
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PNPLA2-EPS8L2 (FusionGDB2 ID:66764) |
Fusion Gene Summary for PNPLA2-EPS8L2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PNPLA2-EPS8L2 | Fusion gene ID: 66764 | Hgene | Tgene | Gene symbol | PNPLA2 | EPS8L2 | Gene ID | 57104 | 64787 |
| Gene name | patatin like phospholipase domain containing 2 | EPS8 like 2 | |
| Synonyms | 1110001C14Rik|ATGL|FP17548|PEDF-R|TTS-2.2|TTS2|iPLA2zeta | DFNB106|EPS8R2 | |
| Cytomap | 11p15.5 | 11p15.5 | |
| Type of gene | protein-coding | protein-coding | |
| Description | patatin-like phospholipase domain-containing protein 2IPLA2-zetaTTS2.2adipose triglyceride lipasecalcium-independent phospholipase A2desnutrinmutant patatin-like phospholipase domain containing 2pigment epithelium-derived factortransport-secretion | epidermal growth factor receptor kinase substrate 8-like protein 2EPS8-related protein 2epidermal growth factor receptor pathway substrate 8-related protein 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q9H6S3 | |
| Ensembl transtripts involved in fusion gene | ENST00000336615, | ENST00000534449, ENST00000318562, ENST00000526198, ENST00000530636, ENST00000533256, | |
| Fusion gene scores | * DoF score | 6 X 5 X 4=120 | 9 X 7 X 8=504 |
| # samples | 7 | 15 | |
| ** MAII score | log2(7/120*10)=-0.777607578663552 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(15/504*10)=-1.74846123300404 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PNPLA2 [Title/Abstract] AND EPS8L2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PNPLA2(822606)-EPS8L2(720062), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PNPLA2 | GO:0010891 | negative regulation of sequestering of triglyceride | 16679289 |
| Hgene | PNPLA2 | GO:0010898 | positive regulation of triglyceride catabolic process | 16679289 |
| Tgene | EPS8L2 | GO:0007266 | Rho protein signal transduction | 14565974 |
| Tgene | EPS8L2 | GO:0035023 | regulation of Rho protein signal transduction | 14565974 |
| Fusion gene breakpoints across PNPLA2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across EPS8L2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-BR-8485-01A | PNPLA2 | chr11 | 822606 | - | EPS8L2 | chr11 | 720062 | + |
| ChimerDB4 | STAD | TCGA-BR-8485-01A | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + |
| ChimerDB4 | STAD | TCGA-BR-8485 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + |
Top |
Fusion Gene ORF analysis for PNPLA2-EPS8L2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000336615 | ENST00000534449 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + |
| 5CDS-intron | ENST00000336615 | ENST00000534449 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + |
| In-frame | ENST00000336615 | ENST00000318562 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + |
| In-frame | ENST00000336615 | ENST00000318562 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + |
| In-frame | ENST00000336615 | ENST00000526198 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + |
| In-frame | ENST00000336615 | ENST00000526198 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + |
| In-frame | ENST00000336615 | ENST00000530636 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + |
| In-frame | ENST00000336615 | ENST00000530636 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + |
| In-frame | ENST00000336615 | ENST00000533256 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + |
| In-frame | ENST00000336615 | ENST00000533256 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000336615 | PNPLA2 | chr11 | 822606 | + | ENST00000318562 | EPS8L2 | chr11 | 720062 | + | 3627 | 898 | 106 | 2880 | 924 |
| ENST00000336615 | PNPLA2 | chr11 | 822606 | + | ENST00000533256 | EPS8L2 | chr11 | 720062 | + | 3624 | 898 | 106 | 2880 | 924 |
| ENST00000336615 | PNPLA2 | chr11 | 822606 | + | ENST00000530636 | EPS8L2 | chr11 | 720062 | + | 2951 | 898 | 106 | 2880 | 924 |
| ENST00000336615 | PNPLA2 | chr11 | 822606 | + | ENST00000526198 | EPS8L2 | chr11 | 720062 | + | 2982 | 898 | 106 | 2928 | 940 |
| ENST00000336615 | PNPLA2 | chr11 | 822606 | + | ENST00000318562 | EPS8L2 | chr11 | 720061 | + | 3627 | 898 | 106 | 2880 | 924 |
| ENST00000336615 | PNPLA2 | chr11 | 822606 | + | ENST00000533256 | EPS8L2 | chr11 | 720061 | + | 3624 | 898 | 106 | 2880 | 924 |
| ENST00000336615 | PNPLA2 | chr11 | 822606 | + | ENST00000530636 | EPS8L2 | chr11 | 720061 | + | 2951 | 898 | 106 | 2880 | 924 |
| ENST00000336615 | PNPLA2 | chr11 | 822606 | + | ENST00000526198 | EPS8L2 | chr11 | 720061 | + | 2982 | 898 | 106 | 2928 | 940 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000336615 | ENST00000318562 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + | 0.007768596 | 0.99223137 |
| ENST00000336615 | ENST00000533256 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + | 0.007737878 | 0.9922621 |
| ENST00000336615 | ENST00000530636 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + | 0.014061359 | 0.9859386 |
| ENST00000336615 | ENST00000526198 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720062 | + | 0.010831688 | 0.9891683 |
| ENST00000336615 | ENST00000318562 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + | 0.007768596 | 0.99223137 |
| ENST00000336615 | ENST00000533256 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + | 0.007737878 | 0.9922621 |
| ENST00000336615 | ENST00000530636 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + | 0.014061359 | 0.9859386 |
| ENST00000336615 | ENST00000526198 | PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + | 0.010831688 | 0.9891683 |
Top |
Fusion Genomic Features for PNPLA2-EPS8L2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + | 4.05E-11 | 1 |
| PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + | 4.05E-11 | 1 |
| PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + | 4.05E-11 | 1 |
| PNPLA2 | chr11 | 822606 | + | EPS8L2 | chr11 | 720061 | + | 4.05E-11 | 1 |
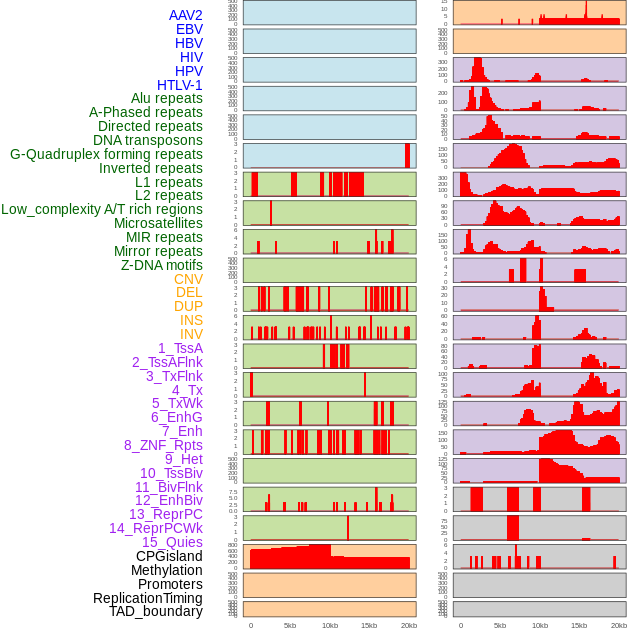
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
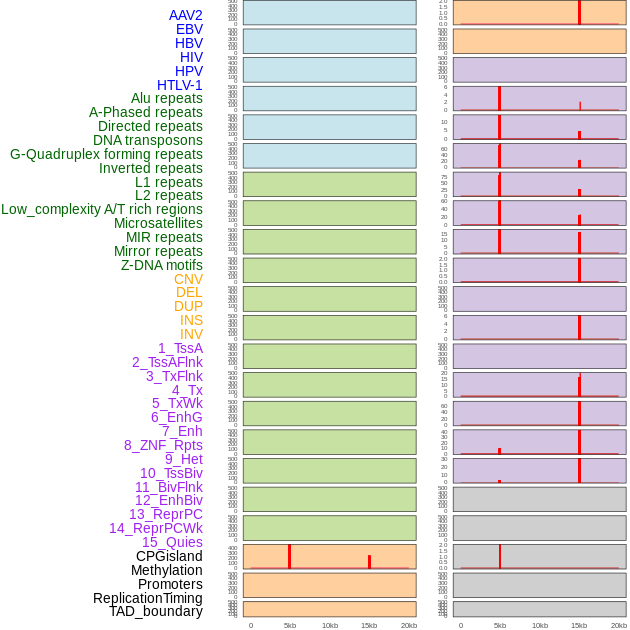
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for PNPLA2-EPS8L2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:822606/chr11:720062) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | EPS8L2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Stimulates guanine exchange activity of SOS1. May play a role in membrane ruffling and remodeling of the actin cytoskeleton. In the cochlea, is required for stereocilia maintenance in adult hair cells (By similarity). {ECO:0000250|UniProtKB:Q99K30, ECO:0000269|PubMed:14565974}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PNPLA2 | chr11:822606 | chr11:720061 | ENST00000336615 | + | 5 | 10 | 10_179 | 232 | 505.0 | Domain | PNPLA |
| Hgene | PNPLA2 | chr11:822606 | chr11:720062 | ENST00000336615 | + | 5 | 10 | 10_179 | 232 | 505.0 | Domain | PNPLA |
| Hgene | PNPLA2 | chr11:822606 | chr11:720061 | ENST00000336615 | + | 5 | 10 | 14_19 | 232 | 505.0 | Motif | GXGXXG |
| Hgene | PNPLA2 | chr11:822606 | chr11:720061 | ENST00000336615 | + | 5 | 10 | 166_168 | 232 | 505.0 | Motif | DGA/G |
| Hgene | PNPLA2 | chr11:822606 | chr11:720061 | ENST00000336615 | + | 5 | 10 | 45_49 | 232 | 505.0 | Motif | GXSXG |
| Hgene | PNPLA2 | chr11:822606 | chr11:720062 | ENST00000336615 | + | 5 | 10 | 14_19 | 232 | 505.0 | Motif | GXGXXG |
| Hgene | PNPLA2 | chr11:822606 | chr11:720062 | ENST00000336615 | + | 5 | 10 | 166_168 | 232 | 505.0 | Motif | DGA/G |
| Hgene | PNPLA2 | chr11:822606 | chr11:720062 | ENST00000336615 | + | 5 | 10 | 45_49 | 232 | 505.0 | Motif | GXSXG |
| Hgene | PNPLA2 | chr11:822606 | chr11:720061 | ENST00000336615 | + | 5 | 10 | 1_8 | 232 | 505.0 | Topological domain | Cytoplasmic |
| Hgene | PNPLA2 | chr11:822606 | chr11:720062 | ENST00000336615 | + | 5 | 10 | 1_8 | 232 | 505.0 | Topological domain | Cytoplasmic |
| Hgene | PNPLA2 | chr11:822606 | chr11:720061 | ENST00000336615 | + | 5 | 10 | 9_29 | 232 | 505.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | PNPLA2 | chr11:822606 | chr11:720062 | ENST00000336615 | + | 5 | 10 | 9_29 | 232 | 505.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Tgene | EPS8L2 | chr11:822606 | chr11:720061 | ENST00000318562 | 3 | 21 | 492_551 | 55 | 716.0 | Domain | SH3 | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720061 | ENST00000530636 | 3 | 21 | 492_551 | 55 | 716.0 | Domain | SH3 | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720061 | ENST00000533256 | 4 | 22 | 492_551 | 55 | 716.0 | Domain | SH3 | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720062 | ENST00000318562 | 3 | 21 | 492_551 | 55 | 716.0 | Domain | SH3 | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720062 | ENST00000530636 | 3 | 21 | 492_551 | 55 | 716.0 | Domain | SH3 | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720062 | ENST00000533256 | 4 | 22 | 492_551 | 55 | 716.0 | Domain | SH3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PNPLA2 | chr11:822606 | chr11:720061 | ENST00000336615 | + | 5 | 10 | 30_504 | 232 | 505.0 | Topological domain | Lumenal |
| Hgene | PNPLA2 | chr11:822606 | chr11:720062 | ENST00000336615 | + | 5 | 10 | 30_504 | 232 | 505.0 | Topological domain | Lumenal |
| Tgene | EPS8L2 | chr11:822606 | chr11:720061 | ENST00000318562 | 3 | 21 | 46_202 | 55 | 716.0 | Domain | PID | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720061 | ENST00000530636 | 3 | 21 | 46_202 | 55 | 716.0 | Domain | PID | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720061 | ENST00000533256 | 4 | 22 | 46_202 | 55 | 716.0 | Domain | PID | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720062 | ENST00000318562 | 3 | 21 | 46_202 | 55 | 716.0 | Domain | PID | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720062 | ENST00000530636 | 3 | 21 | 46_202 | 55 | 716.0 | Domain | PID | |
| Tgene | EPS8L2 | chr11:822606 | chr11:720062 | ENST00000533256 | 4 | 22 | 46_202 | 55 | 716.0 | Domain | PID |
Top |
Fusion Gene Sequence for PNPLA2-EPS8L2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >66764_66764_1_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720061_ENST00000318562_length(transcript)=3627nt_BP=898nt GCGGCCCCAGTCAGACGCAGGCAGCCCCAAAGCCTGAACAGGCAGGGCCAGACCCAGCTTCTTCGCCTCCGCCAGCGGGGACCCCGAGCT AGAGCCGCAGCGGGACCTGCCCGGCCCCCGGCTCCAGCGAGCGAGCGGCGAGCAGGCGGCTCACAGAGGCCTGGCCGCCCACGGAACCCG GGGCCCGGCGGCCGCCGCCGCGATGTTTCCCCGCGAGAAGACGTGGAACATCTCGTTCGCGGGCTGCGGCTTCCTCGGCGTCTACTACGT CGGCGTGGCCTCCTGCCTCCGCGAGCACGCGCCCTTCCTGGTGGCCAACGCCACGCACATCTACGGCGCCTCGGCCGGGGCGCTCACGGC CACGGCGCTGGTCACCGGGGTCTGCCTGGGTGAGGCTGGTGCCAAGTTCATTGAGGTATCTAAAGAGGCCCGGAAGCGGTTCCTGGGCCC CCTGCACCCCTCCTTCAACCTGGTAAAGATCATCCGCAGTTTCCTGCTGAAGGTCCTGCCTGCTGATAGCCATGAGCATGCCAGTGGGCG CCTGGGCATCTCCCTGACCCGCGTGTCAGACGGCGAGAATGTCATTATATCCCACTTCAACTCCAAGGACGAGCTCATCCAGGCCAATGT CTGCAGCGGTTTCATCCCCGTGTACTGTGGGCTCATCCCTCCCTCCCTCCAGGGGGTGCGCTACGTGGATGGTGGCATTTCAGACAACCT GCCACTCTATGAGCTTAAGAACACCATCACAGTGTCCCCCTTCTCGGGCGAGAGTGACATCTGTCCGCAGGACAGCTCCACCAACATCCA CGAGCTGCGGGTCACCAACACCAGCATCCAGTTCAACCTGCGCAACCTCTACCGCCTCTCCAAGGCCCTCTTCCCGCCGGAGCCCCTGCA CCTGGCCACATTCATCATGGACAAGAGCGAAGCCATCACGTCTGTGGACGACGCCATCCGGAAGCTGGTGCAGCTGAGCTCCAAGGAGAA GATCTGGACCCAGGAGATGCTGCTGCAGGTGAACGACCAGTCGCTGCGGCTGCTGGACATCGAGTCACAGGAGGAGCTGGAAGACTTCCC GCTGCCCACGGTGCAGCGCAGCCAGACGGTCCTCAACCAGCTGCGCTACCCGTCTGTGCTGCTGCTCGTGTGCCAGGACTCGGAGCAGAG CAAGCCGGATGTCCACTTCTTCCACTGCGATGAGGTGGAGGCAGAGCTGGTGCACGAGGACATCGAGAGCGCGTTGGCCGACTGCCGGCT GGGCAAGAAGATGCGGCCGCAGACCCTGAAGGGACACCAGGAGAAGATTCGGCAGCGGCAGTCCATCCTGCCTCCTCCCCAGGGCCCGGC GCCCATCCCCTTCCAGCACCGCGGCGGGGATTCCCCGGAGGCCAAGAATCGCGTGGGCCCGCAGGTGCCACTCAGCGAGCCAGGTTTCCG CCGTCGGGAGTCGCAGGAGGAGCCGCGGGCCGTGCTGGCTCAGAAGATAGAGAAGGAGACGCAAATCCTCAACTGCGCCCTGGACGACAT CGAGTGGTTTGTGGCCCGGCTGCAGAAGGCAGCCGAGGCTTTCAAGCAGCTGAACCAGCGGAAAAAGGGGAAGAAGAAGGGCAAGAAGGC GCCAGCAGAGGGCGTCCTCACACTGCGGGCACGGCCCCCCTCTGAGGGCGAGTTCATCGACTGCTTCCAGAAAATCAAGCTGGCGATTAA CTTGCTGGCAAAGCTGCAGAAGCACATCCAGAACCCCAGCGCCGCGGAGCTCGTGCACTTCCTCTTCGGGCCTCTGGACCTGATCGTCAA CACCTGCAGTGGCCCAGACATCGCACGCTCCGTCTCCTGCCCACTGCTCTCCCGAGATGCCGTGGACTTCCTGCGCGGCCACCTGGTCCC TAAGGAGATGTCGCTGTGGGAGTCACTGGGAGAGAGCTGGATGCGGCCCCGTTCCGAGTGGCCGCGGGAGCCACAGGTGCCCCTCTACGT GCCCAAGTTCCACAGCGGCTGGGAGCCTCCTGTGGATGTGCTGCAGGAGGCCCCCTGGGAGGTGGAGGGGCTGGCGTCTGCCCCCATCGA GGAGGTGAGTCCAGTGAGCCGACAGTCCATAAGAAACTCCCAGAAGCACAGCCCCACTTCAGAGCCCACCCCCCCGGGGGATGCCCTACC ACCAGTCAGCTCCCCACATACTCACAGGGGCTACCAGCCAACACCAGCCATGGCCAAGTACGTCAAGATCCTGTATGACTTCACAGCCCG AAATGCCAACGAGCTATCGGTGCTCAAGGATGAGGTCCTAGAGGTGCTGGAGGACGGCCGGCAGTGGTGGAAGCTGCGCAGCCGCAGCGG CCAGGCGGGGTACGTGCCCTGCAACATCCTAGGCGAGGCGCGACCGGAGGACGCCGGCGCCCCGTTCGAGCAGGCCGGTCAGAAGTACTG GGGCCCCGCCAGCCCGACCCACAAGCTACCCCCAAGCTTCCCGGGGAACAAAGACGAGCTCATGCAGCACATGGACGAGGTCAACGACGA GCTCATCCGGAAAATCAGCAACATCAGGGCGCAGCCACAGAGGCACTTCCGCGTGGAGCGCAGCCAGCCCGTGAGCCAGCCGCTCACCTA CGAGTCGGGTCCGGACGAGGTCCGCGCCTGGCTGGAAGCCAAGGCCTTCAGCCCGCGGATCGTGGAGAACCTGGGCATCCTGACCGGGCC GCAGCTCTTCTCCCTCAACAAGGAGGAGCTGAAGAAAGTGTGCGGCGAGGAGGGCGTCCGCGTGTACAGCCAGCTCACCATGCAGAAGGC CTTCCTGGAGAAGCAGCAAAGTGGGTCGGAGCTGGAAGAACTCATGAACAAGTTTCATTCCATGAATCAGAGGAGGGGGGAGGACAGCTA GGCCCAGCTGCCTTGGGCTGGGGCCTGCGGAGGGGAAGCCCACCCACAATGCATGGAGTATTATTTTTATATGTGTATGTATTTTGTATC AAGGACACGGAGGGGGTGTGGTGCTGGCTAGAGGTCCCTGCCCCTGTCTGGAGGCACAACGCCCATCCTTAGGCCAAACAGTACCCAAGG CCTCAGCCCACACCAAGACTAATCTCAGCCAAACCTGCTGCTTGGTGGTGCCAGCCCCTTGTCCACCTTCTCTTGAGGCCACAGAACTCC CTGGGGCTGGGGCCTCTTTCTCTGGCCTCCCCTGTGCACCTGGGGGGTCCTGGCCCCTGTGATGCTCCCCCATCCCCACCCACTTCTACA TCCATCCACACCCCAGGGTGAGCTGGAGCTCCAGGCTGGCCAGGCTGAACCTCGCACACACGCAGAGTTCTGCTCCCTGAGGGGGGCCCG GGAGGGGCTCCAGCAGGAGGCCGTGGGTGCCATTCGGGGGAAAGTGGGGGAACGACACACACTTCACCTGCAAGGGCCGACAACGCAGGG GACACCGTGCCGGCTTCAGACACTCCCAGCGCCCACTCTTACAGGCCCAGGACTGGAGCTTTCTCTGGCCAAGTTTCAGGCCAATGATCC CCGCATGGTGTTGGGGGTGCTGGTGTGTCTTGGTGCCTGGACTTGAGTCTCACCCTACAGATGAGAGGTGGCTGAGGCACCAGGGCTAAG >66764_66764_1_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720061_ENST00000318562_length(amino acids)=924AA_BP=262 MPGPRLQRASGEQAAHRGLAAHGTRGPAAAAAMFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVT GVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFI PVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLHLATFI MDKSEAITSVDDAIRKLVQLSSKEKIWTQEMLLQVNDQSLRLLDIESQEELEDFPLPTVQRSQTVLNQLRYPSVLLLVCQDSEQSKPDVH FFHCDEVEAELVHEDIESALADCRLGKKMRPQTLKGHQEKIRQRQSILPPPQGPAPIPFQHRGGDSPEAKNRVGPQVPLSEPGFRRRESQ EEPRAVLAQKIEKETQILNCALDDIEWFVARLQKAAEAFKQLNQRKKGKKKGKKAPAEGVLTLRARPPSEGEFIDCFQKIKLAINLLAKL QKHIQNPSAAELVHFLFGPLDLIVNTCSGPDIARSVSCPLLSRDAVDFLRGHLVPKEMSLWESLGESWMRPRSEWPREPQVPLYVPKFHS GWEPPVDVLQEAPWEVEGLASAPIEEVSPVSRQSIRNSQKHSPTSEPTPPGDALPPVSSPHTHRGYQPTPAMAKYVKILYDFTARNANEL SVLKDEVLEVLEDGRQWWKLRSRSGQAGYVPCNILGEARPEDAGAPFEQAGQKYWGPASPTHKLPPSFPGNKDELMQHMDEVNDELIRKI SNIRAQPQRHFRVERSQPVSQPLTYESGPDEVRAWLEAKAFSPRIVENLGILTGPQLFSLNKEELKKVCGEEGVRVYSQLTMQKAFLEKQ -------------------------------------------------------------- >66764_66764_2_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720061_ENST00000526198_length(transcript)=2982nt_BP=898nt GCGGCCCCAGTCAGACGCAGGCAGCCCCAAAGCCTGAACAGGCAGGGCCAGACCCAGCTTCTTCGCCTCCGCCAGCGGGGACCCCGAGCT AGAGCCGCAGCGGGACCTGCCCGGCCCCCGGCTCCAGCGAGCGAGCGGCGAGCAGGCGGCTCACAGAGGCCTGGCCGCCCACGGAACCCG GGGCCCGGCGGCCGCCGCCGCGATGTTTCCCCGCGAGAAGACGTGGAACATCTCGTTCGCGGGCTGCGGCTTCCTCGGCGTCTACTACGT CGGCGTGGCCTCCTGCCTCCGCGAGCACGCGCCCTTCCTGGTGGCCAACGCCACGCACATCTACGGCGCCTCGGCCGGGGCGCTCACGGC CACGGCGCTGGTCACCGGGGTCTGCCTGGGTGAGGCTGGTGCCAAGTTCATTGAGGTATCTAAAGAGGCCCGGAAGCGGTTCCTGGGCCC CCTGCACCCCTCCTTCAACCTGGTAAAGATCATCCGCAGTTTCCTGCTGAAGGTCCTGCCTGCTGATAGCCATGAGCATGCCAGTGGGCG CCTGGGCATCTCCCTGACCCGCGTGTCAGACGGCGAGAATGTCATTATATCCCACTTCAACTCCAAGGACGAGCTCATCCAGGCCAATGT CTGCAGCGGTTTCATCCCCGTGTACTGTGGGCTCATCCCTCCCTCCCTCCAGGGGGTGCGCTACGTGGATGGTGGCATTTCAGACAACCT GCCACTCTATGAGCTTAAGAACACCATCACAGTGTCCCCCTTCTCGGGCGAGAGTGACATCTGTCCGCAGGACAGCTCCACCAACATCCA CGAGCTGCGGGTCACCAACACCAGCATCCAGTTCAACCTGCGCAACCTCTACCGCCTCTCCAAGGCCCTCTTCCCGCCGGAGCCCCTGCA CCTGGCCACATTCATCATGGACAAGAGCGAAGCCATCACGTCTGTGGACGACGCCATCCGGAAGCTGGTGCAGCTGAGCTCCAAGGAGAA GATCTGGACCCAGGAGATGCTGCTGCAGGTGAACGACCAGTCGCTGCGGCTGCTGGACATCGAGTCACAGAGTGCCCAGACCCCGGGTGC GAGTCGTGTCCGCGCGATGTACCCGCAGGAGGAGCTGGAAGACTTCCCGCTGCCCACGGTGCAGCGCAGCCAGACGGTCCTCAACCAGCT GCGCTACCCGTCTGTGCTGCTGCTCGTGTGCCAGGACTCGGAGCAGAGCAAGCCGGATGTCCACTTCTTCCACTGCGATGAGGTGGAGGC AGAGCTGGTGCACGAGGACATCGAGAGCGCGTTGGCCGACTGCCGGCTGGGCAAGAAGATGCGGCCGCAGACCCTGAAGGGACACCAGGA GAAGATTCGGCAGCGGCAGTCCATCCTGCCTCCTCCCCAGGGCCCGGCGCCCATCCCCTTCCAGCACCGCGGCGGGGATTCCCCGGAGGC CAAGAATCGCGTGGGCCCGCAGGTGCCACTCAGCGAGCCAGGTTTCCGCCGTCGGGAGTCGCAGGAGGAGCCGCGGGCCGTGCTGGCTCA GAAGATAGAGAAGGAGACGCAAATCCTCAACTGCGCCCTGGACGACATCGAGTGGTTTGTGGCCCGGCTGCAGAAGGCAGCCGAGGCTTT CAAGCAGCTGAACCAGCGGAAAAAGGGGAAGAAGAAGGGCAAGAAGGCGCCAGCAGAGGGCGTCCTCACACTGCGGGCACGGCCCCCCTC TGAGGGCGAGTTCATCGACTGCTTCCAGAAAATCAAGCTGGCGATTAACTTGCTGGCAAAGCTGCAGAAGCACATCCAGAACCCCAGCGC CGCGGAGCTCGTGCACTTCCTCTTCGGGCCTCTGGACCTGATCGTCAACACCTGCAGTGGCCCAGACATCGCACGCTCCGTCTCCTGCCC ACTGCTCTCCCGAGATGCCGTGGACTTCCTGCGCGGCCACCTGGTCCCTAAGGAGATGTCGCTGTGGGAGTCACTGGGAGAGAGCTGGAT GCGGCCCCGTTCCGAGTGGCCGCGGGAGCCACAGGTGCCCCTCTACGTGCCCAAGTTCCACAGCGGCTGGGAGCCTCCTGTGGATGTGCT GCAGGAGGCCCCCTGGGAGGTGGAGGGGCTGGCGTCTGCCCCCATCGAGGAGGTGAGTCCAGTGAGCCGACAGTCCATAAGAAACTCCCA GAAGCACAGCCCCACTTCAGAGCCCACCCCCCCGGGGGATGCCCTACCACCAGTCAGCTCCCCACATACTCACAGGGGCTACCAGCCAAC ACCAGCCATGGCCAAGTACGTCAAGATCCTGTATGACTTCACAGCCCGAAATGCCAACGAGCTATCGGTGCTCAAGGATGAGGTCCTAGA GGTGCTGGAGGACGGCCGGCAGTGGTGGAAGCTGCGCAGCCGCAGCGGCCAGGCGGGGTACGTGCCCTGCAACATCCTAGGCGAGGCGCG ACCGGAGGACGCCGGCGCCCCGTTCGAGCAGGCCGGTCAGAAGTACTGGGGCCCCGCCAGCCCGACCCACAAGCTACCCCCAAGCTTCCC GGGGAACAAAGACGAGCTCATGCAGCACATGGACGAGGTCAACGACGAGCTCATCCGGAAAATCAGCAACATCAGGGCGCAGCCACAGAG GCACTTCCGCGTGGAGCGCAGCCAGCCCGTGAGCCAGCCGCTCACCTACGAGTCGGGTCCGGACGAGGTCCGCGCCTGGCTGGAAGCCAA GGCCTTCAGCCCGCGGATCGTGGAGAACCTGGGCATCCTGACCGGGCCGCAGCTCTTCTCCCTCAACAAGGAGGAGCTGAAGAAAGTGTG CGGCGAGGAGGGCGTCCGCGTGTACAGCCAGCTCACCATGCAGAAGGCCTTCCTGGAGAAGCAGCAAAGTGGGTCGGAGCTGGAAGAACT CATGAACAAGTTTCATTCCATGAATCAGAGGAGGGGGGAGGACAGCTAGGCCCAGCTGCCTTGGGCTGGGGCCTGCGGAGGGGAAGCCCA >66764_66764_2_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720061_ENST00000526198_length(amino acids)=940AA_BP=262 MPGPRLQRASGEQAAHRGLAAHGTRGPAAAAAMFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVT GVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFI PVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLHLATFI MDKSEAITSVDDAIRKLVQLSSKEKIWTQEMLLQVNDQSLRLLDIESQSAQTPGASRVRAMYPQEELEDFPLPTVQRSQTVLNQLRYPSV LLLVCQDSEQSKPDVHFFHCDEVEAELVHEDIESALADCRLGKKMRPQTLKGHQEKIRQRQSILPPPQGPAPIPFQHRGGDSPEAKNRVG PQVPLSEPGFRRRESQEEPRAVLAQKIEKETQILNCALDDIEWFVARLQKAAEAFKQLNQRKKGKKKGKKAPAEGVLTLRARPPSEGEFI DCFQKIKLAINLLAKLQKHIQNPSAAELVHFLFGPLDLIVNTCSGPDIARSVSCPLLSRDAVDFLRGHLVPKEMSLWESLGESWMRPRSE WPREPQVPLYVPKFHSGWEPPVDVLQEAPWEVEGLASAPIEEVSPVSRQSIRNSQKHSPTSEPTPPGDALPPVSSPHTHRGYQPTPAMAK YVKILYDFTARNANELSVLKDEVLEVLEDGRQWWKLRSRSGQAGYVPCNILGEARPEDAGAPFEQAGQKYWGPASPTHKLPPSFPGNKDE LMQHMDEVNDELIRKISNIRAQPQRHFRVERSQPVSQPLTYESGPDEVRAWLEAKAFSPRIVENLGILTGPQLFSLNKEELKKVCGEEGV -------------------------------------------------------------- >66764_66764_3_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720061_ENST00000530636_length(transcript)=2951nt_BP=898nt GCGGCCCCAGTCAGACGCAGGCAGCCCCAAAGCCTGAACAGGCAGGGCCAGACCCAGCTTCTTCGCCTCCGCCAGCGGGGACCCCGAGCT AGAGCCGCAGCGGGACCTGCCCGGCCCCCGGCTCCAGCGAGCGAGCGGCGAGCAGGCGGCTCACAGAGGCCTGGCCGCCCACGGAACCCG GGGCCCGGCGGCCGCCGCCGCGATGTTTCCCCGCGAGAAGACGTGGAACATCTCGTTCGCGGGCTGCGGCTTCCTCGGCGTCTACTACGT CGGCGTGGCCTCCTGCCTCCGCGAGCACGCGCCCTTCCTGGTGGCCAACGCCACGCACATCTACGGCGCCTCGGCCGGGGCGCTCACGGC CACGGCGCTGGTCACCGGGGTCTGCCTGGGTGAGGCTGGTGCCAAGTTCATTGAGGTATCTAAAGAGGCCCGGAAGCGGTTCCTGGGCCC CCTGCACCCCTCCTTCAACCTGGTAAAGATCATCCGCAGTTTCCTGCTGAAGGTCCTGCCTGCTGATAGCCATGAGCATGCCAGTGGGCG CCTGGGCATCTCCCTGACCCGCGTGTCAGACGGCGAGAATGTCATTATATCCCACTTCAACTCCAAGGACGAGCTCATCCAGGCCAATGT CTGCAGCGGTTTCATCCCCGTGTACTGTGGGCTCATCCCTCCCTCCCTCCAGGGGGTGCGCTACGTGGATGGTGGCATTTCAGACAACCT GCCACTCTATGAGCTTAAGAACACCATCACAGTGTCCCCCTTCTCGGGCGAGAGTGACATCTGTCCGCAGGACAGCTCCACCAACATCCA CGAGCTGCGGGTCACCAACACCAGCATCCAGTTCAACCTGCGCAACCTCTACCGCCTCTCCAAGGCCCTCTTCCCGCCGGAGCCCCTGCA CCTGGCCACATTCATCATGGACAAGAGCGAAGCCATCACGTCTGTGGACGACGCCATCCGGAAGCTGGTGCAGCTGAGCTCCAAGGAGAA GATCTGGACCCAGGAGATGCTGCTGCAGGTGAACGACCAGTCGCTGCGGCTGCTGGACATCGAGTCACAGGAGGAGCTGGAAGACTTCCC GCTGCCCACGGTGCAGCGCAGCCAGACGGTCCTCAACCAGCTGCGCTACCCGTCTGTGCTGCTGCTCGTGTGCCAGGACTCGGAGCAGAG CAAGCCGGATGTCCACTTCTTCCACTGCGATGAGGTGGAGGCAGAGCTGGTGCACGAGGACATCGAGAGCGCGTTGGCCGACTGCCGGCT GGGCAAGAAGATGCGGCCGCAGACCCTGAAGGGACACCAGGAGAAGATTCGGCAGCGGCAGTCCATCCTGCCTCCTCCCCAGGGCCCGGC GCCCATCCCCTTCCAGCACCGCGGCGGGGATTCCCCGGAGGCCAAGAATCGCGTGGGCCCGCAGGTGCCACTCAGCGAGCCAGGTTTCCG CCGTCGGGAGTCGCAGGAGGAGCCGCGGGCCGTGCTGGCTCAGAAGATAGAGAAGGAGACGCAAATCCTCAACTGCGCCCTGGACGACAT CGAGTGGTTTGTGGCCCGGCTGCAGAAGGCAGCCGAGGCTTTCAAGCAGCTGAACCAGCGGAAAAAGGGGAAGAAGAAGGGCAAGAAGGC GCCAGCAGAGGGCGTCCTCACACTGCGGGCACGGCCCCCCTCTGAGGGCGAGTTCATCGACTGCTTCCAGAAAATCAAGCTGGCGATTAA CTTGCTGGCAAAGCTGCAGAAGCACATCCAGAACCCCAGCGCCGCGGAGCTCGTGCACTTCCTCTTCGGGCCTCTGGACCTGATCGTCAA CACCTGCAGTGGCCCAGACATCGCACGCTCCGTCTCCTGCCCACTGCTCTCCCGAGATGCCGTGGACTTCCTGCGCGGCCACCTGGTCCC TAAGGAGATGTCGCTGTGGGAGTCACTGGGAGAGAGCTGGATGCGGCCCCGTTCCGAGTGGCCGCGGGAGCCACAGGTGCCCCTCTACGT GCCCAAGTTCCACAGCGGCTGGGAGCCTCCTGTGGATGTGCTGCAGGAGGCCCCCTGGGAGGTGGAGGGGCTGGCGTCTGCCCCCATCGA GGAGGTGAGTCCAGTGAGCCGACAGTCCATAAGAAACTCCCAGAAGCACAGCCCCACTTCAGAGCCCACCCCCCCGGGGGATGCCCTACC ACCAGTCAGCTCCCCACATACTCACAGGGGCTACCAGCCAACACCAGCCATGGCCAAGTACGTCAAGATCCTGTATGACTTCACAGCCCG AAATGCCAACGAGCTATCGGTGCTCAAGGATGAGGTCCTAGAGGTGCTGGAGGACGGCCGGCAGTGGTGGAAGCTGCGCAGCCGCAGCGG CCAGGCGGGGTACGTGCCCTGCAACATCCTAGGCGAGGCGCGACCGGAGGACGCCGGCGCCCCGTTCGAGCAGGCCGGTCAGAAGTACTG GGGCCCCGCCAGCCCGACCCACAAGCTACCCCCAAGCTTCCCGGGGAACAAAGACGAGCTCATGCAGCACATGGACGAGGTCAACGACGA GCTCATCCGGAAAATCAGCAACATCAGGGCGCAGCCACAGAGGCACTTCCGCGTGGAGCGCAGCCAGCCCGTGAGCCAGCCGCTCACCTA CGAGTCGGGTCCGGACGAGGTCCGCGCCTGGCTGGAAGCCAAGGCCTTCAGCCCGCGGATCGTGGAGAACCTGGGCATCCTGACCGGGCC GCAGCTCTTCTCCCTCAACAAGGAGGAGCTGAAGAAAGTGTGCGGCGAGGAGGGCGTCCGCGTGTACAGCCAGCTCACCATGCAGAAGGC CTTCCTGGAGAAGCAGCAAAGTGGGTCGGAGCTGGAAGAACTCATGAACAAGTTTCATTCCATGAATCAGAGGAGGGGGGAGGACAGCTA >66764_66764_3_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720061_ENST00000530636_length(amino acids)=924AA_BP=262 MPGPRLQRASGEQAAHRGLAAHGTRGPAAAAAMFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVT GVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFI PVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLHLATFI MDKSEAITSVDDAIRKLVQLSSKEKIWTQEMLLQVNDQSLRLLDIESQEELEDFPLPTVQRSQTVLNQLRYPSVLLLVCQDSEQSKPDVH FFHCDEVEAELVHEDIESALADCRLGKKMRPQTLKGHQEKIRQRQSILPPPQGPAPIPFQHRGGDSPEAKNRVGPQVPLSEPGFRRRESQ EEPRAVLAQKIEKETQILNCALDDIEWFVARLQKAAEAFKQLNQRKKGKKKGKKAPAEGVLTLRARPPSEGEFIDCFQKIKLAINLLAKL QKHIQNPSAAELVHFLFGPLDLIVNTCSGPDIARSVSCPLLSRDAVDFLRGHLVPKEMSLWESLGESWMRPRSEWPREPQVPLYVPKFHS GWEPPVDVLQEAPWEVEGLASAPIEEVSPVSRQSIRNSQKHSPTSEPTPPGDALPPVSSPHTHRGYQPTPAMAKYVKILYDFTARNANEL SVLKDEVLEVLEDGRQWWKLRSRSGQAGYVPCNILGEARPEDAGAPFEQAGQKYWGPASPTHKLPPSFPGNKDELMQHMDEVNDELIRKI SNIRAQPQRHFRVERSQPVSQPLTYESGPDEVRAWLEAKAFSPRIVENLGILTGPQLFSLNKEELKKVCGEEGVRVYSQLTMQKAFLEKQ -------------------------------------------------------------- >66764_66764_4_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720061_ENST00000533256_length(transcript)=3624nt_BP=898nt GCGGCCCCAGTCAGACGCAGGCAGCCCCAAAGCCTGAACAGGCAGGGCCAGACCCAGCTTCTTCGCCTCCGCCAGCGGGGACCCCGAGCT AGAGCCGCAGCGGGACCTGCCCGGCCCCCGGCTCCAGCGAGCGAGCGGCGAGCAGGCGGCTCACAGAGGCCTGGCCGCCCACGGAACCCG GGGCCCGGCGGCCGCCGCCGCGATGTTTCCCCGCGAGAAGACGTGGAACATCTCGTTCGCGGGCTGCGGCTTCCTCGGCGTCTACTACGT CGGCGTGGCCTCCTGCCTCCGCGAGCACGCGCCCTTCCTGGTGGCCAACGCCACGCACATCTACGGCGCCTCGGCCGGGGCGCTCACGGC CACGGCGCTGGTCACCGGGGTCTGCCTGGGTGAGGCTGGTGCCAAGTTCATTGAGGTATCTAAAGAGGCCCGGAAGCGGTTCCTGGGCCC CCTGCACCCCTCCTTCAACCTGGTAAAGATCATCCGCAGTTTCCTGCTGAAGGTCCTGCCTGCTGATAGCCATGAGCATGCCAGTGGGCG CCTGGGCATCTCCCTGACCCGCGTGTCAGACGGCGAGAATGTCATTATATCCCACTTCAACTCCAAGGACGAGCTCATCCAGGCCAATGT CTGCAGCGGTTTCATCCCCGTGTACTGTGGGCTCATCCCTCCCTCCCTCCAGGGGGTGCGCTACGTGGATGGTGGCATTTCAGACAACCT GCCACTCTATGAGCTTAAGAACACCATCACAGTGTCCCCCTTCTCGGGCGAGAGTGACATCTGTCCGCAGGACAGCTCCACCAACATCCA CGAGCTGCGGGTCACCAACACCAGCATCCAGTTCAACCTGCGCAACCTCTACCGCCTCTCCAAGGCCCTCTTCCCGCCGGAGCCCCTGCA CCTGGCCACATTCATCATGGACAAGAGCGAAGCCATCACGTCTGTGGACGACGCCATCCGGAAGCTGGTGCAGCTGAGCTCCAAGGAGAA GATCTGGACCCAGGAGATGCTGCTGCAGGTGAACGACCAGTCGCTGCGGCTGCTGGACATCGAGTCACAGGAGGAGCTGGAAGACTTCCC GCTGCCCACGGTGCAGCGCAGCCAGACGGTCCTCAACCAGCTGCGCTACCCGTCTGTGCTGCTGCTCGTGTGCCAGGACTCGGAGCAGAG CAAGCCGGATGTCCACTTCTTCCACTGCGATGAGGTGGAGGCAGAGCTGGTGCACGAGGACATCGAGAGCGCGTTGGCCGACTGCCGGCT GGGCAAGAAGATGCGGCCGCAGACCCTGAAGGGACACCAGGAGAAGATTCGGCAGCGGCAGTCCATCCTGCCTCCTCCCCAGGGCCCGGC GCCCATCCCCTTCCAGCACCGCGGCGGGGATTCCCCGGAGGCCAAGAATCGCGTGGGCCCGCAGGTGCCACTCAGCGAGCCAGGTTTCCG CCGTCGGGAGTCGCAGGAGGAGCCGCGGGCCGTGCTGGCTCAGAAGATAGAGAAGGAGACGCAAATCCTCAACTGCGCCCTGGACGACAT CGAGTGGTTTGTGGCCCGGCTGCAGAAGGCAGCCGAGGCTTTCAAGCAGCTGAACCAGCGGAAAAAGGGGAAGAAGAAGGGCAAGAAGGC GCCAGCAGAGGGCGTCCTCACACTGCGGGCACGGCCCCCCTCTGAGGGCGAGTTCATCGACTGCTTCCAGAAAATCAAGCTGGCGATTAA CTTGCTGGCAAAGCTGCAGAAGCACATCCAGAACCCCAGCGCCGCGGAGCTCGTGCACTTCCTCTTCGGGCCTCTGGACCTGATCGTCAA CACCTGCAGTGGCCCAGACATCGCACGCTCCGTCTCCTGCCCACTGCTCTCCCGAGATGCCGTGGACTTCCTGCGCGGCCACCTGGTCCC TAAGGAGATGTCGCTGTGGGAGTCACTGGGAGAGAGCTGGATGCGGCCCCGTTCCGAGTGGCCGCGGGAGCCACAGGTGCCCCTCTACGT GCCCAAGTTCCACAGCGGCTGGGAGCCTCCTGTGGATGTGCTGCAGGAGGCCCCCTGGGAGGTGGAGGGGCTGGCGTCTGCCCCCATCGA GGAGGTGAGTCCAGTGAGCCGACAGTCCATAAGAAACTCCCAGAAGCACAGCCCCACTTCAGAGCCCACCCCCCCGGGGGATGCCCTACC ACCAGTCAGCTCCCCACATACTCACAGGGGCTACCAGCCAACACCAGCCATGGCCAAGTACGTCAAGATCCTGTATGACTTCACAGCCCG AAATGCCAACGAGCTATCGGTGCTCAAGGATGAGGTCCTAGAGGTGCTGGAGGACGGCCGGCAGTGGTGGAAGCTGCGCAGCCGCAGCGG CCAGGCGGGGTACGTGCCCTGCAACATCCTAGGCGAGGCGCGACCGGAGGACGCCGGCGCCCCGTTCGAGCAGGCCGGTCAGAAGTACTG GGGCCCCGCCAGCCCGACCCACAAGCTACCCCCAAGCTTCCCGGGGAACAAAGACGAGCTCATGCAGCACATGGACGAGGTCAACGACGA GCTCATCCGGAAAATCAGCAACATCAGGGCGCAGCCACAGAGGCACTTCCGCGTGGAGCGCAGCCAGCCCGTGAGCCAGCCGCTCACCTA CGAGTCGGGTCCGGACGAGGTCCGCGCCTGGCTGGAAGCCAAGGCCTTCAGCCCGCGGATCGTGGAGAACCTGGGCATCCTGACCGGGCC GCAGCTCTTCTCCCTCAACAAGGAGGAGCTGAAGAAAGTGTGCGGCGAGGAGGGCGTCCGCGTGTACAGCCAGCTCACCATGCAGAAGGC CTTCCTGGAGAAGCAGCAAAGTGGGTCGGAGCTGGAAGAACTCATGAACAAGTTTCATTCCATGAATCAGAGGAGGGGGGAGGACAGCTA GGCCCAGCTGCCTTGGGCTGGGGCCTGCGGAGGGGAAGCCCACCCACAATGCATGGAGTATTATTTTTATATGTGTATGTATTTTGTATC AAGGACACGGAGGGGGTGTGGTGCTGGCTAGAGGTCCCTGCCCCTGTCTGGAGGCACAACGCCCATCCTTAGGCCAAACAGTACCCAAGG CCTCAGCCCACACCAAGACTAATCTCAGCCAAACCTGCTGCTTGGTGGTGCCAGCCCCTTGTCCACCTTCTCTTGAGGCCACAGAACTCC CTGGGGCTGGGGCCTCTTTCTCTGGCCTCCCCTGTGCACCTGGGGGGTCCTGGCCCCTGTGATGCTCCCCCATCCCCACCCACTTCTACA TCCATCCACACCCCAGGGTGAGCTGGAGCTCCAGGCTGGCCAGGCTGAACCTCGCACACACGCAGAGTTCTGCTCCCTGAGGGGGGCCCG GGAGGGGCTCCAGCAGGAGGCCGTGGGTGCCATTCGGGGGAAAGTGGGGGAACGACACACACTTCACCTGCAAGGGCCGACAACGCAGGG GACACCGTGCCGGCTTCAGACACTCCCAGCGCCCACTCTTACAGGCCCAGGACTGGAGCTTTCTCTGGCCAAGTTTCAGGCCAATGATCC CCGCATGGTGTTGGGGGTGCTGGTGTGTCTTGGTGCCTGGACTTGAGTCTCACCCTACAGATGAGAGGTGGCTGAGGCACCAGGGCTAAG >66764_66764_4_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720061_ENST00000533256_length(amino acids)=924AA_BP=262 MPGPRLQRASGEQAAHRGLAAHGTRGPAAAAAMFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVT GVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFI PVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLHLATFI MDKSEAITSVDDAIRKLVQLSSKEKIWTQEMLLQVNDQSLRLLDIESQEELEDFPLPTVQRSQTVLNQLRYPSVLLLVCQDSEQSKPDVH FFHCDEVEAELVHEDIESALADCRLGKKMRPQTLKGHQEKIRQRQSILPPPQGPAPIPFQHRGGDSPEAKNRVGPQVPLSEPGFRRRESQ EEPRAVLAQKIEKETQILNCALDDIEWFVARLQKAAEAFKQLNQRKKGKKKGKKAPAEGVLTLRARPPSEGEFIDCFQKIKLAINLLAKL QKHIQNPSAAELVHFLFGPLDLIVNTCSGPDIARSVSCPLLSRDAVDFLRGHLVPKEMSLWESLGESWMRPRSEWPREPQVPLYVPKFHS GWEPPVDVLQEAPWEVEGLASAPIEEVSPVSRQSIRNSQKHSPTSEPTPPGDALPPVSSPHTHRGYQPTPAMAKYVKILYDFTARNANEL SVLKDEVLEVLEDGRQWWKLRSRSGQAGYVPCNILGEARPEDAGAPFEQAGQKYWGPASPTHKLPPSFPGNKDELMQHMDEVNDELIRKI SNIRAQPQRHFRVERSQPVSQPLTYESGPDEVRAWLEAKAFSPRIVENLGILTGPQLFSLNKEELKKVCGEEGVRVYSQLTMQKAFLEKQ -------------------------------------------------------------- >66764_66764_5_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720062_ENST00000318562_length(transcript)=3627nt_BP=898nt GCGGCCCCAGTCAGACGCAGGCAGCCCCAAAGCCTGAACAGGCAGGGCCAGACCCAGCTTCTTCGCCTCCGCCAGCGGGGACCCCGAGCT AGAGCCGCAGCGGGACCTGCCCGGCCCCCGGCTCCAGCGAGCGAGCGGCGAGCAGGCGGCTCACAGAGGCCTGGCCGCCCACGGAACCCG GGGCCCGGCGGCCGCCGCCGCGATGTTTCCCCGCGAGAAGACGTGGAACATCTCGTTCGCGGGCTGCGGCTTCCTCGGCGTCTACTACGT CGGCGTGGCCTCCTGCCTCCGCGAGCACGCGCCCTTCCTGGTGGCCAACGCCACGCACATCTACGGCGCCTCGGCCGGGGCGCTCACGGC CACGGCGCTGGTCACCGGGGTCTGCCTGGGTGAGGCTGGTGCCAAGTTCATTGAGGTATCTAAAGAGGCCCGGAAGCGGTTCCTGGGCCC CCTGCACCCCTCCTTCAACCTGGTAAAGATCATCCGCAGTTTCCTGCTGAAGGTCCTGCCTGCTGATAGCCATGAGCATGCCAGTGGGCG CCTGGGCATCTCCCTGACCCGCGTGTCAGACGGCGAGAATGTCATTATATCCCACTTCAACTCCAAGGACGAGCTCATCCAGGCCAATGT CTGCAGCGGTTTCATCCCCGTGTACTGTGGGCTCATCCCTCCCTCCCTCCAGGGGGTGCGCTACGTGGATGGTGGCATTTCAGACAACCT GCCACTCTATGAGCTTAAGAACACCATCACAGTGTCCCCCTTCTCGGGCGAGAGTGACATCTGTCCGCAGGACAGCTCCACCAACATCCA CGAGCTGCGGGTCACCAACACCAGCATCCAGTTCAACCTGCGCAACCTCTACCGCCTCTCCAAGGCCCTCTTCCCGCCGGAGCCCCTGCA CCTGGCCACATTCATCATGGACAAGAGCGAAGCCATCACGTCTGTGGACGACGCCATCCGGAAGCTGGTGCAGCTGAGCTCCAAGGAGAA GATCTGGACCCAGGAGATGCTGCTGCAGGTGAACGACCAGTCGCTGCGGCTGCTGGACATCGAGTCACAGGAGGAGCTGGAAGACTTCCC GCTGCCCACGGTGCAGCGCAGCCAGACGGTCCTCAACCAGCTGCGCTACCCGTCTGTGCTGCTGCTCGTGTGCCAGGACTCGGAGCAGAG CAAGCCGGATGTCCACTTCTTCCACTGCGATGAGGTGGAGGCAGAGCTGGTGCACGAGGACATCGAGAGCGCGTTGGCCGACTGCCGGCT GGGCAAGAAGATGCGGCCGCAGACCCTGAAGGGACACCAGGAGAAGATTCGGCAGCGGCAGTCCATCCTGCCTCCTCCCCAGGGCCCGGC GCCCATCCCCTTCCAGCACCGCGGCGGGGATTCCCCGGAGGCCAAGAATCGCGTGGGCCCGCAGGTGCCACTCAGCGAGCCAGGTTTCCG CCGTCGGGAGTCGCAGGAGGAGCCGCGGGCCGTGCTGGCTCAGAAGATAGAGAAGGAGACGCAAATCCTCAACTGCGCCCTGGACGACAT CGAGTGGTTTGTGGCCCGGCTGCAGAAGGCAGCCGAGGCTTTCAAGCAGCTGAACCAGCGGAAAAAGGGGAAGAAGAAGGGCAAGAAGGC GCCAGCAGAGGGCGTCCTCACACTGCGGGCACGGCCCCCCTCTGAGGGCGAGTTCATCGACTGCTTCCAGAAAATCAAGCTGGCGATTAA CTTGCTGGCAAAGCTGCAGAAGCACATCCAGAACCCCAGCGCCGCGGAGCTCGTGCACTTCCTCTTCGGGCCTCTGGACCTGATCGTCAA CACCTGCAGTGGCCCAGACATCGCACGCTCCGTCTCCTGCCCACTGCTCTCCCGAGATGCCGTGGACTTCCTGCGCGGCCACCTGGTCCC TAAGGAGATGTCGCTGTGGGAGTCACTGGGAGAGAGCTGGATGCGGCCCCGTTCCGAGTGGCCGCGGGAGCCACAGGTGCCCCTCTACGT GCCCAAGTTCCACAGCGGCTGGGAGCCTCCTGTGGATGTGCTGCAGGAGGCCCCCTGGGAGGTGGAGGGGCTGGCGTCTGCCCCCATCGA GGAGGTGAGTCCAGTGAGCCGACAGTCCATAAGAAACTCCCAGAAGCACAGCCCCACTTCAGAGCCCACCCCCCCGGGGGATGCCCTACC ACCAGTCAGCTCCCCACATACTCACAGGGGCTACCAGCCAACACCAGCCATGGCCAAGTACGTCAAGATCCTGTATGACTTCACAGCCCG AAATGCCAACGAGCTATCGGTGCTCAAGGATGAGGTCCTAGAGGTGCTGGAGGACGGCCGGCAGTGGTGGAAGCTGCGCAGCCGCAGCGG CCAGGCGGGGTACGTGCCCTGCAACATCCTAGGCGAGGCGCGACCGGAGGACGCCGGCGCCCCGTTCGAGCAGGCCGGTCAGAAGTACTG GGGCCCCGCCAGCCCGACCCACAAGCTACCCCCAAGCTTCCCGGGGAACAAAGACGAGCTCATGCAGCACATGGACGAGGTCAACGACGA GCTCATCCGGAAAATCAGCAACATCAGGGCGCAGCCACAGAGGCACTTCCGCGTGGAGCGCAGCCAGCCCGTGAGCCAGCCGCTCACCTA CGAGTCGGGTCCGGACGAGGTCCGCGCCTGGCTGGAAGCCAAGGCCTTCAGCCCGCGGATCGTGGAGAACCTGGGCATCCTGACCGGGCC GCAGCTCTTCTCCCTCAACAAGGAGGAGCTGAAGAAAGTGTGCGGCGAGGAGGGCGTCCGCGTGTACAGCCAGCTCACCATGCAGAAGGC CTTCCTGGAGAAGCAGCAAAGTGGGTCGGAGCTGGAAGAACTCATGAACAAGTTTCATTCCATGAATCAGAGGAGGGGGGAGGACAGCTA GGCCCAGCTGCCTTGGGCTGGGGCCTGCGGAGGGGAAGCCCACCCACAATGCATGGAGTATTATTTTTATATGTGTATGTATTTTGTATC AAGGACACGGAGGGGGTGTGGTGCTGGCTAGAGGTCCCTGCCCCTGTCTGGAGGCACAACGCCCATCCTTAGGCCAAACAGTACCCAAGG CCTCAGCCCACACCAAGACTAATCTCAGCCAAACCTGCTGCTTGGTGGTGCCAGCCCCTTGTCCACCTTCTCTTGAGGCCACAGAACTCC CTGGGGCTGGGGCCTCTTTCTCTGGCCTCCCCTGTGCACCTGGGGGGTCCTGGCCCCTGTGATGCTCCCCCATCCCCACCCACTTCTACA TCCATCCACACCCCAGGGTGAGCTGGAGCTCCAGGCTGGCCAGGCTGAACCTCGCACACACGCAGAGTTCTGCTCCCTGAGGGGGGCCCG GGAGGGGCTCCAGCAGGAGGCCGTGGGTGCCATTCGGGGGAAAGTGGGGGAACGACACACACTTCACCTGCAAGGGCCGACAACGCAGGG GACACCGTGCCGGCTTCAGACACTCCCAGCGCCCACTCTTACAGGCCCAGGACTGGAGCTTTCTCTGGCCAAGTTTCAGGCCAATGATCC CCGCATGGTGTTGGGGGTGCTGGTGTGTCTTGGTGCCTGGACTTGAGTCTCACCCTACAGATGAGAGGTGGCTGAGGCACCAGGGCTAAG >66764_66764_5_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720062_ENST00000318562_length(amino acids)=924AA_BP=262 MPGPRLQRASGEQAAHRGLAAHGTRGPAAAAAMFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVT GVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFI PVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLHLATFI MDKSEAITSVDDAIRKLVQLSSKEKIWTQEMLLQVNDQSLRLLDIESQEELEDFPLPTVQRSQTVLNQLRYPSVLLLVCQDSEQSKPDVH FFHCDEVEAELVHEDIESALADCRLGKKMRPQTLKGHQEKIRQRQSILPPPQGPAPIPFQHRGGDSPEAKNRVGPQVPLSEPGFRRRESQ EEPRAVLAQKIEKETQILNCALDDIEWFVARLQKAAEAFKQLNQRKKGKKKGKKAPAEGVLTLRARPPSEGEFIDCFQKIKLAINLLAKL QKHIQNPSAAELVHFLFGPLDLIVNTCSGPDIARSVSCPLLSRDAVDFLRGHLVPKEMSLWESLGESWMRPRSEWPREPQVPLYVPKFHS GWEPPVDVLQEAPWEVEGLASAPIEEVSPVSRQSIRNSQKHSPTSEPTPPGDALPPVSSPHTHRGYQPTPAMAKYVKILYDFTARNANEL SVLKDEVLEVLEDGRQWWKLRSRSGQAGYVPCNILGEARPEDAGAPFEQAGQKYWGPASPTHKLPPSFPGNKDELMQHMDEVNDELIRKI SNIRAQPQRHFRVERSQPVSQPLTYESGPDEVRAWLEAKAFSPRIVENLGILTGPQLFSLNKEELKKVCGEEGVRVYSQLTMQKAFLEKQ -------------------------------------------------------------- >66764_66764_6_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720062_ENST00000526198_length(transcript)=2982nt_BP=898nt GCGGCCCCAGTCAGACGCAGGCAGCCCCAAAGCCTGAACAGGCAGGGCCAGACCCAGCTTCTTCGCCTCCGCCAGCGGGGACCCCGAGCT AGAGCCGCAGCGGGACCTGCCCGGCCCCCGGCTCCAGCGAGCGAGCGGCGAGCAGGCGGCTCACAGAGGCCTGGCCGCCCACGGAACCCG GGGCCCGGCGGCCGCCGCCGCGATGTTTCCCCGCGAGAAGACGTGGAACATCTCGTTCGCGGGCTGCGGCTTCCTCGGCGTCTACTACGT CGGCGTGGCCTCCTGCCTCCGCGAGCACGCGCCCTTCCTGGTGGCCAACGCCACGCACATCTACGGCGCCTCGGCCGGGGCGCTCACGGC CACGGCGCTGGTCACCGGGGTCTGCCTGGGTGAGGCTGGTGCCAAGTTCATTGAGGTATCTAAAGAGGCCCGGAAGCGGTTCCTGGGCCC CCTGCACCCCTCCTTCAACCTGGTAAAGATCATCCGCAGTTTCCTGCTGAAGGTCCTGCCTGCTGATAGCCATGAGCATGCCAGTGGGCG CCTGGGCATCTCCCTGACCCGCGTGTCAGACGGCGAGAATGTCATTATATCCCACTTCAACTCCAAGGACGAGCTCATCCAGGCCAATGT CTGCAGCGGTTTCATCCCCGTGTACTGTGGGCTCATCCCTCCCTCCCTCCAGGGGGTGCGCTACGTGGATGGTGGCATTTCAGACAACCT GCCACTCTATGAGCTTAAGAACACCATCACAGTGTCCCCCTTCTCGGGCGAGAGTGACATCTGTCCGCAGGACAGCTCCACCAACATCCA CGAGCTGCGGGTCACCAACACCAGCATCCAGTTCAACCTGCGCAACCTCTACCGCCTCTCCAAGGCCCTCTTCCCGCCGGAGCCCCTGCA CCTGGCCACATTCATCATGGACAAGAGCGAAGCCATCACGTCTGTGGACGACGCCATCCGGAAGCTGGTGCAGCTGAGCTCCAAGGAGAA GATCTGGACCCAGGAGATGCTGCTGCAGGTGAACGACCAGTCGCTGCGGCTGCTGGACATCGAGTCACAGAGTGCCCAGACCCCGGGTGC GAGTCGTGTCCGCGCGATGTACCCGCAGGAGGAGCTGGAAGACTTCCCGCTGCCCACGGTGCAGCGCAGCCAGACGGTCCTCAACCAGCT GCGCTACCCGTCTGTGCTGCTGCTCGTGTGCCAGGACTCGGAGCAGAGCAAGCCGGATGTCCACTTCTTCCACTGCGATGAGGTGGAGGC AGAGCTGGTGCACGAGGACATCGAGAGCGCGTTGGCCGACTGCCGGCTGGGCAAGAAGATGCGGCCGCAGACCCTGAAGGGACACCAGGA GAAGATTCGGCAGCGGCAGTCCATCCTGCCTCCTCCCCAGGGCCCGGCGCCCATCCCCTTCCAGCACCGCGGCGGGGATTCCCCGGAGGC CAAGAATCGCGTGGGCCCGCAGGTGCCACTCAGCGAGCCAGGTTTCCGCCGTCGGGAGTCGCAGGAGGAGCCGCGGGCCGTGCTGGCTCA GAAGATAGAGAAGGAGACGCAAATCCTCAACTGCGCCCTGGACGACATCGAGTGGTTTGTGGCCCGGCTGCAGAAGGCAGCCGAGGCTTT CAAGCAGCTGAACCAGCGGAAAAAGGGGAAGAAGAAGGGCAAGAAGGCGCCAGCAGAGGGCGTCCTCACACTGCGGGCACGGCCCCCCTC TGAGGGCGAGTTCATCGACTGCTTCCAGAAAATCAAGCTGGCGATTAACTTGCTGGCAAAGCTGCAGAAGCACATCCAGAACCCCAGCGC CGCGGAGCTCGTGCACTTCCTCTTCGGGCCTCTGGACCTGATCGTCAACACCTGCAGTGGCCCAGACATCGCACGCTCCGTCTCCTGCCC ACTGCTCTCCCGAGATGCCGTGGACTTCCTGCGCGGCCACCTGGTCCCTAAGGAGATGTCGCTGTGGGAGTCACTGGGAGAGAGCTGGAT GCGGCCCCGTTCCGAGTGGCCGCGGGAGCCACAGGTGCCCCTCTACGTGCCCAAGTTCCACAGCGGCTGGGAGCCTCCTGTGGATGTGCT GCAGGAGGCCCCCTGGGAGGTGGAGGGGCTGGCGTCTGCCCCCATCGAGGAGGTGAGTCCAGTGAGCCGACAGTCCATAAGAAACTCCCA GAAGCACAGCCCCACTTCAGAGCCCACCCCCCCGGGGGATGCCCTACCACCAGTCAGCTCCCCACATACTCACAGGGGCTACCAGCCAAC ACCAGCCATGGCCAAGTACGTCAAGATCCTGTATGACTTCACAGCCCGAAATGCCAACGAGCTATCGGTGCTCAAGGATGAGGTCCTAGA GGTGCTGGAGGACGGCCGGCAGTGGTGGAAGCTGCGCAGCCGCAGCGGCCAGGCGGGGTACGTGCCCTGCAACATCCTAGGCGAGGCGCG ACCGGAGGACGCCGGCGCCCCGTTCGAGCAGGCCGGTCAGAAGTACTGGGGCCCCGCCAGCCCGACCCACAAGCTACCCCCAAGCTTCCC GGGGAACAAAGACGAGCTCATGCAGCACATGGACGAGGTCAACGACGAGCTCATCCGGAAAATCAGCAACATCAGGGCGCAGCCACAGAG GCACTTCCGCGTGGAGCGCAGCCAGCCCGTGAGCCAGCCGCTCACCTACGAGTCGGGTCCGGACGAGGTCCGCGCCTGGCTGGAAGCCAA GGCCTTCAGCCCGCGGATCGTGGAGAACCTGGGCATCCTGACCGGGCCGCAGCTCTTCTCCCTCAACAAGGAGGAGCTGAAGAAAGTGTG CGGCGAGGAGGGCGTCCGCGTGTACAGCCAGCTCACCATGCAGAAGGCCTTCCTGGAGAAGCAGCAAAGTGGGTCGGAGCTGGAAGAACT CATGAACAAGTTTCATTCCATGAATCAGAGGAGGGGGGAGGACAGCTAGGCCCAGCTGCCTTGGGCTGGGGCCTGCGGAGGGGAAGCCCA >66764_66764_6_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720062_ENST00000526198_length(amino acids)=940AA_BP=262 MPGPRLQRASGEQAAHRGLAAHGTRGPAAAAAMFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVT GVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFI PVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLHLATFI MDKSEAITSVDDAIRKLVQLSSKEKIWTQEMLLQVNDQSLRLLDIESQSAQTPGASRVRAMYPQEELEDFPLPTVQRSQTVLNQLRYPSV LLLVCQDSEQSKPDVHFFHCDEVEAELVHEDIESALADCRLGKKMRPQTLKGHQEKIRQRQSILPPPQGPAPIPFQHRGGDSPEAKNRVG PQVPLSEPGFRRRESQEEPRAVLAQKIEKETQILNCALDDIEWFVARLQKAAEAFKQLNQRKKGKKKGKKAPAEGVLTLRARPPSEGEFI DCFQKIKLAINLLAKLQKHIQNPSAAELVHFLFGPLDLIVNTCSGPDIARSVSCPLLSRDAVDFLRGHLVPKEMSLWESLGESWMRPRSE WPREPQVPLYVPKFHSGWEPPVDVLQEAPWEVEGLASAPIEEVSPVSRQSIRNSQKHSPTSEPTPPGDALPPVSSPHTHRGYQPTPAMAK YVKILYDFTARNANELSVLKDEVLEVLEDGRQWWKLRSRSGQAGYVPCNILGEARPEDAGAPFEQAGQKYWGPASPTHKLPPSFPGNKDE LMQHMDEVNDELIRKISNIRAQPQRHFRVERSQPVSQPLTYESGPDEVRAWLEAKAFSPRIVENLGILTGPQLFSLNKEELKKVCGEEGV -------------------------------------------------------------- >66764_66764_7_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720062_ENST00000530636_length(transcript)=2951nt_BP=898nt GCGGCCCCAGTCAGACGCAGGCAGCCCCAAAGCCTGAACAGGCAGGGCCAGACCCAGCTTCTTCGCCTCCGCCAGCGGGGACCCCGAGCT AGAGCCGCAGCGGGACCTGCCCGGCCCCCGGCTCCAGCGAGCGAGCGGCGAGCAGGCGGCTCACAGAGGCCTGGCCGCCCACGGAACCCG GGGCCCGGCGGCCGCCGCCGCGATGTTTCCCCGCGAGAAGACGTGGAACATCTCGTTCGCGGGCTGCGGCTTCCTCGGCGTCTACTACGT CGGCGTGGCCTCCTGCCTCCGCGAGCACGCGCCCTTCCTGGTGGCCAACGCCACGCACATCTACGGCGCCTCGGCCGGGGCGCTCACGGC CACGGCGCTGGTCACCGGGGTCTGCCTGGGTGAGGCTGGTGCCAAGTTCATTGAGGTATCTAAAGAGGCCCGGAAGCGGTTCCTGGGCCC CCTGCACCCCTCCTTCAACCTGGTAAAGATCATCCGCAGTTTCCTGCTGAAGGTCCTGCCTGCTGATAGCCATGAGCATGCCAGTGGGCG CCTGGGCATCTCCCTGACCCGCGTGTCAGACGGCGAGAATGTCATTATATCCCACTTCAACTCCAAGGACGAGCTCATCCAGGCCAATGT CTGCAGCGGTTTCATCCCCGTGTACTGTGGGCTCATCCCTCCCTCCCTCCAGGGGGTGCGCTACGTGGATGGTGGCATTTCAGACAACCT GCCACTCTATGAGCTTAAGAACACCATCACAGTGTCCCCCTTCTCGGGCGAGAGTGACATCTGTCCGCAGGACAGCTCCACCAACATCCA CGAGCTGCGGGTCACCAACACCAGCATCCAGTTCAACCTGCGCAACCTCTACCGCCTCTCCAAGGCCCTCTTCCCGCCGGAGCCCCTGCA CCTGGCCACATTCATCATGGACAAGAGCGAAGCCATCACGTCTGTGGACGACGCCATCCGGAAGCTGGTGCAGCTGAGCTCCAAGGAGAA GATCTGGACCCAGGAGATGCTGCTGCAGGTGAACGACCAGTCGCTGCGGCTGCTGGACATCGAGTCACAGGAGGAGCTGGAAGACTTCCC GCTGCCCACGGTGCAGCGCAGCCAGACGGTCCTCAACCAGCTGCGCTACCCGTCTGTGCTGCTGCTCGTGTGCCAGGACTCGGAGCAGAG CAAGCCGGATGTCCACTTCTTCCACTGCGATGAGGTGGAGGCAGAGCTGGTGCACGAGGACATCGAGAGCGCGTTGGCCGACTGCCGGCT GGGCAAGAAGATGCGGCCGCAGACCCTGAAGGGACACCAGGAGAAGATTCGGCAGCGGCAGTCCATCCTGCCTCCTCCCCAGGGCCCGGC GCCCATCCCCTTCCAGCACCGCGGCGGGGATTCCCCGGAGGCCAAGAATCGCGTGGGCCCGCAGGTGCCACTCAGCGAGCCAGGTTTCCG CCGTCGGGAGTCGCAGGAGGAGCCGCGGGCCGTGCTGGCTCAGAAGATAGAGAAGGAGACGCAAATCCTCAACTGCGCCCTGGACGACAT CGAGTGGTTTGTGGCCCGGCTGCAGAAGGCAGCCGAGGCTTTCAAGCAGCTGAACCAGCGGAAAAAGGGGAAGAAGAAGGGCAAGAAGGC GCCAGCAGAGGGCGTCCTCACACTGCGGGCACGGCCCCCCTCTGAGGGCGAGTTCATCGACTGCTTCCAGAAAATCAAGCTGGCGATTAA CTTGCTGGCAAAGCTGCAGAAGCACATCCAGAACCCCAGCGCCGCGGAGCTCGTGCACTTCCTCTTCGGGCCTCTGGACCTGATCGTCAA CACCTGCAGTGGCCCAGACATCGCACGCTCCGTCTCCTGCCCACTGCTCTCCCGAGATGCCGTGGACTTCCTGCGCGGCCACCTGGTCCC TAAGGAGATGTCGCTGTGGGAGTCACTGGGAGAGAGCTGGATGCGGCCCCGTTCCGAGTGGCCGCGGGAGCCACAGGTGCCCCTCTACGT GCCCAAGTTCCACAGCGGCTGGGAGCCTCCTGTGGATGTGCTGCAGGAGGCCCCCTGGGAGGTGGAGGGGCTGGCGTCTGCCCCCATCGA GGAGGTGAGTCCAGTGAGCCGACAGTCCATAAGAAACTCCCAGAAGCACAGCCCCACTTCAGAGCCCACCCCCCCGGGGGATGCCCTACC ACCAGTCAGCTCCCCACATACTCACAGGGGCTACCAGCCAACACCAGCCATGGCCAAGTACGTCAAGATCCTGTATGACTTCACAGCCCG AAATGCCAACGAGCTATCGGTGCTCAAGGATGAGGTCCTAGAGGTGCTGGAGGACGGCCGGCAGTGGTGGAAGCTGCGCAGCCGCAGCGG CCAGGCGGGGTACGTGCCCTGCAACATCCTAGGCGAGGCGCGACCGGAGGACGCCGGCGCCCCGTTCGAGCAGGCCGGTCAGAAGTACTG GGGCCCCGCCAGCCCGACCCACAAGCTACCCCCAAGCTTCCCGGGGAACAAAGACGAGCTCATGCAGCACATGGACGAGGTCAACGACGA GCTCATCCGGAAAATCAGCAACATCAGGGCGCAGCCACAGAGGCACTTCCGCGTGGAGCGCAGCCAGCCCGTGAGCCAGCCGCTCACCTA CGAGTCGGGTCCGGACGAGGTCCGCGCCTGGCTGGAAGCCAAGGCCTTCAGCCCGCGGATCGTGGAGAACCTGGGCATCCTGACCGGGCC GCAGCTCTTCTCCCTCAACAAGGAGGAGCTGAAGAAAGTGTGCGGCGAGGAGGGCGTCCGCGTGTACAGCCAGCTCACCATGCAGAAGGC CTTCCTGGAGAAGCAGCAAAGTGGGTCGGAGCTGGAAGAACTCATGAACAAGTTTCATTCCATGAATCAGAGGAGGGGGGAGGACAGCTA >66764_66764_7_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720062_ENST00000530636_length(amino acids)=924AA_BP=262 MPGPRLQRASGEQAAHRGLAAHGTRGPAAAAAMFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVT GVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFI PVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLHLATFI MDKSEAITSVDDAIRKLVQLSSKEKIWTQEMLLQVNDQSLRLLDIESQEELEDFPLPTVQRSQTVLNQLRYPSVLLLVCQDSEQSKPDVH FFHCDEVEAELVHEDIESALADCRLGKKMRPQTLKGHQEKIRQRQSILPPPQGPAPIPFQHRGGDSPEAKNRVGPQVPLSEPGFRRRESQ EEPRAVLAQKIEKETQILNCALDDIEWFVARLQKAAEAFKQLNQRKKGKKKGKKAPAEGVLTLRARPPSEGEFIDCFQKIKLAINLLAKL QKHIQNPSAAELVHFLFGPLDLIVNTCSGPDIARSVSCPLLSRDAVDFLRGHLVPKEMSLWESLGESWMRPRSEWPREPQVPLYVPKFHS GWEPPVDVLQEAPWEVEGLASAPIEEVSPVSRQSIRNSQKHSPTSEPTPPGDALPPVSSPHTHRGYQPTPAMAKYVKILYDFTARNANEL SVLKDEVLEVLEDGRQWWKLRSRSGQAGYVPCNILGEARPEDAGAPFEQAGQKYWGPASPTHKLPPSFPGNKDELMQHMDEVNDELIRKI SNIRAQPQRHFRVERSQPVSQPLTYESGPDEVRAWLEAKAFSPRIVENLGILTGPQLFSLNKEELKKVCGEEGVRVYSQLTMQKAFLEKQ -------------------------------------------------------------- >66764_66764_8_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720062_ENST00000533256_length(transcript)=3624nt_BP=898nt GCGGCCCCAGTCAGACGCAGGCAGCCCCAAAGCCTGAACAGGCAGGGCCAGACCCAGCTTCTTCGCCTCCGCCAGCGGGGACCCCGAGCT AGAGCCGCAGCGGGACCTGCCCGGCCCCCGGCTCCAGCGAGCGAGCGGCGAGCAGGCGGCTCACAGAGGCCTGGCCGCCCACGGAACCCG GGGCCCGGCGGCCGCCGCCGCGATGTTTCCCCGCGAGAAGACGTGGAACATCTCGTTCGCGGGCTGCGGCTTCCTCGGCGTCTACTACGT CGGCGTGGCCTCCTGCCTCCGCGAGCACGCGCCCTTCCTGGTGGCCAACGCCACGCACATCTACGGCGCCTCGGCCGGGGCGCTCACGGC CACGGCGCTGGTCACCGGGGTCTGCCTGGGTGAGGCTGGTGCCAAGTTCATTGAGGTATCTAAAGAGGCCCGGAAGCGGTTCCTGGGCCC CCTGCACCCCTCCTTCAACCTGGTAAAGATCATCCGCAGTTTCCTGCTGAAGGTCCTGCCTGCTGATAGCCATGAGCATGCCAGTGGGCG CCTGGGCATCTCCCTGACCCGCGTGTCAGACGGCGAGAATGTCATTATATCCCACTTCAACTCCAAGGACGAGCTCATCCAGGCCAATGT CTGCAGCGGTTTCATCCCCGTGTACTGTGGGCTCATCCCTCCCTCCCTCCAGGGGGTGCGCTACGTGGATGGTGGCATTTCAGACAACCT GCCACTCTATGAGCTTAAGAACACCATCACAGTGTCCCCCTTCTCGGGCGAGAGTGACATCTGTCCGCAGGACAGCTCCACCAACATCCA CGAGCTGCGGGTCACCAACACCAGCATCCAGTTCAACCTGCGCAACCTCTACCGCCTCTCCAAGGCCCTCTTCCCGCCGGAGCCCCTGCA CCTGGCCACATTCATCATGGACAAGAGCGAAGCCATCACGTCTGTGGACGACGCCATCCGGAAGCTGGTGCAGCTGAGCTCCAAGGAGAA GATCTGGACCCAGGAGATGCTGCTGCAGGTGAACGACCAGTCGCTGCGGCTGCTGGACATCGAGTCACAGGAGGAGCTGGAAGACTTCCC GCTGCCCACGGTGCAGCGCAGCCAGACGGTCCTCAACCAGCTGCGCTACCCGTCTGTGCTGCTGCTCGTGTGCCAGGACTCGGAGCAGAG CAAGCCGGATGTCCACTTCTTCCACTGCGATGAGGTGGAGGCAGAGCTGGTGCACGAGGACATCGAGAGCGCGTTGGCCGACTGCCGGCT GGGCAAGAAGATGCGGCCGCAGACCCTGAAGGGACACCAGGAGAAGATTCGGCAGCGGCAGTCCATCCTGCCTCCTCCCCAGGGCCCGGC GCCCATCCCCTTCCAGCACCGCGGCGGGGATTCCCCGGAGGCCAAGAATCGCGTGGGCCCGCAGGTGCCACTCAGCGAGCCAGGTTTCCG CCGTCGGGAGTCGCAGGAGGAGCCGCGGGCCGTGCTGGCTCAGAAGATAGAGAAGGAGACGCAAATCCTCAACTGCGCCCTGGACGACAT CGAGTGGTTTGTGGCCCGGCTGCAGAAGGCAGCCGAGGCTTTCAAGCAGCTGAACCAGCGGAAAAAGGGGAAGAAGAAGGGCAAGAAGGC GCCAGCAGAGGGCGTCCTCACACTGCGGGCACGGCCCCCCTCTGAGGGCGAGTTCATCGACTGCTTCCAGAAAATCAAGCTGGCGATTAA CTTGCTGGCAAAGCTGCAGAAGCACATCCAGAACCCCAGCGCCGCGGAGCTCGTGCACTTCCTCTTCGGGCCTCTGGACCTGATCGTCAA CACCTGCAGTGGCCCAGACATCGCACGCTCCGTCTCCTGCCCACTGCTCTCCCGAGATGCCGTGGACTTCCTGCGCGGCCACCTGGTCCC TAAGGAGATGTCGCTGTGGGAGTCACTGGGAGAGAGCTGGATGCGGCCCCGTTCCGAGTGGCCGCGGGAGCCACAGGTGCCCCTCTACGT GCCCAAGTTCCACAGCGGCTGGGAGCCTCCTGTGGATGTGCTGCAGGAGGCCCCCTGGGAGGTGGAGGGGCTGGCGTCTGCCCCCATCGA GGAGGTGAGTCCAGTGAGCCGACAGTCCATAAGAAACTCCCAGAAGCACAGCCCCACTTCAGAGCCCACCCCCCCGGGGGATGCCCTACC ACCAGTCAGCTCCCCACATACTCACAGGGGCTACCAGCCAACACCAGCCATGGCCAAGTACGTCAAGATCCTGTATGACTTCACAGCCCG AAATGCCAACGAGCTATCGGTGCTCAAGGATGAGGTCCTAGAGGTGCTGGAGGACGGCCGGCAGTGGTGGAAGCTGCGCAGCCGCAGCGG CCAGGCGGGGTACGTGCCCTGCAACATCCTAGGCGAGGCGCGACCGGAGGACGCCGGCGCCCCGTTCGAGCAGGCCGGTCAGAAGTACTG GGGCCCCGCCAGCCCGACCCACAAGCTACCCCCAAGCTTCCCGGGGAACAAAGACGAGCTCATGCAGCACATGGACGAGGTCAACGACGA GCTCATCCGGAAAATCAGCAACATCAGGGCGCAGCCACAGAGGCACTTCCGCGTGGAGCGCAGCCAGCCCGTGAGCCAGCCGCTCACCTA CGAGTCGGGTCCGGACGAGGTCCGCGCCTGGCTGGAAGCCAAGGCCTTCAGCCCGCGGATCGTGGAGAACCTGGGCATCCTGACCGGGCC GCAGCTCTTCTCCCTCAACAAGGAGGAGCTGAAGAAAGTGTGCGGCGAGGAGGGCGTCCGCGTGTACAGCCAGCTCACCATGCAGAAGGC CTTCCTGGAGAAGCAGCAAAGTGGGTCGGAGCTGGAAGAACTCATGAACAAGTTTCATTCCATGAATCAGAGGAGGGGGGAGGACAGCTA GGCCCAGCTGCCTTGGGCTGGGGCCTGCGGAGGGGAAGCCCACCCACAATGCATGGAGTATTATTTTTATATGTGTATGTATTTTGTATC AAGGACACGGAGGGGGTGTGGTGCTGGCTAGAGGTCCCTGCCCCTGTCTGGAGGCACAACGCCCATCCTTAGGCCAAACAGTACCCAAGG CCTCAGCCCACACCAAGACTAATCTCAGCCAAACCTGCTGCTTGGTGGTGCCAGCCCCTTGTCCACCTTCTCTTGAGGCCACAGAACTCC CTGGGGCTGGGGCCTCTTTCTCTGGCCTCCCCTGTGCACCTGGGGGGTCCTGGCCCCTGTGATGCTCCCCCATCCCCACCCACTTCTACA TCCATCCACACCCCAGGGTGAGCTGGAGCTCCAGGCTGGCCAGGCTGAACCTCGCACACACGCAGAGTTCTGCTCCCTGAGGGGGGCCCG GGAGGGGCTCCAGCAGGAGGCCGTGGGTGCCATTCGGGGGAAAGTGGGGGAACGACACACACTTCACCTGCAAGGGCCGACAACGCAGGG GACACCGTGCCGGCTTCAGACACTCCCAGCGCCCACTCTTACAGGCCCAGGACTGGAGCTTTCTCTGGCCAAGTTTCAGGCCAATGATCC CCGCATGGTGTTGGGGGTGCTGGTGTGTCTTGGTGCCTGGACTTGAGTCTCACCCTACAGATGAGAGGTGGCTGAGGCACCAGGGCTAAG >66764_66764_8_PNPLA2-EPS8L2_PNPLA2_chr11_822606_ENST00000336615_EPS8L2_chr11_720062_ENST00000533256_length(amino acids)=924AA_BP=262 MPGPRLQRASGEQAAHRGLAAHGTRGPAAAAAMFPREKTWNISFAGCGFLGVYYVGVASCLREHAPFLVANATHIYGASAGALTATALVT GVCLGEAGAKFIEVSKEARKRFLGPLHPSFNLVKIIRSFLLKVLPADSHEHASGRLGISLTRVSDGENVIISHFNSKDELIQANVCSGFI PVYCGLIPPSLQGVRYVDGGISDNLPLYELKNTITVSPFSGESDICPQDSSTNIHELRVTNTSIQFNLRNLYRLSKALFPPEPLHLATFI MDKSEAITSVDDAIRKLVQLSSKEKIWTQEMLLQVNDQSLRLLDIESQEELEDFPLPTVQRSQTVLNQLRYPSVLLLVCQDSEQSKPDVH FFHCDEVEAELVHEDIESALADCRLGKKMRPQTLKGHQEKIRQRQSILPPPQGPAPIPFQHRGGDSPEAKNRVGPQVPLSEPGFRRRESQ EEPRAVLAQKIEKETQILNCALDDIEWFVARLQKAAEAFKQLNQRKKGKKKGKKAPAEGVLTLRARPPSEGEFIDCFQKIKLAINLLAKL QKHIQNPSAAELVHFLFGPLDLIVNTCSGPDIARSVSCPLLSRDAVDFLRGHLVPKEMSLWESLGESWMRPRSEWPREPQVPLYVPKFHS GWEPPVDVLQEAPWEVEGLASAPIEEVSPVSRQSIRNSQKHSPTSEPTPPGDALPPVSSPHTHRGYQPTPAMAKYVKILYDFTARNANEL SVLKDEVLEVLEDGRQWWKLRSRSGQAGYVPCNILGEARPEDAGAPFEQAGQKYWGPASPTHKLPPSFPGNKDELMQHMDEVNDELIRKI SNIRAQPQRHFRVERSQPVSQPLTYESGPDEVRAWLEAKAFSPRIVENLGILTGPQLFSLNKEELKKVCGEEGVRVYSQLTMQKAFLEKQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PNPLA2-EPS8L2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PNPLA2-EPS8L2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PNPLA2-EPS8L2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies