
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PPAP2A-MAPK1 (FusionGDB2 ID:67299) |
Fusion Gene Summary for PPAP2A-MAPK1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PPAP2A-MAPK1 | Fusion gene ID: 67299 | Hgene | Tgene | Gene symbol | PPAP2A | MAPK1 | Gene ID | 8611 | 5594 |
| Gene name | phospholipid phosphatase 1 | mitogen-activated protein kinase 1 | |
| Synonyms | LLP1a|LPP1|PAP-2a|PAP2|PPAP2A | ERK|ERK-2|ERK2|ERT1|MAPK2|P42MAPK|PRKM1|PRKM2|p38|p40|p41|p41mapk|p42-MAPK | |
| Cytomap | 5q11.2 | 22q11.22 | |
| Type of gene | protein-coding | protein-coding | |
| Description | phospholipid phosphatase 1lipid phosphate phosphohydrolase 1aphosphatidate phosphohydrolase type 2aphosphatidic acid phosphatase 2aphosphatidic acid phosphatase type 2Aphosphatidic acid phosphohydrolase type 2atype-2 phosphatidic acid phosphatase al | mitogen-activated protein kinase 1MAP kinase 1MAP kinase 2MAP kinase isoform p42MAPK 2extracellular signal-regulated kinase 2mitogen-activated protein kinase 2protein tyrosine kinase ERK2 | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | . | Q8NDC0 | |
| Ensembl transtripts involved in fusion gene | ENST00000264775, ENST00000307259, ENST00000515132, | ENST00000491588, ENST00000215832, ENST00000398822, ENST00000544786, | |
| Fusion gene scores | * DoF score | 17 X 8 X 6=816 | 15 X 8 X 9=1080 |
| # samples | 23 | 16 | |
| ** MAII score | log2(23/816*10)=-1.82693529102712 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(16/1080*10)=-2.75488750216347 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PPAP2A [Title/Abstract] AND MAPK1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PPAP2A(54830400)-MAPK1(22143097), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PPAP2A | GO:0006644 | phospholipid metabolic process | 9305923|9705349|15461590 |
| Hgene | PPAP2A | GO:0006670 | sphingosine metabolic process | 9705349 |
| Hgene | PPAP2A | GO:0006672 | ceramide metabolic process | 9305923|9705349 |
| Hgene | PPAP2A | GO:0046839 | phospholipid dephosphorylation | 9305923|9705349|15461590|16464866 |
| Tgene | MAPK1 | GO:0006468 | protein phosphorylation | 23184662 |
| Tgene | MAPK1 | GO:0010800 | positive regulation of peptidyl-threonine phosphorylation | 16314496 |
| Tgene | MAPK1 | GO:0018105 | peptidyl-serine phosphorylation | 15850461 |
| Tgene | MAPK1 | GO:0034198 | cellular response to amino acid starvation | 11096076 |
| Tgene | MAPK1 | GO:0038127 | ERBB signaling pathway | 15133037 |
| Tgene | MAPK1 | GO:0051403 | stress-activated MAPK cascade | 11096076 |
| Tgene | MAPK1 | GO:0070371 | ERK1 and ERK2 cascade | 16314496 |
| Tgene | MAPK1 | GO:0070849 | response to epidermal growth factor | 18794356 |
| Fusion gene breakpoints across PPAP2A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MAPK1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-J4-A67N-01A | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| ChimerDB4 | PRAD | TCGA-J4-A67N | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
Top |
Fusion Gene ORF analysis for PPAP2A-MAPK1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000264775 | ENST00000491588 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| 5CDS-intron | ENST00000307259 | ENST00000491588 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| 5UTR-3CDS | ENST00000515132 | ENST00000215832 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| 5UTR-3CDS | ENST00000515132 | ENST00000398822 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| 5UTR-3CDS | ENST00000515132 | ENST00000544786 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| 5UTR-intron | ENST00000515132 | ENST00000491588 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| In-frame | ENST00000264775 | ENST00000215832 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| In-frame | ENST00000264775 | ENST00000398822 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| In-frame | ENST00000264775 | ENST00000544786 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| In-frame | ENST00000307259 | ENST00000215832 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| In-frame | ENST00000307259 | ENST00000398822 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| In-frame | ENST00000307259 | ENST00000544786 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000264775 | PPAP2A | chr5 | 54830400 | - | ENST00000215832 | MAPK1 | chr22 | 22143097 | - | 10622 | 398 | 344 | 871 | 175 |
| ENST00000264775 | PPAP2A | chr5 | 54830400 | - | ENST00000398822 | MAPK1 | chr22 | 22143097 | - | 1036 | 398 | 344 | 871 | 175 |
| ENST00000264775 | PPAP2A | chr5 | 54830400 | - | ENST00000544786 | MAPK1 | chr22 | 22143097 | - | 740 | 398 | 344 | 739 | 132 |
| ENST00000307259 | PPAP2A | chr5 | 54830400 | - | ENST00000215832 | MAPK1 | chr22 | 22143097 | - | 10703 | 479 | 425 | 952 | 175 |
| ENST00000307259 | PPAP2A | chr5 | 54830400 | - | ENST00000398822 | MAPK1 | chr22 | 22143097 | - | 1117 | 479 | 425 | 952 | 175 |
| ENST00000307259 | PPAP2A | chr5 | 54830400 | - | ENST00000544786 | MAPK1 | chr22 | 22143097 | - | 821 | 479 | 425 | 820 | 132 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000264775 | ENST00000215832 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - | 0.007316154 | 0.9926838 |
| ENST00000264775 | ENST00000398822 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - | 0.010151631 | 0.98984843 |
| ENST00000264775 | ENST00000544786 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - | 0.012134708 | 0.98786527 |
| ENST00000307259 | ENST00000215832 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - | 0.007492401 | 0.99250764 |
| ENST00000307259 | ENST00000398822 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - | 0.015626095 | 0.9843739 |
| ENST00000307259 | ENST00000544786 | PPAP2A | chr5 | 54830400 | - | MAPK1 | chr22 | 22143097 | - | 0.025196323 | 0.9748037 |
Top |
Fusion Genomic Features for PPAP2A-MAPK1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
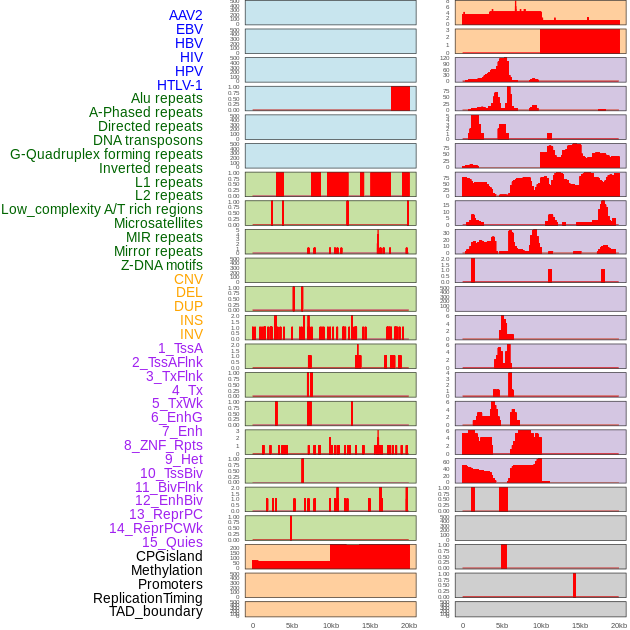 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PPAP2A-MAPK1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:54830400/chr22:22143097) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | MAPK1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 5_7 | 19 | 286.0 | Motif | PDZ-binding%3B involved in localization to the apical cell membrane |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 5_7 | 19 | 285.0 | Motif | PDZ-binding%3B involved in localization to the apical cell membrane |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 1_6 | 19 | 286.0 | Topological domain | Cytoplasmic |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 1_6 | 19 | 285.0 | Topological domain | Cytoplasmic |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 259_277 | 203 | 3486.3333333333335 | DNA binding | . | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 259_277 | 203 | 361.0 | DNA binding | . | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 259_277 | 203 | 317.0 | DNA binding | . | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 318_322 | 203 | 3486.3333333333335 | Motif | Cytoplasmic retention motif | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 327_333 | 203 | 3486.3333333333335 | Motif | Nuclear translocation motif | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 318_322 | 203 | 361.0 | Motif | Cytoplasmic retention motif | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 327_333 | 203 | 361.0 | Motif | Nuclear translocation motif | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 318_322 | 203 | 317.0 | Motif | Cytoplasmic retention motif | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 327_333 | 203 | 317.0 | Motif | Nuclear translocation motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 120_128 | 19 | 286.0 | Region | Phosphatase sequence motif I |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 168_171 | 19 | 286.0 | Region | Phosphatase sequence motif II |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 216_227 | 19 | 286.0 | Region | Phosphatase sequence motif III |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 120_128 | 19 | 285.0 | Region | Phosphatase sequence motif I |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 168_171 | 19 | 285.0 | Region | Phosphatase sequence motif II |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 216_227 | 19 | 285.0 | Region | Phosphatase sequence motif III |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 116_164 | 19 | 286.0 | Topological domain | Extracellular |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 186_199 | 19 | 286.0 | Topological domain | Cytoplasmic |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 221_229 | 19 | 286.0 | Topological domain | Extracellular |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 251_284 | 19 | 286.0 | Topological domain | Cytoplasmic |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 28_53 | 19 | 286.0 | Topological domain | Extracellular |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 75_94 | 19 | 286.0 | Topological domain | Cytoplasmic |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 116_164 | 19 | 285.0 | Topological domain | Extracellular |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 186_199 | 19 | 285.0 | Topological domain | Cytoplasmic |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 221_229 | 19 | 285.0 | Topological domain | Extracellular |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 251_284 | 19 | 285.0 | Topological domain | Cytoplasmic |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 28_53 | 19 | 285.0 | Topological domain | Extracellular |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 75_94 | 19 | 285.0 | Topological domain | Cytoplasmic |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 165_185 | 19 | 286.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 200_220 | 19 | 286.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 230_250 | 19 | 286.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 54_74 | 19 | 286.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 7_27 | 19 | 286.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000264775 | - | 1 | 6 | 95_115 | 19 | 286.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 165_185 | 19 | 285.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 200_220 | 19 | 285.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 230_250 | 19 | 285.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 54_74 | 19 | 285.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 7_27 | 19 | 285.0 | Transmembrane | Helical |
| Hgene | PPAP2A | chr5:54830400 | chr22:22143097 | ENST00000307259 | - | 1 | 6 | 95_115 | 19 | 285.0 | Transmembrane | Helical |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 2_9 | 203 | 3486.3333333333335 | Compositional bias | Note=Poly-Ala | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 2_9 | 203 | 361.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 2_9 | 203 | 317.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 25_313 | 203 | 3486.3333333333335 | Domain | Protein kinase | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 25_313 | 203 | 361.0 | Domain | Protein kinase | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 25_313 | 203 | 317.0 | Domain | Protein kinase | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 185_187 | 203 | 3486.3333333333335 | Motif | TXY | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 185_187 | 203 | 361.0 | Motif | TXY | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 185_187 | 203 | 317.0 | Motif | TXY | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 31_39 | 203 | 3486.3333333333335 | Nucleotide binding | ATP | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 31_39 | 203 | 361.0 | Nucleotide binding | ATP | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 31_39 | 203 | 317.0 | Nucleotide binding | ATP | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 105_108 | 203 | 3486.3333333333335 | Region | Note=Inhibitor-binding | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000215832 | 3 | 9 | 153_154 | 203 | 3486.3333333333335 | Region | Note=Inhibitor-binding | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 105_108 | 203 | 361.0 | Region | Note=Inhibitor-binding | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000398822 | 3 | 8 | 153_154 | 203 | 361.0 | Region | Note=Inhibitor-binding | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 105_108 | 203 | 317.0 | Region | Note=Inhibitor-binding | |
| Tgene | MAPK1 | chr5:54830400 | chr22:22143097 | ENST00000544786 | 3 | 7 | 153_154 | 203 | 317.0 | Region | Note=Inhibitor-binding |
Top |
Fusion Gene Sequence for PPAP2A-MAPK1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >67299_67299_1_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000264775_MAPK1_chr22_22143097_ENST00000215832_length(transcript)=10622nt_BP=398nt CCTGTGGGAGAGAGCGCCGGGATCCGGACGGGGAGCAACCGGGGCAGGCCGTGCCGGCTGAGGAGGTCCTGAGGCTACAGAGCTGCCGCG GCTGGCACACGAGCGCCTCGGCACTAACCGAGTGTTCGCGGGGGCTGTGAGGGGAGGGCCCCGGGCGCCATTGCTGGCGGTGGGAGCGCC GCCCGGTCTCAGCCCGCCCTCGGCTGCTCTCCTCCTCCGGCTGGGAGGGGCCGTAGCTCGGGGCCGTCGCCAGCCCCGGCCCGGGCTCGA GAATCAAGGGCCTCGGCCGCCGTCCCGCAGCTCAGTCCATCGCCCTTGCCGGGCAGCCCGGGCAGAGACCATGTTTGACAAGACGCGGCT GCCGTACGTGGCCCTCGATGTGCTCTGCGTGTTGCTGGGGCTACACCAAGTCCATTGATATTTGGTCTGTAGGCTGCATTCTGGCAGAAA TGCTTTCTAACAGGCCCATCTTTCCAGGGAAGCATTATCTTGACCAGCTGAACCACATTTTGGGTATTCTTGGATCCCCATCACAAGAAG ACCTGAATTGTATAATAAATTTAAAAGCTAGGAACTATTTGCTTTCTCTTCCACACAAAAATAAGGTGCCATGGAACAGGCTGTTCCCAA ATGCTGACTCCAAAGCTCTGGACTTATTGGACAAAATGTTGACATTCAACCCACACAAGAGGATTGAAGTAGAACAGGCTCTGGCCCACC CATATCTGGAGCAGTATTACGACCCGAGTGACGAGCCCATCGCCGAAGCACCATTCAAGTTCGACATGGAATTGGATGACTTGCCTAAGG AAAAGCTCAAAGAACTAATTTTTGAAGAGACTGCTAGATTCCAGCCAGGATACAGATCTTAAATTTGTCAGGACAAGGGCTCAGAGGACT GGACGTGCTCAGACATCGGTGTTCTTCTTCCCAGTTCTTGACCCCTGGTCCTGTCTCCAGCCCGTCTTGGCTTATCCACTTTGACTCCTT TGAGCCGTTTGGAGGGGCGGTTTCTGGTAGTTGTGGCTTTTATGCTTTCAAAGAATTTCTTCAGTCCAGAGAATTCCTCCTGGCAGCCCT GTGTGTGTCACCCATTGGTGACCTGCGGCAGTATGTACTTCAGTGCACCTACTGCTTACTGTTGCTTTAGTCACTAATTGCTTTCTGGTT TGAAAGATGCAGTGGTTCCTCCCTCTCCTGAATCCTTTTCTACATGATGCCCTGCTGACCATGCAGCCGCACCAGAGAGAGATTCTTCCC CAATTGGCTCTAGTCACTGGCATCTCACTTTATGATAGGGAAGGCTACTACCTAGGGCACTTTAAGTCAGTGACAGCCCCTTATTTGCAC TTCACCTTTTGACCATAACTGTTTCCCCAGAGCAGGAGCTTGTGGAAATACCTTGGCTGATGTTGCAGCCTGCAGCAAGTGCTTCCGTCT CCGGAATCCTTGGGGAGCACTTGTCCACGTCTTTTCTCATATCATGGTAGTCACTAACATATATAAGGTATGTGCTATTGGCCCAGCTTT TAGAAAATGCAGTCATTTTTCTAAATAAAAAGGAAGTACTGCACCCAGCAGTGTCACTCTGTAGTTACTGTGGTCACTTGTACCATATAG AGGTGTAACACTTGTCAAGAAGCGTTATGTGCAGTACTTAATGTTTGTAAGACTTACAAAAAAAGATTTAAAGTGGCAGCTTCACTCGAC ATTTGGTGAGAGAAGTACAAAGGTTGCAGTGCTGAGCTGTGGGCGGTTTCTGGGGATGTCCCAGGGTGGAACTCCACATGCTGGTGCATA TACGCCCTTGAGCTACTTCAAATGTGGGTGTTTCAGTAACCACGTTCCATGCCTGAGGATTTAGCAGAGAGGAACACTGCGTCTTTAAAT GAGAAAGTATACAATTCTTTTTCCTTCTACAGCATGTCAGCATCTCAAGTTCATTTTTCAACCTACAGTATAACAATTTGTAATAAAGCC TCCAGGAGCTCATGACGTGAAGCACTGTTCTGTCCTCAAGTACTCAAATATTTCTGATACTGCTGAGTCAGACTGTCAGAAAAAGCTAGC ACTAACTCGTGTTTGGAGCTCTATCCATATTTTACTGATCTCTTTAAGTATTTGTTCCTGCCACTGTGTACTGTGGAGTTGACTCGGTGT TCTGTCCCAGTGCGGTGCCTCCTCTTGACTTCCCCACTGCTCTCTGTGGTGAGAAATTTGCCTTGTTCAATAATTACTGTACCCTCGCAT GACTGTTACAGCTTTCTGTGCAGAGATGACTGTCCAAGTGCCACATGCCTACGATTGAAATGAAAACTCTATTGTTACCTCTGAGTTGTG TTCCACGGAAAATGCTATCCAGCAGATCATTTAGGAAAAATAATTCTATTTTTAGCTTTTCATTTCTCAGCTGTCCTTTTTTCTTGTTTG ATTTTTGACAGCAATGGAGAATGGGTTATATAAAGACTGCCTGCTAATATGAACAGAAATGCATTTGTAATTCATGAAAATAAATGTACA TCTTCTATCTTCACATTCATGTTAAGATTCAGTGTTGCTTTCCTCTGGATCAGCGTGTCTGAATGGACAGTCAGGTTCAGGTTGTGCTGA ACACAGAAATGCTCACAGGCCTCACTTTGCCGCCCAGGCACTGGCCCAGCACTTGGATTTACATAAGATGAGTTAGAAAGGTACTTCTGT AGGGTCCTTTTTACCTCTGCTCGGCAGAGAATCGATGCTGTCATGTTCCTTTATTCACAATCTTAGGTCTCAAATATTCTGTCAAACCCT AACAAAGAAGCCCCGACATCTCAGGTTGGATTCCCTGGTTCTCTCTAAAGAGGGCCTGCCCTTGTGCCCCAGAGGTGCTGCTGGGCACAG CCAAGAGTTGGGAAGGGCCGCCCCACAGTACGCAGTCCTCACCACCCAGCCCAGGGTGCTCACGCTCACCACTCCTGTGGCTGAGGAAGG ATAGCTGGCTCATCCTCGGAAAACAGACCCACATCTCTATTCTTGCCCTGAAATACGCGCTTTTCACTTGCGTGCTCAGAGCTGCCGTCT GAAGGTCCACACAGCATTGACGGGACACAGAAATGTGACTGTTACCGGATAACACTGATTAGTCAGTTTTCATTTATAAAAAAGCATTGA CAGTTTTATTACTCTTGTTTCTTTTTAAATGGAAAGTTACTATTATAAGGTTAATTTGGAGTCCTCTTCTAAATAGAAAACCATATCCTT GGCTACTAACATCTGGAGACTGTGAGCTCCTTCCCATTCCCCTTCCTGGTACTGTGGAGTCAGATTGGCATGAAACCACTAACTTCATTC TAGAATCATTGTAGCCATAAGTTGTGTGCTTTTTATTAATCATGCCAAACATAATGTAACTGGGCAGAGAATGGTCCTAACCAAGGTACC TATGAAAAGCGCTAGCTATCATGTGTAGTAGATGCATCATTTTGGCTCTTCTTACATTTGTAAAAATGTACAGATTAGGTCATCTTAATT CATATTAGTGACACGGAACAGCACCTCCACTATTTGTATGTTCAAATAAGCTTTCAGACTAATAGCTTTTTTGGTGTCTAAAATGTAAGC AAAAAATTCCTGCTGAAACATTCCAGTCCTTTCATTTAGTATAAAAGAAATACTGAACAAGCCAGTGGGATGGAATTGAAAGAACTAATC ATGAGGACTCTGTCCTGACACAGGTCCTCAAAGCTAGCAGAGATACGCAGACATTGTGGCATCTGGGTAGAAGAATACTGTATTGTGTGT GCAGTGCACAGTGTGTGGTGTGTGCACACTCATTCCTTCTGCTCTTGGGCACAGGCAGTGGGTGTAGAGGTAACCAGTAGCTTTGAGAAG CTACATGTAGCTCACCAGTGGTTTTCTCTAAGGAATCACAAAAGTAAACTACCCAACCACATGCCACGTAATATTTCAGCCATTCAGAGG AAACTGTTTTCTCTTTATTTGCTTATATGTTAATATGGTTTTTAAATTGGTAACTTTTATATAGTATGGTAACAGTATGTTAATACACAC ATACATACGCACACATGCTTTGGGTCCTTCCATAATACTTTTATATTTGTAAATCAATGTTTTGGAGCAATCCCAAGTTTAAGGGAAATA TTTTTGTAAATGTAATGGTTTTGAAAATCTGAGCAATCCTTTTGCTTATACATTTTTAAAGCATTTGTGCTTTAAAATTGTTATGCTGGT GTTTGAAACATGATACTCCTGTGGTGCAGATGAGAAGCTATAACAGTGAATATGTGGTTTCTCTTACGTCATCCACCTTGACATGATGGG TCAGAAACAAATGGAAATCCAGAGCAAGTCCTCCAGGGTTGCACCAGGTTTACCTAAAGCTTGTTGCCTTTTCTTGTGCTGTTTATGCGT GTAGAGCACTCAAGAAAGTTCTGAAACTGCTTTGTATCTGCTTTGTACTGTTGGTGCCTTCTTGGTATTGTACCCCAAAATTCTGCATAG ATTATTTAGTATAATGGTAAGTTAAAAAATGTTAAAGGAAGATTTTATTAAGAATCTGAATGTTTATTCATTATATTGTTACAATTTAAC ATTAACATTTATTTGTGGTATTTGTGATTTGGTTAATCTGTATAAAAATTGTAAGTAGAAAGGTTTATATTTCATCTTAATTCTTTTGAT GTTGTAAACGTACTTTTTAAAAGATGGATTATTTGAATGTTTATGGCACCTGACTTGTAAAAAAAAAAAACTACAAAAAAATCCTTAGAA TCATTAAATTGTGTCCCTGTATTACCAAAATAACACAGCACCGTGCATGTATAGTTTAATTGCAGTTTCATCTGTGAAAACGTGAAATTG TCTAGTCCTTCGTTATGTTCCCCAGATGTCTTCCAGATTTGCTCTGCATGTGGTAACTTGTGTTAGGGCTGTGAGCTGTTCCTCGAGTTG AATGGGGATGTCAGTGCTCCTAGGGTTCTCCAGGTGGTTCTTCAGACCTTCACCTGTGGGGGGGGGGGTAGGCGGTGCCCACGCCCATCT CCTCATCCTCCTGAACTTCTGCAACCCCACTGCTGGGCAGACATCCTGGGCAACCCCTTTTTTCAGAGCAAGAAGTCATAAAGATAGGAT TTCTTGGACATTTGGTTCTTATCAATATTGGGCATTATGTAATGACTTATTTACAAAACAAAGATACTGGAAAATGTTTTGGATGTGGTG TTATGGAAAGAGCACAGGCCTTGGACCCATCCAGCTGGGTTCAGAACTACCCCCTGCTTATAACTGCGGCTGGCTGTGGGCCAGTCATTC TGCGTCTCTGCTTTCTTCCTCTGCTTCAGACTGTCAGCTGTAAAGTGGAAGCAATATTACTTGCCTTGTATATGGTAAAGATTATAAAAA TACATTTCAACTGTTCAGCATAGTACTTCAAAGCAAGTACTCAGTAAATAGCAAGTCTTTTTAAATGCTGCTTTATTTCACTAAATTTTG TTGTGAGGTGTCACTAAAATGCCTGCAAACAAACGTAACTGCTAATCTGAGAGGAAACCCTCTTACTAATCAGAGAAGAAACCCTCCTGT CAGAAACCTTCAGGGAAGTGAGCTGATCACACCTAAACTGGGAGTTTGCAATGGGGTATTTGAAGCACTGTGGGAGTATTCCACTGGCCC TCTCCCTGAGAGACTTAACAGTCTTCCCTGTTGTCCAGATTCTGTATAAGGCAATCAGAATAATCATCTTCCTTGTTCAGCAGAGGAGCC TGGTCCCATTTTCCCCACTTTGTGATGGGCTTCTCTCAGCGGTAGCTCAGCAGTTCCAGATGGCAGTTTGGACCAGCATCTAGGCTGGCC AGTTCGCTGTGTTTACTTAGAACCAACACGTTCAGAGCTGGCCTGGACCATCTGAGGGGAACAGGAAACACCCCTAGGCTGTGGAAGCAA GTGCAGACCCCCACCCCCGGCCCTGAAGCCAAGGGGGCAGGGTTTGGGAGTGGCCAAAGAGAAGCAGTGCAGGGATGGGTTTTCCTAGGG ACAGGCTTAGCATTCCTGACTCTAGGAAGAAGGAGCAGTGAGGCGGAGAAACAGTGGAGGGGATGGTGGCATTGGGCCCCATGGGGCCGA GATGGACACAGGGCTCGTTCTCTTGAGTCTGGTGCCAAGGACAGCTGAAGACGACATCATTTTCAGGTGGAGAGGAGAGAGTGGAGGGAG ATCATGCCCTGTGATGTGTCTTTTGCAGGTGAAGGTGGGAGACAAGGTCTCTGCTGACGATGAGGCAGAGCCACCGTGAAAGTTGTAATA GGAGGACTGCCCGCCGCTGGAAGGGCCTGCAGTGACGCTAGGACACCCTCTGCCTGCATGTCACGTTAGCTGGGCTGGGCGAAGTAGAAG ACCAAGGGGAAGAGGTGCAGTGGGGAGACCAGGTGGGATGCAACCACAGGACCAGTGGAGGGGCTGTGGCACGTGGGCGGAGACTGAGTG GCTGGGCATGTGTTGTGGCTGAGCATGTGGTGTGGGCAGTGGTCCTAGACCCCGCCATGTCCGGACAATGATATAGAGCGTCTCAGCATC GCCAGTCTAGACTGTCTATGGAGAGCAGAAAGTTGTCTGGGGCTGCCTGGGGAACTGTGAGGCCAGCTATATCACCGTCGCTGATGGTGA CATTACGGTGGTGGCAGGAGCAAGGAGAGAGGGAAGAAGGACCCCGTCCAGCTTTAGTCACAAAATACCCAATGGAAGATGCCAGTGCCA ATCCTGTGGGTTTCCTTGGGACTTCACACTGGCTTTCTTATCTGCTCCAGATCCATTCAGTAGTCACTGAGTTCCTGCCAAATACTTTGT AGCGCCAGAAGCCAGGAGCGGGGTCTGCAGCAGGGCAGTCCCCATTTTCAGGAAATGCCTGGAGCTGCTGGTCCCTGAGAGAAAGGAAAA CATCTTTCAGCCGTACGCAGGCCAAGAAGGCCAATGTCCAGTAGCTTTGTGATTTTTTTTATATTTTTTTATTTATTTATTTTTGAGATA GAGTCTTGCTCTGTCGCTCAGGCTGGAGTGCAGTGGCGTGATCTCCACTCACTGCAACTTCCGCCTCCTGGGGTCAAGCAGTTCTGCCTC AGCCTCCCGAGTAGCTGGGATTACAGGCACACGCCACCACACCCAGCTAATTTTTGTGTTTTTAGTAGAGACGGTTTCACCATGTCGGCC AGGCTGGTCTCAAACTCCTGACCTCAGATGATTCAGCCTCCCAAAGTGCTGGGATTACAGGTGTGAGCCACTGCACCCAGCCTGTGATGT TTCTGTGGGGTTCCACAAATGTGTGTGTGTGTAAAAGCTGATGATTACAGCAAGAATGTGAACAGTAGCAGTTTTCCATTTGAAGGCAAG TTTTGTCTTTATCTGGGTATCAGAAGGACCCTCTGGGCCATTGTCGCTTCCTGTACTCAGAGCCACCCTAGTACTACGGGCACACACAGA AAACAGCAGCCTGCGTACTTTCAAAGGAAAGGCATCTTTAATCACCAATGCCTGGAAAAATTATTTTGTTTCCCTCTTCCTTCCGTCTTG TTTCCTAACTTCTTACCAAAGTTTAGAGTCTGAGTTTTTCGTATAATAATGTCCCACATCCACACATCGGGCCTACAGATGCTCTCCCTT GAATCGACTGGAAACATGACACCGGTTCCATGCTCTGGAACTGTCACCTGTGATGTGCTGGGCTGTGTCCCAAGCACAGGAATCCCAGCA GTTTCAGCTCGATGCAGAACCACCATGCTCCAGACACAGGCTTGGGAAAGACACGTCAAAATTAAAATACTAGGTAAGAGAAGCACCTGA TTGGGTAGAAGTTGGAGAGGAATCCTGGAATTTTGTGGCCAGAAGGAGCCACTGCCCCTTTTGTTTAGTAAGACTAGACAGTAACAGAAG CCAGTTGTCAGCTATGAAAGTGGTGGGTGAAGCAGGGGAGGCTCCTCTATGGTGGGACCCTGGACAAGGGAAGCCGAATGTGTGAAGAAG GGGTGCGGGGGTGTGCGGTGCCCTAGGACACTAGGGCAAAGGTTTCAAACCTGGAACAAGGCACTGGAGGAAGATCTGCTGCCAGTCAGC AGTGCGGGCCCTCGAGTTAGCAGTCCGTGCGCAGAGGGGCCAGTTCTGAGACCAGTTTGGAGAGTCAGGCAGTGACCCATTGGCCATGTC ATAATTCCTTCAGCCTGCCTCCTCTTTAATCCCAGAGAGTGCTCTTTCTTCATACTTCCTTTAAAATACTAAATTGTTCCCATTCCATGG GGAGCTGGCTAGGCTTTACAGGCTAGGAAATGTAGGTTTTCTGAGATGGAACCATCTACACAAGGAGGAGGAAGGCACTAAGACTACAGA TGAGACCCATGACAGGGCTGAGCATTTGGAAGCCAACCCTGGTTGCTTTTCAAGAATTGCTTTGTGGCTGGGTGCAGTGGTTCACACCTG TAATTGCAGCACTTTGGGAGGCTGAGGCAGGTGGATTGCTTGAACCCAGGAGTTCGAGACCAGCCTGGGCAACATATGGGACACCCCACC GCCCCCGGCTCTGCAAAAAAATTAAAAATTAGCCAGGCGTGGTGTCATGAGCCTGTGGTCTCAACTACTCAGGAGGCTGAGGCTGGAGGA TCGCTTGAACCTGGGAGGTCAAGGCTCCAGTGAACCATAATTGTGCCACTGCACTGCAGCCTGGGCGACAATTTGTTTTCTAAATTGCTT TTGAAAGTCTACTGCATTACATATTCCAAAAAGCAGTGGTTTTCAAATACTTTTATCACCGATATCCTTTTATGAAATGAAATCAGTAGA ACTTTCTCTGCTCTGAATAAGCAAGGGTGGGAACCTGTCTACCTCCCACAGATAGCATAATGTGCCTGCCATAGAGGAGCCAAAAAATGG TGATGGGAACTGAGAGGAGAGCAAATGTCACAAAAGACTGAGCAATTGAGAAAACAAAACAAGACCACAGATGACTGTTAACGCCTCCAC AGTGGACCAAGAAAGGACAGAGAGCTGGCAGCATGGGCATCACTGTCTGGTCGGCAGCAGGAAGGCCTCGCTAGGGAATTGAGTACAGTC ATCTAACTAGTTTAAAAGTACAGGAAGGATGATTAAGGCTATTGGAGAGGTCATACAAATAGGGGAGGGGCAGGCAATGGCTGATAAGAC ATGAATTTGTAAGGCGATGAGTATTGCAGTCAGCAAAACAAACGAGACTGCTCTCCCAACACATAACTCAGCAGGGAGGCCAGGCATTGG TTTAACCATTTAATATAAAGAAGTTAAAATTACAAATGCGCTAAGTGCCTAAAGAAGAATAAGTGCAGGAATGAGAGCAGCATGGACTGC CACAGTTTTAGAATAAGCACTGTCACTGCTAGATTGGAAACAAAAATCCATAAATTTGGCCCGGTGTGGTGGCGGACGCCTGTAGTCCCA GCTACTTGGAGGCTGAGGCGTGAGAATCGCTTGAACCCGGGAGGCGGAGGTTGCAGTGAGCCGAGATGGCGCCACTGCACTCCAGCCTGG GCGTCAGAGTGAGAACTCTGTATCAAAAAATAAAAATAAAAAAAAGTCCATAAATCTGCAATGTCTCAGTTAAGAAAGAAAGACTGGGCC AATGCAGATTTCAAACCGGAGAAAGTCATACTGTCAGTGAAGGCCGCCTGTGGCCGGAAGGCGCCAGGGGATTAGCACCCTGGACTCAGT GTTGCTGGGAAACAGGGCCCCAAGGCTGGGAGCACAGTGTTTAAAGGGCATCTACCCAAGAAGGGAGCACAGGGCAAGGAGGAGCTGCAG GGGGGCTTGGCTGCCAAAGTGAATTCTGAGGAGAGAGCTATTGCTGCCTACGATATGCAGGCTGCACAGAACACAAGTGGAATCAGCAGG CAGGAGAGGCAGCTAACGACGCAGCCCGTTTCTTATTTCTGTTTTCTCACAAGCGATGAAAGTGGAAAAGAGGGTGAGCAGGTGGCCCAC ACATGTGCCTCCAGTGCTGCGGCCCCTCCGGGGACCATCAGCCAGGCCCCGGGGAGGGAGCCAGCCACAGTGTGTCCGGCTCTTCTCTGA AGGGAAGAGAGCCTTGAATAGACTGAAGCGAAGACGGTTCTGCAAGGACAAGGCAGACCGAAGGCATTGGTTTTTTTTTTCAGATAAGGA GAATTAGACTCCCAAGTAGACACCAGAGTCACTGTTTGGTTGGTGGGTGATAGTGGGGTCACAGTGGCTGCCTGTGCTCCCCCAGGGTGA GCGTGACTGTGCTAACCTGGGTGGGGCAGCATGCACACCCCTCTGGCAGCCCTTTGTTGCTCGCTGATGACAAGTTTGGATGATCCCGCC AAACAGCTTGCTAAGATGTAGTCCCCAGTGTTGGAGGTGGGGCCTGATGGGAGGTGCTACCCTTGTGAGATAAGGTTGTGTAAAAGCCTG TGGCACCTCCCCACACTGACGCTCTCACCCCTGCTCTGGCCATGTGCCGCGCCTGCTCCCACTTCCCCTTCTGCCAGGAGTAAAAGCCCC CGAGACCTCCCAGAAGCCAAGCAGATGCTAGTGCCATGCTTCCTCTGCAGCCTGCAGAACTGTGAGCCAATTAAACCTCTTTTCTCTATA >67299_67299_1_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000264775_MAPK1_chr22_22143097_ENST00000215832_length(amino acids)=175AA_BP=18 MTRRGCRTWPSMCSACCWGYTKSIDIWSVGCILAEMLSNRPIFPGKHYLDQLNHILGILGSPSQEDLNCIINLKARNYLLSLPHKNKVPW -------------------------------------------------------------- >67299_67299_2_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000264775_MAPK1_chr22_22143097_ENST00000398822_length(transcript)=1036nt_BP=398nt CCTGTGGGAGAGAGCGCCGGGATCCGGACGGGGAGCAACCGGGGCAGGCCGTGCCGGCTGAGGAGGTCCTGAGGCTACAGAGCTGCCGCG GCTGGCACACGAGCGCCTCGGCACTAACCGAGTGTTCGCGGGGGCTGTGAGGGGAGGGCCCCGGGCGCCATTGCTGGCGGTGGGAGCGCC GCCCGGTCTCAGCCCGCCCTCGGCTGCTCTCCTCCTCCGGCTGGGAGGGGCCGTAGCTCGGGGCCGTCGCCAGCCCCGGCCCGGGCTCGA GAATCAAGGGCCTCGGCCGCCGTCCCGCAGCTCAGTCCATCGCCCTTGCCGGGCAGCCCGGGCAGAGACCATGTTTGACAAGACGCGGCT GCCGTACGTGGCCCTCGATGTGCTCTGCGTGTTGCTGGGGCTACACCAAGTCCATTGATATTTGGTCTGTAGGCTGCATTCTGGCAGAAA TGCTTTCTAACAGGCCCATCTTTCCAGGGAAGCATTATCTTGACCAGCTGAACCACATTTTGGGTATTCTTGGATCCCCATCACAAGAAG ACCTGAATTGTATAATAAATTTAAAAGCTAGGAACTATTTGCTTTCTCTTCCACACAAAAATAAGGTGCCATGGAACAGGCTGTTCCCAA ATGCTGACTCCAAAGCTCTGGACTTATTGGACAAAATGTTGACATTCAACCCACACAAGAGGATTGAAGTAGAACAGGCTCTGGCCCACC CATATCTGGAGCAGTATTACGACCCGAGTGACGAGCCCATCGCCGAAGCACCATTCAAGTTCGACATGGAATTGGATGACTTGCCTAAGG AAAAGCTCAAAGAACTAATTTTTGAAGAGACTGCTAGATTCCAGCCAGGATACAGATCTTAAATTTGTCAGGTACCTGGAGTTTAATACA GTGAGCTCTAGCAAGGGAGGCGCTGCCTTTTGTTTCTAGAATATTATGTTCCTCAAGGTCCATTATTTTGTATTCTTTTCCAAGCTCCTT >67299_67299_2_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000264775_MAPK1_chr22_22143097_ENST00000398822_length(amino acids)=175AA_BP=18 MTRRGCRTWPSMCSACCWGYTKSIDIWSVGCILAEMLSNRPIFPGKHYLDQLNHILGILGSPSQEDLNCIINLKARNYLLSLPHKNKVPW -------------------------------------------------------------- >67299_67299_3_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000264775_MAPK1_chr22_22143097_ENST00000544786_length(transcript)=740nt_BP=398nt CCTGTGGGAGAGAGCGCCGGGATCCGGACGGGGAGCAACCGGGGCAGGCCGTGCCGGCTGAGGAGGTCCTGAGGCTACAGAGCTGCCGCG GCTGGCACACGAGCGCCTCGGCACTAACCGAGTGTTCGCGGGGGCTGTGAGGGGAGGGCCCCGGGCGCCATTGCTGGCGGTGGGAGCGCC GCCCGGTCTCAGCCCGCCCTCGGCTGCTCTCCTCCTCCGGCTGGGAGGGGCCGTAGCTCGGGGCCGTCGCCAGCCCCGGCCCGGGCTCGA GAATCAAGGGCCTCGGCCGCCGTCCCGCAGCTCAGTCCATCGCCCTTGCCGGGCAGCCCGGGCAGAGACCATGTTTGACAAGACGCGGCT GCCGTACGTGGCCCTCGATGTGCTCTGCGTGTTGCTGGGGCTACACCAAGTCCATTGATATTTGGTCTGTAGGCTGCATTCTGGCAGAAA TGCTTTCTAACAGGCCCATCTTTCCAGGGAAGCATTATCTTGACCAGCTGAACCACATTTTGGCTCTGGACTTATTGGACAAAATGTTGA CATTCAACCCACACAAGAGGATTGAAGTAGAACAGGCTCTGGCCCACCCATATCTGGAGCAGTATTACGACCCGAGTGACGAGCCCATCG CCGAAGCACCATTCAAGTTCGACATGGAATTGGATGACTTGCCTAAGGAAAAGCTCAAAGAACTAATTTTTGAAGAGACTGCTAGATTCC >67299_67299_3_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000264775_MAPK1_chr22_22143097_ENST00000544786_length(amino acids)=132AA_BP=18 MTRRGCRTWPSMCSACCWGYTKSIDIWSVGCILAEMLSNRPIFPGKHYLDQLNHILALDLLDKMLTFNPHKRIEVEQALAHPYLEQYYDP -------------------------------------------------------------- >67299_67299_4_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000307259_MAPK1_chr22_22143097_ENST00000215832_length(transcript)=10703nt_BP=479nt GCTGCTCAGCGGGAGGGGCTGGACCCCGCGTTCCTCCTCCCTGCCGGTCCCCATCCTTAAAGCGAGAGTCTGGACGCCCCGCCTGTGGGA GAGAGCGCCGGGATCCGGACGGGGAGCAACCGGGGCAGGCCGTGCCGGCTGAGGAGGTCCTGAGGCTACAGAGCTGCCGCGGCTGGCACA CGAGCGCCTCGGCACTAACCGAGTGTTCGCGGGGGCTGTGAGGGGAGGGCCCCGGGCGCCATTGCTGGCGGTGGGAGCGCCGCCCGGTCT CAGCCCGCCCTCGGCTGCTCTCCTCCTCCGGCTGGGAGGGGCCGTAGCTCGGGGCCGTCGCCAGCCCCGGCCCGGGCTCGAGAATCAAGG GCCTCGGCCGCCGTCCCGCAGCTCAGTCCATCGCCCTTGCCGGGCAGCCCGGGCAGAGACCATGTTTGACAAGACGCGGCTGCCGTACGT GGCCCTCGATGTGCTCTGCGTGTTGCTGGGGCTACACCAAGTCCATTGATATTTGGTCTGTAGGCTGCATTCTGGCAGAAATGCTTTCTA ACAGGCCCATCTTTCCAGGGAAGCATTATCTTGACCAGCTGAACCACATTTTGGGTATTCTTGGATCCCCATCACAAGAAGACCTGAATT GTATAATAAATTTAAAAGCTAGGAACTATTTGCTTTCTCTTCCACACAAAAATAAGGTGCCATGGAACAGGCTGTTCCCAAATGCTGACT CCAAAGCTCTGGACTTATTGGACAAAATGTTGACATTCAACCCACACAAGAGGATTGAAGTAGAACAGGCTCTGGCCCACCCATATCTGG AGCAGTATTACGACCCGAGTGACGAGCCCATCGCCGAAGCACCATTCAAGTTCGACATGGAATTGGATGACTTGCCTAAGGAAAAGCTCA AAGAACTAATTTTTGAAGAGACTGCTAGATTCCAGCCAGGATACAGATCTTAAATTTGTCAGGACAAGGGCTCAGAGGACTGGACGTGCT CAGACATCGGTGTTCTTCTTCCCAGTTCTTGACCCCTGGTCCTGTCTCCAGCCCGTCTTGGCTTATCCACTTTGACTCCTTTGAGCCGTT TGGAGGGGCGGTTTCTGGTAGTTGTGGCTTTTATGCTTTCAAAGAATTTCTTCAGTCCAGAGAATTCCTCCTGGCAGCCCTGTGTGTGTC ACCCATTGGTGACCTGCGGCAGTATGTACTTCAGTGCACCTACTGCTTACTGTTGCTTTAGTCACTAATTGCTTTCTGGTTTGAAAGATG CAGTGGTTCCTCCCTCTCCTGAATCCTTTTCTACATGATGCCCTGCTGACCATGCAGCCGCACCAGAGAGAGATTCTTCCCCAATTGGCT CTAGTCACTGGCATCTCACTTTATGATAGGGAAGGCTACTACCTAGGGCACTTTAAGTCAGTGACAGCCCCTTATTTGCACTTCACCTTT TGACCATAACTGTTTCCCCAGAGCAGGAGCTTGTGGAAATACCTTGGCTGATGTTGCAGCCTGCAGCAAGTGCTTCCGTCTCCGGAATCC TTGGGGAGCACTTGTCCACGTCTTTTCTCATATCATGGTAGTCACTAACATATATAAGGTATGTGCTATTGGCCCAGCTTTTAGAAAATG CAGTCATTTTTCTAAATAAAAAGGAAGTACTGCACCCAGCAGTGTCACTCTGTAGTTACTGTGGTCACTTGTACCATATAGAGGTGTAAC ACTTGTCAAGAAGCGTTATGTGCAGTACTTAATGTTTGTAAGACTTACAAAAAAAGATTTAAAGTGGCAGCTTCACTCGACATTTGGTGA GAGAAGTACAAAGGTTGCAGTGCTGAGCTGTGGGCGGTTTCTGGGGATGTCCCAGGGTGGAACTCCACATGCTGGTGCATATACGCCCTT GAGCTACTTCAAATGTGGGTGTTTCAGTAACCACGTTCCATGCCTGAGGATTTAGCAGAGAGGAACACTGCGTCTTTAAATGAGAAAGTA TACAATTCTTTTTCCTTCTACAGCATGTCAGCATCTCAAGTTCATTTTTCAACCTACAGTATAACAATTTGTAATAAAGCCTCCAGGAGC TCATGACGTGAAGCACTGTTCTGTCCTCAAGTACTCAAATATTTCTGATACTGCTGAGTCAGACTGTCAGAAAAAGCTAGCACTAACTCG TGTTTGGAGCTCTATCCATATTTTACTGATCTCTTTAAGTATTTGTTCCTGCCACTGTGTACTGTGGAGTTGACTCGGTGTTCTGTCCCA GTGCGGTGCCTCCTCTTGACTTCCCCACTGCTCTCTGTGGTGAGAAATTTGCCTTGTTCAATAATTACTGTACCCTCGCATGACTGTTAC AGCTTTCTGTGCAGAGATGACTGTCCAAGTGCCACATGCCTACGATTGAAATGAAAACTCTATTGTTACCTCTGAGTTGTGTTCCACGGA AAATGCTATCCAGCAGATCATTTAGGAAAAATAATTCTATTTTTAGCTTTTCATTTCTCAGCTGTCCTTTTTTCTTGTTTGATTTTTGAC AGCAATGGAGAATGGGTTATATAAAGACTGCCTGCTAATATGAACAGAAATGCATTTGTAATTCATGAAAATAAATGTACATCTTCTATC TTCACATTCATGTTAAGATTCAGTGTTGCTTTCCTCTGGATCAGCGTGTCTGAATGGACAGTCAGGTTCAGGTTGTGCTGAACACAGAAA TGCTCACAGGCCTCACTTTGCCGCCCAGGCACTGGCCCAGCACTTGGATTTACATAAGATGAGTTAGAAAGGTACTTCTGTAGGGTCCTT TTTACCTCTGCTCGGCAGAGAATCGATGCTGTCATGTTCCTTTATTCACAATCTTAGGTCTCAAATATTCTGTCAAACCCTAACAAAGAA GCCCCGACATCTCAGGTTGGATTCCCTGGTTCTCTCTAAAGAGGGCCTGCCCTTGTGCCCCAGAGGTGCTGCTGGGCACAGCCAAGAGTT GGGAAGGGCCGCCCCACAGTACGCAGTCCTCACCACCCAGCCCAGGGTGCTCACGCTCACCACTCCTGTGGCTGAGGAAGGATAGCTGGC TCATCCTCGGAAAACAGACCCACATCTCTATTCTTGCCCTGAAATACGCGCTTTTCACTTGCGTGCTCAGAGCTGCCGTCTGAAGGTCCA CACAGCATTGACGGGACACAGAAATGTGACTGTTACCGGATAACACTGATTAGTCAGTTTTCATTTATAAAAAAGCATTGACAGTTTTAT TACTCTTGTTTCTTTTTAAATGGAAAGTTACTATTATAAGGTTAATTTGGAGTCCTCTTCTAAATAGAAAACCATATCCTTGGCTACTAA CATCTGGAGACTGTGAGCTCCTTCCCATTCCCCTTCCTGGTACTGTGGAGTCAGATTGGCATGAAACCACTAACTTCATTCTAGAATCAT TGTAGCCATAAGTTGTGTGCTTTTTATTAATCATGCCAAACATAATGTAACTGGGCAGAGAATGGTCCTAACCAAGGTACCTATGAAAAG CGCTAGCTATCATGTGTAGTAGATGCATCATTTTGGCTCTTCTTACATTTGTAAAAATGTACAGATTAGGTCATCTTAATTCATATTAGT GACACGGAACAGCACCTCCACTATTTGTATGTTCAAATAAGCTTTCAGACTAATAGCTTTTTTGGTGTCTAAAATGTAAGCAAAAAATTC CTGCTGAAACATTCCAGTCCTTTCATTTAGTATAAAAGAAATACTGAACAAGCCAGTGGGATGGAATTGAAAGAACTAATCATGAGGACT CTGTCCTGACACAGGTCCTCAAAGCTAGCAGAGATACGCAGACATTGTGGCATCTGGGTAGAAGAATACTGTATTGTGTGTGCAGTGCAC AGTGTGTGGTGTGTGCACACTCATTCCTTCTGCTCTTGGGCACAGGCAGTGGGTGTAGAGGTAACCAGTAGCTTTGAGAAGCTACATGTA GCTCACCAGTGGTTTTCTCTAAGGAATCACAAAAGTAAACTACCCAACCACATGCCACGTAATATTTCAGCCATTCAGAGGAAACTGTTT TCTCTTTATTTGCTTATATGTTAATATGGTTTTTAAATTGGTAACTTTTATATAGTATGGTAACAGTATGTTAATACACACATACATACG CACACATGCTTTGGGTCCTTCCATAATACTTTTATATTTGTAAATCAATGTTTTGGAGCAATCCCAAGTTTAAGGGAAATATTTTTGTAA ATGTAATGGTTTTGAAAATCTGAGCAATCCTTTTGCTTATACATTTTTAAAGCATTTGTGCTTTAAAATTGTTATGCTGGTGTTTGAAAC ATGATACTCCTGTGGTGCAGATGAGAAGCTATAACAGTGAATATGTGGTTTCTCTTACGTCATCCACCTTGACATGATGGGTCAGAAACA AATGGAAATCCAGAGCAAGTCCTCCAGGGTTGCACCAGGTTTACCTAAAGCTTGTTGCCTTTTCTTGTGCTGTTTATGCGTGTAGAGCAC TCAAGAAAGTTCTGAAACTGCTTTGTATCTGCTTTGTACTGTTGGTGCCTTCTTGGTATTGTACCCCAAAATTCTGCATAGATTATTTAG TATAATGGTAAGTTAAAAAATGTTAAAGGAAGATTTTATTAAGAATCTGAATGTTTATTCATTATATTGTTACAATTTAACATTAACATT TATTTGTGGTATTTGTGATTTGGTTAATCTGTATAAAAATTGTAAGTAGAAAGGTTTATATTTCATCTTAATTCTTTTGATGTTGTAAAC GTACTTTTTAAAAGATGGATTATTTGAATGTTTATGGCACCTGACTTGTAAAAAAAAAAAACTACAAAAAAATCCTTAGAATCATTAAAT TGTGTCCCTGTATTACCAAAATAACACAGCACCGTGCATGTATAGTTTAATTGCAGTTTCATCTGTGAAAACGTGAAATTGTCTAGTCCT TCGTTATGTTCCCCAGATGTCTTCCAGATTTGCTCTGCATGTGGTAACTTGTGTTAGGGCTGTGAGCTGTTCCTCGAGTTGAATGGGGAT GTCAGTGCTCCTAGGGTTCTCCAGGTGGTTCTTCAGACCTTCACCTGTGGGGGGGGGGGTAGGCGGTGCCCACGCCCATCTCCTCATCCT CCTGAACTTCTGCAACCCCACTGCTGGGCAGACATCCTGGGCAACCCCTTTTTTCAGAGCAAGAAGTCATAAAGATAGGATTTCTTGGAC ATTTGGTTCTTATCAATATTGGGCATTATGTAATGACTTATTTACAAAACAAAGATACTGGAAAATGTTTTGGATGTGGTGTTATGGAAA GAGCACAGGCCTTGGACCCATCCAGCTGGGTTCAGAACTACCCCCTGCTTATAACTGCGGCTGGCTGTGGGCCAGTCATTCTGCGTCTCT GCTTTCTTCCTCTGCTTCAGACTGTCAGCTGTAAAGTGGAAGCAATATTACTTGCCTTGTATATGGTAAAGATTATAAAAATACATTTCA ACTGTTCAGCATAGTACTTCAAAGCAAGTACTCAGTAAATAGCAAGTCTTTTTAAATGCTGCTTTATTTCACTAAATTTTGTTGTGAGGT GTCACTAAAATGCCTGCAAACAAACGTAACTGCTAATCTGAGAGGAAACCCTCTTACTAATCAGAGAAGAAACCCTCCTGTCAGAAACCT TCAGGGAAGTGAGCTGATCACACCTAAACTGGGAGTTTGCAATGGGGTATTTGAAGCACTGTGGGAGTATTCCACTGGCCCTCTCCCTGA GAGACTTAACAGTCTTCCCTGTTGTCCAGATTCTGTATAAGGCAATCAGAATAATCATCTTCCTTGTTCAGCAGAGGAGCCTGGTCCCAT TTTCCCCACTTTGTGATGGGCTTCTCTCAGCGGTAGCTCAGCAGTTCCAGATGGCAGTTTGGACCAGCATCTAGGCTGGCCAGTTCGCTG TGTTTACTTAGAACCAACACGTTCAGAGCTGGCCTGGACCATCTGAGGGGAACAGGAAACACCCCTAGGCTGTGGAAGCAAGTGCAGACC CCCACCCCCGGCCCTGAAGCCAAGGGGGCAGGGTTTGGGAGTGGCCAAAGAGAAGCAGTGCAGGGATGGGTTTTCCTAGGGACAGGCTTA GCATTCCTGACTCTAGGAAGAAGGAGCAGTGAGGCGGAGAAACAGTGGAGGGGATGGTGGCATTGGGCCCCATGGGGCCGAGATGGACAC AGGGCTCGTTCTCTTGAGTCTGGTGCCAAGGACAGCTGAAGACGACATCATTTTCAGGTGGAGAGGAGAGAGTGGAGGGAGATCATGCCC TGTGATGTGTCTTTTGCAGGTGAAGGTGGGAGACAAGGTCTCTGCTGACGATGAGGCAGAGCCACCGTGAAAGTTGTAATAGGAGGACTG CCCGCCGCTGGAAGGGCCTGCAGTGACGCTAGGACACCCTCTGCCTGCATGTCACGTTAGCTGGGCTGGGCGAAGTAGAAGACCAAGGGG AAGAGGTGCAGTGGGGAGACCAGGTGGGATGCAACCACAGGACCAGTGGAGGGGCTGTGGCACGTGGGCGGAGACTGAGTGGCTGGGCAT GTGTTGTGGCTGAGCATGTGGTGTGGGCAGTGGTCCTAGACCCCGCCATGTCCGGACAATGATATAGAGCGTCTCAGCATCGCCAGTCTA GACTGTCTATGGAGAGCAGAAAGTTGTCTGGGGCTGCCTGGGGAACTGTGAGGCCAGCTATATCACCGTCGCTGATGGTGACATTACGGT GGTGGCAGGAGCAAGGAGAGAGGGAAGAAGGACCCCGTCCAGCTTTAGTCACAAAATACCCAATGGAAGATGCCAGTGCCAATCCTGTGG GTTTCCTTGGGACTTCACACTGGCTTTCTTATCTGCTCCAGATCCATTCAGTAGTCACTGAGTTCCTGCCAAATACTTTGTAGCGCCAGA AGCCAGGAGCGGGGTCTGCAGCAGGGCAGTCCCCATTTTCAGGAAATGCCTGGAGCTGCTGGTCCCTGAGAGAAAGGAAAACATCTTTCA GCCGTACGCAGGCCAAGAAGGCCAATGTCCAGTAGCTTTGTGATTTTTTTTATATTTTTTTATTTATTTATTTTTGAGATAGAGTCTTGC TCTGTCGCTCAGGCTGGAGTGCAGTGGCGTGATCTCCACTCACTGCAACTTCCGCCTCCTGGGGTCAAGCAGTTCTGCCTCAGCCTCCCG AGTAGCTGGGATTACAGGCACACGCCACCACACCCAGCTAATTTTTGTGTTTTTAGTAGAGACGGTTTCACCATGTCGGCCAGGCTGGTC TCAAACTCCTGACCTCAGATGATTCAGCCTCCCAAAGTGCTGGGATTACAGGTGTGAGCCACTGCACCCAGCCTGTGATGTTTCTGTGGG GTTCCACAAATGTGTGTGTGTGTAAAAGCTGATGATTACAGCAAGAATGTGAACAGTAGCAGTTTTCCATTTGAAGGCAAGTTTTGTCTT TATCTGGGTATCAGAAGGACCCTCTGGGCCATTGTCGCTTCCTGTACTCAGAGCCACCCTAGTACTACGGGCACACACAGAAAACAGCAG CCTGCGTACTTTCAAAGGAAAGGCATCTTTAATCACCAATGCCTGGAAAAATTATTTTGTTTCCCTCTTCCTTCCGTCTTGTTTCCTAAC TTCTTACCAAAGTTTAGAGTCTGAGTTTTTCGTATAATAATGTCCCACATCCACACATCGGGCCTACAGATGCTCTCCCTTGAATCGACT GGAAACATGACACCGGTTCCATGCTCTGGAACTGTCACCTGTGATGTGCTGGGCTGTGTCCCAAGCACAGGAATCCCAGCAGTTTCAGCT CGATGCAGAACCACCATGCTCCAGACACAGGCTTGGGAAAGACACGTCAAAATTAAAATACTAGGTAAGAGAAGCACCTGATTGGGTAGA AGTTGGAGAGGAATCCTGGAATTTTGTGGCCAGAAGGAGCCACTGCCCCTTTTGTTTAGTAAGACTAGACAGTAACAGAAGCCAGTTGTC AGCTATGAAAGTGGTGGGTGAAGCAGGGGAGGCTCCTCTATGGTGGGACCCTGGACAAGGGAAGCCGAATGTGTGAAGAAGGGGTGCGGG GGTGTGCGGTGCCCTAGGACACTAGGGCAAAGGTTTCAAACCTGGAACAAGGCACTGGAGGAAGATCTGCTGCCAGTCAGCAGTGCGGGC CCTCGAGTTAGCAGTCCGTGCGCAGAGGGGCCAGTTCTGAGACCAGTTTGGAGAGTCAGGCAGTGACCCATTGGCCATGTCATAATTCCT TCAGCCTGCCTCCTCTTTAATCCCAGAGAGTGCTCTTTCTTCATACTTCCTTTAAAATACTAAATTGTTCCCATTCCATGGGGAGCTGGC TAGGCTTTACAGGCTAGGAAATGTAGGTTTTCTGAGATGGAACCATCTACACAAGGAGGAGGAAGGCACTAAGACTACAGATGAGACCCA TGACAGGGCTGAGCATTTGGAAGCCAACCCTGGTTGCTTTTCAAGAATTGCTTTGTGGCTGGGTGCAGTGGTTCACACCTGTAATTGCAG CACTTTGGGAGGCTGAGGCAGGTGGATTGCTTGAACCCAGGAGTTCGAGACCAGCCTGGGCAACATATGGGACACCCCACCGCCCCCGGC TCTGCAAAAAAATTAAAAATTAGCCAGGCGTGGTGTCATGAGCCTGTGGTCTCAACTACTCAGGAGGCTGAGGCTGGAGGATCGCTTGAA CCTGGGAGGTCAAGGCTCCAGTGAACCATAATTGTGCCACTGCACTGCAGCCTGGGCGACAATTTGTTTTCTAAATTGCTTTTGAAAGTC TACTGCATTACATATTCCAAAAAGCAGTGGTTTTCAAATACTTTTATCACCGATATCCTTTTATGAAATGAAATCAGTAGAACTTTCTCT GCTCTGAATAAGCAAGGGTGGGAACCTGTCTACCTCCCACAGATAGCATAATGTGCCTGCCATAGAGGAGCCAAAAAATGGTGATGGGAA CTGAGAGGAGAGCAAATGTCACAAAAGACTGAGCAATTGAGAAAACAAAACAAGACCACAGATGACTGTTAACGCCTCCACAGTGGACCA AGAAAGGACAGAGAGCTGGCAGCATGGGCATCACTGTCTGGTCGGCAGCAGGAAGGCCTCGCTAGGGAATTGAGTACAGTCATCTAACTA GTTTAAAAGTACAGGAAGGATGATTAAGGCTATTGGAGAGGTCATACAAATAGGGGAGGGGCAGGCAATGGCTGATAAGACATGAATTTG TAAGGCGATGAGTATTGCAGTCAGCAAAACAAACGAGACTGCTCTCCCAACACATAACTCAGCAGGGAGGCCAGGCATTGGTTTAACCAT TTAATATAAAGAAGTTAAAATTACAAATGCGCTAAGTGCCTAAAGAAGAATAAGTGCAGGAATGAGAGCAGCATGGACTGCCACAGTTTT AGAATAAGCACTGTCACTGCTAGATTGGAAACAAAAATCCATAAATTTGGCCCGGTGTGGTGGCGGACGCCTGTAGTCCCAGCTACTTGG AGGCTGAGGCGTGAGAATCGCTTGAACCCGGGAGGCGGAGGTTGCAGTGAGCCGAGATGGCGCCACTGCACTCCAGCCTGGGCGTCAGAG TGAGAACTCTGTATCAAAAAATAAAAATAAAAAAAAGTCCATAAATCTGCAATGTCTCAGTTAAGAAAGAAAGACTGGGCCAATGCAGAT TTCAAACCGGAGAAAGTCATACTGTCAGTGAAGGCCGCCTGTGGCCGGAAGGCGCCAGGGGATTAGCACCCTGGACTCAGTGTTGCTGGG AAACAGGGCCCCAAGGCTGGGAGCACAGTGTTTAAAGGGCATCTACCCAAGAAGGGAGCACAGGGCAAGGAGGAGCTGCAGGGGGGCTTG GCTGCCAAAGTGAATTCTGAGGAGAGAGCTATTGCTGCCTACGATATGCAGGCTGCACAGAACACAAGTGGAATCAGCAGGCAGGAGAGG CAGCTAACGACGCAGCCCGTTTCTTATTTCTGTTTTCTCACAAGCGATGAAAGTGGAAAAGAGGGTGAGCAGGTGGCCCACACATGTGCC TCCAGTGCTGCGGCCCCTCCGGGGACCATCAGCCAGGCCCCGGGGAGGGAGCCAGCCACAGTGTGTCCGGCTCTTCTCTGAAGGGAAGAG AGCCTTGAATAGACTGAAGCGAAGACGGTTCTGCAAGGACAAGGCAGACCGAAGGCATTGGTTTTTTTTTTCAGATAAGGAGAATTAGAC TCCCAAGTAGACACCAGAGTCACTGTTTGGTTGGTGGGTGATAGTGGGGTCACAGTGGCTGCCTGTGCTCCCCCAGGGTGAGCGTGACTG TGCTAACCTGGGTGGGGCAGCATGCACACCCCTCTGGCAGCCCTTTGTTGCTCGCTGATGACAAGTTTGGATGATCCCGCCAAACAGCTT GCTAAGATGTAGTCCCCAGTGTTGGAGGTGGGGCCTGATGGGAGGTGCTACCCTTGTGAGATAAGGTTGTGTAAAAGCCTGTGGCACCTC CCCACACTGACGCTCTCACCCCTGCTCTGGCCATGTGCCGCGCCTGCTCCCACTTCCCCTTCTGCCAGGAGTAAAAGCCCCCGAGACCTC >67299_67299_4_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000307259_MAPK1_chr22_22143097_ENST00000215832_length(amino acids)=175AA_BP=18 MTRRGCRTWPSMCSACCWGYTKSIDIWSVGCILAEMLSNRPIFPGKHYLDQLNHILGILGSPSQEDLNCIINLKARNYLLSLPHKNKVPW -------------------------------------------------------------- >67299_67299_5_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000307259_MAPK1_chr22_22143097_ENST00000398822_length(transcript)=1117nt_BP=479nt GCTGCTCAGCGGGAGGGGCTGGACCCCGCGTTCCTCCTCCCTGCCGGTCCCCATCCTTAAAGCGAGAGTCTGGACGCCCCGCCTGTGGGA GAGAGCGCCGGGATCCGGACGGGGAGCAACCGGGGCAGGCCGTGCCGGCTGAGGAGGTCCTGAGGCTACAGAGCTGCCGCGGCTGGCACA CGAGCGCCTCGGCACTAACCGAGTGTTCGCGGGGGCTGTGAGGGGAGGGCCCCGGGCGCCATTGCTGGCGGTGGGAGCGCCGCCCGGTCT CAGCCCGCCCTCGGCTGCTCTCCTCCTCCGGCTGGGAGGGGCCGTAGCTCGGGGCCGTCGCCAGCCCCGGCCCGGGCTCGAGAATCAAGG GCCTCGGCCGCCGTCCCGCAGCTCAGTCCATCGCCCTTGCCGGGCAGCCCGGGCAGAGACCATGTTTGACAAGACGCGGCTGCCGTACGT GGCCCTCGATGTGCTCTGCGTGTTGCTGGGGCTACACCAAGTCCATTGATATTTGGTCTGTAGGCTGCATTCTGGCAGAAATGCTTTCTA ACAGGCCCATCTTTCCAGGGAAGCATTATCTTGACCAGCTGAACCACATTTTGGGTATTCTTGGATCCCCATCACAAGAAGACCTGAATT GTATAATAAATTTAAAAGCTAGGAACTATTTGCTTTCTCTTCCACACAAAAATAAGGTGCCATGGAACAGGCTGTTCCCAAATGCTGACT CCAAAGCTCTGGACTTATTGGACAAAATGTTGACATTCAACCCACACAAGAGGATTGAAGTAGAACAGGCTCTGGCCCACCCATATCTGG AGCAGTATTACGACCCGAGTGACGAGCCCATCGCCGAAGCACCATTCAAGTTCGACATGGAATTGGATGACTTGCCTAAGGAAAAGCTCA AAGAACTAATTTTTGAAGAGACTGCTAGATTCCAGCCAGGATACAGATCTTAAATTTGTCAGGTACCTGGAGTTTAATACAGTGAGCTCT AGCAAGGGAGGCGCTGCCTTTTGTTTCTAGAATATTATGTTCCTCAAGGTCCATTATTTTGTATTCTTTTCCAAGCTCCTTATTGGAAGG >67299_67299_5_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000307259_MAPK1_chr22_22143097_ENST00000398822_length(amino acids)=175AA_BP=18 MTRRGCRTWPSMCSACCWGYTKSIDIWSVGCILAEMLSNRPIFPGKHYLDQLNHILGILGSPSQEDLNCIINLKARNYLLSLPHKNKVPW -------------------------------------------------------------- >67299_67299_6_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000307259_MAPK1_chr22_22143097_ENST00000544786_length(transcript)=821nt_BP=479nt GCTGCTCAGCGGGAGGGGCTGGACCCCGCGTTCCTCCTCCCTGCCGGTCCCCATCCTTAAAGCGAGAGTCTGGACGCCCCGCCTGTGGGA GAGAGCGCCGGGATCCGGACGGGGAGCAACCGGGGCAGGCCGTGCCGGCTGAGGAGGTCCTGAGGCTACAGAGCTGCCGCGGCTGGCACA CGAGCGCCTCGGCACTAACCGAGTGTTCGCGGGGGCTGTGAGGGGAGGGCCCCGGGCGCCATTGCTGGCGGTGGGAGCGCCGCCCGGTCT CAGCCCGCCCTCGGCTGCTCTCCTCCTCCGGCTGGGAGGGGCCGTAGCTCGGGGCCGTCGCCAGCCCCGGCCCGGGCTCGAGAATCAAGG GCCTCGGCCGCCGTCCCGCAGCTCAGTCCATCGCCCTTGCCGGGCAGCCCGGGCAGAGACCATGTTTGACAAGACGCGGCTGCCGTACGT GGCCCTCGATGTGCTCTGCGTGTTGCTGGGGCTACACCAAGTCCATTGATATTTGGTCTGTAGGCTGCATTCTGGCAGAAATGCTTTCTA ACAGGCCCATCTTTCCAGGGAAGCATTATCTTGACCAGCTGAACCACATTTTGGCTCTGGACTTATTGGACAAAATGTTGACATTCAACC CACACAAGAGGATTGAAGTAGAACAGGCTCTGGCCCACCCATATCTGGAGCAGTATTACGACCCGAGTGACGAGCCCATCGCCGAAGCAC CATTCAAGTTCGACATGGAATTGGATGACTTGCCTAAGGAAAAGCTCAAAGAACTAATTTTTGAAGAGACTGCTAGATTCCAGCCAGGAT >67299_67299_6_PPAP2A-MAPK1_PPAP2A_chr5_54830400_ENST00000307259_MAPK1_chr22_22143097_ENST00000544786_length(amino acids)=132AA_BP=18 MTRRGCRTWPSMCSACCWGYTKSIDIWSVGCILAEMLSNRPIFPGKHYLDQLNHILALDLLDKMLTFNPHKRIEVEQALAHPYLEQYYDP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PPAP2A-MAPK1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PPAP2A-MAPK1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PPAP2A-MAPK1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies