
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PIAS1-HMCN2 (FusionGDB2 ID:65097) |
Fusion Gene Summary for PIAS1-HMCN2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PIAS1-HMCN2 | Fusion gene ID: 65097 | Hgene | Tgene | Gene symbol | PIAS1 | HMCN2 | Gene ID | 8554 | 256158 |
| Gene name | protein inhibitor of activated STAT 1 | hemicentin 2 | |
| Synonyms | DDXBP1|GBP|GU/RH-II|ZMIZ3 | - | |
| Cytomap | 15q23 | 9q34.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | E3 SUMO-protein ligase PIAS1AR interacting proteinDEAD/H (Asp-Glu-Ala-Asp/His) box binding protein 1DEAD/H box-binding protein 1E3 SUMO-protein transferase PIAS1RNA helicase II-binding proteingu-binding proteinprotein inhibitor of activated STAT pr | hemicentin-2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q8NDA2 | |
| Ensembl transtripts involved in fusion gene | ENST00000249636, ENST00000545237, ENST00000567417, | ENST00000302481, ENST00000487727, ENST00000428715, | |
| Fusion gene scores | * DoF score | 13 X 12 X 7=1092 | 4 X 4 X 4=64 |
| # samples | 15 | 5 | |
| ** MAII score | log2(15/1092*10)=-2.86393845042397 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/64*10)=-0.356143810225275 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PIAS1 [Title/Abstract] AND HMCN2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PIAS1(68379088)-HMCN2(133297964), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PIAS1 | GO:0016925 | protein sumoylation | 18579533 |
| Hgene | PIAS1 | GO:0033235 | positive regulation of protein sumoylation | 17696781|21965678 |
| Fusion gene breakpoints across PIAS1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across HMCN2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-KK-A7B1-01A | PIAS1 | chr15 | 68379088 | - | HMCN2 | chr9 | 133297964 | + |
| ChimerDB4 | PRAD | TCGA-KK-A7B1-01A | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| ChimerDB4 | PRAD | TCGA-KK-A7B1 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
Top |
Fusion Gene ORF analysis for PIAS1-HMCN2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000249636 | ENST00000302481 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| 5CDS-intron | ENST00000249636 | ENST00000487727 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| 5CDS-intron | ENST00000545237 | ENST00000302481 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| 5CDS-intron | ENST00000545237 | ENST00000487727 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| In-frame | ENST00000249636 | ENST00000428715 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| In-frame | ENST00000545237 | ENST00000428715 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| intron-3CDS | ENST00000567417 | ENST00000428715 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| intron-intron | ENST00000567417 | ENST00000302481 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| intron-intron | ENST00000567417 | ENST00000487727 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000249636 | PIAS1 | chr15 | 68379088 | + | ENST00000428715 | HMCN2 | chr9 | 133297964 | + | 3056 | 617 | 148 | 2625 | 825 |
| ENST00000545237 | PIAS1 | chr15 | 68379088 | + | ENST00000428715 | HMCN2 | chr9 | 133297964 | + | 3655 | 1216 | 741 | 3224 | 827 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000249636 | ENST00000428715 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + | 0.022321424 | 0.97767854 |
| ENST00000545237 | ENST00000428715 | PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297964 | + | 0.015531789 | 0.98446816 |
Top |
Fusion Genomic Features for PIAS1-HMCN2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297963 | + | 2.98E-07 | 0.99999964 |
| PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297963 | + | 2.98E-07 | 0.99999964 |
| PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297963 | + | 2.98E-07 | 0.99999964 |
| PIAS1 | chr15 | 68379088 | + | HMCN2 | chr9 | 133297963 | + | 2.98E-07 | 0.99999964 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
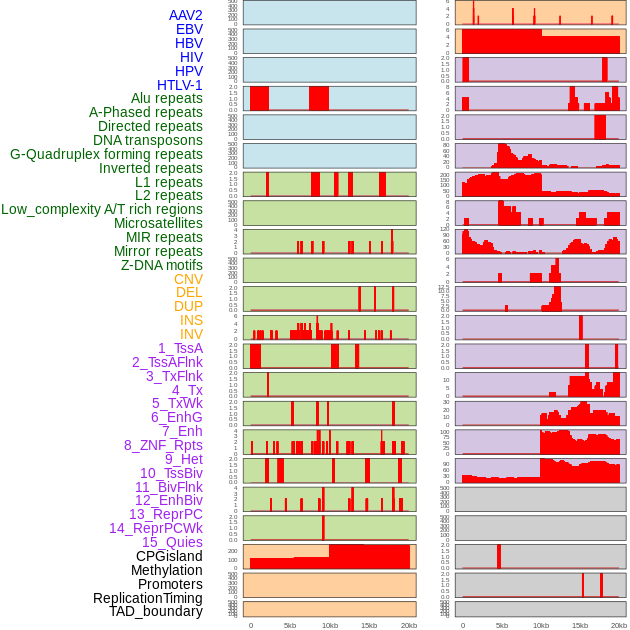 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
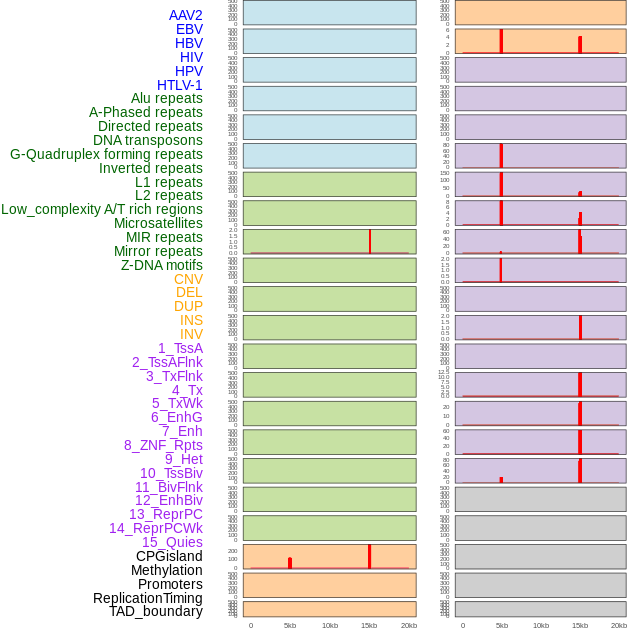 |
Top |
Fusion Protein Features for PIAS1-HMCN2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr15:68379088/chr9:133297964) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | HMCN2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 11_45 | 156 | 652.0 | Domain | SAP |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 19_23 | 156 | 652.0 | Motif | Note=LXXLL motif |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 56_64 | 156 | 652.0 | Motif | Nuclear localization signal |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1066_1159 | 0 | 221.0 | Domain | Ig-like C2-type 7 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1164_1244 | 0 | 221.0 | Domain | Ig-like C2-type 8 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1265_1338 | 0 | 221.0 | Domain | Ig-like C2-type 9 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1343_1429 | 0 | 221.0 | Domain | Ig-like C2-type 10 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1436_1525 | 0 | 221.0 | Domain | Ig-like C2-type 11 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1530_1618 | 0 | 221.0 | Domain | Ig-like C2-type 12 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1623_1714 | 0 | 221.0 | Domain | Ig-like C2-type 13 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1717_1805 | 0 | 221.0 | Domain | Ig-like C2-type 14 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1810_1887 | 0 | 221.0 | Domain | Ig-like C2-type 15 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1894_1982 | 0 | 221.0 | Domain | Ig-like C2-type 16 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 1985_2074 | 0 | 221.0 | Domain | Ig-like C2-type 17 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2079_2165 | 0 | 221.0 | Domain | Ig-like C2-type 18 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2170_2261 | 0 | 221.0 | Domain | Ig-like C2-type 19 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2264_2353 | 0 | 221.0 | Domain | Ig-like C2-type 20 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2358_2447 | 0 | 221.0 | Domain | Ig-like C2-type 21 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2452_2540 | 0 | 221.0 | Domain | Ig-like C2-type 22 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2545_2636 | 0 | 221.0 | Domain | Ig-like C2-type 23 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2641_2732 | 0 | 221.0 | Domain | Ig-like C2-type 24 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2739_2833 | 0 | 221.0 | Domain | Ig-like C2-type 25 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2849_2938 | 0 | 221.0 | Domain | Ig-like C2-type 26 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 2945_3032 | 0 | 221.0 | Domain | Ig-like C2-type 27 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3037_3127 | 0 | 221.0 | Domain | Ig-like C2-type 28 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3131_3219 | 0 | 221.0 | Domain | Ig-like C2-type 29 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3224_3314 | 0 | 221.0 | Domain | Ig-like C2-type 30 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3319_3406 | 0 | 221.0 | Domain | Ig-like C2-type 31 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3412_3497 | 0 | 221.0 | Domain | Ig-like C2-type 32 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3502_3588 | 0 | 221.0 | Domain | Ig-like C2-type 33 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3593_3681 | 0 | 221.0 | Domain | Ig-like C2-type 34 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3686_3772 | 0 | 221.0 | Domain | Ig-like C2-type 35 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3777_3848 | 0 | 221.0 | Domain | Ig-like C2-type 36 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3851_3937 | 0 | 221.0 | Domain | Ig-like C2-type 37 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 38_205 | 0 | 221.0 | Domain | Note=VWFA | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 3942_4027 | 0 | 221.0 | Domain | Ig-like C2-type 38 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4031_4118 | 0 | 221.0 | Domain | Ig-like C2-type 39 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4123_4204 | 0 | 221.0 | Domain | Ig-like C2-type 40 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4212_4295 | 0 | 221.0 | Domain | Ig-like C2-type 41 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4303_4388 | 0 | 221.0 | Domain | Ig-like C2-type 42 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4392_4614 | 0 | 221.0 | Domain | Nidogen G2 beta-barrel | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4628_4668 | 0 | 221.0 | Domain | EGF-like 1%3B calcium-binding | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4669_4712 | 0 | 221.0 | Domain | EGF-like 2%3B calcium-binding | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4713_4751 | 0 | 221.0 | Domain | EGF-like 3%3B calcium-binding | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4756_4796 | 0 | 221.0 | Domain | EGF-like 4%3B calcium-binding | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 4863_4902 | 0 | 221.0 | Domain | EGF-like 5%3B calcium-binding | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 517_602 | 0 | 221.0 | Domain | Ig-like C2-type 1 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 607_690 | 0 | 221.0 | Domain | Ig-like C2-type 2 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 697_780 | 0 | 221.0 | Domain | Ig-like C2-type 3 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 785_879 | 0 | 221.0 | Domain | Ig-like C2-type 4 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 884_970 | 0 | 221.0 | Domain | Ig-like C2-type 5 | |
| Tgene | HMCN2 | chr15:68379088 | chr9:133297964 | ENST00000302481 | 0 | 4 | 975_1061 | 0 | 221.0 | Domain | Ig-like C2-type 6 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 577_634 | 156 | 652.0 | Compositional bias | Note=Ser-rich |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 124_288 | 156 | 652.0 | Domain | PINIT |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 368_380 | 156 | 652.0 | Motif | Nuclear localization signal |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 462_473 | 156 | 652.0 | Region | SUMO1-binding |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 520_615 | 156 | 652.0 | Region | Note=4 X 4 AA repeats of N-T-S-L |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 520_523 | 156 | 652.0 | Repeat | Note=1 |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 557_560 | 156 | 652.0 | Repeat | Note=2 |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 598_601 | 156 | 652.0 | Repeat | Note=3%3B approximate |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 612_615 | 156 | 652.0 | Repeat | Note=4%3B approximate |
| Hgene | PIAS1 | chr15:68379088 | chr9:133297964 | ENST00000249636 | + | 2 | 14 | 320_397 | 156 | 652.0 | Zinc finger | SP-RING-type |
Top |
Fusion Gene Sequence for PIAS1-HMCN2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >65097_65097_1_PIAS1-HMCN2_PIAS1_chr15_68379088_ENST00000249636_HMCN2_chr9_133297964_ENST00000428715_length(transcript)=3056nt_BP=617nt GGGGCTTCGAGCGCCCTGAGCGGGGCGGAGGCTAGAGGCGGGCTGGGAAGGTGGAGGGGCGGGCCGGGGCGGGGCCAGGCCGGCTAGAGG GGCGGGTCTAGCGGCGGCCCCCGGCGAAGTTCACTGCGCTTGCGCTGACAGACGCAAGATGGCGGACAGTGCGGAACTAAAGCAAATGGT TATGAGCCTTAGAGTTTCTGAACTCCAAGTACTGTTGGGCTACGCCGGGAGAAACAAGCACGGACGCAAACACGAACTTCTCACAAAAGC CCTGCATTTGCTAAAGGCTGGCTGTAGTCCTGCTGTGCAAATGAAAATTAAGGAACTCTATAGGCGGCGGTTCCCACAGAAAATCATGAC GCCTGCAGACTTGTCCATCCCCAACGTACATTCAAGTCCTATGCCAGCAACTTTGTCTCCATCTACCATTCCACAACTCACTTACGATGG TCACCCTGCATCATCGCCATTACTCCCTGTTTCTCTTCTGGGACCTAAACATGAACTGGAACTCCCACATCTTACATCAGCTCTTCACCC AGTCCATCCGGATATAAAACTTCAAAAATTACCATTTTATGATTTACTGGATGAACTGATAAAACCCACCAGTCTAGGGGAGCCCCAGGG GAGCTGGGGCAGCATGACTGGGGTGATAAATGGCCGGAAATTTGGCGTGGCCACACTCAACACCAGCGTGATGCAGGAGGCACACTCCGG GGTCAGCAGCATCCACAGCAGCATCCGCCATGTCCCAGCAAACGTGGGGCCTCTGATGCGGGTGCTCGTGGTCACCATCGCCCCCATCTA CTGGGCCCTGGCCAGAGAGAGTGGGGAAGCCCTGAATGGCCACTCTCTGACTGGGGGCAGGTTCCGGCAGGAGTCACACGTGGAGTTTGC TACAGGGGAGCTGCTCACGATGACCCAGGTGGCCCGGGGTCTGGATCCCGATGGCCTCCTGCTCCTCGACGTGGTGGTCAATGGCGTTGT CCCCGAGAGCCTGGCTGACGCAGATCTTCAAGTGCAGGACTTTGAGGAGCACTACGTGCAAACAGGGCCTGGCCAGCTGTTCGTGGGCTC CACACAGCGCTTCTTCCAGGGCGGCCTCCCCTCGTTCCTACGCTGCAACCACAGCATCCAGTACAACGCGGCCCGGGGCCCCCAGCCCCA GCTGGTGCAGCACCTGCGGGCCTCAGCTATCAGCTCGGCCTTTGATCCAGAGGCCGAGGCCCTGCGCTTCCAGCTCGCTACAGCCCTGCA GGCGGAGGAGAACGAGGTCGGCTGCCCCGAGGGCTTTGAGCTGGACTCCCAGGGAGCGTTTTGTGTGGACAGGGACGAGTGCTCAGGAGG CCCTAGCCCCTGCTCCCATGCCTGCCTTAATGCACCCGGCCGCTTCTCCTGCACCTGCCCCACTGGCTTCGCCCTGGCCTGGGATGACAG GAACTGCAGAGATGTGGACGAGTGTGCGTGGGATGCTCACCTCTGCCGAGAGGGACAGCGCTGTGTGAACCTGCTCGGGTCCTACCGCTG CCTCCCCGACTGTGGGCCTGGCTTCCGGGTGGCTGATGGGGCCGGCTGTGAAGATGTGGACGAATGCCTGGAGGGGTTGGACGACTGTCA CTACAACCAGCTCTGCGAGAACACCCCAGGCGGTCACCGCTGCAGCTGCCCCAGGGGTTACCGGATGCAGGGCCCCAGCCTGCCCTGCCT AGATGTCAATGAGTGCCTGCAGCTGCCCAAGGCCTGCGCCTACCAGTGCCACAACCTCCAGGGCAGCTACCGCTGCCTGTGCCCCCCAGG CCAGACCCTCCTTCGCGACGGCAAGGCCTGCACCTCACTGGAGCGGAATGGACAAAATGTGACCACCGTCAGCCACCGAGGCCCTCTATT GCCCTGGCTGCGGCCCTGGGCCTCGATCCCCGGTACCTCCTACCACGCCTGGGTCTCTCTCCGTCCGGGTCCCATGGCCCTGAGCAGTGT GGGCCGGGCCTGGTGCCCTCCTGGTTTCATCAGGCAGAACGGAGTCTGCACAGACCTTGACGAGTGCCGCGTGAGGAACCTGTGTCAGCA CGCCTGCCGCAACACTGAGGGCAGCTACCAGTGCCTGTGCCCCGCCGGCTACCGTCTGCTCCCCAGCGGGAAGAACTGCCAGGACATCAA CGAGTGCGAGGAGGAGAGCATCGAGTGTGGACCCGGCCAGATGTGCTTCAACACCCGTGGCAGCTACCAGTGTGTGGACACACCCTGTCC TGCCACCTACCGGCAGGGCCCCAGCCCTGGGACGTGCTTCCGGCGCTGCTCGCAGGACTGCGGCACGGGCGGCCCCTCTACGCTGCAGTA CCGGCTGCTGCCGCTGCCCCTGGGCGTGCGCGCCCACCACGACGTGGCCCGCCTCACCGCCTTCTCCGAGGTCGGCGTCCCCGCCAACCG CACCGAGCTCAGCATGCTGGAGCCCGACCCCCGCAGCCCCTTCGCGCTGCGTCCGCTGCGCGCGGGCCTTGGCGCGGTCTACACCCGTCG CGCGCTCACCCGCGCCGGCCTCTACCGGCTCACCGTGCGTGCTGCGGCACCGCGCCACCAAAGCGTCTTCGTCTTGCTCATCGCCGTGTC CCCCTACCCCTACTAAACGGGAGAGGGCATTGGCGGCCGCCCTGGCGTGACCCCCGAGGAAGGGGTCGAGGAGAAGCTTGGTCCACGCCA CCTGCTGTGGCAAGCGGAGCGTCATCGTCTCCCGCCCCGTGCGTCAGCGAGACCTTGGGTCAACACGACCCTGCGCACAGCCTTGACCCC CGACAGCGAGGACCTGACCTCACAGAGGGAGGCGTCCAGGGCGGCCCTTGGGTGGCCAGTCCCGCAGGCAGGGCCCGGGGAAGCCCGGAT CAGACCTCCAGGTCTGATCCGCCCCTCAGTGGGAGCGGGACAGGGACACAGGGCACCTGGACGCGCGGGAGAGGGGGCAGACCCCGCGTT >65097_65097_1_PIAS1-HMCN2_PIAS1_chr15_68379088_ENST00000249636_HMCN2_chr9_133297964_ENST00000428715_length(amino acids)=825AA_BP=156 MADSAELKQMVMSLRVSELQVLLGYAGRNKHGRKHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPATLS PSTIPQLTYDGHPASSPLLPVSLLGPKHELELPHLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLGEPQGSWGSMTGVINGRKFGVATL NTSVMQEAHSGVSSIHSSIRHVPANVGPLMRVLVVTIAPIYWALARESGEALNGHSLTGGRFRQESHVEFATGELLTMTQVARGLDPDGL LLLDVVVNGVVPESLADADLQVQDFEEHYVQTGPGQLFVGSTQRFFQGGLPSFLRCNHSIQYNAARGPQPQLVQHLRASAISSAFDPEAE ALRFQLATALQAEENEVGCPEGFELDSQGAFCVDRDECSGGPSPCSHACLNAPGRFSCTCPTGFALAWDDRNCRDVDECAWDAHLCREGQ RCVNLLGSYRCLPDCGPGFRVADGAGCEDVDECLEGLDDCHYNQLCENTPGGHRCSCPRGYRMQGPSLPCLDVNECLQLPKACAYQCHNL QGSYRCLCPPGQTLLRDGKACTSLERNGQNVTTVSHRGPLLPWLRPWASIPGTSYHAWVSLRPGPMALSSVGRAWCPPGFIRQNGVCTDL DECRVRNLCQHACRNTEGSYQCLCPAGYRLLPSGKNCQDINECEEESIECGPGQMCFNTRGSYQCVDTPCPATYRQGPSPGTCFRRCSQD CGTGGPSTLQYRLLPLPLGVRAHHDVARLTAFSEVGVPANRTELSMLEPDPRSPFALRPLRAGLGAVYTRRALTRAGLYRLTVRAAAPRH -------------------------------------------------------------- >65097_65097_2_PIAS1-HMCN2_PIAS1_chr15_68379088_ENST00000545237_HMCN2_chr9_133297964_ENST00000428715_length(transcript)=3655nt_BP=1216nt TTGTTGTGGGCGCCTCTGGCGGGGGTGGCGGGGGAAGAGATAGGGAGTCCGGAGGTAGGGGCTGCAGCTGTCTCATGGGCTCGGCTTTTT CACCTTCCAGTTAGCCTCCCTGCCCCCCATGGGGAGCTGGGGCTGGGGGCAGGGTGCTCTCGTAGGGGGGATTGGGAAAGCTCCCCGTGG CCGCTTCCTCTTCCTCCTTTGCAGTCCCGGGCTCCTGTCAGGCGCTCTTCTCAGACCCCCGGGAACTTGGCTTCGGCCGCCCCGCCCCTC CGTGGATCCCAGTAGCCCCCGCCCCGGACTCGGCTTTCCCCGGCTGCTCGCTTGTCAGGAAGCGCCTGGGGTGCCCCGCTTGTGGGAAGC GCGATCCCGGGGCGATAGGGTGGGGATCTGGGGGAGAAGCTCTGGTAAAGTTTAGCGAGCCCCGGGCCGGCGTTGGGGTTCGGCTGAGAG GTAGTGAGCGGGACGTTACTCTTTCTCTCTGATTCCGGGCAGCCGAGGGGAGAAACCCCCTCGAAGAGTGTGTCTTTGGAAGCAGTGTTG GGAGGGGGGGATGCAGCTACCTCTCTCCCTTCTTTTGCCTTAGCTGGTGTGGAGGGTGAGAGGAGCCTTTGGGGGTCTCTGCACACACCA TGATGGCGATGCTGTAGCTGATGGAGAACAACCAAATGCCAGATTTGATTCTGTAGAGTTTTTCCTGTGGAATATCCTCACCGAAAGAGC TTTTCTCCTAATAACTTCACAATGTTTACACTCCAAGATTCGTATGTTAAGCAAATGGTTATGAGCCTTAGAGTTTCTGAACTCCAAGTA CTGTTGGGCTACGCCGGGAGAAACAAGCACGGACGCAAACACGAACTTCTCACAAAAGCCCTGCATTTGCTAAAGGCTGGCTGTAGTCCT GCTGTGCAAATGAAAATTAAGGAACTCTATAGGCGGCGGTTCCCACAGAAAATCATGACGCCTGCAGACTTGTCCATCCCCAACGTACAT TCAAGTCCTATGCCAGCAACTTTGTCTCCATCTACCATTCCACAACTCACTTACGATGGTCACCCTGCATCATCGCCATTACTCCCTGTT TCTCTTCTGGGACCTAAACATGAACTGGAACTCCCACATCTTACATCAGCTCTTCACCCAGTCCATCCGGATATAAAACTTCAAAAATTA CCATTTTATGATTTACTGGATGAACTGATAAAACCCACCAGTCTAGGGGAGCCCCAGGGGAGCTGGGGCAGCATGACTGGGGTGATAAAT GGCCGGAAATTTGGCGTGGCCACACTCAACACCAGCGTGATGCAGGAGGCACACTCCGGGGTCAGCAGCATCCACAGCAGCATCCGCCAT GTCCCAGCAAACGTGGGGCCTCTGATGCGGGTGCTCGTGGTCACCATCGCCCCCATCTACTGGGCCCTGGCCAGAGAGAGTGGGGAAGCC CTGAATGGCCACTCTCTGACTGGGGGCAGGTTCCGGCAGGAGTCACACGTGGAGTTTGCTACAGGGGAGCTGCTCACGATGACCCAGGTG GCCCGGGGTCTGGATCCCGATGGCCTCCTGCTCCTCGACGTGGTGGTCAATGGCGTTGTCCCCGAGAGCCTGGCTGACGCAGATCTTCAA GTGCAGGACTTTGAGGAGCACTACGTGCAAACAGGGCCTGGCCAGCTGTTCGTGGGCTCCACACAGCGCTTCTTCCAGGGCGGCCTCCCC TCGTTCCTACGCTGCAACCACAGCATCCAGTACAACGCGGCCCGGGGCCCCCAGCCCCAGCTGGTGCAGCACCTGCGGGCCTCAGCTATC AGCTCGGCCTTTGATCCAGAGGCCGAGGCCCTGCGCTTCCAGCTCGCTACAGCCCTGCAGGCGGAGGAGAACGAGGTCGGCTGCCCCGAG GGCTTTGAGCTGGACTCCCAGGGAGCGTTTTGTGTGGACAGGGACGAGTGCTCAGGAGGCCCTAGCCCCTGCTCCCATGCCTGCCTTAAT GCACCCGGCCGCTTCTCCTGCACCTGCCCCACTGGCTTCGCCCTGGCCTGGGATGACAGGAACTGCAGAGATGTGGACGAGTGTGCGTGG GATGCTCACCTCTGCCGAGAGGGACAGCGCTGTGTGAACCTGCTCGGGTCCTACCGCTGCCTCCCCGACTGTGGGCCTGGCTTCCGGGTG GCTGATGGGGCCGGCTGTGAAGATGTGGACGAATGCCTGGAGGGGTTGGACGACTGTCACTACAACCAGCTCTGCGAGAACACCCCAGGC GGTCACCGCTGCAGCTGCCCCAGGGGTTACCGGATGCAGGGCCCCAGCCTGCCCTGCCTAGATGTCAATGAGTGCCTGCAGCTGCCCAAG GCCTGCGCCTACCAGTGCCACAACCTCCAGGGCAGCTACCGCTGCCTGTGCCCCCCAGGCCAGACCCTCCTTCGCGACGGCAAGGCCTGC ACCTCACTGGAGCGGAATGGACAAAATGTGACCACCGTCAGCCACCGAGGCCCTCTATTGCCCTGGCTGCGGCCCTGGGCCTCGATCCCC GGTACCTCCTACCACGCCTGGGTCTCTCTCCGTCCGGGTCCCATGGCCCTGAGCAGTGTGGGCCGGGCCTGGTGCCCTCCTGGTTTCATC AGGCAGAACGGAGTCTGCACAGACCTTGACGAGTGCCGCGTGAGGAACCTGTGTCAGCACGCCTGCCGCAACACTGAGGGCAGCTACCAG TGCCTGTGCCCCGCCGGCTACCGTCTGCTCCCCAGCGGGAAGAACTGCCAGGACATCAACGAGTGCGAGGAGGAGAGCATCGAGTGTGGA CCCGGCCAGATGTGCTTCAACACCCGTGGCAGCTACCAGTGTGTGGACACACCCTGTCCTGCCACCTACCGGCAGGGCCCCAGCCCTGGG ACGTGCTTCCGGCGCTGCTCGCAGGACTGCGGCACGGGCGGCCCCTCTACGCTGCAGTACCGGCTGCTGCCGCTGCCCCTGGGCGTGCGC GCCCACCACGACGTGGCCCGCCTCACCGCCTTCTCCGAGGTCGGCGTCCCCGCCAACCGCACCGAGCTCAGCATGCTGGAGCCCGACCCC CGCAGCCCCTTCGCGCTGCGTCCGCTGCGCGCGGGCCTTGGCGCGGTCTACACCCGTCGCGCGCTCACCCGCGCCGGCCTCTACCGGCTC ACCGTGCGTGCTGCGGCACCGCGCCACCAAAGCGTCTTCGTCTTGCTCATCGCCGTGTCCCCCTACCCCTACTAAACGGGAGAGGGCATT GGCGGCCGCCCTGGCGTGACCCCCGAGGAAGGGGTCGAGGAGAAGCTTGGTCCACGCCACCTGCTGTGGCAAGCGGAGCGTCATCGTCTC CCGCCCCGTGCGTCAGCGAGACCTTGGGTCAACACGACCCTGCGCACAGCCTTGACCCCCGACAGCGAGGACCTGACCTCACAGAGGGAG GCGTCCAGGGCGGCCCTTGGGTGGCCAGTCCCGCAGGCAGGGCCCGGGGAAGCCCGGATCAGACCTCCAGGTCTGATCCGCCCCTCAGTG GGAGCGGGACAGGGACACAGGGCACCTGGACGCGCGGGAGAGGGGGCAGACCCCGCGTTAGGGGTGGCAGCAGCTGTCGCCCGGCCACAC >65097_65097_2_PIAS1-HMCN2_PIAS1_chr15_68379088_ENST00000545237_HMCN2_chr9_133297964_ENST00000428715_length(amino acids)=827AA_BP=158 MFTLQDSYVKQMVMSLRVSELQVLLGYAGRNKHGRKHELLTKALHLLKAGCSPAVQMKIKELYRRRFPQKIMTPADLSIPNVHSSPMPAT LSPSTIPQLTYDGHPASSPLLPVSLLGPKHELELPHLTSALHPVHPDIKLQKLPFYDLLDELIKPTSLGEPQGSWGSMTGVINGRKFGVA TLNTSVMQEAHSGVSSIHSSIRHVPANVGPLMRVLVVTIAPIYWALARESGEALNGHSLTGGRFRQESHVEFATGELLTMTQVARGLDPD GLLLLDVVVNGVVPESLADADLQVQDFEEHYVQTGPGQLFVGSTQRFFQGGLPSFLRCNHSIQYNAARGPQPQLVQHLRASAISSAFDPE AEALRFQLATALQAEENEVGCPEGFELDSQGAFCVDRDECSGGPSPCSHACLNAPGRFSCTCPTGFALAWDDRNCRDVDECAWDAHLCRE GQRCVNLLGSYRCLPDCGPGFRVADGAGCEDVDECLEGLDDCHYNQLCENTPGGHRCSCPRGYRMQGPSLPCLDVNECLQLPKACAYQCH NLQGSYRCLCPPGQTLLRDGKACTSLERNGQNVTTVSHRGPLLPWLRPWASIPGTSYHAWVSLRPGPMALSSVGRAWCPPGFIRQNGVCT DLDECRVRNLCQHACRNTEGSYQCLCPAGYRLLPSGKNCQDINECEEESIECGPGQMCFNTRGSYQCVDTPCPATYRQGPSPGTCFRRCS QDCGTGGPSTLQYRLLPLPLGVRAHHDVARLTAFSEVGVPANRTELSMLEPDPRSPFALRPLRAGLGAVYTRRALTRAGLYRLTVRAAAP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PIAS1-HMCN2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PIAS1-HMCN2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PIAS1-HMCN2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies