNLTEPPGGGGGGSSDGVGAPPHSAAAALPPPAYGFGQPYGRSPSAVAAAAAAVFHQQHGGQQSPG LAALQSGGGGGLEPYAGPQQNSHDHGFPNHQYNSYYPNRSAYPPPAPAYALSSPRGGTPGSGAAAAAGSKPPPSSSASASSSSSSFAQQR FGAMGGGGPSAAGGGTPQPTATPTLNQLLTSPSSARGYQGYPGGDYSGGPQDGGAGKGPADMASQCWGAAAAAAAAAAASGGAQQRSHHA PMSPGSSGGGGQPLARTPQPSSPMDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQ IPPYGQQGPSGYGQQGQTPYYNQQSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQST TQQHPQSQPPYSQPQAQSPYQQQQPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNL SLQSRPSSLPLITQTFSHHNQLAQKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKELTDEEAERLQLEIDQKKDAENHEAQLK NGSLDSPGKQDTEEDEEEDEKDKGKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKDMVVDIQRRHLRVGLKGQPAIIDGELY NEVKVEESSWLIEDGKVVTVHLEKINKMEWWSRLVSSDPEINTKKINPENSKLSDLDSETRSMVEKMMYDQRQKSMGLPTSDEQKKQEIL -------------------------------------------------------------- >6382_6382_3_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000324856_NUDC_chr1_27267948_ENST00000321265_length(transcript)=3809nt_BP=2291nt GAAAGCGGAGAGTCACAGCGGGGCCAGGCCCTGGGGAGCGGAGCCTCCACCGCCCCCCTCATTCCCAGGCAAGGGCTTGGGGGGAATGAG CCGGGAGAGCCGGGTCCCGAGCCTACAGAGCCGGGAGCAGCTGAGCCGCCGGCGCCTCGGCCGCCGCCGCCGCCTCCTCCTCCTCCGCCG CCGCCAGCCCGGAGCCTGAGCCGGCGGGGCGGGGGGGAGAGGAGCGAGCGCAGCGCAGCAGCGGAGCCCCGCGAGGCCCGCCCGGGCGGG TGGGGAGGGCAGCCCGGGGGACTGGGCCCCGGGGCGGGGTGGGAGGGGGGGAGAAGACGAAGACAGGGCCGGGTCTCTCCGCGGACGAGA CAGCGGGGATCATGGCCGCGCAGGTCGCCCCCGCCGCCGCCAGCAGCCTGGGCAACCCGCCGCCGCCGCCGCCCTCGGAGCTGAAGAAAG CCGAGCAGCAGCAGCGGGAGGAGGCGGGGGGCGAGGCGGCGGCGGCGGCAGCGGCCGAGCGCGGGGAAATGAAGGCAGCCGCCGGGCAGG AAAGCGAGGGCCCCGCCGTGGGGCCGCCGCAGCCGCTGGGAAAGGAGCTGCAGGACGGGGCCGAGAGCAATGGGGGTGGCGGCGGCGGCG GAGCCGGCAGCGGCGGCGGGCCCGGCGCGGAGCCGGACCTGAAGAACTCGAACGGGAACGCGGGCCCTAGGCCCGCCCTGAACAATAACC TCACGGAGCCGCCCGGCGGCGGCGGTGGCGGCAGCAGCGATGGGGTGGGGGCGCCTCCTCACTCAGCCGCGGCCGCCTTGCCGCCCCCAG CCTACGGCTTCGGGCAACCCTACGGCCGGAGCCCGTCTGCCGTCGCCGCCGCCGCGGCCGCCGTCTTCCACCAACAACATGGCGGACAAC AAAGCCCTGGCCTGGCAGCGCTGCAGAGCGGCGGCGGCGGGGGCCTGGAGCCCTACGCGGGGCCCCAGCAGAACTCTCACGACCACGGCT TCCCCAACCACCAGTACAACTCCTACTACCCCAACCGCAGCGCCTACCCCCCGCCCGCCCCGGCCTACGCGCTGAGCTCCCCGAGAGGTG GCACTCCGGGCTCCGGCGCGGCGGCGGCTGCCGGCTCCAAGCCGCCTCCCTCCTCCAGCGCCTCCGCCTCCTCGTCGTCTTCGTCCTTCG CTCAGCAGCGCTTCGGGGCCATGGGGGGAGGCGGCCCCTCCGCGGCCGGCGGGGGAACTCCCCAGCCCACCGCCACCCCCACCCTCAACC AACTGCTCACGTCGCCCAGCTCGGCCCGGGGCTACCAGGGCTACCCCGGGGGCGACTACAGTGGCGGGCCCCAGGACGGGGGCGCCGGCA AGGGCCCGGCGGACATGGCCTCGCAGTGTTGGGGGGCTGCGGCGGCGGCAGCTGCGGCGGCGGCCGCCTCGGGAGGGGCCCAACAAAGGA GCCACCACGCGCCCATGAGCCCCGGGAGCAGCGGCGGCGGGGGGCAGCCGCTCGCCCGGACCCCTCAGCCATCCAGTCCAATGGATCAGA TGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTCAGGACCGCAGCAAGGACATGGGT ACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCAGAGTGCCATGGGCGGCCTCTCTT ATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCCATATTACAACCAGCAAAGTCCTC ACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTCGTATCAGCAGCAGCCACAGTCTC AACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCAGTCCCCGGCTCCATACCCCTCCC AGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCCTTACCAGCAGCAGCAACCTCAGC AGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCAAACTGCCTATTCCCAGCAGCGCT TCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGACCTCCAGTAAGGGAGGGCAAGAAG ATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTATCACACAGACTTTCAGCCACCACAATCAGCTGGCACAGAAGACCC GGCGGGAGAAGAGAGCCCGGCAGGAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGCCAAGGAAGCCAAGTCAGAGACCT CAGGGCCCCAGATCAAGGAGCTAACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAAAAAGGATGCAGAGAATCATGAGG CCCAGCTCAAGAACGGCAGCCTTGACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGATGAGAAGGACAAAGGAAAACTGA AGCCCAACCTAGGCAACGGGGCAGACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGACCTGGCGGTCCCTTTCTGTGTGA ACTTCCGGCTGAAAGGGAAGGACATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAAGGGGCAGCCAGCGATCATTGATG GGGAGCTCTACAATGAAGTGAAGGTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGACTGTGCATCTGGAGAAGATCAATA AGATGGAGTGGTGGAGCCGCTTGGTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGAGAATTCCAAGCTGTCAGACCTGG ACAGTGAGACTCGCAGCATGGTGGAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCCAACTTCAGACGAACAGAAGAAAC AGGAGATTCTGAAGAAGTTCATGGATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTAGCCCCTGTTTTTTCCTCCCTGAA CTCTTGGGGCTGAGCTGCAACCACCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAGGGCTTGGGGCAGGCATGGGACTG GCCCAGGCACACAGGTCCCGGGGCATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTTGGCCTACTGTTACACATTAAAAC GATTTGCCCAGCTCCTTCTGTGTCCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACGGCTGCTGCTGGGAACTGGGAGTT TGGCTTCTAGCCCAGATTCTGCCATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTTCTCATTACTTAAAGATTAAAACA AGGCTTGGCCGGGTGTGATGGTTCATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGATCACCTGATGTCAGGAGTTTGAGA CCAGCTTGGCCAACATGGAGAAACCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGTGCACACCTGTAATCCCAGCTACT CGGGAGGCTGAGGCAGGAGAATCGCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCACTACTTCACTCCAGCATGGGTGAC >6382_6382_3_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000324856_NUDC_chr1_27267948_ENST00000321265_length(amino acids)=918AA_BP=0 MAAQVAPAAASSLGNPPPPPPSELKKAEQQQREEAGGEAAAAAAAERGEMKAAAGQESEGPAVGPPQPLGKELQDGAESNGGGGGGGAGS GGGPGAEPDLKNSNGNAGPRPALNNNLTEPPGGGGGGSSDGVGAPPHSAAAALPPPAYGFGQPYGRSPSAVAAAAAAVFHQQHGGQQSPG LAALQSGGGGGLEPYAGPQQNSHDHGFPNHQYNSYYPNRSAYPPPAPAYALSSPRGGTPGSGAAAAAGSKPPPSSSASASSSSSSFAQQR FGAMGGGGPSAAGGGTPQPTATPTLNQLLTSPSSARGYQGYPGGDYSGGPQDGGAGKGPADMASQCWGAAAAAAAAAAASGGAQQRSHHA PMSPGSSGGGGQPLARTPQPSSPMDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQ IPPYGQQGPSGYGQQGQTPYYNQQSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQST TQQHPQSQPPYSQPQAQSPYQQQQPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNL SLQSRPSSLPLITQTFSHHNQLAQKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKELTDEEAERLQLEIDQKKDAENHEAQLK NGSLDSPGKQDTEEDEEEDEKDKGKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKDMVVDIQRRHLRVGLKGQPAIIDGELY NEVKVEESSWLIEDGKVVTVHLEKINKMEWWSRLVSSDPEINTKKINPENSKLSDLDSETRSMVEKMMYDQRQKSMGLPTSDEQKKQEIL -------------------------------------------------------------- >6382_6382_4_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000374152_NUDC_chr1_27250580_ENST00000321265_length(transcript)=2650nt_BP=1054nt TGGATCTCAAGCAGTACCACAGTTACAAAGTAGTTTTTAGCTTACAAGGTGTTTTCACAAATAGGTGGTATTTTCATTTTTCAAATGACA AAATTAGGGTTCTGAGGCGGGTCAGTTGACTTAAAGGTTACTAGGTTGGTCTCATTGCTCTTTCAAAGTAACTGTATTTCTTTATAGCAT ACAGACTAAAAAAACCTGTGTACTTGGGTTATATATTCAGTGGCCAGAGGCCATCAAAGCTCAGGTTAATGAAATGCTCTTTATTTTGTA GCCATCCAGTCCAATGGATCAGATGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTC AGGACCGCAGCAAGGACATGGGTACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCA GAGTGCCATGGGCGGCCTCTCTTATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCC ATATTACAACCAGCAAAGTCCTCACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTC GTATCAGCAGCAGCCACAGTCTCAACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCA GTCCCCGGCTCCATACCCCTCCCAGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCC TTACCAGCAGCAGCAACCTCAGCAGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCA AACTGCCTATTCCCAGCAGCGCTTCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGAC CTCCAGTAAGGGAGGGCAAGAAGATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTGTGAACACCTTCTTCAGCTTCCT TCGACGCAAAACAGACTTTTTCATTGGAGGAGAAGAAGGGATGGCAGAGAAGCTTATCACACAGACTTTCAGCCACCACAATCAGCTGGC ACAGAAGACCCGGCGGGAGAAGAGAGCCCGGCAGGAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGCCAAGGAAGCCAA GTCAGAGACCTCAGGGCCCCAGATCAAGGAGCTAACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAAAAAGGATGCAGA GAATCATGAGGCCCAGCTCAAGAACGGCAGCCTTGACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGATGAGAAGGACAA AGGAAAACTGAAGCCCAACCTAGGCAACGGGGCAGACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGACCTGGCGGTCCC TTTCTGTGTGAACTTCCGGCTGAAAGGGAAGGACATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAAGGGGCAGCCAGC GATCATTGATGGGGAGCTCTACAATGAAGTGAAGGTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGACTGTGCATCTGGA GAAGATCAATAAGATGGAGTGGTGGAGCCGCTTGGTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGAGAATTCCAAGCT GTCAGACCTGGACAGTGAGACTCGCAGCATGGTGGAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCCAACTTCAGACGA ACAGAAGAAACAGGAGATTCTGAAGAAGTTCATGGATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTAGCCCCTGTTTTT TCCTCCCTGAACTCTTGGGGCTGAGCTGCAACCACCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAGGGCTTGGGGCAG GCATGGGACTGGCCCAGGCACACAGGTCCCGGGGCATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTTGGCCTACTGTTA CACATTAAAACGATTTGCCCAGCTCCTTCTGTGTCCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACGGCTGCTGCTGGG AACTGGGAGTTTGGCTTCTAGCCCAGATTCTGCCATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTTCTCATTACTTAA AGATTAAAACAAGGCTTGGCCGGGTGTGATGGTTCATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGATCACCTGATGTCA GGAGTTTGAGACCAGCTTGGCCAACATGGAGAAACCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGTGCACACCTGTAA TCCCAGCTACTCGGGAGGCTGAGGCAGGAGAATCGCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCACTACTTCACTCCA >6382_6382_4_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000374152_NUDC_chr1_27250580_ENST00000321265_length(amino acids)=561AA_BP=0 MDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQIPPYGQQGPSGYGQQGQTPYYNQ QSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQSTTQQHPQSQPPYSQPQAQSPYQQQ QPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNLSLQSRPSSLPLVNTFFSFLRRKT DFFIGGEEGMAEKLITQTFSHHNQLAQKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKELTDEEAERLQLEIDQKKDAENHEA QLKNGSLDSPGKQDTEEDEEEDEKDKGKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKDMVVDIQRRHLRVGLKGQPAIIDG ELYNEVKVEESSWLIEDGKVVTVHLEKINKMEWWSRLVSSDPEINTKKINPENSKLSDLDSETRSMVEKMMYDQRQKSMGLPTSDEQKKQ -------------------------------------------------------------- >6382_6382_5_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000374152_NUDC_chr1_27267947_ENST00000321265_length(transcript)=2572nt_BP=1054nt TGGATCTCAAGCAGTACCACAGTTACAAAGTAGTTTTTAGCTTACAAGGTGTTTTCACAAATAGGTGGTATTTTCATTTTTCAAATGACA AAATTAGGGTTCTGAGGCGGGTCAGTTGACTTAAAGGTTACTAGGTTGGTCTCATTGCTCTTTCAAAGTAACTGTATTTCTTTATAGCAT ACAGACTAAAAAAACCTGTGTACTTGGGTTATATATTCAGTGGCCAGAGGCCATCAAAGCTCAGGTTAATGAAATGCTCTTTATTTTGTA GCCATCCAGTCCAATGGATCAGATGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTC AGGACCGCAGCAAGGACATGGGTACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCA GAGTGCCATGGGCGGCCTCTCTTATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCC ATATTACAACCAGCAAAGTCCTCACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTC GTATCAGCAGCAGCCACAGTCTCAACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCA GTCCCCGGCTCCATACCCCTCCCAGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCC TTACCAGCAGCAGCAACCTCAGCAGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCA AACTGCCTATTCCCAGCAGCGCTTCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGAC CTCCAGTAAGGGAGGGCAAGAAGATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTATCACACAGACTTTCAGCCACCA CAATCAGCTGGCACAGAAGACCCGGCGGGAGAAGAGAGCCCGGCAGGAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGC CAAGGAAGCCAAGTCAGAGACCTCAGGGCCCCAGATCAAGGAGCTAACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAA AAAGGATGCAGAGAATCATGAGGCCCAGCTCAAGAACGGCAGCCTTGACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGA TGAGAAGGACAAAGGAAAACTGAAGCCCAACCTAGGCAACGGGGCAGACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGA CCTGGCGGTCCCTTTCTGTGTGAACTTCCGGCTGAAAGGGAAGGACATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAA GGGGCAGCCAGCGATCATTGATGGGGAGCTCTACAATGAAGTGAAGGTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGAC TGTGCATCTGGAGAAGATCAATAAGATGGAGTGGTGGAGCCGCTTGGTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGA GAATTCCAAGCTGTCAGACCTGGACAGTGAGACTCGCAGCATGGTGGAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCC AACTTCAGACGAACAGAAGAAACAGGAGATTCTGAAGAAGTTCATGGATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTA GCCCCTGTTTTTTCCTCCCTGAACTCTTGGGGCTGAGCTGCAACCACCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAG GGCTTGGGGCAGGCATGGGACTGGCCCAGGCACACAGGTCCCGGGGCATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTT GGCCTACTGTTACACATTAAAACGATTTGCCCAGCTCCTTCTGTGTCCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACG GCTGCTGCTGGGAACTGGGAGTTTGGCTTCTAGCCCAGATTCTGCCATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTT CTCATTACTTAAAGATTAAAACAAGGCTTGGCCGGGTGTGATGGTTCATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGAT CACCTGATGTCAGGAGTTTGAGACCAGCTTGGCCAACATGGAGAAACCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGT GCACACCTGTAATCCCAGCTACTCGGGAGGCTGAGGCAGGAGAATCGCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCAC >6382_6382_5_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000374152_NUDC_chr1_27267947_ENST00000321265_length(amino acids)=535AA_BP=0 MDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQIPPYGQQGPSGYGQQGQTPYYNQ QSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQSTTQQHPQSQPPYSQPQAQSPYQQQ QPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNLSLQSRPSSLPLITQTFSHHNQLA QKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKELTDEEAERLQLEIDQKKDAENHEAQLKNGSLDSPGKQDTEEDEEEDEKDK GKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKDMVVDIQRRHLRVGLKGQPAIIDGELYNEVKVEESSWLIEDGKVVTVHLE -------------------------------------------------------------- >6382_6382_6_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000374152_NUDC_chr1_27267948_ENST00000321265_length(transcript)=2572nt_BP=1054nt TGGATCTCAAGCAGTACCACAGTTACAAAGTAGTTTTTAGCTTACAAGGTGTTTTCACAAATAGGTGGTATTTTCATTTTTCAAATGACA AAATTAGGGTTCTGAGGCGGGTCAGTTGACTTAAAGGTTACTAGGTTGGTCTCATTGCTCTTTCAAAGTAACTGTATTTCTTTATAGCAT ACAGACTAAAAAAACCTGTGTACTTGGGTTATATATTCAGTGGCCAGAGGCCATCAAAGCTCAGGTTAATGAAATGCTCTTTATTTTGTA GCCATCCAGTCCAATGGATCAGATGGGCAAGATGAGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTC AGGACCGCAGCAAGGACATGGGTACCCAGGGCAGCCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCA GAGTGCCATGGGCGGCCTCTCTTATACACAGCAGATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCC ATATTACAACCAGCAAAGTCCTCACCCTCAGCAGCAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTC GTATCAGCAGCAGCCACAGTCTCAACCACCACAGCTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCA GTCCCCGGCTCCATACCCCTCCCAGCAGTCGACGACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCC TTACCAGCAGCAGCAACCTCAGCAGCCAGCACCCTCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCA AACTGCCTATTCCCAGCAGCGCTTCCCTCCACCGCAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGAC CTCCAGTAAGGGAGGGCAAGAAGATATGAACCTGAGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTATCACACAGACTTTCAGCCACCA CAATCAGCTGGCACAGAAGACCCGGCGGGAGAAGAGAGCCCGGCAGGAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGC CAAGGAAGCCAAGTCAGAGACCTCAGGGCCCCAGATCAAGGAGCTAACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAA AAAGGATGCAGAGAATCATGAGGCCCAGCTCAAGAACGGCAGCCTTGACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGA TGAGAAGGACAAAGGAAAACTGAAGCCCAACCTAGGCAACGGGGCAGACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGA CCTGGCGGTCCCTTTCTGTGTGAACTTCCGGCTGAAAGGGAAGGACATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAA GGGGCAGCCAGCGATCATTGATGGGGAGCTCTACAATGAAGTGAAGGTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGAC TGTGCATCTGGAGAAGATCAATAAGATGGAGTGGTGGAGCCGCTTGGTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGA GAATTCCAAGCTGTCAGACCTGGACAGTGAGACTCGCAGCATGGTGGAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCC AACTTCAGACGAACAGAAGAAACAGGAGATTCTGAAGAAGTTCATGGATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTA GCCCCTGTTTTTTCCTCCCTGAACTCTTGGGGCTGAGCTGCAACCACCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAG GGCTTGGGGCAGGCATGGGACTGGCCCAGGCACACAGGTCCCGGGGCATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTT GGCCTACTGTTACACATTAAAACGATTTGCCCAGCTCCTTCTGTGTCCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACG GCTGCTGCTGGGAACTGGGAGTTTGGCTTCTAGCCCAGATTCTGCCATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTT CTCATTACTTAAAGATTAAAACAAGGCTTGGCCGGGTGTGATGGTTCATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGAT CACCTGATGTCAGGAGTTTGAGACCAGCTTGGCCAACATGGAGAAACCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGT GCACACCTGTAATCCCAGCTACTCGGGAGGCTGAGGCAGGAGAATCGCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCAC >6382_6382_6_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000374152_NUDC_chr1_27267948_ENST00000321265_length(amino acids)=535AA_BP=0 MDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQIPPYGQQGPSGYGQQGQTPYYNQ QSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQSTTQQHPQSQPPYSQPQAQSPYQQQ QPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNLSLQSRPSSLPLITQTFSHHNQLA QKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKELTDEEAERLQLEIDQKKDAENHEAQLKNGSLDSPGKQDTEEDEEEDEKDK GKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKDMVVDIQRRHLRVGLKGQPAIIDGELYNEVKVEESSWLIEDGKVVTVHLE -------------------------------------------------------------- >6382_6382_7_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000457599_NUDC_chr1_27250580_ENST00000321265_length(transcript)=3516nt_BP=1920nt ATGGCCGCGCAGGTCGCCCCCGCCGCCGCCAGCAGCCTGGGCAACCCGCCGCCGCCGCCGCCCTCGGAGCTGAAGAAAGCCGAGCAGCAG CAGCGGGAGGAGGCGGGGGGCGAGGCGGCGGCGGCGGCAGCGGCCGAGCGCGGGGAAATGAAGGCAGCCGCCGGGCAGGAAAGCGAGGGC CCCGCCGTGGGGCCGCCGCAGCCGCTGGGAAAGGAGCTGCAGGACGGGGCCGAGAGCAATGGGGGTGGCGGCGGCGGCGGAGCCGGCAGC GGCGGCGGGCCCGGCGCGGAGCCGGACCTGAAGAACTCGAACGGGAACGCGGGCCCTAGGCCCGCCCTGAACAATAACCTCACGGAGCCG CCCGGCGGCGGCGGTGGCGGCAGCAGCGATGGGGTGGGGGCGCCTCCTCACTCAGCCGCGGCCGCCTTGCCGCCCCCAGCCTACGGCTTC GGGCAACCCTACGGCCGGAGCCCGTCTGCCGTCGCCGCCGCCGCGGCCGCCGTCTTCCACCAACAACATGGCGGACAACAAAGCCCTGGC CTGGCAGCGCTGCAGAGCGGCGGCGGCGGGGGCCTGGAGCCCTACGCGGGGCCCCAGCAGAACTCTCACGACCACGGCTTCCCCAACCAC CAGTACAACTCCTACTACCCCAACCGCAGCGCCTACCCCCCGCCCGCCCCGGCCTACGCGCTGAGCTCCCCGAGAGGTGGCACTCCGGGC TCCGGCGCGGCGGCGGCTGCCGGCTCCAAGCCGCCTCCCTCCTCCAGCGCCTCCGCCTCCTCGTCGTCTTCGTCCTTCGCTCAGCAGCGC TTCGGGGCCATGGGGGGAGGCGGCCCCTCCGCGGCCGGCGGGGGAACTCCCCAGCCCACCGCCACCCCCACCCTCAACCAACTGCTCACG TCGCCCAGCTCGGCCCGGGGCTACCAGGGCTACCCCGGGGGCGACTACAGTGGCGGGCCCCAGGACGGGGGCGCCGGCAAGGGCCCGGCG GACATGGCCTCGCAGTGTTGGGGGGCTGCGGCGGCGGCAGCTGCGGCGGCGGCCGCCTCGGGAGGGGCCCAACAAAGGAGCCACCACGCG CCCATGAGCCCCGGGAGCAGCGGCGGCGGGGGGCAGCCGCTCGCCCGGACCCCTCAGCCATCCAGTCCAATGGATCAGATGGGCAAGATG AGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTCAGGACCGCAGCAAGGACATGGGTACCCAGGGCAG CCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCAGAGTGCCATGGGCGGCCTCTCTTATACACAGCAG ATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCCATATTACAACCAGCAAAGTCCTCACCCTCAGCAG CAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTCGTATCAGCAGCAGCCACAGTCTCAACCACCACAG CTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCAGTCCCCGGCTCCATACCCCTCCCAGCAGTCGACG ACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCCTTACCAGCAGCAGCAACCTCAGCAGCCAGCACCC TCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCAAACTGCCTATTCCCAGCAGCGCTTCCCTCCACCG CAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGACCTCCAGTAAGGGAGGGCAAGAAGATATGAACCTG AGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTGTGAACACCTTCTTCAGCTTCCTTCGACGCAAAACAGACTTTTTCATTGGAGGAGAA GAAGGGATGGCAGAGAAGCTTATCACACAGACTTTCAGCCACCACAATCAGCTGGCACAGAAGACCCGGCGGGAGAAGAGAGCCCGGCAG GAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGCCAAGGAAGCCAAGTCAGAGACCTCAGGGCCCCAGATCAAGGAGCTA ACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAAAAAGGATGCAGAGAATCATGAGGCCCAGCTCAAGAACGGCAGCCTT GACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGATGAGAAGGACAAAGGAAAACTGAAGCCCAACCTAGGCAACGGGGCA GACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGACCTGGCGGTCCCTTTCTGTGTGAACTTCCGGCTGAAAGGGAAGGAC ATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAAGGGGCAGCCAGCGATCATTGATGGGGAGCTCTACAATGAAGTGAAG GTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGACTGTGCATCTGGAGAAGATCAATAAGATGGAGTGGTGGAGCCGCTTG GTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGAGAATTCCAAGCTGTCAGACCTGGACAGTGAGACTCGCAGCATGGTG GAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCCAACTTCAGACGAACAGAAGAAACAGGAGATTCTGAAGAAGTTCATG GATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTAGCCCCTGTTTTTTCCTCCCTGAACTCTTGGGGCTGAGCTGCAACCA CCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAGGGCTTGGGGCAGGCATGGGACTGGCCCAGGCACACAGGTCCCGGGG CATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTTGGCCTACTGTTACACATTAAAACGATTTGCCCAGCTCCTTCTGTGT CCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACGGCTGCTGCTGGGAACTGGGAGTTTGGCTTCTAGCCCAGATTCTGCC ATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTTCTCATTACTTAAAGATTAAAACAAGGCTTGGCCGGGTGTGATGGTT CATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGATCACCTGATGTCAGGAGTTTGAGACCAGCTTGGCCAACATGGAGAAA CCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGTGCACACCTGTAATCCCAGCTACTCGGGAGGCTGAGGCAGGAGAATC GCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCACTACTTCACTCCAGCATGGGTGACAGAGACTCCATCTCAAAAAAATA >6382_6382_7_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000457599_NUDC_chr1_27250580_ENST00000321265_length(amino acids)=944AA_BP=0 MAAQVAPAAASSLGNPPPPPPSELKKAEQQQREEAGGEAAAAAAAERGEMKAAAGQESEGPAVGPPQPLGKELQDGAESNGGGGGGGAGS GGGPGAEPDLKNSNGNAGPRPALNNNLTEPPGGGGGGSSDGVGAPPHSAAAALPPPAYGFGQPYGRSPSAVAAAAAAVFHQQHGGQQSPG LAALQSGGGGGLEPYAGPQQNSHDHGFPNHQYNSYYPNRSAYPPPAPAYALSSPRGGTPGSGAAAAAGSKPPPSSSASASSSSSSFAQQR FGAMGGGGPSAAGGGTPQPTATPTLNQLLTSPSSARGYQGYPGGDYSGGPQDGGAGKGPADMASQCWGAAAAAAAAAAASGGAQQRSHHA PMSPGSSGGGGQPLARTPQPSSPMDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQ IPPYGQQGPSGYGQQGQTPYYNQQSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQST TQQHPQSQPPYSQPQAQSPYQQQQPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNL SLQSRPSSLPLVNTFFSFLRRKTDFFIGGEEGMAEKLITQTFSHHNQLAQKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKEL TDEEAERLQLEIDQKKDAENHEAQLKNGSLDSPGKQDTEEDEEEDEKDKGKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKD MVVDIQRRHLRVGLKGQPAIIDGELYNEVKVEESSWLIEDGKVVTVHLEKINKMEWWSRLVSSDPEINTKKINPENSKLSDLDSETRSMV -------------------------------------------------------------- >6382_6382_8_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000457599_NUDC_chr1_27267947_ENST00000321265_length(transcript)=3438nt_BP=1920nt ATGGCCGCGCAGGTCGCCCCCGCCGCCGCCAGCAGCCTGGGCAACCCGCCGCCGCCGCCGCCCTCGGAGCTGAAGAAAGCCGAGCAGCAG CAGCGGGAGGAGGCGGGGGGCGAGGCGGCGGCGGCGGCAGCGGCCGAGCGCGGGGAAATGAAGGCAGCCGCCGGGCAGGAAAGCGAGGGC CCCGCCGTGGGGCCGCCGCAGCCGCTGGGAAAGGAGCTGCAGGACGGGGCCGAGAGCAATGGGGGTGGCGGCGGCGGCGGAGCCGGCAGC GGCGGCGGGCCCGGCGCGGAGCCGGACCTGAAGAACTCGAACGGGAACGCGGGCCCTAGGCCCGCCCTGAACAATAACCTCACGGAGCCG CCCGGCGGCGGCGGTGGCGGCAGCAGCGATGGGGTGGGGGCGCCTCCTCACTCAGCCGCGGCCGCCTTGCCGCCCCCAGCCTACGGCTTC GGGCAACCCTACGGCCGGAGCCCGTCTGCCGTCGCCGCCGCCGCGGCCGCCGTCTTCCACCAACAACATGGCGGACAACAAAGCCCTGGC CTGGCAGCGCTGCAGAGCGGCGGCGGCGGGGGCCTGGAGCCCTACGCGGGGCCCCAGCAGAACTCTCACGACCACGGCTTCCCCAACCAC CAGTACAACTCCTACTACCCCAACCGCAGCGCCTACCCCCCGCCCGCCCCGGCCTACGCGCTGAGCTCCCCGAGAGGTGGCACTCCGGGC TCCGGCGCGGCGGCGGCTGCCGGCTCCAAGCCGCCTCCCTCCTCCAGCGCCTCCGCCTCCTCGTCGTCTTCGTCCTTCGCTCAGCAGCGC TTCGGGGCCATGGGGGGAGGCGGCCCCTCCGCGGCCGGCGGGGGAACTCCCCAGCCCACCGCCACCCCCACCCTCAACCAACTGCTCACG TCGCCCAGCTCGGCCCGGGGCTACCAGGGCTACCCCGGGGGCGACTACAGTGGCGGGCCCCAGGACGGGGGCGCCGGCAAGGGCCCGGCG GACATGGCCTCGCAGTGTTGGGGGGCTGCGGCGGCGGCAGCTGCGGCGGCGGCCGCCTCGGGAGGGGCCCAACAAAGGAGCCACCACGCG CCCATGAGCCCCGGGAGCAGCGGCGGCGGGGGGCAGCCGCTCGCCCGGACCCCTCAGCCATCCAGTCCAATGGATCAGATGGGCAAGATG AGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTCAGGACCGCAGCAAGGACATGGGTACCCAGGGCAG CCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCAGAGTGCCATGGGCGGCCTCTCTTATACACAGCAG ATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCCATATTACAACCAGCAAAGTCCTCACCCTCAGCAG CAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTCGTATCAGCAGCAGCCACAGTCTCAACCACCACAG CTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCAGTCCCCGGCTCCATACCCCTCCCAGCAGTCGACG ACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCCTTACCAGCAGCAGCAACCTCAGCAGCCAGCACCC TCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCAAACTGCCTATTCCCAGCAGCGCTTCCCTCCACCG CAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGACCTCCAGTAAGGGAGGGCAAGAAGATATGAACCTG AGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTATCACACAGACTTTCAGCCACCACAATCAGCTGGCACAGAAGACCCGGCGGGAGAAG AGAGCCCGGCAGGAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGCCAAGGAAGCCAAGTCAGAGACCTCAGGGCCCCAG ATCAAGGAGCTAACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAAAAAGGATGCAGAGAATCATGAGGCCCAGCTCAAG AACGGCAGCCTTGACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGATGAGAAGGACAAAGGAAAACTGAAGCCCAACCTA GGCAACGGGGCAGACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGACCTGGCGGTCCCTTTCTGTGTGAACTTCCGGCTG AAAGGGAAGGACATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAAGGGGCAGCCAGCGATCATTGATGGGGAGCTCTAC AATGAAGTGAAGGTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGACTGTGCATCTGGAGAAGATCAATAAGATGGAGTGG TGGAGCCGCTTGGTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGAGAATTCCAAGCTGTCAGACCTGGACAGTGAGACT CGCAGCATGGTGGAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCCAACTTCAGACGAACAGAAGAAACAGGAGATTCTG AAGAAGTTCATGGATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTAGCCCCTGTTTTTTCCTCCCTGAACTCTTGGGGCT GAGCTGCAACCACCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAGGGCTTGGGGCAGGCATGGGACTGGCCCAGGCACA CAGGTCCCGGGGCATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTTGGCCTACTGTTACACATTAAAACGATTTGCCCAG CTCCTTCTGTGTCCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACGGCTGCTGCTGGGAACTGGGAGTTTGGCTTCTAGC CCAGATTCTGCCATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTTCTCATTACTTAAAGATTAAAACAAGGCTTGGCCG GGTGTGATGGTTCATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGATCACCTGATGTCAGGAGTTTGAGACCAGCTTGGCC AACATGGAGAAACCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGTGCACACCTGTAATCCCAGCTACTCGGGAGGCTGA GGCAGGAGAATCGCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCACTACTTCACTCCAGCATGGGTGACAGAGACTCCAT >6382_6382_8_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000457599_NUDC_chr1_27267947_ENST00000321265_length(amino acids)=918AA_BP=0 MAAQVAPAAASSLGNPPPPPPSELKKAEQQQREEAGGEAAAAAAAERGEMKAAAGQESEGPAVGPPQPLGKELQDGAESNGGGGGGGAGS GGGPGAEPDLKNSNGNAGPRPALNNNLTEPPGGGGGGSSDGVGAPPHSAAAALPPPAYGFGQPYGRSPSAVAAAAAAVFHQQHGGQQSPG LAALQSGGGGGLEPYAGPQQNSHDHGFPNHQYNSYYPNRSAYPPPAPAYALSSPRGGTPGSGAAAAAGSKPPPSSSASASSSSSSFAQQR FGAMGGGGPSAAGGGTPQPTATPTLNQLLTSPSSARGYQGYPGGDYSGGPQDGGAGKGPADMASQCWGAAAAAAAAAAASGGAQQRSHHA PMSPGSSGGGGQPLARTPQPSSPMDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQ IPPYGQQGPSGYGQQGQTPYYNQQSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQST TQQHPQSQPPYSQPQAQSPYQQQQPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNL SLQSRPSSLPLITQTFSHHNQLAQKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKELTDEEAERLQLEIDQKKDAENHEAQLK NGSLDSPGKQDTEEDEEEDEKDKGKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKDMVVDIQRRHLRVGLKGQPAIIDGELY NEVKVEESSWLIEDGKVVTVHLEKINKMEWWSRLVSSDPEINTKKINPENSKLSDLDSETRSMVEKMMYDQRQKSMGLPTSDEQKKQEIL -------------------------------------------------------------- >6382_6382_9_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000457599_NUDC_chr1_27267948_ENST00000321265_length(transcript)=3438nt_BP=1920nt ATGGCCGCGCAGGTCGCCCCCGCCGCCGCCAGCAGCCTGGGCAACCCGCCGCCGCCGCCGCCCTCGGAGCTGAAGAAAGCCGAGCAGCAG CAGCGGGAGGAGGCGGGGGGCGAGGCGGCGGCGGCGGCAGCGGCCGAGCGCGGGGAAATGAAGGCAGCCGCCGGGCAGGAAAGCGAGGGC CCCGCCGTGGGGCCGCCGCAGCCGCTGGGAAAGGAGCTGCAGGACGGGGCCGAGAGCAATGGGGGTGGCGGCGGCGGCGGAGCCGGCAGC GGCGGCGGGCCCGGCGCGGAGCCGGACCTGAAGAACTCGAACGGGAACGCGGGCCCTAGGCCCGCCCTGAACAATAACCTCACGGAGCCG CCCGGCGGCGGCGGTGGCGGCAGCAGCGATGGGGTGGGGGCGCCTCCTCACTCAGCCGCGGCCGCCTTGCCGCCCCCAGCCTACGGCTTC GGGCAACCCTACGGCCGGAGCCCGTCTGCCGTCGCCGCCGCCGCGGCCGCCGTCTTCCACCAACAACATGGCGGACAACAAAGCCCTGGC CTGGCAGCGCTGCAGAGCGGCGGCGGCGGGGGCCTGGAGCCCTACGCGGGGCCCCAGCAGAACTCTCACGACCACGGCTTCCCCAACCAC CAGTACAACTCCTACTACCCCAACCGCAGCGCCTACCCCCCGCCCGCCCCGGCCTACGCGCTGAGCTCCCCGAGAGGTGGCACTCCGGGC TCCGGCGCGGCGGCGGCTGCCGGCTCCAAGCCGCCTCCCTCCTCCAGCGCCTCCGCCTCCTCGTCGTCTTCGTCCTTCGCTCAGCAGCGC TTCGGGGCCATGGGGGGAGGCGGCCCCTCCGCGGCCGGCGGGGGAACTCCCCAGCCCACCGCCACCCCCACCCTCAACCAACTGCTCACG TCGCCCAGCTCGGCCCGGGGCTACCAGGGCTACCCCGGGGGCGACTACAGTGGCGGGCCCCAGGACGGGGGCGCCGGCAAGGGCCCGGCG GACATGGCCTCGCAGTGTTGGGGGGCTGCGGCGGCGGCAGCTGCGGCGGCGGCCGCCTCGGGAGGGGCCCAACAAAGGAGCCACCACGCG CCCATGAGCCCCGGGAGCAGCGGCGGCGGGGGGCAGCCGCTCGCCCGGACCCCTCAGCCATCCAGTCCAATGGATCAGATGGGCAAGATG AGACCTCAGCCATATGGCGGGACTAACCCATACTCGCAGCAACAGGGACCTCCGTCAGGACCGCAGCAAGGACATGGGTACCCAGGGCAG CCATACGGGTCCCAGACCCCGCAGCGGTACCCGATGACCATGCAGGGCCGGGCGCAGAGTGCCATGGGCGGCCTCTCTTATACACAGCAG ATTCCTCCTTATGGACAACAAGGCCCCAGCGGGTATGGTCAACAGGGCCAGACTCCATATTACAACCAGCAAAGTCCTCACCCTCAGCAG CAGCAGCCACCCTACTCCCAGCAACCACCGTCCCAGACCCCTCATGCCCAACCTTCGTATCAGCAGCAGCCACAGTCTCAACCACCACAG CTCCAGTCCTCTCAGCCTCCATACTCCCAGCAGCCATCCCAGCCTCCACATCAGCAGTCCCCGGCTCCATACCCCTCCCAGCAGTCGACG ACACAGCAGCACCCCCAGAGCCAGCCCCCCTACTCACAGCCACAGGCTCAGTCTCCTTACCAGCAGCAGCAACCTCAGCAGCCAGCACCC TCGACGCTCTCCCAGCAGGCTGCGTATCCTCAGCCCCAGTCTCAGCAGTCCCAGCAAACTGCCTATTCCCAGCAGCGCTTCCCTCCACCG CAGGAGCTATCTCAAGATTCATTTGGGTCTCAGGCATCCTCAGCCCCCTCAATGACCTCCAGTAAGGGAGGGCAAGAAGATATGAACCTG AGCCTTCAGTCAAGACCCTCCAGCTTGCCTCTTATCACACAGACTTTCAGCCACCACAATCAGCTGGCACAGAAGACCCGGCGGGAGAAG AGAGCCCGGCAGGAGGCCGAGCGGCGGGAGAAGGCGGAGCGGGCGGCCAGACTGGCCAAGGAAGCCAAGTCAGAGACCTCAGGGCCCCAG ATCAAGGAGCTAACTGATGAAGAGGCAGAGAGGCTGCAGCTAGAGATTGACCAGAAAAAGGATGCAGAGAATCATGAGGCCCAGCTCAAG AACGGCAGCCTTGACTCCCCAGGGAAGCAGGATACTGAGGAAGATGAGGAGGAAGATGAGAAGGACAAAGGAAAACTGAAGCCCAACCTA GGCAACGGGGCAGACCTGCCCAATTACCGCTGGACCCAGACCCTGTCGGAGCTGGACCTGGCGGTCCCTTTCTGTGTGAACTTCCGGCTG AAAGGGAAGGACATGGTGGTGGACATCCAGCGGCGGCACCTCCGGGTGGGGCTCAAGGGGCAGCCAGCGATCATTGATGGGGAGCTCTAC AATGAAGTGAAGGTGGAGGAGAGCTCGTGGCTCATTGAGGACGGCAAGGTGGTGACTGTGCATCTGGAGAAGATCAATAAGATGGAGTGG TGGAGCCGCTTGGTGTCCAGTGACCCTGAGATCAACACCAAGAAGATTAACCCTGAGAATTCCAAGCTGTCAGACCTGGACAGTGAGACT CGCAGCATGGTGGAAAAGATGATGTATGACCAGCGACAGAAGTCCATGGGGCTGCCAACTTCAGACGAACAGAAGAAACAGGAGATTCTG AAGAAGTTCATGGATCAACATCCGGAGATGGATTTTTCCAAGGCTAAATTCAACTAGCCCCTGTTTTTTCCTCCCTGAACTCTTGGGGCT GAGCTGCAACCACCCAACTTTCTTTCCCACTCTTCTCTGGGACTTGTGGGCCTCAGGGCTTGGGGCAGGCATGGGACTGGCCCAGGCACA CAGGTCCCGGGGCATCAGGAGAAAGGCTGGGTCTTGGGACCTTGTCCTCCCCAGTTGGCCTACTGTTACACATTAAAACGATTTGCCCAG CTCCTTCTGTGTCCTCTCTTGCCTCTGGCCTTTCTCTGGGGCACAGGCCTCTTACGGCTGCTGCTGGGAACTGGGAGTTTGGCTTCTAGC CCAGATTCTGCCATGTGACCTAGGGCACATCCTTGCCCCTCTCTGGGCCTCAGTTTCTCATTACTTAAAGATTAAAACAAGGCTTGGCCG GGTGTGATGGTTCATGTCTGTAATCCCAGCACTTTGGGAGGCTGAGGGGAGCAGATCACCTGATGTCAGGAGTTTGAGACCAGCTTGGCC AACATGGAGAAACCCAGTCTCTACTAAAAATACAAAAATTAGCCGGGTGTGGTGGTGCACACCTGTAATCCCAGCTACTCGGGAGGCTGA GGCAGGAGAATCGCTTGAACCCGGGTGGCGGAGGTTGCAGTGAGCCGAGATTGCACTACTTCACTCCAGCATGGGTGACAGAGACTCCAT >6382_6382_9_ARID1A-NUDC_ARID1A_chr1_27059283_ENST00000457599_NUDC_chr1_27267948_ENST00000321265_length(amino acids)=918AA_BP=0 MAAQVAPAAASSLGNPPPPPPSELKKAEQQQREEAGGEAAAAAAAERGEMKAAAGQESEGPAVGPPQPLGKELQDGAESNGGGGGGGAGS GGGPGAEPDLKNSNGNAGPRPALNNNLTEPPGGGGGGSSDGVGAPPHSAAAALPPPAYGFGQPYGRSPSAVAAAAAAVFHQQHGGQQSPG LAALQSGGGGGLEPYAGPQQNSHDHGFPNHQYNSYYPNRSAYPPPAPAYALSSPRGGTPGSGAAAAAGSKPPPSSSASASSSSSSFAQQR FGAMGGGGPSAAGGGTPQPTATPTLNQLLTSPSSARGYQGYPGGDYSGGPQDGGAGKGPADMASQCWGAAAAAAAAAAASGGAQQRSHHA PMSPGSSGGGGQPLARTPQPSSPMDQMGKMRPQPYGGTNPYSQQQGPPSGPQQGHGYPGQPYGSQTPQRYPMTMQGRAQSAMGGLSYTQQ IPPYGQQGPSGYGQQGQTPYYNQQSPHPQQQQPPYSQQPPSQTPHAQPSYQQQPQSQPPQLQSSQPPYSQQPSQPPHQQSPAPYPSQQST TQQHPQSQPPYSQPQAQSPYQQQQPQQPAPSTLSQQAAYPQPQSQQSQQTAYSQQRFPPPQELSQDSFGSQASSAPSMTSSKGGQEDMNL SLQSRPSSLPLITQTFSHHNQLAQKTRREKRARQEAERREKAERAARLAKEAKSETSGPQIKELTDEEAERLQLEIDQKKDAENHEAQLK NGSLDSPGKQDTEEDEEEDEKDKGKLKPNLGNGADLPNYRWTQTLSELDLAVPFCVNFRLKGKDMVVDIQRRHLRVGLKGQPAIIDGELY NEVKVEESSWLIEDGKVVTVHLEKINKMEWWSRLVSSDPEINTKKINPENSKLSDLDSETRSMVEKMMYDQRQKSMGLPTSDEQKKQEIL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARID1A-NUDC |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | NUDC | chr1:27059283 | chr1:27250580 | ENST00000321265 | 0 | 9 | 173_331 | 27.0 | 332.0 | EML4 | |
| Tgene | NUDC | chr1:27059283 | chr1:27267947 | ENST00000321265 | 1 | 9 | 173_331 | 53.0 | 332.0 | EML4 | |
| Tgene | NUDC | chr1:27059283 | chr1:27267948 | ENST00000321265 | 1 | 9 | 173_331 | 53.0 | 332.0 | EML4 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARID1A-NUDC |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARID1A-NUDC |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies