
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PGD-PEX14 (FusionGDB2 ID:64597) |
Fusion Gene Summary for PGD-PEX14 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PGD-PEX14 | Fusion gene ID: 64597 | Hgene | Tgene | Gene symbol | PGD | PEX14 | Gene ID | 26227 | 5195 |
| Gene name | phosphoglycerate dehydrogenase | peroxisomal biogenesis factor 14 | |
| Synonyms | 3-PGDH|3PGDH|HEL-S-113|NLS|NLS1|PDG|PGAD|PGD|PGDH|PHGDHD|SERA | NAPP2|PBD13A|Pex14p|dJ734G22.2 | |
| Cytomap | 1p12 | 1p36.22 | |
| Type of gene | protein-coding | protein-coding | |
| Description | D-3-phosphoglycerate dehydrogenase2-oxoglutarate reductase3-phosphoglycerate dehydrogenaseepididymis secretory protein Li 113malate dehydrogenase | peroxisomal membrane protein PEX14NF-E2 associated polypeptide 2PTS1 receptor docking proteinperoxin-14peroxisomal membrane anchor protein PEX14peroxisomal membrane anchor protein Pex14p | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000270776, ENST00000538557, ENST00000541529, ENST00000498356, | ENST00000492696, ENST00000538836, ENST00000356607, | |
| Fusion gene scores | * DoF score | 11 X 8 X 6=528 | 13 X 10 X 7=910 |
| # samples | 12 | 13 | |
| ** MAII score | log2(12/528*10)=-2.13750352374993 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(13/910*10)=-2.8073549220576 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PGD [Title/Abstract] AND PEX14 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PGD(10460629)-PEX14(10596270), # samples:2 PEX14(10535059)-PGD(10459685), # samples:1 PEX14(10535059)-PGD(10459686), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | PEX14-PGD seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. PEX14-PGD seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PEX14 | GO:0016561 | protein import into peroxisome matrix, translocation | 21525035 |
| Tgene | PEX14 | GO:0032091 | negative regulation of protein binding | 21976670 |
| Tgene | PEX14 | GO:0034453 | microtubule anchoring | 21525035 |
| Tgene | PEX14 | GO:0036250 | peroxisome transport along microtubule | 21525035 |
| Tgene | PEX14 | GO:0043433 | negative regulation of DNA-binding transcription factor activity | 11863372 |
| Tgene | PEX14 | GO:0044721 | protein import into peroxisome matrix, substrate release | 21976670 |
| Tgene | PEX14 | GO:0045892 | negative regulation of transcription, DNA-templated | 11863372 |
| Tgene | PEX14 | GO:0065003 | protein-containing complex assembly | 21525035 |
| Fusion gene breakpoints across PGD (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PEX14 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | CESC | TCGA-DS-A1OD-01A | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
Top |
Fusion Gene ORF analysis for PGD-PEX14 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000270776 | ENST00000492696 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| 5CDS-3UTR | ENST00000538557 | ENST00000492696 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| 5CDS-3UTR | ENST00000541529 | ENST00000492696 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| 5CDS-intron | ENST00000270776 | ENST00000538836 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| 5CDS-intron | ENST00000538557 | ENST00000538836 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| 5CDS-intron | ENST00000541529 | ENST00000538836 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| In-frame | ENST00000270776 | ENST00000356607 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| In-frame | ENST00000538557 | ENST00000356607 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| In-frame | ENST00000541529 | ENST00000356607 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| intron-3CDS | ENST00000498356 | ENST00000356607 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| intron-3UTR | ENST00000498356 | ENST00000492696 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| intron-intron | ENST00000498356 | ENST00000538836 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000541529 | PGD | chr1 | 10460629 | + | ENST00000356607 | PEX14 | chr1 | 10596270 | + | 2134 | 313 | 37 | 1362 | 441 |
| ENST00000270776 | PGD | chr1 | 10460629 | + | ENST00000356607 | PEX14 | chr1 | 10596270 | + | 2123 | 302 | 26 | 1351 | 441 |
| ENST00000538557 | PGD | chr1 | 10460629 | + | ENST00000356607 | PEX14 | chr1 | 10596270 | + | 2290 | 469 | 193 | 1518 | 441 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000541529 | ENST00000356607 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + | 0.003537034 | 0.996463 |
| ENST00000270776 | ENST00000356607 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + | 0.003701565 | 0.9962985 |
| ENST00000538557 | ENST00000356607 | PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596270 | + | 0.004449609 | 0.9955504 |
Top |
Fusion Genomic Features for PGD-PEX14 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596269 | + | 1.13E-10 | 1 |
| PGD | chr1 | 10460629 | + | PEX14 | chr1 | 10596269 | + | 1.13E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
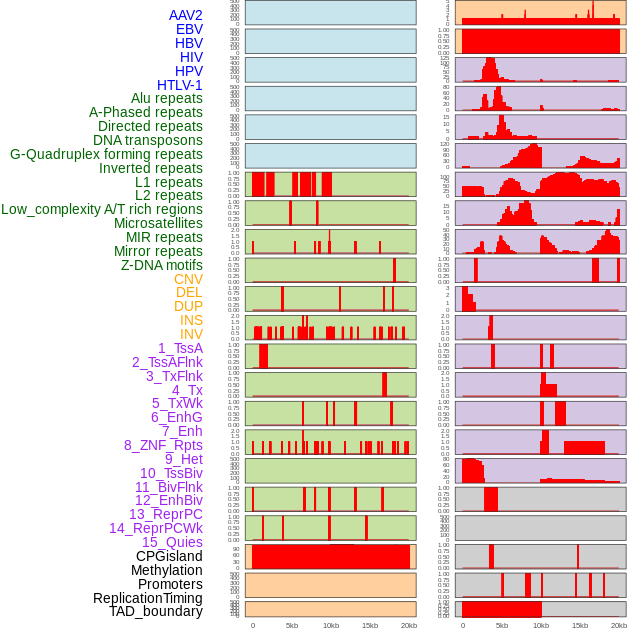 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
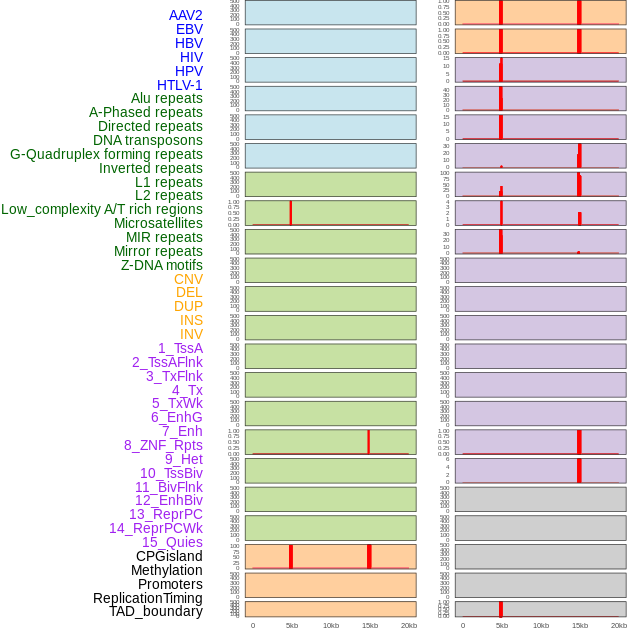 |
Top |
Fusion Protein Features for PGD-PEX14 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:10460629/chr1:10596270) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PGD | chr1:10460629 | chr1:10596270 | ENST00000270776 | + | 3 | 13 | 10_15 | 88 | 484.0 | Nucleotide binding | NADP |
| Hgene | PGD | chr1:10460629 | chr1:10596270 | ENST00000270776 | + | 3 | 13 | 33_35 | 88 | 484.0 | Nucleotide binding | NADP |
| Hgene | PGD | chr1:10460629 | chr1:10596270 | ENST00000270776 | + | 3 | 13 | 75_77 | 88 | 484.0 | Nucleotide binding | NADP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PGD | chr1:10460629 | chr1:10596270 | ENST00000270776 | + | 3 | 13 | 478_481 | 88 | 484.0 | Nucleotide binding | NADP%3B shared with dimeric partner |
| Hgene | PGD | chr1:10460629 | chr1:10596270 | ENST00000270776 | + | 3 | 13 | 129_131 | 88 | 484.0 | Region | Substrate binding |
| Hgene | PGD | chr1:10460629 | chr1:10596270 | ENST00000270776 | + | 3 | 13 | 187_188 | 88 | 484.0 | Region | Substrate binding |
Top |
Fusion Gene Sequence for PGD-PEX14 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >64597_64597_1_PGD-PEX14_PGD_chr1_10460629_ENST00000270776_PEX14_chr1_10596270_ENST00000356607_length(transcript)=2123nt_BP=302nt GCGCGTCGCCGCTCTTCGGTTCTGCTCTGTCCGCCGCCATGGCCCAAGCTGACATCGCGCTGATCGGATTGGCCGTCATGGGCCAGAACT TAATTCTGAACATGAATGACCACGGCTTTGTGGTCTGTGCTTTTAATAGGACTGTCTCCAAAGTTGATGATTTCTTGGCCAATGAGGCAA AGGGAACCAAAGTGGTGGGTGCCCAGTCCCTGAAAGAGATGGTCTCCAAGCTGAAGAAGCCCCGGCGGATCATCCTCCTGGTGAAGGCTG GGCAAGCTGTGGATGATTTCATCGAGAAATTGATTGCCACGGCAGTGAAGTTTCTACAGAATTCCCGGGTCCGCCAGAGCCCACTTGCAA CCAGGAGAGCATTCCTAAAGAAGAAAGGGCTGACAGATGAAGAGATTGATATGGCCTTCCAGCAGTCGGGCACTGCTGCCGATGAGCCTT CGTCCTTGGGCCCAGCCACACAGGTGGTTCCTGTCCAGCCCCCTCACCTCATATCTCAGCCATACAGTCCCGCAGGCTCCCGATGGCGAG ATTACGGCGCCCTGGCCATCATCATGGCAGGCATTGCATTTGGCTTTCACCAGCTCTACAAGAAATACCTGCTCCCCCTCATCCTGGGCG GCCGAGAGGACAGAAAGCAGCTGGAGAGGATGGAGGCCGGTCTCTCTGAGCTGAGTGGCAGCGTGGCCCAGACAGTGACTCAGTTACAGA CGACCCTCGCCTCCGTCCAGGAGCTGCTGATTCAGCAGCAGCAGAAGATCCAGGAGCTTGCCCACGAGCTGGCCGCTGCCAAGGCCACCA CATCCACCAACTGGATCCTGGAGTCCCAGAATATCAACGAACTCAAGTCCGAAATTAACTCCTTGAAAGGGCTTCTTTTAAATCGGAGGC AGTTCCCTCCATCCCCATCAGCCCCGAAGATCCCCTCCTGGCAGATCCCAGTCAAGTCACCGTCACCCTCCAGCCCTGCGGCCGTGAACC ACCACAGCAGCAGCGACATCTCACCTGTCAGCAACGAGTCCACGTCGTCCTCGCCTGGGAAGGAGGGCCACAGCCCCGAGGGCTCCACGG TCACCTACCACTTGCTGGGCCCCCAGGAGGAAGGCGAGGGGGTGGTGGACGTCAAGGGCCAGGTGCGGATGGAGGTGCAAGGCGAGGAGG AGAAGAGGGAGGACAAGGAGGACGAGGAGGATGAGGAGGATGATGATGTGAGCCATGTGGACGAGGAGGACTGCCTGGGGGTGCAGAGGG AGGACCGCCGGGGCGGGGATGGGCAGATCAACGAGCAGGTGGAGAAGCTGCGGCGGCCCGAGGGCGCCAGCAACGAGAGTGAGCGGGACT AGGGCTGCGCCTGCTGCCTCCAGCCCTGAGGATGGCATCTAGTGTGCCCGTGCGTGGCCATACCCTGCCTCCCTCTCTGGCCCTGGGAGG GCAGCTTGGAGCCCAGGTAGGGGGCAGAGCTGTCCTCAGCTGCACTGCGGCCTGGTGGCAGTGTGGGGAGTCACACTTCTGTCCACCTGG CCTCCTCTCGCCTGGCCGCCAGCCCCAGCCCCAGCCCCAGCCCCAGGCCCAGCTGCCTTTGGCTTTGATCTCAAGTCAGGCTGAAGGCAG CGAAGCCTCGGGGCCCAAGCCCCTCCCCAGCCCCCTCTCCCGGACAGACGCCTTGCCCAGGGTGTGTTTGCTGAGTGTCTTGACTACCGT GACACCACGCATGGCCAGAGCTAGCGTCCCTACTGCCTCCCGACTCCTCAGTGGAGGAGGAGCTGCGGTCCCTCTGGTGTCTGCCATCCC CCTCCCTCCCTGGGCCCGGCCCTGGACCCGTCAGGTGCCTGTCCCCAGCCCCAACCCCACTCATGCCCCGTCGTCCTCCCAGACAAATGA AACCACGCTGCGCTTCCGATGCCCCCGCTTGCCGTGTAATGGTTCAGCTAATCCCATGGCGAGATGGGGGCTCACTCCGGAGGAGGAGCC AGGCAGCAGGGCCTTCCTGACCAACAGCCAGCTCTGTCCTTCCCCCCAGGAAACACATGTTCATTTGTGTGATCATGTATAGACCTCAGA >64597_64597_1_PGD-PEX14_PGD_chr1_10460629_ENST00000270776_PEX14_chr1_10596270_ENST00000356607_length(amino acids)=441AA_BP=7 MSAAMAQADIALIGLAVMGQNLILNMNDHGFVVCAFNRTVSKVDDFLANEAKGTKVVGAQSLKEMVSKLKKPRRIILLVKAGQAVDDFIE KLIATAVKFLQNSRVRQSPLATRRAFLKKKGLTDEEIDMAFQQSGTAADEPSSLGPATQVVPVQPPHLISQPYSPAGSRWRDYGALAIIM AGIAFGFHQLYKKYLLPLILGGREDRKQLERMEAGLSELSGSVAQTVTQLQTTLASVQELLIQQQQKIQELAHELAAAKATTSTNWILES QNINELKSEINSLKGLLLNRRQFPPSPSAPKIPSWQIPVKSPSPSSPAAVNHHSSSDISPVSNESTSSSPGKEGHSPEGSTVTYHLLGPQ -------------------------------------------------------------- >64597_64597_2_PGD-PEX14_PGD_chr1_10460629_ENST00000538557_PEX14_chr1_10596270_ENST00000356607_length(transcript)=2290nt_BP=469nt ATGGCCCAGTGAGTGACTCGCCAGGGGCAGCCCGGCTCGGCCTCAGCGGGCGGGGAACTCTTTGGGGGTCGAGATCTCCCTCGTTCTCTC CGACGCCTCCCACCCTGGGGGTCGCCTGAGCTCACTTGGGGCTCTGTGACCCTGGCCCTACGGCGTCTCGGGCCCAGAGCTCCTTCCCTG CGGGCCCGGCCCCCTGCCCTCTCGGCCGCGCAGAGCTGACATCGCGCTGATCGGATTGGCCGTCATGGGCCAGAACTTAATTCTGAACAT GAATGACCACGGCTTTGTGGTCTGTGCTTTTAATAGGACTGTCTCCAAAGTTGATGATTTCTTGGCCAATGAGGCAAAGGGAACCAAAGT GGTGGGTGCCCAGTCCCTGAAAGAGATGGTCTCCAAGCTGAAGAAGCCCCGGCGGATCATCCTCCTGGTGAAGGCTGGGCAAGCTGTGGA TGATTTCATCGAGAAATTGATTGCCACGGCAGTGAAGTTTCTACAGAATTCCCGGGTCCGCCAGAGCCCACTTGCAACCAGGAGAGCATT CCTAAAGAAGAAAGGGCTGACAGATGAAGAGATTGATATGGCCTTCCAGCAGTCGGGCACTGCTGCCGATGAGCCTTCGTCCTTGGGCCC AGCCACACAGGTGGTTCCTGTCCAGCCCCCTCACCTCATATCTCAGCCATACAGTCCCGCAGGCTCCCGATGGCGAGATTACGGCGCCCT GGCCATCATCATGGCAGGCATTGCATTTGGCTTTCACCAGCTCTACAAGAAATACCTGCTCCCCCTCATCCTGGGCGGCCGAGAGGACAG AAAGCAGCTGGAGAGGATGGAGGCCGGTCTCTCTGAGCTGAGTGGCAGCGTGGCCCAGACAGTGACTCAGTTACAGACGACCCTCGCCTC CGTCCAGGAGCTGCTGATTCAGCAGCAGCAGAAGATCCAGGAGCTTGCCCACGAGCTGGCCGCTGCCAAGGCCACCACATCCACCAACTG GATCCTGGAGTCCCAGAATATCAACGAACTCAAGTCCGAAATTAACTCCTTGAAAGGGCTTCTTTTAAATCGGAGGCAGTTCCCTCCATC CCCATCAGCCCCGAAGATCCCCTCCTGGCAGATCCCAGTCAAGTCACCGTCACCCTCCAGCCCTGCGGCCGTGAACCACCACAGCAGCAG CGACATCTCACCTGTCAGCAACGAGTCCACGTCGTCCTCGCCTGGGAAGGAGGGCCACAGCCCCGAGGGCTCCACGGTCACCTACCACTT GCTGGGCCCCCAGGAGGAAGGCGAGGGGGTGGTGGACGTCAAGGGCCAGGTGCGGATGGAGGTGCAAGGCGAGGAGGAGAAGAGGGAGGA CAAGGAGGACGAGGAGGATGAGGAGGATGATGATGTGAGCCATGTGGACGAGGAGGACTGCCTGGGGGTGCAGAGGGAGGACCGCCGGGG CGGGGATGGGCAGATCAACGAGCAGGTGGAGAAGCTGCGGCGGCCCGAGGGCGCCAGCAACGAGAGTGAGCGGGACTAGGGCTGCGCCTG CTGCCTCCAGCCCTGAGGATGGCATCTAGTGTGCCCGTGCGTGGCCATACCCTGCCTCCCTCTCTGGCCCTGGGAGGGCAGCTTGGAGCC CAGGTAGGGGGCAGAGCTGTCCTCAGCTGCACTGCGGCCTGGTGGCAGTGTGGGGAGTCACACTTCTGTCCACCTGGCCTCCTCTCGCCT GGCCGCCAGCCCCAGCCCCAGCCCCAGCCCCAGGCCCAGCTGCCTTTGGCTTTGATCTCAAGTCAGGCTGAAGGCAGCGAAGCCTCGGGG CCCAAGCCCCTCCCCAGCCCCCTCTCCCGGACAGACGCCTTGCCCAGGGTGTGTTTGCTGAGTGTCTTGACTACCGTGACACCACGCATG GCCAGAGCTAGCGTCCCTACTGCCTCCCGACTCCTCAGTGGAGGAGGAGCTGCGGTCCCTCTGGTGTCTGCCATCCCCCTCCCTCCCTGG GCCCGGCCCTGGACCCGTCAGGTGCCTGTCCCCAGCCCCAACCCCACTCATGCCCCGTCGTCCTCCCAGACAAATGAAACCACGCTGCGC TTCCGATGCCCCCGCTTGCCGTGTAATGGTTCAGCTAATCCCATGGCGAGATGGGGGCTCACTCCGGAGGAGGAGCCAGGCAGCAGGGCC TTCCTGACCAACAGCCAGCTCTGTCCTTCCCCCCAGGAAACACATGTTCATTTGTGTGATCATGTATAGACCTCAGAACGGAAGATAGGA >64597_64597_2_PGD-PEX14_PGD_chr1_10460629_ENST00000538557_PEX14_chr1_10596270_ENST00000356607_length(amino acids)=441AA_BP=6 MPSRPRRADIALIGLAVMGQNLILNMNDHGFVVCAFNRTVSKVDDFLANEAKGTKVVGAQSLKEMVSKLKKPRRIILLVKAGQAVDDFIE KLIATAVKFLQNSRVRQSPLATRRAFLKKKGLTDEEIDMAFQQSGTAADEPSSLGPATQVVPVQPPHLISQPYSPAGSRWRDYGALAIIM AGIAFGFHQLYKKYLLPLILGGREDRKQLERMEAGLSELSGSVAQTVTQLQTTLASVQELLIQQQQKIQELAHELAAAKATTSTNWILES QNINELKSEINSLKGLLLNRRQFPPSPSAPKIPSWQIPVKSPSPSSPAAVNHHSSSDISPVSNESTSSSPGKEGHSPEGSTVTYHLLGPQ -------------------------------------------------------------- >64597_64597_3_PGD-PEX14_PGD_chr1_10460629_ENST00000541529_PEX14_chr1_10596270_ENST00000356607_length(transcript)=2134nt_BP=313nt ACTCGTCCTCCGCGCGTCGCCGCTCTTCGGTTCTGCTCTGTCCGCCGCCATGGCCCAAGCTGACATCGCGCTGATCGGATTGGCCGTCAT GGGCCAGAACTTAATTCTGAACATGAATGACCACGGCTTTGTGGTCTGTGCTTTTAATAGGACTGTCTCCAAAGTTGATGATTTCTTGGC CAATGAGGCAAAGGGAACCAAAGTGGTGGGTGCCCAGTCCCTGAAAGAGATGGTCTCCAAGCTGAAGAAGCCCCGGCGGATCATCCTCCT GGTGAAGGCTGGGCAAGCTGTGGATGATTTCATCGAGAAATTGATTGCCACGGCAGTGAAGTTTCTACAGAATTCCCGGGTCCGCCAGAG CCCACTTGCAACCAGGAGAGCATTCCTAAAGAAGAAAGGGCTGACAGATGAAGAGATTGATATGGCCTTCCAGCAGTCGGGCACTGCTGC CGATGAGCCTTCGTCCTTGGGCCCAGCCACACAGGTGGTTCCTGTCCAGCCCCCTCACCTCATATCTCAGCCATACAGTCCCGCAGGCTC CCGATGGCGAGATTACGGCGCCCTGGCCATCATCATGGCAGGCATTGCATTTGGCTTTCACCAGCTCTACAAGAAATACCTGCTCCCCCT CATCCTGGGCGGCCGAGAGGACAGAAAGCAGCTGGAGAGGATGGAGGCCGGTCTCTCTGAGCTGAGTGGCAGCGTGGCCCAGACAGTGAC TCAGTTACAGACGACCCTCGCCTCCGTCCAGGAGCTGCTGATTCAGCAGCAGCAGAAGATCCAGGAGCTTGCCCACGAGCTGGCCGCTGC CAAGGCCACCACATCCACCAACTGGATCCTGGAGTCCCAGAATATCAACGAACTCAAGTCCGAAATTAACTCCTTGAAAGGGCTTCTTTT AAATCGGAGGCAGTTCCCTCCATCCCCATCAGCCCCGAAGATCCCCTCCTGGCAGATCCCAGTCAAGTCACCGTCACCCTCCAGCCCTGC GGCCGTGAACCACCACAGCAGCAGCGACATCTCACCTGTCAGCAACGAGTCCACGTCGTCCTCGCCTGGGAAGGAGGGCCACAGCCCCGA GGGCTCCACGGTCACCTACCACTTGCTGGGCCCCCAGGAGGAAGGCGAGGGGGTGGTGGACGTCAAGGGCCAGGTGCGGATGGAGGTGCA AGGCGAGGAGGAGAAGAGGGAGGACAAGGAGGACGAGGAGGATGAGGAGGATGATGATGTGAGCCATGTGGACGAGGAGGACTGCCTGGG GGTGCAGAGGGAGGACCGCCGGGGCGGGGATGGGCAGATCAACGAGCAGGTGGAGAAGCTGCGGCGGCCCGAGGGCGCCAGCAACGAGAG TGAGCGGGACTAGGGCTGCGCCTGCTGCCTCCAGCCCTGAGGATGGCATCTAGTGTGCCCGTGCGTGGCCATACCCTGCCTCCCTCTCTG GCCCTGGGAGGGCAGCTTGGAGCCCAGGTAGGGGGCAGAGCTGTCCTCAGCTGCACTGCGGCCTGGTGGCAGTGTGGGGAGTCACACTTC TGTCCACCTGGCCTCCTCTCGCCTGGCCGCCAGCCCCAGCCCCAGCCCCAGCCCCAGGCCCAGCTGCCTTTGGCTTTGATCTCAAGTCAG GCTGAAGGCAGCGAAGCCTCGGGGCCCAAGCCCCTCCCCAGCCCCCTCTCCCGGACAGACGCCTTGCCCAGGGTGTGTTTGCTGAGTGTC TTGACTACCGTGACACCACGCATGGCCAGAGCTAGCGTCCCTACTGCCTCCCGACTCCTCAGTGGAGGAGGAGCTGCGGTCCCTCTGGTG TCTGCCATCCCCCTCCCTCCCTGGGCCCGGCCCTGGACCCGTCAGGTGCCTGTCCCCAGCCCCAACCCCACTCATGCCCCGTCGTCCTCC CAGACAAATGAAACCACGCTGCGCTTCCGATGCCCCCGCTTGCCGTGTAATGGTTCAGCTAATCCCATGGCGAGATGGGGGCTCACTCCG GAGGAGGAGCCAGGCAGCAGGGCCTTCCTGACCAACAGCCAGCTCTGTCCTTCCCCCCAGGAAACACATGTTCATTTGTGTGATCATGTA >64597_64597_3_PGD-PEX14_PGD_chr1_10460629_ENST00000541529_PEX14_chr1_10596270_ENST00000356607_length(amino acids)=441AA_BP=7 MSAAMAQADIALIGLAVMGQNLILNMNDHGFVVCAFNRTVSKVDDFLANEAKGTKVVGAQSLKEMVSKLKKPRRIILLVKAGQAVDDFIE KLIATAVKFLQNSRVRQSPLATRRAFLKKKGLTDEEIDMAFQQSGTAADEPSSLGPATQVVPVQPPHLISQPYSPAGSRWRDYGALAIIM AGIAFGFHQLYKKYLLPLILGGREDRKQLERMEAGLSELSGSVAQTVTQLQTTLASVQELLIQQQQKIQELAHELAAAKATTSTNWILES QNINELKSEINSLKGLLLNRRQFPPSPSAPKIPSWQIPVKSPSPSSPAAVNHHSSSDISPVSNESTSSSPGKEGHSPEGSTVTYHLLGPQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PGD-PEX14 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PGD-PEX14 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PGD-PEX14 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies