
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ASAH1-TRAPPC9 (FusionGDB2 ID:6946) |
Fusion Gene Summary for ASAH1-TRAPPC9 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ASAH1-TRAPPC9 | Fusion gene ID: 6946 | Hgene | Tgene | Gene symbol | ASAH1 | TRAPPC9 | Gene ID | 427 | 83696 |
| Gene name | N-acylsphingosine amidohydrolase 1 | trafficking protein particle complex 9 | |
| Synonyms | AC|ACDase|ASAH|PHP|PHP32|SMAPME | IBP|IKBKBBP|MRT13|NIBP|T1|TRS120 | |
| Cytomap | 8p22 | 8q24.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | acid ceramidaseN-acylethanolamine hydrolase ASAH1N-acylsphingosine amidohydrolase (acid ceramidase) 1acid CDaseacylsphingosine deacylaseputative 32 kDa heart protein | trafficking protein particle complex subunit 9IKK2 binding proteinNIK and IKK-beta binding proteinNIK- and IKBKB-binding proteinTRAPP 120 kDa subunittularik gene 1 protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q13510 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000262097, ENST00000314146, ENST00000381733, ENST00000417108, ENST00000520781, ENST00000520051, | ENST00000522504, ENST00000389327, ENST00000389328, ENST00000438773, | |
| Fusion gene scores | * DoF score | 15 X 16 X 7=1680 | 20 X 19 X 14=5320 |
| # samples | 16 | 40 | |
| ** MAII score | log2(16/1680*10)=-3.39231742277876 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(40/5320*10)=-3.73335434061383 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ASAH1 [Title/Abstract] AND TRAPPC9 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ASAH1(17924729)-TRAPPC9(140744445), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ASAH1 | GO:0046512 | sphingosine biosynthetic process | 12815059 |
| Hgene | ASAH1 | GO:0046513 | ceramide biosynthetic process | 12764132|12815059 |
| Hgene | ASAH1 | GO:0046514 | ceramide catabolic process | 12815059 |
| Fusion gene breakpoints across ASAH1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TRAPPC9 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
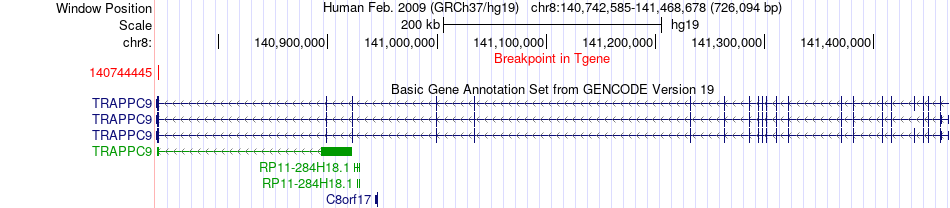 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-8534-01A | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
Top |
Fusion Gene ORF analysis for ASAH1-TRAPPC9 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000262097 | ENST00000522504 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| 5CDS-5UTR | ENST00000314146 | ENST00000522504 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| 5CDS-5UTR | ENST00000381733 | ENST00000522504 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| 5CDS-5UTR | ENST00000417108 | ENST00000522504 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| 5CDS-5UTR | ENST00000520781 | ENST00000522504 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000262097 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000262097 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000262097 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000314146 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000314146 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000314146 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000381733 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000381733 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000381733 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000417108 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000417108 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000417108 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000520781 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000520781 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| In-frame | ENST00000520781 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| intron-3CDS | ENST00000520051 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| intron-3CDS | ENST00000520051 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| intron-3CDS | ENST00000520051 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| intron-5UTR | ENST00000520051 | ENST00000522504 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000262097 | ASAH1 | chr8 | 17924729 | - | ENST00000389327 | TRAPPC9 | chr8 | 140744445 | - | 1804 | 694 | 15 | 1085 | 356 |
| ENST00000262097 | ASAH1 | chr8 | 17924729 | - | ENST00000389328 | TRAPPC9 | chr8 | 140744445 | - | 1804 | 694 | 15 | 1085 | 356 |
| ENST00000262097 | ASAH1 | chr8 | 17924729 | - | ENST00000438773 | TRAPPC9 | chr8 | 140744445 | - | 1802 | 694 | 15 | 1085 | 356 |
| ENST00000381733 | ASAH1 | chr8 | 17924729 | - | ENST00000389327 | TRAPPC9 | chr8 | 140744445 | - | 1707 | 597 | 5 | 988 | 327 |
| ENST00000381733 | ASAH1 | chr8 | 17924729 | - | ENST00000389328 | TRAPPC9 | chr8 | 140744445 | - | 1707 | 597 | 5 | 988 | 327 |
| ENST00000381733 | ASAH1 | chr8 | 17924729 | - | ENST00000438773 | TRAPPC9 | chr8 | 140744445 | - | 1705 | 597 | 5 | 988 | 327 |
| ENST00000417108 | ASAH1 | chr8 | 17924729 | - | ENST00000389327 | TRAPPC9 | chr8 | 140744445 | - | 1528 | 418 | 21 | 809 | 262 |
| ENST00000417108 | ASAH1 | chr8 | 17924729 | - | ENST00000389328 | TRAPPC9 | chr8 | 140744445 | - | 1528 | 418 | 21 | 809 | 262 |
| ENST00000417108 | ASAH1 | chr8 | 17924729 | - | ENST00000438773 | TRAPPC9 | chr8 | 140744445 | - | 1526 | 418 | 21 | 809 | 262 |
| ENST00000520781 | ASAH1 | chr8 | 17924729 | - | ENST00000389327 | TRAPPC9 | chr8 | 140744445 | - | 1804 | 694 | 15 | 1085 | 356 |
| ENST00000520781 | ASAH1 | chr8 | 17924729 | - | ENST00000389328 | TRAPPC9 | chr8 | 140744445 | - | 1804 | 694 | 15 | 1085 | 356 |
| ENST00000520781 | ASAH1 | chr8 | 17924729 | - | ENST00000438773 | TRAPPC9 | chr8 | 140744445 | - | 1802 | 694 | 15 | 1085 | 356 |
| ENST00000314146 | ASAH1 | chr8 | 17924729 | - | ENST00000389327 | TRAPPC9 | chr8 | 140744445 | - | 1658 | 548 | 22 | 939 | 305 |
| ENST00000314146 | ASAH1 | chr8 | 17924729 | - | ENST00000389328 | TRAPPC9 | chr8 | 140744445 | - | 1658 | 548 | 22 | 939 | 305 |
| ENST00000314146 | ASAH1 | chr8 | 17924729 | - | ENST00000438773 | TRAPPC9 | chr8 | 140744445 | - | 1656 | 548 | 22 | 939 | 305 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000262097 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.012154566 | 0.9878455 |
| ENST00000262097 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.012154566 | 0.9878455 |
| ENST00000262097 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.012173605 | 0.9878264 |
| ENST00000381733 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.05603633 | 0.9439637 |
| ENST00000381733 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.05603633 | 0.9439637 |
| ENST00000381733 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.056059986 | 0.94394 |
| ENST00000417108 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.014075394 | 0.98592454 |
| ENST00000417108 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.014075394 | 0.98592454 |
| ENST00000417108 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.014113361 | 0.9858867 |
| ENST00000520781 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.012154566 | 0.9878455 |
| ENST00000520781 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.012154566 | 0.9878455 |
| ENST00000520781 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.012173605 | 0.9878264 |
| ENST00000314146 | ENST00000389327 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.08761259 | 0.91238743 |
| ENST00000314146 | ENST00000389328 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.08761259 | 0.91238743 |
| ENST00000314146 | ENST00000438773 | ASAH1 | chr8 | 17924729 | - | TRAPPC9 | chr8 | 140744445 | - | 0.08822042 | 0.9117795 |
Top |
Fusion Genomic Features for ASAH1-TRAPPC9 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
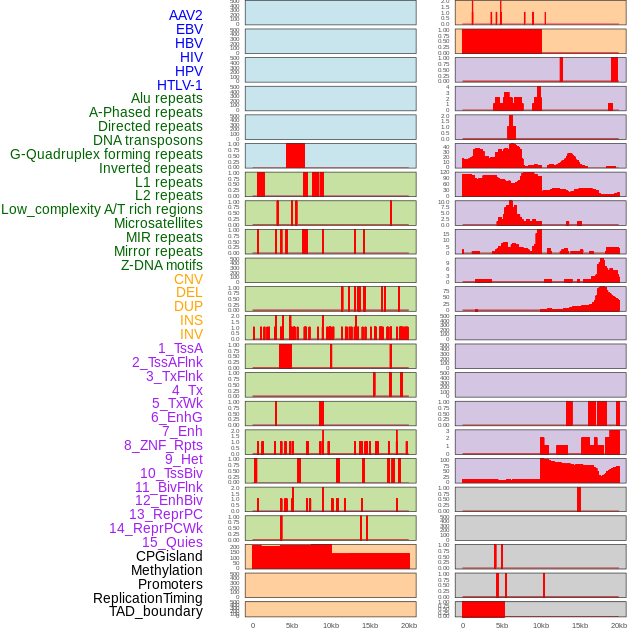 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ASAH1-TRAPPC9 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:17924729/chr8:140744445) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ASAH1 | . |
| FUNCTION: Lysosomal ceramidase that hydrolyzes sphingolipid ceramides into sphingosine and free fatty acids at acidic pH (PubMed:10610716, PubMed:7744740, PubMed:15655246, PubMed:11451951). Ceramides, sphingosine, and its phosphorylated form sphingosine-1-phosphate are bioactive lipids that mediate cellular signaling pathways regulating several biological processes including cell proliferation, apoptosis and differentiation (PubMed:10610716). Has a higher catalytic efficiency towards C12-ceramides versus other ceramides (PubMed:7744740, PubMed:15655246). Also catalyzes the reverse reaction allowing the synthesis of ceramides from fatty acids and sphingosine (PubMed:12764132, PubMed:12815059). For the reverse synthetic reaction, the natural sphingosine D-erythro isomer is more efficiently utilized as a substrate compared to D-erythro-dihydrosphingosine and D-erythro-phytosphingosine, while the fatty acids with chain lengths of 12 or 14 carbons are the most efficiently used (PubMed:12764132). Has also an N-acylethanolamine hydrolase activity (PubMed:15655246). By regulating the levels of ceramides, sphingosine and sphingosine-1-phosphate in the epidermis, mediates the calcium-induced differentiation of epidermal keratinocytes (PubMed:17713573). Also indirectly regulates tumor necrosis factor/TNF-induced apoptosis (By similarity). By regulating the intracellular balance between ceramides and sphingosine, in adrenocortical cells, probably also acts as a regulator of steroidogenesis (PubMed:22261821). {ECO:0000250|UniProtKB:Q9WV54, ECO:0000269|PubMed:10610716, ECO:0000269|PubMed:11451951, ECO:0000269|PubMed:12764132, ECO:0000269|PubMed:12815059, ECO:0000269|PubMed:15655246, ECO:0000269|PubMed:17713573, ECO:0000269|PubMed:22261821, ECO:0000269|PubMed:7744740, ECO:0000303|PubMed:10610716}.; FUNCTION: [Isoform 2]: May directly regulate steroidogenesis by binding the nuclear receptor NR5A1 and negatively regulating its transcriptional activity. {ECO:0000305|PubMed:22927646}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for ASAH1-TRAPPC9 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6946_6946_1_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000262097_TRAPPC9_chr8_140744445_ENST00000389327_length(transcript)=1804nt_BP=694nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGT GACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCC TTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGC ACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCAC ATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAG GCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTT CACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGA AGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAA AGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCA GAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCT TCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTA GGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTG GGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTCTGCAAGCAGTTCTTCAATAAATGGCCTGCCTCCC >6946_6946_1_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000262097_TRAPPC9_chr8_140744445_ENST00000389327_length(amino acids)=356AA_BP=226 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTV -------------------------------------------------------------- >6946_6946_2_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000262097_TRAPPC9_chr8_140744445_ENST00000389328_length(transcript)=1804nt_BP=694nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGT GACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCC TTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGC ACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCAC ATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAG GCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTT CACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGA AGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAA AGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCA GAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCT TCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTA GGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTG GGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTCTGCAAGCAGTTCTTCAATAAATGGCCTGCCTCCC >6946_6946_2_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000262097_TRAPPC9_chr8_140744445_ENST00000389328_length(amino acids)=356AA_BP=226 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTV -------------------------------------------------------------- >6946_6946_3_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000262097_TRAPPC9_chr8_140744445_ENST00000438773_length(transcript)=1802nt_BP=694nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGT GACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCC TTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGC ACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCAC ATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAG GCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTT CACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGA AGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAA AGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCA GAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCT TCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTA GGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTG GGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTCTGCAAGCAGTTCTTCAATAAATGGCCTGCCTCCC >6946_6946_3_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000262097_TRAPPC9_chr8_140744445_ENST00000438773_length(amino acids)=356AA_BP=226 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTV -------------------------------------------------------------- >6946_6946_4_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000314146_TRAPPC9_chr8_140744445_ENST00000389327_length(transcript)=1658nt_BP=548nt GGGCAGGATTTCCTGCTGGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCC CCCTGCCGAGCTACTCGCGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCG CTTAATGAACTGCTGCATCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGC CTCAATTCTGGGATTTGGCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACTGT CTTCCCTGCTGTTATAAGGTACAGAGGTGCAGTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGAT GCTTGACAAGGCACCAGTGCCTGGCCTACTTGGCAACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATAT ACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCG GCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGA CCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCT CCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCT GCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCT GGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTG TTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTG GACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTG GGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCA TGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCC CCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGT CCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTC >6946_6946_4_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000314146_TRAPPC9_chr8_140744445_ENST00000389327_length(amino acids)=305AA_BP=175 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTVFPAVIRYRGAVPWYTINLDLPPYKRWHELMLDKAPVPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVD GQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYLDAVQPSGQSACLGALLFLYTGD -------------------------------------------------------------- >6946_6946_5_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000314146_TRAPPC9_chr8_140744445_ENST00000389328_length(transcript)=1658nt_BP=548nt GGGCAGGATTTCCTGCTGGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCC CCCTGCCGAGCTACTCGCGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCG CTTAATGAACTGCTGCATCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGC CTCAATTCTGGGATTTGGCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACTGT CTTCCCTGCTGTTATAAGGTACAGAGGTGCAGTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGAT GCTTGACAAGGCACCAGTGCCTGGCCTACTTGGCAACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATAT ACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCG GCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGA CCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCT CCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCT GCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCT GGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTG TTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTG GACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTG GGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCA TGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCC CCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGT CCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTC >6946_6946_5_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000314146_TRAPPC9_chr8_140744445_ENST00000389328_length(amino acids)=305AA_BP=175 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTVFPAVIRYRGAVPWYTINLDLPPYKRWHELMLDKAPVPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVD GQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYLDAVQPSGQSACLGALLFLYTGD -------------------------------------------------------------- >6946_6946_6_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000314146_TRAPPC9_chr8_140744445_ENST00000438773_length(transcript)=1656nt_BP=548nt GGGCAGGATTTCCTGCTGGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCC CCCTGCCGAGCTACTCGCGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCG CTTAATGAACTGCTGCATCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGC CTCAATTCTGGGATTTGGCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACTGT CTTCCCTGCTGTTATAAGGTACAGAGGTGCAGTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGAT GCTTGACAAGGCACCAGTGCCTGGCCTACTTGGCAACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATAT ACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCG GCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGA CCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCT CCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCT GCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCT GGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTG TTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTG GACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTG GGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCA TGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCC CCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGT CCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTC >6946_6946_6_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000314146_TRAPPC9_chr8_140744445_ENST00000438773_length(amino acids)=305AA_BP=175 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTVFPAVIRYRGAVPWYTINLDLPPYKRWHELMLDKAPVPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVD GQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYLDAVQPSGQSACLGALLFLYTGD -------------------------------------------------------------- >6946_6946_7_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000381733_TRAPPC9_chr8_140744445_ENST00000389327_length(transcript)=1707nt_BP=597nt GGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCCCCCTGCCGAGCTACTCG CGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCGCTTAATGAACTGCTGCA TCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGCCTCAATTCTGGGATTTG GCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCAT GGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAATT CTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTTC CTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGCG AGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCCC TCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTCT ACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGGT TCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGAG CCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGCA GCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCCG GACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGGT GCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGAC CTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCACC CTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGTC GTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCTC >6946_6946_7_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000381733_TRAPPC9_chr8_140744445_ENST00000389327_length(amino acids)=327AA_BP=197 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMINTFVPSGKIMQVVDEKLPGLLGNFPG PFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYL -------------------------------------------------------------- >6946_6946_8_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000381733_TRAPPC9_chr8_140744445_ENST00000389328_length(transcript)=1707nt_BP=597nt GGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCCCCCTGCCGAGCTACTCG CGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCGCTTAATGAACTGCTGCA TCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGCCTCAATTCTGGGATTTG GCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCAT GGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAATT CTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTTC CTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGCG AGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCCC TCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTCT ACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGGT TCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGAG CCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGCA GCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCCG GACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGGT GCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGAC CTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCACC CTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGTC GTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCTC >6946_6946_8_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000381733_TRAPPC9_chr8_140744445_ENST00000389328_length(amino acids)=327AA_BP=197 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMINTFVPSGKIMQVVDEKLPGLLGNFPG PFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYL -------------------------------------------------------------- >6946_6946_9_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000381733_TRAPPC9_chr8_140744445_ENST00000438773_length(transcript)=1705nt_BP=597nt GGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCCCCCTGCCGAGCTACTCG CGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCGCTTAATGAACTGCTGCA TCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGCCTCAATTCTGGGATTTG GCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCAT GGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAATT CTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTTC CTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGCG AGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCCC TCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTCT ACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGGT TCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGAG CCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGCA GCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCCG GACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGGT GCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGAC CTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCACC CTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGTC GTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCTC >6946_6946_9_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000381733_TRAPPC9_chr8_140744445_ENST00000438773_length(amino acids)=327AA_BP=197 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMINTFVPSGKIMQVVDEKLPGLLGNFPG PFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQDHQNGVHNYDLHDTVSFVGSSTFYL -------------------------------------------------------------- >6946_6946_10_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000417108_TRAPPC9_chr8_140744445_ENST00000389327_length(transcript)=1528nt_BP=418nt GCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTCAGCTGT GCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCA TGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAAT TCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTT CCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGC GAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCC CTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTC TACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGG TTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGA GCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGC AGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCC GGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGG TGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGA CCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCAC CCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGT CGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCT >6946_6946_10_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000417108_TRAPPC9_chr8_140744445_ENST00000389327_length(amino acids)=262AA_BP=132 MAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMIN TFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQ -------------------------------------------------------------- >6946_6946_11_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000417108_TRAPPC9_chr8_140744445_ENST00000389328_length(transcript)=1528nt_BP=418nt GCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTCAGCTGT GCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCA TGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAAT TCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTT CCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGC GAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCC CTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTC TACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGG TTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGA GCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGC AGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCC GGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGG TGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGA CCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCAC CCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGT CGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCT >6946_6946_11_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000417108_TRAPPC9_chr8_140744445_ENST00000389328_length(amino acids)=262AA_BP=132 MAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMIN TFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQ -------------------------------------------------------------- >6946_6946_12_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000417108_TRAPPC9_chr8_140744445_ENST00000438773_length(transcript)=1526nt_BP=418nt GCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTCAGCTGT GCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCA TGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAAT TCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTT CCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGTGACCGC GAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCCTTCGCC CTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGCACCTTC TACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCACATCCGG TTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAGGCCTGA GCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTTCACTGC AGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGAAGCCCC GGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAAAGCGGG TGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCAGAGGGA CCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCTTCCCAC CCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTAGGAGGT CGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTGGGTGCT >6946_6946_12_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000417108_TRAPPC9_chr8_140744445_ENST00000438773_length(amino acids)=262AA_BP=132 MAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMIN TFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTVVPFQ -------------------------------------------------------------- >6946_6946_13_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000520781_TRAPPC9_chr8_140744445_ENST00000389327_length(transcript)=1804nt_BP=694nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGT GACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCC TTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGC ACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCAC ATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAG GCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTT CACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGA AGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAA AGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCA GAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCT TCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTA GGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTG GGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTCTGCAAGCAGTTCTTCAATAAATGGCCTGCCTCCC >6946_6946_13_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000520781_TRAPPC9_chr8_140744445_ENST00000389327_length(amino acids)=356AA_BP=226 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTV -------------------------------------------------------------- >6946_6946_14_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000520781_TRAPPC9_chr8_140744445_ENST00000389328_length(transcript)=1804nt_BP=694nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGT GACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCC TTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGC ACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCAC ATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAG GCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTT CACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGA AGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAA AGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCA GAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCT TCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTA GGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTG GGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTCTGCAAGCAGTTCTTCAATAAATGGCCTGCCTCCC >6946_6946_14_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000520781_TRAPPC9_chr8_140744445_ENST00000389328_length(amino acids)=356AA_BP=226 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTV -------------------------------------------------------------- >6946_6946_15_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000520781_TRAPPC9_chr8_140744445_ENST00000438773_length(transcript)=1802nt_BP=694nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGATGTGCTGGTGGACGGACAGCCATGT GACCGCGAGGCTGTGGCGGCCTGCCAGGTGGGCGACCCCGTGCGCCTGGAGGTGCGGCTGACCAACCGGAGCCCGCGCAGCGTAGGGCCC TTCGCCCTCACTGTGGTCCCCTTCCAGGACCACCAGAACGGCGTGCACAACTACGACCTGCACGACACCGTCTCCTTCGTGGGCTCCAGC ACCTTCTACCTCGACGCGGTGCAGCCGTCCGGCCAGTCGGCCTGCCTCGGGGCCCTCCTCTTCCTCTACACGGGAGACTTCTTCCTCCAC ATCCGGTTCCACGAGGACAGCACCAGCAAGGAGCTGCCACCCTCTTGGTTCTGCCTGCCCAGTGTGCACGTGTGTGCCCTGGAGGCGCAG GCCTGAGCCCGCCTACTTCCGTCCCTCTTTCTGCAGGGCCAGAGGTGACCCTGCCTGGCCTCCCACACCCCCTGCAATGAGCAAGGCCTT CACTGCAGCCCCATCTCCTCCTCCTCCCCCAGACCCCTCCCAGCCCTCTCCTCCTGTTCCTCCTGTAGCATCTTTGCTGGGCTACGCAGA AGCCCCGGACATGGCAGCCCCACCCCATGCCACGCCCCTTCCTACACTGTTCCCTGGACCATACACAGGCTGAAGCAGAGGAAATCCCAA AGCGGGTGCCCATCCAGCCCAGGTCCCAGGATCCCTGCACCCATTTCTGTGACCTGGGGCCCCAGCCGTGCTGTGCTGCTCATCCCAGCA GAGGGACCTCCCTCGTCCAGCGACTTCCCTTTGGCCATAGAAAGAAATGGTGAGCATGAGACTGGGCACAGCCTGAGGGCGTGGGCAGCT TCCCACCCTCCCTGGGCCTTGGAATCCCCCAAGGCTGGTTTTCTTCCTGGAGACCCCCATGGGCAACTTGGCAGGAGAGATGGTGCCGTA GGAGGTCGTGGATGGTTGATGCCAAGAGAGGCCCTCCACCCGTGGTGGGCAAATGTCCAGGCCTGGGCTGGCAGCCCAGGGCTGTTTCTG GGTGCTCCCTGGCCCCAGGGTGGCGTCTGGTTACCATGGCTGTGTGTGTCCATGTCTGCAAGCAGTTCTTCAATAAATGGCCTGCCTCCC >6946_6946_15_ASAH1-TRAPPC9_ASAH1_chr8_17924729_ENST00000520781_TRAPPC9_chr8_140744445_ENST00000438773_length(amino acids)=356AA_BP=226 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLDVLVDGQPCDREAVAACQVGDPVRLEVRLTNRSPRSVGPFALTV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ASAH1-TRAPPC9 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ASAH1-TRAPPC9 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ASAH1-TRAPPC9 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies