
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PPHLN1-PTPRZ1 (FusionGDB2 ID:67481) |
Fusion Gene Summary for PPHLN1-PTPRZ1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PPHLN1-PTPRZ1 | Fusion gene ID: 67481 | Hgene | Tgene | Gene symbol | PPHLN1 | PTPRZ1 | Gene ID | 51535 | 5803 |
| Gene name | periphilin 1 | protein tyrosine phosphatase receptor type Z1 | |
| Synonyms | CR|HSPC206|HSPC232 | HPTPZ|HPTPzeta|PTP-ZETA|PTP18|PTPRZ|PTPZ|R-PTP-zeta-2|RPTPB|RPTPbeta|phosphacan | |
| Cytomap | 12q12 | 7q31.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | periphilin-1CDC7 expression repressorgastric cancer antigen Ga50 | receptor-type tyrosine-protein phosphatase zetaprotein tyrosine phosphatase, receptor-type, Z polypeptide 1protein tyrosine phosphatase, receptor-type, zeta polypeptide 1protein-tyrosine phosphatase receptor type Z polypeptide 2receptor-type tyrosine | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000550535, ENST00000317560, ENST00000337898, ENST00000358314, ENST00000395568, ENST00000395580, ENST00000432191, ENST00000449194, ENST00000549190, ENST00000552761, ENST00000256678, | ENST00000393386, ENST00000449182, ENST00000483028, | |
| Fusion gene scores | * DoF score | 8 X 9 X 4=288 | 9 X 8 X 4=288 |
| # samples | 9 | 11 | |
| ** MAII score | log2(9/288*10)=-1.67807190511264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/288*10)=-1.38856528791765 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PPHLN1 [Title/Abstract] AND PTPRZ1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PPHLN1(42749024)-PTPRZ1(121699806), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PPHLN1 | GO:0045814 | negative regulation of gene expression, epigenetic | 26022416|28581500 |
| Hgene | PPHLN1 | GO:0090309 | positive regulation of methylation-dependent chromatin silencing | 28581500 |
| Hgene | PPHLN1 | GO:0097355 | protein localization to heterochromatin | 28581500 |
| Fusion gene breakpoints across PPHLN1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
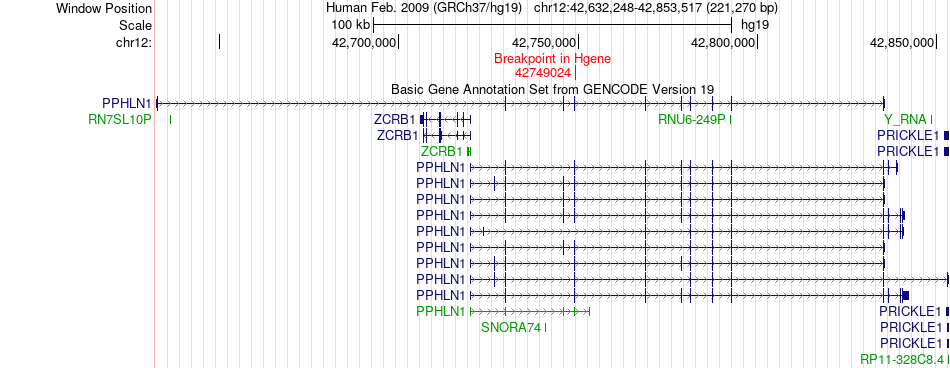 |
| Fusion gene breakpoints across PTPRZ1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-D6-6823 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
Top |
Fusion Gene ORF analysis for PPHLN1-PTPRZ1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000550535 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 3UTR-3CDS | ENST00000550535 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 3UTR-intron | ENST00000550535 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000317560 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000337898 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000358314 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000395568 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000395580 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000432191 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000449194 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000549190 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| 5CDS-intron | ENST00000552761 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000317560 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000317560 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000337898 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000337898 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000358314 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000358314 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000395568 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000395568 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000395580 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000395580 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000432191 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000432191 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000449194 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000449194 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000549190 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000549190 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000552761 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| In-frame | ENST00000552761 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| intron-3CDS | ENST00000256678 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| intron-3CDS | ENST00000256678 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| intron-intron | ENST00000256678 | ENST00000483028 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000549190 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1627 | 534 | 97 | 810 | 237 |
| ENST00000549190 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 952 | 534 | 97 | 810 | 237 |
| ENST00000395580 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1540 | 447 | 127 | 723 | 198 |
| ENST00000395580 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 865 | 447 | 127 | 723 | 198 |
| ENST00000337898 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1332 | 239 | 105 | 515 | 136 |
| ENST00000337898 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 657 | 239 | 105 | 515 | 136 |
| ENST00000358314 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1485 | 392 | 93 | 668 | 191 |
| ENST00000358314 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 810 | 392 | 93 | 668 | 191 |
| ENST00000395568 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1476 | 383 | 84 | 659 | 191 |
| ENST00000395568 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 801 | 383 | 84 | 659 | 191 |
| ENST00000449194 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1474 | 381 | 82 | 657 | 191 |
| ENST00000449194 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 799 | 381 | 82 | 657 | 191 |
| ENST00000552761 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1349 | 256 | 101 | 532 | 143 |
| ENST00000552761 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 674 | 256 | 101 | 532 | 143 |
| ENST00000317560 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1346 | 253 | 98 | 529 | 143 |
| ENST00000317560 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 671 | 253 | 98 | 529 | 143 |
| ENST00000432191 | PPHLN1 | chr12 | 42749024 | + | ENST00000393386 | PTPRZ1 | chr7 | 121699806 | + | 1299 | 206 | 72 | 482 | 136 |
| ENST00000432191 | PPHLN1 | chr12 | 42749024 | + | ENST00000449182 | PTPRZ1 | chr7 | 121699806 | + | 624 | 206 | 72 | 482 | 136 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000549190 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.000983411 | 0.9990165 |
| ENST00000549190 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.001668673 | 0.99833137 |
| ENST00000395580 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.000924273 | 0.99907565 |
| ENST00000395580 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.001722475 | 0.99827754 |
| ENST00000337898 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.004139091 | 0.9958609 |
| ENST00000337898 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.004775127 | 0.99522483 |
| ENST00000358314 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.000749389 | 0.9992506 |
| ENST00000358314 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.001820807 | 0.9981792 |
| ENST00000395568 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.000864074 | 0.9991359 |
| ENST00000395568 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.001596758 | 0.99840325 |
| ENST00000449194 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.000911747 | 0.9990883 |
| ENST00000449194 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.001520395 | 0.99847966 |
| ENST00000552761 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.005209052 | 0.9947909 |
| ENST00000552761 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.003827998 | 0.996172 |
| ENST00000317560 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.003751653 | 0.9962483 |
| ENST00000317560 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.003202553 | 0.9967975 |
| ENST00000432191 | ENST00000393386 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.005653857 | 0.9943461 |
| ENST00000432191 | ENST00000449182 | PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 0.003485379 | 0.9965146 |
Top |
Fusion Genomic Features for PPHLN1-PTPRZ1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 8.31E-10 | 1 |
| PPHLN1 | chr12 | 42749024 | + | PTPRZ1 | chr7 | 121699806 | + | 8.31E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for PPHLN1-PTPRZ1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:42749024/chr7:121699806) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000395580 | + | 5 | 11 | 103_109 | 106 | 375.0 | Motif | Nuclear localization signal |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000358314 | + | 4 | 10 | 140_215 | 99 | 368.0 | Compositional bias | Note=Ser-rich |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000395568 | + | 4 | 13 | 140_215 | 99 | 459.0 | Compositional bias | Note=Ser-rich |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000395580 | + | 5 | 11 | 140_215 | 106 | 375.0 | Compositional bias | Note=Ser-rich |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000432191 | + | 3 | 12 | 140_215 | 44 | 435.0 | Compositional bias | Note=Ser-rich |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000552761 | + | 4 | 10 | 140_215 | 51 | 320.0 | Compositional bias | Note=Ser-rich |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000358314 | + | 4 | 10 | 103_109 | 99 | 368.0 | Motif | Nuclear localization signal |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000395568 | + | 4 | 13 | 103_109 | 99 | 459.0 | Motif | Nuclear localization signal |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000432191 | + | 3 | 12 | 103_109 | 44 | 435.0 | Motif | Nuclear localization signal |
| Hgene | PPHLN1 | chr12:42749024 | chr7:121699806 | ENST00000552761 | + | 4 | 10 | 103_109 | 51 | 320.0 | Motif | Nuclear localization signal |
| Tgene | PTPRZ1 | chr12:42749024 | chr7:121699806 | ENST00000393386 | 27 | 30 | 1717_1992 | 2223 | 2316.0 | Domain | Tyrosine-protein phosphatase 1 | |
| Tgene | PTPRZ1 | chr12:42749024 | chr7:121699806 | ENST00000393386 | 27 | 30 | 2023_2282 | 2223 | 2316.0 | Domain | Tyrosine-protein phosphatase 2 | |
| Tgene | PTPRZ1 | chr12:42749024 | chr7:121699806 | ENST00000393386 | 27 | 30 | 314_413 | 2223 | 2316.0 | Domain | Fibronectin type-III | |
| Tgene | PTPRZ1 | chr12:42749024 | chr7:121699806 | ENST00000393386 | 27 | 30 | 36_300 | 2223 | 2316.0 | Domain | Alpha-carbonic anhydrase | |
| Tgene | PTPRZ1 | chr12:42749024 | chr7:121699806 | ENST00000393386 | 27 | 30 | 1933_1939 | 2223 | 2316.0 | Region | Substrate binding | |
| Tgene | PTPRZ1 | chr12:42749024 | chr7:121699806 | ENST00000393386 | 27 | 30 | 1663_2315 | 2223 | 2316.0 | Topological domain | Cytoplasmic | |
| Tgene | PTPRZ1 | chr12:42749024 | chr7:121699806 | ENST00000393386 | 27 | 30 | 25_1636 | 2223 | 2316.0 | Topological domain | Extracellular | |
| Tgene | PTPRZ1 | chr12:42749024 | chr7:121699806 | ENST00000393386 | 27 | 30 | 1637_1662 | 2223 | 2316.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for PPHLN1-PTPRZ1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >67481_67481_1_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000317560_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1346nt_BP=253nt ATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGGAAATTGTTGAAAACGTTAAATTTGATTCCTAAA AGGACTCAATGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAA GTCATCCCAGTGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGG CAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATC TGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGA ATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGG GGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCAT CACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAAATTTATATCATTAACAATGTGTGCCTTTTTGCAAGACTTGTAATTTACT TATTATGTTTGAACTAAAATGATTGAATTTTACAGTATTTCTAAGAATGGAATTGTGGTATTTTTTTCTGTATTGATTTTAACAGAAAAT TTCAATTTATAGAGGTTAGGAATTCCAAACTACAGAAAATGTTTGTTTTTAGTGTCAAATTTTTAGCTGTATTTGTAGCAATTATCAGGT TTGCTAGAAATATAACTTTTAATACAGTAGCCTGTAAATAAAACACTCTTCCATATGATATTCAACATTTTACAACTGCAGTATTCACCT AAAGTAGAAATAATCTGTTACTTATTGTAAATACTGCCCTAGTGTCTCCATGGACCAAATTTATATTTATAATTGTAGATTTTTATATTT TACTACTGAGTCAAGTTTTCTAGTTCTGTGTAATTGTTTAGTTTAATGACGTAGTTCATTAGCTGGTCTTACTCTACCAGTTTTCTGACA TTGTATTGTGTTACCTAAGTCATTAACTTTGTTTCAGCATGTAATTTTAACTTTTGTGGAAAATAGAAATACCTTCATTTTGAAAGAAGT >67481_67481_1_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000317560_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=143AA_BP=51 MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMR -------------------------------------------------------------- >67481_67481_2_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000317560_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=671nt_BP=253nt ATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGGAAATTGTTGAAAACGTTAAATTTGATTCCTAAA AGGACTCAATGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAA GTCATCCCAGTGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGG CAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATC TGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGA ATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGG GGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCAT >67481_67481_2_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000317560_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=143AA_BP=51 MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMR -------------------------------------------------------------- >67481_67481_3_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000337898_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1332nt_BP=239nt ATTGCGCGCGCCGGAAGTACCTACCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCT TACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGAT GAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGT GCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGA GTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCT CTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCA CATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCATCACCTGACAGTAAC TTTCATGACATAGGATTCTGCCGCCAAATTTATATCATTAACAATGTGTGCCTTTTTGCAAGACTTGTAATTTACTTATTATGTTTGAAC TAAAATGATTGAATTTTACAGTATTTCTAAGAATGGAATTGTGGTATTTTTTTCTGTATTGATTTTAACAGAAAATTTCAATTTATAGAG GTTAGGAATTCCAAACTACAGAAAATGTTTGTTTTTAGTGTCAAATTTTTAGCTGTATTTGTAGCAATTATCAGGTTTGCTAGAAATATA ACTTTTAATACAGTAGCCTGTAAATAAAACACTCTTCCATATGATATTCAACATTTTACAACTGCAGTATTCACCTAAAGTAGAAATAAT CTGTTACTTATTGTAAATACTGCCCTAGTGTCTCCATGGACCAAATTTATATTTATAATTGTAGATTTTTATATTTTACTACTGAGTCAA GTTTTCTAGTTCTGTGTAATTGTTTAGTTTAATGACGTAGTTCATTAGCTGGTCTTACTCTACCAGTTTTCTGACATTGTATTGTGTTAC CTAAGTCATTAACTTTGTTTCAGCATGTAATTTTAACTTTTGTGGAAAATAGAAATACCTTCATTTTGAAAGAAGTTTTTATGAGAATAA >67481_67481_3_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000337898_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=136AA_BP=44 MWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADI -------------------------------------------------------------- >67481_67481_4_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000337898_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=657nt_BP=239nt ATTGCGCGCGCCGGAAGTACCTACCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCT TACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGAT GAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGT GCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGA GTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCT CTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCA CATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCATCACCTGACAGTAAC >67481_67481_4_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000337898_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=136AA_BP=44 MWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADI -------------------------------------------------------------- >67481_67481_5_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000358314_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1485nt_BP=392nt GGAAGTACCTACCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCTTACAGAAGAGAC GAAATGTGGTCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGA CTAGTTAATATTGTGCCAAAGAAACCACCACTGCTAGACAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGA GACTATGACGAGGGCCGCAGTTTTTCTCATGATCGAAGAAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGAC GATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTA GAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAG TTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCT GATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTA AAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCATCACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAA ATTTATATCATTAACAATGTGTGCCTTTTTGCAAGACTTGTAATTTACTTATTATGTTTGAACTAAAATGATTGAATTTTACAGTATTTC TAAGAATGGAATTGTGGTATTTTTTTCTGTATTGATTTTAACAGAAAATTTCAATTTATAGAGGTTAGGAATTCCAAACTACAGAAAATG TTTGTTTTTAGTGTCAAATTTTTAGCTGTATTTGTAGCAATTATCAGGTTTGCTAGAAATATAACTTTTAATACAGTAGCCTGTAAATAA AACACTCTTCCATATGATATTCAACATTTTACAACTGCAGTATTCACCTAAAGTAGAAATAATCTGTTACTTATTGTAAATACTGCCCTA GTGTCTCCATGGACCAAATTTATATTTATAATTGTAGATTTTTATATTTTACTACTGAGTCAAGTTTTCTAGTTCTGTGTAATTGTTTAG TTTAATGACGTAGTTCATTAGCTGGTCTTACTCTACCAGTTTTCTGACATTGTATTGTGTTACCTAAGTCATTAACTTTGTTTCAGCATG TAATTTTAACTTTTGTGGAAAATAGAAATACCTTCATTTTGAAAGAAGTTTTTATGAGAATAACACCTTACCAAACATTGTTCAAATGGT >67481_67481_5_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000358314_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=191AA_BP=99 MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDD HSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADIEQYQFLYKVILSLVSTRQEENPSTSLDSNGAALPD -------------------------------------------------------------- >67481_67481_6_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000358314_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=810nt_BP=392nt GGAAGTACCTACCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCTTACAGAAGAGAC GAAATGTGGTCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGA CTAGTTAATATTGTGCCAAAGAAACCACCACTGCTAGACAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGA GACTATGACGAGGGCCGCAGTTTTTCTCATGATCGAAGAAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGAC GATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTA GAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAG TTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCT GATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTA AAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCATCACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAA >67481_67481_6_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000358314_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=191AA_BP=99 MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDD HSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADIEQYQFLYKVILSLVSTRQEENPSTSLDSNGAALPD -------------------------------------------------------------- >67481_67481_7_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000395568_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1476nt_BP=383nt TACCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCTTACAGAAGAGACGAAATGTGG TCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGACTAGTTAAT ATTGTGCCAAAGAAACCACCACTGCTAGACAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGAGACTATGAC GAGGGCCGCAGTTTTTCTCATGATCGAAGAAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCT GCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAA AATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTAC AAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAAT ATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGC AGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCATCACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAAATTTATATC ATTAACAATGTGTGCCTTTTTGCAAGACTTGTAATTTACTTATTATGTTTGAACTAAAATGATTGAATTTTACAGTATTTCTAAGAATGG AATTGTGGTATTTTTTTCTGTATTGATTTTAACAGAAAATTTCAATTTATAGAGGTTAGGAATTCCAAACTACAGAAAATGTTTGTTTTT AGTGTCAAATTTTTAGCTGTATTTGTAGCAATTATCAGGTTTGCTAGAAATATAACTTTTAATACAGTAGCCTGTAAATAAAACACTCTT CCATATGATATTCAACATTTTACAACTGCAGTATTCACCTAAAGTAGAAATAATCTGTTACTTATTGTAAATACTGCCCTAGTGTCTCCA TGGACCAAATTTATATTTATAATTGTAGATTTTTATATTTTACTACTGAGTCAAGTTTTCTAGTTCTGTGTAATTGTTTAGTTTAATGAC GTAGTTCATTAGCTGGTCTTACTCTACCAGTTTTCTGACATTGTATTGTGTTACCTAAGTCATTAACTTTGTTTCAGCATGTAATTTTAA CTTTTGTGGAAAATAGAAATACCTTCATTTTGAAAGAAGTTTTTATGAGAATAACACCTTACCAAACATTGTTCAAATGGTTTTTATCCA >67481_67481_7_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000395568_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=191AA_BP=99 MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDD HSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADIEQYQFLYKVILSLVSTRQEENPSTSLDSNGAALPD -------------------------------------------------------------- >67481_67481_8_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000395568_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=801nt_BP=383nt TACCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCTTACAGAAGAGACGAAATGTGG TCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGACTAGTTAAT ATTGTGCCAAAGAAACCACCACTGCTAGACAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGAGACTATGAC GAGGGCCGCAGTTTTTCTCATGATCGAAGAAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCT GCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAA AATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTAC AAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAAT ATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGC >67481_67481_8_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000395568_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=191AA_BP=99 MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDD HSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADIEQYQFLYKVILSLVSTRQEENPSTSLDSNGAALPD -------------------------------------------------------------- >67481_67481_9_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000395580_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1540nt_BP=447nt ATTGCGCGCGCCGGAAGTACCTACCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGGAAAT TGTTGAAAACGTTAAATTTGATTCCTAAAAGGACTCAATGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAG AATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGACTAGTTAATATTGTGCCAAAGAAACCACCACTGCT AGACAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGAGACTATGACGAGGGCCGCAGTTTTTCTCATGATCG AAGAAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCA TGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGC CAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCAC AAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGT TTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATC TGTTGATTTCCCATCACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAAATTTATATCATTAACAATGTGTGCCTTTTTGCAAG ACTTGTAATTTACTTATTATGTTTGAACTAAAATGATTGAATTTTACAGTATTTCTAAGAATGGAATTGTGGTATTTTTTTCTGTATTGA TTTTAACAGAAAATTTCAATTTATAGAGGTTAGGAATTCCAAACTACAGAAAATGTTTGTTTTTAGTGTCAAATTTTTAGCTGTATTTGT AGCAATTATCAGGTTTGCTAGAAATATAACTTTTAATACAGTAGCCTGTAAATAAAACACTCTTCCATATGATATTCAACATTTTACAAC TGCAGTATTCACCTAAAGTAGAAATAATCTGTTACTTATTGTAAATACTGCCCTAGTGTCTCCATGGACCAAATTTATATTTATAATTGT AGATTTTTATATTTTACTACTGAGTCAAGTTTTCTAGTTCTGTGTAATTGTTTAGTTTAATGACGTAGTTCATTAGCTGGTCTTACTCTA CCAGTTTTCTGACATTGTATTGTGTTACCTAAGTCATTAACTTTGTTTCAGCATGTAATTTTAACTTTTGTGGAAAATAGAAATACCTTC ATTTTGAAAGAAGTTTTTATGAGAATAACACCTTACCAAACATTGTTCAAATGGTTTTTATCCAAGGAATTGCAAAAATAAATATAAATA >67481_67481_9_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000395580_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=198AA_BP=106 MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESG YRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADIEQYQFLYKVILSLVSTRQEENPSTSLDS -------------------------------------------------------------- >67481_67481_10_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000395580_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=865nt_BP=447nt ATTGCGCGCGCCGGAAGTACCTACCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGGAAAT TGTTGAAAACGTTAAATTTGATTCCTAAAAGGACTCAATGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAG AATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGACTAGTTAATATTGTGCCAAAGAAACCACCACTGCT AGACAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGAGACTATGACGAGGGCCGCAGTTTTTCTCATGATCG AAGAAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCA TGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGC CAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCAC AAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGT TTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATC >67481_67481_10_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000395580_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=198AA_BP=106 MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESG YRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADIEQYQFLYKVILSLVSTRQEENPSTSLDS -------------------------------------------------------------- >67481_67481_11_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000432191_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1299nt_BP=206nt CGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGA TATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGAATCTGGTTATAGATGGACAAGAGACGATCAT TCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAA GAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTC TACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGA AATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTA GGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCATCACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAAATTTAT ATCATTAACAATGTGTGCCTTTTTGCAAGACTTGTAATTTACTTATTATGTTTGAACTAAAATGATTGAATTTTACAGTATTTCTAAGAA TGGAATTGTGGTATTTTTTTCTGTATTGATTTTAACAGAAAATTTCAATTTATAGAGGTTAGGAATTCCAAACTACAGAAAATGTTTGTT TTTAGTGTCAAATTTTTAGCTGTATTTGTAGCAATTATCAGGTTTGCTAGAAATATAACTTTTAATACAGTAGCCTGTAAATAAAACACT CTTCCATATGATATTCAACATTTTACAACTGCAGTATTCACCTAAAGTAGAAATAATCTGTTACTTATTGTAAATACTGCCCTAGTGTCT CCATGGACCAAATTTATATTTATAATTGTAGATTTTTATATTTTACTACTGAGTCAAGTTTTCTAGTTCTGTGTAATTGTTTAGTTTAAT GACGTAGTTCATTAGCTGGTCTTACTCTACCAGTTTTCTGACATTGTATTGTGTTACCTAAGTCATTAACTTTGTTTCAGCATGTAATTT TAACTTTTGTGGAAAATAGAAATACCTTCATTTTGAAAGAAGTTTTTATGAGAATAACACCTTACCAAACATTGTTCAAATGGTTTTTAT >67481_67481_11_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000432191_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=136AA_BP=44 MWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADI -------------------------------------------------------------- >67481_67481_12_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000432191_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=624nt_BP=206nt CGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGA TATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGAATCTGGTTATAGATGGACAAGAGACGATCAT TCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAA GAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTC TACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGA AATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTA >67481_67481_12_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000432191_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=136AA_BP=44 MWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADI -------------------------------------------------------------- >67481_67481_13_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000449194_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1474nt_BP=381nt CCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCTTACAGAAGAGACGAAATGTGGTC TGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGACTAGTTAATAT TGTGCCAAAGAAACCACCACTGCTAGACAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGAGACTATGACGA GGGCCGCAGTTTTTCTCATGATCGAAGAAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGC AAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAA TTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAA AGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATAT AGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAG GAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCCCATCACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAAATTTATATCAT TAACAATGTGTGCCTTTTTGCAAGACTTGTAATTTACTTATTATGTTTGAACTAAAATGATTGAATTTTACAGTATTTCTAAGAATGGAA TTGTGGTATTTTTTTCTGTATTGATTTTAACAGAAAATTTCAATTTATAGAGGTTAGGAATTCCAAACTACAGAAAATGTTTGTTTTTAG TGTCAAATTTTTAGCTGTATTTGTAGCAATTATCAGGTTTGCTAGAAATATAACTTTTAATACAGTAGCCTGTAAATAAAACACTCTTCC ATATGATATTCAACATTTTACAACTGCAGTATTCACCTAAAGTAGAAATAATCTGTTACTTATTGTAAATACTGCCCTAGTGTCTCCATG GACCAAATTTATATTTATAATTGTAGATTTTTATATTTTACTACTGAGTCAAGTTTTCTAGTTCTGTGTAATTGTTTAGTTTAATGACGT AGTTCATTAGCTGGTCTTACTCTACCAGTTTTCTGACATTGTATTGTGTTACCTAAGTCATTAACTTTGTTTCAGCATGTAATTTTAACT TTTGTGGAAAATAGAAATACCTTCATTTTGAAAGAAGTTTTTATGAGAATAACACCTTACCAAACATTGTTCAAATGGTTTTTATCCAAG >67481_67481_13_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000449194_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=191AA_BP=99 MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDD HSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADIEQYQFLYKVILSLVSTRQEENPSTSLDSNGAALPD -------------------------------------------------------------- >67481_67481_14_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000449194_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=799nt_BP=381nt CCTGGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGTGGCTTACAGAAGAGACGAAATGTGGTC TGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGACTAGTTAATAT TGTGCCAAAGAAACCACCACTGCTAGACAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGAGACTATGACGA GGGCCGCAGTTTTTCTCATGATCGAAGAAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGC AAGCAGGCAACCTGAATACAGGCATGGAGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAA TTCCGTGGATGTTTACCAGGTAGCCAAGATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAA AGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATAT AGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAG >67481_67481_14_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000449194_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=191AA_BP=99 MWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRPGEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDD HSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMRPGVFADIEQYQFLYKVILSLVSTRQEENPSTSLDSNGAALPD -------------------------------------------------------------- >67481_67481_15_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000549190_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1627nt_BP=534nt GGCGAGTTAGCCGGCGGGCGGTGCGGGGGTGGCCGCGGTGGCCGCGGCTGCCTCGGGCGCCGGCGCCGCCTCTCCGCGCTGTTCCCCCGT TGCCCCCTTGGTACCCCCGGCTGCCGGGGACTGCCTCGCGCTCCAGAGCCCCTCTGAGGAGGAAAACGTCTGTCCCACCGACTGGCAGGG GATGCTCCGTCATCCCGTGCGAAGCCTGGTCCAAGTGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAGAAT TCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGACTAGTTAATATTGTGCCAAAGAAACCACCACTGCTAGA CAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGAGACTATGACGAGGGCCGCAGTTTTTCTCATGATCGAAG AAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGG AGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAA GATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAG GCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTA ACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGT TGATTTCCCATCACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAAATTTATATCATTAACAATGTGTGCCTTTTTGCAAGACT TGTAATTTACTTATTATGTTTGAACTAAAATGATTGAATTTTACAGTATTTCTAAGAATGGAATTGTGGTATTTTTTTCTGTATTGATTT TAACAGAAAATTTCAATTTATAGAGGTTAGGAATTCCAAACTACAGAAAATGTTTGTTTTTAGTGTCAAATTTTTAGCTGTATTTGTAGC AATTATCAGGTTTGCTAGAAATATAACTTTTAATACAGTAGCCTGTAAATAAAACACTCTTCCATATGATATTCAACATTTTACAACTGC AGTATTCACCTAAAGTAGAAATAATCTGTTACTTATTGTAAATACTGCCCTAGTGTCTCCATGGACCAAATTTATATTTATAATTGTAGA TTTTTATATTTTACTACTGAGTCAAGTTTTCTAGTTCTGTGTAATTGTTTAGTTTAATGACGTAGTTCATTAGCTGGTCTTACTCTACCA GTTTTCTGACATTGTATTGTGTTACCTAAGTCATTAACTTTGTTTCAGCATGTAATTTTAACTTTTGTGGAAAATAGAAATACCTTCATT TTGAAAGAAGTTTTTATGAGAATAACACCTTACCAAACATTGTTCAAATGGTTTTTATCCAAGGAATTGCAAAAATAAATATAAATATTG >67481_67481_15_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000549190_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=237AA_BP=145 MVPPAAGDCLALQSPSEEENVCPTDWQGMLRHPVRSLVQVAYRRDEMWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRP GEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMI -------------------------------------------------------------- >67481_67481_16_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000549190_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=952nt_BP=534nt GGCGAGTTAGCCGGCGGGCGGTGCGGGGGTGGCCGCGGTGGCCGCGGCTGCCTCGGGCGCCGGCGCCGCCTCTCCGCGCTGTTCCCCCGT TGCCCCCTTGGTACCCCCGGCTGCCGGGGACTGCCTCGCGCTCCAGAGCCCCTCTGAGGAGGAAAACGTCTGTCCCACCGACTGGCAGGG GATGCTCCGTCATCCCGTGCGAAGCCTGGTCCAAGTGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAGAAT TCCGAGAGAACGAGCACCTCCTCGAAGTCATCCCAGTGATGGCTACAATAGACTAGTTAATATTGTGCCAAAGAAACCACCACTGCTAGA CAGACCTGGTGAAGGAAGCTACAATAGATATTACAGTCATGTTGATTACCGAGACTATGACGAGGGCCGCAGTTTTTCTCATGATCGAAG AAGTGGTCCACCTCACAGAGGAGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGG AGGAGTGACGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAA GATGATCAATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAG GCAGGAAGAGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTA ACACAGAAAGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGT >67481_67481_16_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000549190_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=237AA_BP=145 MVPPAAGDCLALQSPSEEENVCPTDWQGMLRHPVRSLVQVAYRRDEMWSEGRYEYERIPRERAPPRSHPSDGYNRLVNIVPKKPPLLDRP GEGSYNRYYSHVDYRDYDEGRSFSHDRRSGPPHRGDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMI -------------------------------------------------------------- >67481_67481_17_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000552761_PTPRZ1_chr7_121699806_ENST00000393386_length(transcript)=1349nt_BP=256nt GGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGGAAATTGTTGAAAACGTTAAATTTGATTCCT AAAAGGACTCAATGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTC GAAGTCATCCCAGTGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGA CGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCA ATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAG AGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAA AGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCC CATCACCTGACAGTAACTTTCATGACATAGGATTCTGCCGCCAAATTTATATCATTAACAATGTGTGCCTTTTTGCAAGACTTGTAATTT ACTTATTATGTTTGAACTAAAATGATTGAATTTTACAGTATTTCTAAGAATGGAATTGTGGTATTTTTTTCTGTATTGATTTTAACAGAA AATTTCAATTTATAGAGGTTAGGAATTCCAAACTACAGAAAATGTTTGTTTTTAGTGTCAAATTTTTAGCTGTATTTGTAGCAATTATCA GGTTTGCTAGAAATATAACTTTTAATACAGTAGCCTGTAAATAAAACACTCTTCCATATGATATTCAACATTTTACAACTGCAGTATTCA CCTAAAGTAGAAATAATCTGTTACTTATTGTAAATACTGCCCTAGTGTCTCCATGGACCAAATTTATATTTATAATTGTAGATTTTTATA TTTTACTACTGAGTCAAGTTTTCTAGTTCTGTGTAATTGTTTAGTTTAATGACGTAGTTCATTAGCTGGTCTTACTCTACCAGTTTTCTG ACATTGTATTGTGTTACCTAAGTCATTAACTTTGTTTCAGCATGTAATTTTAACTTTTGTGGAAAATAGAAATACCTTCATTTTGAAAGA >67481_67481_17_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000552761_PTPRZ1_chr7_121699806_ENST00000393386_length(amino acids)=143AA_BP=51 MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMR -------------------------------------------------------------- >67481_67481_18_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000552761_PTPRZ1_chr7_121699806_ENST00000449182_length(transcript)=674nt_BP=256nt GGGATAACGGCGGCGAGCGGACGGCTGCATTTACGGGGTCTCCCGGAGGGCCAGAGTCGGAAATTGTTGAAAACGTTAAATTTGATTCCT AAAAGGACTCAATGGCTTACAGAAGAGACGAAATGTGGTCTGAGGGACGATATGAATATGAAAGAATTCCGAGAGAACGAGCACCTCCTC GAAGTCATCCCAGTGATGAATCTGGTTATAGATGGACAAGAGACGATCATTCTGCAAGCAGGCAACCTGAATACAGGCATGGAGGAGTGA CGGCAGGAACTTTCTGTGCTCTGACAACCCTTATGCACCAACTAGAAAAAGAAAATTCCGTGGATGTTTACCAGGTAGCCAAGATGATCA ATCTGATGAGGCCAGGAGTCTTTGCTGACATTGAGCAGTATCAGTTTCTCTACAAAGTGATCCTCAGCCTTGTGAGCACAAGGCAGGAAG AGAATCCATCCACCTCTCTGGACAGTAATGGTGCAGCATTGCCTGATGGAAATATAGCTGAGAGCTTAGAGTCTTTAGTTTAACACAGAA AGGGGTGGGGGAACTCACATCTGAGCATTGTTTTCCTCTTCCTAAAATTAGGCAGGAAAATCAGTCTAGTTCTGTTATCTGTTGATTTCC >67481_67481_18_PPHLN1-PTPRZ1_PPHLN1_chr12_42749024_ENST00000552761_PTPRZ1_chr7_121699806_ENST00000449182_length(amino acids)=143AA_BP=51 MAYRRDEMWSEGRYEYERIPRERAPPRSHPSDESGYRWTRDDHSASRQPEYRHGGVTAGTFCALTTLMHQLEKENSVDVYQVAKMINLMR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PPHLN1-PTPRZ1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PPHLN1-PTPRZ1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PPHLN1-PTPRZ1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies