
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARID3A-MORC2 (FusionGDB2 ID:6448) |
Fusion Gene Summary for ARID3A-MORC2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARID3A-MORC2 | Fusion gene ID: 6448 | Hgene | Tgene | Gene symbol | ARID3A | MORC2 | Gene ID | 1820 | 22880 |
| Gene name | AT-rich interaction domain 3A | MORC family CW-type zinc finger 2 | |
| Synonyms | BRIGHT|DRIL1|DRIL3|E2FBP1 | CMT2Z|ZCW3|ZCWCC1 | |
| Cytomap | 19p13.3 | 22q12.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AT-rich interactive domain-containing protein 3AARID domain-containing 3AARID domain-containing protein 3AAT rich interactive domain 3A (BRIGHT- like) proteinAT rich interactive domain 3A (BRIGHT-like)B-cell regulator of IgH transcriptionE2F-binding | ATPase MORC2zinc finger CW-type coiled-coil domain protein 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q99856 | Q9Y6X9 | |
| Ensembl transtripts involved in fusion gene | ENST00000263620, ENST00000592216, | ENST00000469915, ENST00000215862, ENST00000397641, | |
| Fusion gene scores | * DoF score | 7 X 6 X 6=252 | 5 X 5 X 5=125 |
| # samples | 8 | 5 | |
| ** MAII score | log2(8/252*10)=-1.65535182861255 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/125*10)=-1.32192809488736 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARID3A [Title/Abstract] AND MORC2 [Title/Abstract] AND fusion [Title/Abstract] | ||
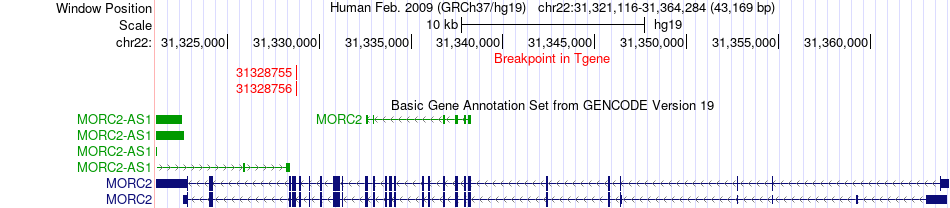
| Most frequent breakpoint | ARID3A(929896)-MORC2(31328756), # samples:4 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | MORC2 | GO:0006338 | chromatin remodeling | 23260667 |
| Tgene | MORC2 | GO:0006974 | cellular response to DNA damage stimulus | 23260667 |
| Tgene | MORC2 | GO:0045814 | negative regulation of gene expression, epigenetic | 28581500|29211708 |
| Tgene | MORC2 | GO:0090309 | positive regulation of methylation-dependent chromatin silencing | 28581500|29211708 |
| Fusion gene breakpoints across ARID3A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MORC2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCEC | TCGA-EY-A2ON-01A | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - |
| ChimerDB4 | UCEC | TCGA-EY-A2ON-01A | ARID3A | chr19 | 929896 | - | MORC2 | chr22 | 31328756 | - |
| ChimerDB4 | UCEC | TCGA-EY-A2ON-01A | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - |
| ChimerDB4 | UCEC | TCGA-EY-A2ON | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - |
Top |
Fusion Gene ORF analysis for ARID3A-MORC2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000263620 | ENST00000469915 | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - |
| 5CDS-intron | ENST00000263620 | ENST00000469915 | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - |
| In-frame | ENST00000263620 | ENST00000215862 | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - |
| In-frame | ENST00000263620 | ENST00000215862 | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - |
| In-frame | ENST00000263620 | ENST00000397641 | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - |
| In-frame | ENST00000263620 | ENST00000397641 | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - |
| intron-3CDS | ENST00000592216 | ENST00000215862 | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - |
| intron-3CDS | ENST00000592216 | ENST00000215862 | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - |
| intron-3CDS | ENST00000592216 | ENST00000397641 | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - |
| intron-3CDS | ENST00000592216 | ENST00000397641 | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - |
| intron-intron | ENST00000592216 | ENST00000469915 | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - |
| intron-intron | ENST00000592216 | ENST00000469915 | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000263620 | ARID3A | chr19 | 929896 | + | ENST00000397641 | MORC2 | chr22 | 31328756 | - | 2945 | 695 | 186 | 1271 | 361 |
| ENST00000263620 | ARID3A | chr19 | 929896 | + | ENST00000215862 | MORC2 | chr22 | 31328756 | - | 1464 | 695 | 186 | 1271 | 361 |
| ENST00000263620 | ARID3A | chr19 | 929895 | + | ENST00000397641 | MORC2 | chr22 | 31328755 | - | 2945 | 695 | 186 | 1271 | 361 |
| ENST00000263620 | ARID3A | chr19 | 929895 | + | ENST00000215862 | MORC2 | chr22 | 31328755 | - | 1464 | 695 | 186 | 1271 | 361 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000263620 | ENST00000397641 | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - | 0.001437452 | 0.9985625 |
| ENST00000263620 | ENST00000215862 | ARID3A | chr19 | 929896 | + | MORC2 | chr22 | 31328756 | - | 0.003753719 | 0.9962463 |
| ENST00000263620 | ENST00000397641 | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - | 0.001437452 | 0.9985625 |
| ENST00000263620 | ENST00000215862 | ARID3A | chr19 | 929895 | + | MORC2 | chr22 | 31328755 | - | 0.003753719 | 0.9962463 |
Top |
Fusion Genomic Features for ARID3A-MORC2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
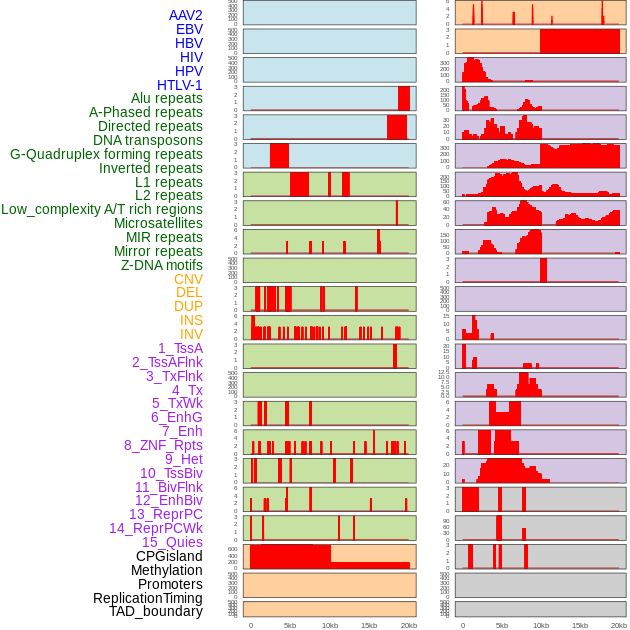 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ARID3A-MORC2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:929896/chr22:31328756) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARID3A | MORC2 |
| FUNCTION: Transcription factor which may be involved in the control of cell cycle progression by the RB1/E2F1 pathway and in B-cell differentiation. {ECO:0000269|PubMed:11812999, ECO:0000269|PubMed:12692263}. | FUNCTION: Essential for epigenetic silencing by the HUSH (human silencing hub) complex. Recruited by HUSH to target site in heterochromatin, the ATPase activity and homodimerization are critical for HUSH-mediated silencing (PubMed:28581500, PubMed:29440755). Represses germ cell-related genes and L1 retrotransposons in collaboration with SETDB1 and the HUSH complex, the silencing is dependent of repressive epigenetic modifications, such as H3K9me3 mark. Silencing events often occur within introns of transcriptionally active genes, and lead to the down-regulation of host gene expression (PubMed:29211708). During DNA damage response, regulates chromatin remodeling through ATP hydrolysis. Upon DNA damage, is phosphorylated by PAK1, both colocalize to chromatin and induce H2AX expression. ATPase activity is required and dependent of phosphorylation by PAK1 and presence of DNA (PubMed:23260667). Recruits histone deacetylases, such as HDAC4, to promoter regions, causing local histone H3 deacetylation and transcriptional repression of genes such as CA9 (PubMed:20225202, PubMed:20110259). Exhibits a cytosolic function in lipogenesis, adipogenic differentiation, and lipid homeostasis by increasing the activity of ACLY, possibly preventing its dephosphorylation (PubMed:24286864). {ECO:0000269|PubMed:20110259, ECO:0000269|PubMed:20225202, ECO:0000269|PubMed:23260667, ECO:0000269|PubMed:24286864, ECO:0000269|PubMed:28581500, ECO:0000269|PubMed:29211708, ECO:0000269|PubMed:29440755}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 67_70 | 122 | 594.0 | Compositional bias | Note=Poly-Ala |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 67_70 | 122 | 594.0 | Compositional bias | Note=Poly-Ala |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000215862 | 22 | 27 | 966_1016 | 778 | 971.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000397641 | 21 | 26 | 966_1016 | 840 | 1033.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000215862 | 22 | 27 | 966_1016 | 778 | 971.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000397641 | 21 | 26 | 966_1016 | 840 | 1033.0 | Coiled coil | Ontology_term=ECO:0000255 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 424_445 | 122 | 594.0 | Compositional bias | Note=Ala-rich |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 550_579 | 122 | 594.0 | Compositional bias | Note=Gly-rich |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 89_157 | 122 | 594.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 424_445 | 122 | 594.0 | Compositional bias | Note=Ala-rich |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 550_579 | 122 | 594.0 | Compositional bias | Note=Gly-rich |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 89_157 | 122 | 594.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 238_330 | 122 | 594.0 | Domain | ARID |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 444_541 | 122 | 594.0 | Domain | REKLES |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 238_330 | 122 | 594.0 | Domain | ARID |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 444_541 | 122 | 594.0 | Domain | REKLES |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 119_156 | 122 | 594.0 | Region | Note=Acidic |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 445_488 | 122 | 594.0 | Region | Important for nuclear localization |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 490_513 | 122 | 594.0 | Region | Note=Homodimerization |
| Hgene | ARID3A | chr19:929895 | chr22:31328755 | ENST00000263620 | + | 2 | 9 | 537_557 | 122 | 594.0 | Region | Important for cytoplasmic localization |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 119_156 | 122 | 594.0 | Region | Note=Acidic |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 445_488 | 122 | 594.0 | Region | Important for nuclear localization |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 490_513 | 122 | 594.0 | Region | Note=Homodimerization |
| Hgene | ARID3A | chr19:929896 | chr22:31328756 | ENST00000263620 | + | 2 | 9 | 537_557 | 122 | 594.0 | Region | Important for cytoplasmic localization |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000215862 | 22 | 27 | 282_362 | 778 | 971.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000215862 | 22 | 27 | 547_584 | 778 | 971.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000215862 | 22 | 27 | 741_761 | 778 | 971.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000397641 | 21 | 26 | 282_362 | 840 | 1033.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000397641 | 21 | 26 | 547_584 | 840 | 1033.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000397641 | 21 | 26 | 741_761 | 840 | 1033.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000215862 | 22 | 27 | 282_362 | 778 | 971.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000215862 | 22 | 27 | 547_584 | 778 | 971.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000215862 | 22 | 27 | 741_761 | 778 | 971.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000397641 | 21 | 26 | 282_362 | 840 | 1033.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000397641 | 21 | 26 | 547_584 | 840 | 1033.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000397641 | 21 | 26 | 741_761 | 840 | 1033.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000215862 | 22 | 27 | 87_89 | 778 | 971.0 | Nucleotide binding | ATP | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000215862 | 22 | 27 | 99_105 | 778 | 971.0 | Nucleotide binding | ATP | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000397641 | 21 | 26 | 87_89 | 840 | 1033.0 | Nucleotide binding | ATP | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000397641 | 21 | 26 | 99_105 | 840 | 1033.0 | Nucleotide binding | ATP | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000215862 | 22 | 27 | 87_89 | 778 | 971.0 | Nucleotide binding | ATP | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000215862 | 22 | 27 | 99_105 | 778 | 971.0 | Nucleotide binding | ATP | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000397641 | 21 | 26 | 87_89 | 840 | 1033.0 | Nucleotide binding | ATP | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000397641 | 21 | 26 | 99_105 | 840 | 1033.0 | Nucleotide binding | ATP | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000215862 | 22 | 27 | 490_544 | 778 | 971.0 | Zinc finger | CW-type | |
| Tgene | MORC2 | chr19:929895 | chr22:31328755 | ENST00000397641 | 21 | 26 | 490_544 | 840 | 1033.0 | Zinc finger | CW-type | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000215862 | 22 | 27 | 490_544 | 778 | 971.0 | Zinc finger | CW-type | |
| Tgene | MORC2 | chr19:929896 | chr22:31328756 | ENST00000397641 | 21 | 26 | 490_544 | 840 | 1033.0 | Zinc finger | CW-type |
Top |
Fusion Gene Sequence for ARID3A-MORC2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6448_6448_1_ARID3A-MORC2_ARID3A_chr19_929895_ENST00000263620_MORC2_chr22_31328755_ENST00000215862_length(transcript)=1464nt_BP=695nt GCGGGGCGCCTCTTACCAATCGGGCGGAGGGGTGTAGACGCGGACGCGGCTGGCGGCTCGGTTTCTGCAAATGCGTGAATGAGCCGGATG CCAGCCTCTGTCCCCTGGAGCCCAGCGTGAGGAAGAGGCATGCCCCATCAGCCTTCAGCTTGAGCCCGGCGGCCCCCGCCCCCGCCCCCT GCCACCCTGCACTGCCCCGGCTCCCCCGCGGCCCCCACGCTGCAGTGCGGCCGGGCCCCCTCCCCGCAGGGGCCGCCCCCGCCGCCCACC CCTAGCGCCCGTGGTGGTGGTGGTGGTGGTGGTGGTGGTGGCCCGGGCCGCAGGGCCATGAAACTACAGGCCGTGATGGAGACGCTGTTG CAGCGGCAGCAGCGGGCGCGCCAGGAGCTGGAGGCCCGGCAGCAGCTGCCCCCCGATCCCCCTGCTGCACCCCCCGGCCGGGCCCGGGCT GCCCCCGACGAGGACAGAGAGCCCGAGAGTGCCCGGATGCAGCGGGCTCAGATGGCCGCACTGGCAGCCATGCGGGCTGCAGCTGCGGGC CTGGGACACCCAGCCAGCCCCGGCGGCTCTGAGGATGGGCCCCCAGGCTCGGAGGAGGAGGACGCGGCCCGGGAGGGGACACCGGGCTCA CCCGGGCGAGGCAGAGAAGGGCCAGGAGAGGAGCACTTTGAGGACATGGCCTCCGACGAGGACATGGTGGAGAAAGGCAGTGAGGATGTG CGGCTGATGAAACCCCCTTCTCCGGAACATCAGAGCCTTGATACACAACAGGAGGGCGGGGAGGAGGAGGTGGGCCCTGTGGCCCAGCAG GCCATAGCTGTCGCAGAGCCCTCCACTTCCGAATGCCTCCGCATTGAGCCTGACACCACTGCCCTGAGCACCAATCACGAGACCATCGAC CTGCTTGTCCAGATCCTCCGGAATTGTTTACGGTACTTCCTGCCTCCAAGTTTCCCCATCTCCAAGAAGCAGCTGAGTGCTATGAATTCA GATGAGCTAATATCTTTTCCTCTGAAGGAGTACTTCAAGCAATATGAAGTAGGGCTCCAAAACCTGTGCAATTCCTACCAGAGCCGTGCT GACTCCCGGGCCAAGGCCTCCGAGGAAAGCCTGCGCACCTCCGAGAGGAAGCTCCGCGAGACGGAGGAGAAGCTGCAGAAGCTGAGGACC AACATCGTGGCACTCCTGCAAAAGGTGCAGGAGGACATAGACATCAACACAGATGATGAGCTGGACGCCTACATTGAGGACCTCATCACC AAGGGGGACTGAAGGCAGGAGAGAGAGCAGCTCCCCTGCCCACCTGCCCCTCAACCCTGTAGCTGCAGGGGGAGGGGACTTCATTCATGG GTTGGTGGTCGCACCTTGGTTTGACTTACACGGGACATTTGTGTTTTTGGAGGAAAAGATACCCTGATTCTTTGAATCTTCCTTAAGTTT >6448_6448_1_ARID3A-MORC2_ARID3A_chr19_929895_ENST00000263620_MORC2_chr22_31328755_ENST00000215862_length(amino acids)=361AA_BP=170 MHCPGSPAAPTLQCGRAPSPQGPPPPPTPSARGGGGGGGGGGPGRRAMKLQAVMETLLQRQQRARQELEARQQLPPDPPAAPPGRARAAP DEDREPESARMQRAQMAALAAMRAAAAGLGHPASPGGSEDGPPGSEEEDAAREGTPGSPGRGREGPGEEHFEDMASDEDMVEKGSEDVRL MKPPSPEHQSLDTQQEGGEEEVGPVAQQAIAVAEPSTSECLRIEPDTTALSTNHETIDLLVQILRNCLRYFLPPSFPISKKQLSAMNSDE LISFPLKEYFKQYEVGLQNLCNSYQSRADSRAKASEESLRTSERKLRETEEKLQKLRTNIVALLQKVQEDIDINTDDELDAYIEDLITKG -------------------------------------------------------------- >6448_6448_2_ARID3A-MORC2_ARID3A_chr19_929895_ENST00000263620_MORC2_chr22_31328755_ENST00000397641_length(transcript)=2945nt_BP=695nt GCGGGGCGCCTCTTACCAATCGGGCGGAGGGGTGTAGACGCGGACGCGGCTGGCGGCTCGGTTTCTGCAAATGCGTGAATGAGCCGGATG CCAGCCTCTGTCCCCTGGAGCCCAGCGTGAGGAAGAGGCATGCCCCATCAGCCTTCAGCTTGAGCCCGGCGGCCCCCGCCCCCGCCCCCT GCCACCCTGCACTGCCCCGGCTCCCCCGCGGCCCCCACGCTGCAGTGCGGCCGGGCCCCCTCCCCGCAGGGGCCGCCCCCGCCGCCCACC CCTAGCGCCCGTGGTGGTGGTGGTGGTGGTGGTGGTGGTGGCCCGGGCCGCAGGGCCATGAAACTACAGGCCGTGATGGAGACGCTGTTG CAGCGGCAGCAGCGGGCGCGCCAGGAGCTGGAGGCCCGGCAGCAGCTGCCCCCCGATCCCCCTGCTGCACCCCCCGGCCGGGCCCGGGCT GCCCCCGACGAGGACAGAGAGCCCGAGAGTGCCCGGATGCAGCGGGCTCAGATGGCCGCACTGGCAGCCATGCGGGCTGCAGCTGCGGGC CTGGGACACCCAGCCAGCCCCGGCGGCTCTGAGGATGGGCCCCCAGGCTCGGAGGAGGAGGACGCGGCCCGGGAGGGGACACCGGGCTCA CCCGGGCGAGGCAGAGAAGGGCCAGGAGAGGAGCACTTTGAGGACATGGCCTCCGACGAGGACATGGTGGAGAAAGGCAGTGAGGATGTG CGGCTGATGAAACCCCCTTCTCCGGAACATCAGAGCCTTGATACACAACAGGAGGGCGGGGAGGAGGAGGTGGGCCCTGTGGCCCAGCAG GCCATAGCTGTCGCAGAGCCCTCCACTTCCGAATGCCTCCGCATTGAGCCTGACACCACTGCCCTGAGCACCAATCACGAGACCATCGAC CTGCTTGTCCAGATCCTCCGGAATTGTTTACGGTACTTCCTGCCTCCAAGTTTCCCCATCTCCAAGAAGCAGCTGAGTGCTATGAATTCA GATGAGCTAATATCTTTTCCTCTGAAGGAGTACTTCAAGCAATATGAAGTAGGGCTCCAAAACCTGTGCAATTCCTACCAGAGCCGTGCT GACTCCCGGGCCAAGGCCTCCGAGGAAAGCCTGCGCACCTCCGAGAGGAAGCTCCGCGAGACGGAGGAGAAGCTGCAGAAGCTGAGGACC AACATCGTGGCACTCCTGCAAAAGGTGCAGGAGGACATAGACATCAACACAGATGATGAGCTGGACGCCTACATTGAGGACCTCATCACC AAGGGGGACTGAAGGCAGGAGAGAGAGCAGCTCCCCTGCCCACCTGCCCCTCAACCCTGTAGCTGCAGGGGGAGGGGACTTCATTCATGG GTTGGTGGTCGCACCTTGGTTTGACTTACACGGGACATTTGTGTTTTTGGAGGAAAAGATACCCTGATTCTTTGAATCTTCCTTAAGTTT ATAAATATTTATTTTTTAAAAGAAGATGCTGTGCCTGTGAGACCATACTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTGGTGAC TGCAAAGGACAGAGAACCTTTCCACTTTGGCCATACTGGGTTGCTAAGCCGGAGCCATTTCAGCTCCTGGCTCCTCAAGATAACGGCGAG TCCAGTGCCATCTTGGAGAAGCTCCAGGGGCAGGGCTGACTTTTCTCCTACAGGAGGAACAATGTGGGGATCTGAGGGATGGGAGGGAGA CTTCCCCCTAGAGTGGTGGTCCTGCTGGGGGCTCATATCCAGGGACCCAAAAGGGGGGCTGTGTAGGAGGTTCCACATTGGAGGGGCTCT CTCTCTCGCAGCTGTCAGAGTTGGTCCTGGCTGTGGCGTCCAAACAGCTTGAGGGAAAAAGATCCTGTCTAACCACCTCATCTACTACTC AAGTTCTTTCTGAAGGAGGGATTTCTTCAGTTAACCATGGACAGTGAGGTTTCTCACCACAGTAACTTGAGTCCAGGTTGAGGGGGAGAC AGATCTGTGGTAAATCTCTGACTTGGGCAGCACACTGAGTGTGGAACCCCACAGGACTCCTTAGGGAAGGAGCTTGTGTGTGAAAGAACC CCTGGGGCTGAGCTGGTGACCTCCATGTGTGGGTGCAGCAGGGCCTTGGATGGTGCCAATTGATCTGGACAGCCTGTTGATGCTTTTCTA CTTCCACCCTTCGGCCTGGCCCCACTGAGCCCCATCAAGGTGCCTGAAGAGGGGGCCAGTGAGATCCCGTGGCCACAGGGACTCCAGAGG CATCTCTGCAGGAAGCACACCATGCCTTCCCTCCATGTTCCATCACGGCGCCACAATCTGTGTCCCTTAACTTCTCAGGGTCAAAGACAA AGGCAAGCGTTGCTGAATTTTCTCTTTAATGGCCATTGGAAGAGTCTGGTTCAGTTTTTCCCAACTCTCTTCCCACTCGTATTTGGGGCC TCTGGGTTTTCTGAAGGCACAAGGACTGTGACTTTGTACCACTAACCTGTGGTTCAAACCTGGGTGTGTTTCTGGCATCTCCCTAACCCA GATCAGCAATGGCCACCCTGCTCCTCTGAGGTCAGCAGAAGACTGGGAAGCAGAGGTGAGGGATGCAGGCCACACTGGAATGGGAAGTCT TTTCCCCACTGGATGTGCCTGTCTGGTGGGTTTTGGACCTTCCCAGACTACATCTCTAGGAGAGGCCTGTTTGGAGTAGTACACTGAGAG ACCCTGGCCTCTTCTGCTGGAAGACTGTCCAAGTCTTGGGGTTTCTTGAGCTGGTGATTCCTCTGCCATCCTGCTCTCTCTCTTCATCTC AGGCAGCATGGGGTCCACTTTTGTCCCCAAACCTAATGTTTTAATCCAAATGCAAATTGGTTCCACATTTTTACTGGAGGGTAATCAGTT >6448_6448_2_ARID3A-MORC2_ARID3A_chr19_929895_ENST00000263620_MORC2_chr22_31328755_ENST00000397641_length(amino acids)=361AA_BP=170 MHCPGSPAAPTLQCGRAPSPQGPPPPPTPSARGGGGGGGGGGPGRRAMKLQAVMETLLQRQQRARQELEARQQLPPDPPAAPPGRARAAP DEDREPESARMQRAQMAALAAMRAAAAGLGHPASPGGSEDGPPGSEEEDAAREGTPGSPGRGREGPGEEHFEDMASDEDMVEKGSEDVRL MKPPSPEHQSLDTQQEGGEEEVGPVAQQAIAVAEPSTSECLRIEPDTTALSTNHETIDLLVQILRNCLRYFLPPSFPISKKQLSAMNSDE LISFPLKEYFKQYEVGLQNLCNSYQSRADSRAKASEESLRTSERKLRETEEKLQKLRTNIVALLQKVQEDIDINTDDELDAYIEDLITKG -------------------------------------------------------------- >6448_6448_3_ARID3A-MORC2_ARID3A_chr19_929896_ENST00000263620_MORC2_chr22_31328756_ENST00000215862_length(transcript)=1464nt_BP=695nt GCGGGGCGCCTCTTACCAATCGGGCGGAGGGGTGTAGACGCGGACGCGGCTGGCGGCTCGGTTTCTGCAAATGCGTGAATGAGCCGGATG CCAGCCTCTGTCCCCTGGAGCCCAGCGTGAGGAAGAGGCATGCCCCATCAGCCTTCAGCTTGAGCCCGGCGGCCCCCGCCCCCGCCCCCT GCCACCCTGCACTGCCCCGGCTCCCCCGCGGCCCCCACGCTGCAGTGCGGCCGGGCCCCCTCCCCGCAGGGGCCGCCCCCGCCGCCCACC CCTAGCGCCCGTGGTGGTGGTGGTGGTGGTGGTGGTGGTGGCCCGGGCCGCAGGGCCATGAAACTACAGGCCGTGATGGAGACGCTGTTG CAGCGGCAGCAGCGGGCGCGCCAGGAGCTGGAGGCCCGGCAGCAGCTGCCCCCCGATCCCCCTGCTGCACCCCCCGGCCGGGCCCGGGCT GCCCCCGACGAGGACAGAGAGCCCGAGAGTGCCCGGATGCAGCGGGCTCAGATGGCCGCACTGGCAGCCATGCGGGCTGCAGCTGCGGGC CTGGGACACCCAGCCAGCCCCGGCGGCTCTGAGGATGGGCCCCCAGGCTCGGAGGAGGAGGACGCGGCCCGGGAGGGGACACCGGGCTCA CCCGGGCGAGGCAGAGAAGGGCCAGGAGAGGAGCACTTTGAGGACATGGCCTCCGACGAGGACATGGTGGAGAAAGGCAGTGAGGATGTG CGGCTGATGAAACCCCCTTCTCCGGAACATCAGAGCCTTGATACACAACAGGAGGGCGGGGAGGAGGAGGTGGGCCCTGTGGCCCAGCAG GCCATAGCTGTCGCAGAGCCCTCCACTTCCGAATGCCTCCGCATTGAGCCTGACACCACTGCCCTGAGCACCAATCACGAGACCATCGAC CTGCTTGTCCAGATCCTCCGGAATTGTTTACGGTACTTCCTGCCTCCAAGTTTCCCCATCTCCAAGAAGCAGCTGAGTGCTATGAATTCA GATGAGCTAATATCTTTTCCTCTGAAGGAGTACTTCAAGCAATATGAAGTAGGGCTCCAAAACCTGTGCAATTCCTACCAGAGCCGTGCT GACTCCCGGGCCAAGGCCTCCGAGGAAAGCCTGCGCACCTCCGAGAGGAAGCTCCGCGAGACGGAGGAGAAGCTGCAGAAGCTGAGGACC AACATCGTGGCACTCCTGCAAAAGGTGCAGGAGGACATAGACATCAACACAGATGATGAGCTGGACGCCTACATTGAGGACCTCATCACC AAGGGGGACTGAAGGCAGGAGAGAGAGCAGCTCCCCTGCCCACCTGCCCCTCAACCCTGTAGCTGCAGGGGGAGGGGACTTCATTCATGG GTTGGTGGTCGCACCTTGGTTTGACTTACACGGGACATTTGTGTTTTTGGAGGAAAAGATACCCTGATTCTTTGAATCTTCCTTAAGTTT >6448_6448_3_ARID3A-MORC2_ARID3A_chr19_929896_ENST00000263620_MORC2_chr22_31328756_ENST00000215862_length(amino acids)=361AA_BP=170 MHCPGSPAAPTLQCGRAPSPQGPPPPPTPSARGGGGGGGGGGPGRRAMKLQAVMETLLQRQQRARQELEARQQLPPDPPAAPPGRARAAP DEDREPESARMQRAQMAALAAMRAAAAGLGHPASPGGSEDGPPGSEEEDAAREGTPGSPGRGREGPGEEHFEDMASDEDMVEKGSEDVRL MKPPSPEHQSLDTQQEGGEEEVGPVAQQAIAVAEPSTSECLRIEPDTTALSTNHETIDLLVQILRNCLRYFLPPSFPISKKQLSAMNSDE LISFPLKEYFKQYEVGLQNLCNSYQSRADSRAKASEESLRTSERKLRETEEKLQKLRTNIVALLQKVQEDIDINTDDELDAYIEDLITKG -------------------------------------------------------------- >6448_6448_4_ARID3A-MORC2_ARID3A_chr19_929896_ENST00000263620_MORC2_chr22_31328756_ENST00000397641_length(transcript)=2945nt_BP=695nt GCGGGGCGCCTCTTACCAATCGGGCGGAGGGGTGTAGACGCGGACGCGGCTGGCGGCTCGGTTTCTGCAAATGCGTGAATGAGCCGGATG CCAGCCTCTGTCCCCTGGAGCCCAGCGTGAGGAAGAGGCATGCCCCATCAGCCTTCAGCTTGAGCCCGGCGGCCCCCGCCCCCGCCCCCT GCCACCCTGCACTGCCCCGGCTCCCCCGCGGCCCCCACGCTGCAGTGCGGCCGGGCCCCCTCCCCGCAGGGGCCGCCCCCGCCGCCCACC CCTAGCGCCCGTGGTGGTGGTGGTGGTGGTGGTGGTGGTGGCCCGGGCCGCAGGGCCATGAAACTACAGGCCGTGATGGAGACGCTGTTG CAGCGGCAGCAGCGGGCGCGCCAGGAGCTGGAGGCCCGGCAGCAGCTGCCCCCCGATCCCCCTGCTGCACCCCCCGGCCGGGCCCGGGCT GCCCCCGACGAGGACAGAGAGCCCGAGAGTGCCCGGATGCAGCGGGCTCAGATGGCCGCACTGGCAGCCATGCGGGCTGCAGCTGCGGGC CTGGGACACCCAGCCAGCCCCGGCGGCTCTGAGGATGGGCCCCCAGGCTCGGAGGAGGAGGACGCGGCCCGGGAGGGGACACCGGGCTCA CCCGGGCGAGGCAGAGAAGGGCCAGGAGAGGAGCACTTTGAGGACATGGCCTCCGACGAGGACATGGTGGAGAAAGGCAGTGAGGATGTG CGGCTGATGAAACCCCCTTCTCCGGAACATCAGAGCCTTGATACACAACAGGAGGGCGGGGAGGAGGAGGTGGGCCCTGTGGCCCAGCAG GCCATAGCTGTCGCAGAGCCCTCCACTTCCGAATGCCTCCGCATTGAGCCTGACACCACTGCCCTGAGCACCAATCACGAGACCATCGAC CTGCTTGTCCAGATCCTCCGGAATTGTTTACGGTACTTCCTGCCTCCAAGTTTCCCCATCTCCAAGAAGCAGCTGAGTGCTATGAATTCA GATGAGCTAATATCTTTTCCTCTGAAGGAGTACTTCAAGCAATATGAAGTAGGGCTCCAAAACCTGTGCAATTCCTACCAGAGCCGTGCT GACTCCCGGGCCAAGGCCTCCGAGGAAAGCCTGCGCACCTCCGAGAGGAAGCTCCGCGAGACGGAGGAGAAGCTGCAGAAGCTGAGGACC AACATCGTGGCACTCCTGCAAAAGGTGCAGGAGGACATAGACATCAACACAGATGATGAGCTGGACGCCTACATTGAGGACCTCATCACC AAGGGGGACTGAAGGCAGGAGAGAGAGCAGCTCCCCTGCCCACCTGCCCCTCAACCCTGTAGCTGCAGGGGGAGGGGACTTCATTCATGG GTTGGTGGTCGCACCTTGGTTTGACTTACACGGGACATTTGTGTTTTTGGAGGAAAAGATACCCTGATTCTTTGAATCTTCCTTAAGTTT ATAAATATTTATTTTTTAAAAGAAGATGCTGTGCCTGTGAGACCATACTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTGGTGAC TGCAAAGGACAGAGAACCTTTCCACTTTGGCCATACTGGGTTGCTAAGCCGGAGCCATTTCAGCTCCTGGCTCCTCAAGATAACGGCGAG TCCAGTGCCATCTTGGAGAAGCTCCAGGGGCAGGGCTGACTTTTCTCCTACAGGAGGAACAATGTGGGGATCTGAGGGATGGGAGGGAGA CTTCCCCCTAGAGTGGTGGTCCTGCTGGGGGCTCATATCCAGGGACCCAAAAGGGGGGCTGTGTAGGAGGTTCCACATTGGAGGGGCTCT CTCTCTCGCAGCTGTCAGAGTTGGTCCTGGCTGTGGCGTCCAAACAGCTTGAGGGAAAAAGATCCTGTCTAACCACCTCATCTACTACTC AAGTTCTTTCTGAAGGAGGGATTTCTTCAGTTAACCATGGACAGTGAGGTTTCTCACCACAGTAACTTGAGTCCAGGTTGAGGGGGAGAC AGATCTGTGGTAAATCTCTGACTTGGGCAGCACACTGAGTGTGGAACCCCACAGGACTCCTTAGGGAAGGAGCTTGTGTGTGAAAGAACC CCTGGGGCTGAGCTGGTGACCTCCATGTGTGGGTGCAGCAGGGCCTTGGATGGTGCCAATTGATCTGGACAGCCTGTTGATGCTTTTCTA CTTCCACCCTTCGGCCTGGCCCCACTGAGCCCCATCAAGGTGCCTGAAGAGGGGGCCAGTGAGATCCCGTGGCCACAGGGACTCCAGAGG CATCTCTGCAGGAAGCACACCATGCCTTCCCTCCATGTTCCATCACGGCGCCACAATCTGTGTCCCTTAACTTCTCAGGGTCAAAGACAA AGGCAAGCGTTGCTGAATTTTCTCTTTAATGGCCATTGGAAGAGTCTGGTTCAGTTTTTCCCAACTCTCTTCCCACTCGTATTTGGGGCC TCTGGGTTTTCTGAAGGCACAAGGACTGTGACTTTGTACCACTAACCTGTGGTTCAAACCTGGGTGTGTTTCTGGCATCTCCCTAACCCA GATCAGCAATGGCCACCCTGCTCCTCTGAGGTCAGCAGAAGACTGGGAAGCAGAGGTGAGGGATGCAGGCCACACTGGAATGGGAAGTCT TTTCCCCACTGGATGTGCCTGTCTGGTGGGTTTTGGACCTTCCCAGACTACATCTCTAGGAGAGGCCTGTTTGGAGTAGTACACTGAGAG ACCCTGGCCTCTTCTGCTGGAAGACTGTCCAAGTCTTGGGGTTTCTTGAGCTGGTGATTCCTCTGCCATCCTGCTCTCTCTCTTCATCTC AGGCAGCATGGGGTCCACTTTTGTCCCCAAACCTAATGTTTTAATCCAAATGCAAATTGGTTCCACATTTTTACTGGAGGGTAATCAGTT >6448_6448_4_ARID3A-MORC2_ARID3A_chr19_929896_ENST00000263620_MORC2_chr22_31328756_ENST00000397641_length(amino acids)=361AA_BP=170 MHCPGSPAAPTLQCGRAPSPQGPPPPPTPSARGGGGGGGGGGPGRRAMKLQAVMETLLQRQQRARQELEARQQLPPDPPAAPPGRARAAP DEDREPESARMQRAQMAALAAMRAAAAGLGHPASPGGSEDGPPGSEEEDAAREGTPGSPGRGREGPGEEHFEDMASDEDMVEKGSEDVRL MKPPSPEHQSLDTQQEGGEEEVGPVAQQAIAVAEPSTSECLRIEPDTTALSTNHETIDLLVQILRNCLRYFLPPSFPISKKQLSAMNSDE LISFPLKEYFKQYEVGLQNLCNSYQSRADSRAKASEESLRTSERKLRETEEKLQKLRTNIVALLQKVQEDIDINTDDELDAYIEDLITKG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARID3A-MORC2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARID3A-MORC2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARID3A-MORC2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies