
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PISD-EIF4ENIF1 (FusionGDB2 ID:65544) |
Fusion Gene Summary for PISD-EIF4ENIF1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PISD-EIF4ENIF1 | Fusion gene ID: 65544 | Hgene | Tgene | Gene symbol | PISD | EIF4ENIF1 | Gene ID | 23761 | 56478 |
| Gene name | phosphatidylserine decarboxylase | eukaryotic translation initiation factor 4E nuclear import factor 1 | |
| Synonyms | DJ858B16|PSD|PSDC|PSSC|dJ858B16.2 | 4E-T|Clast4 | |
| Cytomap | 22q12.2 | 22q12.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | phosphatidylserine decarboxylase proenzyme, mitochondrial | eukaryotic translation initiation factor 4E transporter2610509L04Rik4E-transportereIF4E transporter | |
| Modification date | 20200329 | 20200327 | |
| UniProtAcc | . | Q9NRA8 | |
| Ensembl transtripts involved in fusion gene | ENST00000336566, ENST00000439502, ENST00000266095, ENST00000382151, ENST00000397500, ENST00000478893, | ENST00000382180, ENST00000441289, ENST00000330125, ENST00000344710, ENST00000397523, ENST00000397525, | |
| Fusion gene scores | * DoF score | 7 X 9 X 5=315 | 10 X 7 X 9=630 |
| # samples | 9 | 11 | |
| ** MAII score | log2(9/315*10)=-1.8073549220576 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/630*10)=-2.51784830486262 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PISD [Title/Abstract] AND EIF4ENIF1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PISD(32044087)-EIF4ENIF1(31867903), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across PISD (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
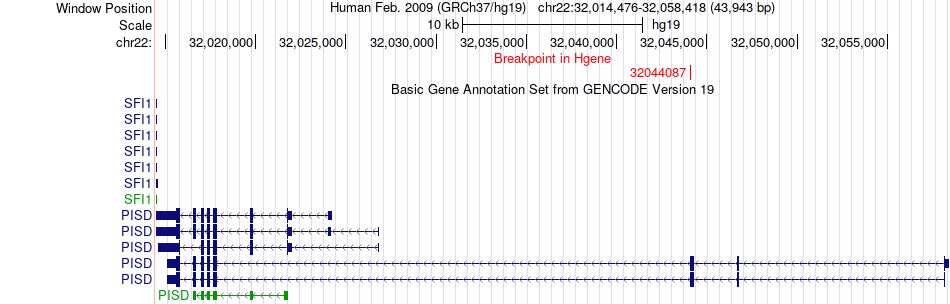 |
| Fusion gene breakpoints across EIF4ENIF1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-VQ-A8P3-01A | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
Top |
Fusion Gene ORF analysis for PISD-EIF4ENIF1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000336566 | ENST00000382180 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| 5CDS-intron | ENST00000336566 | ENST00000441289 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| 5CDS-intron | ENST00000439502 | ENST00000382180 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| 5CDS-intron | ENST00000439502 | ENST00000441289 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| In-frame | ENST00000336566 | ENST00000330125 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| In-frame | ENST00000336566 | ENST00000344710 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| In-frame | ENST00000336566 | ENST00000397523 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| In-frame | ENST00000336566 | ENST00000397525 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| In-frame | ENST00000439502 | ENST00000330125 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| In-frame | ENST00000439502 | ENST00000344710 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| In-frame | ENST00000439502 | ENST00000397523 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| In-frame | ENST00000439502 | ENST00000397525 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000266095 | ENST00000330125 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000266095 | ENST00000344710 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000266095 | ENST00000397523 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000266095 | ENST00000397525 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000382151 | ENST00000330125 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000382151 | ENST00000344710 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000382151 | ENST00000397523 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000382151 | ENST00000397525 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000397500 | ENST00000330125 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000397500 | ENST00000344710 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000397500 | ENST00000397523 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000397500 | ENST00000397525 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000478893 | ENST00000330125 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000478893 | ENST00000344710 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000478893 | ENST00000397523 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-3CDS | ENST00000478893 | ENST00000397525 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-intron | ENST00000266095 | ENST00000382180 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-intron | ENST00000266095 | ENST00000441289 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-intron | ENST00000382151 | ENST00000382180 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-intron | ENST00000382151 | ENST00000441289 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-intron | ENST00000397500 | ENST00000382180 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-intron | ENST00000397500 | ENST00000441289 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-intron | ENST00000478893 | ENST00000382180 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| intron-intron | ENST00000478893 | ENST00000441289 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000336566 | PISD | chr22 | 32044087 | - | ENST00000344710 | EIF4ENIF1 | chr22 | 31867903 | - | 3178 | 321 | 0 | 2660 | 886 |
| ENST00000336566 | PISD | chr22 | 32044087 | - | ENST00000397525 | EIF4ENIF1 | chr22 | 31867903 | - | 3696 | 321 | 0 | 3182 | 1060 |
| ENST00000336566 | PISD | chr22 | 32044087 | - | ENST00000330125 | EIF4ENIF1 | chr22 | 31867903 | - | 3694 | 321 | 0 | 3182 | 1060 |
| ENST00000336566 | PISD | chr22 | 32044087 | - | ENST00000397523 | EIF4ENIF1 | chr22 | 31867903 | - | 3618 | 321 | 0 | 3110 | 1036 |
| ENST00000439502 | PISD | chr22 | 32044087 | - | ENST00000344710 | EIF4ENIF1 | chr22 | 31867903 | - | 3402 | 545 | 224 | 2884 | 886 |
| ENST00000439502 | PISD | chr22 | 32044087 | - | ENST00000397525 | EIF4ENIF1 | chr22 | 31867903 | - | 3920 | 545 | 224 | 3406 | 1060 |
| ENST00000439502 | PISD | chr22 | 32044087 | - | ENST00000330125 | EIF4ENIF1 | chr22 | 31867903 | - | 3918 | 545 | 224 | 3406 | 1060 |
| ENST00000439502 | PISD | chr22 | 32044087 | - | ENST00000397523 | EIF4ENIF1 | chr22 | 31867903 | - | 3842 | 545 | 224 | 3334 | 1036 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000336566 | ENST00000344710 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - | 0.001512217 | 0.9984877 |
| ENST00000336566 | ENST00000397525 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - | 0.000349335 | 0.9996507 |
| ENST00000336566 | ENST00000330125 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - | 0.000344344 | 0.9996556 |
| ENST00000336566 | ENST00000397523 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - | 0.000987012 | 0.99901295 |
| ENST00000439502 | ENST00000344710 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - | 0.001622785 | 0.9983772 |
| ENST00000439502 | ENST00000397525 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - | 0.000486644 | 0.9995134 |
| ENST00000439502 | ENST00000330125 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - | 0.000480241 | 0.9995198 |
| ENST00000439502 | ENST00000397523 | PISD | chr22 | 32044087 | - | EIF4ENIF1 | chr22 | 31867903 | - | 0.001340896 | 0.99865913 |
Top |
Fusion Genomic Features for PISD-EIF4ENIF1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PISD-EIF4ENIF1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:32044087/chr22:31867903) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | EIF4ENIF1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: EIF4E-binding protein that regulates translation and stability of mRNAs in processing bodies (P-bodies) (PubMed:16157702, PubMed:24335285, PubMed:27342281, PubMed:32354837). Plays a key role in P-bodies to coordinate the storage of translationally inactive mRNAs in the cytoplasm and prevent their degradation (PubMed:24335285, PubMed:32354837). Acts as a binding platform for multiple RNA-binding proteins: promotes deadenylation of mRNAs via its interaction with the CCR4-NOT complex, and blocks decapping via interaction with eIF4E (EIF4E and EIF4E2), thereby protecting deadenylated and repressed mRNAs from degradation (PubMed:27342281, PubMed:32354837). Component of a multiprotein complex that sequesters and represses translation of proneurogenic factors during neurogenesis (By similarity). Promotes miRNA-mediated translational repression (PubMed:24335285, PubMed:27342281, PubMed:28487484). Required for the formation of P-bodies (PubMed:16157702, PubMed:22966201, PubMed:27342281, PubMed:32354837). Involved in mRNA translational repression mediated by the miRNA effector TNRC6B by protecting TNRC6B-targeted mRNAs from decapping and subsequent decay (PubMed:32354837). Also acts as a nucleoplasmic shuttling protein, which mediates the nuclear import of EIF4E and DDX6 by a piggy-back mechanism (PubMed:10856257, PubMed:28216671). {ECO:0000250|UniProtKB:Q9EST3, ECO:0000269|PubMed:10856257, ECO:0000269|PubMed:16157702, ECO:0000269|PubMed:22966201, ECO:0000269|PubMed:24335285, ECO:0000269|PubMed:27342281, ECO:0000269|PubMed:28216671, ECO:0000269|PubMed:28487484, ECO:0000269|PubMed:32354837}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000336566 | - | 3 | 8 | 53_63 | 107 | 409.0 | Topological domain | Mitochondrial matrix |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000439502 | - | 3 | 8 | 53_63 | 107 | 410.0 | Topological domain | Mitochondrial matrix |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000336566 | - | 3 | 8 | 64_82 | 107 | 409.0 | Transmembrane | Helical |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000439502 | - | 3 | 8 | 64_82 | 107 | 410.0 | Transmembrane | Helical |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 148_210 | 32 | 986.0 | Compositional bias | Note=Arg-rich | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 148_210 | 32 | 812.0 | Compositional bias | Note=Arg-rich | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 148_210 | 32 | 986.0 | Compositional bias | Note=Arg-rich | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 195_211 | 32 | 986.0 | Motif | Nuclear localization signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 438_447 | 32 | 986.0 | Motif | Nuclear export signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 613_638 | 32 | 986.0 | Motif | Nuclear export signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 195_211 | 32 | 812.0 | Motif | Nuclear localization signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 438_447 | 32 | 812.0 | Motif | Nuclear export signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 613_638 | 32 | 812.0 | Motif | Nuclear export signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 195_211 | 32 | 986.0 | Motif | Nuclear localization signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 438_447 | 32 | 986.0 | Motif | Nuclear export signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 613_638 | 32 | 986.0 | Motif | Nuclear export signal | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 664_693 | 32 | 986.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 707_803 | 32 | 986.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 922_953 | 32 | 986.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 664_693 | 32 | 812.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 707_803 | 32 | 812.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 922_953 | 32 | 812.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 664_693 | 32 | 986.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 707_803 | 32 | 986.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 922_953 | 32 | 986.0 | Region | Disordered |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000266095 | - | 1 | 9 | 53_63 | 0 | 376.0 | Topological domain | Mitochondrial matrix |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000266095 | - | 1 | 9 | 83_409 | 0 | 376.0 | Topological domain | Mitochondrial intermembrane |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000336566 | - | 3 | 8 | 83_409 | 107 | 409.0 | Topological domain | Mitochondrial intermembrane |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000382151 | - | 1 | 8 | 53_63 | 0 | 376.0 | Topological domain | Mitochondrial matrix |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000382151 | - | 1 | 8 | 83_409 | 0 | 376.0 | Topological domain | Mitochondrial intermembrane |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000439502 | - | 3 | 8 | 83_409 | 107 | 410.0 | Topological domain | Mitochondrial intermembrane |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000266095 | - | 1 | 9 | 64_82 | 0 | 376.0 | Transmembrane | Helical |
| Hgene | PISD | chr22:32044087 | chr22:31867903 | ENST00000382151 | - | 1 | 8 | 64_82 | 0 | 376.0 | Transmembrane | Helical |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 1_24 | 32 | 986.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 1_24 | 32 | 812.0 | Region | Disordered | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 1_24 | 32 | 986.0 | Region | Disordered |
Top |
Fusion Gene Sequence for PISD-EIF4ENIF1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >65544_65544_1_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000336566_EIF4ENIF1_chr22_31867903_ENST00000330125_length(transcript)=3694nt_BP=321nt ATGGCGACGTCCGTGGGGCACCGATGTCTGGGATTACTGCACGGGGTCGCGCCGTGGCGGAGCAGCCTCCATCCCTGTGAGATCACTGCC CTGAGCCAATCCCTACAGCCCTTACGGAAGCTGCCTTTTAGAGCCTTTCGCACAGATGCCAGAAAAATCCACACTGCCCCTGCCCGAACC ATGTTCCTGCTGCGTCCCCTGCCCATTCTGTTGGTGACAGGCGGCGGGTATGCAGGGTACCGGCAGTATGAGAAGTACAGGGAGCGAGAG CTGGAGAAGCTGGGATTGGAGATTCCACCCAAACTTGCTGGTCACTGGGAGGAAGAACTCTTGGATATAAAAGAACTCCCCCATTCCAAA CAGAGGCCTTCATGCCTTTCTGAAAAATATGACAGTGATGGTGTCTGGGACCCTGAGAAGTGGCATGCCTCTCTCTACCCAGCTTCAGGG CGGAGCTCACCAGTGGAAAGTCTGAAGAAAGAGTTGGATACAGACCGGCCTTCCCTGGTGCGCAGGATAGTAGATCCACGAGAGCGTGTG AAAGAAGATGACTTAGATGTTGTTCTCAGCCCTCAGAGACGGAGCTTTGGAGGGGGCTGCCACGTGACAGCCGCTGTTAGCTCCCGGCGC TCAGGAAGTCCATTAGAGAAAGATAGTGATGGGCTTCGTCTGCTTGGTGGACGTAGGATTGGCAGTGGGAGGATAATCTCTGCCCGGACC TTTGAGAAGGATCACCGTCTTAGCGATAAGGACCTGCGGGACTTGAGAGACAGAGACCGAGAGAGGGACTTCAAGGACAAGCGTTTCAGG AGAGAGTTTGGAGATAGTAAGCGTGTCTTTGGTGAGCGTAGAAGAAATGATTCTTACACAGAAGAAGAACCAGAGTGGTTCTCTGCTGGA CCCACAAGTCAGTCTGAAACCATCGAACTGACTGGCTTTGATGATAAGATACTAGAAGAAGATCACAAAGGGAGAAAAAGAACAAGGCGA CGGACAGCCTCTGTGAAGGAAGGTATAGTAGAGTGCAATGGAGGAGTGGCCGAAGAGGATGAAGTGGAGGTCATCCTTGCACAGGAGCCT GCGGCTGATCAGGAAGTGCCAAGGGATGCTGTCTTGCCTGAGCAGTCCCCAGGAGACTTTGACTTTAATGAGTTCTTTAACCTTGATAAG GTGCCATGCTTGGCTTCGATGATAGAAGATGTTTTGGGAGAAGGGTCAGTCTCTGCCAGTCGGTTCAGTAGGTGGTTCTCTAACCCGAGC AGATCAGGAAGCCGATCCAGCAGTCTTGGGTCAACACCACATGAAGAGCTAGAGAGACTTGCAGGTCTGGAGCAAGCCATCCTCTCTCCT GGACAGAACTCGGGGAATTACTTTGCTCCTATACCATTGGAAGACCATGCTGAAAATAAAGTGGATATTTTAGAAATGCTACAGAAAGCC AAAGTGGATTTGAAACCTCTTCTTTCCAGCCTTTCTGCAAATAAAGAAAAACTTAAAGAAAGCTCACATTCAGGGGTTGTGCTTTCAGTG GAGGAGGTAGAAGCAGGTCTGAAGGGCTTGAAGGTTGACCAGCAAGTGAAGAATTCAACTCCCTTCATGGCAGAACACCTAGAAGAGACC TTGAGTGCCGTAACCAACAATCGACAACTGAAGAAAGACGGAGACATGACTGCGTTCAACAAGCTAGTGAGCACAATGAAGGCAAGTGGG ACTTTGCCTTCTCAGCCCAAAGTCAGCCGAAACCTTGAAAGCCATTTGATGTCCCCTGCTGAGATTCCAGGCCAGCCTGTCCCTAAGAAC ATCCTGCAGGAACTTCTGGGTCAACCAGTTCAGAGACCTGCTTCTTCCAATCTTCTGAGTGGCCTTATGGGGAGCTTGGAGCCTACAACA TCTTTACTGGGCCAAAGAGCACCCTCTCCTCCCTTGTCACAGGTGTTTCAAACTCGAGCAGCCTCAGCTGACTACCTTCGCCCAAGAATA CCATCACCAATTGGTTTCACACCAGGACCACAGCAGCTACTCGGAGATCCATTCCAAGGCATGCGCAAACCCATGAGCCCCATCACAGCC CAGATGAGCCAGCTGGAGTTGCAACAGGCAGCTTTAGAAGGGCTGGCCTTGCCACATGACCTTGCTGTACAGGCAGCAAACTTCTACCAG CCTGGTTTTGGCAAACCACAGGTGGACAGAACCAGAGATGGATTCAGAAACAGGCAACAGCGAGTGACCAAGTCACCAGCACCCGTGCAT CGAGGGAATTCCTCTTCCCCTGCCCCTGCTGCCTCCATCACAAGCATGCTTTCTCCTTCCTTTACCCCTACCTCAGTGATTCGTAAGATG TACGAGAGCAAAGAGAAAAGCAAGGAGGAGCCAGCATCTGGAAAAGCAGCTCTTGGTGACAGTAAAGAGGATACTCAGAAGGCCAGTGAA GAAAACCTCCTGTCATCCAGCTCTGTACCCAGTGCCGATCGAGACTCTTCTCCCACTACAAATTCCAAACTGTCAGCATTACAGAGGTCT TCGTGTTCCACCCCACTGTCCCAGGCCAACCGTTACACCAAAGAACAAGATTATCGACCTAAAGCAACTGGGAGAAAAACACCCACCTTG GCATCCCCAGTTCCTACAACACCTTTTCTCCGCCCTGTCCACCAAGTTCCCCTTGTCCCCCATGTCCCTATGGTTAGGCCTGCTCACCAG CTTCACCCAGGGTTGGTACAGAGGATGCTGGCCCAGGGAGTACATCCACAGCATCTTCCAAGTTTGCTCCAAACTGGTGTGCTTCCTCCT GGGATGGACTTGAGTCATTTACAGGGAATATCTGGCCCCATCCTGGGTCAGCCCTTTTACCCTTTACCTGCTGCTAGTCACCCTCTCTTA AACCCTCGTCCTGGAACACCTCTGCATCTGGCAATGGTGCAACAGCAGCTACAGCGCTCAGTTCTGCATCCTCCAGGCTCTGGTTCCCAT GCAGCAGCTGTCAGCGTTCAGACAACCCCTCAGAACGTGCCCAGCCGGTCAGGCCTGCCCCACATGCACTCCCAGCTGGAGCATCGCCCC AGCCAGAGGAGCAGCTCCCCTGTGGGCCTTGCCAAATGGTTTGGCTCAGATGTGCTACAGCAACCCCTGCCCTCCATGCCCGCCAAAGTT ATCAGTGTAGATGAATTGGAATACCGACAGTGAGCAGGGCAGGCAGACTCAACTAAGCCCGGACCTGTGGTGGCACACTGGGCAGGACCC TGCTTCATCTCGGGTTGGTTTATGGGCTTTTACTTTGGAGCACTCTGTGTGAAGCTGTTTGGTGGAACCCATGCATCTGGTGTGGTCCGC ATTATGATGGAAGGATCTTAACCAGTCGAGTGGAGTGTACATTGTCTGAATACAGGATGCACAATGTTGTCAATCCTGGAAATGGTCTTT CTTTTTTGTAAGATATGTGAATGAAGTGTTGGTGTCCTCACCAAGAGGTGGCACCTAAGGGTTCTGAGGAAATAAATGTATAGACCCTTA TGTACAGACCTGTGTATAAACAACTTTTGTATATACATATAGGATAGCTTTTTTGAACTATACAGCTGTACATAAAAGTAGCTGATATTA GTTAGGCCTGTGTCAACAGTTTGGATTTTTTTCACTTGTACATTTGGGATTTTCTTTTGGTTGATTAAAATTGCATATGCTAAGTGTGTG >65544_65544_1_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000336566_EIF4ENIF1_chr22_31867903_ENST00000330125_length(amino acids)=1060AA_BP=0 MATSVGHRCLGLLHGVAPWRSSLHPCEITALSQSLQPLRKLPFRAFRTDARKIHTAPARTMFLLRPLPILLVTGGGYAGYRQYEKYRERE LEKLGLEIPPKLAGHWEEELLDIKELPHSKQRPSCLSEKYDSDGVWDPEKWHASLYPASGRSSPVESLKKELDTDRPSLVRRIVDPRERV KEDDLDVVLSPQRRSFGGGCHVTAAVSSRRSGSPLEKDSDGLRLLGGRRIGSGRIISARTFEKDHRLSDKDLRDLRDRDRERDFKDKRFR REFGDSKRVFGERRRNDSYTEEEPEWFSAGPTSQSETIELTGFDDKILEEDHKGRKRTRRRTASVKEGIVECNGGVAEEDEVEVILAQEP AADQEVPRDAVLPEQSPGDFDFNEFFNLDKVPCLASMIEDVLGEGSVSASRFSRWFSNPSRSGSRSSSLGSTPHEELERLAGLEQAILSP GQNSGNYFAPIPLEDHAENKVDILEMLQKAKVDLKPLLSSLSANKEKLKESSHSGVVLSVEEVEAGLKGLKVDQQVKNSTPFMAEHLEET LSAVTNNRQLKKDGDMTAFNKLVSTMKASGTLPSQPKVSRNLESHLMSPAEIPGQPVPKNILQELLGQPVQRPASSNLLSGLMGSLEPTT SLLGQRAPSPPLSQVFQTRAASADYLRPRIPSPIGFTPGPQQLLGDPFQGMRKPMSPITAQMSQLELQQAALEGLALPHDLAVQAANFYQ PGFGKPQVDRTRDGFRNRQQRVTKSPAPVHRGNSSSPAPAASITSMLSPSFTPTSVIRKMYESKEKSKEEPASGKAALGDSKEDTQKASE ENLLSSSSVPSADRDSSPTTNSKLSALQRSSCSTPLSQANRYTKEQDYRPKATGRKTPTLASPVPTTPFLRPVHQVPLVPHVPMVRPAHQ LHPGLVQRMLAQGVHPQHLPSLLQTGVLPPGMDLSHLQGISGPILGQPFYPLPAASHPLLNPRPGTPLHLAMVQQQLQRSVLHPPGSGSH -------------------------------------------------------------- >65544_65544_2_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000336566_EIF4ENIF1_chr22_31867903_ENST00000344710_length(transcript)=3178nt_BP=321nt ATGGCGACGTCCGTGGGGCACCGATGTCTGGGATTACTGCACGGGGTCGCGCCGTGGCGGAGCAGCCTCCATCCCTGTGAGATCACTGCC CTGAGCCAATCCCTACAGCCCTTACGGAAGCTGCCTTTTAGAGCCTTTCGCACAGATGCCAGAAAAATCCACACTGCCCCTGCCCGAACC ATGTTCCTGCTGCGTCCCCTGCCCATTCTGTTGGTGACAGGCGGCGGGTATGCAGGGTACCGGCAGTATGAGAAGTACAGGGAGCGAGAG CTGGAGAAGCTGGGATTGGAGATTCCACCCAAACTTGCTGGTCACTGGGAGGAAGAACTCTTGGATATAAAAGAACTCCCCCATTCCAAA CAGAGGCCTTCATGCCTTTCTGAAAAATATGACAGTGATGGTGTCTGGGACCCTGAGAAGTGGCATGCCTCTCTCTACCCAGCTTCAGGG CGGAGCTCACCAGTGGAAAGTCTGAAGAAAGAGTTGGATACAGACCGGCCTTCCCTGGTGCGCAGGATAGTAGGTATAGTAGAGTGCAAT GGAGGAGTGGCCGAAGAGGATGAAGTGGAGGTCATCCTTGCACAGGAGCCTGCGGCTGATCAGGAAGTGCCAAGGGATGCTGTCTTGCCT GAGCAGTCCCCAGGAGACTTTGACTTTAATGAGTTCTTTAACCTTGATAAGGTGCCATGCTTGGCTTCGATGATAGAAGATGTTTTGGGA GAAGGGTCAGTCTCTGCCAGTCGGTTCAGTAGGTGGTTCTCTAACCCGAGCAGATCAGGAAGCCGATCCAGCAGTCTTGGGTCAACACCA CATGAAGAGCTAGAGAGACTTGCAGGTCTGGAGCAAGCCATCCTCTCTCCTGGACAGAACTCGGGGAATTACTTTGCTCCTATACCATTG GAAGACCATGCTGAAAATAAAGTGGATATTTTAGAAATGCTACAGAAAGCCAAAGTGGATTTGAAACCTCTTCTTTCCAGCCTTTCTGCA AATAAAGAAAAACTTAAAGAAAGCTCACATTCAGGGGTTGTGCTTTCAGTGGAGGAGGTAGAAGCAGGTCTGAAGGGCTTGAAGGTTGAC CAGCAAGTGAAGAATTCAACTCCCTTCATGGCAGAACACCTAGAAGAGACCTTGAGTGCCGTAACCAACAATCGACAACTGAAGAAAGAC GGAGACATGACTGCGTTCAACAAGCTAGTGAGCACAATGAAGCGAAACCTTGAAAGCCATTTGATGTCCCCTGCTGAGATTCCAGGCCAG CCTGTCCCTAAGAACATCCTGCAGGAACTTCTGGGTCAACCAGTTCAGAGACCTGCTTCTTCCAATCTTCTGAGTGGCCTTATGGGGAGC TTGGAGCCTACAACATCTTTACTGGGCCAAAGAGCACCCTCTCCTCCCTTGTCACAGGTGTTTCAAACTCGAGCAGCCTCAGCTGACTAC CTTCGCCCAAGAATACCATCACCAATTGGTTTCACACCAGGACCACAGCAGCTACTCGGAGATCCATTCCAAGGCATGCGCAAACCCATG AGCCCCATCACAGCCCAGCAGATGAGCCAGCTGGAGTTGCAACAGGCAGCTTTAGAAGGGCTGGCCTTGCCACATGACCTTGCTGTACAG GCAGCAAACTTCTACCAGCCTGGTTTTGGCAAACCACAGGTGGACAGAACCAGAGATGGATTCAGAAACAGGCAACAGCGAGTGACCAAG TCACCAGCACCCGTGCATCGAGGGAATTCCTCTTCCCCTGCCCCTGCTGCCTCCATCACAAGCATGCTTTCTCCTTCCTTTACCCCTACC TCAGTGATTCGTAAGATGTACGAGAGCAAAGAGAAAAGCAAGGAGGAGCCAGCATCTGGAAAAGCAGCTCTTGGTGACAGTAAAGAGGAT ACTCAGAAGGCCAGTGAAGAAAACCTCCTGTCATCCAGCTCTGTACCCAGTGCCGATCGAGACTCTTCTCCCACTACAAATTCCAAACTG TCAGCATTACAGAGGTCTTCGTGTTCCACCCCACTGTCCCAGGCCAACCGTTACACCAAAGAACAAGATTATCGACCTAAAGCAACTGGG AGAAAAACACCCACCTTGGCATCCCCAGTTCCTACAACACCTTTTCTCCGCCCTGTCCACCAAGTTCCCCTTGTCCCCCATGTCCCTATG GTTAGGCCTGCTCACCAGCTTCACCCAGGGTTGGTACAGAGGATGCTGGCCCAGGGAGTACATCCACAGCATCTTCCAAGTTTGCTCCAA ACTGGTGTGCTTCCTCCTGGGATGGACTTGAGTCATTTACAGGGAATATCTGGCCCCATCCTGGGTCAGCCCTTTTACCCTTTACCTGCT GCTAGTCACCCTCTCTTAAACCCTCGTCCTGGAACACCTCTGCATCTGGCAATGGTGCAACAGCAGCTACAGCGCTCAGTTCTGCATCCT CCAGGCTCTGGTTCCCATGCAGCAGCTGTCAGCGTTCAGACAACCCCTCAGAACGTGCCCAGCCGGTCAGGCCTGCCCCACATGCACTCC CAGCTGGAGCATCGCCCCAGCCAGAGGAGCAGCTCCCCTGTGGGCCTTGCCAAATGGTTTGGCTCAGATGTGCTACAGCAACCCCTGCCC TCCATGCCCGCCAAAGTTATCAGTGTAGATGAATTGGAATACCGACAGTGAGCAGGGCAGGCAGACTCAACTAAGCCCGGACCTGTGGTG GCACACTGGGCAGGACCCTGCTTCATCTCGGGTTGGTTTATGGGCTTTTACTTTGGAGCACTCTGTGTGAAGCTGTTTGGTGGAACCCAT GCATCTGGTGTGGTCCGCATTATGATGGAAGGATCTTAACCAGTCGAGTGGAGTGTACATTGTCTGAATACAGGATGCACAATGTTGTCA ATCCTGGAAATGGTCTTTCTTTTTTGTAAGATATGTGAATGAAGTGTTGGTGTCCTCACCAAGAGGTGGCACCTAAGGGTTCTGAGGAAA TAAATGTATAGACCCTTATGTACAGACCTGTGTATAAACAACTTTTGTATATACATATAGGATAGCTTTTTTGAACTATACAGCTGTACA TAAAAGTAGCTGATATTAGTTAGGCCTGTGTCAACAGTTTGGATTTTTTTCACTTGTACATTTGGGATTTTCTTTTGGTTGATTAAAATT >65544_65544_2_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000336566_EIF4ENIF1_chr22_31867903_ENST00000344710_length(amino acids)=886AA_BP=0 MATSVGHRCLGLLHGVAPWRSSLHPCEITALSQSLQPLRKLPFRAFRTDARKIHTAPARTMFLLRPLPILLVTGGGYAGYRQYEKYRERE LEKLGLEIPPKLAGHWEEELLDIKELPHSKQRPSCLSEKYDSDGVWDPEKWHASLYPASGRSSPVESLKKELDTDRPSLVRRIVGIVECN GGVAEEDEVEVILAQEPAADQEVPRDAVLPEQSPGDFDFNEFFNLDKVPCLASMIEDVLGEGSVSASRFSRWFSNPSRSGSRSSSLGSTP HEELERLAGLEQAILSPGQNSGNYFAPIPLEDHAENKVDILEMLQKAKVDLKPLLSSLSANKEKLKESSHSGVVLSVEEVEAGLKGLKVD QQVKNSTPFMAEHLEETLSAVTNNRQLKKDGDMTAFNKLVSTMKRNLESHLMSPAEIPGQPVPKNILQELLGQPVQRPASSNLLSGLMGS LEPTTSLLGQRAPSPPLSQVFQTRAASADYLRPRIPSPIGFTPGPQQLLGDPFQGMRKPMSPITAQQMSQLELQQAALEGLALPHDLAVQ AANFYQPGFGKPQVDRTRDGFRNRQQRVTKSPAPVHRGNSSSPAPAASITSMLSPSFTPTSVIRKMYESKEKSKEEPASGKAALGDSKED TQKASEENLLSSSSVPSADRDSSPTTNSKLSALQRSSCSTPLSQANRYTKEQDYRPKATGRKTPTLASPVPTTPFLRPVHQVPLVPHVPM VRPAHQLHPGLVQRMLAQGVHPQHLPSLLQTGVLPPGMDLSHLQGISGPILGQPFYPLPAASHPLLNPRPGTPLHLAMVQQQLQRSVLHP -------------------------------------------------------------- >65544_65544_3_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000336566_EIF4ENIF1_chr22_31867903_ENST00000397523_length(transcript)=3618nt_BP=321nt ATGGCGACGTCCGTGGGGCACCGATGTCTGGGATTACTGCACGGGGTCGCGCCGTGGCGGAGCAGCCTCCATCCCTGTGAGATCACTGCC CTGAGCCAATCCCTACAGCCCTTACGGAAGCTGCCTTTTAGAGCCTTTCGCACAGATGCCAGAAAAATCCACACTGCCCCTGCCCGAACC ATGTTCCTGCTGCGTCCCCTGCCCATTCTGTTGGTGACAGGCGGCGGGTATGCAGGGTACCGGCAGTATGAGAAGTACAGGGAGCGAGAG CTGGAGAAGCTGGGATTGGAGATTCCACCCAAACTTGCTGGTCACTGGGAGGAAGAACTCTTGGATATAAAAGAACTCCCCCATTCCAAA CAGAGGCCTTCATGCCTTTCTGAAAAATATGACAGTGATGGTGTCTGGGACCCTGAGAAGTGGCATGCCTCTCTCTACCCAGCTTCAGGG CGGAGCTCACCAGTGGAAAGTCTGAAGAAAGAGTTGGATACAGACCGGCCTTCCCTGGTGCGCAGGATAGTAGATCCACGAGAGCGTGTG AAAGAAGATGACTTAGATGTTGTTCTCAGCCCTCAGAGACGGAGCTTTGGAGGGGGCTGCCACGTGACAGCCGCTGTTAGCTCCCGGCGC TCAGGAAGTCCATTAGAGAAAGATAGTGATGGGCTTCGTCTGCTTGGTGGACGTAGGATTGGCAGTGGGAGGATAATCTCTGCCCGGACC TTTGAGAAGGATCACCGTCTTAGCGATAAGGACCTGCGGGACTTGAGAGACAGAGACCGAGAGAGGGACTTCAAGGACAAGCGTTTCAGG AGAGAGTTTGGAGATAGTAAGCGTGTCTTTGGTGAGCGTAGAAGAAATGATTCTTACACAGAAGAAGAACCAGAGTGGTTCTCTGCTGGA CCCACAAGTCAGTCTGAAACCATCGAACTGACTGGCTTTGATGATAAGATACTAGAAGAAGATCACAAAGGGAGAAAAAGAACAAGGCGA CGGACAGCCTCTGTGAAGGAAGGTATAGTAGAGTGCAATGGAGGAGTGGCCGAAGAGGATGAAGTGGAGGTCATCCTTGCACAGGAGCCT GCGGCTGATCAGGAAGTGCCAAGGGATGCTGTCTTGCCTGAGCAGTCCCCAGGAGACTTTGACTTTAATGAGTTCTTTAACCTTGATAAG GTGCCATGCTTGGCTTCGATGATAGAAGATGTTTTGGGAGAAGGGTCAGTCTCTGCCAGTCGGTTCAGTAGGTGGTTCTCTAACCCGAGC AGATCAGGAAGCCGATCCAGCAGTCTTGGGTCAACACCACATGAAGAGCTAGAGAGACTTGCAGGTCTGGAGCAAGCCATCCTCTCTCCT GGACAGAACTCGGGGAATTACTTTGCTCCTATACCATTGGAAGACCATGCTGAAAATAAAGTGGATATTTTAGAAATGCTACAGAAAGCC AAAGTGGATTTGAAACCTCTTCTTTCCAGCCTTTCTGCAAATAAAGAAAAACTTAAAGAAAGCTCACATTCAGGGGTTGTGCTTTCAGTG GAGGAGGTAGAAGCAGGTCTGAAGGGCTTGAAGGTTGACCAGCAAGTGAAGAATTCAACTCCCTTCATGGCAGAACACCTAGAAGAGACC TTGAGTGCCGTAACCAACAATCGACAACTGAAGAAAGACGGAGACATGACTGCGTTCAACAAGCTAGTGAGCACAATGAAGGCAAGTGGG ACTTTGCCTTCTCAGCCCAAAGTCAGCGAACTTCTGGGTCAACCAGTTCAGAGACCTGCTTCTTCCAATCTTCTGAGTGGCCTTATGGGG AGCTTGGAGCCTACAACATCTTTACTGGGCCAAAGAGCACCCTCTCCTCCCTTGTCACAGGTGTTTCAAACTCGAGCAGCCTCAGCTGAC TACCTTCGCCCAAGAATACCATCACCAATTGGTTTCACACCAGGACCACAGCAGCTACTCGGAGATCCATTCCAAGGCATGCGCAAACCC ATGAGCCCCATCACAGCCCAGATGAGCCAGCTGGAGTTGCAACAGGCAGCTTTAGAAGGGCTGGCCTTGCCACATGACCTTGCTGTACAG GCAGCAAACTTCTACCAGCCTGGTTTTGGCAAACCACAGGTGGACAGAACCAGAGATGGATTCAGAAACAGGCAACAGCGAGTGACCAAG TCACCAGCACCCGTGCATCGAGGGAATTCCTCTTCCCCTGCCCCTGCTGCCTCCATCACAAGCATGCTTTCTCCTTCCTTTACCCCTACC TCAGTGATTCGTAAGATGTACGAGAGCAAAGAGAAAAGCAAGGAGGAGCCAGCATCTGGAAAAGCAGCTCTTGGTGACAGTAAAGAGGAT ACTCAGAAGGCCAGTGAAGAAAACCTCCTGTCATCCAGCTCTGTACCCAGTGCCGATCGAGACTCTTCTCCCACTACAAATTCCAAACTG TCAGCATTACAGAGGTCTTCGTGTTCCACCCCACTGTCCCAGGCCAACCGTTACACCAAAGAACAAGATTATCGACCTAAAGCAACTGGG AGAAAAACACCCACCTTGGCATCCCCAGTTCCTACAACACCTTTTCTCCGCCCTGTCCACCAAGTTCCCCTTGTCCCCCATGTCCCTATG GTTAGGCCTGCTCACCAGCTTCACCCAGGGTTGGTACAGAGGATGCTGGCCCAGGGAGTACATCCACAGCATCTTCCAAGTTTGCTCCAA ACTGGTGTGCTTCCTCCTGGGATGGACTTGAGTCATTTACAGGGAATATCTGGCCCCATCCTGGGTCAGCCCTTTTACCCTTTACCTGCT GCTAGTCACCCTCTCTTAAACCCTCGTCCTGGAACACCTCTGCATCTGGCAATGGTGCAACAGCAGCTACAGCGCTCAGTTCTGCATCCT CCAGGCTCTGGTTCCCATGCAGCAGCTGTCAGCGTTCAGACAACCCCTCAGAACGTGCCCAGCCGGTCAGGCCTGCCCCACATGCACTCC CAGCTGGAGCATCGCCCCAGCCAGAGGAGCAGCTCCCCTGTGGGCCTTGCCAAATGGTTTGGCTCAGATGTGCTACAGCAACCCCTGCCC TCCATGCCCGCCAAAGTTATCAGTGTAGATGAATTGGAATACCGACAGTGAGCAGGGCAGGCAGACTCAACTAAGCCCGGACCTGTGGTG GCACACTGGGCAGGACCCTGCTTCATCTCGGGTTGGTTTATGGGCTTTTACTTTGGAGCACTCTGTGTGAAGCTGTTTGGTGGAACCCAT GCATCTGGTGTGGTCCGCATTATGATGGAAGGATCTTAACCAGTCGAGTGGAGTGTACATTGTCTGAATACAGGATGCACAATGTTGTCA ATCCTGGAAATGGTCTTTCTTTTTTGTAAGATATGTGAATGAAGTGTTGGTGTCCTCACCAAGAGGTGGCACCTAAGGGTTCTGAGGAAA TAAATGTATAGACCCTTATGTACAGACCTGTGTATAAACAACTTTTGTATATACATATAGGATAGCTTTTTTGAACTATACAGCTGTACA TAAAAGTAGCTGATATTAGTTAGGCCTGTGTCAACAGTTTGGATTTTTTTCACTTGTACATTTGGGATTTTCTTTTGGTTGATTAAAATT >65544_65544_3_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000336566_EIF4ENIF1_chr22_31867903_ENST00000397523_length(amino acids)=1036AA_BP=0 MATSVGHRCLGLLHGVAPWRSSLHPCEITALSQSLQPLRKLPFRAFRTDARKIHTAPARTMFLLRPLPILLVTGGGYAGYRQYEKYRERE LEKLGLEIPPKLAGHWEEELLDIKELPHSKQRPSCLSEKYDSDGVWDPEKWHASLYPASGRSSPVESLKKELDTDRPSLVRRIVDPRERV KEDDLDVVLSPQRRSFGGGCHVTAAVSSRRSGSPLEKDSDGLRLLGGRRIGSGRIISARTFEKDHRLSDKDLRDLRDRDRERDFKDKRFR REFGDSKRVFGERRRNDSYTEEEPEWFSAGPTSQSETIELTGFDDKILEEDHKGRKRTRRRTASVKEGIVECNGGVAEEDEVEVILAQEP AADQEVPRDAVLPEQSPGDFDFNEFFNLDKVPCLASMIEDVLGEGSVSASRFSRWFSNPSRSGSRSSSLGSTPHEELERLAGLEQAILSP GQNSGNYFAPIPLEDHAENKVDILEMLQKAKVDLKPLLSSLSANKEKLKESSHSGVVLSVEEVEAGLKGLKVDQQVKNSTPFMAEHLEET LSAVTNNRQLKKDGDMTAFNKLVSTMKASGTLPSQPKVSELLGQPVQRPASSNLLSGLMGSLEPTTSLLGQRAPSPPLSQVFQTRAASAD YLRPRIPSPIGFTPGPQQLLGDPFQGMRKPMSPITAQMSQLELQQAALEGLALPHDLAVQAANFYQPGFGKPQVDRTRDGFRNRQQRVTK SPAPVHRGNSSSPAPAASITSMLSPSFTPTSVIRKMYESKEKSKEEPASGKAALGDSKEDTQKASEENLLSSSSVPSADRDSSPTTNSKL SALQRSSCSTPLSQANRYTKEQDYRPKATGRKTPTLASPVPTTPFLRPVHQVPLVPHVPMVRPAHQLHPGLVQRMLAQGVHPQHLPSLLQ TGVLPPGMDLSHLQGISGPILGQPFYPLPAASHPLLNPRPGTPLHLAMVQQQLQRSVLHPPGSGSHAAAVSVQTTPQNVPSRSGLPHMHS -------------------------------------------------------------- >65544_65544_4_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000336566_EIF4ENIF1_chr22_31867903_ENST00000397525_length(transcript)=3696nt_BP=321nt ATGGCGACGTCCGTGGGGCACCGATGTCTGGGATTACTGCACGGGGTCGCGCCGTGGCGGAGCAGCCTCCATCCCTGTGAGATCACTGCC CTGAGCCAATCCCTACAGCCCTTACGGAAGCTGCCTTTTAGAGCCTTTCGCACAGATGCCAGAAAAATCCACACTGCCCCTGCCCGAACC ATGTTCCTGCTGCGTCCCCTGCCCATTCTGTTGGTGACAGGCGGCGGGTATGCAGGGTACCGGCAGTATGAGAAGTACAGGGAGCGAGAG CTGGAGAAGCTGGGATTGGAGATTCCACCCAAACTTGCTGGTCACTGGGAGGAAGAACTCTTGGATATAAAAGAACTCCCCCATTCCAAA CAGAGGCCTTCATGCCTTTCTGAAAAATATGACAGTGATGGTGTCTGGGACCCTGAGAAGTGGCATGCCTCTCTCTACCCAGCTTCAGGG CGGAGCTCACCAGTGGAAAGTCTGAAGAAAGAGTTGGATACAGACCGGCCTTCCCTGGTGCGCAGGATAGTAGATCCACGAGAGCGTGTG AAAGAAGATGACTTAGATGTTGTTCTCAGCCCTCAGAGACGGAGCTTTGGAGGGGGCTGCCACGTGACAGCCGCTGTTAGCTCCCGGCGC TCAGGAAGTCCATTAGAGAAAGATAGTGATGGGCTTCGTCTGCTTGGTGGACGTAGGATTGGCAGTGGGAGGATAATCTCTGCCCGGACC TTTGAGAAGGATCACCGTCTTAGCGATAAGGACCTGCGGGACTTGAGAGACAGAGACCGAGAGAGGGACTTCAAGGACAAGCGTTTCAGG AGAGAGTTTGGAGATAGTAAGCGTGTCTTTGGTGAGCGTAGAAGAAATGATTCTTACACAGAAGAAGAACCAGAGTGGTTCTCTGCTGGA CCCACAAGTCAGTCTGAAACCATCGAACTGACTGGCTTTGATGATAAGATACTAGAAGAAGATCACAAAGGGAGAAAAAGAACAAGGCGA CGGACAGCCTCTGTGAAGGAAGGTATAGTAGAGTGCAATGGAGGAGTGGCCGAAGAGGATGAAGTGGAGGTCATCCTTGCACAGGAGCCT GCGGCTGATCAGGAAGTGCCAAGGGATGCTGTCTTGCCTGAGCAGTCCCCAGGAGACTTTGACTTTAATGAGTTCTTTAACCTTGATAAG GTGCCATGCTTGGCTTCGATGATAGAAGATGTTTTGGGAGAAGGGTCAGTCTCTGCCAGTCGGTTCAGTAGGTGGTTCTCTAACCCGAGC AGATCAGGAAGCCGATCCAGCAGTCTTGGGTCAACACCACATGAAGAGCTAGAGAGACTTGCAGGTCTGGAGCAAGCCATCCTCTCTCCT GGACAGAACTCGGGGAATTACTTTGCTCCTATACCATTGGAAGACCATGCTGAAAATAAAGTGGATATTTTAGAAATGCTACAGAAAGCC AAAGTGGATTTGAAACCTCTTCTTTCCAGCCTTTCTGCAAATAAAGAAAAACTTAAAGAAAGCTCACATTCAGGGGTTGTGCTTTCAGTG GAGGAGGTAGAAGCAGGTCTGAAGGGCTTGAAGGTTGACCAGCAAGTGAAGAATTCAACTCCCTTCATGGCAGAACACCTAGAAGAGACC TTGAGTGCCGTAACCAACAATCGACAACTGAAGAAAGACGGAGACATGACTGCGTTCAACAAGCTAGTGAGCACAATGAAGGCAAGTGGG ACTTTGCCTTCTCAGCCCAAAGTCAGCCGAAACCTTGAAAGCCATTTGATGTCCCCTGCTGAGATTCCAGGCCAGCCTGTCCCTAAGAAC ATCCTGCAGGAACTTCTGGGTCAACCAGTTCAGAGACCTGCTTCTTCCAATCTTCTGAGTGGCCTTATGGGGAGCTTGGAGCCTACAACA TCTTTACTGGGCCAAAGAGCACCCTCTCCTCCCTTGTCACAGGTGTTTCAAACTCGAGCAGCCTCAGCTGACTACCTTCGCCCAAGAATA CCATCACCAATTGGTTTCACACCAGGACCACAGCAGCTACTCGGAGATCCATTCCAAGGCATGCGCAAACCCATGAGCCCCATCACAGCC CAGATGAGCCAGCTGGAGTTGCAACAGGCAGCTTTAGAAGGGCTGGCCTTGCCACATGACCTTGCTGTACAGGCAGCAAACTTCTACCAG CCTGGTTTTGGCAAACCACAGGTGGACAGAACCAGAGATGGATTCAGAAACAGGCAACAGCGAGTGACCAAGTCACCAGCACCCGTGCAT CGAGGGAATTCCTCTTCCCCTGCCCCTGCTGCCTCCATCACAAGCATGCTTTCTCCTTCCTTTACCCCTACCTCAGTGATTCGTAAGATG TACGAGAGCAAAGAGAAAAGCAAGGAGGAGCCAGCATCTGGAAAAGCAGCTCTTGGTGACAGTAAAGAGGATACTCAGAAGGCCAGTGAA GAAAACCTCCTGTCATCCAGCTCTGTACCCAGTGCCGATCGAGACTCTTCTCCCACTACAAATTCCAAACTGTCAGCATTACAGAGGTCT TCGTGTTCCACCCCACTGTCCCAGGCCAACCGTTACACCAAAGAACAAGATTATCGACCTAAAGCAACTGGGAGAAAAACACCCACCTTG GCATCCCCAGTTCCTACAACACCTTTTCTCCGCCCTGTCCACCAAGTTCCCCTTGTCCCCCATGTCCCTATGGTTAGGCCTGCTCACCAG CTTCACCCAGGGTTGGTACAGAGGATGCTGGCCCAGGGAGTACATCCACAGCATCTTCCAAGTTTGCTCCAAACTGGTGTGCTTCCTCCT GGGATGGACTTGAGTCATTTACAGGGAATATCTGGCCCCATCCTGGGTCAGCCCTTTTACCCTTTACCTGCTGCTAGTCACCCTCTCTTA AACCCTCGTCCTGGAACACCTCTGCATCTGGCAATGGTGCAACAGCAGCTACAGCGCTCAGTTCTGCATCCTCCAGGCTCTGGTTCCCAT GCAGCAGCTGTCAGCGTTCAGACAACCCCTCAGAACGTGCCCAGCCGGTCAGGCCTGCCCCACATGCACTCCCAGCTGGAGCATCGCCCC AGCCAGAGGAGCAGCTCCCCTGTGGGCCTTGCCAAATGGTTTGGCTCAGATGTGCTACAGCAACCCCTGCCCTCCATGCCCGCCAAAGTT ATCAGTGTAGATGAATTGGAATACCGACAGTGAGCAGGGCAGGCAGACTCAACTAAGCCCGGACCTGTGGTGGCACACTGGGCAGGACCC TGCTTCATCTCGGGTTGGTTTATGGGCTTTTACTTTGGAGCACTCTGTGTGAAGCTGTTTGGTGGAACCCATGCATCTGGTGTGGTCCGC ATTATGATGGAAGGATCTTAACCAGTCGAGTGGAGTGTACATTGTCTGAATACAGGATGCACAATGTTGTCAATCCTGGAAATGGTCTTT CTTTTTTGTAAGATATGTGAATGAAGTGTTGGTGTCCTCACCAAGAGGTGGCACCTAAGGGTTCTGAGGAAATAAATGTATAGACCCTTA TGTACAGACCTGTGTATAAACAACTTTTGTATATACATATAGGATAGCTTTTTTGAACTATACAGCTGTACATAAAAGTAGCTGATATTA GTTAGGCCTGTGTCAACAGTTTGGATTTTTTTCACTTGTACATTTGGGATTTTCTTTTGGTTGATTAAAATTGCATATGCTAAGTGTGTG >65544_65544_4_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000336566_EIF4ENIF1_chr22_31867903_ENST00000397525_length(amino acids)=1060AA_BP=0 MATSVGHRCLGLLHGVAPWRSSLHPCEITALSQSLQPLRKLPFRAFRTDARKIHTAPARTMFLLRPLPILLVTGGGYAGYRQYEKYRERE LEKLGLEIPPKLAGHWEEELLDIKELPHSKQRPSCLSEKYDSDGVWDPEKWHASLYPASGRSSPVESLKKELDTDRPSLVRRIVDPRERV KEDDLDVVLSPQRRSFGGGCHVTAAVSSRRSGSPLEKDSDGLRLLGGRRIGSGRIISARTFEKDHRLSDKDLRDLRDRDRERDFKDKRFR REFGDSKRVFGERRRNDSYTEEEPEWFSAGPTSQSETIELTGFDDKILEEDHKGRKRTRRRTASVKEGIVECNGGVAEEDEVEVILAQEP AADQEVPRDAVLPEQSPGDFDFNEFFNLDKVPCLASMIEDVLGEGSVSASRFSRWFSNPSRSGSRSSSLGSTPHEELERLAGLEQAILSP GQNSGNYFAPIPLEDHAENKVDILEMLQKAKVDLKPLLSSLSANKEKLKESSHSGVVLSVEEVEAGLKGLKVDQQVKNSTPFMAEHLEET LSAVTNNRQLKKDGDMTAFNKLVSTMKASGTLPSQPKVSRNLESHLMSPAEIPGQPVPKNILQELLGQPVQRPASSNLLSGLMGSLEPTT SLLGQRAPSPPLSQVFQTRAASADYLRPRIPSPIGFTPGPQQLLGDPFQGMRKPMSPITAQMSQLELQQAALEGLALPHDLAVQAANFYQ PGFGKPQVDRTRDGFRNRQQRVTKSPAPVHRGNSSSPAPAASITSMLSPSFTPTSVIRKMYESKEKSKEEPASGKAALGDSKEDTQKASE ENLLSSSSVPSADRDSSPTTNSKLSALQRSSCSTPLSQANRYTKEQDYRPKATGRKTPTLASPVPTTPFLRPVHQVPLVPHVPMVRPAHQ LHPGLVQRMLAQGVHPQHLPSLLQTGVLPPGMDLSHLQGISGPILGQPFYPLPAASHPLLNPRPGTPLHLAMVQQQLQRSVLHPPGSGSH -------------------------------------------------------------- >65544_65544_5_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000439502_EIF4ENIF1_chr22_31867903_ENST00000330125_length(transcript)=3918nt_BP=545nt CTGCGACCAAGCCCAGGTTTAGCGAAACCTACAGCTCCACTAGTTCCCCTACCTCCGCAGGTGCCAAGCGGGTTAGGTGGGGAGTAGCCA CAGGGCGGAGCTTAGTCGGCTCCGCCCCCAACCCGCGCTTTTCTCATTGGCCCACTGAACTCGAGACTCGTGACGCCTTAAGCGTGCGCC CAGCGTGTGAAGGGGGCGTGGCACGCTGAGAAGGAGCAGACAAGATGGCGACGTCCGTGGGGCACCGATGTCTGGGATTACTGCACGGGG TCGCGCCGTGGCGGAGCAGCCTCCATCCCTGTGAGATCACTGCCCTGAGCCAATCCCTACAGCCCTTACGGAAGCTGCCTTTTAGAGCCT TTCGCACAGATGCCAGAAAAATCCACACTGCCCCTGCCCGAACCATGTTCCTGCTGCGTCCCCTGCCCATTCTGTTGGTGACAGGCGGCG GGTATGCAGGGTACCGGCAGTATGAGAAGTACAGGGAGCGAGAGCTGGAGAAGCTGGGATTGGAGATTCCACCCAAACTTGCTGGTCACT GGGAGGAAGAACTCTTGGATATAAAAGAACTCCCCCATTCCAAACAGAGGCCTTCATGCCTTTCTGAAAAATATGACAGTGATGGTGTCT GGGACCCTGAGAAGTGGCATGCCTCTCTCTACCCAGCTTCAGGGCGGAGCTCACCAGTGGAAAGTCTGAAGAAAGAGTTGGATACAGACC GGCCTTCCCTGGTGCGCAGGATAGTAGATCCACGAGAGCGTGTGAAAGAAGATGACTTAGATGTTGTTCTCAGCCCTCAGAGACGGAGCT TTGGAGGGGGCTGCCACGTGACAGCCGCTGTTAGCTCCCGGCGCTCAGGAAGTCCATTAGAGAAAGATAGTGATGGGCTTCGTCTGCTTG GTGGACGTAGGATTGGCAGTGGGAGGATAATCTCTGCCCGGACCTTTGAGAAGGATCACCGTCTTAGCGATAAGGACCTGCGGGACTTGA GAGACAGAGACCGAGAGAGGGACTTCAAGGACAAGCGTTTCAGGAGAGAGTTTGGAGATAGTAAGCGTGTCTTTGGTGAGCGTAGAAGAA ATGATTCTTACACAGAAGAAGAACCAGAGTGGTTCTCTGCTGGACCCACAAGTCAGTCTGAAACCATCGAACTGACTGGCTTTGATGATA AGATACTAGAAGAAGATCACAAAGGGAGAAAAAGAACAAGGCGACGGACAGCCTCTGTGAAGGAAGGTATAGTAGAGTGCAATGGAGGAG TGGCCGAAGAGGATGAAGTGGAGGTCATCCTTGCACAGGAGCCTGCGGCTGATCAGGAAGTGCCAAGGGATGCTGTCTTGCCTGAGCAGT CCCCAGGAGACTTTGACTTTAATGAGTTCTTTAACCTTGATAAGGTGCCATGCTTGGCTTCGATGATAGAAGATGTTTTGGGAGAAGGGT CAGTCTCTGCCAGTCGGTTCAGTAGGTGGTTCTCTAACCCGAGCAGATCAGGAAGCCGATCCAGCAGTCTTGGGTCAACACCACATGAAG AGCTAGAGAGACTTGCAGGTCTGGAGCAAGCCATCCTCTCTCCTGGACAGAACTCGGGGAATTACTTTGCTCCTATACCATTGGAAGACC ATGCTGAAAATAAAGTGGATATTTTAGAAATGCTACAGAAAGCCAAAGTGGATTTGAAACCTCTTCTTTCCAGCCTTTCTGCAAATAAAG AAAAACTTAAAGAAAGCTCACATTCAGGGGTTGTGCTTTCAGTGGAGGAGGTAGAAGCAGGTCTGAAGGGCTTGAAGGTTGACCAGCAAG TGAAGAATTCAACTCCCTTCATGGCAGAACACCTAGAAGAGACCTTGAGTGCCGTAACCAACAATCGACAACTGAAGAAAGACGGAGACA TGACTGCGTTCAACAAGCTAGTGAGCACAATGAAGGCAAGTGGGACTTTGCCTTCTCAGCCCAAAGTCAGCCGAAACCTTGAAAGCCATT TGATGTCCCCTGCTGAGATTCCAGGCCAGCCTGTCCCTAAGAACATCCTGCAGGAACTTCTGGGTCAACCAGTTCAGAGACCTGCTTCTT CCAATCTTCTGAGTGGCCTTATGGGGAGCTTGGAGCCTACAACATCTTTACTGGGCCAAAGAGCACCCTCTCCTCCCTTGTCACAGGTGT TTCAAACTCGAGCAGCCTCAGCTGACTACCTTCGCCCAAGAATACCATCACCAATTGGTTTCACACCAGGACCACAGCAGCTACTCGGAG ATCCATTCCAAGGCATGCGCAAACCCATGAGCCCCATCACAGCCCAGATGAGCCAGCTGGAGTTGCAACAGGCAGCTTTAGAAGGGCTGG CCTTGCCACATGACCTTGCTGTACAGGCAGCAAACTTCTACCAGCCTGGTTTTGGCAAACCACAGGTGGACAGAACCAGAGATGGATTCA GAAACAGGCAACAGCGAGTGACCAAGTCACCAGCACCCGTGCATCGAGGGAATTCCTCTTCCCCTGCCCCTGCTGCCTCCATCACAAGCA TGCTTTCTCCTTCCTTTACCCCTACCTCAGTGATTCGTAAGATGTACGAGAGCAAAGAGAAAAGCAAGGAGGAGCCAGCATCTGGAAAAG CAGCTCTTGGTGACAGTAAAGAGGATACTCAGAAGGCCAGTGAAGAAAACCTCCTGTCATCCAGCTCTGTACCCAGTGCCGATCGAGACT CTTCTCCCACTACAAATTCCAAACTGTCAGCATTACAGAGGTCTTCGTGTTCCACCCCACTGTCCCAGGCCAACCGTTACACCAAAGAAC AAGATTATCGACCTAAAGCAACTGGGAGAAAAACACCCACCTTGGCATCCCCAGTTCCTACAACACCTTTTCTCCGCCCTGTCCACCAAG TTCCCCTTGTCCCCCATGTCCCTATGGTTAGGCCTGCTCACCAGCTTCACCCAGGGTTGGTACAGAGGATGCTGGCCCAGGGAGTACATC CACAGCATCTTCCAAGTTTGCTCCAAACTGGTGTGCTTCCTCCTGGGATGGACTTGAGTCATTTACAGGGAATATCTGGCCCCATCCTGG GTCAGCCCTTTTACCCTTTACCTGCTGCTAGTCACCCTCTCTTAAACCCTCGTCCTGGAACACCTCTGCATCTGGCAATGGTGCAACAGC AGCTACAGCGCTCAGTTCTGCATCCTCCAGGCTCTGGTTCCCATGCAGCAGCTGTCAGCGTTCAGACAACCCCTCAGAACGTGCCCAGCC GGTCAGGCCTGCCCCACATGCACTCCCAGCTGGAGCATCGCCCCAGCCAGAGGAGCAGCTCCCCTGTGGGCCTTGCCAAATGGTTTGGCT CAGATGTGCTACAGCAACCCCTGCCCTCCATGCCCGCCAAAGTTATCAGTGTAGATGAATTGGAATACCGACAGTGAGCAGGGCAGGCAG ACTCAACTAAGCCCGGACCTGTGGTGGCACACTGGGCAGGACCCTGCTTCATCTCGGGTTGGTTTATGGGCTTTTACTTTGGAGCACTCT GTGTGAAGCTGTTTGGTGGAACCCATGCATCTGGTGTGGTCCGCATTATGATGGAAGGATCTTAACCAGTCGAGTGGAGTGTACATTGTC TGAATACAGGATGCACAATGTTGTCAATCCTGGAAATGGTCTTTCTTTTTTGTAAGATATGTGAATGAAGTGTTGGTGTCCTCACCAAGA GGTGGCACCTAAGGGTTCTGAGGAAATAAATGTATAGACCCTTATGTACAGACCTGTGTATAAACAACTTTTGTATATACATATAGGATA GCTTTTTTGAACTATACAGCTGTACATAAAAGTAGCTGATATTAGTTAGGCCTGTGTCAACAGTTTGGATTTTTTTCACTTGTACATTTG >65544_65544_5_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000439502_EIF4ENIF1_chr22_31867903_ENST00000330125_length(amino acids)=1060AA_BP=0 MATSVGHRCLGLLHGVAPWRSSLHPCEITALSQSLQPLRKLPFRAFRTDARKIHTAPARTMFLLRPLPILLVTGGGYAGYRQYEKYRERE LEKLGLEIPPKLAGHWEEELLDIKELPHSKQRPSCLSEKYDSDGVWDPEKWHASLYPASGRSSPVESLKKELDTDRPSLVRRIVDPRERV KEDDLDVVLSPQRRSFGGGCHVTAAVSSRRSGSPLEKDSDGLRLLGGRRIGSGRIISARTFEKDHRLSDKDLRDLRDRDRERDFKDKRFR REFGDSKRVFGERRRNDSYTEEEPEWFSAGPTSQSETIELTGFDDKILEEDHKGRKRTRRRTASVKEGIVECNGGVAEEDEVEVILAQEP AADQEVPRDAVLPEQSPGDFDFNEFFNLDKVPCLASMIEDVLGEGSVSASRFSRWFSNPSRSGSRSSSLGSTPHEELERLAGLEQAILSP GQNSGNYFAPIPLEDHAENKVDILEMLQKAKVDLKPLLSSLSANKEKLKESSHSGVVLSVEEVEAGLKGLKVDQQVKNSTPFMAEHLEET LSAVTNNRQLKKDGDMTAFNKLVSTMKASGTLPSQPKVSRNLESHLMSPAEIPGQPVPKNILQELLGQPVQRPASSNLLSGLMGSLEPTT SLLGQRAPSPPLSQVFQTRAASADYLRPRIPSPIGFTPGPQQLLGDPFQGMRKPMSPITAQMSQLELQQAALEGLALPHDLAVQAANFYQ PGFGKPQVDRTRDGFRNRQQRVTKSPAPVHRGNSSSPAPAASITSMLSPSFTPTSVIRKMYESKEKSKEEPASGKAALGDSKEDTQKASE ENLLSSSSVPSADRDSSPTTNSKLSALQRSSCSTPLSQANRYTKEQDYRPKATGRKTPTLASPVPTTPFLRPVHQVPLVPHVPMVRPAHQ LHPGLVQRMLAQGVHPQHLPSLLQTGVLPPGMDLSHLQGISGPILGQPFYPLPAASHPLLNPRPGTPLHLAMVQQQLQRSVLHPPGSGSH -------------------------------------------------------------- >65544_65544_6_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000439502_EIF4ENIF1_chr22_31867903_ENST00000344710_length(transcript)=3402nt_BP=545nt CTGCGACCAAGCCCAGGTTTAGCGAAACCTACAGCTCCACTAGTTCCCCTACCTCCGCAGGTGCCAAGCGGGTTAGGTGGGGAGTAGCCA CAGGGCGGAGCTTAGTCGGCTCCGCCCCCAACCCGCGCTTTTCTCATTGGCCCACTGAACTCGAGACTCGTGACGCCTTAAGCGTGCGCC CAGCGTGTGAAGGGGGCGTGGCACGCTGAGAAGGAGCAGACAAGATGGCGACGTCCGTGGGGCACCGATGTCTGGGATTACTGCACGGGG TCGCGCCGTGGCGGAGCAGCCTCCATCCCTGTGAGATCACTGCCCTGAGCCAATCCCTACAGCCCTTACGGAAGCTGCCTTTTAGAGCCT TTCGCACAGATGCCAGAAAAATCCACACTGCCCCTGCCCGAACCATGTTCCTGCTGCGTCCCCTGCCCATTCTGTTGGTGACAGGCGGCG GGTATGCAGGGTACCGGCAGTATGAGAAGTACAGGGAGCGAGAGCTGGAGAAGCTGGGATTGGAGATTCCACCCAAACTTGCTGGTCACT GGGAGGAAGAACTCTTGGATATAAAAGAACTCCCCCATTCCAAACAGAGGCCTTCATGCCTTTCTGAAAAATATGACAGTGATGGTGTCT GGGACCCTGAGAAGTGGCATGCCTCTCTCTACCCAGCTTCAGGGCGGAGCTCACCAGTGGAAAGTCTGAAGAAAGAGTTGGATACAGACC GGCCTTCCCTGGTGCGCAGGATAGTAGGTATAGTAGAGTGCAATGGAGGAGTGGCCGAAGAGGATGAAGTGGAGGTCATCCTTGCACAGG AGCCTGCGGCTGATCAGGAAGTGCCAAGGGATGCTGTCTTGCCTGAGCAGTCCCCAGGAGACTTTGACTTTAATGAGTTCTTTAACCTTG ATAAGGTGCCATGCTTGGCTTCGATGATAGAAGATGTTTTGGGAGAAGGGTCAGTCTCTGCCAGTCGGTTCAGTAGGTGGTTCTCTAACC CGAGCAGATCAGGAAGCCGATCCAGCAGTCTTGGGTCAACACCACATGAAGAGCTAGAGAGACTTGCAGGTCTGGAGCAAGCCATCCTCT CTCCTGGACAGAACTCGGGGAATTACTTTGCTCCTATACCATTGGAAGACCATGCTGAAAATAAAGTGGATATTTTAGAAATGCTACAGA AAGCCAAAGTGGATTTGAAACCTCTTCTTTCCAGCCTTTCTGCAAATAAAGAAAAACTTAAAGAAAGCTCACATTCAGGGGTTGTGCTTT CAGTGGAGGAGGTAGAAGCAGGTCTGAAGGGCTTGAAGGTTGACCAGCAAGTGAAGAATTCAACTCCCTTCATGGCAGAACACCTAGAAG AGACCTTGAGTGCCGTAACCAACAATCGACAACTGAAGAAAGACGGAGACATGACTGCGTTCAACAAGCTAGTGAGCACAATGAAGCGAA ACCTTGAAAGCCATTTGATGTCCCCTGCTGAGATTCCAGGCCAGCCTGTCCCTAAGAACATCCTGCAGGAACTTCTGGGTCAACCAGTTC AGAGACCTGCTTCTTCCAATCTTCTGAGTGGCCTTATGGGGAGCTTGGAGCCTACAACATCTTTACTGGGCCAAAGAGCACCCTCTCCTC CCTTGTCACAGGTGTTTCAAACTCGAGCAGCCTCAGCTGACTACCTTCGCCCAAGAATACCATCACCAATTGGTTTCACACCAGGACCAC AGCAGCTACTCGGAGATCCATTCCAAGGCATGCGCAAACCCATGAGCCCCATCACAGCCCAGCAGATGAGCCAGCTGGAGTTGCAACAGG CAGCTTTAGAAGGGCTGGCCTTGCCACATGACCTTGCTGTACAGGCAGCAAACTTCTACCAGCCTGGTTTTGGCAAACCACAGGTGGACA GAACCAGAGATGGATTCAGAAACAGGCAACAGCGAGTGACCAAGTCACCAGCACCCGTGCATCGAGGGAATTCCTCTTCCCCTGCCCCTG CTGCCTCCATCACAAGCATGCTTTCTCCTTCCTTTACCCCTACCTCAGTGATTCGTAAGATGTACGAGAGCAAAGAGAAAAGCAAGGAGG AGCCAGCATCTGGAAAAGCAGCTCTTGGTGACAGTAAAGAGGATACTCAGAAGGCCAGTGAAGAAAACCTCCTGTCATCCAGCTCTGTAC CCAGTGCCGATCGAGACTCTTCTCCCACTACAAATTCCAAACTGTCAGCATTACAGAGGTCTTCGTGTTCCACCCCACTGTCCCAGGCCA ACCGTTACACCAAAGAACAAGATTATCGACCTAAAGCAACTGGGAGAAAAACACCCACCTTGGCATCCCCAGTTCCTACAACACCTTTTC TCCGCCCTGTCCACCAAGTTCCCCTTGTCCCCCATGTCCCTATGGTTAGGCCTGCTCACCAGCTTCACCCAGGGTTGGTACAGAGGATGC TGGCCCAGGGAGTACATCCACAGCATCTTCCAAGTTTGCTCCAAACTGGTGTGCTTCCTCCTGGGATGGACTTGAGTCATTTACAGGGAA TATCTGGCCCCATCCTGGGTCAGCCCTTTTACCCTTTACCTGCTGCTAGTCACCCTCTCTTAAACCCTCGTCCTGGAACACCTCTGCATC TGGCAATGGTGCAACAGCAGCTACAGCGCTCAGTTCTGCATCCTCCAGGCTCTGGTTCCCATGCAGCAGCTGTCAGCGTTCAGACAACCC CTCAGAACGTGCCCAGCCGGTCAGGCCTGCCCCACATGCACTCCCAGCTGGAGCATCGCCCCAGCCAGAGGAGCAGCTCCCCTGTGGGCC TTGCCAAATGGTTTGGCTCAGATGTGCTACAGCAACCCCTGCCCTCCATGCCCGCCAAAGTTATCAGTGTAGATGAATTGGAATACCGAC AGTGAGCAGGGCAGGCAGACTCAACTAAGCCCGGACCTGTGGTGGCACACTGGGCAGGACCCTGCTTCATCTCGGGTTGGTTTATGGGCT TTTACTTTGGAGCACTCTGTGTGAAGCTGTTTGGTGGAACCCATGCATCTGGTGTGGTCCGCATTATGATGGAAGGATCTTAACCAGTCG AGTGGAGTGTACATTGTCTGAATACAGGATGCACAATGTTGTCAATCCTGGAAATGGTCTTTCTTTTTTGTAAGATATGTGAATGAAGTG TTGGTGTCCTCACCAAGAGGTGGCACCTAAGGGTTCTGAGGAAATAAATGTATAGACCCTTATGTACAGACCTGTGTATAAACAACTTTT GTATATACATATAGGATAGCTTTTTTGAACTATACAGCTGTACATAAAAGTAGCTGATATTAGTTAGGCCTGTGTCAACAGTTTGGATTT >65544_65544_6_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000439502_EIF4ENIF1_chr22_31867903_ENST00000344710_length(amino acids)=886AA_BP=0 MATSVGHRCLGLLHGVAPWRSSLHPCEITALSQSLQPLRKLPFRAFRTDARKIHTAPARTMFLLRPLPILLVTGGGYAGYRQYEKYRERE LEKLGLEIPPKLAGHWEEELLDIKELPHSKQRPSCLSEKYDSDGVWDPEKWHASLYPASGRSSPVESLKKELDTDRPSLVRRIVGIVECN GGVAEEDEVEVILAQEPAADQEVPRDAVLPEQSPGDFDFNEFFNLDKVPCLASMIEDVLGEGSVSASRFSRWFSNPSRSGSRSSSLGSTP HEELERLAGLEQAILSPGQNSGNYFAPIPLEDHAENKVDILEMLQKAKVDLKPLLSSLSANKEKLKESSHSGVVLSVEEVEAGLKGLKVD QQVKNSTPFMAEHLEETLSAVTNNRQLKKDGDMTAFNKLVSTMKRNLESHLMSPAEIPGQPVPKNILQELLGQPVQRPASSNLLSGLMGS LEPTTSLLGQRAPSPPLSQVFQTRAASADYLRPRIPSPIGFTPGPQQLLGDPFQGMRKPMSPITAQQMSQLELQQAALEGLALPHDLAVQ AANFYQPGFGKPQVDRTRDGFRNRQQRVTKSPAPVHRGNSSSPAPAASITSMLSPSFTPTSVIRKMYESKEKSKEEPASGKAALGDSKED TQKASEENLLSSSSVPSADRDSSPTTNSKLSALQRSSCSTPLSQANRYTKEQDYRPKATGRKTPTLASPVPTTPFLRPVHQVPLVPHVPM VRPAHQLHPGLVQRMLAQGVHPQHLPSLLQTGVLPPGMDLSHLQGISGPILGQPFYPLPAASHPLLNPRPGTPLHLAMVQQQLQRSVLHP -------------------------------------------------------------- >65544_65544_7_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000439502_EIF4ENIF1_chr22_31867903_ENST00000397523_length(transcript)=3842nt_BP=545nt CTGCGACCAAGCCCAGGTTTAGCGAAACCTACAGCTCCACTAGTTCCCCTACCTCCGCAGGTGCCAAGCGGGTTAGGTGGGGAGTAGCCA CAGGGCGGAGCTTAGTCGGCTCCGCCCCCAACCCGCGCTTTTCTCATTGGCCCACTGAACTCGAGACTCGTGACGCCTTAAGCGTGCGCC CAGCGTGTGAAGGGGGCGTGGCACGCTGAGAAGGAGCAGACAAGATGGCGACGTCCGTGGGGCACCGATGTCTGGGATTACTGCACGGGG TCGCGCCGTGGCGGAGCAGCCTCCATCCCTGTGAGATCACTGCCCTGAGCCAATCCCTACAGCCCTTACGGAAGCTGCCTTTTAGAGCCT TTCGCACAGATGCCAGAAAAATCCACACTGCCCCTGCCCGAACCATGTTCCTGCTGCGTCCCCTGCCCATTCTGTTGGTGACAGGCGGCG GGTATGCAGGGTACCGGCAGTATGAGAAGTACAGGGAGCGAGAGCTGGAGAAGCTGGGATTGGAGATTCCACCCAAACTTGCTGGTCACT GGGAGGAAGAACTCTTGGATATAAAAGAACTCCCCCATTCCAAACAGAGGCCTTCATGCCTTTCTGAAAAATATGACAGTGATGGTGTCT GGGACCCTGAGAAGTGGCATGCCTCTCTCTACCCAGCTTCAGGGCGGAGCTCACCAGTGGAAAGTCTGAAGAAAGAGTTGGATACAGACC GGCCTTCCCTGGTGCGCAGGATAGTAGATCCACGAGAGCGTGTGAAAGAAGATGACTTAGATGTTGTTCTCAGCCCTCAGAGACGGAGCT TTGGAGGGGGCTGCCACGTGACAGCCGCTGTTAGCTCCCGGCGCTCAGGAAGTCCATTAGAGAAAGATAGTGATGGGCTTCGTCTGCTTG GTGGACGTAGGATTGGCAGTGGGAGGATAATCTCTGCCCGGACCTTTGAGAAGGATCACCGTCTTAGCGATAAGGACCTGCGGGACTTGA GAGACAGAGACCGAGAGAGGGACTTCAAGGACAAGCGTTTCAGGAGAGAGTTTGGAGATAGTAAGCGTGTCTTTGGTGAGCGTAGAAGAA ATGATTCTTACACAGAAGAAGAACCAGAGTGGTTCTCTGCTGGACCCACAAGTCAGTCTGAAACCATCGAACTGACTGGCTTTGATGATA AGATACTAGAAGAAGATCACAAAGGGAGAAAAAGAACAAGGCGACGGACAGCCTCTGTGAAGGAAGGTATAGTAGAGTGCAATGGAGGAG TGGCCGAAGAGGATGAAGTGGAGGTCATCCTTGCACAGGAGCCTGCGGCTGATCAGGAAGTGCCAAGGGATGCTGTCTTGCCTGAGCAGT CCCCAGGAGACTTTGACTTTAATGAGTTCTTTAACCTTGATAAGGTGCCATGCTTGGCTTCGATGATAGAAGATGTTTTGGGAGAAGGGT CAGTCTCTGCCAGTCGGTTCAGTAGGTGGTTCTCTAACCCGAGCAGATCAGGAAGCCGATCCAGCAGTCTTGGGTCAACACCACATGAAG AGCTAGAGAGACTTGCAGGTCTGGAGCAAGCCATCCTCTCTCCTGGACAGAACTCGGGGAATTACTTTGCTCCTATACCATTGGAAGACC ATGCTGAAAATAAAGTGGATATTTTAGAAATGCTACAGAAAGCCAAAGTGGATTTGAAACCTCTTCTTTCCAGCCTTTCTGCAAATAAAG AAAAACTTAAAGAAAGCTCACATTCAGGGGTTGTGCTTTCAGTGGAGGAGGTAGAAGCAGGTCTGAAGGGCTTGAAGGTTGACCAGCAAG TGAAGAATTCAACTCCCTTCATGGCAGAACACCTAGAAGAGACCTTGAGTGCCGTAACCAACAATCGACAACTGAAGAAAGACGGAGACA TGACTGCGTTCAACAAGCTAGTGAGCACAATGAAGGCAAGTGGGACTTTGCCTTCTCAGCCCAAAGTCAGCGAACTTCTGGGTCAACCAG TTCAGAGACCTGCTTCTTCCAATCTTCTGAGTGGCCTTATGGGGAGCTTGGAGCCTACAACATCTTTACTGGGCCAAAGAGCACCCTCTC CTCCCTTGTCACAGGTGTTTCAAACTCGAGCAGCCTCAGCTGACTACCTTCGCCCAAGAATACCATCACCAATTGGTTTCACACCAGGAC CACAGCAGCTACTCGGAGATCCATTCCAAGGCATGCGCAAACCCATGAGCCCCATCACAGCCCAGATGAGCCAGCTGGAGTTGCAACAGG CAGCTTTAGAAGGGCTGGCCTTGCCACATGACCTTGCTGTACAGGCAGCAAACTTCTACCAGCCTGGTTTTGGCAAACCACAGGTGGACA GAACCAGAGATGGATTCAGAAACAGGCAACAGCGAGTGACCAAGTCACCAGCACCCGTGCATCGAGGGAATTCCTCTTCCCCTGCCCCTG CTGCCTCCATCACAAGCATGCTTTCTCCTTCCTTTACCCCTACCTCAGTGATTCGTAAGATGTACGAGAGCAAAGAGAAAAGCAAGGAGG AGCCAGCATCTGGAAAAGCAGCTCTTGGTGACAGTAAAGAGGATACTCAGAAGGCCAGTGAAGAAAACCTCCTGTCATCCAGCTCTGTAC CCAGTGCCGATCGAGACTCTTCTCCCACTACAAATTCCAAACTGTCAGCATTACAGAGGTCTTCGTGTTCCACCCCACTGTCCCAGGCCA ACCGTTACACCAAAGAACAAGATTATCGACCTAAAGCAACTGGGAGAAAAACACCCACCTTGGCATCCCCAGTTCCTACAACACCTTTTC TCCGCCCTGTCCACCAAGTTCCCCTTGTCCCCCATGTCCCTATGGTTAGGCCTGCTCACCAGCTTCACCCAGGGTTGGTACAGAGGATGC TGGCCCAGGGAGTACATCCACAGCATCTTCCAAGTTTGCTCCAAACTGGTGTGCTTCCTCCTGGGATGGACTTGAGTCATTTACAGGGAA TATCTGGCCCCATCCTGGGTCAGCCCTTTTACCCTTTACCTGCTGCTAGTCACCCTCTCTTAAACCCTCGTCCTGGAACACCTCTGCATC TGGCAATGGTGCAACAGCAGCTACAGCGCTCAGTTCTGCATCCTCCAGGCTCTGGTTCCCATGCAGCAGCTGTCAGCGTTCAGACAACCC CTCAGAACGTGCCCAGCCGGTCAGGCCTGCCCCACATGCACTCCCAGCTGGAGCATCGCCCCAGCCAGAGGAGCAGCTCCCCTGTGGGCC TTGCCAAATGGTTTGGCTCAGATGTGCTACAGCAACCCCTGCCCTCCATGCCCGCCAAAGTTATCAGTGTAGATGAATTGGAATACCGAC AGTGAGCAGGGCAGGCAGACTCAACTAAGCCCGGACCTGTGGTGGCACACTGGGCAGGACCCTGCTTCATCTCGGGTTGGTTTATGGGCT TTTACTTTGGAGCACTCTGTGTGAAGCTGTTTGGTGGAACCCATGCATCTGGTGTGGTCCGCATTATGATGGAAGGATCTTAACCAGTCG AGTGGAGTGTACATTGTCTGAATACAGGATGCACAATGTTGTCAATCCTGGAAATGGTCTTTCTTTTTTGTAAGATATGTGAATGAAGTG TTGGTGTCCTCACCAAGAGGTGGCACCTAAGGGTTCTGAGGAAATAAATGTATAGACCCTTATGTACAGACCTGTGTATAAACAACTTTT GTATATACATATAGGATAGCTTTTTTGAACTATACAGCTGTACATAAAAGTAGCTGATATTAGTTAGGCCTGTGTCAACAGTTTGGATTT >65544_65544_7_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000439502_EIF4ENIF1_chr22_31867903_ENST00000397523_length(amino acids)=1036AA_BP=0 MATSVGHRCLGLLHGVAPWRSSLHPCEITALSQSLQPLRKLPFRAFRTDARKIHTAPARTMFLLRPLPILLVTGGGYAGYRQYEKYRERE LEKLGLEIPPKLAGHWEEELLDIKELPHSKQRPSCLSEKYDSDGVWDPEKWHASLYPASGRSSPVESLKKELDTDRPSLVRRIVDPRERV KEDDLDVVLSPQRRSFGGGCHVTAAVSSRRSGSPLEKDSDGLRLLGGRRIGSGRIISARTFEKDHRLSDKDLRDLRDRDRERDFKDKRFR REFGDSKRVFGERRRNDSYTEEEPEWFSAGPTSQSETIELTGFDDKILEEDHKGRKRTRRRTASVKEGIVECNGGVAEEDEVEVILAQEP AADQEVPRDAVLPEQSPGDFDFNEFFNLDKVPCLASMIEDVLGEGSVSASRFSRWFSNPSRSGSRSSSLGSTPHEELERLAGLEQAILSP GQNSGNYFAPIPLEDHAENKVDILEMLQKAKVDLKPLLSSLSANKEKLKESSHSGVVLSVEEVEAGLKGLKVDQQVKNSTPFMAEHLEET LSAVTNNRQLKKDGDMTAFNKLVSTMKASGTLPSQPKVSELLGQPVQRPASSNLLSGLMGSLEPTTSLLGQRAPSPPLSQVFQTRAASAD YLRPRIPSPIGFTPGPQQLLGDPFQGMRKPMSPITAQMSQLELQQAALEGLALPHDLAVQAANFYQPGFGKPQVDRTRDGFRNRQQRVTK SPAPVHRGNSSSPAPAASITSMLSPSFTPTSVIRKMYESKEKSKEEPASGKAALGDSKEDTQKASEENLLSSSSVPSADRDSSPTTNSKL SALQRSSCSTPLSQANRYTKEQDYRPKATGRKTPTLASPVPTTPFLRPVHQVPLVPHVPMVRPAHQLHPGLVQRMLAQGVHPQHLPSLLQ TGVLPPGMDLSHLQGISGPILGQPFYPLPAASHPLLNPRPGTPLHLAMVQQQLQRSVLHPPGSGSHAAAVSVQTTPQNVPSRSGLPHMHS -------------------------------------------------------------- >65544_65544_8_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000439502_EIF4ENIF1_chr22_31867903_ENST00000397525_length(transcript)=3920nt_BP=545nt CTGCGACCAAGCCCAGGTTTAGCGAAACCTACAGCTCCACTAGTTCCCCTACCTCCGCAGGTGCCAAGCGGGTTAGGTGGGGAGTAGCCA CAGGGCGGAGCTTAGTCGGCTCCGCCCCCAACCCGCGCTTTTCTCATTGGCCCACTGAACTCGAGACTCGTGACGCCTTAAGCGTGCGCC CAGCGTGTGAAGGGGGCGTGGCACGCTGAGAAGGAGCAGACAAGATGGCGACGTCCGTGGGGCACCGATGTCTGGGATTACTGCACGGGG TCGCGCCGTGGCGGAGCAGCCTCCATCCCTGTGAGATCACTGCCCTGAGCCAATCCCTACAGCCCTTACGGAAGCTGCCTTTTAGAGCCT TTCGCACAGATGCCAGAAAAATCCACACTGCCCCTGCCCGAACCATGTTCCTGCTGCGTCCCCTGCCCATTCTGTTGGTGACAGGCGGCG GGTATGCAGGGTACCGGCAGTATGAGAAGTACAGGGAGCGAGAGCTGGAGAAGCTGGGATTGGAGATTCCACCCAAACTTGCTGGTCACT GGGAGGAAGAACTCTTGGATATAAAAGAACTCCCCCATTCCAAACAGAGGCCTTCATGCCTTTCTGAAAAATATGACAGTGATGGTGTCT GGGACCCTGAGAAGTGGCATGCCTCTCTCTACCCAGCTTCAGGGCGGAGCTCACCAGTGGAAAGTCTGAAGAAAGAGTTGGATACAGACC GGCCTTCCCTGGTGCGCAGGATAGTAGATCCACGAGAGCGTGTGAAAGAAGATGACTTAGATGTTGTTCTCAGCCCTCAGAGACGGAGCT TTGGAGGGGGCTGCCACGTGACAGCCGCTGTTAGCTCCCGGCGCTCAGGAAGTCCATTAGAGAAAGATAGTGATGGGCTTCGTCTGCTTG GTGGACGTAGGATTGGCAGTGGGAGGATAATCTCTGCCCGGACCTTTGAGAAGGATCACCGTCTTAGCGATAAGGACCTGCGGGACTTGA GAGACAGAGACCGAGAGAGGGACTTCAAGGACAAGCGTTTCAGGAGAGAGTTTGGAGATAGTAAGCGTGTCTTTGGTGAGCGTAGAAGAA ATGATTCTTACACAGAAGAAGAACCAGAGTGGTTCTCTGCTGGACCCACAAGTCAGTCTGAAACCATCGAACTGACTGGCTTTGATGATA AGATACTAGAAGAAGATCACAAAGGGAGAAAAAGAACAAGGCGACGGACAGCCTCTGTGAAGGAAGGTATAGTAGAGTGCAATGGAGGAG TGGCCGAAGAGGATGAAGTGGAGGTCATCCTTGCACAGGAGCCTGCGGCTGATCAGGAAGTGCCAAGGGATGCTGTCTTGCCTGAGCAGT CCCCAGGAGACTTTGACTTTAATGAGTTCTTTAACCTTGATAAGGTGCCATGCTTGGCTTCGATGATAGAAGATGTTTTGGGAGAAGGGT CAGTCTCTGCCAGTCGGTTCAGTAGGTGGTTCTCTAACCCGAGCAGATCAGGAAGCCGATCCAGCAGTCTTGGGTCAACACCACATGAAG AGCTAGAGAGACTTGCAGGTCTGGAGCAAGCCATCCTCTCTCCTGGACAGAACTCGGGGAATTACTTTGCTCCTATACCATTGGAAGACC ATGCTGAAAATAAAGTGGATATTTTAGAAATGCTACAGAAAGCCAAAGTGGATTTGAAACCTCTTCTTTCCAGCCTTTCTGCAAATAAAG AAAAACTTAAAGAAAGCTCACATTCAGGGGTTGTGCTTTCAGTGGAGGAGGTAGAAGCAGGTCTGAAGGGCTTGAAGGTTGACCAGCAAG TGAAGAATTCAACTCCCTTCATGGCAGAACACCTAGAAGAGACCTTGAGTGCCGTAACCAACAATCGACAACTGAAGAAAGACGGAGACA TGACTGCGTTCAACAAGCTAGTGAGCACAATGAAGGCAAGTGGGACTTTGCCTTCTCAGCCCAAAGTCAGCCGAAACCTTGAAAGCCATT TGATGTCCCCTGCTGAGATTCCAGGCCAGCCTGTCCCTAAGAACATCCTGCAGGAACTTCTGGGTCAACCAGTTCAGAGACCTGCTTCTT CCAATCTTCTGAGTGGCCTTATGGGGAGCTTGGAGCCTACAACATCTTTACTGGGCCAAAGAGCACCCTCTCCTCCCTTGTCACAGGTGT TTCAAACTCGAGCAGCCTCAGCTGACTACCTTCGCCCAAGAATACCATCACCAATTGGTTTCACACCAGGACCACAGCAGCTACTCGGAG ATCCATTCCAAGGCATGCGCAAACCCATGAGCCCCATCACAGCCCAGATGAGCCAGCTGGAGTTGCAACAGGCAGCTTTAGAAGGGCTGG CCTTGCCACATGACCTTGCTGTACAGGCAGCAAACTTCTACCAGCCTGGTTTTGGCAAACCACAGGTGGACAGAACCAGAGATGGATTCA GAAACAGGCAACAGCGAGTGACCAAGTCACCAGCACCCGTGCATCGAGGGAATTCCTCTTCCCCTGCCCCTGCTGCCTCCATCACAAGCA TGCTTTCTCCTTCCTTTACCCCTACCTCAGTGATTCGTAAGATGTACGAGAGCAAAGAGAAAAGCAAGGAGGAGCCAGCATCTGGAAAAG CAGCTCTTGGTGACAGTAAAGAGGATACTCAGAAGGCCAGTGAAGAAAACCTCCTGTCATCCAGCTCTGTACCCAGTGCCGATCGAGACT CTTCTCCCACTACAAATTCCAAACTGTCAGCATTACAGAGGTCTTCGTGTTCCACCCCACTGTCCCAGGCCAACCGTTACACCAAAGAAC AAGATTATCGACCTAAAGCAACTGGGAGAAAAACACCCACCTTGGCATCCCCAGTTCCTACAACACCTTTTCTCCGCCCTGTCCACCAAG TTCCCCTTGTCCCCCATGTCCCTATGGTTAGGCCTGCTCACCAGCTTCACCCAGGGTTGGTACAGAGGATGCTGGCCCAGGGAGTACATC CACAGCATCTTCCAAGTTTGCTCCAAACTGGTGTGCTTCCTCCTGGGATGGACTTGAGTCATTTACAGGGAATATCTGGCCCCATCCTGG GTCAGCCCTTTTACCCTTTACCTGCTGCTAGTCACCCTCTCTTAAACCCTCGTCCTGGAACACCTCTGCATCTGGCAATGGTGCAACAGC AGCTACAGCGCTCAGTTCTGCATCCTCCAGGCTCTGGTTCCCATGCAGCAGCTGTCAGCGTTCAGACAACCCCTCAGAACGTGCCCAGCC GGTCAGGCCTGCCCCACATGCACTCCCAGCTGGAGCATCGCCCCAGCCAGAGGAGCAGCTCCCCTGTGGGCCTTGCCAAATGGTTTGGCT CAGATGTGCTACAGCAACCCCTGCCCTCCATGCCCGCCAAAGTTATCAGTGTAGATGAATTGGAATACCGACAGTGAGCAGGGCAGGCAG ACTCAACTAAGCCCGGACCTGTGGTGGCACACTGGGCAGGACCCTGCTTCATCTCGGGTTGGTTTATGGGCTTTTACTTTGGAGCACTCT GTGTGAAGCTGTTTGGTGGAACCCATGCATCTGGTGTGGTCCGCATTATGATGGAAGGATCTTAACCAGTCGAGTGGAGTGTACATTGTC TGAATACAGGATGCACAATGTTGTCAATCCTGGAAATGGTCTTTCTTTTTTGTAAGATATGTGAATGAAGTGTTGGTGTCCTCACCAAGA GGTGGCACCTAAGGGTTCTGAGGAAATAAATGTATAGACCCTTATGTACAGACCTGTGTATAAACAACTTTTGTATATACATATAGGATA GCTTTTTTGAACTATACAGCTGTACATAAAAGTAGCTGATATTAGTTAGGCCTGTGTCAACAGTTTGGATTTTTTTCACTTGTACATTTG >65544_65544_8_PISD-EIF4ENIF1_PISD_chr22_32044087_ENST00000439502_EIF4ENIF1_chr22_31867903_ENST00000397525_length(amino acids)=1060AA_BP=0 MATSVGHRCLGLLHGVAPWRSSLHPCEITALSQSLQPLRKLPFRAFRTDARKIHTAPARTMFLLRPLPILLVTGGGYAGYRQYEKYRERE LEKLGLEIPPKLAGHWEEELLDIKELPHSKQRPSCLSEKYDSDGVWDPEKWHASLYPASGRSSPVESLKKELDTDRPSLVRRIVDPRERV KEDDLDVVLSPQRRSFGGGCHVTAAVSSRRSGSPLEKDSDGLRLLGGRRIGSGRIISARTFEKDHRLSDKDLRDLRDRDRERDFKDKRFR REFGDSKRVFGERRRNDSYTEEEPEWFSAGPTSQSETIELTGFDDKILEEDHKGRKRTRRRTASVKEGIVECNGGVAEEDEVEVILAQEP AADQEVPRDAVLPEQSPGDFDFNEFFNLDKVPCLASMIEDVLGEGSVSASRFSRWFSNPSRSGSRSSSLGSTPHEELERLAGLEQAILSP GQNSGNYFAPIPLEDHAENKVDILEMLQKAKVDLKPLLSSLSANKEKLKESSHSGVVLSVEEVEAGLKGLKVDQQVKNSTPFMAEHLEET LSAVTNNRQLKKDGDMTAFNKLVSTMKASGTLPSQPKVSRNLESHLMSPAEIPGQPVPKNILQELLGQPVQRPASSNLLSGLMGSLEPTT SLLGQRAPSPPLSQVFQTRAASADYLRPRIPSPIGFTPGPQQLLGDPFQGMRKPMSPITAQMSQLELQQAALEGLALPHDLAVQAANFYQ PGFGKPQVDRTRDGFRNRQQRVTKSPAPVHRGNSSSPAPAASITSMLSPSFTPTSVIRKMYESKEKSKEEPASGKAALGDSKEDTQKASE ENLLSSSSVPSADRDSSPTTNSKLSALQRSSCSTPLSQANRYTKEQDYRPKATGRKTPTLASPVPTTPFLRPVHQVPLVPHVPMVRPAHQ LHPGLVQRMLAQGVHPQHLPSLLQTGVLPPGMDLSHLQGISGPILGQPFYPLPAASHPLLNPRPGTPLHLAMVQQQLQRSVLHPPGSGSH -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PISD-EIF4ENIF1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 131_161 | 32.0 | 986.0 | CSDE1 | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 131_161 | 32.0 | 812.0 | CSDE1 | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 131_161 | 32.0 | 986.0 | CSDE1 | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 219_240 | 32.0 | 986.0 | DDX6 | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 219_240 | 32.0 | 812.0 | DDX6 | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 219_240 | 32.0 | 986.0 | DDX6 | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 448_490 | 32.0 | 986.0 | LSM14A | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 940_985 | 32.0 | 986.0 | LSM14A | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 448_490 | 32.0 | 812.0 | LSM14A | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 940_985 | 32.0 | 812.0 | LSM14A | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 448_490 | 32.0 | 986.0 | LSM14A | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 940_985 | 32.0 | 986.0 | LSM14A | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000330125 | 1 | 19 | 695_713 | 32.0 | 986.0 | PATL1 | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000344710 | 1 | 17 | 695_713 | 32.0 | 812.0 | PATL1 | |
| Tgene | EIF4ENIF1 | chr22:32044087 | chr22:31867903 | ENST00000397525 | 1 | 19 | 695_713 | 32.0 | 986.0 | PATL1 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PISD-EIF4ENIF1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PISD-EIF4ENIF1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies