
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:RELB-TNFRSF8 (FusionGDB2 ID:73431) |
Fusion Gene Summary for RELB-TNFRSF8 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: RELB-TNFRSF8 | Fusion gene ID: 73431 | Hgene | Tgene | Gene symbol | RELB | TNFRSF8 | Gene ID | 5971 | 943 |
| Gene name | RELB proto-oncogene, NF-kB subunit | TNF receptor superfamily member 8 | |
| Synonyms | I-REL|IMD53|IREL|REL-B | CD30|D1S166E|Ki-1 | |
| Cytomap | 19q13.32 | 1p36.22 | |
| Type of gene | protein-coding | protein-coding | |
| Description | transcription factor RelBv-rel avian reticuloendotheliosis viral oncogene homolog B (nuclear factor of kappa light polypeptide gene enhancer in B-cells 3)v-rel reticuloendotheliosis viral oncogene homolog B, nuclear factor of kappa light polypeptide gen | tumor necrosis factor receptor superfamily member 8CD30L receptorKi-1 antigencytokine receptor CD30lymphocyte activation antigen CD30 | |
| Modification date | 20200315 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000221452, ENST00000505236, ENST00000540120, | ENST00000413146, ENST00000479933, ENST00000263932, ENST00000417814, | |
| Fusion gene scores | * DoF score | 7 X 4 X 5=140 | 5 X 6 X 5=150 |
| # samples | 8 | 5 | |
| ** MAII score | log2(8/140*10)=-0.807354922057604 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/150*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: RELB [Title/Abstract] AND TNFRSF8 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | RELB(45504943)-TNFRSF8(12175634), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | TNFRSF8 | GO:0042535 | positive regulation of tumor necrosis factor biosynthetic process | 16108830 |
| Tgene | TNFRSF8 | GO:0043065 | positive regulation of apoptotic process | 16108830 |
| Tgene | TNFRSF8 | GO:0045556 | positive regulation of TRAIL biosynthetic process | 16108830 |
| Fusion gene breakpoints across RELB (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TNFRSF8 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-BR-8295-01A | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
Top |
Fusion Gene ORF analysis for RELB-TNFRSF8 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000221452 | ENST00000413146 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| 5CDS-intron | ENST00000221452 | ENST00000479933 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| 5CDS-intron | ENST00000505236 | ENST00000413146 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| 5CDS-intron | ENST00000505236 | ENST00000479933 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| 5CDS-intron | ENST00000540120 | ENST00000413146 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| 5CDS-intron | ENST00000540120 | ENST00000479933 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| In-frame | ENST00000221452 | ENST00000263932 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| In-frame | ENST00000221452 | ENST00000417814 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| In-frame | ENST00000505236 | ENST00000263932 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| In-frame | ENST00000505236 | ENST00000417814 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| In-frame | ENST00000540120 | ENST00000263932 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| In-frame | ENST00000540120 | ENST00000417814 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000221452 | RELB | chr19 | 45504943 | + | ENST00000263932 | TNFRSF8 | chr1 | 12175634 | + | 2927 | 256 | 150 | 1250 | 366 |
| ENST00000221452 | RELB | chr19 | 45504943 | + | ENST00000417814 | TNFRSF8 | chr1 | 12175634 | + | 1834 | 256 | 150 | 1247 | 365 |
| ENST00000540120 | RELB | chr19 | 45504943 | + | ENST00000263932 | TNFRSF8 | chr1 | 12175634 | + | 2903 | 232 | 126 | 1226 | 366 |
| ENST00000540120 | RELB | chr19 | 45504943 | + | ENST00000417814 | TNFRSF8 | chr1 | 12175634 | + | 1810 | 232 | 126 | 1223 | 365 |
| ENST00000505236 | RELB | chr19 | 45504943 | + | ENST00000263932 | TNFRSF8 | chr1 | 12175634 | + | 2896 | 225 | 119 | 1219 | 366 |
| ENST00000505236 | RELB | chr19 | 45504943 | + | ENST00000417814 | TNFRSF8 | chr1 | 12175634 | + | 1803 | 225 | 119 | 1216 | 365 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000221452 | ENST00000263932 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + | 0.028258406 | 0.9717416 |
| ENST00000221452 | ENST00000417814 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + | 0.048930995 | 0.95106894 |
| ENST00000540120 | ENST00000263932 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + | 0.0280392 | 0.97196084 |
| ENST00000540120 | ENST00000417814 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + | 0.048413526 | 0.9515865 |
| ENST00000505236 | ENST00000263932 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + | 0.02809947 | 0.9719006 |
| ENST00000505236 | ENST00000417814 | RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175634 | + | 0.0490109 | 0.95098907 |
Top |
Fusion Genomic Features for RELB-TNFRSF8 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175633 | + | 3.98E-13 | 1 |
| RELB | chr19 | 45504943 | + | TNFRSF8 | chr1 | 12175633 | + | 3.98E-13 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
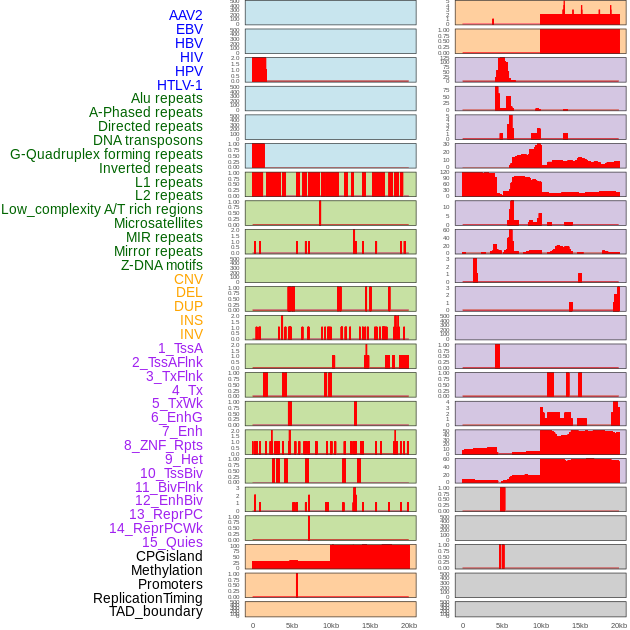 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
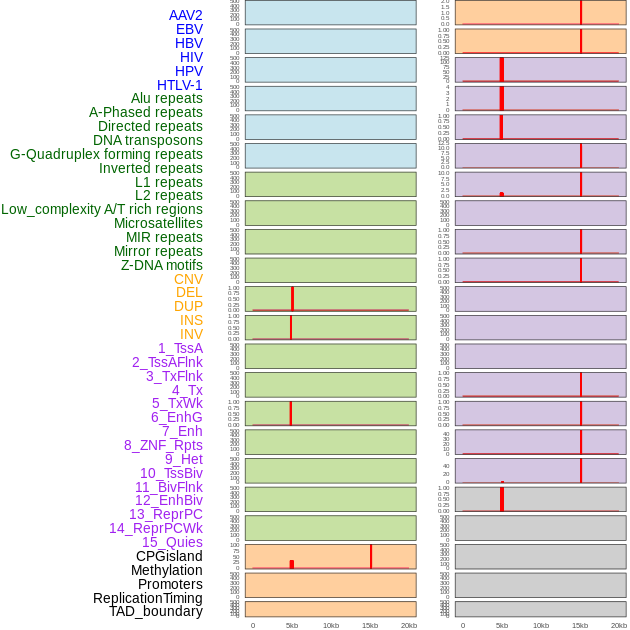 |
Top |
Fusion Protein Features for RELB-TNFRSF8 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:45504943/chr1:12175634) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 347_377 | 0 | 133.0 | Compositional bias | Note=Pro/Ser/Thr-rich | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 107_150 | 0 | 133.0 | Repeat | Note=TNFR-Cys 3 | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 205_241 | 0 | 133.0 | Repeat | Note=TNFR-Cys 4 | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 243_281 | 0 | 133.0 | Repeat | Note=TNFR-Cys 5 | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 282_325 | 0 | 133.0 | Repeat | Note=TNFR-Cys 6 | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 28_66 | 0 | 133.0 | Repeat | Note=TNFR-Cys 1 | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 68_106 | 0 | 133.0 | Repeat | Note=TNFR-Cys 2 | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 19_385 | 0 | 133.0 | Topological domain | Extracellular | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 407_595 | 0 | 133.0 | Topological domain | Cytoplasmic | |
| Tgene | TNFRSF8 | chr19:45504943 | chr1:12175634 | ENST00000413146 | 0 | 5 | 386_406 | 0 | 133.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | RELB | chr19:45504943 | chr1:12175634 | ENST00000221452 | + | 1 | 12 | 125_440 | 35 | 580.0 | Domain | RHD |
| Hgene | RELB | chr19:45504943 | chr1:12175634 | ENST00000540120 | + | 1 | 12 | 125_440 | 35 | 580.0 | Domain | RHD |
| Hgene | RELB | chr19:45504943 | chr1:12175634 | ENST00000221452 | + | 1 | 12 | 433_438 | 35 | 580.0 | Motif | Nuclear localization signal |
| Hgene | RELB | chr19:45504943 | chr1:12175634 | ENST00000540120 | + | 1 | 12 | 433_438 | 35 | 580.0 | Motif | Nuclear localization signal |
| Hgene | RELB | chr19:45504943 | chr1:12175634 | ENST00000221452 | + | 1 | 12 | 40_68 | 35 | 580.0 | Region | Note=Leucine-zipper |
| Hgene | RELB | chr19:45504943 | chr1:12175634 | ENST00000540120 | + | 1 | 12 | 40_68 | 35 | 580.0 | Region | Note=Leucine-zipper |
Top |
Fusion Gene Sequence for RELB-TNFRSF8 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >73431_73431_1_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000221452_TNFRSF8_chr1_12175634_ENST00000263932_length(transcript)=2927nt_BP=256nt CCCGCCGCCCGCCCGGCCCGGCCCCGCGCCCCGCGCAGCCCCGGGCGCCGCGCGTCCTGCCCGGCCTGCGGCCCCAGCCCTTGCGCCGCT CGTCCGACCCGCGATCGTCCACCAGACCGTGCCTCCCGGCCGCCCGGCCGGCCCGCGTGCATGCTTCGGTCTGGGCCAGCCTCTGGGCCG TCCGTCCCCACTGGCCGGGCCATGCCGAGTCGCCGCGTCGCCAGACCGCCGGCTGCGCCGGAGCTGGGGGCCTTAGATGACCTTGTGGAG AAGACGCCATGTGCATGGAACTCCTCCCGCACCTGCGAATGTCGACCTGGCATGATCTGTGCCACATCAGCCACCAACTCCCGTGCCCGC TGTGTCCCCTACCCAATCTGTGCAGCAGAGACGGTCACCAAGCCCCAGGATATGGCTGAGAAGGACACCACCTTTGAGGCGCCACCCCTG GGGACCCAGCCGGACTGCAACCCCACCCCAGAGAATGGCGAGGCGCCTGCCAGCACCAGCCCCACTCAGAGCTTGCTGGTGGACTCCCAG GCCAGTAAGACGCTGCCCATCCCAACCAGCGCTCCCGTCGCTCTCTCCTCCACGGGGAAGCCCGTTCTGGATGCAGGGCCAGTGCTCTTC TGGGTGATCCTGGTGTTGGTTGTGGTGGTCGGCTCCAGCGCCTTCCTCCTGTGCCACCGGAGGGCCTGCAGGAAGCGAATTCGGCAGAAG CTCCACCTGTGCTACCCGGTCCAGACCTCCCAGCCCAAGCTAGAGCTTGTGGATTCCAGACCCAGGAGGAGCTCAACGCAGCTGAGGAGT GGTGCGTCGGTGACAGAACCCGTCGCGGAAGAGCGAGGGTTAATGAGCCAGCCACTGATGGAGACCTGCCACAGCGTGGGGGCAGCCTAC CTGGAGAGCCTGCCGCTGCAGGATGCCAGCCCGGCCGGGGGCCCCTCGTCCCCCAGGGACCTTCCTGAGCCCCGGGTGTCCACGGAGCAC ACCAATAACAAGATTGAGAAAATCTACATCATGAAGGCTGACACCGTGATCGTGGGGACCGTGAAGGCTGAGCTGCCGGAGGGCCGGGGC CTGGCGGGGCCAGCAGAGCCCGAGTTGGAGGAGGAGCTGGAGGCGGACCATACCCCCCACTACCCCGAGCAGGAGACAGAACCGCCTCTG GGCAGCTGCAGCGATGTCATGCTCTCAGTGGAAGAGGAAGGGAAAGAAGACCCCTTGCCCACAGCTGCCTCTGGAAAGTGAGGCCTGGGC TGGGCTGGGGCTAGGAGGGCAGCAGGGTGGCCTCTGGGAGGCCAGGATGGCACTGTTGGCACCGAGGTTGGGGGCAGAGGCCCATCTGGC CTGAACTGAGGCTCCAGCATCTAGTGGTGGACCGGCCGGTCACTGCAGGGGTCTGGTGGTCTCTGCTTGCATCCCCAACTTAGCTGTCCC CTGACCCAGAGCCTAGGGGATCCGGGGCTTGTACAGAAGAGACAGTCCAAGGGGACTGGATCCCAGCAGTGATGTTGGTTGAGGCAGCAA ACAGATGGCAGGATGGGCACTGCCGAGAACAGCATTGGTCCCAGAGCCCTGGGCATCAGACCTTAACCACCAGGCCCACAGCCCAGCGAG GGAGAGGTCGTGAGGCCAGCTCCCGGGGCCCCTGTAACCCTACTCTCCTCTCTCCCTGGACCTCAGAGGTGACACCCATTGGGCCCTTCC GGCATGCCCCCAGTTACTGTAAATGTGGCCCCCAGTGGGCATGGAGCCAGTGCCTGTGGTTGTTTCTCCAGAGTCAAAAGGGAAGTCGAG GGATGGGGCGTCGTCAGCTGGCACTGTCTCTGCTGCAGCGGCCACACTGTACTCTGCACTGGTGTGAGGGCCCCTGCCTGGACTGTGGGA CCCTCCTGGTGCTGCCCACCTTCCCTGTCCTGTAGCCCCCTCGGTGGGCCCAGGGCCTAGGGCCCAGGATCAAGTCACTCATCTCAGAAT GTCCCCACCAATCCCCGCCACAGCAGGCGCCTCGGGTCCCAGATGTCTGCAGCCCTCAGCAGCTGCAGACCGCCCCTCACCAACCCAGAG AACCTGCTTTACTTTGCCCAGGGACTTCCTCCCCATGTGAACATGGGGAACTTCGGGCCCTGCCTGGAGTCCTTGACCGCTCTCTGTGGG CCCCACCCACTCTGTCCTGGGAAATGAAGAAGCATCTTCCTTAGGTCTGCCCTGCTTGCAAATCCACTAGCACCGACCCCACCACCTGGT TCCGGCTCTGCACGCTTTGGGGTGTGGATGTCGAGAGGCACCACGGCCTCACCCAGGCATCTGCTTTACTCTGGACCATAGGAAACAAGA CCGTTTGGAGGTTTCATCAGGATTTTGGGTTTTTCACATTTCACGCTAAGGAGTAGTGGCCCTGACTTCCGGTCGGCTGGCCAGCTGACT CCCTAGGGCCTTCAGACGTGTATGCAAATGAGTGATGGATAAGGATGAGTCTTGGAGTTGCGGGCAGCCTGGAGACTCGTGGACTTACCG CCTGGAGGCAGGCCCGGGAAGGCTGCTGTTTACTCATCGGGCAGCCACGTGCTCTCTGGAGGAAGTGATAGTTTCTGAAACCGCTCAGAT GTTTTGGGGAAAGTTGGAGAAGCCGTGGCCTTGCGAGAGGTGGTTACACCAGAACCTGGACATTGGCCAGAAGAAGCTTAAGTGGGCAGA CACTGTTTGCCCAGTGTTTGTGCAAGGATGGAGTGGGTGTCTCTGCATCACCCACAGCCGCAGCTGTAAGGCACGCTGGAAGGCACACGC CTGCCAGGCAGGGCAGTCTGGCGCCCATGATGGGAGGGATTGACATGTTTCAACAAAATAATGCACTTCCTTACCTAGTGGCCCTTCACA >73431_73431_1_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000221452_TNFRSF8_chr1_12175634_ENST00000263932_length(amino acids)=366AA_BP=23 MLRSGPASGPSVPTGRAMPSRRVARPPAAPELGALDDLVEKTPCAWNSSRTCECRPGMICATSATNSRARCVPYPICAAETVTKPQDMAE KDTTFEAPPLGTQPDCNPTPENGEAPASTSPTQSLLVDSQASKTLPIPTSAPVALSSTGKPVLDAGPVLFWVILVLVVVVGSSAFLLCHR RACRKRIRQKLHLCYPVQTSQPKLELVDSRPRRSSTQLRSGASVTEPVAEERGLMSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRD LPEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLP -------------------------------------------------------------- >73431_73431_2_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000221452_TNFRSF8_chr1_12175634_ENST00000417814_length(transcript)=1834nt_BP=256nt CCCGCCGCCCGCCCGGCCCGGCCCCGCGCCCCGCGCAGCCCCGGGCGCCGCGCGTCCTGCCCGGCCTGCGGCCCCAGCCCTTGCGCCGCT CGTCCGACCCGCGATCGTCCACCAGACCGTGCCTCCCGGCCGCCCGGCCGGCCCGCGTGCATGCTTCGGTCTGGGCCAGCCTCTGGGCCG TCCGTCCCCACTGGCCGGGCCATGCCGAGTCGCCGCGTCGCCAGACCGCCGGCTGCGCCGGAGCTGGGGGCCTTAGATGACCTTGTGGAG AAGACGCCATGTGCATGGAACTCCTCCCGCACCTGCGAATGTCGACCTGGCATGATCTGTGCCACATCAGCCACCAACTCCCGTGCCCGC TGTGTCCCCTACCCAATCTGTGCAGCAGAGACGGTCACCAAGCCCCAGGATATGGCTGAGAAGGACACCACCTTTGAGGCGCCACCCCTG GGGACCCAGCCGGACTGCAACCCCACCCCAGAGAATGGCGAGGCGCCTGCCAGCACCAGCCCCACTCAGAGCTTGCTGGTGGACTCCCAG GCCAGTAAGACGCTGCCCATCCCAACCAGCGCTCCCGTCGCTCTCTCCTCCACGGGGAAGCCCGTTCTGGATGCAGGGCCAGTGCTCTTC TGGGTGATCCTGGTGTTGGTTGTGGTGGTCGGCTCCAGCGCCTTCCTCCTGTGCCACCGGAGGGCCTGCAGGAAGCGAATTCGGCAGAAG CTCCACCTGTGCTACCCGGTCCAGACCTCCCAGCCCAAGCTAGAGCTTGTGGATTCCAGACCCAGGAGGAGCTCAACGCTGAGGAGTGGT GCGTCGGTGACAGAACCCGTCGCGGAAGAGCGAGGGTTAATGAGCCAGCCACTGATGGAGACCTGCCACAGCGTGGGGGCAGCCTACCTG GAGAGCCTGCCGCTGCAGGATGCCAGCCCGGCCGGGGGCCCCTCGTCCCCCAGGGACCTTCCTGAGCCCCGGGTGTCCACGGAGCACACC AATAACAAGATTGAGAAAATCTACATCATGAAGGCTGACACCGTGATCGTGGGGACCGTGAAGGCTGAGCTGCCGGAGGGCCGGGGCCTG GCGGGGCCAGCAGAGCCCGAGTTGGAGGAGGAGCTGGAGGCGGACCATACCCCCCACTACCCCGAGCAGGAGACAGAACCGCCTCTGGGC AGCTGCAGCGATGTCATGCTCTCAGTGGAAGAGGAAGGGAAAGAAGACCCCTTGCCCACAGCTGCCTCTGGAAAGTGAGGCCTGGGCTGG GCTGGGGCTAGGAGGGCAGCAGGGTGGCCTCTGGGAGGCCAGGATGGCACTGTTGGCACCGAGGTTGGGGGCAGAGGCCCATCTGGCCTG AACTGAGGCTCCAGCATCTAGTGGTGGACCGGCCGGTCACTGCAGGGGTCTGGTGGTCTCTGCTTGCATCCCCAACTTAGCTGTCCCCTG ACCCAGAGCCTAGGGGATCCGGGGCTTGTACAGAAGAGACAGTCCAAGGGGACTGGATCCCAGCAGTGATGTTGGTTGAGGCAGCAAACA GATGGCAGGATGGGCACTGCCGAGAACAGCATTGGTCCCAGAGCCCTGGGCATCAGACCTTAACCACCAGGCCCACAGCCCAGCGAGGGA GAGGTCGTGAGGCCAGCTCCCGGGGCCCCTGTAACCCTACTCTCCTCTCTCCCTGGACCTCAGAGGTGACACCCATTGGGCCCTTCCGGC ATGCCCCCAGTTACTGTAAATGTGGCCCCCAGTGGGCATGGAGCCAGTGCCTGTGGTTGTTTCTCCAGAGTCAAAAGGGAAGTCGAGGGA >73431_73431_2_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000221452_TNFRSF8_chr1_12175634_ENST00000417814_length(amino acids)=365AA_BP=23 MLRSGPASGPSVPTGRAMPSRRVARPPAAPELGALDDLVEKTPCAWNSSRTCECRPGMICATSATNSRARCVPYPICAAETVTKPQDMAE KDTTFEAPPLGTQPDCNPTPENGEAPASTSPTQSLLVDSQASKTLPIPTSAPVALSSTGKPVLDAGPVLFWVILVLVVVVGSSAFLLCHR RACRKRIRQKLHLCYPVQTSQPKLELVDSRPRRSSTLRSGASVTEPVAEERGLMSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRDL PEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLPT -------------------------------------------------------------- >73431_73431_3_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000505236_TNFRSF8_chr1_12175634_ENST00000263932_length(transcript)=2896nt_BP=225nt CGCGCAGCCCCGGGCGCCGCGCGTCCTGCCCGGCCTGCGGCCCCAGCCCTTGCGCCGCTCGTCCGACCCGCGATCGTCCACCAGACCGTG CCTCCCGGCCGCCCGGCCGGCCCGCGTGCATGCTTCGGTCTGGGCCAGCCTCTGGGCCGTCCGTCCCCACTGGCCGGGCCATGCCGAGTC GCCGCGTCGCCAGACCGCCGGCTGCGCCGGAGCTGGGGGCCTTAGATGACCTTGTGGAGAAGACGCCATGTGCATGGAACTCCTCCCGCA CCTGCGAATGTCGACCTGGCATGATCTGTGCCACATCAGCCACCAACTCCCGTGCCCGCTGTGTCCCCTACCCAATCTGTGCAGCAGAGA CGGTCACCAAGCCCCAGGATATGGCTGAGAAGGACACCACCTTTGAGGCGCCACCCCTGGGGACCCAGCCGGACTGCAACCCCACCCCAG AGAATGGCGAGGCGCCTGCCAGCACCAGCCCCACTCAGAGCTTGCTGGTGGACTCCCAGGCCAGTAAGACGCTGCCCATCCCAACCAGCG CTCCCGTCGCTCTCTCCTCCACGGGGAAGCCCGTTCTGGATGCAGGGCCAGTGCTCTTCTGGGTGATCCTGGTGTTGGTTGTGGTGGTCG GCTCCAGCGCCTTCCTCCTGTGCCACCGGAGGGCCTGCAGGAAGCGAATTCGGCAGAAGCTCCACCTGTGCTACCCGGTCCAGACCTCCC AGCCCAAGCTAGAGCTTGTGGATTCCAGACCCAGGAGGAGCTCAACGCAGCTGAGGAGTGGTGCGTCGGTGACAGAACCCGTCGCGGAAG AGCGAGGGTTAATGAGCCAGCCACTGATGGAGACCTGCCACAGCGTGGGGGCAGCCTACCTGGAGAGCCTGCCGCTGCAGGATGCCAGCC CGGCCGGGGGCCCCTCGTCCCCCAGGGACCTTCCTGAGCCCCGGGTGTCCACGGAGCACACCAATAACAAGATTGAGAAAATCTACATCA TGAAGGCTGACACCGTGATCGTGGGGACCGTGAAGGCTGAGCTGCCGGAGGGCCGGGGCCTGGCGGGGCCAGCAGAGCCCGAGTTGGAGG AGGAGCTGGAGGCGGACCATACCCCCCACTACCCCGAGCAGGAGACAGAACCGCCTCTGGGCAGCTGCAGCGATGTCATGCTCTCAGTGG AAGAGGAAGGGAAAGAAGACCCCTTGCCCACAGCTGCCTCTGGAAAGTGAGGCCTGGGCTGGGCTGGGGCTAGGAGGGCAGCAGGGTGGC CTCTGGGAGGCCAGGATGGCACTGTTGGCACCGAGGTTGGGGGCAGAGGCCCATCTGGCCTGAACTGAGGCTCCAGCATCTAGTGGTGGA CCGGCCGGTCACTGCAGGGGTCTGGTGGTCTCTGCTTGCATCCCCAACTTAGCTGTCCCCTGACCCAGAGCCTAGGGGATCCGGGGCTTG TACAGAAGAGACAGTCCAAGGGGACTGGATCCCAGCAGTGATGTTGGTTGAGGCAGCAAACAGATGGCAGGATGGGCACTGCCGAGAACA GCATTGGTCCCAGAGCCCTGGGCATCAGACCTTAACCACCAGGCCCACAGCCCAGCGAGGGAGAGGTCGTGAGGCCAGCTCCCGGGGCCC CTGTAACCCTACTCTCCTCTCTCCCTGGACCTCAGAGGTGACACCCATTGGGCCCTTCCGGCATGCCCCCAGTTACTGTAAATGTGGCCC CCAGTGGGCATGGAGCCAGTGCCTGTGGTTGTTTCTCCAGAGTCAAAAGGGAAGTCGAGGGATGGGGCGTCGTCAGCTGGCACTGTCTCT GCTGCAGCGGCCACACTGTACTCTGCACTGGTGTGAGGGCCCCTGCCTGGACTGTGGGACCCTCCTGGTGCTGCCCACCTTCCCTGTCCT GTAGCCCCCTCGGTGGGCCCAGGGCCTAGGGCCCAGGATCAAGTCACTCATCTCAGAATGTCCCCACCAATCCCCGCCACAGCAGGCGCC TCGGGTCCCAGATGTCTGCAGCCCTCAGCAGCTGCAGACCGCCCCTCACCAACCCAGAGAACCTGCTTTACTTTGCCCAGGGACTTCCTC CCCATGTGAACATGGGGAACTTCGGGCCCTGCCTGGAGTCCTTGACCGCTCTCTGTGGGCCCCACCCACTCTGTCCTGGGAAATGAAGAA GCATCTTCCTTAGGTCTGCCCTGCTTGCAAATCCACTAGCACCGACCCCACCACCTGGTTCCGGCTCTGCACGCTTTGGGGTGTGGATGT CGAGAGGCACCACGGCCTCACCCAGGCATCTGCTTTACTCTGGACCATAGGAAACAAGACCGTTTGGAGGTTTCATCAGGATTTTGGGTT TTTCACATTTCACGCTAAGGAGTAGTGGCCCTGACTTCCGGTCGGCTGGCCAGCTGACTCCCTAGGGCCTTCAGACGTGTATGCAAATGA GTGATGGATAAGGATGAGTCTTGGAGTTGCGGGCAGCCTGGAGACTCGTGGACTTACCGCCTGGAGGCAGGCCCGGGAAGGCTGCTGTTT ACTCATCGGGCAGCCACGTGCTCTCTGGAGGAAGTGATAGTTTCTGAAACCGCTCAGATGTTTTGGGGAAAGTTGGAGAAGCCGTGGCCT TGCGAGAGGTGGTTACACCAGAACCTGGACATTGGCCAGAAGAAGCTTAAGTGGGCAGACACTGTTTGCCCAGTGTTTGTGCAAGGATGG AGTGGGTGTCTCTGCATCACCCACAGCCGCAGCTGTAAGGCACGCTGGAAGGCACACGCCTGCCAGGCAGGGCAGTCTGGCGCCCATGAT GGGAGGGATTGACATGTTTCAACAAAATAATGCACTTCCTTACCTAGTGGCCCTTCACACAACTTTTGAATCTCTAAAAATCCATAAAAT >73431_73431_3_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000505236_TNFRSF8_chr1_12175634_ENST00000263932_length(amino acids)=366AA_BP=23 MLRSGPASGPSVPTGRAMPSRRVARPPAAPELGALDDLVEKTPCAWNSSRTCECRPGMICATSATNSRARCVPYPICAAETVTKPQDMAE KDTTFEAPPLGTQPDCNPTPENGEAPASTSPTQSLLVDSQASKTLPIPTSAPVALSSTGKPVLDAGPVLFWVILVLVVVVGSSAFLLCHR RACRKRIRQKLHLCYPVQTSQPKLELVDSRPRRSSTQLRSGASVTEPVAEERGLMSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRD LPEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLP -------------------------------------------------------------- >73431_73431_4_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000505236_TNFRSF8_chr1_12175634_ENST00000417814_length(transcript)=1803nt_BP=225nt CGCGCAGCCCCGGGCGCCGCGCGTCCTGCCCGGCCTGCGGCCCCAGCCCTTGCGCCGCTCGTCCGACCCGCGATCGTCCACCAGACCGTG CCTCCCGGCCGCCCGGCCGGCCCGCGTGCATGCTTCGGTCTGGGCCAGCCTCTGGGCCGTCCGTCCCCACTGGCCGGGCCATGCCGAGTC GCCGCGTCGCCAGACCGCCGGCTGCGCCGGAGCTGGGGGCCTTAGATGACCTTGTGGAGAAGACGCCATGTGCATGGAACTCCTCCCGCA CCTGCGAATGTCGACCTGGCATGATCTGTGCCACATCAGCCACCAACTCCCGTGCCCGCTGTGTCCCCTACCCAATCTGTGCAGCAGAGA CGGTCACCAAGCCCCAGGATATGGCTGAGAAGGACACCACCTTTGAGGCGCCACCCCTGGGGACCCAGCCGGACTGCAACCCCACCCCAG AGAATGGCGAGGCGCCTGCCAGCACCAGCCCCACTCAGAGCTTGCTGGTGGACTCCCAGGCCAGTAAGACGCTGCCCATCCCAACCAGCG CTCCCGTCGCTCTCTCCTCCACGGGGAAGCCCGTTCTGGATGCAGGGCCAGTGCTCTTCTGGGTGATCCTGGTGTTGGTTGTGGTGGTCG GCTCCAGCGCCTTCCTCCTGTGCCACCGGAGGGCCTGCAGGAAGCGAATTCGGCAGAAGCTCCACCTGTGCTACCCGGTCCAGACCTCCC AGCCCAAGCTAGAGCTTGTGGATTCCAGACCCAGGAGGAGCTCAACGCTGAGGAGTGGTGCGTCGGTGACAGAACCCGTCGCGGAAGAGC GAGGGTTAATGAGCCAGCCACTGATGGAGACCTGCCACAGCGTGGGGGCAGCCTACCTGGAGAGCCTGCCGCTGCAGGATGCCAGCCCGG CCGGGGGCCCCTCGTCCCCCAGGGACCTTCCTGAGCCCCGGGTGTCCACGGAGCACACCAATAACAAGATTGAGAAAATCTACATCATGA AGGCTGACACCGTGATCGTGGGGACCGTGAAGGCTGAGCTGCCGGAGGGCCGGGGCCTGGCGGGGCCAGCAGAGCCCGAGTTGGAGGAGG AGCTGGAGGCGGACCATACCCCCCACTACCCCGAGCAGGAGACAGAACCGCCTCTGGGCAGCTGCAGCGATGTCATGCTCTCAGTGGAAG AGGAAGGGAAAGAAGACCCCTTGCCCACAGCTGCCTCTGGAAAGTGAGGCCTGGGCTGGGCTGGGGCTAGGAGGGCAGCAGGGTGGCCTC TGGGAGGCCAGGATGGCACTGTTGGCACCGAGGTTGGGGGCAGAGGCCCATCTGGCCTGAACTGAGGCTCCAGCATCTAGTGGTGGACCG GCCGGTCACTGCAGGGGTCTGGTGGTCTCTGCTTGCATCCCCAACTTAGCTGTCCCCTGACCCAGAGCCTAGGGGATCCGGGGCTTGTAC AGAAGAGACAGTCCAAGGGGACTGGATCCCAGCAGTGATGTTGGTTGAGGCAGCAAACAGATGGCAGGATGGGCACTGCCGAGAACAGCA TTGGTCCCAGAGCCCTGGGCATCAGACCTTAACCACCAGGCCCACAGCCCAGCGAGGGAGAGGTCGTGAGGCCAGCTCCCGGGGCCCCTG TAACCCTACTCTCCTCTCTCCCTGGACCTCAGAGGTGACACCCATTGGGCCCTTCCGGCATGCCCCCAGTTACTGTAAATGTGGCCCCCA GTGGGCATGGAGCCAGTGCCTGTGGTTGTTTCTCCAGAGTCAAAAGGGAAGTCGAGGGATGGGGCGTCGTCAGCTGGCACTGTCTCTGCT >73431_73431_4_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000505236_TNFRSF8_chr1_12175634_ENST00000417814_length(amino acids)=365AA_BP=23 MLRSGPASGPSVPTGRAMPSRRVARPPAAPELGALDDLVEKTPCAWNSSRTCECRPGMICATSATNSRARCVPYPICAAETVTKPQDMAE KDTTFEAPPLGTQPDCNPTPENGEAPASTSPTQSLLVDSQASKTLPIPTSAPVALSSTGKPVLDAGPVLFWVILVLVVVVGSSAFLLCHR RACRKRIRQKLHLCYPVQTSQPKLELVDSRPRRSSTLRSGASVTEPVAEERGLMSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRDL PEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLPT -------------------------------------------------------------- >73431_73431_5_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000540120_TNFRSF8_chr1_12175634_ENST00000263932_length(transcript)=2903nt_BP=232nt CGCGCCCCGCGCAGCCCCGGGCGCCGCGCGTCCTGCCCGGCCTGCGGCCCCAGCCCTTGCGCCGCTCGTCCGACCCGCGATCGTCCACCA GACCGTGCCTCCCGGCCGCCCGGCCGGCCCGCGTGCATGCTTCGGTCTGGGCCAGCCTCTGGGCCGTCCGTCCCCACTGGCCGGGCCATG CCGAGTCGCCGCGTCGCCAGACCGCCGGCTGCGCCGGAGCTGGGGGCCTTAGATGACCTTGTGGAGAAGACGCCATGTGCATGGAACTCC TCCCGCACCTGCGAATGTCGACCTGGCATGATCTGTGCCACATCAGCCACCAACTCCCGTGCCCGCTGTGTCCCCTACCCAATCTGTGCA GCAGAGACGGTCACCAAGCCCCAGGATATGGCTGAGAAGGACACCACCTTTGAGGCGCCACCCCTGGGGACCCAGCCGGACTGCAACCCC ACCCCAGAGAATGGCGAGGCGCCTGCCAGCACCAGCCCCACTCAGAGCTTGCTGGTGGACTCCCAGGCCAGTAAGACGCTGCCCATCCCA ACCAGCGCTCCCGTCGCTCTCTCCTCCACGGGGAAGCCCGTTCTGGATGCAGGGCCAGTGCTCTTCTGGGTGATCCTGGTGTTGGTTGTG GTGGTCGGCTCCAGCGCCTTCCTCCTGTGCCACCGGAGGGCCTGCAGGAAGCGAATTCGGCAGAAGCTCCACCTGTGCTACCCGGTCCAG ACCTCCCAGCCCAAGCTAGAGCTTGTGGATTCCAGACCCAGGAGGAGCTCAACGCAGCTGAGGAGTGGTGCGTCGGTGACAGAACCCGTC GCGGAAGAGCGAGGGTTAATGAGCCAGCCACTGATGGAGACCTGCCACAGCGTGGGGGCAGCCTACCTGGAGAGCCTGCCGCTGCAGGAT GCCAGCCCGGCCGGGGGCCCCTCGTCCCCCAGGGACCTTCCTGAGCCCCGGGTGTCCACGGAGCACACCAATAACAAGATTGAGAAAATC TACATCATGAAGGCTGACACCGTGATCGTGGGGACCGTGAAGGCTGAGCTGCCGGAGGGCCGGGGCCTGGCGGGGCCAGCAGAGCCCGAG TTGGAGGAGGAGCTGGAGGCGGACCATACCCCCCACTACCCCGAGCAGGAGACAGAACCGCCTCTGGGCAGCTGCAGCGATGTCATGCTC TCAGTGGAAGAGGAAGGGAAAGAAGACCCCTTGCCCACAGCTGCCTCTGGAAAGTGAGGCCTGGGCTGGGCTGGGGCTAGGAGGGCAGCA GGGTGGCCTCTGGGAGGCCAGGATGGCACTGTTGGCACCGAGGTTGGGGGCAGAGGCCCATCTGGCCTGAACTGAGGCTCCAGCATCTAG TGGTGGACCGGCCGGTCACTGCAGGGGTCTGGTGGTCTCTGCTTGCATCCCCAACTTAGCTGTCCCCTGACCCAGAGCCTAGGGGATCCG GGGCTTGTACAGAAGAGACAGTCCAAGGGGACTGGATCCCAGCAGTGATGTTGGTTGAGGCAGCAAACAGATGGCAGGATGGGCACTGCC GAGAACAGCATTGGTCCCAGAGCCCTGGGCATCAGACCTTAACCACCAGGCCCACAGCCCAGCGAGGGAGAGGTCGTGAGGCCAGCTCCC GGGGCCCCTGTAACCCTACTCTCCTCTCTCCCTGGACCTCAGAGGTGACACCCATTGGGCCCTTCCGGCATGCCCCCAGTTACTGTAAAT GTGGCCCCCAGTGGGCATGGAGCCAGTGCCTGTGGTTGTTTCTCCAGAGTCAAAAGGGAAGTCGAGGGATGGGGCGTCGTCAGCTGGCAC TGTCTCTGCTGCAGCGGCCACACTGTACTCTGCACTGGTGTGAGGGCCCCTGCCTGGACTGTGGGACCCTCCTGGTGCTGCCCACCTTCC CTGTCCTGTAGCCCCCTCGGTGGGCCCAGGGCCTAGGGCCCAGGATCAAGTCACTCATCTCAGAATGTCCCCACCAATCCCCGCCACAGC AGGCGCCTCGGGTCCCAGATGTCTGCAGCCCTCAGCAGCTGCAGACCGCCCCTCACCAACCCAGAGAACCTGCTTTACTTTGCCCAGGGA CTTCCTCCCCATGTGAACATGGGGAACTTCGGGCCCTGCCTGGAGTCCTTGACCGCTCTCTGTGGGCCCCACCCACTCTGTCCTGGGAAA TGAAGAAGCATCTTCCTTAGGTCTGCCCTGCTTGCAAATCCACTAGCACCGACCCCACCACCTGGTTCCGGCTCTGCACGCTTTGGGGTG TGGATGTCGAGAGGCACCACGGCCTCACCCAGGCATCTGCTTTACTCTGGACCATAGGAAACAAGACCGTTTGGAGGTTTCATCAGGATT TTGGGTTTTTCACATTTCACGCTAAGGAGTAGTGGCCCTGACTTCCGGTCGGCTGGCCAGCTGACTCCCTAGGGCCTTCAGACGTGTATG CAAATGAGTGATGGATAAGGATGAGTCTTGGAGTTGCGGGCAGCCTGGAGACTCGTGGACTTACCGCCTGGAGGCAGGCCCGGGAAGGCT GCTGTTTACTCATCGGGCAGCCACGTGCTCTCTGGAGGAAGTGATAGTTTCTGAAACCGCTCAGATGTTTTGGGGAAAGTTGGAGAAGCC GTGGCCTTGCGAGAGGTGGTTACACCAGAACCTGGACATTGGCCAGAAGAAGCTTAAGTGGGCAGACACTGTTTGCCCAGTGTTTGTGCA AGGATGGAGTGGGTGTCTCTGCATCACCCACAGCCGCAGCTGTAAGGCACGCTGGAAGGCACACGCCTGCCAGGCAGGGCAGTCTGGCGC CCATGATGGGAGGGATTGACATGTTTCAACAAAATAATGCACTTCCTTACCTAGTGGCCCTTCACACAACTTTTGAATCTCTAAAAATCC >73431_73431_5_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000540120_TNFRSF8_chr1_12175634_ENST00000263932_length(amino acids)=366AA_BP=23 MLRSGPASGPSVPTGRAMPSRRVARPPAAPELGALDDLVEKTPCAWNSSRTCECRPGMICATSATNSRARCVPYPICAAETVTKPQDMAE KDTTFEAPPLGTQPDCNPTPENGEAPASTSPTQSLLVDSQASKTLPIPTSAPVALSSTGKPVLDAGPVLFWVILVLVVVVGSSAFLLCHR RACRKRIRQKLHLCYPVQTSQPKLELVDSRPRRSSTQLRSGASVTEPVAEERGLMSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRD LPEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLP -------------------------------------------------------------- >73431_73431_6_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000540120_TNFRSF8_chr1_12175634_ENST00000417814_length(transcript)=1810nt_BP=232nt CGCGCCCCGCGCAGCCCCGGGCGCCGCGCGTCCTGCCCGGCCTGCGGCCCCAGCCCTTGCGCCGCTCGTCCGACCCGCGATCGTCCACCA GACCGTGCCTCCCGGCCGCCCGGCCGGCCCGCGTGCATGCTTCGGTCTGGGCCAGCCTCTGGGCCGTCCGTCCCCACTGGCCGGGCCATG CCGAGTCGCCGCGTCGCCAGACCGCCGGCTGCGCCGGAGCTGGGGGCCTTAGATGACCTTGTGGAGAAGACGCCATGTGCATGGAACTCC TCCCGCACCTGCGAATGTCGACCTGGCATGATCTGTGCCACATCAGCCACCAACTCCCGTGCCCGCTGTGTCCCCTACCCAATCTGTGCA GCAGAGACGGTCACCAAGCCCCAGGATATGGCTGAGAAGGACACCACCTTTGAGGCGCCACCCCTGGGGACCCAGCCGGACTGCAACCCC ACCCCAGAGAATGGCGAGGCGCCTGCCAGCACCAGCCCCACTCAGAGCTTGCTGGTGGACTCCCAGGCCAGTAAGACGCTGCCCATCCCA ACCAGCGCTCCCGTCGCTCTCTCCTCCACGGGGAAGCCCGTTCTGGATGCAGGGCCAGTGCTCTTCTGGGTGATCCTGGTGTTGGTTGTG GTGGTCGGCTCCAGCGCCTTCCTCCTGTGCCACCGGAGGGCCTGCAGGAAGCGAATTCGGCAGAAGCTCCACCTGTGCTACCCGGTCCAG ACCTCCCAGCCCAAGCTAGAGCTTGTGGATTCCAGACCCAGGAGGAGCTCAACGCTGAGGAGTGGTGCGTCGGTGACAGAACCCGTCGCG GAAGAGCGAGGGTTAATGAGCCAGCCACTGATGGAGACCTGCCACAGCGTGGGGGCAGCCTACCTGGAGAGCCTGCCGCTGCAGGATGCC AGCCCGGCCGGGGGCCCCTCGTCCCCCAGGGACCTTCCTGAGCCCCGGGTGTCCACGGAGCACACCAATAACAAGATTGAGAAAATCTAC ATCATGAAGGCTGACACCGTGATCGTGGGGACCGTGAAGGCTGAGCTGCCGGAGGGCCGGGGCCTGGCGGGGCCAGCAGAGCCCGAGTTG GAGGAGGAGCTGGAGGCGGACCATACCCCCCACTACCCCGAGCAGGAGACAGAACCGCCTCTGGGCAGCTGCAGCGATGTCATGCTCTCA GTGGAAGAGGAAGGGAAAGAAGACCCCTTGCCCACAGCTGCCTCTGGAAAGTGAGGCCTGGGCTGGGCTGGGGCTAGGAGGGCAGCAGGG TGGCCTCTGGGAGGCCAGGATGGCACTGTTGGCACCGAGGTTGGGGGCAGAGGCCCATCTGGCCTGAACTGAGGCTCCAGCATCTAGTGG TGGACCGGCCGGTCACTGCAGGGGTCTGGTGGTCTCTGCTTGCATCCCCAACTTAGCTGTCCCCTGACCCAGAGCCTAGGGGATCCGGGG CTTGTACAGAAGAGACAGTCCAAGGGGACTGGATCCCAGCAGTGATGTTGGTTGAGGCAGCAAACAGATGGCAGGATGGGCACTGCCGAG AACAGCATTGGTCCCAGAGCCCTGGGCATCAGACCTTAACCACCAGGCCCACAGCCCAGCGAGGGAGAGGTCGTGAGGCCAGCTCCCGGG GCCCCTGTAACCCTACTCTCCTCTCTCCCTGGACCTCAGAGGTGACACCCATTGGGCCCTTCCGGCATGCCCCCAGTTACTGTAAATGTG GCCCCCAGTGGGCATGGAGCCAGTGCCTGTGGTTGTTTCTCCAGAGTCAAAAGGGAAGTCGAGGGATGGGGCGTCGTCAGCTGGCACTGT >73431_73431_6_RELB-TNFRSF8_RELB_chr19_45504943_ENST00000540120_TNFRSF8_chr1_12175634_ENST00000417814_length(amino acids)=365AA_BP=23 MLRSGPASGPSVPTGRAMPSRRVARPPAAPELGALDDLVEKTPCAWNSSRTCECRPGMICATSATNSRARCVPYPICAAETVTKPQDMAE KDTTFEAPPLGTQPDCNPTPENGEAPASTSPTQSLLVDSQASKTLPIPTSAPVALSSTGKPVLDAGPVLFWVILVLVVVVGSSAFLLCHR RACRKRIRQKLHLCYPVQTSQPKLELVDSRPRRSSTLRSGASVTEPVAEERGLMSQPLMETCHSVGAAYLESLPLQDASPAGGPSSPRDL PEPRVSTEHTNNKIEKIYIMKADTVIVGTVKAELPEGRGLAGPAEPELEEELEADHTPHYPEQETEPPLGSCSDVMLSVEEEGKEDPLPT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for RELB-TNFRSF8 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for RELB-TNFRSF8 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for RELB-TNFRSF8 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies