
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PDGFB-DGCR2 (FusionGDB2 ID:63834) |
Fusion Gene Summary for PDGFB-DGCR2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PDGFB-DGCR2 | Fusion gene ID: 63834 | Hgene | Tgene | Gene symbol | PDGFB | DGCR2 | Gene ID | 5155 | 9993 |
| Gene name | platelet derived growth factor subunit B | DiGeorge syndrome critical region gene 2 | |
| Synonyms | IBGC5|PDGF-2|PDGF2|SIS|SSV|c-sis | DGS-C|IDD|LAN|SEZ-12 | |
| Cytomap | 22q13.1 | 22q11.21 | |
| Type of gene | protein-coding | protein-coding | |
| Description | platelet-derived growth factor subunit BPDGF subunit BPDGF, B chainbecaplerminepididymis secretory sperm binding proteinplatelet-derived growth factor 2platelet-derived growth factor B chainplatelet-derived growth factor beta polypeptide (simian sa | integral membrane protein DGCR2/IDDDiGeorge syndrome critical region protein 2integral membrane protein deleted in DiGeorge syndrome | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | P98153 | |
| Ensembl transtripts involved in fusion gene | ENST00000331163, ENST00000381551, | ENST00000263196, ENST00000473832, ENST00000537045, ENST00000545799, | |
| Fusion gene scores | * DoF score | 4 X 5 X 3=60 | 10 X 10 X 5=500 |
| # samples | 5 | 11 | |
| ** MAII score | log2(5/60*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/500*10)=-2.18442457113743 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PDGFB [Title/Abstract] AND DGCR2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PDGFB(39626089)-DGCR2(19077003), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | PDGFB-DGCR2 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. PDGFB-DGCR2 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PDGFB | GO:0001938 | positive regulation of endothelial cell proliferation | 9685360 |
| Hgene | PDGFB | GO:0002548 | monocyte chemotaxis | 17991872 |
| Hgene | PDGFB | GO:0006468 | protein phosphorylation | 17942966 |
| Hgene | PDGFB | GO:0008284 | positive regulation of cell proliferation | 2439522|2836953|7073684 |
| Hgene | PDGFB | GO:0009611 | response to wounding | 2538439 |
| Hgene | PDGFB | GO:0010512 | negative regulation of phosphatidylinositol biosynthetic process | 2538439 |
| Hgene | PDGFB | GO:0010544 | negative regulation of platelet activation | 2538439 |
| Hgene | PDGFB | GO:0010628 | positive regulation of gene expression | 23554459|24008408 |
| Hgene | PDGFB | GO:0010629 | negative regulation of gene expression | 23554459|25089138 |
| Hgene | PDGFB | GO:0014068 | positive regulation of phosphatidylinositol 3-kinase signaling | 10734101|11788434|17942966 |
| Hgene | PDGFB | GO:0014911 | positive regulation of smooth muscle cell migration | 9409235 |
| Hgene | PDGFB | GO:0018105 | peptidyl-serine phosphorylation | 16530387 |
| Hgene | PDGFB | GO:0018108 | peptidyl-tyrosine phosphorylation | 10734101|16530387 |
| Hgene | PDGFB | GO:0030335 | positive regulation of cell migration | 11788434|21245381 |
| Hgene | PDGFB | GO:0031954 | positive regulation of protein autophosphorylation | 12070119|16530387 |
| Hgene | PDGFB | GO:0032091 | negative regulation of protein binding | 22619279 |
| Hgene | PDGFB | GO:0032147 | activation of protein kinase activity | 16530387 |
| Hgene | PDGFB | GO:0032148 | activation of protein kinase B activity | 16530387 |
| Hgene | PDGFB | GO:0035655 | interleukin-18-mediated signaling pathway | 21321938 |
| Hgene | PDGFB | GO:0035793 | positive regulation of metanephric mesenchymal cell migration by platelet-derived growth factor receptor-beta signaling pathway | 19019919 |
| Hgene | PDGFB | GO:0043406 | positive regulation of MAP kinase activity | 9685360|11788434|16530387|17942966 |
| Hgene | PDGFB | GO:0043536 | positive regulation of blood vessel endothelial cell migration | 9685360 |
| Hgene | PDGFB | GO:0043552 | positive regulation of phosphatidylinositol 3-kinase activity | 16530387 |
| Hgene | PDGFB | GO:0045737 | positive regulation of cyclin-dependent protein serine/threonine kinase activity | 16530387 |
| Hgene | PDGFB | GO:0045840 | positive regulation of mitotic nuclear division | 10644978|10734101|17942966 |
| Hgene | PDGFB | GO:0045892 | negative regulation of transcription, DNA-templated | 16530387|25089138 |
| Hgene | PDGFB | GO:0045893 | positive regulation of transcription, DNA-templated | 16530387|17324121 |
| Hgene | PDGFB | GO:0048008 | platelet-derived growth factor receptor signaling pathway | 2439522|2536956|2836953|19088079|21245381|23554459 |
| Hgene | PDGFB | GO:0048146 | positive regulation of fibroblast proliferation | 2439522|10644978|17324121 |
| Hgene | PDGFB | GO:0048661 | positive regulation of smooth muscle cell proliferation | 21321938 |
| Hgene | PDGFB | GO:0050731 | positive regulation of peptidyl-tyrosine phosphorylation | 21245381 |
| Hgene | PDGFB | GO:0050921 | positive regulation of chemotaxis | 9409235|19019919 |
| Hgene | PDGFB | GO:0060326 | cell chemotaxis | 16014047|17991872|21245381 |
| Hgene | PDGFB | GO:0061098 | positive regulation of protein tyrosine kinase activity | 16530387 |
| Hgene | PDGFB | GO:0070374 | positive regulation of ERK1 and ERK2 cascade | 11788434|16530387|17942966 |
| Hgene | PDGFB | GO:0071363 | cellular response to growth factor stimulus | 21245381 |
| Hgene | PDGFB | GO:0072126 | positive regulation of glomerular mesangial cell proliferation | 11788434|16014047 |
| Hgene | PDGFB | GO:0090280 | positive regulation of calcium ion import | 19019919 |
| Hgene | PDGFB | GO:1900127 | positive regulation of hyaluronan biosynthetic process | 17324121 |
| Hgene | PDGFB | GO:1902894 | negative regulation of pri-miRNA transcription by RNA polymerase II | 26493107 |
| Hgene | PDGFB | GO:1902895 | positive regulation of pri-miRNA transcription by RNA polymerase II | 19088079 |
| Hgene | PDGFB | GO:1904707 | positive regulation of vascular smooth muscle cell proliferation | 12070119|19088079|23554459 |
| Hgene | PDGFB | GO:1904754 | positive regulation of vascular associated smooth muscle cell migration | 12070119|19088079|23554459 |
| Hgene | PDGFB | GO:1905064 | negative regulation of vascular smooth muscle cell differentiation | 19088079 |
| Hgene | PDGFB | GO:1905176 | positive regulation of vascular smooth muscle cell dedifferentiation | 19088079 |
| Hgene | PDGFB | GO:2000379 | positive regulation of reactive oxygen species metabolic process | 19019919 |
| Hgene | PDGFB | GO:2000573 | positive regulation of DNA biosynthetic process | 10644978|10734101|11788434|12070119|16530387|17942966|19019919 |
| Hgene | PDGFB | GO:2000591 | positive regulation of metanephric mesenchymal cell migration | 10734101 |
| Fusion gene breakpoints across PDGFB (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across DGCR2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
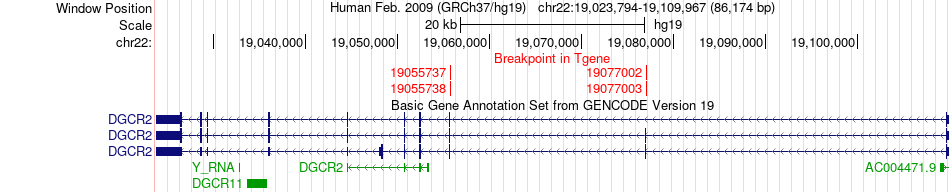 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LGG | TCGA-TM-A84J-01A | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| ChimerDB4 | LGG | TCGA-TM-A84J-01A | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| ChimerDB4 | LGG | TCGA-TM-A84J-01A | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| ChimerDB4 | LGG | TCGA-TM-A84J | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| ChimerDB4 | LGG | TCGA-TM-A84J | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| ChimerDB4 | LGG | TCGA-TM-A84J | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
Top |
Fusion Gene ORF analysis for PDGFB-DGCR2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000331163 | ENST00000263196 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| 5CDS-intron | ENST00000331163 | ENST00000263196 | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000331163 | ENST00000263196 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000331163 | ENST00000473832 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| 5CDS-intron | ENST00000331163 | ENST00000473832 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| 5CDS-intron | ENST00000331163 | ENST00000473832 | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000331163 | ENST00000473832 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| 5CDS-intron | ENST00000331163 | ENST00000473832 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000331163 | ENST00000537045 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| 5CDS-intron | ENST00000331163 | ENST00000537045 | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000331163 | ENST00000537045 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000331163 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| 5CDS-intron | ENST00000331163 | ENST00000545799 | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000331163 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000381551 | ENST00000263196 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| 5CDS-intron | ENST00000381551 | ENST00000263196 | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000381551 | ENST00000263196 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000381551 | ENST00000473832 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| 5CDS-intron | ENST00000381551 | ENST00000473832 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| 5CDS-intron | ENST00000381551 | ENST00000473832 | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000381551 | ENST00000473832 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| 5CDS-intron | ENST00000381551 | ENST00000473832 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000381551 | ENST00000537045 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| 5CDS-intron | ENST00000381551 | ENST00000537045 | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000381551 | ENST00000537045 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000381551 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077002 | - |
| 5CDS-intron | ENST00000381551 | ENST00000545799 | PDGFB | chr22 | 39626089 | - | DGCR2 | chr22 | 19077003 | - |
| 5CDS-intron | ENST00000381551 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19077003 | - |
| Frame-shift | ENST00000331163 | ENST00000263196 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| Frame-shift | ENST00000331163 | ENST00000263196 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| Frame-shift | ENST00000331163 | ENST00000537045 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| Frame-shift | ENST00000331163 | ENST00000537045 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| Frame-shift | ENST00000381551 | ENST00000263196 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| Frame-shift | ENST00000381551 | ENST00000263196 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| Frame-shift | ENST00000381551 | ENST00000537045 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| Frame-shift | ENST00000381551 | ENST00000537045 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| In-frame | ENST00000331163 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| In-frame | ENST00000331163 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| In-frame | ENST00000381551 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - |
| In-frame | ENST00000381551 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000331163 | PDGFB | chr22 | 39626088 | - | ENST00000545799 | DGCR2 | chr22 | 19055738 | - | 5798 | 1389 | 1831 | 473 | 452 |
| ENST00000381551 | PDGFB | chr22 | 39626088 | - | ENST00000545799 | DGCR2 | chr22 | 19055738 | - | 5002 | 593 | 19 | 1200 | 393 |
| ENST00000331163 | PDGFB | chr22 | 39626088 | - | ENST00000545799 | DGCR2 | chr22 | 19055737 | - | 5798 | 1389 | 1831 | 473 | 452 |
| ENST00000381551 | PDGFB | chr22 | 39626088 | - | ENST00000545799 | DGCR2 | chr22 | 19055737 | - | 5002 | 593 | 19 | 1200 | 393 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000331163 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - | 0.14309576 | 0.8569042 |
| ENST00000381551 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055738 | - | 0.14971963 | 0.8502804 |
| ENST00000331163 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - | 0.14309576 | 0.8569042 |
| ENST00000381551 | ENST00000545799 | PDGFB | chr22 | 39626088 | - | DGCR2 | chr22 | 19055737 | - | 0.14971963 | 0.8502804 |
Top |
Fusion Genomic Features for PDGFB-DGCR2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PDGFB-DGCR2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:39626089/chr22:19077003) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | DGCR2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Putative adhesion receptor, that could be involved in cell-cell or cell-matrix interactions required for normal cell differentiation and migration. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000263196 | 1 | 10 | 115_241 | 67 | 551.0 | Domain | C-type lectin | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000263196 | 1 | 10 | 270_333 | 67 | 551.0 | Domain | Note=VWFC | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000537045 | 0 | 9 | 115_241 | 26 | 510.0 | Domain | C-type lectin | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000537045 | 0 | 9 | 270_333 | 26 | 510.0 | Domain | Note=VWFC | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000537045 | 0 | 9 | 28_68 | 26 | 510.0 | Domain | LDL-receptor class A | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000263196 | 1 | 10 | 115_241 | 67 | 551.0 | Domain | C-type lectin | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000263196 | 1 | 10 | 270_333 | 67 | 551.0 | Domain | Note=VWFC | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000537045 | 0 | 9 | 115_241 | 26 | 510.0 | Domain | C-type lectin | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000537045 | 0 | 9 | 270_333 | 26 | 510.0 | Domain | Note=VWFC | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000537045 | 0 | 9 | 28_68 | 26 | 510.0 | Domain | LDL-receptor class A | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000263196 | 1 | 10 | 369_550 | 67 | 551.0 | Topological domain | Cytoplasmic | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000537045 | 0 | 9 | 369_550 | 26 | 510.0 | Topological domain | Cytoplasmic | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000263196 | 1 | 10 | 369_550 | 67 | 551.0 | Topological domain | Cytoplasmic | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000537045 | 0 | 9 | 369_550 | 26 | 510.0 | Topological domain | Cytoplasmic | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000263196 | 1 | 10 | 350_368 | 67 | 551.0 | Transmembrane | Helical | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000537045 | 0 | 9 | 350_368 | 26 | 510.0 | Transmembrane | Helical | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000263196 | 1 | 10 | 350_368 | 67 | 551.0 | Transmembrane | Helical | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000537045 | 0 | 9 | 350_368 | 26 | 510.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000263196 | 1 | 10 | 28_68 | 67 | 551.0 | Domain | LDL-receptor class A | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000263196 | 1 | 10 | 28_68 | 67 | 551.0 | Domain | LDL-receptor class A | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000263196 | 1 | 10 | 21_349 | 67 | 551.0 | Topological domain | Extracellular | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055737 | ENST00000537045 | 0 | 9 | 21_349 | 26 | 510.0 | Topological domain | Extracellular | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000263196 | 1 | 10 | 21_349 | 67 | 551.0 | Topological domain | Extracellular | |
| Tgene | DGCR2 | chr22:39626088 | chr22:19055738 | ENST00000537045 | 0 | 9 | 21_349 | 26 | 510.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for PDGFB-DGCR2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >63834_63834_1_PDGFB-DGCR2_PDGFB_chr22_39626088_ENST00000331163_DGCR2_chr22_19055737_ENST00000545799_length(transcript)=5798nt_BP=1389nt GCAGCTCGCAGCTCGCAGCCCGCAGCCCGCAGAGGACGCCCAGAGCGGCGAGCGGGCGGGCAGACGGACCGACGGACTCGCGCCGCGTCC ACCTGTCGGCCGGGCCCAGCCGAGCGCGCAGCGGGCACGCCGCGCGCGCGGAGCAGCCGTGCCCGCCGCCCGGGCCCCGCGCCAGGGCGC ACACGCTCCCGCCCCCCTACCCGGCCCGGGCGGGAGTTTGCACCTCTCCCTGCCCGGGTGCTCGAGCTGCCGTTGCAAAGCCAACTTTGG AAAAAGTTTTTTGGGGGAGACTTGGGCCTTGAGGTGCCCAGCTCCGCGCTTTCCGATTTTGGGGGCCTTTCCAGAAAATGTTGCAAAAAA GCTAAGCCGGCGGGCAGAGGAAAACGCCTGTAGCCGGCGAGTGAAGACGAACCATCGACTGCCGTGTTCCTTTTCCTCTTGGAGGTTGGA GTCCCCTGGGCGCCCCCACACGGCTAGACGCCTCGGCTGGTTCGCGACGCAGCCCCCCGGCCGTGGATGCTCACTCGGGCTCGGGATCCG CCCAGGTAGCGGCCTCGGACCCAGGTCCTGCGCCCAGGTCCTCCCCTGCCCCCCAGCGACGGAGCCGGGGCCGGGGGCGGCGGCGCCCGG GGGCCATGCGGGTGAGCCGCGGCTGCAGAGGCCTGAGCGCCTGATCGCCGCGGACCCGAGCCGAGCCCACCCCCCTCCCCAGCCCCCCAC CCTGGCCGCGGGGGCGGCGCGCTCGATCTACGCGTCCGGGGCCCCGCGGGGCCGGGCCCGGAGTCGGCATGAATCGCTGCTGGGCGCTCT TCCTGTCTCTCTGCTGCTACCTGCGTCTGGTCAGCGCCGAGGGGGACCCCATTCCCGAGGAGCTTTATGAGATGCTGAGTGACCACTCGA TCCGCTCCTTTGATGATCTCCAACGCCTGCTGCACGGAGACCCCGGAGAGGAAGATGGGGCCGAGTTGGACCTGAACATGACCCGCTCCC ACTCTGGAGGCGAGCTGGAGAGCTTGGCTCGTGGAAGAAGGAGCCTGGGTTCCCTGACCATTGCTGAGCCGGCCATGATCGCCGAGTGCA AGACGCGCACCGAGGTGTTCGAGATCTCCCGGCGCCTCATAGACCGCACCAACGCCAACTTCCTGGTGTGGCCGCCCTGTGTGGAGGTGC AGCGCTGCTCCGGCTGCTGCAACAACCGCAACGTGCAGTGCCGCCCCACCCAGGTGCAGCTGCGACCTGTCCAGGTGAGAAAGATCGAGA TTGTGCGGAAGAAGCCAATCTTTAAGAAGGCCACGGTGACGCTGGAAGACCACCTGGCATGCAAGTGTGAGACAGTGGCAGCTGCACGGC CTGTGACCCGAAGCCCGGGGGGTTCCCAGGAGCAGCGAGAAGTGACCGGGGAGGTGCGTCCTCATCATGGGAAGGAGGCTGTGGATCCGC GGCAGGGGCGGGCCAGAGGAGGCGACCCTTCGCACTTCCACGCGGTGAACGTGGCGCAGCCCGTTCGCTTCAGCAGGAAGTGCCCGACAG GGTGGCACCACTACGAAGGCACGGCCAGCTGCTACCGGGTCTACCTGAGCGGGGAGAACTACTGGGATGCCGCGCAGACCTGCCAGCGCC TGAATGGCTCTCTCGCCACCTTCTCCACTGACCAGGAGCTGCGCTTTGTCCTGGCCCAGGAATGGGACCAGCCCGAGCGGAGCTTTGGTT GGAAGGACCAGCGCAAGTTGTGGGTTGGCTATCAGTATGTTATCACTGGCCGGAACCGCTCCTTGGAAGGTCGCTGGGAGGTGGCATTCA AAGATTGGGGTGTGAGTGATACCATGGTACATAGACGCTTACTATGCCCATGTGTCGGTACCCTGCACACACATTTGAAGTTGGGAGCTC GTTTCCGCAGGGTTCCTGTGCGCCTTGGTGGAGCGCTCTCCAGGCGCTCCCCCAGGCCCACACCAGCCTGTGAGCCCCGCCTGGGGGCCA AGACCCTGCAGGTTTGACAGCACCAGGTCATGATGTGCCCTGGAGACAGAACTGCCGCTGCTGCTGCCAGAAGACATGAGGCCAGGATTT CTGTAACATTTGTGCAGAAAGGTTGAAAAAGTACAGATCCTTGTGTAGGGAGAATCATCCACACCGCCCCACGTGCTGCTCCCAGGGCCT TCCCGTCAGCACCAGCAGTGTAGCTTCTGTCTGGCTCTTCAGAGGTGTTCCTGCCCCCAGACCCCATCTTTGCCTCGGCCATGTCTGAGA ACGACAACGTGTTCTGTGCCCAGCTTCAGTGCTTCCATTTCCCCACCCTGCGGCACCACGACCTCCACAGCTGGCACGCCGAGAGCTGCT ACGAGAAGTCTTCATTTCTGTGTAAAAGAAGTCAAACATGTGTTGACATCAAGGACAACGTGGTGGATGAAGGGTTCTACTTCACCCCTA AGGGGGACGACCCATGCCTGAGCTGCACCTGCCATGGAGGGGAGCCTGAGATGTGTGTGGCTGCTCTCTGTGAGAGGCCCCAGGGCTGCC AACAGTACCGCAAGGACCCCAAAGAGTGCTGCAAGTTCATGTGTCTGGACCCAGATGGCAACAGTCTGTTTGACTCCATGGCCAGCGGGA TGCGCCTGGTCGTCAGCTGCATCTCCTCCTTCCTCATCCTGTCACTGCTGCTCTTCATGGTCCACCGGCTGCGCCAGCGGCGCCGGGAGC GCATCGAGTCCCTGATTGGAGCAAACTTGCACCACTTCAACCTCGGCCGCAGGATCCCTGGCTTTGATTACGGCCCAGACGGGTTTGGCA CGGGCCTCACGCCGCTGCATCTTTCTGACGACGGAGAGGGTGGGACTTTCCATTTCCACGACCCTCCACCTCCCTACACGGCATACAAGT ACCCGGACATCGGCCAGCCCGACGACCCTCCGCCGCCCTACGAGGCCTCCATCCACCCGGACAGTGTGTTCTATGACCCTGCAGACGATG ATGCTTTTGAGCCTGTGGAGGTCAGCCTGCCAGCCCCTGGGGATGGTGGGAGTGAAGGTGCATTACTCCGGCGCCTGGAGCAGCCTCTGC CCACTGCGGGGGCCTCTCTGGCAGACCTGGAAGACTCTGCCGACAGCAGCAGCGCCCTGCTCGTGCCCCCTGACCCTGCCCAGAGCGGGA GCACCCCAGCTGCAGAGGCACTGCCAGGGGGTGGCCGCCACAGCCGCAGCTCCCTCAATACTGTGGTGTAGACGGCCTGGCCTGTACCCC AACGGTCTGGGAGCACCTGTCTGTTGTAGAAAACACCGGTCCCTGGGGAGACTTGAAAGGCCCCTGTCCCAGCCTGGACGCCACGCACTG CCGCACGTCACTGGCGGGCTCGCGTGTGTACATAGAGACCACAGCCCGCCTTCTGCCAAAAGAAGTGATGGCCTGCACCGAGCTTCCTTG AGGGCTTCAGAAACATGCATAGCTTTGGATCACTGTCTTCTCCTTTATAAATGGCAGAAGAGTGACAAAATTCATTCAGACCGCACATGT TAGAGGCAGGGAATGAAGAAGGTACTGTGGGCCATGGCCACACCTGATGCGTTTTTGGTGGGCTTACTTGGTGCAGTGTGCTGTCCAGAG AGACCTGCTGACCCAGTCTGGGACAGGCACAGTGGGAGCTGCCACAGTGCCCCTTGCTGGCCGCCCTCAGGAGGGGGCCTCTGGACCGTC AGTGTGGCGTAGGCAGTGGGTCTGCTTCAGGGAGGCAGCCTCTTGACTTTGTCACAACGGTTGCACTGAAGATGGCCCCCACAAGCCCAG TTGTGAATATCAAGGTGACCCTGCCCCTGGCTGGGAGCTCCCCTGGGGCTCTGGAACCTGAAGCCCTGAGAAGGAGAGCTTGGAAGGAGG TTGAGCTCTTCACTGTGTCTTTCCATCTGGGCTCTGCAGCCCAGCTCTGTGGCAGGAGGCCTGACCCCACCCCATCAGTCCCTCTCCCAG CATTGCTGTGCATGGCTCCCTCAGGAAGAAGCTCTGGAGTGGGGCCGAGGCCCCAGATGCTCTGCTGGGGTCTGGGGACTGAGCTGCCTC CTGTCTCTCCACTCTGGAGCCCTGGGCTCTTGCCTCCTGTTGAATTGCCCCTGGGCCTGCCCCCGGCCCCATTTGTGCCATAAAGGGTTG CTTCATTGCAGGAGGGGTGGCTGAAACCACCATCCTGGGCTGCATCTATCTCCTTAAAGTCCACTCCTTACATCACCGCCACTACTGCAG CTCAGTGCCCAGCGGCCGCATGCACACCTCCCGGCCCCTCCTCAGCAGCGCAGGGGCTGGGGGCCCTTCCTGGCACCCTTTTGCCTGACG GACCCTGTTGCCTGCTCCTGGGCAGTGGTTTTGTTGCCTGACACAGGGCCTTTAACATTTCTGAGGTTTGGAGATTAAGCGGGTTCTGTG CGATTTTTAGCACATCCATATCTTTTCTACGTTGAATGTCTGGATCTTTCCTTTGTATGTTTGTGTCTCTGTGTGTGTATGTGGCCAAGC GTCTGCAGGTGAGGGTGGCACATGGAACTTCACGGGTCACTGGGGGCCCACTCTTCCAGGGTCATCGATGCATCCTGGGCTGTGCTGAGG CAGTGCTGTCTCGCTCAGTCTTTCCAGACCAGCGGGGCAGCACCTGGGAGGCCTGTCTGAAGCATGCAGTTCTGTGGTGCTGCTCGGGGA TGGACTCCATGCACAGTCCACTTCTTGACACATTCTCACACTGTGGCTGGAGACCCATTTTTTCCATCCCATGTGGAATGAGAATCTTGA GTTGCCCACAGACAGACTTGACCTTTGTGCCAGAACTGTCCAGAGCTGTGAGTTTTGTTACTGAATTGCCTGTCCCTGAGCTTGGCCTGC TGGAGCATGATGCTGGAGGCTGTGTGCGGGCAGGCTTGTGCTCCCCTTGGAGAAGGGCTGCTACTTAACAAGGAAGTCCTGGCCACAGGA GTCCCCTACTGGCTGCAGAGGACGAAGCAGGAAGCATGCCGTGGATCCCACATGCACTGGGGCAGGGCAGCCAGGTTCCAGAGCAGCAGG CATGTGCATTATGGGTGCCAGGTGGCCAGTGAGGGCCCGAGGACCACGCAGCAGAGTCCCCCACGGGCCTGAGCCTGAGAGCTCAGAGGA TTCCTGCCAGGCCTCAGAACTGTGTGTGCGGGACAGGGTGGCTGGCACGAGATGTGTGGGACTGGGACGCTTCCTTTGGGGACCAGAGGA ACATTAGGGGCCGGTCAGACACGTAGGGGGCAGTGAGGAAACGGGGTAAAGTGGACCATGCAGGCTGCAGAGGGTGGGCCTTGGGCTGGC CGGGGTTGCTGGGTGGCCCCTTCCCCATGGGCCTCCACAAGCACTCAGGCCACTGGCACGTTGGGCCAGGCAGAAGGTCCACATGGCAGG GCTGCCTGGAACACCGCTGCCACTGTGGCTCCAGGAGGCCCTTGGGAGCATGAGGAGAGCTGGACTCGCTCATCTGTTCTTGCACCACCA TCCAGAATGCCCCCTTTGCAAGGCCTGCTGCAGTCCCCAGTCTGACCAGCAAGTCCCGGGGTCACCCTTGCTGAACCTTGTGCTCCAGGG GTCCTCCTCCTCTAGGACCAGCTTGCCACGGTTTCTCAGAGCCCAGGTGCCCTCTGACCTGCCATGCGGAGGTGGGATTTGATACTGTAC ATTGTCTTGATGCCTGTTTTTTTATGTTTTCATTAAGGGTTTTTAGTTTTTGGTTGGGTTGACACTAACTTTTCTTAAGATGCTGTGAGA >63834_63834_1_PDGFB-DGCR2_PDGFB_chr22_39626088_ENST00000331163_DGCR2_chr22_19055737_ENST00000545799_length(amino acids)=452AA_BP=0 MYHGITHTPIFECHLPATFQGAVPASDNILIANPQLALVLPTKAPLGLVPFLGQDKAQLLVSGEGGERAIQALAGLRGIPVVLPAQVDPV AAGRAFVVVPPCRALPAEANGLRHVHRVEVRRVASSGPPLPRIHSLLPMMRTHLPGHFSLLLGTPRASGHRPCSCHCLTLACQVVFQRHR GLLKDWLLPHNLDLSHLDRSQLHLGGAALHVAVVAAAGAALHLHTGRPHQEVGVGAVYEAPGDLEHLGARLALGDHGRLSNGQGTQAPSS TSQALQLASRVGAGHVQVQLGPIFLSGVSVQQALEIIKGADRVVTQHLIKLLGNGVPLGADQTQVAAERQEERPAAIHADSGPGPAGPRT RRSSAPPPRPGWGAGEGGGLGSGPRRSGAQASAAAAHPHGPRAPPPPAPAPSLGGRGGPGRRTWVRGRYLGGSRARVSIHGRGAASRTSR -------------------------------------------------------------- >63834_63834_2_PDGFB-DGCR2_PDGFB_chr22_39626088_ENST00000331163_DGCR2_chr22_19055738_ENST00000545799_length(transcript)=5798nt_BP=1389nt GCAGCTCGCAGCTCGCAGCCCGCAGCCCGCAGAGGACGCCCAGAGCGGCGAGCGGGCGGGCAGACGGACCGACGGACTCGCGCCGCGTCC ACCTGTCGGCCGGGCCCAGCCGAGCGCGCAGCGGGCACGCCGCGCGCGCGGAGCAGCCGTGCCCGCCGCCCGGGCCCCGCGCCAGGGCGC ACACGCTCCCGCCCCCCTACCCGGCCCGGGCGGGAGTTTGCACCTCTCCCTGCCCGGGTGCTCGAGCTGCCGTTGCAAAGCCAACTTTGG AAAAAGTTTTTTGGGGGAGACTTGGGCCTTGAGGTGCCCAGCTCCGCGCTTTCCGATTTTGGGGGCCTTTCCAGAAAATGTTGCAAAAAA GCTAAGCCGGCGGGCAGAGGAAAACGCCTGTAGCCGGCGAGTGAAGACGAACCATCGACTGCCGTGTTCCTTTTCCTCTTGGAGGTTGGA GTCCCCTGGGCGCCCCCACACGGCTAGACGCCTCGGCTGGTTCGCGACGCAGCCCCCCGGCCGTGGATGCTCACTCGGGCTCGGGATCCG CCCAGGTAGCGGCCTCGGACCCAGGTCCTGCGCCCAGGTCCTCCCCTGCCCCCCAGCGACGGAGCCGGGGCCGGGGGCGGCGGCGCCCGG GGGCCATGCGGGTGAGCCGCGGCTGCAGAGGCCTGAGCGCCTGATCGCCGCGGACCCGAGCCGAGCCCACCCCCCTCCCCAGCCCCCCAC CCTGGCCGCGGGGGCGGCGCGCTCGATCTACGCGTCCGGGGCCCCGCGGGGCCGGGCCCGGAGTCGGCATGAATCGCTGCTGGGCGCTCT TCCTGTCTCTCTGCTGCTACCTGCGTCTGGTCAGCGCCGAGGGGGACCCCATTCCCGAGGAGCTTTATGAGATGCTGAGTGACCACTCGA TCCGCTCCTTTGATGATCTCCAACGCCTGCTGCACGGAGACCCCGGAGAGGAAGATGGGGCCGAGTTGGACCTGAACATGACCCGCTCCC ACTCTGGAGGCGAGCTGGAGAGCTTGGCTCGTGGAAGAAGGAGCCTGGGTTCCCTGACCATTGCTGAGCCGGCCATGATCGCCGAGTGCA AGACGCGCACCGAGGTGTTCGAGATCTCCCGGCGCCTCATAGACCGCACCAACGCCAACTTCCTGGTGTGGCCGCCCTGTGTGGAGGTGC AGCGCTGCTCCGGCTGCTGCAACAACCGCAACGTGCAGTGCCGCCCCACCCAGGTGCAGCTGCGACCTGTCCAGGTGAGAAAGATCGAGA TTGTGCGGAAGAAGCCAATCTTTAAGAAGGCCACGGTGACGCTGGAAGACCACCTGGCATGCAAGTGTGAGACAGTGGCAGCTGCACGGC CTGTGACCCGAAGCCCGGGGGGTTCCCAGGAGCAGCGAGAAGTGACCGGGGAGGTGCGTCCTCATCATGGGAAGGAGGCTGTGGATCCGC GGCAGGGGCGGGCCAGAGGAGGCGACCCTTCGCACTTCCACGCGGTGAACGTGGCGCAGCCCGTTCGCTTCAGCAGGAAGTGCCCGACAG GGTGGCACCACTACGAAGGCACGGCCAGCTGCTACCGGGTCTACCTGAGCGGGGAGAACTACTGGGATGCCGCGCAGACCTGCCAGCGCC TGAATGGCTCTCTCGCCACCTTCTCCACTGACCAGGAGCTGCGCTTTGTCCTGGCCCAGGAATGGGACCAGCCCGAGCGGAGCTTTGGTT GGAAGGACCAGCGCAAGTTGTGGGTTGGCTATCAGTATGTTATCACTGGCCGGAACCGCTCCTTGGAAGGTCGCTGGGAGGTGGCATTCA AAGATTGGGGTGTGAGTGATACCATGGTACATAGACGCTTACTATGCCCATGTGTCGGTACCCTGCACACACATTTGAAGTTGGGAGCTC GTTTCCGCAGGGTTCCTGTGCGCCTTGGTGGAGCGCTCTCCAGGCGCTCCCCCAGGCCCACACCAGCCTGTGAGCCCCGCCTGGGGGCCA AGACCCTGCAGGTTTGACAGCACCAGGTCATGATGTGCCCTGGAGACAGAACTGCCGCTGCTGCTGCCAGAAGACATGAGGCCAGGATTT CTGTAACATTTGTGCAGAAAGGTTGAAAAAGTACAGATCCTTGTGTAGGGAGAATCATCCACACCGCCCCACGTGCTGCTCCCAGGGCCT TCCCGTCAGCACCAGCAGTGTAGCTTCTGTCTGGCTCTTCAGAGGTGTTCCTGCCCCCAGACCCCATCTTTGCCTCGGCCATGTCTGAGA ACGACAACGTGTTCTGTGCCCAGCTTCAGTGCTTCCATTTCCCCACCCTGCGGCACCACGACCTCCACAGCTGGCACGCCGAGAGCTGCT ACGAGAAGTCTTCATTTCTGTGTAAAAGAAGTCAAACATGTGTTGACATCAAGGACAACGTGGTGGATGAAGGGTTCTACTTCACCCCTA AGGGGGACGACCCATGCCTGAGCTGCACCTGCCATGGAGGGGAGCCTGAGATGTGTGTGGCTGCTCTCTGTGAGAGGCCCCAGGGCTGCC AACAGTACCGCAAGGACCCCAAAGAGTGCTGCAAGTTCATGTGTCTGGACCCAGATGGCAACAGTCTGTTTGACTCCATGGCCAGCGGGA TGCGCCTGGTCGTCAGCTGCATCTCCTCCTTCCTCATCCTGTCACTGCTGCTCTTCATGGTCCACCGGCTGCGCCAGCGGCGCCGGGAGC GCATCGAGTCCCTGATTGGAGCAAACTTGCACCACTTCAACCTCGGCCGCAGGATCCCTGGCTTTGATTACGGCCCAGACGGGTTTGGCA CGGGCCTCACGCCGCTGCATCTTTCTGACGACGGAGAGGGTGGGACTTTCCATTTCCACGACCCTCCACCTCCCTACACGGCATACAAGT ACCCGGACATCGGCCAGCCCGACGACCCTCCGCCGCCCTACGAGGCCTCCATCCACCCGGACAGTGTGTTCTATGACCCTGCAGACGATG ATGCTTTTGAGCCTGTGGAGGTCAGCCTGCCAGCCCCTGGGGATGGTGGGAGTGAAGGTGCATTACTCCGGCGCCTGGAGCAGCCTCTGC CCACTGCGGGGGCCTCTCTGGCAGACCTGGAAGACTCTGCCGACAGCAGCAGCGCCCTGCTCGTGCCCCCTGACCCTGCCCAGAGCGGGA GCACCCCAGCTGCAGAGGCACTGCCAGGGGGTGGCCGCCACAGCCGCAGCTCCCTCAATACTGTGGTGTAGACGGCCTGGCCTGTACCCC AACGGTCTGGGAGCACCTGTCTGTTGTAGAAAACACCGGTCCCTGGGGAGACTTGAAAGGCCCCTGTCCCAGCCTGGACGCCACGCACTG CCGCACGTCACTGGCGGGCTCGCGTGTGTACATAGAGACCACAGCCCGCCTTCTGCCAAAAGAAGTGATGGCCTGCACCGAGCTTCCTTG AGGGCTTCAGAAACATGCATAGCTTTGGATCACTGTCTTCTCCTTTATAAATGGCAGAAGAGTGACAAAATTCATTCAGACCGCACATGT TAGAGGCAGGGAATGAAGAAGGTACTGTGGGCCATGGCCACACCTGATGCGTTTTTGGTGGGCTTACTTGGTGCAGTGTGCTGTCCAGAG AGACCTGCTGACCCAGTCTGGGACAGGCACAGTGGGAGCTGCCACAGTGCCCCTTGCTGGCCGCCCTCAGGAGGGGGCCTCTGGACCGTC AGTGTGGCGTAGGCAGTGGGTCTGCTTCAGGGAGGCAGCCTCTTGACTTTGTCACAACGGTTGCACTGAAGATGGCCCCCACAAGCCCAG TTGTGAATATCAAGGTGACCCTGCCCCTGGCTGGGAGCTCCCCTGGGGCTCTGGAACCTGAAGCCCTGAGAAGGAGAGCTTGGAAGGAGG TTGAGCTCTTCACTGTGTCTTTCCATCTGGGCTCTGCAGCCCAGCTCTGTGGCAGGAGGCCTGACCCCACCCCATCAGTCCCTCTCCCAG CATTGCTGTGCATGGCTCCCTCAGGAAGAAGCTCTGGAGTGGGGCCGAGGCCCCAGATGCTCTGCTGGGGTCTGGGGACTGAGCTGCCTC CTGTCTCTCCACTCTGGAGCCCTGGGCTCTTGCCTCCTGTTGAATTGCCCCTGGGCCTGCCCCCGGCCCCATTTGTGCCATAAAGGGTTG CTTCATTGCAGGAGGGGTGGCTGAAACCACCATCCTGGGCTGCATCTATCTCCTTAAAGTCCACTCCTTACATCACCGCCACTACTGCAG CTCAGTGCCCAGCGGCCGCATGCACACCTCCCGGCCCCTCCTCAGCAGCGCAGGGGCTGGGGGCCCTTCCTGGCACCCTTTTGCCTGACG GACCCTGTTGCCTGCTCCTGGGCAGTGGTTTTGTTGCCTGACACAGGGCCTTTAACATTTCTGAGGTTTGGAGATTAAGCGGGTTCTGTG CGATTTTTAGCACATCCATATCTTTTCTACGTTGAATGTCTGGATCTTTCCTTTGTATGTTTGTGTCTCTGTGTGTGTATGTGGCCAAGC GTCTGCAGGTGAGGGTGGCACATGGAACTTCACGGGTCACTGGGGGCCCACTCTTCCAGGGTCATCGATGCATCCTGGGCTGTGCTGAGG CAGTGCTGTCTCGCTCAGTCTTTCCAGACCAGCGGGGCAGCACCTGGGAGGCCTGTCTGAAGCATGCAGTTCTGTGGTGCTGCTCGGGGA TGGACTCCATGCACAGTCCACTTCTTGACACATTCTCACACTGTGGCTGGAGACCCATTTTTTCCATCCCATGTGGAATGAGAATCTTGA GTTGCCCACAGACAGACTTGACCTTTGTGCCAGAACTGTCCAGAGCTGTGAGTTTTGTTACTGAATTGCCTGTCCCTGAGCTTGGCCTGC TGGAGCATGATGCTGGAGGCTGTGTGCGGGCAGGCTTGTGCTCCCCTTGGAGAAGGGCTGCTACTTAACAAGGAAGTCCTGGCCACAGGA GTCCCCTACTGGCTGCAGAGGACGAAGCAGGAAGCATGCCGTGGATCCCACATGCACTGGGGCAGGGCAGCCAGGTTCCAGAGCAGCAGG CATGTGCATTATGGGTGCCAGGTGGCCAGTGAGGGCCCGAGGACCACGCAGCAGAGTCCCCCACGGGCCTGAGCCTGAGAGCTCAGAGGA TTCCTGCCAGGCCTCAGAACTGTGTGTGCGGGACAGGGTGGCTGGCACGAGATGTGTGGGACTGGGACGCTTCCTTTGGGGACCAGAGGA ACATTAGGGGCCGGTCAGACACGTAGGGGGCAGTGAGGAAACGGGGTAAAGTGGACCATGCAGGCTGCAGAGGGTGGGCCTTGGGCTGGC CGGGGTTGCTGGGTGGCCCCTTCCCCATGGGCCTCCACAAGCACTCAGGCCACTGGCACGTTGGGCCAGGCAGAAGGTCCACATGGCAGG GCTGCCTGGAACACCGCTGCCACTGTGGCTCCAGGAGGCCCTTGGGAGCATGAGGAGAGCTGGACTCGCTCATCTGTTCTTGCACCACCA TCCAGAATGCCCCCTTTGCAAGGCCTGCTGCAGTCCCCAGTCTGACCAGCAAGTCCCGGGGTCACCCTTGCTGAACCTTGTGCTCCAGGG GTCCTCCTCCTCTAGGACCAGCTTGCCACGGTTTCTCAGAGCCCAGGTGCCCTCTGACCTGCCATGCGGAGGTGGGATTTGATACTGTAC ATTGTCTTGATGCCTGTTTTTTTATGTTTTCATTAAGGGTTTTTAGTTTTTGGTTGGGTTGACACTAACTTTTCTTAAGATGCTGTGAGA >63834_63834_2_PDGFB-DGCR2_PDGFB_chr22_39626088_ENST00000331163_DGCR2_chr22_19055738_ENST00000545799_length(amino acids)=452AA_BP=0 MYHGITHTPIFECHLPATFQGAVPASDNILIANPQLALVLPTKAPLGLVPFLGQDKAQLLVSGEGGERAIQALAGLRGIPVVLPAQVDPV AAGRAFVVVPPCRALPAEANGLRHVHRVEVRRVASSGPPLPRIHSLLPMMRTHLPGHFSLLLGTPRASGHRPCSCHCLTLACQVVFQRHR GLLKDWLLPHNLDLSHLDRSQLHLGGAALHVAVVAAAGAALHLHTGRPHQEVGVGAVYEAPGDLEHLGARLALGDHGRLSNGQGTQAPSS TSQALQLASRVGAGHVQVQLGPIFLSGVSVQQALEIIKGADRVVTQHLIKLLGNGVPLGADQTQVAAERQEERPAAIHADSGPGPAGPRT RRSSAPPPRPGWGAGEGGGLGSGPRRSGAQASAAAAHPHGPRAPPPPAPAPSLGGRGGPGRRTWVRGRYLGGSRARVSIHGRGAASRTSR -------------------------------------------------------------- >63834_63834_3_PDGFB-DGCR2_PDGFB_chr22_39626088_ENST00000381551_DGCR2_chr22_19055737_ENST00000545799_length(transcript)=5002nt_BP=593nt AGAGAGAGAGAGAGACTGACTGAGCAGGAATGGTGAGATGTTTATCATGGGCCTCGGGGACCCCATTCCCGAGGAGCTTTATGAGATGCT GAGTGACCACTCGATCCGCTCCTTTGATGATCTCCAACGCCTGCTGCACGGAGACCCCGGAGAGGAAGATGGGGCCGAGTTGGACCTGAA CATGACCCGCTCCCACTCTGGAGGCGAGCTGGAGAGCTTGGCTCGTGGAAGAAGGAGCCTGGGTTCCCTGACCATTGCTGAGCCGGCCAT GATCGCCGAGTGCAAGACGCGCACCGAGGTGTTCGAGATCTCCCGGCGCCTCATAGACCGCACCAACGCCAACTTCCTGGTGTGGCCGCC CTGTGTGGAGGTGCAGCGCTGCTCCGGCTGCTGCAACAACCGCAACGTGCAGTGCCGCCCCACCCAGGTGCAGCTGCGACCTGTCCAGGT GAGAAAGATCGAGATTGTGCGGAAGAAGCCAATCTTTAAGAAGGCCACGGTGACGCTGGAAGACCACCTGGCATGCAAGTGTGAGACAGT GGCAGCTGCACGGCCTGTGACCCGAAGCCCGGGGGGTTCCCAGGAGCAGCGAGAAGTGACCGGGGAGGTGCGTCCTCATCATGGGAAGGA GGCTGTGGATCCGCGGCAGGGGCGGGCCAGAGGAGGCGACCCTTCGCACTTCCACGCGGTGAACGTGGCGCAGCCCGTTCGCTTCAGCAG GAAGTGCCCGACAGGGTGGCACCACTACGAAGGCACGGCCAGCTGCTACCGGGTCTACCTGAGCGGGGAGAACTACTGGGATGCCGCGCA GACCTGCCAGCGCCTGAATGGCTCTCTCGCCACCTTCTCCACTGACCAGGAGCTGCGCTTTGTCCTGGCCCAGGAATGGGACCAGCCCGA GCGGAGCTTTGGTTGGAAGGACCAGCGCAAGTTGTGGGTTGGCTATCAGTATGTTATCACTGGCCGGAACCGCTCCTTGGAAGGTCGCTG GGAGGTGGCATTCAAAGATTGGGGTGTGAGTGATACCATGGTACATAGACGCTTACTATGCCCATGTGTCGGTACCCTGCACACACATTT GAAGTTGGGAGCTCGTTTCCGCAGGGTTCCTGTGCGCCTTGGTGGAGCGCTCTCCAGGCGCTCCCCCAGGCCCACACCAGCCTGTGAGCC CCGCCTGGGGGCCAAGACCCTGCAGGTTTGACAGCACCAGGTCATGATGTGCCCTGGAGACAGAACTGCCGCTGCTGCTGCCAGAAGACA TGAGGCCAGGATTTCTGTAACATTTGTGCAGAAAGGTTGAAAAAGTACAGATCCTTGTGTAGGGAGAATCATCCACACCGCCCCACGTGC TGCTCCCAGGGCCTTCCCGTCAGCACCAGCAGTGTAGCTTCTGTCTGGCTCTTCAGAGGTGTTCCTGCCCCCAGACCCCATCTTTGCCTC GGCCATGTCTGAGAACGACAACGTGTTCTGTGCCCAGCTTCAGTGCTTCCATTTCCCCACCCTGCGGCACCACGACCTCCACAGCTGGCA CGCCGAGAGCTGCTACGAGAAGTCTTCATTTCTGTGTAAAAGAAGTCAAACATGTGTTGACATCAAGGACAACGTGGTGGATGAAGGGTT CTACTTCACCCCTAAGGGGGACGACCCATGCCTGAGCTGCACCTGCCATGGAGGGGAGCCTGAGATGTGTGTGGCTGCTCTCTGTGAGAG GCCCCAGGGCTGCCAACAGTACCGCAAGGACCCCAAAGAGTGCTGCAAGTTCATGTGTCTGGACCCAGATGGCAACAGTCTGTTTGACTC CATGGCCAGCGGGATGCGCCTGGTCGTCAGCTGCATCTCCTCCTTCCTCATCCTGTCACTGCTGCTCTTCATGGTCCACCGGCTGCGCCA GCGGCGCCGGGAGCGCATCGAGTCCCTGATTGGAGCAAACTTGCACCACTTCAACCTCGGCCGCAGGATCCCTGGCTTTGATTACGGCCC AGACGGGTTTGGCACGGGCCTCACGCCGCTGCATCTTTCTGACGACGGAGAGGGTGGGACTTTCCATTTCCACGACCCTCCACCTCCCTA CACGGCATACAAGTACCCGGACATCGGCCAGCCCGACGACCCTCCGCCGCCCTACGAGGCCTCCATCCACCCGGACAGTGTGTTCTATGA CCCTGCAGACGATGATGCTTTTGAGCCTGTGGAGGTCAGCCTGCCAGCCCCTGGGGATGGTGGGAGTGAAGGTGCATTACTCCGGCGCCT GGAGCAGCCTCTGCCCACTGCGGGGGCCTCTCTGGCAGACCTGGAAGACTCTGCCGACAGCAGCAGCGCCCTGCTCGTGCCCCCTGACCC TGCCCAGAGCGGGAGCACCCCAGCTGCAGAGGCACTGCCAGGGGGTGGCCGCCACAGCCGCAGCTCCCTCAATACTGTGGTGTAGACGGC CTGGCCTGTACCCCAACGGTCTGGGAGCACCTGTCTGTTGTAGAAAACACCGGTCCCTGGGGAGACTTGAAAGGCCCCTGTCCCAGCCTG GACGCCACGCACTGCCGCACGTCACTGGCGGGCTCGCGTGTGTACATAGAGACCACAGCCCGCCTTCTGCCAAAAGAAGTGATGGCCTGC ACCGAGCTTCCTTGAGGGCTTCAGAAACATGCATAGCTTTGGATCACTGTCTTCTCCTTTATAAATGGCAGAAGAGTGACAAAATTCATT CAGACCGCACATGTTAGAGGCAGGGAATGAAGAAGGTACTGTGGGCCATGGCCACACCTGATGCGTTTTTGGTGGGCTTACTTGGTGCAG TGTGCTGTCCAGAGAGACCTGCTGACCCAGTCTGGGACAGGCACAGTGGGAGCTGCCACAGTGCCCCTTGCTGGCCGCCCTCAGGAGGGG GCCTCTGGACCGTCAGTGTGGCGTAGGCAGTGGGTCTGCTTCAGGGAGGCAGCCTCTTGACTTTGTCACAACGGTTGCACTGAAGATGGC CCCCACAAGCCCAGTTGTGAATATCAAGGTGACCCTGCCCCTGGCTGGGAGCTCCCCTGGGGCTCTGGAACCTGAAGCCCTGAGAAGGAG AGCTTGGAAGGAGGTTGAGCTCTTCACTGTGTCTTTCCATCTGGGCTCTGCAGCCCAGCTCTGTGGCAGGAGGCCTGACCCCACCCCATC AGTCCCTCTCCCAGCATTGCTGTGCATGGCTCCCTCAGGAAGAAGCTCTGGAGTGGGGCCGAGGCCCCAGATGCTCTGCTGGGGTCTGGG GACTGAGCTGCCTCCTGTCTCTCCACTCTGGAGCCCTGGGCTCTTGCCTCCTGTTGAATTGCCCCTGGGCCTGCCCCCGGCCCCATTTGT GCCATAAAGGGTTGCTTCATTGCAGGAGGGGTGGCTGAAACCACCATCCTGGGCTGCATCTATCTCCTTAAAGTCCACTCCTTACATCAC CGCCACTACTGCAGCTCAGTGCCCAGCGGCCGCATGCACACCTCCCGGCCCCTCCTCAGCAGCGCAGGGGCTGGGGGCCCTTCCTGGCAC CCTTTTGCCTGACGGACCCTGTTGCCTGCTCCTGGGCAGTGGTTTTGTTGCCTGACACAGGGCCTTTAACATTTCTGAGGTTTGGAGATT AAGCGGGTTCTGTGCGATTTTTAGCACATCCATATCTTTTCTACGTTGAATGTCTGGATCTTTCCTTTGTATGTTTGTGTCTCTGTGTGT GTATGTGGCCAAGCGTCTGCAGGTGAGGGTGGCACATGGAACTTCACGGGTCACTGGGGGCCCACTCTTCCAGGGTCATCGATGCATCCT GGGCTGTGCTGAGGCAGTGCTGTCTCGCTCAGTCTTTCCAGACCAGCGGGGCAGCACCTGGGAGGCCTGTCTGAAGCATGCAGTTCTGTG GTGCTGCTCGGGGATGGACTCCATGCACAGTCCACTTCTTGACACATTCTCACACTGTGGCTGGAGACCCATTTTTTCCATCCCATGTGG AATGAGAATCTTGAGTTGCCCACAGACAGACTTGACCTTTGTGCCAGAACTGTCCAGAGCTGTGAGTTTTGTTACTGAATTGCCTGTCCC TGAGCTTGGCCTGCTGGAGCATGATGCTGGAGGCTGTGTGCGGGCAGGCTTGTGCTCCCCTTGGAGAAGGGCTGCTACTTAACAAGGAAG TCCTGGCCACAGGAGTCCCCTACTGGCTGCAGAGGACGAAGCAGGAAGCATGCCGTGGATCCCACATGCACTGGGGCAGGGCAGCCAGGT TCCAGAGCAGCAGGCATGTGCATTATGGGTGCCAGGTGGCCAGTGAGGGCCCGAGGACCACGCAGCAGAGTCCCCCACGGGCCTGAGCCT GAGAGCTCAGAGGATTCCTGCCAGGCCTCAGAACTGTGTGTGCGGGACAGGGTGGCTGGCACGAGATGTGTGGGACTGGGACGCTTCCTT TGGGGACCAGAGGAACATTAGGGGCCGGTCAGACACGTAGGGGGCAGTGAGGAAACGGGGTAAAGTGGACCATGCAGGCTGCAGAGGGTG GGCCTTGGGCTGGCCGGGGTTGCTGGGTGGCCCCTTCCCCATGGGCCTCCACAAGCACTCAGGCCACTGGCACGTTGGGCCAGGCAGAAG GTCCACATGGCAGGGCTGCCTGGAACACCGCTGCCACTGTGGCTCCAGGAGGCCCTTGGGAGCATGAGGAGAGCTGGACTCGCTCATCTG TTCTTGCACCACCATCCAGAATGCCCCCTTTGCAAGGCCTGCTGCAGTCCCCAGTCTGACCAGCAAGTCCCGGGGTCACCCTTGCTGAAC CTTGTGCTCCAGGGGTCCTCCTCCTCTAGGACCAGCTTGCCACGGTTTCTCAGAGCCCAGGTGCCCTCTGACCTGCCATGCGGAGGTGGG ATTTGATACTGTACATTGTCTTGATGCCTGTTTTTTTATGTTTTCATTAAGGGTTTTTAGTTTTTGGTTGGGTTGACACTAACTTTTCTT >63834_63834_3_PDGFB-DGCR2_PDGFB_chr22_39626088_ENST00000381551_DGCR2_chr22_19055737_ENST00000545799_length(amino acids)=393AA_BP=191 MSRNGEMFIMGLGDPIPEELYEMLSDHSIRSFDDLQRLLHGDPGEEDGAELDLNMTRSHSGGELESLARGRRSLGSLTIAEPAMIAECKT RTEVFEISRRLIDRTNANFLVWPPCVEVQRCSGCCNNRNVQCRPTQVQLRPVQVRKIEIVRKKPIFKKATVTLEDHLACKCETVAAARPV TRSPGGSQEQREVTGEVRPHHGKEAVDPRQGRARGGDPSHFHAVNVAQPVRFSRKCPTGWHHYEGTASCYRVYLSGENYWDAAQTCQRLN GSLATFSTDQELRFVLAQEWDQPERSFGWKDQRKLWVGYQYVITGRNRSLEGRWEVAFKDWGVSDTMVHRRLLCPCVGTLHTHLKLGARF -------------------------------------------------------------- >63834_63834_4_PDGFB-DGCR2_PDGFB_chr22_39626088_ENST00000381551_DGCR2_chr22_19055738_ENST00000545799_length(transcript)=5002nt_BP=593nt AGAGAGAGAGAGAGACTGACTGAGCAGGAATGGTGAGATGTTTATCATGGGCCTCGGGGACCCCATTCCCGAGGAGCTTTATGAGATGCT GAGTGACCACTCGATCCGCTCCTTTGATGATCTCCAACGCCTGCTGCACGGAGACCCCGGAGAGGAAGATGGGGCCGAGTTGGACCTGAA CATGACCCGCTCCCACTCTGGAGGCGAGCTGGAGAGCTTGGCTCGTGGAAGAAGGAGCCTGGGTTCCCTGACCATTGCTGAGCCGGCCAT GATCGCCGAGTGCAAGACGCGCACCGAGGTGTTCGAGATCTCCCGGCGCCTCATAGACCGCACCAACGCCAACTTCCTGGTGTGGCCGCC CTGTGTGGAGGTGCAGCGCTGCTCCGGCTGCTGCAACAACCGCAACGTGCAGTGCCGCCCCACCCAGGTGCAGCTGCGACCTGTCCAGGT GAGAAAGATCGAGATTGTGCGGAAGAAGCCAATCTTTAAGAAGGCCACGGTGACGCTGGAAGACCACCTGGCATGCAAGTGTGAGACAGT GGCAGCTGCACGGCCTGTGACCCGAAGCCCGGGGGGTTCCCAGGAGCAGCGAGAAGTGACCGGGGAGGTGCGTCCTCATCATGGGAAGGA GGCTGTGGATCCGCGGCAGGGGCGGGCCAGAGGAGGCGACCCTTCGCACTTCCACGCGGTGAACGTGGCGCAGCCCGTTCGCTTCAGCAG GAAGTGCCCGACAGGGTGGCACCACTACGAAGGCACGGCCAGCTGCTACCGGGTCTACCTGAGCGGGGAGAACTACTGGGATGCCGCGCA GACCTGCCAGCGCCTGAATGGCTCTCTCGCCACCTTCTCCACTGACCAGGAGCTGCGCTTTGTCCTGGCCCAGGAATGGGACCAGCCCGA GCGGAGCTTTGGTTGGAAGGACCAGCGCAAGTTGTGGGTTGGCTATCAGTATGTTATCACTGGCCGGAACCGCTCCTTGGAAGGTCGCTG GGAGGTGGCATTCAAAGATTGGGGTGTGAGTGATACCATGGTACATAGACGCTTACTATGCCCATGTGTCGGTACCCTGCACACACATTT GAAGTTGGGAGCTCGTTTCCGCAGGGTTCCTGTGCGCCTTGGTGGAGCGCTCTCCAGGCGCTCCCCCAGGCCCACACCAGCCTGTGAGCC CCGCCTGGGGGCCAAGACCCTGCAGGTTTGACAGCACCAGGTCATGATGTGCCCTGGAGACAGAACTGCCGCTGCTGCTGCCAGAAGACA TGAGGCCAGGATTTCTGTAACATTTGTGCAGAAAGGTTGAAAAAGTACAGATCCTTGTGTAGGGAGAATCATCCACACCGCCCCACGTGC TGCTCCCAGGGCCTTCCCGTCAGCACCAGCAGTGTAGCTTCTGTCTGGCTCTTCAGAGGTGTTCCTGCCCCCAGACCCCATCTTTGCCTC GGCCATGTCTGAGAACGACAACGTGTTCTGTGCCCAGCTTCAGTGCTTCCATTTCCCCACCCTGCGGCACCACGACCTCCACAGCTGGCA CGCCGAGAGCTGCTACGAGAAGTCTTCATTTCTGTGTAAAAGAAGTCAAACATGTGTTGACATCAAGGACAACGTGGTGGATGAAGGGTT CTACTTCACCCCTAAGGGGGACGACCCATGCCTGAGCTGCACCTGCCATGGAGGGGAGCCTGAGATGTGTGTGGCTGCTCTCTGTGAGAG GCCCCAGGGCTGCCAACAGTACCGCAAGGACCCCAAAGAGTGCTGCAAGTTCATGTGTCTGGACCCAGATGGCAACAGTCTGTTTGACTC CATGGCCAGCGGGATGCGCCTGGTCGTCAGCTGCATCTCCTCCTTCCTCATCCTGTCACTGCTGCTCTTCATGGTCCACCGGCTGCGCCA GCGGCGCCGGGAGCGCATCGAGTCCCTGATTGGAGCAAACTTGCACCACTTCAACCTCGGCCGCAGGATCCCTGGCTTTGATTACGGCCC AGACGGGTTTGGCACGGGCCTCACGCCGCTGCATCTTTCTGACGACGGAGAGGGTGGGACTTTCCATTTCCACGACCCTCCACCTCCCTA CACGGCATACAAGTACCCGGACATCGGCCAGCCCGACGACCCTCCGCCGCCCTACGAGGCCTCCATCCACCCGGACAGTGTGTTCTATGA CCCTGCAGACGATGATGCTTTTGAGCCTGTGGAGGTCAGCCTGCCAGCCCCTGGGGATGGTGGGAGTGAAGGTGCATTACTCCGGCGCCT GGAGCAGCCTCTGCCCACTGCGGGGGCCTCTCTGGCAGACCTGGAAGACTCTGCCGACAGCAGCAGCGCCCTGCTCGTGCCCCCTGACCC TGCCCAGAGCGGGAGCACCCCAGCTGCAGAGGCACTGCCAGGGGGTGGCCGCCACAGCCGCAGCTCCCTCAATACTGTGGTGTAGACGGC CTGGCCTGTACCCCAACGGTCTGGGAGCACCTGTCTGTTGTAGAAAACACCGGTCCCTGGGGAGACTTGAAAGGCCCCTGTCCCAGCCTG GACGCCACGCACTGCCGCACGTCACTGGCGGGCTCGCGTGTGTACATAGAGACCACAGCCCGCCTTCTGCCAAAAGAAGTGATGGCCTGC ACCGAGCTTCCTTGAGGGCTTCAGAAACATGCATAGCTTTGGATCACTGTCTTCTCCTTTATAAATGGCAGAAGAGTGACAAAATTCATT CAGACCGCACATGTTAGAGGCAGGGAATGAAGAAGGTACTGTGGGCCATGGCCACACCTGATGCGTTTTTGGTGGGCTTACTTGGTGCAG TGTGCTGTCCAGAGAGACCTGCTGACCCAGTCTGGGACAGGCACAGTGGGAGCTGCCACAGTGCCCCTTGCTGGCCGCCCTCAGGAGGGG GCCTCTGGACCGTCAGTGTGGCGTAGGCAGTGGGTCTGCTTCAGGGAGGCAGCCTCTTGACTTTGTCACAACGGTTGCACTGAAGATGGC CCCCACAAGCCCAGTTGTGAATATCAAGGTGACCCTGCCCCTGGCTGGGAGCTCCCCTGGGGCTCTGGAACCTGAAGCCCTGAGAAGGAG AGCTTGGAAGGAGGTTGAGCTCTTCACTGTGTCTTTCCATCTGGGCTCTGCAGCCCAGCTCTGTGGCAGGAGGCCTGACCCCACCCCATC AGTCCCTCTCCCAGCATTGCTGTGCATGGCTCCCTCAGGAAGAAGCTCTGGAGTGGGGCCGAGGCCCCAGATGCTCTGCTGGGGTCTGGG GACTGAGCTGCCTCCTGTCTCTCCACTCTGGAGCCCTGGGCTCTTGCCTCCTGTTGAATTGCCCCTGGGCCTGCCCCCGGCCCCATTTGT GCCATAAAGGGTTGCTTCATTGCAGGAGGGGTGGCTGAAACCACCATCCTGGGCTGCATCTATCTCCTTAAAGTCCACTCCTTACATCAC CGCCACTACTGCAGCTCAGTGCCCAGCGGCCGCATGCACACCTCCCGGCCCCTCCTCAGCAGCGCAGGGGCTGGGGGCCCTTCCTGGCAC CCTTTTGCCTGACGGACCCTGTTGCCTGCTCCTGGGCAGTGGTTTTGTTGCCTGACACAGGGCCTTTAACATTTCTGAGGTTTGGAGATT AAGCGGGTTCTGTGCGATTTTTAGCACATCCATATCTTTTCTACGTTGAATGTCTGGATCTTTCCTTTGTATGTTTGTGTCTCTGTGTGT GTATGTGGCCAAGCGTCTGCAGGTGAGGGTGGCACATGGAACTTCACGGGTCACTGGGGGCCCACTCTTCCAGGGTCATCGATGCATCCT GGGCTGTGCTGAGGCAGTGCTGTCTCGCTCAGTCTTTCCAGACCAGCGGGGCAGCACCTGGGAGGCCTGTCTGAAGCATGCAGTTCTGTG GTGCTGCTCGGGGATGGACTCCATGCACAGTCCACTTCTTGACACATTCTCACACTGTGGCTGGAGACCCATTTTTTCCATCCCATGTGG AATGAGAATCTTGAGTTGCCCACAGACAGACTTGACCTTTGTGCCAGAACTGTCCAGAGCTGTGAGTTTTGTTACTGAATTGCCTGTCCC TGAGCTTGGCCTGCTGGAGCATGATGCTGGAGGCTGTGTGCGGGCAGGCTTGTGCTCCCCTTGGAGAAGGGCTGCTACTTAACAAGGAAG TCCTGGCCACAGGAGTCCCCTACTGGCTGCAGAGGACGAAGCAGGAAGCATGCCGTGGATCCCACATGCACTGGGGCAGGGCAGCCAGGT TCCAGAGCAGCAGGCATGTGCATTATGGGTGCCAGGTGGCCAGTGAGGGCCCGAGGACCACGCAGCAGAGTCCCCCACGGGCCTGAGCCT GAGAGCTCAGAGGATTCCTGCCAGGCCTCAGAACTGTGTGTGCGGGACAGGGTGGCTGGCACGAGATGTGTGGGACTGGGACGCTTCCTT TGGGGACCAGAGGAACATTAGGGGCCGGTCAGACACGTAGGGGGCAGTGAGGAAACGGGGTAAAGTGGACCATGCAGGCTGCAGAGGGTG GGCCTTGGGCTGGCCGGGGTTGCTGGGTGGCCCCTTCCCCATGGGCCTCCACAAGCACTCAGGCCACTGGCACGTTGGGCCAGGCAGAAG GTCCACATGGCAGGGCTGCCTGGAACACCGCTGCCACTGTGGCTCCAGGAGGCCCTTGGGAGCATGAGGAGAGCTGGACTCGCTCATCTG TTCTTGCACCACCATCCAGAATGCCCCCTTTGCAAGGCCTGCTGCAGTCCCCAGTCTGACCAGCAAGTCCCGGGGTCACCCTTGCTGAAC CTTGTGCTCCAGGGGTCCTCCTCCTCTAGGACCAGCTTGCCACGGTTTCTCAGAGCCCAGGTGCCCTCTGACCTGCCATGCGGAGGTGGG ATTTGATACTGTACATTGTCTTGATGCCTGTTTTTTTATGTTTTCATTAAGGGTTTTTAGTTTTTGGTTGGGTTGACACTAACTTTTCTT >63834_63834_4_PDGFB-DGCR2_PDGFB_chr22_39626088_ENST00000381551_DGCR2_chr22_19055738_ENST00000545799_length(amino acids)=393AA_BP=191 MSRNGEMFIMGLGDPIPEELYEMLSDHSIRSFDDLQRLLHGDPGEEDGAELDLNMTRSHSGGELESLARGRRSLGSLTIAEPAMIAECKT RTEVFEISRRLIDRTNANFLVWPPCVEVQRCSGCCNNRNVQCRPTQVQLRPVQVRKIEIVRKKPIFKKATVTLEDHLACKCETVAAARPV TRSPGGSQEQREVTGEVRPHHGKEAVDPRQGRARGGDPSHFHAVNVAQPVRFSRKCPTGWHHYEGTASCYRVYLSGENYWDAAQTCQRLN GSLATFSTDQELRFVLAQEWDQPERSFGWKDQRKLWVGYQYVITGRNRSLEGRWEVAFKDWGVSDTMVHRRLLCPCVGTLHTHLKLGARF -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PDGFB-DGCR2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PDGFB-DGCR2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PDGFB-DGCR2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies