
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:RC3H2-GNA14 (FusionGDB2 ID:73115) |
Fusion Gene Summary for RC3H2-GNA14 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: RC3H2-GNA14 | Fusion gene ID: 73115 | Hgene | Tgene | Gene symbol | RC3H2 | GNA14 | Gene ID | 54542 | 9630 |
| Gene name | ring finger and CCCH-type domains 2 | G protein subunit alpha 14 | |
| Synonyms | MNAB|RNF164 | - | |
| Cytomap | 9q33.2 | 9q21.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | roquin-2RING finger protein 164RING-type E3 ubiquitin transferase Roquin-2membrane associated DNA binding proteinmembrane-associated nucleic acid-binding proteinring finger and CCCH-type zinc finger domain-containing protein 2ring finger and CCCH-ty | guanine nucleotide-binding protein subunit alpha-14g alpha-14guanine nucleotide binding protein (G protein), alpha 14guanine nucleotide-binding protein 14 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | O95837 | |
| Ensembl transtripts involved in fusion gene | ENST00000335387, ENST00000357244, ENST00000373665, ENST00000373670, ENST00000423239, ENST00000471874, ENST00000478216, | ENST00000464095, ENST00000341700, | |
| Fusion gene scores | * DoF score | 7 X 8 X 6=336 | 7 X 4 X 5=140 |
| # samples | 7 | 7 | |
| ** MAII score | log2(7/336*10)=-2.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/140*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: RC3H2 [Title/Abstract] AND GNA14 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | RC3H2(125645483)-GNA14(80049438), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | RC3H2 | GO:0000209 | protein polyubiquitination | 26489670 |
| Fusion gene breakpoints across RC3H2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
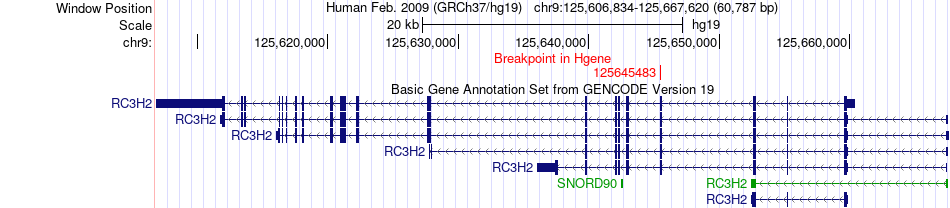 |
| Fusion gene breakpoints across GNA14 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A2-A4RW-01A | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
Top |
Fusion Gene ORF analysis for RC3H2-GNA14 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000335387 | ENST00000464095 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| 5CDS-intron | ENST00000357244 | ENST00000464095 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| 5CDS-intron | ENST00000373665 | ENST00000464095 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| 5CDS-intron | ENST00000373670 | ENST00000464095 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| 5CDS-intron | ENST00000423239 | ENST00000464095 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| In-frame | ENST00000335387 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| In-frame | ENST00000357244 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| In-frame | ENST00000373665 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| In-frame | ENST00000373670 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| In-frame | ENST00000423239 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| intron-3CDS | ENST00000471874 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| intron-3CDS | ENST00000478216 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| intron-intron | ENST00000471874 | ENST00000464095 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| intron-intron | ENST00000478216 | ENST00000464095 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000373670 | RC3H2 | chr9 | 125645483 | - | ENST00000341700 | GNA14 | chr9 | 80049438 | - | 3019 | 1360 | 601 | 2118 | 505 |
| ENST00000357244 | RC3H2 | chr9 | 125645483 | - | ENST00000341700 | GNA14 | chr9 | 80049438 | - | 2659 | 1000 | 241 | 1758 | 505 |
| ENST00000423239 | RC3H2 | chr9 | 125645483 | - | ENST00000341700 | GNA14 | chr9 | 80049438 | - | 2717 | 1058 | 299 | 1816 | 505 |
| ENST00000373665 | RC3H2 | chr9 | 125645483 | - | ENST00000341700 | GNA14 | chr9 | 80049438 | - | 2659 | 1000 | 241 | 1758 | 505 |
| ENST00000335387 | RC3H2 | chr9 | 125645483 | - | ENST00000341700 | GNA14 | chr9 | 80049438 | - | 2591 | 932 | 173 | 1690 | 505 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000373670 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - | 0.000178845 | 0.9998211 |
| ENST00000357244 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - | 0.000291407 | 0.9997086 |
| ENST00000423239 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - | 0.000288071 | 0.99971193 |
| ENST00000373665 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - | 0.000291407 | 0.9997086 |
| ENST00000335387 | ENST00000341700 | RC3H2 | chr9 | 125645483 | - | GNA14 | chr9 | 80049438 | - | 0.000286325 | 0.9997136 |
Top |
Fusion Genomic Features for RC3H2-GNA14 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
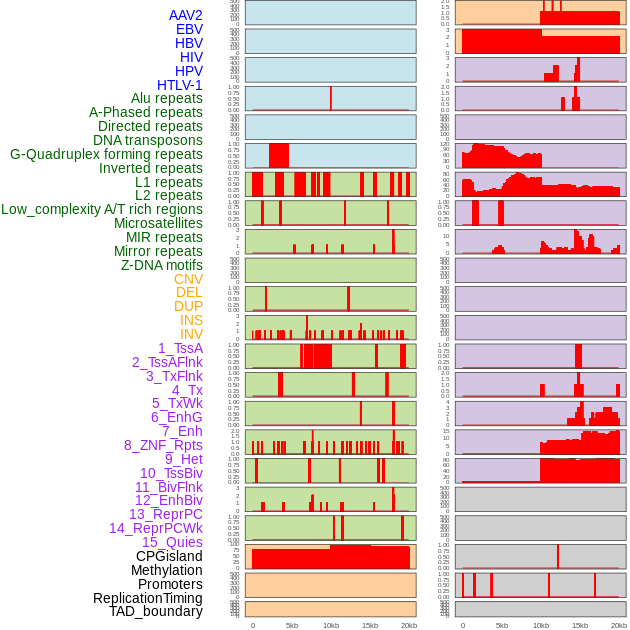 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for RC3H2-GNA14 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:125645483/chr9:80049438) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | GNA14 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Guanine nucleotide-binding proteins (G proteins) are involved as modulators or transducers in various transmembrane signaling systems. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000357244 | - | 5 | 21 | 91_170 | 253 | 1192.0 | Region | HEPN-N |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373665 | - | 5 | 11 | 91_170 | 253 | 479.0 | Region | HEPN-N |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373670 | - | 4 | 20 | 91_170 | 253 | 1192.0 | Region | HEPN-N |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000423239 | - | 5 | 18 | 91_170 | 253 | 1065.0 | Region | HEPN-N |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000357244 | - | 5 | 21 | 14_54 | 253 | 1192.0 | Zinc finger | RING-type%3B degenerate |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373665 | - | 5 | 11 | 14_54 | 253 | 479.0 | Zinc finger | RING-type%3B degenerate |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373670 | - | 4 | 20 | 14_54 | 253 | 1192.0 | Zinc finger | RING-type%3B degenerate |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000423239 | - | 5 | 18 | 14_54 | 253 | 1065.0 | Zinc finger | RING-type%3B degenerate |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 176_182 | 103 | 356.0 | Nucleotide binding | GTP | |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 201_205 | 103 | 356.0 | Nucleotide binding | GTP | |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 270_273 | 103 | 356.0 | Nucleotide binding | GTP | |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 174_182 | 103 | 356.0 | Region | G2 motif | |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 197_206 | 103 | 356.0 | Region | G3 motif | |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 266_273 | 103 | 356.0 | Region | G4 motif | |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 325_330 | 103 | 356.0 | Region | G5 motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000357244 | - | 5 | 21 | 576_704 | 253 | 1192.0 | Compositional bias | Note=Pro-rich |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373665 | - | 5 | 11 | 576_704 | 253 | 479.0 | Compositional bias | Note=Pro-rich |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373670 | - | 4 | 20 | 576_704 | 253 | 1192.0 | Compositional bias | Note=Pro-rich |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000423239 | - | 5 | 18 | 576_704 | 253 | 1065.0 | Compositional bias | Note=Pro-rich |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000471874 | - | 1 | 3 | 576_704 | 0 | 219.0 | Compositional bias | Note=Pro-rich |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000357244 | - | 5 | 21 | 171_325 | 253 | 1192.0 | Region | ROQ |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000357244 | - | 5 | 21 | 326_396 | 253 | 1192.0 | Region | HEPN-C |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373665 | - | 5 | 11 | 171_325 | 253 | 479.0 | Region | ROQ |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373665 | - | 5 | 11 | 326_396 | 253 | 479.0 | Region | HEPN-C |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373670 | - | 4 | 20 | 171_325 | 253 | 1192.0 | Region | ROQ |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373670 | - | 4 | 20 | 326_396 | 253 | 1192.0 | Region | HEPN-C |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000423239 | - | 5 | 18 | 171_325 | 253 | 1065.0 | Region | ROQ |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000423239 | - | 5 | 18 | 326_396 | 253 | 1065.0 | Region | HEPN-C |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000471874 | - | 1 | 3 | 171_325 | 0 | 219.0 | Region | ROQ |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000471874 | - | 1 | 3 | 326_396 | 0 | 219.0 | Region | HEPN-C |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000471874 | - | 1 | 3 | 91_170 | 0 | 219.0 | Region | HEPN-N |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000357244 | - | 5 | 21 | 410_438 | 253 | 1192.0 | Zinc finger | C3H1-type |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373665 | - | 5 | 11 | 410_438 | 253 | 479.0 | Zinc finger | C3H1-type |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000373670 | - | 4 | 20 | 410_438 | 253 | 1192.0 | Zinc finger | C3H1-type |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000423239 | - | 5 | 18 | 410_438 | 253 | 1065.0 | Zinc finger | C3H1-type |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000471874 | - | 1 | 3 | 14_54 | 0 | 219.0 | Zinc finger | RING-type%3B degenerate |
| Hgene | RC3H2 | chr9:125645483 | chr9:80049438 | ENST00000471874 | - | 1 | 3 | 410_438 | 0 | 219.0 | Zinc finger | C3H1-type |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 34_355 | 103 | 356.0 | Domain | G-alpha | |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 42_49 | 103 | 356.0 | Nucleotide binding | GTP | |
| Tgene | GNA14 | chr9:125645483 | chr9:80049438 | ENST00000341700 | 1 | 7 | 37_50 | 103 | 356.0 | Region | G1 motif |
Top |
Fusion Gene Sequence for RC3H2-GNA14 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >73115_73115_1_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000335387_GNA14_chr9_80049438_ENST00000341700_length(transcript)=2591nt_BP=932nt CTCCGCCGAGCTCTGCCCCGGCGAGACGAGGCGCCTCCGTCGCCAAGCCGCGCCGTCGCGGGGCTCCCGGGAGCGGCCCTTAGCGACCCC GCCCGGGCCCCCTCAGCTTACAAAACACTACACAGCAAAATAATGATCTGCTAGACTGCTAACCCGAGCATCCAGCTTCCACAATGCCTG TGCAGGCAGCTCAATGGACAGAATTTCTGTCCTGTCCAATCTGCTATAATGAATTTGATGAGAATGTGCACAAACCCATCAGTTTAGGTT GTTCACACACTGTTTGCAAGACCTGCTTGAATAAACTTCATCGAAAAGCTTGTCCTTTTGACCAGACTGCCATCAACACAGATATTGATG TACTTCCTGTCAACTTCGCACTTCTCCAGTTAGTTGGAGCCCAGGTACCAGATCATCAGTCAATTAAGTTAAGTAATCTAGGTGAGAATA AACACTATGAGGTTGCAAAGAAATGCGTTGAGGATTTGGCACTCTACTTAAAACCACTAAGTGGAGGTAAAGGTGTAGCTAGCTTGAACC AGAGTGCACTGAGCCGTCCAATGCAAAGGAAACTGGTGACACTTGTAAACTGTCAACTGGTGGAGGAAGAAGGTCGTGTAAGAGCCATGC GAGCAGCTCGTTCCCTTGGAGAAAGAACTGTAACAGAACTGATATTACAGCACCAGAACCCTCAGCAGTTGTCTGCCAATCTATGGGCCG CTGTCAGGGCTCGAGGATGCCAGTTTTTAGGGCCAGCTATGCAAGAAGAGGCCTTGAAGCTGGTGTTACTGGCATTAGAAGATGGTTCTG CCCTCTCAAGGAAAGTTCTGGTACTTTTTGTTGTGCAGAGACTAGAACCAAGATTTCCTCAGGCATCAAAAACAAGTATTGGTCATGTTG TGCAACTACTGTATCGAGCTTCTTGTTTTAAGGAAAATGCCCAGATAATCAGAGAAGTGGAAGTGGACAAGGTCTCCATGCTCTCCAGGG AGCAGGTGGAGGCCATCAAGCAGCTCTGGCAAGATCCAGGCATCCAGGAGTGTTACGACAGGAGGAGGGAGTACCAGCTGTCGGACTCTG CCAAATATTACCTGACTGACATTGACCGCATCGCCACACCATCATTCGTGCCTACCCAACAAGATGTGCTTCGCGTCCGAGTGCCCACCA CCGGCATCATTGAGTATCCATTTGACTTGGAAAACATCATCTTTCGGATGGTGGATGTTGGTGGCCAACGATCGGAAAGACGGAAGTGGA TTCACTGCTTTGAGAGTGTCACCTCCATTATTTTCTTGGTTGCTCTGAGTGAATATGACCAGGTCCTGGCTGAGTGTGACAACGAGAATC GCATGGAAGAGAGCAAAGCCTTATTTAAAACCATCATCACCTACCCCTGGTTTCTGAATTCGTCTGTGATTTTATTCTTGAACAAGAAGG ATCTTTTGGAAGAGAAAATCATGTACTCTCATCTAATTAGCTATTTCCCAGAATACACAGGACCGAAACAGGATGTCAGAGCTGCCAGAG ACTTTATCCTGAAGCTTTACCAAGATCAGAATCCTGACAAAGAGAAAGTCATCTACTCTCACTTCACATGTGCTACAGATACAGACAATA TTCGCTTTGTGTTTGCTGCTGTCAAAGACACAATTCTACAGCTAAACCTAAGGGAATTCAACCTTGTCTAAAAGCTGCTGCCCACTCCTC CCCTATAACAGAAGATGTGATTTGCAAACTCCTTGTTTTATTTGCAAGTGCTTCTGACATCACCAGAGCCAGCCCCATGCCAGGAACTAA GGATGTCATGTAGATCGTGGGGACAGAGATGGGTGATGGAACTTGGAAGATATTTGAGTTTACCAACATACTTTAAAAGTCCTTACATCC CAAATTGTGTTTATAATTATTTTCTTGACTTTTGGCTATAAGATTTTGTGTAATTTTTGAATTTGGTGTTTTCTAGAATTTTTAAAAGCC ACTTTGATTTAGTTTTAAATATGTTTAAAAATAGCGATTAAAATTATGTAAGCAAGGAGCCTGTTAGTTTATAGATCATGCCTTCAAACC TCTAGAGTTAATTTGGGTGACTTTTTTAAAAATAAGAATGTTAATGGGTTTGAAGCTTTTTATTAAACCTTGTAATTTAGAGACATTTTT AATTGTGTTTCTCACCTCATGCTGAAGGGTGACTCCTTTAACATGCCACCAAAGATTTTTTTTAAACACTTGGTTCTTTTTGTGTGTTAA CTTTCTAAGCCAAATTAATGGATATATAAGTATATCTAATTTAGCTTTGCCACAGTTTGATCACCAAGAAGCCAAAGCTGACATAGAGTA AATGGGCTCTAGATAGCATATATGTTTTATTGGTGAAAAATGTGTGTGTGTGCACGTGTGTGTGTGTGTACATTTTTACCCCCAATGTAT ATGACCAGATCTTAAAAATGTATGAAATGGCTAGAAGTCCACATTGTTTGACAAATGTTACGTAACCCTGCCAAAGTTCTGATGGCCACC >73115_73115_1_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000335387_GNA14_chr9_80049438_ENST00000341700_length(amino acids)=505AA_BP=253 MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLG ENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANL WAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKENAQIIREVEVDKVSML SREQVEAIKQLWQDPGIQECYDRRREYQLSDSAKYYLTDIDRIATPSFVPTQQDVLRVRVPTTGIIEYPFDLENIIFRMVDVGGQRSERR KWIHCFESVTSIIFLVALSEYDQVLAECDNENRMEESKALFKTIITYPWFLNSSVILFLNKKDLLEEKIMYSHLISYFPEYTGPKQDVRA -------------------------------------------------------------- >73115_73115_2_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000357244_GNA14_chr9_80049438_ENST00000341700_length(transcript)=2659nt_BP=1000nt GTCGCGGCCTTCGCCGCCGCCAACGGGGCTGTCCCTGTAGCTCCCGATGGAGTTTGAGGTCGTGAAACCTCCGCCGAGCTCTGCCCCGGC GAGACGAGGCGCCTCCGTCGCCAAGCCGCGCCGTCGCGGGGCTCCCGGGAGCGGCCCTTAGCGACCCCGCCCGGGCCCCCTCAGCTTACA AAACACTACACAGCAAAATAATGATCTGCTAGACTGCTAACCCGAGCATCCAGCTTCCACAATGCCTGTGCAGGCAGCTCAATGGACAGA ATTTCTGTCCTGTCCAATCTGCTATAATGAATTTGATGAGAATGTGCACAAACCCATCAGTTTAGGTTGTTCACACACTGTTTGCAAGAC CTGCTTGAATAAACTTCATCGAAAAGCTTGTCCTTTTGACCAGACTGCCATCAACACAGATATTGATGTACTTCCTGTCAACTTCGCACT TCTCCAGTTAGTTGGAGCCCAGGTACCAGATCATCAGTCAATTAAGTTAAGTAATCTAGGTGAGAATAAACACTATGAGGTTGCAAAGAA ATGCGTTGAGGATTTGGCACTCTACTTAAAACCACTAAGTGGAGGTAAAGGTGTAGCTAGCTTGAACCAGAGTGCACTGAGCCGTCCAAT GCAAAGGAAACTGGTGACACTTGTAAACTGTCAACTGGTGGAGGAAGAAGGTCGTGTAAGAGCCATGCGAGCAGCTCGTTCCCTTGGAGA AAGAACTGTAACAGAACTGATATTACAGCACCAGAACCCTCAGCAGTTGTCTGCCAATCTATGGGCCGCTGTCAGGGCTCGAGGATGCCA GTTTTTAGGGCCAGCTATGCAAGAAGAGGCCTTGAAGCTGGTGTTACTGGCATTAGAAGATGGTTCTGCCCTCTCAAGGAAAGTTCTGGT ACTTTTTGTTGTGCAGAGACTAGAACCAAGATTTCCTCAGGCATCAAAAACAAGTATTGGTCATGTTGTGCAACTACTGTATCGAGCTTC TTGTTTTAAGGAAAATGCCCAGATAATCAGAGAAGTGGAAGTGGACAAGGTCTCCATGCTCTCCAGGGAGCAGGTGGAGGCCATCAAGCA GCTCTGGCAAGATCCAGGCATCCAGGAGTGTTACGACAGGAGGAGGGAGTACCAGCTGTCGGACTCTGCCAAATATTACCTGACTGACAT TGACCGCATCGCCACACCATCATTCGTGCCTACCCAACAAGATGTGCTTCGCGTCCGAGTGCCCACCACCGGCATCATTGAGTATCCATT TGACTTGGAAAACATCATCTTTCGGATGGTGGATGTTGGTGGCCAACGATCGGAAAGACGGAAGTGGATTCACTGCTTTGAGAGTGTCAC CTCCATTATTTTCTTGGTTGCTCTGAGTGAATATGACCAGGTCCTGGCTGAGTGTGACAACGAGAATCGCATGGAAGAGAGCAAAGCCTT ATTTAAAACCATCATCACCTACCCCTGGTTTCTGAATTCGTCTGTGATTTTATTCTTGAACAAGAAGGATCTTTTGGAAGAGAAAATCAT GTACTCTCATCTAATTAGCTATTTCCCAGAATACACAGGACCGAAACAGGATGTCAGAGCTGCCAGAGACTTTATCCTGAAGCTTTACCA AGATCAGAATCCTGACAAAGAGAAAGTCATCTACTCTCACTTCACATGTGCTACAGATACAGACAATATTCGCTTTGTGTTTGCTGCTGT CAAAGACACAATTCTACAGCTAAACCTAAGGGAATTCAACCTTGTCTAAAAGCTGCTGCCCACTCCTCCCCTATAACAGAAGATGTGATT TGCAAACTCCTTGTTTTATTTGCAAGTGCTTCTGACATCACCAGAGCCAGCCCCATGCCAGGAACTAAGGATGTCATGTAGATCGTGGGG ACAGAGATGGGTGATGGAACTTGGAAGATATTTGAGTTTACCAACATACTTTAAAAGTCCTTACATCCCAAATTGTGTTTATAATTATTT TCTTGACTTTTGGCTATAAGATTTTGTGTAATTTTTGAATTTGGTGTTTTCTAGAATTTTTAAAAGCCACTTTGATTTAGTTTTAAATAT GTTTAAAAATAGCGATTAAAATTATGTAAGCAAGGAGCCTGTTAGTTTATAGATCATGCCTTCAAACCTCTAGAGTTAATTTGGGTGACT TTTTTAAAAATAAGAATGTTAATGGGTTTGAAGCTTTTTATTAAACCTTGTAATTTAGAGACATTTTTAATTGTGTTTCTCACCTCATGC TGAAGGGTGACTCCTTTAACATGCCACCAAAGATTTTTTTTAAACACTTGGTTCTTTTTGTGTGTTAACTTTCTAAGCCAAATTAATGGA TATATAAGTATATCTAATTTAGCTTTGCCACAGTTTGATCACCAAGAAGCCAAAGCTGACATAGAGTAAATGGGCTCTAGATAGCATATA TGTTTTATTGGTGAAAAATGTGTGTGTGTGCACGTGTGTGTGTGTGTACATTTTTACCCCCAATGTATATGACCAGATCTTAAAAATGTA TGAAATGGCTAGAAGTCCACATTGTTTGACAAATGTTACGTAACCCTGCCAAAGTTCTGATGGCCACCACAGATTTGCTGTTTGAATTAT >73115_73115_2_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000357244_GNA14_chr9_80049438_ENST00000341700_length(amino acids)=505AA_BP=253 MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLG ENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANL WAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKENAQIIREVEVDKVSML SREQVEAIKQLWQDPGIQECYDRRREYQLSDSAKYYLTDIDRIATPSFVPTQQDVLRVRVPTTGIIEYPFDLENIIFRMVDVGGQRSERR KWIHCFESVTSIIFLVALSEYDQVLAECDNENRMEESKALFKTIITYPWFLNSSVILFLNKKDLLEEKIMYSHLISYFPEYTGPKQDVRA -------------------------------------------------------------- >73115_73115_3_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000373665_GNA14_chr9_80049438_ENST00000341700_length(transcript)=2659nt_BP=1000nt GTCGCGGCCTTCGCCGCCGCCAACGGGGCTGTCCCTGTAGCTCCCGATGGAGTTTGAGGTCGTGAAACCTCCGCCGAGCTCTGCCCCGGC GAGACGAGGCGCCTCCGTCGCCAAGCCGCGCCGTCGCGGGGCTCCCGGGAGCGGCCCTTAGCGACCCCGCCCGGGCCCCCTCAGCTTACA AAACACTACACAGCAAAATAATGATCTGCTAGACTGCTAACCCGAGCATCCAGCTTCCACAATGCCTGTGCAGGCAGCTCAATGGACAGA ATTTCTGTCCTGTCCAATCTGCTATAATGAATTTGATGAGAATGTGCACAAACCCATCAGTTTAGGTTGTTCACACACTGTTTGCAAGAC CTGCTTGAATAAACTTCATCGAAAAGCTTGTCCTTTTGACCAGACTGCCATCAACACAGATATTGATGTACTTCCTGTCAACTTCGCACT TCTCCAGTTAGTTGGAGCCCAGGTACCAGATCATCAGTCAATTAAGTTAAGTAATCTAGGTGAGAATAAACACTATGAGGTTGCAAAGAA ATGCGTTGAGGATTTGGCACTCTACTTAAAACCACTAAGTGGAGGTAAAGGTGTAGCTAGCTTGAACCAGAGTGCACTGAGCCGTCCAAT GCAAAGGAAACTGGTGACACTTGTAAACTGTCAACTGGTGGAGGAAGAAGGTCGTGTAAGAGCCATGCGAGCAGCTCGTTCCCTTGGAGA AAGAACTGTAACAGAACTGATATTACAGCACCAGAACCCTCAGCAGTTGTCTGCCAATCTATGGGCCGCTGTCAGGGCTCGAGGATGCCA GTTTTTAGGGCCAGCTATGCAAGAAGAGGCCTTGAAGCTGGTGTTACTGGCATTAGAAGATGGTTCTGCCCTCTCAAGGAAAGTTCTGGT ACTTTTTGTTGTGCAGAGACTAGAACCAAGATTTCCTCAGGCATCAAAAACAAGTATTGGTCATGTTGTGCAACTACTGTATCGAGCTTC TTGTTTTAAGGAAAATGCCCAGATAATCAGAGAAGTGGAAGTGGACAAGGTCTCCATGCTCTCCAGGGAGCAGGTGGAGGCCATCAAGCA GCTCTGGCAAGATCCAGGCATCCAGGAGTGTTACGACAGGAGGAGGGAGTACCAGCTGTCGGACTCTGCCAAATATTACCTGACTGACAT TGACCGCATCGCCACACCATCATTCGTGCCTACCCAACAAGATGTGCTTCGCGTCCGAGTGCCCACCACCGGCATCATTGAGTATCCATT TGACTTGGAAAACATCATCTTTCGGATGGTGGATGTTGGTGGCCAACGATCGGAAAGACGGAAGTGGATTCACTGCTTTGAGAGTGTCAC CTCCATTATTTTCTTGGTTGCTCTGAGTGAATATGACCAGGTCCTGGCTGAGTGTGACAACGAGAATCGCATGGAAGAGAGCAAAGCCTT ATTTAAAACCATCATCACCTACCCCTGGTTTCTGAATTCGTCTGTGATTTTATTCTTGAACAAGAAGGATCTTTTGGAAGAGAAAATCAT GTACTCTCATCTAATTAGCTATTTCCCAGAATACACAGGACCGAAACAGGATGTCAGAGCTGCCAGAGACTTTATCCTGAAGCTTTACCA AGATCAGAATCCTGACAAAGAGAAAGTCATCTACTCTCACTTCACATGTGCTACAGATACAGACAATATTCGCTTTGTGTTTGCTGCTGT CAAAGACACAATTCTACAGCTAAACCTAAGGGAATTCAACCTTGTCTAAAAGCTGCTGCCCACTCCTCCCCTATAACAGAAGATGTGATT TGCAAACTCCTTGTTTTATTTGCAAGTGCTTCTGACATCACCAGAGCCAGCCCCATGCCAGGAACTAAGGATGTCATGTAGATCGTGGGG ACAGAGATGGGTGATGGAACTTGGAAGATATTTGAGTTTACCAACATACTTTAAAAGTCCTTACATCCCAAATTGTGTTTATAATTATTT TCTTGACTTTTGGCTATAAGATTTTGTGTAATTTTTGAATTTGGTGTTTTCTAGAATTTTTAAAAGCCACTTTGATTTAGTTTTAAATAT GTTTAAAAATAGCGATTAAAATTATGTAAGCAAGGAGCCTGTTAGTTTATAGATCATGCCTTCAAACCTCTAGAGTTAATTTGGGTGACT TTTTTAAAAATAAGAATGTTAATGGGTTTGAAGCTTTTTATTAAACCTTGTAATTTAGAGACATTTTTAATTGTGTTTCTCACCTCATGC TGAAGGGTGACTCCTTTAACATGCCACCAAAGATTTTTTTTAAACACTTGGTTCTTTTTGTGTGTTAACTTTCTAAGCCAAATTAATGGA TATATAAGTATATCTAATTTAGCTTTGCCACAGTTTGATCACCAAGAAGCCAAAGCTGACATAGAGTAAATGGGCTCTAGATAGCATATA TGTTTTATTGGTGAAAAATGTGTGTGTGTGCACGTGTGTGTGTGTGTACATTTTTACCCCCAATGTATATGACCAGATCTTAAAAATGTA TGAAATGGCTAGAAGTCCACATTGTTTGACAAATGTTACGTAACCCTGCCAAAGTTCTGATGGCCACCACAGATTTGCTGTTTGAATTAT >73115_73115_3_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000373665_GNA14_chr9_80049438_ENST00000341700_length(amino acids)=505AA_BP=253 MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLG ENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANL WAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKENAQIIREVEVDKVSML SREQVEAIKQLWQDPGIQECYDRRREYQLSDSAKYYLTDIDRIATPSFVPTQQDVLRVRVPTTGIIEYPFDLENIIFRMVDVGGQRSERR KWIHCFESVTSIIFLVALSEYDQVLAECDNENRMEESKALFKTIITYPWFLNSSVILFLNKKDLLEEKIMYSHLISYFPEYTGPKQDVRA -------------------------------------------------------------- >73115_73115_4_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000373670_GNA14_chr9_80049438_ENST00000341700_length(transcript)=3019nt_BP=1360nt AGCCAAGTCTTGTCAGAGATTTCCTCTTTCAGGTGGCAAAGCTGTTTTCTTCACACTTGAGTCTCTACAATATTGTTTGGATCAGTAGTT TCCAAAGTTCATTAACTCCTGGCCATACTTTATTATGTTTTGGGGTACTGGTTATCCAAGGGAAACACTTTTTTAAACAACAAAACAAAA AAACCGCCCAGCAGTCCAAAGTAATTTGTGTTCCTAAAAATGGAATATGGAAAGTTAATTTGCTTGTTTGATGTGGTCGTTGAGAAAAAT ACATAAAAGCTTTGATGTTTATTATGTGAGCAACCAATATAAATACAGTTTAGTTGAAAGGAACACTATTAAGGTATTGTTTCCAGGCAG AATTTCAGAAATGTAATTAATTCAGCAAATAGGTTTTTTAAAAAAGACATCCAAAGGTTATAAAATTATTTAGAAGTATTTTAGGTCTGA AGCTGTAATAGTTGACTTAAGCAATTAACTCTTCAAAGGTGAATGATGAATATGTGGTTAATTCATACTTTTGTCCATTTCTAGCTTACA AAACACTACACAGCAAAATAATGATCTGCTAGACTGCTAACCCGAGCATCCAGCTTCCACAATGCCTGTGCAGGCAGCTCAATGGACAGA ATTTCTGTCCTGTCCAATCTGCTATAATGAATTTGATGAGAATGTGCACAAACCCATCAGTTTAGGTTGTTCACACACTGTTTGCAAGAC CTGCTTGAATAAACTTCATCGAAAAGCTTGTCCTTTTGACCAGACTGCCATCAACACAGATATTGATGTACTTCCTGTCAACTTCGCACT TCTCCAGTTAGTTGGAGCCCAGGTACCAGATCATCAGTCAATTAAGTTAAGTAATCTAGGTGAGAATAAACACTATGAGGTTGCAAAGAA ATGCGTTGAGGATTTGGCACTCTACTTAAAACCACTAAGTGGAGGTAAAGGTGTAGCTAGCTTGAACCAGAGTGCACTGAGCCGTCCAAT GCAAAGGAAACTGGTGACACTTGTAAACTGTCAACTGGTGGAGGAAGAAGGTCGTGTAAGAGCCATGCGAGCAGCTCGTTCCCTTGGAGA AAGAACTGTAACAGAACTGATATTACAGCACCAGAACCCTCAGCAGTTGTCTGCCAATCTATGGGCCGCTGTCAGGGCTCGAGGATGCCA GTTTTTAGGGCCAGCTATGCAAGAAGAGGCCTTGAAGCTGGTGTTACTGGCATTAGAAGATGGTTCTGCCCTCTCAAGGAAAGTTCTGGT ACTTTTTGTTGTGCAGAGACTAGAACCAAGATTTCCTCAGGCATCAAAAACAAGTATTGGTCATGTTGTGCAACTACTGTATCGAGCTTC TTGTTTTAAGGAAAATGCCCAGATAATCAGAGAAGTGGAAGTGGACAAGGTCTCCATGCTCTCCAGGGAGCAGGTGGAGGCCATCAAGCA GCTCTGGCAAGATCCAGGCATCCAGGAGTGTTACGACAGGAGGAGGGAGTACCAGCTGTCGGACTCTGCCAAATATTACCTGACTGACAT TGACCGCATCGCCACACCATCATTCGTGCCTACCCAACAAGATGTGCTTCGCGTCCGAGTGCCCACCACCGGCATCATTGAGTATCCATT TGACTTGGAAAACATCATCTTTCGGATGGTGGATGTTGGTGGCCAACGATCGGAAAGACGGAAGTGGATTCACTGCTTTGAGAGTGTCAC CTCCATTATTTTCTTGGTTGCTCTGAGTGAATATGACCAGGTCCTGGCTGAGTGTGACAACGAGAATCGCATGGAAGAGAGCAAAGCCTT ATTTAAAACCATCATCACCTACCCCTGGTTTCTGAATTCGTCTGTGATTTTATTCTTGAACAAGAAGGATCTTTTGGAAGAGAAAATCAT GTACTCTCATCTAATTAGCTATTTCCCAGAATACACAGGACCGAAACAGGATGTCAGAGCTGCCAGAGACTTTATCCTGAAGCTTTACCA AGATCAGAATCCTGACAAAGAGAAAGTCATCTACTCTCACTTCACATGTGCTACAGATACAGACAATATTCGCTTTGTGTTTGCTGCTGT CAAAGACACAATTCTACAGCTAAACCTAAGGGAATTCAACCTTGTCTAAAAGCTGCTGCCCACTCCTCCCCTATAACAGAAGATGTGATT TGCAAACTCCTTGTTTTATTTGCAAGTGCTTCTGACATCACCAGAGCCAGCCCCATGCCAGGAACTAAGGATGTCATGTAGATCGTGGGG ACAGAGATGGGTGATGGAACTTGGAAGATATTTGAGTTTACCAACATACTTTAAAAGTCCTTACATCCCAAATTGTGTTTATAATTATTT TCTTGACTTTTGGCTATAAGATTTTGTGTAATTTTTGAATTTGGTGTTTTCTAGAATTTTTAAAAGCCACTTTGATTTAGTTTTAAATAT GTTTAAAAATAGCGATTAAAATTATGTAAGCAAGGAGCCTGTTAGTTTATAGATCATGCCTTCAAACCTCTAGAGTTAATTTGGGTGACT TTTTTAAAAATAAGAATGTTAATGGGTTTGAAGCTTTTTATTAAACCTTGTAATTTAGAGACATTTTTAATTGTGTTTCTCACCTCATGC TGAAGGGTGACTCCTTTAACATGCCACCAAAGATTTTTTTTAAACACTTGGTTCTTTTTGTGTGTTAACTTTCTAAGCCAAATTAATGGA TATATAAGTATATCTAATTTAGCTTTGCCACAGTTTGATCACCAAGAAGCCAAAGCTGACATAGAGTAAATGGGCTCTAGATAGCATATA TGTTTTATTGGTGAAAAATGTGTGTGTGTGCACGTGTGTGTGTGTGTACATTTTTACCCCCAATGTATATGACCAGATCTTAAAAATGTA TGAAATGGCTAGAAGTCCACATTGTTTGACAAATGTTACGTAACCCTGCCAAAGTTCTGATGGCCACCACAGATTTGCTGTTTGAATTAT >73115_73115_4_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000373670_GNA14_chr9_80049438_ENST00000341700_length(amino acids)=505AA_BP=253 MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLG ENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANL WAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKENAQIIREVEVDKVSML SREQVEAIKQLWQDPGIQECYDRRREYQLSDSAKYYLTDIDRIATPSFVPTQQDVLRVRVPTTGIIEYPFDLENIIFRMVDVGGQRSERR KWIHCFESVTSIIFLVALSEYDQVLAECDNENRMEESKALFKTIITYPWFLNSSVILFLNKKDLLEEKIMYSHLISYFPEYTGPKQDVRA -------------------------------------------------------------- >73115_73115_5_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000423239_GNA14_chr9_80049438_ENST00000341700_length(transcript)=2717nt_BP=1058nt CCGTGGTGAGGAGGAGGAGGAGGAGGAGGCGGAGGTGGAGGGAGGAGGAGGAGGCCCCGTCGCGGCCTTCGCCGCCGCCAACGGGGCTGT CCCTGTAGCTCCCGATGGAGTTTGAGGTCGTGAAACCTCCGCCGAGCTCTGCCCCGGCGAGACGAGGCGCCTCCGTCGCCAAGCCGCGCC GTCGCGGGGCTCCCGGGAGCGGCCCTTAGCGACCCCGCCCGGGCCCCCTCAGCTTACAAAACACTACACAGCAAAATAATGATCTGCTAG ACTGCTAACCCGAGCATCCAGCTTCCACAATGCCTGTGCAGGCAGCTCAATGGACAGAATTTCTGTCCTGTCCAATCTGCTATAATGAAT TTGATGAGAATGTGCACAAACCCATCAGTTTAGGTTGTTCACACACTGTTTGCAAGACCTGCTTGAATAAACTTCATCGAAAAGCTTGTC CTTTTGACCAGACTGCCATCAACACAGATATTGATGTACTTCCTGTCAACTTCGCACTTCTCCAGTTAGTTGGAGCCCAGGTACCAGATC ATCAGTCAATTAAGTTAAGTAATCTAGGTGAGAATAAACACTATGAGGTTGCAAAGAAATGCGTTGAGGATTTGGCACTCTACTTAAAAC CACTAAGTGGAGGTAAAGGTGTAGCTAGCTTGAACCAGAGTGCACTGAGCCGTCCAATGCAAAGGAAACTGGTGACACTTGTAAACTGTC AACTGGTGGAGGAAGAAGGTCGTGTAAGAGCCATGCGAGCAGCTCGTTCCCTTGGAGAAAGAACTGTAACAGAACTGATATTACAGCACC AGAACCCTCAGCAGTTGTCTGCCAATCTATGGGCCGCTGTCAGGGCTCGAGGATGCCAGTTTTTAGGGCCAGCTATGCAAGAAGAGGCCT TGAAGCTGGTGTTACTGGCATTAGAAGATGGTTCTGCCCTCTCAAGGAAAGTTCTGGTACTTTTTGTTGTGCAGAGACTAGAACCAAGAT TTCCTCAGGCATCAAAAACAAGTATTGGTCATGTTGTGCAACTACTGTATCGAGCTTCTTGTTTTAAGGAAAATGCCCAGATAATCAGAG AAGTGGAAGTGGACAAGGTCTCCATGCTCTCCAGGGAGCAGGTGGAGGCCATCAAGCAGCTCTGGCAAGATCCAGGCATCCAGGAGTGTT ACGACAGGAGGAGGGAGTACCAGCTGTCGGACTCTGCCAAATATTACCTGACTGACATTGACCGCATCGCCACACCATCATTCGTGCCTA CCCAACAAGATGTGCTTCGCGTCCGAGTGCCCACCACCGGCATCATTGAGTATCCATTTGACTTGGAAAACATCATCTTTCGGATGGTGG ATGTTGGTGGCCAACGATCGGAAAGACGGAAGTGGATTCACTGCTTTGAGAGTGTCACCTCCATTATTTTCTTGGTTGCTCTGAGTGAAT ATGACCAGGTCCTGGCTGAGTGTGACAACGAGAATCGCATGGAAGAGAGCAAAGCCTTATTTAAAACCATCATCACCTACCCCTGGTTTC TGAATTCGTCTGTGATTTTATTCTTGAACAAGAAGGATCTTTTGGAAGAGAAAATCATGTACTCTCATCTAATTAGCTATTTCCCAGAAT ACACAGGACCGAAACAGGATGTCAGAGCTGCCAGAGACTTTATCCTGAAGCTTTACCAAGATCAGAATCCTGACAAAGAGAAAGTCATCT ACTCTCACTTCACATGTGCTACAGATACAGACAATATTCGCTTTGTGTTTGCTGCTGTCAAAGACACAATTCTACAGCTAAACCTAAGGG AATTCAACCTTGTCTAAAAGCTGCTGCCCACTCCTCCCCTATAACAGAAGATGTGATTTGCAAACTCCTTGTTTTATTTGCAAGTGCTTC TGACATCACCAGAGCCAGCCCCATGCCAGGAACTAAGGATGTCATGTAGATCGTGGGGACAGAGATGGGTGATGGAACTTGGAAGATATT TGAGTTTACCAACATACTTTAAAAGTCCTTACATCCCAAATTGTGTTTATAATTATTTTCTTGACTTTTGGCTATAAGATTTTGTGTAAT TTTTGAATTTGGTGTTTTCTAGAATTTTTAAAAGCCACTTTGATTTAGTTTTAAATATGTTTAAAAATAGCGATTAAAATTATGTAAGCA AGGAGCCTGTTAGTTTATAGATCATGCCTTCAAACCTCTAGAGTTAATTTGGGTGACTTTTTTAAAAATAAGAATGTTAATGGGTTTGAA GCTTTTTATTAAACCTTGTAATTTAGAGACATTTTTAATTGTGTTTCTCACCTCATGCTGAAGGGTGACTCCTTTAACATGCCACCAAAG ATTTTTTTTAAACACTTGGTTCTTTTTGTGTGTTAACTTTCTAAGCCAAATTAATGGATATATAAGTATATCTAATTTAGCTTTGCCACA GTTTGATCACCAAGAAGCCAAAGCTGACATAGAGTAAATGGGCTCTAGATAGCATATATGTTTTATTGGTGAAAAATGTGTGTGTGTGCA CGTGTGTGTGTGTGTACATTTTTACCCCCAATGTATATGACCAGATCTTAAAAATGTATGAAATGGCTAGAAGTCCACATTGTTTGACAA ATGTTACGTAACCCTGCCAAAGTTCTGATGGCCACCACAGATTTGCTGTTTGAATTATGTATGCTGTGCCTTTCTGAGGAGGCTAAGAAT >73115_73115_5_RC3H2-GNA14_RC3H2_chr9_125645483_ENST00000423239_GNA14_chr9_80049438_ENST00000341700_length(amino acids)=505AA_BP=253 MPVQAAQWTEFLSCPICYNEFDENVHKPISLGCSHTVCKTCLNKLHRKACPFDQTAINTDIDVLPVNFALLQLVGAQVPDHQSIKLSNLG ENKHYEVAKKCVEDLALYLKPLSGGKGVASLNQSALSRPMQRKLVTLVNCQLVEEEGRVRAMRAARSLGERTVTELILQHQNPQQLSANL WAAVRARGCQFLGPAMQEEALKLVLLALEDGSALSRKVLVLFVVQRLEPRFPQASKTSIGHVVQLLYRASCFKENAQIIREVEVDKVSML SREQVEAIKQLWQDPGIQECYDRRREYQLSDSAKYYLTDIDRIATPSFVPTQQDVLRVRVPTTGIIEYPFDLENIIFRMVDVGGQRSERR KWIHCFESVTSIIFLVALSEYDQVLAECDNENRMEESKALFKTIITYPWFLNSSVILFLNKKDLLEEKIMYSHLISYFPEYTGPKQDVRA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for RC3H2-GNA14 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for RC3H2-GNA14 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for RC3H2-GNA14 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies