
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PIAS3-BZRAP1 (FusionGDB2 ID:65119) |
Fusion Gene Summary for PIAS3-BZRAP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PIAS3-BZRAP1 | Fusion gene ID: 65119 | Hgene | Tgene | Gene symbol | PIAS3 | BZRAP1 | Gene ID | 10401 | 9256 |
| Gene name | protein inhibitor of activated STAT 3 | TSPO associated protein 1 | |
| Synonyms | ZMIZ5 | BZRAP1|PBR-IP|PRAX-1|PRAX1|RIM-BP1|RIMBP1 | |
| Cytomap | 1q21.1 | 17q22 | |
| Type of gene | protein-coding | protein-coding | |
| Description | E3 SUMO-protein ligase PIAS3E3 SUMO-protein transferase PIAS3protein inhibitor of activated STAT protein 3zinc finger, MIZ-type containing 5 | peripheral-type benzodiazepine receptor-associated protein 1RIMS-binding protein 1benzodiazapine receptor peripheral-associated protein 1benzodiazepine receptor (peripheral) associated protein 1peripheral benzodiazepine receptor-interacting protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000369298, ENST00000393045, ENST00000369299, | ENST00000268893, ENST00000343736, ENST00000355701, | |
| Fusion gene scores | * DoF score | 5 X 6 X 3=90 | 1 X 1 X 1=1 |
| # samples | 6 | 1 | |
| ** MAII score | log2(6/90*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: PIAS3 [Title/Abstract] AND BZRAP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PIAS3(145584836)-BZRAP1(56384329), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PIAS3 | GO:0033234 | negative regulation of protein sumoylation | 24651376 |
| Hgene | PIAS3 | GO:0033235 | positive regulation of protein sumoylation | 17696781|21965678 |
| Fusion gene breakpoints across PIAS3 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across BZRAP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SARC | TCGA-DX-AB3A-01A | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
Top |
Fusion Gene ORF analysis for PIAS3-BZRAP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000369298 | ENST00000268893 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| In-frame | ENST00000369298 | ENST00000343736 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| In-frame | ENST00000369298 | ENST00000355701 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| In-frame | ENST00000393045 | ENST00000268893 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| In-frame | ENST00000393045 | ENST00000343736 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| In-frame | ENST00000393045 | ENST00000355701 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| intron-3CDS | ENST00000369299 | ENST00000268893 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| intron-3CDS | ENST00000369299 | ENST00000343736 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| intron-3CDS | ENST00000369299 | ENST00000355701 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000393045 | PIAS3 | chr1 | 145584836 | - | ENST00000268893 | BZRAP1 | chr17 | 56384329 | - | 3550 | 1710 | 66 | 2300 | 744 |
| ENST00000393045 | PIAS3 | chr1 | 145584836 | - | ENST00000355701 | BZRAP1 | chr17 | 56384329 | - | 3482 | 1710 | 66 | 2450 | 794 |
| ENST00000393045 | PIAS3 | chr1 | 145584836 | - | ENST00000343736 | BZRAP1 | chr17 | 56384329 | - | 2510 | 1710 | 66 | 2300 | 744 |
| ENST00000369298 | PIAS3 | chr1 | 145584836 | - | ENST00000268893 | BZRAP1 | chr17 | 56384329 | - | 3410 | 1570 | 31 | 2160 | 709 |
| ENST00000369298 | PIAS3 | chr1 | 145584836 | - | ENST00000355701 | BZRAP1 | chr17 | 56384329 | - | 3342 | 1570 | 31 | 2310 | 759 |
| ENST00000369298 | PIAS3 | chr1 | 145584836 | - | ENST00000343736 | BZRAP1 | chr17 | 56384329 | - | 2370 | 1570 | 31 | 2160 | 709 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000393045 | ENST00000268893 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - | 0.003833858 | 0.9961661 |
| ENST00000393045 | ENST00000355701 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - | 0.003191447 | 0.99680847 |
| ENST00000393045 | ENST00000343736 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - | 0.005263388 | 0.9947366 |
| ENST00000369298 | ENST00000268893 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - | 0.007219214 | 0.99278075 |
| ENST00000369298 | ENST00000355701 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - | 0.006286279 | 0.9937137 |
| ENST00000369298 | ENST00000343736 | PIAS3 | chr1 | 145584836 | - | BZRAP1 | chr17 | 56384329 | - | 0.009078875 | 0.99092114 |
Top |
Fusion Genomic Features for PIAS3-BZRAP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
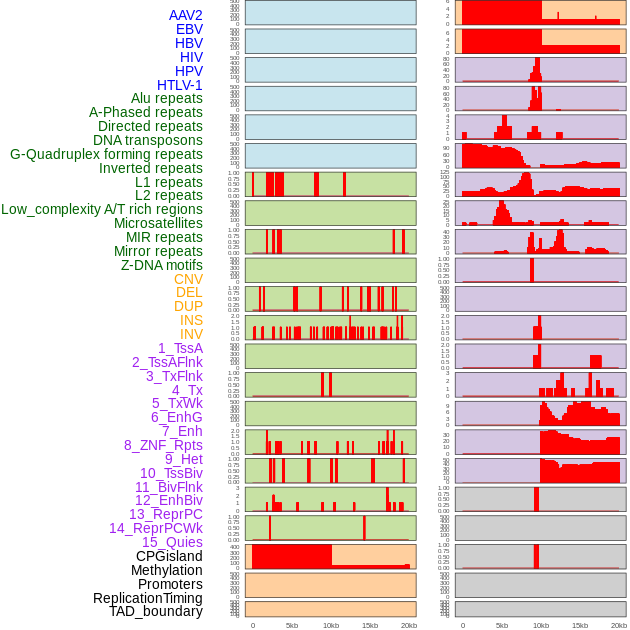 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PIAS3-BZRAP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:145584836/chr17:56384329) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PIAS3 | chr1:145584836 | chr17:56384329 | ENST00000393045 | - | 13 | 14 | 81_133 | 540 | 629.0 | Compositional bias | Note=Pro-rich |
| Hgene | PIAS3 | chr1:145584836 | chr17:56384329 | ENST00000393045 | - | 13 | 14 | 115_280 | 540 | 629.0 | Domain | PINIT |
| Hgene | PIAS3 | chr1:145584836 | chr17:56384329 | ENST00000393045 | - | 13 | 14 | 11_45 | 540 | 629.0 | Domain | SAP |
| Hgene | PIAS3 | chr1:145584836 | chr17:56384329 | ENST00000393045 | - | 13 | 14 | 19_23 | 540 | 629.0 | Motif | Note=LXXLL motif |
| Hgene | PIAS3 | chr1:145584836 | chr17:56384329 | ENST00000393045 | - | 13 | 14 | 450_460 | 540 | 629.0 | Region | SUMO1-binding |
| Hgene | PIAS3 | chr1:145584836 | chr17:56384329 | ENST00000393045 | - | 13 | 14 | 303_380 | 540 | 629.0 | Zinc finger | SP-RING-type |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 1625_1693 | 1601 | 1797.3333333333333 | Domain | SH3 2 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 1764_1831 | 1601 | 1797.3333333333333 | Domain | SH3 3 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 1764_1831 | 1661 | 1736.0 | Domain | SH3 3 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 1764_1831 | 1661 | 1908.0 | Domain | SH3 3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 1071_1150 | 1601 | 1797.3333333333333 | Compositional bias | Note=Pro-rich | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 1262_1274 | 1601 | 1797.3333333333333 | Compositional bias | Note=Poly-Glu | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 1334_1346 | 1601 | 1797.3333333333333 | Compositional bias | Note=Poly-Glu | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 1071_1150 | 1661 | 1736.0 | Compositional bias | Note=Pro-rich | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 1262_1274 | 1661 | 1736.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 1334_1346 | 1661 | 1736.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 1071_1150 | 1661 | 1908.0 | Compositional bias | Note=Pro-rich | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 1262_1274 | 1661 | 1908.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 1334_1346 | 1661 | 1908.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 653_720 | 1601 | 1797.3333333333333 | Domain | SH3 1 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 791_882 | 1601 | 1797.3333333333333 | Domain | Fibronectin type-III 1 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 884_976 | 1601 | 1797.3333333333333 | Domain | Fibronectin type-III 2 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000268893 | 22 | 31 | 981_1081 | 1601 | 1797.3333333333333 | Domain | Fibronectin type-III 3 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 1625_1693 | 1661 | 1736.0 | Domain | SH3 2 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 653_720 | 1661 | 1736.0 | Domain | SH3 1 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 791_882 | 1661 | 1736.0 | Domain | Fibronectin type-III 1 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 884_976 | 1661 | 1736.0 | Domain | Fibronectin type-III 2 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000343736 | 23 | 32 | 981_1081 | 1661 | 1736.0 | Domain | Fibronectin type-III 3 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 1625_1693 | 1661 | 1908.0 | Domain | SH3 2 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 653_720 | 1661 | 1908.0 | Domain | SH3 1 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 791_882 | 1661 | 1908.0 | Domain | Fibronectin type-III 1 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 884_976 | 1661 | 1908.0 | Domain | Fibronectin type-III 2 | |
| Tgene | BZRAP1 | chr1:145584836 | chr17:56384329 | ENST00000355701 | 23 | 31 | 981_1081 | 1661 | 1908.0 | Domain | Fibronectin type-III 3 |
Top |
Fusion Gene Sequence for PIAS3-BZRAP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >65119_65119_1_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000369298_BZRAP1_chr17_56384329_ENST00000268893_length(transcript)=3410nt_BP=1570nt GCCGGTCCCTGGGCCTGAGCTCCGGCTCCGGCTGGGGCGCCTGCGATGTCTCAAGATGGCGGAGCTGGGCGAATTAAAGCACATGGTGAT GAGTTTCCGGGTGTCTGAGCTCCAGGTGCTTCTTGGCTTTGCTGGCCGGAACAAGAGTGGACGGAAGCACGAGCTCCTGGCCAAGGCTCT GCACCTCCTGAAGTCCAGCTGTGCCCCTAGTGTCCAGATGAAGATCAAAGAGCTTTACCGACGACGCTTTCCCCGGAAGACCCTGGGGCC CTCTGATCTCTCCCTTCTCTCTTTGCCCCCTGGCACCTCTCCTCCTGTGCACCCTGATGTCACCATGAAACCATTGCCCTTCTATGAAGT CTATGGGGAGCTCATCCGGCCCACCACCCTTGCATCCACTTCTAGCCAGCGGTTTGAGGAAGCGCACTTTACCTTTGCCCTCACACCCCA GCAAGTGCAGCAGATTCTTACATCCAGAGAGGTTCTGCCAGGAGCCAAATGTGATTATACCATACAGGTGCAGCTAAGGTTCTGTCTCTG TGAGACCAGCTGCCCCCAGGAAGATTATTTTCCCCCCAACCTCTTTGTCAAGGTCAATGGGAAACTGTGCCCCCTGCCGGGTTACCTTCC CCCAACCAAGAATGGGGCCGAGCCCAAGAGGCCCAGCCGCCCCATCAACATCACACCCCTGGCTCGACTCTCAGCCACTGTTCCCAACAC CATTGTGGTCAATTGGTCATCTGAGTTCGGACGGAATTACTCCTTGTCTGTGTACCTGGTGAGGCAGTTGACTGCAGGAACCCTTCTACA AAAACTCAGAGCAAAGGGTATCCGGAACCCAGACCACTCGCGGGCACTGATCAAGGAGAAATTGACTGCTGACCCTGACAGTGAGGTGGC CACTACAAGTCTCCGGGTGTCACTCATGTGCCCGCTAGGGAAGATGCGCCTGACTGTCCCTTGTCGTGCCCTCACCTGCGCCCACCTGCA GAGCTTCGATGCTGCCCTTTATCTACAGATGAATGAGAAGAAGCCTACATGGACATGTCCTGTGTGTGACAAGAAGGCTCCCTATGAATC TCTTATCATTGATGGTTTATTTATGGAGATTCTTAGTTCCTGTTCAGATTGTGATGAGATCCAATTCATGGAAGATGGATCCTGGTGCCC AATGAAACCCAAGAAGGAGGCATCTGAGGTTTGCCCCCCGCCAGGGTATGGGCTGGATGGCCTCCAGTACAGCCCAGTCCAGGGGGGAGA TCCATCAGAGAATAAGAAGAAGGTCGAAGTTATTGACTTGACAATAGAAAGCTCATCAGATGAGGAGGATCTGCCCCCTACCAAGAAGCA CTGTTCTGTCACCTCAGCTGCCATCCCGGCCCTACCTGGAAGCAAAGGAGTCCTGACATCTGGCCACCAGCCATCCTCGGTGCTAAGGAG CCCTGCTATGGGCACGTTGGGTGGGGATTTCCTGTCCAGTCTCCCACTACATGAGTACCCACCTGCCTTCCCACTGGGAGCCGACATCCA AGGTTTAGATTTATTTTCATTTCTTCAGACAGAGAGTCAGGTGTTTGGGGACAAGGATGCCGATGGCTTCTACCAGGGCGAAGGTGGGGG CCGGACAGGCTACATTCCCTGCAACATGGTGGCTGAGGTGGCTGTGGACAGCCCTGCTGGGAGACAGCAACTGCTCCAGCGGGGTTATTT GTCCCCAGATATTCTCCTTGAGGGCTCAGGGAATGGTCCGTTTGTGTACTCCACAGCCCACACAACTGGGCCTCCTCCCAAGCCCCGCCG CTCCAAGAAAGCTGAGTCGGAAGGCCCTGCCCAGCCCTGTCCAGGCCCCCCTAAGCTGGTCCCCTCTGCTGACCTGAAAGCTCCCCACTC CATGGTGGCTGCATTTGACTACAACCCCCAGGAGAGTTCCCCCAATATGGACGTGGAGGCAGAGCTGCCCTTCCGGGCAGGGGATGTCAT TACTGTGTTTGGGGGCATGGACGATGACGGTTTCTACTATGGGGAATTAAATGGACAAAGGGGCCTGGTTCCATCCAACTTCCTGGAGGG CCCTGGGCCTGAGGCAGGCGGCCTGGACAGGGAACCCAGGACACCCCAGGCTGAGAGTCAGAGAACGAGGAGGAGAAGAGTCCAGTGCTA GATGGAGATAGATATATGTAGAGAGAGCAACATGACTGGGGCTGCACCACACAAGGGTCCCCAGGGCCCCCAGGTGGGCCTTGTACCCCC AGCTCTGGCAGCGCCCCCAGGATTGAACGTGGGGAGCCCCAGGGCAGAAGCGAGAAGGTGTGGGGTTTCTTCTCCAAGGGGAAGCAGCTC CTCAGGAGGCTGGGCTCTGGGAAGAAGGAGTGAAGCTGTGGCCCATCCTGCAGGCAGAAGAGGCCCTGAGAGGCCCCCAGATCACTGTCT CTGCTGAGCAGGGAAGGCTCAGACTGGGCCCAGAGCCCCCGTTCTTCTGCGTTAACACTGTGGCATTCAGAGGGAATCAAAGAGCCTTGG TGAAGGTCAGAGCTAAATGGCTCCTTAAGGATGAACTCTCTAGAGAAGCACCTTCCTCCTACAGGAGGGGAAACTGAGCCCACAGTGAGT ATGTAACTTGACCAAGGTCACTGAGCCAGGACTGGACCCAGGACCCTCGCGTCCTGGTCCACCCACCTCGTCTACTAGTGTCCCACAGTG CTGCGCTAGTCCCTTCTGCCACCCTTCCCAGTCCCAGGACGGGCCCTGGAGGGAGAAAGGAGCCTGTGCCCCCTGATGGCTCTGGCTGTC CTGATCCTGTCTTCCCTCCCCTGAAGGAAAGTTTGCACTGGATTTTATTGGAGCCCCATCTCCCCAGCGGGCAGGCGGGCGGAGCCTGTA TATATGTATATACTCAGTGCCTCAGTTCAGCTTCCTCCACCTCGCTTCCACTGCACAGGCCCAGGAAGGAGAAAGGCCAAGCCAAAGTGG GCCCCACCCTGCCCCCGTCGTGCTCCATCCTTCCCTGCCGGGGCCTGCTGGCCCCTGTAAGGTCCCGCCCCCAAAGACCCTGGGGCCAGC GGGGCCGAAAGCGGAGTTGGGTTTGCCTTATTTTGCTCATTGGATTCAAGTTCTTTTGCATAGTTTTCTTCTAACCCCTGTTGGAGTCCA GGGGCTGGAGAAAAGGACAGATTTATGCAGCTATTTTCATACATTCCCTGTTCAGAGTGGGGTAGGGGTTCTCCGCCGTTACCCGATCCA CTCCATCCCCCACCCTCTGAGGGGTGAGTGTGTCTTTGCATGTTTCCTTTGCTGTGGTGGGAGATAGTTTGACTGAACCCCCACCTTGAC >65119_65119_1_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000369298_BZRAP1_chr17_56384329_ENST00000268893_length(amino acids)=709AA_BP=512 MGRLRCLKMAELGELKHMVMSFRVSELQVLLGFAGRNKSGRKHELLAKALHLLKSSCAPSVQMKIKELYRRRFPRKTLGPSDLSLLSLPP GTSPPVHPDVTMKPLPFYEVYGELIRPTTLASTSSQRFEEAHFTFALTPQQVQQILTSREVLPGAKCDYTIQVQLRFCLCETSCPQEDYF PPNLFVKVNGKLCPLPGYLPPTKNGAEPKRPSRPINITPLARLSATVPNTIVVNWSSEFGRNYSLSVYLVRQLTAGTLLQKLRAKGIRNP DHSRALIKEKLTADPDSEVATTSLRVSLMCPLGKMRLTVPCRALTCAHLQSFDAALYLQMNEKKPTWTCPVCDKKAPYESLIIDGLFMEI LSSCSDCDEIQFMEDGSWCPMKPKKEASEVCPPPGYGLDGLQYSPVQGGDPSENKKKVEVIDLTIESSSDEEDLPPTKKHCSVTSAAIPA LPGSKGVLTSGHQPSSVLRSPAMGTLGGDFLSSLPLHEYPPAFPLGADIQGLDLFSFLQTESQVFGDKDADGFYQGEGGGRTGYIPCNMV AEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAESEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQ -------------------------------------------------------------- >65119_65119_2_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000369298_BZRAP1_chr17_56384329_ENST00000343736_length(transcript)=2370nt_BP=1570nt GCCGGTCCCTGGGCCTGAGCTCCGGCTCCGGCTGGGGCGCCTGCGATGTCTCAAGATGGCGGAGCTGGGCGAATTAAAGCACATGGTGAT GAGTTTCCGGGTGTCTGAGCTCCAGGTGCTTCTTGGCTTTGCTGGCCGGAACAAGAGTGGACGGAAGCACGAGCTCCTGGCCAAGGCTCT GCACCTCCTGAAGTCCAGCTGTGCCCCTAGTGTCCAGATGAAGATCAAAGAGCTTTACCGACGACGCTTTCCCCGGAAGACCCTGGGGCC CTCTGATCTCTCCCTTCTCTCTTTGCCCCCTGGCACCTCTCCTCCTGTGCACCCTGATGTCACCATGAAACCATTGCCCTTCTATGAAGT CTATGGGGAGCTCATCCGGCCCACCACCCTTGCATCCACTTCTAGCCAGCGGTTTGAGGAAGCGCACTTTACCTTTGCCCTCACACCCCA GCAAGTGCAGCAGATTCTTACATCCAGAGAGGTTCTGCCAGGAGCCAAATGTGATTATACCATACAGGTGCAGCTAAGGTTCTGTCTCTG TGAGACCAGCTGCCCCCAGGAAGATTATTTTCCCCCCAACCTCTTTGTCAAGGTCAATGGGAAACTGTGCCCCCTGCCGGGTTACCTTCC CCCAACCAAGAATGGGGCCGAGCCCAAGAGGCCCAGCCGCCCCATCAACATCACACCCCTGGCTCGACTCTCAGCCACTGTTCCCAACAC CATTGTGGTCAATTGGTCATCTGAGTTCGGACGGAATTACTCCTTGTCTGTGTACCTGGTGAGGCAGTTGACTGCAGGAACCCTTCTACA AAAACTCAGAGCAAAGGGTATCCGGAACCCAGACCACTCGCGGGCACTGATCAAGGAGAAATTGACTGCTGACCCTGACAGTGAGGTGGC CACTACAAGTCTCCGGGTGTCACTCATGTGCCCGCTAGGGAAGATGCGCCTGACTGTCCCTTGTCGTGCCCTCACCTGCGCCCACCTGCA GAGCTTCGATGCTGCCCTTTATCTACAGATGAATGAGAAGAAGCCTACATGGACATGTCCTGTGTGTGACAAGAAGGCTCCCTATGAATC TCTTATCATTGATGGTTTATTTATGGAGATTCTTAGTTCCTGTTCAGATTGTGATGAGATCCAATTCATGGAAGATGGATCCTGGTGCCC AATGAAACCCAAGAAGGAGGCATCTGAGGTTTGCCCCCCGCCAGGGTATGGGCTGGATGGCCTCCAGTACAGCCCAGTCCAGGGGGGAGA TCCATCAGAGAATAAGAAGAAGGTCGAAGTTATTGACTTGACAATAGAAAGCTCATCAGATGAGGAGGATCTGCCCCCTACCAAGAAGCA CTGTTCTGTCACCTCAGCTGCCATCCCGGCCCTACCTGGAAGCAAAGGAGTCCTGACATCTGGCCACCAGCCATCCTCGGTGCTAAGGAG CCCTGCTATGGGCACGTTGGGTGGGGATTTCCTGTCCAGTCTCCCACTACATGAGTACCCACCTGCCTTCCCACTGGGAGCCGACATCCA AGGTTTAGATTTATTTTCATTTCTTCAGACAGAGAGTCAGGTGTTTGGGGACAAGGATGCCGATGGCTTCTACCAGGGCGAAGGTGGGGG CCGGACAGGCTACATTCCCTGCAACATGGTGGCTGAGGTGGCTGTGGACAGCCCTGCTGGGAGACAGCAACTGCTCCAGCGGGGTTATTT GTCCCCAGATATTCTCCTTGAGGGCTCAGGGAATGGTCCGTTTGTGTACTCCACAGCCCACACAACTGGGCCTCCTCCCAAGCCCCGCCG CTCCAAGAAAGCTGAGTCGGAAGGCCCTGCCCAGCCCTGTCCAGGCCCCCCTAAGCTGGTCCCCTCTGCTGACCTGAAAGCTCCCCACTC CATGGTGGCTGCATTTGACTACAACCCCCAGGAGAGTTCCCCCAATATGGACGTGGAGGCAGAGCTGCCCTTCCGGGCAGGGGATGTCAT TACTGTGTTTGGGGGCATGGACGATGACGGTTTCTACTATGGGGAATTAAATGGACAAAGGGGCCTGGTTCCATCCAACTTCCTGGAGGG CCCTGGGCCTGAGGCAGGCGGCCTGGACAGGGAACCCAGGACACCCCAGGCTGAGAGTCAGAGAACGAGGAGGAGAAGAGTCCAGTGCTA GATGGAGATAGATATATGTAGAGAGAGCAACATGACTGGGGCTGCACCACACAAGGGTCCCCAGGGCCCCCAGGTGGGCCTTGTACCCCC AGCTCTGGCAGCGCCCCCAGGATTGAACGTGGGGAGCCCCAGGGCAGAAGCGAGAAGGTGTGGGGTTTCTTCTCCAAGGGGAAGCAGCTC >65119_65119_2_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000369298_BZRAP1_chr17_56384329_ENST00000343736_length(amino acids)=709AA_BP=512 MGRLRCLKMAELGELKHMVMSFRVSELQVLLGFAGRNKSGRKHELLAKALHLLKSSCAPSVQMKIKELYRRRFPRKTLGPSDLSLLSLPP GTSPPVHPDVTMKPLPFYEVYGELIRPTTLASTSSQRFEEAHFTFALTPQQVQQILTSREVLPGAKCDYTIQVQLRFCLCETSCPQEDYF PPNLFVKVNGKLCPLPGYLPPTKNGAEPKRPSRPINITPLARLSATVPNTIVVNWSSEFGRNYSLSVYLVRQLTAGTLLQKLRAKGIRNP DHSRALIKEKLTADPDSEVATTSLRVSLMCPLGKMRLTVPCRALTCAHLQSFDAALYLQMNEKKPTWTCPVCDKKAPYESLIIDGLFMEI LSSCSDCDEIQFMEDGSWCPMKPKKEASEVCPPPGYGLDGLQYSPVQGGDPSENKKKVEVIDLTIESSSDEEDLPPTKKHCSVTSAAIPA LPGSKGVLTSGHQPSSVLRSPAMGTLGGDFLSSLPLHEYPPAFPLGADIQGLDLFSFLQTESQVFGDKDADGFYQGEGGGRTGYIPCNMV AEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAESEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQ -------------------------------------------------------------- >65119_65119_3_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000369298_BZRAP1_chr17_56384329_ENST00000355701_length(transcript)=3342nt_BP=1570nt GCCGGTCCCTGGGCCTGAGCTCCGGCTCCGGCTGGGGCGCCTGCGATGTCTCAAGATGGCGGAGCTGGGCGAATTAAAGCACATGGTGAT GAGTTTCCGGGTGTCTGAGCTCCAGGTGCTTCTTGGCTTTGCTGGCCGGAACAAGAGTGGACGGAAGCACGAGCTCCTGGCCAAGGCTCT GCACCTCCTGAAGTCCAGCTGTGCCCCTAGTGTCCAGATGAAGATCAAAGAGCTTTACCGACGACGCTTTCCCCGGAAGACCCTGGGGCC CTCTGATCTCTCCCTTCTCTCTTTGCCCCCTGGCACCTCTCCTCCTGTGCACCCTGATGTCACCATGAAACCATTGCCCTTCTATGAAGT CTATGGGGAGCTCATCCGGCCCACCACCCTTGCATCCACTTCTAGCCAGCGGTTTGAGGAAGCGCACTTTACCTTTGCCCTCACACCCCA GCAAGTGCAGCAGATTCTTACATCCAGAGAGGTTCTGCCAGGAGCCAAATGTGATTATACCATACAGGTGCAGCTAAGGTTCTGTCTCTG TGAGACCAGCTGCCCCCAGGAAGATTATTTTCCCCCCAACCTCTTTGTCAAGGTCAATGGGAAACTGTGCCCCCTGCCGGGTTACCTTCC CCCAACCAAGAATGGGGCCGAGCCCAAGAGGCCCAGCCGCCCCATCAACATCACACCCCTGGCTCGACTCTCAGCCACTGTTCCCAACAC CATTGTGGTCAATTGGTCATCTGAGTTCGGACGGAATTACTCCTTGTCTGTGTACCTGGTGAGGCAGTTGACTGCAGGAACCCTTCTACA AAAACTCAGAGCAAAGGGTATCCGGAACCCAGACCACTCGCGGGCACTGATCAAGGAGAAATTGACTGCTGACCCTGACAGTGAGGTGGC CACTACAAGTCTCCGGGTGTCACTCATGTGCCCGCTAGGGAAGATGCGCCTGACTGTCCCTTGTCGTGCCCTCACCTGCGCCCACCTGCA GAGCTTCGATGCTGCCCTTTATCTACAGATGAATGAGAAGAAGCCTACATGGACATGTCCTGTGTGTGACAAGAAGGCTCCCTATGAATC TCTTATCATTGATGGTTTATTTATGGAGATTCTTAGTTCCTGTTCAGATTGTGATGAGATCCAATTCATGGAAGATGGATCCTGGTGCCC AATGAAACCCAAGAAGGAGGCATCTGAGGTTTGCCCCCCGCCAGGGTATGGGCTGGATGGCCTCCAGTACAGCCCAGTCCAGGGGGGAGA TCCATCAGAGAATAAGAAGAAGGTCGAAGTTATTGACTTGACAATAGAAAGCTCATCAGATGAGGAGGATCTGCCCCCTACCAAGAAGCA CTGTTCTGTCACCTCAGCTGCCATCCCGGCCCTACCTGGAAGCAAAGGAGTCCTGACATCTGGCCACCAGCCATCCTCGGTGCTAAGGAG CCCTGCTATGGGCACGTTGGGTGGGGATTTCCTGTCCAGTCTCCCACTACATGAGTACCCACCTGCCTTCCCACTGGGAGCCGACATCCA AGGTTTAGATTTATTTTCATTTCTTCAGACAGAGAGTCAGGTGTTTGGGGACAAGGATGCCGATGGCTTCTACCAGGGCGAAGGTGGGGG CCGGACAGGCTACATTCCCTGCAACATGGTGGCTGAGGTGGCTGTGGACAGCCCTGCTGGGAGACAGCAACTGCTCCAGCGGGGTTATTT GTCCCCAGATATTCTCCTTGAGGGCTCAGGGAATGGTCCGTTTGTGTACTCCACAGCCCACACAACTGGGCCTCCTCCCAAGCCCCGCCG CTCCAAGAAAGCTGAGTCGGAAGGCCCTGCCCAGCCCTGTCCAGGCCCCCCTAAGCTGGTCCCCTCTGCTGACCTGAAAGCTCCCCACTC CATGGTGGCTGCATTTGACTACAACCCCCAGGAGAGTTCCCCCAATATGGACGTGGAGGCAGAGCTGCCCTTCCGGGCAGGGGATGTCAT TACTGTGTTTGGGGGCATGGACGATGACGGTTTCTACTATGGGGAATTAAATGGACAAAGGGGCCTGGTTCCATCCAACTTCCTGGAGGG CCCTGGGCCTGAGGCAGGCGGCCTGGACAGGGAACCCAGGACACCCCAGGCTGAGAGTCAGGACTGGGGCTGCACCACACAAGGGTCCCC AGGGCCCCCAGGTGGGCCTTGTACCCCCAGCTCTGGCAGCGCCCCCAGGATTGAACGTGGGGAGCCCCAGGGCAGAAGCGAGAAGGTGTG GGGTTTCTTCTCCAAGGGGAAGCAGCTCCTCAGGAGGCTGGGCTCTGGGAAGAAGGAGTGAAGCTGTGGCCCATCCTGCAGGCAGAAGAG GCCCTGAGAGGCCCCCAGATCACTGTCTCTGCTGAGCAGGGAAGGCTCAGACTGGGCCCAGAGCCCCCGTTCTTCTGCGTTAACACTGTG GCATTCAGAGGGAATCAAAGAGCCTTGGTGAAGGTCAGAGCTAAATGGCTCCTTAAGGATGAACTCTCTAGAGAAGCACCTTCCTCCTAC AGGAGGGGAAACTGAGCCCACAGTGAGTATGTAACTTGACCAAGGTCACTGAGCCAGGACTGGACCCAGGACCCTCGCGTCCTGGTCCAC CCACCTCGTCTACTAGTGTCCCACAGTGCTGCGCTAGTCCCTTCTGCCACCCTTCCCAGTCCCAGGACGGGCCCTGGAGGGAGAAAGGAG CCTGTGCCCCCTGATGGCTCTGGCTGTCCTGATCCTGTCTTCCCTCCCCTGAAGGAAAGTTTGCACTGGATTTTATTGGAGCCCCATCTC CCCAGCGGGCAGGCGGGCGGAGCCTGTATATATGTATATACTCAGTGCCTCAGTTCAGCTTCCTCCACCTCGCTTCCACTGCACAGGCCC AGGAAGGAGAAAGGCCAAGCCAAAGTGGGCCCCACCCTGCCCCCGTCGTGCTCCATCCTTCCCTGCCGGGGCCTGCTGGCCCCTGTAAGG TCCCGCCCCCAAAGACCCTGGGGCCAGCGGGGCCGAAAGCGGAGTTGGGTTTGCCTTATTTTGCTCATTGGATTCAAGTTCTTTTGCATA GTTTTCTTCTAACCCCTGTTGGAGTCCAGGGGCTGGAGAAAAGGACAGATTTATGCAGCTATTTTCATACATTCCCTGTTCAGAGTGGGG TAGGGGTTCTCCGCCGTTACCCGATCCACTCCATCCCCCACCCTCTGAGGGGTGAGTGTGTCTTTGCATGTTTCCTTTGCTGTGGTGGGA GATAGTTTGACTGAACCCCCACCTTGACCTTGGTCTCCAGGGGTGTGGAATGGTGGGGGAATTTGTTTAAAAAGACATTTTATTATAATA >65119_65119_3_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000369298_BZRAP1_chr17_56384329_ENST00000355701_length(amino acids)=759AA_BP=512 MGRLRCLKMAELGELKHMVMSFRVSELQVLLGFAGRNKSGRKHELLAKALHLLKSSCAPSVQMKIKELYRRRFPRKTLGPSDLSLLSLPP GTSPPVHPDVTMKPLPFYEVYGELIRPTTLASTSSQRFEEAHFTFALTPQQVQQILTSREVLPGAKCDYTIQVQLRFCLCETSCPQEDYF PPNLFVKVNGKLCPLPGYLPPTKNGAEPKRPSRPINITPLARLSATVPNTIVVNWSSEFGRNYSLSVYLVRQLTAGTLLQKLRAKGIRNP DHSRALIKEKLTADPDSEVATTSLRVSLMCPLGKMRLTVPCRALTCAHLQSFDAALYLQMNEKKPTWTCPVCDKKAPYESLIIDGLFMEI LSSCSDCDEIQFMEDGSWCPMKPKKEASEVCPPPGYGLDGLQYSPVQGGDPSENKKKVEVIDLTIESSSDEEDLPPTKKHCSVTSAAIPA LPGSKGVLTSGHQPSSVLRSPAMGTLGGDFLSSLPLHEYPPAFPLGADIQGLDLFSFLQTESQVFGDKDADGFYQGEGGGRTGYIPCNMV AEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAESEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQ ESSPNMDVEAELPFRAGDVITVFGGMDDDGFYYGELNGQRGLVPSNFLEGPGPEAGGLDREPRTPQAESQDWGCTTQGSPGPPGGPCTPS -------------------------------------------------------------- >65119_65119_4_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000393045_BZRAP1_chr17_56384329_ENST00000268893_length(transcript)=3550nt_BP=1710nt GCATTTGCGGCCGGCGCCAGGGTGGAGAGTTGTGCGCCGGTCCCTGGGCCTGAGCTCCGGCTCCGGCTGGGGCGCCTGCGATGTCTCAAG ATGGCGGAGCTGGGCGAATTAAAGCACATGGTGATGAGTTTCCGGGTGTCTGAGCTCCAGGTGCTTCTTGGCTTTGCTGGCCGGAACAAG AGTGGACGGAAGCACGAGCTCCTGGCCAAGGCTCTGCACCTCCTGAAGTCCAGCTGTGCCCCTAGTGTCCAGATGAAGATCAAAGAGCTT TACCGACGACGCTTTCCCCGGAAGACCCTGGGGCCCTCTGATCTCTCCCTTCTCTCTTTGCCCCCTGGCACCTCTCCTGTAGGCTCCCCT GGTCCTCTAGCTCCCATTCCCCCAACGCTGTTGGCCCCTGGCACCCTGCTGGGCCCCAAGCGTGAGGTGGACATGCACCCCCCTCTGCCC CAGCCTGTGCACCCTGATGTCACCATGAAACCATTGCCCTTCTATGAAGTCTATGGGGAGCTCATCCGGCCCACCACCCTTGCATCCACT TCTAGCCAGCGGTTTGAGGAAGCGCACTTTACCTTTGCCCTCACACCCCAGCAAGTGCAGCAGATTCTTACATCCAGAGAGGTTCTGCCA GGAGCCAAATGTGATTATACCATACAGGTGCAGCTAAGGTTCTGTCTCTGTGAGACCAGCTGCCCCCAGGAAGATTATTTTCCCCCCAAC CTCTTTGTCAAGGTCAATGGGAAACTGTGCCCCCTGCCGGGTTACCTTCCCCCAACCAAGAATGGGGCCGAGCCCAAGAGGCCCAGCCGC CCCATCAACATCACACCCCTGGCTCGACTCTCAGCCACTGTTCCCAACACCATTGTGGTCAATTGGTCATCTGAGTTCGGACGGAATTAC TCCTTGTCTGTGTACCTGGTGAGGCAGTTGACTGCAGGAACCCTTCTACAAAAACTCAGAGCAAAGGGTATCCGGAACCCAGACCACTCG CGGGCACTGATCAAGGAGAAATTGACTGCTGACCCTGACAGTGAGGTGGCCACTACAAGTCTCCGGGTGTCACTCATGTGCCCGCTAGGG AAGATGCGCCTGACTGTCCCTTGTCGTGCCCTCACCTGCGCCCACCTGCAGAGCTTCGATGCTGCCCTTTATCTACAGATGAATGAGAAG AAGCCTACATGGACATGTCCTGTGTGTGACAAGAAGGCTCCCTATGAATCTCTTATCATTGATGGTTTATTTATGGAGATTCTTAGTTCC TGTTCAGATTGTGATGAGATCCAATTCATGGAAGATGGATCCTGGTGCCCAATGAAACCCAAGAAGGAGGCATCTGAGGTTTGCCCCCCG CCAGGGTATGGGCTGGATGGCCTCCAGTACAGCCCAGTCCAGGGGGGAGATCCATCAGAGAATAAGAAGAAGGTCGAAGTTATTGACTTG ACAATAGAAAGCTCATCAGATGAGGAGGATCTGCCCCCTACCAAGAAGCACTGTTCTGTCACCTCAGCTGCCATCCCGGCCCTACCTGGA AGCAAAGGAGTCCTGACATCTGGCCACCAGCCATCCTCGGTGCTAAGGAGCCCTGCTATGGGCACGTTGGGTGGGGATTTCCTGTCCAGT CTCCCACTACATGAGTACCCACCTGCCTTCCCACTGGGAGCCGACATCCAAGGTTTAGATTTATTTTCATTTCTTCAGACAGAGAGTCAG GTGTTTGGGGACAAGGATGCCGATGGCTTCTACCAGGGCGAAGGTGGGGGCCGGACAGGCTACATTCCCTGCAACATGGTGGCTGAGGTG GCTGTGGACAGCCCTGCTGGGAGACAGCAACTGCTCCAGCGGGGTTATTTGTCCCCAGATATTCTCCTTGAGGGCTCAGGGAATGGTCCG TTTGTGTACTCCACAGCCCACACAACTGGGCCTCCTCCCAAGCCCCGCCGCTCCAAGAAAGCTGAGTCGGAAGGCCCTGCCCAGCCCTGT CCAGGCCCCCCTAAGCTGGTCCCCTCTGCTGACCTGAAAGCTCCCCACTCCATGGTGGCTGCATTTGACTACAACCCCCAGGAGAGTTCC CCCAATATGGACGTGGAGGCAGAGCTGCCCTTCCGGGCAGGGGATGTCATTACTGTGTTTGGGGGCATGGACGATGACGGTTTCTACTAT GGGGAATTAAATGGACAAAGGGGCCTGGTTCCATCCAACTTCCTGGAGGGCCCTGGGCCTGAGGCAGGCGGCCTGGACAGGGAACCCAGG ACACCCCAGGCTGAGAGTCAGAGAACGAGGAGGAGAAGAGTCCAGTGCTAGATGGAGATAGATATATGTAGAGAGAGCAACATGACTGGG GCTGCACCACACAAGGGTCCCCAGGGCCCCCAGGTGGGCCTTGTACCCCCAGCTCTGGCAGCGCCCCCAGGATTGAACGTGGGGAGCCCC AGGGCAGAAGCGAGAAGGTGTGGGGTTTCTTCTCCAAGGGGAAGCAGCTCCTCAGGAGGCTGGGCTCTGGGAAGAAGGAGTGAAGCTGTG GCCCATCCTGCAGGCAGAAGAGGCCCTGAGAGGCCCCCAGATCACTGTCTCTGCTGAGCAGGGAAGGCTCAGACTGGGCCCAGAGCCCCC GTTCTTCTGCGTTAACACTGTGGCATTCAGAGGGAATCAAAGAGCCTTGGTGAAGGTCAGAGCTAAATGGCTCCTTAAGGATGAACTCTC TAGAGAAGCACCTTCCTCCTACAGGAGGGGAAACTGAGCCCACAGTGAGTATGTAACTTGACCAAGGTCACTGAGCCAGGACTGGACCCA GGACCCTCGCGTCCTGGTCCACCCACCTCGTCTACTAGTGTCCCACAGTGCTGCGCTAGTCCCTTCTGCCACCCTTCCCAGTCCCAGGAC GGGCCCTGGAGGGAGAAAGGAGCCTGTGCCCCCTGATGGCTCTGGCTGTCCTGATCCTGTCTTCCCTCCCCTGAAGGAAAGTTTGCACTG GATTTTATTGGAGCCCCATCTCCCCAGCGGGCAGGCGGGCGGAGCCTGTATATATGTATATACTCAGTGCCTCAGTTCAGCTTCCTCCAC CTCGCTTCCACTGCACAGGCCCAGGAAGGAGAAAGGCCAAGCCAAAGTGGGCCCCACCCTGCCCCCGTCGTGCTCCATCCTTCCCTGCCG GGGCCTGCTGGCCCCTGTAAGGTCCCGCCCCCAAAGACCCTGGGGCCAGCGGGGCCGAAAGCGGAGTTGGGTTTGCCTTATTTTGCTCAT TGGATTCAAGTTCTTTTGCATAGTTTTCTTCTAACCCCTGTTGGAGTCCAGGGGCTGGAGAAAAGGACAGATTTATGCAGCTATTTTCAT ACATTCCCTGTTCAGAGTGGGGTAGGGGTTCTCCGCCGTTACCCGATCCACTCCATCCCCCACCCTCTGAGGGGTGAGTGTGTCTTTGCA TGTTTCCTTTGCTGTGGTGGGAGATAGTTTGACTGAACCCCCACCTTGACCTTGGTCTCCAGGGGTGTGGAATGGTGGGGGAATTTGTTT >65119_65119_4_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000393045_BZRAP1_chr17_56384329_ENST00000268893_length(amino acids)=744AA_BP=547 MGRLRCLKMAELGELKHMVMSFRVSELQVLLGFAGRNKSGRKHELLAKALHLLKSSCAPSVQMKIKELYRRRFPRKTLGPSDLSLLSLPP GTSPVGSPGPLAPIPPTLLAPGTLLGPKREVDMHPPLPQPVHPDVTMKPLPFYEVYGELIRPTTLASTSSQRFEEAHFTFALTPQQVQQI LTSREVLPGAKCDYTIQVQLRFCLCETSCPQEDYFPPNLFVKVNGKLCPLPGYLPPTKNGAEPKRPSRPINITPLARLSATVPNTIVVNW SSEFGRNYSLSVYLVRQLTAGTLLQKLRAKGIRNPDHSRALIKEKLTADPDSEVATTSLRVSLMCPLGKMRLTVPCRALTCAHLQSFDAA LYLQMNEKKPTWTCPVCDKKAPYESLIIDGLFMEILSSCSDCDEIQFMEDGSWCPMKPKKEASEVCPPPGYGLDGLQYSPVQGGDPSENK KKVEVIDLTIESSSDEEDLPPTKKHCSVTSAAIPALPGSKGVLTSGHQPSSVLRSPAMGTLGGDFLSSLPLHEYPPAFPLGADIQGLDLF SFLQTESQVFGDKDADGFYQGEGGGRTGYIPCNMVAEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAE SEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQESSPNMDVEAELPFRAGDVITVFGGMDDDGFYYGELNGQRGLVPSNFLEGPGPEA -------------------------------------------------------------- >65119_65119_5_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000393045_BZRAP1_chr17_56384329_ENST00000343736_length(transcript)=2510nt_BP=1710nt GCATTTGCGGCCGGCGCCAGGGTGGAGAGTTGTGCGCCGGTCCCTGGGCCTGAGCTCCGGCTCCGGCTGGGGCGCCTGCGATGTCTCAAG ATGGCGGAGCTGGGCGAATTAAAGCACATGGTGATGAGTTTCCGGGTGTCTGAGCTCCAGGTGCTTCTTGGCTTTGCTGGCCGGAACAAG AGTGGACGGAAGCACGAGCTCCTGGCCAAGGCTCTGCACCTCCTGAAGTCCAGCTGTGCCCCTAGTGTCCAGATGAAGATCAAAGAGCTT TACCGACGACGCTTTCCCCGGAAGACCCTGGGGCCCTCTGATCTCTCCCTTCTCTCTTTGCCCCCTGGCACCTCTCCTGTAGGCTCCCCT GGTCCTCTAGCTCCCATTCCCCCAACGCTGTTGGCCCCTGGCACCCTGCTGGGCCCCAAGCGTGAGGTGGACATGCACCCCCCTCTGCCC CAGCCTGTGCACCCTGATGTCACCATGAAACCATTGCCCTTCTATGAAGTCTATGGGGAGCTCATCCGGCCCACCACCCTTGCATCCACT TCTAGCCAGCGGTTTGAGGAAGCGCACTTTACCTTTGCCCTCACACCCCAGCAAGTGCAGCAGATTCTTACATCCAGAGAGGTTCTGCCA GGAGCCAAATGTGATTATACCATACAGGTGCAGCTAAGGTTCTGTCTCTGTGAGACCAGCTGCCCCCAGGAAGATTATTTTCCCCCCAAC CTCTTTGTCAAGGTCAATGGGAAACTGTGCCCCCTGCCGGGTTACCTTCCCCCAACCAAGAATGGGGCCGAGCCCAAGAGGCCCAGCCGC CCCATCAACATCACACCCCTGGCTCGACTCTCAGCCACTGTTCCCAACACCATTGTGGTCAATTGGTCATCTGAGTTCGGACGGAATTAC TCCTTGTCTGTGTACCTGGTGAGGCAGTTGACTGCAGGAACCCTTCTACAAAAACTCAGAGCAAAGGGTATCCGGAACCCAGACCACTCG CGGGCACTGATCAAGGAGAAATTGACTGCTGACCCTGACAGTGAGGTGGCCACTACAAGTCTCCGGGTGTCACTCATGTGCCCGCTAGGG AAGATGCGCCTGACTGTCCCTTGTCGTGCCCTCACCTGCGCCCACCTGCAGAGCTTCGATGCTGCCCTTTATCTACAGATGAATGAGAAG AAGCCTACATGGACATGTCCTGTGTGTGACAAGAAGGCTCCCTATGAATCTCTTATCATTGATGGTTTATTTATGGAGATTCTTAGTTCC TGTTCAGATTGTGATGAGATCCAATTCATGGAAGATGGATCCTGGTGCCCAATGAAACCCAAGAAGGAGGCATCTGAGGTTTGCCCCCCG CCAGGGTATGGGCTGGATGGCCTCCAGTACAGCCCAGTCCAGGGGGGAGATCCATCAGAGAATAAGAAGAAGGTCGAAGTTATTGACTTG ACAATAGAAAGCTCATCAGATGAGGAGGATCTGCCCCCTACCAAGAAGCACTGTTCTGTCACCTCAGCTGCCATCCCGGCCCTACCTGGA AGCAAAGGAGTCCTGACATCTGGCCACCAGCCATCCTCGGTGCTAAGGAGCCCTGCTATGGGCACGTTGGGTGGGGATTTCCTGTCCAGT CTCCCACTACATGAGTACCCACCTGCCTTCCCACTGGGAGCCGACATCCAAGGTTTAGATTTATTTTCATTTCTTCAGACAGAGAGTCAG GTGTTTGGGGACAAGGATGCCGATGGCTTCTACCAGGGCGAAGGTGGGGGCCGGACAGGCTACATTCCCTGCAACATGGTGGCTGAGGTG GCTGTGGACAGCCCTGCTGGGAGACAGCAACTGCTCCAGCGGGGTTATTTGTCCCCAGATATTCTCCTTGAGGGCTCAGGGAATGGTCCG TTTGTGTACTCCACAGCCCACACAACTGGGCCTCCTCCCAAGCCCCGCCGCTCCAAGAAAGCTGAGTCGGAAGGCCCTGCCCAGCCCTGT CCAGGCCCCCCTAAGCTGGTCCCCTCTGCTGACCTGAAAGCTCCCCACTCCATGGTGGCTGCATTTGACTACAACCCCCAGGAGAGTTCC CCCAATATGGACGTGGAGGCAGAGCTGCCCTTCCGGGCAGGGGATGTCATTACTGTGTTTGGGGGCATGGACGATGACGGTTTCTACTAT GGGGAATTAAATGGACAAAGGGGCCTGGTTCCATCCAACTTCCTGGAGGGCCCTGGGCCTGAGGCAGGCGGCCTGGACAGGGAACCCAGG ACACCCCAGGCTGAGAGTCAGAGAACGAGGAGGAGAAGAGTCCAGTGCTAGATGGAGATAGATATATGTAGAGAGAGCAACATGACTGGG GCTGCACCACACAAGGGTCCCCAGGGCCCCCAGGTGGGCCTTGTACCCCCAGCTCTGGCAGCGCCCCCAGGATTGAACGTGGGGAGCCCC >65119_65119_5_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000393045_BZRAP1_chr17_56384329_ENST00000343736_length(amino acids)=744AA_BP=547 MGRLRCLKMAELGELKHMVMSFRVSELQVLLGFAGRNKSGRKHELLAKALHLLKSSCAPSVQMKIKELYRRRFPRKTLGPSDLSLLSLPP GTSPVGSPGPLAPIPPTLLAPGTLLGPKREVDMHPPLPQPVHPDVTMKPLPFYEVYGELIRPTTLASTSSQRFEEAHFTFALTPQQVQQI LTSREVLPGAKCDYTIQVQLRFCLCETSCPQEDYFPPNLFVKVNGKLCPLPGYLPPTKNGAEPKRPSRPINITPLARLSATVPNTIVVNW SSEFGRNYSLSVYLVRQLTAGTLLQKLRAKGIRNPDHSRALIKEKLTADPDSEVATTSLRVSLMCPLGKMRLTVPCRALTCAHLQSFDAA LYLQMNEKKPTWTCPVCDKKAPYESLIIDGLFMEILSSCSDCDEIQFMEDGSWCPMKPKKEASEVCPPPGYGLDGLQYSPVQGGDPSENK KKVEVIDLTIESSSDEEDLPPTKKHCSVTSAAIPALPGSKGVLTSGHQPSSVLRSPAMGTLGGDFLSSLPLHEYPPAFPLGADIQGLDLF SFLQTESQVFGDKDADGFYQGEGGGRTGYIPCNMVAEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAE SEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQESSPNMDVEAELPFRAGDVITVFGGMDDDGFYYGELNGQRGLVPSNFLEGPGPEA -------------------------------------------------------------- >65119_65119_6_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000393045_BZRAP1_chr17_56384329_ENST00000355701_length(transcript)=3482nt_BP=1710nt GCATTTGCGGCCGGCGCCAGGGTGGAGAGTTGTGCGCCGGTCCCTGGGCCTGAGCTCCGGCTCCGGCTGGGGCGCCTGCGATGTCTCAAG ATGGCGGAGCTGGGCGAATTAAAGCACATGGTGATGAGTTTCCGGGTGTCTGAGCTCCAGGTGCTTCTTGGCTTTGCTGGCCGGAACAAG AGTGGACGGAAGCACGAGCTCCTGGCCAAGGCTCTGCACCTCCTGAAGTCCAGCTGTGCCCCTAGTGTCCAGATGAAGATCAAAGAGCTT TACCGACGACGCTTTCCCCGGAAGACCCTGGGGCCCTCTGATCTCTCCCTTCTCTCTTTGCCCCCTGGCACCTCTCCTGTAGGCTCCCCT GGTCCTCTAGCTCCCATTCCCCCAACGCTGTTGGCCCCTGGCACCCTGCTGGGCCCCAAGCGTGAGGTGGACATGCACCCCCCTCTGCCC CAGCCTGTGCACCCTGATGTCACCATGAAACCATTGCCCTTCTATGAAGTCTATGGGGAGCTCATCCGGCCCACCACCCTTGCATCCACT TCTAGCCAGCGGTTTGAGGAAGCGCACTTTACCTTTGCCCTCACACCCCAGCAAGTGCAGCAGATTCTTACATCCAGAGAGGTTCTGCCA GGAGCCAAATGTGATTATACCATACAGGTGCAGCTAAGGTTCTGTCTCTGTGAGACCAGCTGCCCCCAGGAAGATTATTTTCCCCCCAAC CTCTTTGTCAAGGTCAATGGGAAACTGTGCCCCCTGCCGGGTTACCTTCCCCCAACCAAGAATGGGGCCGAGCCCAAGAGGCCCAGCCGC CCCATCAACATCACACCCCTGGCTCGACTCTCAGCCACTGTTCCCAACACCATTGTGGTCAATTGGTCATCTGAGTTCGGACGGAATTAC TCCTTGTCTGTGTACCTGGTGAGGCAGTTGACTGCAGGAACCCTTCTACAAAAACTCAGAGCAAAGGGTATCCGGAACCCAGACCACTCG CGGGCACTGATCAAGGAGAAATTGACTGCTGACCCTGACAGTGAGGTGGCCACTACAAGTCTCCGGGTGTCACTCATGTGCCCGCTAGGG AAGATGCGCCTGACTGTCCCTTGTCGTGCCCTCACCTGCGCCCACCTGCAGAGCTTCGATGCTGCCCTTTATCTACAGATGAATGAGAAG AAGCCTACATGGACATGTCCTGTGTGTGACAAGAAGGCTCCCTATGAATCTCTTATCATTGATGGTTTATTTATGGAGATTCTTAGTTCC TGTTCAGATTGTGATGAGATCCAATTCATGGAAGATGGATCCTGGTGCCCAATGAAACCCAAGAAGGAGGCATCTGAGGTTTGCCCCCCG CCAGGGTATGGGCTGGATGGCCTCCAGTACAGCCCAGTCCAGGGGGGAGATCCATCAGAGAATAAGAAGAAGGTCGAAGTTATTGACTTG ACAATAGAAAGCTCATCAGATGAGGAGGATCTGCCCCCTACCAAGAAGCACTGTTCTGTCACCTCAGCTGCCATCCCGGCCCTACCTGGA AGCAAAGGAGTCCTGACATCTGGCCACCAGCCATCCTCGGTGCTAAGGAGCCCTGCTATGGGCACGTTGGGTGGGGATTTCCTGTCCAGT CTCCCACTACATGAGTACCCACCTGCCTTCCCACTGGGAGCCGACATCCAAGGTTTAGATTTATTTTCATTTCTTCAGACAGAGAGTCAG GTGTTTGGGGACAAGGATGCCGATGGCTTCTACCAGGGCGAAGGTGGGGGCCGGACAGGCTACATTCCCTGCAACATGGTGGCTGAGGTG GCTGTGGACAGCCCTGCTGGGAGACAGCAACTGCTCCAGCGGGGTTATTTGTCCCCAGATATTCTCCTTGAGGGCTCAGGGAATGGTCCG TTTGTGTACTCCACAGCCCACACAACTGGGCCTCCTCCCAAGCCCCGCCGCTCCAAGAAAGCTGAGTCGGAAGGCCCTGCCCAGCCCTGT CCAGGCCCCCCTAAGCTGGTCCCCTCTGCTGACCTGAAAGCTCCCCACTCCATGGTGGCTGCATTTGACTACAACCCCCAGGAGAGTTCC CCCAATATGGACGTGGAGGCAGAGCTGCCCTTCCGGGCAGGGGATGTCATTACTGTGTTTGGGGGCATGGACGATGACGGTTTCTACTAT GGGGAATTAAATGGACAAAGGGGCCTGGTTCCATCCAACTTCCTGGAGGGCCCTGGGCCTGAGGCAGGCGGCCTGGACAGGGAACCCAGG ACACCCCAGGCTGAGAGTCAGGACTGGGGCTGCACCACACAAGGGTCCCCAGGGCCCCCAGGTGGGCCTTGTACCCCCAGCTCTGGCAGC GCCCCCAGGATTGAACGTGGGGAGCCCCAGGGCAGAAGCGAGAAGGTGTGGGGTTTCTTCTCCAAGGGGAAGCAGCTCCTCAGGAGGCTG GGCTCTGGGAAGAAGGAGTGAAGCTGTGGCCCATCCTGCAGGCAGAAGAGGCCCTGAGAGGCCCCCAGATCACTGTCTCTGCTGAGCAGG GAAGGCTCAGACTGGGCCCAGAGCCCCCGTTCTTCTGCGTTAACACTGTGGCATTCAGAGGGAATCAAAGAGCCTTGGTGAAGGTCAGAG CTAAATGGCTCCTTAAGGATGAACTCTCTAGAGAAGCACCTTCCTCCTACAGGAGGGGAAACTGAGCCCACAGTGAGTATGTAACTTGAC CAAGGTCACTGAGCCAGGACTGGACCCAGGACCCTCGCGTCCTGGTCCACCCACCTCGTCTACTAGTGTCCCACAGTGCTGCGCTAGTCC CTTCTGCCACCCTTCCCAGTCCCAGGACGGGCCCTGGAGGGAGAAAGGAGCCTGTGCCCCCTGATGGCTCTGGCTGTCCTGATCCTGTCT TCCCTCCCCTGAAGGAAAGTTTGCACTGGATTTTATTGGAGCCCCATCTCCCCAGCGGGCAGGCGGGCGGAGCCTGTATATATGTATATA CTCAGTGCCTCAGTTCAGCTTCCTCCACCTCGCTTCCACTGCACAGGCCCAGGAAGGAGAAAGGCCAAGCCAAAGTGGGCCCCACCCTGC CCCCGTCGTGCTCCATCCTTCCCTGCCGGGGCCTGCTGGCCCCTGTAAGGTCCCGCCCCCAAAGACCCTGGGGCCAGCGGGGCCGAAAGC GGAGTTGGGTTTGCCTTATTTTGCTCATTGGATTCAAGTTCTTTTGCATAGTTTTCTTCTAACCCCTGTTGGAGTCCAGGGGCTGGAGAA AAGGACAGATTTATGCAGCTATTTTCATACATTCCCTGTTCAGAGTGGGGTAGGGGTTCTCCGCCGTTACCCGATCCACTCCATCCCCCA CCCTCTGAGGGGTGAGTGTGTCTTTGCATGTTTCCTTTGCTGTGGTGGGAGATAGTTTGACTGAACCCCCACCTTGACCTTGGTCTCCAG >65119_65119_6_PIAS3-BZRAP1_PIAS3_chr1_145584836_ENST00000393045_BZRAP1_chr17_56384329_ENST00000355701_length(amino acids)=794AA_BP=547 MGRLRCLKMAELGELKHMVMSFRVSELQVLLGFAGRNKSGRKHELLAKALHLLKSSCAPSVQMKIKELYRRRFPRKTLGPSDLSLLSLPP GTSPVGSPGPLAPIPPTLLAPGTLLGPKREVDMHPPLPQPVHPDVTMKPLPFYEVYGELIRPTTLASTSSQRFEEAHFTFALTPQQVQQI LTSREVLPGAKCDYTIQVQLRFCLCETSCPQEDYFPPNLFVKVNGKLCPLPGYLPPTKNGAEPKRPSRPINITPLARLSATVPNTIVVNW SSEFGRNYSLSVYLVRQLTAGTLLQKLRAKGIRNPDHSRALIKEKLTADPDSEVATTSLRVSLMCPLGKMRLTVPCRALTCAHLQSFDAA LYLQMNEKKPTWTCPVCDKKAPYESLIIDGLFMEILSSCSDCDEIQFMEDGSWCPMKPKKEASEVCPPPGYGLDGLQYSPVQGGDPSENK KKVEVIDLTIESSSDEEDLPPTKKHCSVTSAAIPALPGSKGVLTSGHQPSSVLRSPAMGTLGGDFLSSLPLHEYPPAFPLGADIQGLDLF SFLQTESQVFGDKDADGFYQGEGGGRTGYIPCNMVAEVAVDSPAGRQQLLQRGYLSPDILLEGSGNGPFVYSTAHTTGPPPKPRRSKKAE SEGPAQPCPGPPKLVPSADLKAPHSMVAAFDYNPQESSPNMDVEAELPFRAGDVITVFGGMDDDGFYYGELNGQRGLVPSNFLEGPGPEA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PIAS3-BZRAP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Hgene | PIAS3 | chr1:145584836 | chr17:56384329 | ENST00000393045 | - | 13 | 14 | 1_200 | 540.0 | 629.0 | CCAR2 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PIAS3-BZRAP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PIAS3-BZRAP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies