
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PPP2R4-PRRX2 (FusionGDB2 ID:68058) |
Fusion Gene Summary for PPP2R4-PRRX2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PPP2R4-PRRX2 | Fusion gene ID: 68058 | Hgene | Tgene | Gene symbol | PPP2R4 | PRRX2 | Gene ID | 5524 | 51450 |
| Gene name | protein phosphatase 2 phosphatase activator | paired related homeobox 2 | |
| Synonyms | PP2A|PPP2R4|PR53 | PMX2|PRX2 | |
| Cytomap | 9q34.11 | 9q34.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | serine/threonine-protein phosphatase 2A activatorPP2A phosphatase activatorPP2A subunit B' isoform PR53phosphotyrosyl phosphatase activatorprotein phosphatase 2 regulatory subunit 4protein phosphatase 2A activator, regulatory subunit 4protein phosph | paired mesoderm homeobox protein 2PRX-2paired-like homeodomain protein PRX2paired-related homeobox protein 2testicular tissue protein Li 148testicular tissue protein Li 160 | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000337738, ENST00000348141, ENST00000355007, ENST00000357197, ENST00000358994, ENST00000393370, ENST00000452489, ENST00000347048, ENST00000414510, ENST00000419582, ENST00000423100, ENST00000432124, ENST00000432651, ENST00000434095, ENST00000435132, ENST00000435305, ENST00000436883, ENST00000524946, | ENST00000372469, | |
| Fusion gene scores | * DoF score | 10 X 9 X 8=720 | 5 X 4 X 6=120 |
| # samples | 12 | 7 | |
| ** MAII score | log2(12/720*10)=-2.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/120*10)=-0.777607578663552 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PPP2R4 [Title/Abstract] AND PRRX2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PPP2R4(131898874)-PRRX2(132481509), # samples:1 PRRX2(132428405)-PPP2R4(131882791), # samples:1 PRRX2(132428405)-PPP2R4(131882792), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PPP2R4 | GO:0032515 | negative regulation of phosphoprotein phosphatase activity | 16916641 |
| Hgene | PPP2R4 | GO:0032516 | positive regulation of phosphoprotein phosphatase activity | 16916641 |
| Hgene | PPP2R4 | GO:0035307 | positive regulation of protein dephosphorylation | 16916641 |
| Hgene | PPP2R4 | GO:0035308 | negative regulation of protein dephosphorylation | 16916641 |
| Hgene | PPP2R4 | GO:0043065 | positive regulation of apoptotic process | 17333320 |
| Hgene | PPP2R4 | GO:0043666 | regulation of phosphoprotein phosphatase activity | 16916641 |
| Fusion gene breakpoints across PPP2R4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
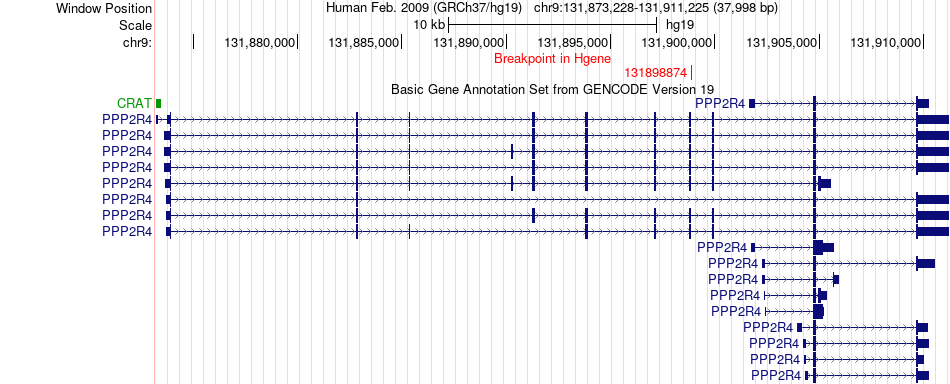 |
| Fusion gene breakpoints across PRRX2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-2H-A9GR | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
Top |
Fusion Gene ORF analysis for PPP2R4-PRRX2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000337738 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| In-frame | ENST00000348141 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| In-frame | ENST00000355007 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| In-frame | ENST00000357197 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| In-frame | ENST00000358994 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| In-frame | ENST00000393370 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| In-frame | ENST00000452489 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000347048 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000414510 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000419582 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000423100 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000432124 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000432651 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000434095 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000435132 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000435305 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000436883 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| intron-3CDS | ENST00000524946 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000358994 | PPP2R4 | chr9 | 131898874 | + | ENST00000372469 | PRRX2 | chr9 | 132481509 | + | 1644 | 897 | 8 | 1399 | 463 |
| ENST00000393370 | PPP2R4 | chr9 | 131898874 | + | ENST00000372469 | PRRX2 | chr9 | 132481509 | + | 1715 | 968 | 169 | 1470 | 433 |
| ENST00000337738 | PPP2R4 | chr9 | 131898874 | + | ENST00000372469 | PRRX2 | chr9 | 132481509 | + | 1804 | 1057 | 153 | 1559 | 468 |
| ENST00000348141 | PPP2R4 | chr9 | 131898874 | + | ENST00000372469 | PRRX2 | chr9 | 132481509 | + | 1715 | 968 | 151 | 1470 | 439 |
| ENST00000452489 | PPP2R4 | chr9 | 131898874 | + | ENST00000372469 | PRRX2 | chr9 | 132481509 | + | 1750 | 1003 | 99 | 1505 | 468 |
| ENST00000357197 | PPP2R4 | chr9 | 131898874 | + | ENST00000372469 | PRRX2 | chr9 | 132481509 | + | 1537 | 790 | 78 | 1292 | 404 |
| ENST00000355007 | PPP2R4 | chr9 | 131898874 | + | ENST00000372469 | PRRX2 | chr9 | 132481509 | + | 1493 | 746 | 73 | 1248 | 391 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000358994 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 0.016912274 | 0.9830877 |
| ENST00000393370 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 0.013333802 | 0.98666614 |
| ENST00000337738 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 0.008633498 | 0.99136645 |
| ENST00000348141 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 0.013839127 | 0.9861609 |
| ENST00000452489 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 0.009482493 | 0.99051756 |
| ENST00000357197 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 0.02192586 | 0.9780741 |
| ENST00000355007 | ENST00000372469 | PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 0.017804958 | 0.9821951 |
Top |
Fusion Genomic Features for PPP2R4-PRRX2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 2.25E-06 | 0.99999774 |
| PPP2R4 | chr9 | 131898874 | + | PRRX2 | chr9 | 132481509 | + | 2.25E-06 | 0.99999774 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
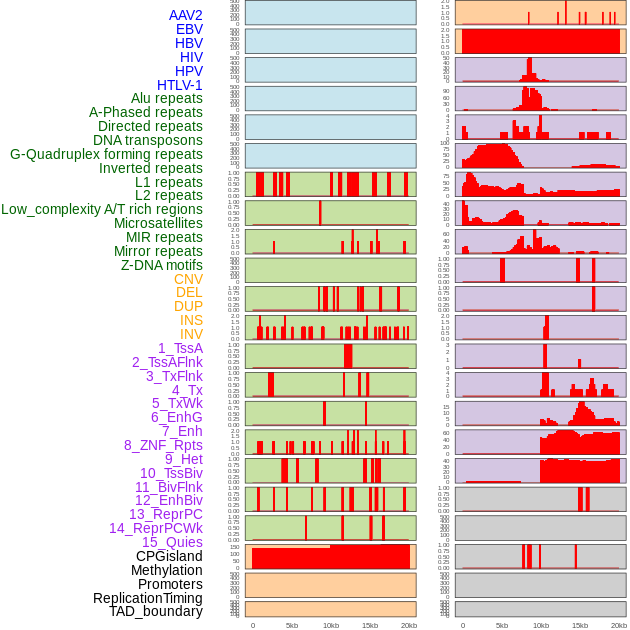 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
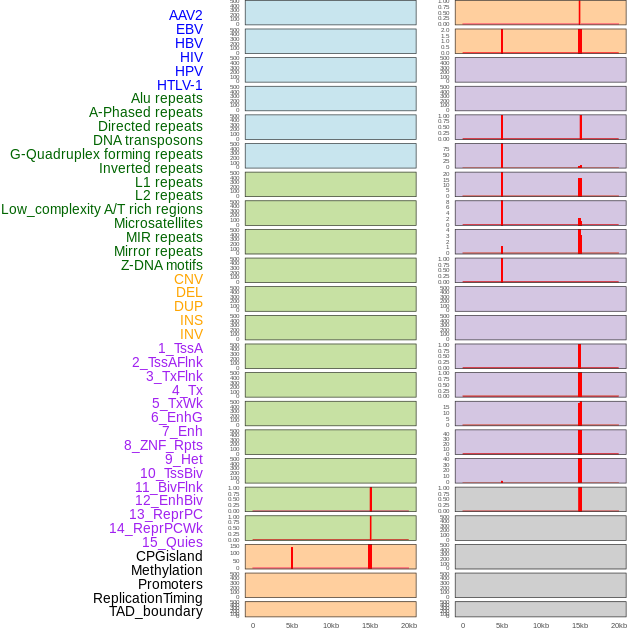 |
Top |
Fusion Protein Features for PPP2R4-PRRX2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:131898874/chr9:132481509) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000337738 | + | 8 | 11 | 183_189 | 263 | 359.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000337738 | + | 8 | 11 | 240_242 | 263 | 359.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000355007 | + | 6 | 9 | 183_189 | 186 | 282.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000357197 | + | 6 | 9 | 183_189 | 199 | 295.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000358994 | + | 8 | 11 | 183_189 | 228 | 324.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000393370 | + | 7 | 10 | 183_189 | 228 | 324.0 | Nucleotide binding | Note=ATP |
| Tgene | PRRX2 | chr9:131898874 | chr9:132481509 | ENST00000372469 | 0 | 4 | 104_163 | 86 | 254.0 | DNA binding | Homeobox | |
| Tgene | PRRX2 | chr9:131898874 | chr9:132481509 | ENST00000372469 | 0 | 4 | 230_243 | 86 | 254.0 | Motif | OAR |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000337738 | + | 8 | 11 | 342_343 | 263 | 359.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000355007 | + | 6 | 9 | 240_242 | 186 | 282.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000355007 | + | 6 | 9 | 342_343 | 186 | 282.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000357197 | + | 6 | 9 | 240_242 | 199 | 295.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000357197 | + | 6 | 9 | 342_343 | 199 | 295.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000358994 | + | 8 | 11 | 240_242 | 228 | 324.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000358994 | + | 8 | 11 | 342_343 | 228 | 324.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000393370 | + | 7 | 10 | 240_242 | 228 | 324.0 | Nucleotide binding | Note=ATP |
| Hgene | PPP2R4 | chr9:131898874 | chr9:132481509 | ENST00000393370 | + | 7 | 10 | 342_343 | 228 | 324.0 | Nucleotide binding | Note=ATP |
Top |
Fusion Gene Sequence for PPP2R4-PRRX2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >68058_68058_1_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000337738_PRRX2_chr9_132481509_ENST00000372469_length(transcript)=1804nt_BP=1057nt CCGCACTGACATGGCCGTCGCCCGGTTCCGCGCGTCCGCCGCGCGCCGGCCGTTAATAGGCTTGCTCCCTGAGCGCCCCGCACCGACATG GCGGCCGTCTTCGCTGTGGTGACTTTAACTCTCGGTTTTCGGTTATAGCCGGCCGGCGCTCACTTGTCTTCAGGAAGCTCGGAGCCTTTG GTGGAGCCGGGGAGAGGAAGGGTGGGTGCAAGAGTGAAAGGCGAGAGGGGACTGCAAGCATCCGGGTCGGCTCCTGGCCGGAGCAAGATG GCTGAGGGCGAGCGGCAGCCGCCGCCAGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGGAGATCCAC ACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTGTGAAGGGG AAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGATGTGGAATGAGGTTCATGAGGAAAAGGAGCAGGCTGCAAAGCAGAGTGTGTCCTGC GATGAATGCATACCATTACCCCGCGCCGGGCACTGTGCACCTTCGGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAGG TGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGCA GAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCC ACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGAC CAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGC CAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGGTGAGTGTCCCAGCCCGGGGCGC GGTAGCGCCGCCAAGCGGAAGAAGAAGCAGCGGCGGAACCGCACCACGTTCAACAGCAGCCAACTGCAGGCGCTGGAGCGCGTGTTCGAG CGCACGCACTACCCCGACGCCTTTGTGCGCGAGGAGCTTGCCCGGCGCGTCAACCTCAGCGAGGCGCGCGTTCAGGTCTGGTTTCAGAAC CGCCGCGCCAAGTTCCGCAGGAATGAAAGGGCCATGCTGGCCAGCCGCTCTGCCTCGCTGCTCAAGTCCTACAGCCAGGAGGCCGCCATC GAGCAGCCCGTGGCTCCCCGGCCCACCGCCCTGAGTCCAGATTATCTCTCCTGGACAGCCTCGTCCCCCTACAGCACAGTGCCACCCTAC AGCCCTGGGAGCTCAGGCCCCGCAACCCCAGGGGTCAACATGGCCAACAGCATCGCCAGCCTCCGTCTCAAGGCCAAGGAGTTCAGCCTG CACCACAGCCAGGTGCCTACGGTGAACTGAAGTCCAGTCCCACCAGGACCCAGACGCCTCCCTGGGTGGACAGCAATAGAAAAGGGGGCA GACGCCCAGGAAGTGACCTTCTCCTGGATGAGCTCTCCTGGCCCGTCTGTCCAGCCTGGACTCCCGAGCCCACGAGGCTGTTGAGGCCCC TGCAGCCGGGCCCAGCTCTTCTGTCCTTGGCCACCAGAGACTGCAGCCCACAACCCTTGGAGGGGTTGGGCCGGAAGGTGGAAGAGCCTG >68058_68058_1_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000337738_PRRX2_chr9_132481509_ENST00000372469_length(amino acids)=468AA_BP=1 MSSGSSEPLVEPGRGRVGARVKGERGLQASGSAPGRSKMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAYADYIGFI LTLNEGVKGKKLTFEYRVSEMWNEVHEEKEQAAKQSVSCDECIPLPRAGHCAPSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRT WYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQK TYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIGECPSPGRGSAAKRKKKQRRNRTTFNSSQLQALERVFERTHYPDAFVREELARRVNLSE ARVQVWFQNRRAKFRRNERAMLASRSASLLKSYSQEAAIEQPVAPRPTALSPDYLSWTASSPYSTVPPYSPGSSGPATPGVNMANSIASL -------------------------------------------------------------- >68058_68058_2_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000348141_PRRX2_chr9_132481509_ENST00000372469_length(transcript)=1715nt_BP=968nt GCACTGACATGGCCGTCGCCCGGTTCCGCGCGTCCGCCGCGCGCCGGCCGTTAATAGGCTTGCTCCCTGAGCGCCCCGCACCGACATGGC GGCCGTCTTCGCTGTGGTGACTTTAACTCTCGGTTTTCGGTTATAGCCGGCCGGCGCTCACTTGTCTTCAGGAAGCTCGGAGCCTTTGGT GGAGCCGGGGAGAGGAAGGGTGGGTGCAAGAGTGAAAGGCGAGAGGGGACTGCAAGCATCCGGGTCGGCTCCTGGCCGGAGCAAGATGGC TGAGGGCGAGCGGCAGCCGCCGCCAGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGGAGATCCACAC AGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGTACCATTTGGAACTGTGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAA CGAAGGTGTGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAG GTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGC AGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTC CACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGA CCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAG CCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGGTGAGTGTCCCAGCCCGGGGCG CGGTAGCGCCGCCAAGCGGAAGAAGAAGCAGCGGCGGAACCGCACCACGTTCAACAGCAGCCAACTGCAGGCGCTGGAGCGCGTGTTCGA GCGCACGCACTACCCCGACGCCTTTGTGCGCGAGGAGCTTGCCCGGCGCGTCAACCTCAGCGAGGCGCGCGTTCAGGTCTGGTTTCAGAA CCGCCGCGCCAAGTTCCGCAGGAATGAAAGGGCCATGCTGGCCAGCCGCTCTGCCTCGCTGCTCAAGTCCTACAGCCAGGAGGCCGCCAT CGAGCAGCCCGTGGCTCCCCGGCCCACCGCCCTGAGTCCAGATTATCTCTCCTGGACAGCCTCGTCCCCCTACAGCACAGTGCCACCCTA CAGCCCTGGGAGCTCAGGCCCCGCAACCCCAGGGGTCAACATGGCCAACAGCATCGCCAGCCTCCGTCTCAAGGCCAAGGAGTTCAGCCT GCACCACAGCCAGGTGCCTACGGTGAACTGAAGTCCAGTCCCACCAGGACCCAGACGCCTCCCTGGGTGGACAGCAATAGAAAAGGGGGC AGACGCCCAGGAAGTGACCTTCTCCTGGATGAGCTCTCCTGGCCCGTCTGTCCAGCCTGGACTCCCGAGCCCACGAGGCTGTTGAGGCCC CTGCAGCCGGGCCCAGCTCTTCTGTCCTTGGCCACCAGAGACTGCAGCCCACAACCCTTGGAGGGGTTGGGCCGGAAGGTGGAAGAGCCT >68058_68058_2_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000348141_PRRX2_chr9_132481509_ENST00000372469_length(amino acids)=439AA_BP=1 MSSGSSEPLVEPGRGRVGARVKGERGLQASGSAPGRSKMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQVPFGTVAYA DYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVA VYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQ LIGECPSPGRGSAAKRKKKQRRNRTTFNSSQLQALERVFERTHYPDAFVREELARRVNLSEARVQVWFQNRRAKFRRNERAMLASRSASL -------------------------------------------------------------- >68058_68058_3_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000355007_PRRX2_chr9_132481509_ENST00000372469_length(transcript)=1493nt_BP=746nt CACCGACATGGCGGCCGTCTTCGCTGTGGTGACTTTAACTCTCGGTTTTCGGTTATAGCCGGCCGGCGCTCACTTGTCTTCAGGAAGCTC GGAGCCTTTGGTGGAGCCGGGGAGAGGAAGGGTGGGTGCAAGAGTGAAAGGCGAGAGGGGACTGCAAGCATCCGGGTCGGCTCCTGGCCG GAGCAAGATGGCTGAGGGCGAGCGGCAGCCGCCGCCAGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAA GGAGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGG TGTGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGC TGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGC TGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGA GGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTT CATCTGGGGCAGTTCGCAGCTGATAGGTGAGTGTCCCAGCCCGGGGCGCGGTAGCGCCGCCAAGCGGAAGAAGAAGCAGCGGCGGAACCG CACCACGTTCAACAGCAGCCAACTGCAGGCGCTGGAGCGCGTGTTCGAGCGCACGCACTACCCCGACGCCTTTGTGCGCGAGGAGCTTGC CCGGCGCGTCAACCTCAGCGAGGCGCGCGTTCAGGTCTGGTTTCAGAACCGCCGCGCCAAGTTCCGCAGGAATGAAAGGGCCATGCTGGC CAGCCGCTCTGCCTCGCTGCTCAAGTCCTACAGCCAGGAGGCCGCCATCGAGCAGCCCGTGGCTCCCCGGCCCACCGCCCTGAGTCCAGA TTATCTCTCCTGGACAGCCTCGTCCCCCTACAGCACAGTGCCACCCTACAGCCCTGGGAGCTCAGGCCCCGCAACCCCAGGGGTCAACAT GGCCAACAGCATCGCCAGCCTCCGTCTCAAGGCCAAGGAGTTCAGCCTGCACCACAGCCAGGTGCCTACGGTGAACTGAAGTCCAGTCCC ACCAGGACCCAGACGCCTCCCTGGGTGGACAGCAATAGAAAAGGGGGCAGACGCCCAGGAAGTGACCTTCTCCTGGATGAGCTCTCCTGG CCCGTCTGTCCAGCCTGGACTCCCGAGCCCACGAGGCTGTTGAGGCCCCTGCAGCCGGGCCCAGCTCTTCTGTCCTTGGCCACCAGAGAC >68058_68058_3_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000355007_PRRX2_chr9_132481509_ENST00000372469_length(amino acids)=391AA_BP=1 MSSGSSEPLVEPGRGRVGARVKGERGLQASGSAPGRSKMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAYADYIGFI LTLNEGVKGKKLTFEYRVSEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKV FNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIGECPSPGRGSAAKRKKKQRRNRTTFNSSQLQALERVFERTHYPDAF VREELARRVNLSEARVQVWFQNRRAKFRRNERAMLASRSASLLKSYSQEAAIEQPVAPRPTALSPDYLSWTASSPYSTVPPYSPGSSGPA -------------------------------------------------------------- >68058_68058_4_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000357197_PRRX2_chr9_132481509_ENST00000372469_length(transcript)=1537nt_BP=790nt CCCCGCACCGACATGGCGGCCGTCTTCGCTGTGGTGACTTTAACTCTCGGTTTTCGGTTATAGCCGGCCGGCGCTCACTTGTCTTCAGGA AGCTCGGAGCCTTTGGTGGAGCCGGGGAGAGGAAGGGTGGGTGCAAGAGTGAAAGGCGAGAGGGGACTGCAAGCATCCGGGTCGGCTCCT GGCCGGAGCAAGATGGCTGAGGGCGAGCGGCAGCCGCCGCCAGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCA AAAAAGGAGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGAC AGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAA GCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAAC TCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGAT GACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGC AGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGGTGAGTGTCCCAGCCCGGGG CGCGGTAGCGCCGCCAAGCGGAAGAAGAAGCAGCGGCGGAACCGCACCACGTTCAACAGCAGCCAACTGCAGGCGCTGGAGCGCGTGTTC GAGCGCACGCACTACCCCGACGCCTTTGTGCGCGAGGAGCTTGCCCGGCGCGTCAACCTCAGCGAGGCGCGCGTTCAGGTCTGGTTTCAG AACCGCCGCGCCAAGTTCCGCAGGAATGAAAGGGCCATGCTGGCCAGCCGCTCTGCCTCGCTGCTCAAGTCCTACAGCCAGGAGGCCGCC ATCGAGCAGCCCGTGGCTCCCCGGCCCACCGCCCTGAGTCCAGATTATCTCTCCTGGACAGCCTCGTCCCCCTACAGCACAGTGCCACCC TACAGCCCTGGGAGCTCAGGCCCCGCAACCCCAGGGGTCAACATGGCCAACAGCATCGCCAGCCTCCGTCTCAAGGCCAAGGAGTTCAGC CTGCACCACAGCCAGGTGCCTACGGTGAACTGAAGTCCAGTCCCACCAGGACCCAGACGCCTCCCTGGGTGGACAGCAATAGAAAAGGGG GCAGACGCCCAGGAAGTGACCTTCTCCTGGATGAGCTCTCCTGGCCCGTCTGTCCAGCCTGGACTCCCGAGCCCACGAGGCTGTTGAGGC CCCTGCAGCCGGGCCCAGCTCTTCTGTCCTTGGCCACCAGAGACTGCAGCCCACAACCCTTGGAGGGGTTGGGCCGGAAGGTGGAAGAGC >68058_68058_4_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000357197_PRRX2_chr9_132481509_ENST00000372469_length(amino acids)=404AA_BP=1 MSSGSSEPLVEPGRGRVGARVKGERGLQASGSAPGRSKMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAIEKLVALL NTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGV LRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIGECPSPGRGSAAKRKKKQRRNRTTFNSSQLQAL ERVFERTHYPDAFVREELARRVNLSEARVQVWFQNRRAKFRRNERAMLASRSASLLKSYSQEAAIEQPVAPRPTALSPDYLSWTASSPYS -------------------------------------------------------------- >68058_68058_5_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000358994_PRRX2_chr9_132481509_ENST00000372469_length(transcript)=1644nt_BP=897nt ATTGAGACCTGTGGAGGAGGAAGGAGGAGGTCACCGTCCAGCTGTCTCTCCCCTGTCCCCACATGTCTTCTAAGCTGTTGGAGCCGGCCG GCGCTCACTTGTCTTCAGGAAGCTCGGAGCCTTTGGTGGAGCCGGGGAGAGGAAGGGTGGGTGCAAGAGTGAAAGGCGAGAGGGGACTGC AAGCATCCGGGTCGGCTCCTGGCCGGAGCAAGATGGCTGAGGGCGAGCGGCAGCCGCCGCCAGATTCTTCAGAGGAGGCCCCTCCAGCCA CTCAGAACTTCATCATTCCAAAAAAGGAGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCG GATTCATCCTTACCCTCAACGAAGGTGTGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTC TTCTCAACACGCTGGACAGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATG CCAAACTTGATGAGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAA AGGAGTCAGTGGGGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTG GGGTGCTCCGGGTGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACA GGATGGAGCCAGCCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGGTG AGTGTCCCAGCCCGGGGCGCGGTAGCGCCGCCAAGCGGAAGAAGAAGCAGCGGCGGAACCGCACCACGTTCAACAGCAGCCAACTGCAGG CGCTGGAGCGCGTGTTCGAGCGCACGCACTACCCCGACGCCTTTGTGCGCGAGGAGCTTGCCCGGCGCGTCAACCTCAGCGAGGCGCGCG TTCAGGTCTGGTTTCAGAACCGCCGCGCCAAGTTCCGCAGGAATGAAAGGGCCATGCTGGCCAGCCGCTCTGCCTCGCTGCTCAAGTCCT ACAGCCAGGAGGCCGCCATCGAGCAGCCCGTGGCTCCCCGGCCCACCGCCCTGAGTCCAGATTATCTCTCCTGGACAGCCTCGTCCCCCT ACAGCACAGTGCCACCCTACAGCCCTGGGAGCTCAGGCCCCGCAACCCCAGGGGTCAACATGGCCAACAGCATCGCCAGCCTCCGTCTCA AGGCCAAGGAGTTCAGCCTGCACCACAGCCAGGTGCCTACGGTGAACTGAAGTCCAGTCCCACCAGGACCCAGACGCCTCCCTGGGTGGA CAGCAATAGAAAAGGGGGCAGACGCCCAGGAAGTGACCTTCTCCTGGATGAGCTCTCCTGGCCCGTCTGTCCAGCCTGGACTCCCGAGCC CACGAGGCTGTTGAGGCCCCTGCAGCCGGGCCCAGCTCTTCTGTCCTTGGCCACCAGAGACTGCAGCCCACAACCCTTGGAGGGGTTGGG >68058_68058_5_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000358994_PRRX2_chr9_132481509_ENST00000372469_length(amino acids)=463AA_BP=1 MWRRKEEVTVQLSLPCPHMSSKLLEPAGAHLSSGSSEPLVEPGRGRVGARVKGERGLQASGSAPGRSKMAEGERQPPPDSSEEAPPATQN FIIPKKEIHTVPDMGKWKRSQAYADYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKL DEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRME PAGSQGVWGLDDFQFLPFIWGSSQLIGECPSPGRGSAAKRKKKQRRNRTTFNSSQLQALERVFERTHYPDAFVREELARRVNLSEARVQV WFQNRRAKFRRNERAMLASRSASLLKSYSQEAAIEQPVAPRPTALSPDYLSWTASSPYSTVPPYSPGSSGPATPGVNMANSIASLRLKAK -------------------------------------------------------------- >68058_68058_6_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000393370_PRRX2_chr9_132481509_ENST00000372469_length(transcript)=1715nt_BP=968nt ATGCGCCCCGCGCGCCCCGCACTGACATGGCCGTCGCCCGGTTCCGCGCGTCCGCCGCGCGCCGGCCGTTAATAGGCTTGCTCCCTGAGC GCCCCGCACCGACATGGCGGCCGTCTTCGCTGTGGTGACTTTAACTCTCGGTTTTCGGTTATAGCCGGCCGGCGCTCACTTGTCTTCAGG AAGCTCGGAGCCTTTGGTGGAGCCGGGGAGAGGAAGGGTGGGTGCAAGAGTGAAAGGCGAGAGGGGACTGCAAGCATCCGGGTCGGCTCC TGGCCGGAGCAAGATGGCTGAGGGCGAGCGGCAGCCGCCGCCAGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCC AAAAAAGGAGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAA CGAAGGTGTGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAG GTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGC AGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTC CACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGA CCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAG CCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGGTGAGTGTCCCAGCCCGGGGCG CGGTAGCGCCGCCAAGCGGAAGAAGAAGCAGCGGCGGAACCGCACCACGTTCAACAGCAGCCAACTGCAGGCGCTGGAGCGCGTGTTCGA GCGCACGCACTACCCCGACGCCTTTGTGCGCGAGGAGCTTGCCCGGCGCGTCAACCTCAGCGAGGCGCGCGTTCAGGTCTGGTTTCAGAA CCGCCGCGCCAAGTTCCGCAGGAATGAAAGGGCCATGCTGGCCAGCCGCTCTGCCTCGCTGCTCAAGTCCTACAGCCAGGAGGCCGCCAT CGAGCAGCCCGTGGCTCCCCGGCCCACCGCCCTGAGTCCAGATTATCTCTCCTGGACAGCCTCGTCCCCCTACAGCACAGTGCCACCCTA CAGCCCTGGGAGCTCAGGCCCCGCAACCCCAGGGGTCAACATGGCCAACAGCATCGCCAGCCTCCGTCTCAAGGCCAAGGAGTTCAGCCT GCACCACAGCCAGGTGCCTACGGTGAACTGAAGTCCAGTCCCACCAGGACCCAGACGCCTCCCTGGGTGGACAGCAATAGAAAAGGGGGC AGACGCCCAGGAAGTGACCTTCTCCTGGATGAGCTCTCCTGGCCCGTCTGTCCAGCCTGGACTCCCGAGCCCACGAGGCTGTTGAGGCCC CTGCAGCCGGGCCCAGCTCTTCTGTCCTTGGCCACCAGAGACTGCAGCCCACAACCCTTGGAGGGGTTGGGCCGGAAGGTGGAAGAGCCT >68058_68058_6_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000393370_PRRX2_chr9_132481509_ENST00000372469_length(amino acids)=433AA_BP=1 MSSGSSEPLVEPGRGRVGARVKGERGLQASGSAPGRSKMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAYADYIGFI LTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKES VGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIGECP SPGRGSAAKRKKKQRRNRTTFNSSQLQALERVFERTHYPDAFVREELARRVNLSEARVQVWFQNRRAKFRRNERAMLASRSASLLKSYSQ -------------------------------------------------------------- >68058_68058_7_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000452489_PRRX2_chr9_132481509_ENST00000372469_length(transcript)=1750nt_BP=1003nt AATAGGCTTGCTCCCTGAGCGCCCCGCACCGACATGGCGGCCGTCTTCGCTGTGGTGACTTTAACTCTCGGTTTTCGGTTATAGCCGGCC GGCGCTCACTTGTCTTCAGGAAGCTCGGAGCCTTTGGTGGAGCCGGGGAGAGGAAGGGTGGGTGCAAGAGTGAAAGGCGAGAGGGGACTG CAAGCATCCGGGTCGGCTCCTGGCCGGAGCAAGATGGCTGAGGGCGAGCGGCAGCCGCCGCCAGATTCTTCAGAGGAGGCCCCTCCAGCC ACTCAGAACTTCATCATTCCAAAAAAGGAGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATC GGATTCATCCTTACCCTCAACGAAGGTGTGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGATGTGGAATGAGGTTCATGAG GAAAAGGAGCAGGCTGCAAAGCAGAGTGTGTCCTGCGATGAATGCATACCATTACCCCGCGCCGGGCACTGTGCACCTTCGGAGGCCATT GAGAAACTAGTCGCTCTTCTCAACACGCTGGACAGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCA TACAGGACCTGGTATGCCAAACTTGATGAGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAG GTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGC TGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAA CTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGT TCGCAGCTGATAGGTGAGTGTCCCAGCCCGGGGCGCGGTAGCGCCGCCAAGCGGAAGAAGAAGCAGCGGCGGAACCGCACCACGTTCAAC AGCAGCCAACTGCAGGCGCTGGAGCGCGTGTTCGAGCGCACGCACTACCCCGACGCCTTTGTGCGCGAGGAGCTTGCCCGGCGCGTCAAC CTCAGCGAGGCGCGCGTTCAGGTCTGGTTTCAGAACCGCCGCGCCAAGTTCCGCAGGAATGAAAGGGCCATGCTGGCCAGCCGCTCTGCC TCGCTGCTCAAGTCCTACAGCCAGGAGGCCGCCATCGAGCAGCCCGTGGCTCCCCGGCCCACCGCCCTGAGTCCAGATTATCTCTCCTGG ACAGCCTCGTCCCCCTACAGCACAGTGCCACCCTACAGCCCTGGGAGCTCAGGCCCCGCAACCCCAGGGGTCAACATGGCCAACAGCATC GCCAGCCTCCGTCTCAAGGCCAAGGAGTTCAGCCTGCACCACAGCCAGGTGCCTACGGTGAACTGAAGTCCAGTCCCACCAGGACCCAGA CGCCTCCCTGGGTGGACAGCAATAGAAAAGGGGGCAGACGCCCAGGAAGTGACCTTCTCCTGGATGAGCTCTCCTGGCCCGTCTGTCCAG CCTGGACTCCCGAGCCCACGAGGCTGTTGAGGCCCCTGCAGCCGGGCCCAGCTCTTCTGTCCTTGGCCACCAGAGACTGCAGCCCACAAC >68058_68058_7_PPP2R4-PRRX2_PPP2R4_chr9_131898874_ENST00000452489_PRRX2_chr9_132481509_ENST00000372469_length(amino acids)=468AA_BP=1 MSSGSSEPLVEPGRGRVGARVKGERGLQASGSAPGRSKMAEGERQPPPDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRSQAYADYIGFI LTLNEGVKGKKLTFEYRVSEMWNEVHEEKEQAAKQSVSCDECIPLPRAGHCAPSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRT WYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQK TYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIGECPSPGRGSAAKRKKKQRRNRTTFNSSQLQALERVFERTHYPDAFVREELARRVNLSE ARVQVWFQNRRAKFRRNERAMLASRSASLLKSYSQEAAIEQPVAPRPTALSPDYLSWTASSPYSTVPPYSPGSSGPATPGVNMANSIASL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PPP2R4-PRRX2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PPP2R4-PRRX2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PPP2R4-PRRX2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies