
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PRRX2-PPP2R4 (FusionGDB2 ID:69285) |
Fusion Gene Summary for PRRX2-PPP2R4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PRRX2-PPP2R4 | Fusion gene ID: 69285 | Hgene | Tgene | Gene symbol | PRRX2 | PPP2R4 | Gene ID | 51450 | 5524 |
| Gene name | paired related homeobox 2 | protein phosphatase 2 phosphatase activator | |
| Synonyms | PMX2|PRX2 | PP2A|PPP2R4|PR53 | |
| Cytomap | 9q34.11 | 9q34.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | paired mesoderm homeobox protein 2PRX-2paired-like homeodomain protein PRX2paired-related homeobox protein 2testicular tissue protein Li 148testicular tissue protein Li 160 | serine/threonine-protein phosphatase 2A activatorPP2A phosphatase activatorPP2A subunit B' isoform PR53phosphotyrosyl phosphatase activatorprotein phosphatase 2 regulatory subunit 4protein phosphatase 2A activator, regulatory subunit 4protein phosph | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000372469, | ENST00000414510, ENST00000419582, ENST00000423100, ENST00000432124, ENST00000432651, ENST00000434095, ENST00000435132, ENST00000435305, ENST00000436883, ENST00000524946, ENST00000337738, ENST00000347048, ENST00000348141, ENST00000355007, ENST00000357197, ENST00000358994, ENST00000393370, ENST00000452489, | |
| Fusion gene scores | * DoF score | 3 X 1 X 2=6 | 3 X 4 X 2=24 |
| # samples | 4 | 4 | |
| ** MAII score | log2(4/6*10)=2.73696559416621 | log2(4/24*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: PRRX2 [Title/Abstract] AND PPP2R4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PPP2R4(131898874)-PRRX2(132481509), # samples:1 PRRX2(132428405)-PPP2R4(131882791), # samples:1 PRRX2(132428405)-PPP2R4(131882792), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PPP2R4 | GO:0032515 | negative regulation of phosphoprotein phosphatase activity | 16916641 |
| Tgene | PPP2R4 | GO:0032516 | positive regulation of phosphoprotein phosphatase activity | 16916641 |
| Tgene | PPP2R4 | GO:0035307 | positive regulation of protein dephosphorylation | 16916641 |
| Tgene | PPP2R4 | GO:0035308 | negative regulation of protein dephosphorylation | 16916641 |
| Tgene | PPP2R4 | GO:0043065 | positive regulation of apoptotic process | 17333320 |
| Tgene | PPP2R4 | GO:0043666 | regulation of phosphoprotein phosphatase activity | 16916641 |
| Fusion gene breakpoints across PRRX2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PPP2R4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
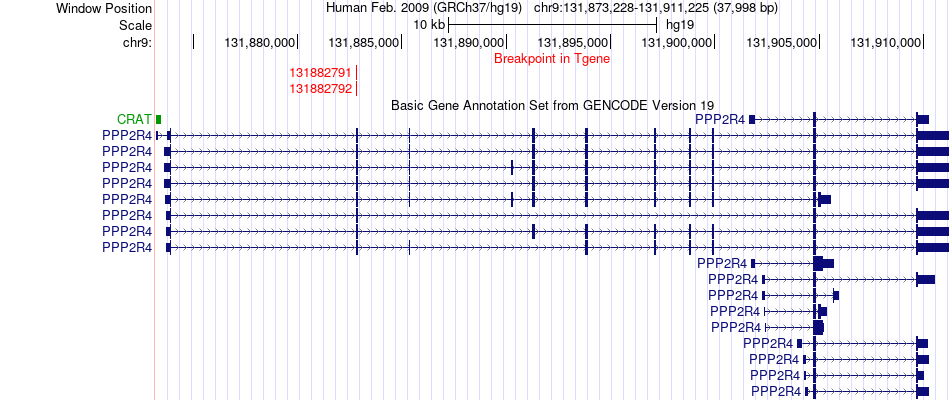 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-1553-01A | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| ChimerDB4 | OV | TCGA-24-1553 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
Top |
Fusion Gene ORF analysis for PRRX2-PPP2R4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000372469 | ENST00000414510 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000414510 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000419582 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000419582 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000423100 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000423100 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000432124 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000432124 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000432651 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000432651 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000434095 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000434095 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000435132 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000435132 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000435305 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000435305 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000436883 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000436883 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| 5CDS-intron | ENST00000372469 | ENST00000524946 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| 5CDS-intron | ENST00000372469 | ENST00000524946 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| In-frame | ENST00000372469 | ENST00000337738 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| In-frame | ENST00000372469 | ENST00000337738 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| In-frame | ENST00000372469 | ENST00000347048 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| In-frame | ENST00000372469 | ENST00000347048 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| In-frame | ENST00000372469 | ENST00000348141 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| In-frame | ENST00000372469 | ENST00000348141 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| In-frame | ENST00000372469 | ENST00000355007 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| In-frame | ENST00000372469 | ENST00000355007 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| In-frame | ENST00000372469 | ENST00000357197 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| In-frame | ENST00000372469 | ENST00000357197 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| In-frame | ENST00000372469 | ENST00000358994 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| In-frame | ENST00000372469 | ENST00000358994 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| In-frame | ENST00000372469 | ENST00000393370 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| In-frame | ENST00000372469 | ENST00000393370 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| In-frame | ENST00000372469 | ENST00000452489 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + |
| In-frame | ENST00000372469 | ENST00000452489 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000358994 | PPP2R4 | chr9 | 131882791 | + | 2907 | 486 | 41 | 1426 | 461 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000393370 | PPP2R4 | chr9 | 131882791 | + | 2909 | 486 | 41 | 1426 | 461 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000337738 | PPP2R4 | chr9 | 131882791 | + | 3012 | 486 | 41 | 1531 | 496 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000348141 | PPP2R4 | chr9 | 131882791 | + | 2927 | 486 | 41 | 1444 | 467 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000452489 | PPP2R4 | chr9 | 131882791 | + | 2079 | 486 | 41 | 1579 | 512 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000357197 | PPP2R4 | chr9 | 131882791 | + | 2821 | 486 | 41 | 1339 | 432 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000347048 | PPP2R4 | chr9 | 131882791 | + | 2252 | 486 | 41 | 769 | 242 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000355007 | PPP2R4 | chr9 | 131882791 | + | 2783 | 486 | 41 | 1300 | 419 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000358994 | PPP2R4 | chr9 | 131882792 | + | 2907 | 486 | 41 | 1426 | 461 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000393370 | PPP2R4 | chr9 | 131882792 | + | 2909 | 486 | 41 | 1426 | 461 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000337738 | PPP2R4 | chr9 | 131882792 | + | 3012 | 486 | 41 | 1531 | 496 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000348141 | PPP2R4 | chr9 | 131882792 | + | 2927 | 486 | 41 | 1444 | 467 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000452489 | PPP2R4 | chr9 | 131882792 | + | 2079 | 486 | 41 | 1579 | 512 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000357197 | PPP2R4 | chr9 | 131882792 | + | 2821 | 486 | 41 | 1339 | 432 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000347048 | PPP2R4 | chr9 | 131882792 | + | 2252 | 486 | 41 | 769 | 242 |
| ENST00000372469 | PRRX2 | chr9 | 132428405 | + | ENST00000355007 | PPP2R4 | chr9 | 131882792 | + | 2783 | 486 | 41 | 1300 | 419 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000372469 | ENST00000358994 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 0.002443119 | 0.9975568 |
| ENST00000372469 | ENST00000393370 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 0.002425032 | 0.997575 |
| ENST00000372469 | ENST00000337738 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 0.003381097 | 0.99661887 |
| ENST00000372469 | ENST00000348141 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 0.003374843 | 0.9966252 |
| ENST00000372469 | ENST00000452489 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 0.008425246 | 0.9915747 |
| ENST00000372469 | ENST00000357197 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 0.003800298 | 0.99619967 |
| ENST00000372469 | ENST00000347048 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 0.061164547 | 0.9388354 |
| ENST00000372469 | ENST00000355007 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 0.002921884 | 0.9970782 |
| ENST00000372469 | ENST00000358994 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + | 0.002443119 | 0.9975568 |
| ENST00000372469 | ENST00000393370 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + | 0.002425032 | 0.997575 |
| ENST00000372469 | ENST00000337738 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + | 0.003381097 | 0.99661887 |
| ENST00000372469 | ENST00000348141 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + | 0.003374843 | 0.9966252 |
| ENST00000372469 | ENST00000452489 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + | 0.008425246 | 0.9915747 |
| ENST00000372469 | ENST00000357197 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + | 0.003800298 | 0.99619967 |
| ENST00000372469 | ENST00000347048 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + | 0.061164547 | 0.9388354 |
| ENST00000372469 | ENST00000355007 | PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882792 | + | 0.002921884 | 0.9970782 |
Top |
Fusion Genomic Features for PRRX2-PPP2R4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 1.52E-10 | 1 |
| PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 1.52E-10 | 1 |
| PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 1.52E-10 | 1 |
| PRRX2 | chr9 | 132428405 | + | PPP2R4 | chr9 | 131882791 | + | 1.52E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
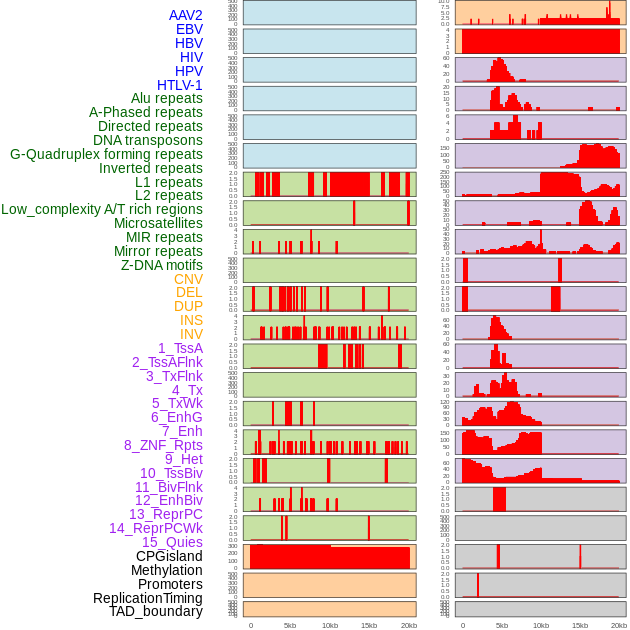 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
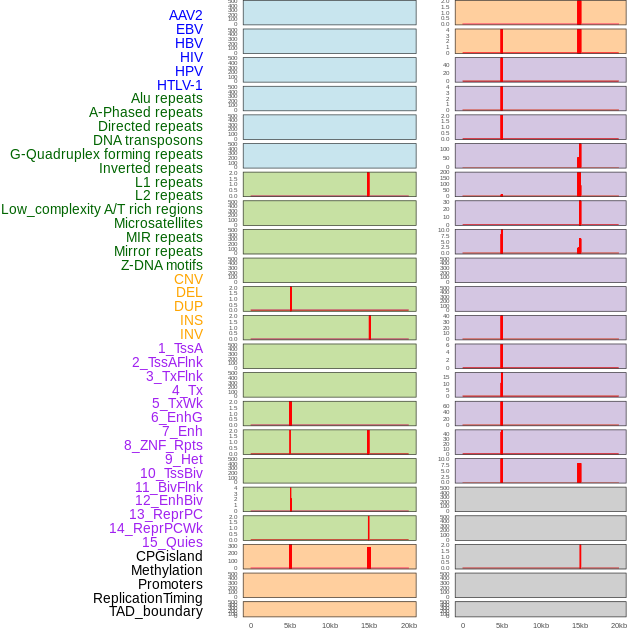 |
Top |
Fusion Protein Features for PRRX2-PPP2R4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:131898874/chr9:132481509) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000337738 | 0 | 11 | 183_189 | 10 | 359.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000337738 | 0 | 11 | 240_242 | 10 | 359.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000337738 | 0 | 11 | 342_343 | 10 | 359.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000355007 | 0 | 9 | 183_189 | 10 | 282.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000355007 | 0 | 9 | 240_242 | 10 | 282.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000355007 | 0 | 9 | 342_343 | 10 | 282.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000357197 | 0 | 9 | 183_189 | 10 | 295.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000357197 | 0 | 9 | 240_242 | 10 | 295.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000357197 | 0 | 9 | 342_343 | 10 | 295.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000358994 | 1 | 11 | 183_189 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000358994 | 1 | 11 | 240_242 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000358994 | 1 | 11 | 342_343 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000393370 | 0 | 10 | 183_189 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000393370 | 0 | 10 | 240_242 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882791 | ENST00000393370 | 0 | 10 | 342_343 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000337738 | 0 | 11 | 183_189 | 10 | 359.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000337738 | 0 | 11 | 240_242 | 10 | 359.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000337738 | 0 | 11 | 342_343 | 10 | 359.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000355007 | 0 | 9 | 183_189 | 10 | 282.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000355007 | 0 | 9 | 240_242 | 10 | 282.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000355007 | 0 | 9 | 342_343 | 10 | 282.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000357197 | 0 | 9 | 183_189 | 10 | 295.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000357197 | 0 | 9 | 240_242 | 10 | 295.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000357197 | 0 | 9 | 342_343 | 10 | 295.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000358994 | 1 | 11 | 183_189 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000358994 | 1 | 11 | 240_242 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000358994 | 1 | 11 | 342_343 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000393370 | 0 | 10 | 183_189 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000393370 | 0 | 10 | 240_242 | 10 | 324.0 | Nucleotide binding | Note=ATP | |
| Tgene | PPP2R4 | chr9:132428405 | chr9:131882792 | ENST00000393370 | 0 | 10 | 342_343 | 10 | 324.0 | Nucleotide binding | Note=ATP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PRRX2 | chr9:132428405 | chr9:131882791 | ENST00000372469 | + | 1 | 4 | 104_163 | 86 | 254.0 | DNA binding | Homeobox |
| Hgene | PRRX2 | chr9:132428405 | chr9:131882792 | ENST00000372469 | + | 1 | 4 | 104_163 | 86 | 254.0 | DNA binding | Homeobox |
| Hgene | PRRX2 | chr9:132428405 | chr9:131882791 | ENST00000372469 | + | 1 | 4 | 230_243 | 86 | 254.0 | Motif | OAR |
| Hgene | PRRX2 | chr9:132428405 | chr9:131882792 | ENST00000372469 | + | 1 | 4 | 230_243 | 86 | 254.0 | Motif | OAR |
Top |
Fusion Gene Sequence for PRRX2-PPP2R4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >69285_69285_1_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000337738_length(transcript)=3012nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGATGTGGAATGAGGTTCATGAGGAAAAGGAGCAGGCTGCAAAGCAGAGTG TGTCCTGCGATGAATGCATACCATTACCCCGCGCCGGGCACTGTGCACCTTCGGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGC TGGACAGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATG AGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGG GGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGG TGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAG CCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGG AGCCCAGACACTTTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGA AGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCA TGTATAAGGCCGAGTGCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCT AGGAGGGGCCAAGCCGAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTC TGTTCGTCCCGTTTGATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAA GTTGGGAGAAGTGACCAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGG CCACTCTCTCCTGTTTCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAG GGAGGAGAGATACCTGCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGT CAGTTTCCCAGGCCATGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGG GGTCGGGTGGTGGAGAGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTG TCCAAGCCTCCCCCTGGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGT AACCTAGCCAATGGAAGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTT CCCTGGCAGGGAGGGGATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGC CCGGCCACTTCTGCTACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCC CAGAAGGTGGCAGTCCCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCC CAGGCTTTGGCACTCAGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGC CTGGCTCTTACAGGCTCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCA CTGAGAAGCACAGCACAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTT CTCAGAAGAGGCCCAGCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCA >69285_69285_1_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000337738_length(amino acids)=496AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEMWNEVHEEKEQAAKQSVSCDECIPLPRAGHCAPSEAIEKLVALLNTLDRWIDETPPVDQP SRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNR YLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWN -------------------------------------------------------------- >69285_69285_2_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000347048_length(transcript)=2252nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGATGAAGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACA TCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCGAGTGCCTGGAGAAGTTCCCTGTGATCCAGC ACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAAGCCGAAGAGCCACCCAGGCCACAGTTCCTG TGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGTTTGATGAGAGGCTGTTTACTGGGGTGGGGT GGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGTGACCAAAGTGTAGCCAGTTTTCTGAGTTCC CGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCTGTTTCTGGCCTCTTCTCCCTTCACTCCCGT CCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATACCTGCTGCTTCCATTGCTTTTCCCTTCCTG GAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGGCCATGCCGGGGTGGCCATCTATGGTAGGGC TGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTGGAGAGGCCTTAGCTGTCCTGGCTGGTGCCC CTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCCCCTGGCTCTTCAGTTCTCTAGCCCTTGGCT CTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAATGGAAGCTGCCCTTTGGGTAGGTGCTGGGCT CCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGAGGGGATGGCAGAAACTCAGGGAGGGGCTTG GGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCTGCTACCTTTGCGCTGCTGTGAGCCTCACCC TGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCAGTCCCACACCTTGTCCTCCCACCTCCCTGA ACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCACTCAGAATGGGCCCAGTGGGGGCTGGGCAG GCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACAGGCTCGTCCCCCAGGCCTGCCCTTCTCCAC TGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACAGCACAGGGGCTCAGCCTGGGATCCGGTGAT GGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGCCCAGCGTCCACCTCTCTCCCAGGGCCAGAC AGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCACCCTCATTGCTGTTCAGATTAAAGCCTCTGTTTTGCACCTGT >69285_69285_2_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000347048_length(amino acids)=242AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS -------------------------------------------------------------- >69285_69285_3_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000348141_length(transcript)=2927nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGTACCATTTGGAACTGTGGCATACGCTGACTACATCGGATTCATCC TTACCCTCAACGAAGGTGTGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACA CGCTGGACAGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTG ATGAGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAG TGGGGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCC GGGTGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGC CAGCCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACC TGGAGCCCAGACACTTTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGA TGAAGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCC GCATGTATAAGGCCGAGTGCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGG GCTAGGAGGGGCCAAGCCGAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCC CTCTGTTCGTCCCGTTTGATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCC CAAGTTGGGAGAAGTGACCAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACT CGGCCACTCTCTCCTGTTTCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGG AAGGGAGGAGAGATACCTGCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCG GGTCAGTTTCCCAGGCCATGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGG TGGGGTCGGGTGGTGGAGAGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCT GTGTCCAAGCCTCCCCCTGGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAG GGTAACCTAGCCAATGGAAGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAAC TTTCCCTGGCAGGGAGGGGATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTA GGCCCGGCCACTTCTGCTACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGG GCCCAGAAGGTGGCAGTCCCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAA GCCCAGGCTTTGGCACTCAGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTG GGCCTGGCTCTTACAGGCTCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGA GCACTGAGAAGCACAGCACAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAG TTTCTCAGAAGAGGCCCAGCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTT >69285_69285_3_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000348141_length(amino acids)=467AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QVPFGTVAYADYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPT HLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQ FLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVI -------------------------------------------------------------- >69285_69285_4_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000355007_length(transcript)=2783nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTG CTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTG CTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGG TTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCA TCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGGAGCCCAGACACTTTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACT ACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGAAGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCG TCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCGAGTGCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGT TCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAAGCCGAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCT TCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGTTTGATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATG GGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGTGACCAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTA GACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCTGTTTCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGG TTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATACCTGCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATG CCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGGCCATGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTG AGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTGGAGAGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGC TCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCCCCTGGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGT TTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAATGGAAGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGG GCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGAGGGGATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATT GTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCTGCTACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCT GGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCAGTCCCACACCTTGTCCTCCCACCTCCCTGAACTGTCCAT TGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCACTCAGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGA GGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACAGGCTCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTC CTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACAGCACAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGC AGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGCCCAGCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCC >69285_69285_4_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000355007_length(amino acids)=419AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRV DDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMK -------------------------------------------------------------- >69285_69285_5_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000357197_length(transcript)=2821nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAGGTGGA TTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGCAGAAA ACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGC GCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAA TAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGG GAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGGAGCCCAGACACT TTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGAAGACTGGCCCAT TTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCG AGTGCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAA GCCGAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGT TTGATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGT GACCAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCT GTTTCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATA CCTGCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGG CCATGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTG GAGAGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCC CCTGGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAAT GGAAGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGA GGGGATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCT GCTACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCA GTCCCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCA CTCAGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACA GGCTCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACA GCACAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGC CCAGCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCACCCTCATTGCTG >69285_69285_5_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000357197_length(amino acids)=432AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAA FLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDY -------------------------------------------------------------- >69285_69285_6_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000358994_length(transcript)=2907nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAGGTGGATTG ATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGCAGAAAACT TGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGCGCA TTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAATAG CTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGGGAG TGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGGAGCCCAGACACTTTG TGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGAAGACTGGCCCATTTG CAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCGAGT GCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAAGCC GAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGTTTG ATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGTGAC CAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCTGTT TCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATACCT GCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGGCCA TGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTGGAG AGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCCCCT GGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAATGGA AGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGAGGG GATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCTGCT ACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCAGTC CCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCACTC AGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACAGGC TCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACAGCA CAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGCCCA GCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCACCCTCATTGCTGTTC >69285_69285_6_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000358994_length(amino acids)=461AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAV PEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIW GSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVIQHFKFG -------------------------------------------------------------- >69285_69285_7_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000393370_length(transcript)=2909nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAGGTGGATTG ATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGCAGAAAACT TGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGCGCA TTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAATAG CTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGGGAG TGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGGAGCCCAGACACTTTG TGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGAAGACTGGCCCATTTG CAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCGAGT GCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAAGCC GAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGTTTG ATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGTGAC CAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCTGTT TCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATACCT GCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGGCCA TGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTGGAG AGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCCCCT GGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAATGGA AGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGAGGG GATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCTGCT ACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCAGTC CCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCACTC AGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACAGGC TCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACAGCA CAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGCCCA GCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCACCCTCATTGCTGTTC >69285_69285_7_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000393370_length(amino acids)=461AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAV PEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIW GSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVIQHFKFG -------------------------------------------------------------- >69285_69285_8_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000452489_length(transcript)=2079nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGATGTGGAATGAGGTTCATGAGGAAAAGGAGCAGGCTGCAAAGCAGAGTG TGTCCTGCGATGAATGCATACCATTACCCCGCGCCGGGCACTGTGCACCTTCGGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGC TGGACAGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATG AGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGG GGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGG TGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAG CCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGG AGCCCAGACACTTTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGA AGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCA TGTATAAGGCCGAGGCCAGCCCCTCTGACACTTGGGGCCTCGGAATCTCCCATCTGGGGCATGGGCAGTCAGAGAAGCACCAGCCACCCC AGCCCCGAAAAGCTGCAGTCCAGCTCTGTCCTGATGAGCTTGGAGGCTGAGGCAAGGACCTGCTGCATGGGGAGTGGGGGCGATGGGGGC CTCCCTTCTCCTTTATCAAGTGGCCAAAGGCTCCTCAAAGCTCGGGCAGTCTGAGTCTGGCTCTCCCATGGCATACCTGGGAAGGGTCTT ACCCTTTGGAGGCATCTCCAAAGTGCTGCCTTCAAATGTTAGTGTGTATGATCACTGAGTGGTGGGAGGTCTGAGGGTAGGCCGAGAATT GGCATTTTTATGGACCGCTTCAGGGATTTTGATGCAAATGGTTTTCCCTGCTCTCAAATCAGATGCTGAGGAGAGGAGAGCTGAGGCTTC CTGGAGCTCCCCCTGCTGGCAGGCAGCCGAGGGTGTCTCCTGCCCTCTTGGCACTGTTCTCCCAGCCAAGGAGGTGGCCTTTTCTCTCTT CCAAGTGGGGAGGAGACATTTTATTTCTACTCTGTCCCTTCTGCTAGCTCCTCCCACTTCCTGGGAAGACTAATTCTAGAACTGCTTGAC >69285_69285_8_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882791_ENST00000452489_length(amino acids)=512AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEMWNEVHEEKEQAAKQSVSCDECIPLPRAGHCAPSEAIEKLVALLNTLDRWIDETPPVDQP SRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNR YLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWN -------------------------------------------------------------- >69285_69285_9_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000337738_length(transcript)=3012nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGATGTGGAATGAGGTTCATGAGGAAAAGGAGCAGGCTGCAAAGCAGAGTG TGTCCTGCGATGAATGCATACCATTACCCCGCGCCGGGCACTGTGCACCTTCGGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGC TGGACAGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATG AGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGG GGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGG TGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAG CCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGG AGCCCAGACACTTTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGA AGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCA TGTATAAGGCCGAGTGCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCT AGGAGGGGCCAAGCCGAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTC TGTTCGTCCCGTTTGATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAA GTTGGGAGAAGTGACCAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGG CCACTCTCTCCTGTTTCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAG GGAGGAGAGATACCTGCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGT CAGTTTCCCAGGCCATGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGG GGTCGGGTGGTGGAGAGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTG TCCAAGCCTCCCCCTGGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGT AACCTAGCCAATGGAAGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTT CCCTGGCAGGGAGGGGATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGC CCGGCCACTTCTGCTACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCC CAGAAGGTGGCAGTCCCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCC CAGGCTTTGGCACTCAGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGC CTGGCTCTTACAGGCTCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCA CTGAGAAGCACAGCACAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTT CTCAGAAGAGGCCCAGCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCA >69285_69285_9_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000337738_length(amino acids)=496AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEMWNEVHEEKEQAAKQSVSCDECIPLPRAGHCAPSEAIEKLVALLNTLDRWIDETPPVDQP SRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNR YLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWN -------------------------------------------------------------- >69285_69285_10_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000347048_length(transcript)=2252nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGATGAAGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACA TCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCGAGTGCCTGGAGAAGTTCCCTGTGATCCAGC ACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAAGCCGAAGAGCCACCCAGGCCACAGTTCCTG TGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGTTTGATGAGAGGCTGTTTACTGGGGTGGGGT GGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGTGACCAAAGTGTAGCCAGTTTTCTGAGTTCC CGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCTGTTTCTGGCCTCTTCTCCCTTCACTCCCGT CCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATACCTGCTGCTTCCATTGCTTTTCCCTTCCTG GAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGGCCATGCCGGGGTGGCCATCTATGGTAGGGC TGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTGGAGAGGCCTTAGCTGTCCTGGCTGGTGCCC CTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCCCCTGGCTCTTCAGTTCTCTAGCCCTTGGCT CTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAATGGAAGCTGCCCTTTGGGTAGGTGCTGGGCT CCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGAGGGGATGGCAGAAACTCAGGGAGGGGCTTG GGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCTGCTACCTTTGCGCTGCTGTGAGCCTCACCC TGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCAGTCCCACACCTTGTCCTCCCACCTCCCTGA ACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCACTCAGAATGGGCCCAGTGGGGGCTGGGCAG GCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACAGGCTCGTCCCCCAGGCCTGCCCTTCTCCAC TGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACAGCACAGGGGCTCAGCCTGGGATCCGGTGAT GGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGCCCAGCGTCCACCTCTCTCCCAGGGCCAGAC AGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCACCCTCATTGCTGTTCAGATTAAAGCCTCTGTTTTGCACCTGT >69285_69285_10_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000347048_length(amino acids)=242AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS -------------------------------------------------------------- >69285_69285_11_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000348141_length(transcript)=2927nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGTACCATTTGGAACTGTGGCATACGCTGACTACATCGGATTCATCC TTACCCTCAACGAAGGTGTGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACA CGCTGGACAGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTG ATGAGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAG TGGGGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCC GGGTGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGC CAGCCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACC TGGAGCCCAGACACTTTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGA TGAAGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCC GCATGTATAAGGCCGAGTGCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGG GCTAGGAGGGGCCAAGCCGAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCC CTCTGTTCGTCCCGTTTGATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCC CAAGTTGGGAGAAGTGACCAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACT CGGCCACTCTCTCCTGTTTCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGG AAGGGAGGAGAGATACCTGCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCG GGTCAGTTTCCCAGGCCATGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGG TGGGGTCGGGTGGTGGAGAGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCT GTGTCCAAGCCTCCCCCTGGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAG GGTAACCTAGCCAATGGAAGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAAC TTTCCCTGGCAGGGAGGGGATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTA GGCCCGGCCACTTCTGCTACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGG GCCCAGAAGGTGGCAGTCCCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAA GCCCAGGCTTTGGCACTCAGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTG GGCCTGGCTCTTACAGGCTCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGA GCACTGAGAAGCACAGCACAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAG TTTCTCAGAAGAGGCCCAGCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTT >69285_69285_11_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000348141_length(amino acids)=467AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QVPFGTVAYADYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPT HLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQ FLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVI -------------------------------------------------------------- >69285_69285_12_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000355007_length(transcript)=2783nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTG CTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTG CTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGG TTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCA TCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGGAGCCCAGACACTTTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACT ACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGAAGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCG TCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCGAGTGCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGT TCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAAGCCGAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCT TCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGTTTGATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATG GGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGTGACCAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTA GACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCTGTTTCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGG TTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATACCTGCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATG CCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGGCCATGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTG AGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTGGAGAGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGC TCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCCCCTGGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGT TTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAATGGAAGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGG GCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGAGGGGATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATT GTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCTGCTACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCT GGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCAGTCCCACACCTTGTCCTCCCACCTCCCTGAACTGTCCAT TGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCACTCAGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGA GGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACAGGCTCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTC CTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACAGCACAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGC AGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGCCCAGCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCC >69285_69285_12_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000355007_length(amino acids)=419AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRV DDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMK -------------------------------------------------------------- >69285_69285_13_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000357197_length(transcript)=2821nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAGGTGGA TTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGCAGAAA ACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGC GCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAA TAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGG GAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGGAGCCCAGACACT TTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGAAGACTGGCCCAT TTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCG AGTGCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAA GCCGAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGT TTGATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGT GACCAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCT GTTTCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATA CCTGCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGG CCATGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTG GAGAGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCC CCTGGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAAT GGAAGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGA GGGGATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCT GCTACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCA GTCCCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCA CTCAGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACA GGCTCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACA GCACAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGC CCAGCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCACCCTCATTGCTG >69285_69285_13_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000357197_length(amino acids)=432AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAA FLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDY -------------------------------------------------------------- >69285_69285_14_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000358994_length(transcript)=2907nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAGGTGGATTG ATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGCAGAAAACT TGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGCGCA TTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAATAG CTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGGGAG TGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGGAGCCCAGACACTTTG TGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGAAGACTGGCCCATTTG CAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCGAGT GCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAAGCC GAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGTTTG ATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGTGAC CAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCTGTT TCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATACCT GCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGGCCA TGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTGGAG AGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCCCCT GGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAATGGA AGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGAGGG GATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCTGCT ACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCAGTC CCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCACTC AGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACAGGC TCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACAGCA CAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGCCCA GCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCACCCTCATTGCTGTTC >69285_69285_14_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000358994_length(amino acids)=461AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAV PEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIW GSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVIQHFKFG -------------------------------------------------------------- >69285_69285_15_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000393370_length(transcript)=2909nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGCTGGACAGGTGGATTG ATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATGAGGAAGCAGAAAACT TGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGGGGAACTCCACGCGCA TTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGGTGGATGACCAAATAG CTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAGCCGGCAGCCAGGGAG TGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGGAGCCCAGACACTTTG TGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGAAGACTGGCCCATTTG CAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCATGTATAAGGCCGAGT GCCTGGAGAAGTTCCCTGTGATCCAGCACTTCAAGTTCGGGAGCCTGCTGCCCATCCATCCTGTCACGTCGGGCTAGGAGGGGCCAAGCC GAAGAGCCACCCAGGCCACAGTTCCTGTGCCTGCCTTCCCCACCCCAGCAGTGGCCCCTCCCCATCCCCTCCCTCTGTTCGTCCCGTTTG ATGAGAGGCTGTTTACTGGGGTGGGGTGGCGAGATGGGCTTGAGGGGGCTCAGAGCATAAGGCTTCAGGGCCCAAGTTGGGAGAAGTGAC CAAAGTGTAGCCAGTTTTCTGAGTTCCCGTGTGCTAGACTGGCCAGAAGAGAGGGTCTGGGGCCTGGTCACTCGGCCACTCTCTCCTGTT TCTGGCCTCTTCTCCCTTCACTCCCGTCCAGTCTGGTTTTGAGAGCAGGGGCTGTTCTGCAGCACCGCAGGGAAGGGAGGAGAGATACCT GCTGCTTCCATTGCTTTTCCCTTCCTGGAGTCGATGCCTTTCTAAGGGTTGGAGCTGCTCCTTGCAGGGGCGGGTCAGTTTCCCAGGCCA TGCCGGGGTGGCCATCTATGGTAGGGCTGGAAGCTGAGGCTGGCCGCCAGCTGTGGGCTGGGGTGGGGTGGGTGGGGTCGGGTGGTGGAG AGGCCTTAGCTGTCCTGGCTGGTGCCCCTCCCAGGCTCCTTTTCACCCTGCCCCCTGGGCCTGAGGCCCCCTGTGTCCAAGCCTCCCCCT GGCTCTTCAGTTCTCTAGCCCTTGGCTCTGCTGGGTTTCCTGACTGTAGCCACATCTCTCCCGCTCCCTAAGGGTAACCTAGCCAATGGA AGCTGCCCTTTGGGTAGGTGCTGGGCTCCTGGGAGGGCCCAGATGATGGGGTGAGGCATGTCTTTCCAGAACTTTCCCTGGCAGGGAGGG GATGGCAGAAACTCAGGGAGGGGCTTGGGGCCCATTGTATCTGGAGAGCCTGGATTCCTCTTGGCAGTCTTAGGCCCGGCCACTTCTGCT ACCTTTGCGCTGCTGTGAGCCTCACCCTGGGCCCCTGGGCCCTGCTTCTCTGCTCCCCTGGGTGATGGGTGGGCCCAGAAGGTGGCAGTC CCACACCTTGTCCTCCCACCTCCCTGAACTGTCCATTGCTTTTATAGGGTGAGGTAAGAGACAGCCTCCCAAGCCCAGGCTTTGGCACTC AGAATGGGCCCAGTGGGGGCTGGGCAGGCCCATTGAGGGCCACCGCCGAGGTTTCTCCTAGGGCTGTTCCTGGGCCTGGCTCTTACAGGC TCGTCCCCCAGGCCTGCCCTTCTCCACTGCCCCCTCCTGTGTCTGGGTCCACACACCCTTCAGGAAGGGGGAGCACTGAGAAGCACAGCA CAGGGGCTCAGCCTGGGATCCGGTGATGGTCTGGGCAGAGGCTGGGTCAGGAGTCCCAAAGGTCAGTGACAGTTTCTCAGAAGAGGCCCA GCGTCCACCTCTCTCCCAGGGCCAGACAGCCCTTCCTGGCTCCCCCATCCCCCTATGGGCTCCCAGCCCCTTGCACCCTCATTGCTGTTC >69285_69285_15_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000393370_length(amino acids)=461AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEAIEKLVALLNTLDRWIDETPPVDQPSRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAV PEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNRYLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIW GSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWNISAVPSWSKVNQGLIRMYKAECLEKFPVIQHFKFG -------------------------------------------------------------- >69285_69285_16_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000452489_length(transcript)=2079nt_BP=486nt CGCAGCGCGTGCACCAGCGGCTCCGGAGCGAGCGGCCGTGGCTGAGAAGGGGAGGGCGGAAAGTTTGTTTCCCCGACGTCAGCGCCGGGC GGGCCGCGAGGCTAGGAGGCGGCGGGAGCTGGGCAGAGCGCGGGGCGGCCGGGGCTCTCGCTCCGACCCGCGCCCGCGACCCTTCCTGGG ACCCGAGCCCGAGACCCCCGCCGGCCCCCCCGGGGCCGCTCGCGGGCATGGACAGCGCGGCCGCCGCCTTCGCCCTGGACAAGCCGGCGC TGGGCCCGGGGCCGCCGCCGCCTCCACCCGCGCTGGGGCCCGGCGACTGCGCCCAGGCGCGCAAGAACTTCTCGGTGAGCCACCTCCTGG ACCTGGAAGAGGTGGCGGCGGCCGGGCGGCTGGCGGCGCGCCCCGGGGCCAGGGCCGAGGCGCGGGAGGGCGCAGCACGGGAGCCGTCCG GGGGCAGCAGCGGCAGCGAGGCGGCGCCGCAGGATGATTCTTCAGAGGAGGCCCCTCCAGCCACTCAGAACTTCATCATTCCAAAAAAGG AGATCCACACAGTTCCAGACATGGGCAAATGGAAGCGTTCTCAGGCATACGCTGACTACATCGGATTCATCCTTACCCTCAACGAAGGTG TGAAGGGGAAGAAGCTGACCTTCGAGTACAGAGTCTCCGAGATGTGGAATGAGGTTCATGAGGAAAAGGAGCAGGCTGCAAAGCAGAGTG TGTCCTGCGATGAATGCATACCATTACCCCGCGCCGGGCACTGTGCACCTTCGGAGGCCATTGAGAAACTAGTCGCTCTTCTCAACACGC TGGACAGGTGGATTGATGAGACTCCTCCAGTGGACCAGCCCTCTCGGTTTGGGAATAAGGCATACAGGACCTGGTATGCCAAACTTGATG AGGAAGCAGAAAACTTGGTGGCCACAGTGGTCCCTACCCATCTGGCAGCTGCTGTGCCTGAGGTGGCTGTTTACCTAAAGGAGTCAGTGG GGAACTCCACGCGCATTGACTACGGCACAGGGCATGAGGCAGCCTTCGCTGCTTTCCTCTGCTGTCTCTGCAAGATTGGGGTGCTCCGGG TGGATGACCAAATAGCTATTGTCTTCAAGGTGTTCAATCGGTACCTTGAGGTTATGCGGAAACTCCAGAAAACATACAGGATGGAGCCAG CCGGCAGCCAGGGAGTGTGGGGTCTGGATGACTTCCAGTTTCTGCCCTTCATCTGGGGCAGTTCGCAGCTGATAGACCACCCATACCTGG AGCCCAGACACTTTGTGGATGAGAAGGCCGTGAATGAGAACCACAAGGACTACATGTTCCTGGAGTGTATCCTGTTTATTACCGAGATGA AGACTGGCCCATTTGCAGAGCACTCCAACCAGCTGTGGAACATCAGCGCCGTCCCTTCCTGGTCCAAAGTGAACCAGGGTCTCATCCGCA TGTATAAGGCCGAGGCCAGCCCCTCTGACACTTGGGGCCTCGGAATCTCCCATCTGGGGCATGGGCAGTCAGAGAAGCACCAGCCACCCC AGCCCCGAAAAGCTGCAGTCCAGCTCTGTCCTGATGAGCTTGGAGGCTGAGGCAAGGACCTGCTGCATGGGGAGTGGGGGCGATGGGGGC CTCCCTTCTCCTTTATCAAGTGGCCAAAGGCTCCTCAAAGCTCGGGCAGTCTGAGTCTGGCTCTCCCATGGCATACCTGGGAAGGGTCTT ACCCTTTGGAGGCATCTCCAAAGTGCTGCCTTCAAATGTTAGTGTGTATGATCACTGAGTGGTGGGAGGTCTGAGGGTAGGCCGAGAATT GGCATTTTTATGGACCGCTTCAGGGATTTTGATGCAAATGGTTTTCCCTGCTCTCAAATCAGATGCTGAGGAGAGGAGAGCTGAGGCTTC CTGGAGCTCCCCCTGCTGGCAGGCAGCCGAGGGTGTCTCCTGCCCTCTTGGCACTGTTCTCCCAGCCAAGGAGGTGGCCTTTTCTCTCTT CCAAGTGGGGAGGAGACATTTTATTTCTACTCTGTCCCTTCTGCTAGCTCCTCCCACTTCCTGGGAAGACTAATTCTAGAACTGCTTGAC >69285_69285_16_PRRX2-PPP2R4_PRRX2_chr9_132428405_ENST00000372469_PPP2R4_chr9_131882792_ENST00000452489_length(amino acids)=512AA_BP=32 MRRGGRKVCFPDVSAGRAARLGGGGSWAERGAAGALAPTRARDPSWDPSPRPPPAPPGPLAGMDSAAAAFALDKPALGPGPPPPPPALGP GDCAQARKNFSVSHLLDLEEVAAAGRLAARPGARAEAREGAAREPSGGSSGSEAAPQDDSSEEAPPATQNFIIPKKEIHTVPDMGKWKRS QAYADYIGFILTLNEGVKGKKLTFEYRVSEMWNEVHEEKEQAAKQSVSCDECIPLPRAGHCAPSEAIEKLVALLNTLDRWIDETPPVDQP SRFGNKAYRTWYAKLDEEAENLVATVVPTHLAAAVPEVAVYLKESVGNSTRIDYGTGHEAAFAAFLCCLCKIGVLRVDDQIAIVFKVFNR YLEVMRKLQKTYRMEPAGSQGVWGLDDFQFLPFIWGSSQLIDHPYLEPRHFVDEKAVNENHKDYMFLECILFITEMKTGPFAEHSNQLWN -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PRRX2-PPP2R4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PRRX2-PPP2R4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PRRX2-PPP2R4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies