
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:RARA-C16orf45 (FusionGDB2 ID:72282) |
Fusion Gene Summary for RARA-C16orf45 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: RARA-C16orf45 | Fusion gene ID: 72282 | Hgene | Tgene | Gene symbol | RARA | C16orf45 | Gene ID | 5914 | 89927 |
| Gene name | retinoic acid receptor alpha | bMERB domain containing 1 | |
| Synonyms | NR1B1|RAR | C16orf45|MINP | |
| Cytomap | 17q21.2 | 16p13.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | retinoic acid receptor alphaRAR-alphanuclear receptor subfamily 1 group B member 1nucleophosmin-retinoic acid receptor alpha fusion protein NPM-RAR long formretinoic acid nuclear receptor alpha variant 1retinoic acid nuclear receptor alpha variant 2 | bMERB domain-containing protein 1migration inhibitory proteinuncharacterized protein C16orf45 | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000254066, ENST00000394089, ENST00000425707, ENST00000394081, ENST00000394086, ENST00000420042, | ENST00000561692, ENST00000565913, ENST00000300006, ENST00000452191, ENST00000566490, | |
| Fusion gene scores | * DoF score | 47 X 22 X 8=8272 | 14 X 11 X 8=1232 |
| # samples | 74 | 16 | |
| ** MAII score | log2(74/8272*10)=-3.48263900979862 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(16/1232*10)=-2.94485844580754 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: RARA [Title/Abstract] AND C16orf45 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | RARA(38487648)-C16orf45(15609161), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | RARA | GO:0007165 | signal transduction | 2825025 |
| Hgene | RARA | GO:0030853 | negative regulation of granulocyte differentiation | 19917671 |
| Hgene | RARA | GO:0032689 | negative regulation of interferon-gamma production | 18416830 |
| Hgene | RARA | GO:0032720 | negative regulation of tumor necrosis factor production | 18416830 |
| Hgene | RARA | GO:0032736 | positive regulation of interleukin-13 production | 18416830 |
| Hgene | RARA | GO:0032753 | positive regulation of interleukin-4 production | 18416830 |
| Hgene | RARA | GO:0032754 | positive regulation of interleukin-5 production | 18416830 |
| Hgene | RARA | GO:0045630 | positive regulation of T-helper 2 cell differentiation | 18416830 |
| Hgene | RARA | GO:0045892 | negative regulation of transcription, DNA-templated | 20080953 |
| Hgene | RARA | GO:0045893 | positive regulation of transcription, DNA-templated | 18845237|19850744|20080953 |
| Hgene | RARA | GO:0045944 | positive regulation of transcription by RNA polymerase II | 19850744|21131358 |
| Hgene | RARA | GO:0071300 | cellular response to retinoic acid | 19917671 |
| Hgene | RARA | GO:0071391 | cellular response to estrogen stimulus | 20080953 |
| Fusion gene breakpoints across RARA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
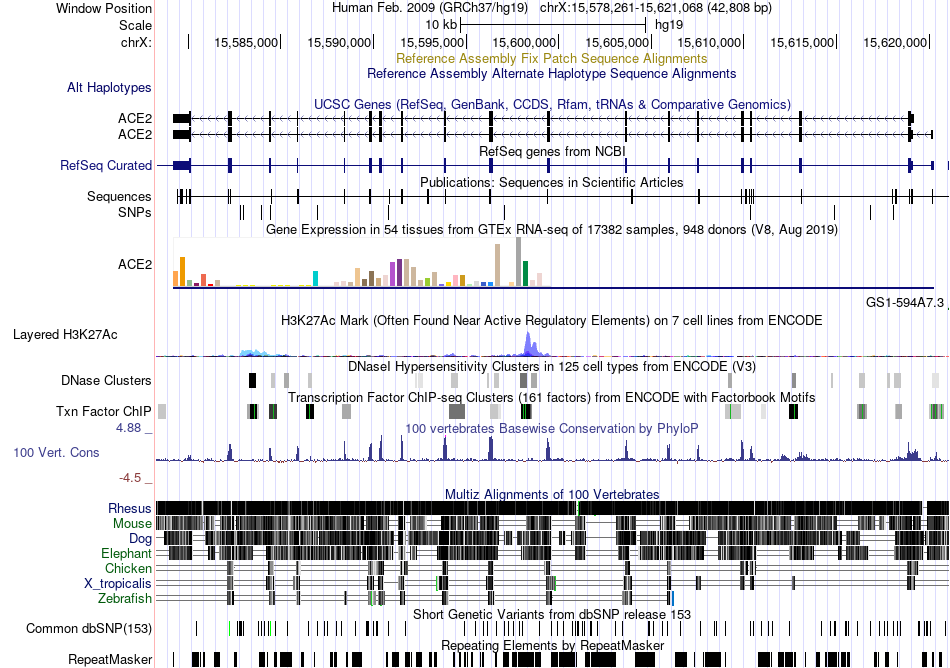 |
| Fusion gene breakpoints across C16orf45 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
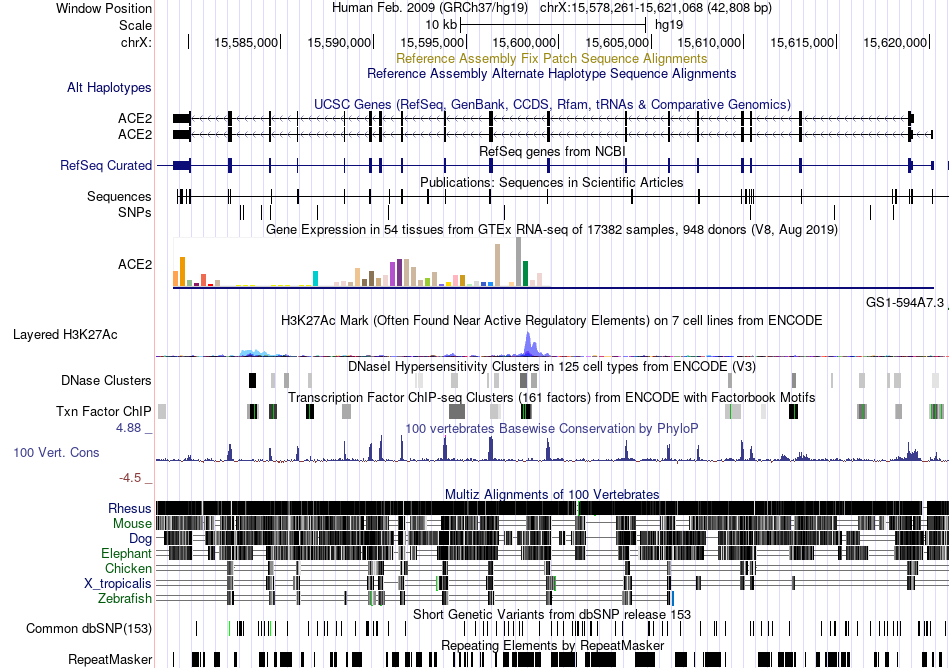 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-AN-A046 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
Top |
Fusion Gene ORF analysis for RARA-C16orf45 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000254066 | ENST00000561692 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| 5CDS-intron | ENST00000254066 | ENST00000565913 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| 5CDS-intron | ENST00000394089 | ENST00000561692 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| 5CDS-intron | ENST00000394089 | ENST00000565913 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| 5CDS-intron | ENST00000425707 | ENST00000561692 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| 5CDS-intron | ENST00000425707 | ENST00000565913 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000254066 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000254066 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000254066 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000394089 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000394089 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000394089 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000425707 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000425707 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| In-frame | ENST00000425707 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000394081 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000394081 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000394081 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000394086 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000394086 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000394086 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000420042 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000420042 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-3CDS | ENST00000420042 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-intron | ENST00000394081 | ENST00000561692 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-intron | ENST00000394081 | ENST00000565913 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-intron | ENST00000394086 | ENST00000561692 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-intron | ENST00000394086 | ENST00000565913 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-intron | ENST00000420042 | ENST00000561692 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| intron-intron | ENST00000420042 | ENST00000565913 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000254066 | RARA | chr17 | 38487648 | + | ENST00000300006 | C16orf45 | chr16 | 15609161 | + | 2572 | 633 | 1448 | 2191 | 247 |
| ENST00000254066 | RARA | chr17 | 38487648 | + | ENST00000566490 | C16orf45 | chr16 | 15609161 | + | 2202 | 633 | 1365 | 2108 | 247 |
| ENST00000254066 | RARA | chr17 | 38487648 | + | ENST00000452191 | C16orf45 | chr16 | 15609161 | + | 2387 | 633 | 1448 | 2191 | 247 |
| ENST00000394089 | RARA | chr17 | 38487648 | + | ENST00000300006 | C16orf45 | chr16 | 15609161 | + | 2647 | 708 | 1523 | 2266 | 247 |
| ENST00000394089 | RARA | chr17 | 38487648 | + | ENST00000566490 | C16orf45 | chr16 | 15609161 | + | 2277 | 708 | 1440 | 2183 | 247 |
| ENST00000394089 | RARA | chr17 | 38487648 | + | ENST00000452191 | C16orf45 | chr16 | 15609161 | + | 2462 | 708 | 1523 | 2266 | 247 |
| ENST00000425707 | RARA | chr17 | 38487648 | + | ENST00000300006 | C16orf45 | chr16 | 15609161 | + | 2643 | 704 | 1519 | 2262 | 247 |
| ENST00000425707 | RARA | chr17 | 38487648 | + | ENST00000566490 | C16orf45 | chr16 | 15609161 | + | 2273 | 704 | 1436 | 2179 | 247 |
| ENST00000425707 | RARA | chr17 | 38487648 | + | ENST00000452191 | C16orf45 | chr16 | 15609161 | + | 2458 | 704 | 1519 | 2262 | 247 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000254066 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.003711526 | 0.9962884 |
| ENST00000254066 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.20424241 | 0.79575765 |
| ENST00000254066 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.004408114 | 0.9955918 |
| ENST00000394089 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.002637542 | 0.99736243 |
| ENST00000394089 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.13826185 | 0.86173815 |
| ENST00000394089 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.003034354 | 0.9969657 |
| ENST00000425707 | ENST00000300006 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.002864089 | 0.9971359 |
| ENST00000425707 | ENST00000566490 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.18604054 | 0.8139595 |
| ENST00000425707 | ENST00000452191 | RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 0.003304835 | 0.99669516 |
Top |
Fusion Genomic Features for RARA-C16orf45 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 1.19E-07 | 0.9999999 |
| RARA | chr17 | 38487648 | + | C16orf45 | chr16 | 15609161 | + | 1.19E-07 | 0.9999999 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
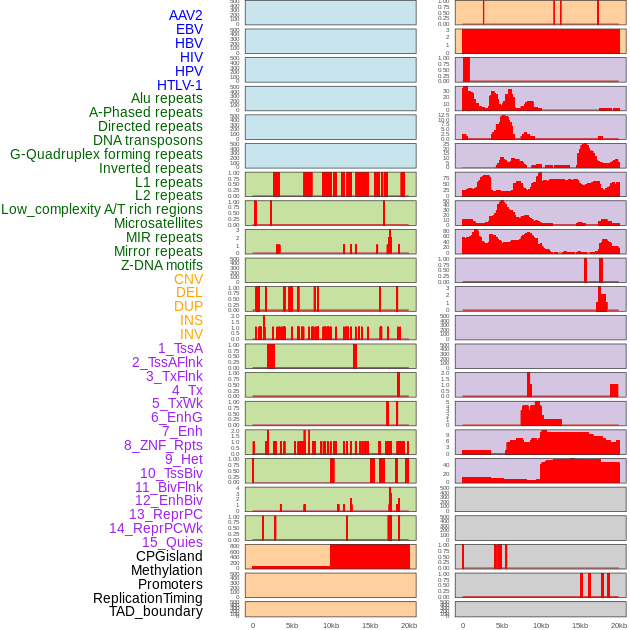 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
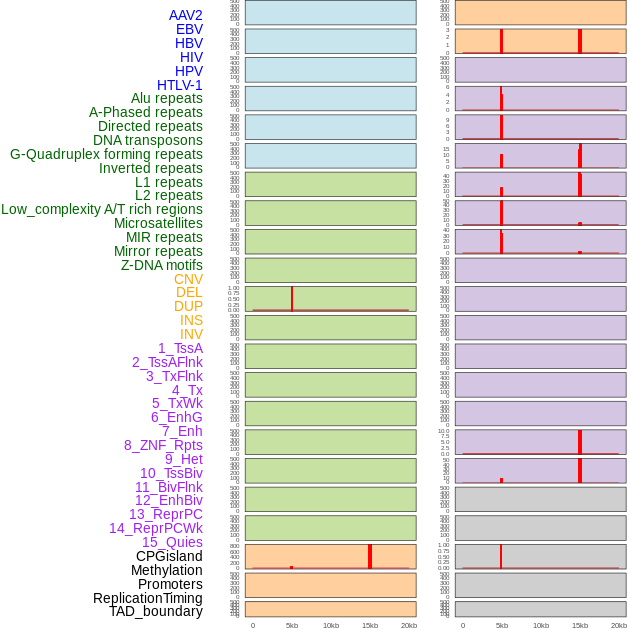 |
Top |
Fusion Protein Features for RARA-C16orf45 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:38487648/chr16:15609161) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000254066 | + | 2 | 9 | 88_153 | 59 | 463.0 | DNA binding | Nuclear receptor |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394081 | + | 1 | 8 | 88_153 | 0 | 458.0 | DNA binding | Nuclear receptor |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394089 | + | 2 | 9 | 88_153 | 59 | 463.0 | DNA binding | Nuclear receptor |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000425707 | + | 2 | 7 | 88_153 | 59 | 366.0 | DNA binding | Nuclear receptor |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000254066 | + | 2 | 9 | 183_417 | 59 | 463.0 | Domain | NR LBD |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394081 | + | 1 | 8 | 183_417 | 0 | 458.0 | Domain | NR LBD |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394089 | + | 2 | 9 | 183_417 | 59 | 463.0 | Domain | NR LBD |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000425707 | + | 2 | 7 | 183_417 | 59 | 366.0 | Domain | NR LBD |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000254066 | + | 2 | 9 | 408_416 | 59 | 463.0 | Motif | 9aaTAD |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394081 | + | 1 | 8 | 408_416 | 0 | 458.0 | Motif | 9aaTAD |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394089 | + | 2 | 9 | 408_416 | 59 | 463.0 | Motif | 9aaTAD |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000425707 | + | 2 | 7 | 408_416 | 59 | 366.0 | Motif | 9aaTAD |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000254066 | + | 2 | 9 | 154_182 | 59 | 463.0 | Region | Note=Hinge |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000254066 | + | 2 | 9 | 1_87 | 59 | 463.0 | Region | Note=Modulating |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000254066 | + | 2 | 9 | 404_419 | 59 | 463.0 | Region | Note=Required for binding corepressor NCOR1 |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394081 | + | 1 | 8 | 154_182 | 0 | 458.0 | Region | Note=Hinge |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394081 | + | 1 | 8 | 1_87 | 0 | 458.0 | Region | Note=Modulating |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394081 | + | 1 | 8 | 404_419 | 0 | 458.0 | Region | Note=Required for binding corepressor NCOR1 |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394089 | + | 2 | 9 | 154_182 | 59 | 463.0 | Region | Note=Hinge |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394089 | + | 2 | 9 | 1_87 | 59 | 463.0 | Region | Note=Modulating |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394089 | + | 2 | 9 | 404_419 | 59 | 463.0 | Region | Note=Required for binding corepressor NCOR1 |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000425707 | + | 2 | 7 | 154_182 | 59 | 366.0 | Region | Note=Hinge |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000425707 | + | 2 | 7 | 1_87 | 59 | 366.0 | Region | Note=Modulating |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000425707 | + | 2 | 7 | 404_419 | 59 | 366.0 | Region | Note=Required for binding corepressor NCOR1 |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000254066 | + | 2 | 9 | 124_148 | 59 | 463.0 | Zinc finger | NR C4-type |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000254066 | + | 2 | 9 | 88_108 | 59 | 463.0 | Zinc finger | NR C4-type |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394081 | + | 1 | 8 | 124_148 | 0 | 458.0 | Zinc finger | NR C4-type |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394081 | + | 1 | 8 | 88_108 | 0 | 458.0 | Zinc finger | NR C4-type |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394089 | + | 2 | 9 | 124_148 | 59 | 463.0 | Zinc finger | NR C4-type |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000394089 | + | 2 | 9 | 88_108 | 59 | 463.0 | Zinc finger | NR C4-type |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000425707 | + | 2 | 7 | 124_148 | 59 | 366.0 | Zinc finger | NR C4-type |
| Hgene | RARA | chr17:38487648 | chr16:15609161 | ENST00000425707 | + | 2 | 7 | 88_108 | 59 | 366.0 | Zinc finger | NR C4-type |
| Tgene | C16orf45 | chr17:38487648 | chr16:15609161 | ENST00000300006 | 0 | 6 | 3_150 | 35 | 205.0 | Domain | bMERB | |
| Tgene | C16orf45 | chr17:38487648 | chr16:15609161 | ENST00000452191 | 0 | 6 | 3_150 | 18 | 188.0 | Domain | bMERB |
Top |
Fusion Gene Sequence for RARA-C16orf45 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >72282_72282_1_RARA-C16orf45_RARA_chr17_38487648_ENST00000254066_C16orf45_chr16_15609161_ENST00000300006_length(transcript)=2572nt_BP=633nt CAGAAGCAGGGGGGAATCCTGAATCGAGCTGAGAGGGCTTCCCCGGTTCTCCTGGGAACCCCATCGGCCCCCTGCCAGCACACACCTGAG CAGCATCACAGGACATGGCCCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGA CCTTCCCAGGAAAAGTGCCAGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGG GTGGGGGCTCCAGGAGACTGAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCT GGGCCCAGGCCCCATGCCCCGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGC TTGGCATGGCCAGCAACAGCAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCC CCCCTATGCTGGGTGGACTCTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAG CCAATCAGCTGGACATCATCTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGG AAGTCTTGGTCCGCCGGGAGTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGC AGAACTTGGTCGCCATCCCAGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGC AGAAGAGAGACTTCCTGGTGGACGATGCGGAGGTCGAGCGGTTAAGGGAGCAAGAAGAAGACAAGGAAATGGCTGATTTCCTGAGAATCA AGTTAAAACCTCTAGACAAAGTAACCAAATCTCCAGCCAGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCCACGGTGG CCAAGACGGGGCTGGCACTGATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGGGCCATGG GGACCCCCCCCCACCCTCTTGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCAAGCCCGT GACTGTCACCAGAGGCCATGGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCGCATGGTC CTCCCCAGAGCATGCCGAACCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATCTCCACTT CTCTCTAGCTGTATCTAACCCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAACAATCTA GCACCATGTCGGACACGTTCCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCTGTCCTCT CCCAGCAACTGTGCCCTGGAGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATCTGTAAAG ATCGAGCTTGTGTGTGGTGTCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGTCCATTGT GCTCTCAGTCTGCCTCAGGTGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCGGAAGCTC TGATGTCAAGGCCAGAGCAGTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGAGATGCCA GCAGGATGCCACTTTGCCAGCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTGTGTCCCG TCATTGGGTGGCATATGTTAACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTACAGCCTGT GTGACTTCTCTGTATGTGTGTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATCAGAGAAA ATAAAAATGGAAACCACGTTCACAGCATTTTAAAAGTTTTTACTTTTTTTCTTGATTATGGAAGTAATCCATGTACATAGTAAATCATTT TAAAAGTACAAAAAGTATGAAGAAGTTTGTCTTAAAAAAAAAAAAAATTATTCCTCCAACTAGAGACCACTCTGATGTTTCGACGTTTTA AAAAAGTCTTTTTTTGTGCATTTTTTCATCGTTGACATCATATTGTGGTATCATTTATAACCAGTTTTTTCCTACTTATTATACCACCAT >72282_72282_1_RARA-C16orf45_RARA_chr17_38487648_ENST00000254066_C16orf45_chr16_15609161_ENST00000300006_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- >72282_72282_2_RARA-C16orf45_RARA_chr17_38487648_ENST00000254066_C16orf45_chr16_15609161_ENST00000452191_length(transcript)=2387nt_BP=633nt CAGAAGCAGGGGGGAATCCTGAATCGAGCTGAGAGGGCTTCCCCGGTTCTCCTGGGAACCCCATCGGCCCCCTGCCAGCACACACCTGAG CAGCATCACAGGACATGGCCCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGA CCTTCCCAGGAAAAGTGCCAGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGG GTGGGGGCTCCAGGAGACTGAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCT GGGCCCAGGCCCCATGCCCCGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGC TTGGCATGGCCAGCAACAGCAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCC CCCCTATGCTGGGTGGACTCTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAG CCAATCAGCTGGACATCATCTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGG AAGTCTTGGTCCGCCGGGAGTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGC AGAACTTGGTCGCCATCCCAGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGC AGAAGAGAGACTTCCTGGTGGACGATGCGGAGGTCGAGCGGTTAAGGGAGCAAGAAGAAGACAAGGAAATGGCTGATTTCCTGAGAATCA AGTTAAAACCTCTAGACAAAGTAACCAAATCTCCAGCCAGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCCACGGTGG CCAAGACGGGGCTGGCACTGATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGGGCCATGG GGACCCCCCCCCACCCTCTTGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCAAGCCCGT GACTGTCACCAGAGGCCATGGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCGCATGGTC CTCCCCAGAGCATGCCGAACCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATCTCCACTT CTCTCTAGCTGTATCTAACCCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAACAATCTA GCACCATGTCGGACACGTTCCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCTGTCCTCT CCCAGCAACTGTGCCCTGGAGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATCTGTAAAG ATCGAGCTTGTGTGTGGTGTCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGTCCATTGT GCTCTCAGTCTGCCTCAGGTGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCGGAAGCTC TGATGTCAAGGCCAGAGCAGTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGAGATGCCA GCAGGATGCCACTTTGCCAGCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTGTGTCCCG TCATTGGGTGGCATATGTTAACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTACAGCCTGT GTGACTTCTCTGTATGTGTGTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATCAGAGAAA ATAAAAATGGAAACCACGTTCACAGCATTTTAAAAGTTTTTACTTTTTTTCTTGATTATGGAAGTAATCCATGTACATAGTAAATCATTT >72282_72282_2_RARA-C16orf45_RARA_chr17_38487648_ENST00000254066_C16orf45_chr16_15609161_ENST00000452191_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- >72282_72282_3_RARA-C16orf45_RARA_chr17_38487648_ENST00000254066_C16orf45_chr16_15609161_ENST00000566490_length(transcript)=2202nt_BP=633nt CAGAAGCAGGGGGGAATCCTGAATCGAGCTGAGAGGGCTTCCCCGGTTCTCCTGGGAACCCCATCGGCCCCCTGCCAGCACACACCTGAG CAGCATCACAGGACATGGCCCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGA CCTTCCCAGGAAAAGTGCCAGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGG GTGGGGGCTCCAGGAGACTGAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCT GGGCCCAGGCCCCATGCCCCGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGC TTGGCATGGCCAGCAACAGCAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCC CCCCTATGCTGGGTGGACTCTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAG CCAATCAGCTGGACATCATCTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGG AAGTCTTGGTCCGCCGGGAGTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGC AGAACTTGGTCGCCATCCCAGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGC AGAAGAGAGACTTCCTGGTGGACGATGCGGAGGTCGAGCGGTTAAGGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCC ACGGTGGCCAAGACGGGGCTGGCACTGATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGG GCCATGGGGACCCCCCCCCACCCTCTTGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCA AGCCCGTGACTGTCACCAGAGGCCATGGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCG CATGGTCCTCCCCAGAGCATGCCGAACCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATC TCCACTTCTCTCTAGCTGTATCTAACCCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAA CAATCTAGCACCATGTCGGACACGTTCCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCT GTCCTCTCCCAGCAACTGTGCCCTGGAGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATC TGTAAAGATCGAGCTTGTGTGTGGTGTCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGT CCATTGTGCTCTCAGTCTGCCTCAGGTGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCG GAAGCTCTGATGTCAAGGCCAGAGCAGTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGA GATGCCAGCAGGATGCCACTTTGCCAGCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTG TGTCCCGTCATTGGGTGGCATATGTTAACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTAC AGCCTGTGTGACTTCTCTGTATGTGTGTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATC >72282_72282_3_RARA-C16orf45_RARA_chr17_38487648_ENST00000254066_C16orf45_chr16_15609161_ENST00000566490_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- >72282_72282_4_RARA-C16orf45_RARA_chr17_38487648_ENST00000394089_C16orf45_chr16_15609161_ENST00000300006_length(transcript)=2647nt_BP=708nt GTGACTCGCTATGGCCGCTGCCATCGCCCCGCGCCCCTGAGCCGCGGCCCCCTGGACGGCTCCTCTCCCGGGACCCCGCACCCTGATGCC GAGCAGCACCAGGGCGCCGGGTTAGGGCAGACGCTGTGCTCGCTGGCACCCCGAACGGGTTGCTTCCCCCGCTGCGAGCATCACAGGACA TGGCCCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGACCTTCCCAGGAAAAG TGCCAGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGGGTGGGGGCTCCAGGA GACTGAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCTGGGCCCAGGCCCCAT GCCCCGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGCTTGGCATGGCCAGCA ACAGCAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCCCCCCTATGCTGGGTG GACTCTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAGCCAATCAGCTGGACA TCATCTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGGAAGTCTTGGTCCGCC GGGAGTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGCAGAACTTGGTCGCCA TCCCAGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGCAGAAGAGAGACTTCC TGGTGGACGATGCGGAGGTCGAGCGGTTAAGGGAGCAAGAAGAAGACAAGGAAATGGCTGATTTCCTGAGAATCAAGTTAAAACCTCTAG ACAAAGTAACCAAATCTCCAGCCAGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCCACGGTGGCCAAGACGGGGCTGG CACTGATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGGGCCATGGGGACCCCCCCCCACC CTCTTGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCAAGCCCGTGACTGTCACCAGAGG CCATGGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCGCATGGTCCTCCCCAGAGCATGC CGAACCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATCTCCACTTCTCTCTAGCTGTATC TAACCCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAACAATCTAGCACCATGTCGGACA CGTTCCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCTGTCCTCTCCCAGCAACTGTGCC CTGGAGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATCTGTAAAGATCGAGCTTGTGTGT GGTGTCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGTCCATTGTGCTCTCAGTCTGCCT CAGGTGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCGGAAGCTCTGATGTCAAGGCCAG AGCAGTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGAGATGCCAGCAGGATGCCACTTT GCCAGCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTGTGTCCCGTCATTGGGTGGCATA TGTTAACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTACAGCCTGTGTGACTTCTCTGTAT GTGTGTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATCAGAGAAAATAAAAATGGAAACC ACGTTCACAGCATTTTAAAAGTTTTTACTTTTTTTCTTGATTATGGAAGTAATCCATGTACATAGTAAATCATTTTAAAAGTACAAAAAG TATGAAGAAGTTTGTCTTAAAAAAAAAAAAAATTATTCCTCCAACTAGAGACCACTCTGATGTTTCGACGTTTTAAAAAAGTCTTTTTTT GTGCATTTTTTCATCGTTGACATCATATTGTGGTATCATTTATAACCAGTTTTTTCCTACTTATTATACCACCATCTTCCACATCATTAA >72282_72282_4_RARA-C16orf45_RARA_chr17_38487648_ENST00000394089_C16orf45_chr16_15609161_ENST00000300006_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- >72282_72282_5_RARA-C16orf45_RARA_chr17_38487648_ENST00000394089_C16orf45_chr16_15609161_ENST00000452191_length(transcript)=2462nt_BP=708nt GTGACTCGCTATGGCCGCTGCCATCGCCCCGCGCCCCTGAGCCGCGGCCCCCTGGACGGCTCCTCTCCCGGGACCCCGCACCCTGATGCC GAGCAGCACCAGGGCGCCGGGTTAGGGCAGACGCTGTGCTCGCTGGCACCCCGAACGGGTTGCTTCCCCCGCTGCGAGCATCACAGGACA TGGCCCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGACCTTCCCAGGAAAAG TGCCAGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGGGTGGGGGCTCCAGGA GACTGAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCTGGGCCCAGGCCCCAT GCCCCGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGCTTGGCATGGCCAGCA ACAGCAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCCCCCCTATGCTGGGTG GACTCTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAGCCAATCAGCTGGACA TCATCTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGGAAGTCTTGGTCCGCC GGGAGTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGCAGAACTTGGTCGCCA TCCCAGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGCAGAAGAGAGACTTCC TGGTGGACGATGCGGAGGTCGAGCGGTTAAGGGAGCAAGAAGAAGACAAGGAAATGGCTGATTTCCTGAGAATCAAGTTAAAACCTCTAG ACAAAGTAACCAAATCTCCAGCCAGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCCACGGTGGCCAAGACGGGGCTGG CACTGATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGGGCCATGGGGACCCCCCCCCACC CTCTTGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCAAGCCCGTGACTGTCACCAGAGG CCATGGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCGCATGGTCCTCCCCAGAGCATGC CGAACCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATCTCCACTTCTCTCTAGCTGTATC TAACCCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAACAATCTAGCACCATGTCGGACA CGTTCCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCTGTCCTCTCCCAGCAACTGTGCC CTGGAGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATCTGTAAAGATCGAGCTTGTGTGT GGTGTCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGTCCATTGTGCTCTCAGTCTGCCT CAGGTGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCGGAAGCTCTGATGTCAAGGCCAG AGCAGTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGAGATGCCAGCAGGATGCCACTTT GCCAGCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTGTGTCCCGTCATTGGGTGGCATA TGTTAACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTACAGCCTGTGTGACTTCTCTGTAT GTGTGTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATCAGAGAAAATAAAAATGGAAACC ACGTTCACAGCATTTTAAAAGTTTTTACTTTTTTTCTTGATTATGGAAGTAATCCATGTACATAGTAAATCATTTTAAAAGTACAAAAAG >72282_72282_5_RARA-C16orf45_RARA_chr17_38487648_ENST00000394089_C16orf45_chr16_15609161_ENST00000452191_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- >72282_72282_6_RARA-C16orf45_RARA_chr17_38487648_ENST00000394089_C16orf45_chr16_15609161_ENST00000566490_length(transcript)=2277nt_BP=708nt GTGACTCGCTATGGCCGCTGCCATCGCCCCGCGCCCCTGAGCCGCGGCCCCCTGGACGGCTCCTCTCCCGGGACCCCGCACCCTGATGCC GAGCAGCACCAGGGCGCCGGGTTAGGGCAGACGCTGTGCTCGCTGGCACCCCGAACGGGTTGCTTCCCCCGCTGCGAGCATCACAGGACA TGGCCCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGACCTTCCCAGGAAAAG TGCCAGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGGGTGGGGGCTCCAGGA GACTGAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCTGGGCCCAGGCCCCAT GCCCCGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGCTTGGCATGGCCAGCA ACAGCAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCCCCCCTATGCTGGGTG GACTCTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAGCCAATCAGCTGGACA TCATCTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGGAAGTCTTGGTCCGCC GGGAGTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGCAGAACTTGGTCGCCA TCCCAGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGCAGAAGAGAGACTTCC TGGTGGACGATGCGGAGGTCGAGCGGTTAAGGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCCACGGTGGCCAAGACG GGGCTGGCACTGATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGGGCCATGGGGACCCCC CCCCACCCTCTTGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCAAGCCCGTGACTGTCA CCAGAGGCCATGGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCGCATGGTCCTCCCCAG AGCATGCCGAACCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATCTCCACTTCTCTCTAG CTGTATCTAACCCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAACAATCTAGCACCATG TCGGACACGTTCCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCTGTCCTCTCCCAGCAA CTGTGCCCTGGAGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATCTGTAAAGATCGAGCT TGTGTGTGGTGTCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGTCCATTGTGCTCTCAG TCTGCCTCAGGTGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCGGAAGCTCTGATGTCA AGGCCAGAGCAGTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGAGATGCCAGCAGGATG CCACTTTGCCAGCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTGTGTCCCGTCATTGGG TGGCATATGTTAACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTACAGCCTGTGTGACTTC TCTGTATGTGTGTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATCAGAGAAAATAAAAAT >72282_72282_6_RARA-C16orf45_RARA_chr17_38487648_ENST00000394089_C16orf45_chr16_15609161_ENST00000566490_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- >72282_72282_7_RARA-C16orf45_RARA_chr17_38487648_ENST00000425707_C16orf45_chr16_15609161_ENST00000300006_length(transcript)=2643nt_BP=704nt CTCGCTATGGCCGCTGCCATCGCCCCGCGCCCCTGAGCCGCGGCCCCCTGGACGGCTCCTCTCCCGGGACCCCGCACCCTGATGCCGAGC AGCACCAGGGCGCCGGGTTAGGGCAGACGCTGTGCTCGCTGGCACCCCGAACGGGTTGCTTCCCCCGCTGCGAGCATCACAGGACATGGC CCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGACCTTCCCAGGAAAAGTGCC AGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGGGTGGGGGCTCCAGGAGACT GAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCTGGGCCCAGGCCCCATGCCC CGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGCTTGGCATGGCCAGCAACAG CAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCCCCCCTATGCTGGGTGGACT CTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAGCCAATCAGCTGGACATCAT CTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGGAAGTCTTGGTCCGCCGGGA GTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGCAGAACTTGGTCGCCATCCC AGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGCAGAAGAGAGACTTCCTGGT GGACGATGCGGAGGTCGAGCGGTTAAGGGAGCAAGAAGAAGACAAGGAAATGGCTGATTTCCTGAGAATCAAGTTAAAACCTCTAGACAA AGTAACCAAATCTCCAGCCAGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCCACGGTGGCCAAGACGGGGCTGGCACT GATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGGGCCATGGGGACCCCCCCCCACCCTCT TGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCAAGCCCGTGACTGTCACCAGAGGCCAT GGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCGCATGGTCCTCCCCAGAGCATGCCGAA CCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATCTCCACTTCTCTCTAGCTGTATCTAAC CCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAACAATCTAGCACCATGTCGGACACGTT CCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCTGTCCTCTCCCAGCAACTGTGCCCTGG AGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATCTGTAAAGATCGAGCTTGTGTGTGGTG TCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGTCCATTGTGCTCTCAGTCTGCCTCAGG TGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCGGAAGCTCTGATGTCAAGGCCAGAGCA GTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGAGATGCCAGCAGGATGCCACTTTGCCA GCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTGTGTCCCGTCATTGGGTGGCATATGTT AACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTACAGCCTGTGTGACTTCTCTGTATGTGT GTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATCAGAGAAAATAAAAATGGAAACCACGT TCACAGCATTTTAAAAGTTTTTACTTTTTTTCTTGATTATGGAAGTAATCCATGTACATAGTAAATCATTTTAAAAGTACAAAAAGTATG AAGAAGTTTGTCTTAAAAAAAAAAAAAATTATTCCTCCAACTAGAGACCACTCTGATGTTTCGACGTTTTAAAAAAGTCTTTTTTTGTGC ATTTTTTCATCGTTGACATCATATTGTGGTATCATTTATAACCAGTTTTTTCCTACTTATTATACCACCATCTTCCACATCATTAAAAGC >72282_72282_7_RARA-C16orf45_RARA_chr17_38487648_ENST00000425707_C16orf45_chr16_15609161_ENST00000300006_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- >72282_72282_8_RARA-C16orf45_RARA_chr17_38487648_ENST00000425707_C16orf45_chr16_15609161_ENST00000452191_length(transcript)=2458nt_BP=704nt CTCGCTATGGCCGCTGCCATCGCCCCGCGCCCCTGAGCCGCGGCCCCCTGGACGGCTCCTCTCCCGGGACCCCGCACCCTGATGCCGAGC AGCACCAGGGCGCCGGGTTAGGGCAGACGCTGTGCTCGCTGGCACCCCGAACGGGTTGCTTCCCCCGCTGCGAGCATCACAGGACATGGC CCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGACCTTCCCAGGAAAAGTGCC AGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGGGTGGGGGCTCCAGGAGACT GAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCTGGGCCCAGGCCCCATGCCC CGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGCTTGGCATGGCCAGCAACAG CAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCCCCCCTATGCTGGGTGGACT CTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAGCCAATCAGCTGGACATCAT CTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGGAAGTCTTGGTCCGCCGGGA GTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGCAGAACTTGGTCGCCATCCC AGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGCAGAAGAGAGACTTCCTGGT GGACGATGCGGAGGTCGAGCGGTTAAGGGAGCAAGAAGAAGACAAGGAAATGGCTGATTTCCTGAGAATCAAGTTAAAACCTCTAGACAA AGTAACCAAATCTCCAGCCAGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCCACGGTGGCCAAGACGGGGCTGGCACT GATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGGGCCATGGGGACCCCCCCCCACCCTCT TGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCAAGCCCGTGACTGTCACCAGAGGCCAT GGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCGCATGGTCCTCCCCAGAGCATGCCGAA CCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATCTCCACTTCTCTCTAGCTGTATCTAAC CCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAACAATCTAGCACCATGTCGGACACGTT CCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCTGTCCTCTCCCAGCAACTGTGCCCTGG AGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATCTGTAAAGATCGAGCTTGTGTGTGGTG TCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGTCCATTGTGCTCTCAGTCTGCCTCAGG TGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCGGAAGCTCTGATGTCAAGGCCAGAGCA GTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGAGATGCCAGCAGGATGCCACTTTGCCA GCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTGTGTCCCGTCATTGGGTGGCATATGTT AACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTACAGCCTGTGTGACTTCTCTGTATGTGT GTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATCAGAGAAAATAAAAATGGAAACCACGT TCACAGCATTTTAAAAGTTTTTACTTTTTTTCTTGATTATGGAAGTAATCCATGTACATAGTAAATCATTTTAAAAGTACAAAAAGTATG >72282_72282_8_RARA-C16orf45_RARA_chr17_38487648_ENST00000425707_C16orf45_chr16_15609161_ENST00000452191_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- >72282_72282_9_RARA-C16orf45_RARA_chr17_38487648_ENST00000425707_C16orf45_chr16_15609161_ENST00000566490_length(transcript)=2273nt_BP=704nt CTCGCTATGGCCGCTGCCATCGCCCCGCGCCCCTGAGCCGCGGCCCCCTGGACGGCTCCTCTCCCGGGACCCCGCACCCTGATGCCGAGC AGCACCAGGGCGCCGGGTTAGGGCAGACGCTGTGCTCGCTGGCACCCCGAACGGGTTGCTTCCCCCGCTGCGAGCATCACAGGACATGGC CCCCTCAGCCACCTAGCTGGGGCCCATCTAGGAGTGGCATCTTTTTTGGTGCCCTGAAGGCCAGCTCTGGACCTTCCCAGGAAAAGTGCC AGCTCACAGAACTGCTTGACCAAAGGACCGGCTCTTGAGACATCCCCCAACCCACCTGGCCCCCAGCTAGGGTGGGGGCTCCAGGAGACT GAGATTAGCCTGCCCTCTTTGGACAGCAGCTCCAGGACAGGGCGGGTGGGCTGACCACCCAAACCCCATCTGGGCCCAGGCCCCATGCCC CGAGGAGGGGTGGTCTGAAGCCCACCAGAGCCCCCTGCCAGACTGTCTGCCTCCCTTCTGACTGTGGCCGCTTGGCATGGCCAGCAACAG CAGCTCCTGCCCGACACCTGGGGGCGGGCACCTCAATGGGTACCCGGTGCCTCCCTACGCCTTCTTCTTCCCCCCTATGCTGGGTGGACT CTCCCCGCCAGGCGCTCTGACCACTCTCCAGCACCAGCTTCCAGTTAGTGGATATAGCACACCATCCCCAGCCAATCAGCTGGACATCAT CTCCATGGCGGAGACAACCATGATGCCAGAGGAGATTGAGCTGGAGATGGCAAAAATTCAGCGTCTCCGGGAAGTCTTGGTCCGCCGGGA GTCTGAGCTCAGGTTCATGATGGATGACATCCAGCTCTGCAAGGACATCATGGACTTGAAGCAGGAGCTGCAGAACTTGGTCGCCATCCC AGAAAAAGAAAAAACCAAACTGCAGAAGCAGAGAGAGGATGAGCTAATCCAGAAGATCCACAAACTGGTGCAGAAGAGAGACTTCCTGGT GGACGATGCGGAGGTCGAGCGGTTAAGGCTCCCGGGCAGAGAAGAAAGCAGAGCCCCCACCTAGCAAGCCCACGGTGGCCAAGACGGGGC TGGCACTGATCAAGGATTGTTGCGGGGCCACCCAGTGCAACATCATGTAGCCCCCACGTGGGGTGCCCTGGGCCATGGGGACCCCCCCCC ACCCTCTTGTCTTTATAGCCCCCATTTCACCGGGGCCCAAGAGCTCTCCAAGGCAGAAGGGGTTGAAGGCAAGCCCGTGACTGTCACCAG AGGCCATGGGCACGGCAGGCGGGCCTGGCCACCCTGTACAGAGTGTAGCAGTAGGGAGTCTCTCACCGTCGCATGGTCCTCCCCAGAGCA TGCCGAACCCAGGAGTCTGTCTCACTGTTTATCCAAACACCAGGAAAGGTCCTCCCTCAAAAAAGCATATCTCCACTTCTCTCTAGCTGT ATCTAACCCACCGTGTGAATGAACTGGGAGAGGGGCATGCTCCCCAGCTGTGTGTAGTCGTGACTTCTCAACAATCTAGCACCATGTCGG ACACGTTCCCCATCCACCCTCCTAGCTCTGCTCTCAGAGCTAGGCACATGGGCACAGGTCCCCTCCCGTCTGTCCTCTCCCAGCAACTGT GCCCTGGAGGGCTCCACATGGCCCCCGTGTCTCTCGGGCACCACCCATATAGCAGTCCCAGAGGGCCCATCTGTAAAGATCGAGCTTGTG TGTGGTGTCGTGGTCACATCTCCCGCTTCCCCCCATCCTGTGTCTGGGCACAGTTCACATCAGGACAGCGTCCATTGTGCTCTCAGTCTG CCTCAGGTGTGTGCCTGGAGGGGGCCTGGACTGGCATGGATCCAGTGTGCAGAAGAGCCAGCAGGGAACCGGAAGCTCTGATGTCAAGGC CAGAGCAGTTGAGAATGGGACCCAGAGTAGATGCTGACCTGGGCACTCCACCATTCCGGGGCCACCACAGAGATGCCAGCAGGATGCCAC TTTGCCAGCCCGACACACGGACCTTTGTAAAGAACAGCAACAGGCAGGAGAGGCAGCGTGTGACCAGATTGTGTCCCGTCATTGGGTGGC ATATGTTAACTAGCTGCCAAACAACTTCAACCCGTGTAATTCATGTACATTTGCAACAGCCAGCCCGGTACAGCCTGTGTGACTTCTCTG TATGTGTGTGTGTGTCGTGACCAGCCTAAGTAGTTAGCATAACTCAAGATGCTGATGTGCAGTCACCCATCAGAGAAAATAAAAATGGAA >72282_72282_9_RARA-C16orf45_RARA_chr17_38487648_ENST00000425707_C16orf45_chr16_15609161_ENST00000566490_length(amino acids)=247AA_BP= MYLTHRVNELGEGHAPQLCVVVTSQQSSTMSDTFPIHPPSSALRARHMGTGPLPSVLSQQLCPGGLHMAPVSLGHHPYSSPRGPICKDRA CVWCRGHISRFPPSCVWAQFTSGQRPLCSQSASGVCLEGAWTGMDPVCRRASREPEALMSRPEQLRMGPRVDADLGTPPFRGHHRDASRM -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for RARA-C16orf45 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for RARA-C16orf45 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for RARA-C16orf45 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies