
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PVR-SIRT2 (FusionGDB2 ID:70766) |
Fusion Gene Summary for PVR-SIRT2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PVR-SIRT2 | Fusion gene ID: 70766 | Hgene | Tgene | Gene symbol | PVR | SIRT2 | Gene ID | 5817 | 22933 |
| Gene name | PVR cell adhesion molecule | sirtuin 2 | |
| Synonyms | CD155|HVED|NECL5|Necl-5|PVS|TAGE4 | SIR2|SIR2L|SIR2L2 | |
| Cytomap | 19q13.31 | 19q13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | poliovirus receptornectin-like protein 5 | NAD-dependent protein deacetylase sirtuin-2NAD-dependent deacetylase sirtuin-2SIR2-like protein 2regulatory protein SIR2 homolog 2silent information regulator 2sir2-related protein type 2sirtuin type 2 | |
| Modification date | 20200329 | 20200329 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000344956, ENST00000403059, ENST00000406449, ENST00000425690, | ENST00000481381, ENST00000249396, ENST00000358931, ENST00000392081, | |
| Fusion gene scores | * DoF score | 5 X 7 X 5=175 | 6 X 6 X 6=216 |
| # samples | 6 | 7 | |
| ** MAII score | log2(6/175*10)=-1.54432051622381 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/216*10)=-1.6256044852185 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PVR [Title/Abstract] AND SIRT2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PVR(45147475)-SIRT2(39372131), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PVR | GO:0060370 | susceptibility to T cell mediated cytotoxicity | 15039383 |
| Tgene | SIRT2 | GO:0000122 | negative regulation of transcription by RNA polymerase II | 18722353 |
| Tgene | SIRT2 | GO:0006471 | protein ADP-ribosylation | 10381378 |
| Tgene | SIRT2 | GO:0006476 | protein deacetylation | 17172643|20543840|21949390 |
| Tgene | SIRT2 | GO:0034983 | peptidyl-lysine deacetylation | 23932781 |
| Tgene | SIRT2 | GO:0035729 | cellular response to hepatocyte growth factor stimulus | 23908241 |
| Tgene | SIRT2 | GO:0045843 | negative regulation of striated muscle tissue development | 12887892 |
| Tgene | SIRT2 | GO:0045892 | negative regulation of transcription, DNA-templated | 12887892 |
| Tgene | SIRT2 | GO:0048012 | hepatocyte growth factor receptor signaling pathway | 23908241 |
| Tgene | SIRT2 | GO:0070933 | histone H4 deacetylation | 16648462|17488717 |
| Tgene | SIRT2 | GO:0071219 | cellular response to molecule of bacterial origin | 23908241 |
| Tgene | SIRT2 | GO:0071456 | cellular response to hypoxia | 24681946 |
| Tgene | SIRT2 | GO:0090042 | tubulin deacetylation | 18722353|23886946 |
| Fusion gene breakpoints across PVR (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SIRT2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCS | TCGA-N7-A4Y8-01A | PVR | chr19 | 45147475 | - | SIRT2 | chr19 | 39372131 | - |
| ChimerDB4 | UCS | TCGA-N7-A4Y8-01A | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
Top |
Fusion Gene ORF analysis for PVR-SIRT2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000344956 | ENST00000481381 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| 5CDS-intron | ENST00000403059 | ENST00000481381 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| 5CDS-intron | ENST00000406449 | ENST00000481381 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| 5CDS-intron | ENST00000425690 | ENST00000481381 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000344956 | ENST00000249396 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000344956 | ENST00000358931 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000344956 | ENST00000392081 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000403059 | ENST00000249396 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000403059 | ENST00000358931 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000403059 | ENST00000392081 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000406449 | ENST00000249396 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000406449 | ENST00000358931 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000406449 | ENST00000392081 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000425690 | ENST00000249396 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000425690 | ENST00000358931 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| In-frame | ENST00000425690 | ENST00000392081 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000425690 | PVR | chr19 | 45147475 | + | ENST00000249396 | SIRT2 | chr19 | 39372131 | - | 1515 | 378 | 122 | 916 | 264 |
| ENST00000425690 | PVR | chr19 | 45147475 | + | ENST00000392081 | SIRT2 | chr19 | 39372131 | - | 1515 | 378 | 122 | 916 | 264 |
| ENST00000425690 | PVR | chr19 | 45147475 | + | ENST00000358931 | SIRT2 | chr19 | 39372131 | - | 1339 | 378 | 122 | 562 | 146 |
| ENST00000344956 | PVR | chr19 | 45147475 | + | ENST00000249396 | SIRT2 | chr19 | 39372131 | - | 1515 | 378 | 122 | 916 | 264 |
| ENST00000344956 | PVR | chr19 | 45147475 | + | ENST00000392081 | SIRT2 | chr19 | 39372131 | - | 1515 | 378 | 122 | 916 | 264 |
| ENST00000344956 | PVR | chr19 | 45147475 | + | ENST00000358931 | SIRT2 | chr19 | 39372131 | - | 1339 | 378 | 122 | 562 | 146 |
| ENST00000403059 | PVR | chr19 | 45147475 | + | ENST00000249396 | SIRT2 | chr19 | 39372131 | - | 1403 | 266 | 10 | 804 | 264 |
| ENST00000403059 | PVR | chr19 | 45147475 | + | ENST00000392081 | SIRT2 | chr19 | 39372131 | - | 1403 | 266 | 10 | 804 | 264 |
| ENST00000403059 | PVR | chr19 | 45147475 | + | ENST00000358931 | SIRT2 | chr19 | 39372131 | - | 1227 | 266 | 10 | 450 | 146 |
| ENST00000406449 | PVR | chr19 | 45147475 | + | ENST00000249396 | SIRT2 | chr19 | 39372131 | - | 1216 | 79 | 0 | 617 | 205 |
| ENST00000406449 | PVR | chr19 | 45147475 | + | ENST00000392081 | SIRT2 | chr19 | 39372131 | - | 1216 | 79 | 0 | 617 | 205 |
| ENST00000406449 | PVR | chr19 | 45147475 | + | ENST00000358931 | SIRT2 | chr19 | 39372131 | - | 1040 | 79 | 547 | 119 | 142 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000425690 | ENST00000249396 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.041034237 | 0.9589658 |
| ENST00000425690 | ENST00000392081 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.041034237 | 0.9589658 |
| ENST00000425690 | ENST00000358931 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.9518947 | 0.048105367 |
| ENST00000344956 | ENST00000249396 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.041034237 | 0.9589658 |
| ENST00000344956 | ENST00000392081 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.041034237 | 0.9589658 |
| ENST00000344956 | ENST00000358931 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.9518947 | 0.048105367 |
| ENST00000403059 | ENST00000249396 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.050171968 | 0.9498281 |
| ENST00000403059 | ENST00000392081 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.050171968 | 0.9498281 |
| ENST00000403059 | ENST00000358931 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.9634427 | 0.036557317 |
| ENST00000406449 | ENST00000249396 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.04372925 | 0.95627075 |
| ENST00000406449 | ENST00000392081 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.04372925 | 0.95627075 |
| ENST00000406449 | ENST00000358931 | PVR | chr19 | 45147475 | + | SIRT2 | chr19 | 39372131 | - | 0.96900606 | 0.03099397 |
Top |
Fusion Genomic Features for PVR-SIRT2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
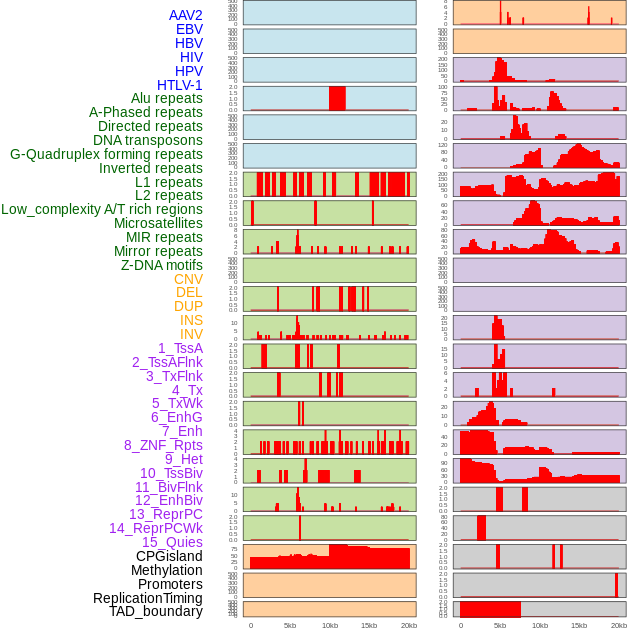 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for PVR-SIRT2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:45147475/chr19:39372131) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 262_263 | 210 | 390.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 286_288 | 210 | 390.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 262_263 | 210 | 452.6666666666667 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 286_288 | 210 | 452.6666666666667 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 262_263 | 173 | 353.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 286_288 | 173 | 353.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 232_301 | 210 | 390.0 | Region | Note=Peptide inhibitor binding | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 232_301 | 210 | 452.6666666666667 | Region | Note=Peptide inhibitor binding | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 232_301 | 173 | 353.0 | Region | Note=Peptide inhibitor binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000344956 | + | 1 | 7 | 145_237 | 26 | 365.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000344956 | + | 1 | 7 | 244_328 | 26 | 365.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000344956 | + | 1 | 7 | 24_139 | 26 | 365.0 | Domain | Note=Ig-like V-type |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000403059 | + | 1 | 8 | 145_237 | 26 | 373.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000403059 | + | 1 | 8 | 244_328 | 26 | 373.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000403059 | + | 1 | 8 | 24_139 | 26 | 373.0 | Domain | Note=Ig-like V-type |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000406449 | + | 1 | 6 | 145_237 | 26 | 393.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000406449 | + | 1 | 6 | 244_328 | 26 | 393.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000406449 | + | 1 | 6 | 24_139 | 26 | 393.0 | Domain | Note=Ig-like V-type |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000425690 | + | 1 | 8 | 145_237 | 26 | 418.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000425690 | + | 1 | 8 | 244_328 | 26 | 418.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000425690 | + | 1 | 8 | 24_139 | 26 | 418.0 | Domain | Note=Ig-like V-type |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000344956 | + | 1 | 7 | 396_401 | 26 | 365.0 | Motif | Note=ITIM motif |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000403059 | + | 1 | 8 | 396_401 | 26 | 373.0 | Motif | Note=ITIM motif |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000406449 | + | 1 | 6 | 396_401 | 26 | 393.0 | Motif | Note=ITIM motif |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000425690 | + | 1 | 8 | 396_401 | 26 | 418.0 | Motif | Note=ITIM motif |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000344956 | + | 1 | 7 | 368_372 | 26 | 365.0 | Region | Note=DYNLT1 binding |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000403059 | + | 1 | 8 | 368_372 | 26 | 373.0 | Region | Note=DYNLT1 binding |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000406449 | + | 1 | 6 | 368_372 | 26 | 393.0 | Region | Note=DYNLT1 binding |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000425690 | + | 1 | 8 | 368_372 | 26 | 418.0 | Region | Note=DYNLT1 binding |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000344956 | + | 1 | 7 | 21_343 | 26 | 365.0 | Topological domain | Extracellular |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000344956 | + | 1 | 7 | 368_417 | 26 | 365.0 | Topological domain | Cytoplasmic |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000403059 | + | 1 | 8 | 21_343 | 26 | 373.0 | Topological domain | Extracellular |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000403059 | + | 1 | 8 | 368_417 | 26 | 373.0 | Topological domain | Cytoplasmic |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000406449 | + | 1 | 6 | 21_343 | 26 | 393.0 | Topological domain | Extracellular |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000406449 | + | 1 | 6 | 368_417 | 26 | 393.0 | Topological domain | Cytoplasmic |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000425690 | + | 1 | 8 | 21_343 | 26 | 418.0 | Topological domain | Extracellular |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000425690 | + | 1 | 8 | 368_417 | 26 | 418.0 | Topological domain | Cytoplasmic |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000344956 | + | 1 | 7 | 344_367 | 26 | 365.0 | Transmembrane | Helical |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000403059 | + | 1 | 8 | 344_367 | 26 | 373.0 | Transmembrane | Helical |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000406449 | + | 1 | 6 | 344_367 | 26 | 393.0 | Transmembrane | Helical |
| Hgene | PVR | chr19:45147475 | chr19:39372131 | ENST00000425690 | + | 1 | 8 | 344_367 | 26 | 418.0 | Transmembrane | Helical |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 65_340 | 210 | 390.0 | Domain | Deacetylase sirtuin-type | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 65_340 | 210 | 452.6666666666667 | Domain | Deacetylase sirtuin-type | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 65_340 | 173 | 353.0 | Domain | Deacetylase sirtuin-type | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 41_51 | 210 | 390.0 | Motif | Note=Nuclear export signal | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 41_51 | 210 | 452.6666666666667 | Motif | Note=Nuclear export signal | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 41_51 | 173 | 353.0 | Motif | Note=Nuclear export signal | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 167_170 | 210 | 390.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 85_89 | 210 | 390.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 95_97 | 210 | 390.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 167_170 | 210 | 452.6666666666667 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 85_89 | 210 | 452.6666666666667 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 95_97 | 210 | 452.6666666666667 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 167_170 | 173 | 353.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 85_89 | 173 | 353.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 95_97 | 173 | 353.0 | Nucleotide binding | NAD | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000249396 | 8 | 16 | 116_120 | 210 | 390.0 | Region | Note=Peptide inhibitor binding | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000358931 | 8 | 14 | 116_120 | 210 | 452.6666666666667 | Region | Note=Peptide inhibitor binding | |
| Tgene | SIRT2 | chr19:45147475 | chr19:39372131 | ENST00000392081 | 7 | 15 | 116_120 | 173 | 353.0 | Region | Note=Peptide inhibitor binding |
Top |
Fusion Gene Sequence for PVR-SIRT2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >70766_70766_1_PVR-SIRT2_PVR_chr19_45147475_ENST00000344956_SIRT2_chr19_39372131_ENST00000249396_length(transcript)=1515nt_BP=378nt AGCGGGACTGAGCGCCGGGAGAGACCTGCGCAGGCGCAGGCGCGCGGGAAGGGCCAGCCTGGGTGGCCCACCCCGCGCCTGGCGGGACTG GCCGCCAACTCCCCTCCGCTCCAGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCC CCCGGGGATTCCAGGACCTGAGCTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGC GGGAGGCCCAGCTGCTCGGAGCAACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCT GGCCACCCCCAGGAACCGAGAAGATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTT TTGGTGAGAGCCTCCCAGCGCGTTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGC AGGTGCAGCCCTTTGCCTCCCTCATCAGCAAGGCACCCCTCTCCACCCCTCGCCTGCTCATCAACAAGGAGAAAGCTGGCCAGTCGGACC CTTTCCTGGGGATGATTATGGGCCTCGGAGGAGGCATGGACTTTGACTCCAAGAAGGCCTACAGGGACGTGGCCTGGCTGGGTGAATGCG ACCAGGGCTGCCTGGCCCTTGCTGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCC AGTCGGGGGCGGGGGTCCCCAACCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGA GGGAGAAACCCCAGTGACAGCTGCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTT AACCAGCAGTTCTTGTCTGGGGAGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCC CAACCCCAGCAAATCTCTAACACCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTA AGGAGTAACCTCCCTCATCTCTAACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCC CCACTCTGTCTCCTGCCCCCGGGGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCA CACCCAGCGTAGGGGGAGTCTGAGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGA >70766_70766_1_PVR-SIRT2_PVR_chr19_45147475_ENST00000344956_SIRT2_chr19_39372131_ENST00000249396_length(amino acids)=264AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS EVTPKCEDCQSLVKPDIVFFGESLPARFFSCMQSDFLKVDLLLVMGTSLQVQPFASLISKAPLSTPRLLINKEKAGQSDPFLGMIMGLGG -------------------------------------------------------------- >70766_70766_2_PVR-SIRT2_PVR_chr19_45147475_ENST00000344956_SIRT2_chr19_39372131_ENST00000358931_length(transcript)=1339nt_BP=378nt AGCGGGACTGAGCGCCGGGAGAGACCTGCGCAGGCGCAGGCGCGCGGGAAGGGCCAGCCTGGGTGGCCCACCCCGCGCCTGGCGGGACTG GCCGCCAACTCCCCTCCGCTCCAGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCC CCCGGGGATTCCAGGACCTGAGCTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGC GGGAGGCCCAGCTGCTCGGAGCAACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCT GGCCACCCCCAGGAACCGAGAAGATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTT TTGGTGAGAGCCTCCCAGCGCGTTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGC AGGGACGTGGCCTGGCTGGGTGAATGCGACCAGGGCTGCCTGGCCCTTGCTGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTC CGGAGGGAGCACGCCAGCATAGATGCCCAGTCGGGGGCGGGGGTCCCCAACCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCT GCCAAGGACGAGGCCAGGACAACAGAGAGGGAGAAACCCCAGTGACAGCTGCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCT GAGCCCCAACCGGGCCTGGCCCCCTCTTAACCAGCAGTTCTTGTCTGGGGAGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCA AAACTGGGGTCCCAGCAACCCTGGCCCCCAACCCCAGCAAATCTCTAACACCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGC CCCACTGTCTCTAACCACTCCTGGGCTAAGGAGTAACCTCCCTCATCTCTAACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAA CTCTTCCAGGACAGGGAGCTTCGGGCCCCCACTCTGTCTCCTGCCCCCGGGGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGT GTGGGTGTGGGCCTCTGAATATAACCCACACCCAGCGTAGGGGGAGTCTGAGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAA >70766_70766_2_PVR-SIRT2_PVR_chr19_45147475_ENST00000344956_SIRT2_chr19_39372131_ENST00000358931_length(amino acids)=146AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS -------------------------------------------------------------- >70766_70766_3_PVR-SIRT2_PVR_chr19_45147475_ENST00000344956_SIRT2_chr19_39372131_ENST00000392081_length(transcript)=1515nt_BP=378nt AGCGGGACTGAGCGCCGGGAGAGACCTGCGCAGGCGCAGGCGCGCGGGAAGGGCCAGCCTGGGTGGCCCACCCCGCGCCTGGCGGGACTG GCCGCCAACTCCCCTCCGCTCCAGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCC CCCGGGGATTCCAGGACCTGAGCTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGC GGGAGGCCCAGCTGCTCGGAGCAACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCT GGCCACCCCCAGGAACCGAGAAGATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTT TTGGTGAGAGCCTCCCAGCGCGTTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGC AGGTGCAGCCCTTTGCCTCCCTCATCAGCAAGGCACCCCTCTCCACCCCTCGCCTGCTCATCAACAAGGAGAAAGCTGGCCAGTCGGACC CTTTCCTGGGGATGATTATGGGCCTCGGAGGAGGCATGGACTTTGACTCCAAGAAGGCCTACAGGGACGTGGCCTGGCTGGGTGAATGCG ACCAGGGCTGCCTGGCCCTTGCTGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCC AGTCGGGGGCGGGGGTCCCCAACCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGA GGGAGAAACCCCAGTGACAGCTGCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTT AACCAGCAGTTCTTGTCTGGGGAGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCC CAACCCCAGCAAATCTCTAACACCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTA AGGAGTAACCTCCCTCATCTCTAACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCC CCACTCTGTCTCCTGCCCCCGGGGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCA CACCCAGCGTAGGGGGAGTCTGAGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGA >70766_70766_3_PVR-SIRT2_PVR_chr19_45147475_ENST00000344956_SIRT2_chr19_39372131_ENST00000392081_length(amino acids)=264AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS EVTPKCEDCQSLVKPDIVFFGESLPARFFSCMQSDFLKVDLLLVMGTSLQVQPFASLISKAPLSTPRLLINKEKAGQSDPFLGMIMGLGG -------------------------------------------------------------- >70766_70766_4_PVR-SIRT2_PVR_chr19_45147475_ENST00000403059_SIRT2_chr19_39372131_ENST00000249396_length(transcript)=1403nt_BP=266nt AGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCCCCCGGGGATTCCAGGACCTGAG CTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGCGGGAGGCCCAGCTGCTCGGAGC AACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCTGGCCACCCCCAGGAACCGAGAA GATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTTTTGGTGAGAGCCTCCCAGCGCG TTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGCAGGTGCAGCCCTTTGCCTCCCT CATCAGCAAGGCACCCCTCTCCACCCCTCGCCTGCTCATCAACAAGGAGAAAGCTGGCCAGTCGGACCCTTTCCTGGGGATGATTATGGG CCTCGGAGGAGGCATGGACTTTGACTCCAAGAAGGCCTACAGGGACGTGGCCTGGCTGGGTGAATGCGACCAGGGCTGCCTGGCCCTTGC TGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCCAGTCGGGGGCGGGGGTCCCCAA CCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGAGGGAGAAACCCCAGTGACAGCT GCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTTAACCAGCAGTTCTTGTCTGGGG AGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCCCAACCCCAGCAAATCTCTAACA CCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTAAGGAGTAACCTCCCTCATCTCT AACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCCCCACTCTGTCTCCTGCCCCCGG GGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCACACCCAGCGTAGGGGGAGTCTG AGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGACCCACTTCCCATGCTGGATGGG >70766_70766_4_PVR-SIRT2_PVR_chr19_45147475_ENST00000403059_SIRT2_chr19_39372131_ENST00000249396_length(amino acids)=264AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS EVTPKCEDCQSLVKPDIVFFGESLPARFFSCMQSDFLKVDLLLVMGTSLQVQPFASLISKAPLSTPRLLINKEKAGQSDPFLGMIMGLGG -------------------------------------------------------------- >70766_70766_5_PVR-SIRT2_PVR_chr19_45147475_ENST00000403059_SIRT2_chr19_39372131_ENST00000358931_length(transcript)=1227nt_BP=266nt AGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCCCCCGGGGATTCCAGGACCTGAG CTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGCGGGAGGCCCAGCTGCTCGGAGC AACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCTGGCCACCCCCAGGAACCGAGAA GATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTTTTGGTGAGAGCCTCCCAGCGCG TTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGCAGGGACGTGGCCTGGCTGGGTG AATGCGACCAGGGCTGCCTGGCCCTTGCTGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAG ATGCCCAGTCGGGGGCGGGGGTCCCCAACCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAA CAGAGAGGGAGAAACCCCAGTGACAGCTGCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCC CCTCTTAACCAGCAGTTCTTGTCTGGGGAGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCT GGCCCCCAACCCCAGCAAATCTCTAACACCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCT GGGCTAAGGAGTAACCTCCCTCATCTCTAACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTC GGGCCCCCACTCTGTCTCCTGCCCCCGGGGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATAT AACCCACACCCAGCGTAGGGGGAGTCTGAGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCAC >70766_70766_5_PVR-SIRT2_PVR_chr19_45147475_ENST00000403059_SIRT2_chr19_39372131_ENST00000358931_length(amino acids)=146AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS -------------------------------------------------------------- >70766_70766_6_PVR-SIRT2_PVR_chr19_45147475_ENST00000403059_SIRT2_chr19_39372131_ENST00000392081_length(transcript)=1403nt_BP=266nt AGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCCCCCGGGGATTCCAGGACCTGAG CTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGCGGGAGGCCCAGCTGCTCGGAGC AACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCTGGCCACCCCCAGGAACCGAGAA GATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTTTTGGTGAGAGCCTCCCAGCGCG TTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGCAGGTGCAGCCCTTTGCCTCCCT CATCAGCAAGGCACCCCTCTCCACCCCTCGCCTGCTCATCAACAAGGAGAAAGCTGGCCAGTCGGACCCTTTCCTGGGGATGATTATGGG CCTCGGAGGAGGCATGGACTTTGACTCCAAGAAGGCCTACAGGGACGTGGCCTGGCTGGGTGAATGCGACCAGGGCTGCCTGGCCCTTGC TGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCCAGTCGGGGGCGGGGGTCCCCAA CCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGAGGGAGAAACCCCAGTGACAGCT GCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTTAACCAGCAGTTCTTGTCTGGGG AGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCCCAACCCCAGCAAATCTCTAACA CCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTAAGGAGTAACCTCCCTCATCTCT AACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCCCCACTCTGTCTCCTGCCCCCGG GGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCACACCCAGCGTAGGGGGAGTCTG AGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGACCCACTTCCCATGCTGGATGGG >70766_70766_6_PVR-SIRT2_PVR_chr19_45147475_ENST00000403059_SIRT2_chr19_39372131_ENST00000392081_length(amino acids)=264AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS EVTPKCEDCQSLVKPDIVFFGESLPARFFSCMQSDFLKVDLLLVMGTSLQVQPFASLISKAPLSTPRLLINKEKAGQSDPFLGMIMGLGG -------------------------------------------------------------- >70766_70766_7_PVR-SIRT2_PVR_chr19_45147475_ENST00000406449_SIRT2_chr19_39372131_ENST00000249396_length(transcript)=1216nt_BP=79nt ATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCTGGCCACCCCCAGGAACCGAGAAGATCTTC TCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTTTTGGTGAGAGCCTCCCAGCGCGTTTCTTC TCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGCAGGTGCAGCCCTTTGCCTCCCTCATCAGC AAGGCACCCCTCTCCACCCCTCGCCTGCTCATCAACAAGGAGAAAGCTGGCCAGTCGGACCCTTTCCTGGGGATGATTATGGGCCTCGGA GGAGGCATGGACTTTGACTCCAAGAAGGCCTACAGGGACGTGGCCTGGCTGGGTGAATGCGACCAGGGCTGCCTGGCCCTTGCTGAGCTC CTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCCAGTCGGGGGCGGGGGTCCCCAACCCCAGC ACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGAGGGAGAAACCCCAGTGACAGCTGCATCTC CCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTTAACCAGCAGTTCTTGTCTGGGGAGCTCAG AACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCCCAACCCCAGCAAATCTCTAACACCTCCTA GAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTAAGGAGTAACCTCCCTCATCTCTAACTGCC CCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCCCCACTCTGTCTCCTGCCCCCGGGGGCCTG TGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCACACCCAGCGTAGGGGGAGTCTGAGCCGGG AGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGACCCACTTCCCATGCTGGATGGGCAGAAGA >70766_70766_7_PVR-SIRT2_PVR_chr19_45147475_ENST00000406449_SIRT2_chr19_39372131_ENST00000249396_length(amino acids)=205AA_BP=18 MARAMAAAWPLLLVALLVLSWPPPGTEKIFSEVTPKCEDCQSLVKPDIVFFGESLPARFFSCMQSDFLKVDLLLVMGTSLQVQPFASLIS KAPLSTPRLLINKEKAGQSDPFLGMIMGLGGGMDFDSKKAYRDVAWLGECDQGCLALAELLGWKKELEDLVRREHASIDAQSGAGVPNPS -------------------------------------------------------------- >70766_70766_8_PVR-SIRT2_PVR_chr19_45147475_ENST00000406449_SIRT2_chr19_39372131_ENST00000358931_length(transcript)=1040nt_BP=79nt ATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCTGGCCACCCCCAGGAACCGAGAAGATCTTC TCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTTTTGGTGAGAGCCTCCCAGCGCGTTTCTTC TCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGCAGGGACGTGGCCTGGCTGGGTGAATGCGA CCAGGGCTGCCTGGCCCTTGCTGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCCA GTCGGGGGCGGGGGTCCCCAACCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGAG GGAGAAACCCCAGTGACAGCTGCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTTA ACCAGCAGTTCTTGTCTGGGGAGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCCC AACCCCAGCAAATCTCTAACACCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTAA GGAGTAACCTCCCTCATCTCTAACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCCC CACTCTGTCTCCTGCCCCCGGGGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCAC ACCCAGCGTAGGGGGAGTCTGAGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGAC >70766_70766_8_PVR-SIRT2_PVR_chr19_45147475_ENST00000406449_SIRT2_chr19_39372131_ENST00000358931_length(amino acids)=142AA_BP= MLVKRGPGPVGAQLSLRSSASRLGDAAVTGVSPSLLSWPRPWQVAGTSWGKLKCWGWGPPPPTGHLCWRAPSGQGPPAPSSIQGAQQGPG -------------------------------------------------------------- >70766_70766_9_PVR-SIRT2_PVR_chr19_45147475_ENST00000406449_SIRT2_chr19_39372131_ENST00000392081_length(transcript)=1216nt_BP=79nt ATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCTGGCCACCCCCAGGAACCGAGAAGATCTTC TCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTTTTGGTGAGAGCCTCCCAGCGCGTTTCTTC TCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGCAGGTGCAGCCCTTTGCCTCCCTCATCAGC AAGGCACCCCTCTCCACCCCTCGCCTGCTCATCAACAAGGAGAAAGCTGGCCAGTCGGACCCTTTCCTGGGGATGATTATGGGCCTCGGA GGAGGCATGGACTTTGACTCCAAGAAGGCCTACAGGGACGTGGCCTGGCTGGGTGAATGCGACCAGGGCTGCCTGGCCCTTGCTGAGCTC CTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCCAGTCGGGGGCGGGGGTCCCCAACCCCAGC ACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGAGGGAGAAACCCCAGTGACAGCTGCATCTC CCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTTAACCAGCAGTTCTTGTCTGGGGAGCTCAG AACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCCCAACCCCAGCAAATCTCTAACACCTCCTA GAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTAAGGAGTAACCTCCCTCATCTCTAACTGCC CCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCCCCACTCTGTCTCCTGCCCCCGGGGGCCTG TGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCACACCCAGCGTAGGGGGAGTCTGAGCCGGG AGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGACCCACTTCCCATGCTGGATGGGCAGAAGA >70766_70766_9_PVR-SIRT2_PVR_chr19_45147475_ENST00000406449_SIRT2_chr19_39372131_ENST00000392081_length(amino acids)=205AA_BP=18 MARAMAAAWPLLLVALLVLSWPPPGTEKIFSEVTPKCEDCQSLVKPDIVFFGESLPARFFSCMQSDFLKVDLLLVMGTSLQVQPFASLIS KAPLSTPRLLINKEKAGQSDPFLGMIMGLGGGMDFDSKKAYRDVAWLGECDQGCLALAELLGWKKELEDLVRREHASIDAQSGAGVPNPS -------------------------------------------------------------- >70766_70766_10_PVR-SIRT2_PVR_chr19_45147475_ENST00000425690_SIRT2_chr19_39372131_ENST00000249396_length(transcript)=1515nt_BP=378nt AGCGGGACTGAGCGCCGGGAGAGACCTGCGCAGGCGCAGGCGCGCGGGAAGGGCCAGCCTGGGTGGCCCACCCCGCGCCTGGCGGGACTG GCCGCCAACTCCCCTCCGCTCCAGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCC CCCGGGGATTCCAGGACCTGAGCTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGC GGGAGGCCCAGCTGCTCGGAGCAACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCT GGCCACCCCCAGGAACCGAGAAGATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTT TTGGTGAGAGCCTCCCAGCGCGTTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGC AGGTGCAGCCCTTTGCCTCCCTCATCAGCAAGGCACCCCTCTCCACCCCTCGCCTGCTCATCAACAAGGAGAAAGCTGGCCAGTCGGACC CTTTCCTGGGGATGATTATGGGCCTCGGAGGAGGCATGGACTTTGACTCCAAGAAGGCCTACAGGGACGTGGCCTGGCTGGGTGAATGCG ACCAGGGCTGCCTGGCCCTTGCTGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCC AGTCGGGGGCGGGGGTCCCCAACCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGA GGGAGAAACCCCAGTGACAGCTGCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTT AACCAGCAGTTCTTGTCTGGGGAGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCC CAACCCCAGCAAATCTCTAACACCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTA AGGAGTAACCTCCCTCATCTCTAACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCC CCACTCTGTCTCCTGCCCCCGGGGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCA CACCCAGCGTAGGGGGAGTCTGAGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGA >70766_70766_10_PVR-SIRT2_PVR_chr19_45147475_ENST00000425690_SIRT2_chr19_39372131_ENST00000249396_length(amino acids)=264AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS EVTPKCEDCQSLVKPDIVFFGESLPARFFSCMQSDFLKVDLLLVMGTSLQVQPFASLISKAPLSTPRLLINKEKAGQSDPFLGMIMGLGG -------------------------------------------------------------- >70766_70766_11_PVR-SIRT2_PVR_chr19_45147475_ENST00000425690_SIRT2_chr19_39372131_ENST00000358931_length(transcript)=1339nt_BP=378nt AGCGGGACTGAGCGCCGGGAGAGACCTGCGCAGGCGCAGGCGCGCGGGAAGGGCCAGCCTGGGTGGCCCACCCCGCGCCTGGCGGGACTG GCCGCCAACTCCCCTCCGCTCCAGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCC CCCGGGGATTCCAGGACCTGAGCTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGC GGGAGGCCCAGCTGCTCGGAGCAACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCT GGCCACCCCCAGGAACCGAGAAGATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTT TTGGTGAGAGCCTCCCAGCGCGTTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGC AGGGACGTGGCCTGGCTGGGTGAATGCGACCAGGGCTGCCTGGCCCTTGCTGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTC CGGAGGGAGCACGCCAGCATAGATGCCCAGTCGGGGGCGGGGGTCCCCAACCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCT GCCAAGGACGAGGCCAGGACAACAGAGAGGGAGAAACCCCAGTGACAGCTGCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCT GAGCCCCAACCGGGCCTGGCCCCCTCTTAACCAGCAGTTCTTGTCTGGGGAGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCA AAACTGGGGTCCCAGCAACCCTGGCCCCCAACCCCAGCAAATCTCTAACACCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGC CCCACTGTCTCTAACCACTCCTGGGCTAAGGAGTAACCTCCCTCATCTCTAACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAA CTCTTCCAGGACAGGGAGCTTCGGGCCCCCACTCTGTCTCCTGCCCCCGGGGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGT GTGGGTGTGGGCCTCTGAATATAACCCACACCCAGCGTAGGGGGAGTCTGAGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAA >70766_70766_11_PVR-SIRT2_PVR_chr19_45147475_ENST00000425690_SIRT2_chr19_39372131_ENST00000358931_length(amino acids)=146AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS -------------------------------------------------------------- >70766_70766_12_PVR-SIRT2_PVR_chr19_45147475_ENST00000425690_SIRT2_chr19_39372131_ENST00000392081_length(transcript)=1515nt_BP=378nt AGCGGGACTGAGCGCCGGGAGAGACCTGCGCAGGCGCAGGCGCGCGGGAAGGGCCAGCCTGGGTGGCCCACCCCGCGCCTGGCGGGACTG GCCGCCAACTCCCCTCCGCTCCAGTCACTTGTCTGGAGCTTGAAGAAGTGGGTATTCCCCTTCCCACCCCAGGCACTGGAGGAGCGGCCC CCCGGGGATTCCAGGACCTGAGCTCCGGGAGCTGGACTCGCAGCGACCGCGGCAGAGCGAGCGGGCGCCGGGAAGCGAGGAGACGCCCGC GGGAGGCCCAGCTGCTCGGAGCAACTGGCATGGCCCGAGCCATGGCCGCCGCGTGGCCGCTGCTGCTGGTGGCGCTACTGGTGCTGTCCT GGCCACCCCCAGGAACCGAGAAGATCTTCTCTGAGGTGACGCCCAAGTGTGAAGACTGTCAGAGCCTGGTGAAGCCTGATATCGTCTTTT TTGGTGAGAGCCTCCCAGCGCGTTTCTTCTCCTGTATGCAGTCAGACTTCCTGAAGGTGGACCTCCTCCTGGTCATGGGTACCTCCTTGC AGGTGCAGCCCTTTGCCTCCCTCATCAGCAAGGCACCCCTCTCCACCCCTCGCCTGCTCATCAACAAGGAGAAAGCTGGCCAGTCGGACC CTTTCCTGGGGATGATTATGGGCCTCGGAGGAGGCATGGACTTTGACTCCAAGAAGGCCTACAGGGACGTGGCCTGGCTGGGTGAATGCG ACCAGGGCTGCCTGGCCCTTGCTGAGCTCCTTGGATGGAAGAAGGAGCTGGAGGACCTTGTCCGGAGGGAGCACGCCAGCATAGATGCCC AGTCGGGGGCGGGGGTCCCCAACCCCAGCACTTCAGCTTCCCCCAAGAAGTCCCCGCCACCTGCCAAGGACGAGGCCAGGACAACAGAGA GGGAGAAACCCCAGTGACAGCTGCATCTCCCAGGCGGGATGCCGAGCTCCTCAGGGACAGCTGAGCCCCAACCGGGCCTGGCCCCCTCTT AACCAGCAGTTCTTGTCTGGGGAGCTCAGAACATCCCCCAATCTCTTACAGCTCCCTCCCCAAAACTGGGGTCCCAGCAACCCTGGCCCC CAACCCCAGCAAATCTCTAACACCTCCTAGAGGCCAAGGCTTAAACAGGCATCTCTACCAGCCCCACTGTCTCTAACCACTCCTGGGCTA AGGAGTAACCTCCCTCATCTCTAACTGCCCCCACGGGGCCAGGGCTACCCCAGAACTTTTAACTCTTCCAGGACAGGGAGCTTCGGGCCC CCACTCTGTCTCCTGCCCCCGGGGGCCTGTGGCTAAGTAAACCATACCTAACCTACCCCAGTGTGGGTGTGGGCCTCTGAATATAACCCA CACCCAGCGTAGGGGGAGTCTGAGCCGGGAGGGCTCCCGAGTCTCTGCCTTCAGCTCCCAAAGTGGGTGGTGGGCCCCCTTCACGTGGGA >70766_70766_12_PVR-SIRT2_PVR_chr19_45147475_ENST00000425690_SIRT2_chr19_39372131_ENST00000392081_length(amino acids)=264AA_BP=77 MELEEVGIPLPTPGTGGAAPRGFQDLSSGSWTRSDRGRASGRREARRRPREAQLLGATGMARAMAAAWPLLLVALLVLSWPPPGTEKIFS EVTPKCEDCQSLVKPDIVFFGESLPARFFSCMQSDFLKVDLLLVMGTSLQVQPFASLISKAPLSTPRLLINKEKAGQSDPFLGMIMGLGG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PVR-SIRT2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PVR-SIRT2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PVR-SIRT2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies