
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PTPRN2-VIPR2 (FusionGDB2 ID:70506) |
Fusion Gene Summary for PTPRN2-VIPR2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PTPRN2-VIPR2 | Fusion gene ID: 70506 | Hgene | Tgene | Gene symbol | PTPRN2 | VIPR2 | Gene ID | 5799 | 7434 |
| Gene name | protein tyrosine phosphatase receptor type N2 | vasoactive intestinal peptide receptor 2 | |
| Synonyms | IA-2beta|IAR|ICAAR|PTPRP|R-PTP-N2 | C16DUPq36.3|DUP7q36.3|PACAP-R-3|PACAP-R3|VIP-R-2|VPAC2|VPAC2R|VPCAP2R | |
| Cytomap | 7q36.3 | 7q36.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | receptor-type tyrosine-protein phosphatase N2IAR/receptor-like protein-tyrosine phosphataseislet cell autoantigen-related proteinphogrinprotein tyrosine phosphatase receptor piprotein tyrosine phosphatase, receptor type, N polypeptide 2tyrosine phos | vasoactive intestinal polypeptide receptor 2PACAP type III receptorVIP and PACAP receptor 2helodermin-preferring VIP receptorpituitary adenylate cyclase-activating polypeptide type III receptor | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000389413, ENST00000389416, ENST00000389418, ENST00000409483, ENST00000404321, | ENST00000421760, ENST00000262178, ENST00000377633, ENST00000402066, | |
| Fusion gene scores | * DoF score | 20 X 17 X 7=2380 | 5 X 5 X 5=125 |
| # samples | 23 | 7 | |
| ** MAII score | log2(23/2380*10)=-3.37125580725093 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/125*10)=-0.836501267717121 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PTPRN2 [Title/Abstract] AND VIPR2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PTPRN2(158380249)-VIPR2(158851269), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across PTPRN2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across VIPR2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-VQ-A92D | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
Top |
Fusion Gene ORF analysis for PTPRN2-VIPR2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000389413 | ENST00000421760 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| 5CDS-intron | ENST00000389416 | ENST00000421760 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| 5CDS-intron | ENST00000389418 | ENST00000421760 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| 5CDS-intron | ENST00000409483 | ENST00000421760 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389413 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389413 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389413 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389416 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389416 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389416 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389418 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389418 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000389418 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000409483 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000409483 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| In-frame | ENST00000409483 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| intron-3CDS | ENST00000404321 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| intron-3CDS | ENST00000404321 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| intron-3CDS | ENST00000404321 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| intron-intron | ENST00000404321 | ENST00000421760 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000389413 | PTPRN2 | chr7 | 158380249 | - | ENST00000262178 | VIPR2 | chr7 | 158851269 | - | 3617 | 216 | 165 | 1175 | 336 |
| ENST00000389413 | PTPRN2 | chr7 | 158380249 | - | ENST00000377633 | VIPR2 | chr7 | 158851269 | - | 1337 | 216 | 165 | 1175 | 336 |
| ENST00000389413 | PTPRN2 | chr7 | 158380249 | - | ENST00000402066 | VIPR2 | chr7 | 158851269 | - | 1274 | 216 | 165 | 1175 | 336 |
| ENST00000409483 | PTPRN2 | chr7 | 158380249 | - | ENST00000262178 | VIPR2 | chr7 | 158851269 | - | 3632 | 231 | 180 | 1190 | 336 |
| ENST00000409483 | PTPRN2 | chr7 | 158380249 | - | ENST00000377633 | VIPR2 | chr7 | 158851269 | - | 1352 | 231 | 180 | 1190 | 336 |
| ENST00000409483 | PTPRN2 | chr7 | 158380249 | - | ENST00000402066 | VIPR2 | chr7 | 158851269 | - | 1289 | 231 | 180 | 1190 | 336 |
| ENST00000389416 | PTPRN2 | chr7 | 158380249 | - | ENST00000262178 | VIPR2 | chr7 | 158851269 | - | 3555 | 154 | 103 | 1113 | 336 |
| ENST00000389416 | PTPRN2 | chr7 | 158380249 | - | ENST00000377633 | VIPR2 | chr7 | 158851269 | - | 1275 | 154 | 103 | 1113 | 336 |
| ENST00000389416 | PTPRN2 | chr7 | 158380249 | - | ENST00000402066 | VIPR2 | chr7 | 158851269 | - | 1212 | 154 | 103 | 1113 | 336 |
| ENST00000389418 | PTPRN2 | chr7 | 158380249 | - | ENST00000262178 | VIPR2 | chr7 | 158851269 | - | 3523 | 122 | 71 | 1081 | 336 |
| ENST00000389418 | PTPRN2 | chr7 | 158380249 | - | ENST00000377633 | VIPR2 | chr7 | 158851269 | - | 1243 | 122 | 71 | 1081 | 336 |
| ENST00000389418 | PTPRN2 | chr7 | 158380249 | - | ENST00000402066 | VIPR2 | chr7 | 158851269 | - | 1180 | 122 | 71 | 1081 | 336 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000389413 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.09585751 | 0.9041425 |
| ENST00000389413 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.052608613 | 0.9473914 |
| ENST00000389413 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.054242916 | 0.9457571 |
| ENST00000409483 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.09916668 | 0.90083337 |
| ENST00000409483 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.05610615 | 0.9438938 |
| ENST00000409483 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.057208143 | 0.9427918 |
| ENST00000389416 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.097534545 | 0.90246546 |
| ENST00000389416 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.066053286 | 0.93394667 |
| ENST00000389416 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.06482136 | 0.9351787 |
| ENST00000389418 | ENST00000262178 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.09949982 | 0.90050024 |
| ENST00000389418 | ENST00000377633 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.08013844 | 0.9198616 |
| ENST00000389418 | ENST00000402066 | PTPRN2 | chr7 | 158380249 | - | VIPR2 | chr7 | 158851269 | - | 0.08063965 | 0.91936034 |
Top |
Fusion Genomic Features for PTPRN2-VIPR2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
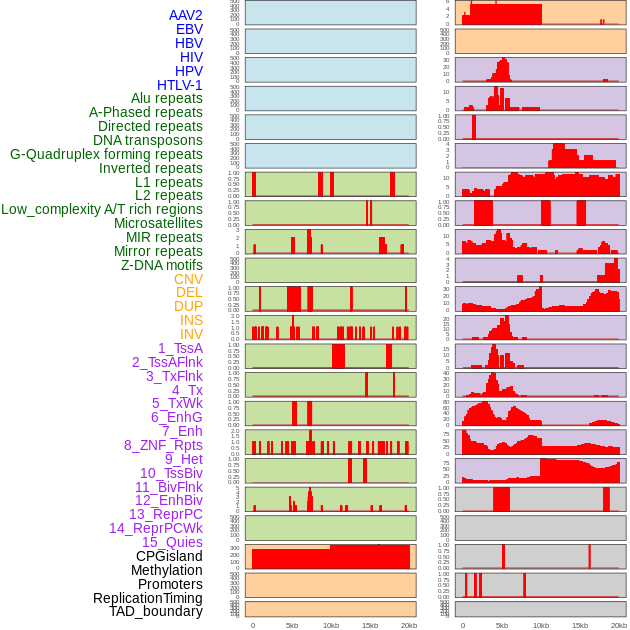 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PTPRN2-VIPR2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:158380249/chr7:158851269) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 152_158 | 119 | 439.0 | Topological domain | Cytoplasmic | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 179_203 | 119 | 439.0 | Topological domain | Extracellular | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 228_240 | 119 | 439.0 | Topological domain | Cytoplasmic | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 263_279 | 119 | 439.0 | Topological domain | Extracellular | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 304_328 | 119 | 439.0 | Topological domain | Cytoplasmic | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 349_360 | 119 | 439.0 | Topological domain | Extracellular | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 381_438 | 119 | 439.0 | Topological domain | Cytoplasmic | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 127_151 | 119 | 439.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 159_178 | 119 | 439.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 204_227 | 119 | 439.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 241_262 | 119 | 439.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 280_303 | 119 | 439.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 329_348 | 119 | 439.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 361_380 | 119 | 439.0 | Transmembrane | Helical%3B Name%3D7 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389413 | - | 1 | 22 | 745_1005 | 37 | 987.0 | Domain | Tyrosine-protein phosphatase |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389416 | - | 1 | 22 | 745_1005 | 37 | 999.0 | Domain | Tyrosine-protein phosphatase |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389418 | - | 1 | 23 | 745_1005 | 37 | 1016.0 | Domain | Tyrosine-protein phosphatase |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000404321 | - | 1 | 23 | 745_1005 | 0 | 1039.0 | Domain | Tyrosine-protein phosphatase |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389413 | - | 1 | 22 | 1004_1010 | 37 | 987.0 | Motif | Leucine-based sorting signal |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389413 | - | 1 | 22 | 666_675 | 37 | 987.0 | Motif | Tyrosine-based internalization motif |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389416 | - | 1 | 22 | 1004_1010 | 37 | 999.0 | Motif | Leucine-based sorting signal |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389416 | - | 1 | 22 | 666_675 | 37 | 999.0 | Motif | Tyrosine-based internalization motif |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389418 | - | 1 | 23 | 1004_1010 | 37 | 1016.0 | Motif | Leucine-based sorting signal |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389418 | - | 1 | 23 | 666_675 | 37 | 1016.0 | Motif | Tyrosine-based internalization motif |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000404321 | - | 1 | 23 | 1004_1010 | 0 | 1039.0 | Motif | Leucine-based sorting signal |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000404321 | - | 1 | 23 | 666_675 | 0 | 1039.0 | Motif | Tyrosine-based internalization motif |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389413 | - | 1 | 22 | 945_951 | 37 | 987.0 | Region | Substrate binding |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389416 | - | 1 | 22 | 945_951 | 37 | 999.0 | Region | Substrate binding |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389418 | - | 1 | 23 | 945_951 | 37 | 1016.0 | Region | Substrate binding |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000404321 | - | 1 | 23 | 945_951 | 0 | 1039.0 | Region | Substrate binding |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389413 | - | 1 | 22 | 22_615 | 37 | 987.0 | Topological domain | Extracellular |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389413 | - | 1 | 22 | 637_1015 | 37 | 987.0 | Topological domain | Cytoplasmic |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389416 | - | 1 | 22 | 22_615 | 37 | 999.0 | Topological domain | Extracellular |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389416 | - | 1 | 22 | 637_1015 | 37 | 999.0 | Topological domain | Cytoplasmic |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389418 | - | 1 | 23 | 22_615 | 37 | 1016.0 | Topological domain | Extracellular |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389418 | - | 1 | 23 | 637_1015 | 37 | 1016.0 | Topological domain | Cytoplasmic |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000404321 | - | 1 | 23 | 22_615 | 0 | 1039.0 | Topological domain | Extracellular |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000404321 | - | 1 | 23 | 637_1015 | 0 | 1039.0 | Topological domain | Cytoplasmic |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389413 | - | 1 | 22 | 616_636 | 37 | 987.0 | Transmembrane | Helical |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389416 | - | 1 | 22 | 616_636 | 37 | 999.0 | Transmembrane | Helical |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000389418 | - | 1 | 23 | 616_636 | 37 | 1016.0 | Transmembrane | Helical |
| Hgene | PTPRN2 | chr7:158380249 | chr7:158851269 | ENST00000404321 | - | 1 | 23 | 616_636 | 0 | 1039.0 | Transmembrane | Helical |
| Tgene | VIPR2 | chr7:158380249 | chr7:158851269 | ENST00000262178 | 3 | 13 | 24_126 | 119 | 439.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for PTPRN2-VIPR2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >70506_70506_1_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389413_VIPR2_chr7_158851269_ENST00000262178_length(transcript)=3617nt_BP=216nt GGCGGGAGGAGCCGGCGGCGCGCGCCTCCCTGGGCCCGGACTCGGCCGCCTCCCGCCGCCTCCCGCGCGGCCATGGACTGAGCGCCGCCG GCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGCCTGCCGCCCCTTCGT CCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTGGGCTACAGTGTCTCT CTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCACCTGAACCTGTTCCTG TCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGCCCTGACCAGCCATCC TCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTGGAGGGGCTCTACCTC CACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCCACCGTCTGCATCGGT GCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGGGTCATACGAATACCG ATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCCCCAGATGTCGGCGGC AACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATGGTGTTTGCCGTGTTT CCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCCGTCCTCTACTGTTTC CTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGATTACAGGGTCTGCGGT TCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAAACGGAGACCTCGGTC ATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGGCTTCCTCCTTCCAGA TGCCCGAGCACCGTGTCGGGCAGGTCAGCGCGGTCCTGACTCCGTCAAGCTGGTTGTCCACTAAACCCCATACCTGGAATTGGAGTCGTG TTGTCATTGACTCGATTTAAACTCCAGCATTTAGATAATCTTGTGCAAAATGTGTTTCAGCCGTATAGTGGATCCACTTTTTTTTTTTTT TTTTTTTTTGAGACGGAGTCTCGCTCTGTCGCCCAGGCTGGACTGCAGTGGCCTGATCTCTGCTCCCTGCAAGCTCCGCCTCCCGGGTTC ACGCCATTCTCCTGCCTCAGCCTCCCATAGCTGGGACTACAGGCGCCCGCCAACACGCCTGGCTAATTTTTTGTATTTTTAGTAGAGACA GGGTTTCACCATGTTAGCCAGGATGGTCTCGATCTCCTGACCTCGTGATGGGCCCGCCTCGGCCTCCCAAAGTGCTGGGATTAAGGCGTG AGCCACTGCGCCCGGCCCAAGAGAATAGGGGAGCCAAGGAGGAAATGTGGAAACGCAGTTGTGTGGCCCAGCACGAGCCTGGGCGACCAC CGGGTGACATCCGTCCCACATCAGGGCGGCCTCCCAGGTCCCATAAGGGTAGCCCCCTCATCTGCAGGACAGAGGGAAGCCAGTCAGGGC CCCCCTGACGTTAGGACCAGGAGAAATCAACAGGAGGGCAGCCCGTCCTCTCTCTTGGGGCGCCCACCCGGCCCGGCTGAGCCCTGCCCC ACCCAACTCCACAGGGCTGTTTTGCCTCCCCACGGAAGGCGGGCTGAGGAGACAACCAGATCAGGAGAGCAAGGTCATGAAGGAGGGGAC CTCTCCACACAGGTGTTCCGTGGGACCCTCAGCAGCTCTGGCTCTGCCTCAGGAGGTCACCTGCCGCCCTGTGGGAGCCGCAGAGCCTGA CGCTCAGCCCCAGGCCAGCTGCGGCCAGGCCTGCGGGCCCCTGGTGATGGGGTTACGTGGGGTGCGGGATACAGCTGAGTGGGAACCGGA AACCTATTCTCTTTTTAACAAAAATAATCTTAGGATAAGAATTATTTTAACAACATATAAAACTGTTTCAAGCCCTCCTCCCCAGAGCTG GCGCTCAGCAGCCCTAGCGGCTGCTCCTTCAGGCGAAGGGTGGTTTGCAGATGTGGGGAGGGTGTCTGGGGACGTTGCTGAGCCAGCTGC AGAAGGGTGGGGATATCAGGGCACAGTCTCCATGTGTGTGCCAAGCCCTGGCCCCCACAGCGCTCGATGGACCTCAGCAAGCTGCCCAGC CCTGGCCCAGGTGCCCCGACTGTGGGACTCAGTTGTTCTGAGCACATTTGACTCCACTTTTCCCTTAAAAATGAATGTCTTGTTCCTGTG CATTGGTGGCATCACAGACCCCAGCTGGGGCGCGATGTCAAAGGTCGGGACAGCTGTGCCGGGAGGCAGCCACAGGGAAGCTCACACATC CTGTCAGTGTCACCTTGGTTTGCAAAACCCATATCCCCGGTAAAATGAGGCCGGACAGAGGGGCTGTTAGGACAGCAAAGCAGCAGTGTC CAGAGACCCCTCAATCCCCAAAGGTCCGCACCCTGTCCTGCACACCCTGGGCCACGCCGGCCACACCCCTCTGCTGCAACAAGCTCATCC CTGGACTTCTGGGAGAATGAACCCGAGGTTGGTTTGGGGAGACAGGTGAGGCGGTCGGATCTACAGAACAACCCACCATTTCTGGGGGCC GCAGAGGATCCATCACAGACGGATACTGGGGAGTAAACGGCCCAGGCCAGGTGCCCAGGAAAGGACGGCTGAGCATGTGGAGCGAGAGGG AGGCAGGTGGACGCTGCAGACCCCAGGTTCAGTGCGGCCCCTCGGCTGTTCCTCCCCTGTAGGGTTTGGACAGACCCACCCCCAGCCTTG CCCAGCTTTCAAAGGACAAAAGGGAGCATCCCCCACCTACTCTCAGGTTTTTGAGGAAACAAAGATTTGTGGTAACTGAAGGTGTTGGGT CAGTGGCCAGGTGCCGACACTGAGCTGTGACCCAGAGGGGACGCTGAGGAAGTGGGCGTGAGTGGACGTGTCAGGTGGTTACCAGGCACT GGTTGTTGATGGTCGGTGGTTGGGTGTGGGCAGTCATCAGTCATCAGGTGTGCTCAGGGGACAATCTCCCCTCAACCGCACATGTGCCAC TGTTCAGCGGAGCTGACTGGTTTCTCCTGGTAGAGGGGCCGGCTGTTTCCTGACAGATGCCTGGTGAGCAGGGGAAGCAGGACCCAGTGG TCAGCAGGTGTCTTTAACTGTCATTGTGTGTGGAATGTCGCAGACTCCTCCACGTGGCGGGAATGAGCTGTGTAAATACTTCAATAAAGC >70506_70506_1_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389413_VIPR2_chr7_158851269_ENST00000262178_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_2_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389413_VIPR2_chr7_158851269_ENST00000377633_length(transcript)=1337nt_BP=216nt GGCGGGAGGAGCCGGCGGCGCGCGCCTCCCTGGGCCCGGACTCGGCCGCCTCCCGCCGCCTCCCGCGCGGCCATGGACTGAGCGCCGCCG GCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGCCTGCCGCCCCTTCGT CCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTGGGCTACAGTGTCTCT CTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCACCTGAACCTGTTCCTG TCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGCCCTGACCAGCCATCC TCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTGGAGGGGCTCTACCTC CACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCCACCGTCTGCATCGGT GCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGGGTCATACGAATACCG ATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCCCCAGATGTCGGCGGC AACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATGGTGTTTGCCGTGTTT CCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCCGTCCTCTACTGTTTC CTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGATTACAGGGTCTGCGGT TCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAAACGGAGACCTCGGTC ATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGGCTTCCTCCTTCCAGA >70506_70506_2_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389413_VIPR2_chr7_158851269_ENST00000377633_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_3_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389413_VIPR2_chr7_158851269_ENST00000402066_length(transcript)=1274nt_BP=216nt GGCGGGAGGAGCCGGCGGCGCGCGCCTCCCTGGGCCCGGACTCGGCCGCCTCCCGCCGCCTCCCGCGCGGCCATGGACTGAGCGCCGCCG GCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGCCTGCCGCCCCTTCGT CCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTGGGCTACAGTGTCTCT CTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCACCTGAACCTGTTCCTG TCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGCCCTGACCAGCCATCC TCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTGGAGGGGCTCTACCTC CACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCCACCGTCTGCATCGGT GCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGGGTCATACGAATACCG ATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCCCCAGATGTCGGCGGC AACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATGGTGTTTGCCGTGTTT CCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCCGTCCTCTACTGTTTC CTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGATTACAGGGTCTGCGGT TCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAAACGGAGACCTCGGTC ATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGGCTTCCTCCTTCCAGA >70506_70506_3_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389413_VIPR2_chr7_158851269_ENST00000402066_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_4_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389416_VIPR2_chr7_158851269_ENST00000262178_length(transcript)=3555nt_BP=154nt CCGCGCGGCCATGGACTGAGCGCCGCCGGCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCG CCACGCGTCCTGCCTGCCGCCCCTTCGTCCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGC CATTTATACACTGGGCTACAGTGTCTCTCTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAG GAATTACATCCACCTGAACCTGTTCCTGTCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGG CACGTTGCACTGCCCTGACCAGCCATCCTCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTT CTGGCTGCTGGTGGAGGGGCTCTACCTCCACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGG ATGGGGCCTCCCCACCGTCTGCATCGGTGCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAG TGTGCCCTGGTGGGTCATACGAATACCGATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCA GAAGTTAACATCCCCAGATGTCGGCGGCAACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGG CGTCCACTACATGGTGTTTGCCGTGTTTCCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGG CCTGGTGGTGGCCGTCCTCTACTGTTTCCTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTC CGCGAGCCGGGATTACAGGGTCTGCGGTTCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCA GTCCTTCCTGCAAACGGAGACCTCGGTCATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGG GCTGAGACGCCGGCTTCCTCCTTCCAGATGCCCGAGCACCGTGTCGGGCAGGTCAGCGCGGTCCTGACTCCGTCAAGCTGGTTGTCCACT AAACCCCATACCTGGAATTGGAGTCGTGTTGTCATTGACTCGATTTAAACTCCAGCATTTAGATAATCTTGTGCAAAATGTGTTTCAGCC GTATAGTGGATCCACTTTTTTTTTTTTTTTTTTTTTTGAGACGGAGTCTCGCTCTGTCGCCCAGGCTGGACTGCAGTGGCCTGATCTCTG CTCCCTGCAAGCTCCGCCTCCCGGGTTCACGCCATTCTCCTGCCTCAGCCTCCCATAGCTGGGACTACAGGCGCCCGCCAACACGCCTGG CTAATTTTTTGTATTTTTAGTAGAGACAGGGTTTCACCATGTTAGCCAGGATGGTCTCGATCTCCTGACCTCGTGATGGGCCCGCCTCGG CCTCCCAAAGTGCTGGGATTAAGGCGTGAGCCACTGCGCCCGGCCCAAGAGAATAGGGGAGCCAAGGAGGAAATGTGGAAACGCAGTTGT GTGGCCCAGCACGAGCCTGGGCGACCACCGGGTGACATCCGTCCCACATCAGGGCGGCCTCCCAGGTCCCATAAGGGTAGCCCCCTCATC TGCAGGACAGAGGGAAGCCAGTCAGGGCCCCCCTGACGTTAGGACCAGGAGAAATCAACAGGAGGGCAGCCCGTCCTCTCTCTTGGGGCG CCCACCCGGCCCGGCTGAGCCCTGCCCCACCCAACTCCACAGGGCTGTTTTGCCTCCCCACGGAAGGCGGGCTGAGGAGACAACCAGATC AGGAGAGCAAGGTCATGAAGGAGGGGACCTCTCCACACAGGTGTTCCGTGGGACCCTCAGCAGCTCTGGCTCTGCCTCAGGAGGTCACCT GCCGCCCTGTGGGAGCCGCAGAGCCTGACGCTCAGCCCCAGGCCAGCTGCGGCCAGGCCTGCGGGCCCCTGGTGATGGGGTTACGTGGGG TGCGGGATACAGCTGAGTGGGAACCGGAAACCTATTCTCTTTTTAACAAAAATAATCTTAGGATAAGAATTATTTTAACAACATATAAAA CTGTTTCAAGCCCTCCTCCCCAGAGCTGGCGCTCAGCAGCCCTAGCGGCTGCTCCTTCAGGCGAAGGGTGGTTTGCAGATGTGGGGAGGG TGTCTGGGGACGTTGCTGAGCCAGCTGCAGAAGGGTGGGGATATCAGGGCACAGTCTCCATGTGTGTGCCAAGCCCTGGCCCCCACAGCG CTCGATGGACCTCAGCAAGCTGCCCAGCCCTGGCCCAGGTGCCCCGACTGTGGGACTCAGTTGTTCTGAGCACATTTGACTCCACTTTTC CCTTAAAAATGAATGTCTTGTTCCTGTGCATTGGTGGCATCACAGACCCCAGCTGGGGCGCGATGTCAAAGGTCGGGACAGCTGTGCCGG GAGGCAGCCACAGGGAAGCTCACACATCCTGTCAGTGTCACCTTGGTTTGCAAAACCCATATCCCCGGTAAAATGAGGCCGGACAGAGGG GCTGTTAGGACAGCAAAGCAGCAGTGTCCAGAGACCCCTCAATCCCCAAAGGTCCGCACCCTGTCCTGCACACCCTGGGCCACGCCGGCC ACACCCCTCTGCTGCAACAAGCTCATCCCTGGACTTCTGGGAGAATGAACCCGAGGTTGGTTTGGGGAGACAGGTGAGGCGGTCGGATCT ACAGAACAACCCACCATTTCTGGGGGCCGCAGAGGATCCATCACAGACGGATACTGGGGAGTAAACGGCCCAGGCCAGGTGCCCAGGAAA GGACGGCTGAGCATGTGGAGCGAGAGGGAGGCAGGTGGACGCTGCAGACCCCAGGTTCAGTGCGGCCCCTCGGCTGTTCCTCCCCTGTAG GGTTTGGACAGACCCACCCCCAGCCTTGCCCAGCTTTCAAAGGACAAAAGGGAGCATCCCCCACCTACTCTCAGGTTTTTGAGGAAACAA AGATTTGTGGTAACTGAAGGTGTTGGGTCAGTGGCCAGGTGCCGACACTGAGCTGTGACCCAGAGGGGACGCTGAGGAAGTGGGCGTGAG TGGACGTGTCAGGTGGTTACCAGGCACTGGTTGTTGATGGTCGGTGGTTGGGTGTGGGCAGTCATCAGTCATCAGGTGTGCTCAGGGGAC AATCTCCCCTCAACCGCACATGTGCCACTGTTCAGCGGAGCTGACTGGTTTCTCCTGGTAGAGGGGCCGGCTGTTTCCTGACAGATGCCT GGTGAGCAGGGGAAGCAGGACCCAGTGGTCAGCAGGTGTCTTTAACTGTCATTGTGTGTGGAATGTCGCAGACTCCTCCACGTGGCGGGA >70506_70506_4_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389416_VIPR2_chr7_158851269_ENST00000262178_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_5_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389416_VIPR2_chr7_158851269_ENST00000377633_length(transcript)=1275nt_BP=154nt CCGCGCGGCCATGGACTGAGCGCCGCCGGCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCG CCACGCGTCCTGCCTGCCGCCCCTTCGTCCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGC CATTTATACACTGGGCTACAGTGTCTCTCTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAG GAATTACATCCACCTGAACCTGTTCCTGTCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGG CACGTTGCACTGCCCTGACCAGCCATCCTCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTT CTGGCTGCTGGTGGAGGGGCTCTACCTCCACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGG ATGGGGCCTCCCCACCGTCTGCATCGGTGCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAG TGTGCCCTGGTGGGTCATACGAATACCGATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCA GAAGTTAACATCCCCAGATGTCGGCGGCAACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGG CGTCCACTACATGGTGTTTGCCGTGTTTCCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGG CCTGGTGGTGGCCGTCCTCTACTGTTTCCTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTC CGCGAGCCGGGATTACAGGGTCTGCGGTTCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCA GTCCTTCCTGCAAACGGAGACCTCGGTCATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGG GCTGAGACGCCGGCTTCCTCCTTCCAGATGCCCGAGCACCGTGTCGGGCAGGTCAGCGCGGTCCTGACTCCGTCAAGCTGGTTGTCCACT >70506_70506_5_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389416_VIPR2_chr7_158851269_ENST00000377633_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_6_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389416_VIPR2_chr7_158851269_ENST00000402066_length(transcript)=1212nt_BP=154nt CCGCGCGGCCATGGACTGAGCGCCGCCGGCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCG CCACGCGTCCTGCCTGCCGCCCCTTCGTCCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGC CATTTATACACTGGGCTACAGTGTCTCTCTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAG GAATTACATCCACCTGAACCTGTTCCTGTCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGG CACGTTGCACTGCCCTGACCAGCCATCCTCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTT CTGGCTGCTGGTGGAGGGGCTCTACCTCCACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGG ATGGGGCCTCCCCACCGTCTGCATCGGTGCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAG TGTGCCCTGGTGGGTCATACGAATACCGATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCA GAAGTTAACATCCCCAGATGTCGGCGGCAACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGG CGTCCACTACATGGTGTTTGCCGTGTTTCCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGG CCTGGTGGTGGCCGTCCTCTACTGTTTCCTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTC CGCGAGCCGGGATTACAGGGTCTGCGGTTCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCA GTCCTTCCTGCAAACGGAGACCTCGGTCATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGG >70506_70506_6_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389416_VIPR2_chr7_158851269_ENST00000402066_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_7_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389418_VIPR2_chr7_158851269_ENST00000262178_length(transcript)=3523nt_BP=122nt GGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGCCTGCCGCCCCTTCGTCCGT CCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTGGGCTACAGTGTCTCTCTGA TGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCACCTGAACCTGTTCCTGTCCT TCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGCCCTGACCAGCCATCCTCCT GGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTGGAGGGGCTCTACCTCCACA CCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCCACCGTCTGCATCGGTGCAT GGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGGGTCATACGAATACCGATTT TAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCCCCAGATGTCGGCGGCAACG ACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATGGTGTTTGCCGTGTTTCCCA TCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCCGTCCTCTACTGTTTCCTGA ACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGATTACAGGGTCTGCGGTTCCT CCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAAACGGAGACCTCGGTCATCT AGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGGCTTCCTCCTTCCAGATGCC CGAGCACCGTGTCGGGCAGGTCAGCGCGGTCCTGACTCCGTCAAGCTGGTTGTCCACTAAACCCCATACCTGGAATTGGAGTCGTGTTGT CATTGACTCGATTTAAACTCCAGCATTTAGATAATCTTGTGCAAAATGTGTTTCAGCCGTATAGTGGATCCACTTTTTTTTTTTTTTTTT TTTTTGAGACGGAGTCTCGCTCTGTCGCCCAGGCTGGACTGCAGTGGCCTGATCTCTGCTCCCTGCAAGCTCCGCCTCCCGGGTTCACGC CATTCTCCTGCCTCAGCCTCCCATAGCTGGGACTACAGGCGCCCGCCAACACGCCTGGCTAATTTTTTGTATTTTTAGTAGAGACAGGGT TTCACCATGTTAGCCAGGATGGTCTCGATCTCCTGACCTCGTGATGGGCCCGCCTCGGCCTCCCAAAGTGCTGGGATTAAGGCGTGAGCC ACTGCGCCCGGCCCAAGAGAATAGGGGAGCCAAGGAGGAAATGTGGAAACGCAGTTGTGTGGCCCAGCACGAGCCTGGGCGACCACCGGG TGACATCCGTCCCACATCAGGGCGGCCTCCCAGGTCCCATAAGGGTAGCCCCCTCATCTGCAGGACAGAGGGAAGCCAGTCAGGGCCCCC CTGACGTTAGGACCAGGAGAAATCAACAGGAGGGCAGCCCGTCCTCTCTCTTGGGGCGCCCACCCGGCCCGGCTGAGCCCTGCCCCACCC AACTCCACAGGGCTGTTTTGCCTCCCCACGGAAGGCGGGCTGAGGAGACAACCAGATCAGGAGAGCAAGGTCATGAAGGAGGGGACCTCT CCACACAGGTGTTCCGTGGGACCCTCAGCAGCTCTGGCTCTGCCTCAGGAGGTCACCTGCCGCCCTGTGGGAGCCGCAGAGCCTGACGCT CAGCCCCAGGCCAGCTGCGGCCAGGCCTGCGGGCCCCTGGTGATGGGGTTACGTGGGGTGCGGGATACAGCTGAGTGGGAACCGGAAACC TATTCTCTTTTTAACAAAAATAATCTTAGGATAAGAATTATTTTAACAACATATAAAACTGTTTCAAGCCCTCCTCCCCAGAGCTGGCGC TCAGCAGCCCTAGCGGCTGCTCCTTCAGGCGAAGGGTGGTTTGCAGATGTGGGGAGGGTGTCTGGGGACGTTGCTGAGCCAGCTGCAGAA GGGTGGGGATATCAGGGCACAGTCTCCATGTGTGTGCCAAGCCCTGGCCCCCACAGCGCTCGATGGACCTCAGCAAGCTGCCCAGCCCTG GCCCAGGTGCCCCGACTGTGGGACTCAGTTGTTCTGAGCACATTTGACTCCACTTTTCCCTTAAAAATGAATGTCTTGTTCCTGTGCATT GGTGGCATCACAGACCCCAGCTGGGGCGCGATGTCAAAGGTCGGGACAGCTGTGCCGGGAGGCAGCCACAGGGAAGCTCACACATCCTGT CAGTGTCACCTTGGTTTGCAAAACCCATATCCCCGGTAAAATGAGGCCGGACAGAGGGGCTGTTAGGACAGCAAAGCAGCAGTGTCCAGA GACCCCTCAATCCCCAAAGGTCCGCACCCTGTCCTGCACACCCTGGGCCACGCCGGCCACACCCCTCTGCTGCAACAAGCTCATCCCTGG ACTTCTGGGAGAATGAACCCGAGGTTGGTTTGGGGAGACAGGTGAGGCGGTCGGATCTACAGAACAACCCACCATTTCTGGGGGCCGCAG AGGATCCATCACAGACGGATACTGGGGAGTAAACGGCCCAGGCCAGGTGCCCAGGAAAGGACGGCTGAGCATGTGGAGCGAGAGGGAGGC AGGTGGACGCTGCAGACCCCAGGTTCAGTGCGGCCCCTCGGCTGTTCCTCCCCTGTAGGGTTTGGACAGACCCACCCCCAGCCTTGCCCA GCTTTCAAAGGACAAAAGGGAGCATCCCCCACCTACTCTCAGGTTTTTGAGGAAACAAAGATTTGTGGTAACTGAAGGTGTTGGGTCAGT GGCCAGGTGCCGACACTGAGCTGTGACCCAGAGGGGACGCTGAGGAAGTGGGCGTGAGTGGACGTGTCAGGTGGTTACCAGGCACTGGTT GTTGATGGTCGGTGGTTGGGTGTGGGCAGTCATCAGTCATCAGGTGTGCTCAGGGGACAATCTCCCCTCAACCGCACATGTGCCACTGTT CAGCGGAGCTGACTGGTTTCTCCTGGTAGAGGGGCCGGCTGTTTCCTGACAGATGCCTGGTGAGCAGGGGAAGCAGGACCCAGTGGTCAG CAGGTGTCTTTAACTGTCATTGTGTGTGGAATGTCGCAGACTCCTCCACGTGGCGGGAATGAGCTGTGTAAATACTTCAATAAAGCCTGA >70506_70506_7_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389418_VIPR2_chr7_158851269_ENST00000262178_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_8_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389418_VIPR2_chr7_158851269_ENST00000377633_length(transcript)=1243nt_BP=122nt GGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGCCTGCCGCCCCTTCGTCCGT CCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTGGGCTACAGTGTCTCTCTGA TGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCACCTGAACCTGTTCCTGTCCT TCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGCCCTGACCAGCCATCCTCCT GGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTGGAGGGGCTCTACCTCCACA CCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCCACCGTCTGCATCGGTGCAT GGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGGGTCATACGAATACCGATTT TAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCCCCAGATGTCGGCGGCAACG ACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATGGTGTTTGCCGTGTTTCCCA TCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCCGTCCTCTACTGTTTCCTGA ACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGATTACAGGGTCTGCGGTTCCT CCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAAACGGAGACCTCGGTCATCT AGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGGCTTCCTCCTTCCAGATGCC >70506_70506_8_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389418_VIPR2_chr7_158851269_ENST00000377633_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_9_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389418_VIPR2_chr7_158851269_ENST00000402066_length(transcript)=1180nt_BP=122nt GGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGCCTGCCGCCCCTTCGTCCGT CCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTGGGCTACAGTGTCTCTCTGA TGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCACCTGAACCTGTTCCTGTCCT TCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGCCCTGACCAGCCATCCTCCT GGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTGGAGGGGCTCTACCTCCACA CCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCCACCGTCTGCATCGGTGCAT GGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGGGTCATACGAATACCGATTT TAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCCCCAGATGTCGGCGGCAACG ACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATGGTGTTTGCCGTGTTTCCCA TCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCCGTCCTCTACTGTTTCCTGA ACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGATTACAGGGTCTGCGGTTCCT CCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAAACGGAGACCTCGGTCATCT AGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGGCTTCCTCCTTCCAGATGCC >70506_70506_9_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000389418_VIPR2_chr7_158851269_ENST00000402066_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_10_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000409483_VIPR2_chr7_158851269_ENST00000262178_length(transcript)=3632nt_BP=231nt GAGCGCGAGAGGCGCGGCGGGAGGAGCCGGCGGCGCGCGCCTCCCTGGGCCCGGACTCGGCCGCCTCCCGCCGCCTCCCGCGCGGCCATG GACTGAGCGCCGCCGGCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGC CTGCCGCCCCTTCGTCCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTG GGCTACAGTGTCTCTCTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCAC CTGAACCTGTTCCTGTCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGC CCTGACCAGCCATCCTCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTG GAGGGGCTCTACCTCCACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCC ACCGTCTGCATCGGTGCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGG GTCATACGAATACCGATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCC CCAGATGTCGGCGGCAACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATG GTGTTTGCCGTGTTTCCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCC GTCCTCTACTGTTTCCTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGAT TACAGGGTCTGCGGTTCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAA ACGGAGACCTCGGTCATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGG CTTCCTCCTTCCAGATGCCCGAGCACCGTGTCGGGCAGGTCAGCGCGGTCCTGACTCCGTCAAGCTGGTTGTCCACTAAACCCCATACCT GGAATTGGAGTCGTGTTGTCATTGACTCGATTTAAACTCCAGCATTTAGATAATCTTGTGCAAAATGTGTTTCAGCCGTATAGTGGATCC ACTTTTTTTTTTTTTTTTTTTTTTGAGACGGAGTCTCGCTCTGTCGCCCAGGCTGGACTGCAGTGGCCTGATCTCTGCTCCCTGCAAGCT CCGCCTCCCGGGTTCACGCCATTCTCCTGCCTCAGCCTCCCATAGCTGGGACTACAGGCGCCCGCCAACACGCCTGGCTAATTTTTTGTA TTTTTAGTAGAGACAGGGTTTCACCATGTTAGCCAGGATGGTCTCGATCTCCTGACCTCGTGATGGGCCCGCCTCGGCCTCCCAAAGTGC TGGGATTAAGGCGTGAGCCACTGCGCCCGGCCCAAGAGAATAGGGGAGCCAAGGAGGAAATGTGGAAACGCAGTTGTGTGGCCCAGCACG AGCCTGGGCGACCACCGGGTGACATCCGTCCCACATCAGGGCGGCCTCCCAGGTCCCATAAGGGTAGCCCCCTCATCTGCAGGACAGAGG GAAGCCAGTCAGGGCCCCCCTGACGTTAGGACCAGGAGAAATCAACAGGAGGGCAGCCCGTCCTCTCTCTTGGGGCGCCCACCCGGCCCG GCTGAGCCCTGCCCCACCCAACTCCACAGGGCTGTTTTGCCTCCCCACGGAAGGCGGGCTGAGGAGACAACCAGATCAGGAGAGCAAGGT CATGAAGGAGGGGACCTCTCCACACAGGTGTTCCGTGGGACCCTCAGCAGCTCTGGCTCTGCCTCAGGAGGTCACCTGCCGCCCTGTGGG AGCCGCAGAGCCTGACGCTCAGCCCCAGGCCAGCTGCGGCCAGGCCTGCGGGCCCCTGGTGATGGGGTTACGTGGGGTGCGGGATACAGC TGAGTGGGAACCGGAAACCTATTCTCTTTTTAACAAAAATAATCTTAGGATAAGAATTATTTTAACAACATATAAAACTGTTTCAAGCCC TCCTCCCCAGAGCTGGCGCTCAGCAGCCCTAGCGGCTGCTCCTTCAGGCGAAGGGTGGTTTGCAGATGTGGGGAGGGTGTCTGGGGACGT TGCTGAGCCAGCTGCAGAAGGGTGGGGATATCAGGGCACAGTCTCCATGTGTGTGCCAAGCCCTGGCCCCCACAGCGCTCGATGGACCTC AGCAAGCTGCCCAGCCCTGGCCCAGGTGCCCCGACTGTGGGACTCAGTTGTTCTGAGCACATTTGACTCCACTTTTCCCTTAAAAATGAA TGTCTTGTTCCTGTGCATTGGTGGCATCACAGACCCCAGCTGGGGCGCGATGTCAAAGGTCGGGACAGCTGTGCCGGGAGGCAGCCACAG GGAAGCTCACACATCCTGTCAGTGTCACCTTGGTTTGCAAAACCCATATCCCCGGTAAAATGAGGCCGGACAGAGGGGCTGTTAGGACAG CAAAGCAGCAGTGTCCAGAGACCCCTCAATCCCCAAAGGTCCGCACCCTGTCCTGCACACCCTGGGCCACGCCGGCCACACCCCTCTGCT GCAACAAGCTCATCCCTGGACTTCTGGGAGAATGAACCCGAGGTTGGTTTGGGGAGACAGGTGAGGCGGTCGGATCTACAGAACAACCCA CCATTTCTGGGGGCCGCAGAGGATCCATCACAGACGGATACTGGGGAGTAAACGGCCCAGGCCAGGTGCCCAGGAAAGGACGGCTGAGCA TGTGGAGCGAGAGGGAGGCAGGTGGACGCTGCAGACCCCAGGTTCAGTGCGGCCCCTCGGCTGTTCCTCCCCTGTAGGGTTTGGACAGAC CCACCCCCAGCCTTGCCCAGCTTTCAAAGGACAAAAGGGAGCATCCCCCACCTACTCTCAGGTTTTTGAGGAAACAAAGATTTGTGGTAA CTGAAGGTGTTGGGTCAGTGGCCAGGTGCCGACACTGAGCTGTGACCCAGAGGGGACGCTGAGGAAGTGGGCGTGAGTGGACGTGTCAGG TGGTTACCAGGCACTGGTTGTTGATGGTCGGTGGTTGGGTGTGGGCAGTCATCAGTCATCAGGTGTGCTCAGGGGACAATCTCCCCTCAA CCGCACATGTGCCACTGTTCAGCGGAGCTGACTGGTTTCTCCTGGTAGAGGGGCCGGCTGTTTCCTGACAGATGCCTGGTGAGCAGGGGA AGCAGGACCCAGTGGTCAGCAGGTGTCTTTAACTGTCATTGTGTGTGGAATGTCGCAGACTCCTCCACGTGGCGGGAATGAGCTGTGTAA >70506_70506_10_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000409483_VIPR2_chr7_158851269_ENST00000262178_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_11_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000409483_VIPR2_chr7_158851269_ENST00000377633_length(transcript)=1352nt_BP=231nt GAGCGCGAGAGGCGCGGCGGGAGGAGCCGGCGGCGCGCGCCTCCCTGGGCCCGGACTCGGCCGCCTCCCGCCGCCTCCCGCGCGGCCATG GACTGAGCGCCGCCGGCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGC CTGCCGCCCCTTCGTCCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTG GGCTACAGTGTCTCTCTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCAC CTGAACCTGTTCCTGTCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGC CCTGACCAGCCATCCTCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTG GAGGGGCTCTACCTCCACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCC ACCGTCTGCATCGGTGCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGG GTCATACGAATACCGATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCC CCAGATGTCGGCGGCAACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATG GTGTTTGCCGTGTTTCCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCC GTCCTCTACTGTTTCCTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGAT TACAGGGTCTGCGGTTCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAA ACGGAGACCTCGGTCATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGG CTTCCTCCTTCCAGATGCCCGAGCACCGTGTCGGGCAGGTCAGCGCGGTCCTGACTCCGTCAAGCTGGTTGTCCACTAAACCCCATACCT >70506_70506_11_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000409483_VIPR2_chr7_158851269_ENST00000377633_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- >70506_70506_12_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000409483_VIPR2_chr7_158851269_ENST00000402066_length(transcript)=1289nt_BP=231nt GAGCGCGAGAGGCGCGGCGGGAGGAGCCGGCGGCGCGCGCCTCCCTGGGCCCGGACTCGGCCGCCTCCCGCCGCCTCCCGCGCGGCCATG GACTGAGCGCCGCCGGCCAGGCCGCGGGGATGGGGCCGCCGCTCCCGCTGCTGCTGCTGCTACTGCTGCTGCTGCCGCCACGCGTCCTGC CTGCCGCCCCTTCGTCCGTCCCCCGCGGCCGGCAGCTCCCGGGGCGTCTGGATCACGTTTTATATTCTGGTGAAGGCCATTTATACACTG GGCTACAGTGTCTCTCTGATGTCTCTTGCAACAGGAAGCATAATTCTGTGCCTCTTCAGGAAGCTGCACTGCACCAGGAATTACATCCAC CTGAACCTGTTCCTGTCCTTCATCCTGAGAGCCATCTCAGTGCTGGTCAAGGACGACGTTCTCTACTCCAGCTCTGGCACGTTGCACTGC CCTGACCAGCCATCCTCCTGGGTGGGCTGCAAGCTGAGCCTGGTCTTCCTGCAGTACTGCATCATGGCCAACTTCTTCTGGCTGCTGGTG GAGGGGCTCTACCTCCACACCCTCCTGGTGGCCATGCTCCCCCCTAGAAGGTGCTTCCTGGCCTACCTCCTGATCGGATGGGGCCTCCCC ACCGTCTGCATCGGTGCATGGACTGCGGCCAGGCTCTACTTAGAAGACACCGGTTGCTGGGATACAAACGACCACAGTGTGCCCTGGTGG GTCATACGAATACCGATTTTAATTTCCATCATCGTCAATTTTGTCCTTTTCATTAGTATTATACGAATTTTGCTGCAGAAGTTAACATCC CCAGATGTCGGCGGCAACGACCAGTCTCAGTACAAGAGGCTGGCCAAGTCCACGCTCCTGCTTATCCCGCTGTTCGGCGTCCACTACATG GTGTTTGCCGTGTTTCCCATCAGCATCTCCTCCAAATACCAGATACTGTTTGAGCTGTGCCTCGGGTCGTTCCAGGGCCTGGTGGTGGCC GTCCTCTACTGTTTCCTGAACAGTGAGGTGCAGTGCGAGCTGAAGCGAAAATGGCGAAGCCGGTGCCCGACCCCGTCCGCGAGCCGGGAT TACAGGGTCTGCGGTTCCTCCTTCTCCCGCAACGGCTCGGAGGGCGCCCTGCAGTTCCACCGCGGCTCCCGCGCCCAGTCCTTCCTGCAA ACGGAGACCTCGGTCATCTAGCCCCACCCCTGCCTGTCGGACGCGGCGGGAGGCCCACGGTTCGGGGCTTCTGCGGGGCTGAGACGCCGG >70506_70506_12_PTPRN2-VIPR2_PTPRN2_chr7_158380249_ENST00000409483_VIPR2_chr7_158851269_ENST00000402066_length(amino acids)=336AA_BP=17 MPPLRPSPAAGSSRGVWITFYILVKAIYTLGYSVSLMSLATGSIILCLFRKLHCTRNYIHLNLFLSFILRAISVLVKDDVLYSSSGTLHC PDQPSSWVGCKLSLVFLQYCIMANFFWLLVEGLYLHTLLVAMLPPRRCFLAYLLIGWGLPTVCIGAWTAARLYLEDTGCWDTNDHSVPWW VIRIPILISIIVNFVLFISIIRILLQKLTSPDVGGNDQSQYKRLAKSTLLLIPLFGVHYMVFAVFPISISSKYQILFELCLGSFQGLVVA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PTPRN2-VIPR2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PTPRN2-VIPR2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PTPRN2-VIPR2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies