
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PDGFD-PRCP (FusionGDB2 ID:63848) |
Fusion Gene Summary for PDGFD-PRCP |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PDGFD-PRCP | Fusion gene ID: 63848 | Hgene | Tgene | Gene symbol | PDGFD | PRCP | Gene ID | 80310 | 5547 |
| Gene name | platelet derived growth factor D | prolylcarboxypeptidase | |
| Synonyms | IEGF|MSTP036|SCDGF-B|SCDGFB | HUMPCP|PCP | |
| Cytomap | 11q22.3 | 11q14.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | platelet-derived growth factor DPDGF-Diris-expressed growth factorspinal cord-derived growth factor B | lysosomal Pro-X carboxypeptidaseangiotensinase Clysosomal carboxypeptidase Cproline carboxypeptidase | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000302251, ENST00000393158, | ENST00000525772, ENST00000535099, ENST00000313010, ENST00000393399, | |
| Fusion gene scores | * DoF score | 6 X 6 X 3=108 | 9 X 8 X 6=432 |
| # samples | 7 | 11 | |
| ** MAII score | log2(7/108*10)=-0.625604485218502 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/432*10)=-1.97352778863881 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PDGFD [Title/Abstract] AND PRCP [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PDGFD(104034531)-PRCP(82571159), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across PDGFD (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PRCP (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-8532 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
Top |
Fusion Gene ORF analysis for PDGFD-PRCP |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000302251 | ENST00000525772 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
| 5CDS-intron | ENST00000302251 | ENST00000535099 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
| 5CDS-intron | ENST00000393158 | ENST00000525772 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
| 5CDS-intron | ENST00000393158 | ENST00000535099 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
| In-frame | ENST00000302251 | ENST00000313010 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
| In-frame | ENST00000302251 | ENST00000393399 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
| In-frame | ENST00000393158 | ENST00000313010 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
| In-frame | ENST00000393158 | ENST00000393399 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000393158 | PDGFD | chr11 | 104034531 | - | ENST00000313010 | PRCP | chr11 | 82571159 | - | 3031 | 304 | 244 | 1626 | 460 |
| ENST00000393158 | PDGFD | chr11 | 104034531 | - | ENST00000393399 | PRCP | chr11 | 82571159 | - | 2165 | 304 | 244 | 1626 | 460 |
| ENST00000302251 | PDGFD | chr11 | 104034531 | - | ENST00000313010 | PRCP | chr11 | 82571159 | - | 3303 | 576 | 516 | 1898 | 460 |
| ENST00000302251 | PDGFD | chr11 | 104034531 | - | ENST00000393399 | PRCP | chr11 | 82571159 | - | 2437 | 576 | 516 | 1898 | 460 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000393158 | ENST00000313010 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - | 0.000846515 | 0.9991535 |
| ENST00000393158 | ENST00000393399 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - | 0.001832072 | 0.9981679 |
| ENST00000302251 | ENST00000313010 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - | 0.001191295 | 0.99880874 |
| ENST00000302251 | ENST00000393399 | PDGFD | chr11 | 104034531 | - | PRCP | chr11 | 82571159 | - | 0.002812214 | 0.9971878 |
Top |
Fusion Genomic Features for PDGFD-PRCP |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
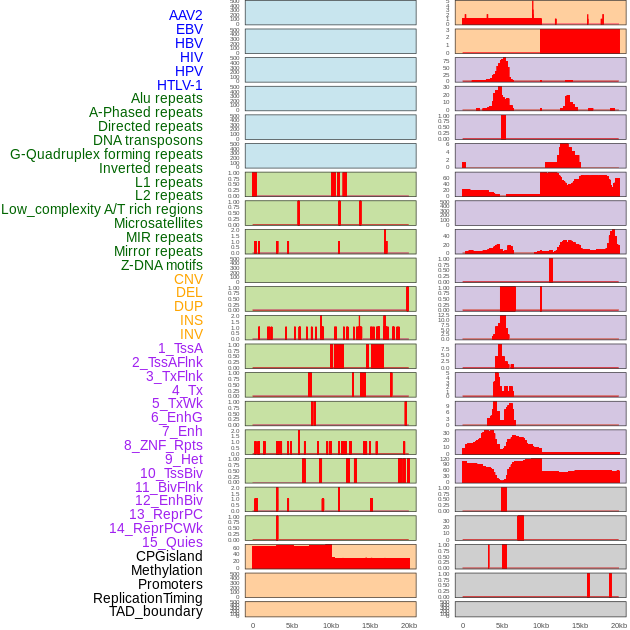 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PDGFD-PRCP |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:104034531/chr11:82571159) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PRCP | chr11:104034531 | chr11:82571159 | ENST00000313010 | 0 | 9 | 194_334 | 56 | 497.0 | Region | Note=SKS domain | |
| Tgene | PRCP | chr11:104034531 | chr11:82571159 | ENST00000393399 | 1 | 10 | 194_334 | 77 | 518.0 | Region | Note=SKS domain |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PDGFD | chr11:104034531 | chr11:82571159 | ENST00000302251 | - | 1 | 7 | 52_170 | 41 | 365.0 | Domain | CUB |
| Hgene | PDGFD | chr11:104034531 | chr11:82571159 | ENST00000393158 | - | 1 | 7 | 52_170 | 41 | 371.0 | Domain | CUB |
Top |
Fusion Gene Sequence for PDGFD-PRCP |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >63848_63848_1_PDGFD-PRCP_PDGFD_chr11_104034531_ENST00000302251_PRCP_chr11_82571159_ENST00000313010_length(transcript)=3303nt_BP=576nt GGCAGAGCAGGTTTAGGCCCGGCCTGGGAAACTGGGGAGCTGAGGTGCTCGCGCCGCCGCTCTGAGCCCGAGTGCGCGCCTCTCAGGGGC CGCGGCCGGGGCTGGAGAACGCTGCTGCTCCGCTCGCCTGCCCCGCTAGATTCGGCGCTGCCCGCCCCCTGCAGCCTGTGCTGCAGCTGC CGGCCACCGGAGGGGGCGAACAAACAAACGTCAACCTGTTGTTTGTCCCGTCACCATTTATCAGCTCAGCACCACAAGGAAGTGCGGCAC CCACACGCGCTCGGAAAGTTCAGCATGCAGGAAGTTTGGGGAGAGCTCGGCGATTAGCACAGCGACCCGGGCCAGCGCAGGGCGAGCGCA GGCGGCGAGAGCGCAGGGCGGCGCGGCGTCGGTCCCGGGAGCAGAACCCGGCTTTTTCTTGGAGCGACGCTGTCTCTAGTCGCTGATCCC AAATGCACCGGCTCATCTTTGTCTACACTCTAATCTGCGCAAACTTTTGCAGCTGTCGGGACACTTCTGCAACCCCGCAGAGCGCATCCA TCAAAGCTTTGCGCAACGCCAACCTCAGGCGAGATGGTTGATCATTTTGGATTTAATACTGTGAAAACTTTTAATCAGCGGTACCTAGTA GCTGATAAATACTGGAAGAAAAATGGTGGATCAATACTTTTCTACACTGGTAATGAAGGGGACATTATCTGGTTTTGTAATAACACGGGG TTCATGTGGGATGTGGCTGAGGAACTGAAAGCTATGTTGGTGTTTGCTGAACATCGATACTATGGAGAGTCTCTCCCCTTTGGTGACAAC TCATTCAAGGATTCCAGACACTTGAATTTCCTGACATCAGAACAAGCTCTGGCTGATTTTGCAGAGTTAATCAAACACTTGAAAAGAACA ATCCCAGGAGCTGAAAATCAACCTGTCATTGCCATAGGAGGCTCCTATGGTGGCATGCTTGCCGCCTGGTTTAGGATGAAATATCCTCAT ATGGTAGTTGGAGCTCTTGCAGCTTCTGCCCCTATCTGGCAGTTTGAGGATTTAGTACCTTGTGGTGTATTTATGAAGATCGTAACTACA GATTTTAGGAAAAGCGGTCCACATTGTTCAGAGAGCATCCACAGGTCCTGGGATGCCATTAATCGACTCTCAAATACTGGCAGTGGTTTG CAGTGGCTTACTGGAGCCCTTCACTTATGCAGCCCATTAACTTCTCAGGACATCCAACATTTGAAAGACTGGATCTCTGAAACCTGGGTG AATCTGGCAATGGTGGACTATCCTTATGCCTCTAACTTTTTACAGCCTTTGCCTGCTTGGCCTATCAAGGTAGTGTGCCAGTATTTGAAA AATCCCAATGTATCTGATTCACTGCTGCTGCAGAATATTTTCCAAGCTCTGAATGTATATTACAATTATTCGGGCCAGGTGAAATGCCTG AATATTTCAGAGACAGCAACTAGCAGTCTGGGAACACTGGGTTGGAGCTATCAGGCCTGCACAGAAGTAGTCATGCCCTTTTGTACTAAT GGTGTCGATGACATGTTTGAACCTCACTCATGGAACTTAAAGGAACTTTCTGATGACTGTTTTCAACAGTGGGGTGTGAGACCAAGGCCC TCCTGGATCACTACTATGTATGGAGGCAAAAACATTAGTTCACACACAAACATTGTTTTCAGCAATGGTGAACTAGACCCCTGGTCAGGA GGTGGAGTAACTAAGGATATCACAGACACTCTGGTTGCAGTCACCATCTCAGAGGGGGCCCACCACTTAGATCTCCGCACCAAGAATGCC TTGGATCCTATGTCTGTGCTGTTAGCCCGCTCCTTGGAAGTTAGACATATGAAGAATTGGATCAGAGATTTCTATGACAGTGCGGGAAAG CAGCACTGAGAAACTTTTGATTGTTTTCAATTTCTTCTTTTATGTTCACACCACCACATTCCCATTCACTTTGATTTTCTACATGTAATT ACCTTCTTTTGTTTATCATTAGATTTGATGGGGCCAAAGTTGAGATAGAATAGAGGGTGATGACGGTAAGAGCAAGTGTCCCATGAATGT GATTTCCTGGGTTCTCACTGTCTTTGCACCACGTCTAGGAAGAATCTTCTTGATAGCTCTCCCACACCATCAGTGGCCCTCATAACTGGA GTAGAGTTCCTGGTTGCTTTTCATAAGAGGGAGAGTTACTTTCTTTGTATCTCTGCAAGCAGAGATTTCTCTTTGGTTTTGAGGTTGAAG TGTCTTTGGCCCATTTGTAAGTCCCCATCCCTACCCTACACAAAGTAAAAGCAGAAGATAGATAAAAAATGATGTAATTGCAGCTGGTAG GATGTCTGGTGCCAATCCAGGAAGTGAGAGCCATTTCTTTTGTACCGGATTTAATGACTTTGAACTGTGCTGTAAATAAATAATACAGCT GGACCTTATACCTGTGTGTTGCTTCTGAAGCTCACTTCAACTCCGGCTGATGGAAATGCTGTGTGCACTGGGCTTAGCTGTTTTTGGAAA GTCCTTTAATTTTTTCTCTTCCACTTGGCAGCTTTTCTTAGTTCTGGGATGTTGGCCACTGTGGTACTGCCAGTAAGAAATCTGGCCTTT TTCTGCTCCATTTCTCTTTGTTTCTAAGGTCAGTTTTAATTTGTTTGAATTCTGCCAGTTTAGGAAAATGACTCTGTTTTGTCTTTTTAA ATCTGAGCAAGCTTTATGCTGTAGTCACTAATTATATTTCAGTAAGAAGCCTTTAAAAATTGATGAATCAGCTATTCCAAAAGTAGAATA TAGTAATATTCAGCTTTTAAATTTTTAAAATTTTATTTTCTGATAGTTGTTACTGCTGTCATTAAAACCAGAAGTGTTAGACACTAACAG GCAGGTGCACAAGAACTTTTCTGTATGACTTCCAAAAGACAAGCTGACTAATTCATGCAGGCAGCATATTTGACATTAATAAATGGCCAA GCCATTCCTATTTCCAAGGGGTTGGCTTCTTTCAAGCAGTTCTTACACTGAGACCTTTCTTCAGAGAGCTTTTCTAGGATAACAAATAGG GTTGGATCAAAACCTTTCAGGGACACAGAGAGACAGAGAGAGAGAGACTAACAGTTTCTACTCTGTTGAAAGATTTCTTCCTCCTTGTTT CTTTTCATTTTCTCTCAATAATTTTTTTTTCTTCACCCTGCCTTGGGAACATTTTCTGCTTTTAAAAAACTGTACCTTGAGCTTGATCAT >63848_63848_1_PDGFD-PRCP_PDGFD_chr11_104034531_ENST00000302251_PRCP_chr11_82571159_ENST00000313010_length(amino acids)=460AA_BP=20 MQPRRAHPSKLCATPTSGEMVDHFGFNTVKTFNQRYLVADKYWKKNGGSILFYTGNEGDIIWFCNNTGFMWDVAEELKAMLVFAEHRYYG ESLPFGDNSFKDSRHLNFLTSEQALADFAELIKHLKRTIPGAENQPVIAIGGSYGGMLAAWFRMKYPHMVVGALAASAPIWQFEDLVPCG VFMKIVTTDFRKSGPHCSESIHRSWDAINRLSNTGSGLQWLTGALHLCSPLTSQDIQHLKDWISETWVNLAMVDYPYASNFLQPLPAWPI KVVCQYLKNPNVSDSLLLQNIFQALNVYYNYSGQVKCLNISETATSSLGTLGWSYQACTEVVMPFCTNGVDDMFEPHSWNLKELSDDCFQ QWGVRPRPSWITTMYGGKNISSHTNIVFSNGELDPWSGGGVTKDITDTLVAVTISEGAHHLDLRTKNALDPMSVLLARSLEVRHMKNWIR -------------------------------------------------------------- >63848_63848_2_PDGFD-PRCP_PDGFD_chr11_104034531_ENST00000302251_PRCP_chr11_82571159_ENST00000393399_length(transcript)=2437nt_BP=576nt GGCAGAGCAGGTTTAGGCCCGGCCTGGGAAACTGGGGAGCTGAGGTGCTCGCGCCGCCGCTCTGAGCCCGAGTGCGCGCCTCTCAGGGGC CGCGGCCGGGGCTGGAGAACGCTGCTGCTCCGCTCGCCTGCCCCGCTAGATTCGGCGCTGCCCGCCCCCTGCAGCCTGTGCTGCAGCTGC CGGCCACCGGAGGGGGCGAACAAACAAACGTCAACCTGTTGTTTGTCCCGTCACCATTTATCAGCTCAGCACCACAAGGAAGTGCGGCAC CCACACGCGCTCGGAAAGTTCAGCATGCAGGAAGTTTGGGGAGAGCTCGGCGATTAGCACAGCGACCCGGGCCAGCGCAGGGCGAGCGCA GGCGGCGAGAGCGCAGGGCGGCGCGGCGTCGGTCCCGGGAGCAGAACCCGGCTTTTTCTTGGAGCGACGCTGTCTCTAGTCGCTGATCCC AAATGCACCGGCTCATCTTTGTCTACACTCTAATCTGCGCAAACTTTTGCAGCTGTCGGGACACTTCTGCAACCCCGCAGAGCGCATCCA TCAAAGCTTTGCGCAACGCCAACCTCAGGCGAGATGGTTGATCATTTTGGATTTAATACTGTGAAAACTTTTAATCAGCGGTACCTAGTA GCTGATAAATACTGGAAGAAAAATGGTGGATCAATACTTTTCTACACTGGTAATGAAGGGGACATTATCTGGTTTTGTAATAACACGGGG TTCATGTGGGATGTGGCTGAGGAACTGAAAGCTATGTTGGTGTTTGCTGAACATCGATACTATGGAGAGTCTCTCCCCTTTGGTGACAAC TCATTCAAGGATTCCAGACACTTGAATTTCCTGACATCAGAACAAGCTCTGGCTGATTTTGCAGAGTTAATCAAACACTTGAAAAGAACA ATCCCAGGAGCTGAAAATCAACCTGTCATTGCCATAGGAGGCTCCTATGGTGGCATGCTTGCCGCCTGGTTTAGGATGAAATATCCTCAT ATGGTAGTTGGAGCTCTTGCAGCTTCTGCCCCTATCTGGCAGTTTGAGGATTTAGTACCTTGTGGTGTATTTATGAAGATCGTAACTACA GATTTTAGGAAAAGCGGTCCACATTGTTCAGAGAGCATCCACAGGTCCTGGGATGCCATTAATCGACTCTCAAATACTGGCAGTGGTTTG CAGTGGCTTACTGGAGCCCTTCACTTATGCAGCCCATTAACTTCTCAGGACATCCAACATTTGAAAGACTGGATCTCTGAAACCTGGGTG AATCTGGCAATGGTGGACTATCCTTATGCCTCTAACTTTTTACAGCCTTTGCCTGCTTGGCCTATCAAGGTAGTGTGCCAGTATTTGAAA AATCCCAATGTATCTGATTCACTGCTGCTGCAGAATATTTTCCAAGCTCTGAATGTATATTACAATTATTCGGGCCAGGTGAAATGCCTG AATATTTCAGAGACAGCAACTAGCAGTCTGGGAACACTGGGTTGGAGCTATCAGGCCTGCACAGAAGTAGTCATGCCCTTTTGTACTAAT GGTGTCGATGACATGTTTGAACCTCACTCATGGAACTTAAAGGAACTTTCTGATGACTGTTTTCAACAGTGGGGTGTGAGACCAAGGCCC TCCTGGATCACTACTATGTATGGAGGCAAAAACATTAGTTCACACACAAACATTGTTTTCAGCAATGGTGAACTAGACCCCTGGTCAGGA GGTGGAGTAACTAAGGATATCACAGACACTCTGGTTGCAGTCACCATCTCAGAGGGGGCCCACCACTTAGATCTCCGCACCAAGAATGCC TTGGATCCTATGTCTGTGCTGTTAGCCCGCTCCTTGGAAGTTAGACATATGAAGAATTGGATCAGAGATTTCTATGACAGTGCGGGAAAG CAGCACTGAGAAACTTTTGATTGTTTTCAATTTCTTCTTTTATGTTCACACCACCACATTCCCATTCACTTTGATTTTCTACATGTAATT ACCTTCTTTTGTTTATCATTAGATTTGATGGGGCCAAAGTTGAGATAGAATAGAGGGTGATGACGGTAAGAGCAAGTGTCCCATGAATGT GATTTCCTGGGTTCTCACTGTCTTTGCACCACGTCTAGGAAGAATCTTCTTGATAGCTCTCCCACACCATCAGTGGCCCTCATAACTGGA GTAGAGTTCCTGGTTGCTTTTCATAAGAGGGAGAGTTACTTTCTTTGTATCTCTGCAAGCAGAGATTTCTCTTTGGTTTTGAGGTTGAAG TGTCTTTGGCCCATTTGTAAGTCCCCATCCCTACCCTACACAAAGTAAAAGCAGAAGATAGATAAAAAATGATGTAATTGCAGCTGGTAG GATGTCTGGTGCCAATCCAGGAAGTGAGAGCCATTTCTTTTGTACCGGATTTAATGACTTTGAACTGTGCTGTAAATAAATAATACAGCT >63848_63848_2_PDGFD-PRCP_PDGFD_chr11_104034531_ENST00000302251_PRCP_chr11_82571159_ENST00000393399_length(amino acids)=460AA_BP=20 MQPRRAHPSKLCATPTSGEMVDHFGFNTVKTFNQRYLVADKYWKKNGGSILFYTGNEGDIIWFCNNTGFMWDVAEELKAMLVFAEHRYYG ESLPFGDNSFKDSRHLNFLTSEQALADFAELIKHLKRTIPGAENQPVIAIGGSYGGMLAAWFRMKYPHMVVGALAASAPIWQFEDLVPCG VFMKIVTTDFRKSGPHCSESIHRSWDAINRLSNTGSGLQWLTGALHLCSPLTSQDIQHLKDWISETWVNLAMVDYPYASNFLQPLPAWPI KVVCQYLKNPNVSDSLLLQNIFQALNVYYNYSGQVKCLNISETATSSLGTLGWSYQACTEVVMPFCTNGVDDMFEPHSWNLKELSDDCFQ QWGVRPRPSWITTMYGGKNISSHTNIVFSNGELDPWSGGGVTKDITDTLVAVTISEGAHHLDLRTKNALDPMSVLLARSLEVRHMKNWIR -------------------------------------------------------------- >63848_63848_3_PDGFD-PRCP_PDGFD_chr11_104034531_ENST00000393158_PRCP_chr11_82571159_ENST00000313010_length(transcript)=3031nt_BP=304nt ACACGCGCTCGGAAAGTTCAGCATGCAGGAAGTTTGGGGAGAGCTCGGCGATTAGCACAGCGACCCGGGCCAGCGCAGGGCGAGCGCAGG CGGCGAGAGCGCAGGGCGGCGCGGCGTCGGTCCCGGGAGCAGAACCCGGCTTTTTCTTGGAGCGACGCTGTCTCTAGTCGCTGATCCCAA ATGCACCGGCTCATCTTTGTCTACACTCTAATCTGCGCAAACTTTTGCAGCTGTCGGGACACTTCTGCAACCCCGCAGAGCGCATCCATC AAAGCTTTGCGCAACGCCAACCTCAGGCGAGATGGTTGATCATTTTGGATTTAATACTGTGAAAACTTTTAATCAGCGGTACCTAGTAGC TGATAAATACTGGAAGAAAAATGGTGGATCAATACTTTTCTACACTGGTAATGAAGGGGACATTATCTGGTTTTGTAATAACACGGGGTT CATGTGGGATGTGGCTGAGGAACTGAAAGCTATGTTGGTGTTTGCTGAACATCGATACTATGGAGAGTCTCTCCCCTTTGGTGACAACTC ATTCAAGGATTCCAGACACTTGAATTTCCTGACATCAGAACAAGCTCTGGCTGATTTTGCAGAGTTAATCAAACACTTGAAAAGAACAAT CCCAGGAGCTGAAAATCAACCTGTCATTGCCATAGGAGGCTCCTATGGTGGCATGCTTGCCGCCTGGTTTAGGATGAAATATCCTCATAT GGTAGTTGGAGCTCTTGCAGCTTCTGCCCCTATCTGGCAGTTTGAGGATTTAGTACCTTGTGGTGTATTTATGAAGATCGTAACTACAGA TTTTAGGAAAAGCGGTCCACATTGTTCAGAGAGCATCCACAGGTCCTGGGATGCCATTAATCGACTCTCAAATACTGGCAGTGGTTTGCA GTGGCTTACTGGAGCCCTTCACTTATGCAGCCCATTAACTTCTCAGGACATCCAACATTTGAAAGACTGGATCTCTGAAACCTGGGTGAA TCTGGCAATGGTGGACTATCCTTATGCCTCTAACTTTTTACAGCCTTTGCCTGCTTGGCCTATCAAGGTAGTGTGCCAGTATTTGAAAAA TCCCAATGTATCTGATTCACTGCTGCTGCAGAATATTTTCCAAGCTCTGAATGTATATTACAATTATTCGGGCCAGGTGAAATGCCTGAA TATTTCAGAGACAGCAACTAGCAGTCTGGGAACACTGGGTTGGAGCTATCAGGCCTGCACAGAAGTAGTCATGCCCTTTTGTACTAATGG TGTCGATGACATGTTTGAACCTCACTCATGGAACTTAAAGGAACTTTCTGATGACTGTTTTCAACAGTGGGGTGTGAGACCAAGGCCCTC CTGGATCACTACTATGTATGGAGGCAAAAACATTAGTTCACACACAAACATTGTTTTCAGCAATGGTGAACTAGACCCCTGGTCAGGAGG TGGAGTAACTAAGGATATCACAGACACTCTGGTTGCAGTCACCATCTCAGAGGGGGCCCACCACTTAGATCTCCGCACCAAGAATGCCTT GGATCCTATGTCTGTGCTGTTAGCCCGCTCCTTGGAAGTTAGACATATGAAGAATTGGATCAGAGATTTCTATGACAGTGCGGGAAAGCA GCACTGAGAAACTTTTGATTGTTTTCAATTTCTTCTTTTATGTTCACACCACCACATTCCCATTCACTTTGATTTTCTACATGTAATTAC CTTCTTTTGTTTATCATTAGATTTGATGGGGCCAAAGTTGAGATAGAATAGAGGGTGATGACGGTAAGAGCAAGTGTCCCATGAATGTGA TTTCCTGGGTTCTCACTGTCTTTGCACCACGTCTAGGAAGAATCTTCTTGATAGCTCTCCCACACCATCAGTGGCCCTCATAACTGGAGT AGAGTTCCTGGTTGCTTTTCATAAGAGGGAGAGTTACTTTCTTTGTATCTCTGCAAGCAGAGATTTCTCTTTGGTTTTGAGGTTGAAGTG TCTTTGGCCCATTTGTAAGTCCCCATCCCTACCCTACACAAAGTAAAAGCAGAAGATAGATAAAAAATGATGTAATTGCAGCTGGTAGGA TGTCTGGTGCCAATCCAGGAAGTGAGAGCCATTTCTTTTGTACCGGATTTAATGACTTTGAACTGTGCTGTAAATAAATAATACAGCTGG ACCTTATACCTGTGTGTTGCTTCTGAAGCTCACTTCAACTCCGGCTGATGGAAATGCTGTGTGCACTGGGCTTAGCTGTTTTTGGAAAGT CCTTTAATTTTTTCTCTTCCACTTGGCAGCTTTTCTTAGTTCTGGGATGTTGGCCACTGTGGTACTGCCAGTAAGAAATCTGGCCTTTTT CTGCTCCATTTCTCTTTGTTTCTAAGGTCAGTTTTAATTTGTTTGAATTCTGCCAGTTTAGGAAAATGACTCTGTTTTGTCTTTTTAAAT CTGAGCAAGCTTTATGCTGTAGTCACTAATTATATTTCAGTAAGAAGCCTTTAAAAATTGATGAATCAGCTATTCCAAAAGTAGAATATA GTAATATTCAGCTTTTAAATTTTTAAAATTTTATTTTCTGATAGTTGTTACTGCTGTCATTAAAACCAGAAGTGTTAGACACTAACAGGC AGGTGCACAAGAACTTTTCTGTATGACTTCCAAAAGACAAGCTGACTAATTCATGCAGGCAGCATATTTGACATTAATAAATGGCCAAGC CATTCCTATTTCCAAGGGGTTGGCTTCTTTCAAGCAGTTCTTACACTGAGACCTTTCTTCAGAGAGCTTTTCTAGGATAACAAATAGGGT TGGATCAAAACCTTTCAGGGACACAGAGAGACAGAGAGAGAGAGACTAACAGTTTCTACTCTGTTGAAAGATTTCTTCCTCCTTGTTTCT TTTCATTTTCTCTCAATAATTTTTTTTTCTTCACCCTGCCTTGGGAACATTTTCTGCTTTTAAAAAACTGTACCTTGAGCTTGATCATTT >63848_63848_3_PDGFD-PRCP_PDGFD_chr11_104034531_ENST00000393158_PRCP_chr11_82571159_ENST00000313010_length(amino acids)=460AA_BP=20 MQPRRAHPSKLCATPTSGEMVDHFGFNTVKTFNQRYLVADKYWKKNGGSILFYTGNEGDIIWFCNNTGFMWDVAEELKAMLVFAEHRYYG ESLPFGDNSFKDSRHLNFLTSEQALADFAELIKHLKRTIPGAENQPVIAIGGSYGGMLAAWFRMKYPHMVVGALAASAPIWQFEDLVPCG VFMKIVTTDFRKSGPHCSESIHRSWDAINRLSNTGSGLQWLTGALHLCSPLTSQDIQHLKDWISETWVNLAMVDYPYASNFLQPLPAWPI KVVCQYLKNPNVSDSLLLQNIFQALNVYYNYSGQVKCLNISETATSSLGTLGWSYQACTEVVMPFCTNGVDDMFEPHSWNLKELSDDCFQ QWGVRPRPSWITTMYGGKNISSHTNIVFSNGELDPWSGGGVTKDITDTLVAVTISEGAHHLDLRTKNALDPMSVLLARSLEVRHMKNWIR -------------------------------------------------------------- >63848_63848_4_PDGFD-PRCP_PDGFD_chr11_104034531_ENST00000393158_PRCP_chr11_82571159_ENST00000393399_length(transcript)=2165nt_BP=304nt ACACGCGCTCGGAAAGTTCAGCATGCAGGAAGTTTGGGGAGAGCTCGGCGATTAGCACAGCGACCCGGGCCAGCGCAGGGCGAGCGCAGG CGGCGAGAGCGCAGGGCGGCGCGGCGTCGGTCCCGGGAGCAGAACCCGGCTTTTTCTTGGAGCGACGCTGTCTCTAGTCGCTGATCCCAA ATGCACCGGCTCATCTTTGTCTACACTCTAATCTGCGCAAACTTTTGCAGCTGTCGGGACACTTCTGCAACCCCGCAGAGCGCATCCATC AAAGCTTTGCGCAACGCCAACCTCAGGCGAGATGGTTGATCATTTTGGATTTAATACTGTGAAAACTTTTAATCAGCGGTACCTAGTAGC TGATAAATACTGGAAGAAAAATGGTGGATCAATACTTTTCTACACTGGTAATGAAGGGGACATTATCTGGTTTTGTAATAACACGGGGTT CATGTGGGATGTGGCTGAGGAACTGAAAGCTATGTTGGTGTTTGCTGAACATCGATACTATGGAGAGTCTCTCCCCTTTGGTGACAACTC ATTCAAGGATTCCAGACACTTGAATTTCCTGACATCAGAACAAGCTCTGGCTGATTTTGCAGAGTTAATCAAACACTTGAAAAGAACAAT CCCAGGAGCTGAAAATCAACCTGTCATTGCCATAGGAGGCTCCTATGGTGGCATGCTTGCCGCCTGGTTTAGGATGAAATATCCTCATAT GGTAGTTGGAGCTCTTGCAGCTTCTGCCCCTATCTGGCAGTTTGAGGATTTAGTACCTTGTGGTGTATTTATGAAGATCGTAACTACAGA TTTTAGGAAAAGCGGTCCACATTGTTCAGAGAGCATCCACAGGTCCTGGGATGCCATTAATCGACTCTCAAATACTGGCAGTGGTTTGCA GTGGCTTACTGGAGCCCTTCACTTATGCAGCCCATTAACTTCTCAGGACATCCAACATTTGAAAGACTGGATCTCTGAAACCTGGGTGAA TCTGGCAATGGTGGACTATCCTTATGCCTCTAACTTTTTACAGCCTTTGCCTGCTTGGCCTATCAAGGTAGTGTGCCAGTATTTGAAAAA TCCCAATGTATCTGATTCACTGCTGCTGCAGAATATTTTCCAAGCTCTGAATGTATATTACAATTATTCGGGCCAGGTGAAATGCCTGAA TATTTCAGAGACAGCAACTAGCAGTCTGGGAACACTGGGTTGGAGCTATCAGGCCTGCACAGAAGTAGTCATGCCCTTTTGTACTAATGG TGTCGATGACATGTTTGAACCTCACTCATGGAACTTAAAGGAACTTTCTGATGACTGTTTTCAACAGTGGGGTGTGAGACCAAGGCCCTC CTGGATCACTACTATGTATGGAGGCAAAAACATTAGTTCACACACAAACATTGTTTTCAGCAATGGTGAACTAGACCCCTGGTCAGGAGG TGGAGTAACTAAGGATATCACAGACACTCTGGTTGCAGTCACCATCTCAGAGGGGGCCCACCACTTAGATCTCCGCACCAAGAATGCCTT GGATCCTATGTCTGTGCTGTTAGCCCGCTCCTTGGAAGTTAGACATATGAAGAATTGGATCAGAGATTTCTATGACAGTGCGGGAAAGCA GCACTGAGAAACTTTTGATTGTTTTCAATTTCTTCTTTTATGTTCACACCACCACATTCCCATTCACTTTGATTTTCTACATGTAATTAC CTTCTTTTGTTTATCATTAGATTTGATGGGGCCAAAGTTGAGATAGAATAGAGGGTGATGACGGTAAGAGCAAGTGTCCCATGAATGTGA TTTCCTGGGTTCTCACTGTCTTTGCACCACGTCTAGGAAGAATCTTCTTGATAGCTCTCCCACACCATCAGTGGCCCTCATAACTGGAGT AGAGTTCCTGGTTGCTTTTCATAAGAGGGAGAGTTACTTTCTTTGTATCTCTGCAAGCAGAGATTTCTCTTTGGTTTTGAGGTTGAAGTG TCTTTGGCCCATTTGTAAGTCCCCATCCCTACCCTACACAAAGTAAAAGCAGAAGATAGATAAAAAATGATGTAATTGCAGCTGGTAGGA TGTCTGGTGCCAATCCAGGAAGTGAGAGCCATTTCTTTTGTACCGGATTTAATGACTTTGAACTGTGCTGTAAATAAATAATACAGCTGG >63848_63848_4_PDGFD-PRCP_PDGFD_chr11_104034531_ENST00000393158_PRCP_chr11_82571159_ENST00000393399_length(amino acids)=460AA_BP=20 MQPRRAHPSKLCATPTSGEMVDHFGFNTVKTFNQRYLVADKYWKKNGGSILFYTGNEGDIIWFCNNTGFMWDVAEELKAMLVFAEHRYYG ESLPFGDNSFKDSRHLNFLTSEQALADFAELIKHLKRTIPGAENQPVIAIGGSYGGMLAAWFRMKYPHMVVGALAASAPIWQFEDLVPCG VFMKIVTTDFRKSGPHCSESIHRSWDAINRLSNTGSGLQWLTGALHLCSPLTSQDIQHLKDWISETWVNLAMVDYPYASNFLQPLPAWPI KVVCQYLKNPNVSDSLLLQNIFQALNVYYNYSGQVKCLNISETATSSLGTLGWSYQACTEVVMPFCTNGVDDMFEPHSWNLKELSDDCFQ QWGVRPRPSWITTMYGGKNISSHTNIVFSNGELDPWSGGGVTKDITDTLVAVTISEGAHHLDLRTKNALDPMSVLLARSLEVRHMKNWIR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PDGFD-PRCP |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PDGFD-PRCP |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PDGFD-PRCP |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies