
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PTGDS-HIP1R (FusionGDB2 ID:69945) |
Fusion Gene Summary for PTGDS-HIP1R |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PTGDS-HIP1R | Fusion gene ID: 69945 | Hgene | Tgene | Gene symbol | PTGDS | HIP1R | Gene ID | 5730 | 9026 |
| Gene name | prostaglandin D2 synthase | huntingtin interacting protein 1 related | |
| Synonyms | L-PGDS|LPGDS|PDS|PGD2|PGDS|PGDS2 | HIP12|HIP3|ILWEQ | |
| Cytomap | 9q34.3 | 12q24.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | prostaglandin-H2 D-isomerasePGD2 synthasebeta-trace proteincerebrin-28glutathione-independent PGD synthaseglutathione-independent PGD synthetaselipocalin-type prostaglandin D synthaseprostaglandin D synthaseprostaglandin D2 synthase 21kDa (brain) | huntingtin-interacting protein 1-related proteinHIP-12HIP1-related proteinhuntingtin interacting protein 12 | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | . | O75146 | |
| Ensembl transtripts involved in fusion gene | ENST00000224167, ENST00000371625, ENST00000460340, | ENST00000537322, ENST00000253083, | |
| Fusion gene scores | * DoF score | 17 X 10 X 6=1020 | 6 X 7 X 4=168 |
| # samples | 19 | 8 | |
| ** MAII score | log2(19/1020*10)=-2.42449782852791 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/168*10)=-1.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PTGDS [Title/Abstract] AND HIP1R [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PTGDS(139872144)-HIP1R(123342648), # samples:1 PTGDS(139872143)-HIP1R(123342648), # samples:1 PTGDS(139872044)-HIP1R(123343442), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | PTGDS-HIP1R seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. PTGDS-HIP1R seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PTGDS | GO:0001516 | prostaglandin biosynthetic process | 20667974 |
| Tgene | HIP1R | GO:0006919 | activation of cysteine-type endopeptidase activity involved in apoptotic process | 19255499 |
| Tgene | HIP1R | GO:0032092 | positive regulation of protein binding | 19255499 |
| Tgene | HIP1R | GO:0050821 | protein stabilization | 14732715 |
| Fusion gene breakpoints across PTGDS (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across HIP1R (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LGG | TCGA-E1-A7YK-01A | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + |
| ChimerDB4 | LGG | TCGA-E1-A7YK | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + |
| ChiTaRS5.0 | N/A | CB153680 | PTGDS | chr9 | 139872044 | + | HIP1R | chr12 | 123343442 | + |
Top |
Fusion Gene ORF analysis for PTGDS-HIP1R |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000224167 | ENST00000537322 | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + |
| 5CDS-intron | ENST00000224167 | ENST00000537322 | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + |
| 5CDS-intron | ENST00000224167 | ENST00000537322 | PTGDS | chr9 | 139872044 | + | HIP1R | chr12 | 123343442 | + |
| 5CDS-intron | ENST00000371625 | ENST00000537322 | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + |
| 5CDS-intron | ENST00000371625 | ENST00000537322 | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + |
| 5CDS-intron | ENST00000371625 | ENST00000537322 | PTGDS | chr9 | 139872044 | + | HIP1R | chr12 | 123343442 | + |
| Frame-shift | ENST00000224167 | ENST00000253083 | PTGDS | chr9 | 139872044 | + | HIP1R | chr12 | 123343442 | + |
| Frame-shift | ENST00000371625 | ENST00000253083 | PTGDS | chr9 | 139872044 | + | HIP1R | chr12 | 123343442 | + |
| In-frame | ENST00000224167 | ENST00000253083 | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + |
| In-frame | ENST00000224167 | ENST00000253083 | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + |
| In-frame | ENST00000371625 | ENST00000253083 | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + |
| In-frame | ENST00000371625 | ENST00000253083 | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + |
| intron-3CDS | ENST00000460340 | ENST00000253083 | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + |
| intron-3CDS | ENST00000460340 | ENST00000253083 | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + |
| intron-3CDS | ENST00000460340 | ENST00000253083 | PTGDS | chr9 | 139872044 | + | HIP1R | chr12 | 123343442 | + |
| intron-intron | ENST00000460340 | ENST00000537322 | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + |
| intron-intron | ENST00000460340 | ENST00000537322 | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + |
| intron-intron | ENST00000460340 | ENST00000537322 | PTGDS | chr9 | 139872044 | + | HIP1R | chr12 | 123343442 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000224167 | PTGDS | chr9 | 139872144 | + | ENST00000253083 | HIP1R | chr12 | 123342648 | + | 2788 | 189 | 36 | 1580 | 514 |
| ENST00000371625 | PTGDS | chr9 | 139872144 | + | ENST00000253083 | HIP1R | chr12 | 123342648 | + | 2787 | 188 | 35 | 1579 | 514 |
| ENST00000224167 | PTGDS | chr9 | 139872143 | + | ENST00000253083 | HIP1R | chr12 | 123342648 | + | 2788 | 189 | 36 | 1580 | 514 |
| ENST00000371625 | PTGDS | chr9 | 139872143 | + | ENST00000253083 | HIP1R | chr12 | 123342648 | + | 2787 | 188 | 35 | 1579 | 514 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000224167 | ENST00000253083 | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + | 0.010973682 | 0.98902637 |
| ENST00000371625 | ENST00000253083 | PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + | 0.010911839 | 0.9890882 |
| ENST00000224167 | ENST00000253083 | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + | 0.010973682 | 0.98902637 |
| ENST00000371625 | ENST00000253083 | PTGDS | chr9 | 139872143 | + | HIP1R | chr12 | 123342648 | + | 0.010911839 | 0.9890882 |
Top |
Fusion Genomic Features for PTGDS-HIP1R |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + | 0.22254388 | 0.77745616 |
| PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + | 0.22254388 | 0.77745616 |
| PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + | 0.22254388 | 0.77745616 |
| PTGDS | chr9 | 139872144 | + | HIP1R | chr12 | 123342648 | + | 0.22254388 | 0.77745616 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
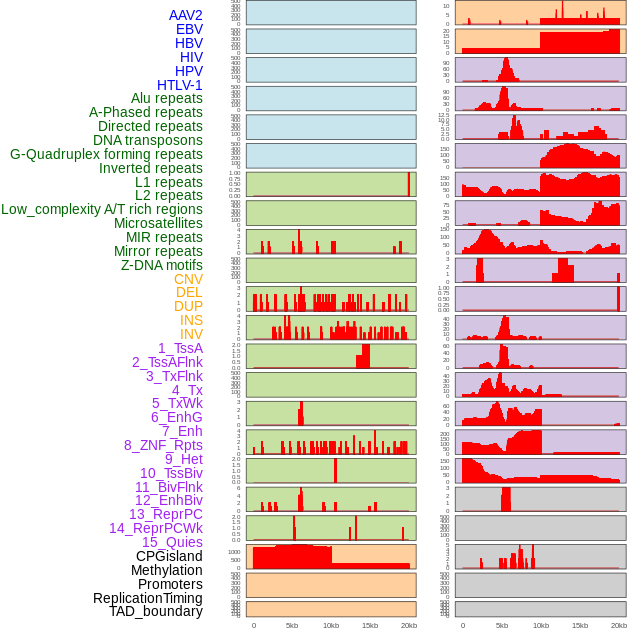 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
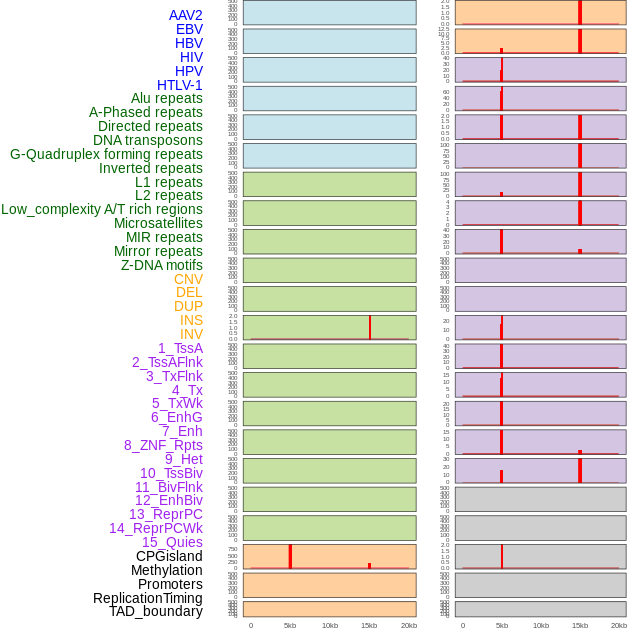 |
Top |
Fusion Protein Features for PTGDS-HIP1R |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:139872144/chr12:123342648) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | HIP1R |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Component of clathrin-coated pits and vesicles, that may link the endocytic machinery to the actin cytoskeleton. Binds 3-phosphoinositides (via ENTH domain). May act through the ENTH domain to promote cell survival by stabilizing receptor tyrosine kinases following ligand-induced endocytosis. {ECO:0000269|PubMed:11889126, ECO:0000269|PubMed:14732715}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | HIP1R | chr9:139872143 | chr12:123342648 | ENST00000253083 | 17 | 32 | 771_1012 | 605 | 1069.0 | Domain | I/LWEQ | |
| Tgene | HIP1R | chr9:139872144 | chr12:123342648 | ENST00000253083 | 17 | 32 | 771_1012 | 605 | 1069.0 | Domain | I/LWEQ | |
| Tgene | HIP1R | chr9:139872143 | chr12:123342648 | ENST00000253083 | 17 | 32 | 867_924 | 605 | 1069.0 | Region | Note=Important for actin binding | |
| Tgene | HIP1R | chr9:139872144 | chr12:123342648 | ENST00000253083 | 17 | 32 | 867_924 | 605 | 1069.0 | Region | Note=Important for actin binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | HIP1R | chr9:139872143 | chr12:123342648 | ENST00000253083 | 17 | 32 | 347_599 | 605 | 1069.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | HIP1R | chr9:139872144 | chr12:123342648 | ENST00000253083 | 17 | 32 | 347_599 | 605 | 1069.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | HIP1R | chr9:139872143 | chr12:123342648 | ENST00000253083 | 17 | 32 | 23_151 | 605 | 1069.0 | Domain | ENTH | |
| Tgene | HIP1R | chr9:139872144 | chr12:123342648 | ENST00000253083 | 17 | 32 | 23_151 | 605 | 1069.0 | Domain | ENTH |
Top |
Fusion Gene Sequence for PTGDS-HIP1R |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >69945_69945_1_PTGDS-HIP1R_PTGDS_chr9_139872143_ENST00000224167_HIP1R_chr12_123342648_ENST00000253083_length(transcript)=2788nt_BP=189nt GCTCCTCCTGCACACCTCCCTCGCTCTCCCACACCACTGGCACCAGGCCCCGGACACCCGCTCTGCTGCAGGAGAATGGCTACTCATCAC ACACTGTGGATGGGACTGGCCCTGCTGGGGGTGCTGGGCGACCTGCAGGCAGCACCGGAGGCCCAGGTCTCCGTGCAGCCCAACTTCCAG CAGGACAAGGAGTCTCAGGAGCAGGGGCTGCGGCAGAGGCTGCTGGACGAGCAGTTCGCAGTGTTGCGGGGCGCTGCTGCCGAGGCCGCG GGCATCCTGCAGGATGCCGTGAGCAAGCTGGACGACCCCCTGCACCTGCGCTGTACCAGCTCCCCAGACTACCTGGTGAGCAGGGCCCAG GAGGCCTTGGATGCCGTGAGCACCCTGGAGGAGGGCCACGCCCAGTACCTGACCTCCTTGGCAGACGCCTCCGCCCTGGTGGCAGCTCTG ACCCGCTTCTCCCACCTGGCTGCGGATACCATCATCAATGGCGGTGCCACCTCGCACCTGGCTCCCACCGACCCTGCCGACCGCCTCATA GACACCTGCAGGGAGTGCGGGGCCCGGGCTCTGGAGCTCATGGGGCAGCTGCAGGACCAGCAGGCTCTGCGGCACATGCAGGCCAGCCTG GTGCGGACACCCCTGCAGGGCATCCTTCAGCTGGGCCAGGAACTGAAACCCAAGAGCCTAGATGTGCGGCAGGAGGAGCTGGGGGCCGTG GTCGACAAGGAGATGGCGGCCACATCCGCAGCCATTGAAGATGCTGTGCGGAGGATTGAGGACATGATGAACCAGGCACGCCACGCCAGC TCGGGGGTGAAGCTGGAGGTGAACGAGAGGATCCTCAACTCCTGCACAGACCTGATGAAGGCTATCCGGCTCCTGGTGACGACATCCACT AGCCTGCAGAAGGAGATCGTGGAGAGCGGCAGGGGGGCAGCCACGCAGCAGGAATTTTACGCCAAGAACTCGCGCTGGACCGAAGGCCTC ATCTCGGCCTCCAAGGCTGTGGGCTGGGGAGCCACACAGCTGGTGGAGGCAGCTGACAAGGTGGTGCTTCACACGGGCAAGTATGAGGAG CTCATCGTCTGCTCCCACGAGATCGCAGCCAGCACGGCCCAGCTGGTGGCGGCCTCCAAGGTGAAGGCCAACAAGCACAGCCCCCACCTG AGCCGCCTGCAGGAATGTTCTCGCACAGTCAATGAGAGGGCTGCCAATGTGGTGGCCTCCACCAAGTCAGGCCAGGAGCAGATTGAGGAC AGAGACACCATGGATTTCTCCGGCCTGTCCCTCATCAAGCTGAAGAAGCAGGAGATGGAGACCCAGGTGCGTGTCCTGGAGCTGGAGAAG ACGCTGGAGGCTGAACGCATGCGGCTGGGGGAGTTGCGGAAGCAACACTACGTGCTGGCTGGGGCATCAGGCAGCCCTGGAGAGGAGGTG GCCATCCGGCCCAGCACTGCCCCCCGAAGTGTAACCACCAAGAAACCACCCCTGGCCCAGAAGCCCAGCGTGGCCCCCAGACAGGACCAC CAGCTTGACAAAAAGGATGGCATCTACCCAGCTCAACTCGTGAACTACTAGGCCCCCCAGGGGTCCAGCAGGGTGGCTGGTGACAGGCCT GGGCCTCTGCAACTGCCCTGACAGGACCGAGAGGCCTTGCCCCTCCACCTGGTGCCCAAGCCTCCCGCCCCACCGTCTGGATCAATGTCC TCAAGGCCCCTGGCCCTTACTGAGCCTGCAGGGTCCTGGGCCATGTGGGTGGTGCTTCTGGATGTGAGTCTCTTATTTATCTGCAGAAGG AACTTTGGGGTGCAGCCAGGACCCGGTAGGCCTGAGCCTCAACTCTTCAGAAAATAGTGTTTTTAATATTCCTCTTCAGAAAATAGTGTT TTTAATATTCCGAGCTAGAGCTCTTCTTCCTACGTTTGTAGTCAGCACACTGGGAAACCGGGCCAGCGTGGGGCTCCCTGCCTTCTGGAC TCCTGAAGGTCGTGGATGGATGGAAGGCACACAGCCCGTGCCGGCTGATGGGACGAGGGTCAGGCATCCTGTCTGTGGCCTTCTGGGGCA CCGATTCTACCAGGCCCTCCAGCTGCGTGGTCTCCGCAGACCAGGCTCTGTGTGGGCTAGAGGAATGTCGCCCATTACTCCTCAGGCCTG GCCCTCGGGCCTCCGTGATGGGAGCCCCCCAGGAGGGGTCAGATGCTGGAAGGGGCCGCTTTCTGGGGAGTGAGGTGAGACATAGCGGCC CGGGCGCTGCCTTCACTCCTGGAGTGAGTTTCCATTTCCAGCTGGAATCTGCAGCCACCCCCATTTCCTGTTTTCCATTCCCCCGTTCTG GCCGCGCCCCACTGCCCACCTGAAGGGGTGGTTTCCAGCCCTCCGGAGAGTGGGCTTGGCCCTAGGCCCTCCAGCTCAGCCAGAAAAAGC CCAGAAACCCAGGTGCTGGACCAGGGCCCTCAGGGAGGGGACCCTGCGGCTAGAGTGGGCTAGGCCCTGGCTTTGCCCGTCAGATTTGAA CGAATGTGTGTCCCTTGAGCCCAAGGAGAGCGGCAGGAGGGGTGGGACCAGGCTGGGAGGACAGAGCCAGCAGCTGCCATGCCCTCCTGC TCCCCCCACCCCAGCCCTAGCCCTTTAGCCTTTCACCCTGTGCTCTGGAAAGGCTACCAAATACTGGCCAAGGTCAGGAGGAGCAAAAAT >69945_69945_1_PTGDS-HIP1R_PTGDS_chr9_139872143_ENST00000224167_HIP1R_chr12_123342648_ENST00000253083_length(amino acids)=514AA_BP=51 MAPGPGHPLCCRRMATHHTLWMGLALLGVLGDLQAAPEAQVSVQPNFQQDKESQEQGLRQRLLDEQFAVLRGAAAEAAGILQDAVSKLDD PLHLRCTSSPDYLVSRAQEALDAVSTLEEGHAQYLTSLADASALVAALTRFSHLAADTIINGGATSHLAPTDPADRLIDTCRECGARALE LMGQLQDQQALRHMQASLVRTPLQGILQLGQELKPKSLDVRQEELGAVVDKEMAATSAAIEDAVRRIEDMMNQARHASSGVKLEVNERIL NSCTDLMKAIRLLVTTSTSLQKEIVESGRGAATQQEFYAKNSRWTEGLISASKAVGWGATQLVEAADKVVLHTGKYEELIVCSHEIAAST AQLVAASKVKANKHSPHLSRLQECSRTVNERAANVVASTKSGQEQIEDRDTMDFSGLSLIKLKKQEMETQVRVLELEKTLEAERMRLGEL -------------------------------------------------------------- >69945_69945_2_PTGDS-HIP1R_PTGDS_chr9_139872143_ENST00000371625_HIP1R_chr12_123342648_ENST00000253083_length(transcript)=2787nt_BP=188nt CTCCTCCTGCACACCTCCCTCGCTCTCCCACACCACTGGCACCAGGCCCCGGACACCCGCTCTGCTGCAGGAGAATGGCTACTCATCACA CACTGTGGATGGGACTGGCCCTGCTGGGGGTGCTGGGCGACCTGCAGGCAGCACCGGAGGCCCAGGTCTCCGTGCAGCCCAACTTCCAGC AGGACAAGGAGTCTCAGGAGCAGGGGCTGCGGCAGAGGCTGCTGGACGAGCAGTTCGCAGTGTTGCGGGGCGCTGCTGCCGAGGCCGCGG GCATCCTGCAGGATGCCGTGAGCAAGCTGGACGACCCCCTGCACCTGCGCTGTACCAGCTCCCCAGACTACCTGGTGAGCAGGGCCCAGG AGGCCTTGGATGCCGTGAGCACCCTGGAGGAGGGCCACGCCCAGTACCTGACCTCCTTGGCAGACGCCTCCGCCCTGGTGGCAGCTCTGA CCCGCTTCTCCCACCTGGCTGCGGATACCATCATCAATGGCGGTGCCACCTCGCACCTGGCTCCCACCGACCCTGCCGACCGCCTCATAG ACACCTGCAGGGAGTGCGGGGCCCGGGCTCTGGAGCTCATGGGGCAGCTGCAGGACCAGCAGGCTCTGCGGCACATGCAGGCCAGCCTGG TGCGGACACCCCTGCAGGGCATCCTTCAGCTGGGCCAGGAACTGAAACCCAAGAGCCTAGATGTGCGGCAGGAGGAGCTGGGGGCCGTGG TCGACAAGGAGATGGCGGCCACATCCGCAGCCATTGAAGATGCTGTGCGGAGGATTGAGGACATGATGAACCAGGCACGCCACGCCAGCT CGGGGGTGAAGCTGGAGGTGAACGAGAGGATCCTCAACTCCTGCACAGACCTGATGAAGGCTATCCGGCTCCTGGTGACGACATCCACTA GCCTGCAGAAGGAGATCGTGGAGAGCGGCAGGGGGGCAGCCACGCAGCAGGAATTTTACGCCAAGAACTCGCGCTGGACCGAAGGCCTCA TCTCGGCCTCCAAGGCTGTGGGCTGGGGAGCCACACAGCTGGTGGAGGCAGCTGACAAGGTGGTGCTTCACACGGGCAAGTATGAGGAGC TCATCGTCTGCTCCCACGAGATCGCAGCCAGCACGGCCCAGCTGGTGGCGGCCTCCAAGGTGAAGGCCAACAAGCACAGCCCCCACCTGA GCCGCCTGCAGGAATGTTCTCGCACAGTCAATGAGAGGGCTGCCAATGTGGTGGCCTCCACCAAGTCAGGCCAGGAGCAGATTGAGGACA GAGACACCATGGATTTCTCCGGCCTGTCCCTCATCAAGCTGAAGAAGCAGGAGATGGAGACCCAGGTGCGTGTCCTGGAGCTGGAGAAGA CGCTGGAGGCTGAACGCATGCGGCTGGGGGAGTTGCGGAAGCAACACTACGTGCTGGCTGGGGCATCAGGCAGCCCTGGAGAGGAGGTGG CCATCCGGCCCAGCACTGCCCCCCGAAGTGTAACCACCAAGAAACCACCCCTGGCCCAGAAGCCCAGCGTGGCCCCCAGACAGGACCACC AGCTTGACAAAAAGGATGGCATCTACCCAGCTCAACTCGTGAACTACTAGGCCCCCCAGGGGTCCAGCAGGGTGGCTGGTGACAGGCCTG GGCCTCTGCAACTGCCCTGACAGGACCGAGAGGCCTTGCCCCTCCACCTGGTGCCCAAGCCTCCCGCCCCACCGTCTGGATCAATGTCCT CAAGGCCCCTGGCCCTTACTGAGCCTGCAGGGTCCTGGGCCATGTGGGTGGTGCTTCTGGATGTGAGTCTCTTATTTATCTGCAGAAGGA ACTTTGGGGTGCAGCCAGGACCCGGTAGGCCTGAGCCTCAACTCTTCAGAAAATAGTGTTTTTAATATTCCTCTTCAGAAAATAGTGTTT TTAATATTCCGAGCTAGAGCTCTTCTTCCTACGTTTGTAGTCAGCACACTGGGAAACCGGGCCAGCGTGGGGCTCCCTGCCTTCTGGACT CCTGAAGGTCGTGGATGGATGGAAGGCACACAGCCCGTGCCGGCTGATGGGACGAGGGTCAGGCATCCTGTCTGTGGCCTTCTGGGGCAC CGATTCTACCAGGCCCTCCAGCTGCGTGGTCTCCGCAGACCAGGCTCTGTGTGGGCTAGAGGAATGTCGCCCATTACTCCTCAGGCCTGG CCCTCGGGCCTCCGTGATGGGAGCCCCCCAGGAGGGGTCAGATGCTGGAAGGGGCCGCTTTCTGGGGAGTGAGGTGAGACATAGCGGCCC GGGCGCTGCCTTCACTCCTGGAGTGAGTTTCCATTTCCAGCTGGAATCTGCAGCCACCCCCATTTCCTGTTTTCCATTCCCCCGTTCTGG CCGCGCCCCACTGCCCACCTGAAGGGGTGGTTTCCAGCCCTCCGGAGAGTGGGCTTGGCCCTAGGCCCTCCAGCTCAGCCAGAAAAAGCC CAGAAACCCAGGTGCTGGACCAGGGCCCTCAGGGAGGGGACCCTGCGGCTAGAGTGGGCTAGGCCCTGGCTTTGCCCGTCAGATTTGAAC GAATGTGTGTCCCTTGAGCCCAAGGAGAGCGGCAGGAGGGGTGGGACCAGGCTGGGAGGACAGAGCCAGCAGCTGCCATGCCCTCCTGCT CCCCCCACCCCAGCCCTAGCCCTTTAGCCTTTCACCCTGTGCTCTGGAAAGGCTACCAAATACTGGCCAAGGTCAGGAGGAGCAAAAATG >69945_69945_2_PTGDS-HIP1R_PTGDS_chr9_139872143_ENST00000371625_HIP1R_chr12_123342648_ENST00000253083_length(amino acids)=514AA_BP=51 MAPGPGHPLCCRRMATHHTLWMGLALLGVLGDLQAAPEAQVSVQPNFQQDKESQEQGLRQRLLDEQFAVLRGAAAEAAGILQDAVSKLDD PLHLRCTSSPDYLVSRAQEALDAVSTLEEGHAQYLTSLADASALVAALTRFSHLAADTIINGGATSHLAPTDPADRLIDTCRECGARALE LMGQLQDQQALRHMQASLVRTPLQGILQLGQELKPKSLDVRQEELGAVVDKEMAATSAAIEDAVRRIEDMMNQARHASSGVKLEVNERIL NSCTDLMKAIRLLVTTSTSLQKEIVESGRGAATQQEFYAKNSRWTEGLISASKAVGWGATQLVEAADKVVLHTGKYEELIVCSHEIAAST AQLVAASKVKANKHSPHLSRLQECSRTVNERAANVVASTKSGQEQIEDRDTMDFSGLSLIKLKKQEMETQVRVLELEKTLEAERMRLGEL -------------------------------------------------------------- >69945_69945_3_PTGDS-HIP1R_PTGDS_chr9_139872144_ENST00000224167_HIP1R_chr12_123342648_ENST00000253083_length(transcript)=2788nt_BP=189nt GCTCCTCCTGCACACCTCCCTCGCTCTCCCACACCACTGGCACCAGGCCCCGGACACCCGCTCTGCTGCAGGAGAATGGCTACTCATCAC ACACTGTGGATGGGACTGGCCCTGCTGGGGGTGCTGGGCGACCTGCAGGCAGCACCGGAGGCCCAGGTCTCCGTGCAGCCCAACTTCCAG CAGGACAAGGAGTCTCAGGAGCAGGGGCTGCGGCAGAGGCTGCTGGACGAGCAGTTCGCAGTGTTGCGGGGCGCTGCTGCCGAGGCCGCG GGCATCCTGCAGGATGCCGTGAGCAAGCTGGACGACCCCCTGCACCTGCGCTGTACCAGCTCCCCAGACTACCTGGTGAGCAGGGCCCAG GAGGCCTTGGATGCCGTGAGCACCCTGGAGGAGGGCCACGCCCAGTACCTGACCTCCTTGGCAGACGCCTCCGCCCTGGTGGCAGCTCTG ACCCGCTTCTCCCACCTGGCTGCGGATACCATCATCAATGGCGGTGCCACCTCGCACCTGGCTCCCACCGACCCTGCCGACCGCCTCATA GACACCTGCAGGGAGTGCGGGGCCCGGGCTCTGGAGCTCATGGGGCAGCTGCAGGACCAGCAGGCTCTGCGGCACATGCAGGCCAGCCTG GTGCGGACACCCCTGCAGGGCATCCTTCAGCTGGGCCAGGAACTGAAACCCAAGAGCCTAGATGTGCGGCAGGAGGAGCTGGGGGCCGTG GTCGACAAGGAGATGGCGGCCACATCCGCAGCCATTGAAGATGCTGTGCGGAGGATTGAGGACATGATGAACCAGGCACGCCACGCCAGC TCGGGGGTGAAGCTGGAGGTGAACGAGAGGATCCTCAACTCCTGCACAGACCTGATGAAGGCTATCCGGCTCCTGGTGACGACATCCACT AGCCTGCAGAAGGAGATCGTGGAGAGCGGCAGGGGGGCAGCCACGCAGCAGGAATTTTACGCCAAGAACTCGCGCTGGACCGAAGGCCTC ATCTCGGCCTCCAAGGCTGTGGGCTGGGGAGCCACACAGCTGGTGGAGGCAGCTGACAAGGTGGTGCTTCACACGGGCAAGTATGAGGAG CTCATCGTCTGCTCCCACGAGATCGCAGCCAGCACGGCCCAGCTGGTGGCGGCCTCCAAGGTGAAGGCCAACAAGCACAGCCCCCACCTG AGCCGCCTGCAGGAATGTTCTCGCACAGTCAATGAGAGGGCTGCCAATGTGGTGGCCTCCACCAAGTCAGGCCAGGAGCAGATTGAGGAC AGAGACACCATGGATTTCTCCGGCCTGTCCCTCATCAAGCTGAAGAAGCAGGAGATGGAGACCCAGGTGCGTGTCCTGGAGCTGGAGAAG ACGCTGGAGGCTGAACGCATGCGGCTGGGGGAGTTGCGGAAGCAACACTACGTGCTGGCTGGGGCATCAGGCAGCCCTGGAGAGGAGGTG GCCATCCGGCCCAGCACTGCCCCCCGAAGTGTAACCACCAAGAAACCACCCCTGGCCCAGAAGCCCAGCGTGGCCCCCAGACAGGACCAC CAGCTTGACAAAAAGGATGGCATCTACCCAGCTCAACTCGTGAACTACTAGGCCCCCCAGGGGTCCAGCAGGGTGGCTGGTGACAGGCCT GGGCCTCTGCAACTGCCCTGACAGGACCGAGAGGCCTTGCCCCTCCACCTGGTGCCCAAGCCTCCCGCCCCACCGTCTGGATCAATGTCC TCAAGGCCCCTGGCCCTTACTGAGCCTGCAGGGTCCTGGGCCATGTGGGTGGTGCTTCTGGATGTGAGTCTCTTATTTATCTGCAGAAGG AACTTTGGGGTGCAGCCAGGACCCGGTAGGCCTGAGCCTCAACTCTTCAGAAAATAGTGTTTTTAATATTCCTCTTCAGAAAATAGTGTT TTTAATATTCCGAGCTAGAGCTCTTCTTCCTACGTTTGTAGTCAGCACACTGGGAAACCGGGCCAGCGTGGGGCTCCCTGCCTTCTGGAC TCCTGAAGGTCGTGGATGGATGGAAGGCACACAGCCCGTGCCGGCTGATGGGACGAGGGTCAGGCATCCTGTCTGTGGCCTTCTGGGGCA CCGATTCTACCAGGCCCTCCAGCTGCGTGGTCTCCGCAGACCAGGCTCTGTGTGGGCTAGAGGAATGTCGCCCATTACTCCTCAGGCCTG GCCCTCGGGCCTCCGTGATGGGAGCCCCCCAGGAGGGGTCAGATGCTGGAAGGGGCCGCTTTCTGGGGAGTGAGGTGAGACATAGCGGCC CGGGCGCTGCCTTCACTCCTGGAGTGAGTTTCCATTTCCAGCTGGAATCTGCAGCCACCCCCATTTCCTGTTTTCCATTCCCCCGTTCTG GCCGCGCCCCACTGCCCACCTGAAGGGGTGGTTTCCAGCCCTCCGGAGAGTGGGCTTGGCCCTAGGCCCTCCAGCTCAGCCAGAAAAAGC CCAGAAACCCAGGTGCTGGACCAGGGCCCTCAGGGAGGGGACCCTGCGGCTAGAGTGGGCTAGGCCCTGGCTTTGCCCGTCAGATTTGAA CGAATGTGTGTCCCTTGAGCCCAAGGAGAGCGGCAGGAGGGGTGGGACCAGGCTGGGAGGACAGAGCCAGCAGCTGCCATGCCCTCCTGC TCCCCCCACCCCAGCCCTAGCCCTTTAGCCTTTCACCCTGTGCTCTGGAAAGGCTACCAAATACTGGCCAAGGTCAGGAGGAGCAAAAAT >69945_69945_3_PTGDS-HIP1R_PTGDS_chr9_139872144_ENST00000224167_HIP1R_chr12_123342648_ENST00000253083_length(amino acids)=514AA_BP=51 MAPGPGHPLCCRRMATHHTLWMGLALLGVLGDLQAAPEAQVSVQPNFQQDKESQEQGLRQRLLDEQFAVLRGAAAEAAGILQDAVSKLDD PLHLRCTSSPDYLVSRAQEALDAVSTLEEGHAQYLTSLADASALVAALTRFSHLAADTIINGGATSHLAPTDPADRLIDTCRECGARALE LMGQLQDQQALRHMQASLVRTPLQGILQLGQELKPKSLDVRQEELGAVVDKEMAATSAAIEDAVRRIEDMMNQARHASSGVKLEVNERIL NSCTDLMKAIRLLVTTSTSLQKEIVESGRGAATQQEFYAKNSRWTEGLISASKAVGWGATQLVEAADKVVLHTGKYEELIVCSHEIAAST AQLVAASKVKANKHSPHLSRLQECSRTVNERAANVVASTKSGQEQIEDRDTMDFSGLSLIKLKKQEMETQVRVLELEKTLEAERMRLGEL -------------------------------------------------------------- >69945_69945_4_PTGDS-HIP1R_PTGDS_chr9_139872144_ENST00000371625_HIP1R_chr12_123342648_ENST00000253083_length(transcript)=2787nt_BP=188nt CTCCTCCTGCACACCTCCCTCGCTCTCCCACACCACTGGCACCAGGCCCCGGACACCCGCTCTGCTGCAGGAGAATGGCTACTCATCACA CACTGTGGATGGGACTGGCCCTGCTGGGGGTGCTGGGCGACCTGCAGGCAGCACCGGAGGCCCAGGTCTCCGTGCAGCCCAACTTCCAGC AGGACAAGGAGTCTCAGGAGCAGGGGCTGCGGCAGAGGCTGCTGGACGAGCAGTTCGCAGTGTTGCGGGGCGCTGCTGCCGAGGCCGCGG GCATCCTGCAGGATGCCGTGAGCAAGCTGGACGACCCCCTGCACCTGCGCTGTACCAGCTCCCCAGACTACCTGGTGAGCAGGGCCCAGG AGGCCTTGGATGCCGTGAGCACCCTGGAGGAGGGCCACGCCCAGTACCTGACCTCCTTGGCAGACGCCTCCGCCCTGGTGGCAGCTCTGA CCCGCTTCTCCCACCTGGCTGCGGATACCATCATCAATGGCGGTGCCACCTCGCACCTGGCTCCCACCGACCCTGCCGACCGCCTCATAG ACACCTGCAGGGAGTGCGGGGCCCGGGCTCTGGAGCTCATGGGGCAGCTGCAGGACCAGCAGGCTCTGCGGCACATGCAGGCCAGCCTGG TGCGGACACCCCTGCAGGGCATCCTTCAGCTGGGCCAGGAACTGAAACCCAAGAGCCTAGATGTGCGGCAGGAGGAGCTGGGGGCCGTGG TCGACAAGGAGATGGCGGCCACATCCGCAGCCATTGAAGATGCTGTGCGGAGGATTGAGGACATGATGAACCAGGCACGCCACGCCAGCT CGGGGGTGAAGCTGGAGGTGAACGAGAGGATCCTCAACTCCTGCACAGACCTGATGAAGGCTATCCGGCTCCTGGTGACGACATCCACTA GCCTGCAGAAGGAGATCGTGGAGAGCGGCAGGGGGGCAGCCACGCAGCAGGAATTTTACGCCAAGAACTCGCGCTGGACCGAAGGCCTCA TCTCGGCCTCCAAGGCTGTGGGCTGGGGAGCCACACAGCTGGTGGAGGCAGCTGACAAGGTGGTGCTTCACACGGGCAAGTATGAGGAGC TCATCGTCTGCTCCCACGAGATCGCAGCCAGCACGGCCCAGCTGGTGGCGGCCTCCAAGGTGAAGGCCAACAAGCACAGCCCCCACCTGA GCCGCCTGCAGGAATGTTCTCGCACAGTCAATGAGAGGGCTGCCAATGTGGTGGCCTCCACCAAGTCAGGCCAGGAGCAGATTGAGGACA GAGACACCATGGATTTCTCCGGCCTGTCCCTCATCAAGCTGAAGAAGCAGGAGATGGAGACCCAGGTGCGTGTCCTGGAGCTGGAGAAGA CGCTGGAGGCTGAACGCATGCGGCTGGGGGAGTTGCGGAAGCAACACTACGTGCTGGCTGGGGCATCAGGCAGCCCTGGAGAGGAGGTGG CCATCCGGCCCAGCACTGCCCCCCGAAGTGTAACCACCAAGAAACCACCCCTGGCCCAGAAGCCCAGCGTGGCCCCCAGACAGGACCACC AGCTTGACAAAAAGGATGGCATCTACCCAGCTCAACTCGTGAACTACTAGGCCCCCCAGGGGTCCAGCAGGGTGGCTGGTGACAGGCCTG GGCCTCTGCAACTGCCCTGACAGGACCGAGAGGCCTTGCCCCTCCACCTGGTGCCCAAGCCTCCCGCCCCACCGTCTGGATCAATGTCCT CAAGGCCCCTGGCCCTTACTGAGCCTGCAGGGTCCTGGGCCATGTGGGTGGTGCTTCTGGATGTGAGTCTCTTATTTATCTGCAGAAGGA ACTTTGGGGTGCAGCCAGGACCCGGTAGGCCTGAGCCTCAACTCTTCAGAAAATAGTGTTTTTAATATTCCTCTTCAGAAAATAGTGTTT TTAATATTCCGAGCTAGAGCTCTTCTTCCTACGTTTGTAGTCAGCACACTGGGAAACCGGGCCAGCGTGGGGCTCCCTGCCTTCTGGACT CCTGAAGGTCGTGGATGGATGGAAGGCACACAGCCCGTGCCGGCTGATGGGACGAGGGTCAGGCATCCTGTCTGTGGCCTTCTGGGGCAC CGATTCTACCAGGCCCTCCAGCTGCGTGGTCTCCGCAGACCAGGCTCTGTGTGGGCTAGAGGAATGTCGCCCATTACTCCTCAGGCCTGG CCCTCGGGCCTCCGTGATGGGAGCCCCCCAGGAGGGGTCAGATGCTGGAAGGGGCCGCTTTCTGGGGAGTGAGGTGAGACATAGCGGCCC GGGCGCTGCCTTCACTCCTGGAGTGAGTTTCCATTTCCAGCTGGAATCTGCAGCCACCCCCATTTCCTGTTTTCCATTCCCCCGTTCTGG CCGCGCCCCACTGCCCACCTGAAGGGGTGGTTTCCAGCCCTCCGGAGAGTGGGCTTGGCCCTAGGCCCTCCAGCTCAGCCAGAAAAAGCC CAGAAACCCAGGTGCTGGACCAGGGCCCTCAGGGAGGGGACCCTGCGGCTAGAGTGGGCTAGGCCCTGGCTTTGCCCGTCAGATTTGAAC GAATGTGTGTCCCTTGAGCCCAAGGAGAGCGGCAGGAGGGGTGGGACCAGGCTGGGAGGACAGAGCCAGCAGCTGCCATGCCCTCCTGCT CCCCCCACCCCAGCCCTAGCCCTTTAGCCTTTCACCCTGTGCTCTGGAAAGGCTACCAAATACTGGCCAAGGTCAGGAGGAGCAAAAATG >69945_69945_4_PTGDS-HIP1R_PTGDS_chr9_139872144_ENST00000371625_HIP1R_chr12_123342648_ENST00000253083_length(amino acids)=514AA_BP=51 MAPGPGHPLCCRRMATHHTLWMGLALLGVLGDLQAAPEAQVSVQPNFQQDKESQEQGLRQRLLDEQFAVLRGAAAEAAGILQDAVSKLDD PLHLRCTSSPDYLVSRAQEALDAVSTLEEGHAQYLTSLADASALVAALTRFSHLAADTIINGGATSHLAPTDPADRLIDTCRECGARALE LMGQLQDQQALRHMQASLVRTPLQGILQLGQELKPKSLDVRQEELGAVVDKEMAATSAAIEDAVRRIEDMMNQARHASSGVKLEVNERIL NSCTDLMKAIRLLVTTSTSLQKEIVESGRGAATQQEFYAKNSRWTEGLISASKAVGWGATQLVEAADKVVLHTGKYEELIVCSHEIAAST AQLVAASKVKANKHSPHLSRLQECSRTVNERAANVVASTKSGQEQIEDRDTMDFSGLSLIKLKKQEMETQVRVLELEKTLEAERMRLGEL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PTGDS-HIP1R |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PTGDS-HIP1R |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PTGDS-HIP1R |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies