
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PDZD8-ENO4 (FusionGDB2 ID:64158) |
Fusion Gene Summary for PDZD8-ENO4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PDZD8-ENO4 | Fusion gene ID: 64158 | Hgene | Tgene | Gene symbol | PDZD8 | ENO4 | Gene ID | 118987 | 387712 |
| Gene name | PDZ domain containing 8 | enolase 4 | |
| Synonyms | PDZK8 | C10orf134 | |
| Cytomap | 10q25.3-q26.11 | 10q25.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | PDZ domain-containing protein 8sarcoma antigen NY-SAR-84/NY-SAR-104 | enolase 42-phospho-D-glycerate hydro-lyaseenolase family member 4enolase-like protein ENO4 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000334464, ENST00000482496, | ENST00000369207, ENST00000409522, ENST00000341276, | |
| Fusion gene scores | * DoF score | 13 X 9 X 7=819 | 4 X 6 X 2=48 |
| # samples | 14 | 4 | |
| ** MAII score | log2(14/819*10)=-2.54843662469604 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PDZD8 [Title/Abstract] AND ENO4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PDZD8(119078383)-ENO4(118615134), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PDZD8 | GO:0051560 | mitochondrial calcium ion homeostasis | 29097544 |
| Hgene | PDZD8 | GO:1990456 | mitochondrion-endoplasmic reticulum membrane tethering | 29097544 |
| Fusion gene breakpoints across PDZD8 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ENO4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
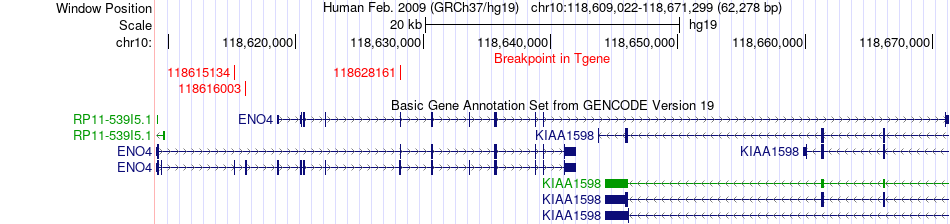 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SKCM | TCGA-DA-A1I8-06A | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118615134 | + |
| ChimerDB4 | SKCM | TCGA-DA-A1I8-06A | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118616003 | + |
| ChimerDB4 | SKCM | TCGA-DA-A1I8-06A | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + |
Top |
Fusion Gene ORF analysis for PDZD8-ENO4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000334464 | ENST00000369207 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118615134 | + |
| 5CDS-intron | ENST00000334464 | ENST00000369207 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118616003 | + |
| 5CDS-intron | ENST00000334464 | ENST00000409522 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118615134 | + |
| 5CDS-intron | ENST00000334464 | ENST00000409522 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118616003 | + |
| In-frame | ENST00000334464 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118615134 | + |
| In-frame | ENST00000334464 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118616003 | + |
| In-frame | ENST00000334464 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + |
| In-frame | ENST00000334464 | ENST00000369207 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + |
| In-frame | ENST00000334464 | ENST00000409522 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + |
| intron-3CDS | ENST00000482496 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118615134 | + |
| intron-3CDS | ENST00000482496 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118616003 | + |
| intron-3CDS | ENST00000482496 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + |
| intron-3CDS | ENST00000482496 | ENST00000369207 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + |
| intron-3CDS | ENST00000482496 | ENST00000409522 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + |
| intron-intron | ENST00000482496 | ENST00000369207 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118615134 | + |
| intron-intron | ENST00000482496 | ENST00000369207 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118616003 | + |
| intron-intron | ENST00000482496 | ENST00000409522 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118615134 | + |
| intron-intron | ENST00000482496 | ENST00000409522 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118616003 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000334464 | PDZD8 | chr10 | 119078383 | - | ENST00000341276 | ENO4 | chr10 | 118615134 | + | 3894 | 1338 | 240 | 3056 | 938 |
| ENST00000334464 | PDZD8 | chr10 | 119078383 | - | ENST00000341276 | ENO4 | chr10 | 118616003 | + | 3765 | 1338 | 240 | 2927 | 895 |
| ENST00000334464 | PDZD8 | chr10 | 119078383 | - | ENST00000341276 | ENO4 | chr10 | 118628161 | + | 3063 | 1338 | 240 | 2225 | 661 |
| ENST00000334464 | PDZD8 | chr10 | 119078383 | - | ENST00000409522 | ENO4 | chr10 | 118628161 | + | 2958 | 1338 | 240 | 2099 | 619 |
| ENST00000334464 | PDZD8 | chr10 | 119078383 | - | ENST00000369207 | ENO4 | chr10 | 118628161 | + | 2361 | 1338 | 240 | 2144 | 634 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000334464 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118615134 | + | 0.000479347 | 0.99952066 |
| ENST00000334464 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118616003 | + | 0.000585311 | 0.9994147 |
| ENST00000334464 | ENST00000341276 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + | 0.001143516 | 0.99885654 |
| ENST00000334464 | ENST00000409522 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + | 0.000956912 | 0.99904305 |
| ENST00000334464 | ENST00000369207 | PDZD8 | chr10 | 119078383 | - | ENO4 | chr10 | 118628161 | + | 0.001729645 | 0.9982704 |
Top |
Fusion Genomic Features for PDZD8-ENO4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PDZD8 | chr10 | 119078382 | - | ENO4 | chr10 | 118628160 | + | 7.44E-05 | 0.9999256 |
| PDZD8 | chr10 | 119078382 | - | ENO4 | chr10 | 118615133 | + | 1.55E-06 | 0.99999845 |
| PDZD8 | chr10 | 119078382 | - | ENO4 | chr10 | 118616002 | + | 4.64E-07 | 0.9999995 |
| PDZD8 | chr10 | 119078382 | - | ENO4 | chr10 | 118628160 | + | 7.44E-05 | 0.9999256 |
| PDZD8 | chr10 | 119078382 | - | ENO4 | chr10 | 118615133 | + | 1.55E-06 | 0.99999845 |
| PDZD8 | chr10 | 119078382 | - | ENO4 | chr10 | 118616002 | + | 4.64E-07 | 0.9999995 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
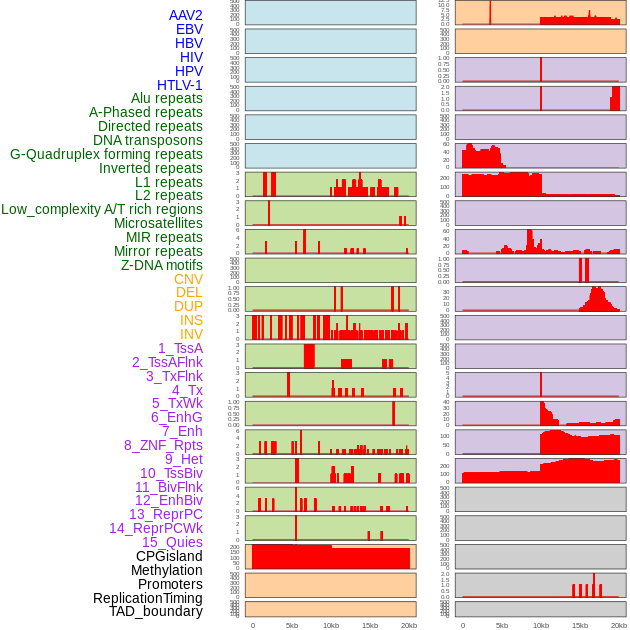 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
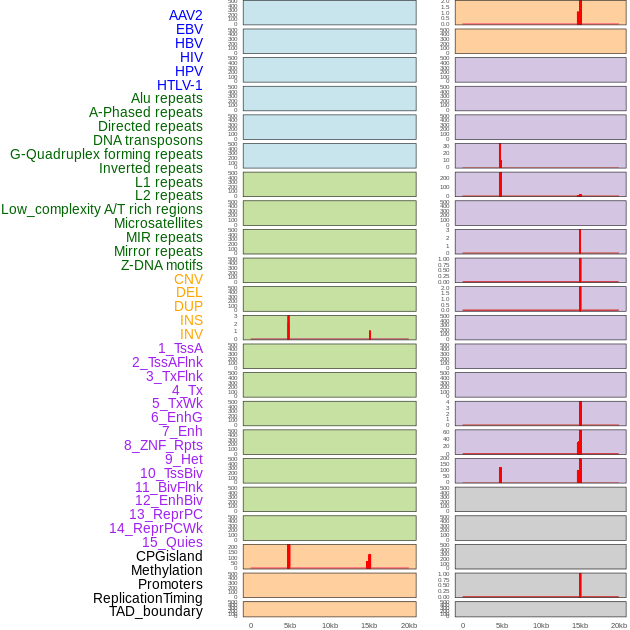 |
Top |
Fusion Protein Features for PDZD8-ENO4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:119078383/chr10:118615134) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PDZD8 | chr10:119078383 | chr10:118615134 | ENST00000334464 | - | 3 | 5 | 91_294 | 366 | 1155.0 | Domain | SMP-LTD |
| Hgene | PDZD8 | chr10:119078383 | chr10:118616003 | ENST00000334464 | - | 3 | 5 | 91_294 | 366 | 1155.0 | Domain | SMP-LTD |
| Hgene | PDZD8 | chr10:119078383 | chr10:118628161 | ENST00000334464 | - | 3 | 5 | 91_294 | 366 | 1155.0 | Domain | SMP-LTD |
| Hgene | PDZD8 | chr10:119078383 | chr10:118615134 | ENST00000334464 | - | 3 | 5 | 2_24 | 366 | 1155.0 | Transmembrane | Helical |
| Hgene | PDZD8 | chr10:119078383 | chr10:118616003 | ENST00000334464 | - | 3 | 5 | 2_24 | 366 | 1155.0 | Transmembrane | Helical |
| Hgene | PDZD8 | chr10:119078383 | chr10:118628161 | ENST00000334464 | - | 3 | 5 | 2_24 | 366 | 1155.0 | Transmembrane | Helical |
| Tgene | ENO4 | chr10:119078383 | chr10:118615134 | ENST00000409522 | 0 | 7 | 189_231 | 0 | 309.0 | Compositional bias | Note=Pro-rich | |
| Tgene | ENO4 | chr10:119078383 | chr10:118616003 | ENST00000409522 | 0 | 7 | 189_231 | 0 | 309.0 | Compositional bias | Note=Pro-rich | |
| Tgene | ENO4 | chr10:119078383 | chr10:118628161 | ENST00000409522 | 0 | 7 | 189_231 | 55 | 309.0 | Compositional bias | Note=Pro-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PDZD8 | chr10:119078383 | chr10:118615134 | ENST00000334464 | - | 3 | 5 | 1028_1063 | 366 | 1155.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PDZD8 | chr10:119078383 | chr10:118616003 | ENST00000334464 | - | 3 | 5 | 1028_1063 | 366 | 1155.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PDZD8 | chr10:119078383 | chr10:118628161 | ENST00000334464 | - | 3 | 5 | 1028_1063 | 366 | 1155.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PDZD8 | chr10:119078383 | chr10:118615134 | ENST00000334464 | - | 3 | 5 | 551_626 | 366 | 1155.0 | Compositional bias | Note=Pro-rich |
| Hgene | PDZD8 | chr10:119078383 | chr10:118616003 | ENST00000334464 | - | 3 | 5 | 551_626 | 366 | 1155.0 | Compositional bias | Note=Pro-rich |
| Hgene | PDZD8 | chr10:119078383 | chr10:118628161 | ENST00000334464 | - | 3 | 5 | 551_626 | 366 | 1155.0 | Compositional bias | Note=Pro-rich |
| Hgene | PDZD8 | chr10:119078383 | chr10:118615134 | ENST00000334464 | - | 3 | 5 | 366_449 | 366 | 1155.0 | Domain | PDZ |
| Hgene | PDZD8 | chr10:119078383 | chr10:118616003 | ENST00000334464 | - | 3 | 5 | 366_449 | 366 | 1155.0 | Domain | PDZ |
| Hgene | PDZD8 | chr10:119078383 | chr10:118628161 | ENST00000334464 | - | 3 | 5 | 366_449 | 366 | 1155.0 | Domain | PDZ |
| Hgene | PDZD8 | chr10:119078383 | chr10:118615134 | ENST00000334464 | - | 3 | 5 | 840_891 | 366 | 1155.0 | Zinc finger | Phorbol-ester/DAG-type |
| Hgene | PDZD8 | chr10:119078383 | chr10:118616003 | ENST00000334464 | - | 3 | 5 | 840_891 | 366 | 1155.0 | Zinc finger | Phorbol-ester/DAG-type |
| Hgene | PDZD8 | chr10:119078383 | chr10:118628161 | ENST00000334464 | - | 3 | 5 | 840_891 | 366 | 1155.0 | Zinc finger | Phorbol-ester/DAG-type |
Top |
Fusion Gene Sequence for PDZD8-ENO4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >64158_64158_1_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118615134_ENST00000341276_length(transcript)=3894nt_BP=1338nt GGTCCCGGCCCCGCTGCCGCCGCCGCCACACCGGCCCTTCGGGAGCGTCTGAGGAGGCGCGGGCCGCTGCGGGCTCGGGCGCCGCAGCGC GCCGGCCCGAGCCCCTGGACGAGGCCCACGGAGCCGCTCGCCCCGACCCAGCCGCCCGATGTCCTCAAAATGGAGGCAGCGGGGGCGGCG GCGTGAAGAAAGCGGCGCTGTGGGCGCGGGAGTAGGGGCCCGGGCGGAGGCGGTGGCGGGATGGGGCTGCTGCTCATGATCCTGGCGTCG GCCGTGCTGGGTTCCTTCCTCACGCTCCTCGCCCAGTTCTTCCTGCTGTACCGCAGACAGCCCGAGCCGCCGGCGGACGAGGCCGCCCGC GCGGGCGAGGGCTTCCGCTACATCAAGCCAGTGCCGGGCCTGCTCCTAAGGGAGTACCTTTATGGCGGCGGCCGGGATGAGGAGCCCTCC GGAGCGGCCCCTGAGGGCGGCGCGACCCCCACCGCGGCCCCCGAGACCCCCGCCCCGCCGACGCGGGAGACTTGCTACTTCCTCAACGCC ACCATCCTATTCCTGTTCCGGGAGTTGCGGGACACCGCGCTGACCCGCCGCTGGGTCACCAAGAAGATCAAGGTGGAGTTCGAGGAGCTG CTGCAGACCAAGACGGCCGGGCGCCTGCTGGAGGGGCTGAGCCTGCGGGACGTGTTCCTGGGCGAGACGGTGCCCTTCATCAAGACCATC CGGCTCGTGCGGCCAGTCGTGCCCTCGGCCACCGGGGAGCCCGATGGCCCTGAAGGGGAGGCGCTGCCCGCCGCCTGCCCCGAGGAGCTG GCCTTCGAGGCGGAGGTGGAGTACAACGGGGGCTTCCACCTGGCCATCGACGTGGACCTGGTCTTCGGCAAGTCCGCCTACTTGTTTGTC AAGCTGTCCCGCGTGGTGGGAAGGCTGCGCTTGGTCTTTACGCGCGTGCCCTTCACCCACTGGTTCTTCTCCTTCGTGGAAGACCCGCTG ATCGACTTCGAGGTGCGCTCCCAGTTTGAAGGGCGGCCCATGCCCCAGCTCACCTCCATCATCGTCAACCAGCTCAAGAAGATCATCAAG CGCAAGCACACCCTACCGAATTACAAGATCAGGTTTAAGCCGTTTTTTCCATACCAGACCTTGCAAGGATTTGAAGAAGATGAAGAGCAT ATCCATATACAACAATGGGCACTTACTGAAGGCCGTCTTAAAGTTACGTTGTTAGAATGTAGCAGGTTACTCATTTTTGGATCCTATGAC AGAGAGGCAAATGTTCATTGCACACTTGAGTTAAGCAGTAGTGTTTGGGAAGAAAAACAGAGGAGTTCTATTAAGACGGCAAACTGCTTT TCTAAACTTGCAAAGCCTCCCACCATATGCAAAATAGTGGGGAAAGACGTACTAGATGGACTGGGGCTTCCAACCCTGCAAGTGGACATA TTCTGCACCATTCAAAACTTTCCCAAGAACGTATGTTCTGTGGTGATCTCGACTCATTTTGAAGTCCATGAGAATGCTCTGCCCGAGCTG GCCAAGGCGGAGGAGGCAGAGAGGGCCAGCGCGGTGAGCACCGCCGTGCAGTGGGTCAACAGCACCATCACGCACGAGCTCCAGGGGATG GCACCCTCTGACCAGGCAGAGGTGGATCACCTACTCAGGATATTCTTCGCAAGTAAAGTACAAGAAGATAAGGGGAGAAAAGAATTGGAA AAGAGCCTGGAATACTCAACAGTGCCTACACCTCTACCTCCAGTACCACCACCACCACCCCCTCCACCTCCTACCAAAAAAAAGGGGCAA AAGCCAGGGAGGAAGGATACTATTACAGAGAAACCTATTGCGCCTGCAGAGCCTGTTGAGCCTGTACTCAGTGGCAGTATGGCCATAGGG GCCGTGTCACTAGCTGTTGCCAAAGCCTGTGCCATGCTGCTTAATAAACCTCTGTACTTAAATATCGCTCTACTGAAGCACAATCAGGAA CAGCCAACAACGCTATCTATGCCTTTGCTGATGGTATCGCTGGTCAGCTGTGGGAAGTCATCATCTGGGAAGCTAAATTTAATGAAAGAA GTGATTTGTATACCCCATCCTGAATTAACAACCAAACAAGGTGTCGAGATGCTTATGGAAATGCAGAAACATATCAACAAAATAATTGAA ATGGTATCACCCTCTCCTCCAAAAGCAGAGACAAAAAAAGGGCACGATGGAAGCAAAAGAGGTCAACAGCAGATCACTGGCAAGATGTCT CATCTTGGCTGTTTAACCATTAACTGTGACTCCATAGAACAGCCACTGCTTCTAATACAGGAAATCTGTGCCAACCTGGGGCTAGAACTG GGAACAAATCTGCATCTAGCTATCAACTGTGCTGGACATGAGCTGATGGACTACAATAAAGGAAAGTATGAAGTGATCATGGGCACATAC AAAAATGCAGCGGAGATGGTTGACCTGTATGTGGATCTGATCAACAAGTACCCTTCAATTATTGCCTTAATTGATCCTTTCAGGAAGGAG GACTCTGAACAGTGGGACAGCATCTATCACGCACTTGGTTCCAGGTGTTACATAATTGCAGGAACTGCTTCCAAAAGCATTTCTAAACTT CTAGAGCAAGGAAACATCAGCATCCCCAAATCCAATGGGCTGATCATAAAACACACAAACCAAACTACAATGTCTGACTTGGTGGAAATA ACCAATCTGATTGACAGTAAGAAGCACATCACTGTCTTTGGAAGTACAGAAGGAGAATCATCTGATGACAGCCTTGTCGATTTGGCTGTT GGGCTTGGTGTCCGGTTCATCAAGTTGGGGGGTCTTTCCCGTGGTGAACGAGTGACTAAATACAACCGCCTTCTCACTATAGAGGAAGAA CTTGTCCAGAATGGAACACTGGGTTTCAAAGAAGAACACACTTTTTTTTACTTTAATGAGGAAGCTGAAAAGGCTGCGGAGGCACTTGAG GCTGCTGCGGCTAGGGAGCCGCTGGTGCCCACCTTCCCCACACAAGGTGTAGAGGAATCAGCCGAAACAGGAGCATCCTCTGGATAGGGC TGTACACACCCCAGGTTCCAGCCACACCATCAGTATTAGTAGACCGGGAGGTCTGAAGTACGGCGCCGTGTCTCCACATGGAGTTTCCTC TTCAACTTCACCAACTCTTGTGGTTTTTATTCTTCTAATTCCACTGTTTGGTAAATTACATATATGATGTTTTTGCCTGAAATTCTGTGA ACTTCGTTTTGCAGCCACCACACTTCCATGTGGATTTTGTTTGTCTATTAGCTCTCCTGTCCATTTTTCAGGGACACGCTCCAGTAAAAG AGGCCAATATTTTTGTTGCCAACTCCACACTCAGTCAAACACCCCATCCTTTACCAATCAGAATATCTCTGAGAACAAAAACCTAATGAC CCTAGAAGCTCTCTGTGCTGGGAACAGATGTCCATCTTCTGTGTTTATTCTACATGTCTGTGCTGAAAAGCACTGACACATTTTTGTAAC CAACCTCACGTAGAAGTGTGAGAGCATCACCATTTTTTGTAAGAGCCAATTTCATCTCACTTTCCTACCCTTGATTCCTTTTTTCCTAAT TCCCTCTCCTTTTTAAATTTTAGTTTTTCTTGTATTATTTTTATCTTTGCGAGTCTTCTTAGATCCTTTTTGGAGTAAGAATGAGTATAA ATGAATAAGCACATCAGTAAATGAATTAATATTCTCAAGGTTATTAAATGCCCAGTTATTCATACCACAGCATTTAAAAAGCAATCCGCA AGTGATAAAAAAAAAAAAAAAAAATGATGTGACATATCCATTGCCTGAATTGCTCTTTTGTAAGCCAGTGTTGGGATTATAGCAGAGGAG >64158_64158_1_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118615134_ENST00000341276_length(amino acids)=938AA_BP=366 MGLLLMILASAVLGSFLTLLAQFFLLYRRQPEPPADEAARAGEGFRYIKPVPGLLLREYLYGGGRDEEPSGAAPEGGATPTAAPETPAPP TRETCYFLNATILFLFRELRDTALTRRWVTKKIKVEFEELLQTKTAGRLLEGLSLRDVFLGETVPFIKTIRLVRPVVPSATGEPDGPEGE ALPAACPEELAFEAEVEYNGGFHLAIDVDLVFGKSAYLFVKLSRVVGRLRLVFTRVPFTHWFFSFVEDPLIDFEVRSQFEGRPMPQLTSI IVNQLKKIIKRKHTLPNYKIRFKPFFPYQTLQGFEEDEEHIHIQQWALTEGRLKVTLLECSRLLIFGSYDREANVHCTLELSSSVWEEKQ RSSIKTANCFSKLAKPPTICKIVGKDVLDGLGLPTLQVDIFCTIQNFPKNVCSVVISTHFEVHENALPELAKAEEAERASAVSTAVQWVN STITHELQGMAPSDQAEVDHLLRIFFASKVQEDKGRKELEKSLEYSTVPTPLPPVPPPPPPPPPTKKKGQKPGRKDTITEKPIAPAEPVE PVLSGSMAIGAVSLAVAKACAMLLNKPLYLNIALLKHNQEQPTTLSMPLLMVSLVSCGKSSSGKLNLMKEVICIPHPELTTKQGVEMLME MQKHINKIIEMVSPSPPKAETKKGHDGSKRGQQQITGKMSHLGCLTINCDSIEQPLLLIQEICANLGLELGTNLHLAINCAGHELMDYNK GKYEVIMGTYKNAAEMVDLYVDLINKYPSIIALIDPFRKEDSEQWDSIYHALGSRCYIIAGTASKSISKLLEQGNISIPKSNGLIIKHTN QTTMSDLVEITNLIDSKKHITVFGSTEGESSDDSLVDLAVGLGVRFIKLGGLSRGERVTKYNRLLTIEEELVQNGTLGFKEEHTFFYFNE -------------------------------------------------------------- >64158_64158_2_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118616003_ENST00000341276_length(transcript)=3765nt_BP=1338nt GGTCCCGGCCCCGCTGCCGCCGCCGCCACACCGGCCCTTCGGGAGCGTCTGAGGAGGCGCGGGCCGCTGCGGGCTCGGGCGCCGCAGCGC GCCGGCCCGAGCCCCTGGACGAGGCCCACGGAGCCGCTCGCCCCGACCCAGCCGCCCGATGTCCTCAAAATGGAGGCAGCGGGGGCGGCG GCGTGAAGAAAGCGGCGCTGTGGGCGCGGGAGTAGGGGCCCGGGCGGAGGCGGTGGCGGGATGGGGCTGCTGCTCATGATCCTGGCGTCG GCCGTGCTGGGTTCCTTCCTCACGCTCCTCGCCCAGTTCTTCCTGCTGTACCGCAGACAGCCCGAGCCGCCGGCGGACGAGGCCGCCCGC GCGGGCGAGGGCTTCCGCTACATCAAGCCAGTGCCGGGCCTGCTCCTAAGGGAGTACCTTTATGGCGGCGGCCGGGATGAGGAGCCCTCC GGAGCGGCCCCTGAGGGCGGCGCGACCCCCACCGCGGCCCCCGAGACCCCCGCCCCGCCGACGCGGGAGACTTGCTACTTCCTCAACGCC ACCATCCTATTCCTGTTCCGGGAGTTGCGGGACACCGCGCTGACCCGCCGCTGGGTCACCAAGAAGATCAAGGTGGAGTTCGAGGAGCTG CTGCAGACCAAGACGGCCGGGCGCCTGCTGGAGGGGCTGAGCCTGCGGGACGTGTTCCTGGGCGAGACGGTGCCCTTCATCAAGACCATC CGGCTCGTGCGGCCAGTCGTGCCCTCGGCCACCGGGGAGCCCGATGGCCCTGAAGGGGAGGCGCTGCCCGCCGCCTGCCCCGAGGAGCTG GCCTTCGAGGCGGAGGTGGAGTACAACGGGGGCTTCCACCTGGCCATCGACGTGGACCTGGTCTTCGGCAAGTCCGCCTACTTGTTTGTC AAGCTGTCCCGCGTGGTGGGAAGGCTGCGCTTGGTCTTTACGCGCGTGCCCTTCACCCACTGGTTCTTCTCCTTCGTGGAAGACCCGCTG ATCGACTTCGAGGTGCGCTCCCAGTTTGAAGGGCGGCCCATGCCCCAGCTCACCTCCATCATCGTCAACCAGCTCAAGAAGATCATCAAG CGCAAGCACACCCTACCGAATTACAAGATCAGGTTTAAGCCGTTTTTTCCATACCAGACCTTGCAAGGATTTGAAGAAGATGAAGAGCAT ATCCATATACAACAATGGGCACTTACTGAAGGCCGTCTTAAAGTTACGTTGTTAGAATGTAGCAGGTTACTCATTTTTGGATCCTATGAC AGAGAGGCAAATGTTCATTGCACACTTGAGTTAAGCAGTAGTGTTTGGGAAGAAAAACAGAGGAGTTCTATTAAGACGAACGTATGTTCT GTGGTGATCTCGACTCATTTTGAAGTCCATGAGAATGCTCTGCCCGAGCTGGCCAAGGCGGAGGAGGCAGAGAGGGCCAGCGCGGTGAGC ACCGCCGTGCAGTGGGTCAACAGCACCATCACGCACGAGCTCCAGGGGATGGCACCCTCTGACCAGGCAGAGGTGGATCACCTACTCAGG ATATTCTTCGCAAGTAAAGTACAAGAAGATAAGGGGAGAAAAGAATTGGAAAAGAGCCTGGAATACTCAACAGTGCCTACACCTCTACCT CCAGTACCACCACCACCACCCCCTCCACCTCCTACCAAAAAAAAGGGGCAAAAGCCAGGGAGGAAGGATACTATTACAGAGAAACCTATT GCGCCTGCAGAGCCTGTTGAGCCTGTACTCAGTGGCAGTATGGCCATAGGGGCCGTGTCACTAGCTGTTGCCAAAGCCTGTGCCATGCTG CTTAATAAACCTCTGTACTTAAATATCGCTCTACTGAAGCACAATCAGGAACAGCCAACAACGCTATCTATGCCTTTGCTGATGGTATCG CTGGTCAGCTGTGGGAAGTCATCATCTGGGAAGCTAAATTTAATGAAAGAAGTGATTTGTATACCCCATCCTGAATTAACAACCAAACAA GGTGTCGAGATGCTTATGGAAATGCAGAAACATATCAACAAAATAATTGAAATGGTATCACCCTCTCCTCCAAAAGCAGAGACAAAAAAA GGGCACGATGGAAGCAAAAGAGGTCAACAGCAGATCACTGGCAAGATGTCTCATCTTGGCTGTTTAACCATTAACTGTGACTCCATAGAA CAGCCACTGCTTCTAATACAGGAAATCTGTGCCAACCTGGGGCTAGAACTGGGAACAAATCTGCATCTAGCTATCAACTGTGCTGGACAT GAGCTGATGGACTACAATAAAGGAAAGTATGAAGTGATCATGGGCACATACAAAAATGCAGCGGAGATGGTTGACCTGTATGTGGATCTG ATCAACAAGTACCCTTCAATTATTGCCTTAATTGATCCTTTCAGGAAGGAGGACTCTGAACAGTGGGACAGCATCTATCACGCACTTGGT TCCAGGTGTTACATAATTGCAGGAACTGCTTCCAAAAGCATTTCTAAACTTCTAGAGCAAGGAAACATCAGCATCCCCAAATCCAATGGG CTGATCATAAAACACACAAACCAAACTACAATGTCTGACTTGGTGGAAATAACCAATCTGATTGACAGTAAGAAGCACATCACTGTCTTT GGAAGTACAGAAGGAGAATCATCTGATGACAGCCTTGTCGATTTGGCTGTTGGGCTTGGTGTCCGGTTCATCAAGTTGGGGGGTCTTTCC CGTGGTGAACGAGTGACTAAATACAACCGCCTTCTCACTATAGAGGAAGAACTTGTCCAGAATGGAACACTGGGTTTCAAAGAAGAACAC ACTTTTTTTTACTTTAATGAGGAAGCTGAAAAGGCTGCGGAGGCACTTGAGGCTGCTGCGGCTAGGGAGCCGCTGGTGCCCACCTTCCCC ACACAAGGTGTAGAGGAATCAGCCGAAACAGGAGCATCCTCTGGATAGGGCTGTACACACCCCAGGTTCCAGCCACACCATCAGTATTAG TAGACCGGGAGGTCTGAAGTACGGCGCCGTGTCTCCACATGGAGTTTCCTCTTCAACTTCACCAACTCTTGTGGTTTTTATTCTTCTAAT TCCACTGTTTGGTAAATTACATATATGATGTTTTTGCCTGAAATTCTGTGAACTTCGTTTTGCAGCCACCACACTTCCATGTGGATTTTG TTTGTCTATTAGCTCTCCTGTCCATTTTTCAGGGACACGCTCCAGTAAAAGAGGCCAATATTTTTGTTGCCAACTCCACACTCAGTCAAA CACCCCATCCTTTACCAATCAGAATATCTCTGAGAACAAAAACCTAATGACCCTAGAAGCTCTCTGTGCTGGGAACAGATGTCCATCTTC TGTGTTTATTCTACATGTCTGTGCTGAAAAGCACTGACACATTTTTGTAACCAACCTCACGTAGAAGTGTGAGAGCATCACCATTTTTTG TAAGAGCCAATTTCATCTCACTTTCCTACCCTTGATTCCTTTTTTCCTAATTCCCTCTCCTTTTTAAATTTTAGTTTTTCTTGTATTATT TTTATCTTTGCGAGTCTTCTTAGATCCTTTTTGGAGTAAGAATGAGTATAAATGAATAAGCACATCAGTAAATGAATTAATATTCTCAAG GTTATTAAATGCCCAGTTATTCATACCACAGCATTTAAAAAGCAATCCGCAAGTGATAAAAAAAAAAAAAAAAAATGATGTGACATATCC >64158_64158_2_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118616003_ENST00000341276_length(amino acids)=895AA_BP=366 MGLLLMILASAVLGSFLTLLAQFFLLYRRQPEPPADEAARAGEGFRYIKPVPGLLLREYLYGGGRDEEPSGAAPEGGATPTAAPETPAPP TRETCYFLNATILFLFRELRDTALTRRWVTKKIKVEFEELLQTKTAGRLLEGLSLRDVFLGETVPFIKTIRLVRPVVPSATGEPDGPEGE ALPAACPEELAFEAEVEYNGGFHLAIDVDLVFGKSAYLFVKLSRVVGRLRLVFTRVPFTHWFFSFVEDPLIDFEVRSQFEGRPMPQLTSI IVNQLKKIIKRKHTLPNYKIRFKPFFPYQTLQGFEEDEEHIHIQQWALTEGRLKVTLLECSRLLIFGSYDREANVHCTLELSSSVWEEKQ RSSIKTNVCSVVISTHFEVHENALPELAKAEEAERASAVSTAVQWVNSTITHELQGMAPSDQAEVDHLLRIFFASKVQEDKGRKELEKSL EYSTVPTPLPPVPPPPPPPPPTKKKGQKPGRKDTITEKPIAPAEPVEPVLSGSMAIGAVSLAVAKACAMLLNKPLYLNIALLKHNQEQPT TLSMPLLMVSLVSCGKSSSGKLNLMKEVICIPHPELTTKQGVEMLMEMQKHINKIIEMVSPSPPKAETKKGHDGSKRGQQQITGKMSHLG CLTINCDSIEQPLLLIQEICANLGLELGTNLHLAINCAGHELMDYNKGKYEVIMGTYKNAAEMVDLYVDLINKYPSIIALIDPFRKEDSE QWDSIYHALGSRCYIIAGTASKSISKLLEQGNISIPKSNGLIIKHTNQTTMSDLVEITNLIDSKKHITVFGSTEGESSDDSLVDLAVGLG -------------------------------------------------------------- >64158_64158_3_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118628161_ENST00000341276_length(transcript)=3063nt_BP=1338nt GGTCCCGGCCCCGCTGCCGCCGCCGCCACACCGGCCCTTCGGGAGCGTCTGAGGAGGCGCGGGCCGCTGCGGGCTCGGGCGCCGCAGCGC GCCGGCCCGAGCCCCTGGACGAGGCCCACGGAGCCGCTCGCCCCGACCCAGCCGCCCGATGTCCTCAAAATGGAGGCAGCGGGGGCGGCG GCGTGAAGAAAGCGGCGCTGTGGGCGCGGGAGTAGGGGCCCGGGCGGAGGCGGTGGCGGGATGGGGCTGCTGCTCATGATCCTGGCGTCG GCCGTGCTGGGTTCCTTCCTCACGCTCCTCGCCCAGTTCTTCCTGCTGTACCGCAGACAGCCCGAGCCGCCGGCGGACGAGGCCGCCCGC GCGGGCGAGGGCTTCCGCTACATCAAGCCAGTGCCGGGCCTGCTCCTAAGGGAGTACCTTTATGGCGGCGGCCGGGATGAGGAGCCCTCC GGAGCGGCCCCTGAGGGCGGCGCGACCCCCACCGCGGCCCCCGAGACCCCCGCCCCGCCGACGCGGGAGACTTGCTACTTCCTCAACGCC ACCATCCTATTCCTGTTCCGGGAGTTGCGGGACACCGCGCTGACCCGCCGCTGGGTCACCAAGAAGATCAAGGTGGAGTTCGAGGAGCTG CTGCAGACCAAGACGGCCGGGCGCCTGCTGGAGGGGCTGAGCCTGCGGGACGTGTTCCTGGGCGAGACGGTGCCCTTCATCAAGACCATC CGGCTCGTGCGGCCAGTCGTGCCCTCGGCCACCGGGGAGCCCGATGGCCCTGAAGGGGAGGCGCTGCCCGCCGCCTGCCCCGAGGAGCTG GCCTTCGAGGCGGAGGTGGAGTACAACGGGGGCTTCCACCTGGCCATCGACGTGGACCTGGTCTTCGGCAAGTCCGCCTACTTGTTTGTC AAGCTGTCCCGCGTGGTGGGAAGGCTGCGCTTGGTCTTTACGCGCGTGCCCTTCACCCACTGGTTCTTCTCCTTCGTGGAAGACCCGCTG ATCGACTTCGAGGTGCGCTCCCAGTTTGAAGGGCGGCCCATGCCCCAGCTCACCTCCATCATCGTCAACCAGCTCAAGAAGATCATCAAG CGCAAGCACACCCTACCGAATTACAAGATCAGGTTTAAGCCGTTTTTTCCATACCAGACCTTGCAAGGATTTGAAGAAGATGAAGAGCAT ATCCATATACAACAATGGGCACTTACTGAAGGCCGTCTTAAAGTTACGTTGTTAGAATGTAGCAGGTTACTCATTTTTGGATCCTATGAC AGAGAGGCAAATGTTCATTGCACACTTGAGTTAAGCAGTAGTGTTTGGGAAGAAAAACAGAGGAGTTCTATTAAGACGCCCTCTCCTCCA AAAGCAGAGACAAAAAAAGGGCACGATGGAAGCAAAAGAGGTCAACAGCAGATCACTGGCAAGATGTCTCATCTTGGCTGTTTAACCATT AACTGTGACTCCATAGAACAGCCACTGCTTCTAATACAGGAAATCTGTGCCAACCTGGGGCTAGAACTGGGAACAAATCTGCATCTAGCT ATCAACTGTGCTGGACATGAGCTGATGGACTACAATAAAGGAAAGTATGAAGTGATCATGGGCACATACAAAAATGCAGCGGAGATGGTT GACCTGTATGTGGATCTGATCAACAAGTACCCTTCAATTATTGCCTTAATTGATCCTTTCAGGAAGGAGGACTCTGAACAGTGGGACAGC ATCTATCACGCACTTGGTTCCAGGTGTTACATAATTGCAGGAACTGCTTCCAAAAGCATTTCTAAACTTCTAGAGCAAGGAAACATCAGC ATCCCCAAATCCAATGGGCTGATCATAAAACACACAAACCAAACTACAATGTCTGACTTGGTGGAAATAACCAATCTGATTGACAGTAAG AAGCACATCACTGTCTTTGGAAGTACAGAAGGAGAATCATCTGATGACAGCCTTGTCGATTTGGCTGTTGGGCTTGGTGTCCGGTTCATC AAGTTGGGGGGTCTTTCCCGTGGTGAACGAGTGACTAAATACAACCGCCTTCTCACTATAGAGGAAGAACTTGTCCAGAATGGAACACTG GGTTTCAAAGAAGAACACACTTTTTTTTACTTTAATGAGGAAGCTGAAAAGGCTGCGGAGGCACTTGAGGCTGCTGCGGCTAGGGAGCCG CTGGTGCCCACCTTCCCCACACAAGGTGTAGAGGAATCAGCCGAAACAGGAGCATCCTCTGGATAGGGCTGTACACACCCCAGGTTCCAG CCACACCATCAGTATTAGTAGACCGGGAGGTCTGAAGTACGGCGCCGTGTCTCCACATGGAGTTTCCTCTTCAACTTCACCAACTCTTGT GGTTTTTATTCTTCTAATTCCACTGTTTGGTAAATTACATATATGATGTTTTTGCCTGAAATTCTGTGAACTTCGTTTTGCAGCCACCAC ACTTCCATGTGGATTTTGTTTGTCTATTAGCTCTCCTGTCCATTTTTCAGGGACACGCTCCAGTAAAAGAGGCCAATATTTTTGTTGCCA ACTCCACACTCAGTCAAACACCCCATCCTTTACCAATCAGAATATCTCTGAGAACAAAAACCTAATGACCCTAGAAGCTCTCTGTGCTGG GAACAGATGTCCATCTTCTGTGTTTATTCTACATGTCTGTGCTGAAAAGCACTGACACATTTTTGTAACCAACCTCACGTAGAAGTGTGA GAGCATCACCATTTTTTGTAAGAGCCAATTTCATCTCACTTTCCTACCCTTGATTCCTTTTTTCCTAATTCCCTCTCCTTTTTAAATTTT AGTTTTTCTTGTATTATTTTTATCTTTGCGAGTCTTCTTAGATCCTTTTTGGAGTAAGAATGAGTATAAATGAATAAGCACATCAGTAAA TGAATTAATATTCTCAAGGTTATTAAATGCCCAGTTATTCATACCACAGCATTTAAAAAGCAATCCGCAAGTGATAAAAAAAAAAAAAAA AAATGATGTGACATATCCATTGCCTGAATTGCTCTTTTGTAAGCCAGTGTTGGGATTATAGCAGAGGAGTAGCAGAAATAAATATATTCA >64158_64158_3_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118628161_ENST00000341276_length(amino acids)=661AA_BP=361 MGLLLMILASAVLGSFLTLLAQFFLLYRRQPEPPADEAARAGEGFRYIKPVPGLLLREYLYGGGRDEEPSGAAPEGGATPTAAPETPAPP TRETCYFLNATILFLFRELRDTALTRRWVTKKIKVEFEELLQTKTAGRLLEGLSLRDVFLGETVPFIKTIRLVRPVVPSATGEPDGPEGE ALPAACPEELAFEAEVEYNGGFHLAIDVDLVFGKSAYLFVKLSRVVGRLRLVFTRVPFTHWFFSFVEDPLIDFEVRSQFEGRPMPQLTSI IVNQLKKIIKRKHTLPNYKIRFKPFFPYQTLQGFEEDEEHIHIQQWALTEGRLKVTLLECSRLLIFGSYDREANVHCTLELSSSVWEEKQ RSSIKTPSPPKAETKKGHDGSKRGQQQITGKMSHLGCLTINCDSIEQPLLLIQEICANLGLELGTNLHLAINCAGHELMDYNKGKYEVIM GTYKNAAEMVDLYVDLINKYPSIIALIDPFRKEDSEQWDSIYHALGSRCYIIAGTASKSISKLLEQGNISIPKSNGLIIKHTNQTTMSDL VEITNLIDSKKHITVFGSTEGESSDDSLVDLAVGLGVRFIKLGGLSRGERVTKYNRLLTIEEELVQNGTLGFKEEHTFFYFNEEAEKAAE -------------------------------------------------------------- >64158_64158_4_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118628161_ENST00000369207_length(transcript)=2361nt_BP=1338nt GGTCCCGGCCCCGCTGCCGCCGCCGCCACACCGGCCCTTCGGGAGCGTCTGAGGAGGCGCGGGCCGCTGCGGGCTCGGGCGCCGCAGCGC GCCGGCCCGAGCCCCTGGACGAGGCCCACGGAGCCGCTCGCCCCGACCCAGCCGCCCGATGTCCTCAAAATGGAGGCAGCGGGGGCGGCG GCGTGAAGAAAGCGGCGCTGTGGGCGCGGGAGTAGGGGCCCGGGCGGAGGCGGTGGCGGGATGGGGCTGCTGCTCATGATCCTGGCGTCG GCCGTGCTGGGTTCCTTCCTCACGCTCCTCGCCCAGTTCTTCCTGCTGTACCGCAGACAGCCCGAGCCGCCGGCGGACGAGGCCGCCCGC GCGGGCGAGGGCTTCCGCTACATCAAGCCAGTGCCGGGCCTGCTCCTAAGGGAGTACCTTTATGGCGGCGGCCGGGATGAGGAGCCCTCC GGAGCGGCCCCTGAGGGCGGCGCGACCCCCACCGCGGCCCCCGAGACCCCCGCCCCGCCGACGCGGGAGACTTGCTACTTCCTCAACGCC ACCATCCTATTCCTGTTCCGGGAGTTGCGGGACACCGCGCTGACCCGCCGCTGGGTCACCAAGAAGATCAAGGTGGAGTTCGAGGAGCTG CTGCAGACCAAGACGGCCGGGCGCCTGCTGGAGGGGCTGAGCCTGCGGGACGTGTTCCTGGGCGAGACGGTGCCCTTCATCAAGACCATC CGGCTCGTGCGGCCAGTCGTGCCCTCGGCCACCGGGGAGCCCGATGGCCCTGAAGGGGAGGCGCTGCCCGCCGCCTGCCCCGAGGAGCTG GCCTTCGAGGCGGAGGTGGAGTACAACGGGGGCTTCCACCTGGCCATCGACGTGGACCTGGTCTTCGGCAAGTCCGCCTACTTGTTTGTC AAGCTGTCCCGCGTGGTGGGAAGGCTGCGCTTGGTCTTTACGCGCGTGCCCTTCACCCACTGGTTCTTCTCCTTCGTGGAAGACCCGCTG ATCGACTTCGAGGTGCGCTCCCAGTTTGAAGGGCGGCCCATGCCCCAGCTCACCTCCATCATCGTCAACCAGCTCAAGAAGATCATCAAG CGCAAGCACACCCTACCGAATTACAAGATCAGGTTTAAGCCGTTTTTTCCATACCAGACCTTGCAAGGATTTGAAGAAGATGAAGAGCAT ATCCATATACAACAATGGGCACTTACTGAAGGCCGTCTTAAAGTTACGTTGTTAGAATGTAGCAGGTTACTCATTTTTGGATCCTATGAC AGAGAGGCAAATGTTCATTGCACACTTGAGTTAAGCAGTAGTGTTTGGGAAGAAAAACAGAGGAGTTCTATTAAGACGCCCTCTCCTCCA AAAGCAGAGACAAAAAAAGGGCACGATGGAAGCAAAAGAGGTCAACAGCAGATCACTGGCAAGATGTCTCATCTTGGCTGTTTAACCATT AACTGTGACTCCATAGAACAGCCACTGCTTCTAATACAGGAAATCTGTGCCAACCTGGGGCTAGAACTGGGAACAAATCTGCATCTAGCT ATCAACTGTGCTGGACATGAGCTGATGGACTACAATAAAGGAAAGTATGAAGTGATCATGGGCACATACAAAAATGCAGCGGAGATGGTT GACCTGTATGTGGATCTGATCAACAAGTACCCTTCAATTATTGCCTTAATTGATCCTTTCAGGAAGGAGGACTCTGAACAGTGGGACAGC ATCTATCACGCACTTGGTTCCAGGTGTTACATAATTGCAGGAACTGCTTCCAAAAGCATTTCTAAACTTCTAGAGCAAGGAAACATCAGC ATCCCCAAATCCAATGGGCTGATCATAAAACACACAAACCAAACTACAATGTCTGACTTGGTGGAAATAACCAATCTGATTGACAGTAAG AAGCACATCACTGTCTTTGGAAGTACAGAAGGAGAATCATCTGATGACAGCCTTGTCGATTTGGCTGTTGGGCTTGGTGTCCGGTTCATC AAGTTGGGGGGTCTTTCCCGTGGTGAACGAGTGACTAAATACAACCGCCTTCTCACTATAGAGGAAGAACTTGTCCAGAATGGAACACTG GCCACTTCATCTTCAAGCTGTGATGCCAGGATTGGAGGGCAAGAACAGGAAACAATGACTTTGGTGAAAGTGTAACCACTCTTTTAGAAC AAAAACAGCACAGTGTTATTTGAAAAATTATTAACATATGTGATGGAGCAGTCTGTAAGCACGATCAAATAAACTGGCCAAAGATGAGGC TAATTGTAAATGGGAATAAAACACACCACAAACAATTCACAAAAAACAGATTTTAAAATACTCTCCTTTCATTTCCCCATTAGCTAAACA >64158_64158_4_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118628161_ENST00000369207_length(amino acids)=634AA_BP=361 MGLLLMILASAVLGSFLTLLAQFFLLYRRQPEPPADEAARAGEGFRYIKPVPGLLLREYLYGGGRDEEPSGAAPEGGATPTAAPETPAPP TRETCYFLNATILFLFRELRDTALTRRWVTKKIKVEFEELLQTKTAGRLLEGLSLRDVFLGETVPFIKTIRLVRPVVPSATGEPDGPEGE ALPAACPEELAFEAEVEYNGGFHLAIDVDLVFGKSAYLFVKLSRVVGRLRLVFTRVPFTHWFFSFVEDPLIDFEVRSQFEGRPMPQLTSI IVNQLKKIIKRKHTLPNYKIRFKPFFPYQTLQGFEEDEEHIHIQQWALTEGRLKVTLLECSRLLIFGSYDREANVHCTLELSSSVWEEKQ RSSIKTPSPPKAETKKGHDGSKRGQQQITGKMSHLGCLTINCDSIEQPLLLIQEICANLGLELGTNLHLAINCAGHELMDYNKGKYEVIM GTYKNAAEMVDLYVDLINKYPSIIALIDPFRKEDSEQWDSIYHALGSRCYIIAGTASKSISKLLEQGNISIPKSNGLIIKHTNQTTMSDL VEITNLIDSKKHITVFGSTEGESSDDSLVDLAVGLGVRFIKLGGLSRGERVTKYNRLLTIEEELVQNGTLATSSSSCDARIGGQEQETMT -------------------------------------------------------------- >64158_64158_5_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118628161_ENST00000409522_length(transcript)=2958nt_BP=1338nt GGTCCCGGCCCCGCTGCCGCCGCCGCCACACCGGCCCTTCGGGAGCGTCTGAGGAGGCGCGGGCCGCTGCGGGCTCGGGCGCCGCAGCGC GCCGGCCCGAGCCCCTGGACGAGGCCCACGGAGCCGCTCGCCCCGACCCAGCCGCCCGATGTCCTCAAAATGGAGGCAGCGGGGGCGGCG GCGTGAAGAAAGCGGCGCTGTGGGCGCGGGAGTAGGGGCCCGGGCGGAGGCGGTGGCGGGATGGGGCTGCTGCTCATGATCCTGGCGTCG GCCGTGCTGGGTTCCTTCCTCACGCTCCTCGCCCAGTTCTTCCTGCTGTACCGCAGACAGCCCGAGCCGCCGGCGGACGAGGCCGCCCGC GCGGGCGAGGGCTTCCGCTACATCAAGCCAGTGCCGGGCCTGCTCCTAAGGGAGTACCTTTATGGCGGCGGCCGGGATGAGGAGCCCTCC GGAGCGGCCCCTGAGGGCGGCGCGACCCCCACCGCGGCCCCCGAGACCCCCGCCCCGCCGACGCGGGAGACTTGCTACTTCCTCAACGCC ACCATCCTATTCCTGTTCCGGGAGTTGCGGGACACCGCGCTGACCCGCCGCTGGGTCACCAAGAAGATCAAGGTGGAGTTCGAGGAGCTG CTGCAGACCAAGACGGCCGGGCGCCTGCTGGAGGGGCTGAGCCTGCGGGACGTGTTCCTGGGCGAGACGGTGCCCTTCATCAAGACCATC CGGCTCGTGCGGCCAGTCGTGCCCTCGGCCACCGGGGAGCCCGATGGCCCTGAAGGGGAGGCGCTGCCCGCCGCCTGCCCCGAGGAGCTG GCCTTCGAGGCGGAGGTGGAGTACAACGGGGGCTTCCACCTGGCCATCGACGTGGACCTGGTCTTCGGCAAGTCCGCCTACTTGTTTGTC AAGCTGTCCCGCGTGGTGGGAAGGCTGCGCTTGGTCTTTACGCGCGTGCCCTTCACCCACTGGTTCTTCTCCTTCGTGGAAGACCCGCTG ATCGACTTCGAGGTGCGCTCCCAGTTTGAAGGGCGGCCCATGCCCCAGCTCACCTCCATCATCGTCAACCAGCTCAAGAAGATCATCAAG CGCAAGCACACCCTACCGAATTACAAGATCAGGTTTAAGCCGTTTTTTCCATACCAGACCTTGCAAGGATTTGAAGAAGATGAAGAGCAT ATCCATATACAACAATGGGCACTTACTGAAGGCCGTCTTAAAGTTACGTTGTTAGAATGTAGCAGGTTACTCATTTTTGGATCCTATGAC AGAGAGGCAAATGTTCATTGCACACTTGAGTTAAGCAGTAGTGTTTGGGAAGAAAAACAGAGGAGTTCTATTAAGACGCCCTCTCCTCCA AAAGCAGAGACAAAAAAAGGGCACGATGGAAGCAAAAGAGGTCAACAGCAGATCACTGGCAAGATGTCTCATCTTGGCTGTTTAACCATT AACTGTGACTCCATAGAACAGCCACTGCTTCTAATACAGGAAATCTGTGCCAACCTGGGGCTAGAACTGGGAACAAATCTGCATCTAGCT ATCAACTGTGCTGGACATGAGCTGATGGACTACGACTCTGAACAGTGGGACAGCATCTATCACGCACTTGGTTCCAGGTGTTACATAATT GCAGGAACTGCTTCCAAAAGCATTTCTAAACTTCTAGAGCAAGGAAACATCAGCATCCCCAAATCCAATGGGCTGATCATAAAACACACA AACCAAACTACAATGTCTGACTTGGTGGAAATAACCAATCTGATTGACAGTAAGAAGCACATCACTGTCTTTGGAAGTACAGAAGGAGAA TCATCTGATGACAGCCTTGTCGATTTGGCTGTTGGGCTTGGTGTCCGGTTCATCAAGTTGGGGGGTCTTTCCCGTGGTGAACGAGTGACT AAATACAACCGCCTTCTCACTATAGAGGAAGAACTTGTCCAGAATGGAACACTGGGTTTCAAAGAAGAACACACTTTTTTTTACTTTAAT GAGGAAGCTGAAAAGGCTGCGGAGGCACTTGAGGCTGCTGCGGCTAGGGAGCCGCTGGTGCCCACCTTCCCCACACAAGGTGTAGAGGAA TCAGCCGAAACAGGAGCATCCTCTGGATAGGGCTGTACACACCCCAGGTTCCAGCCACACCATCAGTATTAGTAGACCGGGAGGTCTGAA GTACGGCGCCGTGTCTCCACATGGAGTTTCCTCTTCAACTTCACCAACTCTTGTGGTTTTTATTCTTCTAATTCCACTGTTTGGTAAATT ACATATATGATGTTTTTGCCTGAAATTCTGTGAACTTCGTTTTGCAGCCACCACACTTCCATGTGGATTTTGTTTGTCTATTAGCTCTCC TGTCCATTTTTCAGGGACACGCTCCAGTAAAAGAGGCCAATATTTTTGTTGCCAACTCCACACTCAGTCAAACACCCCATCCTTTACCAA TCAGAATATCTCTGAGAACAAAAACCTAATGACCCTAGAAGCTCTCTGTGCTGGGAACAGATGTCCATCTTCTGTGTTTATTCTACATGT CTGTGCTGAAAAGCACTGACACATTTTTGTAACCAACCTCACGTAGAAGTGTGAGAGCATCACCATTTTTTGTAAGAGCCAATTTCATCT CACTTTCCTACCCTTGATTCCTTTTTTCCTAATTCCCTCTCCTTTTTAAATTTTAGTTTTTCTTGTATTATTTTTATCTTTGCGAGTCTT CTTAGATCCTTTTTGGAGTAAGAATGAGTATAAATGAATAAGCACATCAGTAAATGAATTAATATTCTCAAGGTTATTAAATGCCCAGTT ATTCATACCACAGCATTTAAAAAGCAATCCGCAAGTGATAAAAAAAAAAAAAAAAAATGATGTGACATATCCATTGCCTGAATTGCTCTT >64158_64158_5_PDZD8-ENO4_PDZD8_chr10_119078383_ENST00000334464_ENO4_chr10_118628161_ENST00000409522_length(amino acids)=619AA_BP=361 MGLLLMILASAVLGSFLTLLAQFFLLYRRQPEPPADEAARAGEGFRYIKPVPGLLLREYLYGGGRDEEPSGAAPEGGATPTAAPETPAPP TRETCYFLNATILFLFRELRDTALTRRWVTKKIKVEFEELLQTKTAGRLLEGLSLRDVFLGETVPFIKTIRLVRPVVPSATGEPDGPEGE ALPAACPEELAFEAEVEYNGGFHLAIDVDLVFGKSAYLFVKLSRVVGRLRLVFTRVPFTHWFFSFVEDPLIDFEVRSQFEGRPMPQLTSI IVNQLKKIIKRKHTLPNYKIRFKPFFPYQTLQGFEEDEEHIHIQQWALTEGRLKVTLLECSRLLIFGSYDREANVHCTLELSSSVWEEKQ RSSIKTPSPPKAETKKGHDGSKRGQQQITGKMSHLGCLTINCDSIEQPLLLIQEICANLGLELGTNLHLAINCAGHELMDYDSEQWDSIY HALGSRCYIIAGTASKSISKLLEQGNISIPKSNGLIIKHTNQTTMSDLVEITNLIDSKKHITVFGSTEGESSDDSLVDLAVGLGVRFIKL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PDZD8-ENO4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PDZD8-ENO4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PDZD8-ENO4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies