
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARRB1-TPCN2 (FusionGDB2 ID:6848) |
Fusion Gene Summary for ARRB1-TPCN2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARRB1-TPCN2 | Fusion gene ID: 6848 | Hgene | Tgene | Gene symbol | ARRB1 | TPCN2 | Gene ID | 408 | 219931 |
| Gene name | arrestin beta 1 | two pore segment channel 2 | |
| Synonyms | ARB1|ARR1 | SHEP10|TPC2 | |
| Cytomap | 11q13.4 | 11q13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | beta-arrestin-1arrestin 2non-visual arrestin-2 | two pore calcium channel protein 2voltage-dependent calcium channel protein TPC2 | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | P49407 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000360025, ENST00000393505, ENST00000420843, | ENST00000442692, ENST00000294309, ENST00000542467, | |
| Fusion gene scores | * DoF score | 18 X 10 X 9=1620 | 11 X 9 X 6=594 |
| # samples | 23 | 12 | |
| ** MAII score | log2(23/1620*10)=-2.81628804682761 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/594*10)=-2.30742852519225 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARRB1 [Title/Abstract] AND TPCN2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARRB1(74994331)-TPCN2(68845950), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ARRB1 | GO:0031397 | negative regulation of protein ubiquitination | 16378096 |
| Hgene | ARRB1 | GO:0032088 | negative regulation of NF-kappaB transcription factor activity | 16378096 |
| Hgene | ARRB1 | GO:0032715 | negative regulation of interleukin-6 production | 16378096 |
| Hgene | ARRB1 | GO:0032717 | negative regulation of interleukin-8 production | 16378096 |
| Hgene | ARRB1 | GO:0070374 | positive regulation of ERK1 and ERK2 cascade | 10644702 |
| Tgene | TPCN2 | GO:0006874 | cellular calcium ion homeostasis | 19387438 |
| Fusion gene breakpoints across ARRB1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TPCN2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-E2-A109-01A | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
Top |
Fusion Gene ORF analysis for ARRB1-TPCN2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000360025 | ENST00000442692 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| 5CDS-3UTR | ENST00000393505 | ENST00000442692 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| 5CDS-3UTR | ENST00000420843 | ENST00000442692 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| In-frame | ENST00000360025 | ENST00000294309 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| In-frame | ENST00000360025 | ENST00000542467 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| In-frame | ENST00000393505 | ENST00000294309 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| In-frame | ENST00000393505 | ENST00000542467 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| In-frame | ENST00000420843 | ENST00000294309 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| In-frame | ENST00000420843 | ENST00000542467 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000420843 | ARRB1 | chr11 | 74994331 | - | ENST00000294309 | TPCN2 | chr11 | 68845950 | + | 2052 | 452 | 32 | 1480 | 482 |
| ENST00000420843 | ARRB1 | chr11 | 74994331 | - | ENST00000542467 | TPCN2 | chr11 | 68845950 | + | 1185 | 452 | 1030 | 2 | 343 |
| ENST00000393505 | ARRB1 | chr11 | 74994331 | - | ENST00000294309 | TPCN2 | chr11 | 68845950 | + | 2176 | 576 | 21 | 1604 | 527 |
| ENST00000393505 | ARRB1 | chr11 | 74994331 | - | ENST00000542467 | TPCN2 | chr11 | 68845950 | + | 1309 | 576 | 1154 | 0 | 385 |
| ENST00000360025 | ARRB1 | chr11 | 74994331 | - | ENST00000294309 | TPCN2 | chr11 | 68845950 | + | 2052 | 452 | 32 | 1480 | 482 |
| ENST00000360025 | ARRB1 | chr11 | 74994331 | - | ENST00000542467 | TPCN2 | chr11 | 68845950 | + | 1185 | 452 | 1030 | 2 | 343 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000420843 | ENST00000294309 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + | 0.005458404 | 0.9945416 |
| ENST00000420843 | ENST00000542467 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + | 0.011873221 | 0.98812675 |
| ENST00000393505 | ENST00000294309 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + | 0.005533908 | 0.9944661 |
| ENST00000393505 | ENST00000542467 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + | 0.008626947 | 0.99137306 |
| ENST00000360025 | ENST00000294309 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + | 0.005458404 | 0.9945416 |
| ENST00000360025 | ENST00000542467 | ARRB1 | chr11 | 74994331 | - | TPCN2 | chr11 | 68845950 | + | 0.011873221 | 0.98812675 |
Top |
Fusion Genomic Features for ARRB1-TPCN2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARRB1 | chr11 | 74994330 | - | TPCN2 | chr11 | 68845949 | + | 1.68E-05 | 0.9999832 |
| ARRB1 | chr11 | 74994330 | - | TPCN2 | chr11 | 68845949 | + | 1.68E-05 | 0.9999832 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
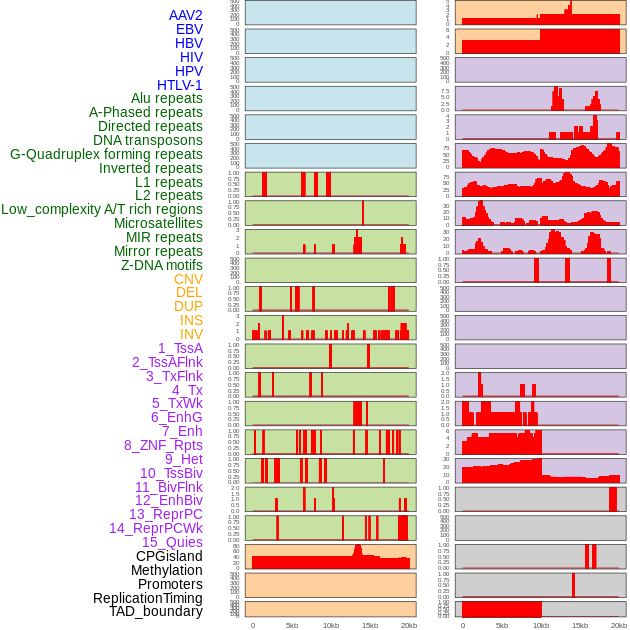 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
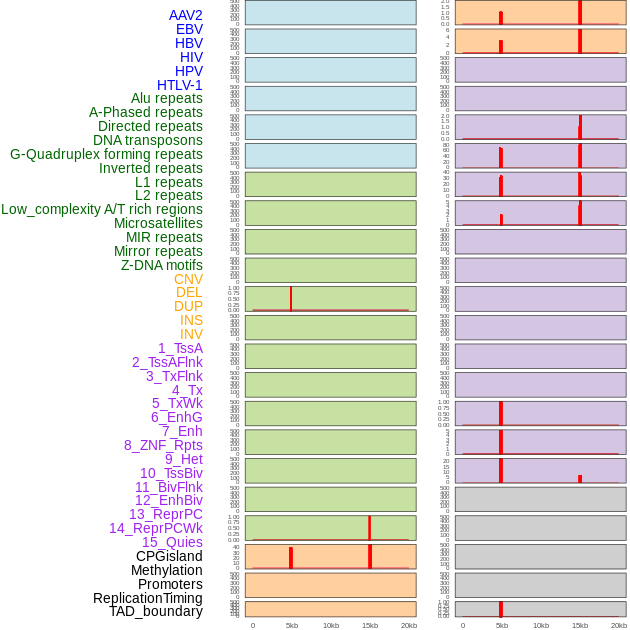 |
Top |
Fusion Protein Features for ARRB1-TPCN2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:74994331/chr11:68845950) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ARRB1 | . |
| FUNCTION: Functions in regulating agonist-mediated G-protein coupled receptor (GPCR) signaling by mediating both receptor desensitization and resensitization processes. During homologous desensitization, beta-arrestins bind to the GPRK-phosphorylated receptor and sterically preclude its coupling to the cognate G-protein; the binding appears to require additional receptor determinants exposed only in the active receptor conformation. The beta-arrestins target many receptors for internalization by acting as endocytic adapters (CLASPs, clathrin-associated sorting proteins) and recruiting the GPRCs to the adapter protein 2 complex 2 (AP-2) in clathrin-coated pits (CCPs). However, the extent of beta-arrestin involvement appears to vary significantly depending on the receptor, agonist and cell type. Internalized arrestin-receptor complexes traffic to intracellular endosomes, where they remain uncoupled from G-proteins. Two different modes of arrestin-mediated internalization occur. Class A receptors, like ADRB2, OPRM1, ENDRA, D1AR and ADRA1B dissociate from beta-arrestin at or near the plasma membrane and undergo rapid recycling. Class B receptors, like AVPR2, AGTR1, NTSR1, TRHR and TACR1 internalize as a complex with arrestin and traffic with it to endosomal vesicles, presumably as desensitized receptors, for extended periods of time. Receptor resensitization then requires that receptor-bound arrestin is removed so that the receptor can be dephosphorylated and returned to the plasma membrane. Involved in internalization of P2RY4 and UTP-stimulated internalization of P2RY2. Involved in phosphorylation-dependent internalization of OPRD1 ands subsequent recycling. Involved in the degradation of cAMP by recruiting cAMP phosphodiesterases to ligand-activated receptors. Beta-arrestins function as multivalent adapter proteins that can switch the GPCR from a G-protein signaling mode that transmits short-lived signals from the plasma membrane via small molecule second messengers and ion channels to a beta-arrestin signaling mode that transmits a distinct set of signals that are initiated as the receptor internalizes and transits the intracellular compartment. Acts as signaling scaffold for MAPK pathways such as MAPK1/3 (ERK1/2). ERK1/2 activated by the beta-arrestin scaffold is largely excluded from the nucleus and confined to cytoplasmic locations such as endocytic vesicles, also called beta-arrestin signalosomes. Recruits c-Src/SRC to ADRB2 resulting in ERK activation. GPCRs for which the beta-arrestin-mediated signaling relies on both ARRB1 and ARRB2 (codependent regulation) include ADRB2, F2RL1 and PTH1R. For some GPCRs the beta-arrestin-mediated signaling relies on either ARRB1 or ARRB2 and is inhibited by the other respective beta-arrestin form (reciprocal regulation). Inhibits ERK1/2 signaling in AGTR1- and AVPR2-mediated activation (reciprocal regulation). Is required for SP-stimulated endocytosis of NK1R and recruits c-Src/SRC to internalized NK1R resulting in ERK1/2 activation, which is required for the antiapoptotic effects of SP. Is involved in proteinase-activated F2RL1-mediated ERK activity. Acts as signaling scaffold for the AKT1 pathway. Is involved in alpha-thrombin-stimulated AKT1 signaling. Is involved in IGF1-stimulated AKT1 signaling leading to increased protection from apoptosis. Involved in activation of the p38 MAPK signaling pathway and in actin bundle formation. Involved in F2RL1-mediated cytoskeletal rearrangement and chemotaxis. Involved in AGTR1-mediated stress fiber formation by acting together with GNAQ to activate RHOA. Appears to function as signaling scaffold involved in regulation of MIP-1-beta-stimulated CCR5-dependent chemotaxis. Involved in attenuation of NF-kappa-B-dependent transcription in response to GPCR or cytokine stimulation by interacting with and stabilizing CHUK. May serve as nuclear messenger for GPCRs. Involved in OPRD1-stimulated transcriptional regulation by translocating to CDKN1B and FOS promoter regions and recruiting EP300 resulting in acetylation of histone H4. Involved in regulation of LEF1 transcriptional activity via interaction with DVL1 and/or DVL2 Also involved in regulation of receptors other than GPCRs. Involved in Toll-like receptor and IL-1 receptor signaling through the interaction with TRAF6 which prevents TRAF6 autoubiquitination and oligomerization required for activation of NF-kappa-B and JUN. Binds phosphoinositides. Binds inositolhexakisphosphate (InsP6) (By similarity). Involved in IL8-mediated granule release in neutrophils. Required for atypical chemokine receptor ACKR2-induced RAC1-LIMK1-PAK1-dependent phosphorylation of cofilin (CFL1) and for the up-regulation of ACKR2 from endosomal compartment to cell membrane, increasing its efficiency in chemokine uptake and degradation. Involved in the internalization of the atypical chemokine receptor ACKR3. Negatively regulates the NOTCH signaling pathway by mediating the ubiquitination and degradation of NOTCH1 by ITCH. Participates in the recruitment of the ubiquitin-protein ligase to the receptor (PubMed:23886940). {ECO:0000250, ECO:0000269|PubMed:12464600, ECO:0000269|PubMed:14711824, ECO:0000269|PubMed:15475570, ECO:0000269|PubMed:15611106, ECO:0000269|PubMed:15671180, ECO:0000269|PubMed:15878855, ECO:0000269|PubMed:16144840, ECO:0000269|PubMed:16280323, ECO:0000269|PubMed:16378096, ECO:0000269|PubMed:16492667, ECO:0000269|PubMed:16709866, ECO:0000269|PubMed:18337459, ECO:0000269|PubMed:18419762, ECO:0000269|PubMed:19620252, ECO:0000269|PubMed:19643177, ECO:0000269|PubMed:22457824, ECO:0000269|PubMed:23341447, ECO:0000269|PubMed:23633677, ECO:0000269|PubMed:23886940}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 636_658 | 410 | 753.0 | Intramembrane | Helical%3B Pore-forming | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 460_465 | 410 | 753.0 | Topological domain | Extracellular | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 487_502 | 410 | 753.0 | Topological domain | Cytoplasmic | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 524_554 | 410 | 753.0 | Topological domain | Extracellular | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 576_580 | 410 | 753.0 | Topological domain | Cytoplasmic | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 602_635 | 410 | 753.0 | Topological domain | Extracellular | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 659_673 | 410 | 753.0 | Topological domain | Extracellular | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 695_752 | 410 | 753.0 | Topological domain | Cytoplasmic | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 437_459 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS1 of repeat II | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 466_486 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS2 of repeat II | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 503_523 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS3 of repeat II | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 555_575 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS4 of repeat II | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 581_601 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS5 of repeat II | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 674_694 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS6 of repeat II |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARRB1 | chr11:74994331 | chr11:68845950 | ENST00000360025 | - | 5 | 15 | 385_395 | 118 | 411.0 | Motif | Note=[DE]-X(1%2C2)-F-X-X-[FL]-X-X-X-R motif |
| Hgene | ARRB1 | chr11:74994331 | chr11:68845950 | ENST00000420843 | - | 5 | 16 | 385_395 | 118 | 419.0 | Motif | Note=[DE]-X(1%2C2)-F-X-X-[FL]-X-X-X-R motif |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 17_20 | 410 | 753.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 255_279 | 410 | 753.0 | Intramembrane | Helical%3B Pore-forming | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 106_127 | 410 | 753.0 | Topological domain | Extracellular | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 149_155 | 410 | 753.0 | Topological domain | Cytoplasmic | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 177_183 | 410 | 753.0 | Topological domain | Extracellular | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 1_84 | 410 | 753.0 | Topological domain | Cytoplasmic | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 205_218 | 410 | 753.0 | Topological domain | Cytoplasmic | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 240_254 | 410 | 753.0 | Topological domain | Extracellular | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 280_289 | 410 | 753.0 | Topological domain | Extracellular | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 311_436 | 410 | 753.0 | Topological domain | Cytoplasmic | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 128_148 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS2 of repeat I | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 156_176 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS3 of repeat I | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 184_204 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS4 of repeat I | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 219_239 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS5 of repeat I | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 290_310 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS6 of repeat I | |
| Tgene | TPCN2 | chr11:74994331 | chr11:68845950 | ENST00000294309 | 12 | 25 | 85_105 | 410 | 753.0 | Transmembrane | Helical%3B Name%3DS1 of repeat I |
Top |
Fusion Gene Sequence for ARRB1-TPCN2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6848_6848_1_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000360025_TPCN2_chr11_68845950_ENST00000294309_length(transcript)=2052nt_BP=452nt GGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCCTGGGCGCTGACGCCGCGGACCTCCCTGCGACCGT CGCGGACCATGGGCGACAAAGGGACCCGAGTGTTCAAGAAGGCCAGTCCAAATGGAAAGCTCACCGTCTACCTGGGAAAGCGGGACTTTG TGGACCACATCGACCTCGTGGACCCTGTGGATGGTGTGGTCCTGGTGGATCCTGAGTATCTCAAAGAGCGGAGAGTCTATGTGACGCTGA CCTGCGCCTTCCGCTATGGCCGGGAGGACCTGGATGTCCTGGGCCTGACCTTTCGCAAGGACCTGTTTGTGGCCAACGTACAGTCGTTCC CACCGGCCCCCGAGGACAAGAAGCCCCTGACGCGGCTGCAGGAACGCCTCATCAAGAAGCTGGGCGAGCACGCTTACCCTTTCACCTTTG AGCACCCGCCGAGGCCCGAGTACCAGTCTCCGTTTCTGCAGAGCGCCCAGTTCCTCTTCGGCCACTACTACTTTGACTACCTGGGGAACC TCATCGCCCTGGCAAACCTGGTGTCCATTTGCGTGTTCCTGGTGCTGGATGCAGATGTGCTGCCTGCTGAGCGTGATGACTTCATCCTGG GGATTCTCAACTGCGTCTTCATTGTGTACTACCTGTTGGAGATGCTGCTCAAGGTCTTTGCCCTGGGCCTGCGAGGGTACCTGTCCTACC CCAGCAACGTGTTTGACGGGCTCCTCACCGTTGTCCTGCTGGTTTTGGAGATCTCAACTCTGGCTGTGTACCGATTGCCACACCCAGGCT GGAGGCCGGAGATGGTGGGCCTGCTGTCGCTGTGGGACATGACCCGCATGCTGAACATGCTCATCGTGTTCCGCTTCCTGCGTATCATCC CCAGCATGAAGCTGATGGCCGTGGTGGCCAGTACCGTCCTGGGCCTGGTGCAGAACATGCGTGCGTTTGGCGGGATCCTGGTGGTGGTCT ACTACGTATTTGCCATCATTGGGATCAACTTGTTTAGAGGCGTCATTGTGGCTCTTCCTGGAAACAGCAGCCTGGCCCCTGCCAATGGCT CGGCGCCCTGTGGGAGCTTCGAGCAGCTGGAGTACTGGGCCAACAACTTCGATGACTTTGCGGCTGCCCTGGTCACTCTGTGGAACTTGA TGGTGGTGAACAACTGGCAGGTGTTTCTGGATGCATATCGGCGCTACTCAGGCCCGTGGTCCAAGATCTATTTTGTATTGTGGTGGCTGG TGTCGTCTGTCATCTGGGTCAACCTGTTTCTGGCCCTGATTCTGGAGAACTTCCTTCACAAGTGGGACCCCCGCAGCCACCTGCAGCCCC TTGCTGGGACCCCAGAGGCCACCTACCAGATGACTGTGGAGCTCCTGTTCAGGGATATTCTGGAGGAGCCCGGGGAGGATGAGCTCACAG AGAGGCTGAGCCAGCACCCGCACCTGTGGCTGTGCAGGTGACGTCCGGGCTGCCGTCCCAGCAGGGGCGGCAGGAGAGAGAGGCTGGCCT ACACAGGTGCCCGTCATGGAAGAGGCGGCCATGCTGTGGCCAGCCAGGCAGGAAGAGACCTTTCCTCTGACGGACCACTAAGCTGGGGAC AGGAACCAAGTCCTTTGCGTGTGGCCCAACAACCATCTACAGAACAGCTGCTGGTGCTTCAGGGAGGCGCCGTGCCCTCCGCTTTCTTTT ATAGCTGCTTCAGTGAGAATTCCCTCGTCGACTCCACAGGGACCTTTCAGACAAAAATGCAAGAAGCAGCGGCCTCCCCTGTCCCCTGCA GCTTCCGTGGTGCCTTTGCTGCCGGCAGCCCTTGGGGACCACAGGCCTGACCAGGGCCTGCACAGGTTAACCGTCAGACTTCCGGGGCAT TCAGGTGGGGATGCTGGTGGTTTGACATGGAGAGAACCTTGACTGTGTTTTATTATTTCATGGCTTGTATGAGTGTGACTGGGTGTGTTT >6848_6848_1_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000360025_TPCN2_chr11_68845950_ENST00000294309_length(amino acids)=482AA_BP=140 MLAGDFPAWALTPRTSLRPSRTMGDKGTRVFKKASPNGKLTVYLGKRDFVDHIDLVDPVDGVVLVDPEYLKERRVYVTLTCAFRYGREDL DVLGLTFRKDLFVANVQSFPPAPEDKKPLTRLQERLIKKLGEHAYPFTFEHPPRPEYQSPFLQSAQFLFGHYYFDYLGNLIALANLVSIC VFLVLDADVLPAERDDFILGILNCVFIVYYLLEMLLKVFALGLRGYLSYPSNVFDGLLTVVLLVLEISTLAVYRLPHPGWRPEMVGLLSL WDMTRMLNMLIVFRFLRIIPSMKLMAVVASTVLGLVQNMRAFGGILVVVYYVFAIIGINLFRGVIVALPGNSSLAPANGSAPCGSFEQLE YWANNFDDFAAALVTLWNLMVVNNWQVFLDAYRRYSGPWSKIYFVLWWLVSSVIWVNLFLALILENFLHKWDPRSHLQPLAGTPEATYQM -------------------------------------------------------------- >6848_6848_2_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000360025_TPCN2_chr11_68845950_ENST00000542467_length(transcript)=1185nt_BP=452nt GGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCCTGGGCGCTGACGCCGCGGACCTCCCTGCGACCGT CGCGGACCATGGGCGACAAAGGGACCCGAGTGTTCAAGAAGGCCAGTCCAAATGGAAAGCTCACCGTCTACCTGGGAAAGCGGGACTTTG TGGACCACATCGACCTCGTGGACCCTGTGGATGGTGTGGTCCTGGTGGATCCTGAGTATCTCAAAGAGCGGAGAGTCTATGTGACGCTGA CCTGCGCCTTCCGCTATGGCCGGGAGGACCTGGATGTCCTGGGCCTGACCTTTCGCAAGGACCTGTTTGTGGCCAACGTACAGTCGTTCC CACCGGCCCCCGAGGACAAGAAGCCCCTGACGCGGCTGCAGGAACGCCTCATCAAGAAGCTGGGCGAGCACGCTTACCCTTTCACCTTTG AGCACCCGCCGAGGCCCGAGTACCAGTCTCCGTTTCTGCAGAGCGCCCAGTTCCTCTTCGGCCACTACTACTTTGACTACCTGGGGAACC TCATCGCCCTGGCAAACCTGGTGTCCATTTGCGTGTTCCTGGTGCTGGATGCAGATGTGCTGCCTGCTGAGCGTGATGACTTCATCCTGG GGATTCTCAACTGCGTCTTCATTGTGTACTACCTGTTGGAGATGCTGCTCAAGGTCTTTGCCCTGGGCCTGCGAGGGTACCTGTCCTACC CCAGCAACGTGTTTGACGGGCTCCTCACCGTTGTCCTGCTGAACTTCCTTCACAAGTGGGACCCCCGCAGCCACCTGCAGCCCCTTGCTG GGACCCCAGAGGCCACCTACCAGATGACTGTGGAGCTCCTGTTCAGGGATATTCTGGAGGAGCCCGGGGAGGATGAGCTCACAGAGAGGC TGAGCCAGCACCCGCACCTGTGGCTGTGCAGGTGACGTCCGGGCTGCCGTCCCAGCAGGGGCGGCAGGAGAGAGAGGCTGGCCTACACAG GTGCCCGTCATGGAAGAGGCGGCCATGCTGTGGCCAGCCAGGCAGGAAGAGACCTTTCCTCTGACGGACCACTAAGCTGGGGACAGGAAC CAAGTCCTTTGCGTGTGGCCCAACAACCATCTACAGAACAGCTGCTGGTGCTTCAGGGAGGCGCCGTGCCCTCCGCTTTCTTTTATAGCT >6848_6848_2_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000360025_TPCN2_chr11_68845950_ENST00000542467_length(amino acids)=343AA_BP=1 MAGHSMAASSMTGTCVGQPLSPAAPAGTAARTSPAQPQVRVLAQPLCELILPGLLQNIPEQELHSHLVGGLWGPSKGLQVAAGVPLVKEV QQDNGEEPVKHVAGVGQVPSQAQGKDLEQHLQQVVHNEDAVENPQDEVITLSRQHICIQHQEHANGHQVCQGDEVPQVVKVVVAEEELGA LQKRRLVLGPRRVLKGERVSVLAQLLDEAFLQPRQGLLVLGGRWERLYVGHKQVLAKGQAQDIQVLPAIAEGAGQRHIDSPLFEILRIHQ -------------------------------------------------------------- >6848_6848_3_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000393505_TPCN2_chr11_68845950_ENST00000294309_length(transcript)=2176nt_BP=576nt ACCCCGCGCGGTTCCACGCCCCTGGCCGCGGCCCGGGCGCTGCGCTGCTCGACGCGGCGGGCGGCGGGCGGGGACCGGGGGCGGGGGCGG CGGCGGCGGCCGGGAGAGCGGAGGAGGCGGAGCAGGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCC TGGGCGCTGACGCCGCGGACCTCCCTGCGACCGTCGCGGACCATGGGCGACAAAGGGACCCGAGTGTTCAAGAAGGCCAGTCCAAATGGA AAGCTCACCGTCTACCTGGGAAAGCGGGACTTTGTGGACCACATCGACCTCGTGGACCCTGTGGATGGTGTGGTCCTGGTGGATCCTGAG TATCTCAAAGAGCGGAGAGTCTATGTGACGCTGACCTGCGCCTTCCGCTATGGCCGGGAGGACCTGGATGTCCTGGGCCTGACCTTTCGC AAGGACCTGTTTGTGGCCAACGTACAGTCGTTCCCACCGGCCCCCGAGGACAAGAAGCCCCTGACGCGGCTGCAGGAACGCCTCATCAAG AAGCTGGGCGAGCACGCTTACCCTTTCACCTTTGAGCACCCGCCGAGGCCCGAGTACCAGTCTCCGTTTCTGCAGAGCGCCCAGTTCCTC TTCGGCCACTACTACTTTGACTACCTGGGGAACCTCATCGCCCTGGCAAACCTGGTGTCCATTTGCGTGTTCCTGGTGCTGGATGCAGAT GTGCTGCCTGCTGAGCGTGATGACTTCATCCTGGGGATTCTCAACTGCGTCTTCATTGTGTACTACCTGTTGGAGATGCTGCTCAAGGTC TTTGCCCTGGGCCTGCGAGGGTACCTGTCCTACCCCAGCAACGTGTTTGACGGGCTCCTCACCGTTGTCCTGCTGGTTTTGGAGATCTCA ACTCTGGCTGTGTACCGATTGCCACACCCAGGCTGGAGGCCGGAGATGGTGGGCCTGCTGTCGCTGTGGGACATGACCCGCATGCTGAAC ATGCTCATCGTGTTCCGCTTCCTGCGTATCATCCCCAGCATGAAGCTGATGGCCGTGGTGGCCAGTACCGTCCTGGGCCTGGTGCAGAAC ATGCGTGCGTTTGGCGGGATCCTGGTGGTGGTCTACTACGTATTTGCCATCATTGGGATCAACTTGTTTAGAGGCGTCATTGTGGCTCTT CCTGGAAACAGCAGCCTGGCCCCTGCCAATGGCTCGGCGCCCTGTGGGAGCTTCGAGCAGCTGGAGTACTGGGCCAACAACTTCGATGAC TTTGCGGCTGCCCTGGTCACTCTGTGGAACTTGATGGTGGTGAACAACTGGCAGGTGTTTCTGGATGCATATCGGCGCTACTCAGGCCCG TGGTCCAAGATCTATTTTGTATTGTGGTGGCTGGTGTCGTCTGTCATCTGGGTCAACCTGTTTCTGGCCCTGATTCTGGAGAACTTCCTT CACAAGTGGGACCCCCGCAGCCACCTGCAGCCCCTTGCTGGGACCCCAGAGGCCACCTACCAGATGACTGTGGAGCTCCTGTTCAGGGAT ATTCTGGAGGAGCCCGGGGAGGATGAGCTCACAGAGAGGCTGAGCCAGCACCCGCACCTGTGGCTGTGCAGGTGACGTCCGGGCTGCCGT CCCAGCAGGGGCGGCAGGAGAGAGAGGCTGGCCTACACAGGTGCCCGTCATGGAAGAGGCGGCCATGCTGTGGCCAGCCAGGCAGGAAGA GACCTTTCCTCTGACGGACCACTAAGCTGGGGACAGGAACCAAGTCCTTTGCGTGTGGCCCAACAACCATCTACAGAACAGCTGCTGGTG CTTCAGGGAGGCGCCGTGCCCTCCGCTTTCTTTTATAGCTGCTTCAGTGAGAATTCCCTCGTCGACTCCACAGGGACCTTTCAGACAAAA ATGCAAGAAGCAGCGGCCTCCCCTGTCCCCTGCAGCTTCCGTGGTGCCTTTGCTGCCGGCAGCCCTTGGGGACCACAGGCCTGACCAGGG CCTGCACAGGTTAACCGTCAGACTTCCGGGGCATTCAGGTGGGGATGCTGGTGGTTTGACATGGAGAGAACCTTGACTGTGTTTTATTAT TTCATGGCTTGTATGAGTGTGACTGGGTGTGTTTCTTTAGGGTTCTGATTGCCAGTTATTTTCATCAATAAGTCTTGCAAAGAATGGGAT >6848_6848_3_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000393505_TPCN2_chr11_68845950_ENST00000294309_length(amino acids)=527AA_BP=185 MAAARALRCSTRRAAGGDRGRGRRRRPGERRRRSREPGAGWPALLLLAGDFPAWALTPRTSLRPSRTMGDKGTRVFKKASPNGKLTVYLG KRDFVDHIDLVDPVDGVVLVDPEYLKERRVYVTLTCAFRYGREDLDVLGLTFRKDLFVANVQSFPPAPEDKKPLTRLQERLIKKLGEHAY PFTFEHPPRPEYQSPFLQSAQFLFGHYYFDYLGNLIALANLVSICVFLVLDADVLPAERDDFILGILNCVFIVYYLLEMLLKVFALGLRG YLSYPSNVFDGLLTVVLLVLEISTLAVYRLPHPGWRPEMVGLLSLWDMTRMLNMLIVFRFLRIIPSMKLMAVVASTVLGLVQNMRAFGGI LVVVYYVFAIIGINLFRGVIVALPGNSSLAPANGSAPCGSFEQLEYWANNFDDFAAALVTLWNLMVVNNWQVFLDAYRRYSGPWSKIYFV -------------------------------------------------------------- >6848_6848_4_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000393505_TPCN2_chr11_68845950_ENST00000542467_length(transcript)=1309nt_BP=576nt ACCCCGCGCGGTTCCACGCCCCTGGCCGCGGCCCGGGCGCTGCGCTGCTCGACGCGGCGGGCGGCGGGCGGGGACCGGGGGCGGGGGCGG CGGCGGCGGCCGGGAGAGCGGAGGAGGCGGAGCAGGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCC TGGGCGCTGACGCCGCGGACCTCCCTGCGACCGTCGCGGACCATGGGCGACAAAGGGACCCGAGTGTTCAAGAAGGCCAGTCCAAATGGA AAGCTCACCGTCTACCTGGGAAAGCGGGACTTTGTGGACCACATCGACCTCGTGGACCCTGTGGATGGTGTGGTCCTGGTGGATCCTGAG TATCTCAAAGAGCGGAGAGTCTATGTGACGCTGACCTGCGCCTTCCGCTATGGCCGGGAGGACCTGGATGTCCTGGGCCTGACCTTTCGC AAGGACCTGTTTGTGGCCAACGTACAGTCGTTCCCACCGGCCCCCGAGGACAAGAAGCCCCTGACGCGGCTGCAGGAACGCCTCATCAAG AAGCTGGGCGAGCACGCTTACCCTTTCACCTTTGAGCACCCGCCGAGGCCCGAGTACCAGTCTCCGTTTCTGCAGAGCGCCCAGTTCCTC TTCGGCCACTACTACTTTGACTACCTGGGGAACCTCATCGCCCTGGCAAACCTGGTGTCCATTTGCGTGTTCCTGGTGCTGGATGCAGAT GTGCTGCCTGCTGAGCGTGATGACTTCATCCTGGGGATTCTCAACTGCGTCTTCATTGTGTACTACCTGTTGGAGATGCTGCTCAAGGTC TTTGCCCTGGGCCTGCGAGGGTACCTGTCCTACCCCAGCAACGTGTTTGACGGGCTCCTCACCGTTGTCCTGCTGAACTTCCTTCACAAG TGGGACCCCCGCAGCCACCTGCAGCCCCTTGCTGGGACCCCAGAGGCCACCTACCAGATGACTGTGGAGCTCCTGTTCAGGGATATTCTG GAGGAGCCCGGGGAGGATGAGCTCACAGAGAGGCTGAGCCAGCACCCGCACCTGTGGCTGTGCAGGTGACGTCCGGGCTGCCGTCCCAGC AGGGGCGGCAGGAGAGAGAGGCTGGCCTACACAGGTGCCCGTCATGGAAGAGGCGGCCATGCTGTGGCCAGCCAGGCAGGAAGAGACCTT TCCTCTGACGGACCACTAAGCTGGGGACAGGAACCAAGTCCTTTGCGTGTGGCCCAACAACCATCTACAGAACAGCTGCTGGTGCTTCAG >6848_6848_4_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000393505_TPCN2_chr11_68845950_ENST00000542467_length(amino acids)=385AA_BP=1 MAGHSMAASSMTGTCVGQPLSPAAPAGTAARTSPAQPQVRVLAQPLCELILPGLLQNIPEQELHSHLVGGLWGPSKGLQVAAGVPLVKEV QQDNGEEPVKHVAGVGQVPSQAQGKDLEQHLQQVVHNEDAVENPQDEVITLSRQHICIQHQEHANGHQVCQGDEVPQVVKVVVAEEELGA LQKRRLVLGPRRVLKGERVSVLAQLLDEAFLQPRQGLLVLGGRWERLYVGHKQVLAKGQAQDIQVLPAIAEGAGQRHIDSPLFEILRIHQ DHTIHRVHEVDVVHKVPLSQVDGELSIWTGLLEHSGPFVAHGPRRSQGGPRRQRPGWKIPSQQEERGPARSRLPAPPPPLSRPPPPPPPP -------------------------------------------------------------- >6848_6848_5_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000420843_TPCN2_chr11_68845950_ENST00000294309_length(transcript)=2052nt_BP=452nt GGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCCTGGGCGCTGACGCCGCGGACCTCCCTGCGACCGT CGCGGACCATGGGCGACAAAGGGACCCGAGTGTTCAAGAAGGCCAGTCCAAATGGAAAGCTCACCGTCTACCTGGGAAAGCGGGACTTTG TGGACCACATCGACCTCGTGGACCCTGTGGATGGTGTGGTCCTGGTGGATCCTGAGTATCTCAAAGAGCGGAGAGTCTATGTGACGCTGA CCTGCGCCTTCCGCTATGGCCGGGAGGACCTGGATGTCCTGGGCCTGACCTTTCGCAAGGACCTGTTTGTGGCCAACGTACAGTCGTTCC CACCGGCCCCCGAGGACAAGAAGCCCCTGACGCGGCTGCAGGAACGCCTCATCAAGAAGCTGGGCGAGCACGCTTACCCTTTCACCTTTG AGCACCCGCCGAGGCCCGAGTACCAGTCTCCGTTTCTGCAGAGCGCCCAGTTCCTCTTCGGCCACTACTACTTTGACTACCTGGGGAACC TCATCGCCCTGGCAAACCTGGTGTCCATTTGCGTGTTCCTGGTGCTGGATGCAGATGTGCTGCCTGCTGAGCGTGATGACTTCATCCTGG GGATTCTCAACTGCGTCTTCATTGTGTACTACCTGTTGGAGATGCTGCTCAAGGTCTTTGCCCTGGGCCTGCGAGGGTACCTGTCCTACC CCAGCAACGTGTTTGACGGGCTCCTCACCGTTGTCCTGCTGGTTTTGGAGATCTCAACTCTGGCTGTGTACCGATTGCCACACCCAGGCT GGAGGCCGGAGATGGTGGGCCTGCTGTCGCTGTGGGACATGACCCGCATGCTGAACATGCTCATCGTGTTCCGCTTCCTGCGTATCATCC CCAGCATGAAGCTGATGGCCGTGGTGGCCAGTACCGTCCTGGGCCTGGTGCAGAACATGCGTGCGTTTGGCGGGATCCTGGTGGTGGTCT ACTACGTATTTGCCATCATTGGGATCAACTTGTTTAGAGGCGTCATTGTGGCTCTTCCTGGAAACAGCAGCCTGGCCCCTGCCAATGGCT CGGCGCCCTGTGGGAGCTTCGAGCAGCTGGAGTACTGGGCCAACAACTTCGATGACTTTGCGGCTGCCCTGGTCACTCTGTGGAACTTGA TGGTGGTGAACAACTGGCAGGTGTTTCTGGATGCATATCGGCGCTACTCAGGCCCGTGGTCCAAGATCTATTTTGTATTGTGGTGGCTGG TGTCGTCTGTCATCTGGGTCAACCTGTTTCTGGCCCTGATTCTGGAGAACTTCCTTCACAAGTGGGACCCCCGCAGCCACCTGCAGCCCC TTGCTGGGACCCCAGAGGCCACCTACCAGATGACTGTGGAGCTCCTGTTCAGGGATATTCTGGAGGAGCCCGGGGAGGATGAGCTCACAG AGAGGCTGAGCCAGCACCCGCACCTGTGGCTGTGCAGGTGACGTCCGGGCTGCCGTCCCAGCAGGGGCGGCAGGAGAGAGAGGCTGGCCT ACACAGGTGCCCGTCATGGAAGAGGCGGCCATGCTGTGGCCAGCCAGGCAGGAAGAGACCTTTCCTCTGACGGACCACTAAGCTGGGGAC AGGAACCAAGTCCTTTGCGTGTGGCCCAACAACCATCTACAGAACAGCTGCTGGTGCTTCAGGGAGGCGCCGTGCCCTCCGCTTTCTTTT ATAGCTGCTTCAGTGAGAATTCCCTCGTCGACTCCACAGGGACCTTTCAGACAAAAATGCAAGAAGCAGCGGCCTCCCCTGTCCCCTGCA GCTTCCGTGGTGCCTTTGCTGCCGGCAGCCCTTGGGGACCACAGGCCTGACCAGGGCCTGCACAGGTTAACCGTCAGACTTCCGGGGCAT TCAGGTGGGGATGCTGGTGGTTTGACATGGAGAGAACCTTGACTGTGTTTTATTATTTCATGGCTTGTATGAGTGTGACTGGGTGTGTTT >6848_6848_5_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000420843_TPCN2_chr11_68845950_ENST00000294309_length(amino acids)=482AA_BP=140 MLAGDFPAWALTPRTSLRPSRTMGDKGTRVFKKASPNGKLTVYLGKRDFVDHIDLVDPVDGVVLVDPEYLKERRVYVTLTCAFRYGREDL DVLGLTFRKDLFVANVQSFPPAPEDKKPLTRLQERLIKKLGEHAYPFTFEHPPRPEYQSPFLQSAQFLFGHYYFDYLGNLIALANLVSIC VFLVLDADVLPAERDDFILGILNCVFIVYYLLEMLLKVFALGLRGYLSYPSNVFDGLLTVVLLVLEISTLAVYRLPHPGWRPEMVGLLSL WDMTRMLNMLIVFRFLRIIPSMKLMAVVASTVLGLVQNMRAFGGILVVVYYVFAIIGINLFRGVIVALPGNSSLAPANGSAPCGSFEQLE YWANNFDDFAAALVTLWNLMVVNNWQVFLDAYRRYSGPWSKIYFVLWWLVSSVIWVNLFLALILENFLHKWDPRSHLQPLAGTPEATYQM -------------------------------------------------------------- >6848_6848_6_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000420843_TPCN2_chr11_68845950_ENST00000542467_length(transcript)=1185nt_BP=452nt GGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCCTGGGCGCTGACGCCGCGGACCTCCCTGCGACCGT CGCGGACCATGGGCGACAAAGGGACCCGAGTGTTCAAGAAGGCCAGTCCAAATGGAAAGCTCACCGTCTACCTGGGAAAGCGGGACTTTG TGGACCACATCGACCTCGTGGACCCTGTGGATGGTGTGGTCCTGGTGGATCCTGAGTATCTCAAAGAGCGGAGAGTCTATGTGACGCTGA CCTGCGCCTTCCGCTATGGCCGGGAGGACCTGGATGTCCTGGGCCTGACCTTTCGCAAGGACCTGTTTGTGGCCAACGTACAGTCGTTCC CACCGGCCCCCGAGGACAAGAAGCCCCTGACGCGGCTGCAGGAACGCCTCATCAAGAAGCTGGGCGAGCACGCTTACCCTTTCACCTTTG AGCACCCGCCGAGGCCCGAGTACCAGTCTCCGTTTCTGCAGAGCGCCCAGTTCCTCTTCGGCCACTACTACTTTGACTACCTGGGGAACC TCATCGCCCTGGCAAACCTGGTGTCCATTTGCGTGTTCCTGGTGCTGGATGCAGATGTGCTGCCTGCTGAGCGTGATGACTTCATCCTGG GGATTCTCAACTGCGTCTTCATTGTGTACTACCTGTTGGAGATGCTGCTCAAGGTCTTTGCCCTGGGCCTGCGAGGGTACCTGTCCTACC CCAGCAACGTGTTTGACGGGCTCCTCACCGTTGTCCTGCTGAACTTCCTTCACAAGTGGGACCCCCGCAGCCACCTGCAGCCCCTTGCTG GGACCCCAGAGGCCACCTACCAGATGACTGTGGAGCTCCTGTTCAGGGATATTCTGGAGGAGCCCGGGGAGGATGAGCTCACAGAGAGGC TGAGCCAGCACCCGCACCTGTGGCTGTGCAGGTGACGTCCGGGCTGCCGTCCCAGCAGGGGCGGCAGGAGAGAGAGGCTGGCCTACACAG GTGCCCGTCATGGAAGAGGCGGCCATGCTGTGGCCAGCCAGGCAGGAAGAGACCTTTCCTCTGACGGACCACTAAGCTGGGGACAGGAAC CAAGTCCTTTGCGTGTGGCCCAACAACCATCTACAGAACAGCTGCTGGTGCTTCAGGGAGGCGCCGTGCCCTCCGCTTTCTTTTATAGCT >6848_6848_6_ARRB1-TPCN2_ARRB1_chr11_74994331_ENST00000420843_TPCN2_chr11_68845950_ENST00000542467_length(amino acids)=343AA_BP=1 MAGHSMAASSMTGTCVGQPLSPAAPAGTAARTSPAQPQVRVLAQPLCELILPGLLQNIPEQELHSHLVGGLWGPSKGLQVAAGVPLVKEV QQDNGEEPVKHVAGVGQVPSQAQGKDLEQHLQQVVHNEDAVENPQDEVITLSRQHICIQHQEHANGHQVCQGDEVPQVVKVVVAEEELGA LQKRRLVLGPRRVLKGERVSVLAQLLDEAFLQPRQGLLVLGGRWERLYVGHKQVLAKGQAQDIQVLPAIAEGAGQRHIDSPLFEILRIHQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARRB1-TPCN2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Hgene | ARRB1 | chr11:74994331 | chr11:68845950 | ENST00000360025 | - | 5 | 15 | 45_86 | 118.0 | 411.0 | CHRM2 |
| Hgene | ARRB1 | chr11:74994331 | chr11:68845950 | ENST00000420843 | - | 5 | 16 | 45_86 | 118.0 | 419.0 | CHRM2 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | ARRB1 | chr11:74994331 | chr11:68845950 | ENST00000360025 | - | 5 | 15 | 1_163 | 118.0 | 411.0 | SRC |
| Hgene | ARRB1 | chr11:74994331 | chr11:68845950 | ENST00000420843 | - | 5 | 16 | 1_163 | 118.0 | 419.0 | SRC |
| Hgene | ARRB1 | chr11:74994331 | chr11:68845950 | ENST00000360025 | - | 5 | 15 | 318_418 | 118.0 | 411.0 | TRAF6 |
| Hgene | ARRB1 | chr11:74994331 | chr11:68845950 | ENST00000420843 | - | 5 | 16 | 318_418 | 118.0 | 419.0 | TRAF6 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARRB1-TPCN2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARRB1-TPCN2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies