
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARID4B-TOMM20 (FusionGDB2 ID:6490) |
Fusion Gene Summary for ARID4B-TOMM20 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARID4B-TOMM20 | Fusion gene ID: 6490 | Hgene | Tgene | Gene symbol | ARID4B | TOMM20 | Gene ID | 51742 | 9804 |
| Gene name | AT-rich interaction domain 4B | translocase of outer mitochondrial membrane 20 | |
| Synonyms | BCAA|BRCAA1|RBBP1L1|RBP1L1|SAP180 | MAS20|MOM19|TOM20 | |
| Cytomap | 1q42.3 | 1q42.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AT-rich interactive domain-containing protein 4B180 kDa Sin3-associated polypeptideARID domain-containing protein 4BAT rich interactive domain 4B (RBP1-like)Rb-binding protein homologSIN3A-associated protein 180breast cancer-associated antigen 1bre | mitochondrial import receptor subunit TOM20 homologmitochondrial 20 kDa outer membrane proteinouter mitochondrial membrane receptor Tom20translocase of outer mitochondrial membrane 20 homolog type II | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | Q4LE39 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000264183, ENST00000349213, ENST00000366603, ENST00000494543, | ENST00000467767, ENST00000366607, | |
| Fusion gene scores | * DoF score | 23 X 20 X 9=4140 | 7 X 6 X 4=168 |
| # samples | 29 | 9 | |
| ** MAII score | log2(29/4140*10)=-3.83550596237175 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/168*10)=-0.900464326449086 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARID4B [Title/Abstract] AND TOMM20 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARID4B(235490229)-TOMM20(235285687), # samples:2 TOMM20(235291910)-ARID4B(235295312), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ARID4B-TOMM20 seems lost the major protein functional domain in Hgene partner, which is a epigenetic factor due to the frame-shifted ORF. ARID4B-TOMM20 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. ARID4B-TOMM20 seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. ARID4B-TOMM20 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | TOMM20 | GO:0006626 | protein targeting to mitochondrion | 14557246 |
| Fusion gene breakpoints across ARID4B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TOMM20 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-AC-A6IW-01A | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| ChimerDB4 | STAD | TCGA-CG-4441-01A | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| ChimerDB4 | STAD | TCGA-D7-6822-01A | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| ChimerDB4 | STAD | TCGA-D7-6822 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
Top |
Fusion Gene ORF analysis for ARID4B-TOMM20 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000264183 | ENST00000467767 | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| 5CDS-5UTR | ENST00000349213 | ENST00000467767 | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| 5CDS-5UTR | ENST00000366603 | ENST00000467767 | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| 5CDS-intron | ENST00000264183 | ENST00000467767 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| 5CDS-intron | ENST00000264183 | ENST00000467767 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
| 5CDS-intron | ENST00000349213 | ENST00000467767 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| 5CDS-intron | ENST00000349213 | ENST00000467767 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
| 5CDS-intron | ENST00000366603 | ENST00000467767 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| 5CDS-intron | ENST00000366603 | ENST00000467767 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
| Frame-shift | ENST00000264183 | ENST00000366607 | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| Frame-shift | ENST00000349213 | ENST00000366607 | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| Frame-shift | ENST00000366603 | ENST00000366607 | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| In-frame | ENST00000264183 | ENST00000366607 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| In-frame | ENST00000264183 | ENST00000366607 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
| In-frame | ENST00000349213 | ENST00000366607 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| In-frame | ENST00000349213 | ENST00000366607 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
| In-frame | ENST00000366603 | ENST00000366607 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| In-frame | ENST00000366603 | ENST00000366607 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
| intron-3CDS | ENST00000494543 | ENST00000366607 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| intron-3CDS | ENST00000494543 | ENST00000366607 | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| intron-3CDS | ENST00000494543 | ENST00000366607 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
| intron-5UTR | ENST00000494543 | ENST00000467767 | ARID4B | chr1 | 235416045 | - | TOMM20 | chr1 | 235275423 | - |
| intron-intron | ENST00000494543 | ENST00000467767 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - |
| intron-intron | ENST00000494543 | ENST00000467767 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000366603 | ARID4B | chr1 | 235490228 | - | ENST00000366607 | TOMM20 | chr1 | 235285687 | - | 3428 | 383 | 30 | 239 | 69 |
| ENST00000264183 | ARID4B | chr1 | 235490228 | - | ENST00000366607 | TOMM20 | chr1 | 235285687 | - | 3549 | 504 | 40 | 501 | 153 |
| ENST00000349213 | ARID4B | chr1 | 235490228 | - | ENST00000366607 | TOMM20 | chr1 | 235285687 | - | 3551 | 506 | 42 | 503 | 153 |
| ENST00000366603 | ARID4B | chr1 | 235490229 | - | ENST00000366607 | TOMM20 | chr1 | 235285687 | - | 3428 | 383 | 30 | 239 | 69 |
| ENST00000264183 | ARID4B | chr1 | 235490229 | - | ENST00000366607 | TOMM20 | chr1 | 235285687 | - | 3549 | 504 | 40 | 501 | 153 |
| ENST00000349213 | ARID4B | chr1 | 235490229 | - | ENST00000366607 | TOMM20 | chr1 | 235285687 | - | 3551 | 506 | 42 | 503 | 153 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000366603 | ENST00000366607 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - | 0.877638 | 0.12236198 |
| ENST00000264183 | ENST00000366607 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - | 0.8897371 | 0.11026291 |
| ENST00000349213 | ENST00000366607 | ARID4B | chr1 | 235490228 | - | TOMM20 | chr1 | 235285687 | - | 0.890322 | 0.10967798 |
| ENST00000366603 | ENST00000366607 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - | 0.877638 | 0.12236198 |
| ENST00000264183 | ENST00000366607 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - | 0.8897371 | 0.11026291 |
| ENST00000349213 | ENST00000366607 | ARID4B | chr1 | 235490229 | - | TOMM20 | chr1 | 235285687 | - | 0.890322 | 0.10967798 |
Top |
Fusion Genomic Features for ARID4B-TOMM20 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
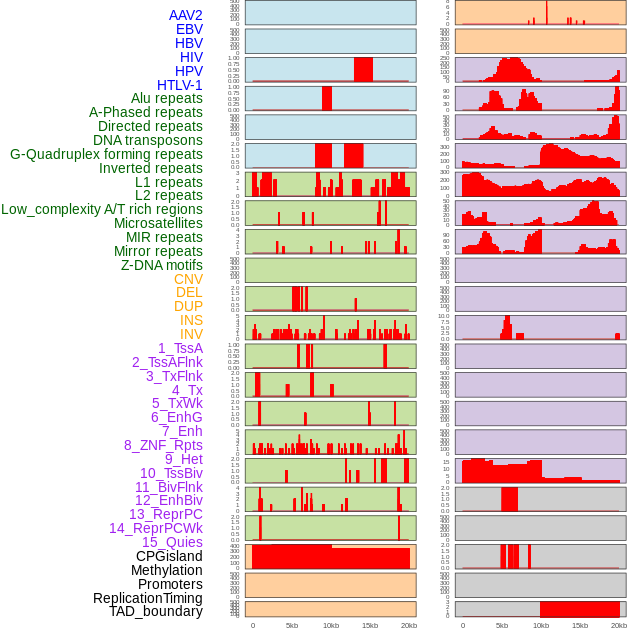 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ARID4B-TOMM20 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:235490229/chr1:235285687) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARID4B | . |
| FUNCTION: Acts as a transcriptional repressor (PubMed:12724404). May function in the assembly and/or enzymatic activity of the Sin3A corepressor complex or in mediating interactions between the complex and other regulatory complexes (PubMed:12724404). Plays a role in the regulation of epigenetic modifications at the PWS/AS imprinting center near the SNRPN promoter, where it might function as part of a complex with RB1 and ARID4A. Involved in spermatogenesis, together with ARID4A, where it functions as a transcriptional coactivator for AR (androgen receptor) and enhances expression of genes required for sperm maturation. Regulates expression of the tight junction protein CLDN3 in the testis, which is important for integrity of the blood-testis barrier. Plays a role in myeloid homeostasis where it regulates the histone methylation state of bone marrow cells and expression of various genes involved in hematopoiesis. May function as a leukemia suppressor (By similarity). {ECO:0000250|UniProtKB:A2CG63, ECO:0000269|PubMed:12724404}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 1231_1270 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 728_754 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 1231_1270 | 2 | 1227.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 728_754 | 2 | 1227.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 1231_1270 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 728_754 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 1231_1270 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 728_754 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 1231_1270 | 2 | 1227.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 728_754 | 2 | 1227.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 1231_1270 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 728_754 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 1095_1101 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 1271_1303 | 2 | 1313.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 154_159 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 268_567 | 2 | 1313.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 1095_1101 | 2 | 1227.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 1271_1303 | 2 | 1227.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 154_159 | 2 | 1227.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 268_567 | 2 | 1227.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 1095_1101 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 1271_1303 | 2 | 1313.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 154_159 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 268_567 | 2 | 1313.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 1095_1101 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 1271_1303 | 2 | 1313.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 154_159 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 268_567 | 2 | 1313.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 1095_1101 | 2 | 1227.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 1271_1303 | 2 | 1227.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 154_159 | 2 | 1227.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 268_567 | 2 | 1227.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 1095_1101 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 1271_1303 | 2 | 1313.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 154_159 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 268_567 | 2 | 1313.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 306_398 | 2 | 1313.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 306_398 | 2 | 1227.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 306_398 | 2 | 1313.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 306_398 | 2 | 1313.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 306_398 | 2 | 1227.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 306_398 | 2 | 1313.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 1130_1137 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 465_473 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 1130_1137 | 2 | 1227.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 465_473 | 2 | 1227.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 1130_1137 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 465_473 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 1130_1137 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000264183 | - | 2 | 24 | 465_473 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 1130_1137 | 2 | 1227.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000349213 | - | 2 | 23 | 465_473 | 2 | 1227.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 1130_1137 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:235285687 | ENST00000366603 | - | 2 | 24 | 465_473 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Tgene | TOMM20 | chr1:235490228 | chr1:235285687 | ENST00000366607 | 0 | 5 | 1_6 | 40 | 146.0 | Topological domain | Mitochondrial intermembrane | |
| Tgene | TOMM20 | chr1:235490228 | chr1:235285687 | ENST00000366607 | 0 | 5 | 25_145 | 40 | 146.0 | Topological domain | Cytoplasmic | |
| Tgene | TOMM20 | chr1:235490229 | chr1:235285687 | ENST00000366607 | 0 | 5 | 1_6 | 40 | 146.0 | Topological domain | Mitochondrial intermembrane | |
| Tgene | TOMM20 | chr1:235490229 | chr1:235285687 | ENST00000366607 | 0 | 5 | 25_145 | 40 | 146.0 | Topological domain | Cytoplasmic | |
| Tgene | TOMM20 | chr1:235490228 | chr1:235285687 | ENST00000366607 | 0 | 5 | 7_24 | 40 | 146.0 | Transmembrane | Helical | |
| Tgene | TOMM20 | chr1:235490229 | chr1:235285687 | ENST00000366607 | 0 | 5 | 7_24 | 40 | 146.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for ARID4B-TOMM20 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6490_6490_1_ARID4B-TOMM20_ARID4B_chr1_235490228_ENST00000264183_TOMM20_chr1_235285687_ENST00000366607_length(transcript)=3549nt_BP=504nt AAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGAGG GAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTCCT CTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCGGC CGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTCCC CATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAAGG TGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGGAAGAAAGAAACAGAAGCTTGCCAAGGAGAGAGCTG GGCTTTCCAAGTTACCTGACCTTAAAGATGCTGAAGCTGTTCAGAAGTTCTTCCTTGAAGAAATACAGCTTGGTGAAGAGTTACTAGCTC AAGGTGAATATGAGAAGGGCGTAGACCATCTGACAAATGCAATTGCTGTGTGTGGACAGCCACAGCAGTTACTGCAGGTCTTACAGCAAA CTCTTCCACCACCAGTGTTCCAGATGCTTCTGACTAAGCTCCCAACAATTAGTCAGAGAATTGTAAGTGCTCAGAGCTTGGCTGAAGATG ATGTGGAATGAGAAACAAATGTCAACATAATAAAATCTCAGTTAAAAATATTTTAAAAATTCTTGGTAGTTGAGCAGCTCTGGGGGAATA AGGGCAAATATGCTTGTTATGAACTACACTGAAATCTACCAAAGTTAATGTTTACTTTGTGTAGATCCATTTGTCTATTTTATTTATTTT TCCCAGTGAAAAGTGTATTTTGATAGAGAACTTTTCATTCTATAAATACACTATGAGTTACTAAAATATCATGGATTTTGTTTATTCCTG AAACATAGTTACATAGTTAAACTGTACATATGACATGGCTTATGTTAAAAATACCCAGTGCTCAGTTTTGAAAGATAGGCAAAAAAAAAA AAGTATAGGAGAAACTGAAGAATGTACACTTTTTTAGAGGGCACATTTTGCTGTAAATCTGGAAATTTGATAGACTTGACTGTGTTTGTG AAAACTGAGCATTAAAGGTTTTGATTGATCCTTTCTTTCCATTTAATCTCTGAGACGTAAATATGTGAGGTGTGCTGCTGTGCTGGGTTA ACAGCTTCCTTCCCTTTCTGTGTAGCAGTCTTGAAATGTTCTGTTTAAATCAGTAGGCTTAATGTGTTCTGGGTATTTATCTCCTTGTAT TTTAAATATATGTAGTTGCAAATAGCACCAGGAATTAGATTTCTGTACACCCCTAATCTAGCCTTGTGAGCTTCGCTAGTTAATGTGTGC TCACTTTCCCTCCATTTGTTACGTGAGAGAATGCGTCTGCTGATCACTGAAGTGTCCCTTTTAGCTTCTGATTCATTGGGTTCTGTTGGG CATCTTTAAATCCACCTTAACCTGAGGAATGTATGTGGGCAACCAGGCCCTGCATTTTTTTATATTCTGAATTTTGCATGCTTGCCTGAC TTAGTATTTCTGAATTGATGTTTTTTTTAATGGTATAACTATCTTGATTTTCACTGAAATTATATGGTTCTGTCACTACTCTGTAAATTA ATCCGAAACTTTTAAGGTAACTGGGATGATCTGCTTGTAAAAATGCTTGTTGCCTTTTGCTTTATCTTCAGTGTACCTCCTTAATCCTGC TTCAACTTGATTATCTTGTGAAACGATGAGAGTAAGTTGCAACCTTGTGACTGAAAACTTGAAAAGAGTGGAGCAGGTGGGACCTCTTAT TCTCAAATAGTGACATATTCTCCGTAGTCACAGTTTCAGAACTGAGTAAGGATCCTTGGTACTTGGTGGCATCTGTTGAACTGAGGAGCA TTTCTCATTGTAAAGATTGCCTTTGTTCTGTCTAAAAGTCTGGAGAAATCCCAAAGACTTTTCCTATGTACTAGGCATTTTATTTTGATT GACTTACAAACTCTTCTTAATCATTATCAATCTCGGTTTTTTTGTGGTGCAGTGGAAGGAGAAATAGGTCTAGTTTCTGCCTCTGATTAG CCGCACAGCCTTGAACAAATCACATTTCATCTTTGAACTTACCTCTACTGTTAGACTAGGCGACTCACATTTGAGGACTTTTCTCGGGTA TCTTGAGGGTTTGTGATCCTGAACCCTTAAACAGTGCTTTTTTGTTACACAGGAGGGCTTTTTTGGGGGGATGACCAGTACAGACATGCC AGTTAGTTTTACTAGTGGGATCCCAAATCCAAAGCAGTGTAGTGGTGATTGGTCAGTGACTAACCAGGCAGCTAAGAAGTCTTAGGCAGC AGCCCAGACATGTATAGAGGGGCAGTTAGAGGGAGAACAGGGGTGGGAAAGGGAGCAAGGGGCAGATAGCTCAGCAAGGAAAGAATGGGC TCAGAAAAAGGAGGGCTGGCTGGAGGAGTGAGGGGCAGCTTAAGTTTGGGGAGGGTAGAAACGCCGTTTCCTTGGGAACTGGAGTGCAGT ATGAGCTGGGTGTCACTTGGCTCTGAACATACTGGCTTTGCTGTAATGCTTGAAAAGGCGTTGGTATCTTCATTTTACAGTTCATTAACC CAAGTACGTTTTCTTATTTAAATGACAACTTTGGTGCTTTAAAATGAGGTACCACTTTTTAAAGCTAGCTGTGTCGAGTTAAAGAAAAAA TCAGCAGTTTTTTCTCCCAGAAATGTAATTGCCAAACACTATTCATCCCCATCTTAAGTTTTACAAGGTGATGTAATCAGCTTGTTGTAG TGATGCTGGCCAAATGGTGCTCAGCAGGTGAGAACAAAAAAACCCCAGATCTCAGTGAACTAATACACAGCTTGAGCGTTTCCATGTGCT AATGTTGCACACTTACTAAAAAACTTTGGAAATGGAAAATAATGTATTAGTGCAACAGTTGATGTGCTTCTTTGGGCAAAGATATAGTTT TGTTCCACAATTTGTACTTAAAAGCGAAAGAACATTGAAAACATAGACTTACTGGCTGTAGCAATGCTGGCCTGTTAACTGATAACTAGA ACTTAGGTTCACGTTTATGTAAAGTGTGTAAAACCTAGTAGAGCTTGCATAGTCGGCACTCAGTAAATGTTTGGTTCCTTTTGCCCCTTG GTAAGTTTATTTTACCATCCTCCCACCTGCCATTCTGACTTTATTAAATCAACATGTGGACCAGAGTGTTAATGAGATGTTATTGCAGAA GAGATTGAGAAAATTGGTATATCATGCAGATAACATACAAAATCTTTTTGTAACGTAAAAAATGCAGTTTTATTATTGCTTGTGCCTCAA >6490_6490_1_ARID4B-TOMM20_ARID4B_chr1_235490228_ENST00000264183_TOMM20_chr1_235285687_ENST00000366607_length(amino acids)=153AA_BP= MPVSRVRSEELGRRSGGRLLSFILPPPRPPPGPLPGGSCRGSIAAVLWRAARLGARTSSPGGIFRRPPPPNQGARAAAKQRYQSPPREEE -------------------------------------------------------------- >6490_6490_2_ARID4B-TOMM20_ARID4B_chr1_235490228_ENST00000349213_TOMM20_chr1_235285687_ENST00000366607_length(transcript)=3551nt_BP=506nt AGAAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGA GGGAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTC CTCTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCG GCCGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTC CCCATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAA GGTGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGGAAGAAAGAAACAGAAGCTTGCCAAGGAGAGAGC TGGGCTTTCCAAGTTACCTGACCTTAAAGATGCTGAAGCTGTTCAGAAGTTCTTCCTTGAAGAAATACAGCTTGGTGAAGAGTTACTAGC TCAAGGTGAATATGAGAAGGGCGTAGACCATCTGACAAATGCAATTGCTGTGTGTGGACAGCCACAGCAGTTACTGCAGGTCTTACAGCA AACTCTTCCACCACCAGTGTTCCAGATGCTTCTGACTAAGCTCCCAACAATTAGTCAGAGAATTGTAAGTGCTCAGAGCTTGGCTGAAGA TGATGTGGAATGAGAAACAAATGTCAACATAATAAAATCTCAGTTAAAAATATTTTAAAAATTCTTGGTAGTTGAGCAGCTCTGGGGGAA TAAGGGCAAATATGCTTGTTATGAACTACACTGAAATCTACCAAAGTTAATGTTTACTTTGTGTAGATCCATTTGTCTATTTTATTTATT TTTCCCAGTGAAAAGTGTATTTTGATAGAGAACTTTTCATTCTATAAATACACTATGAGTTACTAAAATATCATGGATTTTGTTTATTCC TGAAACATAGTTACATAGTTAAACTGTACATATGACATGGCTTATGTTAAAAATACCCAGTGCTCAGTTTTGAAAGATAGGCAAAAAAAA AAAAGTATAGGAGAAACTGAAGAATGTACACTTTTTTAGAGGGCACATTTTGCTGTAAATCTGGAAATTTGATAGACTTGACTGTGTTTG TGAAAACTGAGCATTAAAGGTTTTGATTGATCCTTTCTTTCCATTTAATCTCTGAGACGTAAATATGTGAGGTGTGCTGCTGTGCTGGGT TAACAGCTTCCTTCCCTTTCTGTGTAGCAGTCTTGAAATGTTCTGTTTAAATCAGTAGGCTTAATGTGTTCTGGGTATTTATCTCCTTGT ATTTTAAATATATGTAGTTGCAAATAGCACCAGGAATTAGATTTCTGTACACCCCTAATCTAGCCTTGTGAGCTTCGCTAGTTAATGTGT GCTCACTTTCCCTCCATTTGTTACGTGAGAGAATGCGTCTGCTGATCACTGAAGTGTCCCTTTTAGCTTCTGATTCATTGGGTTCTGTTG GGCATCTTTAAATCCACCTTAACCTGAGGAATGTATGTGGGCAACCAGGCCCTGCATTTTTTTATATTCTGAATTTTGCATGCTTGCCTG ACTTAGTATTTCTGAATTGATGTTTTTTTTAATGGTATAACTATCTTGATTTTCACTGAAATTATATGGTTCTGTCACTACTCTGTAAAT TAATCCGAAACTTTTAAGGTAACTGGGATGATCTGCTTGTAAAAATGCTTGTTGCCTTTTGCTTTATCTTCAGTGTACCTCCTTAATCCT GCTTCAACTTGATTATCTTGTGAAACGATGAGAGTAAGTTGCAACCTTGTGACTGAAAACTTGAAAAGAGTGGAGCAGGTGGGACCTCTT ATTCTCAAATAGTGACATATTCTCCGTAGTCACAGTTTCAGAACTGAGTAAGGATCCTTGGTACTTGGTGGCATCTGTTGAACTGAGGAG CATTTCTCATTGTAAAGATTGCCTTTGTTCTGTCTAAAAGTCTGGAGAAATCCCAAAGACTTTTCCTATGTACTAGGCATTTTATTTTGA TTGACTTACAAACTCTTCTTAATCATTATCAATCTCGGTTTTTTTGTGGTGCAGTGGAAGGAGAAATAGGTCTAGTTTCTGCCTCTGATT AGCCGCACAGCCTTGAACAAATCACATTTCATCTTTGAACTTACCTCTACTGTTAGACTAGGCGACTCACATTTGAGGACTTTTCTCGGG TATCTTGAGGGTTTGTGATCCTGAACCCTTAAACAGTGCTTTTTTGTTACACAGGAGGGCTTTTTTGGGGGGATGACCAGTACAGACATG CCAGTTAGTTTTACTAGTGGGATCCCAAATCCAAAGCAGTGTAGTGGTGATTGGTCAGTGACTAACCAGGCAGCTAAGAAGTCTTAGGCA GCAGCCCAGACATGTATAGAGGGGCAGTTAGAGGGAGAACAGGGGTGGGAAAGGGAGCAAGGGGCAGATAGCTCAGCAAGGAAAGAATGG GCTCAGAAAAAGGAGGGCTGGCTGGAGGAGTGAGGGGCAGCTTAAGTTTGGGGAGGGTAGAAACGCCGTTTCCTTGGGAACTGGAGTGCA GTATGAGCTGGGTGTCACTTGGCTCTGAACATACTGGCTTTGCTGTAATGCTTGAAAAGGCGTTGGTATCTTCATTTTACAGTTCATTAA CCCAAGTACGTTTTCTTATTTAAATGACAACTTTGGTGCTTTAAAATGAGGTACCACTTTTTAAAGCTAGCTGTGTCGAGTTAAAGAAAA AATCAGCAGTTTTTTCTCCCAGAAATGTAATTGCCAAACACTATTCATCCCCATCTTAAGTTTTACAAGGTGATGTAATCAGCTTGTTGT AGTGATGCTGGCCAAATGGTGCTCAGCAGGTGAGAACAAAAAAACCCCAGATCTCAGTGAACTAATACACAGCTTGAGCGTTTCCATGTG CTAATGTTGCACACTTACTAAAAAACTTTGGAAATGGAAAATAATGTATTAGTGCAACAGTTGATGTGCTTCTTTGGGCAAAGATATAGT TTTGTTCCACAATTTGTACTTAAAAGCGAAAGAACATTGAAAACATAGACTTACTGGCTGTAGCAATGCTGGCCTGTTAACTGATAACTA GAACTTAGGTTCACGTTTATGTAAAGTGTGTAAAACCTAGTAGAGCTTGCATAGTCGGCACTCAGTAAATGTTTGGTTCCTTTTGCCCCT TGGTAAGTTTATTTTACCATCCTCCCACCTGCCATTCTGACTTTATTAAATCAACATGTGGACCAGAGTGTTAATGAGATGTTATTGCAG AAGAGATTGAGAAAATTGGTATATCATGCAGATAACATACAAAATCTTTTTGTAACGTAAAAAATGCAGTTTTATTATTGCTTGTGCCTC >6490_6490_2_ARID4B-TOMM20_ARID4B_chr1_235490228_ENST00000349213_TOMM20_chr1_235285687_ENST00000366607_length(amino acids)=153AA_BP= MPVSRVRSEELGRRSGGRLLSFILPPPRPPPGPLPGGSCRGSIAAVLWRAARLGARTSSPGGIFRRPPPPNQGARAAAKQRYQSPPREEE -------------------------------------------------------------- >6490_6490_3_ARID4B-TOMM20_ARID4B_chr1_235490228_ENST00000366603_TOMM20_chr1_235285687_ENST00000366607_length(transcript)=3428nt_BP=383nt GGCGGGGCCAGATGTTGATCTCGCTCCCACTTGTCGGGTCTGAGCCCGGAACGGGACGTGGGCAGGGGCTCTGTGGCGGGCCGGTCCTGC CCGCGGCCCACAGGCCCTCCTGGCCCCTCGGTGGCCCCCGGCCGGCCTCTCGCTCGGACGCGGCGCGTGGGGGCGCGGATTCGCTCGGCC GGGCGCCGAGGCCCTAGGGGAGAGCGGCCGGCCCTGCGCCGGACGCCGGGCTTGTTGTGAGTTTCTTCTCTGACAGAAATGGCGTCATTG TCGTAGACGGGAAACTCCGTCGGGTCTCGACAATGGGGACGGGAAGCTGCCGAGCTGTGTGCAGCTGAACCTGGTGTTTTAGAGGATACC TTGGTCCCAGAGTCATCATGAAGGAAGAAAGAAACAGAAGCTTGCCAAGGAGAGAGCTGGGCTTTCCAAGTTACCTGACCTTAAAGATGC TGAAGCTGTTCAGAAGTTCTTCCTTGAAGAAATACAGCTTGGTGAAGAGTTACTAGCTCAAGGTGAATATGAGAAGGGCGTAGACCATCT GACAAATGCAATTGCTGTGTGTGGACAGCCACAGCAGTTACTGCAGGTCTTACAGCAAACTCTTCCACCACCAGTGTTCCAGATGCTTCT GACTAAGCTCCCAACAATTAGTCAGAGAATTGTAAGTGCTCAGAGCTTGGCTGAAGATGATGTGGAATGAGAAACAAATGTCAACATAAT AAAATCTCAGTTAAAAATATTTTAAAAATTCTTGGTAGTTGAGCAGCTCTGGGGGAATAAGGGCAAATATGCTTGTTATGAACTACACTG AAATCTACCAAAGTTAATGTTTACTTTGTGTAGATCCATTTGTCTATTTTATTTATTTTTCCCAGTGAAAAGTGTATTTTGATAGAGAAC TTTTCATTCTATAAATACACTATGAGTTACTAAAATATCATGGATTTTGTTTATTCCTGAAACATAGTTACATAGTTAAACTGTACATAT GACATGGCTTATGTTAAAAATACCCAGTGCTCAGTTTTGAAAGATAGGCAAAAAAAAAAAAGTATAGGAGAAACTGAAGAATGTACACTT TTTTAGAGGGCACATTTTGCTGTAAATCTGGAAATTTGATAGACTTGACTGTGTTTGTGAAAACTGAGCATTAAAGGTTTTGATTGATCC TTTCTTTCCATTTAATCTCTGAGACGTAAATATGTGAGGTGTGCTGCTGTGCTGGGTTAACAGCTTCCTTCCCTTTCTGTGTAGCAGTCT TGAAATGTTCTGTTTAAATCAGTAGGCTTAATGTGTTCTGGGTATTTATCTCCTTGTATTTTAAATATATGTAGTTGCAAATAGCACCAG GAATTAGATTTCTGTACACCCCTAATCTAGCCTTGTGAGCTTCGCTAGTTAATGTGTGCTCACTTTCCCTCCATTTGTTACGTGAGAGAA TGCGTCTGCTGATCACTGAAGTGTCCCTTTTAGCTTCTGATTCATTGGGTTCTGTTGGGCATCTTTAAATCCACCTTAACCTGAGGAATG TATGTGGGCAACCAGGCCCTGCATTTTTTTATATTCTGAATTTTGCATGCTTGCCTGACTTAGTATTTCTGAATTGATGTTTTTTTTAAT GGTATAACTATCTTGATTTTCACTGAAATTATATGGTTCTGTCACTACTCTGTAAATTAATCCGAAACTTTTAAGGTAACTGGGATGATC TGCTTGTAAAAATGCTTGTTGCCTTTTGCTTTATCTTCAGTGTACCTCCTTAATCCTGCTTCAACTTGATTATCTTGTGAAACGATGAGA GTAAGTTGCAACCTTGTGACTGAAAACTTGAAAAGAGTGGAGCAGGTGGGACCTCTTATTCTCAAATAGTGACATATTCTCCGTAGTCAC AGTTTCAGAACTGAGTAAGGATCCTTGGTACTTGGTGGCATCTGTTGAACTGAGGAGCATTTCTCATTGTAAAGATTGCCTTTGTTCTGT CTAAAAGTCTGGAGAAATCCCAAAGACTTTTCCTATGTACTAGGCATTTTATTTTGATTGACTTACAAACTCTTCTTAATCATTATCAAT CTCGGTTTTTTTGTGGTGCAGTGGAAGGAGAAATAGGTCTAGTTTCTGCCTCTGATTAGCCGCACAGCCTTGAACAAATCACATTTCATC TTTGAACTTACCTCTACTGTTAGACTAGGCGACTCACATTTGAGGACTTTTCTCGGGTATCTTGAGGGTTTGTGATCCTGAACCCTTAAA CAGTGCTTTTTTGTTACACAGGAGGGCTTTTTTGGGGGGATGACCAGTACAGACATGCCAGTTAGTTTTACTAGTGGGATCCCAAATCCA AAGCAGTGTAGTGGTGATTGGTCAGTGACTAACCAGGCAGCTAAGAAGTCTTAGGCAGCAGCCCAGACATGTATAGAGGGGCAGTTAGAG GGAGAACAGGGGTGGGAAAGGGAGCAAGGGGCAGATAGCTCAGCAAGGAAAGAATGGGCTCAGAAAAAGGAGGGCTGGCTGGAGGAGTGA GGGGCAGCTTAAGTTTGGGGAGGGTAGAAACGCCGTTTCCTTGGGAACTGGAGTGCAGTATGAGCTGGGTGTCACTTGGCTCTGAACATA CTGGCTTTGCTGTAATGCTTGAAAAGGCGTTGGTATCTTCATTTTACAGTTCATTAACCCAAGTACGTTTTCTTATTTAAATGACAACTT TGGTGCTTTAAAATGAGGTACCACTTTTTAAAGCTAGCTGTGTCGAGTTAAAGAAAAAATCAGCAGTTTTTTCTCCCAGAAATGTAATTG CCAAACACTATTCATCCCCATCTTAAGTTTTACAAGGTGATGTAATCAGCTTGTTGTAGTGATGCTGGCCAAATGGTGCTCAGCAGGTGA GAACAAAAAAACCCCAGATCTCAGTGAACTAATACACAGCTTGAGCGTTTCCATGTGCTAATGTTGCACACTTACTAAAAAACTTTGGAA ATGGAAAATAATGTATTAGTGCAACAGTTGATGTGCTTCTTTGGGCAAAGATATAGTTTTGTTCCACAATTTGTACTTAAAAGCGAAAGA ACATTGAAAACATAGACTTACTGGCTGTAGCAATGCTGGCCTGTTAACTGATAACTAGAACTTAGGTTCACGTTTATGTAAAGTGTGTAA AACCTAGTAGAGCTTGCATAGTCGGCACTCAGTAAATGTTTGGTTCCTTTTGCCCCTTGGTAAGTTTATTTTACCATCCTCCCACCTGCC ATTCTGACTTTATTAAATCAACATGTGGACCAGAGTGTTAATGAGATGTTATTGCAGAAGAGATTGAGAAAATTGGTATATCATGCAGAT AACATACAAAATCTTTTTGTAACGTAAAAAATGCAGTTTTATTATTGCTTGTGCCTCAACTGTTTAAGTGAATATTAAAGGGCTTGGAGA >6490_6490_3_ARID4B-TOMM20_ARID4B_chr1_235490228_ENST00000366603_TOMM20_chr1_235285687_ENST00000366607_length(amino acids)=69AA_BP= -------------------------------------------------------------- >6490_6490_4_ARID4B-TOMM20_ARID4B_chr1_235490229_ENST00000264183_TOMM20_chr1_235285687_ENST00000366607_length(transcript)=3549nt_BP=504nt AAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGAGG GAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTCCT CTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCGGC CGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTCCC CATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAAGG TGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGGAAGAAAGAAACAGAAGCTTGCCAAGGAGAGAGCTG GGCTTTCCAAGTTACCTGACCTTAAAGATGCTGAAGCTGTTCAGAAGTTCTTCCTTGAAGAAATACAGCTTGGTGAAGAGTTACTAGCTC AAGGTGAATATGAGAAGGGCGTAGACCATCTGACAAATGCAATTGCTGTGTGTGGACAGCCACAGCAGTTACTGCAGGTCTTACAGCAAA CTCTTCCACCACCAGTGTTCCAGATGCTTCTGACTAAGCTCCCAACAATTAGTCAGAGAATTGTAAGTGCTCAGAGCTTGGCTGAAGATG ATGTGGAATGAGAAACAAATGTCAACATAATAAAATCTCAGTTAAAAATATTTTAAAAATTCTTGGTAGTTGAGCAGCTCTGGGGGAATA AGGGCAAATATGCTTGTTATGAACTACACTGAAATCTACCAAAGTTAATGTTTACTTTGTGTAGATCCATTTGTCTATTTTATTTATTTT TCCCAGTGAAAAGTGTATTTTGATAGAGAACTTTTCATTCTATAAATACACTATGAGTTACTAAAATATCATGGATTTTGTTTATTCCTG AAACATAGTTACATAGTTAAACTGTACATATGACATGGCTTATGTTAAAAATACCCAGTGCTCAGTTTTGAAAGATAGGCAAAAAAAAAA AAGTATAGGAGAAACTGAAGAATGTACACTTTTTTAGAGGGCACATTTTGCTGTAAATCTGGAAATTTGATAGACTTGACTGTGTTTGTG AAAACTGAGCATTAAAGGTTTTGATTGATCCTTTCTTTCCATTTAATCTCTGAGACGTAAATATGTGAGGTGTGCTGCTGTGCTGGGTTA ACAGCTTCCTTCCCTTTCTGTGTAGCAGTCTTGAAATGTTCTGTTTAAATCAGTAGGCTTAATGTGTTCTGGGTATTTATCTCCTTGTAT TTTAAATATATGTAGTTGCAAATAGCACCAGGAATTAGATTTCTGTACACCCCTAATCTAGCCTTGTGAGCTTCGCTAGTTAATGTGTGC TCACTTTCCCTCCATTTGTTACGTGAGAGAATGCGTCTGCTGATCACTGAAGTGTCCCTTTTAGCTTCTGATTCATTGGGTTCTGTTGGG CATCTTTAAATCCACCTTAACCTGAGGAATGTATGTGGGCAACCAGGCCCTGCATTTTTTTATATTCTGAATTTTGCATGCTTGCCTGAC TTAGTATTTCTGAATTGATGTTTTTTTTAATGGTATAACTATCTTGATTTTCACTGAAATTATATGGTTCTGTCACTACTCTGTAAATTA ATCCGAAACTTTTAAGGTAACTGGGATGATCTGCTTGTAAAAATGCTTGTTGCCTTTTGCTTTATCTTCAGTGTACCTCCTTAATCCTGC TTCAACTTGATTATCTTGTGAAACGATGAGAGTAAGTTGCAACCTTGTGACTGAAAACTTGAAAAGAGTGGAGCAGGTGGGACCTCTTAT TCTCAAATAGTGACATATTCTCCGTAGTCACAGTTTCAGAACTGAGTAAGGATCCTTGGTACTTGGTGGCATCTGTTGAACTGAGGAGCA TTTCTCATTGTAAAGATTGCCTTTGTTCTGTCTAAAAGTCTGGAGAAATCCCAAAGACTTTTCCTATGTACTAGGCATTTTATTTTGATT GACTTACAAACTCTTCTTAATCATTATCAATCTCGGTTTTTTTGTGGTGCAGTGGAAGGAGAAATAGGTCTAGTTTCTGCCTCTGATTAG CCGCACAGCCTTGAACAAATCACATTTCATCTTTGAACTTACCTCTACTGTTAGACTAGGCGACTCACATTTGAGGACTTTTCTCGGGTA TCTTGAGGGTTTGTGATCCTGAACCCTTAAACAGTGCTTTTTTGTTACACAGGAGGGCTTTTTTGGGGGGATGACCAGTACAGACATGCC AGTTAGTTTTACTAGTGGGATCCCAAATCCAAAGCAGTGTAGTGGTGATTGGTCAGTGACTAACCAGGCAGCTAAGAAGTCTTAGGCAGC AGCCCAGACATGTATAGAGGGGCAGTTAGAGGGAGAACAGGGGTGGGAAAGGGAGCAAGGGGCAGATAGCTCAGCAAGGAAAGAATGGGC TCAGAAAAAGGAGGGCTGGCTGGAGGAGTGAGGGGCAGCTTAAGTTTGGGGAGGGTAGAAACGCCGTTTCCTTGGGAACTGGAGTGCAGT ATGAGCTGGGTGTCACTTGGCTCTGAACATACTGGCTTTGCTGTAATGCTTGAAAAGGCGTTGGTATCTTCATTTTACAGTTCATTAACC CAAGTACGTTTTCTTATTTAAATGACAACTTTGGTGCTTTAAAATGAGGTACCACTTTTTAAAGCTAGCTGTGTCGAGTTAAAGAAAAAA TCAGCAGTTTTTTCTCCCAGAAATGTAATTGCCAAACACTATTCATCCCCATCTTAAGTTTTACAAGGTGATGTAATCAGCTTGTTGTAG TGATGCTGGCCAAATGGTGCTCAGCAGGTGAGAACAAAAAAACCCCAGATCTCAGTGAACTAATACACAGCTTGAGCGTTTCCATGTGCT AATGTTGCACACTTACTAAAAAACTTTGGAAATGGAAAATAATGTATTAGTGCAACAGTTGATGTGCTTCTTTGGGCAAAGATATAGTTT TGTTCCACAATTTGTACTTAAAAGCGAAAGAACATTGAAAACATAGACTTACTGGCTGTAGCAATGCTGGCCTGTTAACTGATAACTAGA ACTTAGGTTCACGTTTATGTAAAGTGTGTAAAACCTAGTAGAGCTTGCATAGTCGGCACTCAGTAAATGTTTGGTTCCTTTTGCCCCTTG GTAAGTTTATTTTACCATCCTCCCACCTGCCATTCTGACTTTATTAAATCAACATGTGGACCAGAGTGTTAATGAGATGTTATTGCAGAA GAGATTGAGAAAATTGGTATATCATGCAGATAACATACAAAATCTTTTTGTAACGTAAAAAATGCAGTTTTATTATTGCTTGTGCCTCAA >6490_6490_4_ARID4B-TOMM20_ARID4B_chr1_235490229_ENST00000264183_TOMM20_chr1_235285687_ENST00000366607_length(amino acids)=153AA_BP= MPVSRVRSEELGRRSGGRLLSFILPPPRPPPGPLPGGSCRGSIAAVLWRAARLGARTSSPGGIFRRPPPPNQGARAAAKQRYQSPPREEE -------------------------------------------------------------- >6490_6490_5_ARID4B-TOMM20_ARID4B_chr1_235490229_ENST00000349213_TOMM20_chr1_235285687_ENST00000366607_length(transcript)=3551nt_BP=506nt AGAAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGA GGGAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTC CTCTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCG GCCGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTC CCCATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAA GGTGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGGAAGAAAGAAACAGAAGCTTGCCAAGGAGAGAGC TGGGCTTTCCAAGTTACCTGACCTTAAAGATGCTGAAGCTGTTCAGAAGTTCTTCCTTGAAGAAATACAGCTTGGTGAAGAGTTACTAGC TCAAGGTGAATATGAGAAGGGCGTAGACCATCTGACAAATGCAATTGCTGTGTGTGGACAGCCACAGCAGTTACTGCAGGTCTTACAGCA AACTCTTCCACCACCAGTGTTCCAGATGCTTCTGACTAAGCTCCCAACAATTAGTCAGAGAATTGTAAGTGCTCAGAGCTTGGCTGAAGA TGATGTGGAATGAGAAACAAATGTCAACATAATAAAATCTCAGTTAAAAATATTTTAAAAATTCTTGGTAGTTGAGCAGCTCTGGGGGAA TAAGGGCAAATATGCTTGTTATGAACTACACTGAAATCTACCAAAGTTAATGTTTACTTTGTGTAGATCCATTTGTCTATTTTATTTATT TTTCCCAGTGAAAAGTGTATTTTGATAGAGAACTTTTCATTCTATAAATACACTATGAGTTACTAAAATATCATGGATTTTGTTTATTCC TGAAACATAGTTACATAGTTAAACTGTACATATGACATGGCTTATGTTAAAAATACCCAGTGCTCAGTTTTGAAAGATAGGCAAAAAAAA AAAAGTATAGGAGAAACTGAAGAATGTACACTTTTTTAGAGGGCACATTTTGCTGTAAATCTGGAAATTTGATAGACTTGACTGTGTTTG TGAAAACTGAGCATTAAAGGTTTTGATTGATCCTTTCTTTCCATTTAATCTCTGAGACGTAAATATGTGAGGTGTGCTGCTGTGCTGGGT TAACAGCTTCCTTCCCTTTCTGTGTAGCAGTCTTGAAATGTTCTGTTTAAATCAGTAGGCTTAATGTGTTCTGGGTATTTATCTCCTTGT ATTTTAAATATATGTAGTTGCAAATAGCACCAGGAATTAGATTTCTGTACACCCCTAATCTAGCCTTGTGAGCTTCGCTAGTTAATGTGT GCTCACTTTCCCTCCATTTGTTACGTGAGAGAATGCGTCTGCTGATCACTGAAGTGTCCCTTTTAGCTTCTGATTCATTGGGTTCTGTTG GGCATCTTTAAATCCACCTTAACCTGAGGAATGTATGTGGGCAACCAGGCCCTGCATTTTTTTATATTCTGAATTTTGCATGCTTGCCTG ACTTAGTATTTCTGAATTGATGTTTTTTTTAATGGTATAACTATCTTGATTTTCACTGAAATTATATGGTTCTGTCACTACTCTGTAAAT TAATCCGAAACTTTTAAGGTAACTGGGATGATCTGCTTGTAAAAATGCTTGTTGCCTTTTGCTTTATCTTCAGTGTACCTCCTTAATCCT GCTTCAACTTGATTATCTTGTGAAACGATGAGAGTAAGTTGCAACCTTGTGACTGAAAACTTGAAAAGAGTGGAGCAGGTGGGACCTCTT ATTCTCAAATAGTGACATATTCTCCGTAGTCACAGTTTCAGAACTGAGTAAGGATCCTTGGTACTTGGTGGCATCTGTTGAACTGAGGAG CATTTCTCATTGTAAAGATTGCCTTTGTTCTGTCTAAAAGTCTGGAGAAATCCCAAAGACTTTTCCTATGTACTAGGCATTTTATTTTGA TTGACTTACAAACTCTTCTTAATCATTATCAATCTCGGTTTTTTTGTGGTGCAGTGGAAGGAGAAATAGGTCTAGTTTCTGCCTCTGATT AGCCGCACAGCCTTGAACAAATCACATTTCATCTTTGAACTTACCTCTACTGTTAGACTAGGCGACTCACATTTGAGGACTTTTCTCGGG TATCTTGAGGGTTTGTGATCCTGAACCCTTAAACAGTGCTTTTTTGTTACACAGGAGGGCTTTTTTGGGGGGATGACCAGTACAGACATG CCAGTTAGTTTTACTAGTGGGATCCCAAATCCAAAGCAGTGTAGTGGTGATTGGTCAGTGACTAACCAGGCAGCTAAGAAGTCTTAGGCA GCAGCCCAGACATGTATAGAGGGGCAGTTAGAGGGAGAACAGGGGTGGGAAAGGGAGCAAGGGGCAGATAGCTCAGCAAGGAAAGAATGG GCTCAGAAAAAGGAGGGCTGGCTGGAGGAGTGAGGGGCAGCTTAAGTTTGGGGAGGGTAGAAACGCCGTTTCCTTGGGAACTGGAGTGCA GTATGAGCTGGGTGTCACTTGGCTCTGAACATACTGGCTTTGCTGTAATGCTTGAAAAGGCGTTGGTATCTTCATTTTACAGTTCATTAA CCCAAGTACGTTTTCTTATTTAAATGACAACTTTGGTGCTTTAAAATGAGGTACCACTTTTTAAAGCTAGCTGTGTCGAGTTAAAGAAAA AATCAGCAGTTTTTTCTCCCAGAAATGTAATTGCCAAACACTATTCATCCCCATCTTAAGTTTTACAAGGTGATGTAATCAGCTTGTTGT AGTGATGCTGGCCAAATGGTGCTCAGCAGGTGAGAACAAAAAAACCCCAGATCTCAGTGAACTAATACACAGCTTGAGCGTTTCCATGTG CTAATGTTGCACACTTACTAAAAAACTTTGGAAATGGAAAATAATGTATTAGTGCAACAGTTGATGTGCTTCTTTGGGCAAAGATATAGT TTTGTTCCACAATTTGTACTTAAAAGCGAAAGAACATTGAAAACATAGACTTACTGGCTGTAGCAATGCTGGCCTGTTAACTGATAACTA GAACTTAGGTTCACGTTTATGTAAAGTGTGTAAAACCTAGTAGAGCTTGCATAGTCGGCACTCAGTAAATGTTTGGTTCCTTTTGCCCCT TGGTAAGTTTATTTTACCATCCTCCCACCTGCCATTCTGACTTTATTAAATCAACATGTGGACCAGAGTGTTAATGAGATGTTATTGCAG AAGAGATTGAGAAAATTGGTATATCATGCAGATAACATACAAAATCTTTTTGTAACGTAAAAAATGCAGTTTTATTATTGCTTGTGCCTC >6490_6490_5_ARID4B-TOMM20_ARID4B_chr1_235490229_ENST00000349213_TOMM20_chr1_235285687_ENST00000366607_length(amino acids)=153AA_BP= MPVSRVRSEELGRRSGGRLLSFILPPPRPPPGPLPGGSCRGSIAAVLWRAARLGARTSSPGGIFRRPPPPNQGARAAAKQRYQSPPREEE -------------------------------------------------------------- >6490_6490_6_ARID4B-TOMM20_ARID4B_chr1_235490229_ENST00000366603_TOMM20_chr1_235285687_ENST00000366607_length(transcript)=3428nt_BP=383nt GGCGGGGCCAGATGTTGATCTCGCTCCCACTTGTCGGGTCTGAGCCCGGAACGGGACGTGGGCAGGGGCTCTGTGGCGGGCCGGTCCTGC CCGCGGCCCACAGGCCCTCCTGGCCCCTCGGTGGCCCCCGGCCGGCCTCTCGCTCGGACGCGGCGCGTGGGGGCGCGGATTCGCTCGGCC GGGCGCCGAGGCCCTAGGGGAGAGCGGCCGGCCCTGCGCCGGACGCCGGGCTTGTTGTGAGTTTCTTCTCTGACAGAAATGGCGTCATTG TCGTAGACGGGAAACTCCGTCGGGTCTCGACAATGGGGACGGGAAGCTGCCGAGCTGTGTGCAGCTGAACCTGGTGTTTTAGAGGATACC TTGGTCCCAGAGTCATCATGAAGGAAGAAAGAAACAGAAGCTTGCCAAGGAGAGAGCTGGGCTTTCCAAGTTACCTGACCTTAAAGATGC TGAAGCTGTTCAGAAGTTCTTCCTTGAAGAAATACAGCTTGGTGAAGAGTTACTAGCTCAAGGTGAATATGAGAAGGGCGTAGACCATCT GACAAATGCAATTGCTGTGTGTGGACAGCCACAGCAGTTACTGCAGGTCTTACAGCAAACTCTTCCACCACCAGTGTTCCAGATGCTTCT GACTAAGCTCCCAACAATTAGTCAGAGAATTGTAAGTGCTCAGAGCTTGGCTGAAGATGATGTGGAATGAGAAACAAATGTCAACATAAT AAAATCTCAGTTAAAAATATTTTAAAAATTCTTGGTAGTTGAGCAGCTCTGGGGGAATAAGGGCAAATATGCTTGTTATGAACTACACTG AAATCTACCAAAGTTAATGTTTACTTTGTGTAGATCCATTTGTCTATTTTATTTATTTTTCCCAGTGAAAAGTGTATTTTGATAGAGAAC TTTTCATTCTATAAATACACTATGAGTTACTAAAATATCATGGATTTTGTTTATTCCTGAAACATAGTTACATAGTTAAACTGTACATAT GACATGGCTTATGTTAAAAATACCCAGTGCTCAGTTTTGAAAGATAGGCAAAAAAAAAAAAGTATAGGAGAAACTGAAGAATGTACACTT TTTTAGAGGGCACATTTTGCTGTAAATCTGGAAATTTGATAGACTTGACTGTGTTTGTGAAAACTGAGCATTAAAGGTTTTGATTGATCC TTTCTTTCCATTTAATCTCTGAGACGTAAATATGTGAGGTGTGCTGCTGTGCTGGGTTAACAGCTTCCTTCCCTTTCTGTGTAGCAGTCT TGAAATGTTCTGTTTAAATCAGTAGGCTTAATGTGTTCTGGGTATTTATCTCCTTGTATTTTAAATATATGTAGTTGCAAATAGCACCAG GAATTAGATTTCTGTACACCCCTAATCTAGCCTTGTGAGCTTCGCTAGTTAATGTGTGCTCACTTTCCCTCCATTTGTTACGTGAGAGAA TGCGTCTGCTGATCACTGAAGTGTCCCTTTTAGCTTCTGATTCATTGGGTTCTGTTGGGCATCTTTAAATCCACCTTAACCTGAGGAATG TATGTGGGCAACCAGGCCCTGCATTTTTTTATATTCTGAATTTTGCATGCTTGCCTGACTTAGTATTTCTGAATTGATGTTTTTTTTAAT GGTATAACTATCTTGATTTTCACTGAAATTATATGGTTCTGTCACTACTCTGTAAATTAATCCGAAACTTTTAAGGTAACTGGGATGATC TGCTTGTAAAAATGCTTGTTGCCTTTTGCTTTATCTTCAGTGTACCTCCTTAATCCTGCTTCAACTTGATTATCTTGTGAAACGATGAGA GTAAGTTGCAACCTTGTGACTGAAAACTTGAAAAGAGTGGAGCAGGTGGGACCTCTTATTCTCAAATAGTGACATATTCTCCGTAGTCAC AGTTTCAGAACTGAGTAAGGATCCTTGGTACTTGGTGGCATCTGTTGAACTGAGGAGCATTTCTCATTGTAAAGATTGCCTTTGTTCTGT CTAAAAGTCTGGAGAAATCCCAAAGACTTTTCCTATGTACTAGGCATTTTATTTTGATTGACTTACAAACTCTTCTTAATCATTATCAAT CTCGGTTTTTTTGTGGTGCAGTGGAAGGAGAAATAGGTCTAGTTTCTGCCTCTGATTAGCCGCACAGCCTTGAACAAATCACATTTCATC TTTGAACTTACCTCTACTGTTAGACTAGGCGACTCACATTTGAGGACTTTTCTCGGGTATCTTGAGGGTTTGTGATCCTGAACCCTTAAA CAGTGCTTTTTTGTTACACAGGAGGGCTTTTTTGGGGGGATGACCAGTACAGACATGCCAGTTAGTTTTACTAGTGGGATCCCAAATCCA AAGCAGTGTAGTGGTGATTGGTCAGTGACTAACCAGGCAGCTAAGAAGTCTTAGGCAGCAGCCCAGACATGTATAGAGGGGCAGTTAGAG GGAGAACAGGGGTGGGAAAGGGAGCAAGGGGCAGATAGCTCAGCAAGGAAAGAATGGGCTCAGAAAAAGGAGGGCTGGCTGGAGGAGTGA GGGGCAGCTTAAGTTTGGGGAGGGTAGAAACGCCGTTTCCTTGGGAACTGGAGTGCAGTATGAGCTGGGTGTCACTTGGCTCTGAACATA CTGGCTTTGCTGTAATGCTTGAAAAGGCGTTGGTATCTTCATTTTACAGTTCATTAACCCAAGTACGTTTTCTTATTTAAATGACAACTT TGGTGCTTTAAAATGAGGTACCACTTTTTAAAGCTAGCTGTGTCGAGTTAAAGAAAAAATCAGCAGTTTTTTCTCCCAGAAATGTAATTG CCAAACACTATTCATCCCCATCTTAAGTTTTACAAGGTGATGTAATCAGCTTGTTGTAGTGATGCTGGCCAAATGGTGCTCAGCAGGTGA GAACAAAAAAACCCCAGATCTCAGTGAACTAATACACAGCTTGAGCGTTTCCATGTGCTAATGTTGCACACTTACTAAAAAACTTTGGAA ATGGAAAATAATGTATTAGTGCAACAGTTGATGTGCTTCTTTGGGCAAAGATATAGTTTTGTTCCACAATTTGTACTTAAAAGCGAAAGA ACATTGAAAACATAGACTTACTGGCTGTAGCAATGCTGGCCTGTTAACTGATAACTAGAACTTAGGTTCACGTTTATGTAAAGTGTGTAA AACCTAGTAGAGCTTGCATAGTCGGCACTCAGTAAATGTTTGGTTCCTTTTGCCCCTTGGTAAGTTTATTTTACCATCCTCCCACCTGCC ATTCTGACTTTATTAAATCAACATGTGGACCAGAGTGTTAATGAGATGTTATTGCAGAAGAGATTGAGAAAATTGGTATATCATGCAGAT AACATACAAAATCTTTTTGTAACGTAAAAAATGCAGTTTTATTATTGCTTGTGCCTCAACTGTTTAAGTGAATATTAAAGGGCTTGGAGA >6490_6490_6_ARID4B-TOMM20_ARID4B_chr1_235490229_ENST00000366603_TOMM20_chr1_235285687_ENST00000366607_length(amino acids)=69AA_BP= -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARID4B-TOMM20 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARID4B-TOMM20 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARID4B-TOMM20 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies