
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PPP3CC-TNFRSF10A (FusionGDB2 ID:68158) |
Fusion Gene Summary for PPP3CC-TNFRSF10A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PPP3CC-TNFRSF10A | Fusion gene ID: 68158 | Hgene | Tgene | Gene symbol | PPP3CC | TNFRSF10A | Gene ID | 5533 | 8797 |
| Gene name | protein phosphatase 3 catalytic subunit gamma | TNF receptor superfamily member 10a | |
| Synonyms | CALNA3|CNA3|PP2Bgamma | APO2|CD261|DR4|TRAILR-1|TRAILR1 | |
| Cytomap | 8p21.3 | 8p21.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | serine/threonine-protein phosphatase 2B catalytic subunit gamma isoformCAM-PRP catalytic subunitcalcineurin, testis-specific catalytic subunitcalmodulin-dependent calcineurin A subunit gamma isoformprotein phosphatase 2B, catalytic subunit, gamma isof | tumor necrosis factor receptor superfamily member 10ATNF-related apoptosis-inducing ligand receptor 1TRAIL receptor 1TRAIL-R1cytotoxic TRAIL receptordeath receptor 4tumor necrosis factor receptor superfamily member 10a variant 2tumor necrosis facto | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000240139, ENST00000289963, ENST00000397775, ENST00000518852, | ENST00000221132, | |
| Fusion gene scores | * DoF score | 12 X 11 X 7=924 | 2 X 2 X 2=8 |
| # samples | 20 | 2 | |
| ** MAII score | log2(20/924*10)=-2.20789285164133 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(2/8*10)=1.32192809488736 | |
| Context | PubMed: PPP3CC [Title/Abstract] AND TNFRSF10A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PPP3CC(22333137)-TNFRSF10A(23069725), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PPP3CC | GO:0006470 | protein dephosphorylation | 19154138 |
| Hgene | PPP3CC | GO:0033173 | calcineurin-NFAT signaling cascade | 19154138 |
| Tgene | TNFRSF10A | GO:0036462 | TRAIL-activated apoptotic signaling pathway | 21785459 |
| Tgene | TNFRSF10A | GO:0097191 | extrinsic apoptotic signaling pathway | 21785459 |
| Fusion gene breakpoints across PPP3CC (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TNFRSF10A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-LN-A49K | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - |
Top |
Fusion Gene ORF analysis for PPP3CC-TNFRSF10A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000240139 | ENST00000221132 | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - |
| In-frame | ENST00000289963 | ENST00000221132 | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - |
| In-frame | ENST00000397775 | ENST00000221132 | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - |
| In-frame | ENST00000518852 | ENST00000221132 | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000518852 | PPP3CC | chr8 | 22333137 | + | ENST00000221132 | TNFRSF10A | chr8 | 23069725 | - | 3306 | 963 | 570 | 2063 | 497 |
| ENST00000240139 | PPP3CC | chr8 | 22333137 | + | ENST00000221132 | TNFRSF10A | chr8 | 23069725 | - | 3042 | 699 | 306 | 1799 | 497 |
| ENST00000289963 | PPP3CC | chr8 | 22333137 | + | ENST00000221132 | TNFRSF10A | chr8 | 23069725 | - | 3001 | 658 | 265 | 1758 | 497 |
| ENST00000397775 | PPP3CC | chr8 | 22333137 | + | ENST00000221132 | TNFRSF10A | chr8 | 23069725 | - | 2989 | 646 | 253 | 1746 | 497 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000518852 | ENST00000221132 | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - | 0.000612253 | 0.99938774 |
| ENST00000240139 | ENST00000221132 | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - | 0.000450858 | 0.9995491 |
| ENST00000289963 | ENST00000221132 | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - | 0.000432636 | 0.99956733 |
| ENST00000397775 | ENST00000221132 | PPP3CC | chr8 | 22333137 | + | TNFRSF10A | chr8 | 23069725 | - | 0.000409639 | 0.99959034 |
Top |
Fusion Genomic Features for PPP3CC-TNFRSF10A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
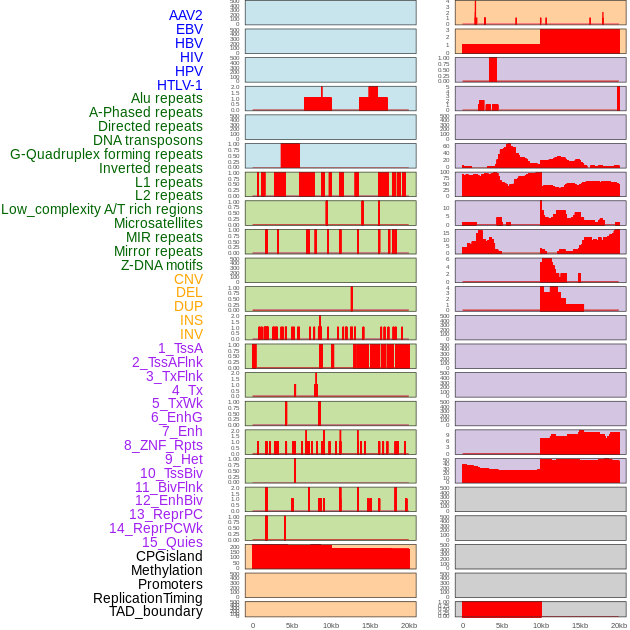 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PPP3CC-TNFRSF10A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:22333137/chr8:23069725) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | TNFRSF10A | chr8:22333137 | chr8:23069725 | ENST00000221132 | 0 | 10 | 365_448 | 102 | 469.0 | Domain | Death | |
| Tgene | TNFRSF10A | chr8:22333137 | chr8:23069725 | ENST00000221132 | 0 | 10 | 107_145 | 102 | 469.0 | Repeat | Note=TNFR-Cys 1 | |
| Tgene | TNFRSF10A | chr8:22333137 | chr8:23069725 | ENST00000221132 | 0 | 10 | 147_188 | 102 | 469.0 | Repeat | Note=TNFR-Cys 2 | |
| Tgene | TNFRSF10A | chr8:22333137 | chr8:23069725 | ENST00000221132 | 0 | 10 | 189_229 | 102 | 469.0 | Repeat | Note=TNFR-Cys 3 | |
| Tgene | TNFRSF10A | chr8:22333137 | chr8:23069725 | ENST00000221132 | 0 | 10 | 263_468 | 102 | 469.0 | Topological domain | Cytoplasmic | |
| Tgene | TNFRSF10A | chr8:22333137 | chr8:23069725 | ENST00000221132 | 0 | 10 | 240_262 | 102 | 469.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000240139 | + | 3 | 14 | 303_307 | 124 | 513.0 | Motif | SAPNY motif |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000289963 | + | 3 | 13 | 303_307 | 124 | 503.0 | Motif | SAPNY motif |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000397775 | + | 3 | 15 | 303_307 | 124 | 522.0 | Motif | SAPNY motif |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000240139 | + | 3 | 14 | 344_366 | 124 | 513.0 | Region | Calcineurin B binding |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000240139 | + | 3 | 14 | 386_400 | 124 | 513.0 | Region | Calmodulin-binding |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000240139 | + | 3 | 14 | 401_408 | 124 | 513.0 | Region | Autoinhibitory segment |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000240139 | + | 3 | 14 | 459_481 | 124 | 513.0 | Region | Autoinhibitory domain |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000240139 | + | 3 | 14 | 52_343 | 124 | 513.0 | Region | Catalytic |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000289963 | + | 3 | 13 | 344_366 | 124 | 503.0 | Region | Calcineurin B binding |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000289963 | + | 3 | 13 | 386_400 | 124 | 503.0 | Region | Calmodulin-binding |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000289963 | + | 3 | 13 | 401_408 | 124 | 503.0 | Region | Autoinhibitory segment |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000289963 | + | 3 | 13 | 459_481 | 124 | 503.0 | Region | Autoinhibitory domain |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000289963 | + | 3 | 13 | 52_343 | 124 | 503.0 | Region | Catalytic |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000397775 | + | 3 | 15 | 344_366 | 124 | 522.0 | Region | Calcineurin B binding |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000397775 | + | 3 | 15 | 386_400 | 124 | 522.0 | Region | Calmodulin-binding |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000397775 | + | 3 | 15 | 401_408 | 124 | 522.0 | Region | Autoinhibitory segment |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000397775 | + | 3 | 15 | 459_481 | 124 | 522.0 | Region | Autoinhibitory domain |
| Hgene | PPP3CC | chr8:22333137 | chr8:23069725 | ENST00000397775 | + | 3 | 15 | 52_343 | 124 | 522.0 | Region | Catalytic |
| Tgene | TNFRSF10A | chr8:22333137 | chr8:23069725 | ENST00000221132 | 0 | 10 | 29_32 | 102 | 469.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | TNFRSF10A | chr8:22333137 | chr8:23069725 | ENST00000221132 | 0 | 10 | 24_239 | 102 | 469.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for PPP3CC-TNFRSF10A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >68158_68158_1_PPP3CC-TNFRSF10A_PPP3CC_chr8_22333137_ENST00000240139_TNFRSF10A_chr8_23069725_ENST00000221132_length(transcript)=3042nt_BP=699nt CACGAGGGCCCGGGCCGCGAGCAGCCGCGGCCGTCCCGGTCGCCACCCTTAGCAGCGGTCGCGGTCGGTGCCGAAGCGGTGTTCCCCGCC TTAGCCGCTGGCGCCTCCCAAGAGAGCGGCCGGTGGGCCCTCGTCCTGTCAGTGGCGTCGGAGGCCGGCGCTGCGGTGGCCGCGCCCTTC TGGTGCTCGGACACCGCTGAGGAGCCGGGGCCGGGCACGGCTGGCTGACGGCTCCGGGCAGCTAAGGCTGCCCGAGGAGAAGGCGGCGGC CGCGGCGTAGGCGCACGTCCGGCGGGCTCCTGGAGCCTGGAGGAGGCCGAGGGGACCATGTCCGGGAGGCGCTTCCACCTCTCCACCACC GACCGCGTCATCAAAGCTGTCCCCTTTCCTCCAACCCAACGGCTTACTTTCAAGGAAGTATTTGAGAATGGGAAACCTAAAGTTGATGTT TTAAAAAACCATTTGGTAAAGGAAGGACGACTGGAAGAGGAAGTAGCCTTAAAGATAATCAATGATGGGGCTGCCATCCTGAGGCAAGAG AAGACTATGATAGAAGTAGATGCTCCAATCACAGTATGTGGTGATATTCATGGACAATTCTTTGACCTAATGAAGTTATTTGAAGTTGGA GGATCACCTAGTAACACACGCTACCTCTTTCTGGGTGACTATGTGGACAGAGGCTATTTCAGTATAGAGGTCGTACCTAGCTCAGCTGCA ACCATCAAACTTCATGATCAATCAATTGGCACACAGCAATGGGAACATAGCCCTTTGGGAGAGTTGTGTCCACCAGGATCTCATAGATCA GAACATCCTGGAGCCTGTAACCGGTGCACAGAGGGTGTGGGTTACACCAATGCTTCCAACAATTTGTTTGCTTGCCTCCCATGTACAGCT TGTAAATCAGATGAAGAAGAGAGAAGTCCCTGCACCACGACCAGGAACACAGCATGTCAGTGCAAACCAGGAACTTTCCGGAATGACAAT TCTGCTGAGATGTGCCGGAAGTGCAGCAGAGGGTGCCCCAGAGGGATGGTCAAGGTCAAGGATTGTACGCCCTGGAGTGACATCGAGTGT GTCCACAAAGAATCAGGCAATGGACATAATATATGGGTGATTTTGGTTGTGACTTTGGTTGTTCCGTTGCTGTTGGTGGCTGTGCTGATT GTCTGTTGTTGCATCGGCTCAGGTTGTGGAGGGGACCCCAAGTGCATGGACAGGGTGTGTTTCTGGCGCTTGGGTCTCCTACGAGGGCCT GGGGCTGAGGACAATGCTCACAACGAGATTCTGAGCAACGCAGACTCGCTGTCCACTTTCGTCTCTGAGCAGCAAATGGAAAGCCAGGAG CCGGCAGATTTGACAGGTGTCACTGTACAGTCCCCAGGGGAGGCACAGTGTCTGCTGGGACCGGCAGAAGCTGAAGGGTCTCAGAGGAGG AGGCTGCTGGTTCCAGCAAATGGTGCTGACCCCACTGAGACTCTGATGCTGTTCTTTGACAAGTTTGCAAACATCGTGCCCTTTGACTCC TGGGACCAGCTCATGAGGCAGCTGGACCTCACGAAAAATGAGATCGATGTGGTCAGAGCTGGTACAGCAGGCCCAGGGGATGCCTTGTAT GCAATGCTGATGAAATGGGTCAACAAAACTGGACGGAACGCCTCGATCCACACCCTGCTGGATGCCTTGGAGAGGATGGAAGAGAGACAT GCAAGAGAGAAGATTCAGGACCTCTTGGTGGACTCTGGAAAGTTCATCTACTTAGAAGATGGCACAGGCTCTGCCGTGTCCTTGGAGTGA AAGACTCTTTTTACCAGAGGTTTCCTCTTAGGTGTTAGGAGTTAATACATATTAGGTTTTTTTTTTTTTTAACATGTATACAAAGTAAAT TCTTAGCCAGGTGTAGTGGCTCATGCCTGTAATCCCAGCACTTTGGGAGGCTGAGGCGGGTGGATCACTTGAGGTCAGAAGTTCAAGACC AGCCTGACCAACATCGTGAAATGCCGTCTTTACAAAAAAATACAAAAATTAACTGGATGTGATGGTGTGTGCATATATTCTCGGCTACTC GGGAGGCTGAGGCAGGAGAATCACTTGAACCCACGAGGCAGTGAGCTGAGATTGCACCACTGCACTCCAGCCTGGGACACAGAGCAAGAC TCTGTCTCAAGATAAAATAAAATAAACTTGAAAGAATTATTGCCCGACTGAGGCTCACATGCCAAAGGAAAATCTGGTTCTCCCCTGAGC TGGCCTCCGTGTGTTTCCTTATCATGGTGGTCAATTGGAGGTGTTAATTTGAATGGATTAAGGAACACCTAGAACACTGGTAAGGCATTA TTTCTGGGACATTATTTCTGGGCATGTCTTCGAGGGTGTTTCCAGAGGGGATTGGCATGCGATCGGGTGGACTGAGTGGAAAAGACCTAC CCTTAATTTGGGGGGGCACCGTCCGACAGACTGGGGAGCAAGATAGAAGAAAACAAAAAAAAAAGGAAAAGCAAATCCATCTGATCTCCT GGAGCTGGGACACTCTTCTGCCTGTGGACATCAGAGTCTAGGATTTCTAGCCCTTGGACTCCAGGGCATACACCAGTGGCCTCCCGAAGG ATCTAAGGATTTTGGCCTTGAACTAAGAATTACACCATCGGCTTCCCTGGGTCTTAGGTTTTTGGGCTGGATTAAGTCCTGCTTCCAGCA TTTCAGGGTCTCTGCTGTGCAGATGGCCTGTTGTGGAACTTCTCAACCTCCATTATCAGATGCATTAATTCCTCCAATAAGTCCCATTTC ATATATAGTCATTTACCCCACAACATTTCAGTCAAGGGAACAGCATATAAGATGGTGGCCGTCCAGTAAGCTAAGGTTAATTTATTAATT ATTTAATTTATTTACCTTGAGTTCAAGTCACAATTAAAGTACATATACCTTTGGAAATTTGGACTTTTGTATATAAAAGTACTTTTTTTT >68158_68158_1_PPP3CC-TNFRSF10A_PPP3CC_chr8_22333137_ENST00000240139_TNFRSF10A_chr8_23069725_ENST00000221132_length(amino acids)=497AA_BP=307 MEEAEGTMSGRRFHLSTTDRVIKAVPFPPTQRLTFKEVFENGKPKVDVLKNHLVKEGRLEEEVALKIINDGAAILRQEKTMIEVDAPITV CGDIHGQFFDLMKLFEVGGSPSNTRYLFLGDYVDRGYFSIEVVPSSAATIKLHDQSIGTQQWEHSPLGELCPPGSHRSEHPGACNRCTEG VGYTNASNNLFACLPCTACKSDEEERSPCTTTRNTACQCKPGTFRNDNSAEMCRKCSRGCPRGMVKVKDCTPWSDIECVHKESGNGHNIW VILVVTLVVPLLLVAVLIVCCCIGSGCGGDPKCMDRVCFWRLGLLRGPGAEDNAHNEILSNADSLSTFVSEQQMESQEPADLTGVTVQSP GEAQCLLGPAEAEGSQRRRLLVPANGADPTETLMLFFDKFANIVPFDSWDQLMRQLDLTKNEIDVVRAGTAGPGDALYAMLMKWVNKTGR -------------------------------------------------------------- >68158_68158_2_PPP3CC-TNFRSF10A_PPP3CC_chr8_22333137_ENST00000289963_TNFRSF10A_chr8_23069725_ENST00000221132_length(transcript)=3001nt_BP=658nt GCCACCCTTAGCAGCGGTCGCGGTCGGTGCCGAAGCGGTGTTCCCCGCCTTAGCCGCTGGCGCCTCCCAAGAGAGCGGCCGGTGGGCCCT CGTCCTGTCAGTGGCGTCGGAGGCCGGCGCTGCGGTGGCCGCGCCCTTCTGGTGCTCGGACACCGCTGAGGAGCCGGGGCCGGGCACGGC TGGCTGACGGCTCCGGGCAGCTAAGGCTGCCCGAGGAGAAGGCGGCGGCCGCGGCGTAGGCGCACGTCCGGCGGGCTCCTGGAGCCTGGA GGAGGCCGAGGGGACCATGTCCGGGAGGCGCTTCCACCTCTCCACCACCGACCGCGTCATCAAAGCTGTCCCCTTTCCTCCAACCCAACG GCTTACTTTCAAGGAAGTATTTGAGAATGGGAAACCTAAAGTTGATGTTTTAAAAAACCATTTGGTAAAGGAAGGACGACTGGAAGAGGA AGTAGCCTTAAAGATAATCAATGATGGGGCTGCCATCCTGAGGCAAGAGAAGACTATGATAGAAGTAGATGCTCCAATCACAGTATGTGG TGATATTCATGGACAATTCTTTGACCTAATGAAGTTATTTGAAGTTGGAGGATCACCTAGTAACACACGCTACCTCTTTCTGGGTGACTA TGTGGACAGAGGCTATTTCAGTATAGAGGTCGTACCTAGCTCAGCTGCAACCATCAAACTTCATGATCAATCAATTGGCACACAGCAATG GGAACATAGCCCTTTGGGAGAGTTGTGTCCACCAGGATCTCATAGATCAGAACATCCTGGAGCCTGTAACCGGTGCACAGAGGGTGTGGG TTACACCAATGCTTCCAACAATTTGTTTGCTTGCCTCCCATGTACAGCTTGTAAATCAGATGAAGAAGAGAGAAGTCCCTGCACCACGAC CAGGAACACAGCATGTCAGTGCAAACCAGGAACTTTCCGGAATGACAATTCTGCTGAGATGTGCCGGAAGTGCAGCAGAGGGTGCCCCAG AGGGATGGTCAAGGTCAAGGATTGTACGCCCTGGAGTGACATCGAGTGTGTCCACAAAGAATCAGGCAATGGACATAATATATGGGTGAT TTTGGTTGTGACTTTGGTTGTTCCGTTGCTGTTGGTGGCTGTGCTGATTGTCTGTTGTTGCATCGGCTCAGGTTGTGGAGGGGACCCCAA GTGCATGGACAGGGTGTGTTTCTGGCGCTTGGGTCTCCTACGAGGGCCTGGGGCTGAGGACAATGCTCACAACGAGATTCTGAGCAACGC AGACTCGCTGTCCACTTTCGTCTCTGAGCAGCAAATGGAAAGCCAGGAGCCGGCAGATTTGACAGGTGTCACTGTACAGTCCCCAGGGGA GGCACAGTGTCTGCTGGGACCGGCAGAAGCTGAAGGGTCTCAGAGGAGGAGGCTGCTGGTTCCAGCAAATGGTGCTGACCCCACTGAGAC TCTGATGCTGTTCTTTGACAAGTTTGCAAACATCGTGCCCTTTGACTCCTGGGACCAGCTCATGAGGCAGCTGGACCTCACGAAAAATGA GATCGATGTGGTCAGAGCTGGTACAGCAGGCCCAGGGGATGCCTTGTATGCAATGCTGATGAAATGGGTCAACAAAACTGGACGGAACGC CTCGATCCACACCCTGCTGGATGCCTTGGAGAGGATGGAAGAGAGACATGCAAGAGAGAAGATTCAGGACCTCTTGGTGGACTCTGGAAA GTTCATCTACTTAGAAGATGGCACAGGCTCTGCCGTGTCCTTGGAGTGAAAGACTCTTTTTACCAGAGGTTTCCTCTTAGGTGTTAGGAG TTAATACATATTAGGTTTTTTTTTTTTTTAACATGTATACAAAGTAAATTCTTAGCCAGGTGTAGTGGCTCATGCCTGTAATCCCAGCAC TTTGGGAGGCTGAGGCGGGTGGATCACTTGAGGTCAGAAGTTCAAGACCAGCCTGACCAACATCGTGAAATGCCGTCTTTACAAAAAAAT ACAAAAATTAACTGGATGTGATGGTGTGTGCATATATTCTCGGCTACTCGGGAGGCTGAGGCAGGAGAATCACTTGAACCCACGAGGCAG TGAGCTGAGATTGCACCACTGCACTCCAGCCTGGGACACAGAGCAAGACTCTGTCTCAAGATAAAATAAAATAAACTTGAAAGAATTATT GCCCGACTGAGGCTCACATGCCAAAGGAAAATCTGGTTCTCCCCTGAGCTGGCCTCCGTGTGTTTCCTTATCATGGTGGTCAATTGGAGG TGTTAATTTGAATGGATTAAGGAACACCTAGAACACTGGTAAGGCATTATTTCTGGGACATTATTTCTGGGCATGTCTTCGAGGGTGTTT CCAGAGGGGATTGGCATGCGATCGGGTGGACTGAGTGGAAAAGACCTACCCTTAATTTGGGGGGGCACCGTCCGACAGACTGGGGAGCAA GATAGAAGAAAACAAAAAAAAAAGGAAAAGCAAATCCATCTGATCTCCTGGAGCTGGGACACTCTTCTGCCTGTGGACATCAGAGTCTAG GATTTCTAGCCCTTGGACTCCAGGGCATACACCAGTGGCCTCCCGAAGGATCTAAGGATTTTGGCCTTGAACTAAGAATTACACCATCGG CTTCCCTGGGTCTTAGGTTTTTGGGCTGGATTAAGTCCTGCTTCCAGCATTTCAGGGTCTCTGCTGTGCAGATGGCCTGTTGTGGAACTT CTCAACCTCCATTATCAGATGCATTAATTCCTCCAATAAGTCCCATTTCATATATAGTCATTTACCCCACAACATTTCAGTCAAGGGAAC AGCATATAAGATGGTGGCCGTCCAGTAAGCTAAGGTTAATTTATTAATTATTTAATTTATTTACCTTGAGTTCAAGTCACAATTAAAGTA CATATACCTTTGGAAATTTGGACTTTTGTATATAAAAGTACTTTTTTTTGGCGGGGGCAGTGGGCAGCTCTCATCCTAAACAAATGTGTT >68158_68158_2_PPP3CC-TNFRSF10A_PPP3CC_chr8_22333137_ENST00000289963_TNFRSF10A_chr8_23069725_ENST00000221132_length(amino acids)=497AA_BP=307 MEEAEGTMSGRRFHLSTTDRVIKAVPFPPTQRLTFKEVFENGKPKVDVLKNHLVKEGRLEEEVALKIINDGAAILRQEKTMIEVDAPITV CGDIHGQFFDLMKLFEVGGSPSNTRYLFLGDYVDRGYFSIEVVPSSAATIKLHDQSIGTQQWEHSPLGELCPPGSHRSEHPGACNRCTEG VGYTNASNNLFACLPCTACKSDEEERSPCTTTRNTACQCKPGTFRNDNSAEMCRKCSRGCPRGMVKVKDCTPWSDIECVHKESGNGHNIW VILVVTLVVPLLLVAVLIVCCCIGSGCGGDPKCMDRVCFWRLGLLRGPGAEDNAHNEILSNADSLSTFVSEQQMESQEPADLTGVTVQSP GEAQCLLGPAEAEGSQRRRLLVPANGADPTETLMLFFDKFANIVPFDSWDQLMRQLDLTKNEIDVVRAGTAGPGDALYAMLMKWVNKTGR -------------------------------------------------------------- >68158_68158_3_PPP3CC-TNFRSF10A_PPP3CC_chr8_22333137_ENST00000397775_TNFRSF10A_chr8_23069725_ENST00000221132_length(transcript)=2989nt_BP=646nt AGCGGTCGCGGTCGGTGCCGAAGCGGTGTTCCCCGCCTTAGCCGCTGGCGCCTCCCAAGAGAGCGGCCGGTGGGCCCTCGTCCTGTCAGT GGCGTCGGAGGCCGGCGCTGCGGTGGCCGCGCCCTTCTGGTGCTCGGACACCGCTGAGGAGCCGGGGCCGGGCACGGCTGGCTGACGGCT CCGGGCAGCTAAGGCTGCCCGAGGAGAAGGCGGCGGCCGCGGCGTAGGCGCACGTCCGGCGGGCTCCTGGAGCCTGGAGGAGGCCGAGGG GACCATGTCCGGGAGGCGCTTCCACCTCTCCACCACCGACCGCGTCATCAAAGCTGTCCCCTTTCCTCCAACCCAACGGCTTACTTTCAA GGAAGTATTTGAGAATGGGAAACCTAAAGTTGATGTTTTAAAAAACCATTTGGTAAAGGAAGGACGACTGGAAGAGGAAGTAGCCTTAAA GATAATCAATGATGGGGCTGCCATCCTGAGGCAAGAGAAGACTATGATAGAAGTAGATGCTCCAATCACAGTATGTGGTGATATTCATGG ACAATTCTTTGACCTAATGAAGTTATTTGAAGTTGGAGGATCACCTAGTAACACACGCTACCTCTTTCTGGGTGACTATGTGGACAGAGG CTATTTCAGTATAGAGGTCGTACCTAGCTCAGCTGCAACCATCAAACTTCATGATCAATCAATTGGCACACAGCAATGGGAACATAGCCC TTTGGGAGAGTTGTGTCCACCAGGATCTCATAGATCAGAACATCCTGGAGCCTGTAACCGGTGCACAGAGGGTGTGGGTTACACCAATGC TTCCAACAATTTGTTTGCTTGCCTCCCATGTACAGCTTGTAAATCAGATGAAGAAGAGAGAAGTCCCTGCACCACGACCAGGAACACAGC ATGTCAGTGCAAACCAGGAACTTTCCGGAATGACAATTCTGCTGAGATGTGCCGGAAGTGCAGCAGAGGGTGCCCCAGAGGGATGGTCAA GGTCAAGGATTGTACGCCCTGGAGTGACATCGAGTGTGTCCACAAAGAATCAGGCAATGGACATAATATATGGGTGATTTTGGTTGTGAC TTTGGTTGTTCCGTTGCTGTTGGTGGCTGTGCTGATTGTCTGTTGTTGCATCGGCTCAGGTTGTGGAGGGGACCCCAAGTGCATGGACAG GGTGTGTTTCTGGCGCTTGGGTCTCCTACGAGGGCCTGGGGCTGAGGACAATGCTCACAACGAGATTCTGAGCAACGCAGACTCGCTGTC CACTTTCGTCTCTGAGCAGCAAATGGAAAGCCAGGAGCCGGCAGATTTGACAGGTGTCACTGTACAGTCCCCAGGGGAGGCACAGTGTCT GCTGGGACCGGCAGAAGCTGAAGGGTCTCAGAGGAGGAGGCTGCTGGTTCCAGCAAATGGTGCTGACCCCACTGAGACTCTGATGCTGTT CTTTGACAAGTTTGCAAACATCGTGCCCTTTGACTCCTGGGACCAGCTCATGAGGCAGCTGGACCTCACGAAAAATGAGATCGATGTGGT CAGAGCTGGTACAGCAGGCCCAGGGGATGCCTTGTATGCAATGCTGATGAAATGGGTCAACAAAACTGGACGGAACGCCTCGATCCACAC CCTGCTGGATGCCTTGGAGAGGATGGAAGAGAGACATGCAAGAGAGAAGATTCAGGACCTCTTGGTGGACTCTGGAAAGTTCATCTACTT AGAAGATGGCACAGGCTCTGCCGTGTCCTTGGAGTGAAAGACTCTTTTTACCAGAGGTTTCCTCTTAGGTGTTAGGAGTTAATACATATT AGGTTTTTTTTTTTTTTAACATGTATACAAAGTAAATTCTTAGCCAGGTGTAGTGGCTCATGCCTGTAATCCCAGCACTTTGGGAGGCTG AGGCGGGTGGATCACTTGAGGTCAGAAGTTCAAGACCAGCCTGACCAACATCGTGAAATGCCGTCTTTACAAAAAAATACAAAAATTAAC TGGATGTGATGGTGTGTGCATATATTCTCGGCTACTCGGGAGGCTGAGGCAGGAGAATCACTTGAACCCACGAGGCAGTGAGCTGAGATT GCACCACTGCACTCCAGCCTGGGACACAGAGCAAGACTCTGTCTCAAGATAAAATAAAATAAACTTGAAAGAATTATTGCCCGACTGAGG CTCACATGCCAAAGGAAAATCTGGTTCTCCCCTGAGCTGGCCTCCGTGTGTTTCCTTATCATGGTGGTCAATTGGAGGTGTTAATTTGAA TGGATTAAGGAACACCTAGAACACTGGTAAGGCATTATTTCTGGGACATTATTTCTGGGCATGTCTTCGAGGGTGTTTCCAGAGGGGATT GGCATGCGATCGGGTGGACTGAGTGGAAAAGACCTACCCTTAATTTGGGGGGGCACCGTCCGACAGACTGGGGAGCAAGATAGAAGAAAA CAAAAAAAAAAGGAAAAGCAAATCCATCTGATCTCCTGGAGCTGGGACACTCTTCTGCCTGTGGACATCAGAGTCTAGGATTTCTAGCCC TTGGACTCCAGGGCATACACCAGTGGCCTCCCGAAGGATCTAAGGATTTTGGCCTTGAACTAAGAATTACACCATCGGCTTCCCTGGGTC TTAGGTTTTTGGGCTGGATTAAGTCCTGCTTCCAGCATTTCAGGGTCTCTGCTGTGCAGATGGCCTGTTGTGGAACTTCTCAACCTCCAT TATCAGATGCATTAATTCCTCCAATAAGTCCCATTTCATATATAGTCATTTACCCCACAACATTTCAGTCAAGGGAACAGCATATAAGAT GGTGGCCGTCCAGTAAGCTAAGGTTAATTTATTAATTATTTAATTTATTTACCTTGAGTTCAAGTCACAATTAAAGTACATATACCTTTG GAAATTTGGACTTTTGTATATAAAAGTACTTTTTTTTGGCGGGGGCAGTGGGCAGCTCTCATCCTAAACAAATGTGTTATTTGGTACCTA >68158_68158_3_PPP3CC-TNFRSF10A_PPP3CC_chr8_22333137_ENST00000397775_TNFRSF10A_chr8_23069725_ENST00000221132_length(amino acids)=497AA_BP=307 MEEAEGTMSGRRFHLSTTDRVIKAVPFPPTQRLTFKEVFENGKPKVDVLKNHLVKEGRLEEEVALKIINDGAAILRQEKTMIEVDAPITV CGDIHGQFFDLMKLFEVGGSPSNTRYLFLGDYVDRGYFSIEVVPSSAATIKLHDQSIGTQQWEHSPLGELCPPGSHRSEHPGACNRCTEG VGYTNASNNLFACLPCTACKSDEEERSPCTTTRNTACQCKPGTFRNDNSAEMCRKCSRGCPRGMVKVKDCTPWSDIECVHKESGNGHNIW VILVVTLVVPLLLVAVLIVCCCIGSGCGGDPKCMDRVCFWRLGLLRGPGAEDNAHNEILSNADSLSTFVSEQQMESQEPADLTGVTVQSP GEAQCLLGPAEAEGSQRRRLLVPANGADPTETLMLFFDKFANIVPFDSWDQLMRQLDLTKNEIDVVRAGTAGPGDALYAMLMKWVNKTGR -------------------------------------------------------------- >68158_68158_4_PPP3CC-TNFRSF10A_PPP3CC_chr8_22333137_ENST00000518852_TNFRSF10A_chr8_23069725_ENST00000221132_length(transcript)=3306nt_BP=963nt GTTCCGGGCCCGGGTAGGGGCTGGCAGGAGAGAAGGGGCCGGCTGCGGGGAGGGCTGGCTGAGAAGAAGCGAAAATGGGCGGTTAGCAGC AGGGACCCGGAGCCGGAGGAGCCGAGAGCAGCGCGTGCGCCGAGCTCTACTGCCTCGCGGGAAGGCGGAAGGGTGGGGAGGGCGGCGCTC GGGGCGGGAGGCCCGGCCGGGTCCGCTAGGACAGCGGGGCCGCTGGGAAGTTGTGAGAGCGGCGCTCGGGGGCGCGCTTGCGTGCACGAG GGCCCGGGCCGCGAGCAGCCGCGGCCGTCCCGGTCGCCACCCTTAGCAGCGGTCGCGGTCGGTGCCGAAGCGGTGTTCCCCGCCTTAGCC GCTGGCGCCTCCCAAGAGAGCGGCCGGTGGGCCCTCGTCCTGTCAGTGGCGTCGGAGGCCGGCGCTGCGGTGGCCGCGCCCTTCTGGTGC TCGGACACCGCTGAGGAGCCGGGGCCGGGCACGGCTGGCTGACGGCTCCGGGCAGCTAAGGCTGCCCGAGGAGAAGGCGGCGGCCGCGGC GTAGGCGCACGTCCGGCGGGCTCCTGGAGCCTGGAGGAGGCCGAGGGGACCATGTCCGGGAGGCGCTTCCACCTCTCCACCACCGACCGC GTCATCAAAGCTGTCCCCTTTCCTCCAACCCAACGGCTTACTTTCAAGGAAGTATTTGAGAATGGGAAACCTAAAGTTGATGTTTTAAAA AACCATTTGGTAAAGGAAGGACGACTGGAAGAGGAAGTAGCCTTAAAGATAATCAATGATGGGGCTGCCATCCTGAGGCAAGAGAAGACT ATGATAGAAGTAGATGCTCCAATCACAGTATGTGGTGATATTCATGGACAATTCTTTGACCTAATGAAGTTATTTGAAGTTGGAGGATCA CCTAGTAACACACGCTACCTCTTTCTGGGTGACTATGTGGACAGAGGCTATTTCAGTATAGAGGTCGTACCTAGCTCAGCTGCAACCATC AAACTTCATGATCAATCAATTGGCACACAGCAATGGGAACATAGCCCTTTGGGAGAGTTGTGTCCACCAGGATCTCATAGATCAGAACAT CCTGGAGCCTGTAACCGGTGCACAGAGGGTGTGGGTTACACCAATGCTTCCAACAATTTGTTTGCTTGCCTCCCATGTACAGCTTGTAAA TCAGATGAAGAAGAGAGAAGTCCCTGCACCACGACCAGGAACACAGCATGTCAGTGCAAACCAGGAACTTTCCGGAATGACAATTCTGCT GAGATGTGCCGGAAGTGCAGCAGAGGGTGCCCCAGAGGGATGGTCAAGGTCAAGGATTGTACGCCCTGGAGTGACATCGAGTGTGTCCAC AAAGAATCAGGCAATGGACATAATATATGGGTGATTTTGGTTGTGACTTTGGTTGTTCCGTTGCTGTTGGTGGCTGTGCTGATTGTCTGT TGTTGCATCGGCTCAGGTTGTGGAGGGGACCCCAAGTGCATGGACAGGGTGTGTTTCTGGCGCTTGGGTCTCCTACGAGGGCCTGGGGCT GAGGACAATGCTCACAACGAGATTCTGAGCAACGCAGACTCGCTGTCCACTTTCGTCTCTGAGCAGCAAATGGAAAGCCAGGAGCCGGCA GATTTGACAGGTGTCACTGTACAGTCCCCAGGGGAGGCACAGTGTCTGCTGGGACCGGCAGAAGCTGAAGGGTCTCAGAGGAGGAGGCTG CTGGTTCCAGCAAATGGTGCTGACCCCACTGAGACTCTGATGCTGTTCTTTGACAAGTTTGCAAACATCGTGCCCTTTGACTCCTGGGAC CAGCTCATGAGGCAGCTGGACCTCACGAAAAATGAGATCGATGTGGTCAGAGCTGGTACAGCAGGCCCAGGGGATGCCTTGTATGCAATG CTGATGAAATGGGTCAACAAAACTGGACGGAACGCCTCGATCCACACCCTGCTGGATGCCTTGGAGAGGATGGAAGAGAGACATGCAAGA GAGAAGATTCAGGACCTCTTGGTGGACTCTGGAAAGTTCATCTACTTAGAAGATGGCACAGGCTCTGCCGTGTCCTTGGAGTGAAAGACT CTTTTTACCAGAGGTTTCCTCTTAGGTGTTAGGAGTTAATACATATTAGGTTTTTTTTTTTTTTAACATGTATACAAAGTAAATTCTTAG CCAGGTGTAGTGGCTCATGCCTGTAATCCCAGCACTTTGGGAGGCTGAGGCGGGTGGATCACTTGAGGTCAGAAGTTCAAGACCAGCCTG ACCAACATCGTGAAATGCCGTCTTTACAAAAAAATACAAAAATTAACTGGATGTGATGGTGTGTGCATATATTCTCGGCTACTCGGGAGG CTGAGGCAGGAGAATCACTTGAACCCACGAGGCAGTGAGCTGAGATTGCACCACTGCACTCCAGCCTGGGACACAGAGCAAGACTCTGTC TCAAGATAAAATAAAATAAACTTGAAAGAATTATTGCCCGACTGAGGCTCACATGCCAAAGGAAAATCTGGTTCTCCCCTGAGCTGGCCT CCGTGTGTTTCCTTATCATGGTGGTCAATTGGAGGTGTTAATTTGAATGGATTAAGGAACACCTAGAACACTGGTAAGGCATTATTTCTG GGACATTATTTCTGGGCATGTCTTCGAGGGTGTTTCCAGAGGGGATTGGCATGCGATCGGGTGGACTGAGTGGAAAAGACCTACCCTTAA TTTGGGGGGGCACCGTCCGACAGACTGGGGAGCAAGATAGAAGAAAACAAAAAAAAAAGGAAAAGCAAATCCATCTGATCTCCTGGAGCT GGGACACTCTTCTGCCTGTGGACATCAGAGTCTAGGATTTCTAGCCCTTGGACTCCAGGGCATACACCAGTGGCCTCCCGAAGGATCTAA GGATTTTGGCCTTGAACTAAGAATTACACCATCGGCTTCCCTGGGTCTTAGGTTTTTGGGCTGGATTAAGTCCTGCTTCCAGCATTTCAG GGTCTCTGCTGTGCAGATGGCCTGTTGTGGAACTTCTCAACCTCCATTATCAGATGCATTAATTCCTCCAATAAGTCCCATTTCATATAT AGTCATTTACCCCACAACATTTCAGTCAAGGGAACAGCATATAAGATGGTGGCCGTCCAGTAAGCTAAGGTTAATTTATTAATTATTTAA TTTATTTACCTTGAGTTCAAGTCACAATTAAAGTACATATACCTTTGGAAATTTGGACTTTTGTATATAAAAGTACTTTTTTTTGGCGGG >68158_68158_4_PPP3CC-TNFRSF10A_PPP3CC_chr8_22333137_ENST00000518852_TNFRSF10A_chr8_23069725_ENST00000221132_length(amino acids)=497AA_BP=307 MEEAEGTMSGRRFHLSTTDRVIKAVPFPPTQRLTFKEVFENGKPKVDVLKNHLVKEGRLEEEVALKIINDGAAILRQEKTMIEVDAPITV CGDIHGQFFDLMKLFEVGGSPSNTRYLFLGDYVDRGYFSIEVVPSSAATIKLHDQSIGTQQWEHSPLGELCPPGSHRSEHPGACNRCTEG VGYTNASNNLFACLPCTACKSDEEERSPCTTTRNTACQCKPGTFRNDNSAEMCRKCSRGCPRGMVKVKDCTPWSDIECVHKESGNGHNIW VILVVTLVVPLLLVAVLIVCCCIGSGCGGDPKCMDRVCFWRLGLLRGPGAEDNAHNEILSNADSLSTFVSEQQMESQEPADLTGVTVQSP GEAQCLLGPAEAEGSQRRRLLVPANGADPTETLMLFFDKFANIVPFDSWDQLMRQLDLTKNEIDVVRAGTAGPGDALYAMLMKWVNKTGR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PPP3CC-TNFRSF10A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PPP3CC-TNFRSF10A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PPP3CC-TNFRSF10A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies