
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ATP1B1-RCSD1 (FusionGDB2 ID:7806) |
Fusion Gene Summary for ATP1B1-RCSD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ATP1B1-RCSD1 | Fusion gene ID: 7806 | Hgene | Tgene | Gene symbol | ATP1B1 | RCSD1 | Gene ID | 481 | 92241 |
| Gene name | ATPase Na+/K+ transporting subunit beta 1 | RCSD domain containing 1 | |
| Synonyms | ATP1B | CAPZIP|MK2S4 | |
| Cytomap | 1q24.2 | 1q24.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | sodium/potassium-transporting ATPase subunit beta-1ATPase, Na+/K+ transporting, beta 1 polypeptideBeta 1-subunit of Na(+),K(+)-ATPaseNa, K-ATPase beta-1 polypeptideadenosinetriphosphatasesodium pump subunit beta-1sodium-potassium ATPase subunit beta | capZ-interacting proteinRCSD domain-containing protein 1protein kinase substrate CapZIPprotein kinase substrate MK2S4 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P05026 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000367813, ENST00000367815, ENST00000367816, ENST00000499679, | ENST00000472038, ENST00000367854, ENST00000537350, | |
| Fusion gene scores | * DoF score | 11 X 12 X 7=924 | 9 X 8 X 6=432 |
| # samples | 16 | 9 | |
| ** MAII score | log2(16/924*10)=-2.5298209465287 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/432*10)=-2.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ATP1B1 [Title/Abstract] AND RCSD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ATP1B1(169099328)-RCSD1(167653137), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ATP1B1 | GO:0006883 | cellular sodium ion homeostasis | 10636900|19542013 |
| Hgene | ATP1B1 | GO:0030007 | cellular potassium ion homeostasis | 10636900|19542013 |
| Hgene | ATP1B1 | GO:0032781 | positive regulation of ATPase activity | 10636900 |
| Hgene | ATP1B1 | GO:0036376 | sodium ion export across plasma membrane | 10636900|19542013 |
| Hgene | ATP1B1 | GO:0046034 | ATP metabolic process | 23954377 |
| Hgene | ATP1B1 | GO:0050821 | protein stabilization | 10636900 |
| Hgene | ATP1B1 | GO:0072659 | protein localization to plasma membrane | 18522992 |
| Hgene | ATP1B1 | GO:0086009 | membrane repolarization | 19542013 |
| Hgene | ATP1B1 | GO:1901018 | positive regulation of potassium ion transmembrane transporter activity | 10636900 |
| Hgene | ATP1B1 | GO:1903278 | positive regulation of sodium ion export across plasma membrane | 10636900 |
| Hgene | ATP1B1 | GO:1903288 | positive regulation of potassium ion import | 10636900 |
| Hgene | ATP1B1 | GO:1990573 | potassium ion import across plasma membrane | 10636900|19542013 |
| Tgene | RCSD1 | GO:0071474 | cellular hyperosmotic response | 15850461 |
| Fusion gene breakpoints across ATP1B1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RCSD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-86-8281-01A | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| ChimerDB4 | LUAD | TCGA-86-8281-01A | ATP1B1 | chr1 | 169099328 | - | RCSD1 | chr1 | 167653137 | + |
| ChimerDB4 | LUAD | TCGA-86-8281-01A | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
Top |
Fusion Gene ORF analysis for ATP1B1-RCSD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000367813 | ENST00000472038 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| 5CDS-intron | ENST00000367813 | ENST00000472038 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| 5CDS-intron | ENST00000367815 | ENST00000472038 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| 5CDS-intron | ENST00000367815 | ENST00000472038 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| 5CDS-intron | ENST00000367816 | ENST00000472038 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| 5CDS-intron | ENST00000367816 | ENST00000472038 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| 5CDS-intron | ENST00000499679 | ENST00000472038 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| 5CDS-intron | ENST00000499679 | ENST00000472038 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| In-frame | ENST00000367813 | ENST00000367854 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| In-frame | ENST00000367813 | ENST00000367854 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| In-frame | ENST00000367813 | ENST00000537350 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| In-frame | ENST00000367813 | ENST00000537350 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| In-frame | ENST00000367815 | ENST00000367854 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| In-frame | ENST00000367815 | ENST00000367854 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| In-frame | ENST00000367815 | ENST00000537350 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| In-frame | ENST00000367815 | ENST00000537350 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| In-frame | ENST00000367816 | ENST00000367854 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| In-frame | ENST00000367816 | ENST00000367854 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| In-frame | ENST00000367816 | ENST00000537350 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| In-frame | ENST00000367816 | ENST00000537350 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| In-frame | ENST00000499679 | ENST00000367854 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| In-frame | ENST00000499679 | ENST00000367854 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| In-frame | ENST00000499679 | ENST00000537350 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + |
| In-frame | ENST00000499679 | ENST00000537350 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000367816 | ATP1B1 | chr1 | 169099328 | + | ENST00000367854 | RCSD1 | chr1 | 167653137 | + | 3975 | 1177 | 529 | 2421 | 630 |
| ENST00000367816 | ATP1B1 | chr1 | 169099328 | + | ENST00000537350 | RCSD1 | chr1 | 167653137 | + | 2422 | 1177 | 529 | 2331 | 600 |
| ENST00000367815 | ATP1B1 | chr1 | 169099328 | + | ENST00000367854 | RCSD1 | chr1 | 167653137 | + | 3953 | 1155 | 507 | 2399 | 630 |
| ENST00000367815 | ATP1B1 | chr1 | 169099328 | + | ENST00000537350 | RCSD1 | chr1 | 167653137 | + | 2400 | 1155 | 507 | 2309 | 600 |
| ENST00000499679 | ATP1B1 | chr1 | 169099328 | + | ENST00000367854 | RCSD1 | chr1 | 167653137 | + | 3512 | 714 | 201 | 1958 | 585 |
| ENST00000499679 | ATP1B1 | chr1 | 169099328 | + | ENST00000537350 | RCSD1 | chr1 | 167653137 | + | 1959 | 714 | 201 | 1868 | 555 |
| ENST00000367813 | ATP1B1 | chr1 | 169099328 | + | ENST00000367854 | RCSD1 | chr1 | 167653137 | + | 3455 | 657 | 24 | 1901 | 625 |
| ENST00000367813 | ATP1B1 | chr1 | 169099328 | + | ENST00000537350 | RCSD1 | chr1 | 167653137 | + | 1902 | 657 | 24 | 1811 | 595 |
| ENST00000367816 | ATP1B1 | chr1 | 169099327 | + | ENST00000367854 | RCSD1 | chr1 | 167653136 | + | 3975 | 1177 | 529 | 2421 | 630 |
| ENST00000367816 | ATP1B1 | chr1 | 169099327 | + | ENST00000537350 | RCSD1 | chr1 | 167653136 | + | 2422 | 1177 | 529 | 2331 | 600 |
| ENST00000367815 | ATP1B1 | chr1 | 169099327 | + | ENST00000367854 | RCSD1 | chr1 | 167653136 | + | 3953 | 1155 | 507 | 2399 | 630 |
| ENST00000367815 | ATP1B1 | chr1 | 169099327 | + | ENST00000537350 | RCSD1 | chr1 | 167653136 | + | 2400 | 1155 | 507 | 2309 | 600 |
| ENST00000499679 | ATP1B1 | chr1 | 169099327 | + | ENST00000367854 | RCSD1 | chr1 | 167653136 | + | 3512 | 714 | 201 | 1958 | 585 |
| ENST00000499679 | ATP1B1 | chr1 | 169099327 | + | ENST00000537350 | RCSD1 | chr1 | 167653136 | + | 1959 | 714 | 201 | 1868 | 555 |
| ENST00000367813 | ATP1B1 | chr1 | 169099327 | + | ENST00000367854 | RCSD1 | chr1 | 167653136 | + | 3455 | 657 | 24 | 1901 | 625 |
| ENST00000367813 | ATP1B1 | chr1 | 169099327 | + | ENST00000537350 | RCSD1 | chr1 | 167653136 | + | 1902 | 657 | 24 | 1811 | 595 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000367816 | ENST00000367854 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + | 0.002002043 | 0.99799794 |
| ENST00000367816 | ENST00000537350 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + | 0.018239781 | 0.9817602 |
| ENST00000367815 | ENST00000367854 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + | 0.001717615 | 0.99828243 |
| ENST00000367815 | ENST00000537350 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + | 0.016269194 | 0.9837308 |
| ENST00000499679 | ENST00000367854 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + | 0.001044879 | 0.99895513 |
| ENST00000499679 | ENST00000537350 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + | 0.008267664 | 0.99173236 |
| ENST00000367813 | ENST00000367854 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + | 0.001076956 | 0.998923 |
| ENST00000367813 | ENST00000537350 | ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653137 | + | 0.009557982 | 0.990442 |
| ENST00000367816 | ENST00000367854 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + | 0.002002043 | 0.99799794 |
| ENST00000367816 | ENST00000537350 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + | 0.018239781 | 0.9817602 |
| ENST00000367815 | ENST00000367854 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + | 0.001717615 | 0.99828243 |
| ENST00000367815 | ENST00000537350 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + | 0.016269194 | 0.9837308 |
| ENST00000499679 | ENST00000367854 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + | 0.001044879 | 0.99895513 |
| ENST00000499679 | ENST00000537350 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + | 0.008267664 | 0.99173236 |
| ENST00000367813 | ENST00000367854 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + | 0.001076956 | 0.998923 |
| ENST00000367813 | ENST00000537350 | ATP1B1 | chr1 | 169099327 | + | RCSD1 | chr1 | 167653136 | + | 0.009557982 | 0.990442 |
Top |
Fusion Genomic Features for ATP1B1-RCSD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653136 | + | 4.34E-08 | 1 |
| ATP1B1 | chr1 | 169099328 | + | RCSD1 | chr1 | 167653136 | + | 4.34E-08 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
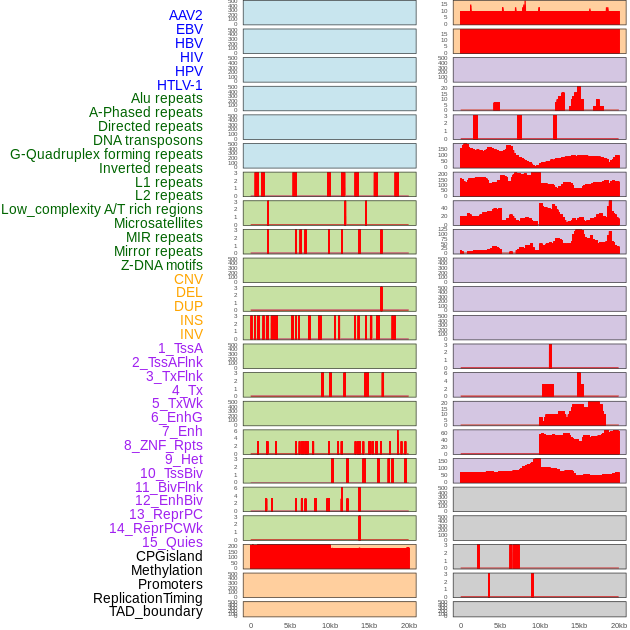 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for ATP1B1-RCSD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:169099328/chr1:167653137) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ATP1B1 | . |
| FUNCTION: This is the non-catalytic component of the active enzyme, which catalyzes the hydrolysis of ATP coupled with the exchange of Na(+) and K(+) ions across the plasma membrane. The beta subunit regulates, through assembly of alpha/beta heterodimers, the number of sodium pumps transported to the plasma membrane. {ECO:0000269|PubMed:19694409}.; FUNCTION: Involved in cell adhesion and establishing epithelial cell polarity. {ECO:0000269|PubMed:19694409}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP1B1 | chr1:169099327 | chr1:167653136 | ENST00000367815 | + | 5 | 6 | 1_34 | 216 | 304.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1B1 | chr1:169099327 | chr1:167653136 | ENST00000367816 | + | 6 | 7 | 1_34 | 216 | 304.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1B1 | chr1:169099328 | chr1:167653137 | ENST00000367815 | + | 5 | 6 | 1_34 | 216 | 304.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1B1 | chr1:169099328 | chr1:167653137 | ENST00000367816 | + | 6 | 7 | 1_34 | 216 | 304.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1B1 | chr1:169099327 | chr1:167653136 | ENST00000367815 | + | 5 | 6 | 35_62 | 216 | 304.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | ATP1B1 | chr1:169099327 | chr1:167653136 | ENST00000367816 | + | 6 | 7 | 35_62 | 216 | 304.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | ATP1B1 | chr1:169099328 | chr1:167653137 | ENST00000367815 | + | 5 | 6 | 35_62 | 216 | 304.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Hgene | ATP1B1 | chr1:169099328 | chr1:167653137 | ENST00000367816 | + | 6 | 7 | 35_62 | 216 | 304.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| Tgene | RCSD1 | chr1:169099327 | chr1:167653136 | ENST00000367854 | 0 | 7 | 227_330 | 2 | 417.0 | Domain | Note=RCSD | |
| Tgene | RCSD1 | chr1:169099328 | chr1:167653137 | ENST00000367854 | 0 | 7 | 227_330 | 2 | 417.0 | Domain | Note=RCSD |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP1B1 | chr1:169099327 | chr1:167653136 | ENST00000367815 | + | 5 | 6 | 191_303 | 216 | 304.0 | Region | Note=immunoglobulin-like |
| Hgene | ATP1B1 | chr1:169099327 | chr1:167653136 | ENST00000367816 | + | 6 | 7 | 191_303 | 216 | 304.0 | Region | Note=immunoglobulin-like |
| Hgene | ATP1B1 | chr1:169099328 | chr1:167653137 | ENST00000367815 | + | 5 | 6 | 191_303 | 216 | 304.0 | Region | Note=immunoglobulin-like |
| Hgene | ATP1B1 | chr1:169099328 | chr1:167653137 | ENST00000367816 | + | 6 | 7 | 191_303 | 216 | 304.0 | Region | Note=immunoglobulin-like |
| Hgene | ATP1B1 | chr1:169099327 | chr1:167653136 | ENST00000367815 | + | 5 | 6 | 63_303 | 216 | 304.0 | Topological domain | Extracellular |
| Hgene | ATP1B1 | chr1:169099327 | chr1:167653136 | ENST00000367816 | + | 6 | 7 | 63_303 | 216 | 304.0 | Topological domain | Extracellular |
| Hgene | ATP1B1 | chr1:169099328 | chr1:167653137 | ENST00000367815 | + | 5 | 6 | 63_303 | 216 | 304.0 | Topological domain | Extracellular |
| Hgene | ATP1B1 | chr1:169099328 | chr1:167653137 | ENST00000367816 | + | 6 | 7 | 63_303 | 216 | 304.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for ATP1B1-RCSD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >7806_7806_1_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367813_RCSD1_chr1_167653136_ENST00000367854_length(transcript)=3455nt_BP=657nt TATTTCAGCCTCCATCCTGTTGTCTTGTTAACTATGGGAAAAAGAAAATGCAGCCCAGCAAGTCAGTCATTATTCTTGTTCCAGTTCCAG AAGATGGAATTAAAATTTAAGATCCTTCTATTCTACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATG CTGCTCACCATCAGTGAATTTAAGCCCACATATCAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAA ATTTCCTTTCGTCCTAATGATCCCAAGAGCTATGAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAG AGGGATGACATGATTTTTGAAGATTGTGGCGATGTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAG GTCTGCAGATTCAAGCTTGAATGGCTGGGAAATTGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATT ATAAAGCTCAACCGAGTTCTAGGCTTCAAACCTAAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAAT GTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGACCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTG GCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCCAAGGAGACACCAGCCAGTAAACCAACCCGAAGGAAACCGCCCTGTTCCCTCCCCCTG TTCCCCCCCAAGGTAGACCTGGGCCAGAATGGTGAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCG CCTCTGATTGAGAAGCTTCAGGCCAATTTAACCTTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCT ATGGTGTCGCCATTTCACAGCCCACCTTCTACCCCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGC TTCGACCAGCCCCCTGAAGGCAGTCATCTGCCCTGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGA TTCCGAAGGTCACAGTCAGACTGTGGAGAACTTGGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGG GATGAAGTGTTGCCATCCAAGAGCAAGGCCCCAGGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCT GCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGCAGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAG GCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAGCACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAA AATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCAGCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAA AATGAAGAGGTGGGACCTGAACATGACAGCCAAGAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCT GGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAGGAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCC CAGACCGGCCCTGCCCAGCTGGAGACCAGCAGTGAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGAC ACTAAAATGTGAAGAACAGCTCATTGTGCCCCAGTGATGAAGTTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAG CAGACGAAGCCATTGCAGAGGCAGAATATGCTGAGTGTCTGGAGTCAGCCTGAAGACACAGGGTGGATTATTTCCTGGCCTCCACACCAA ACGTTCCCTTGCAGATGGAGACTGAATCTGAGGGCAGCAGACTTTTATCAGCTTGAGTTTATGTCATTTGATGGACTTGGTTCAACAACA AGAACTTACTTAAAACAATGTACTGTGGTGATGAGTCCCAGGGGCACTGGTCAGCCTGTGGAGCCCTGGATGCTATCCACACCCACCTAT CCCTGCAGCTAATTTAGCTGATCTCTAATTTAACTGAGCTCTAATTTAGCTGATCAGATTTTGCTTGGGTAAAGTTCCTTTTTAATGTTC TAAAGTGTTTACGGTTCTCAAATATCAGTTAAAAACTAATTTTAGGTGGCCATAAACATAAAATAGAAACCCTGTAAGTTACAGAAGACC CTAAATTGTATCAAAACCCTAGAGACAACTTTTCAATTTGATCCAAATTTGAACTGGCCAACCAGTCTTTAAAACACTGGACTAGAAGAG ATAATGATTGAAACATTTAAAAAAAAAAAGTGCTCCATTCGCAGGAGCTTTTCCTGTCCTGTGGTTTTCCAGTTGGTGACCACCATGGGA GGTCGCTGGCTCGGCTCACTCCCTTCTCCCACCCTTGAGAATGTGGAGAACTCCCATGGAGAGGCAGAATGGCAGGAGGTTTCATGTCCC GCGTTGCATCTCCTCCTGAAAGAAAAGCAGTGATACCTGAATAATGCTGGCTCTCCGATTGATCCTGTGAGGATGAATTTGCATTTCCAG AATCCTTGAGCATGGATTAGATGTTTCCTGGGAGGTGCCTTGAGTACCATTATGTGCAAGCTACATAATTAAAACATTTTTCTTAGTTTC CCTGGGAAGCTTTTCTTGACTCACAGCCCAGGTTCTTCTGCCCAACACAAAAGGAGTGAGTTGGGGTCTTTAGTCTCTTCTTATTGGGTA GCTCTTGCTTTAATATTCTGTTTGGTGAGTGTAAGGGATTCTGCAAGGGACAGGGGGCCTGACTACCCAGTCTTTGACTTGTATCCTCTC CCCTCTTCATACACTCCTGCTGAAAAATGTTAATCCAAATACACATTTAAACTTAGGGTCGGTCCTTATTCTGATTTGAGTATTTTAATG TCTCAGTGTGCTGATTTGGTAGTTGGAAGAATTATTCTTCTGGAGGTCTGTTAGACTACATCCTACACTGACTTCAGAAAACAGTCTGTC AGACAAAAAGGCCTTATGTCACCACTGGTACCTCAGTTTCCTCATCCCATTTACAGTTTTTCTAACTCCAGGGTAGTGTTTAGTGTTAAT ATTTGGGATATATTTTTTTTCAAAACTGTTTTTAAGTAGTTTGTAATTTGTAACAAACTTGTAACCTGGTTGGGACTGATATTGTCATAG >7806_7806_1_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367813_RCSD1_chr1_167653136_ENST00000367854_length(amino acids)=625AA_BP=211 MLTMGKRKCSPASQSLFLFQFQKMELKFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDP KSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLG FKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPPKVDLG QNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGS HLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRR SPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEH -------------------------------------------------------------- >7806_7806_2_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367813_RCSD1_chr1_167653136_ENST00000537350_length(transcript)=1902nt_BP=657nt TATTTCAGCCTCCATCCTGTTGTCTTGTTAACTATGGGAAAAAGAAAATGCAGCCCAGCAAGTCAGTCATTATTCTTGTTCCAGTTCCAG AAGATGGAATTAAAATTTAAGATCCTTCTATTCTACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATG CTGCTCACCATCAGTGAATTTAAGCCCACATATCAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAA ATTTCCTTTCGTCCTAATGATCCCAAGAGCTATGAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAG AGGGATGACATGATTTTTGAAGATTGTGGCGATGTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAG GTCTGCAGATTCAAGCTTGAATGGCTGGGAAATTGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATT ATAAAGCTCAACCGAGTTCTAGGCTTCAAACCTAAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAAT GTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGACCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTG GCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCCAAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCG CCTCTGATTGAGAAGCTTCAGGCCAATTTAACCTTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCT ATGGTGTCGCCATTTCACAGCCCACCTTCTACCCCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGC TTCGACCAGCCCCCTGAAGGCAGTCATCTGCCCTGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGA TTCCGAAGGTCACAGTCAGACTGTGGAGAACTTGGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGG GATGAAGTGTTGCCATCCAAGAGCAAGGCCCCAGGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCT GCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGCAGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAG GCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAGCACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAA AATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCAGCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAA AATGAAGAGGTGGGACCTGAACATGACAGCCAAGAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCT GGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAGGAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCC CAGACCGGCCCTGCCCAGCTGGAGACCAGCAGTGAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGAC ACTAAAATGTGAAGAACAGCTCATTGTGCCCCAGTGATGAAGTTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAG >7806_7806_2_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367813_RCSD1_chr1_167653136_ENST00000537350_length(amino acids)=595AA_BP=211 MLTMGKRKCSPASQSLFLFQFQKMELKFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDP KSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLG FKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKEKSPPNASHPPKFKVKSSPLIEKLQA NLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDC GELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEV DGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDV -------------------------------------------------------------- >7806_7806_3_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367815_RCSD1_chr1_167653136_ENST00000367854_length(transcript)=3953nt_BP=1155nt AATTCCTCGGCTCCTGGCGGGAGTGCCGGTGGCGCCCCGCAGTCCGCTTGTCCGTCCTTCCCTCTCTGACTCTCCTACCCCGGGCCTGTC TCTGCAGAGGTCAGGGGAGGCGGGGGCCCAGCACACGTCCCCAGTGGCAGCGGGAGCGGCAGCTACGGGTTCGCGGAGCCCCCGACCCCC CAAGGGCTAGAGGAGCGCTCGGCGGACCAAAGAAAGCCCGCGAGCGGCTGCGCGCCCACCAATAGGTGCGGGGCTCGGAGCCGCGCAGCC TGCGCCGTCCCTCCCTCCGCCCCCGCCCCGCCGCCGCCGCCGCCGCCGCCTCCCCCTCCTCCTGCTCCTGCCTTGGCTCCTCCGCCGCGC GTCTCGCACTCCGAGAGCCGCAGCGGCAGCGGCGCGTCCTGCCTGCAGAGAGCCAGGCCGGAGAAGCCGAGCGGCGCAGAGGACGCCAGG GCGCGCGCCGCAGCCACCCACCCTCCGGACCGCGGCAGCTGCTGACCCGCCATCGCCATGGCCCGCGGGAAAGCCAAGGAGGAGGGCAGC TGGAAGAAATTCATCTGGAACTCAGAGAAGAAGGAGTTTCTGGGCAGGACCGGTGGCAGTTGGTTTAAGATCCTTCTATTCTACGTAATA TTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATTTAAGCCCACATATCAGGACCGA GTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGATCCCAAGAGCTATGAGGCATAT GTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGAAGATTGTGGCGATGTGCCCAGT GAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGAATGGCTGGGAAATTGCTCTGGA TTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCTAGGCTTCAAACCTAAGCCTCCC AAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGACCGGCAGAG ACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCCAAGGAGACA CCAGCCAGTAAACCAACCCGAAGGAAACCGCCCTGTTCCCTCCCCCTGTTCCCCCCCAAGGTAGACCTGGGCCAGAATGGTGAGGAGAAA TCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCAGGCCAATTTAACCTTTGACCCA GCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAGCCCACCTTCTACCCCCAGCAGC CCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGGCAGTCATCTGCCCTGTTACAAC AAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGACTGTGGAGAACTTGGAGATTTC AGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAAGAGCAAGGCCCCAGGATCCCCT TTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGCAGGACAGAG AAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAGCACCCGGCC CAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCAGCTGGAGAG GAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGAACATGACAGCCAAGAAACAAAG AAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAGGAAAAAGGC AAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCTGGAGACCAGCAGTGAGGTCCAG AGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGCTCATTGTGCCCCAGTGATGAAG TTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAGCAGACGAAGCCATTGCAGAGGCAGAATATGCTGAGTGTCTGG AGTCAGCCTGAAGACACAGGGTGGATTATTTCCTGGCCTCCACACCAAACGTTCCCTTGCAGATGGAGACTGAATCTGAGGGCAGCAGAC TTTTATCAGCTTGAGTTTATGTCATTTGATGGACTTGGTTCAACAACAAGAACTTACTTAAAACAATGTACTGTGGTGATGAGTCCCAGG GGCACTGGTCAGCCTGTGGAGCCCTGGATGCTATCCACACCCACCTATCCCTGCAGCTAATTTAGCTGATCTCTAATTTAACTGAGCTCT AATTTAGCTGATCAGATTTTGCTTGGGTAAAGTTCCTTTTTAATGTTCTAAAGTGTTTACGGTTCTCAAATATCAGTTAAAAACTAATTT TAGGTGGCCATAAACATAAAATAGAAACCCTGTAAGTTACAGAAGACCCTAAATTGTATCAAAACCCTAGAGACAACTTTTCAATTTGAT CCAAATTTGAACTGGCCAACCAGTCTTTAAAACACTGGACTAGAAGAGATAATGATTGAAACATTTAAAAAAAAAAAGTGCTCCATTCGC AGGAGCTTTTCCTGTCCTGTGGTTTTCCAGTTGGTGACCACCATGGGAGGTCGCTGGCTCGGCTCACTCCCTTCTCCCACCCTTGAGAAT GTGGAGAACTCCCATGGAGAGGCAGAATGGCAGGAGGTTTCATGTCCCGCGTTGCATCTCCTCCTGAAAGAAAAGCAGTGATACCTGAAT AATGCTGGCTCTCCGATTGATCCTGTGAGGATGAATTTGCATTTCCAGAATCCTTGAGCATGGATTAGATGTTTCCTGGGAGGTGCCTTG AGTACCATTATGTGCAAGCTACATAATTAAAACATTTTTCTTAGTTTCCCTGGGAAGCTTTTCTTGACTCACAGCCCAGGTTCTTCTGCC CAACACAAAAGGAGTGAGTTGGGGTCTTTAGTCTCTTCTTATTGGGTAGCTCTTGCTTTAATATTCTGTTTGGTGAGTGTAAGGGATTCT GCAAGGGACAGGGGGCCTGACTACCCAGTCTTTGACTTGTATCCTCTCCCCTCTTCATACACTCCTGCTGAAAAATGTTAATCCAAATAC ACATTTAAACTTAGGGTCGGTCCTTATTCTGATTTGAGTATTTTAATGTCTCAGTGTGCTGATTTGGTAGTTGGAAGAATTATTCTTCTG GAGGTCTGTTAGACTACATCCTACACTGACTTCAGAAAACAGTCTGTCAGACAAAAAGGCCTTATGTCACCACTGGTACCTCAGTTTCCT CATCCCATTTACAGTTTTTCTAACTCCAGGGTAGTGTTTAGTGTTAATATTTGGGATATATTTTTTTTCAAAACTGTTTTTAAGTAGTTT >7806_7806_3_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367815_RCSD1_chr1_167653136_ENST00000367854_length(amino acids)=630AA_BP=216 MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISF RPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKL NRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPP KVDLGQNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQ PPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEK PPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEE VGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQQEGAVLEPGCSPQTGPAQLETSSEVQSEPAVPKPEDDTPVQDTKM -------------------------------------------------------------- >7806_7806_4_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367815_RCSD1_chr1_167653136_ENST00000537350_length(transcript)=2400nt_BP=1155nt AATTCCTCGGCTCCTGGCGGGAGTGCCGGTGGCGCCCCGCAGTCCGCTTGTCCGTCCTTCCCTCTCTGACTCTCCTACCCCGGGCCTGTC TCTGCAGAGGTCAGGGGAGGCGGGGGCCCAGCACACGTCCCCAGTGGCAGCGGGAGCGGCAGCTACGGGTTCGCGGAGCCCCCGACCCCC CAAGGGCTAGAGGAGCGCTCGGCGGACCAAAGAAAGCCCGCGAGCGGCTGCGCGCCCACCAATAGGTGCGGGGCTCGGAGCCGCGCAGCC TGCGCCGTCCCTCCCTCCGCCCCCGCCCCGCCGCCGCCGCCGCCGCCGCCTCCCCCTCCTCCTGCTCCTGCCTTGGCTCCTCCGCCGCGC GTCTCGCACTCCGAGAGCCGCAGCGGCAGCGGCGCGTCCTGCCTGCAGAGAGCCAGGCCGGAGAAGCCGAGCGGCGCAGAGGACGCCAGG GCGCGCGCCGCAGCCACCCACCCTCCGGACCGCGGCAGCTGCTGACCCGCCATCGCCATGGCCCGCGGGAAAGCCAAGGAGGAGGGCAGC TGGAAGAAATTCATCTGGAACTCAGAGAAGAAGGAGTTTCTGGGCAGGACCGGTGGCAGTTGGTTTAAGATCCTTCTATTCTACGTAATA TTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATTTAAGCCCACATATCAGGACCGA GTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGATCCCAAGAGCTATGAGGCATAT GTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGAAGATTGTGGCGATGTGCCCAGT GAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGAATGGCTGGGAAATTGCTCTGGA TTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCTAGGCTTCAAACCTAAGCCTCCC AAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGACCGGCAGAG ACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCCAAGGAGAAA TCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCAGGCCAATTTAACCTTTGACCCA GCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAGCCCACCTTCTACCCCCAGCAGC CCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGGCAGTCATCTGCCCTGTTACAAC AAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGACTGTGGAGAACTTGGAGATTTC AGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAAGAGCAAGGCCCCAGGATCCCCT TTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGCAGGACAGAG AAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAGCACCCGGCC CAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCAGCTGGAGAG GAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGAACATGACAGCCAAGAAACAAAG AAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAGGAAAAAGGC AAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCTGGAGACCAGCAGTGAGGTCCAG AGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGCTCATTGTGCCCCAGTGATGAAG >7806_7806_4_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367815_RCSD1_chr1_167653136_ENST00000537350_length(amino acids)=600AA_BP=216 MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISF RPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKL NRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKEKSPPNASHPPKFKVKSSPLI EKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRR SQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARR SSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGV -------------------------------------------------------------- >7806_7806_5_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367816_RCSD1_chr1_167653136_ENST00000367854_length(transcript)=3975nt_BP=1177nt GCCCACAAGGGGCACAGCCGGGCAGTCAGGAACCGGGGCTGCCGGCTGGGCTGGCCTGCAAAGAAGAGGGAAGGGCCGGAACTGCAACCG CAGTGGCGGGGAGTGCGAGGGGGCGGCAGAGGTCAGGGGAGGCGGGGGCCCAGCACACGTCCCCAGTGGCAGCGGGAGCGGCAGCTACGG GTTCGCGGAGCCCCCGACCCCCCAAGGGCTAGAGGAGCGCTCGGCGGACCAAAGAAAGCCCGCGAGCGGCTGCGCGCCCACCAATAGGTG CGGGGCTCGGAGCCGCGCAGCCTGCGCCGTCCCTCCCTCCGCCCCCGCCCCGCCGCCGCCGCCGCCGCCGCCTCCCCCTCCTCCTGCTCC TGCCTTGGCTCCTCCGCCGCGCGTCTCGCACTCCGAGAGCCGCAGCGGCAGCGGCGCGTCCTGCCTGCAGAGAGCCAGGCCGGAGAAGCC GAGCGGCGCAGAGGACGCCAGGGCGCGCGCCGCAGCCACCCACCCTCCGGACCGCGGCAGCTGCTGACCCGCCATCGCCATGGCCCGCGG GAAAGCCAAGGAGGAGGGCAGCTGGAAGAAATTCATCTGGAACTCAGAGAAGAAGGAGTTTCTGGGCAGGACCGGTGGCAGTTGGTTTAA GATCCTTCTATTCTACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATT TAAGCCCACATATCAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGA TCCCAAGAGCTATGAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGA AGATTGTGGCGATGTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGA ATGGCTGGGAAATTGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCT AGGCTTCAAACCTAAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCAC TGGCAAGGAAAGACCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCA GGCGGCTGCAGCCAAGGAGACACCAGCCAGTAAACCAACCCGAAGGAAACCGCCCTGTTCCCTCCCCCTGTTCCCCCCCAAGGTAGACCT GGGCCAGAATGGTGAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCA GGCCAATTTAACCTTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAG CCCACCTTCTACCCCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGG CAGTCATCTGCCCTGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGA CTGTGGAGAACTTGGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAA GAGCAAGGCCCCAGGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAG GAGGTCACCCAGCAGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGA GGTGGACGGCCAGCACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAG GGAGGAAAAGCCAGCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGA ACATGACAGCCAAGAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGA TGTCCCCAAGCAGGAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCT GGAGACCAGCAGTGAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGC TCATTGTGCCCCAGTGATGAAGTTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAGCAGACGAAGCCATTGCAGAG GCAGAATATGCTGAGTGTCTGGAGTCAGCCTGAAGACACAGGGTGGATTATTTCCTGGCCTCCACACCAAACGTTCCCTTGCAGATGGAG ACTGAATCTGAGGGCAGCAGACTTTTATCAGCTTGAGTTTATGTCATTTGATGGACTTGGTTCAACAACAAGAACTTACTTAAAACAATG TACTGTGGTGATGAGTCCCAGGGGCACTGGTCAGCCTGTGGAGCCCTGGATGCTATCCACACCCACCTATCCCTGCAGCTAATTTAGCTG ATCTCTAATTTAACTGAGCTCTAATTTAGCTGATCAGATTTTGCTTGGGTAAAGTTCCTTTTTAATGTTCTAAAGTGTTTACGGTTCTCA AATATCAGTTAAAAACTAATTTTAGGTGGCCATAAACATAAAATAGAAACCCTGTAAGTTACAGAAGACCCTAAATTGTATCAAAACCCT AGAGACAACTTTTCAATTTGATCCAAATTTGAACTGGCCAACCAGTCTTTAAAACACTGGACTAGAAGAGATAATGATTGAAACATTTAA AAAAAAAAAGTGCTCCATTCGCAGGAGCTTTTCCTGTCCTGTGGTTTTCCAGTTGGTGACCACCATGGGAGGTCGCTGGCTCGGCTCACT CCCTTCTCCCACCCTTGAGAATGTGGAGAACTCCCATGGAGAGGCAGAATGGCAGGAGGTTTCATGTCCCGCGTTGCATCTCCTCCTGAA AGAAAAGCAGTGATACCTGAATAATGCTGGCTCTCCGATTGATCCTGTGAGGATGAATTTGCATTTCCAGAATCCTTGAGCATGGATTAG ATGTTTCCTGGGAGGTGCCTTGAGTACCATTATGTGCAAGCTACATAATTAAAACATTTTTCTTAGTTTCCCTGGGAAGCTTTTCTTGAC TCACAGCCCAGGTTCTTCTGCCCAACACAAAAGGAGTGAGTTGGGGTCTTTAGTCTCTTCTTATTGGGTAGCTCTTGCTTTAATATTCTG TTTGGTGAGTGTAAGGGATTCTGCAAGGGACAGGGGGCCTGACTACCCAGTCTTTGACTTGTATCCTCTCCCCTCTTCATACACTCCTGC TGAAAAATGTTAATCCAAATACACATTTAAACTTAGGGTCGGTCCTTATTCTGATTTGAGTATTTTAATGTCTCAGTGTGCTGATTTGGT AGTTGGAAGAATTATTCTTCTGGAGGTCTGTTAGACTACATCCTACACTGACTTCAGAAAACAGTCTGTCAGACAAAAAGGCCTTATGTC ACCACTGGTACCTCAGTTTCCTCATCCCATTTACAGTTTTTCTAACTCCAGGGTAGTGTTTAGTGTTAATATTTGGGATATATTTTTTTT CAAAACTGTTTTTAAGTAGTTTGTAATTTGTAACAAACTTGTAACCTGGTTGGGACTGATATTGTCATAGCTATGATAAACTTTGGATAT >7806_7806_5_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367816_RCSD1_chr1_167653136_ENST00000367854_length(amino acids)=630AA_BP=216 MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISF RPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKL NRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPP KVDLGQNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQ PPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEK PPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEE VGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQQEGAVLEPGCSPQTGPAQLETSSEVQSEPAVPKPEDDTPVQDTKM -------------------------------------------------------------- >7806_7806_6_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367816_RCSD1_chr1_167653136_ENST00000537350_length(transcript)=2422nt_BP=1177nt GCCCACAAGGGGCACAGCCGGGCAGTCAGGAACCGGGGCTGCCGGCTGGGCTGGCCTGCAAAGAAGAGGGAAGGGCCGGAACTGCAACCG CAGTGGCGGGGAGTGCGAGGGGGCGGCAGAGGTCAGGGGAGGCGGGGGCCCAGCACACGTCCCCAGTGGCAGCGGGAGCGGCAGCTACGG GTTCGCGGAGCCCCCGACCCCCCAAGGGCTAGAGGAGCGCTCGGCGGACCAAAGAAAGCCCGCGAGCGGCTGCGCGCCCACCAATAGGTG CGGGGCTCGGAGCCGCGCAGCCTGCGCCGTCCCTCCCTCCGCCCCCGCCCCGCCGCCGCCGCCGCCGCCGCCTCCCCCTCCTCCTGCTCC TGCCTTGGCTCCTCCGCCGCGCGTCTCGCACTCCGAGAGCCGCAGCGGCAGCGGCGCGTCCTGCCTGCAGAGAGCCAGGCCGGAGAAGCC GAGCGGCGCAGAGGACGCCAGGGCGCGCGCCGCAGCCACCCACCCTCCGGACCGCGGCAGCTGCTGACCCGCCATCGCCATGGCCCGCGG GAAAGCCAAGGAGGAGGGCAGCTGGAAGAAATTCATCTGGAACTCAGAGAAGAAGGAGTTTCTGGGCAGGACCGGTGGCAGTTGGTTTAA GATCCTTCTATTCTACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATT TAAGCCCACATATCAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGA TCCCAAGAGCTATGAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGA AGATTGTGGCGATGTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGA ATGGCTGGGAAATTGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCT AGGCTTCAAACCTAAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCAC TGGCAAGGAAAGACCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCA GGCGGCTGCAGCCAAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCA GGCCAATTTAACCTTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAG CCCACCTTCTACCCCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGG CAGTCATCTGCCCTGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGA CTGTGGAGAACTTGGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAA GAGCAAGGCCCCAGGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAG GAGGTCACCCAGCAGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGA GGTGGACGGCCAGCACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAG GGAGGAAAAGCCAGCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGA ACATGACAGCCAAGAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGA TGTCCCCAAGCAGGAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCT GGAGACCAGCAGTGAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGC >7806_7806_6_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000367816_RCSD1_chr1_167653136_ENST00000537350_length(amino acids)=600AA_BP=216 MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISF RPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKL NRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKEKSPPNASHPPKFKVKSSPLI EKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRR SQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARR SSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGV -------------------------------------------------------------- >7806_7806_7_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000499679_RCSD1_chr1_167653136_ENST00000367854_length(transcript)=3512nt_BP=714nt AGTCATTCAGGGAGTCCTGAACAGAGGCCGATTGGTGTTCCTGCTTGGGAGGATCTGTGGGAATCGGCAGGAGAATGAGTCAGGGAAATA GTGCTTAGCTGACATTTTGAAATGGAAGAAGCTGGAATATATGAATTTTTGTAAAGAAAAAAAAATGCAGCCTTTAAGATCCTTCTATTC TACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATTTAAGCCCACATAT CAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGATCCCAAGAGCTAT GAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGAAGATTGTGGCGAT GTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGAATGGCTGGGAAAT TGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCTAGGCTTCAAACCT AAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGA CCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCC AAGGAGACACCAGCCAGTAAACCAACCCGAAGGAAACCGCCCTGTTCCCTCCCCCTGTTCCCCCCCAAGGTAGACCTGGGCCAGAATGGT GAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCAGGCCAATTTAACC TTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAGCCCACCTTCTACC CCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGGCAGTCATCTGCCC TGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGACTGTGGAGAACTT GGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAAGAGCAAGGCCCCA GGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGC AGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAG CACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCA GCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGAACATGACAGCCAA GAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAG GAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCTGGAGACCAGCAGT GAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGCTCATTGTGCCCCA GTGATGAAGTTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAGCAGACGAAGCCATTGCAGAGGCAGAATATGCTG AGTGTCTGGAGTCAGCCTGAAGACACAGGGTGGATTATTTCCTGGCCTCCACACCAAACGTTCCCTTGCAGATGGAGACTGAATCTGAGG GCAGCAGACTTTTATCAGCTTGAGTTTATGTCATTTGATGGACTTGGTTCAACAACAAGAACTTACTTAAAACAATGTACTGTGGTGATG AGTCCCAGGGGCACTGGTCAGCCTGTGGAGCCCTGGATGCTATCCACACCCACCTATCCCTGCAGCTAATTTAGCTGATCTCTAATTTAA CTGAGCTCTAATTTAGCTGATCAGATTTTGCTTGGGTAAAGTTCCTTTTTAATGTTCTAAAGTGTTTACGGTTCTCAAATATCAGTTAAA AACTAATTTTAGGTGGCCATAAACATAAAATAGAAACCCTGTAAGTTACAGAAGACCCTAAATTGTATCAAAACCCTAGAGACAACTTTT CAATTTGATCCAAATTTGAACTGGCCAACCAGTCTTTAAAACACTGGACTAGAAGAGATAATGATTGAAACATTTAAAAAAAAAAAGTGC TCCATTCGCAGGAGCTTTTCCTGTCCTGTGGTTTTCCAGTTGGTGACCACCATGGGAGGTCGCTGGCTCGGCTCACTCCCTTCTCCCACC CTTGAGAATGTGGAGAACTCCCATGGAGAGGCAGAATGGCAGGAGGTTTCATGTCCCGCGTTGCATCTCCTCCTGAAAGAAAAGCAGTGA TACCTGAATAATGCTGGCTCTCCGATTGATCCTGTGAGGATGAATTTGCATTTCCAGAATCCTTGAGCATGGATTAGATGTTTCCTGGGA GGTGCCTTGAGTACCATTATGTGCAAGCTACATAATTAAAACATTTTTCTTAGTTTCCCTGGGAAGCTTTTCTTGACTCACAGCCCAGGT TCTTCTGCCCAACACAAAAGGAGTGAGTTGGGGTCTTTAGTCTCTTCTTATTGGGTAGCTCTTGCTTTAATATTCTGTTTGGTGAGTGTA AGGGATTCTGCAAGGGACAGGGGGCCTGACTACCCAGTCTTTGACTTGTATCCTCTCCCCTCTTCATACACTCCTGCTGAAAAATGTTAA TCCAAATACACATTTAAACTTAGGGTCGGTCCTTATTCTGATTTGAGTATTTTAATGTCTCAGTGTGCTGATTTGGTAGTTGGAAGAATT ATTCTTCTGGAGGTCTGTTAGACTACATCCTACACTGACTTCAGAAAACAGTCTGTCAGACAAAAAGGCCTTATGTCACCACTGGTACCT CAGTTTCCTCATCCCATTTACAGTTTTTCTAACTCCAGGGTAGTGTTTAGTGTTAATATTTGGGATATATTTTTTTTCAAAACTGTTTTT AAGTAGTTTGTAATTTGTAACAAACTTGTAACCTGGTTGGGACTGATATTGTCATAGCTATGATAAACTTTGGATATTAGCAGAATTTGG >7806_7806_7_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000499679_RCSD1_chr1_167653136_ENST00000367854_length(amino acids)=585AA_BP=171 MAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKE RGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNAN VDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPPKVDLGQNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALL PGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVE SSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEV PESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQ -------------------------------------------------------------- >7806_7806_8_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000499679_RCSD1_chr1_167653136_ENST00000537350_length(transcript)=1959nt_BP=714nt AGTCATTCAGGGAGTCCTGAACAGAGGCCGATTGGTGTTCCTGCTTGGGAGGATCTGTGGGAATCGGCAGGAGAATGAGTCAGGGAAATA GTGCTTAGCTGACATTTTGAAATGGAAGAAGCTGGAATATATGAATTTTTGTAAAGAAAAAAAAATGCAGCCTTTAAGATCCTTCTATTC TACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATTTAAGCCCACATAT CAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGATCCCAAGAGCTAT GAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGAAGATTGTGGCGAT GTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGAATGGCTGGGAAAT TGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCTAGGCTTCAAACCT AAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGA CCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCC AAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCAGGCCAATTTAACC TTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAGCCCACCTTCTACC CCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGGCAGTCATCTGCCC TGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGACTGTGGAGAACTT GGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAAGAGCAAGGCCCCA GGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGC AGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAG CACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCA GCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGAACATGACAGCCAA GAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAG GAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCTGGAGACCAGCAGT GAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGCTCATTGTGCCCCA >7806_7806_8_ATP1B1-RCSD1_ATP1B1_chr1_169099327_ENST00000499679_RCSD1_chr1_167653136_ENST00000537350_length(amino acids)=555AA_BP=171 MAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKE RGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNAN VDNSASPSVAQLAGRFREQAAAAKEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVR SRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSE GAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEM EKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQQEGAVLEPGCSPQTGPAQLETSSEVQSEPA -------------------------------------------------------------- >7806_7806_9_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367813_RCSD1_chr1_167653137_ENST00000367854_length(transcript)=3455nt_BP=657nt TATTTCAGCCTCCATCCTGTTGTCTTGTTAACTATGGGAAAAAGAAAATGCAGCCCAGCAAGTCAGTCATTATTCTTGTTCCAGTTCCAG AAGATGGAATTAAAATTTAAGATCCTTCTATTCTACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATG CTGCTCACCATCAGTGAATTTAAGCCCACATATCAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAA ATTTCCTTTCGTCCTAATGATCCCAAGAGCTATGAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAG AGGGATGACATGATTTTTGAAGATTGTGGCGATGTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAG GTCTGCAGATTCAAGCTTGAATGGCTGGGAAATTGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATT ATAAAGCTCAACCGAGTTCTAGGCTTCAAACCTAAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAAT GTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGACCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTG GCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCCAAGGAGACACCAGCCAGTAAACCAACCCGAAGGAAACCGCCCTGTTCCCTCCCCCTG TTCCCCCCCAAGGTAGACCTGGGCCAGAATGGTGAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCG CCTCTGATTGAGAAGCTTCAGGCCAATTTAACCTTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCT ATGGTGTCGCCATTTCACAGCCCACCTTCTACCCCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGC TTCGACCAGCCCCCTGAAGGCAGTCATCTGCCCTGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGA TTCCGAAGGTCACAGTCAGACTGTGGAGAACTTGGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGG GATGAAGTGTTGCCATCCAAGAGCAAGGCCCCAGGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCT GCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGCAGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAG GCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAGCACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAA AATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCAGCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAA AATGAAGAGGTGGGACCTGAACATGACAGCCAAGAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCT GGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAGGAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCC CAGACCGGCCCTGCCCAGCTGGAGACCAGCAGTGAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGAC ACTAAAATGTGAAGAACAGCTCATTGTGCCCCAGTGATGAAGTTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAG CAGACGAAGCCATTGCAGAGGCAGAATATGCTGAGTGTCTGGAGTCAGCCTGAAGACACAGGGTGGATTATTTCCTGGCCTCCACACCAA ACGTTCCCTTGCAGATGGAGACTGAATCTGAGGGCAGCAGACTTTTATCAGCTTGAGTTTATGTCATTTGATGGACTTGGTTCAACAACA AGAACTTACTTAAAACAATGTACTGTGGTGATGAGTCCCAGGGGCACTGGTCAGCCTGTGGAGCCCTGGATGCTATCCACACCCACCTAT CCCTGCAGCTAATTTAGCTGATCTCTAATTTAACTGAGCTCTAATTTAGCTGATCAGATTTTGCTTGGGTAAAGTTCCTTTTTAATGTTC TAAAGTGTTTACGGTTCTCAAATATCAGTTAAAAACTAATTTTAGGTGGCCATAAACATAAAATAGAAACCCTGTAAGTTACAGAAGACC CTAAATTGTATCAAAACCCTAGAGACAACTTTTCAATTTGATCCAAATTTGAACTGGCCAACCAGTCTTTAAAACACTGGACTAGAAGAG ATAATGATTGAAACATTTAAAAAAAAAAAGTGCTCCATTCGCAGGAGCTTTTCCTGTCCTGTGGTTTTCCAGTTGGTGACCACCATGGGA GGTCGCTGGCTCGGCTCACTCCCTTCTCCCACCCTTGAGAATGTGGAGAACTCCCATGGAGAGGCAGAATGGCAGGAGGTTTCATGTCCC GCGTTGCATCTCCTCCTGAAAGAAAAGCAGTGATACCTGAATAATGCTGGCTCTCCGATTGATCCTGTGAGGATGAATTTGCATTTCCAG AATCCTTGAGCATGGATTAGATGTTTCCTGGGAGGTGCCTTGAGTACCATTATGTGCAAGCTACATAATTAAAACATTTTTCTTAGTTTC CCTGGGAAGCTTTTCTTGACTCACAGCCCAGGTTCTTCTGCCCAACACAAAAGGAGTGAGTTGGGGTCTTTAGTCTCTTCTTATTGGGTA GCTCTTGCTTTAATATTCTGTTTGGTGAGTGTAAGGGATTCTGCAAGGGACAGGGGGCCTGACTACCCAGTCTTTGACTTGTATCCTCTC CCCTCTTCATACACTCCTGCTGAAAAATGTTAATCCAAATACACATTTAAACTTAGGGTCGGTCCTTATTCTGATTTGAGTATTTTAATG TCTCAGTGTGCTGATTTGGTAGTTGGAAGAATTATTCTTCTGGAGGTCTGTTAGACTACATCCTACACTGACTTCAGAAAACAGTCTGTC AGACAAAAAGGCCTTATGTCACCACTGGTACCTCAGTTTCCTCATCCCATTTACAGTTTTTCTAACTCCAGGGTAGTGTTTAGTGTTAAT ATTTGGGATATATTTTTTTTCAAAACTGTTTTTAAGTAGTTTGTAATTTGTAACAAACTTGTAACCTGGTTGGGACTGATATTGTCATAG >7806_7806_9_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367813_RCSD1_chr1_167653137_ENST00000367854_length(amino acids)=625AA_BP=211 MLTMGKRKCSPASQSLFLFQFQKMELKFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDP KSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLG FKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPPKVDLG QNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGS HLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRR SPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEH -------------------------------------------------------------- >7806_7806_10_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367813_RCSD1_chr1_167653137_ENST00000537350_length(transcript)=1902nt_BP=657nt TATTTCAGCCTCCATCCTGTTGTCTTGTTAACTATGGGAAAAAGAAAATGCAGCCCAGCAAGTCAGTCATTATTCTTGTTCCAGTTCCAG AAGATGGAATTAAAATTTAAGATCCTTCTATTCTACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATG CTGCTCACCATCAGTGAATTTAAGCCCACATATCAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAA ATTTCCTTTCGTCCTAATGATCCCAAGAGCTATGAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAG AGGGATGACATGATTTTTGAAGATTGTGGCGATGTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAG GTCTGCAGATTCAAGCTTGAATGGCTGGGAAATTGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATT ATAAAGCTCAACCGAGTTCTAGGCTTCAAACCTAAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAAT GTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGACCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTG GCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCCAAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCG CCTCTGATTGAGAAGCTTCAGGCCAATTTAACCTTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCT ATGGTGTCGCCATTTCACAGCCCACCTTCTACCCCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGC TTCGACCAGCCCCCTGAAGGCAGTCATCTGCCCTGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGA TTCCGAAGGTCACAGTCAGACTGTGGAGAACTTGGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGG GATGAAGTGTTGCCATCCAAGAGCAAGGCCCCAGGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCT GCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGCAGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAG GCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAGCACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAA AATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCAGCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAA AATGAAGAGGTGGGACCTGAACATGACAGCCAAGAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCT GGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAGGAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCC CAGACCGGCCCTGCCCAGCTGGAGACCAGCAGTGAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGAC ACTAAAATGTGAAGAACAGCTCATTGTGCCCCAGTGATGAAGTTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAG >7806_7806_10_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367813_RCSD1_chr1_167653137_ENST00000537350_length(amino acids)=595AA_BP=211 MLTMGKRKCSPASQSLFLFQFQKMELKFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDP KSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLG FKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKEKSPPNASHPPKFKVKSSPLIEKLQA NLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDC GELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEV DGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDV -------------------------------------------------------------- >7806_7806_11_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367815_RCSD1_chr1_167653137_ENST00000367854_length(transcript)=3953nt_BP=1155nt AATTCCTCGGCTCCTGGCGGGAGTGCCGGTGGCGCCCCGCAGTCCGCTTGTCCGTCCTTCCCTCTCTGACTCTCCTACCCCGGGCCTGTC TCTGCAGAGGTCAGGGGAGGCGGGGGCCCAGCACACGTCCCCAGTGGCAGCGGGAGCGGCAGCTACGGGTTCGCGGAGCCCCCGACCCCC CAAGGGCTAGAGGAGCGCTCGGCGGACCAAAGAAAGCCCGCGAGCGGCTGCGCGCCCACCAATAGGTGCGGGGCTCGGAGCCGCGCAGCC TGCGCCGTCCCTCCCTCCGCCCCCGCCCCGCCGCCGCCGCCGCCGCCGCCTCCCCCTCCTCCTGCTCCTGCCTTGGCTCCTCCGCCGCGC GTCTCGCACTCCGAGAGCCGCAGCGGCAGCGGCGCGTCCTGCCTGCAGAGAGCCAGGCCGGAGAAGCCGAGCGGCGCAGAGGACGCCAGG GCGCGCGCCGCAGCCACCCACCCTCCGGACCGCGGCAGCTGCTGACCCGCCATCGCCATGGCCCGCGGGAAAGCCAAGGAGGAGGGCAGC TGGAAGAAATTCATCTGGAACTCAGAGAAGAAGGAGTTTCTGGGCAGGACCGGTGGCAGTTGGTTTAAGATCCTTCTATTCTACGTAATA TTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATTTAAGCCCACATATCAGGACCGA GTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGATCCCAAGAGCTATGAGGCATAT GTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGAAGATTGTGGCGATGTGCCCAGT GAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGAATGGCTGGGAAATTGCTCTGGA TTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCTAGGCTTCAAACCTAAGCCTCCC AAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGACCGGCAGAG ACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCCAAGGAGACA CCAGCCAGTAAACCAACCCGAAGGAAACCGCCCTGTTCCCTCCCCCTGTTCCCCCCCAAGGTAGACCTGGGCCAGAATGGTGAGGAGAAA TCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCAGGCCAATTTAACCTTTGACCCA GCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAGCCCACCTTCTACCCCCAGCAGC CCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGGCAGTCATCTGCCCTGTTACAAC AAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGACTGTGGAGAACTTGGAGATTTC AGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAAGAGCAAGGCCCCAGGATCCCCT TTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGCAGGACAGAG AAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAGCACCCGGCC CAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCAGCTGGAGAG GAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGAACATGACAGCCAAGAAACAAAG AAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAGGAAAAAGGC AAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCTGGAGACCAGCAGTGAGGTCCAG AGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGCTCATTGTGCCCCAGTGATGAAG TTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAGCAGACGAAGCCATTGCAGAGGCAGAATATGCTGAGTGTCTGG AGTCAGCCTGAAGACACAGGGTGGATTATTTCCTGGCCTCCACACCAAACGTTCCCTTGCAGATGGAGACTGAATCTGAGGGCAGCAGAC TTTTATCAGCTTGAGTTTATGTCATTTGATGGACTTGGTTCAACAACAAGAACTTACTTAAAACAATGTACTGTGGTGATGAGTCCCAGG GGCACTGGTCAGCCTGTGGAGCCCTGGATGCTATCCACACCCACCTATCCCTGCAGCTAATTTAGCTGATCTCTAATTTAACTGAGCTCT AATTTAGCTGATCAGATTTTGCTTGGGTAAAGTTCCTTTTTAATGTTCTAAAGTGTTTACGGTTCTCAAATATCAGTTAAAAACTAATTT TAGGTGGCCATAAACATAAAATAGAAACCCTGTAAGTTACAGAAGACCCTAAATTGTATCAAAACCCTAGAGACAACTTTTCAATTTGAT CCAAATTTGAACTGGCCAACCAGTCTTTAAAACACTGGACTAGAAGAGATAATGATTGAAACATTTAAAAAAAAAAAGTGCTCCATTCGC AGGAGCTTTTCCTGTCCTGTGGTTTTCCAGTTGGTGACCACCATGGGAGGTCGCTGGCTCGGCTCACTCCCTTCTCCCACCCTTGAGAAT GTGGAGAACTCCCATGGAGAGGCAGAATGGCAGGAGGTTTCATGTCCCGCGTTGCATCTCCTCCTGAAAGAAAAGCAGTGATACCTGAAT AATGCTGGCTCTCCGATTGATCCTGTGAGGATGAATTTGCATTTCCAGAATCCTTGAGCATGGATTAGATGTTTCCTGGGAGGTGCCTTG AGTACCATTATGTGCAAGCTACATAATTAAAACATTTTTCTTAGTTTCCCTGGGAAGCTTTTCTTGACTCACAGCCCAGGTTCTTCTGCC CAACACAAAAGGAGTGAGTTGGGGTCTTTAGTCTCTTCTTATTGGGTAGCTCTTGCTTTAATATTCTGTTTGGTGAGTGTAAGGGATTCT GCAAGGGACAGGGGGCCTGACTACCCAGTCTTTGACTTGTATCCTCTCCCCTCTTCATACACTCCTGCTGAAAAATGTTAATCCAAATAC ACATTTAAACTTAGGGTCGGTCCTTATTCTGATTTGAGTATTTTAATGTCTCAGTGTGCTGATTTGGTAGTTGGAAGAATTATTCTTCTG GAGGTCTGTTAGACTACATCCTACACTGACTTCAGAAAACAGTCTGTCAGACAAAAAGGCCTTATGTCACCACTGGTACCTCAGTTTCCT CATCCCATTTACAGTTTTTCTAACTCCAGGGTAGTGTTTAGTGTTAATATTTGGGATATATTTTTTTTCAAAACTGTTTTTAAGTAGTTT >7806_7806_11_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367815_RCSD1_chr1_167653137_ENST00000367854_length(amino acids)=630AA_BP=216 MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISF RPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKL NRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPP KVDLGQNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQ PPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEK PPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEE VGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQQEGAVLEPGCSPQTGPAQLETSSEVQSEPAVPKPEDDTPVQDTKM -------------------------------------------------------------- >7806_7806_12_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367815_RCSD1_chr1_167653137_ENST00000537350_length(transcript)=2400nt_BP=1155nt AATTCCTCGGCTCCTGGCGGGAGTGCCGGTGGCGCCCCGCAGTCCGCTTGTCCGTCCTTCCCTCTCTGACTCTCCTACCCCGGGCCTGTC TCTGCAGAGGTCAGGGGAGGCGGGGGCCCAGCACACGTCCCCAGTGGCAGCGGGAGCGGCAGCTACGGGTTCGCGGAGCCCCCGACCCCC CAAGGGCTAGAGGAGCGCTCGGCGGACCAAAGAAAGCCCGCGAGCGGCTGCGCGCCCACCAATAGGTGCGGGGCTCGGAGCCGCGCAGCC TGCGCCGTCCCTCCCTCCGCCCCCGCCCCGCCGCCGCCGCCGCCGCCGCCTCCCCCTCCTCCTGCTCCTGCCTTGGCTCCTCCGCCGCGC GTCTCGCACTCCGAGAGCCGCAGCGGCAGCGGCGCGTCCTGCCTGCAGAGAGCCAGGCCGGAGAAGCCGAGCGGCGCAGAGGACGCCAGG GCGCGCGCCGCAGCCACCCACCCTCCGGACCGCGGCAGCTGCTGACCCGCCATCGCCATGGCCCGCGGGAAAGCCAAGGAGGAGGGCAGC TGGAAGAAATTCATCTGGAACTCAGAGAAGAAGGAGTTTCTGGGCAGGACCGGTGGCAGTTGGTTTAAGATCCTTCTATTCTACGTAATA TTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATTTAAGCCCACATATCAGGACCGA GTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGATCCCAAGAGCTATGAGGCATAT GTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGAAGATTGTGGCGATGTGCCCAGT GAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGAATGGCTGGGAAATTGCTCTGGA TTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCTAGGCTTCAAACCTAAGCCTCCC AAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGACCGGCAGAG ACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCCAAGGAGAAA TCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCAGGCCAATTTAACCTTTGACCCA GCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAGCCCACCTTCTACCCCCAGCAGC CCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGGCAGTCATCTGCCCTGTTACAAC AAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGACTGTGGAGAACTTGGAGATTTC AGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAAGAGCAAGGCCCCAGGATCCCCT TTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGCAGGACAGAG AAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAGCACCCGGCC CAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCAGCTGGAGAG GAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGAACATGACAGCCAAGAAACAAAG AAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAGGAAAAAGGC AAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCTGGAGACCAGCAGTGAGGTCCAG AGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGCTCATTGTGCCCCAGTGATGAAG >7806_7806_12_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367815_RCSD1_chr1_167653137_ENST00000537350_length(amino acids)=600AA_BP=216 MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISF RPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKL NRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKEKSPPNASHPPKFKVKSSPLI EKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRR SQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARR SSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGV -------------------------------------------------------------- >7806_7806_13_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367816_RCSD1_chr1_167653137_ENST00000367854_length(transcript)=3975nt_BP=1177nt GCCCACAAGGGGCACAGCCGGGCAGTCAGGAACCGGGGCTGCCGGCTGGGCTGGCCTGCAAAGAAGAGGGAAGGGCCGGAACTGCAACCG CAGTGGCGGGGAGTGCGAGGGGGCGGCAGAGGTCAGGGGAGGCGGGGGCCCAGCACACGTCCCCAGTGGCAGCGGGAGCGGCAGCTACGG GTTCGCGGAGCCCCCGACCCCCCAAGGGCTAGAGGAGCGCTCGGCGGACCAAAGAAAGCCCGCGAGCGGCTGCGCGCCCACCAATAGGTG CGGGGCTCGGAGCCGCGCAGCCTGCGCCGTCCCTCCCTCCGCCCCCGCCCCGCCGCCGCCGCCGCCGCCGCCTCCCCCTCCTCCTGCTCC TGCCTTGGCTCCTCCGCCGCGCGTCTCGCACTCCGAGAGCCGCAGCGGCAGCGGCGCGTCCTGCCTGCAGAGAGCCAGGCCGGAGAAGCC GAGCGGCGCAGAGGACGCCAGGGCGCGCGCCGCAGCCACCCACCCTCCGGACCGCGGCAGCTGCTGACCCGCCATCGCCATGGCCCGCGG GAAAGCCAAGGAGGAGGGCAGCTGGAAGAAATTCATCTGGAACTCAGAGAAGAAGGAGTTTCTGGGCAGGACCGGTGGCAGTTGGTTTAA GATCCTTCTATTCTACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATT TAAGCCCACATATCAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGA TCCCAAGAGCTATGAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGA AGATTGTGGCGATGTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGA ATGGCTGGGAAATTGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCT AGGCTTCAAACCTAAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCAC TGGCAAGGAAAGACCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCA GGCGGCTGCAGCCAAGGAGACACCAGCCAGTAAACCAACCCGAAGGAAACCGCCCTGTTCCCTCCCCCTGTTCCCCCCCAAGGTAGACCT GGGCCAGAATGGTGAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCA GGCCAATTTAACCTTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAG CCCACCTTCTACCCCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGG CAGTCATCTGCCCTGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGA CTGTGGAGAACTTGGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAA GAGCAAGGCCCCAGGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAG GAGGTCACCCAGCAGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGA GGTGGACGGCCAGCACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAG GGAGGAAAAGCCAGCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGA ACATGACAGCCAAGAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGA TGTCCCCAAGCAGGAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCT GGAGACCAGCAGTGAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGC TCATTGTGCCCCAGTGATGAAGTTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAGCAGACGAAGCCATTGCAGAG GCAGAATATGCTGAGTGTCTGGAGTCAGCCTGAAGACACAGGGTGGATTATTTCCTGGCCTCCACACCAAACGTTCCCTTGCAGATGGAG ACTGAATCTGAGGGCAGCAGACTTTTATCAGCTTGAGTTTATGTCATTTGATGGACTTGGTTCAACAACAAGAACTTACTTAAAACAATG TACTGTGGTGATGAGTCCCAGGGGCACTGGTCAGCCTGTGGAGCCCTGGATGCTATCCACACCCACCTATCCCTGCAGCTAATTTAGCTG ATCTCTAATTTAACTGAGCTCTAATTTAGCTGATCAGATTTTGCTTGGGTAAAGTTCCTTTTTAATGTTCTAAAGTGTTTACGGTTCTCA AATATCAGTTAAAAACTAATTTTAGGTGGCCATAAACATAAAATAGAAACCCTGTAAGTTACAGAAGACCCTAAATTGTATCAAAACCCT AGAGACAACTTTTCAATTTGATCCAAATTTGAACTGGCCAACCAGTCTTTAAAACACTGGACTAGAAGAGATAATGATTGAAACATTTAA AAAAAAAAAGTGCTCCATTCGCAGGAGCTTTTCCTGTCCTGTGGTTTTCCAGTTGGTGACCACCATGGGAGGTCGCTGGCTCGGCTCACT CCCTTCTCCCACCCTTGAGAATGTGGAGAACTCCCATGGAGAGGCAGAATGGCAGGAGGTTTCATGTCCCGCGTTGCATCTCCTCCTGAA AGAAAAGCAGTGATACCTGAATAATGCTGGCTCTCCGATTGATCCTGTGAGGATGAATTTGCATTTCCAGAATCCTTGAGCATGGATTAG ATGTTTCCTGGGAGGTGCCTTGAGTACCATTATGTGCAAGCTACATAATTAAAACATTTTTCTTAGTTTCCCTGGGAAGCTTTTCTTGAC TCACAGCCCAGGTTCTTCTGCCCAACACAAAAGGAGTGAGTTGGGGTCTTTAGTCTCTTCTTATTGGGTAGCTCTTGCTTTAATATTCTG TTTGGTGAGTGTAAGGGATTCTGCAAGGGACAGGGGGCCTGACTACCCAGTCTTTGACTTGTATCCTCTCCCCTCTTCATACACTCCTGC TGAAAAATGTTAATCCAAATACACATTTAAACTTAGGGTCGGTCCTTATTCTGATTTGAGTATTTTAATGTCTCAGTGTGCTGATTTGGT AGTTGGAAGAATTATTCTTCTGGAGGTCTGTTAGACTACATCCTACACTGACTTCAGAAAACAGTCTGTCAGACAAAAAGGCCTTATGTC ACCACTGGTACCTCAGTTTCCTCATCCCATTTACAGTTTTTCTAACTCCAGGGTAGTGTTTAGTGTTAATATTTGGGATATATTTTTTTT CAAAACTGTTTTTAAGTAGTTTGTAATTTGTAACAAACTTGTAACCTGGTTGGGACTGATATTGTCATAGCTATGATAAACTTTGGATAT >7806_7806_13_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367816_RCSD1_chr1_167653137_ENST00000367854_length(amino acids)=630AA_BP=216 MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISF RPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKL NRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPP KVDLGQNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQ PPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEK PPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEE VGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQQEGAVLEPGCSPQTGPAQLETSSEVQSEPAVPKPEDDTPVQDTKM -------------------------------------------------------------- >7806_7806_14_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367816_RCSD1_chr1_167653137_ENST00000537350_length(transcript)=2422nt_BP=1177nt GCCCACAAGGGGCACAGCCGGGCAGTCAGGAACCGGGGCTGCCGGCTGGGCTGGCCTGCAAAGAAGAGGGAAGGGCCGGAACTGCAACCG CAGTGGCGGGGAGTGCGAGGGGGCGGCAGAGGTCAGGGGAGGCGGGGGCCCAGCACACGTCCCCAGTGGCAGCGGGAGCGGCAGCTACGG GTTCGCGGAGCCCCCGACCCCCCAAGGGCTAGAGGAGCGCTCGGCGGACCAAAGAAAGCCCGCGAGCGGCTGCGCGCCCACCAATAGGTG CGGGGCTCGGAGCCGCGCAGCCTGCGCCGTCCCTCCCTCCGCCCCCGCCCCGCCGCCGCCGCCGCCGCCGCCTCCCCCTCCTCCTGCTCC TGCCTTGGCTCCTCCGCCGCGCGTCTCGCACTCCGAGAGCCGCAGCGGCAGCGGCGCGTCCTGCCTGCAGAGAGCCAGGCCGGAGAAGCC GAGCGGCGCAGAGGACGCCAGGGCGCGCGCCGCAGCCACCCACCCTCCGGACCGCGGCAGCTGCTGACCCGCCATCGCCATGGCCCGCGG GAAAGCCAAGGAGGAGGGCAGCTGGAAGAAATTCATCTGGAACTCAGAGAAGAAGGAGTTTCTGGGCAGGACCGGTGGCAGTTGGTTTAA GATCCTTCTATTCTACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATT TAAGCCCACATATCAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGA TCCCAAGAGCTATGAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGA AGATTGTGGCGATGTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGA ATGGCTGGGAAATTGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCT AGGCTTCAAACCTAAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCAC TGGCAAGGAAAGACCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCA GGCGGCTGCAGCCAAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCA GGCCAATTTAACCTTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAG CCCACCTTCTACCCCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGG CAGTCATCTGCCCTGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGA CTGTGGAGAACTTGGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAA GAGCAAGGCCCCAGGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAG GAGGTCACCCAGCAGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGA GGTGGACGGCCAGCACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAG GGAGGAAAAGCCAGCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGA ACATGACAGCCAAGAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGA TGTCCCCAAGCAGGAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCT GGAGACCAGCAGTGAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGC >7806_7806_14_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000367816_RCSD1_chr1_167653137_ENST00000537350_length(amino acids)=600AA_BP=216 MARGKAKEEGSWKKFIWNSEKKEFLGRTGGSWFKILLFYVIFYGCLAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISF RPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKERGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKL NRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNANVDNSASPSVAQLAGRFREQAAAAKEKSPPNASHPPKFKVKSSPLI EKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRR SQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARR SSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGV -------------------------------------------------------------- >7806_7806_15_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000499679_RCSD1_chr1_167653137_ENST00000367854_length(transcript)=3512nt_BP=714nt AGTCATTCAGGGAGTCCTGAACAGAGGCCGATTGGTGTTCCTGCTTGGGAGGATCTGTGGGAATCGGCAGGAGAATGAGTCAGGGAAATA GTGCTTAGCTGACATTTTGAAATGGAAGAAGCTGGAATATATGAATTTTTGTAAAGAAAAAAAAATGCAGCCTTTAAGATCCTTCTATTC TACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATTTAAGCCCACATAT CAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGATCCCAAGAGCTAT GAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGAAGATTGTGGCGAT GTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGAATGGCTGGGAAAT TGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCTAGGCTTCAAACCT AAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGA CCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCC AAGGAGACACCAGCCAGTAAACCAACCCGAAGGAAACCGCCCTGTTCCCTCCCCCTGTTCCCCCCCAAGGTAGACCTGGGCCAGAATGGT GAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCAGGCCAATTTAACC TTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAGCCCACCTTCTACC CCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGGCAGTCATCTGCCC TGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGACTGTGGAGAACTT GGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAAGAGCAAGGCCCCA GGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGC AGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAG CACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCA GCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGAACATGACAGCCAA GAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAG GAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCTGGAGACCAGCAGT GAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGCTCATTGTGCCCCA GTGATGAAGTTGCTGGACACATCTCTTTGCAGGTAGCAGCAACAGTTGTAGCAGCAGCAGACGAAGCCATTGCAGAGGCAGAATATGCTG AGTGTCTGGAGTCAGCCTGAAGACACAGGGTGGATTATTTCCTGGCCTCCACACCAAACGTTCCCTTGCAGATGGAGACTGAATCTGAGG GCAGCAGACTTTTATCAGCTTGAGTTTATGTCATTTGATGGACTTGGTTCAACAACAAGAACTTACTTAAAACAATGTACTGTGGTGATG AGTCCCAGGGGCACTGGTCAGCCTGTGGAGCCCTGGATGCTATCCACACCCACCTATCCCTGCAGCTAATTTAGCTGATCTCTAATTTAA CTGAGCTCTAATTTAGCTGATCAGATTTTGCTTGGGTAAAGTTCCTTTTTAATGTTCTAAAGTGTTTACGGTTCTCAAATATCAGTTAAA AACTAATTTTAGGTGGCCATAAACATAAAATAGAAACCCTGTAAGTTACAGAAGACCCTAAATTGTATCAAAACCCTAGAGACAACTTTT CAATTTGATCCAAATTTGAACTGGCCAACCAGTCTTTAAAACACTGGACTAGAAGAGATAATGATTGAAACATTTAAAAAAAAAAAGTGC TCCATTCGCAGGAGCTTTTCCTGTCCTGTGGTTTTCCAGTTGGTGACCACCATGGGAGGTCGCTGGCTCGGCTCACTCCCTTCTCCCACC CTTGAGAATGTGGAGAACTCCCATGGAGAGGCAGAATGGCAGGAGGTTTCATGTCCCGCGTTGCATCTCCTCCTGAAAGAAAAGCAGTGA TACCTGAATAATGCTGGCTCTCCGATTGATCCTGTGAGGATGAATTTGCATTTCCAGAATCCTTGAGCATGGATTAGATGTTTCCTGGGA GGTGCCTTGAGTACCATTATGTGCAAGCTACATAATTAAAACATTTTTCTTAGTTTCCCTGGGAAGCTTTTCTTGACTCACAGCCCAGGT TCTTCTGCCCAACACAAAAGGAGTGAGTTGGGGTCTTTAGTCTCTTCTTATTGGGTAGCTCTTGCTTTAATATTCTGTTTGGTGAGTGTA AGGGATTCTGCAAGGGACAGGGGGCCTGACTACCCAGTCTTTGACTTGTATCCTCTCCCCTCTTCATACACTCCTGCTGAAAAATGTTAA TCCAAATACACATTTAAACTTAGGGTCGGTCCTTATTCTGATTTGAGTATTTTAATGTCTCAGTGTGCTGATTTGGTAGTTGGAAGAATT ATTCTTCTGGAGGTCTGTTAGACTACATCCTACACTGACTTCAGAAAACAGTCTGTCAGACAAAAAGGCCTTATGTCACCACTGGTACCT CAGTTTCCTCATCCCATTTACAGTTTTTCTAACTCCAGGGTAGTGTTTAGTGTTAATATTTGGGATATATTTTTTTTCAAAACTGTTTTT AAGTAGTTTGTAATTTGTAACAAACTTGTAACCTGGTTGGGACTGATATTGTCATAGCTATGATAAACTTTGGATATTAGCAGAATTTGG >7806_7806_15_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000499679_RCSD1_chr1_167653137_ENST00000367854_length(amino acids)=585AA_BP=171 MAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKE RGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNAN VDNSASPSVAQLAGRFREQAAAAKETPASKPTRRKPPCSLPLFPPKVDLGQNGEEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALL PGASPKSPGLKAMVSPFHSPPSTPSSPGVRSRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVE SSQQNGAKEEDGDEVLPSKSKAPGSPLSSEGAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEV PESPQTSGPEAENRCGSPREEKPAGEEAEMEKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQ -------------------------------------------------------------- >7806_7806_16_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000499679_RCSD1_chr1_167653137_ENST00000537350_length(transcript)=1959nt_BP=714nt AGTCATTCAGGGAGTCCTGAACAGAGGCCGATTGGTGTTCCTGCTTGGGAGGATCTGTGGGAATCGGCAGGAGAATGAGTCAGGGAAATA GTGCTTAGCTGACATTTTGAAATGGAAGAAGCTGGAATATATGAATTTTTGTAAAGAAAAAAAAATGCAGCCTTTAAGATCCTTCTATTC TACGTAATATTTTATGGCTGCCTGGCTGGCATCTTCATCGGAACCATCCAAGTGATGCTGCTCACCATCAGTGAATTTAAGCCCACATAT CAGGACCGAGTGGCCCCGCCAGGATTAACACAGATTCCTCAGATCCAGAAGACTGAAATTTCCTTTCGTCCTAATGATCCCAAGAGCTAT GAGGCATATGTACTGAACATAGTTAGGTTCCTGGAAAAGTACAAAGATTCAGCCCAGAGGGATGACATGATTTTTGAAGATTGTGGCGAT GTGCCCAGTGAACCGAAAGAACGAGGAGACTTTAATCATGAACGAGGAGAGCGAAAGGTCTGCAGATTCAAGCTTGAATGGCTGGGAAAT TGCTCTGGATTAAATGATGAAACTTATGGCTACAAAGAGGGCAAACCGTGCATTATTATAAAGCTCAACCGAGTTCTAGGCTTCAAACCT AAGCCTCCCAAGAATGAGTCCTTGGAGACTTACCCAGTGATGAAGTATAACCCAAATGTCCTTCCCGTTCAGTGCACTGGCAAGGAAAGA CCGGCAGAGACCAATGCCAATGTGGACAACTCGGCGTCCCCCTCGGTGGCCCAGCTGGCCGGGCGGTTTAGGGAGCAGGCGGCTGCAGCC AAGGAGAAATCACCACCCAATGCGAGCCACCCTCCTAAATTCAAGGTCAAGAGCTCGCCTCTGATTGAGAAGCTTCAGGCCAATTTAACC TTTGACCCAGCTGCTCTACTGCCTGGGGCCTCACCCAAGAGTCCTGGACTCAAGGCTATGGTGTCGCCATTTCACAGCCCACCTTCTACC CCCAGCAGCCCTGGTGTGCGATCTAGGCCCAGCGAGGCAGAGGAGGTGCCTGTCAGCTTCGACCAGCCCCCTGAAGGCAGTCATCTGCCC TGTTACAACAAGGTGCGGACGAGGGGCTCAATAAAAAGGCGCCCTCCCTCCAGGCGATTCCGAAGGTCACAGTCAGACTGTGGAGAACTT GGAGATTTCAGGGCGGTGGAGTCATCTCAGCAGAACGGTGCTAAGGAAGAGGATGGGGATGAAGTGTTGCCATCCAAGAGCAAGGCCCCA GGATCCCCTTTGTCCAGTGAGGGAGCAGCGGGAGAGGGAGTGAGAACCCTGGGACCTGCTGAAAAGCCTCCTCTGAGGAGGTCACCCAGC AGGACAGAGAAGCAGGAGGAGGACAGGGCCACAGAGGAAGCCAAGAACGGTGAAAAGGCCAGGCGGAGTTCAGAGGAGGTGGACGGCCAG CACCCGGCCCAAGAGGAGGTCCCGGAATCGCCCCAGACCTCTGGCCCAGAGGCAGAAAATAGGTGTGGGAGCCCCAGGGAGGAAAAGCCA GCTGGAGAGGAAGCAGAGATGGAAAAGGCTACAGAGGTGAAGGGGGAGAGGGTGCAAAATGAAGAGGTGGGACCTGAACATGACAGCCAA GAAACAAAGAAGCTGGAGGAGGGAGCTGCAGTGAAGGAGACCCCCCACAGTCCCCCTGGAGGAGTGAAGGGCGGAGATGTCCCCAAGCAG GAAAAAGGCAAGGAAAAACAACAGGAGGGGGCAGTGCTCGAGCCAGGCTGCAGCCCCCAGACCGGCCCTGCCCAGCTGGAGACCAGCAGT GAGGTCCAGAGCGAGCCAGCAGTCCCCAAGCCGGAGGATGACACTCCTGTCCAGGACACTAAAATGTGAAGAACAGCTCATTGTGCCCCA >7806_7806_16_ATP1B1-RCSD1_ATP1B1_chr1_169099328_ENST00000499679_RCSD1_chr1_167653137_ENST00000537350_length(amino acids)=555AA_BP=171 MAGIFIGTIQVMLLTISEFKPTYQDRVAPPGLTQIPQIQKTEISFRPNDPKSYEAYVLNIVRFLEKYKDSAQRDDMIFEDCGDVPSEPKE RGDFNHERGERKVCRFKLEWLGNCSGLNDETYGYKEGKPCIIIKLNRVLGFKPKPPKNESLETYPVMKYNPNVLPVQCTGKERPAETNAN VDNSASPSVAQLAGRFREQAAAAKEKSPPNASHPPKFKVKSSPLIEKLQANLTFDPAALLPGASPKSPGLKAMVSPFHSPPSTPSSPGVR SRPSEAEEVPVSFDQPPEGSHLPCYNKVRTRGSIKRRPPSRRFRRSQSDCGELGDFRAVESSQQNGAKEEDGDEVLPSKSKAPGSPLSSE GAAGEGVRTLGPAEKPPLRRSPSRTEKQEEDRATEEAKNGEKARRSSEEVDGQHPAQEEVPESPQTSGPEAENRCGSPREEKPAGEEAEM EKATEVKGERVQNEEVGPEHDSQETKKLEEGAAVKETPHSPPGGVKGGDVPKQEKGKEKQQEGAVLEPGCSPQTGPAQLETSSEVQSEPA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ATP1B1-RCSD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ATP1B1-RCSD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ATP1B1-RCSD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies